JP4783005B2 - プログラム変換装置、プログラム変換実行装置およびプログラム変換方法、プログラム変換実行方法。 - Google Patents
プログラム変換装置、プログラム変換実行装置およびプログラム変換方法、プログラム変換実行方法。 Download PDFInfo
- Publication number
- JP4783005B2 JP4783005B2 JP2004341236A JP2004341236A JP4783005B2 JP 4783005 B2 JP4783005 B2 JP 4783005B2 JP 2004341236 A JP2004341236 A JP 2004341236A JP 2004341236 A JP2004341236 A JP 2004341236A JP 4783005 B2 JP4783005 B2 JP 4783005B2
- Authority
- JP
- Japan
- Prior art keywords
- execution
- program
- code
- code string
- execution path
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/40—Transformation of program code
- G06F8/41—Compilation
- G06F8/44—Encoding
- G06F8/443—Optimisation
- G06F8/4441—Reducing the execution time required by the program code
Landscapes
- Engineering & Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Devices For Executing Special Programs (AREA)
Description
コンパイラ装置によって生成された実行プログラムの結果が速く出るようにコンパイラ装置は命令のスケジューリングを行うが、そのスケジューリング方法の一つにプログラム中の命令を並べ替えて命令の並列度を上げて実行速度を向上させる広域スケジューリング法があり、その広域スケジューリング法の一つにトレーススケジューリング法というものがある。
トレーススケジューリング法は、この基本ブロックを拡張するべく、条件分岐命令を跨いで一つの基本ブロックから条件分岐命令によって派生する複数の基本ブロックの一つを当該条件分岐命令が存在しないかのように結合、拡張し、拡張された基本ブロック内においてその命令を並べ替えるスケジューリング方法である。元の基本ブロックを拡張した形になるので命令のスケジューリングの自由度が上がり、更にプログラムの実行時間は短縮されることになる。ただし、拡張した基本ブロックの実行経路がプログラムにおいて実際に実行されない場合に備え、値の整合性を保つべく保証用のコードが必要となる。プログラムにおいて、この基本ブロックによる拡張が行われ最適化が施された実行経路を通る場合には実行結果はソースプログラムをそのままコーディングした実行プログラムよりも早く実行結果を得ることができる。その技術を利用した技術が特許文献1に記されている。なお、基本ブロックの拡張は、基本的にプログラムにおいて実行頻度の高い実行経路上の基本ブロックに対して適用される。
例えば、図20(b)においては、ブロックA’2018がそれに相当する。図20(b)では、ブロックB2012から、図20(a)と同じようにそのままブロックD2004に分岐させるとブロックA2001の演算がなされていないことになるので、ブロックA2001の命令に相当する保証コードとしてブロックA’2018をつけて、図20(b)においてブロックB2012、A’2018、D2014、E2015を通る経路が実行経路である場合の値の整合性を保つ。
また、第一プロセッサエレメントが元のソースプログラムに相当するプログラムを実行するので値の整合性もとれる。
また、前記プログラム変換装置は更に、前記ソースプログラムを実行形式に変換した実行プログラムをコンピュータに実行させることで、前記区間において実行された頻度が高い順に、当該頻度が第一位の実行経路を当該コンピュータから取得する実行経路取得手段を備え、前記実行経路指定手段は、前記取得手段により取得された前記第一位の実行経路を指定することとしてよい。
また、前記プログラム変換装置は更に、前記コンピュータが並列実行可能な命令数mを取得する命令上限取得手段を備え、前記実行経路取得手段は更に、前記区間における実行頻度が第2位以下の実行経路を取得し、前記実行経路指定手段は、前記実行経路を前記命令数mに基づき、前記実行経路取得手段によって取得された、第一位から第n(n=m−1)位までの実行経路を指定し、前記第二コード列生成手段は、前記実行経路指定手段によって指定された第一位から第n位までの実行経路を、実行経路ごとに合計n個のコード列に変換し、前記目的プログラム生成手段は、前記第一コード列と前記第二コード列生成手段により生成された前記n個のコード列を並列実行させるようにコードを編成した目的プログラムを生成することとしてよい。
また、前記プログラム変換装置において前記第二コード列生成手段は更に、前記第二コード列生成手段により生成された第一位から第n位のn個のコードのうち、他の実行経路への条件分岐が発生しなかったコード列以外のコード列を停止させる停止コードを含んで生成することとしてよい。
また、前記プログラム変換装置は更に、前記コンピュータのメモリの形態が、前記コンピュータの全てのプロセッサエレメントが一つのメモリを共有するメモリ共有型であるか、前記コンピュータの全てのプロセッサエレメントが固有のメモリを有するメモリ分散型かであるかのいずれの形態のメモリを使用しているかの情報を取得するメモリ情報取得手段を備え、前記目的プログラム生成手段は、前記メモリ情報取得手段により取得したメモリ情報に基づき、メモリ共有型である場合に、前記第一コード列と前記第二コード列において利用される前記ソースプログラム中の元となる変数がそれぞれ独立した変数として扱うコードになっている目的プログラムを生成することとしてよい。
これにより、メモリ共有型のコンピュータにおいてプログラムの演算結果を保証することができるようになる。
これにより、生成されるスレッドが扱う演算データのみが異なる場合に、スレッドを保持し残しているので、演算に必要なデータのみをプロセッサエレメントに渡せばよく、逐次プロセッサエレメントにスレッドの内容と扱うデータの両方を渡すという非効率性を省け、また、目的プログラムの実行時間の短縮にもつながる。
これにより、目的プログラムが中間コードであった場合に対象とするコンピュータの機械語に合わせた実行プログラムを生成できる。
また、条件分岐を含むソースプログラムを実行形式である実行形式プログラムに変換して、かつ、2以上の命令を並列して実行できるプログラム変換実行装置であって、前記ソースプログラムにおいて、条件分岐を跨ぐ一区間についての複数の実行経路のうちの一つの実行経路を指定する実行経路指定手段と、前記区間にある全ての条件分岐を含んだ命令群を基に、その命令群に相当する第一コード列を生成する第一コード列生成手段と、前記第一コード列を含む第一プログラムを実行する実行手段と、前記実行手段が前記第一プログラムを実行することにより得られた前記区間における実行経路のうち実行頻度が高い順に、当該実行頻度が第一位の実行経路を取得する取得手段と、前記取得手段によって取得された実行経路を前記実行経路指定手段によって指定し、当該実行経路上の命令群に相当する第二コード列を生成し、当該生成において条件分岐命令については、他の実行経路への分岐条件が成立しない場合に前記区間における当該条件分岐命令以降の命令を続行し、他の実行経路への分岐条件が成立する場合に前記区間における当該条件分岐以降の命令の実行を中止するコードを当該条件分岐命令に相当するコードとして生成する第二コード列生成手段と、前記ソースプログラムの前記区間に後続する部分の命令群を基に、その命令群に相当する第三コード列を生成する第三コード列生成手段と、前記第一コード列と、前記第二コード列とを、並列実行するように、かつ、前記第二コード列において他の実行経路への条件分岐が発生しない場合には前記第二コード列に継続して前記第三コード列を実行し、前記第二コード列において他の実行経路への条件分岐が発生する場合には前記第一コード列に継続して前記第三コード列を実行するように編成した目的プログラムを生成する目的プログラム生成手段とを備え、前記実行手段は前記第一プログラムを実行する代わりに前記目的プログラムを実行することとしてよい。
また、従来において、保証コードはフローグラフが複雑になるほどに、保証コードの内容も複雑化する。プログラムを逐次解釈実行するインタプリタにおいて部分的なコードの実行性能を上げるために所謂ジャストインタイムコンパイル、つまり動的コンパイル技術が用いられるコンパイラ装置においては、この保証コードの生成は時間のロスになることがあるが、本発明においては保証コードを生成しないので、そういった問題もなくなる。
また、前記プログラム変換実行装置は更に、当該プログラム変換実行装置が並列実行可能な命令数mを取得する命令上限取得手段を備え、前記実行経路取得手段は更に、前記区間における実行頻度が第2位以下の実行経路を取得し、前記実行経路指定手段は、前記実行経路を前記命令数mに基づき、前記実行経路取得手段によって取得された、第一位から第n(n=m−1)位までの実行経路を指定し、前記第二コード生成手段は、前記実行経路指定手段によって指定された第一位から第n位までの実行経路を、実行経路ごとに合計n個のコード列に変換し、前記目的プログラム生成手段は、前記第一コード列と前記第二コード列生成手段により生成された前記n個のコード列を並列実行させるようにコードを編成した目的プログラムを生成することとしてよい。
また、前記プログラム変換実行装置において、前記第二コード列生成手段は更に、前記第二コード列生成手段により生成された第一位から第n位のn個のコード列のうち、他の実行経路への条件分岐が発生しなかったコード列以外のコード列を停止させる停止コードを含んで生成することとしてよい。
また、前記プログラム変換実行装置において前記目的プログラム生成手段は、自機のメモリの形態が、全てのプロセッサエレメントが一つのメモリを共有するメモリ共有型である場合に、前記第一コード列と前記第二コード列において利用される前記ソースプログラム中の元となる変数がそれぞれ独立した変数として扱うコードになっている目的プログラムを生成することとしてよい。
また、前記プログラム変換実行装置において、前記目的プログラム生成手段は、前記停止コードによって停止させられたスレッドをプロセッサエレメントが消去せずに保持しておくコードを含んで目的プログラムを生成することとしてもよい。
また、条件分岐を含むソースプログラムを変換して、2以上の命令を並列して実行できるコンピュータを対象とする目的プログラムを生成するプログラム変換方法であって、前記ソースプログラムにおいて、条件分岐を跨ぐ一区間についての複数の実行経路のうちの一つの実行経路を指定する実行経路指定ステップと、前記区間にある全ての命令群を基に、その命令群に相当する第一コード列を生成する第一コード列生成ステップと、前記実行経路指定ステップにおいて指定される実行経路上の命令群だけに相当する第二コード列を生成し、当該生成において条件分岐命令については、他の実行経路への分岐条件が成立しない場合に前記区間における当該条件分岐命令以降の命令を続行し、他の実行経路への分岐条件が成立する場合に前記区間における当該条件分岐以降の命令の実行を中止するコードを当該条件分岐命令に相当するコードとして生成する第二コード列生成ステップと、前記ソースプログラムの前記区間に後続する部分の命令群を基に、その命令群に相当する第三コード列を生成する第三コード列生成ステップと、前記第一コード列と、前記第二コード列とを、前記コンピュータに並列実行させるように、かつ、前記第二コード列において他の実行経路への分岐条件が成立しない場合には前記第二コード列に継続して前記第三コード列を実行させ、前記第二コード列において他の実行経路への分岐条件が成立する場合には第一コード列に継続して第三コード列を実行させるように編成した目的プログラムを生成する目的プログラム生成ステップとを備えることとしてもよい。
また、前記プログラム生成方法において、前記目的プログラム生成ステップでは、前記コンピュータにおいて前記第一コード列の終了が前記第二コード列の終了よりも早い場合には、前記第二コード列を実行している前記コンピュータのプロセッサエレメントに第二コード列の実行を停止させるコードを前記第一コード列の後に含んで編成された目的プログラムを生成することとしてもよい。
また、前記プログラム変換方法は更に、前記ソースプログラムを実行形式に変換した実行プログラムをコンピュータに実行させることで、前記区間において実行された頻度が高い順に、当該頻度が第一位の実行経路を当該コンピュータから取得する実行経路取得ステップを備え、前記実行経路指定ステップは、前記取得手段により取得された前記第一位の実行経路を指定することとしてもよい。
また、前記プログラム変換方法は更に、前記コンピュータが並列実行可能な命令数mを取得する命令上限取得ステップを備え、前記実行経路取得ステップは更に、前記区間における実行頻度が第2位以下の実行経路を取得し、前記実行経路指定ステップは、前記実行経路を前記命令数mに基づき、前記実行経路取得手段によって取得された、第一位から第n(n=m−1)位までの実行経路を指定し、前記第二コード列生成ステップは、前記実行経路指定手段によって指定された第一位から第n位までの実行経路を、実行経路ごとに合計n個のコード列に変換し、前記目的プログラム生成ステップは、前記第一コード列と前記第二コード列生成手段により生成された前記n個のコード列を並列実行させるようにコードを編成した目的プログラムを生成することとしてもよい。
また、前記プログラム変換方法において、前記第二コード列生成ステップは更に、前記第二コード列生成ステップにより生成された第一位から第n位のn個のコードのうち、他の実行経路への条件分岐が発生しなかったコード列以外のコード列を停止させる停止コードを含んで生成することとしてもよい。
また、前記プログラム変換方法は更に、前記コンピュータのメモリの形態が、前記コンピュータの全てのプロセッサエレメントが一つのメモリを共有するメモリ共有型であるか、前記コンピュータの全てのプロセッサエレメントが固有のメモリを有するメモリ分散型かであるかのいずれの形態のメモリを使用しているかの情報を取得するメモリ情報取得ステップを備え、前記目的プログラム生成手段は、前記メモリ情報取得手段により取得したメモリ情報に基づき、メモリ共有型である場合に、前記第一コード列と前記第二コード列において利用される前記ソースプログラム中の元となる変数がそれぞれ独立した変数として扱うコードになっている目的プログラムを生成することとしてもよい。
また、前記プログラム変換方法において、前記目的プログラム生成ステップは、前記停止コードによって停止させられたスレッドをプロセッサエレメントが消去せずに保持しておくコードを含んで目的プログラムを生成することとしてもよい。
また、前記プログラム変換方法は更に、前記目的プログラムを前記コンピュータに適合するように機械語に変換する機械語変換ステップを備えることとしてもよい。
この方法により、目的プログラムが中間コードであった場合に、対象とするコンピュータの機械語にあわせた実行プログラムを生成することができる。
また、前記目的プログラム生成ステップは、前記コンピュータにおいて前記第一コード列の終了が前記第二コード列の終了よりも早い場合には、前記第二コード列を実行している前記コンピュータのプロセッサエレメントに第二コード列の実行を停止させるコードを前記第一コードの後に含んで編成されたプログラムを生成することとしてもよい。
また、前記プログラム変換実行方法は更に、当該プログラム変換実行方法が並列実行可能な命令数mを取得する命令上限取得ステップを備え、前記実行経路取得ステップは更に、
前記区間における実行頻度が第2位以下の実行経路を取得し、前記実行経路指定ステップは、前記実行経路を前記命令数mに基づき、前記実行経路取得手段によって取得された、第一位から第n(n=m−1)位までの実行経路を指定し、前記第二コード生成ステップは、前記実行経路指定手段によって指定された第一位から第n位までの実行経路を、実行経路ごとに合計n個のコード列に変換し、前記目的プログラム生成ステップは、前記第一コード列と前記第二コード列生成手段により生成された前記n個のコード列を並列実行させるようにコードを編成した目的プログラムを生成することとしてもよい。
また、前記プログラム実行変換方法において、前記第二コード列生成ステップは更に、 前記第二コード列生成ステップにより生成された第一位から第n位のn個のコード列のうち、他の実行経路への条件分岐が発生しなかったコード列以外のコード列を停止させる停止コードを含んで生成することとしてもよい。
また、前記プログラム実行変換方法において、前記目的プログラム生成ステップは、自機のメモリの形態が、全てのプロセッサエレメントが一つのメモリを共有するメモリ共有型である場合に、前記第一コード列と前記第二コード列において利用される前記ソースプログラム中の元となる変数がそれぞれ独立した変数として扱うコードになっている目的プログラムを生成することとしてもよい。
また、前記プログラム変換実行変換方法であって、前記目的プログラム生成ステップは、前記停止コードによって停止させられたスレッドをプロセッサエレメントが消去せずに保持しておくコードを含んで目的プログラムを生成することとしてもよい。
<第一の実施形態>
第一の実施形態におけるコンパイラ装置は、メモリ共有型のコンピュータを対象とする実行プログラムを生成する。
<概要>
本発明の概要を図2および図3を用いて説明する。
なお、ブロックI200、J202、K203、L206、Q204、S205、T208、U207、X201はそれぞれ基本ブロックである。基本ブロックはその途中に分岐を含まない命令列のことである。但し、基本ブロックの最後には分岐があっても良い。また、このコンパイラ装置によって生成される実行プログラムは、2以上の処理を同時に実行できるコンピュータを対象としている。
<構成>
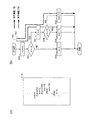
本発明に係るコンパイラ装置100の構成を図1のブロック図を用いて説明する。本発明に係るコンパイラ装置100は、解析部101、実行経路指定部102、最適化部103、コード変換部104からなる。
実行経路指定部102は、解析部101からの実行経路の識別子等を含む解析情報105と、実行プログラムに変換するソースプログラム上の実行経路の実行頻度に関する情報140を取得し、その情報を基に、取得した実行経路のうち実行頻度の高い実行経路を指定し、その内容を最適化部103に送信する機能を有する。
コード変換部104は、最適化部103によって最適化が施されたコードをそれぞれのプロセッサエレメントに割り振った実際に実行する実行プログラム120をターゲットハードウェア130に適合するように生成する機能を有する。生成された実行プログラム120は、ターゲットハードウェア130に渡される。
メモリ共有型は、図4(a)にあるように、複数のプロセッサエレメント400〜402が一つのメモリ403に接続されている。それぞれのプロセッサエレメント400〜402は、メモリ403から必要なデータをロードし、それぞれのレジスタに格納して演算を行い、演算後、その結果に基づきメモリ403に格納されているデータを更新する形態をとっている。
<データ>
コンパイラ装置100に入力されるデータには、実行経路の実行頻度の情報140と、ターゲットハードウェア130のハードウェアの仕様と、ソースプログラム110とがある。以下それらのデータに関する説明を行う。
本実施形態においては、ソースプログラム110の一例として、図5(a)に示す部分ソースプログラム510をコンパイラ装置が変換するものとして説明する。以下、入力される部分ソースプログラム510の内容、及びそれを元に本コンパイラ装置によって作成されるコードの説明を行っていく。
図5(a)は、ソースプログラムのある部分の抜粋の一例であり、この区間におけるプログラムはソースプログラムの全体の中において何度も使用されるものとする。この部分ソースプログラム510を、フローグラフの形式に書き換えると図5(b)のように表される。この部分ソースプログラム510の内容を図5(b)のフローグラフを用いて説明する。
命令ブロック500において得られたxが0以下(分岐ブロック505のno)ならば、ブロック504に進み、xに命令ブロック500において得られたxの値をマイナス値にして格納する。命令ブロック500において得られたxが0以上(分岐ブロック505のyes)ならば、命令ブロック501に進み、yに命令ブロック500において得られたxの値からcを引いた値を格納する。
スレッド600の内容を簡単に説明すると、コード601、609、617、622、627、632はラベルコードで、プログラム中の分岐において命令が飛ぶ先の指定に用いられる。
コード610〜616は、図5(b)のフローグラフにおいて、ブロック501、及びブロック506の命令の内容をコード化したものである。
コード618〜621は、図5(b)のフローグラフにおいて、ブロック502の命令の内容をコード化したものである。
コード628〜631は、図5(b)のフローグラフにおいて、ブロック504の命令の内容をコード化したものである。
そして、コード633、634は、このスレッド600が終了した際の処理を行うコードである。
図7には、図5の実行頻度一位の実行経路551上の命令群をコード化したスレッド700を記してある。コード701、713、719はそれぞれラベルコードである。コード702〜712は、図5のブロック500、501、502を他の実行経路に分岐しないようにコード化した内容になっており、ブロック505、506がこの実行経路を通るかどうかの2択に変えたコードを含んでいる。
コード717、718は、実行経路551が実行されたときにコードを反映させる処理になる。この反映処理は、実行経路551の出口で生存していて、かつ実行経路551で変更されているデータが対象になる。
コード720、721はこのスレッド700の終了処理である。
図8には、実行経路552上の命令をアセンブラコードに変換したスレッド800を記してある。
またコード802〜813は図5におけるブロック500、501、503の命令をコード化した内容になっている。コード815、816は実行経路552を通ることが確定した場合に、他のプロセッサエレメントで実行されているスレッドを停止させ、コード821、822はスレッド800終了処理を行っている。また、コード818、819は、実行経路552が実行されたときにコードを反映させる処理になる。
コード901、909、912、914はそれぞれラベルコードである。
またコード902〜908は図5におけるブロック500、504の命令をコード化した内容になっている。コード910、911はこの実行経路を通ることが確定した場合に、他のプロセッサエレメントで実行されているスレッドを停止させ、コード915、916はスレッド900の終了処理を行っている。また、コード913は、ブロック500、504が実行されたときにコードを反映させる処理になる。
コード1001〜1004においては、解析部101から得た解析情報と、実行経路の実行頻度の情報を基に、実行頻度の高かった実行経路に関するスレッドを生成している。ここでは、ターゲットハードウェアは、十分なプロセッサエレメントを有するものとして、全ての実行経路のスレッドを立ち上げている。
ここから、生成されるプログラムに使用され、図6〜図14及び図21に用いられているコードの説明を行う。
なお、以下において番地は、プロセッサ上の命令の番地であり、レジスタの番地であったり、そのレジスタに格納されている値であったりする。
「add (番地1),(番地2)」は、(番地1)の値と(番地2)の値とを加算し、その結果で得られた値で(番地2)の値を更新するコードである。例えば図6のコード604においては、レジスタD1に格納されている値と、レジスタD0に格納されている値を加算し、計算結果の値でレジスタD0の値を更新する。
「cmp (番地1),(番地2)」は、(番地1)の値と(番地2)とを比較するコードである。例えば図6のコード606においては、0とレジスタD0に格納されている値とを比較している。
「not (番地1)」は、(番地1)の値をビット反転した(1の補数)値にして、その値で(番地1)を更新するコードである。例えば、図6のコード629においては、レジスタD0に格納されている値をビット反転した(1の補数)値にして、レジスタD0に格納しなおしている。
「dec (番地1)」は、(番地1)の値から1減算して、その値で(番地1)を更新するコードである。例えば、図11のコード1113においてはレジスタD1に格納されている値から1引いた、D1−1の値をレジスタD1格納しなおしている。
「asl (番地1),(番地2)」は、ターゲットハードウェアで使用されている命令語長の違いによる番地のずれを防ぐためのコードであり、主にコード間の遷移を行う場合に必要となる。プログラムにおいては各命令の番地は、命令語長の単位で管理されており、例えば、命令語長が8bitであった場合には、命令1の番地が0であった場合に、その次に続く命令2の番地は8になる。命令1の次の命令2に移行したい場合に、単純に命令1の番地に1足しても命令2の番地にならないので命令2は実行されず、番地の整合性が取れなくなる。このコードの実質的内容はというと、命令語長の値を(番地2)の値にかけて、(番地2)のレジスタに格納することがこのコードの内容である。
次に、スレッド制御のためのコードの内容について説明する。
「_createthread (番地1),(番地2)」は、スレッドを生成するコードであり、(番地1)から始まるプロセスを生成する。その実行状態の情報は(番地2)に更新される。例えば、図10のコード1002においては、LABEL500−501−502で始まるスレッド、即ち図7のスレッド700を生成し、その実行情報はTHREAD500−501−502に格納される。
「#endthread」は、スレッドの終了コードで、現在実行しているスレッドを終了状態に設定し、スレッドが終了したことを示す情報を返す。例えば、図7のコード720においてはスレッド700を終了し、終了したことを示す情報をプログラムのメインに返す。
「_killthread (番地)」は、他のプロセッサエレメントで実行されているスレッドの強制終了コードで、(番地)から始まるスレッドを停止させる。例えば、図7のコード714においては、LABEL500−501−503で始まるスレッド、即ち、図8のスレッド800の実行を、実行途中であっても中止させる。
「#commit (番地1)」は、メインプログラム、若しくはスレッドプロセスで生成した情報(番地1)を、メインプログラムと全てのスレッドプロセスに反映させるコードである。
「_getparallelnum (番地)」は、ターゲットハードウェアが同時実行可能なスレッドの数を(番地)に返すコードで、ターゲットハードウェアの並列実行可能なプロセッサエレメントの数を取得するために必要なコードで、特にコンパイル時にターゲットハードウェアの並列実行可能なプロセッサエレメントの数が分からない場合に必要となる。
<動作>
本コンパイラ装置によって生成される実行プログラムの生成における本コンパイラ装置の動作を実行プログラムの生成手順に沿ってフローチャートを用いながら説明する。
一度ソースプログラム110は、最適化部103、コード変換部104を通じて、特別な最適化を施さずに実行プログラムに変換されて、ターゲットハードウェア130上において実際に実行されて実行経路の実行頻度に関する情報を得る。この実行経路の実行頻度の取得方法に関して、図15のフローチャートを用いて説明する。
まずコンパイラ装置100は、大本のソースプログラムをそのまま実行形式に出来るコードに変換した第一コードを作成する(ステップS1901)。そして、実行経路指定部102は、ターゲットハードウェア130から取得した実行経路の実行頻度に関する情報140に基づき、その実行頻度の高かった、即ち実行回数の多かった優先実行経路を実行頻度の高い順に抽出し(S1905)、それとターゲットハードウェア130の並列実行可能なプロセッサエレメントの数により、優先実行経路上の命令を最適化した第二コードを生成する(S1907)。この第二コードはターゲットハードウェア130の並列実行可能なプロセッサエレメントの数より1少ない数まで生成されて良く、実行経路によって内容を変えて生成されて良く、実行頻度の回数の多かった実行経路の順に、それぞれの実行経路上の命令に対応するスレッドを生成して、その実行経路上の命令が最適化される。例えば、ターゲットハードウェア130の並列実行可能なプロセッサエレメントの数が4であった場合には、実行頻度第一位から第三位までの実行経路のスレッドを生成する。第一コードには複数の第二コードを制御するコードも含まれている。
この動作を具体的に図5(a)の部分ソースプログラム510を実行プログラムに変換するとして、その過程において生成されるコード等を用い説明する。
<第二の実施形態>
第二の実施形態においては、ターゲットハードウェアのメモリ形態がメモリ分散型であった場合について、主に、第一の実施形態と異なる点を説明する。
その違いを示すために図12〜図14及び図21のコード列を用意した。図12のスレッド1200の実行内容は、図7のスレッド700に、図13のスレッド1300の実行内容は、図8のスレッド800に、図14のスレッド1400の実行内容は、図9のスレッド900に、相当する。図21は、メモリ分散型の場合のメインスレッドである。
コード2106では、コード2101〜2103で生成されたスレッドにbの値を各プロセッサエレメントのメモリのレジスタD1に格納するように各スレッドを実行しているプロセッサエレメントに通達する。
コード2107では、コード2101〜2103で生成されたスレッドにcの値を各プロセッサエレメントのメモリのレジスタD2に格納するように各スレッドを実行しているプロセッサエレメントに通達する。
メモリ分散型のハードウェアを対象とした場合の実行プログラムの実行手順について、主にスレッドの制御に関する部分を、図17のフローチャートを用いて説明する。
<第三の実施形態>
第一、及び第二の実施形態においては、ターゲットハードウェアの並列実行可能な処理の数がコンパイラ装置には既知の物として説明してきたが、ターゲットハードウェアが並列実行可能なプロセッサエレメントの数が分からない場合もある。つまり、実行経路の実行頻度に関する情報、及びターゲットハードウェアのメモリ形態が予めコンパイラ装置に与えられており、いきなり実行プログラムをターゲットハードウェアに実行させたい場合などである。この場合メインプログラムの中に、当該プロセッサエレメントの数を取得するコードを組み込み、それと生成されるスレッドの数との整合を採るためのコードも組み込む必要が出てくる。そのために必要なコード列を図11に示してあり、その実行内容を説明する。なお、ここでは、ソースプログラムは図6にあるものであり、生成されるスレッドは図7〜9の3つであるものとして説明する。
まず、コンパイラによって生成されるスレッドの数mを取得し、その数mをレジスタD0に格納する(コード1106)。次にターゲットハードウェアの並列実行可能なプロセッサエレメントの数nを取得し、その値をレジスタD1に格納する(コード1107)。そしてレジスタD0に格納されたmとレジスタD1に格納されたnの値を比較し(コード1108)、n≧mならばラベルコード1111に飛び(コード1109)、n<mならばラベルコード1113に飛ぶ(コード1110)。
n<mの場合には、生成されたスレッドの数mの方が並列実行可能な命令数nを上回っているため、すべてのスレッドを実行できない。
そこで、まず、レジスタD1に格納されている値nから1引いた数をD1に格納しなおす(コード1114)。このn−1の数が必要とする実行可能なスレッドの数である。一つ余るプロセッサエレメントは、元のプログラムをそのままコードにした図6のコードを実行する。
ターゲットハードウェアの性能が分からない場合に、その性能を取得する必要があり、その流れを図16のフローチャートに簡単に示しておいた。
<第四の実施形態>
第四の実施形態においては、上記実施の形態と異なり、図18にある機能ブロック図にあるように、上記実施の形態におけるコンパイラ装置にプログラムを実行できる実行部1807を組み込んだプログラム変換実行装置1800の実施の形態を示す。
実行部1807は、実行プログラム格納部1806から実行プログラムを読み出し、当該実行プログラムを実行する機能を有し、MPU、ROM、RAMを含んで構成され、図1におけるターゲットハードウェア130と同等の働きをする。なお、このCPUは複数のプロセッサエレメントで構成されている。
<補足>
なお、上記第一の実施形態及び第二の実施形態においては、ターゲットハードウェアは生成されるスレッド全てを実行できるだけの十分な数のプロセッサエレメントを有するものとして説明したが、例えばプロセッサエレメントの数が少なく2個とかの場合には、スレッド600とスレッド700だけが並列実行されるようにメインスレッドは構成される。この場合、図10においてはコード1003、1004、1007、1008、1011、1012、1015、1016は不要になる。
また、上記実施の形態においてはターゲットハードウェアが複数のプロセッサエレメントを内包するように記述したが、例えば、一台のパソコンを一つのプロセッサエレメントと見立てて、複数のパソコンをネットワークを介して接続して並列実行する形をとっても良い。
101 解析部
102 実行経路指定部
103 最適化部
104 コード変換部
105 解析情報
120 実行プログラム
130 ターゲットハードウェア
140 実行経路の実行頻度の情報
400、401、402、410、411、412 プロセッサエレメント
403、413、414、415 メモリ
500、501、502、503、504 命令ブロック
505、506 分岐ブロック
510 部分ソースプログラム
511 実行頻度一位の実行経路
512 実行頻度二位の実行経路
1806 実行プログラム格納部
1807 実行部
Claims (28)
- 条件分岐を含むソースプログラムを変換して、2以上の命令を並列して実行できるコンピュータを対象とする目的プログラムを生成するプログラム変換装置であって、
前記ソースプログラムにおいて、条件分岐を跨ぐ一区間についての複数の実行経路のうちの一つの実行経路を指定する実行経路指定手段と、
前記区間にある全ての命令群を基に、その命令群に相当する第一コード列を生成する第一コード列生成手段と、
前記実行経路指定手段によって指定される実行経路上の命令群だけに相当する第二コード列を生成し、当該生成において条件分岐命令については、他の実行経路への分岐条件が成立しない場合に前記区間における当該条件分岐命令以降の命令を続行し、他の実行経路への分岐条件が成立する場合に前記区間における当該条件分岐以降の命令の実行を中止するコードを当該条件分岐命令に相当するコードとして生成する第二コード列生成手段と、
前記ソースプログラムの前記区間に後続する部分の命令群を基に、その命令群に相当する第三コード列を生成する第三コード列生成手段と、
前記第一コード列と、前記第二コード列とを、前記コンピュータに並列実行させるように、かつ、前記第二コード列において他の実行経路への分岐条件が成立しない場合には前記第二コード列に継続して前記第三コード列を実行させ、前記第二コード列において他の実行経路への分岐条件が成立する場合には第一コード列に継続して第三コード列を実行させるように編成した目的プログラムを生成する目的プログラム生成手段とを備える
ことを特徴とするプログラム変換装置。 - 前記目的プログラム生成手段は、
前記コンピュータにおいて前記第一コード列の終了が前記第二コード列の終了よりも早い場合には、前記第二コード列を実行している前記コンピュータのプロセッサエレメントに第二コード列の実行を停止させるコードを前記第一コード列の後に含んで編成された目的プログラムを生成する
ことを特徴とする請求項1記載のプログラム変換装置。 - 前記プログラム変換装置は更に、
前記ソースプログラムを実行形式に変換した実行プログラムをコンピュータに実行させることで、前記区間において実行された頻度が高い順に、当該頻度が第一位の実行経路を当該コンピュータから取得する実行経路取得手段を備え、
前記実行経路指定手段は、前記取得手段により取得された前記第一位の実行経路を指定する
ことを特徴とする請求項1記載のプログラム変換装置。 - 前記プログラム変換装置は更に、
前記コンピュータが並列実行可能な命令数mを取得する命令上限取得手段を備え、
前記実行経路取得手段は更に、
前記区間における実行頻度が第2位以下の実行経路を取得し、
前記実行経路指定手段は、
前記実行経路を前記命令数mに基づき、前記実行経路取得手段によって取得された、第一位から第n(n=m−1)位までの実行経路を指定し、
前記第二コード列生成手段は、前記実行経路指定手段によって指定された第一位から第n位までの実行経路を、実行経路ごとに合計n個のコード列に変換し、
前記目的プログラム生成手段は、
前記第一コード列と前記第二コード列生成手段により生成された前記n個のコード列を並列実行させるようにコードを編成した目的プログラムを生成する
ことを特徴とする請求項3記載のプログラム変換装置。 - 前記第二コード列生成手段は更に、
前記第二コード列生成手段により生成された第一位から第n位のn個のコードのうち、他の実行経路への条件分岐が発生しなかったコード列以外のコード列を停止させる停止コードを含んで生成する
ことを特徴とする請求項4記載のプログラム変換装置。 - 前記プログラム変換装置は更に、
前記コンピュータのメモリの形態が、前記コンピュータの全てのプロセッサエレメントが一つのメモリを共有するメモリ共有型であるか、前記コンピュータの全てのプロセッサエレメントが固有のメモリを有するメモリ分散型かであるかのいずれの形態のメモリを使用しているかの情報を取得するメモリ情報取得手段を備え、
前記目的プログラム生成手段は、前記メモリ情報取得手段により取得したメモリ情報に基づき、メモリ共有型である場合に、前記第一コード列と前記第二コード列において利用される前記ソースプログラム中の元となる変数がそれぞれ独立した変数として扱うコードになっている目的プログラムを生成する
ことを特徴とする請求項1記載のプログラム変換装置。 - 前記目的プログラム生成手段は、
前記停止コードによって停止させられたスレッドをプロセッサエレメントが消去せずに保持しておくコードを含んで目的プログラムを生成する
ことを特徴とする請求項5記載のプログラム変換装置。 - 前記プログラム変換装置は更に、
前記目的プログラムを前記コンピュータに適合するように機械語に変換する機械語変換手段を備える
ことを特徴とする請求項1記載のプログラム変換装置。 - 条件分岐を含むソースプログラムを実行形式である実行形式プログラムに変換して、かつ、2以上の命令を並列して実行できるプログラム変換実行装置であって、
前記ソースプログラムにおいて、条件分岐を跨ぐ一区間についての複数の実行経路のうちの一つの実行経路を指定する実行経路指定手段と、
前記区間にある全ての条件分岐を含んだ命令群を基に、その命令群に相当する第一コード列を生成する第一コード列生成手段と、
前記第一コード列を含む第一プログラムを実行する実行手段と、
前記実行手段が前記第一プログラムを実行することにより得られた前記区間における実行経路のうち実行頻度が高い順に、当該実行頻度が第一位の実行経路を取得する取得手段と、
前記取得手段によって取得された実行経路を前記実行経路指定手段によって指定し、当該実行経路上の命令群に相当する第二コード列を生成し、当該生成において条件分岐命令については、他の実行経路への分岐条件が成立しない場合に前記区間における当該条件分岐命令以降の命令を続行し、他の実行経路への分岐条件が成立する場合に前記区間における当該条件分岐以降の命令の実行を中止するコードを当該条件分岐命令に相当するコードとして生成する第二コード列生成手段と、
前記ソースプログラムの前記区間に後続する部分の命令群を基に、その命令群に相当する第三コード列を生成する第三コード列生成手段と、
前記第一コード列と、前記第二コード列とを、並列実行するように、かつ、前記第二コード列において他の実行経路への条件分岐が発生しない場合には前記第二コード列に継続して前記第三コード列を実行し、前記第二コード列において他の実行経路への条件分岐が発生する場合には前記第一コード列に継続して前記第三コード列を実行するように編成した目的プログラムを生成する目的プログラム生成手段とを備え、
前記実行手段は前記第一プログラムを実行する代わりに前記目的プログラムを実行する
ことを特徴とするプログラム変換実行装置。 - 前記目的プログラム生成手段は、
前記コンピュータにおいて前記第一コード列の終了が前記第二コード列の終了よりも早い場合には、前記第二コード列を実行している前記コンピュータのプロセッサエレメントに第二コード列の実行を停止させるコードを前記第一コードの後に含んで編成されたプログラムを生成する
ことを特徴とする請求項9記載のプログラム変換実行装置。 - 前記プログラム変換実行装置は更に、
当該プログラム変換実行装置が並列実行可能な命令数mを取得する命令上限取得手段を備え、
前記実行経路取得手段は更に、
前記区間における実行頻度が第2位以下の実行経路を取得し、
前記実行経路指定手段は、
前記実行経路を前記命令数mに基づき、前記実行経路取得手段によって取得された、第一位から第n(n=m−1)位までの実行経路を指定し、
前記第二コード生成手段は、前記実行経路指定手段によって指定された第一位から第n位までの実行経路を、実行経路ごとに合計n個のコード列に変換し、
前記目的プログラム生成手段は、
前記第一コード列と前記第二コード列生成手段により生成された前記n個のコード列を並列実行させるようにコードを編成した目的プログラムを生成する
ことを特徴とする請求項10記載のプログラム変換実行装置。 - 前記第二コード列生成手段は更に、
前記第二コード列生成手段により生成された第一位から第n位のn個のコード列のうち、他の実行経路への条件分岐が発生しなかったコード列以外のコード列を停止させる停止コードを含んで生成する
ことを特徴とする請求項11記載のプログラム変換実行装置。 - 前記目的プログラム生成手段は、
自機のメモリの形態が、全てのプロセッサエレメントが一つのメモリを共有するメモリ共有型である場合に、前記第一コード列と前記第二コード列において利用される前記ソースプログラム中の元となる変数がそれぞれ独立した変数として扱うコードになっている目的プログラムを生成する
ことを特徴とする請求項9記載のプログラム変換実行装置。 - 前記目的プログラム生成手段は、
前記停止コードによって停止させられたスレッドをプロセッサエレメントが消去せずに保持しておくコードを含んで目的プログラムを生成する
ことを特徴とする請求項12記載のプログラム変換実行装置。 - プログラム変換装置が実行する、条件分岐を含むソースプログラムを変換して2以上の命令を並列して実行できるコンピュータを対象とする目的プログラムを生成するプログラム変換方法であって、
前記ソースプログラムにおいて、条件分岐を跨ぐ一区間についての複数の実行経路のうちの一つの実行経路を指定する実行経路指定ステップと、
前記区間にある全ての命令群を基に、その命令群に相当する第一コード列を生成する第一コード列生成ステップと、
前記実行経路指定ステップにおいて指定される実行経路上の命令群だけに相当する第二コード列を生成し、当該生成において条件分岐命令については、他の実行経路への分岐条件が成立しない場合に前記区間における当該条件分岐命令以降の命令を続行し、他の実行経路への分岐条件が成立する場合に前記区間における当該条件分岐以降の命令の実行を中止するコードを当該条件分岐命令に相当するコードとして生成する第二コード列生成ステップと、
前記ソースプログラムの前記区間に後続する部分の命令群を基に、その命令群に相当する第三コード列を生成する第三コード列生成ステップと、
前記第一コード列と、前記第二コード列とを、前記コンピュータに並列実行させるように、かつ、前記第二コード列において他の実行経路への分岐条件が成立しない場合には前記第二コード列に継続して前記第三コード列を実行させ、前記第二コード列において他の実行経路への分岐条件が成立する場合には第一コード列に継続して第三コード列を実行させるように編成した目的プログラムを生成する目的プログラム生成ステップとを備える
ことを特徴とするプログラム変換方法。 - 前記目的プログラム生成ステップでは、
前記コンピュータにおいて前記第一コード列の終了が前記第二コード列の終了よりも早い場合には、前記第二コード列を実行している前記コンピュータのプロセッサエレメントに第二コード列の実行を停止させるコードを前記第一コード列の後に含んで編成された目的プログラムを生成する
ことを特徴とする請求項15記載のプログラム変換方法。 - 前記プログラム変換方法は更に、
前記ソースプログラムを実行形式に変換した実行プログラムをコンピュータに実行させることで、前記区間において実行された頻度が高い順に、当該頻度が第一位の実行経路を当該コンピュータから取得する実行経路取得ステップを備え、
前記実行経路指定ステップは、前記実行経路取得ステップにおいて取得された前記第一位の実行経路を指定する
ことを特徴とする請求項15記載のプログラム変換方法。 - 前記プログラム変換方法は更に、
前記コンピュータが並列実行可能な命令数mを取得する命令上限取得ステップを備え、
前記実行経路取得ステップは更に、
前記区間における実行頻度が第2位以下の実行経路を取得し、
前記実行経路指定ステップは、
前記実行経路を前記命令数mに基づき、前記実行経路取得ステップにおいて取得された、第一位から第n(n=m−1)位までの実行経路を指定し、
前記第二コード列生成ステップは、前記実行経路指定ステップにおいて指定された第一位から第n位までの実行経路を、実行経路ごとに合計n個のコード列に変換し、
前記目的プログラム生成ステップは、
前記第一コード列と前記第二コード列生成ステップにおいて生成された前記n個のコード列を並列実行させるようにコードを編成した目的プログラムを生成する
ことを特徴とする請求項17記載のプログラム変換方法。 - 前記第二コード列生成ステップは更に、
前記第二コード列生成ステップにより生成された第一位から第n位のn個のコードのうち、他の実行経路への条件分岐が発生しなかったコード列以外のコード列を停止させる停止コードを含んで生成する
ことを特徴とする請求項18記載のプログラム変換方法。 - 前記プログラム変換方法は更に、
前記コンピュータのメモリの形態が、前記コンピュータの全てのプロセッサエレメントが一つのメモリを共有するメモリ共有型であるか、前記コンピュータの全てのプロセッサエレメントが固有のメモリを有するメモリ分散型かであるかのいずれの形態のメモリを使用しているかの情報を取得するメモリ情報取得ステップを備え、
前記目的プログラム生成ステップは、前記メモリ情報取得ステップにおいて取得されたメモリ情報に基づき、メモリ共有型である場合に、前記第一コード列と前記第二コード列において利用される前記ソースプログラム中の元となる変数がそれぞれ独立した変数として扱うコードになっている目的プログラムを生成する
ことを特徴とする請求項15記載のプログラム変換方法。 - 前記目的プログラム生成ステップは、
前記停止コードによって停止させられたスレッドをプロセッサエレメントが消去せずに保持しておくコードを含んで目的プログラムを生成する
ことを特徴とする請求項19記載のプログラム変換方法。 - 前記プログラム変換方法は更に、
前記目的プログラムを前記コンピュータに適合するように機械語に変換する機械語変換ステップを備える
ことを特徴とする請求項15記載のプログラム変換方法。 - プログラム変換実行装置が実行する、条件分岐を含むソースプログラムを実行形式である実行形式プログラムに変換して、かつ、2以上の命令を並列して実行できるプログラム変換実行方法であって、
前記ソースプログラムにおいて、条件分岐を跨ぐ一区間についての複数の実行経路のうちの一つの実行経路を指定する実行経路指定ステップと、
前記区間にある全ての条件分岐を含んだ命令群を基に、その命令群に相当する第一コード列を生成する第一コード列生成ステップと、
前記第一コード列を含む第一プログラムを実行する実行ステップと、
前記実行ステップが前記第一プログラムを実行することにより得られた前記区間における実行経路のうち実行頻度が高い順に、当該実行頻度が第一位の実行経路を取得する取得ステップと、
前記取得ステップによって取得された実行経路を前記実行経路指定ステップによって指定し、当該実行経路上の命令群に相当する第二コード列を生成し、当該生成において条件分岐命令については、他の実行経路への分岐条件が成立しない場合に前記区間における当該条件分岐命令以降の命令を続行し、他の実行経路への分岐条件が成立する場合に前記区間における当該条件分岐以降の命令の実行を中止するコードを当該条件分岐命令に相当するコードとして生成する第二コード列生成ステップと、
前記ソースプログラムの前記区間に後続する部分の命令群を基に、その命令群に相当する第三コード列を生成する第三コード列生成ステップと、
前記第一コード列と、前記第二コード列とを、並列実行するように、かつ、前記第二コード列において他の実行経路への条件分岐が発生しない場合には前記第二コード列に継続して前記第三コード列を実行し、前記第二コード列において他の実行経路への条件分岐が発生する場合には前記第一コード列に継続して前記第三コード列を実行するように編成した目的プログラムを生成する目的プログラム生成ステップとを備え、
前記実行ステップは前記第一プログラムを実行する代わりに前記目的プログラムを実行する
ことを特徴とするプログラム変換実行方法。 - 前記目的プログラム生成ステップは、
前記コンピュータにおいて前記第一コード列の終了が前記第二コード列の終了よりも早い場合には、前記第二コード列を実行している前記コンピュータのプロセッサエレメントに第二コード列の実行を停止させるコードを前記第一コードの後に含んで編成されたプログラムを生成する
ことを特徴とする請求項23記載のプログラム変換実行方法。 - 前記プログラム変換実行方法は更に、
当該プログラム変換実行方法が並列実行可能な命令数mを取得する命令上限取得ステップを備え、
前記実行経路取得ステップは更に、
前記区間における実行頻度が第2位以下の実行経路を取得し、
前記実行経路指定ステップは、
前記実行経路を前記命令数mに基づき、前記実行経路取得ステップにおいて取得された、第一位から第n(n=m−1)位までの実行経路を指定し、
前記第二コード生成ステップは、前記実行経路指定ステップにおいて指定された第一位から第n位までの実行経路を、実行経路ごとに合計n個のコード列に変換し、
前記目的プログラム生成ステップは、
前記第一コード列と前記第二コード列生成ステップにおいて生成された前記n個のコード列を並列実行させるようにコードを編成した目的プログラムを生成する
ことを特徴とする請求項24記載のプログラム変換実行方法。 - 前記第二コード列生成ステップは更に、
前記第二コード列生成ステップにより生成された第一位から第n位のn個のコード列のうち、他の実行経路への条件分岐が発生しなかったコード列以外のコード列を停止させる停止コードを含んで生成する
ことを特徴とする請求項25記載のプログラム変換実行方法。 - 前記目的プログラム生成ステップは、
自機のメモリの形態が、全てのプロセッサエレメントが一つのメモリを共有するメモリ共有型である場合に、前記第一コード列と前記第二コード列において利用される前記ソースプログラム中の元となる変数がそれぞれ独立した変数として扱うコードになっている目的プログラムを生成する
ことを特徴とする請求項23記載のプログラム変換実行方法。 - 前記目的プログラム生成ステップは、
前記停止コードによって停止させられたスレッドをプロセッサエレメントが消去せずに保持しておくコードを含んで目的プログラムを生成する
ことを特徴とする請求項27記載のプログラム変換実行方法。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004341236A JP4783005B2 (ja) | 2004-11-25 | 2004-11-25 | プログラム変換装置、プログラム変換実行装置およびプログラム変換方法、プログラム変換実行方法。 |
| US11/269,705 US20060130012A1 (en) | 2004-11-25 | 2005-11-09 | Program conversion device, program conversion and execution device, program conversion method, and program conversion and execution method |
| CNB2005101236116A CN100562849C (zh) | 2004-11-25 | 2005-11-18 | 程序转换器件及方法、程序转换执行器件及转换执行方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004341236A JP4783005B2 (ja) | 2004-11-25 | 2004-11-25 | プログラム変換装置、プログラム変換実行装置およびプログラム変換方法、プログラム変換実行方法。 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2006154971A JP2006154971A (ja) | 2006-06-15 |
| JP2006154971A5 JP2006154971A5 (ja) | 2008-01-17 |
| JP4783005B2 true JP4783005B2 (ja) | 2011-09-28 |
Family
ID=36585567
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004341236A Expired - Fee Related JP4783005B2 (ja) | 2004-11-25 | 2004-11-25 | プログラム変換装置、プログラム変換実行装置およびプログラム変換方法、プログラム変換実行方法。 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20060130012A1 (ja) |
| JP (1) | JP4783005B2 (ja) |
| CN (1) | CN100562849C (ja) |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4712512B2 (ja) * | 2005-10-14 | 2011-06-29 | 富士通株式会社 | プログラム変換プログラム、プログラム変換装置、プログラム変換方法 |
| EP2093667A4 (en) * | 2006-12-14 | 2012-03-28 | Fujitsu Ltd | COMPILATION METHOD AND COMPILER |
| JP2008158806A (ja) * | 2006-12-22 | 2008-07-10 | Matsushita Electric Ind Co Ltd | 複数プロセッサエレメントを備えるプロセッサ用プログラム及びそのプログラムの生成方法及び生成装置 |
| US8751211B2 (en) | 2008-03-27 | 2014-06-10 | Rocketick Technologies Ltd. | Simulation using parallel processors |
| US9032377B2 (en) * | 2008-07-10 | 2015-05-12 | Rocketick Technologies Ltd. | Efficient parallel computation of dependency problems |
| JP2010039536A (ja) * | 2008-07-31 | 2010-02-18 | Panasonic Corp | プログラム変換装置、プログラム変換方法およびプログラム変換プログラム |
| US9489183B2 (en) | 2010-10-12 | 2016-11-08 | Microsoft Technology Licensing, Llc | Tile communication operator |
| US9430204B2 (en) | 2010-11-19 | 2016-08-30 | Microsoft Technology Licensing, Llc | Read-only communication operator |
| US9507568B2 (en) * | 2010-12-09 | 2016-11-29 | Microsoft Technology Licensing, Llc | Nested communication operator |
| US9395957B2 (en) | 2010-12-22 | 2016-07-19 | Microsoft Technology Licensing, Llc | Agile communication operator |
| US9128748B2 (en) | 2011-04-12 | 2015-09-08 | Rocketick Technologies Ltd. | Parallel simulation using multiple co-simulators |
| US9195443B2 (en) * | 2012-01-18 | 2015-11-24 | International Business Machines Corporation | Providing performance tuned versions of compiled code to a CPU in a system of heterogeneous cores |
| US20150363230A1 (en) * | 2013-01-23 | 2015-12-17 | Waseda University | Parallelism extraction method and method for making program |
| WO2014143042A1 (en) * | 2013-03-15 | 2014-09-18 | Intel Corporation | Path profiling using hardware and software combination |
| IL232836A0 (en) * | 2013-06-02 | 2014-08-31 | Rocketick Technologies Ltd | Efficient parallel computation of dependency problems |
| US9372695B2 (en) | 2013-06-28 | 2016-06-21 | Globalfoundries Inc. | Optimization of instruction groups across group boundaries |
| US9348596B2 (en) | 2013-06-28 | 2016-05-24 | International Business Machines Corporation | Forming instruction groups based on decode time instruction optimization |
| US9335987B2 (en) * | 2013-12-09 | 2016-05-10 | International Business Machines Corporation | Data object with common statement series |
| KR102250617B1 (ko) * | 2014-03-11 | 2021-05-10 | 아이이엑스 그룹, 인크. | 데이터 동기화 및 페일오버 관리를 위한 시스템들 및 방법들 |
| US9858058B2 (en) | 2014-03-31 | 2018-01-02 | International Business Machines Corporation | Partition mobility for partitions with extended code |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2921190B2 (ja) * | 1991-07-25 | 1999-07-19 | 日本電気株式会社 | 並列実行方式 |
| FR2685511B1 (fr) * | 1991-12-19 | 1994-02-04 | Bull Sa | Procede de classification des architectures d'ordinateur. |
| JPH0660047A (ja) * | 1992-08-05 | 1994-03-04 | Seiko Epson Corp | マルチプロセッサ処理装置 |
| JPH0736680A (ja) * | 1993-07-23 | 1995-02-07 | Omron Corp | 並列化プログラム開発支援装置 |
| JPH1196005A (ja) * | 1997-09-19 | 1999-04-09 | Nec Corp | 並列処理装置 |
| US6170083B1 (en) * | 1997-11-12 | 2001-01-02 | Intel Corporation | Method for performing dynamic optimization of computer code |
| US6308261B1 (en) * | 1998-01-30 | 2001-10-23 | Hewlett-Packard Company | Computer system having an instruction for probing memory latency |
| JP2000163266A (ja) * | 1998-11-30 | 2000-06-16 | Mitsubishi Electric Corp | 命令実行方式 |
| JP3641997B2 (ja) * | 2000-03-30 | 2005-04-27 | 日本電気株式会社 | プログラム変換装置及び方法並びに記録媒体 |
| JP3891936B2 (ja) * | 2001-02-28 | 2007-03-14 | 富士通株式会社 | 並列プロセス実行方法、及びマルチプロセッサ型コンピュータ |
| JP2003323304A (ja) * | 2002-04-30 | 2003-11-14 | Fujitsu Ltd | 投機タスク生成方法および装置 |
| JP3896087B2 (ja) * | 2003-01-28 | 2007-03-22 | 松下電器産業株式会社 | コンパイラ装置およびコンパイル方法 |
| JP2004303113A (ja) * | 2003-04-01 | 2004-10-28 | Hitachi Ltd | 階層メモリ向け最適化処理を備えたコンパイラおよびコード生成方法 |
-
2004
- 2004-11-25 JP JP2004341236A patent/JP4783005B2/ja not_active Expired - Fee Related
-
2005
- 2005-11-09 US US11/269,705 patent/US20060130012A1/en not_active Abandoned
- 2005-11-18 CN CNB2005101236116A patent/CN100562849C/zh not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2006154971A (ja) | 2006-06-15 |
| CN1783012A (zh) | 2006-06-07 |
| CN100562849C (zh) | 2009-11-25 |
| US20060130012A1 (en) | 2006-06-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4783005B2 (ja) | プログラム変換装置、プログラム変換実行装置およびプログラム変換方法、プログラム変換実行方法。 | |
| JP5707011B2 (ja) | 統合分岐先・述語予測 | |
| JPH0397059A (ja) | 並列プロセッサで処理する並列な命令ストリームを同期させる方法 | |
| US8359588B2 (en) | Reducing inter-task latency in a multiprocessor system | |
| JP2898105B2 (ja) | コンパイル中にソフトウェア・スケジューリング技術を用いてハードウェアのパイプライン処理の中断を最小化する方法 | |
| KR20090089382A (ko) | 컴파일 방법 및 컴파일러 | |
| US20020095668A1 (en) | Compiler and register allocation method | |
| CN118626415A (zh) | 模型优化方法以及相关装置 | |
| Meng et al. | FPGA acceleration of deep reinforcement learning using on-chip replay management | |
| US12141606B2 (en) | Cascading of graph streaming processors | |
| Kwon | vLLM: An Efficient Inference Engine for Large Language Models | |
| CN113791770A (zh) | 代码编译器、代码编译方法、代码编译系统和计算机介质 | |
| US11436045B2 (en) | Reduction of a number of stages of a graph streaming processor | |
| Anantharaman et al. | A hardware accelerator for speech recognition algorithms | |
| CN119645584A (zh) | 基于异构数据流架构的细粒度多算子并行调度方法及系统 | |
| US20230051505A1 (en) | Configurable scheduler with pre-fetch and invalidate threads in a graph stream processing system | |
| US20060225049A1 (en) | Trace based signal scheduling and compensation code generation | |
| RU2802777C1 (ru) | Способ распределения данных по уровням памяти вычислительной системы с разноуровневой общей памятью | |
| US20250156679A1 (en) | Compilation method, data processing method and apparatus thereof | |
| JP2002318689A (ja) | 資源使用サイクルの遅延指定付き命令を実行するvliwプロセッサおよび遅延指定命令の生成方法 | |
| Chalmers | Process-Based Aho-Corasick Failure Function Construction | |
| JP2017224288A (ja) | 並列化方法、並列化ツール、車載装置 | |
| JP3239963B2 (ja) | マルチ・プロセッサ計算機システム | |
| CN120122956A (zh) | 一种多粒度数据流编译系统与数据流图编译方法 | |
| JP3921722B2 (ja) | コンパイラ処理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20071122 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20071122 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20100223 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110105 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110302 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110621 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110708 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140715 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313111 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |