JP4493397B2 - テキスト圧縮装置 - Google Patents
テキスト圧縮装置 Download PDFInfo
- Publication number
- JP4493397B2 JP4493397B2 JP2004140818A JP2004140818A JP4493397B2 JP 4493397 B2 JP4493397 B2 JP 4493397B2 JP 2004140818 A JP2004140818 A JP 2004140818A JP 2004140818 A JP2004140818 A JP 2004140818A JP 4493397 B2 JP4493397 B2 JP 4493397B2
- Authority
- JP
- Japan
- Prior art keywords
- text
- rule
- sentence
- determined
- candidate
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images
















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/216—Parsing using statistical methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/253—Grammatical analysis; Style critique
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Probability & Statistics with Applications (AREA)
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Description

100 文法的テキスト圧縮システム
200 情報レポジトリ
300 ウェブ対応型パーソナルコンピュータ
400 ウェブ対応型タブレットコンピュータ
500 電話
1000 テキスト
Claims (1)
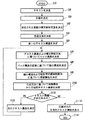
- 複数種類の言語学上の要素を含む文を備えたテキストのデータを受信する受信手段と、
複数種類の言語学上の複数の要素各々の内容に応じ、かつ、テキストを圧縮するために予め定められた、各要素を編集するための規則を記憶する記憶手段と、
を備えたテキスト圧縮装置であって、
前記受信手段により受信された前記データから文を決定し、
前記決定された前記文を、構文解析文法に基づいて、複数種類の言語学上の複数の要素に分解し、
前記文が分解されて得られた前記複数の要素各々と、前記記憶手段に記憶された規則と、に基づいて、前記文が分解されて得られた前記複数の要素各々を編集して複数の編集結果を生成し、
前記編集されて生成された前記複数の編集結果各々の、前記テキストの圧縮結果として適合する順位を、編集結果の単語数に基づく長さ及び文法に基づいて、決定し、
各編集結果について前記決定された順位に基づいて、前記テキストの圧縮結果として最も適合する編集結果を選択する
テキスト圧縮装置。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/435,036 US20040230415A1 (en) | 2003-05-12 | 2003-05-12 | Systems and methods for grammatical text condensation |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2004342104A JP2004342104A (ja) | 2004-12-02 |
| JP2004342104A5 JP2004342104A5 (ja) | 2009-02-19 |
| JP4493397B2 true JP4493397B2 (ja) | 2010-06-30 |
Family
ID=33299561
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004140818A Expired - Fee Related JP4493397B2 (ja) | 2003-05-12 | 2004-05-11 | テキスト圧縮装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20040230415A1 (ja) |
| EP (1) | EP1486885A3 (ja) |
| JP (1) | JP4493397B2 (ja) |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7610190B2 (en) * | 2003-10-15 | 2009-10-27 | Fuji Xerox Co., Ltd. | Systems and methods for hybrid text summarization |
| US7657420B2 (en) * | 2003-12-19 | 2010-02-02 | Palo Alto Research Center Incorporated | Systems and methods for the generation of alternate phrases from packed meaning |
| US7801723B2 (en) * | 2004-11-30 | 2010-09-21 | Palo Alto Research Center Incorporated | Systems and methods for user-interest sensitive condensation |
| US7827029B2 (en) * | 2004-11-30 | 2010-11-02 | Palo Alto Research Center Incorporated | Systems and methods for user-interest sensitive note-taking |
| JP4938298B2 (ja) | 2004-11-30 | 2012-05-23 | パロ・アルト・リサーチ・センター・インコーポレーテッド | テキストの要約に含める文の候補を出力する方法およびプログラム |
| US7401077B2 (en) * | 2004-12-21 | 2008-07-15 | Palo Alto Research Center Incorporated | Systems and methods for using and constructing user-interest sensitive indicators of search results |
| US7613664B2 (en) * | 2005-03-31 | 2009-11-03 | Palo Alto Research Center Incorporated | Systems and methods for determining user interests |
| US20060253205A1 (en) * | 2005-05-09 | 2006-11-09 | Michael Gardiner | Method and apparatus for tabular process control |
| US8527262B2 (en) * | 2007-06-22 | 2013-09-03 | International Business Machines Corporation | Systems and methods for automatic semantic role labeling of high morphological text for natural language processing applications |
| US20090162818A1 (en) * | 2007-12-21 | 2009-06-25 | Martin Kosakowski | Method for the determination of supplementary content in an electronic device |
| US8788260B2 (en) * | 2010-05-11 | 2014-07-22 | Microsoft Corporation | Generating snippets based on content features |
| US20120197630A1 (en) * | 2011-01-28 | 2012-08-02 | Lyons Kenton M | Methods and systems to summarize a source text as a function of contextual information |
| US11468243B2 (en) | 2012-09-24 | 2022-10-11 | Amazon Technologies, Inc. | Identity-based display of text |
| US10497366B2 (en) * | 2018-03-23 | 2019-12-03 | Servicenow, Inc. | Hybrid learning system for natural language understanding |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5438511A (en) * | 1988-10-19 | 1995-08-01 | Xerox Corporation | Disjunctive unification |
| US5338976A (en) * | 1991-06-20 | 1994-08-16 | Ricoh Company, Ltd. | Interactive language conversion system |
| US5689716A (en) * | 1995-04-14 | 1997-11-18 | Xerox Corporation | Automatic method of generating thematic summaries |
| US5745602A (en) * | 1995-05-01 | 1998-04-28 | Xerox Corporation | Automatic method of selecting multi-word key phrases from a document |
| US6061675A (en) * | 1995-05-31 | 2000-05-09 | Oracle Corporation | Methods and apparatus for classifying terminology utilizing a knowledge catalog |
| US5778397A (en) * | 1995-06-28 | 1998-07-07 | Xerox Corporation | Automatic method of generating feature probabilities for automatic extracting summarization |
| US5918240A (en) * | 1995-06-28 | 1999-06-29 | Xerox Corporation | Automatic method of extracting summarization using feature probabilities |
| US5903860A (en) * | 1996-06-21 | 1999-05-11 | Xerox Corporation | Method of conjoining clauses during unification using opaque clauses |
| US5819210A (en) * | 1996-06-21 | 1998-10-06 | Xerox Corporation | Method of lazy contexted copying during unification |
| GB9806085D0 (en) * | 1998-03-23 | 1998-05-20 | Xerox Corp | Text summarisation using light syntactic parsing |
| JP3879321B2 (ja) * | 1998-12-17 | 2007-02-14 | 富士ゼロックス株式会社 | 文書要約装置、文書要約方法及び文書要約プログラムを記録した記録媒体 |
| AU2001261506A1 (en) * | 2000-05-11 | 2001-11-20 | University Of Southern California | Discourse parsing and summarization |
| US7092872B2 (en) * | 2001-06-19 | 2006-08-15 | Fuji Xerox Co., Ltd. | Systems and methods for generating analytic summaries |
-
2003
- 2003-05-12 US US10/435,036 patent/US20040230415A1/en not_active Abandoned
-
2004
- 2004-05-11 JP JP2004140818A patent/JP4493397B2/ja not_active Expired - Fee Related
- 2004-05-12 EP EP04011282A patent/EP1486885A3/en not_active Withdrawn
Also Published As
| Publication number | Publication date |
|---|---|
| EP1486885A2 (en) | 2004-12-15 |
| US20040230415A1 (en) | 2004-11-18 |
| JP2004342104A (ja) | 2004-12-02 |
| EP1486885A3 (en) | 2006-08-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7401077B2 (en) | Systems and methods for using and constructing user-interest sensitive indicators of search results | |
| US9069750B2 (en) | Method and system for semantic searching of natural language texts | |
| US9495358B2 (en) | Cross-language text clustering | |
| US6654731B1 (en) | Automated integration of terminological information into a knowledge base | |
| US9098489B2 (en) | Method and system for semantic searching | |
| US8224641B2 (en) | Language identification for documents containing multiple languages | |
| US7970600B2 (en) | Using a first natural language parser to train a second parser | |
| US7788083B2 (en) | Systems and methods for the generation of alternate phrases from packed meaning | |
| US8280721B2 (en) | Efficiently representing word sense probabilities | |
| US20050203900A1 (en) | Associative retrieval system and associative retrieval method | |
| JP4493397B2 (ja) | テキスト圧縮装置 | |
| JP2009266244A (ja) | 簡潔言語学データを生成かつ使用するシステムおよび方法 | |
| KR20160105400A (ko) | 전자 장치에 텍스트를 입력하는 시스템 및 방법 | |
| MXPA04002816A (es) | Modelos estadisticos informados linguisticamente de una estructura compuesta para ordenar la comprension de una oracion para un sistema de generacion de lenguaje natural. | |
| US7827029B2 (en) | Systems and methods for user-interest sensitive note-taking | |
| US7801723B2 (en) | Systems and methods for user-interest sensitive condensation | |
| CN113330430B (zh) | 语句结构向量化装置、语句结构向量化方法及记录有语句结构向量化程序的记录介质 | |
| Choi et al. | Neural attention model with keyword memory for abstractive document summarization | |
| JP4478042B2 (ja) | 頻度情報付き単語集合生成方法、プログラムおよびプログラム記憶媒体、ならびに、頻度情報付き単語集合生成装置、テキスト索引語作成装置、全文検索装置およびテキスト分類装置 | |
| JP2001101184A (ja) | 構造化文書生成方法及び装置及び構造化文書生成プログラムを格納した記憶媒体 | |
| JP2005531857A (ja) | 簡潔言語学データを生成かつ使用するシステムおよび方法 | |
| Ouersighni | Robust rule-based approach in Arabic processing | |
| JP4635585B2 (ja) | 質問応答システム、質問応答方法及び質問応答プログラム | |
| Kadam | Develop a Marathi Lemmatizer for Common Nouns and Simple Tenses of Verbs | |
| JP4938298B2 (ja) | テキストの要約に含める文の候補を出力する方法およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070509 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20081023 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20081225 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090324 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090616 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20091117 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100215 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20100309 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20100406 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4493397 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130416 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140416 Year of fee payment: 4 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |