JP4299963B2 - 意味的まとまりに基づいて文書を分割する装置および方法 - Google Patents
意味的まとまりに基づいて文書を分割する装置および方法 Download PDFInfo
- Publication number
- JP4299963B2 JP4299963B2 JP2000302321A JP2000302321A JP4299963B2 JP 4299963 B2 JP4299963 B2 JP 4299963B2 JP 2000302321 A JP2000302321 A JP 2000302321A JP 2000302321 A JP2000302321 A JP 2000302321A JP 4299963 B2 JP4299963 B2 JP 4299963B2
- Authority
- JP
- Japan
- Prior art keywords
- document
- segment
- similarity
- dividing
- likelihood
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/137—Hierarchical processing, e.g. outlines
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/14—Tree-structured documents
- G06F40/143—Markup, e.g. Standard Generalized Markup Language [SGML] or Document Type Definition [DTD]
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99941—Database schema or data structure
- Y10S707/99943—Generating database or data structure, e.g. via user interface
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99941—Database schema or data structure
- Y10S707/99944—Object-oriented database structure
- Y10S707/99945—Object-oriented database structure processing
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Facsimiles In General (AREA)
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Description
【発明の属する技術分野】
この発明は、文書の分割技術に関し、より具体的には意味的まとまりにしたがって文書を分割する文書分割技術に関する。
【0002】
【従来の技術】
文書検索により検索された文書が複数の話題を含むような大きな文書の場合、ユーザは表示された文書からユーザにとって必要な部分を探す必要がある。この場合、予め話題ごとに分割した文書セグメントを検索対象にすることができれば、直ちにその文書セグメントを表示することができ、ユーザがさらに必要な部分を探す必要がなくなる。このように文書を話題ごとに分割することができると、様々な文書処理が容易になる。
【0003】
文書分割方法としては、特開平11−242684号公報、特開2000−235574号公報、特開平10−72724号公報等に記載がある。特開平11−242684号公報は、文書を隣接文間の関連だけでなく、広域的な関連も考慮に入れた文書分割装置を提案し、特開2000−235574号公報は、文書を形式段落等で分割し、段落間の関連度を要素とするような正方行列から分割点を求める方法を提案し、特開平10−72724号公報は、複数の窓から各位置における関連度を計算し、各階層ごとに話題境界を求め、それらを統合することによって、話題境界を認定していく方法を提案している。
【0004】
【発明が解決しようとする課題】
上記のような方法を用いることによって文書を話題ごとに分割することは可能である。しかしこれらの方法はサイズなどを考慮に入れてないため、特に携帯電話やPDAなどの表示画面が小さいなどのリソースの制限がある機器では、分割された文書セグメントを表示する際にユーザはスクロール等の操作を行う等の必要があったり、文書セグメントのサイズが機器の記憶領域の制限を越えていることがある。このように従来の文書分割手法によって分割された文書セグメントは、必ずしもユーザや端末装置にとって好ましい分割単位にはなっていない。
【0005】
したがって、文書を意味的なまとまりおよび指定された文書セグメント・サイズに従って分割する手法に対する必要性がある。さらには、携帯電話、PDA等の画面の小さい機器でもユーザに読み易い文書セグメント群を提供する技術に対する必要性がある。
【0006】
【課題を解決するための手段】
この発明の一つの側面によると、文書分割装置は、電子化された文書を分析し、意味的まとまりに基づいて文末ごとの分割点尤度を求める手段と、前記分割点尤度および指定された文書セグメント・サイズに基づいて前記文書を文書セグメントに分割する手段と、を有する。
【0007】
また、この発明のもう一つの側面によると、文書分割装置は、電子化された文書を分析し、意味的まとまりに基づいて文末ごとの分割点尤度を求める手段と、前記分割点尤度に基づいて前記文書を文書セグメントに分割する手段と、を備え、分割された前記文書セグメントが指定されたサイズに基づいて定められるしきい値より大きいとき、該文書セグメント内で最もよい分割点尤度を持つ位置で該文書セグメントを分割するようプログラムされている。
【0008】
この発明の一つの形態によると、文書は指定されたサイズと同程度のサイズを持つ文書セグメント群に分割される。まず、文書中の各文末位置においてその前後に設定された窓に含まれる文書部分間の類似度を計算し、類似度曲線を求める。得られた類似度曲線から各位置における分割点尤度を計算する。そして分割点尤度のよい位置から順に分割点として文書を分割していき、全ての文書セグメントが指定されたサイズと同程度のサイズになるまで分割していく。
【0009】
【発明の実施の形態】
次に図面を参照して発明の一つの実施形態を説明する。図1は、この発明の一実施例のシステムの全体的な構成を示す機能ブロック図である。この実施例は、ハードウェア的には汎用のコンピュータ、ワークステーションまたはパーソナルコンピュータで構成される。この発明を実現するコンピュータ・プログラムを汎用のコンピュータ上で走らせることにより、この発明を実施することができる。図1に示す各ブロックは、このコンピュータ・プログラムによって実現される機能を示す。
【0010】
分割対象となる電子化された文書1を受け取ると、形態素解析部2は、文書中の単語を切り出し、各単語に品詞情報を付加する。窓サイズ設定部3は、文書に含まれる隣接する文章の間の類似度を測定するための窓サイズを設定する。この窓サイズは、文末位置から左右に予め決められた長さとする。類似度測定部4は窓サイズ設定部3で設定された各位置における左右窓に含まれる文書部分間の類似度を測定し、類似度曲線を生成する。
【0011】
分割点尤度計算部5は、類似度測定4で求められた類似度曲線から各文末位置における分割点尤度を計算する。分割点決定部6は、分割点尤度計算部5で求められた分割点尤度を用いて、最も大きな文書セグメントの中でもっともよい分割点尤度を持った位置を分割点として選択する。文書1が分割されていないプロセスの開始部分においては、文書1の全体が最も大きな文書セグメントとなる。
【0012】
サイズ比較部11は、分割点決定部6で決定された文書セグメントの候補のサイズを出力先の機器が指定する文書セグメントのサイズに基づいて定めたサイズしきい値と比較し、文書セグメント候補のサイズがこのしきい値よりも大きいときは、その文書セグメント候補の中で最もよい分割点尤度を持つ位置を分割点として選択する。文書セグメント生成部7は、こうして得られた文書セグメント候補を文書セグメント集合とし、集合内の全ての文書セグメントが指定されたサイズより小さくなるまで分割点決定部6に戻り、サイズ比較部11による処理を受ける。
【0013】
関連度計算部8は文書セグメント生成部7で生成された文書セグメント間の類似度を計算し、その類似度を用いて文書セグメント間の関連付けを行う。リンク生成部は、関連度計算部8による計算結果に基づいて内容的に関連性の高い文書セグメント間にリンクを生成する。こうしてリンクを生成された文書セグメントが要求元のPDA、携帯電話などの端末装置に文書セグメントを送信する。
【0014】
一つの実施形態では、この発明の文書分割装置は、インターネット環境で使われる。たとえばユーザがPDAを用いてインターネット経由でウェブ・サイトにアクセスし、データを検索し、その結果をPDAのブラウザに表示する。この場合、ウェブ・サイトは、PDAに送信する文書をこの発明の文書分割装置により、PDAの表示スクリーンに合わせたサイズの文書セグメントに分割して送信する。文書セグメントは、HTML文書に変換され、関連文書セグメントに対するハイパーリンクを埋め込んでインターネット経由でPDAに送信される。文書セグメントのサイズは、PDAにおける表示サイズに合わせられており、ボタンをクリックする操作により、次の文書セグメントまたは意味的な関連の強い文書セグメントに飛ぶことができるので、小さな表示スクリーン上でも快適に文書を見ることができる。
【0015】
図2および3は、文書分割アルゴリズムのフローチャートである。図4は、文書セグメント間関連付けアルゴリズムのフローチャートを示す。まず図2を参照すると、N個の文書、M個の単語を含む電子文書Dおよび最適セグメントサイズSを受け取る(202)。ここで最適セグメントサイズとはユーザによって指定された文字数、またはPDA、携帯電話などの表示装置の表示文字数から規定されるもので、例えば100文字表示できる端末装置の場合だと最適セグメントサイズSは100文字が選ばれる。
【0016】
次のステップ203では、入力された電子文書Dに対して形態素解析を行い、文書中の単語を切り出し、その単語に品詞情報を与える。そしてその中から2回以上現れる名詞をタームtiとして取り出し、タームリストT(=t1, t2, t3, …,tn)を生成する(204)。
【0017】
続いてステップ205で、窓の幅Bを設定する。窓幅Bは、最初は、文書に含まれる単語の数Mの、たとえば1/5に設定する。こうして文書に含まれる文章のそれぞれの文末位置の左右に幅Bの窓を設定する(206)。そして先ほど求めたタームを要素とするベクトルW=(wt1, wt2, wt3, …、wtn) を左右の窓に含まれる文書部分からそれぞれ求める。ここでwt1は窓の中に含まれる文書中におけるタームt1の出現頻度である。求まった2つのベクトルから余弦測度sim(bl,br)を求め、それをその位置における類似度とする(207)。余弦測度は次に示す(1)式で求められる。
【0018】
【数1】

ここで、bl, brはそれぞれ左の窓、右の窓に含まれる文書部分を表す。また、Wbl, Wbrはそれぞれ左の窓、右の窓に現れるタームの出現頻度を表すベクトルである。(1)式で求められる類似度は、左右の窓に共通して現れるタームの数が多いほど大きな値(最大1)になり、共通のものがないときには0になる。つまり、この値が大きいときは左右の窓で共通の話題を扱っている可能性が高くなり、小さいときは話題の境界である可能性が高い。
【0020】
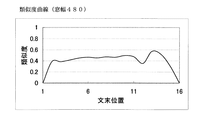
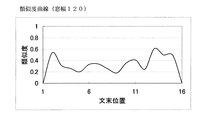
図2に示すサフィックスiは、文書に含まれる文章の番号を示し、文書の頭から1,2,3・・・・NまでのN個の文章が含まれるものとする。iがNに達するまで(ステップ209がNOになるまで)、iをインクリメントし(211)、類似度の計算を各文末位置に対して行う。こうして、文書についての類似度曲線が得られる。図5から8は、次の表に示す入力文書に対する類似度曲線を示す。
【0021】
【表1】
The community of mostly volunteer programmers that has built Linux into a formidable operating system is getting some help from computer industry giants. International Business Machines Inc., Intel Corp., Hewlett-Packard Co. and NEC Corp. are announcing Wednesday that they will create a laboratory with an investment of several million dollars where programmers can test Linux software on the large computer systems that are common in the corporate world. The lab is expected to open by the end of the year near Portland, Ore. Linux is an "open source" operating system that anyone can modify, as long as the modifications are made available for free on the Internet. It has a devoted following among programmers, who collaborate on software projects over the Web. These software engineers can usually only test software on their own desktop computers, part of the reason Linux is now rarely used on larger computers. "The Open Source Development Lab will help fulfill a need that individual Linux and open source developers often have: access to high-end enterprise hardware," said Brian Behlendorf, creator of the open source Web server software Apache. Irving Wladawsky-Berger, the head of IBM's Linux group, said the lab would help companies run hardware from different vendors together, as well as let run "clusters" of computers working as one. The four main sponsors said they will contribute several millions of dollars to the project. The lab is also backed by smaller companies that specialize in Linux products, like Red Hat Inc., Turbolinux Inc., Linuxcare Inc. and VA Linux Systems Inc., as well as Dell Computer Corp. and Silicon Graphics Inc. The founding companies said the lab will be run by a nonprofit organization that will select the software projects that gain access to the lab in an "open, neutral process." Linux is seen as an alternative to proprietary operating systems like Microsoft's Windows and Apple OS. Its backers say the publicly available source code, or software blueprint, makes it more flexible and reliable. Analyst Bill Claybrook at Aberdeen Group said the project sponsors are backing Linux because it gives them a chance to influence an operating system for their computers. "These companies see that they can play a much more important role in developing Linux than they can in, let's say Windows, because Microsoft pretty much decides what to put in Windows," he said.
【0022】
図5から8における横軸は各文末の位置を表し、縦軸は類似度を表す。また、図5から8における窓幅は、左右の窓にそれぞれに含まれる単語数である。
【0023】
こうして求められた類似度曲線から各文末位置cに対して、分割点尤度f(c)を求める。分割点尤度f (c)は以下の式から求められる。ステップ209において、i=Nになると、すなわち、文書に含まれるすべての文章についてB=M/5という条件下での類似度曲線が得られると、i=1にセットし(212)、最初の文章の文末位置に対する分割点尤度を計算する(213)。この計算は、iがNに達するまでiをインクリメントさせて(216)、繰り返される。
【0024】
【数2】
ここで、s(c)は各文末位置cにおける類似度、s(c-)は文末位置cの1つ前の文の文末位置における類似度、s(c+)は文末位置cの1つ後ろの文の文末位置における類似度であり、α、βはパラメータで実験によって求まるものである。
【0026】
(2)式の分割点尤度は類似度が極小な位置や類似度の遷移が大きいときに大きな値をとり、類似度が大きい、あまり類似度の遷移がない時に小さな値をとるようになる。
【0027】
iがNに達すると(ステップ215の判断がNOになると)、窓幅Bを最初の設定の1/2にセットしてステップ206以下のプロセスを繰り返す。そしてこの処理が完了すると、さらにその1/2の窓幅に設定してステップ206以下のプロセスを繰り返す。この繰り返し処理は、jが、類似度曲線の総数であるLに達するまで、すなわちステップ217における判断がNOになるまで、L回繰り返される。
【0028】
こうしてそれぞれの窓幅に対して求められたL個の分割点尤度f(c)を用いて、入力文書Dに対する総合的な分割点尤度F(c)を求める。
【0029】
【数3】
ここでfj(c)はi番目の類似度曲線から求まった分割点尤度f(c)であり、γjは各類似度曲線に対する重み係数であり、γjとしては例えば、1番大きな窓幅の分割点尤度に対して1、その次に対して1/2、その次に1/4と与える。以下、この実施例では文書の分割は、式(5)で求めた分割尤度曲線をもとに行う。図9は、こうして求められた分割尤度曲線を示す。
【0031】
次に図3に示すプロセスに移る。分割前の文書全体を文書セグメントR0で表すことにする(301)。ステップ302において、文書セグメント集合Rの中から最も大きいサイズのセグメントRiを選択する。初期状態では、文書セグメント集合Rは文書全体である文書セグメントR0だけを要素とする集合である。
【0032】
ステップ303に移り、選択された文書セグメントRiのサイズをセグメントサイズ閾値Thsizeと比較する。セグメントサイズ閾値Thsizeは、指定されたサイズすなわち最適セグメントサイズSに基づいて決められる。例えば、セグメントサイズ閾値Thsizeを最適セグメントサイズSの1.1倍にすると、最適セグメントサイズを10%超えるサイズまでの文書セグメントを許容するようことになる。
【0033】
セグメントRiのサイズが閾値Thsizeより大きいときは、ステップ305に進み、セグメントRi内で最もよい分割点尤度fを持つ文末位置cを分割点として選択する。ステップ307において、その文書セグメントRiを分割し、新しい文書セグメントRl’、Rr’を生成する。分割された文書セグメントRl’、Rr’が指定されたサイズSより小さすぎる場合(308)は、分割前の文書セグメントRiに戻し、その中で次によい分割点尤度を持つ位置を分割点として選択し、セグメントに分割する(309)。
【0034】
こうして、指定サイズSにたいして小さすぎないセグメントRl’またはRr’が得られると、文書セグメント集合RからRiを削除し、新たにRl’、Rr’を文書セグメント集合Rに加える(311)。
【0035】
次いで、ステップ302に戻り、全ての文書セグメントの中で最も大きい文書セグメントのサイズがセグメントサイズ閾値Thsizeより小さくなるまで、すなわちステップ303の判断がNOになるまで、閾値Thsizeより大きいサイズの文書セグメントについてステップ305以下のプロセスが繰り返えされる。この様に分割点尤度のよいものから順番に分割していくことによって、文書の大局的な話題の区切りを保持しつつ同程度のサイズをもつ文書セグメントを生成していくことが可能になる。
【0036】
次の表2に最適セグメントサイズを400文字と指定し、表1の入力文書Dを分割した際の文書セグメント群を示す。各セグメントのサイズが指定された通り、400文字程度になっている。また、表3に文書セグメントをマークアップ言語の形で表した例を示す。
【0037】
【表2】
文書セグメント1
The community of mostly volunteer programmers that has built Linux into a formidable operating system is getting some help from computer industry giants . International Business Machines Inc. , Intel Corp. , Hewlett-Packard Co. and NEC Corp. are announcing Wednesday that they will create a laboratory with an investment of several million dollars where programmers can test Linux software on the large computer systems that are common in the corporate world .
文書セグメント2
The lab is expected to open by the end of the year near Portland , Ore . Linux is an " open source " operating system that anyone can modify , as long as the modifications are made available for free on the Internet . It has a devoted following among programmers , who collaborate on software projects over the Web . These software engineers can usually only test software on their own desktop computers , part of the reason Linux is now rarely used on larger computers .
文書セグメント3
" The Open Source Development Lab will help fulfill a need that individual Linux and open source developers often have : access to high-end enterprise hardware , " said Brian Be , creator of the open source Web server software Apache . Irving Wladawsky-Berger , the head of IBM's Linux group , said the lab would help companies run hardware from different vendors together , as well as let run " clusters " of computers working as one .
文書セグメント4
The four main sponsors said they will contribute several millions of dollars to the project . The lab is also backed by smaller companies that specialize in Linux products , like Red Hat Inc. , Turbolinux Inc. , Linuxcare Inc. and VA Linux Systems Inc. , as well as Dell Computer Corp. and Silicon Graphics Inc . The founding companies said the lab will be run by a nonprofit organization that will select the software projects that gain access to the lab in an " open , neutral process . "
文書セグメント5
Linux is seen as an alternative to proprietary operating systems like Microsoft's Windows and Apple OS . Its backers say the publicly available source code , or software blueprint , makes it more flexible and reliable . Analyst Bill Claybrook at Aberdeen Group said the project sponsors are backing Linux because it gives them a chance to influence an operating system for their computers . " These companies see that they can play a much more important role in developing Linux than they can in , let's say Windows , because Microsoft pretty much decides what to put in Windows , " he said .
【0038】
【表3】
次に図4を参照して、文書セグメントの関連付け処理を説明する。以上のプロセスによって求められた文書セグメント間、または重要語と文書セグメント間の類似度qを(1)式を用いて計算し(402)、類似度qが関連閾値Threlevantより大きい時は(403)、文書セグメント間で似たような話題について書いてあると判断し、関連付けリンクを挿入する(405)。関連閾値Threlevantとしては例えば0.5を用いる。また、ユーザがよく関連しているセグメントだけの表示を希望する場合や関連するセグメント全ての表示を希望する場合があるので、この発明の一実施態様では、関連閾値Threlevantはユーザが指定するようにする。
【0040】
話題的に類似性のある文書セグメント間のハイパーリンク化はマークアップ言語でそれぞれの文書セグメントに埋め込まれる。また、リンク先としては1つの文書セグメントに限らず、複数の文書セグメントに対してはられる。例えば、文書セグメントを表すマークアップ言語としてXMLのXpointerを用いれば複数の文書セグメントに対してリンクをはることができ、1つの文書セグメントから複数の関連セグメントを表示する等の機構がブラウザ上で実装可能になる。
【0041】
以上に具体的な実施例について述べた本発明は、英語文書のみを対象とするわけでなく、日本語等の他言語文書に対してもその言語の形態素解析を行えば、同様な処理で文書分割を行うことができる。
【0042】
本発明では、文書を指定されたサイズと同程度の文書セグメントに分割するので、携帯端末等の小さな画面でも、ユーザに対して以下に示すように効率よく文書を提示することができる。文書セグメントは画面サイズに合わせて生成できるので、ユーザは一目でその文書セグメントが必要かそうでないかを判断することができる。一実施形態では文書セグメントを画面サイズの合わせて生成できるので、文書を表示する際に文書セグメント単位でスクロールができる。
【0043】
一実施の形態では、話題として類似する文書セグメント間に関連付けを行っているので、ユーザは簡単に関連する別の文書セグメントにアクセスすることができる。文書を表示する際、文書全体ではなく文書セグメント毎に表示できるので、表示端末では大きな記憶容量を必要としない。文書を携帯端末に表示する際、文書セグメントごとに転送できるので、パケットサイズなどの通信上の制限やハードウェアの制限を考慮して転送することができる。検索結果を文書セグメント単位で提示することによって、ユーザは直ちに必要な文書部分を読むことができる。
【0044】
自動抽出された文書セグメントは意味的なまとまりを表しているので、文献(亀田雅之 1997. “段落間及び文間関連度を利用した段落シフト法に基づく重要文抽出” 情報処理学会自然言語処理研究会報告, 119-126. 121-17.)等の方法を用いて各セグメントに対して重要語、重要文抽出、もしくは文献(仲尾由雄 1998. “文書の意味的階層構造の自動認定に基づく要約作成” 言語処理学会第4回年次大会併設ワークショップ「テキ スト要約の現状と将来」論文集, 72-79.)等を用いて要約文生成を各セグメントに対して行い、それらを提示することによって、ユーザが容易にその文書の概略の理解、斜め読みができる。
【0045】
以上にこの発明を具体的な実施例について説明したが、この発明はこのような実施例に限定されるものではない。
【図面の簡単な説明】
【図1】 この発明の一実施例の文書分割装置の全体的なブロック図。
【図2】 文書分割アルゴリズムの前半部を示すフローチャート。
【図3】 文書分割アルゴリズムの後半部を示すフローチャート。
【図4】 文書セグメント間の関連付けを行うアルゴリズムのフローチャート。
【図5】 窓幅を480単語にしたときの類似度曲線を示す図。
【図6】 窓幅を240単語にしたときの類似度曲線を示す図。
【図7】 窓幅を120単語にしたときの類似度曲線を示す図。
【図8】 窓幅を60単語にしたときの類似度曲線を示す図。
【図9】 分割点尤度曲線を示す図。
【符号の説明】
2 形態素解析部
3 窓サイズ設定部
4 類似度測定部
5 分割点尤度計算部
6 分割点決定部
11 サイズ比較部
7 文書セグメント生成部
8 関連度計算部
12 リンク生成部
Claims (6)
- 電子化された文書の文末の左右に所定幅の窓を設定し、該左右の窓に含まれるタームの類似度を計算する手段と、
前記文書を分析し、該類似度に基づいて文末ごとの分割点尤度を求める手段と、
前記分割点尤度に基づいて前記文書を文書セグメントに分割する手段と、
を備え、
前記分割する手段は、分割された前記文書セグメントが指定サイズに基づいて定められるしきい値より大きいとき、該文書セグメント内で最もよい分割点尤度を持つ位置で該文書セグメントを分割し、前記分割された文書セグメントが前記指定サイズより予め定めた程度以上小さいとき、分割前の文書セグメントに戻り、次によい分割点尤度を持つ位置で該文書セグメントを分割する、文書分割装置。 - 前記類似度を計算する手段は、cを文末位置として、複数(L)の異なる窓幅についてそれぞれ分割点尤度f(c)を計算し、こうして得られた複数の分割点尤度に基づいて総合的な分割点尤度F(c)を計算する、請求項1に記載の文書分割装置。
- 分割された文書セグメント間の類似度を計算し、類似度が予め定めたしきい値以上の文書セグメントに関連づけリンクを形成するようプログラムされた請求項1に記載の文書分割装置。
- 電子化された文書の文末の左右に所定幅の窓を設定し、該左右の窓に含まれるタームの類似度を計算するステップと、
前記文書を分析し、前記類似度に基づいて文末ごとの分割点尤度を求めるステップと、
前記分割点尤度に基づいて前記文書を文書セグメントに分割するステップと、
をコンピュータに実行させるためのプログラムを記録したコンピュータ読み取り可能な記録媒体であって、
前記分割するステップは、分割された前記文書セグメントが指定されたサイズに基づいて定められるしきい値より大きいとき、該文書セグメント内で最もよい分割点尤度を持つ位置で該文書セグメントを分割し、分割された文書セグメントのサイズが指定サイズより予め定めた程度以上小さいとき、分割前の文書セグメントに戻り、次によい分割点尤度を持つ位置で該文書セグメントを分割する、前記記録媒体。 - 前記類似度を計算するステップは、cを文末位置として、複数(L)の異なる窓幅についてそれぞれ分割点尤度f(c)を計算し、こうして得られた複数の分割点尤度に基づいて総合的な分割点尤度F(c)を計算する、請求項4に記載の記録媒体。
- 前記プログラムは、分割された文書セグメント間の類似度を計算し、類似度が予め定めたしきい値以上の文書セグメントに関連づけリンクを形成するステップをコンピュータに実行させる、請求項4に記載の記録媒体。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2000302321A JP4299963B2 (ja) | 2000-10-02 | 2000-10-02 | 意味的まとまりに基づいて文書を分割する装置および方法 |
| US10/182,779 US7113897B2 (en) | 2000-10-02 | 2001-10-02 | Apparatus and method for text segmentation based on coherent units |
| PCT/US2001/030734 WO2002029547A1 (en) | 2000-10-02 | 2001-10-02 | Apparatus and method for text segmentation based on coherent units |
| EP01975645A EP1301853B1 (en) | 2000-10-02 | 2001-10-02 | Apparatus and method for text segmentation based on coherent units |
| DE60139323T DE60139323D1 (de) | 2000-10-02 | 2001-10-02 | Vorrichtung und verfahren zur textsegmentierung auf der grundlage kohärenter einheiten |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2000302321A JP4299963B2 (ja) | 2000-10-02 | 2000-10-02 | 意味的まとまりに基づいて文書を分割する装置および方法 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2002117019A JP2002117019A (ja) | 2002-04-19 |
| JP2002117019A5 JP2002117019A5 (ja) | 2007-12-06 |
| JP4299963B2 true JP4299963B2 (ja) | 2009-07-22 |
Family
ID=18783693
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2000302321A Expired - Fee Related JP4299963B2 (ja) | 2000-10-02 | 2000-10-02 | 意味的まとまりに基づいて文書を分割する装置および方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US7113897B2 (ja) |
| EP (1) | EP1301853B1 (ja) |
| JP (1) | JP4299963B2 (ja) |
| DE (1) | DE60139323D1 (ja) |
| WO (1) | WO2002029547A1 (ja) |
Families Citing this family (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050120011A1 (en) * | 2003-11-26 | 2005-06-02 | Word Data Corp. | Code, method, and system for manipulating texts |
| JP2007241902A (ja) * | 2006-03-10 | 2007-09-20 | Univ Of Tsukuba | テキストデータの分割システム及びテキストデータの分割及び階層化方法 |
| JP5084297B2 (ja) * | 2007-02-21 | 2012-11-28 | 株式会社野村総合研究所 | 会話解析装置および会話解析プログラム |
| JP4646078B2 (ja) * | 2007-03-08 | 2011-03-09 | 日本電信電話株式会社 | 相互に関係する固有表現の組抽出装置及びその方法 |
| JP5256654B2 (ja) * | 2007-06-29 | 2013-08-07 | 富士通株式会社 | 文章分割プログラム、文章分割装置および文章分割方法 |
| KR101472844B1 (ko) | 2007-10-23 | 2014-12-16 | 삼성전자 주식회사 | 적응적 문서 디스플레이 장치 및 방법 |
| EP2416256A4 (en) * | 2009-03-30 | 2017-09-20 | Nec Corporation | Language analysis device, method, and program |
| US8434001B2 (en) | 2010-06-03 | 2013-04-30 | Rhonda Enterprises, Llc | Systems and methods for presenting a content summary of a media item to a user based on a position within the media item |
| US9326116B2 (en) | 2010-08-24 | 2016-04-26 | Rhonda Enterprises, Llc | Systems and methods for suggesting a pause position within electronic text |
| US9087043B2 (en) * | 2010-09-29 | 2015-07-21 | Rhonda Enterprises, Llc | Method, system, and computer readable medium for creating clusters of text in an electronic document |
| CN104468319B (zh) * | 2013-09-18 | 2018-11-16 | 阿里巴巴集团控股有限公司 | 一种会话内容合并方法和系统 |
| CN104090918B (zh) * | 2014-06-16 | 2017-02-22 | 北京理工大学 | 一种基于信息量的句子相似度计算方法 |
| US10402473B2 (en) * | 2016-10-16 | 2019-09-03 | Richard Salisbury | Comparing, and generating revision markings with respect to, an arbitrary number of text segments |
| JP6815184B2 (ja) * | 2016-12-13 | 2021-01-20 | 株式会社東芝 | 情報処理装置、情報処理方法、および情報処理プログラム |
| EP3616090A1 (en) * | 2017-04-26 | 2020-03-04 | Piksel, Inc. | Multimedia stream analysis and retrieval |
| JP6564811B2 (ja) * | 2017-05-18 | 2019-08-21 | 日本電信電話株式会社 | パッセージ提示制御装置、パッセージ提示方法、及びパッセージ提示プログラム |
| CN109492659B (zh) * | 2018-09-25 | 2021-10-01 | 维灵(杭州)信息技术有限公司 | 一种用于心电、脑电波形对比的计算曲线相似度的方法 |
| JP7148077B2 (ja) * | 2019-02-28 | 2022-10-05 | 日本電信電話株式会社 | 木構造解析装置、方法、及びプログラム |
| US11748571B1 (en) * | 2019-05-21 | 2023-09-05 | Educational Testing Service | Text segmentation with two-level transformer and auxiliary coherence modeling |
| CN111797634B (zh) * | 2020-06-04 | 2023-09-08 | 语联网(武汉)信息技术有限公司 | 文档分割方法及装置 |
| CN112597422A (zh) | 2020-12-30 | 2021-04-02 | 深圳市世强元件网络有限公司 | 一种pdf文件分割方法和网页中pdf文件加载方法 |
| CN118446213A (zh) * | 2024-04-29 | 2024-08-06 | 北京医二科技有限公司 | 文本切分方法及装置、计算机程序产品、电子设备 |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| ATE260486T1 (de) * | 1992-07-31 | 2004-03-15 | Ibm | Auffindung von zeichenketten in einer datenbank von zeichenketten |
| US5778397A (en) * | 1995-06-28 | 1998-07-07 | Xerox Corporation | Automatic method of generating feature probabilities for automatic extracting summarization |
| US5761191A (en) * | 1995-11-28 | 1998-06-02 | Telecommunications Techniques Corporation | Statistics collection for ATM networks |
| US6052657A (en) * | 1997-09-09 | 2000-04-18 | Dragon Systems, Inc. | Text segmentation and identification of topic using language models |
| JPH11235574A (ja) | 1998-02-24 | 1999-08-31 | Hitachi Kasei Techno Plant Kk | リサイクル装置及び廃パトローネのリサイクル装置 |
| JP3578618B2 (ja) | 1998-02-26 | 2004-10-20 | 株式会社リコー | 文書分割装置 |
| JP3597697B2 (ja) * | 1998-03-20 | 2004-12-08 | 富士通株式会社 | 文書要約装置およびその方法 |
| US6714909B1 (en) * | 1998-08-13 | 2004-03-30 | At&T Corp. | System and method for automated multimedia content indexing and retrieval |
| US6185524B1 (en) * | 1998-12-31 | 2001-02-06 | Lernout & Hauspie Speech Products N.V. | Method and apparatus for automatic identification of word boundaries in continuous text and computation of word boundary scores |
| US6317708B1 (en) * | 1999-01-07 | 2001-11-13 | Justsystem Corporation | Method for producing summaries of text document |
| JP2000235574A (ja) | 1999-02-16 | 2000-08-29 | Ricoh Co Ltd | 文書処理装置 |
| US6611825B1 (en) * | 1999-06-09 | 2003-08-26 | The Boeing Company | Method and system for text mining using multidimensional subspaces |
| US6411962B1 (en) * | 1999-11-29 | 2002-06-25 | Xerox Corporation | Systems and methods for organizing text |
| US6675174B1 (en) * | 2000-02-02 | 2004-01-06 | International Business Machines Corp. | System and method for measuring similarity between a set of known temporal media segments and a one or more temporal media streams |
-
2000
- 2000-10-02 JP JP2000302321A patent/JP4299963B2/ja not_active Expired - Fee Related
-
2001
- 2001-10-02 WO PCT/US2001/030734 patent/WO2002029547A1/en active Application Filing
- 2001-10-02 EP EP01975645A patent/EP1301853B1/en not_active Expired - Lifetime
- 2001-10-02 DE DE60139323T patent/DE60139323D1/de not_active Expired - Lifetime
- 2001-10-02 US US10/182,779 patent/US7113897B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| EP1301853B1 (en) | 2009-07-22 |
| EP1301853A1 (en) | 2003-04-16 |
| US7113897B2 (en) | 2006-09-26 |
| WO2002029547A1 (en) | 2002-04-11 |
| WO2002029547A9 (en) | 2005-03-17 |
| US20030081811A1 (en) | 2003-05-01 |
| JP2002117019A (ja) | 2002-04-19 |
| DE60139323D1 (de) | 2009-09-03 |
| EP1301853A4 (en) | 2007-03-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4299963B2 (ja) | 意味的まとまりに基づいて文書を分割する装置および方法 | |
| US11720758B2 (en) | Real-time in-context smart summarizer | |
| US20040049374A1 (en) | Translation aid for multilingual Web sites | |
| US20150067476A1 (en) | Title and body extraction from web page | |
| CN100568242C (zh) | 用于提取新复合词的系统和方法 | |
| Song et al. | A hybrid approach for content extraction with text density and visual importance of DOM nodes | |
| US20160085740A1 (en) | Generating training data for disambiguation | |
| JPH08241332A (ja) | 全文登録語検索装置および方法 | |
| US20090313536A1 (en) | Dynamically Providing Relevant Browser Content | |
| US9244891B2 (en) | Adjusting search result rankings based on multiple user highlighting of documents | |
| Levering et al. | The portrait of a common HTML web page | |
| US20100042915A1 (en) | Personalized Document Creation | |
| JP2007072646A (ja) | 検索装置、検索方法およびプログラム | |
| JP2020098596A (ja) | ウェブページから情報を抽出する方法、装置及び記憶媒体 | |
| Ohba et al. | Toward mining" concept keywords" from identifiers in large software projects | |
| JP2009037420A (ja) | 有害コンテンツの評価付与装置、プログラム及び方法 | |
| CN112380337A (zh) | 基于富文本的高亮方法及装置 | |
| US20060136400A1 (en) | Textual search and retrieval systems and methods | |
| JP4030624B2 (ja) | 文書処理装置、文書処理プログラムが記憶された記憶媒体および文書処理方法 | |
| JP2001265774A (ja) | 情報検索方法、装置、および情報検索プログラムを記録した記録媒体、ハイパーテキスト情報検索システム | |
| US8195458B2 (en) | Open class noun classification | |
| Modi et al. | Multimodal web content mining to filter non-learning sites using NLP | |
| KR101909537B1 (ko) | 소셜 데이터 분류 시스템 및 방법 | |
| WO2023162129A1 (ja) | 学習用データ生成装置、リスク検知装置、学習用データ生成方法、リスク検知方法、学習用データ生成プログラム及びリスク検知プログラム | |
| Brüggemann et al. | Topic Detection and Tracking System |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20071001 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20071024 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20081212 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090106 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090318 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090414 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090420 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120424 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |