JP4680714B2 - Speech recognition apparatus and speech recognition method - Google Patents
Speech recognition apparatus and speech recognition method Download PDFInfo
- Publication number
- JP4680714B2 JP4680714B2 JP2005225877A JP2005225877A JP4680714B2 JP 4680714 B2 JP4680714 B2 JP 4680714B2 JP 2005225877 A JP2005225877 A JP 2005225877A JP 2005225877 A JP2005225877 A JP 2005225877A JP 4680714 B2 JP4680714 B2 JP 4680714B2
- Authority
- JP
- Japan
- Prior art keywords
- recognition
- stagnation
- voice
- state
- recognition result
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 title claims description 45
- 230000008859 change Effects 0.000 claims description 46
- 230000004044 response Effects 0.000 claims description 41
- 238000012937 correction Methods 0.000 claims description 5
- 230000006978 adaptation Effects 0.000 description 32
- 230000008569 process Effects 0.000 description 18
- 230000002452 interceptive effect Effects 0.000 description 16
- 238000010586 diagram Methods 0.000 description 15
- 230000013016 learning Effects 0.000 description 11
- 230000007257 malfunction Effects 0.000 description 11
- 230000007704 transition Effects 0.000 description 8
- 238000012545 processing Methods 0.000 description 5
- 235000016496 Panda oleosa Nutrition 0.000 description 3
- 240000000220 Panda oleosa Species 0.000 description 3
- 230000009471 action Effects 0.000 description 2
- 238000009412 basement excavation Methods 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000000354 decomposition reaction Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000003203 everyday effect Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000000306 recurrent effect Effects 0.000 description 1
Images





















Description
本発明は、入力された音声を音声認識辞書を用いて認識し、認識結果によりシステム状態を遷移させて対話を行う音声認識装置に関する。 The present invention relates to a speech recognition apparatus that recognizes input speech using a speech recognition dictionary and performs a dialog by changing a system state based on a recognition result.
一般的な音声認識の方法の一つとして、予め認識辞書内に登録された語彙を表す種々の音響パターンとユーザから入力された音声信号とを比較することでスコアを計算し、最も類似したパターンを示す認識辞書内語彙を認識結果の候補とする手法がある。 As one of the general speech recognition methods, the most similar pattern is calculated by comparing the various acoustic patterns representing the vocabulary registered in the recognition dictionary in advance with the speech signal input from the user. There is a method in which a vocabulary in a recognition dictionary indicating a recognition result candidate is used.
このような一般的な音声認識方法では、多くのユーザに対して高い認識精度を実現するために作成された音響モデルを用いて音声認識を行っているため、ユーザによっては一般的な音響モデルが適応していないために、認識精度が低くなり、誤認識を多く起こしてしまう場合が生じる。 In such a general speech recognition method, speech recognition is performed using an acoustic model created in order to achieve high recognition accuracy for many users. Since it is not adapted, recognition accuracy becomes low, and a lot of misrecognitions occur.
また、従来においては、例えば認識スコアを利用して認識信頼度を計算し、最も類似した認識候補が得られた場合も、認識信頼度に基づいてリジェクトを行い、再入力を促す手法がある。このようなリジェクト機能を設けることで、例えば音声以外の雑音が入力された場合に誤認識が発生してシステムが誤動作するのを防ぐことができる。 In addition, conventionally, for example, there is a technique for calculating a recognition reliability using a recognition score, and rejecting based on the recognition reliability even when the most similar recognition candidate is obtained and prompting re-input. By providing such a reject function, it is possible to prevent the system from malfunctioning due to erroneous recognition when, for example, noise other than speech is input.
このような音声認識方法では、得られた認識信頼度が所定の値より低い場合、リジェクトなどの機能により誤認識・誤システム動作を防ぐことができるが、反面、通常の音声入力に対しても認識信頼度が低い場合にはリジェクトを行うので、ユーザによっては、特定の認識可能な語彙に対して誤ってリジェクトされてしまう場合が生じる。 In such a speech recognition method, when the obtained recognition reliability is lower than a predetermined value, it is possible to prevent erroneous recognition and erroneous system operation by a function such as reject, but on the other hand, even for normal speech input Since the rejection is performed when the recognition reliability is low, a specific recognizable vocabulary may be erroneously rejected depending on the user.
そこで、このような誤認識・誤リジェクトの対策として、音声認識に利用している一般不特定話者向けの音響モデルを現在のユーザの音響モデルに適応するため、ユーザ自身の発声を用いて再学習させる(話者適応・話者学習)ことで認識精度を向上させる方法や、リジェクトが行われた際にユーザの再発声時の認識精度を向上させる方法が提案されている。 Therefore, as a countermeasure against such misrecognition / rejection, in order to adapt the acoustic model for general unspecified speakers used for speech recognition to the current user's acoustic model, the user's own speech is used again. There are proposed a method of improving recognition accuracy by learning (speaker adaptation / speaker learning) and a method of improving recognition accuracy at the time of recurrence of a user when a rejection is made.
例えば、話者適応・話者学習の方法としては、少数の音声を用いて音響モデルを学習し、さらに誤認識される単語については話者学習を行う方法(例えば、特許文献1参照)が開示されている。一方、再発声時の認識精度を向上させる方法としては、言い直しだと判定した場合には前回と今回の両認識候補を用いて認識結果を定める手法(例えば、特許文献2参照)や、言い直しの発声に対しては前回の認識結果の上位候補を認識対象語彙とする手法(例えば、特許文献3参照)が開示されている。
上記のような従来の方法では、少数の学習用発声でユーザの音響モデルを学習可能とする工夫や、再発声時の認識候補や認識対象語彙を変化させることで認識精度を向上させる工夫がされている。 In the conventional methods as described above, a device that can learn the user's acoustic model with a small number of learning utterances, or a device that improves recognition accuracy by changing the recognition candidates and recognition target vocabulary at the time of recurrence is made. ing.
しかしながら、これらの学習による話者適応では、ユーザに適したモデルを学習させる際に少数とはいえ、操作とは直接関係の無い単語を一定量ユーザに発声させるため、ユーザの負担は少なくない。また、再入力時の認識精度向上方法では、再発声時の認識精度は上がるものの、再び前回リジェクトされた発声と同じ発声をユーザが行ったときはやはりリジェクトされてしまい、その度に再発声を行わなくてならない。 However, in speaker adaptation based on these learnings, a small amount of words that are not directly related to the operation are uttered by the user when learning a model suitable for the user, but there is a considerable burden on the user. In addition, the recognition accuracy improvement method at the time of re-input increases the recognition accuracy at the time of recurrence, but when the user utters the same utterance as the previous utterance again, it will be rejected again, Must be done.
例えば、特許文献1では、初めに少数ではあるが話者適応用の学習発声をユーザに促し、さらに度々誤認識する単語については誤認識を起こす部分の発声を話者に促し、その入力を基に話者学習を行うが、ユーザに余分な発声を促すためユーザの負担を増やしてしまう。また、特許文献2では、言い直しと検出された場合に前回の認識結果を含め出力する認識候補を調整するが、前回リジェクトされた発声と同じ発声が入力されたときにリジェクトされてしまい、その度に再発声を行わなくてならない。また、特許文献3では、リジェクトされた次の認識は前回の上位候補のみを認識対象語彙として認識を行うが、特許文献2と同様、前回リジェクトされた発声と同じ発声が入力されたときに正しく認識できない。
For example, in Japanese Patent Application Laid-Open No. 2003-228867, the user is first encouraged to learn speech for adaptation to a speaker, but for words that are frequently misrecognized, the user is prompted to utter the part that causes misrecognition. However, it increases the burden on the user in order to encourage the user to speak extra. Also, in
そこで、本発明はこのような従来の課題を解決するためになされたものであって、ユーザに学習用の特別な発声を要求することなく、ユーザの負担が少なく自然に音声認識の個人適応を行うことができ、かつ誤認識を減らすことできる音声認識装置および音声認識方法を提供することを目的とする。 Therefore, the present invention has been made to solve the above-described conventional problems, and does not require a special utterance for learning from the user, so that the user's burden is reduced and the individual adaptation of voice recognition is naturally performed. An object of the present invention is to provide a speech recognition apparatus and a speech recognition method that can be performed and that can reduce erroneous recognition.
上記目的を達成するため、本発明に係る音声認識装置は、入力された音声を認識し、認識結果に応じて、ユーザとの対話に関するシステムの状態であるシステム状態を遷移させて、対話を行う音声認識装置であって、音声認識辞書を用いて、入力された音声を認識して、認識結果を出力する音声認識手段と、前記音声認識手段の認識結果により前記システム状態を遷移させて応答を行う対話制御手段と、今回の認識結果で前記システム状態が先に進まず停滞している状態である停滞状態から脱出したか否かを判定するとともに、前記停滞状態から脱出したと判定した場合、今回の認識結果が言い直しおよび言い換えの少なくとも1つであるか否かを判定する停滞脱出判定手段と、前記言い直しまたは言い換えであると判定された場合、対話制御に関する設定としてリジェクトの閾値の変更と、音声認識に関する設定の変更として前記音声認識辞書への新規追加または変更との少なくとも1つを行う変更制御手段とを備えることを特徴とする。 In order to achieve the above object, a speech recognition apparatus according to the present invention recognizes an input speech and performs a dialog by changing a system state that is a system state related to a dialog with a user according to a recognition result. a speech recognition apparatus using the voice recognition dictionary, and recognizing the input speech, a speech recognition means for outputting a recognition result, the recognition result by the by transitioning the system state of the voice recognition means responsive When it is determined that the system state has escaped from the stagnation state where the system state has not progressed further and stays stagnant as a result of the current recognition, and has escaped from the stagnation state Stagnation escape determination means for determining whether or not the current recognition result is at least one of rephrasing and paraphrasing; And changes in the reject threshold as settings for, characterized by comprising a change control means for performing at least one of the newly added or changed to the speech recognition dictionary as a change of configuration for voice recognition.
本発明に係る音声認識装置および音声認識方法によれば、ユーザの発声の特徴とシステムの音声認識用パラメータや音声認識辞書の不適合を解消するために、学習用の特別な発声を要求するのではなく、一度の言い直しまたは言い換えにて正しく認識された結果を利用してユーザに適した学習を行うため、ユーザにとって自然で負担の少ない音声認識の個人適応を行うことができる。さらに、音声認識の個人適応を行うので、次からは前回誤認識した発声と同様の発声を行っても正しく認識が可能となるため、誤認識が減ることにより、円滑な音声操作を実現することができる。 According to the speech recognition apparatus and the speech recognition method according to the present invention, a special utterance for learning is required in order to eliminate the mismatch between the features of the utterance of the user and the parameters for speech recognition of the system and the speech recognition dictionary. In addition, since learning suitable for the user is performed using the result correctly recognized by re-phrase or paraphrase once, it is possible to perform personal adaptation of voice recognition that is natural and less burdensome for the user. In addition, since personal recognition of voice recognition is performed, it is possible to recognize correctly even if the utterance is the same as the previously mistaken utterance from the next time, so that smooth voice operation can be realized by reducing the misrecognition. Can do.
本発明の実施の形態に係る音声認識装置は、入力された音声を認識し、認識結果により対話を行う音声認識装置であって、入力された音声を音声認識辞書を用いて認識して認識結果を出力する音声認識手段と、前記音声認識手段の認識結果によりシステム状態を遷移させて応答を行う対話制御手段と、今回の認識結果で前記システム状態が先に進まず停滞している状態である停滞状態から脱出したか否かを判定するとともに、前記停滞状態から脱出したと判定した場合、今回の認識結果が言い直しおよび言い換えの少なくとも1つであるか否かを判定する停滞脱出判定手段と、前記言い直しまたは言い換えであると判定された場合、対話制御に関する設定および音声認識に関する設定の少なくとも1つを変更する変更制御手段とを備えることを特徴とする。 A speech recognition apparatus according to an embodiment of the present invention is a speech recognition apparatus that recognizes an input speech and performs a dialogue based on a recognition result, and recognizes the input speech using a speech recognition dictionary and recognizes the result. Is a state where the system state does not advance further and is stagnant by the current recognition result. A stagnation escape determining means for determining whether or not the vehicle has escaped from the stagnation state and determining whether or not the current recognition result is at least one of rephrasing and paraphrasing when it is determined that the vehicle has escaped from the stagnation state; And a change control means for changing at least one of a setting relating to dialogue control and a setting relating to voice recognition when it is determined that the rephrase or paraphrase is made. And features.
これによって、通常の音声操作の中で、ユーザ適応を随時行っていくため、ユーザ適応のために特別な発声が必要なく、ユーザにとって自然で負担の少ない音声認識の個人適応を行うことができる。さらに、音声認識の個人適応を行うので、次からは前回誤認識した発声と同様の発声を行っても正しく認識が可能となるため、誤認識が減ることにより、円滑な音声操作を実現することができる。 As a result, user adaptation is performed as needed during normal voice operations, so that special utterance is not necessary for user adaptation, and it is possible to perform personal adaptation of voice recognition that is natural and less burdensome for the user. In addition, since personal recognition of voice recognition is performed, it is possible to recognize correctly even if the utterance is the same as the previously mistaken utterance from the next time, so that smooth voice operation can be realized by reducing the misrecognition. Can do.
また、前記システム状態の停滞状態は、前記音声認識結果のリジェクトによる同一システム状態が続く状態であり、前記停滞脱出判定手段は、今回の認識結果が前回の認識結果と同一単語である場合、言い直しであると判定し、今回の認識結果が前回の認識結果と同一単語では無いが、あらかじめ定められた同じシステム動作を実行する認識単語である場合、言い換えであると判定してもよい。 Further, the stagnation state of the system state is a state in which the same system state continues due to the rejection of the voice recognition result, and the stagnation escape judging means says when the current recognition result is the same word as the previous recognition result. If it is determined to be corrected and the current recognition result is not the same word as the previous recognition result, but is a recognition word that executes the same predetermined system operation, it may be determined to be paraphrased.
また、前記システム状態の停滞状態は、2つのシステム状態の往復が繰り返し続く状態であり、前記停滞脱出判定手段は、今回の認識結果が前々回の認識結果と同一単語である場合、言い直しであると判定し、今回の認識結果が前々回の認識結果と同一単語では無いが、あらかじめ定められた同じシステム動作を実行する認識単語である場合、言い換えであると判定してもよい。 In addition, the stagnation state of the system state is a state in which the reciprocation of two system states continues repeatedly, and the stagnation escape determination means is rephrased when the current recognition result is the same word as the previous recognition result. If the current recognition result is not the same word as the previous recognition result, but is a recognition word that executes the same predetermined system operation, it may be determined as a paraphrase.
これによって、誤ってリジェクトされることによる音声操作の停滞および誤って認識されることによる音声操作の停滞が減ることになり、円滑な音声操作が実現できる。 As a result, the stagnation of the voice operation due to erroneous rejection and the stagnation of the voice operation due to erroneous recognition are reduced, and a smooth voice operation can be realized.
前記変更制御手段は、前記対話制御に関する設定の変更としてリジェクトの閾値の変更を行い、前記音声認識に関する設定の変更として前記音声認識辞書への新規追加または変更を行ってもよい。これによって、リジェクション精度及び認識精度向上が可能となり、ユーザにとって負担が少ない音声認識の個人適応と円滑な各種音声操作を実現することができる。 The change control means may change a rejection threshold as a change in the setting related to the dialog control, and may newly add or change the voice recognition dictionary as a change in the setting related to the voice recognition. Thereby, the rejection accuracy and the recognition accuracy can be improved, and personal adaptation of voice recognition and smooth various voice operations can be realized with less burden on the user.
また、前記変更制御手段は、前記リジェクトの閾値を認識対象単語ごとに設定し変更してもよい。これによって、認識対象単語ごとの個人適応が可能となり、よりユーザにとって負担が少ない音声認識の個人適応と円滑な各種音声操作を実現することができる。 Further, the change control means may set and change the rejection threshold for each recognition target word. Thereby, personal adaptation for each recognition target word is possible, and it is possible to realize personal adaptation of voice recognition and smooth various voice operations with less burden on the user.
また、前記変更制御手段は、前記リジェクトの閾値、および、前記音声認識辞書への新規追加または変更を、ユーザごとに設定してもよい。これによって、複数のユーザが利用しても適切な適応が可能となり、よりユーザにとって負担が少ない音声認識の個人適応と円滑な各種音声操作を実現することができる。 Further, the change control means may set the rejection threshold and new addition or change to the speech recognition dictionary for each user. As a result, appropriate adaptation is possible even when used by a plurality of users, and personal adaptation of voice recognition and smooth various voice operations with less burden on the user can be realized.
また、前記音声認識装置は、さらに、前記停滞状態から脱出した際に、今回の認識結果が前回の認識結果と同一単語では無く、かつあらかじめ定められた同じシステム動作を実行する認識単語でない場合、今回の認識結果の省略語を作成する省略語作成手段を備え、前記音声認識手段は、前記省略語を用いて前回の認識結果を再認識し、前記変更制御手段は、前記音声認識手段の再認識結果に応じて前記省略語を前記音声認識辞書へ新規追加してもよい。これによって、省略語をユーザが利用しても適切な適応が可能となり、よりユーザにとって負担が少ない音声認識の個人適応と円滑な各種音声操作を実現することができる。 In addition, when the voice recognition device further escapes from the stagnation state, the current recognition result is not the same word as the previous recognition result and is not a recognition word that executes the same predetermined system operation, An abbreviation creation means for creating an abbreviation for the current recognition result is provided, wherein the speech recognition means re-recognizes the previous recognition result using the abbreviation, and the change control means re-reads the speech recognition means. The abbreviation may be newly added to the speech recognition dictionary according to the recognition result. Accordingly, even if the user uses the abbreviation, appropriate adaptation is possible, and it is possible to realize personal adaptation of voice recognition and smooth various voice operations with less burden on the user.
なお、本発明は、このような音声認識装置として実現することができるだけでなく、このような音声認識装置が備える特徴的な手段をステップとする音声認識方法として実現したり、それらのステップをコンピュータに実行させるプログラムとして実現したりすることもできる。そして、そのようなプログラムは、CD−ROM等の記録媒体やインターネット等の伝送媒体を介して配信することができるのは言うまでもない。 The present invention can be realized not only as such a speech recognition apparatus, but also as a speech recognition method using steps characteristic of the speech recognition apparatus, or by performing these steps as a computer. It can also be realized as a program to be executed. Needless to say, such a program can be distributed via a recording medium such as a CD-ROM or a transmission medium such as the Internet.
以下、本発明の各実施の形態について、それぞれ図面を参照しながら説明する。 Embodiments of the present invention will be described below with reference to the drawings.
(実施の形態1)
図1は、本発明の実施の形態1に係る音声認識装置を備えた音声対話型情報検索システムの構成を示すブロック図である。
(Embodiment 1)
FIG. 1 is a block diagram showing a configuration of a voice interactive information search system provided with a voice recognition device according to
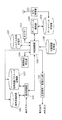
音声対話型情報検索システムは、音声を入力して対話しながら情報を検索するためのシステムであり、図1に示すように音声認識部101、音声認識辞書102、音声認識パラメータ記憶部103、停滞脱出判定部104、対話制御部105、対話履歴記憶部106、システム仕様記憶部107、データベース検索部108、データベース記憶部109、応答音声・画面出力部110、およびタイマー111を備えている。
The voice interactive information search system is a system for searching for information while inputting a voice, and as shown in FIG. 1, the
音声認識部101は、音声認識辞書102および音声認識パラメータ記憶部103を用いて、ユーザより入力された音声の音声認識を行い、認識結果を出力する。音声認識辞書102は、認識対象語彙が登録されている辞書である。音声認識パラメータ記憶部103は、音声認識用パラメータを記憶している。
The
対話制御部105は、予めシステムの開発者によって決められた動作仕様に従って対話を制御し、ユーザからの入力に対し次のシステム状態を決定する。具体的には、対話制御部105は、音声認識部101より入力される音声認識結果、停滞脱出判定部104より入力される停滞脱出か否かの判定結果、対話履歴記憶部106より入力される現在および過去の対話履歴を利用してシステム仕様記憶部107から次のシステム状態を決定する。また、対話制御部105は、必要があれば音声認識辞書102や音声認識パラメータ103の変更、およびデータベース検索をデータベース検索部108に要求する。なお、システム状態とはシステムの開発者によって決められたシステムの動作仕様におけるシステムの一状態を示す。
The
停滞脱出判定部104は、対話制御部105より入力される現在と過去のユーザの認識結果等の情報を用いてシステムの状態遷移が停滞状態から脱出したか否かを判定する。対話履歴記憶部106は、対話制御部105から入力される音声認識結果やシステムの出力(出力画面情報・出力応答情報)結果など各システム状態における様々な情報を保存する。システム仕様記憶部107は、開発者によってあらかじめ決められたシステムの動作仕様を記憶している。
The stagnation
データベース検索部108は、対話制御部105からの情報検索要求に対し、データベース記憶部109にあるデータベースから検索を行う。データベース記憶部109は、データベース検索部108の検索対象データベースを格納している。応答音声・画面出力部110は、対話制御部105より入力されるシステム状態に応じた画面や応答音声を出力する。タイマー111は、対話制御部105の要求により現時刻を対話制御部105に出力する。
In response to the information search request from the
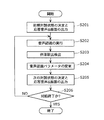
次に、上記のように構成された音声対話型情報検索システムにおいて、番組情報を検索する際の具体的な動作について説明する。図2は音声対話型情報検索システムでの対話全体の動作の流れを示すフローチャートである。 Next, a specific operation when searching for program information in the voice interactive information search system configured as described above will be described. FIG. 2 is a flowchart showing the flow of the entire dialogue in the voice interactive information retrieval system.
対話制御部105は、対話開始のシステム状態を決定し、決定したシステム状態での画面と応答音声を決定し、応答音声・画面出力部110から出力することで、ユーザに対して入力要求を行う(ステップS201)。図3は具体的な出力画面例を示すである。ここでは、例えば図3に示すように番組情報を検索する際のメニュー画面が出力され、エージェントの吹き出しの内容301が応答音声として音声出力される。なお、吹き出し自体も画面表示してもよい。また、この例では図3における認識可能な語彙は四角で囲まれた語彙のみであるとする。例えば、四角「1.番組名検索」302を選択するのに認識可能な語彙としては「1番」「1」「番組名検索」「1.番組名検索」であるとする。
The
音声認識部101は、システムからの応答音声・画面による入力要求に対しするユーザからの入力音声の認識処理を行う(ステップS202)。より詳細には、まず、対話制御部105は、音声認識部101に現在のシステム状態で認識可能な語彙の通知と音声認識処理実行の要求を行う。より具体的には、図3に示すシステム状態においては、音声認識部101は四角で囲まれた語彙を認識対象語彙として音声認識処理を開始する。次に、音声認識部101は、ユーザの入力音声に対して認識処理を行い、対話制御部105に対し、認識結果を出力する。ここで、出力される認識結果は、ユーザの発声に最も近い認識対象語彙の単語だけではなく、認識に関する後に記述するような詳細な情報も含め出力する。
The
図4および図5は出力される認識結果の具体的な例を示す図であり、図4は1位の認識結果を中心とした音声認識の全体的な情報を示しており、図5は他の候補も含めた認識結果の情報を示している。ここで、項目401は認識結果が出力された日時であり、項目402は入力された音声の区間、即ち音声認識部101が認識処理を行っていた区間のうち音声であると判断したで区間である。項目403は認識対象語彙の中で最も近いと判断された単語、即ち認識結果の候補が1位の単語であり、項目404は音声認識辞書とは関係なく音響的に近いカナ文字を認識結果とした文字列であり、一般には音声タイプライタの結果と呼ばれるものである。項目405は入力音声区間の中で認識結果の単語がマッチングした区間である。項目406は認識度合を示す認識スコアであり、スコアが高い方がより認識度合が高いことを示している。項目407は認識信頼度を示し、どの程度認識結果が妥当かを示している。認識信頼度は一般的には、認識候補のスコアの差や音声タイプライタと認識候補の差などを用いて計算する場合が多い。項目408はリジェクト用閾値であり、音声認識パラメータ記憶部102に記憶されている変数である。
4 and 5 are diagrams showing specific examples of the output recognition results. FIG. 4 shows the overall information of the speech recognition centering on the first recognition result, and FIG. The recognition result information including the candidates is shown. Here, the
対話制御部105は、このリジェクト閾値と認識信頼度との比較を行いシステムとして認識結果を受け入れるか否かの判定を行う。具体的にはリジェクト閾値より認識信頼度が低い場合、対話制御部105は認識結果をリジェクト、即ち入力結果として処理せず、再度同じシステム状態での入力を促す。例えば、図4の例では認識信頼度が「4.5」でリジェクト閾値が「3.5」であるので、対話制御部105はこの認識結果「番組名検索」をシステムへの入力として認め対話制御を行う。なお、このリジェクト閾値は、予めシステム開発者が決定しても良いし、評価実験を行うことにより決定してもよい。具体的には何人かの被験者にこの辞書セットの単語を発声させ、その結果を基に決定してもよい。
The
また、図5において、項目501は認識候補の認識スコアのよってソートされた結果の認識候補順位であり、項目502から項目505は各認識候補の情報であり、その内容は図4で説明した認識結果1位の結果の情報と同じである。
Also, in FIG. 5,
対話制御部105は、ステップS202で音声認識部101から入力された音声認識結果と対話履歴記憶部106に蓄積されている前回の認識結果を停滞脱出判定部104に出力する。
The
次に、停滞脱出判定部104は、今回の入力が停滞の脱出であるか否かの判定を行い、その結果を対話制御部105に出力する(ステップS203)。対話制御部105は、この結果を対話履歴記憶部106に書き込む。
Next, the stagnation
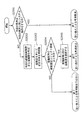
ここで、停滞脱出判定部104における停滞脱出判定動作について、音声認識の誤リジェクトによる停滞を例に取り、詳細に説明する。図6は、停滞脱出判定部104における停滞脱出判定動作の流れを示すフローチャートである。
Here, the stagnation / escape determination operation in the stagnation /
まず、停滞脱出判定部104は、今回の音声認識結果および前回の認識結果を取得する(ステップS601)。そして、その音声認識結果に基づいてリジェクトか否かの判定を行う(ステップS602)。この判定の結果、リジェクトと判定した場合(ステップS602でYES)、停滞脱出判定部104は停滞脱出でないという判定結果を出力する。これは、リジェクトとは認識結果の信頼度が低いため認識結果として採用されないということであるので、その場合は次のシステム状態へ進まない状態、即ち停滞からの脱出ではないためである。
First, the stagnation
一方、リジェクトでないと判定した場合(ステップS602でNO)は、対話履歴から前回の発声がリジェクトであったか否かの判定を行う(ステップS603)。この判定の結果、前回の発声がリジェクトでないと判定した場合(ステップS603でNO)は、前回の発声においては停滞が発生していないため、停滞脱出判定部104は今回の発声は停滞の脱出ではないという判定結果を出力する。
On the other hand, if it is determined not to be rejected (NO in step S602), it is determined from the dialog history whether the previous utterance was rejected (step S603). As a result of this determination, if it is determined that the previous utterance is not rejected (NO in step S603), no stagnation has occurred in the previous utterance, so that the stagnation
一方、前回の発声をリジェクトと判定した場合(ステップS603でYES)、前回の発声によりシステムは停滞状態であったことを示すため、停滞脱出判定部104は、今回の発声により停滞状態から脱出できたという判定し、言い直しであるか否かの判定を行う(ステップS604)。ここでのいい直しとは、前回の発声と今回の発声が同じであることを意味する。例えば、ユーザが図3のような出力画面において「番組名検索」と発声し、リジェクとされて再度入力を促されたときにもう一度「番組名検索」と発声する場合などである。この言い直し判定は、前回の認識結果と今回の認識結果とを比較することで行い、言い直しであると判定した場合(ステップS604でYES)、停滞脱出判定部104は言い直しによる停滞の脱出であるという判定結果を出力する。
On the other hand, when it is determined that the previous utterance is rejected (YES in step S603), the stagnation
一方、言い直しでないと判定した場合(ステップS604でNO)は、停滞脱出判定部104は、言い換えであるか否かの判定を行う(ステップS604)。ここでの言い換えとは、前回の発声と今回の発声が発声語彙は異なるが、発声内容が同じ、即ち発声によるシステム動作が同じ発声を意味する。例えば、ユーザが図3のような出力画面において「番組名検索」と発声し、リジェクトされて再入力を促されたときに「1番」と発声する場合などである。この言い換えの判定は、言い直しの判定と同様に前回の認識結果と今回の認識結果の比較を行うことで判定を行う。より具体的には、前回の認識結果と今回の認識結果との語彙が異なり、且つシステム仕様として認識結果が同じ動作を実行する語彙であれば言い換えであると判定する。システム仕様として認識結果が同じ動作か否かの判定は、システム仕様記憶部107に定義される各システム仕様により判定する。具体的には、システム仕様記憶部107には図7に示されるように、認識結果として受け付ける語彙とその語彙を受け付けたときどの状態に遷移するかが記憶されており、ここで一つの選択可能項目に対応する単語を言い換え対象語として扱う。
On the other hand, when it is determined that it is not rephrasing (NO in step S604), the stagnation
この判定の結果、言い換えであると判定した場合(ステップS605でYES)、停滞脱出判定部104は、言い換えによる停滞脱出であるという判定結果を出力する。一方、言い換えでないと判定した場合(ステップS605でNO)、停滞脱出判定部104は停滞脱出ではないという判定結果を出力する。
As a result of this determination, when it is determined that the paraphrase is made (YES in step S605), the stagnation
以上のように、停滞脱出判定部104は停滞脱出判定の動作を行う。
次に、対話制御部105は、停滞脱出判定処理(ステップS203)までに得られている音声認識結果および停滞脱出判定結果に基づいて、音声認識辞書やリジェクト閾値、音響モデルといった音声認識パラメータの変更を行う(ステップS204)。
As described above, the stagnation
Next, the
次に、対話制御部105は、認識結果に基づいて次のシステム状態と、このシステム状態における応答音声および画面の出力について決定し、応答音声・画面出力部110に出力する(ステップS205)。ここで必要であれば、対話制御部105は、データベース検索部108に対しデータベース記憶部109からのデータの検索を要求した結果を応答音声・画面出力部110に出力する。
Next, the
そして、対話制御部105は、システム仕様記憶部107に定義されているシステム仕様に従い、対話の終了か否かを判定する。この結果、対話の終了でない場合(ステップS206でNO)には、再び入力音声の認識処理(ステップS202)より上記ステップを繰り返し、対話の終了である場合(ステップS206でYES)には、対話を終了する。
Then, the
次に、システムの具体動作例をシステムのシステム出力画面と対話履歴記憶部106に保存される対話履歴データの具体例を用いて説明する。
Next, a specific operation example of the system will be described with reference to a specific example of the system output screen of the system and dialog history data stored in the dialog
図8は、動作例で対象とする対話履歴データの具体例を示す図である。項目801はシステム状態の変化を一元管理するために振られているステップ番号、項目802はシステム状態の種類を示すシステム状態、項目803はシステムが応答を出力した日時を示す応答出力開始時刻、項目804は音声認識部101から得られる音声認識結果の1位候補の単語、項目805も同様に音声認識結果から得られる認識信頼度、項目806は音声認識部101からの音声認識結果に基づいて対話制御部105が判定したリジェクト判定結果、項目807は対話履歴記憶部106に保存される前回の認識結果と今回音声認識部101が出力した認識結果に基づいて停滞脱出判定部104が判定した言い直しによる停滞脱出の判定結果、項目808は項目807と同様にして停滞脱出判定部104が判定した言い換えによる停滞脱出の判定結果、項目809は音声認識パラメータ記憶部103に保存されており、認識結果からも取得できるリジェクト閾値である。なお、この図には示していないが、各ステップにおける図4で示されるような認識結果の詳細情報や図5に示されるような表示画面についての情報、具体的には表示されている単語やシステムがどのような応答文を出力したかを示す出力応答文など他の情報も対話履歴記憶部106には保存してもよい。
FIG. 8 is a diagram illustrating a specific example of dialogue history data targeted in the operation example.
例えば、ユーザが、図3に示すメニュー画面で「番組名検索」と発声したとする。この認識結果の認識信頼度(0.47)がリジェクト閾値(0.35)より高いので、対話制御部105は、次のシステム状態を決定し、画面遷移と応答文の出力を行う(図8のステップ=1)。具体的には、システムからは応答音声・画面出力部110によって図9に示されるような画面と「番組名の頭文字を指定してください」という応答音声が出力される。次に、ユーザは「あ行」と発声し、これも先の発声と同様に、認識確信度(0.36)がリジェクト閾値(0.35)より高いため、正しく受け付けられる(図8のステップ=2)。システムからは応答音声・画面出力部110によって図10のような画面と「どの番組ですか?」という応答が出力される。次に、ユーザはそのリストには見たい番組が無く「次の画面」と発声するが、この発声に対する認識結果では、認識信頼度(0.33)がリジェクト閾値(0.35)より低いためリジェクトであると判定される(図8のステップ=3)。リジェクトと判定された場合、対話制御部105は再度そのシステム状態で(今の場合、対話=状態3)再度入力を促す。なお、この動作はユーザが正しく発声しているのに対し、対話制御部105が誤ってリジェクトしてしまったシステムの誤動作であり、リジェクト閾値がユーザにとって正しく設定されていないため生じる動作である。
For example, assume that the user utters “program name search” on the menu screen shown in FIG. Since the recognition reliability (0.47) of the recognition result is higher than the rejection threshold (0.35), the
再度同じシステム状態で、システムより入力を促されたユーザは再び「次の画面」と発声し、その音声認識の結果における認識信頼度(0.38)はリジェクト閾値(0.35)より高いので、対話制御部105はその結果を受け付ける(図8のステップ=4)。ここで、このステップでは停滞脱出判定部104が「前回の発声はリジェクト」かつ「今回の発声は言い直し」であるので「言い直しによる停滞脱出」と判定し、項目807にその情報が記憶される。更にこのステップでは、対話制御部105は検出した誤動作と正しい動作を用いて、誤動作したはじめの発声を次からは受け付けるよう個人適応を行う。即ち、音声認識パラメータ、今回の例ではリジェクト閾値を変更し、次のステップからこの値を利用して音声認識を行う。具体的には、現在のリジェクト閾値「0.35」を前回の誤ってリジェクトされた発声における信頼度でも正しく認識できるように「0.30」に変更する。この閾値の変更は、システム開発者が予め設定した、決まった割合で変更を行っても良い。また、現在のリジェクト閾値と誤ってリジェクトされたときの認識信頼度を利用した計算により閾値の変更を行ってもよい。より具体的には、現在のリジェクト閾値と誤ってリジェクトされたときの認識信頼度の差分が一定値以内であれば、リジェクト閾値を誤ってリジェクトされたときの認識信頼度に設定し、差分が一定値以上であれば、現在のリジェクト閾値と誤ってリジェクトされたときの認識信頼度の間の重み付き平均値を利用してリジェクト閾値を設定しても良い。また、リジェクトされた単語と正しく認識された単語の認識信頼度を用いて閾値の変更を行ってもよい。具体的には、現在のリジェクト閾値と誤ってリジェクトされたときの認識信頼度を用いた計算方法と同様の方法で決定する。
In the same system state again, the user who is prompted to input by the system speaks again “next screen”, and the recognition reliability (0.38) in the result of the speech recognition is higher than the rejection threshold (0.35). The
言い直しの結果を受け付けた対話制御部105は、次のシステム状態を決定し、画面遷移と応答文の出力を行う。具体的には、システムからは応答音声・画面出力部110によって、図11に示されるような画面と「どの番組ですか?」という応答音声が出力される。ユーザはこの画面にも見たい番組が無いので、さらに「次の画面」と発声する。この発声の認識結果における認識信頼度はステップ3の時と同じ「0.33」である。この認識信頼度はステップ3ではリジェクトされた値であるが、対話制御部105はこの認識信頼度「0.33」と前ステップで適応させたリジェクト閾値「0.3」とを比較した結果、本ステップではこの発声をリジェクトせず、次のシステム状態を決定し、画面遷移と応答文の出力を行う。具体的には、システムからは応答音声・画面出力部110によって、図12に示されるような画面と「どの番組ですか?」という応答音声が出力される(図8のステップ=5)。ユーザはこの画面の中では見たい番組を見つけ、「iしたい」と番組を選択する発声を行う(図8のステップ=6)。図13は、以上の一連の動作をまとめた図であり、上から順に図8のステップ=1からステップ=6に対応する。
Upon receiving the restatement result, the
次に、言い換えを利用したリジェクト閾値の変更動作例について、対話履歴データの具体例を用いて説明する。図14は、動作例で対象とする対話履歴データの具体例を示す図である。なお、対話履歴データの項目は図8と同じであるので、説明は省略する。更に、上記言い直しによるリジェクト閾値の変更動作例との発声の違いはステップ3〜ステップ5のみであるので、図14のステップ3からステップ5の動作例についてのみ説明する。
Next, a reject threshold value changing operation example using paraphrasing will be described using a specific example of dialogue history data. FIG. 14 is a diagram illustrating a specific example of dialogue history data targeted in the operation example. The items of the dialogue history data are the same as those in FIG. Furthermore, since the difference in utterance from the example of the operation of changing the rejection threshold due to the above rewording is
システムから応答音声・画面出力部110によって図10のような画面と「どの番組ですか?」という応答が出力される。ユーザはそのリストには見たい番組が無いため「次の画面」と発声するが、この発声に対する認識結果では、認識信頼度(0.33)はリジェクト閾値(0.35)より低いためリジェクトであると判定される(図14のステップ=3)。リジェクトと判定された場合、対話制御部105は再度そのシステム状態で(今の場合対話=状態3)再度入力を促す。
A response voice /
再度同じシステム状態で、システムより入力を促されたユーザは「次の画面」と同じシステム動作を行うコマンドである「5番」と発声する。この音声認識の結果における認識信頼度(0.38)はリジェクト閾値(0.35)より高いので、対話制御部105はその結果を受け付ける(図14のステップ=4)。ここで、このステップでは停滞脱出判定部104が「前回の発声はリジェクト」かつ「今回の発声は言い換え」であるので「言い換えによる停滞脱出」と判定し、項目1408にその情報が記憶される。さらに、このステップでは、対話制御部105は検出した誤動作と正しい動作を用いて、誤動作したはじめの発声を次からは受け付けるよう個人適応を行う。即ち、音声認識パラメータ、今回の例ではリジェクト閾値を変更し、次のステップからこの値を利用して音声認識を行う。具体的には現在のリジェクト閾値「0.35」を前回の誤ってリジェクトされた発声における信頼度でも正しく認識できるように「0.3」に変更する。以降の動作は上記言い直しによるリジェクト閾値の変更動作例と同じであるので省略する。
Again, in the same system state, the user who is prompted to input by the system utters “No. 5”, which is a command for performing the same system operation as the “next screen”. Since the recognition reliability (0.38) in the voice recognition result is higher than the reject threshold (0.35), the
なお、上記具体例の中では「言い直しまたは言い換えによる停滞脱出」を1回検出した段階でリジェクト閾値を変更したが、音声認識パラメータの変更を行う基準としての停滞脱出検出の回数は可変に設定できるようにしてもよい。例えば3回に設定すると、「言い直しまたは言い換えによる停滞脱出」が3回検出されたらリジェクト閾値の変更を行うことになる。この場合、例えば3回分の認識結果における認識信頼度を用いてリジェクト閾値を変更してもよい。より具体的には、3回分の認識結果における信頼度の最低値や平均値、重み付け平均値により決定する。 In the above specific example, the rejection threshold was changed at the stage where "stagnation escape by rephrasing or paraphrasing" was detected once, but the number of times of stagnation escape detection as a reference for changing the speech recognition parameter is variably set. You may be able to do it. For example, if it is set to 3 times, the rejection threshold value is changed when “stagnation escape by rephrase or paraphrase” is detected 3 times. In this case, for example, the rejection threshold value may be changed using the recognition reliability in the recognition results for three times. More specifically, it is determined by the minimum value, average value, and weighted average value of the reliability in the recognition results for three times.
また、上記具体例ではリジェクト閾値を1つしか持たない例について述べたが、単語ごとにリジェクト閾値を持ち、「言い直しまたは言い換えによる停滞脱出」を単語ごとに検出し、閾値を変更してもよい。具体的には、例えば図15のようなデータを音声認識パラメータ記憶部103に保存する。ここで、項目1501は停滞脱出をしたことによりリジェクト閾値が変更された単語であり、項目1502はその単語のリジェクト閾値である。なお、このリストに無い単語はデフォルト値、例えば上記具体例では「0.35」を利用する。
Also, in the above specific example, an example having only one reject threshold has been described, but even if there is a reject threshold for each word, “stagnation escape by rephrase or paraphrase” is detected for each word, and the threshold is changed. Good. Specifically, for example, data as shown in FIG. 15 is stored in the speech recognition
図16は本実施の形態を利用した場合と利用しない場合の対話シーケンスの例を示す図である。この図16に示す例では、本実施の形態を利用した場合の方がユーザの発声が1回少なくて済む。この例では、ユーザは2ページ目で番組の選択を決定しているが、より多くのページを見ていく場合のように多くのステップを有する対話では本実施の形態の有効性は顕著に現れることになることは容易に理解できる。また、一度検索が終わり、再び同じ番組をはじめから選択する場合も本実施の形態を用いれば前回リジェクトされた発声方法でも初めから認識されることになる。 FIG. 16 is a diagram showing an example of a dialogue sequence when the present embodiment is used and when it is not used. In the example shown in FIG. 16, when the present embodiment is used, the user's utterance can be reduced once. In this example, the user decides to select a program on the second page. However, the effectiveness of the present embodiment appears remarkably in a dialog having many steps as in the case of viewing more pages. It ’s easy to understand. Also, when the search is finished once and the same program is selected again from the beginning, using this embodiment, the utterance method rejected last time can be recognized from the beginning.
このように本実施の形態によると、一連の対話シーケンスの中で、誤動作と正しい動作を検出することで音声認識パラメータを適切に変更することが可能となる。この結果、次に前回誤動作をした発声を行ってもシステムは正しい動作が可能となるため、何度も繰り返し言い直しをする必要が無く、スムーズでユーザに負担の掛からない対話が実現できる。また、本実施の形態による音声認識パラメータの変更は、変更のために特別な発声を促すわけでは無いので、ユーザの負担も少ない。 Thus, according to the present embodiment, it is possible to appropriately change the speech recognition parameter by detecting a malfunction and a correct operation in a series of dialogue sequences. As a result, the system can operate correctly even if the next malfunctioning utterance is performed, so that it is not necessary to repeat it again and again, and a smooth conversation that does not burden the user can be realized. Moreover, since the change of the speech recognition parameter according to the present embodiment does not prompt special utterance for the change, the burden on the user is small.
なお、本実施の形態は、図17に示すように上記構成に加えてEPG(Electronic Program Guide)を受信するEPG受信部201を備え、EPGを対象として音声認識を行って情報を検索する音声対話型情報検索システムにおいても適用することが可能である。この場合、EPG受信部201で受信されたEPGは、データベース記憶部109に記憶される。対話制御部105は、データベース記憶部109に記憶されているEPGを用いて音声認識辞書102を作成する。そして、音声認識部101は、EPGを用いて作成された音声認識辞書102を用いて、ユーザより入力された音声の音声認識を行う。また、データベース検索部108は、データベース記憶部109に記憶されているEPG等を対象として検索を行うことになる。
As shown in FIG. 17, the present embodiment includes an
(実施の形態2)
上記実施の形態1によれば、誤動作と正しい動作を検出することで音声認識パラメータの個人適応が可能となり、ユーザに負担の少ない個人適応が実現できるが、同様の適応を音声認識辞書の追加という形でも行える。本実施の形態では、誤動作と正しい動作の検出しを行い、音声認識辞書の変更または新たに登録を行う方法について述べる。
(Embodiment 2)
According to the first embodiment, it is possible to personally adapt voice recognition parameters by detecting a malfunction and a correct operation, and to realize personal adaptation with less burden on the user. The same adaptation is referred to as addition of a voice recognition dictionary. You can also do it. In this embodiment, a method of detecting a malfunction and a correct operation and changing or newly registering a speech recognition dictionary will be described.
本実施の形態は、上記実施の形態1とは図1における対話制御部105における停滞脱出判定結果に基づいて個人適応する対象が異なるものであり、他は実施の形態1と同様である。従って、基本的には図1から図12を参照することとする。以下、本実施の形態における対話制御部105の動作と、前実施の形態では述べていない音声認識辞書の変更処理ついて説明する。
The present embodiment is different from the above-described first embodiment in that individuals to be personally adapted are based on the stagnation escape determination result in the
本実施の形態における辞書変更・登録による個人適応の動作例について、対話履歴記憶部106に記憶されている対話履歴データの具体例を用いて説明する。
An operation example of personal adaptation by dictionary change / registration in the present embodiment will be described using a specific example of dialogue history data stored in the dialogue
図18は、対話履歴記憶部106に記憶されている対話履歴データの具体例を示す図である。図18に示される対話履歴データの例は実施の形態1での対話シーケンスにおける対話履歴データの例(図8)と同様の履歴であり、図8には示されていなかった項目「認識結果2」が示されている点、および図8に示されていた項目「応答出力開始時刻」が省略されている点を除いては図8と同じものである。なお、既に述べたが認識結果2は音声認識辞書を使わず、音響的に近いかな文字列を音声認識結果として出力されたものであり、認識結果の一例を示した図4における音声認識結果2と同一のものである。
FIG. 18 is a diagram illustrating a specific example of dialogue history data stored in the dialogue
以下、図18の項目「ステップ」を用い、順に具体的動作を説明する。
ステップ3では、ユーザの発声「次の画面」に対し、音声認識部101は認識結果2「スイノダメン」、認識信頼度「0.33」、リジェクト閾値「0.35」を出力する。対話制御部105は、認識信頼度がリジェクト閾値より低いため、リジェクトと判定し、再度そのシステム状態での再度入力を促す。ステップ4では、ユーザの再発声「次の画面」に対し、音声認識部101は認識結果2「ツリノガメン」、認識信頼度「0.38」、リジェクト閾値「0.35」を出力し、停滞脱出判定部104は「言い直しによる停滞脱出」との判定を出力する。対話制御部105は、これらの結果を受けて、誤動作したステップ3における発声が次回からは正しく認識されるように、個人適応を行う。即ち、ステップ3でリジェクトされた発声に対する音声認識結果2の「スリノダメン」をステップ4で正しく認識されたコマンド「次の画面」に対応させて音声認識辞書102に新規に登録を行う。
Hereinafter, specific operations will be described in order using the item “step” in FIG.
In
図19は音声認識辞書の具体例を示す図である。項目1801は単語ごとにユニークに付与される単語番号、項目1802はシステム仕様で同じ意味として扱われる番号を同一番号として付与された意味番号、項目1803は単語の表記、項目1804は単語の読みである。ここで、上記例においては、図19の単語番号130が新規登録されたことになる。
FIG. 19 is a diagram showing a specific example of a speech recognition dictionary. The
ステップ5では、ユーザが「次の画面」と発声する。音声認識部101からはステップ3の時と同様に音声認識結果2として「スイノダメン」という結果が出力されるが、このときの音声認識時には音声認識辞書102に「スイノダメン」が「次の画面」と対応された状態で登録されているため、高い確信度(今の場合0.45)が結果として出力される。このように、ステップ5における発声は個人適応されたことに伴い、ステップ3と同様の発声であるにもかかわらず正しく認識が行われる。
In
なお、上記具体例の中では言い直しの「言い直しによる停滞脱出」を1回検出した段階で認識辞書の変更を行ったが、認識辞書変更を行う基準としての停滞脱出検出の回数は可変に設定できるようにしてもよい。例えば3回に設定すると、「言い直しによる停滞脱出」が3回検出されたら認識辞書の変更を行うことになる。ここで、3回分の認識結果における認識結果を全て登録しても良いが、組み合わせて作成した文字列を登録してもよい。具体的には「ツギノガメン」に対して「スイノダメン」「ツイノダメン」「スギノダメン」に対して、全てが共通している「ダ」の部分だけを変更した「ツギノダメン」を登録してもよい。さらに、変更されたかな文字を記憶し、このユーザは「ガ」を「ダ」とよく間違えると判定した場合、他の単語についても「ガ」を「ダ」に変更してもよい。具体的には「前の画面」に対し「マエノダメン」という読みを付与し、音声認識辞書に追加登録しても良い。 In the above specific example, the recognition dictionary was changed when the rephrasing “stagnation escape by rephrasing” was detected once, but the number of times of stagnation escape detection as a reference for changing the recognition dictionary is variable. It may be settable. For example, if it is set to 3 times, the recognition dictionary will be changed when “stagnation escape by rephrasing” is detected 3 times. Here, all the recognition results in the recognition results for three times may be registered, or a character string created in combination may be registered. Specifically, “Tsugino Damen” obtained by changing only “Da” part that is common to “Shinoda Damen”, “Tsugino Damen”, and “Sugino Damen” may be registered. Furthermore, the kana characters that have been changed are stored, and when it is determined that “ga” is often mistaken for “da”, “ga” may be changed to “da” for other words. Specifically, the reading “Maenodamen” may be assigned to the “previous screen” and additionally registered in the speech recognition dictionary.
また、本実施の形態では言い直しの停滞の判定により音声認識辞書の追加・変更の例についてのみ述べたが、実施の形態1と同様にすれば言い換えの場合も音声認識辞書の追加・変更を行うことができる。 In the present embodiment, only the example of adding / changing the speech recognition dictionary based on the determination of rephrasing stagnation has been described. However, in the same manner as in the first embodiment, addition / change of the speech recognition dictionary is also performed in the case of paraphrasing. It can be carried out.
このように本実施の形態によると、一連の対話シーケンスの中で、誤動作と正しい動作を検出することで音声認識パラメータだけでなく、音声認識辞書についても適切に変更することが可能となる。この結果、次に前回誤動作をした発声を行ってもシステムは正しい動作が可能となるため、何度も繰り返し言い直しをする必要が無く、スムーズでユーザに負担の掛からない対話が実現できる。また、本実施の形態による音声認識辞書の変更は、認識率を上げるために特別な発声を促すわけでは無く自然な対話から認識率を上げるため、ユーザの負担も少ない。 As described above, according to the present embodiment, it is possible to appropriately change not only the speech recognition parameters but also the speech recognition dictionary by detecting a malfunction and a correct operation in a series of dialogue sequences. As a result, the system can operate correctly even if the next malfunctioning utterance is performed, so that it is not necessary to repeat it again and again, and a smooth conversation that does not burden the user can be realized. In addition, the change of the speech recognition dictionary according to the present embodiment does not prompt special utterances to increase the recognition rate, and raises the recognition rate from natural conversation, so the burden on the user is small.
なお、本実施の形態における音声認識辞書への追加・変更と上記実施の形態1における音声認識パラメータの変更とを組み合わせて実施することも可能である。 It should be noted that the addition / change to the voice recognition dictionary in the present embodiment and the change in the voice recognition parameter in the first embodiment may be combined.
(実施の形態3)
上記実施の形態1および実施の形態2によれば、一連の対話シーケンスの中で、誤動作と正しい動作を検出することで音声認識パラメータおよび認識辞書をユーザに適したものに変更しているが、上記実施の形態1および実施の形態2においては、「言い換え」を前回リジェクトされた単語が、今回正しく認識された単語と同一のシステム動作を行う単語であるかをシステム仕様記憶部にある図7のようなデータを用い判定している。しかし、「言い換え」には様々な形があり、事前にシステム仕様に登録できない場合がある。特にEPGを用いた番組検索システムにおいては、日々更新される番組名を認識対象とする必要があり、予め言い換えについてシステム開発者が登録しておくことができない。本実施の形態は、このような場合に対処するものである。
(Embodiment 3)
According to
図20は、本発明の実施の形態3に係る音声認識装置を備えた音声対話型情報検索システムの構成を示すブロック図である。
FIG. 20 is a block diagram showing a configuration of a voice interactive information retrieval system including a voice recognition device according to
本実施の形態3と上記実施の形態1および実施の形態2との相違点は、省略語作成部301とユーザ発声記憶部304が追加されたことによる停滞脱出判定部302の動作が異なる点であり、他の動作は上記実施の形態1および実施の形態2と同一である。従って、本実施の形態においては、動作が異なる停滞脱出判定部302の言い換え判定の動作についてのみ説明する。
The difference between the third embodiment and the first and second embodiments is that the operation of the stagnation /
停滞脱出判定部302は、上記実施の形態1および実施の形態2と同様に図6のフローチャートに従って、言い直しおよび言い換えによる停滞脱出の判定を行うが、図6のステップS605における処理、即ち今回の発声が言い換えか否かの判定を行う処理が異なる。図21は本実施の形態における言い換え判定動作の流れを示すフローチャートである。
The stagnation
まず、今回の発声が前回の発声と同一のシステム動作を行う認識単語であるか否かを判定する(ステップS2001)。この判定の結果、前回の発声と同一のシステム動作を行う認識単語である場合(ステップS2001でYES)、これまでの実施の形態同様の動作であり、言い換えによる停滞脱出と判定する(図6のステップS605でYESの判定)。一方、前回の発声と同一のシステム動作を行う認識単語でない場合(ステップS2001でNO)、今回の認識対象語彙から省略語が作成される(ステップS2002)。省略語の作成は、今回の認識対象語彙を用いて省略語作成部301において行われる。
First, it is determined whether or not the current utterance is a recognized word that performs the same system operation as the previous utterance (step S2001). As a result of this determination, if the recognition word is the recognition word that performs the same system operation as the previous utterance (YES in step S2001), the operation is the same as in the previous embodiments, and it is determined that the stagnation escape due to paraphrase (FIG. 6). (Step S605: YES) On the other hand, if it is not a recognized word that performs the same system operation as the previous utterance (NO in step S2001), an abbreviation is created from the current recognition target vocabulary (step S2002). The abbreviation creation is performed in the
省略語作成部301は、今回の認識対象語彙を受け取り、予め定義されているルールに基づいて省略語を作成する。省略語作成方法としては、形態素解析ツールなどを用いて今回の認識対象語彙を形態素に分解し、その分解結果を基に作成する。例えば、一つの形態素を省略語としても良いし、複数の形態素をつなげて省略語としても良い。より具体的には例えば、「発掘あるある広辞苑」という単語に対して「発掘」「あるある」「広辞苑」「あるある広辞苑」といった省略語を作成したり、「冬のレクイエム」という単語に対して「冬レク」といった省略語を作成したりする。省略語作成部301で作成された省略語は、停滞脱出判定部302を介して対話制御部303に保持される。
The
次に、音声認識部101は、対話制御部303に保持されている省略語作成部301で作成された省略語を用いて、ユーザ発声記憶部304に記憶されている前回リジェクトされた発声について、再度認識を行う(ステップS2003)。
Next, the
そして、停滞脱出判定部302は、再認識結果の信頼度とリジェクト閾値とを比較する(ステップS2004)。ここで、再認識結果の信頼度がリジェクト閾値より高い場合(ステップS2004でYES)、対話制御部303は、認識候補1位の省略語を今回認識された単語と同じ動作を行う単語としてシステム仕様記憶部107および音声認識辞書102に登録(ステップS2005)し、言い換えによる停滞脱出と判定する(図6のステップS605でYESの判定)。一方、再認識結果の信頼度がリジェクト閾値より低い場合(ステップS2004でNO)、停滞脱出判定部302は言い換えによる停滞脱出では無いと判定する(図6のステップS605でNOの判定)。
Then, the stagnation
以上の動作より、システム仕様で音声認識辞書102に登録されていない省略語をユーザが発声してリジェクトされても、次の発声で正しい表現での発声を行い認識されれば、前回発声した省略語は新たに登録されるため、次回から認識が可能となる。これにより、省略語を発声してしまうユーザに対して何度もリジェクトすることが無く、スムーズでユーザに負担の掛からない対話が実現できる。さらに、本実施の形態による省略語の作成には特別な発声を促すわけでは無いので、ユーザの負担も少ない。
As a result of the above operation, even if the user utters an abbreviation that is not registered in the
(実施の形態4)
上記実施の形態1から実施の形態3によれば、一連の対話シーケンスの中で、誤動作と正しい動作を検出することで音声認識パラメータの変更および認識辞書の変更を行い、個人適応を可能としたが、複数のユーザが利用することを想定していないため、複数のユーザが利用した場合、正しく個人適応できない。本実施の形態は、このような場合に対処するものである。
(Embodiment 4)
According to the first to third embodiments, the voice recognition parameters are changed and the recognition dictionary is changed by detecting a malfunction and a correct operation in a series of dialogue sequences, thereby enabling personal adaptation. However, since it is not assumed that a plurality of users will use it, when it is used by a plurality of users, it will not be possible to personally adapt correctly. The present embodiment addresses such a case.
図22は、本発明の実施の形態4に係る音声認識装置を備えた音声対話型情報検索システムの構成を示すブロック図である。
FIG. 22 is a block diagram showing a configuration of a voice interactive information retrieval system including a voice recognition device according to
本実施の形態と上記実施の形態3との相違点は、ユーザ入力部401およびユーザ情報記憶部402が追加されたことによる対話制御部403における個人適応処理が異なる点であり、他は実施の形態1から実施の形態3までと同一である。従って、本実施の形態においては、複数ユーザが利用する際の対話制御部403の動作について説明する。
The difference between the present embodiment and the third embodiment is that the personal adaptation process in the
対話制御部403は、ユーザ入力部401からユーザ名が入力されると、ユーザ情報記憶部402より、入力されたユーザ名に適応された音声認識パラメータや認識対象辞書が登録されていているか否かの確認を行う。もし、入力されたユーザ名に適応された音声認識パラメータや認識対象語彙が無い場合、音声認識パラメータや音声認識辞書は初期値を利用してシステムを動作させる。もし、ユーザ適応されていないユーザが、システムを利用中に停滞脱出判定部302により誤動作と正しい動作のシーケンスが検出され、実施の形態1から実施の形態3で説明したような音声認識パラメータや音声認識対象語彙の変更が必要となると、対話制御部403はユーザ情報記憶部402に新規ユーザのユーザ名と音声認識パラメータや辞書を変更した単語についての各種情報を記憶する。
When a user name is input from the
一方、ユーザ入力部401より入力されたユーザ名に適応された音声認識パラメータや認識対象辞書がユーザ情報記憶部402に登録されている場合、対話制御部403はユーザ情報記憶部402から以前登録されたユーザ名の個人適応後の音声認識パラメータや新規認識辞書登録単語を抽出し、音声認識パラメータ記憶部103や音声認識辞書102にその情報を登録する。
On the other hand, when the speech recognition parameter and the recognition target dictionary adapted to the user name input from the
図23はユーザ情報記憶部402に記憶される各種情報の具体例を示す図である。なお、図23の例では単語ごとにリジェクト閾値を持つ場合の具体例を示す。項目2201はユーザ名であり、項目2202は停滞単語、すなわち音声認識パラメータや辞書を変更した単語であり、項目2203は停滞脱出回数、すなわち何度停滞脱出が検出されたかを示し、項目2204は変更した音声認識パラメータであるリジェクト閾値、項目2205は音声認識辞書に追加した新規登録読みである。
FIG. 23 is a diagram showing specific examples of various information stored in the user
図23に示されるデータがユーザ情報記憶部402に記憶されている場合、ユーザ入力部401からユーザ名Aが入力されると、対話制御部403はユーザ名Aの個人適応情報として「次の画面」の単語に対し、リジェクト閾値「3.4」を、新規読み登録として「ツリノダメン」を、「前の画面」に対しリジェクト閾値「3.5」を、新規読み登録として「マエノダメン」をそれぞれ音声認識パラメータ記憶部103および音声認識辞書102に登録する。
When the data shown in FIG. 23 is stored in the user
以上の動作より、一連の対話シーケンスの中で、誤動作と正しい動作を検出することで音声認識パラメータおよび音声認識辞書の個人適応が可能となるだけではなく、複数のユーザがシステムを利用した際にも正しく個人適応が可能となり、ユーザに負担の少ない個人適応と円滑な対話が実現できる。 From the above operations, it is possible not only to enable individual adaptation of speech recognition parameters and speech recognition dictionaries by detecting malfunctions and correct operations in a series of dialogue sequences, but also when multiple users use the system. Personal adaptation is possible correctly, and personal adaptation and smooth dialogue with less burden on the user can be realized.
なお、本実施の形態ではユーザ入力部の入力を基にユーザの判別を行い、複数のユーザに対応した個人適応を行ったが、話者識別や話者判別の技術は現在一般的に存在するので、それらの技術を用いてユーザの判別を行ってもよい。 In this embodiment, user identification is performed based on input from the user input unit, and personal adaptation corresponding to a plurality of users is performed. However, speaker identification and speaker identification technology currently generally exist. Therefore, the user may be determined using those techniques.
(実施の形態5)
上記実施の形態1から実施の形態4ではシステムの停滞状態として、誤ったリジェクトによる停滞状態を対象としたが、誤認識により誤ったシステム状態へ遷移した場合に発生する停滞状態について述べていない。そこで、本実施の形態は、このような停滞状態に対処するものである。
(Embodiment 5)
In the first to fourth embodiments, the stagnation state caused by an erroneous rejection is targeted as the stagnation state of the system. However, the stagnation state that occurs when the system transitions to the wrong system state due to erroneous recognition is not described. Therefore, this embodiment deals with such a stagnation state.
誤認識により誤ったシステム状態へ遷移した場合に発生するシステムの停滞状態の具体例としては、「時間検索」とユーザが発声したのに対し、システムがこれを「ジャンル検索」と認識し、ユーザが思っていたシステム状態と別のシステム状態へ遷移するような場合がある。このとき、ユーザはこの誤認識によるシステムの誤った状態遷移を基に戻すために「戻る」といった元の状態に戻るためのコマンドを発声する。システムの状態が戻るとユーザは再度「時間検索」を発声する。この一連の動作は2つのシステム状態の往復が繰り返し続く状態であり、一つの停滞状態といえる。 As a specific example of the stagnation state of the system that occurs when a transition to the wrong system state due to misrecognition, the user uttered “time search”, but the system recognizes this as “genre search” and the user There is a case where the system state transitions to a system state different from the system state that was expected. At this time, the user utters a command for returning to the original state such as “return” in order to return the erroneous state transition of the system due to the erroneous recognition. When the system status returns, the user speaks “time search” again. This series of operations is a state in which the reciprocation of two system states continues repeatedly, and can be said to be one stagnation state.
本実施の形態では、上記実施の形態4と比べシステム構成としての変更はなく、異なるのは停滞脱出判定部302における停滞判定の動作処理(図6のフローチャート)であり、他は実施の形態4と同様である。
In the present embodiment, there is no change in the system configuration compared to the above-described fourth embodiment, and the difference is the stagnation determination operation processing (flowchart in FIG. 6) in the stagnation
本実施の形態における停滞脱出判定部302の動作処理について説明する。図24は本実施の形態における停滞脱出判定部302の動作の流れを示すフローチャートである。なお、下記の説明における過去の認識結果は対話履歴記憶部106に記憶されているデータを参照して利用し、言い直しや言い換えの判定は上記実施の形態1から実施の形態4に述べた方法と同じ方法で行う。
The operation process of the stagnation /
まず、停滞脱出判定部302は、今回の音声認識結果を取得する(ステップS2301)。次に、この音声認識結果がリジェクトか否かの判定を行う(ステップS2302)。この判定の結果、リジェクトと判定した場合(ステップS2302でYES)、停滞脱出ではないと判定し、処理を終了する。一方、リジェクトではないと判定した場合(ステップS2302でNO)、前回の発声が状態を戻す発声(上記例では「戻る」)であったか否かを判定する(ステップS2303)。この判定の結果、前回の発声が状態を戻す発声でない場合(ステップS2303でNO)、停滞脱出では無いと判定し、処理を終了する。一方、前回の発声が状態を戻す発声である場合(ステップS2303でYES)、今回の発声が前々回の発声の言い直しか否かの判定を行う(ステップS2304)。この判定の結果、言い直しである場合(ステップS2304でYES)、いい直しによる停滞脱出と判定し、処理を終了する。一方、言い直しでない場合(ステップS2304でNO)、今回の発声が前々回の発声の言い換えか否かの判定を行う(ステップS2305)。この判定の結果、言い換えである場合(ステップS2305でYES)、言い換えによる停滞脱出と判定し、処理を終了する。一方、言い換えでない場合(ステップS2305でNO)、停滞脱出ではないと判定し、処理を終了する。なお、このようにして検出された言い直しや言い換えによる停滞脱出は、上記実施の形態1から実施の形態4で述べた、誤ったリジェクトによる停滞からの脱出と区別して対話履歴保存部106に保存する。
First, the stagnation
このようにして誤認識による停滞脱出の判定を行い、音声認識用パラメータや認識時書の変更を行う。具体的には例えば、上記実施の形態2で述べたような認識辞書の変更を行う。より具体的には、前々回の誤認識された発声に対しての音声認識結果のうち、音声認識辞書を使わず、音響的に近いかな文字列を音声認識結果として出力された結果(例えば図4の認識結果2)を、今回得られた正しく認識された結果の単語に対応付けて音声認識辞書に追加する。 In this way, the determination of escape from stagnation due to misrecognition is performed, and the parameters for speech recognition and the time of recognition are changed. Specifically, for example, the recognition dictionary is changed as described in the second embodiment. More specifically, among the speech recognition results for the previous misrecognized utterances, a result of outputting a character string that is acoustically close without using the speech recognition dictionary (for example, FIG. 4). The recognition result 2) is added to the speech recognition dictionary in association with the correctly recognized word obtained this time.
以上の動作より、誤ったリジェクトによるシステム状態の停滞のみでなく、誤認識によるシステム状態の停滞を利用した個人適応を行うので、次に前回誤動作をした発声を行っても誤認識による停滞が発生しなくなるため、スムーズでユーザに負担の掛からない対話が実現できる。また、本実施の形態による音声認識パラメータや音声認識辞書の変更は、専用の特別な発声を促すわけでは無く自然な対話から認識率を上げるため、ユーザの負担も少ない。 Based on the above operations, not only system status stagnation due to erroneous rejection but also personal adaptation using system status stagnation due to misrecognition, so that stagnation due to misrecognition will occur even if the previous malfunctioned utterance is made Therefore, it is possible to realize a smooth dialogue that does not burden the user. In addition, the change of the speech recognition parameters and the speech recognition dictionary according to the present embodiment does not prompt special special utterances, and raises the recognition rate from natural dialogue, so that the burden on the user is small.
なお、上記各実施の形態において、音声認識部は音声認識手段に、停滞脱出判定部は停滞脱出判定手段に、対話制御部は対話制御手段および変更制御手段に、省略語作成部は省略語作成手段に対応する。 In each of the above embodiments, the speech recognition unit is the speech recognition unit, the stagnation escape determination unit is the stagnation escape determination unit, the dialogue control unit is the dialogue control unit and the change control unit, and the abbreviation creation unit is the abbreviation creation. Corresponds to the means.
本発明に係る音声認識装置および音声認識方法は、音声対話型インタフェースを持つ多くのシステムに対して利用可能であり、例えば家庭内の情報検索システムやカーナビゲーションシステム、携帯端末からの情報検索などにおいて有用であり、その利用可能性は非常に大きい。 The voice recognition apparatus and the voice recognition method according to the present invention can be used for many systems having a voice interactive interface. For example, in a home information search system, a car navigation system, and information search from a portable terminal. It is useful and its availability is very large.
101 音声認識部
102 音声認識辞書部
103 音声認識パラメータ記憶部
104、302 停滞脱出判定部
105、303、403 対話制御部
106 対話履歴記憶部
107 システム仕様記憶部
108 データベース検索部
109 データベース記憶部
110 応答音声・画面出力部
111 タイマー
201 EPG受信部
301 省略語作成部
304 ユーザ発声記憶部
401 ユーザ入力部
402 ユーザ情報記憶部
DESCRIPTION OF
Claims (10)
音声認識辞書を用いて、入力された音声を認識して、認識結果を出力する音声認識手段と、
前記音声認識手段の認識結果により前記システム状態を遷移させて応答を行う対話制御手段と、
今回の認識結果で前記システム状態が先に進まず停滞している状態である停滞状態から脱出したか否かを判定するとともに、前記停滞状態から脱出したと判定した場合、今回の認識結果が言い直しおよび言い換えの少なくとも1つであるか否かを判定する停滞脱出判定手段と、
前記言い直しまたは言い換えであると判定された場合、対話制御に関する設定としてリジェクトの閾値の変更と、音声認識に関する設定の変更として前記音声認識辞書への新規追加または変更との少なくとも1つを行う変更制御手段と
を備えることを特徴とする音声認識装置。 A speech recognition device for recognizing an input voice and changing a system state, which is a system state related to a dialogue with a user, according to a recognition result, and performing a dialogue.
Voice recognition means for recognizing input voice using a voice recognition dictionary and outputting a recognition result;
Dialog control means for making a response by changing the system state according to a recognition result of the voice recognition means;
If it is determined whether or not the system state has escaped from the stagnation state, which is a state where the system state does not proceed further and is stagnant, and the current recognition result indicates that the system state has escaped from the stagnation state. A stagnation escape determination means for determining whether or not it is at least one of correction and paraphrasing;
When it is determined that the rephrasing or paraphrasing, a change that changes at least one of a rejection threshold as a setting related to dialogue control and a new addition or change to the voice recognition dictionary as a change of setting related to voice recognition A speech recognition apparatus comprising: a control unit.
音声認識辞書を用いて、入力された音声を認識して、認識結果を出力する音声認識手段と、
前記音声認識手段の認識結果により前記システム状態を遷移させて応答を行う対話制御手段と、
今回の認識結果により、前記システム状態が、前回の認識結果によるシステム状態と同一の状態である停滞状態から脱出したか否かを判定するとともに、前記停滞状態から脱出したと判定した場合、今回の認識結果が言い直しおよび言い換えの少なくとも1つであるか否かを判定する停滞脱出判定手段と、
前記言い直しまたは言い換えであると判定された場合、対話制御に関する設定としてリジェクトの閾値の変更と、音声認識に関する設定の変更として前記音声認識辞書への新規追加または変更との少なくとも1つを行う変更制御手段と
を備えることを特徴とする音声認識装置。 A speech recognition device for recognizing an input voice and changing a system state, which is a system state related to a dialogue with a user, according to a recognition result, and performing a dialogue.
Voice recognition means for recognizing input voice using a voice recognition dictionary and outputting a recognition result;
Dialog control means for making a response by changing the system state according to a recognition result of the voice recognition means;
When it is determined from the current recognition result whether the system state has escaped from the stagnation state that is the same as the system state according to the previous recognition result, and it is determined that the system state has escaped from the stagnation state, Stagnation escape determination means for determining whether the recognition result is at least one of rephrasing and paraphrasing;
When it is determined that the rephrasing or paraphrasing, a change that changes at least one of a rejection threshold as a setting related to dialogue control and a new addition or change to the voice recognition dictionary as a change of setting related to voice recognition A speech recognition apparatus comprising: a control unit.
態が続く状態であり、
前記停滞脱出判定手段は、今回の認識結果が前回の認識結果と同一単語である場合、言い直しであると判定し、今回の認識結果が前回の認識結果と同一単語では無いが、あらかじめ定められた同じシステム動作を実行する認識単語である場合、言い換えであると判定する
ことを特徴とする請求項1または2に記載の音声認識装置。 The stagnation state of the system state is a state in which the same system state continues due to rejection of the voice recognition result,
The stagnation escape determination means determines that the current recognition result is the same word as the previous recognition result, and determines that the current recognition result is not the same word as the previous recognition result, but is determined in advance. The speech recognition apparatus according to claim 1, wherein when the recognition word is a recognition word that executes the same system operation, it is determined as a paraphrase.
前記停滞脱出判定手段は、今回の認識結果が前々回の認識結果と同一単語である場合、言い直しであると判定し、今回の認識結果が前々回の認識結果と同一単語では無いが、あらかじめ定められた同じシステム動作を実行する認識単語である場合、言い換えであると判定する
ことを特徴とする請求項1または2に記載の音声認識装置。 The stagnation state of the system state is a state in which the round trip between two system states continues repeatedly,
The stagnation escape determination means determines that the current recognition result is the same word as the previous recognition result, and determines that the current recognition result is not the same word as the previous recognition result, but is determined in advance. The speech recognition apparatus according to claim 1, wherein when the recognition word is a recognition word that executes the same system operation, it is determined as a paraphrase.
ことを特徴とする請求項1または2に記載の音声認識装置。 The change control means, the speech recognition apparatus according to claim 1 or 2, characterized in that to change and set the threshold value of the reject each recognition target word.
ことを特徴とする請求項1または2に記載の音声認識装置。 The change control means, the reject threshold, and speech recognition apparatus according to newly added or changed to the speech recognition dictionary, to claim 1 or 2, characterized in that to set for each user.
前記停滞状態から脱出した際に、今回の認識結果が前回の認識結果と同一単語では無く、かつあらかじめ定められた同じシステム動作を実行する認識単語でない場合、今回の認識対象語彙の省略語を作成する省略語作成手段を備え、
前記音声認識手段は、前記省略語を用いて前回の認識結果を再認識し、
前記変更制御手段は、前記音声認識手段の再認識結果に応じて前記省略語を前記音声認識辞書へ新規追加する
ことを特徴とする請求項1または2に記載の音声認識装置。 The voice recognition device further includes:
When the current recognition result is not the same word as the previous recognition result and is not a recognition word that performs the same predetermined system operation when exiting from the stagnation state, an abbreviation of the current recognition target vocabulary is created Abbreviation creation means to
The voice recognition means re-recognizes the previous recognition result using the abbreviation,
The speech recognition apparatus according to claim 1, wherein the change control unit newly adds the abbreviation to the speech recognition dictionary according to a re-recognition result of the speech recognition unit.
電子番組表に対応する音声認識辞書を用いて、入力された電子番組表に関する音声を認識して、認識結果を出力する音声認識手段と、
前記音声認識手段の認識結果により前記システム状態を遷移させて応答を行う対話制御手段と、
今回の認識結果で前記システム状態が先に進まず停滞している状態である停滞状態から脱出したか否かを判定するとともに、前記停滞状態から脱出したと判定した場合、今回の認識結果が言い直しおよび言い換えの少なくとも1つであるか否かを判定する停滞脱出判定手段と、
前記言い直しまたは言い換えであると判定された場合、対話制御に関する設定としてリジェクトの閾値の変更と、音声認識に関する設定の変更として前記音声認識辞書への新規追加または変更との少なくとも1つを行う変更制御手段と
を備えることを特徴とする電子番組表用音声認識装置。 An electronic program guide voice recognition apparatus for recognizing an input voice related to an electronic program guide, performing a dialog by changing a system state that is a system state related to a dialog with a user according to a recognition result,
Voice recognition means for recognizing the voice related to the input electronic program guide using a voice recognition dictionary corresponding to the electronic program guide, and outputting a recognition result;
Dialog control means for making a response by changing the system state according to a recognition result of the voice recognition means;
If it is determined whether or not the system state has escaped from the stagnation state, which is a state where the system state does not proceed further and is stagnant, and the current recognition result indicates that the system state has escaped from the stagnation state. A stagnation escape determination means for determining whether or not it is at least one of correction and paraphrasing;
When it is determined that the rephrasing or paraphrasing, a change that changes at least one of a rejection threshold as a setting related to dialogue control and a new addition or change to the voice recognition dictionary as a change of setting related to voice recognition And an electronic program guide voice recognition device.
音声認識辞書を用いて、入力された音声を認識して、認識結果を出力する音声認識ステップと、
前記音声認識ステップにおける認識結果により前記システム状態を遷移させて応答を行う対話制御ステップと、
今回の認識結果で前記システム状態が先に進まず停滞している状態である停滞状態から脱出したか否かを判定するとともに、前記停滞状態から脱出したと判定した場合、今回の認識結果が言い直しおよび言い換えの少なくとも1つであるか否かを判定する停滞脱出判定ステップと、
前記言い直しまたは言い換えであると判定された場合、対話制御に関する設定としてリジェクトの閾値の変更と、音声認識に関する設定の変更として前記音声認識辞書への新規追加または変更との少なくとも1つを行う変更制御ステップと
を含むことを特徴とする音声認識方法。 A speech recognition method for recognizing an input voice, changing a system state that is a system state related to a dialog with a user according to a recognition result, and performing a dialog,
A speech recognition step of recognizing input speech using a speech recognition dictionary and outputting a recognition result;
A dialog control step of making a response by changing the system state according to a recognition result in the voice recognition step;
If it is determined whether or not the system state has escaped from the stagnation state, which is a state where the system state does not proceed further and is stagnant, and the current recognition result indicates that the system state has escaped from the stagnation state. A stagnation escape determination step of determining whether or not it is at least one of correction and paraphrasing;
When it is determined that the rephrasing or paraphrasing, a change that changes at least one of a rejection threshold as a setting related to dialogue control and a new addition or change to the voice recognition dictionary as a change of setting related to voice recognition A speech recognition method comprising: a control step.
音声認識辞書を用いて、入力された音声を認識して、認識結果を出力する音声認識ステップと、
前記音声認識ステップにおける認識結果により前記システム状態を遷移させて応答を行う対話制御ステップと、
今回の認識結果で前記システム状態が先に進まず停滞している状態である停滞状態から脱出したか否かを判定するとともに、前記停滞状態から脱出したと判定した場合、今回の認識結果が言い直しおよび言い換えの少なくとも1つであるか否かを判定する停滞脱出判定ステップと、
前記言い直しまたは言い換えであると判定された場合、対話制御に関する設定としてリジェクトの閾値の変更と、音声認識に関する設定の変更として前記音声認識辞書への新規追加または変更との少なくとも1つを行う変更制御ステップとをコンピュータに実行させる
ことを特徴とするプログラム。 A program for recognizing an input voice, changing a system state that is a state of a system related to a dialogue with a user according to a recognition result, and performing a dialogue,
A speech recognition step of recognizing input speech using a speech recognition dictionary and outputting a recognition result;
A dialog control step of making a response by changing the system state according to a recognition result in the voice recognition step;
If it is determined whether or not the system state has escaped from the stagnation state, which is a state where the system state does not proceed further and is stagnant, and the current recognition result indicates that the system state has escaped from the stagnation state. A stagnation escape determination step of determining whether or not it is at least one of correction and paraphrasing;
When it is determined that the rephrasing or paraphrasing, a change that changes at least one of a rejection threshold as a setting related to dialogue control and a new addition or change to the voice recognition dictionary as a change of setting related to voice recognition A program characterized by causing a computer to execute control steps.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005225877A JP4680714B2 (en) | 2005-08-03 | 2005-08-03 | Speech recognition apparatus and speech recognition method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005225877A JP4680714B2 (en) | 2005-08-03 | 2005-08-03 | Speech recognition apparatus and speech recognition method |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2007041319A JP2007041319A (en) | 2007-02-15 |
| JP2007041319A5 JP2007041319A5 (en) | 2008-07-10 |
| JP4680714B2 true JP4680714B2 (en) | 2011-05-11 |
Family
ID=37799356
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005225877A Expired - Fee Related JP4680714B2 (en) | 2005-08-03 | 2005-08-03 | Speech recognition apparatus and speech recognition method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4680714B2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11182565B2 (en) | 2018-02-23 | 2021-11-23 | Samsung Electronics Co., Ltd. | Method to learn personalized intents |
| US11314940B2 (en) | 2018-05-22 | 2022-04-26 | Samsung Electronics Co., Ltd. | Cross domain personalized vocabulary learning in intelligent assistants |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2009008115A1 (en) * | 2007-07-09 | 2010-09-02 | 三菱電機株式会社 | Voice recognition device and navigation system |
| JP4938719B2 (en) * | 2008-04-09 | 2012-05-23 | トヨタ自動車株式会社 | In-vehicle information system |
| WO2013102954A1 (en) * | 2012-01-06 | 2013-07-11 | パナソニック株式会社 | Broadcast receiving device and voice dictionary construction processing method |
| CN104584118B (en) * | 2012-06-22 | 2018-06-15 | 威斯通全球技术公司 | Multipass vehicle audio identifying system and method |
| DE102014109122A1 (en) * | 2013-07-12 | 2015-01-15 | Gm Global Technology Operations, Llc | Systems and methods for result-based arbitration in speech dialogue systems |
| US9715878B2 (en) | 2013-07-12 | 2017-07-25 | GM Global Technology Operations LLC | Systems and methods for result arbitration in spoken dialog systems |
| JP6280074B2 (en) * | 2015-03-25 | 2018-02-14 | 日本電信電話株式会社 | Rephrase detection device, speech recognition system, rephrase detection method, program |
| JP6716968B2 (en) * | 2016-03-07 | 2020-07-01 | 株式会社デンソー | Speech recognition device, speech recognition program |
| JP6555553B2 (en) * | 2016-03-25 | 2019-08-07 | パナソニックIpマネジメント株式会社 | Translation device |
| JP6724511B2 (en) * | 2016-04-12 | 2020-07-15 | 富士通株式会社 | Speech recognition device, speech recognition method, and speech recognition program |
| KR102497299B1 (en) | 2016-06-29 | 2023-02-08 | 삼성전자주식회사 | Electronic apparatus and method for controlling the electronic apparatus |
| JP6883471B2 (en) * | 2017-05-11 | 2021-06-09 | オリンパス株式会社 | Sound collecting device, sound collecting method, sound collecting program, dictation method and information processing device |
| JP6966374B2 (en) * | 2018-04-02 | 2021-11-17 | アルパイン株式会社 | Speech recognition system and computer program |
| DE112021008175T5 (en) * | 2021-11-30 | 2024-08-08 | Fanuc Corporation | SPEECH RECOGNITION DEVICE AND COMPUTER-READABLE STORAGE MEDIUM |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001005489A (en) * | 1999-04-13 | 2001-01-12 | Sony Internatl Europ Gmbh | Control method of network |
| JP2001125591A (en) * | 1999-10-27 | 2001-05-11 | Fujitsu Ten Ltd | Speech interactive system |
| JP2003337595A (en) * | 2002-05-22 | 2003-11-28 | Takeaki Kamiyama | Voice recognition device, dictionary preparation device, voice recognition system, method for recognizing voice, method for preparing dictionary, voice recognition program, dictionary preparation program, computer- readable recording medium with voice recognition program recorded thereon, and computer-readable recording medium with dictionary preparation program recorded thereon |
| JP2004109563A (en) * | 2002-09-19 | 2004-04-08 | Fujitsu Ltd | Speech interaction system, program for speech interaction, and speech interaction method |
| WO2004044887A1 (en) * | 2002-11-11 | 2004-05-27 | Matsushita Electric Industrial Co., Ltd. | Speech recognition dictionary creation device and speech recognition device |
| JP2006018028A (en) * | 2004-07-01 | 2006-01-19 | Nippon Telegr & Teleph Corp <Ntt> | Voice interactive method, voice interactive device, voice interactive device, dialog program, voice interactive program, and recording medium |
| JP2006154724A (en) * | 2004-10-28 | 2006-06-15 | Fujitsu Ltd | Interaction system, interaction method, and computer program |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS6232500A (en) * | 1985-08-06 | 1987-02-12 | 日本電気株式会社 | Voice recognition equipment with rejecting function |
| JPH0997095A (en) * | 1995-09-29 | 1997-04-08 | Matsushita Electric Ind Co Ltd | Speech recognition device |
| JP3518195B2 (en) * | 1996-09-19 | 2004-04-12 | 三菱電機株式会社 | Voice recognition device |
| JP3207378B2 (en) * | 1997-09-09 | 2001-09-10 | 日本電信電話株式会社 | Voice recognition method |
| JPH11149294A (en) * | 1997-11-17 | 1999-06-02 | Toyota Motor Corp | Voice recognition device and voice recognition method |
-
2005
- 2005-08-03 JP JP2005225877A patent/JP4680714B2/en not_active Expired - Fee Related
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001005489A (en) * | 1999-04-13 | 2001-01-12 | Sony Internatl Europ Gmbh | Control method of network |
| JP2001125591A (en) * | 1999-10-27 | 2001-05-11 | Fujitsu Ten Ltd | Speech interactive system |
| JP2003337595A (en) * | 2002-05-22 | 2003-11-28 | Takeaki Kamiyama | Voice recognition device, dictionary preparation device, voice recognition system, method for recognizing voice, method for preparing dictionary, voice recognition program, dictionary preparation program, computer- readable recording medium with voice recognition program recorded thereon, and computer-readable recording medium with dictionary preparation program recorded thereon |
| JP2004109563A (en) * | 2002-09-19 | 2004-04-08 | Fujitsu Ltd | Speech interaction system, program for speech interaction, and speech interaction method |
| WO2004044887A1 (en) * | 2002-11-11 | 2004-05-27 | Matsushita Electric Industrial Co., Ltd. | Speech recognition dictionary creation device and speech recognition device |
| JP2006018028A (en) * | 2004-07-01 | 2006-01-19 | Nippon Telegr & Teleph Corp <Ntt> | Voice interactive method, voice interactive device, voice interactive device, dialog program, voice interactive program, and recording medium |
| JP2006154724A (en) * | 2004-10-28 | 2006-06-15 | Fujitsu Ltd | Interaction system, interaction method, and computer program |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11182565B2 (en) | 2018-02-23 | 2021-11-23 | Samsung Electronics Co., Ltd. | Method to learn personalized intents |
| US11314940B2 (en) | 2018-05-22 | 2022-04-26 | Samsung Electronics Co., Ltd. | Cross domain personalized vocabulary learning in intelligent assistants |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2007041319A (en) | 2007-02-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4680714B2 (en) | Speech recognition apparatus and speech recognition method | |
| US7529678B2 (en) | Using a spoken utterance for disambiguation of spelling inputs into a speech recognition system | |
| US7996218B2 (en) | User adaptive speech recognition method and apparatus | |
| US6801893B1 (en) | Method and apparatus for expanding the vocabulary of a speech system | |
| US8380505B2 (en) | System for recognizing speech for searching a database | |
| US9754586B2 (en) | Methods and apparatus for use in speech recognition systems for identifying unknown words and for adding previously unknown words to vocabularies and grammars of speech recognition systems | |
| US20180137109A1 (en) | Methodology for automatic multilingual speech recognition | |
| US5787230A (en) | System and method of intelligent Mandarin speech input for Chinese computers | |
| JP4301102B2 (en) | Audio processing apparatus, audio processing method, program, and recording medium | |
| US6985863B2 (en) | Speech recognition apparatus and method utilizing a language model prepared for expressions unique to spontaneous speech | |
| US8355920B2 (en) | Natural error handling in speech recognition | |
| US8346553B2 (en) | Speech recognition system and method for speech recognition | |
| JP5703491B2 (en) | Language model / speech recognition dictionary creation device and information processing device using language model / speech recognition dictionary created thereby | |
| KR101526918B1 (en) | Multilingual non-native speech recognition | |
| KR20050082249A (en) | Method and apparatus for domain-based dialog speech recognition | |
| JP5824829B2 (en) | Speech recognition apparatus, speech recognition method, and speech recognition program | |
| US20150179169A1 (en) | Speech Recognition By Post Processing Using Phonetic and Semantic Information | |
| WO2002061728A1 (en) | Sentense recognition device, sentense recognition method, program, and medium | |
| US6963834B2 (en) | Method of speech recognition using empirically determined word candidates | |
| KR20210130024A (en) | Dialogue system and method of controlling the same | |
| US20050187767A1 (en) | Dynamic N-best algorithm to reduce speech recognition errors | |
| US11295733B2 (en) | Dialogue system, dialogue processing method, translating apparatus, and method of translation | |
| KR101242182B1 (en) | Apparatus for voice recognition and method for the same | |
| KR20130126570A (en) | Apparatus for discriminative training acoustic model considering error of phonemes in keyword and computer recordable medium storing the method thereof | |
| JP4661239B2 (en) | Voice dialogue apparatus and voice dialogue method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080527 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080527 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20100914 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20101005 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20101108 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110105 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110203 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4680714 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140210 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |