JP4938515B2 - 単語間相関度計算装置および方法、プログラム並びに記録媒体 - Google Patents
単語間相関度計算装置および方法、プログラム並びに記録媒体 Download PDFInfo
- Publication number
- JP4938515B2 JP4938515B2 JP2007068202A JP2007068202A JP4938515B2 JP 4938515 B2 JP4938515 B2 JP 4938515B2 JP 2007068202 A JP2007068202 A JP 2007068202A JP 2007068202 A JP2007068202 A JP 2007068202A JP 4938515 B2 JP4938515 B2 JP 4938515B2
- Authority
- JP
- Japan
- Prior art keywords
- correlation
- specific
- general
- document set
- word
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images







Landscapes
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
また、相関統合部で、対象単語間の相関度として、一方の対象単語の共起情報または語義情報から他方の対象単語を想起する確率を用いるようにしてもよい。
また、相関統合部で計算された相関度で相関データベースを更新する相関DB更新機能をさらに備えてもよい。
また、本発明にかかる記録媒体は、上記プログラムが記録された記録媒体である。
[第1の実施の形態]
まず、図1を参照して、本発明の第1の実施の形態にかかる単語間相関度計算装置について説明する。図1は、本発明の第1の実施の形態にかかる単語間相関度計算装置の構成を示すブロック図である。
この単語間相関度計算装置10は、サーバやパーソナルコンピュータなどの一般的な情報処理装置からなり、文書集合に含まれる対象単語間についてその関係を示す相関度を計算する機能を有している。
単語間相関度計算装置10には、主な機能部として、一般的な情報処理装置と同様に、演算処理部1、記憶部2、入出力インターフェース部(以下、入出力I/F部という)3、通信インターフェース部(以下、通信I/F部という)4、操作入力部5、および画面表示部6が設けられている。
演算処理部1で実現される主な処理部としては、特定相関計算部11、および相関統合部12がある。
記憶部2で記憶する主な処理情報としては、特定文書集合21と相関データベース(以下、相関DBという)22がある。
通信I/F部4は、専用のデータ通信回路からなり、LANなどの通信回線を介して接続されたサーバなどの外部装置との間で、演算処理部1からの指示に応じて、対象単語W、相関結果情報Y、辞書、データベースなどの各種データやプログラムを送受信する機能を有している。
画面表示部6は、LCDやPDPなどの画面表示装置からなり、演算処理部1からの指示に応じて対象単語Wや相関結果情報Yなどの各種データや操作画面を画面表示する機能を有している。
一般文書集合の具体例としては、話題の偏らない大規模コーパスを利用してもよく、国語辞典、専門語辞典、Wikipediaなどのインターネット辞書を利用してもよい。一般相関度の具体例としては、単語類似度、単語共起頻度、あるいは単語間の確率的尺度等が利用できる。
本発明はこのような点に着目し、一般的な文書を元にして計算される単語間の相関度を予め計算して相関DB22に蓄積しておき、相関統合部12により、指定された対象単語の相関度を計算する際、一般的な文書を元にして計算される対象単語間の一般相関度を相関DB22から検索し、特定相関計算部11で計算した特定相関度と統合することにより、特定文書集合21および一般文書集合からなる全体文書集合における対象単語間の相関度を計算している。
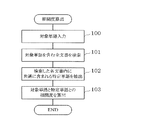
次に、図2を参照して、本発明の第1の実施の形態にかかる単語間相関度計算装置の動作について説明する。ここでは、指定された対象単語Wと関連性の高い特定単語との間の相関度を求める場合を例として説明する。なお、相関度計算を開始するにあたり、特定の話題に関する特定文書集合21と、話題が特定されていない一般文書集合から予め計算した対象単語間の関係を示す一般相関度を蓄積する相関DB22は、予め用意されているものとする。
特定相関計算部11は、まず、記憶部2から特定文書集合21の各文書を読み出し、対象単語Wを含む文書を検索し、検索したこれら文書に含まれる各単語のうち出現頻度の高い複数の単語を特定単語として検索する。
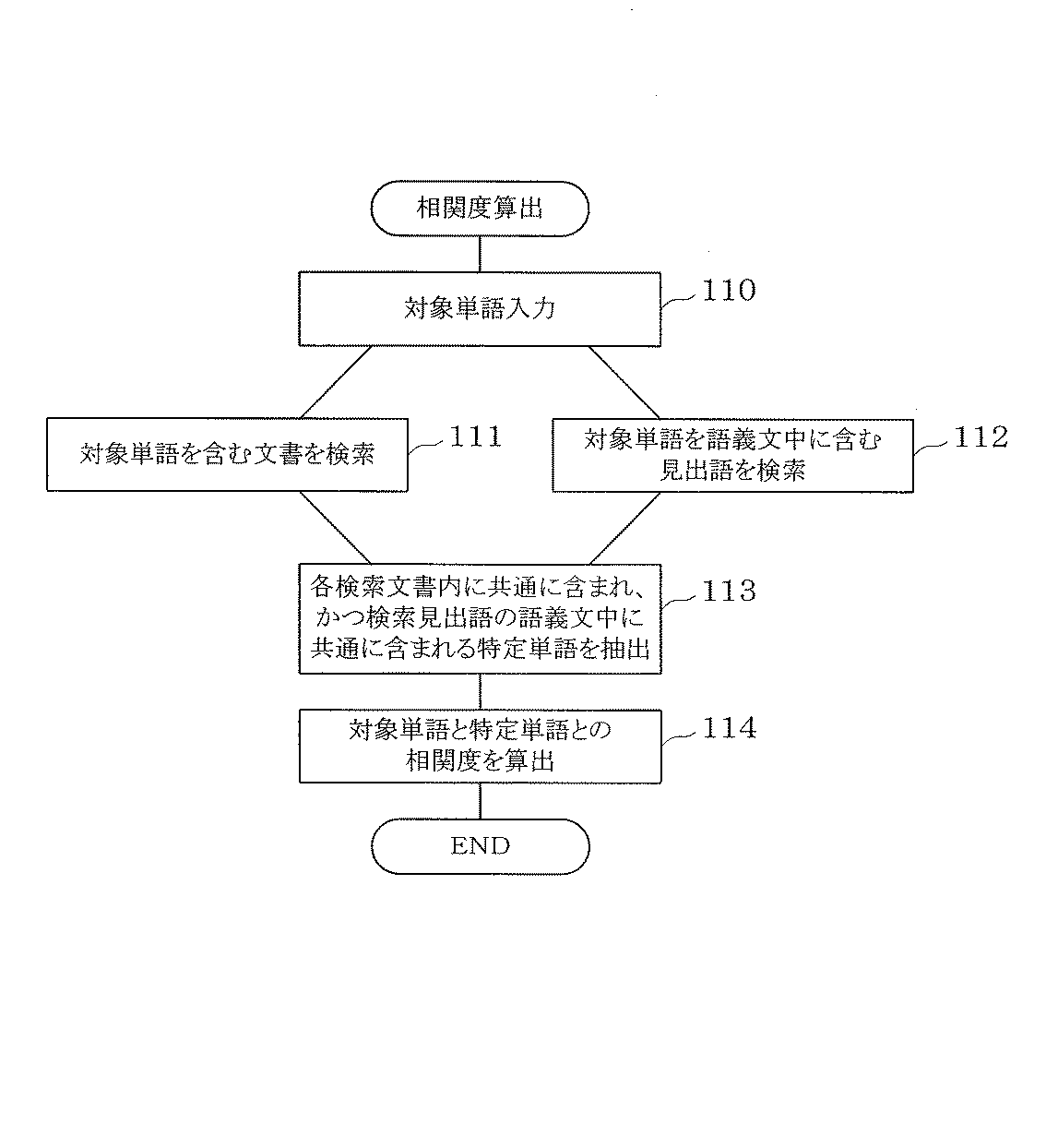
P(Wb|Wa)は、Waが与えられたときにWb,Di,Cjが選択される確率P(Wb,Di,Cj|Wa)を、各Di,Cjごとに合計することにより計算でき、式(3)のように展開できる。
なお、相関計算の手法としては、ベクトル間の角度や内積を用いる方法、相関の統合方法として単純に総和をとる方法、あるいは積をとる方法など、他の公知の手法を適用してもよい。
このように本実施の形態では、記憶部2により、特定の話題に関する特定文書集合21と、話題が特定されていない一般文書集合から予め計算した対象単語間の関係を示す一般相関度を蓄積する相関DB22とを記憶しておき、特定相関計算部11により、記憶部2から特定文書集合21の各文書を読み出し、これら文書における対象単語の出現頻度に基づいて対象単語間に関する特定相関度を計算し、相関統合部12により、記憶部2の相関DB22から対象単語間に関する一般相関度を検索し、当該一般相関度と特定相関計算部11で得られた特定相関度とに基づいて特定文書集合および一般文書集合からなる全体文書集合における対象単語間の相関度を計算するようにしている。
また、単語間の相関度を、特定の話題に関する文書集合に記載の無い単語を介して計算することが可能となる。このことは式(4)からも明らかである。これにより、文書集合単独で計算するよりも、より広い相関を考慮した計算が可能となる。
次に、本発明の第2の実施の形態にかかる単語間相関度計算装置について説明する。
第1の実施の形態では、相関DB22の元となる一般文書集合として、話題の偏らない大規模コーパスやインターネット辞書を単独で用いる場合を例として説明したが、本実施の形態のように、これらを組み合わせて用いてもよい。
例えば、大規模コーパスを利用する場合は話題に偏った単語を補間し、辞書を利用する場合はコーパスと組み合わせておく。これにより、共起情報と意味情報を同時に利用できるとともに、コーパスの話題に偏った専門的な単語を辞書の一般的な単語により補間でき、より多くのパラメータを介した高密度な単語間の相関度を計算することが可能となる。
次に、図8を参照して、本発明の第3の実施の形態にかかる単語間相関度計算装置について説明する。図8は、本発明の第3の実施の形態にかかる単語間相関度計算装置を示すブロック図であり、前述した図1と同じまたは同等部分には同一符号を付してある。
第1の実施の形態では、相関DB22が特定文書集合21のように予め用意されている場合について説明した。本実施の形態では、単語間相関度計算装置10で相関DB22を予め計算する場合について説明する。
以上の各実施の形態では、指定された対象単語と共起頻度が高く関連性の高い特定単語を文書集合から抽出し、対象単語とこれら特定単語との間の相関度を計算する場合を例として説明したが、特定単語についてはこれに限定されるものではない。例えば、対象単語と1つ以上の特定単語を指定し、これら対象単語と特定単語との間の相関度を計算するようにしてもよい。
Claims (8)
- 文書集合に含まれる対象単語間についてその関係を示す相関度を計算する単語間相関度計算装置であって、
特定の話題に関する特定文書集合と、話題が特定されていない一般文書集合から予め計算した前記対象単語間の関係を示す一般相関度を蓄積する相関データベースとを記憶する記憶部と、
前記記憶部から前記特定文書集合の各文書を読み出し、これら文書における対象単語の出現頻度に基づいて前記対象単語間に関する特定相関度を計算する特定相関計算部と、
前記記憶部の相関データベースから前記対象単語間に関する一般相関度を検索し、当該一般相関度と前記特定相関計算部で得られた特定相関度とに基づいて前記特定文書集合および前記一般文書集合からなる全体文書集合における前記対象単語間の相関度を計算する相関統合部と
を備えることを特徴とする単語間相関度計算装置。 - 請求項1に記載の単語間相関度計算装置において、
前記一般文書集合は、見出し語とその語義文の組からなる辞書、または大規模コーパスからなることを特徴とする単語間相関度計算装置。 - 請求項2に記載の単語間相関度計算装置において、
前記一般相関度は、再帰的展開手法により生成されたベクトルを用いることを特徴とする単語間相関度計算装置。 - 請求項3に記載の単語間相関度計算装置において、
相関統合部は、前記対象単語間の相関度として、一方の対象単語の共起情報または語義情報から他方の対象単語を想起する確率を用いることを特徴とする単語間相関度計算装置。 - 請求項1に記載の単語間相関度計算装置において、
前記相関統合部で計算された相関度で前記相関データベースを更新する相関DB更新機能をさらに備えることを特徴とする単語間相関度計算装置。 - 文書集合に含まれる対象単語間についてその関係を示す相関度を計算する単語間相関度計算方法であって、
記憶部により、特定の話題に関する特定文書集合と、話題が特定されていない一般文書集合から予め計算した前記対象単語間の関係を示す一般相関度を蓄積する相関データベースとを記憶する記憶ステップと、
特定相関計算部により、前記記憶部から前記特定文書集合の各文書を読み出し、これら文書における対象単語の出現頻度に基づいて前記対象単語間に関する特定相関度を計算する特定相関計算ステップと、
相関統合部により、前記記憶部の相関データベースから前記対象単語間に関する一般相関度を検索し、当該一般相関度と前記特定相関計算部で得られた特定相関度とに基づいて前記特定文書集合および前記一般文書集合からなる全体文書集合における前記対象単語間の相関度を計算する相関度統合ステップと
を備えることを特徴とする単語間相関度計算方法。 - コンピュータに、請求項5に記載の単語間相関度計算方法の各ステップを実行させるためのプログラム。
- 請求項7に記載のプログラムが記録された記録媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007068202A JP4938515B2 (ja) | 2007-03-16 | 2007-03-16 | 単語間相関度計算装置および方法、プログラム並びに記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007068202A JP4938515B2 (ja) | 2007-03-16 | 2007-03-16 | 単語間相関度計算装置および方法、プログラム並びに記録媒体 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2008233963A JP2008233963A (ja) | 2008-10-02 |
| JP4938515B2 true JP4938515B2 (ja) | 2012-05-23 |
Family
ID=39906719
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007068202A Expired - Fee Related JP4938515B2 (ja) | 2007-03-16 | 2007-03-16 | 単語間相関度計算装置および方法、プログラム並びに記録媒体 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4938515B2 (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6233798B2 (ja) | 2013-09-11 | 2017-11-22 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | データを変換する装置及び方法 |
| KR101727222B1 (ko) * | 2016-09-27 | 2017-04-17 | 한국과학기술정보연구원 | 관계정보 생성 방법 및 장치 |
| JP6737151B2 (ja) * | 2016-11-28 | 2020-08-05 | 富士通株式会社 | 同義表現抽出装置、同義表現抽出方法、及び同義表現抽出プログラム |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004005337A (ja) * | 2002-03-28 | 2004-01-08 | Nippon Telegr & Teleph Corp <Ntt> | 単語関係データベース構築方法および装置、単語関係データベースを用いた単語/文書処理方法および装置、説明表現妥当性検証方法、それらプログラム、それらプログラムを記録した記録媒体、単語の類似度計算方法、単語のグループ化方法、代表語の抽出方法、および単語概念の階層化方法 |
| JP2005122665A (ja) * | 2003-10-20 | 2005-05-12 | Sony Corp | 電子機器装置、関連語データベースの更新方法、プログラム |
| JP4428703B2 (ja) * | 2004-11-11 | 2010-03-10 | 日本電信電話株式会社 | 情報検索方法及びそのシステム並びにコンピュータプログラム |
-
2007
- 2007-03-16 JP JP2007068202A patent/JP4938515B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2008233963A (ja) | 2008-10-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3820242B2 (ja) | 質問応答型文書検索システム及び質問応答型文書検索プログラム | |
| El-Beltagy et al. | KP-Miner: A keyphrase extraction system for English and Arabic documents | |
| US8719246B2 (en) | Generating and presenting a suggested search query | |
| JP5078173B2 (ja) | 多義性解消方法とそのシステム | |
| JP5710581B2 (ja) | 質問応答装置、方法、及びプログラム | |
| US20130018650A1 (en) | Selection of Language Model Training Data | |
| US20130110839A1 (en) | Constructing an analysis of a document | |
| US20110040769A1 (en) | Query-URL N-Gram Features in Web Ranking | |
| AU2016383052A1 (en) | Systems and methods for suggesting emoji | |
| CN111666757B (zh) | 商品评论情感倾向分析方法、装置、设备和可读存储介质 | |
| US10949452B2 (en) | Constructing content based on multi-sentence compression of source content | |
| JP2010204866A (ja) | 重要キーワード抽出装置及び方法及びプログラム | |
| JPWO2012096388A1 (ja) | 意外性判定システム、意外性判定方法およびプログラム | |
| JP5522389B2 (ja) | 類似度算出装置、類似度算出方法、及びプログラム | |
| JP2010287020A (ja) | 同義語展開システム及び同義語展開方法 | |
| Kwon | Reading customers’ minds through textual big data: Challenges, practical guidelines, and proposals | |
| JP5427694B2 (ja) | 関連コンテンツ提示装置及びプログラム | |
| CN112256970B (zh) | 一种新闻文本推送方法、装置、设备及存储介质 | |
| JP4938515B2 (ja) | 単語間相関度計算装置および方法、プログラム並びに記録媒体 | |
| JP5594225B2 (ja) | 知識獲得装置、知識取得方法、及びプログラム | |
| CN103970732A (zh) | 新词译文的挖掘方法和装置 | |
| JP2007219929A (ja) | 感性評価システム及び方法 | |
| Wongchaisuwat | Automatic keyword extraction using textrank | |
| US9336317B2 (en) | System and method for searching aliases associated with an entity | |
| JP5364529B2 (ja) | 辞書登録装置、文書ラベル判定システムおよび辞書登録プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20090109 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20111125 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20111125 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20120209 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120221 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120223 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150302 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150302 Year of fee payment: 3 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |