JP3963141B2 - SINGLE SYNTHESIS DEVICE, SINGE SYNTHESIS PROGRAM, AND COMPUTER-READABLE RECORDING MEDIUM CONTAINING SINGE SYNTHESIS PROGRAM - Google Patents
SINGLE SYNTHESIS DEVICE, SINGE SYNTHESIS PROGRAM, AND COMPUTER-READABLE RECORDING MEDIUM CONTAINING SINGE SYNTHESIS PROGRAM Download PDFInfo
- Publication number
- JP3963141B2 JP3963141B2 JP2002244240A JP2002244240A JP3963141B2 JP 3963141 B2 JP3963141 B2 JP 3963141B2 JP 2002244240 A JP2002244240 A JP 2002244240A JP 2002244240 A JP2002244240 A JP 2002244240A JP 3963141 B2 JP3963141 B2 JP 3963141B2
- Authority
- JP
- Japan
- Prior art keywords
- phoneme
- time length
- transition time
- data
- database
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images
































Landscapes
- Electrophonic Musical Instruments (AREA)
Abstract
Description
【0001】
【発明の属する技術分野】
この発明は、リアルタイムに入力される演奏データに基づいて歌唱を合成する歌唱合成装置、方法及びプログラムに係るものである。
【0002】
【従来の技術】
従来の歌唱合成装置においては、人間の実際の歌声から取得したデータを、例えばテンプレートデータとしてデータベースとして保存しておき、入力された演奏データ(音符、歌詞、表情等)の内容に合致したデータをデータベースより読み出す。そして、この演奏データとテンプレートデータに基づいて、歌唱合成スコアと呼ばれるデータを作成する。
【0003】
この歌唱合成スコアとは、歌唱音声のデータを、音韻、音高(ピッチ)、音韻遷移(アタック、リリースなど)などのパラメータごとに時系列的に記憶させたものである。例えば、音韻データは音韻トラックに、音高データは音高トラックに記憶される。この歌唱合成スコアに、さらに各種の音源制御情報を付加することにより、本物の人の歌声に近い歌唱音声を合成している。
【0004】
歌唱合成装置においては、例えば「sa・i・ta(さいた)」と歌わせる場合、1つ1つの音韻を区切って歌わせるのではなく、先行音韻と後続音韻との間に、両者を滑らかに接続するための音韻遷移部分を挿入する。上の例では、音韻「sa」と音韻「i」との間に音韻遷移部分「ai」を、音韻「i」と音韻「ta」との間に音韻遷移部分「it」を挿入するという具合である。歌唱合成装置から合成される歌唱音声の品質は、各種の改良により年々向上しているが、未だ実際の人歌唱と同等の品質は得られていない。
【0005】
【発明が解決しようとする課題】
本発明の発明者らは、この原因の1つが、データベースより出力される音韻遷移時間長データ(音韻遷移部分の時間的長さを規定するデータ)の利用のされ方にあると考えた。
すなわち、発明者らの分析の結果、実際の人歌唱の場合、この音韻遷移部分の時間的な長さ(音韻遷移時間長)は、前後の音韻の状況によって異なっていることが判った。例えば、前後の音韻の種類が同じでも、音高が異なる場合には、実際の人歌唱では音韻遷移時間長が異なっている(低音の場合には高音の場合に比して音韻遷移時間長が長くされる)。
【0006】
しかしながら、従来の歌唱合成装置では、前後の音韻の状況に関係なく音韻遷移時間長を一律に決定していた。本発明は、この点に鑑み、音韻遷移時間長に変化を与えることにより、自然な歌唱音声を簡易に合成することのできる歌唱合成方法、歌唱合成装置、歌唱合成方法及びプログラムを提供することを目的とする。
【0007】
【課題を解決するための手段】
上記目的達成のため、本出願の第1発明に係る歌唱合成方法は、各種の歌唱データをデータベースに記憶させておき、入力された演奏データの内容に合致した前記歌唱データを前記データベースより読み出すことにより歌唱合成用のスコアを生成する歌唱合成方法において、前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報と、演奏音速さ情報とを含み、前記データベースには、前記音韻情報、前記音高情報又は前記演奏音速さ情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、演奏音速さが所定の標準値付近の場合には演奏音速さの増加に対して音韻遷移時間長伸縮率が単調に減少する一方演奏音速さが所定の標準値よりも十分に大又は小である場合には音韻遷移時間長伸縮率が演奏音速さに関係なく一定となるような演奏音速さと音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、前記演奏データを入力する入力ステップと、前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出しステップと、前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記演奏音速さ情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正ステップとを備えたことを特徴とする。
【0008】
この第1発明によれば、演奏データが入力されると、演奏データと音韻遷移データベースとが対比され、入力された前記演奏データに対応した音韻遷移時間長データが前記データベースより読み出される。読み出された音韻遷移時間長データは、演奏データ中の演奏音速さ情報により補正される。これにより、演奏音速さの状態に応じて音韻遷移時間が変化するので、合成される歌唱音声の自然性が高められる。
【0009】
上記目的達成のため、本出願の第2発明に係る歌唱合成方法は、各種の歌唱データをデータベースに記憶させておき、入力された演奏データの内容に合致した前記歌唱データを前記データベースより読み出すことにより歌唱合成用のスコアを生成する歌唱合成方法において、前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報と、演奏音強さ情報とを含み、前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、演奏音強さが所定の標準値付近の場合には演奏音強さの増加に対して音韻遷移時間長伸縮率が単調に減少する一方演奏音強さが所定の標準値よりも十分に大又は小である場合には音韻遷移時間長伸縮率が演奏音強さに関係なく一定となるような演奏音強さと音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、前記演奏データを入力する入力ステップと、前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出しステップと、前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記演奏音強さ情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正ステップとを備えたことを特徴とする。
【0010】
この第2発明によれば、演奏データが入力されると、演奏データと音韻遷移データベースとが対比され、入力された前記演奏データに対応した音韻遷移時間長データが前記データベースより読み出される。読み出された音韻遷移時間長データは、演奏データ中の演奏音強さ情報により補正される。これにより、演奏音強さの状態に応じて音韻遷移時間が変化するので、合成される歌唱音声の自然性が高められる。
【0011】
上記目的達成のため、本出願の第3発明に係る歌唱合成方法は、各種の歌唱データをデータベースに記憶させておき、入力された演奏データの内容に合致した前記歌唱データを前記データベースより読み出すことにより歌唱合成用のスコアを生成する歌唱合成方法において、前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報とを含み、前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、音高が所定の標準値付近の第1の区間に含まれる場合には音高の変化に関係なく音韻遷移時間伸縮率が一定である一方音高が第1の区間よりも大又は小である第2の区間に含まれる場合には音高の増加に対して音韻遷移時間長が単調に減少し、音高が前記第2の区間よりも大又は小である第3の区間に含まれる場合には音高の変化に関係なく音韻遷移時間長伸縮率が一定となるような音高と音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、前記演奏データを入力する入力ステップと、前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出しステップと、前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記音高情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正ステップとを備えたことを特徴とする。
【0012】
この第3発明によれば、演奏データが入力されると、演奏データと音韻遷移データベースとが対比され、入力された前記演奏データに対応した音韻遷移時間長データが前記データベースより読み出される。読み出された音韻遷移時間長データは、演奏データ中の音高情報により補正される。これにより、音高の状態に応じて音韻遷移時間が変化するので、合成される歌唱音声の自然性が高められる。
【0013】
前記第1乃至第3の発明において、前記演奏データは、前記音韻の状態の遷移を示す状態遷移データを含み、前記音韻遷移時間長データ読出しステップは、前記状態遷移データに応じて異なる音韻遷移時間長データを読み出すように構成することもできる。また、前記第1乃至第3の発明において、前記音韻遷移時間長データ読出しステップは、前記音韻の種類に応じて異なる音韻遷移時間長データを読み出すように構成することもできる。また、前記音韻遷移時間長補正ステップは、補正後の前記音韻遷移時間長に対し、乱数によって与えられるゆらぎ成分を付与するステップを含むこともできる。また、これらの方法を、コンピュータプログラムを利用してコンピュータに実行させるように構成してもよく、また、そのコンピュータプログラムを記録媒体に記録させるようにしてもよい。
【0014】
上記目的達成のため、本出願の第4発明に係る歌唱合成装置は、各種の歌唱データをデータベースに記憶させておき、入力された演奏データの内容に合致した前記歌唱データを前記データベースより読み出すことにより歌唱合成用のスコアを生成する歌唱合成装置において、前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報と、演奏音速さ情報とを含み、前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、演奏音速さが所定の標準値付近の場合には演奏音速さの増加に対して音韻遷移時間長伸縮率が単調に減少する一方演奏音速さが所定の標準値よりも十分に大又は小である場合には音韻遷移時間長伸縮率が演奏音速さに関係なく一定となるような演奏音速さと音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、前記演奏データを入力する演奏データ入力部と、前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出し部と、前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記演奏音速さ情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正部とを備えたことを特徴とする。
【0015】
上記目的達成のため、本出願の第5発明に係る歌唱合成装置は、各種の歌唱データをデータベースに記憶させておき、入力された演奏データの内容に合致した前記歌唱データを前記データベースより読み出すことにより歌唱合成用のスコアを生成する歌唱合成装置において、前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報と、演奏音強さ情報とを含み、前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、演奏音強さが所定の標準値付近の場合には演奏音強さの増加に対して音韻遷移時間長伸縮率が単調に減少する一方演奏音強さが所定の標準値よりも十分に大又は小である場合には音韻遷移時間長伸縮率が演奏音強さに関係なく一定となるような演奏音強さと音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、前記演奏データを入力する演奏データ入力部と、前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出し部と、前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記演奏音強さ情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正部とを備えたことを特徴とする。
【0016】
上記目的達成のため、本出願の第6発明に係る歌唱合成装置は、各種の歌唱データをデータベースに記憶させておき、入力された演奏データの内容に合致した前記歌唱データを前記データベースより読み出すことにより歌唱合成用のスコアを生成する歌唱合成装置において、前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報とを含み、前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、音高が所定の標準値付近の第1の区間に含まれる場合には音高の変化に関係なく音韻遷移時間伸縮率が一定である一方音高が第1の区間よりも大又は小である第2の区間に含まれる場合には音高の増加に対して音韻遷移時間長が単調に減少し、音高が前記第2の区間よりも大又は小である第3の区間に含まれる場合には音高の変化に関係なく音韻遷移時間長伸縮率が一定となるような音高と音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、前記演奏データを入力する演奏データ入力部と、前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出し部と、前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記音高情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正部とを備えたことを特徴とする。
【0017】
前記第4乃至第6発明において、前記演奏データは、前記音韻の状態の遷移を示す状態遷移データを含み、前記音韻遷移時間長データ読出し部は、前記状態遷移データに応じて異なる音韻遷移時間長データを読み出すように構成することができる。また、前記音韻遷移時間長データ読出し部は、さらに前記音韻の種類に応じて異なる音韻遷移時間長データを読み出すように構成することもできる。
また、前記音韻遷移時間長補正ステップは、補正後の前記音韻遷移時間長に対し、乱数によって与えられるゆらぎ成分を付与するステップを含んでいるようにすることもできる。
【0018】
【発明の実施の形態】
以下、本発明の実施の形態を説明する。以下では、日本語の歌唱音声を合成するものとして説明する。日本語の場合、出現する音素は、一般に▲1▼子音と母音の組合せ、▲2▼母音のみ、▲3▼有声子音(鼻音、半母音)のみ、のいずれかとなる。ただし、▲3▼有声子音のみの場合は、有声子音の歌唱開始タイミングが▲2▼母音のみの場合と類似しているので、以下に説明する本実施の形態では、▲3▼は▲2▼とみなして▲2▼と同一の処理を受けるものとする。
【0019】
〔第1の実施の形態〕
以下、本実施の形態の具体的な実施形態を説明する。
図1は、この発明の実施の形態に係る歌唱合成装置の全体構成を示すものである。MIDI(Musical Instrument Digital Interface)機器39と、このMIDI機器39にMIDIインターフェース30を介して接続されたコンピュータシステムCSと、音源回路28と、サウンドシステム38等とから構成されている。コンピュータシステムCSは、CPU12、ROM14,RAM16、操作子群34、表示回路22、表示器36、外部記憶装置24、タイマ26等を備えている。
【0020】
CPU12は、コンピュータシステムCS全体の制御を司る部分である。ROM14は、楽音発生、歌唱合成等の各種プログラムを記憶している。CPU12は、これらのプログラムをROM14から適宜読み込んで各種処理を実行する。
RAM16は、CPU12の各種処理に際して作業領域を提供するための記憶部であり、例えばMIDI機器39から読み込まれた演奏データを書き込むための受信バッファとして機能する。
【0021】
検出回路20は、パネル等の操作子群34からの操作情報を検出するものであり、また、表示回路22は、表示器36の表示動作を制御することにより各種の表示を可能にするものである。
外部記憶装置24は、ハードディスク、フロッピーディスク、CD、DVD、光磁気ディスクドライブなどの記録媒体をドライブするためコンピュータシステムCSに外付けされた記憶装置であり、その記憶内容をRAM16へ転送する他、ハードディスクなどの書き込み可能な記録媒体の場合には、逆にRAM16からデータの転送を受けることもできる。この外部記憶装置は、ROM14の代わりにプログラム記録手段として使用することも出来る。
【0022】
タイマ26は、テンポデータTMの指示するテンポに対応した周期でテンポクロック信号TCLを発生するものである。テンポクロック信号TCLは、CPU12に割込み命令信号として供給される。CPU12は、テンポクロック信号TCLに基づく割込み処理により歌唱合成を行う。テンポデータTMにより指示されるテンポは、操作子群34を操作するなどにより変更することができる。なお、テンポクロック信号TCLの周期は、一例としては1ms程度である。
【0023】
音源回路28は、多数の楽音発生チャンネル及び多数の歌唱合成チャンネルを含んでいる。歌唱合成チャンネルは、フォルマント合成方式により歌唱音声を合成するようになっている。後述する歌唱合成処理では、歌唱合成チャンネルから歌唱音声信号が発生される。発生に係る楽音信号及び歌唱音声信号は、サウンドシステム38により音声に変換される。フォルマント合成方式の代わりに、波形処理方式等の他の方式を用いてもよい。
【0024】
MIDIインターフェース30は、この歌唱合成装置とは別体のMIDI機器39との間でMIDIデータを送受信するためのインターフェースである。
【0025】
次に、図2を用いて、上記の歌唱合成装置の構成において、本実施の形態に係る歌唱合成処理を実行する手順の概略を説明する。図2において、左側のブロック40−48は歌唱合成処理の手順を示しており、また、右側に示された歌唱合成DB14Aは、ROM14などにより構成され、MIDI機器39等により入力された演奏データの内容に応じたデータ変換を行うための各種のテンプレートデータを記憶する部分を示す。
【0026】
歌唱合成DB14Aは、例えば音韻に関するデータを記憶する音韻DB14a、先行音韻から後続音韻への音韻遷移に関する情報を記憶する音韻遷移DB14b、状態遷移(アタック、リリース等)に関するデータを記憶する状態遷移DB14c、ビブラート情報を記憶するビブラートDB14d等を備えている。
【0027】
また、複数の矢印は、どのようなデータがどの手順において歌唱合成DB14Aから読み出されるのかを示している。
【0028】
この歌唱合成処理の手順(ステップ40−48)を、順に説明する。最初に、演奏データがMIDI機器39より入力され、受信バッファとしてのRAM16がこれを受信する(ステップ40)。演奏データの内容については後述する。図3に示すように、演奏データS1−S3は、実歌唱時刻T1、T2、T3よりも早い時刻t1、t2、t3において送信される。
【0029】
続くステップ42では、歌唱合成スコアを形成する。歌唱合成スコアとは、受信された演奏データを、音韻、音高などのパラメータごとのトラックにより時系列的に表現したデータ配列である。歌唱合成スコアの内容については後述する。
歌唱合成スコアを形成するには、歌唱合成DB14A中の音韻DB14a、音韻遷移DB14b等より、受信した演奏データに対応した音韻データ、音韻遷移時間長データ等を獲得する。ここで音韻遷移時間長データとは、複数の音韻間の遷移時間の長さを示すデータである。
【0030】
ステップ44では、歌唱合成エンジンによる歌唱合成を行う。このステップでは、まず、音源制御情報を音韻DB14a、音韻遷移DB14b、状態遷移DB14c及びビブラートDB14dから獲得する。ここで音源制御情報とは、音源回路28において所望の歌唱音声を合成するために必要なフォルマント周波数の情報、及びフォルマントレベルの制御パラメータの情報等を含むものである。
そして、この獲得した音源制御情報と、歌唱合成スコア、演奏データに基づき、歌唱合成を行い、歌唱順に歌唱音声信号を出力する。
【0031】
この歌唱音声信号は音源回路28によりDA変換され(ステップ46)、サウンドシステム38において歌唱音声として出力される(ステップ48)。このとき、図3に示すように、歌唱音声SS1の子音「s」を実歌唱時刻T1より早い時刻T11に発生開始させ、SS1の母音「a」を実歌唱時刻T1に発生開始させる。
また、歌唱音声SS3の子音「t」を実歌唱時刻T3より早い時刻T31に発生開始させ、その母音「a」を実歌唱時刻T3に発生開始させる。また、歌唱音声SS2の母音「i」は実歌唱時刻T2に発生開始させる。このように、歌唱音声が子音と母音の組合せからなる場合、その子音を実歌唱時刻に先行させて発音させる。これにより、歌唱音声が伴奏に対し遅れて発音される感じがなくなり、自然な歌唱音声が発生される。
【0032】
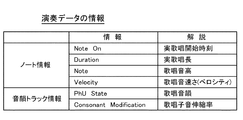
次に、ステップ40で入力される演奏データ内に含まれる情報の内容を図4を用いて説明する。演奏データは、1音節を歌唱するために必要な演奏情報、具体的には、ノート情報、音韻トラック情報等を含んでいる。
ノート情報には、実歌唱開始時刻を表わすノートオン(Note on)情報、実歌唱長を表わすデュレーション(Duration)情報、歌唱音高を表わす歌唱音高情報(Note、ピッチ(Pitch)情報とも呼ばれる)、歌唱音速さを表わすベロシティ(Velocity)等が含まれる。音韻トラック情報には、後述する音韻トラックTpを形成するための情報、例えば、歌唱音韻を表わす音韻(PhUState)情報、歌唱子音伸縮率を表わす子音修正(Consonant Modification)情報等が含まれる。上述の通り、本実施の形態では、▲3▼有声子音(鼻音、半母音)のみからなる音韻を、▲2▼母音のみからなる音韻とみなして処理を行う。音韻(PhUState)情報としては、▲2▼母音のみからなる音韻の場合には、PhUState=Vowelという情報が、▲1▼子音と母音の組合せからなる音韻の場合には、PhUState =Consonant_Vowel という情報が与えられるものとする。
演奏データには、この他、遷移トラックTrを形成するための遷移トラック情報、ビブラートトラックTbを形成するためのビブラートトラック情報等を含めることもできる。
【0033】
次に、図5を参照して、音韻DB14aの記憶情報について説明する。
音韻DB14aには、図5に示すように、音韻(PhU)と音高(Pitch)の組合せごとに異なる値の音源制御情報Control11、Control12・・・が記憶されており、処理中の演奏データ(以下、現演奏データという)に合致するものが適宜読み出されるようになっている。例えば、現演奏データの音韻がaで、音高(ピッチ)がP11の場合には、音源制御情報としてControl11が読み出され、後述する音韻トラックTpの形成に使用される。
【0034】
次に、図6を参照して、音韻遷移DB14bの記憶情報について説明する。音韻遷移DB14bには、例えば図6に示すように、先行音韻PhU1、後続音韻PhU2及び音高Pitchの組合せに対応して、異なる音韻遷移時間長(Duration11、12・・・)及び音源制御情報(Control11、Control12・・・)が記憶されている。例えば、先行音韻がa、後続音韻がi、音高PitchがP11の場合には、音韻遷移時間長としてそれぞれDuration11、Control11という値が読み出される。なお、図6中のPhU1、PhU2の欄において、Mとは母音の「う」を、Aspirationとは呼気音を、Silは無音を表わしている。
【0035】
次に、図7を参照して、状態遷移DB14cの記憶内容を説明する。状態遷移DB14cは、遷移状態、状態タイプ、音韻、音高の組合せに対応して、異なる状態遷移時間長、音源制御情報が記憶されている。遷移状態としては、アタック(Attack)、ノート遷移(Note Transition、以下「NtN」と称す)及びリリース(Release)があり、状態タイプとしては、「Normal」「Sexy」「Sharp」「Soft」等がある。状態遷移時間長とは、これらアタック、ノート遷移又はリリース遷移状態の継続時間の長さを示すものである。このDB14cの内容は、後述する歌唱合成スコアの遷移トラックTrの形成に使用される。
【0036】
次に、図8を参照して、ビブラートDB14dの記憶内容について説明する。
ビブラートDB14dでは、「Normal」「Sexy」「Enka」等の各ビブラートタイプ、音韻、音高の組合せごとに異なる音源制御情報が記憶されており、後述する歌唱合成スコアのビブラートトラックTbの形成に使用される。
【0037】
図9は、ステップ42において形成される歌唱合成スコアの形成例、及びステップ44における歌唱音声の合成例を示すものである。
歌唱合成スコアSCは、RAM16内に形成されるもので、音韻トラックTp、音高トラックTiを備えている。この他、図9に示すように、状態の遷移データを有する遷移トラックTrと、ビブラート情報を有するビブラートトラックTbなどを備える。
【0038】
例えば、・・・・「さ(sa):C3:T1・・・」「い(i):D3:T2・・・」「た(ta):E3:T3・・・」を演奏データとして入力するものとすると、音韻トラックTpには、図9、10に示すように、音韻の種類を示す音韻情報として、Sil、Sil_s、s_a、a・・・a_Sil、Sil等のアイテムが保持される。Silは無音を、Sil_sは無音から子音sへの音韻遷移を示している。
【0039】
図10に示すように、各音韻情報Sil、Sil_s、s_a、a・・・は、開始時刻情報(Begin Time)、継続時間情報(Duration)、音韻情報(PhU)から構成される。ただし、音韻遷移部分を示すアイテムは、音韻情報として、先行音韻情報(PhU1)と後続音韻情報(PhU2)との2種類を有する。音高トラックTiには、図9に示すような音高変化情報90が記憶される。
【0040】
次に、図2に示す各ステップ40−48の詳細な処理内容を説明する。
〔ステップ40(演奏データ入力)〕
まず、ステップ40における演奏データ入力の詳細な手順を図11により説明する。
【0041】
ステップ40−1では初期化処理を行う。ここでは、RAM16内の受信回数カウンタNをゼロにセットする。
【0042】
ステップ40−2では、n=N番目の演奏データを受信し、受信バッファとしてのRAM16内に書き込む。
ステップ40−3では、このn=N番目の演奏データがデータエンド(データの終端)であるか否かが判定される。データエンドである場合(YES)には、ステップ40−6に移動して終端処理を実行する。データエンドでない場合(NO)には、ステップ40−4に移行する。
【0043】
ステップ40−4では、受信されたn=N番目の演奏データに基づいて歌唱合成スコアを形成する。ステップ40−5では、カウンタNの値を1増加させてN+1としてステップ40−2に戻り、次の演奏データを受信する。このようにして演奏データがデータエンドとなるまで繰り返すことにより、すべての演奏データについての歌唱合成スコアSCがRAM16の受信バッファに入力される。
【0044】
[ステップ42(歌唱合成スコア形成)]
次に、ステップ42の歌唱合成スコアの形成手順の詳細を図12を用いて説明する。
まず、ステップ42−1で、CPU12がRAM16の受信バッファより演奏データを受信する。ステップ42−2では、受信された演奏データのうち、歌唱合成スコア形成に必要なものを抽出する。ステップ42−3では、管理データを作成する。管理データは、後続の演奏データを処理する際、先行する演奏データの内容に合わせたデータ処理をするために使用される各種のデータであり、後述するように、例えば音韻状態(PhUState)、音素(Phoneme)、音高(Pitch)、歌唱音速さ(Velocity)、現ノートオン(Current Note On)、現ノートデュレーション(Current Note Duration)、フルデュレーション(Full Duration)、イベント状態(EventState)などの情報を含んでいる。情報の内容、管理データの作成の詳細な手順については次で述べる。
【0045】
次に、ステップ42−4では、演奏データ、前ステップで作成された管理データ、及び先行演奏データについて形成され保存された歌唱合成スコアに基づいて音韻トラックTpを形成する。続くステップ42−5では、演奏データ、前ステップで作成された管理データ、及び先行演奏データについて形成され保存された歌唱合成スコアに基づいて音高トラックTiを形成する。
同様にして、続くステップ42−6、7では、演奏データ、前ステップで作成された管理データ、及び先行演奏データについて形成され保存された歌唱合成スコアに基づいて遷移トラックTr、ビブラートトラックTbを形成する。
そして、ステップ42−8では、後続の演奏データのためのスコアデータを形成し保存する。これを全演奏データについて完了させると、歌唱合成スコアが完成する。
【0046】
〔ステップ42−3(管理データ作成)〕
次に、図12のステップ42−3に示す管理データの作成の詳細な手順を、図13に基づいて説明する。
最初に、ステップ42−3.1において、演奏データを受信し、続くステップ42−3.2においてこの演奏データに含まれる音韻の特性を分析する。具体的には、演奏データに含まれる音韻が▲1▼子音+母音か、又は▲2▼母音のみ(鼻音のみ)かを分析し、その結果PhUStateを保存する。▲1▼の場合はPhUState=Consonant _Vowelと、▲2▼の場合はPhUState=Vowelとする。
【0047】
次に、ステップ42−3.3で、演奏データ中の音高を分析し、その結果Pitchを保存する。
続くステップ42−3.4で、演奏データの歌唱音速さを分析し、その結果Velocityを保存する。
続くステップ42−3.5で、Velocityに基づき、音韻遷移時間長伸縮率Rptのデータを取得する。この音韻遷移時間長伸縮率Rptは、音韻遷移時間長を補正するため、音韻遷移時間長に乗算するために準備されるものである。詳細は後述する。
【0048】
伸縮率Rptは、歌唱音速さVelocityと、例えば図14に示すような関係とすることができ、この関係を示したテーブルをROM14等に記憶させておくことができる。すなわち、歌唱音速さVelocityが図14に示す標準値Default前後である場合には、Rptは歌唱音速さVelocityの増加に対して単調に減少するようにすることができる。また、歌唱音速さVelocityが標準値Defaultよりも十分に大又は小である場合には、Rptは歌唱音速さVelocityの大きさにかかわらず一定とすることができる。この図14に示す関係は1例であって、目的や状況により他の関係を示すテーブルを採用しても良いことはいうまでもない。
【0049】
続くステップ42−3.6で、演奏データに含まれる実歌唱時刻を分析し、得られた実歌唱開始時刻Current Note Onを保存する(図15参照)。このとき、図15に示すように、乱数等によって与えられるΔtだけCurrent Note Onを更新することで、歌唱開始時刻にゆらぎを与えることができる。
【0050】
また、実歌唱長を現ノートデュレーション(Current Note Duration)とし、
実歌唱開始時刻から実歌唱長だけ経過した時間を、現ノートオフ(Current Note Off)とする(図15参照)。
【0051】
続くステップ42−3.7では、管理データに基づき現演奏データの実歌唱時刻を分析する。まず、先行演奏データの並び替えを済ませた受信ナンバーPrevious Event Number、先行演奏データについて形成され保存された歌唱合成スコアのデータPrevious Score Data、先行演奏データの実歌唱終了時刻を表わす先行ノートオフ情報等を取得する。これらの情報に基づき、先行演奏データ、現演奏データの接続状況を分析し、その結果Event Stateを保存する。
図15(a)に示すCase1のように、無音が挿入されず先行演奏データと現演奏データが連続する場合にはEvent State=Transitionとする。一方、図15(b)のCase2のように、先行演奏データと現演奏データとの間に無音が挿入される場合には、Event State=Attackとする。
【0052】
次に、歌唱合成スコアSCを構成する各トラックを形成するための詳細な手順を説明する。ただし、遷移トラックTr、ビブラートトラックTb、音高トラックTiの形成処理については、本発明との関連が薄いため、説明を省略し、音韻トラックTpの形成処理のみについて説明する。
【0053】
[ステップ42−4(音韻トラックTp形成)]
次に、図12のステップ42−4に示す音韻トラックTpの形成処理の詳細な手順を、図16に示すフローチャートにより説明する。
最初に、ステップ42−4.1において、演奏データ、管理データ、歌唱合成スコアを受信する。続くステップ42−4.2では、管理データに基づき、音韻遷移DB14bより音韻遷移時間長データを獲得する。この音韻遷移時間長データの獲得方法の詳細手順については次項で述べる。
【0054】
次に、ステップ42−4.3において、管理データ中のEvent StateがAttackであるか否かが判定される。判定が肯定的(YES)である場合には、ステップ42−4.4のSilence歌唱長算出の手順に移行する。Silence歌唱長の意義については後述する。一方、判定が否定的(NO)、すなわち、EventState=Transitionである場合には、ステップ42−4.5の先行Vowel歌唱長算出の手順に移行する。先行Vowel歌唱長の意義については後述する。
ステップ42−4.4又は5の処理が完了すると、ステップ42−4.6のVowel歌唱長を算出する処理に移行する。詳細は後述する。
【0055】
次に、上述したステップ42−4.2(音韻遷移時間長の獲得)の詳細な手順を図17に示すフローチャートにより説明する。
最初に、ステップ4−2.1で管理データ及び歌唱合成スコアのデータを受信する。続くステップ4−2.2で、RAM16に記憶されている全ての遷移時間長データ(後述のステップ4−2.6、7、9〜12で獲得される音韻遷移時間長)を初期化する。
【0056】
次に、ステップ4−2.3では、管理データに基づいてV_Sil(母音から無音へ)の音韻遷移時間長を音韻遷移DB14bから獲得する。この手順は、一般に日本語が常に母音で終わることから必要となるものである。一例として、管理データの音韻が母音「a」であり、その音高がP1であったとすると、音韻遷移DB14bからは、「a_Sil」と「P1」に対応した音韻遷移時間長が獲得される。
【0057】
次に、ステップ4−2.4において、管理データに基づいてEventState=Attackであるか否かが判定される。判定が肯定的(YES)であれば、ステップ4−2.5へ移行し、否定的(NO)であればステップ4−2.8へ移行する。
ステップ4−2.5では、管理データに基づいて、PhUState=Consonant_Vowelか否かが判定される。この判定結果が肯定的(YES)であれば、ステップ4−2.6に移行し、否定的(NO)であればステップ4−2.11へ移行する。同様にステップ4−2.8では、管理データに基づいて、PhUState=Consonant_Vowelか否かが判定される。この判定結果が肯定的(YES)であれば、ステップ4−2.9に移行し、否定的(NO)であればステップ4−2.12へ移行する。
【0058】
要するに、このステップ4−2.4、4−2.5、4−2.8では、
受信された管理データに係る音韻が、
(a)その音韻が立ち上がり部分(attack)にあり、その音韻が子音と母音の組合せである場合
(b)その音韻が立ち上がり部分(attack)にあり、その音韻が母音のみ(又は有声子音のみ)である場合
(c)その音韻が遷移部分(transition)にあり、その音韻が子音と母音の組合せである場合
(d)その音韻が遷移部分(transition)にあり、その音韻が母音である場合の4つの場合に分け、それぞれに必要なデータを獲得させるようにしているものである。
【0059】
上記(a)の場合には、ステップ4−2.6へ移行する。ステップ4−2.6では、管理データに基づいて音韻遷移DB14bから無音から子音への音韻遷移時間長Silence_Consonantを獲得する。獲得の具体的な方法は、ステップ4−2.3における方法と同様である。続くステップ4−2.7では、管理データに基づいて音韻遷移DB14bから子音から母音への音韻遷移時間長Consonant_Vowelを獲得する。獲得の具体的な方法は、ステップ4−2.3における方法と同様である。これにより(a)の場合の音韻遷移長データの獲得が完了する。
【0060】
上記(b)の場合には、ステップ4−2.11へ移行して、管理データに基づいて、無音から母音への音韻遷移時間長Silence_Vowelを獲得する。獲得の具体的な方法は、ステップ4−2.3における方法と同様である。
上記(c)の場合には、ステップ4−2.9に移行する。日本語の場合、遷移部分の直前の音素は一般に母音であるので、ステップ4−2.9では、管理データ及び歌唱合成スコアに基づいて、先行母音から子音への音韻遷移長pVowel_Consonantを獲得する。獲得の具体的な方法は、ステップ4−2.3における方法と同様である。続いて、ステップ4−2.10において、管理データ及び子音データに基づいて、子音から母音への音韻遷移長Consonant_Vowelを獲得して、必要なデータの獲得が完了する。
【0061】
上記(d)の場合には、ステップ4.2−12に移行し、管理データに基づいて、先行母音から母音への音韻遷移時間長pVowel_Vowelを獲得する。獲得の具体的な方法は、ステップ4−2.3における方法と同様である。
こうして、必要な音韻遷移時間長データが得られたら、これらの音韻遷移時間長データを管理データ中に含まれる歌唱音速さVelocityに基づいて補正する(ステップ4−2.13)。
音韻遷移時間長データの補正は、音韻遷移時間長データに、上記のステップ42−3.5で取得した音韻遷移時間長伸縮率Rptを乗算することにより行われる。
【0062】
このステップ4.2−13による効果を図18、19により説明する。図18は本実施の形態のステップ4.2−13を実施した場合の音韻トラックの状態を示し、図19はこれを実施しない場合の音韻トラック(従来技術)の状態を示している。
図18に示す本実施の形態の場合において、(a)は、「さ(sa):C3:V1・・・」「い(i):D3:V2・・・」「た(ta):E3:V3・・・」と演奏する場合を、(b)は「さ(sa):C3:V4・・・」「い(i):D3:V5・・・」「た(ta):E3:V6・・・」と演奏する場合を示している。すなわち、(a)(b)は音韻(sa、i、ta)と音高(C3,D3,E3)は同じだが、ベロシティ(歌唱音速さ)は変化させた場合(例:V1がV4に変化)を示している。
【0063】
本実施の形態では、ベロシティ(歌唱音速さ)の大きさに基づいて、音韻部分及び音韻遷移部分の時間長が、例えば図14に示すグラフのように変化する。
例えば、音韻「sa」の部分に注目すると、(a)の場合よりも(b)の場合の方がベロシティが高いので(V4>V1)、音韻遷移部分「#_s」「s_a」の部分の時間長は、(a)の場合よりも(b)の場合を短くしている。同様に、「ta」の部分に注目すると、(a)の場合よりも(b)の場合の方がベロシティが低いので(V6<V3)、音韻遷移部分「i_t」「t_a」の部分の時間長は、(a)の場合よりも(b)の場合を長くしている。
【0064】
これに対し、図19に示す従来技術の場合には、同図(a)(b)のように、ベロシティを変化させても音韻遷移時間長は変化せず、これにより合成歌唱音声に不自然さが残る。
【0065】
次に、図16に示すステップ42−4.4のSilence歌唱長を算出する手法を図20〜21により説明する。
図20はSilence歌唱長の算出の手順を示すフローチャートであり、図21は、Silence歌唱長の概念を説明するものである。
Silence歌唱長とは、図21に示すように、EventState=Attackにおいて、
無音部の一部をなす部分の長さを示している。すなわち、無音時間は、
▲1▼先行母音から無音への音韻遷移時間長の無音部
▲2▼Silence歌唱長
▲3▼無音から子音又は母音への音韻遷移時間長の無音部
の3つの合計からなる。
【0066】
従って、Silence歌唱長は、演奏データ、管理データ、歌唱合成スコアから得られる無音時間の長さ、及び上記▲1▼、▲3▼の情報に基づき演算することができる。図21に示すように、Silence歌唱長の大きさは、接続される先行音韻と後続音韻の音韻の種類によって異なる。
【0067】
次に、Silence歌唱長の算出の手順を図20に基づいて説明する。最初に、ステップ4.4−1において演奏データ、管理データ、歌唱合成スコアのデータを受信する。続くステップ4.4−2では、管理データの音韻状態PhUStateがConsonant_Vowelか否かが判定される。判定結果が肯定的(YES)であればステップ4.4−3に移行する。判定結果が否定的(NO)であれば、ステップ4.4−3はスキップしてステップ4.4−4に移行する。
【0068】
ステップ4.4−3では、子音歌唱時間を算出する。子音歌唱時間とは、この後続の音韻中に子音が含まれる場合において、その子音の発音が継続される時間を意味する。この子音歌唱時間は、後続音韻の種類によって異なる。これを図21に基づいて説明する。
図21(A)は、先行母音(「あ」)−無音−子音「さ」と発音させる場合の音韻トラックTpの状態を、同図(B)は、先行母音(「あ」)−無音−子音「ぱ」と発音させる場合の音韻トラックTpの状態を、同図(C)は、先行母音(「あ」)−無音−後続母音「い」と発音させる場合の音韻トラックTpの状態を示している。図21からわかるように、(C)の場合には当然ながら子音歌唱時間は無い。従って、後続音韻が母音のみの場合には、ステップ4.4−2によりステップ4.4−3がスキップされる。
【0069】
次に、ステップ4.4−4において、Silence歌唱長の大きさを算出する。なお、子音歌唱時間は、演奏データに含まれる歌唱子音伸縮率(Consonant Modulation)によって変化する。図22は、このことを説明するための図である。
図22(A)は、歌唱子音伸縮率が1より大きい場合である。この場合、無音から子音への音韻遷移Sil_Cの子音長と、子音から母音への音韻遷移C_Vの子音長との和に歌唱子音伸縮率を掛け合わせたものをConsonant歌唱長として加算することにより、子音歌唱時間を伸長する。
【0070】
一方、図22(B)は、歌唱子音伸縮率が1より小さい場合である。この場合、Sil_Cの子音長と、子音から母音への音韻遷移C_Vの子音長との双方に歌唱子音伸縮率を掛け合わせることにより、子音歌唱時間を短縮する。
【0071】
〔ステップ42−4−5(先行Vowel歌唱長算出)〕
次に、ステップ42−4−5における先行Vowel歌唱長の算出の手法を、図23及び図24を用いて詳細に説明する。この先行Vowel歌唱長とは、先行音韻と後続音韻が無音を挟まず連続している状態(EventState=Transition)の場合において、その先行音韻の母音部分の歌唱時間(以下、先行母音歌唱時間と称す)を伸縮するために設定される時間の長さを意味する。
【0072】
先行音韻と後続音韻との間の時間から、後続音韻の子音部分が歌唱される時間(以下、子音歌唱時間と称す)を差し引いた部分が先行母音歌唱時間である(図24参照)。従って、設定されるべき先行母音歌唱時間の長さは、子音歌唱時間に基づいて決定される。なお、本実施の形態では、この先行母音歌唱時間の長さの決定は、この先行母音歌唱時間の一部としての先行Vowel歌唱長を伸縮することにより行われる。
【0073】
例えば、図24(A)は、先行音韻pV「a」に続いて、後続音韻として「sa」(子音と母音の組合せ)が発音された場合を、同(B)は先行音韻pV「a」に続いて、後続音韻「pa」(子音と母音の組合せ)が発音された場合を、同(C)は先行音韻pV「a」に続いて、後続音韻「i」(母音のみ)が発音された場合を示している。
前2者の場合には、子音歌唱時間が存在するが、(A)のそれのほうが(B)のそれよりも長い。このため、先行母音歌唱時間も、(A)の場合の方が(B)の場合に比して短くなる。(C)の場合には、子音歌唱時間が存在しないので、先行母音歌唱時間は最大となる。
【0074】
なお、子音歌唱時間は、演奏データに含まれる歌唱子音伸縮率(Consonant Modulation)によって変化する。図25は、このことを説明するための図である。
図25(A)は、歌唱子音伸縮率が1より大きい場合である。この場合、先行音韻から後続音韻(この図では子音と母音の組合せ)への音韻遷移pV_Cの子音長と、子音から母音への音韻遷移C_Vの子音長との和に歌唱子音伸縮率を掛け合わせたものをConsonant歌唱長として加算することにより、子音歌唱時間を伸長する。
一方、図25(B)は、歌唱子音伸縮率が1より小さい場合である。この場合、
pV_Cの子音長と、子音から母音への音韻遷移C_Vの子音長との双方に歌唱子音伸縮率を掛け合わせることにより、子音歌唱時間を短縮する。
【0075】
ステップ42−4.6のVowel歌唱長算出の処理を図26及び図27を用いて説明する。Vowel歌唱長は、「次の演奏データとの間に無音が挿入される」という仮定の下、仮定が真実であった場合に後続音韻の母音の後に接続され、真実でなかった場合には破棄されるものである。
Vowel歌唱長を算出するには、まず、演奏データ、管理データ、歌唱合成スコアのデータを受信し(ステップ4.6−1)、これらの受信データに基づいてVowel歌唱長を算出する(ステップ4.6−2)。この算出方法を図27により説明する。最初に、現演奏データ(X_V、なお、Xは無音、子音、先行母音のいずれでも可)と次の演奏データ(図示せず)との間に無音(Sil)が挿入される、と仮定する。
【0076】
この仮定の下では、X_Vから無音Silでの間の母音Vの歌唱時間(母音歌唱時間)は、▲1▼X_Vの母音Vの歌唱時間長、▲2▼Vowel歌唱長、▲3▼V_Silの母音Vの歌唱時間長の和となる。V_Sil内のVとSilの境界が実歌唱終了時刻(Current Note Off)と一致させた後、これにより決定した母音歌唱時間に基づき、Vowel歌唱長が算出される。
【0077】
次の演奏データを受信したとき、現演奏データとの間の接続状態(EventState)が判明し、上記の仮定が真実であったか否かが明らかになる。
真実であった場合(EventState=Attack)には、算出されたVowel歌唱長は更新されずそのまま使用される。真実でなかった場合(EventState=Transition)には、前述のステップ4.5−4によって先行Vowel歌唱長が算出される。
【0078】
〔第2の実施の形態〕
次に、本発明の第2の実施の形態を、図28に基づいて説明する。第1の実施の形態では、音韻遷移データベース14bにおいて、音韻情報PhU1、PhU2、及び音高情報Pitchと対応させて音韻遷移時間長データを記憶させる一方、この音韻遷移データベース14bから読み出した音韻遷移時間長データを、ベロシティの大きさに基づいて補正する。これに対し、本実施の形態では、音高情報Pitchに基づいて音韻遷移長を補正する。すなわち、図17に示すステップ4−2.13での補正の方法が異なり、他の部分は第1の実施の形態と同一である。
【0079】
本実施の形態では、図14に示すテーブルに代えて、図28に示すように、音高pと音韻遷移時間長伸縮率Rptの関係を示すテーブルをROM14等に記憶させている。そして、音高データを演奏データ中から抽出し、この抽出された音高データに対応する音韻遷移時間長伸縮率Rptを図28に示すテーブルから読み出し、音韻遷移時間長の補正を行っている。
これにより、図29(a)(b)に示すように、同じ音韻(sa,i,ta)、ベロシティ(V1、V2、V3)であっても、音高が異なる場合には音韻遷移時間長が変化する。
なお、図28に示すテーブルは、音高が標準値Default2の近辺である場合には音韻遷移時間長伸縮率Rptは音高の変化に拘わらず一定であり、音高がDefault2よりも十分大きい又は小さい場合には音高の増加に応じてRptが単調減少するようなものとしているが、歌唱合成の目的等に応じて適宜変化させることができることは言うまでもない。
【0080】
〔第3の実施の形態〕
次に、本発明の第3の実施の形態を説明する。第3の実施の形態では、演奏データ中に演奏音強さに関する情報を保持し、この演奏音強さの大きさに基づいて、音韻遷移時間長伸縮率Rptを変化させることにより、音韻遷移長を補正している。すなわち、図30に示すような演奏音強さと音韻遷移時間長伸縮率Rptとの関係を示すテーブルをROM14等に記憶しており、読み出された演奏音強さ情報に基づいて伸縮率Rptを決定している。その他の点は第1の実施の形態と同様である。
【0081】
〔第4の実施の形態〕
次に、本発明の第4の実施の形態を説明する。この第4の実施の形態では、第1の実施の形態と同様、ベロシティの大きさにもとづいて音韻遷移時間長伸縮率Rptを変化させている。ただし、図31に示すように、伸縮率Rptに対し、伸縮率ゆらぎレンジを設定し、ベロシティの大きさが同じであっても、場合によって伸縮率Rptの大きさがランダムに変化するようにされる。これにより、合成歌唱音声に変化が加わり、より自然性の高い歌唱音声とすることができる。
【0082】
図31では、ベロシティの大きさがDefaultのときにはゆらぎレンジの大きさをゼロとし、ベロシティとDefaultとの差が大きくなるに従ってゆらぎレンジの大きさが大きくなるようにしている。しかし、図32のように、ゆらぎレンジの大きさをベロシティの大きさに拘わらず略一定としてもよい。また、図33に示すように、ベロシティがDefault付近である場合にゆらぎレンジを最大とし、Defaultから離れるに従ってゆらぎレンジが小さくなるようにしてもよい。
【0083】
なお、この第4の実施の形態では、ベロシティの大きさにもとづいて音韻遷移時間長伸縮率Rptを変化する状況において、伸縮率Rptにゆらぎを与えているが、本発明はこれに限定されるものではない。例えば、第2の実施の形態のように、音高の大きさにもとづいて音韻遷移時間長伸縮率Rptを変化する状況において、伸縮率Rptにゆらぎを与えることもできるし、また、第3の実施の形態のように、歌唱音強さに応じて音韻遷移時間長伸縮率Rptを変化する状況において、伸縮率Rptにゆらぎを与えることもできる。
【0084】
(変形例)
この発明は、上記した実施の形態に限定されるものではなく、種々の改変形態で実施可能なものである。例えば、次のような変更が可能である。
【0085】
(1)上記した実施の形態では、歌唱合成スコアの形成が完了した後、歌唱合成スコアに従って歌唱音声を合成するようにしたが、歌唱合成スコアを形成しつつ形成済みの歌唱合成スコアに従って歌唱音声を合成するようにしてもよい。このためには、例えば演奏データの受信を割込み処理により優先的に行いつつ受信済みの演奏データに基づいて歌唱合成スコアを形成すればよい。
【0086】
(2)上記した実施の形態では、歌唱合成スコアを音韻トラックTp、音高トラックTi、遷移トラックTr、ビブラートトラックTbの4トラックで構成したが、トラック数はこれに限られない。例えば、音韻トラックTpに音高情報も記憶させて音韻トラックTpと音高トラックTiとを合体させてもよいし、全てのトラックを統合して1トラックとしてもよい。
【0087】
【発明の効果】
以上説明したように、本発明によれば、音韻遷移時間長に変化を加えることにより、自然な歌唱音声を簡易に合成することができる。
【図面の簡単な説明】
【図1】 本発明の第1の実施の形態に係る歌唱合成システムの全体構成を示す。
【図2】 図1に示す歌唱合成システムにおける歌唱合成手順の概略を示す。
【図3】 図2に示す歌唱合成手順実行の結果を時系列的に表現したものである。
【図4】 演奏データに含まれる情報の内容を示す。
【図5】 音韻DB14a内に含まれる情報の内容を示す。
【図6】 音韻遷移DB14b内の情報の内容を示す。
【図7】 状態遷移DB14c内の情報の内容を示す。
【図8】 ビブラートDB14d内の情報の内容を示す。
【図9】 図1に示す歌唱合成システムにより形成される歌唱合成スコアSCの構成の一例を示す。
【図10】 歌唱合成スコアSCの音韻トラックTpに含まれるアイテムを説明する表である。
【図11】 図2に示すフローチャートのステップ40の詳細な手順を示すフローチャートである。
【図12】 図2に示すフローチャートのステップ42の詳細な手順を示すフローチャートである。
【図13】 図12に示すフローチャートのステップ42−3(管理データ作成)の詳細な手順を示すフローチャートである。
【図14】 音韻時間遷移長の補正をするためROM14等に記憶されるテーブルを示す。
【図15】 演奏データに含まれる実歌唱時刻を分析する手法を説明する概念図である。
【図16】 図12に示すフローチャートのステップ42−4(音韻トラックTpの形成)の詳細な手順を示すフローチャートである。
【図17】 図16に示すフローチャートのステップ42−4.2(音韻遷移時間長獲得)の詳細な手順を示すフローチャートである。
【図18】 ステップ4−2.13での音韻遷移時間長の補正を実行した場合の音韻トラックTpの様子を示す。
【図19】 ステップ4−2.13での音韻遷移時間長の補正を実行しなかった場合(従来技術)の音韻トラックTpの様子を示す。
【図20】 図16に示すフローチャートのステップ42−4.4(Silence歌唱長算出)の詳細な手順を示すフローチャートである。
【図21】 Silence歌唱長算出の手法を示す説明図である。
【図22】 子音歌唱時間の決定方法を示す説明図である。
【図23】 図16に示すフローチャートのステップ42−4.5(先行Vowel歌唱長の算出)の詳細な手順を示すフローチャートである。
【図24】 先行Vowel歌唱長の算出の手法を示す説明図である。
【図25】 図23に示すフローチャートのステップ4.5−3(子音歌唱時間算出)の手法を示す説明図である。
【図26】 図16に示すフローチャートのステップ42−4.6(Vowel歌唱長の算出)の詳細な手順を示すフローチャートである。
【図27】 Vowel歌唱長の算出の手法を説明するための説明図である。
【図28】 本発明の第2の実施の形態において、音韻時間遷移長の補正をするためのテーブルを示す。
【図29】 本発明の第2の実施の形態において、音韻遷移時間長の補正を実行した場合の音韻トラックTpの様子を示す。
【図30】 本発明の第3の実施の形態において、音韻時間遷移長の補正をするためのテーブルを示す。
【図31】 本発明の第4の実施の形態において、音韻時間遷移長の補正をするためのテーブルを示す。
【図32】 本発明の第4の実施の形態において、音韻時間遷移長の補正をするためのテーブルを示す。
【図33】 本発明の第4の実施の形態において、音韻時間遷移長の補正をするためのテーブルを示す。
【符号の説明】
10・・・バス、 12・・・CPU、 14・・・ROM、 14A・・・歌唱合成DB、16・・・RAM、20・・・検出回路、 22・・・表示回路、 24・・・外部記憶装置、 26・・・タイマ、 28・・・音源回路、 30・・・MIDIインターフェース、34・・・操作子群、 36・・・表示器、 38・・・サウンドシステム、39・・・MIDI機器、 Tp・・・音韻トラック、 Ti・・・音高トラック、 Tr・・・遷移トラック、 Tb・・・ビブラートトラック[0001]
BACKGROUND OF THE INVENTION
The present invention relates to a song synthesizer, a method, and a program for synthesizing a song based on performance data input in real time.
[0002]
[Prior art]
In a conventional singing voice synthesizing apparatus, data obtained from an actual human singing voice is stored as a database as template data, for example, and data that matches the contents of input performance data (notes, lyrics, facial expressions, etc.) is stored. Read from database. Based on the performance data and the template data, data called a singing synthesis score is created.
[0003]
The singing synthesis score is a singing voice data stored in time series for each parameter such as phoneme, pitch (pitch), phoneme transition (attack, release, etc.). For example, phoneme data is stored in a phoneme track, and pitch data is stored in a pitch track. By adding various kinds of sound source control information to the singing synthesis score, the singing voice close to a real person's singing voice is synthesized.
[0004]
In the singing synthesizer, for example, when singing “sa · i · ta (sai)”, not singing each phoneme separately but singing it smoothly between the preceding phoneme and the following phoneme. Insert a phoneme transition part to connect to. In the above example, the phoneme transition portion “ai” is inserted between the phoneme “sa” and the phoneme “i”, and the phoneme transition portion “it” is inserted between the phoneme “i” and the phoneme “ta”. It is. The quality of the singing voice synthesized from the singing synthesizer has been improved year after year by various improvements, but the quality equivalent to that of an actual human singing has not yet been obtained.
[0005]
[Problems to be solved by the invention]
The inventors of the present invention have considered that one of the causes is the use of phonological transition time length data (data defining the temporal length of the phonological transition portion) output from the database.
That is, as a result of analysis by the inventors, it was found that in the case of an actual human song, the time length of the phoneme transition portion (phoneme transition time length) differs depending on the situation of the preceding and following phonemes. For example, if the pitch of the phonemes before and after is the same, but the pitch is different, the actual phonetic singing has a different phonological transition time length (the phonological transition time length is lower in the case of low sounds than in the case of high sounds. Lengthened).
[0006]
However, in the conventional singing voice synthesizing apparatus, the phoneme transition time length is uniformly determined regardless of the situation of the preceding and following phonemes. In view of this point, the present invention provides a singing synthesis method, a singing synthesis device, a singing synthesis method, and a program capable of easily synthesizing a natural singing voice by giving a change to the phoneme transition time length. Objective.
[0007]
[Means for Solving the Problems]
In order to achieve the above object, the singing synthesis method according to the first invention of the present application stores various singing data in a database, and reads out the singing data that matches the contents of the input performance data from the database. In the singing voice synthesis method for generating a score for singing voice synthesis, the performance data includes at least phonological information representing a phoneme, pitch information representing a pitch, and performance sound speed information. Phonological transition database storing phonological transition time length data associated with at least one of phonological information, pitch information, or performance sound speed information When the performance sound speed is near a predetermined standard value, the phonological transition time length expansion / contraction rate decreases monotonously with an increase in the performance sound speed, while the performance sound speed is sufficiently larger or smaller than the predetermined standard value. A phoneme transition time length expansion rate database that stores the relationship between the performance sound speed and the phoneme transition time length expansion rate so that the phoneme transition time length expansion rate is constant regardless of the performance sound speed And the step of inputting the performance data, and comparing the performance data with the phonological transition database, and reading the phonological transition time length data corresponding to the performance data from the database. A reading step; in front The phoneme transition time length data read in the recording phoneme transition time length reading step is By multiplying by the phoneme transition time length expansion / contraction rate obtained by referring to the phoneme transition time length expansion / contraction rate database based on the performance sound speed information And a phonological transition time length data correction step for correction.
[0008]
According to the first aspect, when performance data is input, the performance data and the phoneme transition database are compared, and phoneme transition time length data corresponding to the input performance data is read from the database. The read phoneme transition time length data is corrected by the performance sound speed information in the performance data. Thereby, since the phoneme transition time changes according to the performance sound speed state, the naturalness of the synthesized singing voice is enhanced.
[0009]
To achieve the above object, the singing composition method according to the second invention of the present application stores various singing data in a database, and reads out the singing data that matches the contents of the input performance data from the database. In the singing synthesis method for generating a score for singing synthesis by the above, the performance data includes at least phonological information representing a phoneme, pitch information representing a pitch, and performance tone strength information, and the database includes: A phoneme transition database storing phoneme transition time length data associated with at least one of the phoneme information and the pitch information When the performance sound intensity is near a predetermined standard value, the phoneme transition time length expansion / contraction rate decreases monotonously with an increase in the performance sound intensity, while the performance sound intensity is sufficiently higher than the predetermined standard value. A phoneme transition time length expansion / contraction database that stores the relationship between performance sound strength and phoneme transition time length expansion / contraction rate so that the phoneme transition time length expansion / contraction rate is constant regardless of the performance sound strength when it is large or small When And the step of inputting the performance data, and comparing the performance data with the phonological transition database, and reading the phonological transition time length data corresponding to the performance data from the database. A reading step; in front The phoneme transition time length data read in the recording phoneme transition time length reading step is By multiplying by the phoneme transition time length expansion / contraction rate obtained by referring to the phoneme transition time length expansion / contraction rate database based on the performance sound intensity information And a phonological transition time length data correction step for correction.
[0010]
According to the second aspect, when performance data is input, the performance data and the phoneme transition database are compared, and phoneme transition time length data corresponding to the input performance data is read from the database. The read phoneme transition time length data is corrected by the performance sound intensity information in the performance data. Thereby, since the phoneme transition time changes according to the performance sound intensity state, the naturalness of the synthesized singing voice is enhanced.
[0011]
In order to achieve the above object, the singing composition method according to the third invention of the present application stores various singing data in a database, and reads out the singing data that matches the contents of the input performance data from the database. In the singing composition method for generating a score for singing composition by the above, the performance data includes at least phonemic information representing a phoneme and pitch information representing a pitch, and the database includes the phoneme information, the pitch Phoneme transition database storing phoneme transition time length data corresponding to at least one of the information When the pitch is included in the first section near the predetermined standard value, the phoneme transition time expansion / contraction rate is constant regardless of the change in the pitch, while the pitch is larger or smaller than the first section. , The phoneme transition time length decreases monotonously as the pitch increases, and the pitch is included in the third interval that is larger or smaller than the second interval. A phoneme transition time length expansion rate database that stores the relationship between the pitch and the phoneme transition time length expansion rate so that the phoneme transition time length expansion rate is constant regardless of the pitch change And the step of inputting the performance data, and comparing the performance data with the phonological transition database, and reading the phonological transition time length data corresponding to the performance data from the database. A reading step; in front The phoneme transition time length data read in the recording phoneme transition time length reading step is By multiplying by the phoneme transition time length expansion / contraction rate obtained by referring to the phoneme transition time length expansion / contraction rate database based on the pitch information. And a phonological transition time length data correction step for correction.
[0012]
According to the third aspect, when performance data is input, the performance data and the phoneme transition database are compared, and phoneme transition time length data corresponding to the input performance data is read from the database. The read phoneme transition time length data is corrected by pitch information in the performance data. Thereby, since the phoneme transition time changes according to the state of the pitch, the naturalness of the synthesized singing voice is enhanced.
[0013]
In the first to third inventions, the performance data includes state transition data indicating transitions of the phonological state, and the phonological transition time length data reading step includes different phonological transition times depending on the state transition data. It can also be configured to read long data. In the first to third aspects of the invention, the phoneme transition time length data reading step may be configured to read different phoneme transition time length data depending on the phoneme type. The phonological transition time length correction step may include a step of adding a fluctuation component given by a random number to the corrected phonological transition time length. In addition, these methods may be configured to be executed by a computer using a computer program, or the computer program may be recorded on a recording medium.
[0014]
In order to achieve the above object, the singing voice synthesizing apparatus according to the fourth invention of the present application stores various singing data in a database, and reads out the singing data that matches the contents of the input performance data from the database. In the singing voice synthesizing apparatus for generating a score for singing voice synthesis, the performance data includes at least phoneme information representing a phoneme, pitch information representing a pitch, and performance sound speed information. Phoneme transition database storing phoneme transition time length data corresponding to at least one of the phoneme information and the pitch information When the performance sound speed is near a predetermined standard value, the phonological transition time length expansion / contraction rate decreases monotonously with an increase in the performance sound speed, while the performance sound speed is sufficiently larger or smaller than the predetermined standard value. A phoneme transition time length expansion rate database that stores the relationship between the performance sound speed and the phoneme transition time length expansion rate so that the phoneme transition time length expansion rate is constant regardless of the performance sound speed A phonological transition time for reading out the phonological transition time length data corresponding to the performance data by comparing the performance data and the phonological transition database with a performance data input unit for inputting the performance data A long data reading unit; in front The phoneme transition time length data read in the recording phoneme transition time length reading step is By multiplying by the phoneme transition time length expansion / contraction rate obtained by referring to the phoneme transition time length expansion / contraction rate database based on the performance sound speed information A phonological transition time length data correction unit for correction is provided.
[0015]
In order to achieve the above object, the singing voice synthesizing apparatus according to the fifth invention of the present application stores various singing data in a database, and reads out the singing data that matches the contents of the input performance data from the database. In the singing voice synthesizing apparatus that generates a score for singing voice synthesis, the performance data includes at least phonemic information representing a phoneme, pitch information representing a pitch, and performance sound strength information, and the database includes: A phoneme transition database storing phoneme transition time length data associated with at least one of the phoneme information and the pitch information When the performance sound intensity is near a predetermined standard value, the phoneme transition time length expansion / contraction rate decreases monotonously with an increase in the performance sound intensity, while the performance sound intensity is sufficiently higher than the predetermined standard value. A phoneme transition time length expansion / contraction database that stores the relationship between performance sound strength and phoneme transition time length expansion / contraction rate so that the phoneme transition time length expansion / contraction rate is constant regardless of the performance sound strength when it is large or small When A phonological transition time for reading out the phonological transition time length data corresponding to the performance data by comparing the performance data and the phonological transition database with a performance data input unit for inputting the performance data A long data reading unit; in front The phoneme transition time length data read in the recording phoneme transition time length reading step is By multiplying by the phoneme transition time length expansion / contraction rate obtained by referring to the phoneme transition time length expansion / contraction rate database based on the performance sound intensity information A phonological transition time length data correction unit for correction is provided.
[0016]
In order to achieve the above object, the singing voice synthesizing apparatus according to the sixth invention of the present application stores various singing data in a database, and reads out the singing data matching the contents of the input performance data from the database. In the singing voice synthesizing apparatus that generates a score for singing voice synthesis, the performance data includes at least phonemic information representing a phoneme and pitch information representing a pitch, and the database includes the phoneme information, the pitch Phoneme transition database storing phoneme transition time length data corresponding to at least one of the information When the pitch is included in the first section near the predetermined standard value, the phoneme transition time expansion / contraction rate is constant regardless of the change in the pitch, while the pitch is larger or smaller than the first section. , The phoneme transition time length decreases monotonously as the pitch increases, and the pitch is included in the third interval that is larger or smaller than the second interval. A phoneme transition time length expansion rate database that stores the relationship between the pitch and the phoneme transition time length expansion rate so that the phoneme transition time length expansion rate is constant regardless of the pitch change A phonological transition time for reading out the phonological transition time length data corresponding to the performance data by comparing the performance data and the phonological transition database with a performance data input unit for inputting the performance data A long data reading unit; in front The phoneme transition time length data read in the recording phoneme transition time length reading step is By multiplying by the phoneme transition time length expansion / contraction rate obtained by referring to the phoneme transition time length expansion / contraction rate database based on the pitch information. A phonological transition time length data correction unit for correction is provided.
[0017]
In the fourth to sixth inventions, the performance data includes state transition data indicating transition of the phonological state, and the phonological transition time length data read-out unit has different phonological transition time lengths according to the state transition data. It can be configured to read data. Further, the phoneme transition time length data reading unit may be configured to read different phoneme transition time length data depending on the type of phoneme.
The phonological transition time length correcting step may include a step of adding a fluctuation component given by a random number to the corrected phonological transition time length.
[0018]
DETAILED DESCRIPTION OF THE INVENTION
Embodiments of the present invention will be described below. Below, it demonstrates as what synthesize | combines a Japanese song voice. In the case of Japanese, the phonemes that appear are generally either (1) a combination of consonants and vowels, (2) only vowels, or (3) only voiced consonants (nasal sounds, semi-vowels). However, in the case of (3) voiced consonant only, the singing start timing of the voiced consonant is similar to that in the case of (2) vowel only. Therefore, in this embodiment described below, (3) is (2) It is assumed that the same processing as in (2) is applied.
[0019]
[First Embodiment]
Hereinafter, specific embodiments of the present embodiment will be described.
FIG. 1 shows the overall configuration of a singing voice synthesizing apparatus according to an embodiment of the present invention. It comprises a MIDI (Musical Instrument Digital Interface)
[0020]
The
The
[0021]
The
The
[0022]
The
[0023]
The
[0024]
The
[0025]
Next, with reference to FIG. 2, an outline of a procedure for performing the song synthesis process according to the present embodiment in the configuration of the above-described song synthesis apparatus will be described. In FIG. 2, the blocks 40-48 on the left side show the procedure of the singing synthesis process, and the
[0026]
The
[0027]
The plurality of arrows indicate what data is read from the
[0028]
The procedure of this singing synthesis process (steps 40-48) will be described in order. First, performance data is input from the
[0029]
In the following
In order to form a singing synthesis score, phonological data corresponding to the received performance data, phonological transition time length data, and the like are acquired from the
[0030]
In
And based on this acquired sound source control information, singing synthesis score, and performance data, singing is performed, and singing voice signals are output in the order of singing.
[0031]
This singing voice signal is DA-converted by the sound source circuit 28 (step 46), and is output as a singing voice in the sound system 38 (step 48). At this time, as shown in FIG. 3, the generation of the consonant “s” of the singing voice SS1 is started at time T11 earlier than the actual singing time T1, and the generation of the vowel “a” of SS1 is started at the actual singing time T1.
In addition, the consonant “t” of the singing voice SS3 is started to be generated at time T31 earlier than the actual singing time T3, and the vowel “a” is started to be generated at the actual singing time T3. Further, the vowel “i” of the singing voice SS2 is started to be generated at the actual singing time T2. In this way, when the singing voice is composed of a combination of consonants and vowels, the consonants are pronounced prior to the actual singing time. This eliminates the feeling that the singing voice is delayed with respect to the accompaniment and generates a natural singing voice.
[0032]
Next, the contents of the information included in the performance data input in
The note information includes note on information indicating the actual singing start time, duration information indicating the actual singing length, and singing pitch information indicating the singing pitch (also referred to as note and pitch information). , Velocity representing the speed of singing (Velocity) and the like are included. The phoneme track information includes information for forming a phoneme track Tp to be described later, for example, phoneme (PhUState) information representing a singing phoneme, consonant modification information representing a singing consonant expansion / contraction rate, and the like. As described above, in the present embodiment, processing is performed by regarding a phoneme consisting only of (3) voiced consonants (nasal sounds, semi-vowels) as a phoneme consisting only of (2) vowels. The phoneme (PhUState) information includes (2) information of PhUState = Vowel in the case of a phoneme consisting only of vowels, and (1) information of PhUState = Consonant_Vowel in the case of a phoneme consisting of a combination of consonants and vowels. Shall be given.
In addition to this, the performance data may include transition track information for forming the transition track Tr, vibrato track information for forming the vibrato track Tb, and the like.
[0033]
Next, information stored in the
As shown in FIG. 5, the
[0034]
Next, information stored in the
[0035]
Next, the stored contents of the
[0036]
Next, the stored contents of the
The
[0037]
FIG. 9 shows an example of the singing voice synthesis score formed in
The singing synthesis score SC is formed in the
[0038]
For example, “... (sa): C3: T1...” “I (i): D3: T2...” “Ta (ta): E3: T3. As shown in FIGS. 9 and 10, the phoneme track Tp holds items such as Sil, Sil_s, s_a, a... A_Sil, Sil as phoneme information indicating the type of phoneme. Sil indicates silence, and Sil_s indicates phoneme transition from silence to consonant s.
[0039]
As shown in FIG. 10, each phoneme information Sil, Sil_s, s_a, a... Is composed of start time information (Begin Time), duration information (Duration), and phoneme information (PhU). However, the item indicating the phoneme transition portion has two types of phoneme information: preceding phoneme information (PhU1) and subsequent phoneme information (PhU2). The
[0040]
Next, the detailed processing content of each step 40-48 shown in FIG. 2 is demonstrated.
[Step 40 (Entering performance data)]
First, the detailed procedure of performance data input in
[0041]
In step 40-1, initialization processing is performed. Here, the reception number counter N in the
[0042]
In step 40-2, n = Nth performance data is received and written in the
In Step 40-3, it is determined whether or not the n = Nth performance data is a data end (data end). When it is a data end (YES), it moves to step 40-6 and performs termination processing. If it is not the data end (NO), the process proceeds to step 40-4.
[0043]
In step 40-4, a singing synthesis score is formed based on the received n = Nth performance data. In step 40-5, the value of the counter N is incremented by 1 to set it to N + 1, and the process returns to step 40-2 to receive the next performance data. By repeating until the performance data reaches the data end in this way, the singing synthesis score SC for all the performance data is input to the reception buffer of the
[0044]
[Step 42 (song synthesis score formation)]
Next, the details of the procedure for forming the singing synthesis score in
First, in step 42-1, the
[0045]
Next, in step 42-4, a phoneme track Tp is formed based on the performance data, the management data created in the previous step, and the singing synthesis score formed and stored for the preceding performance data. In the following step 42-5, a pitch track Ti is formed based on the performance data, the management data created in the previous step, and the song synthesis score formed and stored for the preceding performance data.
Similarly, in subsequent steps 42-6 and 7, the transition track Tr and the vibrato track Tb are formed based on the performance data, the management data created in the previous step, and the singing synthesis score formed and stored for the preceding performance data. To do.
In step 42-8, score data for subsequent performance data is formed and stored. When this is completed for all performance data, the singing synthesis score is completed.
[0046]
[Step 42-3 (Create Management Data)]
Next, a detailed procedure for creating management data shown in Step 42-3 in FIG. 12 will be described with reference to FIG.
First, in step 42-3.1, performance data is received, and in step 42-3.2, the characteristics of phonemes included in the performance data are analyzed. Specifically, whether the phoneme included in the performance data is (1) consonant + vowel or (2) only vowel (only nasal sound) is analyzed, and as a result, PhUState is stored. In the case of (1), PhUState = Consonant_Vowel, and in the case of (2), PhUState = Vowel.
[0047]
Next, in step 42-3.3, the pitch in the performance data is analyzed, and as a result, the pitch is stored.
In subsequent steps 42-3.4, the singing speed of the performance data is analyzed, and as a result, the velocity is saved.
In the subsequent step 42-3.5, data of the phoneme transition time length expansion / contraction rate Rpt is acquired based on the velocity. The phoneme transition time length expansion / contraction rate Rpt is prepared for multiplying the phoneme transition time length in order to correct the phoneme transition time length. Details will be described later.
[0048]
The expansion / contraction rate Rpt can be related to the singing sound velocity Velocity, for example, as shown in FIG. 14, and a table showing this relationship can be stored in the
[0049]
In the subsequent step 42-3.6, the actual singing time included in the performance data is analyzed, and the obtained actual singing start time Current Note On is stored (see FIG. 15). At this time, as shown in FIG. 15, the current note On is updated by Δt given by a random number or the like, whereby fluctuations can be given to the singing start time.
[0050]
Also, the actual singing head is the current note duration,
The time elapsed by the actual singing length from the actual singing start time is defined as the current note off (see FIG. 15).
[0051]
In the subsequent step 42-3.7, the actual singing time of the current performance data is analyzed based on the management data. First, the reception number Previous Event Number after rearrangement of the previous performance data, the data of the singing composite score formed and stored for the previous performance data, the previous note-off information indicating the actual singing end time of the previous performance data, etc. To get. Based on these pieces of information, the connection status of the preceding performance data and the current performance data is analyzed, and as a result, the Event State is stored.
As in
[0052]
Next, a detailed procedure for forming each track constituting the singing synthesis score SC will be described. However, since the formation process of the transition track Tr, the vibrato track Tb, and the pitch track Ti is not related to the present invention, the description thereof will be omitted, and only the formation process of the phoneme track Tp will be described.
[0053]
[Step 42-4 (Formation of Phoneme Track Tp)]
Next, the detailed procedure of the phoneme track Tp forming process shown in step 42-4 of FIG. 12 will be described with reference to the flowchart shown in FIG.
First, in step 42-4.1, performance data, management data, and a singing synthesis score are received. In the following step 42-4.2, phoneme transition time length data is acquired from the
[0054]
Next, in step 42-4.3, it is determined whether or not the Event State in the management data is Attack. If the determination is affirmative (YES), the procedure goes to the procedure for calculating the Silence song length in step 42-4.4. The significance of Silence Singer will be described later. On the other hand, if the determination is negative (NO), that is, if EventState = Transition, the process proceeds to the procedure for calculating the preceding Vowel song length in step 42-4.5. The significance of the preceding Vowel chief will be described later.
When the process of step 42-4.4 or 5 is completed, the process proceeds to the process of calculating the Vowel song length of step 42-4.6. Details will be described later.
[0055]
Next, the detailed procedure of step 42-4.2 (acquisition of phoneme transition time length) described above will be described with reference to the flowchart shown in FIG.
First, management data and singing synthesis score data are received in step 4-2.1. In the following step 4-2.2, all transition time length data (phoneme transition time length acquired in steps 4-2.6, 7, and 9 to 12 described later) stored in the
[0056]
Next, in step 4-2.3, the phoneme transition time length of V_Sil (from vowel to silence) is acquired from the
[0057]
Next, in step 4-2.4, it is determined whether EventState = Attack based on the management data. If the determination is affirmative (YES), the process proceeds to step 4-2.5. If the determination is negative (NO), the process proceeds to step 4-2.8.
In Step 4-2.5, it is determined whether or not PhUState = Consonant_Vowel based on the management data. If this determination result is affirmative (YES), the process proceeds to step 4-2.6, and if negative (NO), the process proceeds to step 4-2.11. Similarly, in step 4-2.8, it is determined whether PhUState = Consonant_Vowel based on the management data. If this determination result is affirmative (YES), the process proceeds to step 4-2.9, and if negative (NO), the process proceeds to step 4-2.12.
[0058]
In short, in steps 4-2.4, 4-2.5, 4-2.8,
The phoneme related to the received management data is
(A) When the phoneme is in the rising part (attack) and the phoneme is a combination of consonant and vowel
(B) When the phoneme is in the rising part (attack) and the phoneme is only a vowel (or only a voiced consonant)
(C) When the phoneme is in a transition and the phoneme is a combination of consonants and vowels
(D) The phoneme is in the transition part (transition), and the phoneme is a vowel, which is divided into four cases, each of which obtains necessary data.
[0059]
In the case of (a) above, the process proceeds to step 4-2.6. In step 4-2.6, the phoneme transition time length Silence_Consonant from silence to consonant is acquired from the
[0060]
In the case of the above (b), the process proceeds to Step 4-2.11, and the phoneme transition time length Silence_Vowel from silence to vowel is acquired based on the management data. A specific method of acquisition is the same as the method in Step 4-2.3.
In the case of (c) above, the process proceeds to step 4-2.9. In the case of Japanese, since the phoneme immediately before the transition part is generally a vowel, in step 4-2.9, the phoneme transition length pVowel_Consonant from the preceding vowel to the consonant is obtained based on the management data and the singing synthesis score. A specific method of acquisition is the same as the method in Step 4-2.3. Subsequently, in step 4-2.10, the phoneme transition length Consonant_Vowel from the consonant to the vowel is acquired based on the management data and the consonant data, and acquisition of necessary data is completed.
[0061]
In the case of (d) above, the process proceeds to step 4.2-12, and the phoneme transition time length pVowel_Vowel from the preceding vowel to the vowel is acquired based on the management data. A specific method of acquisition is the same as the method in Step 4-2.3.
When the necessary phoneme transition time length data is obtained in this way, these phoneme transition time length data are corrected based on the singing sound speed Velocity included in the management data (step 4-2.13).
The correction of the phonological transition time length data is performed by multiplying the phonological transition time length data by the phonological transition time length expansion / contraction rate Rpt acquired in Step 42-3.5.
[0062]
The effect of this step 4.2-13 will be described with reference to FIGS. FIG. 18 shows the state of the phoneme track when Step 4.2-13 of this embodiment is performed, and FIG. 19 shows the state of the phoneme track (prior art) when this is not performed.
In the case of the present embodiment shown in FIG. 18, (a) is “sa (sa): C3: V1...” “I (i): D3: V2...” “Ta (ta): E3. : (V3 ...), (b) is "sa: C3: V4 ...""I (i): D3: V5 ...""ta: E3: V6... "Is shown. That is, (a) and (b) have the same phoneme (sa, i, ta) and pitch (C3, D3, E3), but the velocity (singing sound speed) is changed (example: V1 changes to V4) ).
[0063]
In the present embodiment, based on the magnitude of velocity (singing sound speed), the time lengths of the phoneme portion and the phoneme transition portion change as shown in the graph shown in FIG. 14, for example.
For example, paying attention to the phoneme “sa” portion, the velocity in the case of (b) is higher than the case of (a) (V4> V1), so the phoneme transition portions “#_s” and “s_a” The time length is shorter in the case of (b) than in the case of (a). Similarly, paying attention to the “ta” portion, the velocity in the case of (b) is lower than the case of (a) (V6 <V3), so the time of the phoneme transition portions “i_t” and “t_a” portions The length is longer in the case of (b) than in the case of (a).
[0064]
On the other hand, in the case of the prior art shown in FIG. 19, the phonological transition time length does not change even when the velocity is changed, as shown in FIGS. Remains.
[0065]
Next, the method of calculating the Silence song length at step 42-4.4 shown in FIG. 16 will be described with reference to FIGS.
FIG. 20 is a flowchart showing a procedure for calculating the Silence song length, and FIG. 21 explains the concept of the Silence song length.
As shown in FIG. 21, Silence singing chief is EventState = Attack,
The length of the part which forms a part of silence part is shown. That is, the silent time is
(1) Silence part of phonological transition time length from preceding vowel to silence
▲ 2 ▼ Silence Singing Director
(3) Silent part of the phoneme transition time length from silence to consonant or vowel
It consists of three sums.
[0066]
Therefore, the Silence song length can be calculated based on the performance data, the management data, the length of the silent time obtained from the song synthesis score, and the above information (1) and (3). As shown in FIG. 21, the size of the Silence singing length varies depending on the type of phonemes of the preceding phoneme and the succeeding phoneme to be connected.
[0067]
Next, the procedure for calculating the Silence song length will be described with reference to FIG. First, in step 4.4-1, performance data, management data, and singing synthesis score data are received. In the following step 4.4-2, it is determined whether or not the phonological state PhUState of the management data is Consonant_Vowel. If the determination result is affirmative (YES), the process proceeds to step 4.4-3. If the determination result is negative (NO), step 4.4-3 is skipped and the process proceeds to step 4.4-4.
[0068]
In step 4.4-3, the consonant singing time is calculated. The consonant singing time means a time during which the pronunciation of the consonant is continued when the subsequent phoneme includes a consonant. This consonant singing time varies depending on the type of subsequent phonemes. This will be described with reference to FIG.
FIG. 21A shows the state of the phoneme track Tp when the preceding vowel (“A”) — silence—consonant “sa” is pronounced, and FIG. 21B shows the preceding vowel (“A”) — silence— The state of the phoneme track Tp when the consonant “pa” is pronounced is shown in FIG. 10C. The state of the phoneme track Tp when the sound is pronounced as the preceding vowel (“a”) − silence—the subsequent vowel “i” is shown. ing. As can be seen from FIG. 21, in the case of (C), there is of course no consonant singing time. Therefore, if the subsequent phoneme is only a vowel, step 4.4-3 is skipped by step 4.4-2.
[0069]
Next, in step 4.4-4, the size of the Silence song length is calculated. The consonant singing time varies depending on the singing consonant expansion / contraction rate (Consonant Modulation) included in the performance data. FIG. 22 is a diagram for explaining this.
FIG. 22A shows a case where the singing consonant expansion / contraction rate is larger than one. In this case, by adding the sum of the consonant length of the phoneme transition Sil_C from silence to consonant and the consonant length of the phoneme transition C_V from consonant to vowel as the consonant song length, Extend the consonant singing time.
[0070]
On the other hand, FIG. 22B shows a case where the singing consonant expansion / contraction rate is smaller than 1. In this case, the consonant singing time is shortened by multiplying both the consonant length of Sil_C and the consonant length of the phoneme transition C_V from the consonant to the vowel by the singing consonant expansion / contraction rate.
[0071]
[Step 42-4-5 (preceding Vowel song length calculation)]
Next, a method for calculating the preceding Vowel song length in step 42-4-5 will be described in detail with reference to FIGS. The preceding Vowel singing length is the duration of the vowel part of the preceding phoneme (hereinafter referred to as the preceding vowel singing time) when the preceding phoneme and the following phoneme are continuous without any silence (EventState = Transition). ) Means the length of time set to stretch.
[0072]
The portion obtained by subtracting the time during which the consonant portion of the subsequent phoneme is sung (hereinafter referred to as consonant singing time) from the time between the preceding phoneme and the subsequent phoneme is the preceding vowel singing time (see FIG. 24). Therefore, the length of the preceding vowel singing time to be set is determined based on the consonant singing time. In the present embodiment, the length of the preceding vowel singing time is determined by expanding and contracting the preceding Vowel singing length as a part of the preceding vowel singing time.
[0073]
For example, FIG. 24A shows the case where “sa” (combination of consonant and vowel) is pronounced as the subsequent phoneme following the preceding phoneme pV “a”, and FIG. 24B shows the preceding phoneme pV “a”. In the case where the subsequent phoneme “pa” (consonant and vowel combination) is pronounced, the subsequent phoneme “i” (only the vowel) is pronounced after the preceding phoneme pV “a”. Shows the case.
In the former two cases, there is a consonant singing time, but that in (A) is longer than that in (B). For this reason, the preceding vowel singing time is also shorter in the case of (A) than in the case of (B). In the case of (C), since the consonant singing time does not exist, the preceding vowel singing time is maximized.
[0074]
The consonant singing time varies depending on the singing consonant expansion / contraction rate (Consonant Modulation) included in the performance data. FIG. 25 is a diagram for explaining this.
FIG. 25A shows a case where the singing consonant expansion / contraction rate is larger than one. In this case, the sum of the consonant length of the phoneme transition pV_C from the preceding phoneme to the subsequent phoneme (in this figure, a combination of consonant and vowel) and the consonant length of the phoneme transition C_V from consonant to vowel is multiplied by the singing consonant expansion / contraction rate. The consonant singing time is extended by adding the above as the Consonant singer.
On the other hand, FIG. 25B shows a case where the singing consonant expansion / contraction rate is smaller than 1. in this case,
The consonant singing time is shortened by multiplying both the consonant length of pV_C and the consonant length of the phoneme transition C_V from the consonant to the vowel by the singing consonant expansion / contraction rate.
[0075]
The process of calculating the Vowel song length in step 42-4.6 will be described with reference to FIGS. Vowel singer is connected after the vowel of the subsequent phoneme if the assumption is true under the assumption that "silence is inserted between the next performance data" and discarded if it is not true It is what is done.
In order to calculate the Vowel song length, first, performance data, management data, and song synthesis score data are received (step 4.6-1), and the Vowel song length is calculated based on these received data (step 4). .6-2). This calculation method will be described with reference to FIG. First, assume that silence (Sil) is inserted between the current performance data (X_V, where X can be any of silence, consonant, and preceding vowel) and the next performance data (not shown). .
[0076]
Under this assumption, the vowel singing time (vowel singing time) between X_V and silence Sil is as follows: (1) X_V vowel V singing length, (2) Vowel singing length, (3) V_Sil It is the sum of vowel V singing time length. After the boundary between V and Sil in V_Sil matches the actual singing end time (Current Note Off), the Vowel singing length is calculated based on the vowel singing time determined thereby.
[0077]
When the next performance data is received, the connection state (EventState) with the current performance data is found, and it becomes clear whether or not the above assumption is true.
If it is true (EventState = Attack), the calculated Vowel song length is not updated but is used as it is. If it is not true (EventState = Transition), the preceding Vowel song length is calculated in the above-described step 4.5-4.
[0078]
[Second Embodiment]
Next, a second embodiment of the present invention will be described with reference to FIG. In the first embodiment, in the
[0079]
In this embodiment, instead of the table shown in FIG. 14, as shown in FIG. 28, a table showing the relationship between the pitch p and the phoneme transition time length expansion / contraction rate Rpt is stored in the
Thus, as shown in FIGS. 29 (a) and 29 (b), even with the same phoneme (sa, i, ta) and velocity (V1, V2, V3), if the pitch is different, the phoneme transition time length Changes.
In the table shown in FIG. 28, when the pitch is in the vicinity of the standard value Default2, the phoneme transition time length expansion / contraction rate Rpt is constant regardless of the change in the pitch, and the pitch is sufficiently larger than Default2 or When it is small, Rpt monotonously decreases as the pitch increases, but it goes without saying that it can be appropriately changed according to the purpose of singing synthesis.
[0080]
[Third Embodiment]
Next, a third embodiment of the present invention will be described. In the third embodiment, information on performance sound intensity is held in the performance data, and the phoneme transition length is changed by changing the phoneme transition time length expansion / contraction ratio Rpt based on the magnitude of the performance sound intensity. Is corrected. That is, a table showing the relationship between the performance sound intensity and the phoneme transition time length expansion / contraction rate Rpt as shown in FIG. 30 is stored in the
[0081]
[Fourth Embodiment]
Next, a fourth embodiment of the present invention will be described. In the fourth embodiment, as in the first embodiment, the phoneme transition time length expansion / contraction rate Rpt is changed based on the magnitude of velocity. However, as shown in FIG. 31, the expansion rate fluctuation range is set for the expansion rate Rpt, and even if the velocity is the same, the size of the expansion rate Rpt changes randomly. The Thereby, a change is added to a synthetic singing voice and it can be set as a more natural singing voice.
[0082]
In FIG. 31, the magnitude of the fluctuation range is set to zero when the magnitude of the velocity is Default, and the magnitude of the fluctuation range increases as the difference between the velocity and Default increases. However, as shown in FIG. 32, the magnitude of the fluctuation range may be substantially constant regardless of the magnitude of the velocity. Also, as shown in FIG. 33, the fluctuation range may be maximized when the velocity is in the vicinity of Default, and the fluctuation range may be reduced as the distance from Default is increased.
[0083]
In the fourth embodiment, in the situation where the phoneme transition time length expansion / contraction rate Rpt is changed based on the magnitude of velocity, fluctuation is given to the expansion / contraction rate Rpt, but the present invention is limited to this. It is not a thing. For example, in the situation where the phoneme transition time length expansion / contraction rate Rpt is changed based on the pitch as in the second embodiment, the expansion / contraction rate Rpt can be fluctuated, and the third As in the embodiment, in the situation where the phoneme transition time length expansion / contraction rate Rpt is changed according to the singing sound intensity, the expansion / contraction rate Rpt can be fluctuated.
[0084]
(Modification)
The present invention is not limited to the above-described embodiment, and can be implemented in various modifications. For example, the following changes are possible.
[0085]
(1) In the embodiment described above, the singing voice is synthesized according to the singing voice synthesis score after the singing voice synthesis score is completed. May be synthesized. For this purpose, for example, the singing synthesis score may be formed based on the received performance data while receiving performance data preferentially by interruption processing.
[0086]
(2) In the above-described embodiment, the singing synthesis score is composed of the four tracks of the phoneme track Tp, the pitch track Ti, the transition track Tr, and the vibrato track Tb. However, the number of tracks is not limited to this. For example, the pitch information may be stored in the phoneme track Tp to combine the phoneme track Tp and the pitch track Ti, or all the tracks may be integrated into one track.
[0087]
【The invention's effect】
As described above, according to the present invention, a natural singing voice can be easily synthesized by changing the phoneme transition time length.
[Brief description of the drawings]
FIG. 1 shows an overall configuration of a singing voice synthesis system according to a first embodiment of the present invention.
FIG. 2 shows an outline of a song synthesis procedure in the song synthesis system shown in FIG.
3 is a time-series representation of the results of the song synthesis procedure execution shown in FIG.
FIG. 4 shows the contents of information included in performance data.
FIG. 5 shows the contents of information included in the
FIG. 6 shows the contents of information in the
FIG. 7 shows the contents of information in the
FIG. 8 shows the contents of information in the
9 shows an example of the configuration of a song synthesis score SC formed by the song synthesis system shown in FIG.
FIG. 10 is a table for explaining items included in a phonological track Tp of a singing synthesis score SC.
FIG. 11 is a flowchart showing a detailed procedure of
12 is a flowchart showing a detailed procedure of
13 is a flowchart showing a detailed procedure of step 42-3 (management data creation) in the flowchart shown in FIG.
FIG. 14 shows a table stored in the
FIG. 15 is a conceptual diagram illustrating a method of analyzing actual singing time included in performance data.
16 is a flowchart showing a detailed procedure of Step 42-4 (formation of phoneme track Tp) in the flowchart shown in FIG.
FIG. 17 is a flowchart showing a detailed procedure of Step 42-4.2 (acquisition of phoneme transition time length) in the flowchart shown in FIG. 16;
FIG. 18 shows a state of a phoneme track Tp when the correction of the phoneme transition time length in Step 4-2.13 is executed.
FIG. 19 shows a state of a phoneme track Tp when the correction of the phoneme transition time length in Step 4-2.13 is not executed (prior art).
20 is a flowchart showing a detailed procedure of Steps 42-4.4 (Silence song length calculation) in the flowchart shown in FIG.
FIG. 21 is an explanatory diagram showing a method for calculating the Silence song length.
FIG. 22 is an explanatory diagram showing a method for determining a consonant singing time.
FIG. 23 is a flowchart showing a detailed procedure of Step 42-4.5 (calculation of preceding Vowel song length) in the flowchart shown in FIG. 16;
FIG. 24 is an explanatory diagram showing a method for calculating a preceding Vowel song length.
FIG. 25 is an explanatory diagram showing a technique of step 4.5-3 (consonal singing time calculation) in the flowchart shown in FIG. 23;
26 is a flowchart showing a detailed procedure of Steps 42-4.6 (Vowel song length calculation) in the flowchart shown in FIG.
FIG. 27 is an explanatory diagram for explaining a method of calculating a Vowel song length.
FIG. 28 shows a table for correcting the phoneme time transition length in the second embodiment of the present invention.
FIG. 29 shows a state of a phoneme track Tp when the correction of the phoneme transition time length is executed in the second embodiment of the present invention.
FIG. 30 shows a table for correcting the phoneme time transition length in the third embodiment of the present invention.
FIG. 31 shows a table for correcting the phoneme time transition length in the fourth embodiment of the present invention.
FIG. 32 shows a table for correcting the phoneme time transition length in the fourth embodiment of the present invention.
FIG. 33 shows a table for correcting the phoneme time transition length in the fourth embodiment of the present invention.
[Explanation of symbols]
DESCRIPTION OF
Claims (16)
前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報と、演奏音速さ情報とを含み、
前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、演奏音速さが所定の標準値付近の場合には演奏音速さの増加に対して音韻遷移時間長伸縮率が単調に減少する一方演奏音速さが所定の標準値よりも十分に大又は小である場合には音韻遷移時間長伸縮率が演奏音速さに関係なく一定となるような演奏音速さと音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、
前記演奏データを入力する入力ステップと、
前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出しステップと、
前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記演奏音速さ情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正ステップとを備えたことを特徴とする歌唱合成方法。In the singing composition method for storing various singing data in a database and generating a score for singing composition by reading the singing data that matches the content of the input performance data from the database,
The performance data includes at least phoneme information representing a phoneme, pitch information representing a pitch, and performance sound speed information,
The database includes a phonological transition database storing phonological transition time length data corresponding to at least one of the phonological information and the pitch information, and a performance sound speed when the performance sound speed is near a predetermined standard value. The phonological transition time length expansion ratio decreases monotonously with respect to the increase, while the phonological transition time length expansion ratio is not related to the performance sound speed when the performance sound speed is sufficiently larger or smaller than a predetermined standard value. A phoneme transition time length expansion / contraction database that stores the relationship between the performance sound speed and the phoneme transition time length expansion / contraction rate to be constant, and
An input step for inputting the performance data;
A phoneme transition time length data reading step of comparing the performance data with the phoneme transition database and reading the phoneme transition time length data corresponding to the performance data from the database;
Multiplying the previous SL phoneme the phoneme transition time length data read in the transition time length read step, phoneme transition time length scaling factor obtained with reference to the phoneme transition time length scaling factor database on the basis of the performance sound speed information A singing synthesizing method comprising: a phonological transition time length data correcting step for correcting the phonological transition time.
前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報と、演奏音強さ情報とを含み、
前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、演奏音強さが所定の標準値付近の場合には演奏音強さの増加に対して音韻遷移時間長伸縮率が単調に減少する一方演奏音強さが所定の標準値よりも十分に大又は小である場合には音韻遷移時間長伸縮率が演奏音強さに関係なく一定となるような演奏音強さと音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、
前記演奏データを入力する入力ステップと、
前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出しステップと、
前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記演奏音強さ情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正ステップとを備えたことを特徴とする歌唱合成方法。In the singing composition method for storing various singing data in a database and generating a score for singing composition by reading the singing data that matches the content of the input performance data from the database,
The performance data includes at least phoneme information representing a phoneme, pitch information representing a pitch, and performance sound strength information,
The database includes a phonological transition database storing phonological transition time length data corresponding to at least one of the phonological information and the pitch information, and a performance sound when the performance sound intensity is near a predetermined standard value. While the phoneme transition time length expansion rate decreases monotonically with increasing strength, while the performance tone strength is sufficiently larger or smaller than a predetermined standard value, the phoneme transition time length expansion rate is A phoneme transition time length expansion / contraction rate database that stores the relationship between the performance sound strength and the phoneme transition time length expansion / contraction rate, which is constant regardless of the length ,
An input step for inputting the performance data;
A phoneme transition time length data reading step of comparing the performance data with the phoneme transition database and reading the phoneme transition time length data corresponding to the performance data from the database;
Before Symbol phoneme the phoneme transition time length data read in the transition time length read step, phoneme transition time length scaling factor obtained with reference to the phoneme transition time length scaling factor database on the basis of the performance sound intensity information A singing synthesis method comprising: a phonological transition time length data correcting step for correcting by multiplication .
前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報とを含み、
前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、音高が所定の標準値付近の第1の区間に含まれる場合には音高の変化に関係なく音韻遷移時間伸縮率が一定である一方音高が第1の区間よりも大又は小である第2の区間に含まれる場合には音高の増加に対して音韻遷移時間長が単調に減少し、音高が前記第2の区間よりも大又は小である第3の区間に含まれる場合には音高の変化に関係なく音韻遷移時間長伸縮率が一定となるような 音高と音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、
前記演奏データを入力する入力ステップと、
前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出しステップと、
前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記音高情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正ステップとを備えたことを特徴とする歌唱合成方法。In the singing composition method for storing various singing data in a database and generating a score for singing composition by reading the singing data that matches the content of the input performance data from the database,
The performance data includes at least phoneme information representing a phoneme and pitch information representing a pitch,
The database includes a phoneme transition database in which phoneme transition time length data is stored in association with at least one of the phoneme information and the pitch information, and a pitch is included in a first section near a predetermined standard value. In some cases, the phonological transition time expansion rate is constant regardless of the change in pitch, while the pitch is included in the second interval that is larger or smaller than the first interval, When the phoneme transition time length decreases monotonically and the pitch is included in the third section that is larger or smaller than the second section, the phoneme transition time length expansion / contraction rate is set regardless of the change in the pitch. A phoneme transition time length expansion / contraction rate database that stores the relationship between pitches that are constant and phonological transition time length expansion / contraction rates ,
An input step for inputting the performance data;
A phoneme transition time length data reading step of comparing the performance data with the phoneme transition database and reading the phoneme transition time length data corresponding to the performance data from the database;
Multiplying the previous SL phoneme the phoneme transition time length data read in the transition time length read step, phoneme transition time length scaling factor obtained with reference to the phoneme transition time length scaling factor database on the basis of the pitch data singing voice synthesizing method characterized in that a phoneme transition time length data correction step of correcting by.
前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報と、演奏音速さ情報とを含み、前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、演奏音速さが所定の標準値付近の場合には演奏音速さの増加に対して音韻遷移時間長伸縮率が単調に減少する一方演奏音速さが所定の標準値よりも十分に大又は小である場合には音韻遷移時間長伸縮率が演奏音速さに関係なく一定となるような演奏音速さと音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれた状態において、
前記演奏データを入力する入力ステップと、
前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出しステップと、
前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記演奏音速さ情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正ステップとをコンピュータに実行させるように構成されたことを特徴とする歌唱合成用プログラム。A song synthesis program for storing various song data in a database and causing a computer to execute a procedure for generating a score for song synthesis by reading the song data that matches the content of the input performance data from the database. In
The performance data includes at least phoneme information representing phonemes, pitch information representing pitches, and performance sound speed information, and the database corresponds to at least one of the phoneme information and the pitch information. Phonological transition database that stores phonological transition time length data, and when the performance sound speed is near a predetermined standard value, the phonological transition time length expansion rate decreases monotonously with increasing performance sound speed, while the performance sound speed Stores the relationship between the performance sound speed and the phonological transition time length expansion / contraction rate so that the phonological transition time length expansion / contraction rate is constant regardless of the performance sound speed when the value is sufficiently larger or smaller than the predetermined standard value. In the state where the phoneme transition time length expansion / contraction rate database is included,
An input step for inputting the performance data;
A phoneme transition time length data reading step of comparing the performance data with the phoneme transition database and reading the phoneme transition time length data corresponding to the performance data from the database;
Multiplying the previous SL phoneme the phoneme transition time length data read in the transition time length read step, phoneme transition time length scaling factor obtained with reference to the phoneme transition time length scaling factor database on the basis of the performance sound speed information A program for synthesizing a song characterized by causing a computer to execute a phonological transition time length data correction step to be corrected.
前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報と、演奏音強さ情報とを含み、前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、演奏音強さが所定の標準値付近の場合には演奏音強さの増加に対して音韻遷移時間長伸縮率が単調に減少する一方演奏音強さが所定の標準値よりも十分に大又は小である場合には音韻遷移時間長伸縮率が演奏音強さに関係なく一定となるような演奏音強さと音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれた状態において、
前記演奏データを入力する入力ステップと、
前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出しステップと、
前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記演奏音強さ情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正ステップとをコンピュータに実行させるように構成されたことを特徴とする歌唱合成用プログラム。A song synthesis program for storing various song data in a database and causing a computer to execute a procedure for generating a score for song synthesis by reading the song data that matches the content of the input performance data from the database. In
The performance data includes at least phoneme information representing a phoneme, pitch information representing a pitch, and performance sound strength information, and the database includes at least one of the phoneme information and the pitch information. Corresponding phoneme transition database storing phoneme transition time length data, and when the performance sound intensity is near the predetermined standard value, while the phoneme transition time length expansion / contraction rate decreases monotonously with increasing performance sound intensity Performance sound strength and phoneme transition time length expansion / contraction rate so that the phoneme transition time length expansion / contraction rate is constant regardless of the performance sound strength when the performance sound strength is sufficiently larger or smaller than a predetermined standard value In a state that includes a phoneme transition time length expansion / contraction rate database that stores the relationship between
An input step for inputting the performance data;
A phoneme transition time length data reading step of comparing the performance data with the phoneme transition database and reading the phoneme transition time length data corresponding to the performance data from the database;
Before Symbol phoneme the phoneme transition time length data read in the transition time length read step, phoneme transition time length scaling factor obtained with reference to the phoneme transition time length scaling factor database on the basis of the performance sound intensity information A singing composition program characterized by causing a computer to execute a phoneme transition time length data correcting step for correcting by multiplication .
前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報とを含み、前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、音高が所定の標準値付近の第1の区間に含まれる場合には音高の変化に関係なく音韻遷移時間伸縮率が一定である一方音高が第1の区間よりも大又は小である第2の区間に含まれる場合には音高の増加に対して音韻遷移時間長が単調に減少し、音高が前記第2の区間よりも大又は小である第3の区間に含まれる場合には音高の変化に関係なく音韻遷移時間長伸縮率が一定となるような音高と音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれた状態において、
前記演奏データを入力する入力ステップと、
前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出しステップと、
前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記音高情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正ステップとをコンピュータに実行させるように構成されたことを特徴とする歌唱合成用プログラム。A song synthesis program for storing various song data in a database and causing a computer to execute a procedure for generating a score for song synthesis by reading the song data that matches the content of the input performance data from the database. In
The performance data includes at least phoneme information representing a phoneme and pitch information representing a pitch, and the database associates at least one of the phoneme information and the pitch information with phoneme transition time length data. When the pitch is included in the first interval near the predetermined standard value, the phoneme transition time expansion / contraction rate is constant regardless of the change in pitch, while the pitch is the first When included in a second section that is larger or smaller than the section, the phonological transition time length monotonously decreases with an increase in pitch, and the pitch is larger or smaller than the second section. When included in the third section, the phoneme transition time length expansion / contraction rate stores the relationship between the pitch and the phoneme transition time length expansion / contraction rate so that the phoneme transition time length expansion / contraction rate is constant regardless of the change in pitch. In the state that includes the database ,
An input step for inputting the performance data;
A phoneme transition time length data reading step of comparing the performance data with the phoneme transition database and reading the phoneme transition time length data corresponding to the performance data from the database;
Multiplying the previous SL phoneme the phoneme transition time length data read in the transition time length read step, phoneme transition time length scaling factor obtained with reference to the phoneme transition time length scaling factor database on the basis of the pitch data A program for synthesizing a song characterized by causing a computer to execute a phoneme transition time length data correction step to be corrected by this.
前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報と、演奏音速さ情報とを含み、
前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、演奏音速さが所定の標準値付近の場合には演奏音速さの増加に対して音韻遷移時間長伸縮率が単調に減少する一方演奏音速さが所定の標準値よりも十分に大又は小である場合には音韻遷移時間長伸縮率が演奏音速さに関係なく一定となるような演奏音速さと音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、
前記演奏データを入力する演奏データ入力部と、
前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出し部と、
前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記演奏音速さ情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正部とを備えたことを特徴とする歌唱合成装置。In a song synthesizer that stores various song data in a database and generates a score for song synthesis by reading the song data that matches the content of the input performance data from the database.
The performance data includes at least phoneme information representing a phoneme, pitch information representing a pitch, and performance sound speed information,
The database includes a phonological transition database storing phonological transition time length data corresponding to at least one of the phonological information and the pitch information, and a performance sound speed when the performance sound speed is near a predetermined standard value. The phonological transition time length expansion ratio decreases monotonously with respect to the increase, while the phonological transition time length expansion ratio is not related to the performance sound speed when the performance sound speed is sufficiently larger or smaller than a predetermined standard value. A phoneme transition time length expansion / contraction database that stores the relationship between the performance sound speed and the phoneme transition time length expansion / contraction rate to be constant, and
A performance data input unit for inputting the performance data;
A phoneme transition time length data reading unit that compares the performance data with the phoneme transition database and reads the phoneme transition time length data corresponding to the performance data from the database;
Multiplying the previous SL phoneme the phoneme transition time length data read in the transition time length read step, phoneme transition time length scaling factor obtained with reference to the phoneme transition time length scaling factor database on the basis of the performance sound speed information A singing synthesizing apparatus comprising: a phonological transition time length data correcting unit that corrects the phonological transition time.
前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報と、演奏音強さ情報とを含み、
前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、演奏音強さが所定の標準値付近の場合には演奏音強さの増加に対して音韻遷移時間長伸縮率が単調に減少する一方演奏音強さが所定の標準値よりも十分に大又は小である場合には音韻遷移時間長伸縮率が演奏音強さに関係なく一定となるような演奏音強さと音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、
前記演奏データを入力する演奏データ入力部と、
前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出し部と、
前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記演奏音強さ情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正部とを備えたことを特徴とする歌唱合成装置。In a song synthesizer that stores various song data in a database and generates a score for song synthesis by reading the song data that matches the content of the input performance data from the database.
The performance data includes at least phoneme information representing a phoneme, pitch information representing a pitch, and performance sound strength information,
The database includes a phonological transition database storing phonological transition time length data corresponding to at least one of the phonological information and the pitch information, and a performance sound when the performance sound intensity is near a predetermined standard value. While the phoneme transition time length expansion rate decreases monotonically with increasing strength, while the performance tone strength is sufficiently larger or smaller than a predetermined standard value, the phoneme transition time length expansion rate is A phoneme transition time length expansion / contraction rate database that stores the relationship between the performance sound strength and the phoneme transition time length expansion / contraction rate, which is constant regardless of the length ,
A performance data input unit for inputting the performance data;
A phoneme transition time length data reading unit that compares the performance data with the phoneme transition database and reads the phoneme transition time length data corresponding to the performance data from the database;
Before Symbol phoneme the phoneme transition time length data read in the transition time length read step, phoneme transition time length scaling factor obtained with reference to the phoneme transition time length scaling factor database on the basis of the performance sound intensity information A singing synthesizing apparatus comprising: a phonological transition time length data correcting unit that corrects by multiplication .
前記演奏データは、少なくとも音韻を表わす音韻情報と、音高を表わす音高情報とを含み、
前記データベースには、前記音韻情報、前記音高情報のうちの少なくとも1つと対応させ音韻遷移時間長データを記憶した音韻遷移データベースと、音高が所定の標準値付近の第1の区間に含まれる場合には音高の変化に関係なく音韻遷移時間伸縮率が一定である一方音高が第1の区間よりも大又は小である第2の区間に含まれる場合には音高の増加に対して音韻遷移時間長が単調に減少し、音高が前記第2の区間よりも大又は小である第3の区間に含まれる場合には音高の変化に関係なく音韻遷移時間長伸縮率が一定となるような音高と音韻遷移時間長伸縮率との関係を格納する音韻遷移時間長伸縮率データベースとが含まれ、
前記演奏データを入力する演奏データ入力部と、
前記演奏データと前記音韻遷移データベースとを対比して、前記演奏データに対応した前記音韻遷移時間長データを前記データベースより読み出す音韻遷移時間長データ読出し部と、
前記音韻遷移時間長読出しステップにおいて読み出された前記音韻遷移時間長データを、前記音高情報に基づき前記音韻遷移時間長伸縮率データベースを参照して取得した音韻遷移時間長伸縮率で乗算することにより補正する音韻遷移時間長データ補正部とを備えたことを特徴とする歌唱合成装置。In a song synthesizer that stores various song data in a database and generates a score for song synthesis by reading the song data that matches the content of the input performance data from the database.
The performance data includes at least phoneme information representing a phoneme and pitch information representing a pitch,
The database includes a phoneme transition database in which phoneme transition time length data is stored in association with at least one of the phoneme information and the pitch information, and a pitch is included in a first section near a predetermined standard value. In some cases, the phonological transition time expansion rate is constant regardless of the change in pitch, while the pitch is included in the second interval that is larger or smaller than the first interval, When the phoneme transition time length decreases monotonically and the pitch is included in the third section that is larger or smaller than the second section, the phoneme transition time length expansion / contraction rate is set regardless of the change in the pitch. A phoneme transition time length expansion / contraction rate database that stores the relationship between pitches that are constant and phonological transition time length expansion / contraction rates ,
A performance data input unit for inputting the performance data;
A phoneme transition time length data reading unit that compares the performance data with the phoneme transition database and reads the phoneme transition time length data corresponding to the performance data from the database;
Multiplying the previous SL phoneme the phoneme transition time length data read in the transition time length read step, phoneme transition time length scaling factor obtained with reference to the phoneme transition time length scaling factor database on the basis of the pitch data A singing voice synthesizing apparatus comprising a phonological transition time length data correcting unit that corrects the phonological transition time.
前記音韻遷移時間長データ読出し部は、前記状態遷移データに応じて異なる音韻遷移時間長データを読み出すように構成された請求項10乃至12のいずれか1項に記載の歌唱合成装置。The performance data includes state transition data indicating state transition of the phoneme,
The singing synthesizer according to any one of claims 10 to 12, wherein the phonological transition time length data reading unit is configured to read different phonological transition time length data according to the state transition data.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2002244240A JP3963141B2 (en) | 2002-03-22 | 2002-08-23 | SINGLE SYNTHESIS DEVICE, SINGE SYNTHESIS PROGRAM, AND COMPUTER-READABLE RECORDING MEDIUM CONTAINING SINGE SYNTHESIS PROGRAM |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2002080713 | 2002-03-22 | ||
| JP2002244240A JP3963141B2 (en) | 2002-03-22 | 2002-08-23 | SINGLE SYNTHESIS DEVICE, SINGE SYNTHESIS PROGRAM, AND COMPUTER-READABLE RECORDING MEDIUM CONTAINING SINGE SYNTHESIS PROGRAM |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2004004440A JP2004004440A (en) | 2004-01-08 |
| JP2004004440A5 JP2004004440A5 (en) | 2005-05-26 |
| JP3963141B2 true JP3963141B2 (en) | 2007-08-22 |
Family
ID=30445782
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2002244240A Expired - Fee Related JP3963141B2 (en) | 2002-03-22 | 2002-08-23 | SINGLE SYNTHESIS DEVICE, SINGE SYNTHESIS PROGRAM, AND COMPUTER-READABLE RECORDING MEDIUM CONTAINING SINGE SYNTHESIS PROGRAM |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP3963141B2 (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5136128B2 (en) * | 2008-03-12 | 2013-02-06 | ヤマハ株式会社 | Speech synthesizer |
| JP6047922B2 (en) * | 2011-06-01 | 2016-12-21 | ヤマハ株式会社 | Speech synthesis apparatus and speech synthesis method |
| JP6435791B2 (en) * | 2014-11-11 | 2018-12-12 | ヤマハ株式会社 | Display control apparatus and display control method |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0227397A (en) * | 1988-07-15 | 1990-01-30 | Matsushita Electric Works Ltd | Voice synthesizing and singing device |
| JP3267659B2 (en) * | 1992-03-31 | 2002-03-18 | セコム株式会社 | Japanese speech synthesis method |
| JPH07239698A (en) * | 1994-02-28 | 1995-09-12 | Hitachi Ltd | Device for synthesizing phonetic rule |
| JP3518253B2 (en) * | 1997-05-22 | 2004-04-12 | ヤマハ株式会社 | Data editing device |
| JP3017715B2 (en) * | 1997-10-31 | 2000-03-13 | 松下電器産業株式会社 | Audio playback device |
| JP2001013982A (en) * | 1999-04-28 | 2001-01-19 | Victor Co Of Japan Ltd | Voice synthesizer |
| CN1413347A (en) * | 1999-12-22 | 2003-04-23 | 萨尔诺夫公司 | Method and apparatus for smoothing spliced discontinuous audio streams |
| JP3879402B2 (en) * | 2000-12-28 | 2007-02-14 | ヤマハ株式会社 | Singing synthesis method and apparatus, and recording medium |
-
2002
- 2002-08-23 JP JP2002244240A patent/JP3963141B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2004004440A (en) | 2004-01-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3879402B2 (en) | Singing synthesis method and apparatus, and recording medium | |
| JP5293460B2 (en) | Database generating apparatus for singing synthesis and pitch curve generating apparatus | |
| US9355634B2 (en) | Voice synthesis device, voice synthesis method, and recording medium having a voice synthesis program stored thereon | |
| JP2004264676A (en) | Apparatus and program for singing synthesis | |
| JP2011028230A (en) | Apparatus for creating singing synthesizing database, and pitch curve generation apparatus | |
| JP3728173B2 (en) | Speech synthesis method, apparatus and storage medium | |
| JP4026446B2 (en) | SINGLE SYNTHESIS METHOD, SINGE SYNTHESIS DEVICE, AND SINGE SYNTHESIS PROGRAM | |
| JP3963141B2 (en) | SINGLE SYNTHESIS DEVICE, SINGE SYNTHESIS PROGRAM, AND COMPUTER-READABLE RECORDING MEDIUM CONTAINING SINGE SYNTHESIS PROGRAM | |
| JP6044284B2 (en) | Speech synthesizer | |
| WO2022054496A1 (en) | Electronic musical instrument, electronic musical instrument control method, and program | |
| WO2020217801A1 (en) | Audio information playback method and device, audio information generation method and device, and program | |
| JPH11282483A (en) | Karaoke device | |
| JP5176981B2 (en) | Speech synthesizer and program | |
| JP5157922B2 (en) | Speech synthesizer and program | |
| JP4631726B2 (en) | Singing composition apparatus and recording medium | |
| JP2001042879A (en) | Karaoke device | |
| JP5106437B2 (en) | Karaoke apparatus, control method therefor, and control program therefor | |
| JP6406182B2 (en) | Karaoke device and karaoke system | |
| JP3173310B2 (en) | Harmony generator | |
| JP2004061753A (en) | Method and device for synthesizing singing voice | |
| WO2023171497A1 (en) | Acoustic generation method, acoustic generation system, and program | |
| JP4296767B2 (en) | Breath sound synthesis method, breath sound synthesis apparatus and program | |
| JPH04331990A (en) | Voice electronic musical instrument | |
| JP4305022B2 (en) | Data creation device, program, and tone synthesis device | |
| JP2005077763A (en) | System for generating automatic accompaniment, and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20040721 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20040721 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20060725 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20060808 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20061010 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20070501 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20070514 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100601 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110601 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120601 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120601 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130601 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140601 Year of fee payment: 7 |
|
| LAPS | Cancellation because of no payment of annual fees |