JP3921837B2 - 情報判別支援装置、情報判別支援プログラムを記録した記録媒体及び情報判別支援方法 - Google Patents
情報判別支援装置、情報判別支援プログラムを記録した記録媒体及び情報判別支援方法 Download PDFInfo
- Publication number
- JP3921837B2 JP3921837B2 JP27631398A JP27631398A JP3921837B2 JP 3921837 B2 JP3921837 B2 JP 3921837B2 JP 27631398 A JP27631398 A JP 27631398A JP 27631398 A JP27631398 A JP 27631398A JP 3921837 B2 JP3921837 B2 JP 3921837B2
- Authority
- JP
- Japan
- Prior art keywords
- information
- evaluation
- keyword
- unit
- keywords
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images


















Description
【発明の属する技術分野】
本発明は収集した情報を分類するための情報判別支援装置、情報判別支援プログラムを記録した記録媒体及び情報判別支援方法に関し、特に収集した情報を取捨選択する行為を支援するための情報判別支援装置、情報判別支援プログラムを記録した記録媒体及び情報判別支援方法に関する。
【0002】
【従来の技術】
近年、インターネットなどのコンピュータネットワークの普及と様々な情報データベースサービスにより、情報検索サービスや電子メール、電子新聞、ネットニュースなどから、多種多様の電子化された情報を得ることが可能になっている。このため、各種情報サービスから類似した情報、もしくは関連のない情報を含めて多量の情報が届けられ、各情報の判読に忙殺されるという事態が発生しつつある。このような状況下において、氾濫する情報から各個人に有用な情報のみを選択、分類、もしくはフィルタリングして、情報の判読にかかる負荷を軽減させる技術が存在する。
【0003】
このような情報の取捨選択を支援するための従来技術としては、例えば、特開平5−266087号公報の「全文検索装置」がある。この全文検索装置では、検索対象となるテキストを、評価単位と評価単位の集まった抽出単位とに分け、評価単位をユーザが入力したキーワードの出現率で評価する。そして、各評価単位のキーワードの出現率から抽出単位の評価を行う。これにより、例えば、キーワードの出現率の高い文章が集まっている段落を選択してユーザに提示することで、ユーザは文書中の関連ある部分のみを見ることができる。
【0004】
また、特開平9−6799号公報の「文書分類装置及び文書検索装置」では、辞書に登録された単語の文書中の出現回数をその単語の特徴ベクトルとし、出現する単語の特徴ベクトルの要素を足して文書の特徴ベクトルを生成する。この文書の特徴ベクトルを用いて自動的に文書を分類し、ユーザに提示する。
【0005】
また、特開平9−44514号公報の「関連情報判定方法及び装置」では、検索結果から部分情報として、要約やアブストラクト、見出しなどを取り出し、これら部分情報間において共通の文字または文字列がどれくらい存在するかを閾値と比較して、検索結果間の関連性を求め、ユーザに提示する。これにより、検索結果の理解に関して、ユーザの負担を軽減する。
【0006】
これらの他にも、文書管理ツールや要約作成ツールにおいて、文書の関連性を評価し、関連ある文書などを集めて表示すると共に、代表となる文書や要約文を提示し、その概要を比較させるものが存在する。
【0007】
【発明が解決しようとする課題】
しかし、上記の従来技術には、以下のような問題点がある。
特開平5−266087号公報の「全文検索装置」では、ユーザは、装置が抽出した関連部分のみを見ることができるが、検索結果は分類されておらず、装置が抽出した個々の検索結果を全て見ることになる。すると、同じものでも複数回見なければならず、検索結果間の関係は、関連部分を見ながらユーザが判断することになる。このように、関連部分を持つ情報の取捨選択の指針がない。
【0008】
特開平9−6799号公報の「文書分類装置及び文書検索装置」では、文書全体の文書特徴ベクトルを用いて分類するので、情報の部分的な特徴が全体の中に埋もれてしまい、関連する部分はユーザが探し出さなければならない。
【0009】
特開平9−44514号公報の「関連情報判定方法及び装置」では、要約や見出しを用いて部分情報を比較しているが、要約や見出しに含まれる情報によって全て表現されるわけではなく、見出しなどには、注意を引くための誇張などが含まれ、正確に内容を反映していない場合がある。
【0010】
また、要約や重要文を抽出する記述では、情報中の代表的な部分のみを抽出するため、一部分に埋もれた関連情報に関する内容が要約に現れるとは限らない。逆に、抽出された部分が類似していたとしても、その情報のうちどれくらいの部分が関連するものなのか判らない。さらに、その要約や重要文が、文書のどの部分を示しているか判らないため、要約を見て関連ありと判断しても、その関連情報を得るためには、関連情報を含む文書を読まなければならず、文書中から必要な情報を抽出する作業は、人に委ねられる。
【0011】
このように、検索及び分類の結果、関連度の高い情報が集められ、もしくは分類されてユーザに提示されたとしても、それはシステムが判断した結果であり、ユーザはその結果をもとに再度情報の中身を判読し、各情報の必要性の有無を判別し取捨選択を行う必要がある。ところが、従来技術では、提示された情報のどの部分を読めば必要性の有無を判断できるのかが判らなかった。そのため、ユーザは不必要な文書の内容を大量に読まされることになり、非効率的であった。
【0012】
本発明はこのような点に鑑みなされたものであり、情報群の取捨選択の指針となる情報を提示できる情報判別支援装置及び情報判別支援方法を提供することを目的とする。
【0013】
【課題を解決するための手段】
本発明では上記課題を解決するために、情報の内容によって複数の情報群を分類することを支援する情報判別支援装置において、前記情報群内の各情報を評価単位に分割する情報分割手段と、各評価単位に対して形態素解析を行うことで語彙を抽出し、抽出された語彙からなるキーワード、連続した固有名詞または普通名詞の語彙を結合することにより得られる結合キーワード、および1文章中の普通名詞または固有名詞の語彙とその文章中の動詞の直前に存在する普通名詞もしくはサ変名詞の語彙とのペアからなるキーワードペアを含むキーワード群を生成し、すべての評価単位から生成されたキーワード群に含まれるキーワード、結合キーワード、およびキーワードペアを要素とする評価ベクトル空間を生成し、前記評価ベクトル空間の要素に対応するキーワード、結合キーワード、およびキーワードペアが各評価単位のキーワード群に含まれるか否かに基づいて、各評価単位の記述内容の特徴を示す評価ベクトルを生成する評価基準数値化手段と、評価単位同士の評価ベクトルを比較することで評価単位間の類似度を求め、類似する評価単位双方に対して同じ分類番号を付与する類似情報分類手段と、同じ分類番号が付与された評価単位同士を視覚的に判別できるように各情報内の評価単位を表示する情報表示手段と、を有することを特徴とする情報判別支援装置が提供される。
【0014】
このような情報判別支援装置によれば、情報群が与えられると、情報分割手段により、各情報が評価単位に分割される。すると、評価基準数値化手段により、各評価単位に含まれる語彙に基づいてキーワード群が生成され、評価単位毎のキーワード群を解析することで各評価単位の特徴を示す評価ベクトルが生成される。さらに、類似情報分類手段により、評価単位同士の評価ベクトルが比較され、評価単位間の類似度が求められる。そして、情報表示手段により、同じ分類番号が付与された評価単位同士を視覚的に判別できるように各情報内の評価単位が表示される。
【0015】
また、上記課題を解決するために、情報の内容によって情報群を分類することを支援する情報判別支援プログラムを記録したコンピュータ読み取り可能な記録媒体において、前記情報群内の各情報を評価単位に分割する情報分割手段、各評価単位に対して形態素解析を行うことで語彙を抽出し、抽出された語彙からなるキーワード、連続した固有名詞または普通名詞の語彙を結合することにより得られる結合キーワード、および1文章中の普通名詞または固有名詞の語彙とその文章中の動詞の直前に存在する普通名詞もしくはサ変名詞の語彙とのペアからなるキーワードペアを含むキーワード群を生成し、すべての評価単位から生成されたキーワード群に含まれるキーワード、結合キーワード、およびキーワードペアを要素とする評価ベクトル空間を生成し、前記評価ベクトル空間の要素に対応するキーワード、結合キーワード、およびキーワードペアが各評価単位のキーワード群に含まれるか否かに基づいて、各評価単位の記述内容の特徴を示す評価ベクトルを生成する評価基準数値化手段、評価単位同士の評価ベクトルを比較することで評価単位間の類似度を求め、類似する評価単位双方に対して同じ分類番号を付与する類似情報分類手段、同じ分類番号が付与された評価単位同士を視覚的に判別できるように各情報内の評価単位を表示する情報表示手段、としてコンピュータを機能させることを特徴とする情報判別支援プログラムを記録したコンピュータ読み取り可能な記録媒体が提供される。
【0016】
このような記録媒体に記録された情報判別支援プログラムをコンピュータに実行させれば、上記本発明に係る情報判別支援装置に必要な機能がコンピュータ上に実現される。
【0017】
【発明の実施の形態】
以下、本発明の実施の形態を図面を参照して説明する。
図1は、本発明の原理構成図である。本発明の情報判別支援装置は、情報分割手段1、評価基準数値化手段2及び類似情報分類手段3からなる。
【0018】
情報分割手段1は、情報群内の各情報4に形態素解析を行い、評価単位4aに分割する。
評価基準数値化手段2は、各評価単位4aに含まれる語彙に基づいてキーワード群を生成し、評価単位毎のキーワード群を解析することで情報群全体の内容における各評価単位の記述内容の特徴を数値化する。その結果、評価単位毎の評価ベクトル4bが得られる。
【0019】
類似情報分類手段3は、評価単位同士の評価ベクトル4bを比較することで評価単位間の類似度を求め、さらに各情報中及び情報間の各評価単位の類似度に基づいて複数の情報間の類似度を算出する。そして、互いに類似する情報同士の集合に分類する。これにより、類似情報同士の集まりである類似情報群5が複数生成される。
【0020】
このようにして類似情報群5に分類された情報を、情報中の類似する評価単位を選択して比較提示することで、ユーザによる情報の類似性・関連性の判断を容易にし、有用な情報の取捨選択の手間を軽減することができる。
【0021】
次に、本発明の情報判別支援装置により情報を分類し、分類結果をユーザに提示するための実施の形態を説明する。
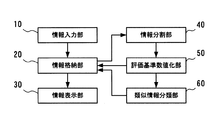
図2は、本発明の実施の形態に係る情報判別支援装置の構成を示すブロック図である。本実施の形態に係る情報判別支援装置は、以下の要素で構成される。
【0022】
情報入力部10は、類似判別を行うべき情報、例えば検索結果として得られた情報群を入力する。情報格納部20は、入力された情報群や類似度判別を行った結果を格納する。情報表示部30は、類似判別結果などを画面上に表示する。情報分割部40は、情報を評価単位に分割する。評価基準数値化部50は、全情報中の各評価単位の内容の位置づけを数値化して、評価ベクトルを生成する。類似情報分類部60は、各情報中及び情報間の各評価単位の類似度と、情報中の類似する評価単位の分布と、情報中の類似する評価単位の含有度を用いて複数の情報間の類似度を算出し類似する情報を分類する。
【0023】
このような情報判別支援装置に情報群を与えると、情報入力部10により、与えられた情報群が情報格納部20に格納される。格納された各情報は、情報分割部40により評価単位に分割される。すると、評価基準数値化部50により、評価単位毎の評価ベクトルが求められる。次に、類似情報分類部60によって、各情報中及び情報間の各評価単位の類似度と、情報中の類似する評価単位の分布と、情報中の類似する評価単位の含有度を用いて複数の情報間の類似度が算出され、類似する情報が分類される。情報の分類結果は、情報格納部20に格納されると共に、情報表示部30によって画面上に表示される。
【0024】
次に、情報判別支援装置の主な構成要素の詳細について説明する。なお、本装置においては、類似判別のための情報としてテキストを用いる。ここでテキストとは、コード化された文字情報をいい、報告書、特許明細書、議事録などの文書、電子メール、電子会議室に貼り付けられた意見、ホームページなどインターネット上に流れるテキスト情報など、電子化されたテキスト情報一般を含む。
【0025】
まず、情報分割部40の詳細について説明する。
図3は、情報分割部の内部構成を示す図である。情報分割部40は、レイアウト判別部41、タイトル削除部42、及び評価単位生成部43で構成される。レイアウト判別部41は、入力された情報からテキスト部分を認識する。タイトル削除部42は、情報中のタイトルや見出し、著者名、出典などの部分を削除する。評価単位生成部43は、抽出されたテキストをテキスト中の区切りを推定しながら評価単位に分割する。
【0026】
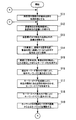
図4は、情報判別支援装置の処理の流れを示すフローチャートである。この処理は、対象となる情報群が情報入力部10によって入力されたときに開始される。この処理をステップ番号に沿って説明する。
[S1]レイアウト判別部41が、入力された情報をテキスト部分とそれ以外の部分に分割する。
[S2]レイアウト判別部41が、写真や図の部分を取り除き、テキスト部分のみを抽出する。そして、抽出したテキスト部分をタイトル削除部42に渡す。
[S3]タイトル削除部42が、レイアウト情報とテキストのフォントやサイズ、句読点の有無などから、本文であるか、見出しやタイトルであるかを判断し、タイトルや見出しの部分を削除する。このとき、著者名や出典、リファレンスなどの情報も削除する。
[S4]タイトル削除部42が、テキスト部分のみになった情報を、評価単位生成部43に送る。
[S5]評価単位生成部43が、テキスト情報を章や段落などの区切りを考慮しながら、評価単位に分割する。例えば、ユーザが指定した評価単位の文字数を200文字程度とすると、200文字前後において、空白行などレイアウト上の区切りがあればその部分で、なければ、改行を示すリターンを検出し、それもなければ読点を検出して情報を分割する。なお、図や表に付随する説明文などは、それらを一塊にして処理し、文字数が評価単位文字数より多い場合は分割を行う。
[S6]評価単位生成部43が、生成された評価単位を評価基準数値化部50へ送る。
【0027】
ここで、具体例を用いて、情報分割部40の処理内容を説明する。
図5は、本装置において処理の対象となる電子化された文書例を示す図である。図に示す文書100には、タイトル110と著者名120が記載されている。その下には、左半分に章題130と文章140とが記載され、右半分に写真170,180が添付されている。その下には、さらに章題150と文章160とが記載されている。
【0028】
このような文書が情報分割部40に入力されると、レイアウト判別部41においてテキスト部分とそれ以外の部分に分割される。この例では、タイトル110、著者名120、章題130,150及び文章140,160がテキスト部分であり、写真170,180の部分がテキスト以外の部分である。そこで、レイアウト判別部41により、テキスト部分が抽出される。抽出されたテキスト部分は、タイトル削除部42によって、レイアウト情報やテキストのフォントやサイズ、句読点の有無などから、本文以外の記載内容であるタイトル110、著者名120、章題130,150が削除される。残った文章140,160の記載内容であるテキスト情報は、評価対象としてタイトル削除部42によって評価単位生成部43に送られる。
【0029】
なお、この実施の形態では、文章として内容を記述している部分のみを、評価対象の情報としている。これは、タイトルなどは相手の気を引くために、もしくは相手をごまかすために、内容と異なる表現や誇張した表現を用いる場合があり、情報の内容を的確に表現しているとは言えないことが多々あるからである。そのため、タイトルなどに入っている語彙は、あえて評価対象から外している。
【0030】
評価単位生成部43に送られたテキスト情報は、章や段落などの区切りを考慮しながら、評価単位に分割される。ここで、生成された評価単位は、評価単位生成部43によって評価基準数値化部50へ送られる。
【0031】
このようにして、文書100中のテキストが評価単位に分割され、評価基準数値化部50に渡される。
ところで、文書などは章や段落を持つ場合が多いが、すべての情報がこのように、意味的な区切りを持っているわけではない。本発明では、章や段落など意味的に区切られていると思われる部分を考慮しつつも、意味的な区切りが認識できず、テキストが続く情報については、文書の認識単位として指定された文字数で情報を区切り、評価単位を生成する。
【0032】
この方法においては、意味的に同じ部分が区切られてしまう可能性が考えられるが、同じ内容が続くならば、それらの情報中に出現する語彙は類似する可能性が高く、区切られたそれぞれの情報が類似する情報として提示されるため問題はない。
【0033】
また、区切られることで、出現語彙が分離され、それぞれの情報の類似度が低下したとすると、それは関連語彙が広範囲に分散しているためであり、情報の密度が低く類似度は低いと考えられる。よって、連続する情報の文字数による分割による影響は少い。
【0034】
次に、評価基準数値化部50の詳細を説明する。
図6は、評価基準数値化部の内部構成を示す図である。図に示す各構成要素の機能を以下に示す。
【0035】
キーワード抽出部51は、テキストを形態素解析し特定品詞の語彙のみをキーワードとして抽出する。結合キーワード生成部52は、抽出されたキーワードから特定品詞が連続している部分を抽出し、キーワードを結合して新たな結合キーワードとする。結合キーワード重み付け部53は、キーワードの結合数に応じて結合キーワードに重みを付ける。キーワードペア生成部54は、あるキーワードと同じ文章中に離れて存在する別の特定品詞のキーワードとを組み合わせて1つのキーワードペアとする。キーワードペア重み付け部55は、生成したキーワードペアにキーワード間の距離を考慮した重みを付ける。評価ベクトル空間生成部56は、生成した結合キーワード及びキーワードペアを用い、情報間で重複する割合の高いもしくは重複のない結合キーワード及びキーワードペアを削除した上で、類似度評価のための評価ベクトル空間を生成する。評価ベクトル生成部57は、各評価単位毎に情報中に存在する結合キーワード及びキーワードペアを検出し評価ベクトルを生成する。
【0036】
このような評価基準数値化部50における処理手順を以下に示す。
図7は、評価基準数値化部の処理手順を示すフローチャートの前半である。
[S11]キーワード抽出部51が、以下のステップS12〜ステップS19の処理を行っていない情報を選択し、その情報から抽出された評価単位群を処理対象とする。
[S12]キーワード抽出部51が、処理対象とした評価単位群の未処理の評価単位を1つ選択し、その評価単位の形態素解析を行い、品詞単位の語彙に分解する。
[S13]キーワード抽出部51が、各語彙の中で特定の品詞以外の語彙を削除する。本実施の形態では、固有名詞、普通名詞、サ変名詞、動詞を抽出し、他の品詞の語彙を削除する。
[S14]キーワード抽出部51が、品詞分解された評価単位中の情報を、句点やピリオドで区切られる1文章単位で情報格納部20に格納する。さらに連続して存在する固有名詞、普通名詞には、次の品詞と連続していたこと示す記号、例えばハイフンを付けて格納する。
[S15]結合キーワード生成部52が、連続した固有名詞、普通名詞を検出し、これらを結合した新たなキーワードを生成する。例えば「情報・分類・装置」のように連続した3つの普通名詞の場合、本実施の形態では、1つ目と2つ目とを結合した「情報分類」と、1つ目、2つ目、及び3つ目を結合した「情報分類装置」を新たなキーワードとする。
【0037】
なお、本実施の形態では用いないが、これら意外にも、3つの普通名詞の組み合わせ方は多数存在し、3つの語彙を2つずつ用いて組み合わせ、語彙の前後を入れ替えて6つの結合ペアを生成してもよい。
[S16]結合キーワード重み付け部53が、結合キーワード生成部52の生成した結合キーワードに対して重み付けを行う。ここでは、通常の1語彙のキーワードを重み「1」とし、2つのキーワードを結合した結合キーワードには重み「2」を付与し、3つのキーワードを結合した結合キーワードには重み「3」を付与する。
[S17]キーワードペア生成部54が、キーワード抽出部51で抽出したキーワード群の中で、離れて存在するが特定の関係にある品詞を組み合わせ、キーワードペアを生成する。
【0038】
例えば、「情報を分類する」というフレーズがあった場合、「情報」という名詞と「分類」というサ変名詞を組み合わせ、これらのペアを1つのキーワードとして用いる。ただし、この場合「情報」と「分類」という語彙は、それぞれ様々な場面で用いられることが予想され、これらをそれぞれキーワードとして用いると、「情報の分類」とは無関係なものまで、関連情報として抽出される可能性がある。そこで、これら関連の深い語彙を組み合わせ、共に存在した場合のみ関連性を認めることで、語彙の意味を限定してキーワードとして用いることを可能とする。本実施の形態では、1文章中の普通名詞、固有名詞と、その文章中の動詞の直前に存在する普通名詞もしくはサ変名詞を組み合わせてキーワードペアとする。
【0039】
なお、本実施の形態では用いないが、形容詞と名詞や形容詞と動詞など、同時に使われることで意味を限定するような組み合わせは、同様に用いることが可能である。
[S18]キーワードペア重み付け部55が、キーワードペアに対して重み付けを行う。これは、通常の1語彙のキーワードを重み「1」とし、1つの語彙のキーワードと組み合わせを行ったキーワードペアには重み「2」を付与し、2つの語彙を結合した結合キーワードと組み合わせを行ったキーワードペアには重み「3」を付与する。
[S19]キーワードペア生成部54は、これらキーワード群の生成処理終了後、キーワード中の動詞と1文字の語彙からなるキーワードとを削除する。これは、動詞は「する」や「行う」など、汎用性が高く意味を限定し難いためであり、1文字の語彙も「今」や「何」といったものが多く含まれるためである。
【0040】
なお、本実施の形態では、重みの決定に際し語彙の出現回数は考慮しない。これは、汎用性のある語彙であれば、文章中に複数回出現するのが普通であり、かといって、特定の語彙が複数回出現した場合に、その出現語彙に関する内容の情報であるかというと、そうでない場合が多いからである。すなわち、情報の内容は、特定の語彙のみでは、情報の持つ意味の範囲が広過ぎて限定できない。通常は、対象と目的や対象と方法など、複数の語彙により情報の内容を限定し、ユーザの目的に合った情報を取捨選択していると考えられる。よって、本実施の形態では、情報の内容は、特定語彙の出現回数ではなく、語彙の組み合わせの方がその内容を表現するのに適していると考え、結合キーワードもしくはキーワードペアとなる語彙の重みのみを考慮する。
【0041】
また、複数の語彙を結合した重みの大きいキーワード含む文書群は、特にキーワードが示す内容に関して一致している可能性が高い。例えば、「情報分類装置」の場合、「情報分類」では、「情報分類機関」や「情報分類の研究者」など装置と直接関連のないものも含まれるが、「情報分類装置」であれば、より関連の高いもののみが選ばれる。また、このような長いキーワードが一致した場合は、そのキーワードを構成する個々のキーワードも一致するため、一致したキーワードの重みだけでなく、一致するキーワード数も多くなり、情報の類似度は飛躍的に高くなる。
【0042】
図8は、評価基準数値化部の処理手順を示すフローチャートの後半である。
[S20]キーワードペア生成部54は、情報中のすべての評価単位の処理が終了したか否かを判断する。情報中のすべての評価単位の処理が終了したのであればステップS21に進み、そうでなければ次の評価単位の処理を行うべき旨の指令をキーワード抽出部51に送信し、処理をステップS12に進める。
[S21]キーワードペア生成部54は、すべての情報に対する処理が終了したか否かを判断する。情報中のすべての評価単位の処理が終了したのであればステップS22に進み、そうでなければ次の情報の処理を行うべき旨の指令をキーワード抽出部51に送信し、処理をステップS11に進める。
【0043】
以上の処理により、各情報中の評価単位に対応するキーワード群が生成される。生成されたキーワード群は、情報格納部20により記憶装置などに格納される。全ての情報の評価単位についてキーワード群が生成された後、ステップS22以降の処理が行われる。
[S22]評価ベクトル空間生成部56が、各評価単位のキーワード群から、一定の割合以上のキーワード群に存在するキーワードを、各評価単位のキーワード群から削除する。これは、大多数の評価単位に存在するキーワードがあった場合、そのキーワードは評価単位を分類するためには何も寄与しないために行われる処理である。例えば、全評価単位の7割以上に含まれるキーワードは削除する。
[S23]評価ベクトル空間生成部56が、各評価単位のキーワード群から、一定の割合以下のキーワード群にしか存在しないキーワードを削除する。これは、全評価単位中の少数の評価単位にしか存在しないキーワードは、評価単位を分類するためには何も寄与しないために行われる処理である。例えば、全評価単位の1割以下にしか含まれないキーワードは削除する。
【0044】
なお、ステップS22,S23で行った削除処理の基準となるキーワードが含まれる割合は、情報の分類の状況やユーザの好みで変更することが可能である。
[S24]評価ベクトル空間生成部56が、不必要と思われるキーワードを削除した全評価単位のキーワード群(すべての情報の各評価単位のキーワード群すべて)を用いて、評価ベクトル空間を生成する。評価ベクトル空間は、全ての評価単位のキーワード群からキーワード、結合キーワード、キーワードペアを抽出し、全種類のキーワード、結合キーワード、キーワードペアを1つずつそろえたものである。評価ベクトル空間生成時には、キーワード群中に重複して存在するものがあったとしても、その出現回数や個数は考慮されない。また、その出現回数や個数に関係なく、存在するキーワードは評価ベクトル空間に1つだけ含まれる。
[S25]評価ベクトル生成部57が、評価ベクトル空間を用いて、各評価単位の評価ベクトルを生成する。評価ベクトルを生成するには、まず、その評価単位のキーワード群を用い、評価ベクトル空間の要素中にキーワード群中のキーワード、結合キーワード、キーワードペアがあれば、一致した要素にキーワードの持つ重みを与える。ここで、キーワード群中に存在しない評価ベクトル空間の要素は0となる。このように重みの値が付与された評価ベクトル空間の要素が、各評価単位の評価ベクトルとなる。
【0045】
このようにして、評価単位に分割された情報に基づいて、部分類似度算出のための、評価ベクトルが生成される。
ここで、評価基準数値化部50における処理を、具体例を用いて説明する。
【0046】
図9は、評価単位となる情報の例を示す図である。これは、処理対象の情報に記載された文章に含まれる評価単位71である。評価基準数値化部50がこのような評価単位71を取得すると、キーワード抽出部51が評価単位71の記載内容を品詞単位の語彙に分解する。
【0047】
図10は、品詞分解をした結果を示す図である。品詞分解が行われると、図のような語彙のリスト72が生成される。例えば、「マルチメディア時代にネットワークに期待されるサービスは何か。」という文は、「マルチメディア」(普通名詞)、「メディア」(普通名詞)、「時代」(普通名詞)、「に」(名詞接続助詞)、「ネットワーク」(普通名詞)、「に」(名詞接続助詞)、「期待」(サ変名詞)、「さ」(動詞)、「れる」(動詞性接尾詞)、「サービス」(サ変名詞)、「は」(副助詞)、「何」(普通名詞)、「か」(終助詞)、「。」(句点)という語彙に分解される。
【0048】
次に、キーワード抽出部51により、評価単位の文から得られた複数の語彙の中から、特定の品詞以外の語彙が削除され、1文章毎に情報格納部20に格納される。
【0049】
図11は、不要な語彙を削除し1文章毎に格納したキーワード群を示す図である。この例に示した評価単位71の文章は、3つの文で構成されるため、3つのキーワード群73a〜73cが生成されている。例えば、キーワード群73aは、「マルチメディア時代にネットワークに期待されるサービスは何か。」という文から生成されたものである。この文の中で、「に」、「れる」、「は」、「か」、「。」という語彙は、固有名詞、普通名詞、サ変名詞、動詞のいずれでもないため削除されている。また、「マルチ」や「メディア」は、次の固有名詞もしくは普通名詞と連続していたため「−」の記号が付加されている。
【0050】
このようにして生成されたキーワード群を用いて、結合キーワード及びキーワードペアが生成され、さらに重みが付けられる。
図12は、1文章毎の結合キーワードとキーワードペアを含んだキーワード群の例を示す図である。キーワード群74a〜74c中のハイフンで繋がれた語彙のペアは、キーワードペアであることを示す。また、各キーワードに付けられている数字は、1語彙のキーワードの重みを1とした場合の、各キーワードに付けられた重みである。例えば、キーワード群74aでは、「マルチ」や「メディア」は単一の語彙であるため、重みの値は1である。また、「マルチメディア時代」は、「マルチ」、「メディア」、「時代」の3つの語彙で構成されるため、重みの値は3である。
【0051】
この文章毎のキーワード群から、重複するキーワードを削除し、各種類のキーワードを1つずつ含んだものが、評価単位のキーワード群となっている。このように文章毎に生成されたキーワード群が統合され、評価単位に対するキーワード群となる。
【0052】
図13は、評価単位のキーワード群を示す図である。このキーワード群75と同様のキーワード群が、すべての情報の評価単位毎に生成され、それらのキーワード群から入力された情報群における評価ベクトル空間が生成される。
【0053】
図14は、評価ベクトル空間を示す図である。この評価ベクトル空間76は、簡略化のため、前述の評価単位とは関連しない評価ベクトル空間を示している。
ここで、図15のようなキーワード群が存在した場合を考える。
【0054】
図15は、評価単位のキーワード群の例を示す図である。このキーワード群77について、図14に示した評価ベクトル空間76での評価を行うと、図16のようになる。
【0055】
図16は、評価単位の評価ベクトルの生成状況を示す図である。このように、評価ベクトル78は、評価ベクトル空間76中の各要素に対応する数値の列で表される。評価ベクトル78中の値を持つ要素数と要素の位置が、評価ベクトル空間76中での評価単位の方向を表わし、評価ベクトル要素の値の大きさがベクトルの大きさを表す。この方向と大きさがその評価単位の情報の特徴を表し、評価ベクトルが類似した方向を向き、類似した大きさならば、その評価単位の内容は類似していると考えられる。
【0056】
このように、情報の分類において、単語や語彙単位の出現頻度ではなく、関連性のある単語や語彙を組み合わせて結合キーワードもしくはキーワードペアとして用いることにより、個々の単語や語彙の意味を限定して類似度を判定することができ、従来より高い精度での分類を実現することを可能とする。
【0057】
次に、類似情報分類部の詳細を説明する。類似情報分類部は、評価基準数値化部で得られた評価ベクトル空間と評価単位の評価ベクトルを用いて、情報を分類すると共に、情報間の部分(評価単位)の類似性を示し、情報の構成の類似性や類似部分の分布、必要な情報の位置を一瞥できるようにするものである。
【0058】
図17は、類似情報分類部の内部構成を示す図である。図に示す各構成要素の機能を以下に示す。
類似部分判別部61は、情報の評価単位毎の評価ベクトルからベクトル間の内積もしくは相対角度とベクトル間距離を求め、評価単位毎の類似度判定を行いグループ分けを行う。情報類似度判定部62は、情報間の類似する評価単位の含有度及び分布状態から情報間の類似度を判別する。インデックス情報検出部63は、類似評価単位中からそのグループの代表となる評価単位及び評価ベクトルを検出する。類似部分提示部64は、複数の類似する評価単位を類似度順などで順次比較表示し、内容の類似度を確認する。類似状況提示部65は、情報間の類似度を確認するために、情報中及び情報間の評価単位の類似部分とその分布が判るように一覧表示する。
【0059】
図18は、類似情報分類部の処理手順を示すフローチャートの前半である。
[S31]類似部分判別部61が、評価ベクトルを用いて評価単位間の類似度を算出する。類似度の判別は、2つの評価単位の評価ベクトルからその内積を求め、内積の値を類似判定値として、その大きさによって類似性を判別する。類似判定のための閾値は、情報の分類状況やユーザの好みによって変更することが可能である。この他にも、ベクトル間の角度とベクトルの大きさから、類似度を判別してもよい。
[S32]類似部分判別部61が、類似度判別の結果、互いに類似している評価単位の双方に対して、類似する相手の評価単位の識別番号、その類似判定値、及び同じ分類であることを示す分類番号を付与する。
[S33]類似部分判別部61が、すべての評価単位間の類似度判別が終了したか否かを判断する。類似度判別が終了したのであればステップS34に進み、そうでなければステップS31に進む。なお、評価単位間の類似度判別は、同一情報内の評価単位同士であるか、異なる情報内の評価単位同士であるかに関わらず、すべての評価単位間で行う。
[S34]情報類似度判定部62が、比較対象となる2つの情報を構成する評価単位の中で、互いに類似する評価単位のそれぞれの情報内における含有度を求める。
[S35]情報類似度判定部62が、類似する評価単位の含有度と、互いに類似する評価単位の類似判定値とから、情報間の類似性を求める。そして、類似性の値が一定の閾値を超えた情報間は類似性があると判断し、同じカテゴリーに分類する。類似性の算出方法としては、例えば、互いに類似する評価単位の含有度に、類似する評価単位間の類似判定値を乗算する。
【0060】
なお、この例では、情報間の類似判定は、大まかな範囲での区分けにとどめる。これは、詳細な判定値を用いて文書を順位付けしても必ずしもユーザの意図と一致しないため、まずは大局的な判断での分類を行い、以後の細かな類似判別はユーザに委ねるためである。
[S36]情報類似度判定部62が、同じカテゴリーに分類された情報に対して、同一のカテゴリーラベルを付与する。なお、情報間の類似度には特に順位付けは行わないが、結果の表示においては、他の評価単位と類似する評価単位の含有度を指針として、含有度の大きいものを優先して表示する。
[S37]情報類似度判定部62は、すべての情報間の類似度判別が終了したか否かを判断する。判別が終了していればステップS38に進み、そうでなければステップS34に進む。
【0061】
図19は、類似情報分類部の処理手順を示すフローチャートの後半である。
[S38]インデックス情報検出部63が、類似判別において情報間毎に行ったカテゴリー分けが適切かどうかを分類された情報間で見直し、複数のカテゴリーに分類された情報については、含有度の高い方を優先し、他方との関連に関しては、補足情報として情報格納部20に格納する。
[S39]インデックス情報検出部63が、ステップS38で行った見直しの処理において、分類したカテゴリー内の情報群の中で最も多く含まれている種類の分類番号を特定し、その分類番号を持つ評価単位を全て抽出する。そして、この同じ分類番号を持つ評価単位の評価ベクトルの中で、中心となる評価ベクトルを選び出し、これをこのカテゴリーのインデックス情報として登録する。この中心となるベクトルの抽出は、例えば、各評価ベクトルのうち最大角度を持つ組み合わせを抽出し、それらの中間にあるもの、それぞれの評価ベクトルと同じ角度を持つものを探し出すことで、カテゴリーの中心となる評価ベクトルを選出できる。
【0062】
インデックス情報は、そのインデックス情報の評価単位が、カテゴリーの情報を表わす代表情報として示される。また、その評価単位から抽出されたキーワード群は、そのカテゴリーのキーワードとして用いられる。さらに、インデックス情報は、新たに入力された情報を分類する場合における、類似性判定の指針としても利用する。
【0063】
これら分類された情報は、類似部分提示部64と類似状況提示部65により、その情報間の関係や内容がユーザに示され、ユーザ自身の手で、必要な情報を取り出すことが可能となる。
[S40]類似部分提示部64が、分類したカテゴリー毎に、その情報内の評価単位の分類番号の同じ評価単位を集め、他の評価単位との間の類似順に各評価単位を並べ、表を作成する。類似順は、分類番号の同じ他の評価単位との間の類似度の合計値を比較することで求める。作成した表は、情報格納部20に格納する。格納された表の内容は、情報表示部30によって表示される。
【0064】
なお、類似順に並べられた評価単位には、他のカテゴリーにある類似評価単位へのリンクが張られている。これによりユーザは、必要とする情報に類似した評価単位を選択することで、収集し分類した情報全体の中で、必要な部分のみを見ることができ、またその評価単位を含む情報がどのカテゴリーに含まれるかを知ることで、新たな関連情報を見つけることができる。
[S41]類似状況提示部65が、分類したカテゴリー内の情報を、類似する評価単位の含有度の大きい順に並べた表を作成し、情報格納部20に格納する。情報格納部20に格納された表は、情報表示部30によって表示される。
[S42]類似状況提示部65が、各情報毎にその評価単位の類似する部分がどこか、どれくらい存在するかを一瞥でき、且つ他の情報との比較が容易なように、一覧にして提示するための表を作成し、情報格納部20に格納する。情報格納部20に格納された表は、情報表示部30によって表示される。
【0065】
これによりユーザは、任意の評価単位の内容を理解することで、その評価単位を含む情報の内容を推定でき、評価単位の分布や情報中に含まれる評価単位の種類などから、情報が有用であるかどうかの判断を行うことができる。また、情報間の含まれる評価単位の分布を比較することで、内容の類似性を確認でき、装置の分類結果の確認を行うこともできる。
【0066】
図20は、類似状況提示部による情報間の類似状況表示の例を示す図である。この図において、同じ模様の部分は同じ分類番号の評価単位であることを示す。これから文書などの情報間で、類似部分がどれくらいある文書なのかが容易に判る。
【0067】
従来は必要な内容が含まれると思われる情報、例えば文書を収集し、その中から必要な部分情報を探し出していた。本発明によれば、情報の構成の類似性や類似部分の分布、必要な情報の位置を一瞥でき、必要な部分情報を探し出してから、その部分情報が含まれる文書を取り出すことが可能となる。
【0068】
また本発明によれば、評価ベクトル空間生成部を用いて生成した評価ベクトル空間を用いて、入力文書や送られてくる情報をフィルタリングし、指定の類似度の評価単位を持つ文書のみを選択し、ユーザに提示するような情報フィルタリング機能を提供することも可能である。
【0069】
また本発明によれば、評価ベクトル空間生成部を用いて生成した評価ベクトル空間を用いて、データベースなどを検索し、規定の類似度の評価単位を持つ情報のみを選択し、ユーザに提示する情報検索装置として用いることも可能である。
【0070】
また、ユーザが求めるものは、必要な情報を含む文書ではなく、文書中に存在する情報である。これまでの検索や分類は、欲しい情報を含んでいると思われる文書を集めるものであり、欲しい情報そのものを提示するものではなかった。本発明は、欲しい情報であると思われる部分が情報全体にどのように分布しているかを提示することができ、ユーザは、情報間の類似や差異を確認した上で、情報の有無を判断できる。
【0071】
さらに、本発明は情報を含む媒体の有用性の判断を促し、また直接的に有用な情報を提示するものであり、これまでの情報の検索や分類で行われていたような、必要な情報の密度を上げるものではなく、情報の取捨選択を効率化するものである。
【0072】
なお、上記の実施の形態では、情報の分類数は不定であったが、インデックス情報となる情報数を指定することで、分類数を指定するようにしてもよい。
また、上記の実施の形態では、インデックス情報をシステムが求め出していたが、ユーザが任意にインデックス情報を指定できるようにしてもよい。この場合、類似情報分類部はユーザの指定した情報をインデックス情報として情報を分類する。
【0073】
また、生成された評価ベクトル空間を用いて入力文書群を検索し、規定の類似度の評価単位を持つ文書のみを選択し、ユーザに提示するような情報検索機能を備えさせることもできる。
【0074】
また、上記の処理機能は、コンピュータによって実現することができる。その場合、情報判別支援装置が有すべき機能の処理内容は、コンピュータで読み取り可能な記録媒体に記録されたプログラムに記述しておく。そして、このプログラムをコンピュータで実行することにより、上記処理がコンピュータで実現される。コンピュータで読み取り可能な記録媒体としては、磁気記録装置や半導体メモリ等がある。市場に流通させる場合には、CD−ROM(Compact Disk Read Only Memory) やフロッピーディスク等の可搬型記録媒体にプログラムを格納して流通させたり、ネットワークを介して接続されたコンピュータの記憶装置に格納しておき、ネットワークを通じて他のコンピュータに転送することもできる。コンピュータで実行する際には、コンピュータ内のハードディスク装置等にプログラムを格納しておき、メインメモリにロードして実行する。
【0075】
【発明の効果】
以上説明したように本発明の情報判別支援装置では、各情報内の評価単位毎の類似度を求めるようにしたため、これらの情報の分類及び評価単位間の類似情報をユーザに提示すれば、欲しい情報であると思われる部分が情報全体にどのように分布しているかを提示することができ、ユーザによる情報の類似性・関連性の判断が容易となり、有用な情報の取捨選択の手間が軽減される。
【0076】
また、本発明の情報判別支援プログラムを記録したコンピュータ読み取り可能な記録媒体では、記録媒体に記録された情報判別支援プログラムをコンピュータに実行させることにより、情報群を互いに類似する情報に分類し、且つ各情報内の評価単位毎の類似度も求めるような処理をコンピュータに実行させることができる。
【図面の簡単な説明】
【図1】 本発明の原理構成図である。
【図2】 本発明の実施の形態に係る情報判別支援装置の構成を示すブロック図である。
【図3】 情報分割部の内部構成を示す図である。
【図4】 情報判別支援装置の処理の流れを示すフローチャートである。
【図5】 本装置において処理の対象となる電子化された文書例を示す図である。
【図6】 評価基準数値化部の内部構成を示す図である。
【図7】 評価基準数値化部の処理手順を示すフローチャートの前半である。
【図8】 評価基準数値化部の処理手順を示すフローチャートの後半である。
【図9】 評価単位となる情報の例を示す図である。
【図10】 品詞分解をした結果を示す図である。
【図11】 不要な語彙を削除し1文章毎に格納したキーワード群を示す図である。
【図12】 1文章毎の結合キーワードとキーワードペアを含んだキーワード群の例を示す図である。
【図13】 評価単位のキーワード群を示す図である。
【図14】 評価ベクトル空間を示す図である。
【図15】 評価単位のキーワード群の例を示す図である。
【図16】 評価単位の評価ベクトルの生成状況を示す図である。
【図17】 類似情報分類部の内部構成を示す図である。
【図18】 類似情報分類部の処理手順を示すフローチャートの前半である。
【図19】 類似情報分類部の処理手順を示すフローチャートの後半である。
【図20】 類似状況提示部による情報間の類似状況表示の例を示す図である。
【符号の説明】
1 情報分割手段
2 評価基準数値化手段
3 類似情報分類手段
4 情報
4a 評価単位
4b 評価ベクトル
5 類似情報群
Claims (9)
- 情報の内容によって複数の情報群を分類することを支援する情報判別支援装置において、
前記情報群内の各情報を評価単位に分割する情報分割手段と、
各評価単位に対して形態素解析を行うことで語彙を抽出し、抽出された語彙からなるキーワード、連続した固有名詞または普通名詞の語彙を結合することにより得られる結合キーワード、および1文章中の普通名詞または固有名詞の語彙と、その文章中の動詞の直前に存在する普通名詞もしくはサ変名詞の語彙とのペアからなるキーワードペアを含むキーワード群を生成し、すべての評価単位から生成されたキーワード群に含まれるキーワード、結合キーワード、およびキーワードペアを要素とする評価ベクトル空間を生成し、前記評価ベクトル空間の要素に対応するキーワード、結合キーワード、およびキーワードペアが各評価単位のキーワード群に含まれるか否かに基づいて、各評価単位の記述内容の特徴を示す評価ベクトルを生成する評価基準数値化手段と、
評価単位同士の評価ベクトルを比較することで評価単位間の類似度を求め、類似する評価単位双方に対して同じ分類番号を付与する類似情報分類手段と、
同じ分類番号が付与された評価単位同士を視覚的に判別できるように各情報内の評価単位を表示する情報表示手段と、
を有することを特徴とする情報判別支援装置。 - 前記情報分割手段は、前記情報群内の各情報から少なくともタイトルと見出しとを削除し、削除処理後の各情報を分割することを特徴とする請求項1記載の情報判別支援装置。
- 前記評価基準数値化手段は、キーワード、結合キーワード、およびキーワードペアに対して、構成する語彙の数に応じた重み付けを行い、キーワード、結合キーワード、およびキーワードペアの重みの値を、各評価単位の前記評価ベクトルにおける対応する要素に付与することを特徴とする請求項1記載の情報判別支援装置。
- 前記類似情報分類手段は、各情報内の分類番号の同じ評価単位を集め、分類番号の同じ他の評価単位との間の類似度の合計値に応じた順番で各評価単位を並べることを特徴とする請求項1記載の情報判別支援装置。
- 前記評価基準数値化手段は、生成したキーワード群からキーワード中の動詞と1文字の語彙からなるキーワードとを削除することを特徴とする請求項1記載の情報判別支援装置。
- 前記評価基準数値化手段は、各評価単位のキーワード群から、一定の割合以上のキーワード群に存在するキーワードを削除することを特徴とする請求項1記載の情報判別支援装置。
- 前記評価基準数値化手段は、各評価単位のキーワード群から、一定の割合以下のキーワード群にしか存在しないキーワードを削除することを特徴とする請求項1記載の情報判別支援装置。
- 情報の内容によって情報群を分類することを支援する情報判別支援プログラムを記録したコンピュータ読み取り可能な記録媒体において、
前記情報群内の各情報を評価単位に分割する情報分割手段、
各評価単位に対して形態素解析を行うことで語彙を抽出し、抽出された語彙からなるキーワード、連続した固有名詞または普通名詞の語彙を結合することにより得られる結合キーワード、および1文章中の普通名詞または固有名詞の語彙と、その文章中の動詞の直前に存在する普通名詞もしくはサ変名詞の語彙とのペアからなるキーワードペアを含むキーワード群を生成し、すべての評価単位から生成されたキーワード群に含まれるキーワード、結合キーワード、およびキーワードペアを要素とする評価ベクトル空間を生成し、前記評価ベクトル空間の要素に対応するキーワード、結合キーワード、およびキーワードペアが各評価単位のキーワード群に含まれるか否かに基づいて、各評価単位の記述内容の特徴を示す評価ベクトルを生成する評価基準数値化手段、
評価単位同士の評価ベクトルを比較することで評価単位間の類似度を求め、類似する評 価単位双方に対して同じ分類番号を付与する類似情報分類手段、
同じ分類番号が付与された評価単位同士を視覚的に判別できるように各情報内の評価単位を表示する情報表示手段、
としてコンピュータを機能させることを特徴とする情報判別支援プログラムを記録したコンピュータ読み取り可能な記録媒体。 - 情報の内容によって複数の情報群を分類することをコンピュータで支援する情報判別支援方法において、
情報分割手段が、前記情報群内の各情報を評価単位に分割し、
評価基準数値化手段が、各評価単位に対して形態素解析を行うことで語彙を抽出し、抽出された語彙からなるキーワード、連続した固有名詞または普通名詞の語彙を結合することにより得られる結合キーワード、および1文章中の普通名詞または固有名詞の語彙と、その文章中の動詞の直前に存在する普通名詞もしくはサ変名詞の語彙とのペアからなるキーワードペアを含むキーワード群を生成し、すべての評価単位から生成されたキーワード群に含まれるキーワード、結合キーワード、およびキーワードペアを要素とする評価ベクトル空間を生成し、前記評価ベクトル空間の要素に対応するキーワード、結合キーワード、およびキーワードペアが各評価単位のキーワード群に含まれるか否かに基づいて、各評価単位の記述内容の特徴を示す評価ベクトルを生成し、
類似情報分類手段が、評価単位同士の評価ベクトルを比較することで評価単位間の類似度を求め、類似する評価単位双方に対して同じ分類番号を付与し、
情報表示手段が、同じ分類番号が付与された評価単位同士を視覚的に判別できるように各情報内の評価単位を表示する、
ことを特徴とする情報判別支援方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP27631398A JP3921837B2 (ja) | 1998-09-30 | 1998-09-30 | 情報判別支援装置、情報判別支援プログラムを記録した記録媒体及び情報判別支援方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP27631398A JP3921837B2 (ja) | 1998-09-30 | 1998-09-30 | 情報判別支援装置、情報判別支援プログラムを記録した記録媒体及び情報判別支援方法 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2000112949A JP2000112949A (ja) | 2000-04-21 |
| JP2000112949A5 JP2000112949A5 (ja) | 2004-10-21 |
| JP3921837B2 true JP3921837B2 (ja) | 2007-05-30 |
Family
ID=17567722
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP27631398A Expired - Fee Related JP3921837B2 (ja) | 1998-09-30 | 1998-09-30 | 情報判別支援装置、情報判別支援プログラムを記録した記録媒体及び情報判別支援方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP3921837B2 (ja) |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100356105B1 (ko) * | 2000-05-30 | 2002-10-19 | 주식회사 엔아이비소프트 | 문서 자동 요약을 이용한 문서 분류 검색 방법 및 문서분류 검색 시스템 |
| JP2003030237A (ja) * | 2001-07-11 | 2003-01-31 | Just Syst Corp | ファイル検索方法とこの方法を利用可能なファイル検索装置、検索サーバ |
| JP4025180B2 (ja) * | 2002-11-19 | 2007-12-19 | 株式会社山武 | 文書管理装置 |
| JP4525433B2 (ja) * | 2005-04-08 | 2010-08-18 | 日本電信電話株式会社 | 文書集約装置及びプログラム |
| JP4595692B2 (ja) * | 2005-06-15 | 2010-12-08 | 日本電信電話株式会社 | 時系列文書集約方法及び装置及びプログラム及びプログラムを格納した記憶媒体 |
| JP2010122823A (ja) * | 2008-11-18 | 2010-06-03 | Nec Corp | テキスト処理システム、情報処理装置、テキストおよび情報の処理方法ならびに処理プログラム |
| JP5537649B2 (ja) * | 2009-04-16 | 2014-07-02 | 株式会社東芝 | データ検索およびインデクシングの方法および装置 |
| US9262735B2 (en) | 2013-08-12 | 2016-02-16 | International Business Machines Corporation | Identifying and amalgamating conditional actions in business processes |
| JP7024364B2 (ja) * | 2017-12-07 | 2022-02-24 | 富士通株式会社 | 特定プログラム、特定方法および情報処理装置 |
| JP7348746B2 (ja) * | 2019-04-26 | 2023-09-21 | 一般財団法人日本特許情報機構 | 調査支援方法、調査支援用コンピュータプログラムおよび調査支援システム |
| WO2022130579A1 (ja) * | 2020-12-17 | 2022-06-23 | 富士通株式会社 | 類似度判定プログラム、類似度判定装置、及び、類似度判定方法 |
| JPWO2022130578A1 (ja) * | 2020-12-17 | 2022-06-23 |
-
1998
- 1998-09-30 JP JP27631398A patent/JP3921837B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2000112949A (ja) | 2000-04-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101078864B1 (ko) | 질의/문서 주제 범주 변화 분석 시스템 및 그 방법과 이를 이용한 질의 확장 기반 정보 검색 시스템 및 그 방법 | |
| US8108405B2 (en) | Refining a search space in response to user input | |
| US20160070803A1 (en) | Conceptual product recommendation | |
| JP3577819B2 (ja) | 情報探索装置及び情報探索方法 | |
| US20040049499A1 (en) | Document retrieval system and question answering system | |
| JP4595692B2 (ja) | 時系列文書集約方法及び装置及びプログラム及びプログラムを格納した記憶媒体 | |
| JP2003167914A (ja) | マルチメディア情報検索方法、プログラム、記録媒体及びシステム | |
| JP3921837B2 (ja) | 情報判別支援装置、情報判別支援プログラムを記録した記録媒体及び情報判別支援方法 | |
| JP4426894B2 (ja) | 文書検索方法、文書検索プログラムおよびこれを実行する文書検索装置 | |
| CN112307336A (zh) | 热点资讯挖掘与预览方法、装置、计算机设备及存储介质 | |
| JP2006318398A (ja) | ベクトル生成方法及び装置及び情報分類方法及び装置及びプログラム及びプログラムを格納したコンピュータ読み取り可能な記憶媒体 | |
| JP4931114B2 (ja) | データ表示装置、データ表示方法及びデータ表示プログラム | |
| JP2006134183A (ja) | 情報分類方法及び装置及びプログラム及びプログラムを格納した記憶媒体 | |
| Malhotra et al. | An effective approach for news article summarization | |
| JP2000163437A (ja) | 文書分類方法および文書分類装置ならびに文書分類処理プログラムを記録した記録媒体 | |
| JP2009086903A (ja) | 検索サービス装置 | |
| JP4525433B2 (ja) | 文書集約装置及びプログラム | |
| JP4009937B2 (ja) | 文書検索装置、文書検索プログラム及び文書検索プログラムを記録した媒体 | |
| JP4428703B2 (ja) | 情報検索方法及びそのシステム並びにコンピュータプログラム | |
| JP2007293377A (ja) | 主観的ページと非主観的ページを分離する入出力装置 | |
| JP4813312B2 (ja) | 電子文書検索方法、電子文書検索装置及びプログラム | |
| Islam et al. | Hybrid text summarizer for Bangla document | |
| Park et al. | Topic word selection for blogs by topic richness using web search result clustering | |
| CN111931026A (zh) | 一种基于词性扩展的搜索优化方法及系统 | |
| JP2000105769A (ja) | 文書表示方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20061019 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20061107 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070109 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20070130 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20070212 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110302 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120302 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130302 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130302 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140302 Year of fee payment: 7 |
|
| LAPS | Cancellation because of no payment of annual fees |