JP4614949B2 - 塩基配列検索装置及び塩基配列検索方法 - Google Patents
塩基配列検索装置及び塩基配列検索方法 Download PDFInfo
- Publication number
- JP4614949B2 JP4614949B2 JP2006511830A JP2006511830A JP4614949B2 JP 4614949 B2 JP4614949 B2 JP 4614949B2 JP 2006511830 A JP2006511830 A JP 2006511830A JP 2006511830 A JP2006511830 A JP 2006511830A JP 4614949 B2 JP4614949 B2 JP 4614949B2
- Authority
- JP
- Japan
- Prior art keywords
- base sequence
- input
- unit
- sequence
- hamming distance
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




























Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/20—Allele or variant detection, e.g. single nucleotide polymorphism [SNP] detection
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/50—Mutagenesis
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/10—Sequence alignment; Homology search
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
Description
杉本直己著、"遺伝子化学"、19ページ、株式会社化学同人発行、2002年 S.F.Altschul,W.Gish,W.Miller,E.W.Myers,and D.J. Lipman,"Basic local alignment search tool",J.Mol.Biol.,215,403−410,1990 T.F.Smith,and M.S.Waterman,"Identification of common molecular subsequences",J.Mol.Biol.,147,195−197,1981
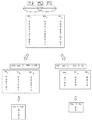
図4は、本発明の実施形態1に係る塩基配列検索装置の機能ブロック図を例示する。塩基配列検索装置400は、塩基配列入力部401と、ハミング距離入力部402と、特定部403と、割当部404と、選択部405と、置換塩基配列生成部406と、検索部407と、を有する。
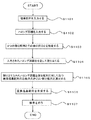
図11は、本実施形態に係る図4の塩基配列検索装置の処理の流れ図を例示する。ステップS1101において、塩基配列入力部401などにより、塩基配列を入力する(塩基配列入力ステップ)。ステップS1102において、ハミング距離入力部402などにより、ハミング距離を入力する(ハミング距離入力ステップ)。ステップS1103において、特定部403などにより、2つの部分配列とその余の部分とを特定する(特定ステップ)。ステップS1104において、割当部404などにより、入力されたハミング距離を分割して割り当てる(割当ステップ)。ステップS1105において、選択部405などにより、割当ステップで割り当てられたハミング距離を有する置換塩基配列の総数の大きくない方の部分配列を重複が発生しないように選択する(選択ステップ)。ステップS1106において、置換塩基配列生成部406などにより、置換塩基配列を生成する(置換塩基配列生成ステップ)。ステップS1107において、検索部407などにより、検索を行なう(検索ステップ)。
本実施形態により、検索のために必要となる計算量を小さくすることができ、また、ハミング距離が所定の値、もしくはそれ以下、もしくは任意の値の組み合わせとなる、似た塩基配列を漏れなく検索することができる。
図14は、本発明の実施形態4に係る塩基配列検索装置の機能ブロック図を例示する。塩基配列検索装置1400は、塩基配列入力部401と、ハミング距離入力部402と、特定部403と、割当部404と、選択部405と、置換塩基配列生成部406と、検索部407と、類似候補塩基配列取得部1401と、判定部1402と、を有している。また、特定部403は、実施形態2で説明した第一特定手段と実施形態3で説明した第二特定手段とのいずれか一方または両方を有していてもよい。したがって、本実施形態に係る塩基配列検索装置は、実施形態1から3のいずれか一の塩基配列検索装置が類似候補塩基配列取得部1401と、判定部1402と、を有している構成となっている。
本実施形態によれば、入力塩基配列に類似する塩基配列を取得することができ、例えば、siRNAにより不活性化する目的の遺伝子以外に不活性化される可能性のある遺伝子の情報を得ることが可能となる。
図15は、本発明の実施形態5に係る塩基配列検索装置の機能ブロック図を例示する。塩基配列検索装置1500は、塩基配列入力部401と、ハミング距離入力部402と、特定部403と、割当部404と、選択部405と、置換塩基配列生成部406と、検索部407と、類似候補塩基配列取得部1401と、判定部1402と、不適合塩基組入力部1501と、を有している。したがって、本実施形態に係る塩基配列検索装置は、実施形態4に係る塩基配列検索装置が不適合塩基組入力部1501を有している構成となっている。
本実施形態によれば、例えば、GとUのように弱いながらも結合する可能性のある塩基の組合せを考慮することができ、より正確な塩基配列の設計を行なうことが可能となる。
図16は、本発明の実施形態6に係る塩基配列検索装置の機能ブロック図を例示する。塩基配列検索装置1600は、塩基配列入力部401と、ハミング距離入力部402と、特定部403と、割当部404と、選択部405と、置換塩基配列生成部406と、検索部407と、類似候補塩基配列取得部1401と、判定部1402と、適合分布入力部1601と、を有しており、判定部1402は、判定手段1602を有している。また、塩基配列検索装置1600は、実施形態5にて説明した不適合塩基組入力部を有していてもよい。したがって、本実施形態に係る塩基配列検索装置は、実施形態4または5に係る塩基配列検索装置が、適合分布入力部1601を有し、判定部1402は、判定手段1602を有している構成となっている。
本実施形態により、より正確な塩基配列の設計を行なうことが可能となる。
図19は、本発明の実施形態10に係る塩基配列検索装置の機能ブロック図を例示する。本実施形態に係る塩基配列検索装置は、実施形態1から8のいずれかの塩基配列検索装置が、リピート配列蓄積部1901と、リピート配列情報蓄積部1902と、を有し、検索部407が、リピート配列判定手段1903と、リピート配列検索手段1904と、を有する構成となっている。図19は、実施形態1に係る塩基配列検索装置が、これらの部、手段を有する場合の機能ブロック図である。
図22は、本実施形態に係る図19の塩基配列検索装置の検索部での処理の流れを説明するフローチャートを例示する。ステップS2201において、リピート配列判定手段により、置換塩基配列がリピート配列であるかどうかを判定する。もし、リピート配列である場合(すなわち、ステップS2201においてYESに分岐する場合)ならば、処理をステップS2202へ進め、リピート配列検索手段1904により、リピート配列情報に基づいて検索を行なう。もし、リピート配列でない場合(すなわち、ステップS2201においてNOへ分岐する場合)ならば、ステップS2203へ処理を進め、実施形態1ないし8による類似塩基配列の検索を行なう。また、リピート配列である場合ならば検索を行なわず、リピート配列でないと判断された場合のみ検索することも可能である。
本実施形態では、置換塩基配列がリピート配列である場合には、リピート配列用の検索処理を行なうことにより、リピート配列による検索スピードの低下を防止することができる。
図23は、本発明の実施形態11に係る塩基配列検索装置の機能ブロック図を例示する。本実施形態に係る塩基配列検索装置は、実施形態4から7のいずれかの塩基配列検索装置が、類似塩基配列蓄積部2301を有する構成となっている。図23は、実施形態4に係る塩基配列検索装置が、類似塩基配列蓄積部2301を有する場合の機能ブロック図である。
図25は、本実施形態に係る塩基配列検索装置の判定部と類似塩基配列蓄積部との処理の流れを説明するフローチャートを例示する。ステップS2501において、判定部により、入力塩基配列と類似塩基配列とのハミング距離が入力されたハミング距離であるかどうかを判定する。もし、そうであれば、ステップS2501のYESの枝へ分岐し、ステップS2502において、類似塩基配列蓄積部2301に、(1)入力塩基配列と、(2)ハミング距離と、(3)類似塩基配列と、を関連付けて蓄積する。ステップS2501でNOの枝へ分岐する場合には、ステップS2502は実行しない。
本実施形態では、塩基配列検索装置の検索結果が類似塩基配列蓄積部2301に蓄積されるので、もし、既に検索対象と同じ入力塩基配列と同じハミング距離とに対して検索が行なわれているかどうかを、類似塩基配列蓄積部2301に蓄積された情報を検索して判断することにより、類似塩基配列の検索を効率よく行なうことができる。本実施形態に係る塩基配列検索装置は、例えば、インターネットなどにより検索のサービスを多数の人に提供する場合に特に有用である。例えば、第一の人が検索を行ないその後、第二の人が同じ検索を行なった場合、第二の人には、第一の人に対して提供した検索の結果を流用することにより、応答時間の短縮や、塩基配列検索装置の負荷の低減を行なうことができる。
図26は、本発明の実施形態12に係る塩基配列検索装置の機能ブロック図を例示する。本実施形態に係る塩基配列検索装置は、実施形態4から7のいずれかの塩基配列検索装置が、会合率計算部2601を有する構成となっている。図26は、実施形態4に係る塩基配列検索装置が、会合率計算部2601を有する場合の機能ブロック図である。
本発明の塩基配列検索装置では、入力塩基配列とハミング距離が所定の値以下の塩基配列を効率よく検索することができ、しかも、実際にウェット実験を行なった場合にどれだけの会合率となるかを得ることができ、実験結果やRNA干渉を用いた薬の効果の予測などを行なうことができる。
図27は、本発明の実施形態13に係る無効果塩基配列生成装置の機能ブロック図を例示する。無効果塩基配列生成装置2700は、塩基配列取得部2701と、無効果候補置換塩基配列生成部2702と、無効果候補置換塩基配列入力部2703と、第二ハミング距離入力部2704と、選択部2705と、を有する。
図28は、本実施形態に係る無効果塩基配列生成装置の処理の流れを説明するフローチャートを例示する。ステップS2801において、塩基配列を、塩基配列取得部2701により取得する。ステップS2802において、無効果候補置換塩基配列を、無効果候補置換塩基配列生成部2702により生成する。ステップS2803において、塩基配列検索装置2706に、無効果候補置換塩基配列と所定のハミング距離を入力する。ステップS2803は、個々の無効果候補置換塩基配列に対して一回ずつ行なわれ、個々の無効果候補置換塩基配列に対して会合率が取得される。ステップS2804においては、会合率の低い無効果候補置換塩基配列を、選択部2705により選択する。
本実施形態により、与えられた塩基配列に似た塩基配列であって、会合率の低いものを選択することができる。選択により得られた塩基配列は、効果のない塩基配列と推定されるので、ウェット実験におけるコントロールなどとして用いることができる。
図30は、本発明の実施形態14に係る塩基配列アラインメント装置の機能ブロック図を例示する。塩基配列アラインメント装置3000は、第二塩基配列取得部3001と、部分塩基配列選択部3002と、部分塩基配列入力部3003と、第三ハミング距離入力部3004と、アラインメント部3005と、を有する。
図31は、本実施形態に係る図30の塩基配列アラインメント装置の処理の流れを説明するフローチャートを例示する。ステップS3101において、第二塩基配列取得部3001により、塩基配列を取得する。ステップS3102において、部分塩基配列選択部3002において、部分塩基配列を選択する。ステップS3103において、部分塩基配列入力部3003と第三ハミング距離入力部3004とにより、部分塩基配列とハミング距離を塩基配列検索装置3006へ入力する。ステップS3104により、塩基配列検索装置3006による検索の結果に基づいて塩基配列を遺伝子塩基配列にアラインメントする。ステップS3104は、ステップS3103で得られた検索の結果だけ繰り返して実行される。
従来のアラインメントの手法では、BLASTなどが用いられていたが、BLASTなどを用いると、例えば連続する7merが一致する塩基配列の検索を行なって類似する塩基配列が遺伝子塩基配列のどこに出現するかを求めることになるので、アラインメントを正確に行なうことが困難な場合があった。本発明では、部分塩基配列の類似塩基配列を検索するので、より正確なアラインメントを行なうことができる。
401 塩基配列入力部
402 ハミング距離入力部
403 特定部
404 割当部
405 選択部
406 置換塩基配列生成部
407 検索部
Claims (16)
- 遺伝子情報を表わす遺伝子塩基配列を格納したデータベースを検索するための索引であり、所定の長さである所定長の塩基配列が前記遺伝子塩基配列の中に出現する位置を検索するための索引、を用いて、入力される塩基配列と同じ長さで類似する塩基配列であり前記遺伝子塩基配列に出現する塩基配列である類似塩基配列を検索するための塩基配列検索装置であって、
前記所定長を超える長さの塩基配列を入力する塩基配列入力部と、
前記塩基配列入力部に入力された塩基配列である入力塩基配列に対して、適合しない塩基への置換の操作を行なう塩基の個数を示すハミング距離を入力するハミング距離入力部と、
前記入力塩基配列の部分配列であって、前記所定長の長さを持ち異なる2つの部分配列と、その余の部分と、を特定する特定部と、
前記特定部で特定された部分配列とその余の部分とに、前記ハミング距離入力部で入力されたハミング距離を分割して割り当てる割当部と、
前記特定部で特定された2つの部分配列のうち、前記割当部で割り当てられたハミング距離で示される個数の塩基を適合しない塩基へ置換する操作を前記部分配列に対して行なって生成される塩基配列である置換塩基配列の総数が大きくない方を選択する選択部と、
前記選択部により選択された部分配列に対して、前記割当部で割り当てられたハミング距離をもつ置換塩基配列を生成する置換塩基配列生成部と、
前記置換塩基配列生成部で生成された置換塩基配列を検索キーとして前記索引を用いて検索を行なう検索部と、
を有する塩基配列検索装置。 - 前記特定部は、
前記塩基配列入力部で入力された塩基配列の塩基数が前記所定長の2倍以下または2倍未満であれば、前記2つの部分配列のうちの一方の部分配列の端を前記入力塩基配列の一方の端と一致させ、前記2つの部分配列のうちの他方の部分配列の端を前記入力塩基配列の他方の端と一致させ、その余の部分が生じず特定されないことにする第一特定手段を有する請求項1に記載の塩基配列検索装置。 - 前記特定部は、
前記塩基配列入力部で入力された塩基配列の塩基数が前記所定長の2倍より大であれば、前記2つの部分配列が重ならないことにして前記2つの部分配列を特定する第二特定手段を有する請求項1または2に記載の塩基配列検索装置。 - 前記検索部での検索結果に基づいて、前記置換塩基配列を含んで遺伝子塩基配列に現れる塩基配列である類似候補塩基配列を取得する類似候補塩基配列取得部と、
前記類似候補塩基配列取得部で取得された類似候補塩基配列と前記入力塩基配列とのハミング距離が前記ハミング距離入力部に入力されたハミング距離と同じ、又はそれ未満であるかどうかを判定する判定部と、
を有する請求項1から3のいずれか一に記載の塩基配列検索装置。 - 適合しない塩基の組を指定する不適合塩基組入力部を有し、不適合塩基組入力部に入力された塩基の組に基づいて、検索部で検索が行なわれ、また、ハミング距離が求められる請求項4に記載の塩基配列検索装置。
- 前記塩基配列入力部に入力された塩基配列と類似塩基配列との対応する塩基の適合の分布を表わす分布情報を入力する適合分布入力部を有し、
前記判定部は、前記適合分布入力部で入力された分布情報が満たされているかどうかを判定する分布判定手段を有する請求項4または5のいずれか一に記載の塩基配列検索装置。 - 前記適合分布入力部で入力される分布情報は、塩基配列と類似塩基配列との対応する塩基が連続して適合する長さの下限である請求項6に記載の塩基配列検索装置。
- 前記塩基配列入力部に入力される塩基配列の長さは15から60であり、前記所定長は、11から14である請求項1から7のいずれか一に記載の塩基配列検索装置。
- 遺伝子情報を表わす遺伝子塩基配列を格納したデータベースを検索するための索引であって、所定の長さである所定長の塩基配列が前記遺伝子塩基配列の中に出現する位置を検索するための索引、を用いて、入力される塩基配列と同じ長さで類似する塩基配列であり前記遺伝子塩基配列に出現する塩基配列である類似塩基配列を検索するための塩基配列検索方法であって、
前記所定長を超えるの長さの塩基配列を入力する塩基配列入力ステップと、
前記塩基配列入力部に入力された塩基配列である入力塩基配列に対して、適合しない塩基への置換の操作を行なう塩基の個数を示すハミング距離を入力するハミング距離入力ステップと、
前記入力塩基配列の部分配列であって、前記所定長の長さを持ち異なる2つの部分配列と、その余の部分と、を特定する特定ステップと、
前記特定ステップで特定された2つの部分配列とその余の部分とに、前記ハミング距離入力ステップにて入力されたハミング距離を分割して割り当てる割当ステップと、
前記特定ステップで特定された2つの部分配列のうち、前記割当部で割り当てられたハミング距離で示される個数の塩基を適合しない塩基へ置換する操作を前記部分配列に対して行なって生成される塩基配列である置換塩基配列の総数が大きくない方を選択する選択ステップと、
前記選択ステップにより選択された部分配列に対して、前記割当ステップにて割り当てられたハミング距離をもつ置換塩基配列を生成する置換塩基配列生成ステップと、
前記置換塩基配列生成ステップで生成された部分配列を検索キーとして前記索引を用いて検索を行なう検索ステップと、
を含む塩基配列検索方法。 - アルファベットが一次元に配列した文字列を格納したデータベースを検索するための索引であり、所定の長さである所定長の文字列が前記データベースに格納された文字列の中に出現する位置を検索するための索引、を用いて、入力される文字列と同じ長さで類似する文字列であり前記前記データベースに格納された文字列に出現する文字列である類似文字列を検索するための文字列検索装置であって、
前記所定長を超える長さの文字列を入力する文字列入力部と、
前記文字列入力部に入力された文字列である入力文字列に対して、適合しないアルファベットへの置換の操作を行なうアルファベットの個数を示すハミング距離を入力するハミング距離入力部と、
前記入力文字列の部分文字列であって、前記所定長の長さを持ち異なる2つの部分文字列と、その余の部分と、を特定する特定部と、
前記特定部で特定された部分文字列とその余の部分とに、前記ハミング距離入力部で入力されたハミング距離を分割して割り当てる割当部と、
前記特定部で特定された2つの部分文字列のうち、前記割当部で割り当てられたハミング距離で示される個数のアルファベットを適合しないアルファベットへ置換する操作を前記部分文字列に対して行なって生成される文字列である置換文字列の総数が大きくない方を選択する選択部と、
前記選択部により選択された部分文字列に対して、前記割当部で割り当てられたハミング距離をもつ置換文字列を生成する置換文字列生成部と、
前記置換文字列生成部で生成された置換文字列を検索キーとして前記索引を用いて検索を行なう検索部と、
を有する文字列検索装置。 - 前記文字列は、ペプチド配列である請求項10に記載の文字列検索装置。
- 遺伝子塩基配列中に繰り返して出現する前記所定長の塩基配列を蓄積するリピート配列蓄積部と、
前記リピート配列蓄積部に蓄積された塩基配列に、その塩基配列の前記遺伝子塩基配列中における出現位置を関連付けた情報であるリピート配列情報を蓄積するリピート配列情報蓄積部と、
を有し、
前記検索部は、
前記置換塩基配列が前記リピート配列蓄積部に蓄積されているかどうかを判定するリピート配列判定手段と、
前記リピート配列判定手段にて前記置換塩基配列が前記リピート配列蓄積部に蓄積されていると判定された場合には、前記リピート配列情報蓄積部に蓄積されたリピート配列情報に基づいて検索を行なうリピート配列検索手段と、
を有する請求項1から8のいずれか一に記載の塩基配列検索装置。 - 前記判定部にて、前記入力塩基配列と、前記類似候補塩基配列取得部により取得された類似候補塩基配列と、のハミング距離が前記ハミング距離入力部に入力されたハミング距離以下であると判定された場合に、前記入力塩基配列と、前記入力塩基配列と前記類似塩基配列とのハミング距離と、前記類似候補塩基配列と、を関連付けて蓄積する類似塩基配列蓄積部を有する請求項4から7のいずれか一に記載の塩基配列検索装置。
- 前記判定部にて、前記類似候補塩基配列取得部により取得された類似候補塩基配列と前記入力塩基配列とのハミング距離が前記ハミング距離入力部に入力されたハミング距離以下であると判定された場合に、前記塩基配列入力部により入力された塩基配列と前記類似候補塩基配列取得部で取得された類似候補塩基配列の会合率を計算する会合率計算部
を有する請求項4から7のいずれか一に記載の塩基配列検索装置。 - 前記所定長を超える長さの塩基配列を取得する塩基配列取得部と、
前記塩基配列取得部で取得された塩基配列の塩基のうち、所定の個数の塩基を置換して得られる塩基配列である無効果候補置換塩基配列を生成する無効果候補置換塩基配列生成部と、
前記無効果候補置換塩基配列生成部で生成された無効果候補置換塩基配列を請求項14に記載の塩基配列検索装置に入力する無効果候補置換塩基配列入力部と、
所定のハミング距離を前記無効果候補置換塩基配列入力部が無効果候補置換塩基配列を入力した塩基配列検索装置に入力する第二ハミング距離入力部と、
前記無効果候補置換塩基配列生成部で生成された無効果候補置換塩基配列の中から、前記無効果候補置換塩基配列入力部による入力と前記第二ハミング距離入力部による入力とによって前記塩基配列検索装置より得られた会合率の低い塩基配列を選択する選択部と、
を備える無効果塩基配列生成装置。 - 前記所定長を超える長さの塩基配列を取得する第二塩基配列取得部と、
前記第二塩基配列取得部で取得された塩基配列の一部分である部分塩基配列を選択する部分塩基配列選択部と、
前記部分塩基配列選択部で選択された部分塩基配列を請求項4から8のいずれか一に記載の塩基配列検索装置に入力する部分塩基配列入力部と、
所定のハミング距離を前記部分塩基配列入力部が部分塩基配列を入力した塩基配列検索装置に入力する第三ハミング距離入力部と、
前記部分塩基配列入力部による入力と前記第三ハミング距離入力部によるの入力とによって前記塩基配列検索装置より得られた検索の結果に基づいて、前記第二塩基配列取得部により取得された塩基配列を前記遺伝子塩基配列にアラインメントするアラインメント部と、
を有する塩基配列アラインメント装置。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004108456 | 2004-03-31 | ||
| JP2004108456 | 2004-03-31 | ||
| PCT/JP2005/006397 WO2005096208A1 (ja) | 2004-03-31 | 2005-03-31 | 塩基配列検索装置及び塩基配列検索方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2005096208A1 JPWO2005096208A1 (ja) | 2008-02-21 |
| JP4614949B2 true JP4614949B2 (ja) | 2011-01-19 |
Family
ID=35063999
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006511830A Active JP4614949B2 (ja) | 2004-03-31 | 2005-03-31 | 塩基配列検索装置及び塩基配列検索方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20080263002A1 (ja) |
| EP (1) | EP1732022A4 (ja) |
| JP (1) | JP4614949B2 (ja) |
| WO (1) | WO2005096208A1 (ja) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101482011B1 (ko) * | 2012-10-29 | 2015-01-14 | 삼성에스디에스 주식회사 | 염기 서열 정렬 시스템 및 방법 |
| KR101508816B1 (ko) * | 2012-10-29 | 2015-04-07 | 삼성에스디에스 주식회사 | 염기 서열 정렬 시스템 및 방법 |
| US10191929B2 (en) | 2013-05-29 | 2019-01-29 | Noblis, Inc. | Systems and methods for SNP analysis and genome sequencing |
| BR112018007092B1 (pt) | 2015-10-21 | 2024-02-20 | Coherent Logix, Incorporated | Alinhamento de dna com o uso de uma tabela de índice hierárquico invertido |
| US11222712B2 (en) | 2017-05-12 | 2022-01-11 | Noblis, Inc. | Primer design using indexed genomic information |
| CN117296100A (zh) | 2021-05-18 | 2023-12-26 | 富士通株式会社 | 信息处理程序、信息处理方法和信息处理装置 |
-
2005
- 2005-03-31 WO PCT/JP2005/006397 patent/WO2005096208A1/ja active Application Filing
- 2005-03-31 EP EP05727509A patent/EP1732022A4/en not_active Withdrawn
- 2005-03-31 JP JP2006511830A patent/JP4614949B2/ja active Active
- 2005-03-31 US US10/594,644 patent/US20080263002A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| US20080263002A1 (en) | 2008-10-23 |
| EP1732022A4 (en) | 2008-09-24 |
| JPWO2005096208A1 (ja) | 2008-02-21 |
| EP1732022A1 (en) | 2006-12-13 |
| WO2005096208A1 (ja) | 2005-10-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Fallmann et al. | Recent advances in RNA folding | |
| US8178503B2 (en) | Ribonucleic acid interference molecules and binding sites derived by analyzing intergenic and intronic regions of genomes | |
| Siebert et al. | MARNA: multiple alignment and consensus structure prediction of RNAs based on sequence structure comparisons | |
| JP4614949B2 (ja) | 塩基配列検索装置及び塩基配列検索方法 | |
| US8731843B2 (en) | Oligomer sequences mapping | |
| WO2010091021A2 (en) | Oligomer sequences mapping | |
| Frid et al. | A simple, practical and complete O-time Algorithm for RNA folding using the Four-Russians Speedup | |
| Al Junid et al. | Optimization of DNA sequences data to accelerate DNA sequence alignment on FPGA | |
| US8065091B2 (en) | Techniques for linking non-coding and gene-coding deoxyribonucleic acid sequences and applications thereof | |
| Frid et al. | An improved Four-Russians method and sparsified Four-Russians algorithm for RNA folding | |
| Olman et al. | Identification of regulatory binding sites using minimum spanning trees | |
| Subramaniyan et al. | Accelerating maximal-exact-match seeding with enumerated radix trees | |
| Kwarciak et al. | Tabu search algorithm for DNA sequencing by hybridization with multiplicity information available | |
| Blin et al. | Fixed-parameter algorithms for protein similarity search under mRNA structure constraints | |
| Horesh et al. | RNAspa: a shortest path approach for comparative prediction of the secondary structure of ncRNA molecules | |
| Al-Absi et al. | Parallel MapReduce: maximizing cloud resource utilization and performance improvement using parallel execution strategies | |
| JPWO2005093631A1 (ja) | 特異的塩基配列探索方法 | |
| Chan et al. | Generic spaced DNA motif discovery using Genetic Algorithm | |
| Cook et al. | Characterizing and optimizing the memory footprint of de novo short read DNA sequence assembly | |
| Masood et al. | An efficient algorithm for identifying (ℓ, d) motif from huge DNA datasets | |
| JP7393439B2 (ja) | 遺伝子シークエンシングデータ処理方法及び遺伝子シークエンシングデータ処理装置 | |
| Ali et al. | Pareto Optimization Technique for Protein Motif Detection in Genomic Data Set | |
| Winkler | Algorithms for finding RNA sequence-structure motifs | |
| Bryant Jr et al. | De novo short-read assembly | |
| Aguena et al. | A Survey on Solutions for Planted Motif Search Challenging Instances |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20071201 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20100219 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20100303 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20101012 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20101019 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4614949 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20131029 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R371 | Transfer withdrawn |
Free format text: JAPANESE INTERMEDIATE CODE: R371 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |