JP3842575B2 - 構造化文書検索方法、構造化文書管理装置及びプログラム - Google Patents
構造化文書検索方法、構造化文書管理装置及びプログラム Download PDFInfo
- Publication number
- JP3842575B2 JP3842575B2 JP2001098188A JP2001098188A JP3842575B2 JP 3842575 B2 JP3842575 B2 JP 3842575B2 JP 2001098188 A JP2001098188 A JP 2001098188A JP 2001098188 A JP2001098188 A JP 2001098188A JP 3842575 B2 JP3842575 B2 JP 3842575B2
- Authority
- JP
- Japan
- Prior art keywords
- search
- document
- structured document
- search request
- request
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images






















































Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
【発明の属する技術分野】
本発明は、異なる文書構造の複数の構造化文書を、階層化された論理構造を持つ構造化文書データベースで管理する構造化文書管理システムに関する。
【0002】
【従来の技術】
現在、IT(情報技術)の進化により、莫大な量の情報が容易に入手できるようになった。その一方で必要な情報が大量のデータに埋没してしまい、十分に活用できないという弊害も発生している。情報が大量に存在していても、それをうまく活用できなければ意味がない。
【0003】
そこで、特定の個人や部門が保有するノウハウや業務データのうち企業の経営に重要なものを蓄積して、「経営資産」として活用しようとする活動、すなわち、ナレッジマネージメントが提唱されている。
【0004】
例えば、特許明細書や、週報など、文書の種類によっては、その書式が予め定められて、1つの書式に統一されているのが一般的である。1つの書式に統一された文書もあれば、全く書式のない自由書式の文書も数多く存在する。
【0005】
従って、ナレッジマネージメントを実現するためには、このような文書構造が予め定められているような文書も、それ以外の自由書式の文書も全て格納管理できるデータベースが必要となる。
【0006】
次世代のナレッジマネージメントの中核技術として期待されている技術がXMLである。XML(Extesible Markup Language)は柔軟な拡張性と連携性を備えた標準のドキュメント記述言語であり、主要ベンダーからのサポートも約束されている。
【0007】
構造化文書データベースとしては、RDB(Relational DataBese)により構造化文書を格納する方式があるが、この場合、1つのスキーマ(データ構造定義)に従った文書構造の構造化文書群しか格納できす、また、文書構造はそのまま表形式に変換することは困難であり、RDBをそのまま構造化文書データベースとして用いることはできない。
【0008】
また、構造化文書は階層的な構造をもつため、構造化文書を構成する各構成要素をオブジェクトとみなしたOODB(オブジェクト指向データベース)と親和性が高いと考えられる。しかし、OODBでは、文書構造は予めスキーマにより決定されていなければならず、子要素の任意繰り返しなど、オブジェクトモデルでモデル化するのは困難であり、OODBをそのまま構造化文書データベースとして用いることはできない。
【0009】
XML文書はツリー構造を持ったデータである。近年、このようなXML文書を蓄積、管理するXMLデータベースが脚光を浴びている。
【0010】
XMLデータベースは、管理対象の複数の構造化文書の各構成要素を1つの巨大な構造化文書の文書構造を構成する構成要素として管理するXML特化のツリー状の階層的なデータ構造を持つ。階層的な構造上の構成要素は「パス」により特定される。パスは、XMLデータベース上の特定のエリアを指し示すための手段である。
【0011】
XMLデータベースに格納されるXML文書群はツリー状の1つの巨大なXML文書として構成される。部分的なXML文書をアクセスするには、XML文書に対するパスというアクセス手段を用いる。このような特徴により、幅広くXML文書を検索したり加工することが可能となる。
【0012】
XMLデータベースで格納されるXML文書の文書構造は、必ずしもスキーマが定義されている必要はないが、スキーマを定義するとしたら、1つのデータベースに1つのスキーマしか許容されていない。すなわち、スキーマを用いなければ、異なる文書構造の文書を混在させて格納・管理することができるが、スキーマを1つ設定したら、それとは異なる文書構造の文書は混在させることはできない。
【0013】
【発明が解決しようとする課題】
異なる文書構造の膨大な数の構造化文書をデータベース上で格納・管理するには、ある特定の種類の文書に特定の文書構造が予め定められている場合、そのような種類の文書は、全て同じ文書構造に統一されている方が、後に、検索等のデータ操作の際に都合がよい。
【0014】
しかし、従来のXMLデータベースでは、1つのデータべース上で種類の違いにより異なる文書構造の文書をそれぞれの種類対応の文書構造で統一性を保持しながら、格納、管理できるものはなかった。すなわち、1つのスキーマに適合した文書の格納・管理はできても、複数のスキーマを混在させてスキーマ対応していない文書とともに、各スキーマ対応の文書の格納・管理はできなかった。
【0015】
複数のスキーマのそれぞれに対応する複数のデータベースを設けることも考えられるが、この場合、スキーマが異なればアクセスするデータベースも異なる。そのため、多種多様な文書構造の膨大な数の文書へのアクセスが統一的でなく、多種多様な膨大な情報の中から関連する情報群を検索・抽出することが困難であった。
【0016】
このように、従来は、多種多様な文書構造定義に従った文書を、その文書の種類対応に予め定められた文書構造の同一性を保持しながら、文書構造の定義がなされていない構造化文書とともに一元管理することができないがため、多種多様な文書構造の文書に対し、統一的なアクセスにて、多種多様な膨大な情報の中から関連する情報群を特定の文書構造に限定されずに検索・抽出することができなかった。
【0017】
また、構造化文書データベースでは、文書構造や語彙を検索条件にして検索を行うようになっている。この場合、管理対象の文書の数が多くなればなるほど、検索時間に長時間を要する。従って、できるだけ、効率のよい検索を行うための手法を講じることが望ましい。特に、頻繁に用いられるような検索条件が存在する場合、そのような検索条件を含む検索を、要求を受けたたびに実行するのでは、効率が悪い。
【0018】
また、構造化文書データベースには、異なる文書構造の数多くの構造化文書が随時追加あるいは削除されるであろう。このような構造化文書データベースの更新が頻繁に発生する状況下においては、構造化文書データベースの現状との整合性を保ちながら効率のよい検索が行えることが望ましい。
【0019】
そこで、本発明は、構造化文書データベースに対する検索が効率よく行える構造化文書検索方法および、それを用いた構造化文書検索装置および構造化文書管理装置を提供することを目的とする。
【0020】
また、本発明は、構造化文書データベースの現状との整合性を保ちながら検索が効率よく行える構造化文書検索方法および、それを用いた構造化文書検索装置および構造化文書管理装置を提供することを目的とする。
【0021】
【課題を解決するための手段】
本発明は、異なる文書構造の複数の構造化文書を格納した階層化された論理構造を持つ構造化文書データベースに対して、前記論理構造を構成する前記構造化文書の構成要素とその値を検索条件に含む検索要求文に基づき検索を行うものであって、前記構造化文書データベースには、該構造化文書データベースに対し検索を行うための予め前記検索条件の設定された複数の検索要求文が格納され、前記複数の検索要求文のうちの1つを指定した検索要求を受け付けたとき、前記指定された検索要求文に基づき検索を行って、得られた検索結果を要求元に送るとともに、該検索結果を該検索要求文に対応付けて記憶し、前記検索要求を受け付けたときに、前記指定された検索要求文に対応付けて検索結果が記憶されているときは、その記憶されている検索結果を読み出して要求元に送ることを特徴とする。
【0022】
本発明によれば、例えば、頻繁に用いられる検索条件のクエリであるとか、予め検索が予想されるクエリ、複数のユーザからユーザグループ内である特定の用途のために用いるクエリなどを構造化文書データベースに予め格納しておき、そのようなクエリの検索が実行されたときは、その結果結果を当該クエリに対応付けて記憶しておくことにより、その後に、再び同じクエリによる検索要求がなされたときは、実際に検索を行わず、記憶した検索結果を要求元へ返すことにより、構造化文書データベースに対する検索が効率よく行える。
【0023】
本発明は、異なる文書構造の複数の構造化文書を格納した階層化された論理構造を持つ構造化文書データベースに対して、前記論理構造を構成する前記構造化文書の構成要素とその値を検索条件に含む検索要求文に基づき検索を行うものであって、前記構造化文書データベースには、該構造化文書データベースに対し検索を行うための予め検索条件の設定された複数の検索要求文が格納され、前記検索要求文には、少なくともその検索要求文に基づく検索実行が許可されている第1の種別のユーザと、該検索要求文に基づく検索実行は許可されていないが該検索要求文対応の検索結果は参照することが許可されている第2の種別のユーザとが設定され、前記第1の種別のユーザから、前記複数の検索要求文のうちの1つを指定した検索要求を受け付けたとき、前記指定された検索要求文に基づき検索を行って、得られた検索結果を要求元に送るとともに、該検索結果を該検索要求文に対応付けて記憶し、前記第2の種別のユーザから前記検索要求を受け付けたときは、前記指定された検索要求文に対応付けて記憶されている検索結果を読み出して要求元に送ることを特徴とする。
【0024】
本発明によれば、ある特定のユーザ(第1の種別のユーザ)のみに、クエリの検索実行の権限を与えて、この権限のあるユーザからの検索要求に対しては、実際に検索を行って、当該クエリに対応付けて記憶した検索結果の更新を行うことにより、構造化文書データベースの更新内容が検索結果に反映することができ、構造化文書データベースの現状との整合性を保ちながら検索が効率よく行える。
【0025】
好ましくは、前記第1の種別のユーザから前記検索要求を受け付けたとき、前回検索を実行した時点から所定時間経過しているときは、前記指定された検索要求文に基づき検索を行い、前記所定時間が経過していないときは、前記指定された検索要求文に対応付けて記憶されている検索結果を読み出す。これにより、ある特定のユーザ(第1の種別のユーザ)のみに、クエリの検索実行の権限を与えて、定期的に当該クエリに対応付けて記憶した検索結果の更新を行うことにより、構造化文書データベースの更新内容が検索結果に反映することができ、構造化文書データベースの現状との整合性を保ちながら検索が効率よく行える。
【0026】
このように、クエリ毎に当該クエリを実行させることが可能なユーザと、当該クエリにより検索結果を参照することが可能なユーザとを限定することにより、例えば、だれもかれもが、むやみやたらに検索を実行して、同じクエリによる検索結果であるのに、(データベースの内容が更新されていることにより)検索結果が様々になってしまうことを防ぐことができる。
【0027】
また、少なくとも上記所定時間の間は、誰が要求をしても同じクエリによる検索結果が同じであるという好ましい状態を作り出すことができる。これは、検索結果とデータベースの内容の整合性と保つためには重要なことである。
【0028】
また、好ましくは、前記構造化文書データベースが更新されたとき、該構造化文書データベースに格納されている前記複数の検索要求文のうち、該構造化文書データベースの更新内容が検索結果に影響するような検索要求文を選択して、その選択された検索要求文に基づき前記構造化文書データベースに対し検索を行って、該検索要求文に対応付けて記憶された検索結果を更新することにより、構造化文書データベース自体の更新に伴い、その更新を検索結果に自動的に反映させることができる。従って、検索結果とデータベースの内容の整合性を保つことが容易に行える。
【0029】
【発明の実施の形態】
まず、本発明の実施形態について説明する前に、構造化文書管理システムについて説明する。
【0030】
(構造化文書管理システムの説明)
構造化文書として、XMLやSGMLなどで記述した文書が挙げられる。SGML(Standard Generalized Markup Language)とは、ISO(国際標準化機構)で定められた規格である。XML(eXtensible Markup Language)とは、W3C(World Wide Web Consortium)にて定められた規格である。それぞれ文書を構造化することを可能とする構造化文書規約である。
【0031】
以下、構造化文書として、XMLにて記述された文書を例に説明を進める。構造化文書の文書構造を定義したデータ(文書構造定義データ)をスキーマと呼ぶ。XMLではそのスキーマを定義するためにXML−SchemaやXDR(XML Data Reduced)などのスキーマ言語が提案されている。ここでは、例えば、XDRでのスキーマを記述する場合を例にとり説明する。
【0032】
スキーマも、構造化文書管理システムの管理対象の構造化文書であり、従って、スキーマ文書と呼ぶことがある。スキーマ文書と区別するために、特許明細書やメール、週報、広告などの種々雑多な内容を有す文書をコンテンツ文書と呼ぶこともある。
【0033】
構造化文書管理システムでは、上記スキーマ文書、上記コンテンツ文書、さらに、後述するようなユーザからの検索要求内容を記述したクエリ、すなわち、クエリ文書も管理対象とし、これらを総称して「文書」と呼ぶ。
【0034】
以下、特にことわりがない場合、「文書」と呼ぶときは、コンテンツ文書、スキーマ文書、クエリ文書を全て指すものとする。
【0035】
まず、実施形態の説明を前に、XMLについて簡単に説明する。
【0036】
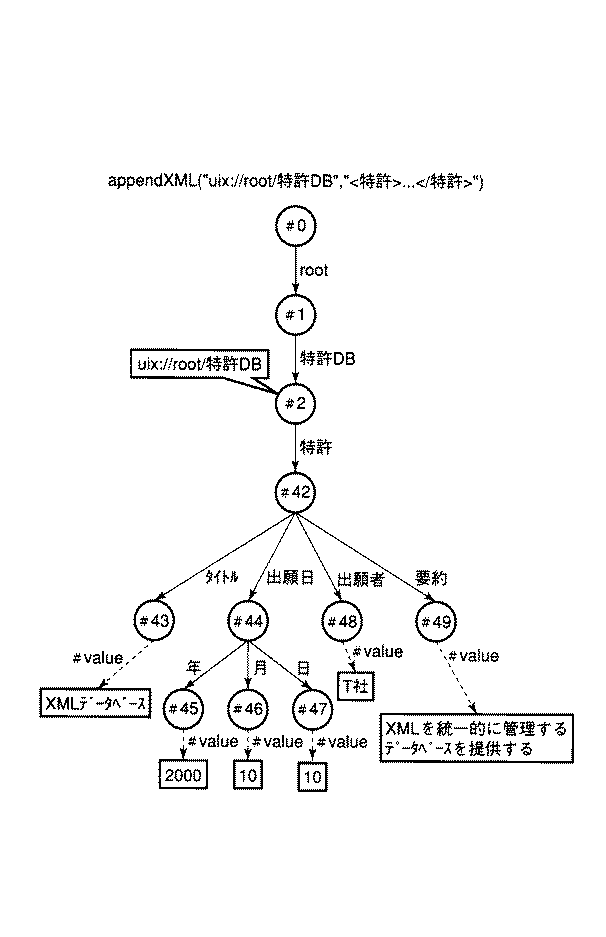
図3は、XMLで記述された構造化文書の一例として、「特許」情報の例を示したものである。XMLやSGMLは、文書の構造の表現にタグが用いられる。タグには、開始タグと終了タグがあり、文書構造情報の構成要素を開始タグと終了タグで囲むことにより、文書中の文字列(テキスト)区切りと、そのテキストが構造上どの構成要素に属するのかを明確に記述することができる。
【0037】
ここで開始タグとは要素名称を記号「<」、「>」で閉じたものであり、終了タグとは要素名称を記号「</」と「>」で閉じたものである。タグに続く構成要素の内容が、テキスト(文字列)または子供の構成要素の繰り返しである。また開始タグには「<要素名称 属性=“属性値”>」などのように属性情報を設定することができる。「<特許DB></特許DB>」のようにテキストを含まない構成要素は、簡易記法として「<特許DB/>」のように表わすこともできる。
【0038】
図3に示した文書は、「特許」タグから始まる要素をルート(根)とし、その子要素として「タイトル」、「出願日」、「出願者」、「要約」タグから始まる要素集合が存在する。また、例えば、「タイトル」タグから始まる要素には「XMLデータベース」といった、1つのテキスト(文字列)が存在する。
【0039】
XMLなどの構造化文書は、任意の構成要素を繰り返し含んでいたり、さらには文書構造があらかじめ決まっていない(RDB(リレーショナルデータベース)やOODB(オブジェクト指向データベース)のスキーマでは定義できない)のが普通である。
【0040】
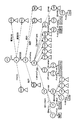
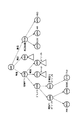
図3に示したような構造化文書を論理的に表現するために、図4に示すようなツリー表現が用いられる。ツリーは、ノード(番号が付され、円形で示されたもの)とアーク(ノードを表す円形間をつなぐデータ付き線)と四角形で囲まれたテキストから構成されている。
【0041】
ノードは文書オブジェクトに対応し、ノードからタグ名や属性名に相当するラベルが付与された複数のアークが出てきている。そのアークの先は、ノードまたは要素値としての文字列(テキスト)である。ノードの中に記載されている英数字(#0、#49)などはオブジェクトIDである。
【0042】
図4に示したツリー構造を図3に示した構造化文書の文書オブジェクトツリーと呼ぶ。
【0043】
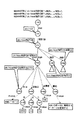
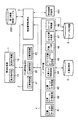
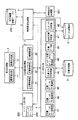
図1は、本実施形態に係る構造化文書管理システムの構成例を示したものである。図1において、構造化文書管理システムは、大きく分けて、要求制御部1、アクセス要求処理部2、検索要求処理部3、データアクセス部4、文書記憶部5、インデックス記憶部6から構成されている。文書記憶部5、インデックス記憶部6は例えば、外部記憶装置を用いて構成される。
【0044】
図1のシステム構成は、ソフトウエアを用いて実現可能である。
【0045】
要求制御部1は、要求受付部11と結果処理部12から構成されている。要求受付部11は、ユーザからの文書格納や文書取得、文書検索などの要求を受け付けて、アクセス要求処理部2を呼び出す。結果処理部12は、アクセス要求処理部2が処理した結果を要求元のユーザに返す処理を行う。
【0046】
アクセス要求処理部2は、ユーザからの文書格納や文書取得などの要求に対応した複数の処理部から構成されている。つまり、文書格納部21、文書取得部22、文書削除部23から構成されている。
【0047】
文書格納部21は、文書記憶部5中の論理的な指定エリアに文書を格納する処理を行う。
【0048】
文書取得部22は、文書記憶部5中の論理的なエリアが指定されたときに、その指定エリアに存在する文書を取得する処理を行う。
【0049】
文書削除部23は、文書記憶部5中の論理的な指定エリアに存在する文書を削除する処理を行う。
【0050】
文書記憶部5は、構造化文書データベースであり、例えば、図8に示すように、文書をUNIXのディレクトリ構造のように階層的にツリー構造状に格納している。
【0051】
図8に示すように、構造化文書データベースは、図4に示したような1つの構造化文書のツリー構造と同様に表現できる。すなわち、任意のノード以下の部分階層木(部分ツリー)は、構造化文書データベースから切り出された構造化文書であり、ここでは、これを文書オブジェクトツリーと呼ぶ。各ノードにはオブジェクトIDが割り当てられている。オブジェクトIDは、構造化文書データベース内ではユニークな数値を持つものとする。
【0052】
階層木のルートとなるノードには、それがルートノードであることを特定するためのオブジェクトID「#0」が割り当てられるものとする。
【0053】
ルートノード、すなわち、「#0」のノードからは「root」タグを先頭に持つ「#1」のノードへリンクが張られている。「#1」のノードからは、「特許DB」タグを先頭にもつ「#2」ノードへのリンクが張られている。「#2」ノードからは、「特許」タグを先頭に持つ「#42」ノード、「#52」ノード、「#62」ノードへのリンクがそれぞれ張られている。
【0054】
図3に示した「特許」情報は、「#42」ノード以下の部分ツリーに対応している。このノードからは「タイトル」タグ、「出願者」タグ、「要約」タグなどを先頭にもつノードへリンクが張られ、末端のノードからは、「XMLデータベース」、「T社」。「XMLを統一的に管理するデータベースを提供する…」などの文字列(要素値)へのリンクが張られている。
【0055】
「#52」ノード以下の部分ツリー、「#62」ノード以下の部分ノードも1つの「特許」情報に対応する部分である。
【0056】
ところで、例えば、「#43」ノードにリンクされた「XMLデータベース」という要素値は、「#43」ノードと「#value」という特殊なタグ名で接続されている。このタグ名は、「#」で始まるためXML規格においては標準的なタグ名として利用することはできない。
【0057】
このような構造化文書データベースの特定ノードを指定するために構造化文書パスを用いる。構造化文書パスは「uix://root」から始まる文字列である。uix(Universal Identifier for XML)は構造化文書パスであることを示す前置文字列である。
【0058】
例えば、「uix://root/特許DB」は、「#1」ノードから「特許DB」が付与されたアークが指し示すノード、つまり「#2」ノードに対応する。このように「root」から「/」で区切られた部分文字列をタグ名とみなすことで「#0」ノードからタグ名の並びに沿って対応するアークを下っていき、その最後のアークが指すノードが、パスの場所を指し示す。
【0059】
例えば、「uix://root/特許DB/特許」は、「#42」ノード、「uix://root/特許DB/出願日/年」は、「#45」ノードを指し示す。
【0060】
「#2」ノード以下に、すなわち、「特許DB」に、複数の「特許」情報を格納する場合には、個々の「特許」情報を識別するために、構造化文書パスにインデックス表現が可能である。
【0061】
「特許DB」の最初の「特許」情報であれば、「uix://root/特許DB/特許[0]」となるが、これは「uix://root/特許DB/特許」と同じとみなす。
【0062】
「特許DB」の2番目の「特許」情報であれば、「uix://root/特許DB/特許[1]DB」の5番目の「特許」情報であれば、「uix://root/特許DB/特許[4]」となる。
【0063】
インデックス記憶部6には検索時に用いる、要素名称生起インデックスとデータ生起インデックスが記憶されている。
【0064】
要素名生起インデックスとは構造化文書データベースに格納されている要素名称のリストと、各要素名称が先頭にある構造化文書(文書オブジェクトツリー)の位置とを関連付けてインデックスファイル化したものである。例えば、図8の構造化文書データベースのように、(「特許」情報に対応する)「特許」という要素名称が「#42」ノード以下の構造化文書、「#52」ノード以下の構造化文書、「#62」ノード以下の構造化文書に存在する場合、これらをインデックス化すると、図9に示すように、それらの親ノード、「#2」ノードが、要素名称生起インデックスファイルに「特許」キーからのチェーンで格納される。
【0065】
このように、親ノードでインデックス化すると、インデックスファイルを圧縮することができる。すなわち、親ノードでインデックス化すれば、子ノードが増大しようとも、親ノードで代用しているので、チェーンサイズは増大しない。これに対し、実ノードをインデックス化すれば「特許」情報の格納数の増大とともにチェーンサイズはそれに比例して増加してしまう。
【0066】
データ生起インデックスとは、構造化文書データベースに格納されている文字列データのリストと各文字列データがある構造化文書(文書オブジェクトツリー)の位置とを関連付けてインデックスファイル化したものである。例えば、図8の構造化文書データベースのように、「XML」という文字列データ(および、「XML」という文字列を含む文字列)が「#43」ノード以下の構造化文書、「#49」ノード以下の構造化文書に存在する場合、これらをインデックス化すると、図10に示すように、「#43」ノード、「#49」ノードが、データ生起インデックスファイルに「XML」キーからのチェーンで格納される。
【0067】
なお、逆階層インデックスなど、その他のインデックスファイルを用いてもよい。逆階層インデックスとは、あるノードとその親ノードとの対応を格納したものである(あるノードからその親ノードを求めることができる)。
【0068】
文書記憶部5中の論理的な指定エリアとは、ユーザにより構造化文書パスを用いて指定された文書の格納場所を指す。構造化文書パスは、ユーザにとって認識可能な表現である。
【0069】
図1の説明に戻る。
【0070】
データアクセス部4は、文書記憶部5をアクセスする基本インターフェイスの集合である。データアクセス部4は、文書オブジェクトツリー格納部47、文書オブジェクトツリー削除部48、文書オブジェクトツリー取得部49、文書文字列取得部44、パスから文書オブジェクトツリー取得部45、文書パーサ部46、合成文書作成部47、インデックス更新部48から構成される。
【0071】
文書オブジェクトツリー格納部41は、文書記憶部5中の物理的な指定エリアに文書オブジェクトツリーを格納する処理を行う。
【0072】
文書オブジェクトツリー削除部42は、文書記憶部5中の物理的な指定エリアに存在する文書オブジェクトツリーを削除する処理を行う。
【0073】
文書オブジェクトツリー取得部43は、文書記憶部5中の物理的な指定エリアに存在する文書オブジェクトツリーを取得する処理を行う。
【0074】
文書文字列取得部44は、文書オブジェクトツリーを構造化文書(XML文書)に変換する処理を行う。
【0075】
パスから文書オブジェクトツリー取得部45は、構造化文書パスを解析して文書記憶部5中の物理的なエリアを特定して、そのエリアに存在する文書オブジェクトツリーを取り出す処理を行う。
【0076】
文書パーサ部46は、ユーザにより入力された構造化文書を読み込んで構文解析して整合性の検査を行い、さらに文書構造定義データであるスキーマが存在すれば構造的に妥当かどうかの検証を行う。出力結果は文書オブジェクトツリーとなる。文書パーサは、通常、lex(lexical analyzer generator)といったレキシカルアナライザ(字句解析を行い,トークンに分解する)とyacc(yet another compiler compiler)といったパーサジェネレータを組み合わせて構築することができる。
【0077】
合成文書作成部47は、文書格納や文書削除などをする際に、スキーマに合致しているかどうか検査しなければならないが、この検査時に必要となるデータを作成して出力する。
【0078】
インデックス更新部48は、文書格納や文書削除などにより、構造化文書データベースの格納内容が更新されるたびに、図9、図10に示した要素名称生起インデックスとデータ生起インデックスを更新する。
【0079】
文書記憶部5中の物理的な指定エリアとは、ファイルオフセットやオブジェクトIDなどの構造化文書データベース内ではユニークな文書データの存在場所を指し示す内部データである。ユーザにとっては認識不能なデータである。
【0080】
文書記憶部5中に格納された文書を検索する処理を行う。要求制御部1の要求受付部11でユーザからの文書検索の要求が受け付けられると、検索要求処理部3には、要求受付部11からクエリ言語で記述されたクエリ文書が入力する。そしてデータアクセス部4を通してインデックス記憶部6,文書記憶部5にアクセスし、検索要求に合致する文書集合を取得して、その結果を結果処理部12を介して出力する。
【0081】
図2は、図1に示した構造化文書管理システムの一利用形態を示したもので、図2では、WWW(World Wide Web)のバックエンドで、図1に示した構成の構造化文書管理システム100が動作している場合を示している。
【0082】
複数(ここでは、例えば3つ)のクライアント端末(例えばパーソナルコンピュータ、携帯通信端末など)102のそれぞれでWWWブラウザ103が動作している。ユーザは、各クライアント端末からWWWサーバ101にアクセスすることにより、構造化文書管理システム100にアクセスすることができる。WWWブラウザ103とWWWサーバ101とは、HTTP(Hyper TextTransfer Protocol)で通信している。また、WWWサーバ101と構造化文書管理システム100とは、CGI(Common Gateway Interface)またはCOM(Component Object Model)などで通信している。
【0083】
ユーザからの文書格納、文書取得、文書検索などの要求は、WWWブラウザ103から送信されて、WWWサーバ101を通して構造化文書管理システム100にて受け付けられ、処理された結果は、WWWサーバ101を通して要求元のWWWブラウザ103へ返信される。
【0084】
以下、図1の構造化文書管理システムの(1)格納機能、(2)検索機能について詳細に説明する。そして、(3)適用例では、概念検索を用いた特許調査の場合を例にとり説明する。
【0085】
(1) 格納機能
図1の構造化文書管理システムにおける格納系のコマンドには以下のものがある。
【0086】
insertXML(パス、N番目、XML):文書格納
appendXML(パス、XML) :文書格納
getXML(パス) :文書取得
removeXML(パス) :文書削除
setSchema(パス、スキーマ) :スキーマ格納
getSchema(パス) :スキーマ取得
「insertXML」は、( )内に指定した構造化文書パス以下のN番目に文書を挿入するコマンド(以下、簡単に挿入コマンドと呼ぶ)である。
【0087】
「appendXML」は、( )内に指定した構造化文書パス以下の最後に文書を挿入するコマンド(以下、簡単に追加コマンドと呼ぶ)である。
【0088】
「getXML」は、( )内に指定した構造化文書パス以下の文書を取り出すコマンド(以下、簡単に取得コマンドと呼ぶ)である。
【0089】
「removeXML」は、( )内に指定した構造化文書パス以下の文書(スキーマ文書以外の文書で、主に、コンテンツ文書)を削除するコマンド(以下、簡単に削除コマンドと呼ぶ)である。
【0090】
「setSchema」は、( )内に指定した構造化文書パスにスキーマを設定するコマンド(以下、簡単にスキーマ格納コマンドと呼ぶ)である。
【0091】
「getSchema」は、( )内に指定した構造化文書パスに設定されているスキーマを取り出すコマンド(以下、簡単にスキーマ取得コマンドと呼ぶ)である。
【0092】
上記コマンドのうち、挿入コマンド、追加コマンド、スキーマ格納コマンドについての処理はアクセス要求処理部2の文書格納部21で実行され、取得コマンド、スキーマ取得コマンドについての処理は文書取得部22で実行され、削除コマンドについての処理は文書削除部23で実行される。
【0093】
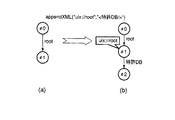
図5を参照して、構造化文書データベースの初期状態(図5(a)参照)において、追加コマンドを実行する場合について説明する。
【0094】
図5(a)に示すように、「#0」ノードと「#1」ノードが「root」アークで接続されている初期状態に対して、
「appendXML(“uix://root”,“<特許DB/>”)」
を実行した結果、図5(b)に示すように、「#2」ノードと「特許DB」アークが作成される。
【0095】
図5(b)に示した状態の構造化文書データベースに対して、取得コマンドを実行する場合について説明する。
【0096】
例えば、「getXML(“uix://root”)」を実行すると、図5(b)の「root」アークが示す「#0」ノード以下の文書オブジェクトツリーが取り出され、それをXMLの文字列表現に変換する。その結果、図6に示すように、「<root><特許DB/></root>」なる文字列が取り出される。取得コマンドの処理は、アクセス要求処理部2の文書取得部22にて実行される。
【0097】
次に、図5(b)に示した状態の構造化文書データベースに対して、図3に示すようなコンテンツ文書(XML文書)としての「特許」情報を格納するための追加コマンドを実行する場合について説明する。すなわち、この場合、「appendXML(“uix://root/特許DB”,“<特許>…</特許>”)」を実行する。このコマンド中「“<特許>…</特許>”」が、図3に示した「特許」情報に対応する。
【0098】
上記追加コマンドの処理が実行されると、図7に示すように、「#2」ノード以下に「#42」ノードをトップとする文書オブジェクトツリー(図4に対応)が追加される。
【0099】
図5(b)に示した状態の構造化文書データベースに対して、次に示すような追加コマンドを3回繰り返して実行したとする。
【0100】
「appendXML(“uix://root/特許DB”,“<特許>…</特許>”)」
上記コマンド中、「<特許>…</特許>」は、図3に示した文書構造のコンテンツ文書に対応する。
【0101】
すると、図8に示すように、「#2」ノード以下に「#42」ノード、「#52」ノード、「#62」ノードをトップとする文書オブジェクトツリーが追加される。
【0102】
次に、図8に示した状態の構造化文書データベースに対して、3つの「特許」情報を取り出すための取得コマンドを実行した場合について説明する。この場合、「getXML(“uix://root/特許DB”)」を実行する。すると、「特許DB」アークが示す「#2」ノード以下の文書オブジェクトツリーが取り出され、それをXMLの文字列表現(XML文書)に変換する。その結果、図11に示すように、「<特許DB><特許>…</特許><特許>…</特許><特許>…</特許></特許DB>」なる文字列が取り出される。
【0103】
構造化文書データベースでは、上記の「特許」情報などのコンテンツ文書(XML文書)の文書構造を定義したデータ、すなわち、スキーマも管理対象とする。
【0104】
図12は、XML文書の文書構造を定義するスキーマの一例を示したものである。ここでは、XMLの文書構造定義言語の一つであるXDR(XML−Data Reduced)を取り上げる。もちろん、XML−Schemaなど他の文書構造定義言語を用いてもかまわない。
【0105】
図12に示したスキーマは、図3に示した「特許」情報の文書構造をXDRで定義したものである。図12からも容易に分かるとおり、スキーマもXML形式の構造化文書である。「Schema」タグから始まる構成要素から始まり、その子要素として、「ElementType」タグから始まる要素集合が存在する。
【0106】
図12に示したスキーマにおいて、例えば、最初の「ElementType」タグから始まる子要素は以下の情報を意味している。
【0107】
・「特許」タグを持つ要素の文書構造定義(「ElementType name=”特許”」)である。
【0108】
・子要素は要素だけ(「content=”eltOnly”」)である。
【0109】
・「タイトル」、「出願日」、「要約」タグから始まる子要素から構成される(「element type=”タイトル”、…」)。さらに、その順番は一意に決まっている(「order=”seq”」)。
【0110】
・上記「特許」タグから始まる要素の文書構造定義の他に、「タイトル」「出願者」「要約」「年」「月」「日」「出願日」の文書構造定義を記述している。すなわち、「出願日」を除く、「タイトル」「出願者」「要約」「年」「月」「日」タグから始まる構成要素の子要素はテキストだけと定義されている(「content=”textOnly”」)。
【0111】
・「出願日」タグから始まる構成要素の子要素は、「年」、「月」、「日」の並びである。
【0112】
図8に示した状態の構造化文書データベースに対して、図12に示したスキーマ文書を格納するためのスキーマ格納コマンドを実行する場合について説明する。この場合、「setSchema(“uix://root/特許DB”,“<Schema>…</Schema>”)」を実行する。このコマンド中、「“<Schema>…</Schema>”」」が図12に示したスキーマ文書に対応する。
【0113】
上記コマンドの実行により、図13に示すように、「#2」ノード以下に「#schema」アークが追加され、その先には、「#3」ノードをトップノードとする文書オブジェクトツリーが追加される。スキーマ自身がXML文書表現になっているため、前述した「特許」情報のようなコンテンツ文書格納のケースと同様にツリー展開可能である。
【0114】
図13において、「@name」など「@」で始まるアークは属性に対応する。タグ名「#schema」も「#」、「@」で始まるためXML規格においては標準的なタグ名として利用することはできない。
【0115】
「#2」ノード下に図12に示したスキーマ文書が格納されたことにより、以後、「#2」ノード以下にこれから格納される文書の文書構造は、図12に示したスキーマ文書により定義された文書構造に適合することが要求される。すなわち、「#2」ノード以下に図12に示したスキーマが設定されることになる。
【0116】
「#2」ノード以下に図12に示したスキーマが設定されると、図14に示すように、「#2」ノードの文書オブジェクトのファイルには、「#2」ノード以下の文書オブジェクトツリーには、当該スキーマが存在する旨の属性値がセットされる。
【0117】
「#2」ノード以下に図12に示したスキーマが設定された後に、このスキーマで定義された文書構造に一致する図3に示したような「特許」情報を、図14に示したように、文書オブジェクトツリーとして構造化文書データベースに格納したとき、この文書の文書構造には図12に示したスキーマが存在する旨の属性値が、当該文書オブジェクトツリーを構成する各文書オブジェクトにセットされる。例えば、当該文書オブジェクトツリーを構成する各文書オブジェクトのファイルに対して、スキーマが存在している旨の属性値(例えば、「スキーマ適合有無」)に「1」がセットされる。図14では、スキーマに適合している各文書オブジェクト(ノード)は2重丸で示している。2重丸で示した各文書オブジェクトには、その文書オブジェクトに対応した文書構造定義が存在することになる。
【0118】
図15は、各文書オブジェクトのファイルの内容を概念的に示したもので、例えば、オブジェクトIDが「#42」の文書オブジェクトのファイルには、その文書オブジェクトにリンクされている他の文書オブジェクトに関する情報(例えば、アークや、リンク先の文書オブジェクトへのポインタ値など)とともに、上記属性値が記述されている。なお、当該文書オブジェクトに適用するスキーマが存在しないときは、「スキーマ適合有無」の値は「0」となる。
【0119】
図16、図17は、図1の構造化文書管理システムで、必要に応じて検索で使用される概念階層を構造化文書で表現した例を示す。図16、図17に示す「概念」情報はXMLで記述したコンテンツ文書である。
【0120】
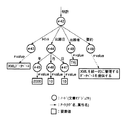
図16に示した「概念」情報の例は、いわゆる特許調査における特許文書の内容を分類するための1つの分類軸として用いる「情報モデル」を概念階層で表現している。「概念」タグで囲まれた「概念」情報は、入れ子構造を持った文書構造をもっている。つまり、図16の例では、概念「情報モデル」の子供概念として、概念「ドキュメント」、概念「リレーション」、概念「オブジェクト」が存在している。また、概念「ドキュメント」の子供概念として、概念「構造化訴求メント」、概念「非構造化ドキュメント」が存在し、さらに、概念「構造化ドキュメント」の子供概念として、概念「XML」、概念「SGML」が存在している。
【0121】
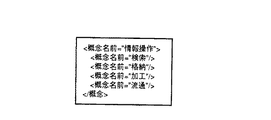
図17に示す「概念」情報の記述例は、図16とは異なる分類軸「情報操作」を概念階層で表現している。図17の例では、概念「情報操作」の子供概念として、概念「検索」、概念「格納」、概念「加工」、概念「流通」が存在している。
【0122】
図16,図17に示したような「概念」情報も、前述の「特許」情報と同様にして、構造化文書データベース内に格納することができる。すなわち、例えば、まず、図8に示した状態の構造化文書データベースに対して、「appendXML(“uix://root”,“<概念DB/>”)」を実行して、図18に示すように、「#201」ノードと「概念DB」アークが作成される。この状態において、図16に示した「概念」情報を格納する場合には、「appendXML(“uix://root/概念DB”,“<概念名前>…</概念>”)」を実行する。このコマンド中「“<概念名前>…</概念>”」が、図16に示した「概念」情報に対応する。
【0123】
上記追加コマンドの処理が実行されると、図19に示すように、「#201」ノード以下に「#202」ノードをトップとする文書オブジェクトツリーが追加される。
【0124】
以上説明したように、図1の構造化文書管理システムでは、構造化文書データベース上に登録される文書構造が異なる膨大な数のXML文書群(コンテンツ文書、スキーマ文書、クエリ文書など)を、図18,図19に示すように、「root」タグを先頭に持つツリー状の1つの巨大なXML文書として取り扱う。そのため、部分的なXML文書をアクセスするには巨大なXML文書に対するパスという文書構造に依存しない統一的なアクセス手段を用いることにより、幅広くXML文書を検索したり加工したりすることが可能になる。
【0125】
また、構造化文書データベース上の一部にスキーマを設定することで、格納しようとする文書の文書構造がそのスキーマにより定義されている文書構造に一致するか否かの妥当性のチェックが自動的に行なえる(後述)。
【0126】
(1−1)文書格納処理
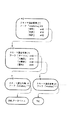
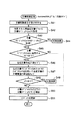
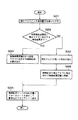
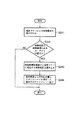
次に、図1の構造化文書管理システムの文書格納処理動作について、図20に示すフローチャートを参照して説明する。
【0127】
クライアント端末から構造化文書管理システムに対し、文書格納要求として、挿入コマンド、追加コマンド、スキーマ格納コマンドのうちのいずれかが送信されて、要求受付部11にて受け付けられたとき、図20に示した処理動作を行う。
【0128】
クライアント端末の所定の表示装置には、構造化文書管理システム100(の例えば、要求制御部1)から提供された、例えば、図31に示すようなユーザインターフェイスとしての画面が表示されている。
【0129】
図31に示す画面には、構造化文書管理システム100への操作項目の一覧(メニュー)が表示されている。操作項目として、「XML登録/削除」、「スキーマ設定」、「XML検索」とがある。
【0130】
ユーザが例えば、この画面上で「XML登録/削除」をマウス等のポインティングデバイスなどを用いて選択すると、図32に示したような文書の格納/削除を行うためのユーザインタフェースとしての画面が表示される。
【0131】
図32において、領域W1には、文書構造化文書データベースの現在のツリー構造の要素名(タグ名)がユーザが理解可能なように簡略的に表示されている。なお、図32では、上位階層の要素名のみを表示しているが、末端の要素名まで表示可能である。また、領域W2は、構造化文書パスの入力領域であり、領域W1の表示内容に従って、構造化文書パスを入力するようになっている。また、領域W3は、格納する文書を入力したり、取得した文書を表示するようになっている。
【0132】
例えば、構造化文書パスとして「root」を入力する場合には、領域W1の「root」をマウス等で選択すればよい。すると、図32に示すように、領域W2の構造化文書パスの入力領域に「uix://root」と表示される。また、新たに、「特許DB」という要素を追加する場合は、図32に示すように、領域W3に、「特許DB」を入力する。そして、「登録」ボタンB1を選択すると、クライアント端末からappendXML(“uix://root”,“<特許DB/>”)」なる追加コマンドが構造化文書管理システムへ送信される。構造化文書管理システムでは、上記追加コマンドを受け、後述するような処理を実行した結果、例えば、図5(b)に示すように、「#2」ノードと「特許DB」アークが作成される。また、領域W1には、図33に示すように、「root」の下に「特許DB」が追加表示される。
【0133】
さて、ユーザが図34に示したような文書の格納/削除画面上の領域W3に、例えば、文書「<A>データ</A>」を入力し(あるいはCD−ROM等の所定の記録媒体等から読み込むことにより入力し)、領域W1の「特許[0]」をマウス等で選択すると、構造化文書パスの入力領域W2に、「uix://root/特許DB/特許[0]」と表示される。そして、「登録」ボタンB1を選択すると、クライアント端末からappendXML(“uix://root”,“<特許DB/>”)」なる追加コマンドが構造化文書管理システムへ送信される。
【0134】
ここでは、例えば、構造化文書データベースが、図14に示した状態のときに、「appendXML(“uix://root/特許DB/特許[0]”,“<A>データ</A>”)」なる追加コマンドを受け付けた場合を例にとり説明する。
【0135】
要求受付部11は、上記追加コマンドを受け付けると、上記追加コマンド中の2つのパラメータである構造化文書パス「uix://root/特許DB/特許[0]」と文書「<A>データ</A>」(以下、格納文書と呼ぶ)とを文書格納部21へ渡す(ステップS1)。
【0136】
まず、文書格納部21は、文書パーサ部46に格納文書を渡す。文書パーサ部46は、格納文書を読み込んで、構文解析を行い、当該格納文書の文書構造がXMLにて規定された正しい形式であるか否かの整合性の検査を行う(ステップS2)。
【0137】
この整合性の検査でエラーが見つかれば(ステップS3)、文書格納部21,結果処理部12を介して、クライアント端末に「文書格納失敗」の旨のメッセージを返す(ステップS4)。
【0138】
整合性の検査でエラーが見つからなければ、次に、文書格納部21は、パスから文書オブジェクトツリー取得部45へ構造化文書パスを渡す。パスから文書オブジェクトツリー取得部45は、構造化文書パスから文書記憶部5中の物理的なエリアを特定することにより、そのエリアに存在する構造化文書パスにて表されたノード(文書オブジェクトOx0)を含む文書オブジェクトツリーを取り出す(ステップS5)。構造化文書パスの指定が正しければ、文書オブジェクトOx0のオブジェクトIDを取得することができるので(ステップS6)、その場合は、ステップS8へ進む。
【0139】
例えば、上記追加コマンドの場合、「#42」ノードが文書オブジェクトOx0となるので、そのオブジェクトIDとして、「#42」を取得するとともに、この「#42」ノードを含む文書オブジェクトツリー(例えば、「#42」ノードの全ての子孫ノードと「#42」ノードと同じ階層にある全ての(兄弟)ノードと、「#42」ノードの親ノードである「#2」ノードとからなる文書オブジェクトツリー)を取得する。
【0140】
指定された構造化文書パスからそれに対応する文書オブジェクトOx0が見つからなければ、エラーとなり(ステップS6)、文書格納部21,結果処理部12を介して、クライアント端末に「文書格納失敗」の旨のメッセージを返す(ステップS7)。
【0141】
例えば、構造化文書データベースが、図18に示した状態のときに、追加コマンドのパラメータとして、構造化文書パスが「uix://root/その他」と表されていたとき、これに対応する文書オブジェクトは存在しないので、ステップS6でエラーとなり、ステップS7へ進む。
【0142】
次に、ステップS8では、文書オブジェクトOx0にスキーマが存在するか否かを検査する。この検査は、前述したように、各文書オブジェクトのファイルに属性値が記述されているので、この値をチェックすればよい。文書オブジェクトOx0のもつ「スキーマ属性有無」の値が「1」のときは、ステップS9へ進む。
【0143】
以下、図20のステップS9の処理(合成文書作成部47の処理)について、図21に示すフローチャートを参照して詳細に説明する。
【0144】
文書格納部21は、ステップS5で取得した文書オブジェクトツリーを合成文書作成部47へ渡す。
【0145】
合成文書作成部47は、この文書オブジェクトツリーを文書オブジェクトOx0から遡り、「Schema」タグを子要素として持つ文書オブジェクトOx1を検索する(ステップS21)。
【0146】
例えば、図14に示した構造化文書データベースでは、文書オブジェクトOx0としての「#42」ノードの親ノードである「#2」ノードから「Schema」タグをトップ(先頭)にもつノード(「#3」ノード)へのリンクが張られているので(「Schema」タグを子要素として持つので)、この「#2」ノードが文書オブジェクトOx1となる。よって、ステップS22をスキップして、ステップS23へ進む。
【0147】
この文書オブジェクトOx1から文書オブジェクトOx0、さらに文書オブジェクトOx0からアークを辿って、その下流にある、文書オブジェクトの属性値の値が「1」である全ての子ノードからなる文書オブジェクトツリーOt1を取り出す(ステップS23)。
【0148】
例えば、上記追加コマンド中のパラメータの構造化文書パスが「uix://root/特許DB/特許[0]」と指定されているとき、文書オブジェクトツリーOt1は、「#42」ノード〜「#49」ノードから構成されたものとなる(図14参照)。
【0149】
次に、ステップS25へ進む。
【0150】
ステップS25では、文書オブジェクトツリーOt1に格納文書の文書オブジェクトツリーを文書オブジェクトOx0の子ノードとして挿入する。その結果得られた新たな文書オブジェクトツリーを文書オブジェクトツリーOt2とする。
【0151】
この文書オブジェクトツリーOt2をXML文書に変換し、それをテンポラリファイルAに出力する(ステップS27)。
【0152】
例えば、上記追加コマンド中のパラメータの格納文書「<A>データ</A>」の文書オブジェクトツリー(この場合は、1つの文書オブジェクト)を「#42」ノード〜「#49」ノードで構成された文書オブジェクトツリーOt1に「#42」ノードの子ノードとして挿入して得られた合成文書の文書オブジェクトツリーOt2をXML文書に変換した結果を図22に示す。この合成文書は、もともとある「特許」情報に「<A>データ</A>」というデータを追加したものとなっている。
【0153】
図22に示したXML文書、すなわち、合成文書がテンポラリファイルAに出力され、テンポラリファイルAに一時格納される。
【0154】
一方、スキーマタグ以下の文書オブジェクトツリーOt3をXML文書に変換して、それをテンポラリファイルBに出力する(ステップS28)。すなわち、テンポラリファイルBには、スキーマ文書が一時格納されることになる。
【0155】
例えば、文書オブジェクトツリーOt3である「#3」ノードをトップノードとする文書オブジェクトツリーをXML文書に変換した結果を図23に示す。図23に示したXML文書がテンポラリファイルBに出力され、テンポラリファイルBに一時格納される。
【0156】
図22に示すように、テンポラリファイルA(「tmp000.xml」)には、もともとある「特許」情報の要素の他に、格納文書、すなわち、ここでは、例えば、「<A>データ</A>」が挿入されている。また、「xmlns=”x−schema:tmp001.xml”」という、テンポラリファイルB(「tmp001.xml」)へのリンク情報の記述がある。この記述は、「特許」情報に適用されるスキーマが出力されているテンポラリファイルBを指定している。
【0157】
次に、図20の説明に戻る。
【0158】
ステップS10では、文書格納部21は文書パーサ部46に、合成文書のテンポラリファイルAとスキーマのテンポラリファイルBとを与えて、合成文書の文書構造の妥当性をチェックする。すなわち、文書パーサ部46は、合成文書のテンポラリファイルAとスキーマのテンポラリファイルBとを読み込み、合成文書の文書構造が、スキーマにより定義されている文書構造に一致するか否かをチェックする。
【0159】
例えば、図22に示した合成文書と、図23に示したスキーマとで妥当性のチェックを行った場合、合成文書には、スキーマにより定義されていない「A」という要素が存在するため、図23の合成文書は、妥当性のチェックでエラーとなる(ステップS11)。この場合、文書格納部21,結果処理部12を介して、クライアント端末に「文書格納失敗」の旨のメッセージを返す(ステップS12)。
【0160】
例えば、クライアント端末の所定の表示装置には、図35に示すようなメッセージが表示される。
【0161】
次に、構造化文書データベースが、図14に示した状態のときに、「appendXML(“uix://root/特許DB”,“<特許>…</特許>”)」なる追加コマンドを受け付けた場合について、図20を参照して説明する。前述同様にして、文書オブジェクトOx0のオブジェクトID「#2」を取得する(ステップS5)、この文書オブジェクトには、スキーマが存在するので(ステップS8)、ステップS9において合成文書を作成する。
【0162】
この場合、文書オブジェクトOx0である「#2」ノード自体から「Schema」タグをトップ(先頭)にもつノード(「#3」ノード)へのリンクが張られているので、この「#2」ノードが文書オブジェクトOx1となる(図21のステップS21)。すなわち、文書オブジェクトOx0と文書オブジェクトOx1が同じなので(ステップS22)、ステップS29へ進み、格納文書「<特許>…</特許>」の文書オブジェクトツリーをXML文書に変換し、テンポラリファイルAに出力する(ステップS29)。
【0163】
例えば、図24に示すように、テンポラリファイルA(「tmp000.xml」)には、格納文書である「特許」情報、すなわち、ここでは、「<特許>…</特許>」が出力されている。また、「xmlns=”x−schema:tmp001.xml”」という、テンポラリファイルB(「tmp001.xml」)へのリンク情報の記述がある。
【0164】
次に、ステップS28へ進む。図25に示すように、テンポラリファイルBには、「#3」ノードをトップノードとするスキーマの文書オブジェクトツリーをXML文書に変換した結果が出力されている。
【0165】
図20のステップS10で、図24に示した合成文書と、図25に示したスキーマとで妥当性のチェックを行ったとき、合成文書の文書構造と、スキーマにより定義されている文書構造とは一致する、この場合、ステップS11からステップS13へ進む。
【0166】
ステップS13では、格納文書の文書オブジェクトツリーが、文書オブジェクトOx0下に追加される。すなわち、文書格納部21により、格納文書の文書オブジェクトツリーを構成する各文書オブジェクト(のファイル)にオブジェクトIDが与えられ、文書オブジェクトOx0から格納文書の文書オブジェクトツリーの先頭の文書オブジェクトへリンクが張られる。そして、文書オブジェクトツリー格納部41により、格納文書の文書オブジェクトツリーを構成する各文書オブジェクト(のファイル)が文書記憶部5に格納される。
【0167】
次に、ステップS14へ進み、インデックス記憶部6のインデックスを更新する。
【0168】
なお、ステップS8で、文書オブジェクトOx0のもつ属性値の値が「0」のときは、上述したスキーマを用いた合成文書の文書構造の妥当性のチェックを行わずに、そのままマステップS13へ進み、格納文書の文書オブジェクトツリーを、文書オブジェクトOx0下に追加し(ステップS13)、それに伴い、インデックス記憶部6のインデックスを更新する(ステップS14)。
【0169】
(1−2)文書取得処理
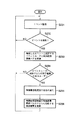
次に、図1の構造化文書管理システムの文書取得処理動作について、図26に示すフローチャートを参照して説明する。
【0170】
クライアント端末から構造化文書管理システムに対し、文書取得要求として、取得コマンド、スキーマ取得コマンドのうちのいずれかが送信されて、要求受付部11にて受け付けられたとき、図26に示した処理動作を行う。
【0171】
例えば、ユーザが図36に示したような文書の格納/削除画面上の領域W1の「特許DB」をマウス等で選択すると(クリックすると)、構造化文書パスの入力領域W2に、「uix://root/特許DB」と表示されとともに、「getXML(“uix://root/特許DB”)」なる取得コマンドが構造化文書管理システムへ送信される。
【0172】
ここでは、例えば、構造化文書データベースが、図8に示した状態のときに、「getXML(“uix://root/特許DB”)」なる取得コマンドを受け付けた場合を例にとり説明する。
【0173】
要求受付部11は、上記取得コマンドを受け付けると、上記取得コマンド中のパラメータである構造化文書パス「uix://root/特許DB」を文書取得部22へ渡す(ステップS31)。
【0174】
文書取得部22は、パスから文書オブジェクトツリー取得部45へ構造化文書パスを渡す。パスから文書オブジェクトツリー取得部45は、構造化文書パスから文書記憶部5中の物理的なエリアを特定することにより、そのエリアに存在する構造化文書パスにて表されたノード(文書オブジェクトOx5)を取り出す(ステップS32)。構造化文書パスの指定が正しければ、文書オブジェクトOx5のオブジェクトIDを取得することができるので(ステップS33)、その場合は、ステップS35へ進む。
【0175】
例えば、上記取得コマンドの場合、「#2」ノードが文書オブジェクトOx5となるので、そのオブジェクトIDとして、「#2」を取得するとともに、この「#2」ノード以下の文書オブジェクトツリーOt5(「#2」ノード、「#42」ノード〜「#49」ノード、「#52」ノード以下、「#62」ノード以下)を取得する(ステップS35)。
【0176】
ステップS32において、指定された構造化文書パスからそれに対応する文書オブジェクトOx5が見つからなければ、エラーとなり(ステップS33)、文書取得部22,結果処理部12を介して、クライアント端末に「文書取得失敗」の旨のメッセージを返す(ステップS34)。
【0177】
ステップS35で取得した文書オブジェクトツリーOt5は、文書文字列取得部44でXML文書に変換される。例えば、上記取得コマンドの場合、取得したXML文書は、図11に示すような3つの「特許」情報のXML文書となる。
【0178】
文書取得部22は、結果処理部12を介して、図11に示したようなXML文書を(例えば、XSL(eXtensible Style Language)といった所定のスタイルシートとともに)、クライアント端末へ返す(ステップS37)。
【0179】
クライアント端末では、図11に示したXML文書を、スタイルシートを用いてHTMLデータに変換して、例えば、図36に示すように、領域W2に表示する。
【0180】
XSLを利用すると、XML文書を様々な形に変換することが出来る。違う構文書造のXML文書に変換することも出来るし、XML文書からHTMLページを生成することも出来る。
【0181】
(1−3)文書削除処理
次に、図1の構造化文書管理システムの文書削除処理動作について、図27に示すフローチャートを参照して説明する。
【0182】
クライアント端末から構造化文書管理システムに対し、文書削除要求として、削除コマンドが送信されて、要求受付部11にて受け付けられたとき、図27に示した処理動作を行う。
【0183】
例えば、ユーザが図36に示したような文書の格納/削除画面上の領域W1の「特許DB」をマウス等で選択すると(クリックすると)、構造化文書パスの入力領域W2に、「uix://root/特許DB」と表示され、さらに、「削除」ボタンB2を選択すると「removeXML(“uix://root/特許DB”)」なる削除コマンドが構造化文書管理システムへ送信される。
【0184】
ここでは、例えば、構造化文書データベースが、図14に示した状態のときに、「removeXML(“uix://root/特許DB/特許[0]/出願日”)」なる削除コマンドを受け付けた場合を例にとり説明する。
【0185】
要求受付部11は、上記削除コマンドを受け付けると、上記削除コマンド中のパラメータである構造化文書パス「uix://root/特許DB/特許[0]/出願日」を文書削除部23へ渡す(ステップS41)。
【0186】
次に、文書削除部23は、パスから文書オブジェクトツリー取得部45へ構造化文書パスを渡す。パスから文書オブジェクトツリー取得部45は、構造化文書パスから文書記憶部5中の物理的なエリアを特定することにより、そのエリアに存在する構造化文書パスにて表されたノード(文書オブジェクトOx0)を含む文書オブジェクトツリーを取り出す(ステップS42)。構造化文書パスの指定が正しければ、文書オブジェクトOx0のオブジェクトIDを取得することができるので(ステップS43)、その場合は、ステップS45へ進む。
【0187】
例えば、上記削除コマンドの場合、「#44」ノードが文書オブジェクトOx0となるので、そのオブジェクトIDとして、「#44」を取得するとともに、この「#44」ノードを含む文書オブジェクトツリー(例えば、「#44」ノードの全ての子孫ノードと「#44」ノードと同じ階層にある全ての(兄弟)ノードと、「#44」ノードの親ノードである「#42」ノード、その親ノードである「#2」ノードとからなる文書オブジェクトツリー)を取得する。
【0188】
指定された構造化文書パスからそれに対応する文書オブジェクトOx0が見つからなければ、エラーとなり(ステップS43)、文書格納部21,結果処理部12を介して、クライアント端末に「文書削除失敗」の旨のメッセージを返す(ステップS44)。
【0189】
次に、ステップS45では、文書オブジェクトOx0にスキーマが存在するか否かを検査する。この検査は、前述したように、各文書オブジェクトのファイルに属性値が記述されているので、この値をチェックすればよい。文書オブジェクトOx0のもつ属性値の値が「1」のときは、ステップS46へ進む。
【0190】
以下、図27のステップS46の処理(合成文書作成部47の処理(削除コマンド用))について、図28に示すフローチャートを参照して詳細に説明する。
【0191】
なお、図28において、図21と同一部分は同一符号を付している。
【0192】
文書格納部21は、ステップS42で取得した文書オブジェクトツリーを合成文書作成部47へ渡す。
【0193】
合成文書作成部47は、この文書オブジェクトツリーを文書オブジェクトOx0から遡り、「Schema」タグを子要素として持つ文書オブジェクトOx1を検索する(ステップS21)。
【0194】
例えば、図14に示した構造化文書データベースでは、文書オブジェクトOx0としての「#44」ノードの上流にある「#2」ノードから「Schema」タグをトップ(先頭)にもつノード(「#3」ノード)へのリンクが張られているので(「Schema」タグを子要素として持つので)、この「#2」ノードが文書オブジェクトOx1となる。
【0195】
この文書オブジェクトOx1から文書オブジェクトOx0、さらに文書オブジェクトOx0からアークを辿って、その下流にある、文書オブジェクトの属性値の値が「1」である全ての子ノードからなる文書オブジェクトツリーOt1を取り出す(ステップS23)。
【0196】
例えば、上記追加コマンド中のパラメータの構造化文書パスが「uix://root/特許DB/特許[0]/出願日」と指定されているとき、文書オブジェクトツリーOt1は、「#42」ノード〜「#49」ノードから構成されたものとなる(図14参照)。
【0197】
次に、ステップS26ヘ進み、文書オブジェクトツリーOt1から文書オブジェクトOx0以下の文書オブジェクトツリーを削除する。その結果得られた新たな文書オブジェクトツリーを文書オブジェクトツリーOt2とする。
【0198】
この文書オブジェクトツリーOt2をXML文書に変換し、それをテンポラリファイルAに出力する(ステップS27)。
【0199】
例えば、上記削除コマンド中のパラメータの構造化文書パス「uix://root/特許DB/特許[0]/出願日」が指し示す「#44」ノード以下の文書オブジェクトツリーを「#42」ノード〜「#49」ノードで構成された文書オブジェクトツリーOt1から削除することにより得られた合成文書の文書オブジェクトツリーOt2をXML文書に変換した結果を図29に示す。この合成文書は、もともとある「特許」情報から「<出願日>…</出願日>」というデータを削除したものとなっている。
【0200】
図29に示したXML文書、すなわち、合成文書がテンポラリファイルAに出力され、テンポラリファイルAに一時格納される。
【0201】
一方、スキーマタグ以下の文書オブジェクトツリーOt3をXML文書に変換して、それをテンポラリファイルBに出力する(ステップS28)。すなわち、テンポラリファイルBには、スキーマ文書が一時格納されることになる。
【0202】
例えば、文書オブジェクトツリーOt3である「#3」ノードをトップノードとする文書オブジェクトツリーをXML文書に変換した結果を図30に示す。図30に示したXML文書がテンポラリファイルBに出力され、テンポラリファイルBに一時格納される。
【0203】
次に、図27の説明に戻る。
【0204】
ステップS47では、文書削除部21は文書パーサ部46に、合成文書のテンポラリファイルAとスキーマのテンポラリファイルBとを与えて、文書格納処理の場合と同様にして、合成文書の文書構造の妥当性をチェックする。
【0205】
例えば、図29に示した合成文書と、図30に示したスキーマとで妥当性のチェックを行った場合、合成文書には、スキーマにより定義されている「出願日」という要素が存在しないため、図29の合成文書は、妥当性のチェックでエラーとなる(ステップS48)。この場合、文書削除部21,結果処理部12を介して、クライアント端末に「文書削除失敗」の旨のメッセージを返す(ステップS49)。
【0206】
なお、構造化文書データベースが、図14に示した状態のときに、「removeXML(“uix://root/特許DB/特許[0]”)」なる削除コマンドを、図27に従って処理を行うと、図28のステップS27において、図24に示したような合成文書がテンポラリファイルAに出力される。テンポラリファイルBは、図30と同様である。
【0207】
このとき、図24に示した合成文書と、図30に示したスキーマとで妥当性のチェックを行った場合、合成文書の文書構造と、スキーマにより定義されている文書構造とは一致するので、ステップS48からステップS50へ進む。
【0208】
ステップS50では、文書オブジェクトOx0以下の文書オブジェクトツリーを削除する。すなわち、文書オブジェクトツリー削除部42により、文書オブジェクトOx0以下の文書オブジェクトツリーを構成する各文書オブジェクト(のファイル)が文書記憶部5から削除される。例えば、「#2」ノードから「#42」ノード以下の文書オブジェクトのファイルが削除される。
【0209】
次に、ステップS51へ進み、インデックス記憶部6のインデックスを更新する。また、クライアント端末の図36に示したような表示画面の領域W1には、「特許[0]」が表示さなくなる。
【0210】
なお、ステップS45で、文書オブジェクトOx0のもつ属性値の値が「0」のときは、上述したスキーマを用いた合成文書の文書構造の妥当性のチェックを行わずに、そのままマステップS50へ進み、文書オブジェクトOx0以下の文書オブジェクトツリーを削除し(ステップS50)、それに伴う、インデックス記憶部6のインデックスを更新する(ステップS51)。
【0211】
(1−4)スキーマの設定、スキーマを用いた文書格納
図31に示した画面上で、ユーザが「Schema設定Win」をマウス等のポインティングデバイスなどを用いて選択すると、図37に示したようなスキーマの設定を行うためのユーザインタフェースとしての画面が表示される。
【0212】
ユーザが、領域W3に、例えば、図12に示したような「特許」情報のスキーマを入力し、この入力したスキーマを「特許DB」以下のノードに設定する場合には、領域W1から「特許DB」をマウス等でクリックして選択した後(領域W2には、「uix://root/特許DB」が表示される)、「スキーマ設定」ボタンB3を選択する。すると、「setSchema(“uix://root/特許DB”,“<Schema>…</Schema>”)」なるスキーマ格納コマンドが構造化文書管理システムへ送信される。このコマンドの処理は前述した文書格納処理動作と同様である。
【0213】
次に、「uix://root/特許DB」の下に「特許」情報を格納しようとするとき、「特許DB」以下のノードに既に設定されているスキーマを用いて「特許」情報を入力する場合について説明する。
【0214】
まず、スキーマを取得する。例えば、図38に示すような文書の格納/削除を行うための画面の領域W1から「スキーマ」をマウス等を用いて選択すると、文書パスの入力領域W2に、「uix://root/特許DB/#Schema」と表示されとともに、「getXML(“uix://root/特許DB/Schema”)」なるスキーマ取得コマンドが構造化文書管理システムへ送信される。
【0215】
このコマンドの処理は、前述した文書取得処理と同様である。構造化文書管理システムから返されるXML文書は、図38の画面の領域W3に表示される。
【0216】
図38に示すように、領域R3には、「特許」情報のデータ入力領域が各要素毎に設定されて表示されている。この表示に従って、ユーザは、データを入力すればよい。例えば、「タイトル」、「年」などのデータ入力領域が階層的に配置され、表示されている。ユーザは、このデータ入力領域にデータを入力することで、スキーマにより定義された文書構造の格納文書が容易に作成することができる。
【0217】
また、領域W3に入力した「特許」情報の格納先として、領域W1で「特許DB」をマウス等を用いて選択すると、領域W2に構造化文書パスとして、「uix://root/特許DB」が表示される。その後、「登録」ボタンB1を選択すると、「appendXML(“uix://root/特許DB”,“<特許>…</特許>”)」なる追加コマンドが構造化文書管理システムへ送信される。
【0218】
この場合、格納文書は、予めスキーマに従って入力されたものなので、図20のステップS10の妥当性チェックでエラーとなることはない。
【0219】
(2)検索機能
図1の構造化文書管理システムにおける検索系のコマンドには以下のものがある。
【0220】
query(ql)
「query」は、パラメータとして( )内のクエリqlを実行し、その結果のXML文書を取得するコマンド(以下、検索コマンドと呼ぶ)である。
【0221】
クエリは、図39に示すように、SQL(Structured QueryLanguage)に似た形式の言語により、検索位置、検索条件、情報抽出部分などを記述した、構造化されたXML文書である。クエリ文書も構造化文書管理システムの管理対象である。
【0222】
「kf:from」タグから始まる要素には、検索位置の指定と文書要素の値に変数を対応付ける記述があり、「kf:where」タグのから始める要素には、変数に関する条件づけの記述があり、「kf:select」タグから始まる要素には、検索結果の出力形式が記述される。
【0223】
検索には、単純検索と概念検索とがある。単純検索とは、クエリ中に指定された検索条件を満たす情報を検索・抽出するものであり、概念検索とは、クエリ中に指定された概念情報を利用して、クエリ中に指定された検索条件を満たす情報を検索・抽出するものである。
【0224】
図40は、単純検索のクエリの例を示したものである。図40のクエリは、例えば、図14に示したような状態の構造化文書データベースに対し、「特許DB」アークが示すノード以下に格納されている「特許」情報の文書群において、「1999年でかつ、「PC」のような内容の「要約」という要素をもつ文書(「特許」情報)の「タイトル」を列挙せよ」という検索要求を意味している。
【0225】
「kf:from」タグから始まる要素の記述により、変数「$t」、「$y」、「$s」に、それぞれ「特許」情報の「タイトル」、「年」、「要約」という文書要素の値が代入される。
【0226】
「kf:where」タグから始める要素の記述により、変数「$y」=「1999」という比較がなされる。また、コンポーネント「MyLike」は変数「$s」と「PC」を引数として、「PC」と類似する値の変数「$s」を検知するための関数である。
【0227】
「kf:from」タグから始まる要素の記述により、変数「$t」が出力値として利用される。
【0228】
なお、「kf:star」タグは構造の曖昧表現であり、例えば「<特許><kf:star><年>」は「タグ名が「特許」である要素の子孫の要素としていずれかに存在し、タグ名が「年」である要素」を意味する。
【0229】
図41に図40の単純検索のクエリを用いた検索結果を示す。この検索結果もXML文書である。
【0230】
図42は、概念検索のクエリの例を示したものである。図42のクエリは、例えば図18,図19に示すような状態の構造化文書データベースに対し、「特許DB」アークが示すノード以下に格納されている「特許」情報の文書群に対し、「概念DB」アークが示すノード以下に格納されている「概念」情報を利用して検索するための検索要求である。ここで、概念「周辺装置」の値をもつタグの子要素の値には、概念「SCSI」、「メモリ」、「HDD」などがあるものとする。また、図18には示していないが、各「特許」情報の構成要素には、「キーワード」タグから始める要素も存在するものとする。
【0231】
すなわち、図42のクエリは、「概念「周辺装置」以下の概念のいずれかを「キーワード」という要素の値にもつ文書(「特許」情報)の「タイトル」を列挙せよ」という検索要求を意味している。
【0232】
「kf:from」タグから始まる要素の記述により、変数「$t」、変数「$k」に、それぞれ、「特許」情報の「タイトル」、「キーワード」という要素の値が代入される。また、変数「$x」は「概念」情報として「周辺装置」の値をもつタグの子要素の値(「SCSI」、「メモリ」、「HDD」など)が代入される。
【0233】
「kf:where」タグから始める要素の記述により、「$k」=「周辺装置」もしくは「$k」=「$x」という比較がなされる。
【0234】
次に、図1の構造化文書管理システムの文書検索処理動作について、図43に示すフローチャートを参照して説明する。
【0235】
図31に示した画面上で、ユーザが「XML検索Win」をマウス等のポインティングデバイスなどを用いて選択すると、図44に示すような文書検索を行うためのユーザインタフェースとしての画面が表示される。
【0236】
図44の検索画面において、領域W1には、前述同様、構造化文書データベースの現在のツリー構造の要素名(タグ名)がユーザが理解可能なように簡略的に表示されてている。
【0237】
領域W2は、検索対象の範囲(ツリー構造上の検索範囲)や、検索条件などを入力するための領域である。領域W3には、検索結果が表示される。
【0238】
例えば、「「uix://root」以下の「特許」を先頭タグに持つ文書の中から、「タイトル」タグに「文書」という文字列を含み、「1998」年以降に作成された文書を検索せよ」という検索要求の場合には、領域W1から「root」をマウス等で選択して検索対象の範囲として、構造化文書パスを入力する。そして、トップノードとして、「特許」を入力する(この場合、領域W1から「特許」をマウス等で選択することにより入力してもよい)。また、検索条件として、「「タイトル」という要素の値に「文書」という文字列を含む」「「年」という要素の値が「1998」以上である」という内容を予め設定されたデータ入力領域に入力すればよい。
【0239】
その後、「検索」ボタンB21を選択することにより、例えば、図45に示すようなクエリが、当該クエリを構造化文書データベース上に格納するための追加コマンドとともに構造化文書管理システムへ送信される。クエリの格納場所は、予め定められており、システム側が自動的に、この追加コマンドのパラメータを設定することとなる。例えば、構造化文書データベースが図18に示した状態のとき、当該クエリの格納場所を表すパラメータとしての構造化文書パスは、「uix://root/クエリDB」となる。また、追加コマンドのもう一方のパラメータは、当該クエリ文書である。
【0240】
要求受付部11は、上記クエリを受け付けると(ステップS101)、当該クエリを検索要求処理部3へ渡す。そして、当該クエリ文書を格納するための追加コマンドのパラメータを文書格納部21へ渡す。この追加コマンドの処理を、前述同様に行って、当該クエリは、文書記憶部5に格納される。
【0241】
例えば、図42に示すようなクエリの場合、構造化文書データベースには、図46に示すように展開されて、構造化文書パス「uix://root/クエリDB」の示す「#301」ノード以下にリンクされる。
【0242】
一方、検索要求処理部3では、受け取ったクエリを基に、データアクセス部4を通してインデックス記憶部6,文書記憶部5にアクセスし、検索要求に合致する文書集合などを取得して、クエリの中で要求された情報を抽出して結果処理部12を介して出力する。
【0243】
例えば、上記クエリの場合、まず、「「タイトル」タグに「文書」という文字列を含む」という条件に合致するものを検索することが検索対象を絞り込む上で効率がよい。そこで、図10に示したようなデータ生起インデックスを用いて、「文書」という文字列にリンクされているノード(文書オブジェクト)のオブジェクトIDを得る。そして、そのそれぞれについて、文書オブジェクトツリーを上流側に1つ遡り、「タイトル」というタグ名にたどり着いたときは、更に上流に辿っていき、「特許」というタグ名にたどり着いたときは、そのノード以下の文書オブジェクトツリーOt11を抽出する。
【0244】
次に、この抽出された複数の文書オブジェクトツリーOt11の中から、さらに、「年」という要素の値が「1998」年以上の文書オブジェクトツリーOt12を抽出する。
【0245】
この文書オブジェクトツリーOt12が上記クエリの内容に適合する文書となる。さらに上記クエリの要求内容に従えば、各文書オブジェクトツリーOt12のトップノードへの構造化文書パスを求める(ステップS102)。
【0246】
なお、上記検索処理は、上記した方法に限るものではなく、インデックス情報を用いた様々な効率のよい検索方法が可能である。
【0247】
検索要求処理部3は、ステップS102で得られた結果を統合して、検索結果としてのXML文書を作成する(ステップS103)。
【0248】
例えば、検索結果のXML文書は、
【0249】
検索要求処理部3は、検索結果処理部12を介して、上記XML文書をスタイルシートとともに、要求元のクライアント端末に返す(ステップS104)。
【0250】
クライアント端末では、図11に示したXML文書を、スタイルシートを用いてHTMLデータに変換して、例えば、図44に示すように、領域W12に表示する。
【0251】
同様にして、スキーマの検索も行える。
【0252】
例えば、「「uix://root」以下の「schema」を先頭タグに持つ文書の中から、「特許」と「要約」というタグ名を持つスキーマを検索せよ」という検索要求の場合には、図47に示すように、領域W1から「root」をマウス等で選択して検索対象の範囲として、構造化文書パスを入力する。そして、トップノードとして、「#schema」を入力する。また、検索条件として、「要素の属性名に「特許」という文字列を含む」「要素の属性名に「要約」という文字列を含む」という内容を予め設定されたデータ入力領域に入力すればよい。
【0253】
その後、「検索」ボタンB21を選択することにより、上記検索要求を記述したクエリ(図48参照)が、当該クエリを構造化文書データベース上に格納するための追加コマンドとともに構造化文書管理システムへ送信される。
【0254】
さて、上記クエリの場合、例えば、「「#schema」を先頭タグに持つ」という条件に合致するものを検索する。そこで、図9に示したような要素名称生起インデックスを用いて、「#schema」という要素にリンクされているノードの(文書オブジェクト)のオブジェクトIDを得る。そして、そのそれぞれについて、文書オブジェクトツリーを下流側にアークを辿っていき、属性名が「特許」と「要約」いう要素にたどり着いたときは、当該「#schema」を先頭タグにもつ文書オブジェクトツリーOt21を抽出する。この文書オブジェクトツリーOt21が上記クエリの内容に適合する文書となる。さらに、図48に示したクエリの要求内容に従えば、各文書オブジェクトツリーOt21のトップノードへの構造化文書パスを求める。
【0255】
検索要求処理部3は、文書オブジェクトツリーOt21が複数あれば、それぞれのトップノードへの構造化文書パスをまとめて、検索結果としてのXML文書を作成し、検索結果処理部12を介して、上記XML文書をスタイルシートとともに、要求元のクライアント端末に返す。
【0256】
クライアント端末では、検索結果として受け取ったXML文書を、スタイルシートを用いてHTMLデータに変換して、例えば、図44に示すように、領域W12に表示する。
【0257】
クライアント端末では、検索結果の中の1つのスキーマを選択して、表示させると、例えば、図38に示すような文書の格納/削除を行うための画面とともに、その領域W3に、「特許」情報のデータ入力領域が各要素毎に設定されて表示される。
【0258】
ユーザは、このデータ入力領域にデータを入力することで、スキーマにより定義された文書構造の格納文書が容易に作成することができる。
【0259】
例えば、図38の領域W3に入力した「特許」情報の格納先として、領域W1で「特許DB」をマウス等を用いて選択すると、領域W2に構造化文書パスとして、「uix://root/特許DB」が表示される。その後、「登録」ボタンB1を選択すると、「appendXML(“uix://root/特許DB”,“<特許>…</特許>”)」なる追加コマンドが構造化文書管理システムへ送信される。
【0260】
この場合、格納文書は、予めスキーマに従って入力されたものなので、図20のステップS10の妥当性チェックでエラーとなることはない。
【0261】
同様にして、クエリの検索も行える。クエリを検索して、検索結果として得られた既存のクエリを加工して、再利用することもできる(クエリの再利用)。
【0262】
クエリの検索は、前述したような構造化文書の検索と同様にして行われ、その検索範囲は、クエリ群の格納されている構造化データベース上の一部の文書オブジェクトツリーとなる。
【0263】
例えば、図18に示したような状態の構造化文書データベースから、「kf:from」タグに「特許DB」を含むクエリを検索する場合について説明する。そのような検索要求を記述したクエリを図49に示す。
【0264】
図49に示すクエリは、「「uix://root/クエリDB」の示す「#301」ノード以下に存在するクエリの中から「kf:from」タグに「特許DB」を含むクエリを検索し、その内容(タグ名が「query」である要素以下の文書オブジェクトツリーの文書)を列挙せよ」を意味するものである。
【0265】
なお、「kf:as」タグの内容で変数「$elt」に、「kf:from」タグに「特許DB」を含むクエリのタグ名が「query」である要素以下の文書オブジェクトツリーが代入される。
【0266】
このクエリを検索要求処理部3が処理する際には、前述同様にして、例えば、図9に示したような要素名称生起インデックスを用いて、「kf:from」という要素にリンクされているノードの(文書オブジェクト)のオブジェクトIDを得る。そして、そのそれぞれについて、文書オブジェクトツリーを下流側にアークを辿っていき、「特許」というタグ名にたどり着いたときは、さらに、上流側にアークを辿って「query」というタグ名に辿りついたとき、当該「query」を先頭タグにもつ文書オブジェクトツリーOt31を抽出する。この文書オブジェクトツリーOt31が上記クエリの内容に適合する文書となる。
【0267】
複数の文書オブジェクトツリーOt31が検索されたら、それらを統合して、XML文書を作成して、それをスタイルシートとともにクライアント端末へ返す。
【0268】
クライアント端末では、検索結果の中の1つのクエリを選択して、表示させると、例えば、図44に示した検索画面の領域W11に、各データ入力領域にデータの入力された状態で、当該クエリに記述された検索要求の内容が表示される。
【0269】
ユーザは、この状態から、「「uix://root」以下の「特許」を先頭タグに持つ文書の中から、「タイトル」タグに「文書」という文字列を含み、「1998」年以降に作成された文書を検索せよ」という当該クエリに記述された検索要求中の「文書」を「XML」に変更して、「検索」ボタンB21を選択すれば、「「uix://root」以下の「特許」を先頭タグに持つ文書の中から、「タイトル」タグに「XML」という文字列を含み、「1998」年以降に作成された文書を検索せよ」という意味のクエリが構造化文書管理システムへ送信される。
【0270】
以上説明したように、図1の構造化文書管理システムでは、構造化文書データベース上に登録される文書構造が異なる膨大な数のXML文書群(コンテンツ文書、スキーマ文書、クエリ文書など)を、図18,図19に示すように、「root」タグを先頭に持つツリー状の1つの巨大なXML文書として取り扱う。従って、文書構造が異なる、様々なスキーマを持つ膨大な数の文書の中から検索条件に合致する文書を容易に検索できる。
【0271】
また、検索に用いるクエリも構造化文書であるので、構造化文書データベースにログとして格納することにより、過去のクエリを再利用するようなアプリケーションも容易に構築することができる。
【0272】
(3)適用例
次に、上記概念検索の特許調査への適用例について説明する。
【0273】
図50は、特許調査における構造化文書データベースの一例であり、「特許」情報の他に、「概念」情報も格納している。
【0274】
特許調査において、最も重要となってくる作業は、関連する「特許」情報を収集し、「特許」情報を様々な観点から分析し、特許マップ(図54参照)を作成することである。特許マップを作成するために、従来、特許マップにおける縦軸、横軸を予め決定し、それに従い、縦軸に並ぶ任意の項目と横軸に並ぶ任意の項目とを検索条件とした検索を逐次行うという方法がとられ、この部分に非常に莫大なコストがかかっていた。しかし、構造化文書管理システムを用いることで、この部分のコストを大幅に減少させることが可能となる。
【0275】
なお、ここで、マップとは、縦軸(y軸)に並ぶ任意の項目と横軸(x軸)に並ぶ任意の項目とを検索条件とした検索結果をx軸とy軸とを分類軸として分類整理するものである。
【0276】
構造化文書管理システムで、クライアント端末のユーザが図54に示すような特許マップを作成しようとする場合、ユーザは、クライアント端末上の表示装置に表示される図50に示すような構造化文書データベースの現在のツリー構造を参照して、図51に示すような検索画面上に、分析対象の範囲とする「特許」情報のパスと、分析の軸(例えば、x軸、y軸)となる要素を、それぞれ領域W21、W22に入力する。分析の軸となる要素は、構造化文書データベース内の「特許」情報の要素、「概念」情報の要素のいずれであってもよい。
【0277】
例えば、図51では、x軸に「機能」、y軸に「技術」という「概念」情報の要素を入力している。
【0278】
その後、ユーザは、「実行」ボタンB31を選択すると、クライアント端末から図1の構造化文書管理システムへ、図52に示したようなクエリが送出される。
【0279】
この場合のクエリには、「「特許DB」アークが示すノード以下に格納されている「特許」情報の文書群の中から、「概念DB」アークが示すノード以下に格納されている、概念「機能」の子要素のいずれかと概念「技術」の子要素のいずれかとを、「キーワード」や「要約」などの要素の値に含む「特許」情報を検索せよ。検索結果として、「機能」の子要素と「技術」の子要素と、それらに対応する「特許」情報の「公開番号」との組を列挙せよ。」という意味の検索要求である。
【0280】
概念「機能」には、「検索」「格納」…「分析支援」という子要素があり、概念「技術」には、「実装データベース」「反構造データベース」「自然言語処理」…という子要素があるものとする。
【0281】
上記クエリを受けた構造化文書検索システムの検索要求処理部3では、例えば、図10に示したようなデータ生起インデックスを用いて、概念「機能」の各子要素(文字列)にリンクされているノード(文書オブジェクト)のオブジェクトIDを得る。そして、そのそれぞれについて、文書オブジェクトツリーを上流側に遡り、「特許」というタグにたどり着いたときは、さらに、そのノード以下の文書オブジェクトツリーを下流側に辿って概念「技術」の子要素(文字列)のいずれかにリンクされているタグ名にたどり着いたときは、当該文書オブジェクトツリーと、その「公開番号」タグにリンクされている文字列(要素値)を抽出する。このようにして、抽出された「特許」情報のそれぞれについて、対応の「機能」の子要素と「技術」の子要素と「公開番号」との組を統合して、図53に示すような検索結果としてのXML文書を作成、要求元のクライアント端末へ、所定のスタイルシートとともに返す。
【0282】
これらを受け取ったクライアント端末の表示装置には、図54に示したような表形式の特許マップが表示されることになる。
【0283】
このように、所望の概念を「軸」として指定するだけで、構造化文書データベースに蓄積された情報を「軸」として指定された概念に基づき集計・分類して、マップ表示するこたが容易に行える。すなわち、構造化文書データベースに蓄積された情報を、「概念」情報を用いて様々な観点で集計・分類することが容易に行える。
【0284】
(本発明の実施形態の説明)
以下、本発明の実施の形態について図面を参照して説明する。
【0285】
クエリに基づき、上記構造化文書データベースに対し検索を行う場合、検索条件などが同一のクエリがクライアント端末から送られてくることもある。このような場合、同じクエリを受け取る度に同じ検索を何度も行うことは効率的でない。そこで、頻繁に実行されるクエリについては、そのクエリを実行した結果、すなわち、検索結果を当該クエリに対応付けて一時格納する。再度同じクエリを受け付けた時には、検索を実行せずに、この一時格納した検索結果を返すようにすることで、検索のための処理時間の短縮が図れる。
【0286】
図55は、上記したような機能を有する構造化文書管理システムの構成例を示したものである。なお、図55において、図1と同一部分には同一符号を付し、異なる部分についてのみ説明する。すなわち、図55では、検索結果を一時記憶する検索結果記憶部201と、実行権限情報テーブル202とが新たに追加されている。
【0287】
検索結果記憶部201には、文書記憶部5、すなわち、構造化文書データベースに格納されているクエリを実行した結果、得られた検索結果が当該クエリに対応付けて記憶されている。
【0288】
実行権限情報テーブル202は、後述するように、クエリ実行権限のあるユーザと、クエリの実行権限はないが、そのクエリの検索結果は参照可能なユーザの識別情報を登録したテーブルである。
【0289】
このような構成の構造化文書管理システムの文書記憶部5に格納されている構造化文書データベースは、現在、図56に示すような状態である場合を考える。。
【0290】
なお、図56に示した構造化文書データベースの構造化文書の格納状態は、ノードやアークを簡略化し、ノードをオブジェクトIDではなく要素名や属性名で表して文書オブジェクトツリーの構造、しいていは、構造化文書データベースの構造を示している。
【0291】
図56において、「root」ノード以下には、「特許DB」ノードと「クエリDB」ノードがある。「特許DB」ノード以下には、図57に示すような文書構造の複数の「特許」情報が格納されている。「クエリDB」ノード以下には、複数のクエリ文書(XML文書)が格納されている。
【0292】
図57に示すように、「特許」情報は、「特許」タグから始まる要素をルート(根)とし、その子要素として「タイトル」、「出願日」、「出願者」、「要約」、「キーワード群」タグから始まる要素集合が存在する。また、「出願日」タグから始まる要素には、「年」「月」「日」タグか始める子要素を有し、「キーワード群」タグから始める要素には、1または複数の「キーワード」タグから始める子要素が存在する。
【0293】
図56に示すように、構造化文書データベースには、予め複数のクエリ(ここでは、インデックス([0]、[1]、…)を用いて表記されたクエリ[0]、クエリ[1]、…をそれぞれクエリA、クエリB、…と呼ぶ)が格納されている。
【0294】
第2の実施形態では、第1の実施形態で説明したような、クライアント端末から検索条件などを入力することにより作成されたクエリを構造化文書管理システムにて受け付けて検索を実行する以外に、構造化文書データベースに予め格納されているクエリから所望のクエリを選択し、検索結果格納部201に当該クエリに対応の検索結果が格納されているときは、その検索結果を読み出して、それをクライアント端末へ返すようになっている。
【0295】
構造化文書データベースに予め格納しておくクエリは、例えば、頻繁に用いられる検索条件のクエリであるとか、予め検索が予想されるクエリ、複数のユーザからユーザグループ内である特定の用途のために用いるクエリなど種々考えられる。
【0296】
例えば、図56に示した構造化文書データベースに格納されているクエリのうちの1つであるクエリA(クエリ[0]ノード以下の部分文書に対応する)は、図58に示すような内容のクエリであったとする。
【0297】
図58に示すクエリは、単純検索のクエリの例を示したもので、図56に示したような状態の構造化文書データベースに対し、「特許DB」アークが示すノード以下に格納されている「特許」情報の文書群において、「1999年以降でかつ、「XML」をキーワードにもつ(「キーワード」という要素の値が「XML」である「特許」情報の「タイトル」を列挙せよ)という検索要求を意味している。
【0298】
図58に示したクエリAを検索要求処理部3で実行することにより、例えば、図59に示したような検索結果Aが得られたとする。
【0299】
検索結果記憶部201には、上記クエリAと上記検索結果Aとが対応付けて、例えば、図60に示すようにテーブル形式で記憶される。
【0300】
クエリAを含む、構造化文書データベースに格納されている各クエリは、その論理的な格納領域を表す構造化文書パスにより、識別される。すなわち、各クエリの識別情報は、その構造化文書パスであり、例えば、クエリAの識別情報は、「uix://root/クエリDB/クエリ[0]」となる。なお、説明の簡単のため、図60以降の記述、および、以下の説明において、クエリ識別情報に関しては、「uix://root」を省略して、「/クエリDB/クエリ[0]」と簡略化する。
【0301】
検索要求処理部3に図60に示しような検索結果記憶部201を持たせることにより、図55の構造化文書管理システムは、図61に示すような動作が可能となる。
【0302】
この場合、クライアント端末の所定の表示装置には、構造化文書管理システム100(の例えば、要求制御部1)から提供された、例えば、図70に示すようなユーザインターフェイスとしての画面が表示されている。
【0303】
図70に示す画面の領域W101には、文書構造化文書データベースの現在のツリー構造のうちの一部であって、クエリ格納領域のツリー構造について、ユーザが理解可能なように簡略的に表示されている。なお、図70では、上位階層の要素名のみを表示しているが、末端の要素名まで表示可能である。また、領域W102は、クエリの構造化文書パスの入力領域であり、領域W101の表示内容に従って、構造化文書パスを入力するようになっている。領域102にユーザが所望のクエリの構造化文書パスを入力した後、「検索実行」ボタンW103をクリックすると、クライアント端末からは、構造化文書パスにてクエリを指定した検索要求が構造化文書管理システムへ送信される。
【0304】
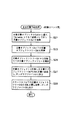
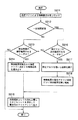
この検索要求は、例えば、予め定められた形式のコマンドとして(以下、簡単に検索要求コマンドと呼ぶ)、要求受付部11で受け付けられる(ステップS201)。要求受付部11は、当該検索要求コマンドを検索要求処理部3へ渡す。検索要求処理部3は、検索要求コマンドに含まれるクエリ識別情報としての構造化文書パスを取出し、検索結果記憶部201から、当該構造化文書パスのクエリ対応の検索結果が格納されているか否かチェックする。
【0305】
当該クエリ対応の検索結果が格納されているときは(ステップS202)、その検索結果を読み出し(ステップS203)、結果処理部12を介して、XML文書としての当該検索結果を所定のスタイルシートとともに、要求元のクライアント端末に返す(ステップS204)。
【0306】
検索要求処理部3が実際に検索を実行するのは、上記ステップS202において、検索結果記憶部201に指定されたクエリ対応の検索結果が格納されていない場合である。この場合は、まず、構造化文書パスにて指定されたクエリをデータアクセス部4で構造化文書データベースから取得する(前述した、パスから文書オブジェクトツリー取得部45における取得コマンドの実行時と同様)。そして、この取得したクエリを用いて、図43のステップS102〜ステップS103に示したようにして、検索処理を行う(ステップS205)。そして、検索結果を要求元のクライアント端末に返す前に、クエリ識別情報に対応付けて検索結果記憶部201に格納する(ステップS206)。
【0307】
さて、構造化文書データベースは、随時、新たな構造化文書が追加登録されたり、削除されたりして更新されるわけだが、構造化文書データベース自体が更新されれば、同じクエリによる検索であってもデータベースの更新前と更新後の検索結果は異なることもある。
【0308】
上記したように、実際には検索を実行せずに、検索結果記憶部201に格納されている検索結果を読み出すといった動作を行う場合、データベース自体の更新に伴い、その更新を検索結果にも反映することが好ましい。
【0309】
そこで本発明では、そのための一手段として、ある特定のユーザが一定時間毎にクエリを実行し、その度に、得られた検索結果で検索結果記憶部201の内容を更新するようにする。このように、一定時間毎に検索結果記憶部201に記憶されている検索結果を更新しておくことで、構造化文書データベースの更新内容が検索結果に反映することができるとともに、検索結果とデータベースの状態との整合性を保つことができる。
【0310】
検索を実行可能な上記特定のユーザを予め定めて、一定時間毎に検索結果の更新をおこなうことにより、データベースと検索結果との内容の整合性を保つために、本発明では、具体的には、クライアント端末のユーザには上記構造化文書パスにて識別される各クエリについて、当該クエリを実行させることが可能なユーザと、当該クエリにより検索結果を参照することが可能なユーザと限定するために、クエリ実行権限と検索結果参照権限なるものを予め定めるようになっている。
【0311】
クエリ実行権限のあるユーザ(クエリ実行権限ユーザ)は、例えば、当該クエリを作成した者とする。また、例えば、このクエリ実行権限ユーザにより当該クエリによる検索結果の参照が許可されたユーザが検索結果参照権限ユーザである。図62に示すように、各クエリ毎に予め定められたクエリ実行権限ユーザと検索結果参照権限ユーザの識別情報をテーブル形式で登録したものが、実行権限情報テーブル202である。
【0312】
なお、クエリ実行権限ユーザは、検索結果参照権限ユーザでもある。
【0313】
図62に示すように、実行権限情報テーブルには、クエリ識別情報としての各クエリの構造化文書パスに対応させて、クエリ実行権限ユーザと検索結果参照権限ユーザのそれぞれのユーザ識別情報が列挙されている。
【0314】
このように、クエリ毎に当該クエリを実行させることが可能なユーザと、当該クエリにより検索結果を参照することが可能なユーザとを限定することにより、例えば、だれもかれもが、むやみやたらに検索を実行して、同じクエリによる検索結果であるのに、(データベースの内容が更新されていることにより)検索結果が様々になってしまうことを防ぎ、少なくとも上記一定期間の間は、誰が要求をしても同じクエリによる検索結果が同じであるという好ましい状態を作り出すことができる。これは、検索結果とデータベースの内容の整合性と保つためには重要なことである。
【0315】
なお、実行権限情報テーブルは、例えば、クライアント端末に図62に示したな入力画面が表示され、このような入力画面から所定の事項を入力して、システムに登録するようになっていてもよい。
【0316】
検索要求処理部3に図60に示しような検索結果記憶部201と図62に示したような実行権限情報テーブル202とを持たせることにより、図55の構造化文書管理システムは、図63に示すような動作が可能となる。
【0317】
すなわち、クライアント端末からは、例えば、図70に示したような入力画面を介して、構造化文書パスにてクエリを指定した検索要求が構造化文書管理システムへ送信される。この検索要求は、例えば、予め定められた形式のコマンドとして(以下、簡単に検索要求コマンドと呼ぶ)、要求受付部11で受け付けられる(ステップS211)。要求受付部11は、当該検索要求コマンドを検索要求処理部3へ渡す。
【0318】
検索要求処理部3は、検索要求コマンドに含まれるクエリ識別情報としての構造化文書パスを取出し、当該クエリによる前回の検索実行時から、予め定められた一定期間が経過したか否かをチェックする。このチェックのために、検索要求処理部3は、予めタイマを持つものとする(ステップS212)。
【0319】
一定期間がまだ経過していないときは、ステップS213へ進み、実行権限情報テーブル202を参照する。
【0320】
検索要求コマンドに含まれる要求元のユーザの識別情報が、実行権限情報テーブル202に当該クエリ対応の検索結果参照権限ユーザあるいはクエリ実行権限ユーザとして登録されているときは(ステップS213)、検索結果記憶部201から、当該構造化文書パスのクエリ対応の検索結果を読み出し(ステップS214)、結果処理部12を介して、XML文書としての当該検索結果を所定のスタイルシートとともに、要求元のクライアント端末に返す(ステップS215)。
【0321】
上記ステップS212において、上記一定期間が経過しているときは、ステップS216へ進み、実行権限情報テーブル202を参照する。
【0322】
検索要求コマンドに含まれる要求元のユーザの識別情報が、実行権限情報テーブル202に当該クエリ対応のクエリ実行権限ユーザとして登録されているときは(ステップS216)、まず、構造化文書パスにて指定されたクエリをデータアクセス部4で構造化文書データベースから取得する(前述した、パスから文書オブジェクトツリー取得部45における取得コマンドの実行時と同様)。そして、この取得したクエリを用いて、図43のステップS102〜ステップS103に示したようにして、検索処理を行う(ステップS217)。そして、検索結果を要求元のクライアント端末に返す(ステップS215)前に、クエリ識別情報に対応付けて検索結果記憶部201に格納する(ステップS218)。
【0323】
前述した、構造化文書データベース自体の更新に伴い、その更新を検索結果にも反映するための他の手段としては、本発明では、構造化文書データベースの更新を検知して、そにより自動的に検索結果を更新するようになっている。
【0324】
この構造化文書データベースの更新を検知して、検索結果の自動更新を行うための主要な機能を担うのが、図64のイベント検出部203である。
【0325】
ここでは、構造化文書データベースの更新をイベントとして検知する。例えば、構造化文書データベースの構造上のどこがどのように更新されたか、また、いつ更新されたかにより、その更新が検索結果に影響を及ぼすクエリとそうでないクエリとが存在するので、各クエリ対応のイベントを設定し、各クエリ対応のイベントを検知するために、各イベントの条件(イベント条件)を設定する。
【0326】
イベント検出部203は、図65に示しようなイベントテーブル204を予め記憶している。このイベントテーブル204には、構造化文書データベースの更新をイベントとして検知するための条件や、当該条件を満たすイベントが検出されたとき、(検索結果を更新すべく)検索を実行するためのクエリを示した検索結果更新パスとが、当該条件を登録したユーザ(イベントユーザ)に対応付けて登録されている。
【0327】
なお、イベントテーブル中の「イベントユーザ」の欄は、イベントテーブルにユーザが明示的に登録するのではなく、構造化文書管理システムにアクセスする際にユーザにより入力されるユーザ識別情報に基づきシステム側が自動的に登録することが望ましい。
【0328】
このイベントテーブルに登録されているイベントには大きく分けて、日時イベントとデータ操作イベントとがある。
【0329】
日時イベントは、構造化文書データベースに対する何らかの操作(例えば、insertXML:文書格納、appendXML:文書格納、removeXML:文書削除、などのコマンドの実行に伴う構造化文書データベースの更新)には関係なく、イベント条件として指定した日時が到来したとき、イベントとして検知される。例えば、図65では、イベント番号「3」に登録されているイベントは「2001年2月27日木曜日12時00分00秒になったときイベントとして検知し、その際、検索結果更新パスで指定されたクエリ「/クエリDB/クエリ[2]」で検索を実行し、検索結果記憶部201に格納されている当該クエリの検索結果を更新する」ためのものである。なお、このようなイベントを登録したユーザ(イベントユーザ)の識別情報が「kanawa」である。
【0330】
データ操作イベントは、構造化文書データベースに対し、イベント条件として指定した構造化文書パス以下に、イベント条件として指定した何らかの操作(例えば、insertXML:文書格納、appendXML:文書格納、removeXML:文書削除、などのコマンドの実行に伴う構造化文書データベースの更新)がなされたときに、イベントとして検知される。例えば、図65では、イベント番号「1」に登録されているイベントは「構造化文書パス「/特許DB」以下の領域に文書格納コマンドが実行されたときイベントとして検知し、その際、検索結果更新パスで指定されたクエリ「/クエリDB/クエリ[0]」で検索を実行し、検索結果記憶部201に格納されている当該クエリの検索結果を更新する」ためのものである。なお、このようなイベントを登録したユーザ(イベントユーザ)の識別情報が「niina」である。
【0331】
例えば、図71に示すような入力画面をクライアント端末に表示して、図65に示したイベントテーブルに各イベントを登録するようにしてもよい。
【0332】
図71に示した入力画面には、日時イベント、データ操作イベント、検索結果更新パスの設定を行うためのそれぞれの入力領域W111〜W114が設けられており、ユーザは、必要な事項を入力してから「登録」ボタンW115をクリックすればよい。すると、構造化文書管理システムへ、上記入力内容が送信されて、イベントテーブル204に登録される。
【0333】
なお、イベントテーブルに登録されている各イベント対応のイベントユーザとは、図62に示した各クエリ毎に定められたクエリ実行権限ユーザに相当する。すなわち、クエリ実行権限ユーザが図65に示したようなイベントテーブルにイベントを登録することにより、クエリ実行権限ユーザが、実際にクエリを実行させるのではなく、クエリ実行権限ユーザに代わってシステム自身がクエリを実行するようになっている。
【0334】
もちろん、上記イベントテーブルに登録された各イベント検知時に各クエリを実行する際に、そのクエリの実行権限の有り無しを考慮せずとも、本発明の目的(構造化文書データベースと検索結果との内容の整合性を保つこと)は達成される。
【0335】
図66は、図64の構造化文書管理システムの処理動作を示したもので、上記イベントテーブルに登録された各イベント検知時に各クエリを実行する際に、そのクエリの実行権限の有り無しを考慮しない場合を示したフローチャートである。
【0336】
イベント検出部203は、データアクセス部4の文書オブジェクトツリー格納部41,文書オブジェクトツリー削除部42などで、insertXML:文書格納、appendXML:文書格納、removeXML:文書削除、などのコマンドに対応する処理の実行がされたか否か、また、イベント検出部203が持つタイマを参照して、イベントテーブルにイベント条件として設定された日時が到来したか否かを常時監視している(ステップS221)。図65に示したイベントテーブルに登録されているイベント条件のいずれかを満たすイベントを検知したとき(ステップS222)、その検知したイベントに対応する検索結果更新パスをイベントテーブルから取得する(ステップS223)。
【0337】
まず、検索結果更新パスにて指定されたクエリをデータアクセス部4で構造化文書データベースから取得する(前述した、パスから文書オブジェクトツリー取得部45における取得コマンドの実行時と同様)。そして、この取得したクエリを検索要求処理部3に渡し、検索要求処理部3では、当該受け取ったクエリを用いて、図43のステップS102〜ステップS103に示したようにして、検索処理を行う(ステップS224)。
【0338】
検索処理部3は、検索結果を当該クエリのクエリ識別情報に対応付けて検索結果記憶部201に格納する(ステップS225)。
【0339】
次に、図67に示すフローチャートを参照して、上記イベントテーブルに登録された各イベント検知時にその検知されたイベント対応のクエリを実行する際に、そのクエリの実行権限の有り無しを考慮する場合の図64に示した構造化文書管理システムの処理動作について説明する。
【0340】
さて、イベント検出部203は、図66の場合と同様、データアクセス部4の文書オブジェクトツリー格納部41,文書オブジェクトツリー削除部42などで、insertXML:文書格納、appendXML:文書格納、removeXML:文書削除、などのコマンドに対応する処理の実行がされたか否か、また、イベント検出部203が持つタイマを参照して、イベントテーブルにイベント条件として設定された日時が到来したか否かを常時監視している(ステップS231)。図65に示したイベントテーブルに登録されているイベント条件のいずれかを満たすイベントを検知したとき(ステップS232)、その検知したイベントに対応するイベントユーザの識別情報と検索結果更新パスとをイベントテーブルから取得する(ステップS233)。
【0341】
この取得したイベントユーザの識別情報と検索結果更新パスは、イベント検出部203から検索要求処理部3へ渡される。
【0342】
検索要求処理部3は、図62に示したような実行権限情報テーブルから、受け取った検索結果更新パスにて指定されたクエリに対し実行権限のあるユーザ(クエリ実行権限ユーザ)の識別情報を取出し、それと、イベント検出部203から受け取ったイベントユーザの識別情報とを比較し(ステップS234)、それらが一致しているときには、ステップS235へ進み、当該検索結果更新パスにて指定されたクエリを実行する(ステップS235)。
【0343】
すなわち、まず、検索結果更新パスにて指定されたクエリをデータアクセス部4で構造化文書データベースから取得する(前述した、パスから文書オブジェクトツリー取得部45における取得コマンドの実行時と同様)。そして、この取得したクエリを検索要求処理部3に渡し、検索要求処理部3では、当該受け取ったクエリを用いて、図43のステップS102〜ステップS103に示したようにして、検索処理を行う(ステップS235)。
【0344】
検索処理部3は、検索結果を当該クエリのクエリ識別情報に対応付けて検索結果記憶部201に格納する(ステップS236)。
【0345】
なお、ステップS234で、クエリ実行権限ユーザとイベントユーザとが異なるときは、イベント検出部203から受け取ったクエリの実行を拒否し、処理を終了する。
【0346】
このように、イベント検知時に、そのイベントの実行権限のあるユーザと、当該イベントの条件を登録したイベントユーザが同じであるか否かをチェックすることにより、例えば、実行権限のないユーザにより、イベントテーブルに、正当なクエリ実行権限ユーザが定められているクエリを用いた検索実行のイベント条件が登録された場合、そのようなイベントにより当該クエリが実行されることを防ぐことができる。従って、検索結果記憶部201に格納されている当該クエリ対応の検索結果を不正に書き換えられることを防ぐことができるという効果がある。
【0347】
次に、図68に示すフローチャートを参照して、構造化文書パスにてクエリを指定した検索要求が送信されてきたときの図64の構造化文書管理システムの処理動作について説明する。なお、図64に示す構成の場合、イベントが登録されている検索結果は自動的に更新されるので、図68に示す検索要求は、検索結果の参照要求としてもよい。
【0348】
さて、検索要求は、例えば、図70に示した入力画面を介して、予め定められた形式のコマンドとして(以下、簡単に検索要求コマンドと呼ぶ)、要求受付部11で受け付けられる(ステップS241)。要求受付部11は、当該検索要求コマンドを検索要求処理部3へ渡す。
【0349】
検索要求処理部3は、検索要求コマンドに含まれる、クエリ識別情報としての構造化文書パスと要求元のユーザの識別情報とを取出す。そして、要求元のユーザの識別情報が検索結果の参照権限のあるユーザか否かをチェックする(ステップS242)。当該要求元のユーザの識別情報が、実行権限情報テーブル202に当該クエリ対応の検索結果参照権限ユーザあるいはクエリ実行権限ユーザとして登録されているときは、検索結果記憶部201から、当該構造化文書パスのクエリ対応の検索結果を読み出し(ステップS243)、結果処理部12を介して、XML文書としての当該検索結果を所定のスタイルシートとともに、要求元のクライアント端末に返す(ステップS244)。
【0350】
なお、ステップS242において、当該要求元のユーザの識別情報が、実行権限情報テーブル202に当該クエリ対応の検索結果参照権限ユーザとしても、また、クエリ実行権限ユーザとしても登録されていないときは、そのまま処理を終了する。
【0351】
図69は、イベントテーブル204の他の例を示したものである。日時イベントの代わりに有効期限イベントがある点で図65とは異なる。
【0352】
有効期限イベントは、イベント条件として、検索結果記憶部201に格納されている検索結果の有効期限として、ある一定の期間が設定され、その期間が経過する度にイベントとして検知される。例えば、図69では、イベント番号「3」に登録されているイベントは「検索結果更新パスにて示されるクエリ「/クエリDB/クエリ[2]」対応の検索結果の有効期限は12時間であり、当該クエリを実行してから12時間経過する度に検索を実行し、検索結果記憶部201に格納されている当該クエリの検索結果を更新する」ためのものである。
【0353】
図69に示したイベントテーブルを用いてイベントを検知し、検索結果を更新するための処理動作は、図67と同様である。
【0354】
以上説明したように、本発明によれば、例えば、頻繁に用いられる検索条件のクエリであるとか、予め検索が予想されるクエリ、複数のユーザからユーザグループ内である特定の用途のために用いるクエリなどを構造化文書データベースに予め格納しておき、そのようなクエリの検索が実行されたときは、その結果結果を当該クエリに対応付けて記憶しておくことにより、その後に、再び同じクエリによる検索要求がなされたときは、実際に検索を行わず、記憶した検索結果を要求元へ返すことにより、構造化文書データベースに対する検索が効率よく行える。
【0355】
ある特定のユーザ(第1の種別のユーザ)のみに、クエリの検索実行の権限を与えて、この権限のあるユーザからの検索要求に対しては、実際に検索を行って、当該クエリに対応付けて記憶した検索結果の更新を行うことにより、構造化文書データベースの更新内容が検索結果に反映することができ、構造化文書データベースの現状との整合性を保ちながら検索が効率よく行える。
【0356】
好ましくは、前記第1の種別のユーザから前記検索要求を受け付けたとき、前回検索を実行した時点から所定時間経過しているときは、前記指定された検索要求文に基づき検索を行い、前記所定時間が経過していないときは、前記指定された検索要求文に対応付けて記憶されている検索結果を読み出す。これにより、ある特定のユーザ(第1の種別のユーザ)のみに、クエリの検索実行の権限を与えて、定期的に当該クエリに対応付けて記憶した検索結果の更新を行うことにより、構造化文書データベースの更新内容が検索結果に反映することができ、構造化文書データベースの現状との整合性を保ちながら検索が効率よく行える。
【0357】
このように、クエリ毎に当該クエリを実行させることが可能なユーザと、当該クエリにより検索結果を参照することが可能なユーザとを限定することにより、例えば、だれもかれもが、むやみやたらに検索を実行して、同じクエリによる検索結果であるのに、(データベースの内容が更新されていることにより)検索結果が様々になってしまうことを防ぐことができる。
【0358】
また、少なくとも上記所定時間の間は、誰が要求をしても同じクエリによる検索結果が同じであるという好ましい状態を作り出すことができる。これは、検索結果とデータベースの内容の整合性と保つためには重要なことである。
【0359】
また、好ましくは、前記構造化文書データベースが更新されたとき、該構造化文書データベースに格納されている前記複数の検索要求文のうち、該構造化文書データベースの更新内容が検索結果に影響するような検索要求文を選択して、その選択された検索要求文に基づき前記構造化文書データベースに対し検索を行って、該検索要求文に対応付けて記憶された検索結果を更新することにより、構造化文書データベース自体の更新に伴い、その更新を検索結果に自動的に反映させることができる。従って、検索結果とデータベースの内容の整合性を保つことが容易に行える。
【0360】
なお、本発明の実施の形態に記載した本発明の手法は、コンピュータに実行させることのできるプログラムとして、磁気ディスク(フロッピーディスク、ハードディスクなど)、光ディスク(CD−ROM、DVDなど)、半導体メモリなどの記録媒体に格納して頒布することもできる。
【0361】
なお、本発明は、上記実施形態に限定されるものではなく、実施段階ではその要旨を逸脱しない範囲で種々に変形することが可能である。さらに、上記実施形態には種々の段階の発明は含まれており、開示される複数の構成用件における適宜な組み合わせにより、種々の発明が抽出され得る。例えば、実施形態に示される全構成要件から幾つかの構成要件が削除されても、発明が解決しようとする課題の欄で述べた課題(の少なくとも1つ)が解決でき、発明の効果の欄で述べられている効果(のなくとも1つ)が得られる場合には、この構成要件が削除された構成が発明として抽出され得る。
【0362】
【発明の効果】
以上説明したように、本発明によれば、構造化文書データベースに対する検索が効率よく行える。また、構造化文書データベースの現状との整合性を保ちながら検索が効率よく行える。
【図面の簡単な説明】
【図1】本発明の実施形態に係る構造化文書管理システムの構成例を示した図。
【図2】図1に示した構造化文書管理システムの一利用形態を示したもので、WWWのバックエンドで、構造化文書管理システムが動作している場合を示した図。
【図3】XMLで記述された構造化文書の一例を示した図。
【図4】図3の構造化文書の文書構造を模式的に示した図。
【図5】追加コマンドの機能を説明するための図で、構造化文書データベースの初期状態に追加コマンドを実行した場合について示している。
【図6】図5(b)に示した状態の構造化文書データベースに対し、取得コマンドを実行した場合の処理結果を示した図。
【図7】図5(b)に示した状態の構造化文書データベースに対し、追加コマンドを実行して1つの「特許」情報の文書オブジェクトツリーを追加した場合を示している。
【図8】図5(b)に示した状態の構造化文書データベースに対し、追加コマンドを実行して3つの「特許」情報の文書オブジェクトツリーを追加した場合を示している。
【図9】要素名生起インデックスの格納例を示した図。
【図10】データ生起インデックスの格納例を示した図。
【図11】図8に示した状態の構造化文書データベースに対して、3つの「特許」情報を取り出すための取得コマンドを実行した場合の実行結果を示した図。
【図12】XML文書の文書構造を定義するスキーマの一例を示した図。
【図13】図8に示した状態の構造化文書データベースに、スキーマ格納コマンドを実行して、図12に示したスキーマを追加格納(設定)した場合を示した図。
【図14】スキーマが設定されて、スキーマが存在している旨の属性値のセットされた文書オブジェクトツリーを示した図。
【図15】各オブジェクトファイルに、スキーマが存在している旨の属性値が格納されている様子を概念的に示した図。
【図16】必要に応じて検索で使用される概念階層を構造化文書で表現した例を示した図。
【図17】必要に応じて検索で使用される概念階層を構造化文書で表現した例を示した図。
【図18】図8に示した状態の構造化文書データベースに対し、追加コマンドを実行して、図16,図17に示した「概念」情報の文書オブジェクトツリーを追加した場合を示した図。
【図19】図8に示した状態の構造化文書データベースに対し、追加コマンドを実行して、図16,図17に示した「概念」情報の文書オブジェクトツリーを追加した場合を示した図。
【図20】図1の構造化文書管理システムの文書格納処理動作について説明するためのフローチャート。
【図21】図20のステップS9の処理(合成文書作成部の処理)について説明するためのフローチャート
【図22】追加コマンド中のパラメータの格納文書の文書オブジェクトツリーを構造化文書データベースから取得した文書オブジェクトツリーに挿入して得られた合成文書の文書オブジェクトツリーをXML文書に変換した結果であって、テンポラリファイルAに格納される合成文書の一例を示した図。
【図23】テンポラリファイルBに格納される、構造化文書データベースから取得されたスキーマ文書の一例を示した図。
【図24】テンポラリファイルAに格納される合成文書の他の例を示した図。
【図25】テンポラリファイルBに格納される、構造化文書データベースから取得されたスキーマ文書の一例を示した図。
【図26】図1の構造化文書管理システムの文書取得処理動作について説明するためのフローチャート。
【図27】図1の構造化文書管理システムの文書削除処理動作について説明するためのフローチャート。
【図28】図27のステップS46の処理(合成文書作成部の処理(削除コマンド用))について説明するためのフローチャート。
【図29】テンポラリファイルAに格納される合成文書のさらに他の例であって、削除コマンドの実行時に作成される合成文書の一例を示した図。
【図30】テンポラリファイルBに格納される、構造化文書データベースから取得されたスキーマ文書の一例を示した図。
【図31】ユーザインタフェースとしての画面の表示例を示した図。
【図32】文書の格納/削除を行うためのユーザインタフェースとしての画面の表示例を示した図。
【図33】文書の格納/削除を行うためのユーザインタフェースとしての画面の表示例を示した図。
【図34】文書の格納/削除を行うためのユーザインタフェースとしての画面の表示例を示した図。
【図35】妥当性のチェックでエラーとなっときにクライアント端末へ返すメッセージの表示例を表示例を示した図。
【図36】文書の格納/削除を行うためのユーザインタフェースとしての画面の表示例を示したもので、文書取得動作を説明するための図。
【図37】スキーマの設定を行うためのユーザインタフェースとしての画面の表示例を示したもので、スキーマの設定動作を説明するための図。
【図38】スキーマの取得するためのユーザインタフェースとしての画面の表示例を示したもので、取得されたスキーマの表示例を示している。
【図39】クエリ(XML文書)の一例を示した図。
【図40】単純検索のクエリ(XML文書)の一例を示した図。
【図41】図40の単純検索のクエリを用いた検索結果(XML文書)を示した図。
【図42】概念検索のクエリ(XML文書)の一例を示した図。
【図43】図1の構造化文書管理システムの文書検索処理動作について説明するためのフローチャート。
【図44】文書検索を行うためのユーザインタフェースとしての画面の表示例を示した図。
【図45】図44に示した画面上から入力された情報に基づき作成されるクエリを示した図。
【図46】図42に示したクエリの構造化文書データベース内における格納例を示した図。
【図47】文書検索を行うためのユーザインタフェースとしての画面の表示例であって、スキーマの検索処理動作を説明するための図。
【図48】スキーマ検索のクエリの一例を示した図。
【図49】クエリを検索するためのクエリの一例を示した図。
【図50】特許調査における構造化文書データベースの一例を示した図。
【図51】概念検索のための入力画面の表示例を示した図。
【図52】図51に示した入力画面上の入力情報に対応するクエリを示した図。
【図53】図52に示したクエリに対応する検索結果としてのXML文書を示した図。
【図54】特許マップの一例を示した図。
【図55】第2の実施形態に係る構造化文書管理システムの構成例を示した図。
【図56】構造化文書データベースの一例を示した図。
【図57】構造化文書の一例であって、「特許」情報を示した図。
【図58】構造化文書データベースに格納されているクエリの一例を示した図。
【図59】図58のクエリを実行した結果得られた検索結果の一例を示した図。
【図60】検索結果記憶部の記憶例を示した図。
【図61】図55の構造化文書管理システムの処理動作を説明するためのフローチャートで、検索要求を行ったユーザのクエリ実行権限の有無を考慮しない場合を示している。
【図62】実行権限情報テーブルの一例を示した図。
【図63】図55の構造化文書管理システムの処理動作を説明するためのフローチャートで、検索要求を行ったユーザのクエリ実行権限の有無を考慮した場合を示している。
【図64】第2の実施形態に係る構造化文書管理システムの他の構成例を示した図。
【図65】イベントテーブルの一例を示した図。
【図66】イベントテーブルに登録された各イベント検知時に、その検知したイベント対応のクエリを実行する際に、そのクエリの実行権限の有り無しを考慮すしない場合の図64に示した構造化文書管理システムの処理動作について説明するためのフローチャート。
【図67】イベントテーブルに登録された各イベント検知時に、その検知したイベント対応のクエリを実行する際に、そのクエリの実行権限の有り無しを考慮する場合の図64に示した構造化文書管理システムの処理動作について説明するためのフローチャート。
【図68】構造化文書パスにてクエリを指定した検索要求(検索結果の参照要求)が送信されてきたときの図64の構造化文書管理システムの処理動作について説明するためのフローチャート。
【図69】イベントテーブルの他の例を示した図。
【図70】クライアント端末に表示される検索画面の一例を示した図。
【図71】クライアント端末に表示されるイベント登録画面の一例を示した図。
【符号の説明】
1…要求制御部
2…アクセス要求処理部
3…検索要求処理部
4…データアクセス部
5…文書記憶部
6…インデックス記憶部
11…受付要求部
12…結果処理部
21…文書格納部
22…文書取得部
23…文書削除部
41…文書オブジェクトツリー格納部
42…文書オブジェクトツリー削除部
43…文書オブジェクトツリー取得部
44…文書文字列取得部
45…パスから文書オブジェクトツリー取得部
46…文書パーサ
47…合成文書作成部
48…インデックス更新部
100…構造化文書管理システム
101…WWWサーバ
102…クライアント端末
103…WWWブラウザ
201…検索結果記憶部
202…実行権限情報テーブル
203…イベント検出部
204…イベントテーブル
Claims (10)
- 複数の要素を含む文書構造を有する複数の構造化文書を記憶するとともに、ルートノードに、構造化文書の種別に対応する種別ノードをリンクし、当該種別ノードに、各構造化文書に含まれる各要素の記憶エリアを当該構造化文書の文書構造に従ってリンクした論理構造により、前記複数の構造化文書を管理する構造化文書データベースと、
前記要素と当該要素に含まれる値とが指定された検索条件と、検索結果の出力形式を指定する出力条件とを含む検索要求文に基づき、前記論理構造から、当該検索要求文中の前記検索条件により指定された値を含む要素を検索し、当該検索された要素を含む構造化文書を求めるとともに、求めた構造化文書から、当該検索要求文中の前記出力条件により指定された出力形式の検索結果を生成する検索手段と、
前記検索要求文と前記検索結果とを対応付けて記憶する記憶手段と、
を備えた構造化文書管理装置における構造化文書検索方法であって、
入力された複数の検索要求文を、前記構造化文書データベースに格納する第1のステップと、
前記複数の検索要求文のうちの1つを指定した検索要求を受け付ける第2のステップと、
前記指定された検索要求文に対応する検索結果が前記記憶手段に記憶されているときは、その記憶されている検索結果を読み出して要求元に出力する第3のステップと、
前記指定された検索要求文に対応する検索結果が前記記憶手段に記憶されていないときには、前記検索手段が当該指定された検索要求文に基づき検索を行って、得られた検索結果を要求元に出力するとともに、当該検索結果を当該指定された検索要求文に対応付けて前記記憶手段に記憶する第4のステップと、
を有する構造化文書検索方法。 - 複数の要素を含む文書構造を有する複数の構造化文書を記憶するとともに、ルートノードに、構造化文書の種別に対応する種別ノードをリンクし、当該種別ノードに、各構造化文書に含まれる各要素の記憶エリアを当該構造化文書の文書構造に従ってリンクした論理構造により、前記複数の構造化文書を管理する構造化文書データベースと、
前記要素と当該要素に含まれる値とが指定された検索条件と、検索結果の出力形式を指定する出力条件とを含む検索要求文に基づき、前記論理構造から、当該検索要求文中の前記検索条件により指定された値を含む要素を検索し、当該検索された要素を含む構造化文書を求めるとともに、求めた構造化文書から、当該検索要求文中の前記出力条件により指定された出力形式の検索結果を生成する検索手段と、
前記検索要求文と前記検索結果とを対応付けて記憶する記憶手段と、
を備えた構造化文書管理装置における構造化文書検索方法であって、
入力された複数の検索要求文を、前記構造化文書データベースに格納する第1のステップと、
前記複数の検索要求文のそれぞれに、その検索要求文に基づく検索実行が許可されている第1の種別のユーザと、該検索要求文に基づく検索実行は許可されていないが該検索要求文対応の検索結果は参照することが許可されている第2の種別のユーザとを設定する第2のステップと、
前記複数の検索要求文のうちの1つを指定した検索要求を受け付ける第3のステップと、
前記第3のステップで、前記第1の種別のユーザから前記検索要求を受け付けたとき、前記検索手段が当該指定された検索要求文に基づき検索を行って、得られた検索結果を要求元に出力するとともに、当該検索結果を当該指定された検索要求文に対応付けて前記記憶手段に記憶する第4のステップと、
前記第3のステップで、前記第2の種別のユーザから前記検索要求を受け付けたときは、前記指定された検索要求文に対応付けて前記記憶手段に記憶されている検索結果を読み出して要求元に出力する第5のステップと、
を有する構造化文書検索方法。 - 前記第4のステップは、
前記第1の種別のユーザから前記検索要求を受け付けたとき、前回検索を実行した時点から所定時間経過しているときは、前記検索手段が当該指定された検索要求文に基づき検索を行って、得られた検索結果を要求元に出力するとともに、当該検索結果を当該指定された検索要求文に対応付けて前記記憶手段に記憶するステップと、
前記第1の種別のユーザから前記検索要求を受け付けたとき、前回検索を実行した時点から所定時間経過していないときは、前記指定された検索要求文に対応付けて前記記憶手段に記憶されている検索結果を読み出して要求元に出力するステップと、
を含むことを特徴とする請求項2記載の構造化文書検索方法。 - 前記複数の検索要求文のうちの特定検索要求文に対し、前記論理構造上の範囲の指定されたイベント条件を設定するステップと、
前記構造化文書データベースに対する構造化文書の格納及び削除を含む複数の操作のうちのいずれかによる、前記イベント条件により指定された範囲の前記論理構造の更新を検知して、前記構造化文書データベースから前記特定検索要求文を取得するステップと、
前記検索手段が、取得された前記特定検索要求文に基づき検索を行って、得られた検索結果で、前記記憶手段に当該特定検索要求文に対応付けて記憶されている検索結果を更新するステップと、
をさらに有する請求項1または2記載の構造化文書検索方法。 - 複数の要素を含む文書構造を有する複数の構造化文書を記憶するとともに、ルートノードに、構造化文書の種別に対応する種別ノードをリンクし、当該種別ノードに、各構造化文書に含まれる各要素の記憶エリアを当該構造化文書の文書構造に従ってリンクした論理構造により、前記複数の構造化文書を管理する構造化文書データベースと、
前記要素と当該要素に含まれる値とが指定された検索条件と、検索結果の出力形式を指定する出力条件とを含む検索要求文に基づき、前記論理構造から、当該検索要求文中の前記検索条件により指定された値を含む要素を検索し、当該検索された要素を含む構造化文書を求めるとともに、求めた構造化文書から、当該検索要求文中の前記出力条件により指定された出力形式の検索結果を生成する検索手段と、
前記検索要求文と前記検索結果とを対応付けて記憶する記憶手段と、
入力された複数の検索要求文を、前記構造化文書データベースに格納する手段と、
前記複数の検索要求文のうちの1つを指定した検索要求を受け付ける検索要求受付手段と、
前記指定された検索要求文に対応する検索結果が前記記憶手段に記憶されているときは、その記憶されている検索結果を読み出して要求元に出力する第1の制御手段と、
前記指定された検索要求文に対応する検索結果が前記記憶手段に記憶されていないときには、前記検索手段に当該指定された検索要求文に基づき検索を行わせ、得られた検索結果を要求元に出力するとともに、当該検索結果を当該指定された検索要求文に対応付けて前記記憶手段に記憶する第2の制御手段と、
を具備したことを特徴とする構造化文書管理装置。 - 複数の要素を含む文書構造を有する複数の構造化文書を記憶するとともに、ルートノードに、構造化文書の種別に対応する種別ノードをリンクし、当該種別ノードに、各構造化文書に含まれる各要素の記憶エリアを当該構造化文書の文書構造に従ってリンクした論理構造により、前記複数の構造化文書を管理する構造化文書データベースと、
前記要素と当該要素に含まれる値とが指定された検索条件と、検索結果の出力形式を指定する出力条件とを含む検索要求文に基づき、前記論理構造から、当該検索要求文中の前 記検索条件により指定された値を含む要素を検索し、当該検索された要素を含む構造化文書を求めるとともに、求めた構造化文書から、当該検索要求文中の前記出力条件により指定された出力形式の検索結果を生成する検索手段と、
前記検索要求文と前記検索結果とを対応付けて記憶する記憶手段と、
入力された複数の検索要求文を、前記構造化文書データベースに格納する手段と、
前記複数の検索要求文のそれぞれに、その検索要求文に基づく検索実行が許可されている第1の種別のユーザと、該検索要求文に基づく検索実行は許可されていないが該検索要求文対応の検索結果は参照することが許可されている第2の種別のユーザとを定めた実行権限情報テーブルと、
前記複数の検索要求文のうちの1つを指定した検索要求を受け付ける検索要求受付手段と、
前記検索要求受付手段で、前記第1の種別のユーザから前記検索要求を受け付けたとき、前記検索手段に当該指定された検索要求文に基づき検索を行わせ、得られた検索結果を要求元に出力するとともに、当該検索結果を当該指定された検索要求文に対応付けて前記記憶手段に記憶する第1の制御手段と、
前記検索要求受付手段で、前記第2の種別のユーザから前記検索要求を受け付けたときは、前記指定された検索要求文に対応付けて前記記憶手段に記憶されている検索結果を読み出して要求元に出力する第2の制御手段と、
を具備したことを特徴とする構造化文書管理装置。 - 前記第1の制御手段は、
前記第1の種別のユーザから前記検索要求を受け付けたとき、前回検索を実行した時点から所定時間経過しているときは、前記検索手段に当該指定された検索要求文に基づき検索を行わせ、得られた検索結果を要求元に出力するとともに、当該検索結果を当該指定された検索要求文に対応付けて前記記憶手段に記憶する手段と、
前記第1の種別のユーザから前記検索要求を受け付けたとき、前回検索を実行した時点から所定時間経過していないときは、前記指定された検索要求文に対応付けて前記記憶手段に記憶されている検索結果を読み出して要求元に出力する手段と、
を含むことを特徴とする請求項6記載の構造化文書管理装置。 - 前記複数の検索要求文のうちの特定検索要求文に対し、前記論理構造上の範囲の指定されたイベント条件を示すイベントテーブルと、
前記構造化文書データベースに対する構造化文書の格納及び削除を含む複数の操作のうちのいずれかによる、前記イベント条件により指定された範囲の前記論理構造の更新を検知して、前記構造化文書データベースから前記特定検索要求文を取得する手段と、
前記検索手段に、取得された前記特定検索要求文に基づき検索を行わせ、得られた検索結果で、前記記憶手段に当該特定検索要求文に対応付けて記憶されている検索結果を更新する第3の制御手段と、
をさらに具備したことを特徴とする請求項5または6記載の構造化文書管理装置。 - 複数の要素を含む文書構造を有する複数の構造化文書を記憶するとともに、ルートノードに、構造化文書の種別に対応する種別ノードをリンクし、当該種別ノードに、各構造化文書に含まれる各要素の記憶エリアを当該構造化文書の文書構造に従ってリンクした論理構造により、前記複数の構造化文書を管理する構造化文書データベースと、
前記要素と当該要素に含まれる値とが指定された検索条件と、検索結果の出力形式を指定する出力条件とを含む検索要求文に基づき、前記論理構造から、当該検索要求文中の前記検索条件により指定された値を含む要素を検索し、当該検索された要素を含む構造化文書を求めるとともに、求めた構造化文書から、当該検索要求文中の前記出力条件により指定された出力形式の検索結果を生成する検索手段と、
前記検索要求文と前記検索結果とを対応付けて記憶する記憶手段と、
を備えたコンピュータに、
入力された複数の検索要求文を、前記構造化文書データベースに格納する第1のステップと、
前記複数の検索要求文のうちの1つを指定した検索要求を受け付ける第2のステップと、
前記指定された検索要求文に対応する検索結果が前記記憶手段に記憶されているときは、その記憶されている検索結果を読み出して要求元に出力する第3のステップと、
前記指定された検索要求文に対応する検索結果が前記記憶手段に記憶されていないときには、前記検索手段に当該指定された検索要求文に基づき検索を行わせ、得られた検索結果を要求元に出力するとともに、当該検索結果を当該指定された検索要求文に対応付けて前記記憶手段に記憶する第4のステップと、
を実行させるためのプログラム。 - 複数の要素を含む文書構造を有する複数の構造化文書を記憶するとともに、ルートノードに、構造化文書の種別に対応する種別ノードをリンクし、当該種別ノードに、各構造化文書に含まれる各要素の記憶エリアを当該構造化文書の文書構造に従ってリンクした論理構造により、前記複数の構造化文書を管理する構造化文書データベースと、
前記要素と当該要素に含まれる値とが指定された検索条件と、検索結果の出力形式を指定する出力条件とを含む検索要求文に基づき、前記論理構造から、当該検索要求文中の前記検索条件により指定された値を含む要素を検索し、当該検索された要素を含む構造化文書を求めるとともに、求めた構造化文書から、当該検索要求文中の前記出力条件により指定された出力形式の検索結果を生成する検索手段と、
前記検索要求文と前記検索結果とを対応付けて記憶する記憶手段と、
を備えたコンピュータに、
入力された複数の検索要求文を、前記構造化文書データベースに格納する第1のステップと、
前記複数の検索要求文のそれぞれに、その検索要求文に基づく検索実行が許可されている第1の種別のユーザと、該検索要求文に基づく検索実行は許可されていないが該検索要求文対応の検索結果は参照することが許可されている第2の種別のユーザとを設定する第2のステップと、
前記複数の検索要求文のうちの1つを指定した検索要求を受け付ける第3のステップと、
前記第3のステップで、前記第1の種別のユーザから前記検索要求を受け付けたとき、前記検索手段に当該指定された検索要求文に基づき検索を行わせ、得られた検索結果を要求元に出力するとともに、当該検索結果を当該指定された検索要求文に対応付けて前記記憶手段に記憶する第4のステップと、
前記第3のステップで、前記第2の種別のユーザから前記検索要求を受け付けたときは、前記指定された検索要求文に対応付けて前記記憶手段に記憶されている検索結果を読み出して要求元に出力する第5のステップと、
を実行させるためのプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2001098188A JP3842575B2 (ja) | 2001-03-30 | 2001-03-30 | 構造化文書検索方法、構造化文書管理装置及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2001098188A JP3842575B2 (ja) | 2001-03-30 | 2001-03-30 | 構造化文書検索方法、構造化文書管理装置及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2002297604A JP2002297604A (ja) | 2002-10-11 |
| JP3842575B2 true JP3842575B2 (ja) | 2006-11-08 |
Family
ID=18951863
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2001098188A Expired - Fee Related JP3842575B2 (ja) | 2001-03-30 | 2001-03-30 | 構造化文書検索方法、構造化文書管理装置及びプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP3842575B2 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5057460B2 (ja) * | 2007-12-25 | 2012-10-24 | キヤノンマーケティングジャパン株式会社 | 文書管理システム、文書管理装装置、文書管理方法、およびプログラム |
| JP4811451B2 (ja) * | 2008-11-13 | 2011-11-09 | コニカミノルタホールディングス株式会社 | データベースシステム、およびデータ生成方法 |
-
2001
- 2001-03-30 JP JP2001098188A patent/JP3842575B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2002297604A (ja) | 2002-10-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3842573B2 (ja) | 構造化文書検索方法、構造化文書管理装置及びプログラム | |
| JP3842577B2 (ja) | 構造化文書検索方法および構造化文書検索装置およびプログラム | |
| US7370061B2 (en) | Method for querying XML documents using a weighted navigational index | |
| US6618727B1 (en) | System and method for performing similarity searching | |
| US20070219959A1 (en) | Computer product, database integration reference method, and database integration reference apparatus | |
| US20080183689A1 (en) | Search method and apparatus for plural databases | |
| US20110087708A1 (en) | Business object based operational reporting and analysis | |
| JP2001147933A (ja) | 構造化文書検索方法、構造化文書検索装置及び構造化文書検索システム | |
| JP3914081B2 (ja) | アクセス権限設定方法および構造化文書管理システム | |
| CN100498771C (zh) | 用于管理结构化文件的系统和方法 | |
| Saputra et al. | A metadata approach for building web application user interface | |
| JP3842572B2 (ja) | 構造化文書管理方法および構造化文書管理装置およびプログラム | |
| JP3842576B2 (ja) | 構造化文書編集方法及び構造化文書編集システム | |
| JP5056384B2 (ja) | 検索プログラム、方法及び装置 | |
| Paradis et al. | A language for publishing virtual documents on the Web | |
| JP3842574B2 (ja) | 情報抽出方法および構造化文書管理装置およびプログラム | |
| JP3842575B2 (ja) | 構造化文書検索方法、構造化文書管理装置及びプログラム | |
| JPH10187680A (ja) | 単語、文、部分の粒度で管理するドキュメントリポジトリ装置 | |
| Yu et al. | Metadata management system: design and implementation | |
| CN1326078C (zh) | 包装器的生成方法 | |
| JP2003316783A (ja) | 異種半構造化情報源統合検索装置、方法、プログラム及び該プログラムを記録した記録媒体 | |
| JP3910901B2 (ja) | 文書構造検索方法、文書構造検索装置および文書構造検索プログラム | |
| JP2004118543A (ja) | 構造化文書検索方法、検索支援方法、検索支援装置および検索支援プログラム | |
| JP2003288365A (ja) | 付加情報管理方法及び付加情報管理システム | |
| Mihaila et al. | Locating and accessing data repositories with WebSemantics |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20051025 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20051108 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20060110 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20060808 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20060810 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100818 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100818 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110818 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120818 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120818 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130818 Year of fee payment: 7 |
|
| LAPS | Cancellation because of no payment of annual fees |