JP3710164B2 - Image processing apparatus and method - Google Patents
Image processing apparatus and method Download PDFInfo
- Publication number
- JP3710164B2 JP3710164B2 JP10853495A JP10853495A JP3710164B2 JP 3710164 B2 JP3710164 B2 JP 3710164B2 JP 10853495 A JP10853495 A JP 10853495A JP 10853495 A JP10853495 A JP 10853495A JP 3710164 B2 JP3710164 B2 JP 3710164B2
- Authority
- JP
- Japan
- Prior art keywords
- character
- character line
- image
- area
- line
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images












Landscapes
- Character Input (AREA)
- Character Discrimination (AREA)
Description
【0001】
【産業上の利用分野】
本発明は画像処理装置及び方法、詳しくは入力された原稿画像中の文字種を判定し下位の処理に渡す画像処理装置及び方法に関するものである。
【0002】
【従来の技術】
情報が溢れる現代社会において情報管理、検索が容易になる情報の電子化が早急に望まれている。情報の電子化には、スキャナなどの入力装置で読み取った画像である文字を文字コードに変換するOCR(光学的文字認識)が必須であり、その精度はどんどん向上してきている。
【0003】
OCRは日本語(漢字、ひらがな、カタカナ)と英語その他(アルファベット)の特性の違いのため、アルファベット(特に小文字)を日本語OCRで認識するのは困難であることから、それぞれ別の認識アルゴリズムを用いたり、アルゴリズムは同じでも辞書の切り替えを行ったりする。従って、アルファベットと日本語を判別するための技術が必要になる。
【0004】
従来、アルファベットと日本語を判別する方法はなかったため、ユーザがオペレーションパネルやキーボード或いはポインティングデバイス等を操作して、それらを区別するための指示を行っていた。
【0005】
【発明が解決しようとする課題】
しかしながら、これではユーザの手間が多大であるし、さらに以下のような問題点がある。
【0006】
複数枚のデータを読み込む際、ADF(オートドキュメントフィーダ)がユーザに原稿指し替え作業を削減するが、その複数ページ中に英語のドキュメント、日本語のドキュメントが入り混じっている可能性がある。一枚読み込む毎にユーザの指示を待っていたのでは、ADFの利点が台無しになってしまう。また、全ページ読み込んだ後にユーザの指示を受ける形式にするには大量のメモリが必要になる。
【0007】
【課題を解決するための手段】
及び
【作用】
本発明はかかる問題点に鑑みなされたものであり、入力された原稿画像中の文字種を効率良く判定することで、下位の処理、例えば文字認識処理における処理精度を上げることを可能にする画像処理装置及び方法を提供しようとするものである。
【0008】
この課題を解決するため、例えば本発明の画像処理装置は以下の構成を備える。すなわち、
入力された原稿画像中の文字の種別を判定し下位の処理に渡す画像処理装置であって、
入力された原稿画像中の文字画像を含む文字行の領域を判別する判別手段と、
判別された文字行領域を、当該文字行の方向と垂直な方向に並んだ4つの領域に分割する分割手段と、
前記分割手段で分割された各領域中の有意なドットを計数する計数手段と、
前記計数手段で計数された各領域の有意なドット数を上の領域から順にB1,B2,B3,B4とした場合、(B2+B3)と(B1+B4)との比に基づいて第1ドット分布R1を算出し、(B3+B4)と(B1+B2)との比に基づいて第2ドット分布R2を算出する算出手段と、
前記算出された第1ドット分布R1が第1の閾値T1以上であるか或いは前記算出された第2ドット分布R2が第2の閾値T2以上であると判断された場合は、当該文字行領域をアルファベット文字行であると判定し、
前記第1ドット分布R1が前記第1の閾値T1より小さく且つ前記第2ドット分布R2が前記第2の閾値T2より小さいと判断された場合は、当該文字行領域を漢字圏文字行であると判定する判定手段とを備える。
【0009】
また、本発明の好適な実施態様に従えば、前記下位処理は文字認識処理であって、前記判定手段で判定された結果に応じて認識処理するときに使用する認識アルゴリズム、又は、認識アルゴリズムと認識辞書、或いは認識辞書を選択させることが望ましい。これによって、認識処理で使用される認識アルゴリズム又は認識辞書を予め選択できるので認識速度及び認識の精度を高めることが可能になる。
【0011】
また、前記判別手段は、文字列パターンの並び方向に投影したドット分布に基づいて行を判別することが望ましい。これによって、精度良く行を判別することが可能になる。
【0012】
また、更に、前記入力された原稿画像中のノイズ除去するノイズ除去手段を備えることが望ましい。この結果、ノイズによる影響をなくすことができるので、行の判別をより精度良く行なえる。
【0013】
また、更に、前記入力された画像を所定角度だけ回転させて、正立画像としての方向を決定する手段を備えることが望ましい。これによって、原稿画像の入力方向に応じて判定することが可能になる。
【0014】
また、更に、前記入力された画像が傾いているときに、傾きを補正する手段を備えることが望ましい。これによって、傾いて入力された原稿画像もより精度良く処理できる。
【0015】
【実施例】
以下、添付図面に従って本発明に係る実施例を詳細に説明する。
【0016】
実施例における文字認識装置のブロック構成を図12に示す。図中、1は装置全体の制御を司るCPU、2はブートプログラム等を記憶しているROM、3はCPU1が実行処理するプログラムやオペレーティングシステム(OS)を記憶するRAMである。4は例えばハードディスク装置等の外部記憶装置であって、ここにOS、文字認識処理に係るプログラム、更には認識辞書(日本語文字用と英語文字用)が格納されている。5はキーボードやポインティングデバイス等で構成される入力装置、6は原稿画像を読み取るイメージスキャナである。7は読み取った画像を一時的に記憶する画像メモリ、8は各種メッセージや認識された情報を表示する表示装置である。
【0017】
上記の構成における実施例の処理を説明する前に、まず、日本語と英語の文字列について考察する。
【0018】
日本語における文字は、概して、その文字高さ一杯に書かれているのに対して、英語ではlやyなどが存在するため高さを数等分した真ん中の部分にその線分(すなわちドット)が集中する。そのため、この集中の度合でもって、認識対象の文字列が日本語であるのか英語であるのかを判別できる。
【0019】
日本語と英語の一例を図7に示す。図7(a)は日本語の一例であり、同図(b)が英語の一例であるが、英語(b)が4等分した場合の領域(2)(3)に黒画素が集中しているのに対して、同図(a)の如く日本語では比較的全体的に分布している。同図(c)はyのような下に出っ張る文字が存在しない場合の英語である。この場合は領域(3)(4)に黒画素が集中する。
【0020】
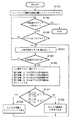
以上の原理に基づいて、第1の実施例の動作処理を図1のフローチャートに従って説明する。尚、同フローチャートに基づくプログラムは外部記憶装置4に格納されていて、それをRAM3上にロードすることで実行する。
【0021】
本実施例では、1行を小領域に分ける時のその分割数nを4とし、その黒画素分布の比の計算を黒画素分布R1、R2を以下のようにして決定する。
【0022】
R1=(B2+B3)/(B1+B4)
R2=(B3+B4)/(B1+B2)
尚、B1〜B4は、それぞれの領域における黒画素数を示している。従って、黒画素分布R1は領域(2)、(3)が領域(1)、(4)に対してどの程度の黒画素を有しているのかを示す値を、R2は領域(3)、(4)が領域(1)、(2)に対してどの程度の黒画素を有しているのかを示す値を意味することになる。尚、特定の領域が占める黒画素の多さを算出するものとしては、上記に限定されるものではなく、それ以外の尺度でもって算出しても良いのは勿論である。さて、スキャナなどの画像入力装置により入力されたビットマップ画像は、ステップS101でブロック分けが行われる。
【0023】
1画素1ビットの2値ビットマップ画像の一例を図2(a)に示す。本実施例では単純2値化された2値画像が好ましい。そのビットマップ画像を図2(b)の形にするのが、ステップS101の領域分離処理である。
【0024】
領域分離処理の一例のフローチャートを図3に示す。ステップS301でビットマップ画像にm×m画素サイズのウインドウを定義し、このウインドウ内に所定数(実施例では“1”とした)の黒画素があったら、該当するウインドウを黒とし、解像度を大幅に減らし文字部分を連結させる。ステップS301の解像度変換した様子を図4に示す。次にステップS302で輪郭線追跡をすると、文字特有の細長いパターンとその他の図形を区別することができる。最後のステップS303では、同一グループ連結処理で、隣接するテキスト部を結合させることによって図2(b)のように領域分離することができる。
【0025】
実施例においては、各ブロックを定義するために、ブロック定義用のデータ構造体を決めた。図5(a)がその構造体であり、ブロックの種別を定義する要素“type”(short 型)、ブロックの左上隅位置x座標及びy座標を定義する要素“startx”,“starty”(各々をshort 型)、ブロックの幅と高さを定義する要素“width”,“height”(各々short型)、そして、次のブロックのアドレスを記憶するための要素“next_address”で構成される。
【0026】
ここで、要素“type”は、0〜2のいずれかの数値が割り当てられ、“0”が該当するブロックは“タイトル”であることを、“1”は“テキスト”、“2”は“その他(図形や写真等)”であることを示す。
【0027】
尚、各ブロックの種別を判定する手法であるが、実施例では図4に示すように解像度を下げて処理した場合(このとき文字パターンどうしは互いに連結されてしまい一塊の黒画素領域になる)、その領域の輪郭を追跡していって、細長い連なりかどうかを判定し、細長い(縦横比が所定条件を満たしている)とき該当する領域は文字列領域であると判定する。ここで、文字列には、タイトル(見出し)と本文のテキストの二種類に分けられるが、前者(タイトル)は一般にその文字サイズが大きい。そこで、文字領域であると判定された細長い黒画素領域の長手方向にほぼ直角な断面の長さが所定以上のとき、タイトルとして判定するようにした。また、一般にタイトルは、本文の上方にある場合が多いので、その存在位置に従ってタイトルかテキストかを判断するようにしても良い。但し、ブロックの判定そのものは本発明の主要な部分ではないので、これ以上の説明は省略する。
【0028】
図5(b)は、上記の構造体で表されるデータの例を示している。各ブロックの要素next_addressには、次のブロックのアドレスが格納され、最後はNULLを代入しておくことでそれ以降のデータは存在しないことを明示させておく。
【0029】
図1の説明に戻る。ステップS101でブロックデータが抽出されると、処理はステップS102に進み、未処理のブロックがなくなるまで(構造体のnext_addressがNULLになるまで)ループする。もし、未処理のブロックがなくなったら本処理を終了するが、未処理のブロックがあるならばステップS103に移る。
【0030】
ステップS103では現在処理しようとするブロックが文字を含んでいれば(要素typeが0又は1)、ステップS104に進み、含んでいなければ102に戻る。
【0031】
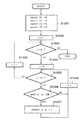
ステップS104ではブロック内のデータをY軸に斜影を行い文字の存在するY軸(行)抽出を行う。Y軸への斜影を例として図2(b)のテキスト2に対して行うと図6に示すようになる。Y軸への斜影をもっと具体的に説明するために図9にフローチャートを示す。
【0032】
尚、以下の説明に先立ち、変数line_h[]、line_sy[]は共にRAMに確保された配列変数であり、line_h[]は1行分の文字列の高さ情報を格納し、line_sy[]は各行の左上隅の、注目ブロックの左上隅座標からの相対的なy座標を記憶する。また、変数iはブロック内における相対的なx座標を、変数jは同y座標を示す。また、flagは、1行分の切り出し処理を行っている最中か否かを示す変数ものであり、kuroは着目している1ドットライン中に黒画素があるか否かの情報を記憶する変数である。また、nlineは、注目ブロック中に何行分の文字列行があるかをカウントする変数である。
【0033】
さて、ステップS901においては、変数nline、flag,jをそれぞれ“0”クリアする。そして、ステップS902で変数i,ステップS903で変数kuroをそれぞれ“0”クリアする。
【0034】
次いで、ステップS904に進んで、変数jが注目ブロックの高さ(注目ブロックがk番目である場合には、BLK[K].heightで得られる)を越えたか否かを判断する。もし、超えていれば、注目ブロック内の全てのラインに対しての処理が完了したことになるから、本処理を終える。
【0035】
従って、ここでは変数jの値が注目ブロックの高さに満たないとして、説明を続ける。
【0036】
この場合、処理はステップS905に進み、画像メモリ7に格納された画像データのx座標がstartx+i,y座標がstarty+jの位置の画素データを読み出し、それが黒画素かどうかを判断する。ここで、startx、startyは注目ブロックの構造体の要素名であることは理解できよう。
【0037】
さて、変数i,jで示される位置の画素が黒画素でないと判断した場合には、ステップS906に進み、その時の変数iと注目ブロックの横幅widthを比較する。この結果、i<widthであると判断した場合には、ステップS907に進んで、変数iを“1”だけインクリメントする。
【0038】
こうして、注目ブロックの第jラインにおいて、変数iが順次インクメントさせていって注目画素が黒画素であると判断されると、処理はステップS908に進み、変数kuroを“1”を代入し、注目ライン(変数jで示されるライン)には少なくとも黒画素が存在したことを示すようにする。
【0039】
この後、処理はステップS909に進み、flagが“0”であるかどうかを判断する。flagが“0”というのは、直前までのラインは空白部分であって、変数jで示されるラインになってはじめて黒画素が発生したことを意味する。従って、この場合には、ステップS910に進み、文字列パターンの発生を検出したことになるから、その時点での変数jを配列変数line_sy[nline]に代入する。文字パターンは複数のドットラインに存在するから、次のラインでステップS910の処理を行なわないように、flagに“1”を代入させておく。
【0040】
また、変数jで示されるライン中に黒画素の存在を検出した場合には、同ラインにおけるそれより右側に位置する画素の状態を検出することは不要になるのでステップS907の処理を行わず、注目ラインの処理を終えたものとして、ステップS912に進む。
【0041】
ステップS912では、kuro=0、且つ、flag=1であるかどうかを判断する。
【0042】
つまり、黒画素が存在するラインが連続して検出されている最中に、空白ラインが検出されたかどうかを判断する。より分かりやすく説明すると、1行分の文字列パターンの領域が決定したかどうかを判断する。
【0043】
否の場合には、ステップS913に進んで、変数jを“1”だけインクリメントし、ステップS902以降の処理を繰り返す。
【0044】
こうして、1行分の文字列パターンの検出がなされたと判断した場合には、ステップS914に進んで、配列変数line_h[nline]に、そのときの変数jからline_sy[nline]を引いた値をセットする。先に説明したように、line_sy[nline]には文字列パターンの左上隅のy座標が格納されているから、line_h[nline]には黒画素が連続するラインの本数、すなわち、文字列パターンの高さ情報が格納されることになる。
【0045】
次いで、ステップS915で、次の文字列パターン(文字列行)の検出に備えて変数flagを“0”クリアし、nlineを“1”だけインクリメントする。
【0046】
以上の結果、最終的に変数jが注目ブロックの高さheightを越えることになり、その時点で本処理を終了する。このとき、nlineは注目ブロックにおいて検出された文字列行数が格納され、line_sy[0]〜line_sy[nline]には各文字列パターンの左上隅のy座標値が、line_h[0]〜line[nline]には各文字列パターンの高さ情報が格納されることになる。
【0047】
以上の図9の処理により各ブロックの文字画像から行数、各行のスタート点および高さを抽出することができる。
【0048】
図1の説明に戻る。ステップS105では抽出された行データの処理のためにループを回す。全ての行の処理が終わっていない場合にはステップS102に戻り、それ以外はステップS106に進む。
【0049】
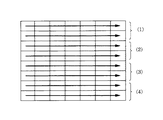
ステップS106では図11のように、ステップS104で抽出された行をラスタ順次に見て、領域(1)内の黒画素数を数えB1を得、続いて領域(2)内の黒画素数を数えB2を得、領域(3)内の黒画素数を数えB3を得、最後に領域(4)内の黒画素数を数えB4を得る(領域1から4の定義は図7参照)。
【0050】
ここで各領域は、先に説明したように、行の高さ情報line_h[]で示される高さを4分割した領域を意味する。
【0051】
その処理の一例のフローチャートを図10に示す。図7に示すようにステップS104の行抽出処理で抽出された行画像の左上を座標(0,0)とし、行画像の幅をW、画素高さをHとする。従って右下の座標は(W−1,H−1)となる。尚、以下の示す各変数もRAM3に確保されているものである。
【0052】
ステップS1001で黒画素カウンタcounter(0)〜counter(3)を“0”クリアする。ここでcounter[0]がB1を、counter[1]がB2を、counter[2]がB3を、counter[3]がB4をそれぞれ係数する変数である。
【0053】
ステップS1002で、二次元の画像を処理するための縦座標カウンタjをリセットする。ステップS1003で縦座標カウンタjが行画像高さHを超えていないかどうかチェックし、超えていたらendに進み本処理を終える。また、超えていなかったらステップS1004に進む。
【0054】
ステップS1004で二次元の画像を処理するための横座標カウンタiをリセットする。ステップS1005で横座標カウンタiが行画像幅Wを超えていないかどうかチェックし、超えていたらステップS1009に進み、超えていなかったらステップS1006に進む。ステップS1006でpixel[i][j]が黒かどうかチェックし、黒ならばステップS1007に進み、白ならばステップS1008に進む。
【0055】
ステップS1007ではpixel[i][j]が黒ということでcounter[j/4]をインクリメントする。
【0056】
但し、“j/4”は整数部分のみを有効する。従って、j/4は0、1、2、3の4つの値のいずれかであり、それでもって、counter[0]〜[3]のいずれか1つがインクリメントする。
【0057】
つまり、小領域(1)中の黒画素はcounter[0]に加算され、小領域2中の黒画素はcounter[1]に加算され、小領域3中の黒画素はcounter[2]に加算され、小領域4中の黒画素はcounter[3]に加算されていく。
【0058】
ステップS1008では、横座標カウンタiをインクリメントし、ステップS1005に戻る。ステップS1009で縦座標カウンタjをインクリメントし、ステップS1003に戻る。
【0059】
以上の処理の結果、B1=counter[0],B2=counter[1],B3=counter[2],B4=counter[3]として各小領域中の黒画素がカウントされる。
【0060】
図1の説明に戻る。ステップS107では、(B2+B3)/(B1+B4)が予め設定されている閾値T1以上であるか否か、或いは、(B3+B4)/(B1+B2)が予め設定されている閾値T2以上であるかを判定する。これらいずれかのを判定が肯定されれば、注目ブロックの注目行は英文字列と判断されるので、ステップS108で、その行に対しての属性を“英語”にする。また、いずれの判定も否定された場合には、注目行は日本語であると判定されるので、その旨の属性を与える。
【0061】
以上説明したように本実施例によれば、行単位に英語か日本語かを判断できるので、後の文字認識処理においては、適正な認識辞書が選択させることが可能となり、認識率を向上させることが可能になる。また、場合によっては、認識アルゴリズム自身を切り替えるようにしても良い。
【0062】
<第2の実施例の説明>
上記第1の実施例においてアルファベット/日本語判別を文字画像の1行毎に行ったがその限りではない。
【0063】
例えば、文字画像の1行目を抽出し、その1行目の黒画素分布を算出しアルファベット日本語判別を行ったらその結果をその画像全体の判別結果としてもよい。
【0064】
または文字画像をY軸への斜影により行切りを行ない、X軸への斜影により文字切りを行ったあと、任意にm文字分選びだし、m文字の黒目分布の平均を算出しその文字画像全体のアルファベット日本語判別を行う方法もある。
【0065】
これらの方法により、計算時間の短縮が計れる。
【0066】
また、上述の第1の実施例において行抽出手段は文字画像に対するY軸への斜影としたが、その限りではなく、例えば、図1におけるステップS101の領域分離により行っても良い。具体的には図3のステップS301の解像度変換、ステップS302の輪郭線追跡を行った後、輪郭線追跡により抽出されたオブジェクトのうち細長いものを文字と判定するが、ステップS303の同一グループ結合を行わずに、行として領域分離をする。この処理により図2(a)を実行した結果は図8の様になり、Y軸への斜影は必要なくなる。しかし、解像度変換の影響で抽出された行の精度が低いのでそれを考慮して閾値Tの値をチューニングする必要がある。この閾値Tは原稿画像にもよるので、入力装置5から適宜調整するようにする。
【0067】
また、入力した原稿画像中にノイズとして、本来空白部分に1画素だけの孤立画素が存在すると、上記処理は正常に行われない可能性がある。そこで、孤立画素については、それを判別し、それを除去する処理を設ける処理が望まれる。孤立画素の判定は、黒画素のまわりの所定距離以内に他の黒画素があるかどうかを判断すれば良いだろう。または、画像をウインドリングしパターンマッチングで消去する方法などを用いても良い。
【0068】
また、第1の実施例では、ステップS101の領域分離処理を施す画像は1画素1ビットの画像としたがその限りでなく、例えば1画素8ビットの多値画像でもよい。その場合、領域分離は微分フィルタをかけて高周波成分を抽出し、文字部、写真部に分ける方法がある。本アルファベット日本語判別を実施するには上記1画素8ビットの多値画像を一定の閾値で2値化すれば良い。
【0069】
また、本アルファベット/日本語自動判別法を施す前に、文字画像の傾きを補正することによって、原稿が傾いた画像に対してより良好な結果を得ることができる。傾き補正は例えば抽出した行の傾きを求めて、座標変換することによって実現できるので、その説明は省略する。
【0070】
また、本アルファベット/日本語自動判別法を施す前に、文字画像の方向を検出することによって、原稿の方向に依存しない結果を得ることができる。文字画像方向の検出は例えば領域分割によって抽出した文字画像を行抽出、文字抽出を実行し、抽出した数画像を0°回転、90°回転、180°回転、270°回転を行いOCRを行う。OCRの確信度が得られるのでそれを利用して文字画像の方向を検出し原画像を行えば良い。
【0071】
また、各小領域中の黒画素数カウントを行画像を抽出した後に行ったが、その限りでなく、例えば、Y軸方向の斜影を行って行画像を抽出する時に同時にカウントしてもよい。その場合、行画像の高さがまだ未明であるのでその行の黒画素数を保持しておいて高さが判明した後に小領域中の黒画素を加算して求めることができる。
【0072】
<第3の実施例の説明>
上記実施例では、文字列の行を4等分に、その中の黒画素の個数比でもって該当する行が日本語か英語かを判別するものであったが、本第3の実施例では、一般に日本語の文字パターンは単位面積当たりのドット数が英語より多いという点に着目し、文字種を判定する例を説明する。
【0073】
尚、装置構成は先に説明した第1の実施例と同様であるものとし、ここではその処理内容について説明する。
【0074】
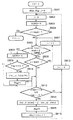
図13のフローチャートに従って本第3の実施例における処理手順を説明する。
【0075】
図13のフローチャート中、ステップS3101〜S3105までは、図1のステップS101〜S105と同じである。すなわち、ブロック化、及び各ブロック内のテキストもしくは見出しの行数の検出にかかる処理は同じであるものとする。
【0076】
ステップS3101〜S3105では、原稿画像の入力からブロック分け、そして、着目しているブロックがタイトルもしくはテキストであって、その行の抽出処理を行う。未処理の行が存在すると判断された場合には、ステップS3106に進む。
【0077】
ステップS3106では図14のように行中の黒画素を見て、文字幅を検出するとともに黒画素数をカウントする。
【0078】
図15にステップS3106の処理内容のフローチャートを示し、以下説明する。
【0079】
尚、図14に示すように、ステップS3104(図9参照)の行抽出処理で抽出された行画像の左上位置を座標(0,0)とし、行画像の画素幅をIW、画素高さをHとする。従って右下の座標は(IW−1,H−1)となる。また、本処理の詳細は以下の説明から明らかになるが、要するに、着目している行の実際に文字列パターンその存在する位置の開始位置(行頭)と、終了位置(行末)の座標及び、それらの間にあるドット数を計数する処理を行うものである。
【0080】
ステップS4001で、黒画素の開始位置を検出した際に、その位置を記憶保持する変数startx(x座標)を更新し、それ以降の処理で当該変数startxを更新しないように制御する変数flag_blkを“0”クリアする。そして、ステップS4002では、黒画素数を計数する変数conterを“0”クリアする。次いで、ステップS4003では、注目画素位置のx座標位置を特定するための変数iを“0”クリアする。次の、ステップS4004では、flag_line2にflag_lineの内容を代入し、次いで、flag_lineを“0”クリアする。尚、最初の段階では、flag_lineには“0”が格納されているものとする。従って、flag_line2は、最初の段階では“0”クリアされることになる。
【0081】
また、flag_lineは現在の変数iで示される縦1ドット列に黒画素があったかどうかを示す情報が格納され、flag_line2には直前の縦1ドット列に黒画素があったかどうかを示す情報が格納される。従って、黒画素が連続して検出されている最中に、文字パターンが途絶えた場合にはflag_line2=1(直前の縦1ドット列に黒画素有り)で、且つ、flag_line=0(注目している縦1ドット列に黒画素無し)の場合であることを判定すれば良い。
【0082】
さて、ステップS4005では、抽出する画素位置のy座標を記憶保持する変数jを“0”クリアする。
【0083】
次いで、ステップS4006で、注目行中の変数i,jで示される位置の画素を画像メモリ7から読み出し、それが黒画素がどうかを判定する。白画素であった場合には、ステップS4012にジャンプし、変数j、すなわち、y座標を1つインクリメントし、ステップS4013で変数jが注目行の高さ以下であると判断されるまで上記ステップS4005以下の処理を繰り返す。
【0084】
こうして、変数jで示される縦1ドット列につき、1つも黒画素が発見できなかった場合、ステップS4013の判定は“NO”になるので、ステップS4014に進み、flag_line2が“1”で、且つ、flag_lineが“0”か否かを判断する。すなわち、文字パターンの終端を見つけたか否かを判断する。否の場合には、変数iをインクリメントし、次の列位置に備える。そして、ステップS4017で変数iと行幅とを比較し、行幅分の処理が終えていないと判断した場合には、ステップS4004の処理に戻り、上記処理を繰り返す。
【0085】
さて、この過程で、最初に黒画素が検出されると、ステップS4007でflag_blkが“0”であると判断されるので、処理はステップS4008に進み、そのときの変数iの値を変数startxに代入する。これにより、文字列パターンの最初のドット位置のx座標がstartxに格納されることになる。
【0086】
次いで、このstartxに代入する処理は、これ以降行なわないようにするため、変数flag_blkに“1”を代入する。
【0087】
次いで、黒画素が1つ検出されたことになるから、変数counterを“1”インクリメントし、且つ、注目縦1ドット列中に黒画素が検出されたわけであるから、flag_lineに“1”を代入し、ステップS4012に進む。
【0088】
以上の結果、注目行中の最初の黒画素が検出された場合には変数startxにそのときのx座標値である変数iを代入し、後はこの処理は行わない。そして、黒画素が検出される度に変数counterが“1”ずつインクリメントされることになる。
【0089】
さて、1つの文字の黒画素を検出していく過程で、その隣の文字パターンとの間に処理は移ると、当然、その間には空白部分があるので、黒画素は検出されなくなる。
【0090】
このとき、ステップS4014の判断は、“Yes”になる。つまり、その時の変数iの値が注目している文字パターンの終わり位置になるから、その位置を仮の行末位置であるとしてendxにその値を代入する。従って、endxの内容は、注目行中に含まれる文字数分だけ更新させるが(図14参照)、最終的に注目行の行末位置にある文字の終わりのx座標値がendxに格納されることになる。
【0091】
以上の結果、注目ブロック内の注目行の行頭文字パターンの開始位置がstartxに、行末文字パターンの終わりがendxに格納され、counterにはその間の黒画素数が格納されることになる。
【0092】
図13の説明に戻る。
【0093】
ステップS3107で白画素数(WN)を
WN=行高さ(H)×行幅(W)−黒画素数(BN)
により求め、黒画素比Rを
R=黒画素数(BN)/白画素数(WN)
によって求める。
【0094】
ここで、行の高さは、先の第1の実施例で説明した通りであり、行幅はendx−startxで得られる値である。
【0095】
ステップS4108であらかじめ決めたあったしきい値TよりRが大きいかどうか(黒画素が多いかどうか)チェックし、R>Tの時はステップS3109に進み、R<=Tの時はステップS3110に進む。ステップS3109ではその文字画像は日本語であると判定し、ステップS3105に戻る。また、ステップS3110ではその文字画像はアルファベットであると判定し、ステップS3105に戻る。
【0096】
以上説明したように本第3の実施例によれば、文字パターンは日本語の場合、そのドット数が多く、逆に英語の場合にはドット数が少ないという特徴を利用して、各ブロック内の行単位の字種を判別できる。従って、文字認識処理に移る場合には、その認識辞書を予め決めておく、もしくは優先する辞書を決めておくことが可能になり、文字認識率を高めることが可能になる。
【0097】
<第4の実施例の説明>
第3の実施例においてアルファベット日本語判別を文字画像の1行毎に行ったがその限りではない。例えば、文字画像の1行目を抽出し、その1行目の黒画素分布を算出しアルファベット日本語判別を行ったらその結果をその画像全体の判別結果としてもよい。
【0098】
または文字画像をX軸への斜影により行切りを行い、Y軸への斜影により文字切りを行ったあと、任意にm文字分選びだし、m文字のRの平均を算出しその文字画像全体のアルファベット日本語判別を行う方法もある。これらの方法により、計算時間の短縮が計れる。
【0099】
また、先に説明した第1の実施例と第3の実施例とを組み合わせて字種を判定するようにしても良い。このようにすると、字種判定に関する精度を向上させることが可能になる。
【0100】
また、文字には様々なフォントや、スタイルがある。そのため、日本語のほうが文字幅の細いフォントで英語のほうが太いフォントだった場合誤判別のおそれが出てくる。そこで、第1の実施例のような処理を行う前に文字の細線処理を行えば、そのような誤判別の危険はなくなる。但し、厳密な細線化処理は、非常に複雑な処理を伴う。しかし、本第3の実施例では、単純に文字の種別を一義的な状態にさせすれば良いので、単純な細線化処理を行なえば良い。
【0101】
以下、簡単な細線処理について説明する。
【0102】
簡単な細線処理はパターンマッチングによる黒画素消去によって可能である。2画像を例えば3×3画素単位に着目し、あらかじめ決めてある消去パターンとウィンドウ中の画像パターンが一致した場合、その注目画素(ウィンドウ中の中央の画素)を黒から白に強制変換する。その処理を反復して細線処理を行う。消去パターンの一例は例えば図16の通りである。
【0103】
また、第3の実施例において、行抽出手段は文字画像に対するY軸への斜影としたが、その限りでなく、例えば、図13のステップS3101の領域分離により行ってもいい。
【0104】
具体的には、先の第1の実施例と同様に、解像度変換、輪郭線追跡を行った後、輪郭線追跡により抽出されたオブジェクトのうち細長いものを文字と判定するが、同一グループ結合を行わずに、行として領域分離をする。この処理により図2(a)を実行した結果は図8の様になり、Y軸への斜影は必要なくなく。しかし、解像度変換の影響で抽出された行の精度が低いのでそれを考慮してしきい値Tの値をチューニングしなければならない。
【0105】
また、上述の第3の実施例において、本処理を施す1画素1ビットの画像にノイズが存在していては本アルファベット日本語判別の能力を生かせられない。従って明らかにノイズとわかる孤立ドットなどを除去すると良いだろう。孤立ドット除去の方法としては画像をウインドリングしパターンマッチングで消去する方法などがある。
【0106】
また、上述の第3の実施例において、図13のステップS3101の領域分離処理を施す画像は1画素1ビットの画像としたがその限りでなく例えば1画素8ビットの多値画像でもよい。その場合、領域分離は微分フィルタをかけて高周波成分を抽出し、文字部、写真部に分ける方法がある。本アルファベット日本語判別を実施するには上記1画素8ビットの多値画像を一定しきい値で二値化する必要がある。
【0107】
また、本アルファベット日本語自動判別法を施す前に、文字画像の傾きを補正することによって、原稿が傾いた画像に対してより良好な結果を得ることができる。傾き補正は例えば抽出した行の傾きを求めて、座標変換することによって実現できる。
【0108】
また、本アルファベット日本語自動判別法を施す前に、文字画像の方向を検出することによって、原稿の方向に依存しない結果を得ることができる。文字画像方向の検出は例えば領域分割によって抽出した文字画像を行抽出、文字抽出を実行し、抽出した数画像を0°回転、90°回転、180°回転、270°回転を行いOCRを行う。OCRの確信度が得られるのでそれを利用して文字画像の方向を検出し原画像を行う。
【0109】
以上説明したように本第1〜第4の実施例に従えば、日本語と英語の文字パターンの分布あるいは密度に応じて文字種を判定することが可能になる。従って、文字認識する前処理として認識するときに使用する辞書を予め決める、もしくはその優先順位を決めることが可能になるので、文字認識率を向上させることが可能になる。
【0110】
尚、第1〜第4の実施例では、いずれも日本語と英語について説明したが、英語の代わりにドイツ語やフランス語を用いても同様であり、且つ、日本語の代わりに漢字圏(例えば中国語)にしても同様であるので、上記例によって本発明が限定されるものではない。
【0111】
また、実施例ではイメージスキャナ6から入力される画像に対して処理を行なったが、画像は例えば通信回線を介して送られてきても良いし、例えば所定の記憶媒体(例えばフロッピーディスク等)に記憶させておいて、そこから画像を読出しても同様に処理できるので、上記実施例によって限定されるものではない。
【0112】
更に、本発明は、複数の機器から構成されるシステムに適用しても、1つの機器から成る装置に適用しても良い。また、本発明はシステム或は装置にプログラムを供給することによって達成される場合にも適用できることはいうまでもない。
【0113】
【発明の効果】
以上説明したように本発明によれば、入力された原稿画像中の文字種を効率良く判定することで、下位の処理、例えば文字認識処理における処理精度を上げることが可能になる。
【0114】
また、本発明の好適な実施態様に従えば、前記下位処理は文字認識処理であって、前記判定手段で判定された結果に応じて認識処理するときに使用する認識アルゴリズム、又は、認識アルゴリズムと認識辞書、或いは認識辞書を選択させるので、認識速度及び認識の精度を高めることが可能になる。
【0115】
また、分割された各領域のほぼ中央の領域に対するドットの存在割合を算出し、前記判定手段は、算出された割合が所定以上の場合には、注目行はアルファベット文字であると判定し、所定以下の場合には漢字圏文字であると判定するので、漢字圏の文字とアルファベットの文字を精度良く判定することが可能になる。
【0116】
また、文字列パターンの並び方向に投影したドット分布に基づいて行を判別するので、精度良く行を判別することが可能になる。
【0117】
また、更に、前記入力された原稿画像中のノイズ除去するノイズ除去手段を備えることにより、ノイズによる影響をなくすことができるので、行の判別をより精度良く行なえる。
【0118】
また、更に、前記入力された画像を所定角度だけ回転させて、正立画像としての方向を決定する手段を備えることにより、原稿画像の入力方向に応じて判定することが可能になる。
【0119】
また、前記入力された画像が傾いているときに、傾きを補正するので、傾いて入力された原稿画像もより精度良く処理できる。
【0120】
【図面の簡単な説明】
【図1】実施例における処理手順を示すフローチャートである。
【図2】原稿画像とブロック分け処理の関係を示す図である。
【図3】実施例のブロック分け処理の一例を示すフローチャートである。
【図4】図3における解像度変換処理を施した様子を示す図である。
【図5】実施例におけるブロック変数の構造体の構造及びそのデータの例を示す図である。
【図6】行判別の概念を示す図である。
【図7】日本語と英語の文字列の一例と、文字識別の原理を説明するための図である。
【図8】実施例におけるブロック分け処理後の各ブロックの属性の一例を示す図である。
【図9】実施例の行識別処理のフローチャートである。
【図10】実施例の画素計数処理内容を示すフローチャートである。
【図11】実施例の画素計数処理の走査内容を示す図である。
【図12】実施例における文字認識装置のブロック構成を示す図である。
【図13】第3の実施例の動作処理手順を示すフローチャートである。
【図14】第3の実施例における処理過程の概要を示す図である。
【図15】第3の実施例における黒画素分布算出処理を示すフローチャートである。
【図16】細線化処理で使用されるパターンの例を示す図である。
【符号の説明】
1 CPU
2 ROM
3 RAM
4 外部記憶装置
5 入力装置
6 イメージスキャナ
7 画像メモリ
8 表示装置[0001]
[Industrial application fields]
The present invention relates to an image processing apparatus and method, and more particularly to an image processing apparatus and method for determining a character type in an input document image and passing it to a lower-level process.
[0002]
[Prior art]
There is an urgent need for computerization of information that facilitates information management and retrieval in a modern society where information is overflowing. In order to digitize information, OCR (optical character recognition) that converts a character, which is an image read by an input device such as a scanner, into a character code is indispensable, and its accuracy is steadily improving.
[0003]
OCR is different from Japanese (Kanji, Hiragana, Katakana) and English and others (alphabet), so it is difficult to recognize alphabets (especially lowercase letters) with Japanese OCR. Use the same algorithm or switch dictionaries. Therefore, a technique for distinguishing between alphabet and Japanese is required.
[0004]
Conventionally, there was no method for discriminating between alphabet and Japanese, so the user operated the operation panel, keyboard, pointing device, or the like to give an instruction to distinguish them.
[0005]
[Problems to be solved by the invention]
However, this requires a great deal of time and trouble for the user.
[0006]
When reading a plurality of pieces of data, an ADF (Auto Document Feeder) reduces the document redirection work to the user, but there is a possibility that English pages and Japanese documents are mixed in the plurality of pages. If it waits for a user's instruction each time one sheet is read, the advantage of ADF is spoiled. In addition, a large amount of memory is required in order to receive a user instruction after reading all pages.
[0007]
[Means for Solving the Problems]
as well as
[Action]
The present invention has been made in view of such problems, and image processing that can improve processing accuracy in lower-level processing, for example, character recognition processing, by efficiently determining the character type in an input document image. An apparatus and method are to be provided.
[0008]
In order to solve this problem, for example, an image processing apparatus of the present invention has the following configuration. That is,
EnteredManuscriptimageAn image processing apparatus that determines the type of characters in the image and passes it to a lower-level process.
In the input document imageText imageincludingcharacterlineAreaDiscriminating means for discriminating;
DeterminedcharacterThe row areacharacterRow direction4 aligned verticallyDividing means for dividing into areas,
In the dividing meansCounting means for counting significant dots in each divided area;
SaidCounted by counting meansWhen the number of significant dots in each region is B1, B2, B3, and B4 in order from the upper region, the first dot distribution R1 is calculated based on the ratio of (B2 + B3) to (B1 + B4), and (B3 + B4) Based on the ratio to (B1 + B2), the second dot distribution R2Calculating means for calculating
SaidCalculatedWhen it is determined that the first dot distribution R1 is greater than or equal to the first threshold value T1 or the calculated second dot distribution R2 is greater than or equal to the second threshold value T2, the character line area is an alphabetic character line. Judge that there is,
When it is determined that the first dot distribution R1 is smaller than the first threshold value T1 and the second dot distribution R2 is smaller than the second threshold value T2, the character line area is a Chinese character area character line.Determination means for determining.
[0009]
Further, according to a preferred embodiment of the present invention, the sub-process is a character recognition process, and a recognition algorithm used when performing a recognition process according to a result determined by the determination means, or a recognition algorithm Recognition dictionary, orrecognitionIt is desirable to have a dictionary selected. As a result, since the recognition algorithm or the recognition dictionary used in the recognition process can be selected in advance, the recognition speed and the recognition accuracy can be increased.
[0011]
The discriminating unit preferably discriminates a row based on a dot distribution projected in the arrangement direction of the character string pattern. Thereby, it becomes possible to discriminate the line with high accuracy.
[0012]
Further, it is desirable to further include noise removing means for removing noise in the inputted document image. As a result, the influence of noise can be eliminated, so that the row can be discriminated more accurately.
[0013]
Furthermore, it is desirable to further comprise means for rotating the input image by a predetermined angle to determine the direction as an erect image. This makes it possible to make a determination according to the input direction of the document image.
[0014]
Furthermore, it is desirable to provide means for correcting the tilt when the input image is tilted. As a result, it is possible to process a document image input with an inclination more accurately.
[0015]
【Example】
Hereinafter, embodiments according to the present invention will be described in detail with reference to the accompanying drawings.
[0016]
FIG. 12 shows a block configuration of the character recognition apparatus in the embodiment. In the figure, 1 is a CPU that controls the entire apparatus, 2 is a ROM that stores a boot program and the like, and 3 is a RAM that stores a program executed by the
[0017]
Before describing the processing of the embodiment in the above configuration, first, Japanese and English character strings will be considered.
[0018]
Characters in Japanese are generally written to their full height, whereas in English there are l and y, etc., so there is a line segment (ie, a dot) in the middle of the height divided into several parts. ) Concentrate. Therefore, it is possible to determine whether the character string to be recognized is Japanese or English based on the degree of concentration.
[0019]
An example of Japanese and English is shown in FIG. FIG. 7 (a) is an example of Japanese, and FIG. 7 (b) is an example of English, but black pixels are concentrated in areas (2) and (3) when English (b) is divided into four equal parts. On the other hand, Japanese is relatively distributed as shown in FIG. FIG. 5C shows the English when there is no character such as y protruding below. In this case, black pixels are concentrated in the areas (3) and (4).
[0020]
Based on the above principle, the operation process of the first embodiment will be described with reference to the flowchart of FIG. A program based on the flowchart is stored in the
[0021]
In this embodiment, the division number n when dividing one row into small areas is set to 4, and the calculation of the ratio of the black pixel distribution is determined as follows for the black pixel distributions R1 and R2.
[0022]
R1 = (B2 + B3) / (B1 + B4)
R2 = (B3 + B4) / (B1 + B2)
B1 to B4 indicate the number of black pixels in each region. Therefore, the black pixel distribution R1 is a value indicating how many black pixels the regions (2) and (3) have with respect to the regions (1) and (4), and R2 is the region (3), (4) means a value indicating how many black pixels the regions (1) and (2) have. Note that the number of black pixels occupied by a specific area is not limited to the above, and may be calculated using other scales. Now, a bitmap image input by an image input device such as a scanner is divided into blocks in step S101.
[0023]
An example of a binary bitmap image with one pixel and one bit is shown in FIG. In this embodiment, a simple binary image is preferable. The bit map image is formed in the form shown in FIG. 2B in the region separation process in step S101.
[0024]
A flowchart of an example of the region separation processing is shown in FIG. In step S301, a window of m × m pixel size is defined in the bitmap image, and if there is a predetermined number of black pixels (in this embodiment, “1”) in this window, the corresponding window is set to black and the resolution is set. Significantly reduce and concatenate character parts. FIG. 4 shows how the resolution is converted in step S301. Next, when the contour line is traced in step S302, it is possible to distinguish the elongated pattern peculiar to the character from other figures. In the last step S303, the regions can be separated as shown in FIG. 2B by combining adjacent text parts in the same group connection process.
[0025]
In the embodiment, in order to define each block, a data structure for block definition is determined. FIG. 5A shows the structure of the element “type” (short type) that defines the type of the block, and elements “startx” and “starty” that define the upper left corner position x-coordinate and y-coordinate of the block (each Short type), elements “width” and “height” (each short type) that define the width and height of the block, and an element “next_address” for storing the address of the next block.
[0026]
Here, the element “type” is assigned any numerical value from 0 to 2, and “0” indicates that the corresponding block is “title”, “1” indicates “text”, and “2” indicates “ Others (graphics, photos, etc.) ”
[0027]
Note that this is a method for determining the type of each block, but in the embodiment, when processing is performed with a reduced resolution as shown in FIG. 4 (at this time, the character patterns are connected to each other to form a lump of black pixel areas). The outline of the area is tracked, and it is determined whether or not it is an elongated series. If the area is elongated (the aspect ratio satisfies a predetermined condition), it is determined that the corresponding area is a character string area. Here, the character string can be divided into two types, title (headline) and body text. The former (title) generally has a large character size. Therefore, when the length of the cross section substantially perpendicular to the longitudinal direction of the elongated black pixel region determined to be a character region is greater than or equal to a predetermined length, it is determined as a title. In general, since the title is often above the body, it may be determined whether it is a title or text according to the position of the title. However, since the block determination itself is not a main part of the present invention, further explanation is omitted.
[0028]
FIG. 5B shows an example of data represented by the above structure. In the element next_address of each block, the address of the next block is stored. Finally, by substituting NULL, it is clearly indicated that there is no subsequent data.
[0029]
Returning to the description of FIG. When block data is extracted in step S101, the process proceeds to step S102 and loops until there is no unprocessed block (until the next_address of the structure becomes NULL). If there is no unprocessed block, the process is terminated. If there is an unprocessed block, the process proceeds to step S103.
[0030]
In step S103, if the block to be processed currently contains a character (element type is 0 or 1), the process proceeds to step S104, and if not, the process returns to 102.
[0031]
In step S104, the data in the block is shaded on the Y axis to extract the Y axis (row) where characters exist. 6 is performed on the
[0032]
Prior to the following description, the variables line_h [] and line_sy [] are both array variables secured in the RAM, line_h [] stores the height information of the character string for one line, and line_sy [] The relative y coordinate of the upper left corner of each row from the upper left corner coordinate of the block of interest is stored. A variable i represents a relative x coordinate in the block, and a variable j represents the same y coordinate. Further, flag is a variable indicating whether or not the cutting process for one line is being performed, and kuro stores information indicating whether or not there is a black pixel in one focused dot line. Is a variable. Nline is a variable that counts the number of character string lines in the block of interest.
[0033]
In step S901, the variables nline, flag, and j are each cleared to “0”. Then, the variable i is cleared to “0” in step S902 and the variable kuro is cleared in step S903.
[0034]
Next, the process proceeds to step S904, and it is determined whether or not the variable j exceeds the height of the target block (obtained by BLK [K] .height if the target block is k-th). If so, the processing for all the lines in the block of interest has been completed, and this processing is terminated.
[0035]
Therefore, the description will be continued here assuming that the value of the variable j is less than the height of the target block.
[0036]
In this case, the process proceeds to step S905, in which pixel data at a position where the x coordinate of the image data stored in the
[0037]
If it is determined that the pixel at the position indicated by the variables i and j is not a black pixel, the process advances to step S906 to compare the variable i at that time with the width width of the block of interest. As a result, if it is determined that i <width, the process proceeds to step S907, and the variable i is incremented by “1”.
[0038]
Thus, when the variable i is sequentially incremented in the j-th line of the block of interest and it is determined that the pixel of interest is a black pixel, the process proceeds to step S908, and the variable kuro is substituted with “1”. It is indicated that at least a black pixel exists in the target line (line indicated by the variable j).
[0039]
Thereafter, the process proceeds to step S909 to determine whether or not the flag is “0”. A flag of “0” means that the previous line is a blank part, and a black pixel is not generated until the line indicated by the variable j. Therefore, in this case, the process proceeds to step S910, and the occurrence of the character string pattern is detected. Therefore, the variable j at that time is substituted into the array variable line_sy [nline]. Since the character pattern exists in a plurality of dot lines, “1” is assigned to flag so that the processing in step S910 is not performed on the next line.
[0040]
Further, when the presence of a black pixel is detected in the line indicated by the variable j, it is not necessary to detect the state of the pixel located on the right side of the line, so the process of step S907 is not performed. Assuming that the processing of the attention line has been completed, the process proceeds to step S912.
[0041]
In step S912, it is determined whether kuro = 0 and flag = 1.
[0042]
That is, it is determined whether or not a blank line is detected while lines with black pixels are being continuously detected. To explain in a more easy-to-understand manner, it is determined whether a character string pattern area for one line has been determined.
[0043]
If not, the process proceeds to step S913, the variable j is incremented by “1”, and the processes in and after step S902 are repeated.
[0044]
When it is determined that the character string pattern for one line has been detected in this way, the process proceeds to step S914, and the array variable line_h [nline] is set to a value obtained by subtracting line_sy [nline] from the variable j at that time. To do. As described above, since line_sy [nline] stores the y coordinate of the upper left corner of the character string pattern, line_h [nline] stores the number of lines of continuous black pixels, that is, the character string pattern. Height information will be stored.
[0045]
In step S915, the variable flag is cleared to “0” and nline is incremented by “1” in preparation for detection of the next character string pattern (character string row).
[0046]
As a result, the variable j eventually exceeds the height height of the block of interest, and this processing is terminated at that time. At this time, the number of character string lines detected in the block of interest is stored in nline, and the y coordinate value of the upper left corner of each character string pattern is stored in line_sy [0] to line_sy [nline], and line_h [0] to line [ nline] stores the height information of each character string pattern.
[0047]
The number of lines, the start point of each line, and the height can be extracted from the character image of each block by the processing of FIG.
[0048]
Returning to the description of FIG. In step S105, a loop is rotated for processing the extracted row data. If all the lines have not been processed, the process returns to step S102, otherwise the process proceeds to step S106.
[0049]
In step S106, as shown in FIG. 11, the rows extracted in step S104 are viewed in raster order, the number of black pixels in area (1) is counted to obtain B1, and then the number of black pixels in area (2) is determined. Count B2 is obtained, the number of black pixels in area (3) is counted to obtain B3, and finally the number of black pixels in area (4) is counted to obtain B4 (refer to FIG. 7 for the definition of
[0050]
Here, each area means an area obtained by dividing the height indicated by the line height information line_h [] into four as described above.
[0051]
A flowchart of an example of the process is shown in FIG. As shown in FIG. 7, the upper left of the line image extracted in the line extraction process of step S104 is the coordinate (0, 0), the width of the line image is W, and the pixel height is H. Therefore, the lower right coordinate is (W-1, H-1). The following variables are also secured in the
[0052]
In step S1001, the black pixel counters counter (0) to counter (3) are cleared to “0”. Here, counter [0] is B1, coefficient [1] is B2, counter [2] is B3, and counter [3] is a variable for coefficient B4.
[0053]
In step S1002, the ordinate counter j for processing a two-dimensional image is reset. In step S1003, it is checked whether or not the ordinate counter j exceeds the line image height H. If it exceeds, the process proceeds to end and ends the process. If not, the process proceeds to step S1004.
[0054]
In step S1004, the abscissa counter i for processing a two-dimensional image is reset. In step S1005, it is checked whether or not the abscissa counter i exceeds the row image width W. If it exceeds, the process proceeds to step S1009, and if not, the process proceeds to step S1006. In step S1006, it is checked whether pixel [i] [j] is black. If black, the process proceeds to step S1007, and if white, the process proceeds to step S1008.
[0055]
In step S1007, counter [j / 4] is incremented because pixel [i] [j] is black.
[0056]
However, “j / 4” is valid only for the integer part. Therefore, j / 4 is one of four
[0057]
That is, the black pixel in the small region (1) is added to counter [0], the black pixel in the
[0058]
In step S1008, the abscissa counter i is incremented, and the process returns to step S1005. In step S1009, the ordinate counter j is incremented, and the process returns to step S1003.
[0059]
As a result of the above processing, black pixels in each small area are counted as B1 = counter [0], B2 = counter [1], B3 = counter [2], and B4 = counter [3].
[0060]
Returning to the description of FIG. In step S107, whether (B2 + B3) / (B1 + B4) is greater than or equal to a preset threshold value T1, or (B3 + B4)/ (B1 + B2)Is greater than or equal to a preset threshold value T2. If the determination of any of these is affirmed, the target line of the target block is determined to be an English character string, so the attribute for that line is set to “English” in step S108. If both determinations are negative, the attention line is determined to be in Japanese, and an attribute to that effect is given.
[0061]
As described above, according to the present embodiment, it is possible to determine whether English or Japanese is used for each line, so that it is possible to select an appropriate recognition dictionary in the subsequent character recognition processing, thereby improving the recognition rate. It becomes possible. In some cases, the recognition algorithm itself may be switched.
[0062]
<Description of the second embodiment>
In the first embodiment, the alphabet / Japanese discrimination is performed for each line of the character image.
[0063]
For example, if the first line of a character image is extracted, the black pixel distribution of the first line is calculated, and alphabet Japanese is determined, the result may be used as the determination result for the entire image.
[0064]
Alternatively, the character image is cut by shading on the Y axis, the character is cut by shading on the X axis, and m characters are arbitrarily selected, and the average of the black eye distribution of the m characters is calculated to calculate the entire character image. There is also a method to determine Japanese alphabet.
[0065]
By these methods, calculation time can be shortened.
[0066]
Further, in the first embodiment described above, the line extraction means is a shadow on the Y axis with respect to the character image. However, the present invention is not limited to this, and for example, it may be performed by area separation in step S101 in FIG. Specifically, after the resolution conversion in step S301 in FIG. 3 and the contour line tracking in step S302, the object extracted by the contour line tracking is determined as a character, but the same group combination in step S303 is determined. Instead, do region separation as rows. The result of executing FIG. 2A by this processing is as shown in FIG. 8, and no shading on the Y axis is necessary. However, since the accuracy of the extracted row is low due to the effect of resolution conversion, it is necessary to tune the value of the threshold value T in consideration of this. Since this threshold value T depends on the document image, it is adjusted from the
[0067]
Also, if there is an isolated pixel that is originally one pixel in the blank area as noise in the input document image, the above processing may not be performed normally. Therefore, it is desirable to provide a process for determining an isolated pixel and removing it. The isolated pixel may be determined by determining whether there is another black pixel within a predetermined distance around the black pixel. Alternatively, a method of winding an image and deleting it by pattern matching may be used.
[0068]
In the first embodiment, the image subjected to the region separation process in step S101 is a 1-pixel 1-bit image, but is not limited thereto, and may be, for example, a 1-pixel 8-bit multi-value image. In that case, there is a method of extracting a high frequency component by applying a differential filter and dividing it into a character part and a photograph part. In order to carry out this alphabet Japanese discrimination, the multi-valued image of 8 bits per pixel may be binarized with a certain threshold value.
[0069]
Further, by correcting the inclination of the character image before performing the alphabet / Japanese automatic discrimination method, a better result can be obtained for an image in which the document is inclined. The tilt correction can be realized, for example, by obtaining the tilt of the extracted line and performing coordinate conversion, and thus description thereof is omitted.
[0070]
Further, by detecting the direction of the character image before applying this alphabet / Japanese automatic discrimination method, a result independent of the direction of the original can be obtained. For example, the character image direction is detected by performing line extraction and character extraction on the character image extracted by area division, and performing OCR by rotating the extracted several images by 0 °, 90 °, 180 °, and 270 °. Since OCR certainty can be obtained, the direction of the character image can be detected and the original image can be obtained.
[0071]
Further, although the number of black pixels in each small area is counted after extracting the row image, it is not limited to this. For example, the number of black pixels in the small area may be counted at the same time when the row image is extracted by performing shading in the Y-axis direction. In that case, since the height of the row image is still unclear, the number of black pixels in the row can be held and the black pixels in the small region can be obtained after the height is known.
[0072]
<Description of the third embodiment>
In the above embodiment, the line of the character string is divided into four equal parts, and whether the corresponding line is Japanese or English is determined by the ratio of the number of black pixels in the line. In the third embodiment, An example of determining the character type will be described by paying attention to the fact that Japanese character patterns generally have more dots per unit area than English.
[0073]
The apparatus configuration is the same as that of the first embodiment described above, and the processing content will be described here.
[0074]
The processing procedure in the third embodiment will be described with reference to the flowchart of FIG.
[0075]
In the flowchart of FIG. 13, steps S3101 to S3105 are the same as steps S101 to S105 of FIG. That is, it is assumed that the processes related to block formation and detection of the number of lines of text or headings in each block are the same.
[0076]
In steps S <b> 3101 to S <b> 3105, the document image is input and divided into blocks, and the target block is a title or text, and the line is extracted. If it is determined that there is an unprocessed line, the process proceeds to step S3106.
[0077]
In step S3106, the black pixels in the row are viewed as shown in FIG. 14, and the character width is detected and the number of black pixels is counted.
[0078]
FIG. 15 shows a flowchart of the processing content of step S3106, which will be described below.
[0079]
As shown in FIG. 14, the upper left position of the row image extracted by the row extraction process in step S3104 (see FIG. 9) is the coordinate (0, 0), the pixel width of the row image is IW, and the pixel height is Let H be. Therefore, the lower right coordinate is (IW-1, H-1). The details of this process will become clear from the following description. In short, the coordinates of the start position (line head) and end position (line end) of the position where the actual character string pattern of the line of interest exists, A process of counting the number of dots between them is performed.
[0080]
When the start position of the black pixel is detected in step S4001, the variable startx (x coordinate) that stores and holds the position is updated, and the variable flag_blk that is controlled so as not to update the variable startx in the subsequent processing is set to “
[0081]
Further, flag_line stores information indicating whether or not there is a black pixel in the vertical 1-dot column indicated by the current variable i, and flag_line2 stores information indicating whether or not there is a black pixel in the immediately preceding vertical 1-dot column. . Therefore, if the character pattern is interrupted while black pixels are being continuously detected, flag_line2 = 1 (there is a black pixel in the immediately preceding vertical one dot row) and flag_line = 0 (notice It is only necessary to determine that there is no black pixel in the vertical one dot row.
[0082]
In step S4005, the variable j that stores and holds the y coordinate of the pixel position to be extracted is cleared to “0”.
[0083]
In step S4006, the pixel at the position indicated by the variables i and j in the target row is read from the
[0084]
Thus, if no black pixel is found for one vertical dot row indicated by the variable j, the determination in step S4013 is “NO”, so the flow proceeds to step S4014, flag_line2 is “1”, and It is determined whether or not flag_line is “0”. That is, it is determined whether the end of the character pattern has been found. If not, the variable i is incremented to prepare for the next column position. In step S4017, the variable i is compared with the line width. If it is determined that the process for the line width has not been completed, the process returns to step S4004 and the above process is repeated.
[0085]
In this process, when a black pixel is detected for the first time, it is determined in step S4007 that flag_blk is “0”. Therefore, the process proceeds to step S4008, and the value of the variable i at that time is set to the variable startx. substitute. As a result, the x coordinate of the first dot position of the character string pattern is stored in startx.
[0086]
Next, “1” is substituted for the variable flag_blk so that the process of substituting for startx is not performed thereafter.
[0087]
Next, since one black pixel is detected, the variable counter is incremented by “1”, and since a black pixel is detected in the vertical column of interest, “1” is assigned to flag_line. Then, the process proceeds to step S4012.
[0088]
As a result, when the first black pixel in the target row is detected, the variable i which is the x coordinate value at that time is substituted for the variable startx, and this process is not performed thereafter. Each time a black pixel is detected, the variable counter is incremented by “1”.
[0089]
Now, in the process of detecting the black pixel of one character, if the process moves between the adjacent character patterns, there is naturally a blank portion between them, so that no black pixel is detected.
[0090]
At this time, the determination in step S4014 is “Yes”. That is, since the value of the variable i at that time is the end position of the character pattern of interest, the value is substituted into endx, assuming that the position is the temporary line end position. Accordingly, the content of endx is updated by the number of characters included in the target line (see FIG. 14), but the x coordinate value at the end of the character at the end position of the target line is finally stored in endx. Become.
[0091]
As a result, the start position of the initial character pattern of the target line in the target block is stored in startx, the end of the end-of-line character pattern is stored in endx, and the number of black pixels between them is stored in counter.
[0092]
Returning to the description of FIG.
[0093]
In step S3107, the number of white pixels (WN) is set.
WN = row height (H) × row width (W) −number of black pixels (BN)
To obtain the black pixel ratio R.
R = number of black pixels (BN) / number of white pixels (WN)
Ask for.
[0094]
Here, the row height is as described in the first embodiment, and the row width is a value obtained by endx-startx.
[0095]
It is checked whether or not R is larger than the threshold value T determined in advance in step S4108 (whether there are many black pixels). If R> T, the process proceeds to step S3109. If R <= T, the process proceeds to step S3110. move on. In step S3109, it is determined that the character image is Japanese, and the process returns to step S3105. In step S3110, it is determined that the character image is an alphabet, and the process returns to step S3105.
[0096]
As described above, according to the third embodiment, the character pattern has a large number of dots when it is Japanese, and conversely, it has a small number of dots when it is English. The character type of each line can be determined. Therefore, when moving to the character recognition process, it is possible to determine the recognition dictionary in advance or to determine a priority dictionary, and to increase the character recognition rate.
[0097]
<Description of the fourth embodiment>
In the third embodiment, alphabetic Japanese discrimination is performed for each line of the character image, but this is not limited. For example, if the first line of a character image is extracted, the black pixel distribution of the first line is calculated, and alphabet Japanese is determined, the result may be used as the determination result for the entire image.
[0098]
Alternatively, a character image is line-cut by shading to the X axis, and after character cutting by shading to the Y-axis, m characters are arbitrarily selected, an average of R of m characters is calculated, and the entire character image is calculated. There is also a method to perform alphabet Japanese discrimination. By these methods, calculation time can be shortened.
[0099]
Further, the character type may be determined by combining the first embodiment and the third embodiment described above. If it does in this way, it will become possible to improve the precision about character type judgment.
[0100]
In addition, there are various fonts and styles for characters. Therefore, if Japanese is a narrower font and English is a thicker font, there is a risk of misclassification. Therefore, if the thin line processing of characters is performed before the processing as in the first embodiment, the risk of such erroneous determination is eliminated. However, a strict thinning process involves a very complicated process. However, in the third embodiment, since the character types are simply made unambiguous, simple thinning processing may be performed.
[0101]
Hereinafter, simple thin line processing will be described.
[0102]
Simple thin line processing is possible by erasing black pixels by pattern matching. Focusing on two images, for example, in units of 3 × 3 pixels, if the predetermined erase pattern matches the image pattern in the window, the target pixel (center pixel in the window) is forcibly converted from black to white. The thin line process is performed by repeating the process. An example of the erase pattern is as shown in FIG.
[0103]
Further, in the third embodiment, the line extracting means is a shadow on the Y axis with respect to the character image. However, the present invention is not limited to this. For example, the line extracting means may be performed by area separation in step S3101 in FIG.
[0104]
Specifically, as in the first embodiment, after performing resolution conversion and contour tracking, an elongated object extracted by contour tracking is determined as a character. Instead, do region separation as rows. The result of executing FIG. 2 (a) by this processing is as shown in FIG. However, since the accuracy of the extracted row is low due to the influence of resolution conversion, the value of the threshold value T must be tuned in consideration thereof.
[0105]
Further, in the third embodiment described above, if there is noise in a 1-pixel 1-bit image to be subjected to this processing, the alphabet-Japanese discrimination ability cannot be utilized. Therefore, it is better to remove isolated dots that are clearly recognized as noise. As a method of removing the isolated dots, there is a method of winding an image and deleting it by pattern matching.
[0106]
In the third embodiment described above, the image subjected to the region separation process in step S3101 in FIG. 13 is a 1-pixel 1-bit image. However, the image is not limited thereto, and may be, for example, a 1-pixel 8-bit multi-value image. In that case, there is a method of extracting a high frequency component by applying a differential filter and dividing it into a character part and a photograph part. In order to carry out this alphabet Japanese discrimination, it is necessary to binarize the multi-valued image of 8 bits per pixel with a constant threshold value.
[0107]
Further, by correcting the inclination of the character image before performing the alphabet automatic Japanese discrimination method, a better result can be obtained for an image in which the document is inclined. The inclination correction can be realized by, for example, obtaining the inclination of the extracted line and performing coordinate conversion.
[0108]
In addition, by detecting the direction of the character image before applying the automatic alphabet / Japanese discrimination method, a result independent of the direction of the document can be obtained. For example, the character image direction is detected by performing line extraction and character extraction on the character image extracted by area division, and performing OCR by rotating the extracted several images by 0 °, 90 °, 180 °, and 270 °. Since the certainty of OCR can be obtained, the direction of the character image is detected and the original image is used.
[0109]
As described above, according to the first to fourth embodiments, it is possible to determine the character type according to the distribution or density of Japanese and English character patterns. Therefore, it is possible to determine a dictionary to be used when recognizing as a pre-process for character recognition, or to determine the priority order thereof, so that the character recognition rate can be improved.
[0110]
In the first to fourth embodiments, both Japanese and English have been described. However, the same applies when German or French is used instead of English, and a kanji range (for example, instead of Japanese) Therefore, the present invention is not limited to the above example.
[0111]
In the embodiment, the image input from the
[0112]
Furthermore, the present invention may be applied to a system composed of a plurality of devices or an apparatus composed of a single device. Needless to say, the present invention can also be applied to a case where the present invention is achieved by supplying a program to a system or apparatus.
[0113]
【The invention's effect】
As described above, according to the present invention, it is possible to increase the processing accuracy in lower-order processing, for example, character recognition processing, by efficiently determining the character type in the input document image.
[0114]
Further, according to a preferred embodiment of the present invention, the sub-process is a character recognition process, and a recognition algorithm used when performing a recognition process according to a result determined by the determination means, or a recognition algorithm Since the recognition dictionary or the recognition dictionary is selected, the recognition speed and the recognition accuracy can be increased.
[0115]
In addition, the dot existence ratio with respect to a substantially central area of each divided area is calculated, and when the calculated ratio is greater than or equal to a predetermined value, the determination unit determines that the attention line is an alphabetic character, In the following cases, since it is determined that the character is a kanji-speaking character, it becomes possible to accurately determine a kanji-speaking character and an alphabetic character.
[0116]
In addition, since the line is determined based on the dot distribution projected in the arrangement direction of the character string pattern, the line can be determined with high accuracy.
[0117]
Furthermore, since noise removal means for removing noise in the input document image can be provided, the influence of noise can be eliminated, so that the line can be determined with higher accuracy.
[0118]
Further, by providing means for rotating the input image by a predetermined angle to determine the direction as an erect image, it is possible to make a determination according to the input direction of the document image.
[0119]
In addition, since the tilt is corrected when the input image is tilted, it is possible to process a document image input tilted with higher accuracy.
[0120]
[Brief description of the drawings]
FIG. 1 is a flowchart illustrating a processing procedure in an embodiment.
FIG. 2 is a diagram illustrating a relationship between a document image and a block dividing process.
FIG. 3 is a flowchart illustrating an example of block division processing according to the embodiment.
4 is a diagram illustrating a state in which the resolution conversion process in FIG. 3 has been performed.
FIG. 5 is a diagram illustrating a structure of a block variable structure and an example of data thereof in the embodiment.
FIG. 6 is a diagram showing a concept of row discrimination.
FIG. 7 is a diagram for explaining an example of Japanese and English character strings and the principle of character identification;
FIG. 8 is a diagram illustrating an example of an attribute of each block after the block dividing process according to the embodiment.
FIG. 9 is a flowchart of row identification processing according to an embodiment.
FIG. 10 is a flowchart illustrating details of pixel counting processing according to the embodiment.
FIG. 11 is a diagram illustrating scanning contents of pixel counting processing according to the embodiment.
FIG. 12 is a diagram illustrating a block configuration of a character recognition device according to an embodiment.
FIG. 13 is a flowchart showing an operation processing procedure of the third embodiment.
FIG. 14 is a diagram showing an outline of a processing process in a third embodiment.
FIG. 15 is a flowchart showing black pixel distribution calculation processing in the third embodiment;
FIG. 16 is a diagram illustrating an example of a pattern used in thinning processing.
[Explanation of symbols]
1 CPU
2 ROM
3 RAM
4 External storage device
5 input devices
6 Image scanner
7 Image memory
8 display devices
Claims (10)
入力された原稿画像中の文字画像を含む文字行の領域を判別する判別手段と、
判別された文字行領域を、当該文字行の方向と垂直な方向に並んだ4つの領域に分割する分割手段と、
前記分割手段で分割された各領域中の有意なドットを計数する計数手段と、
前記計数手段で計数された各領域の有意なドット数を上の領域から順にB1,B2,B3,B4とした場合、(B2+B3)と(B1+B4)との比に基づいて第1ドット分布R1を算出し、(B3+B4)と(B1+B2)との比に基づいて第2ドット分布R2を算出する算出手段と、
前記算出された第1ドット分布R1が第1の閾値T1以上であるか或いは前記算出された第2ドット分布R2が第2の閾値T2以上であると判断された場合は、当該文字行領域をアルファベット文字行であると判定し、
前記第1ドット分布R1が前記第1の閾値T1より小さく且つ前記第2ドット分布R2が前記第2の閾値T2より小さいと判断された場合は、当該文字行領域を漢字圏文字行であると判定する判定手段と
を備えることを特徴とする画像処理装置。An image processing apparatus that determines the type of characters in an input document image and passes it to a lower-level process.
A discriminating means for discriminating a region of the character line including the character image in the input document image;
Dividing means for dividing the determined character line area into four areas arranged in a direction perpendicular to the direction of the character line;
Counting means for counting significant dots in each region divided by the dividing means ;
When the significant number of dots in each area counted by the counting means is B1, B2, B3, and B4 in order from the upper area , the first dot distribution R1 is calculated based on the ratio of (B2 + B3) to (B1 + B4). Calculating means for calculating a second dot distribution R2 based on a ratio of (B3 + B4) and (B1 + B2) ;
When it is determined that the calculated first dot distribution R1 is greater than or equal to the first threshold T1, or the calculated second dot distribution R2 is greater than or equal to the second threshold T2, the character line area is Judge that it is an alphabetic character line,
When it is determined that the first dot distribution R1 is smaller than the first threshold value T1 and the second dot distribution R2 is smaller than the second threshold value T2, the character line area is a Chinese character area character line. An image processing apparatus comprising: determination means for determining.
入力された原稿画像中の文字画像を含む文字行の領域を判別する判別工程と、
判別された文字行領域を、当該文字行の方向と垂直な方向に並んだ4つの領域に分割する分割工程と、
前記分割工程で分割された各領域中の有意なドットを計数する計数工程と、
前記計数工程で計数された各領域の有意なドット数を上の領域から順にB1,B2,B3,B4とした場合、(B2+B3)と(B1+B4)との比に基づいて第1ドット分布R1を算出し、(B3+B4)と(B1+B2)との比に基づいて第2ドット分布R2を算出する算出工程と、
前記算出された第1ドット分布R1が第1の閾値T1以上であるか或いは前記算出された第2ドット分布R2が第2の閾値T2以上であると判断された場合は、当該文字行領域をアルファベット文字行であると判定し、
前記第1ドット分布R1が前記第1の閾値T1より小さく且つ前記第2ドット分布R2 が前記第2の閾値T2より小さいと判断された場合は、当該文字行領域を漢字圏文字行であると判定する判定工程と
を備えることを特徴とする画像処理方法。An image processing method for determining a character type in an input document image and passing it to a lower-level process,
A discriminating step for discriminating a region of a character line including a character image in the input document image;
A dividing step of dividing the determined character line area into four areas arranged in a direction perpendicular to the direction of the character line;
A counting step of counting significant dots in each region divided in the dividing step ;
When the significant number of dots in each area counted in the counting step is B1, B2, B3, and B4 in order from the upper area , the first dot distribution R1 is set based on the ratio of (B2 + B3) to (B1 + B4). A calculation step of calculating and calculating a second dot distribution R2 based on a ratio of (B3 + B4) and (B1 + B2) ;
When it is determined that the calculated first dot distribution R1 is greater than or equal to the first threshold T1, or the calculated second dot distribution R2 is greater than or equal to the second threshold T2, the character line area is Judge that it is an alphabetic character line,
When it is determined that the first dot distribution R1 is smaller than the first threshold value T1 and the second dot distribution R2 is smaller than the second threshold value T2, the character line area is a Chinese character area character line. An image processing method comprising: a determination step of determining.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP10853495A JP3710164B2 (en) | 1995-05-02 | 1995-05-02 | Image processing apparatus and method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP10853495A JP3710164B2 (en) | 1995-05-02 | 1995-05-02 | Image processing apparatus and method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPH08305792A JPH08305792A (en) | 1996-11-22 |
| JP3710164B2 true JP3710164B2 (en) | 2005-10-26 |
Family
ID=14487254
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP10853495A Expired - Fee Related JP3710164B2 (en) | 1995-05-02 | 1995-05-02 | Image processing apparatus and method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP3710164B2 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6125464B2 (en) * | 2014-05-30 | 2017-05-10 | 京セラドキュメントソリューションズ株式会社 | Image forming apparatus |
| CN107481238A (en) * | 2017-09-20 | 2017-12-15 | 众安信息技术服务有限公司 | Image quality measure method and device |
-
1995
- 1995-05-02 JP JP10853495A patent/JP3710164B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JPH08305792A (en) | 1996-11-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US5539841A (en) | Method for comparing image sections to determine similarity therebetween | |
| US5410611A (en) | Method for identifying word bounding boxes in text | |
| US4903312A (en) | Character recognition with variable subdivisions of a character region | |
| US5280544A (en) | Optical character reading apparatus and method | |
| EP0063454B1 (en) | Method for recognizing machine encoded characters | |
| EP2569930B1 (en) | Segmentation of a word bitmap into individual characters or glyphs during an ocr process | |
| US7164795B2 (en) | Apparatus for extracting ruled line from multiple-valued image | |
| EP0381773B1 (en) | Character recognition apparatus | |
| US5129012A (en) | Detecting line segments and predetermined patterns in an optically scanned document | |
| JPH05242292A (en) | Separating method | |
| US6947596B2 (en) | Character recognition method, program and recording medium | |
| JP3411472B2 (en) | Pattern extraction device | |
| US5625710A (en) | Character recognition apparatus using modification of a characteristic quantity | |
| US5982952A (en) | Optical character reader with tangent detection for detecting tilt of image data | |
| JP3710164B2 (en) | Image processing apparatus and method | |
| JP2917427B2 (en) | Drawing reader | |
| EP0767941B1 (en) | Automatic determination of landscape scan in binary images | |
| JP3428504B2 (en) | Character recognition device | |
| JP4439054B2 (en) | Character recognition device and character frame line detection method | |
| KR100286709B1 (en) | How to Separate Individual Characters in English Strings | |
| JPH08339424A (en) | Image processing apparatus and method | |
| JP3277977B2 (en) | Character recognition method | |
| JP2000207491A (en) | Character string reading method and apparatus | |
| JP2006277149A (en) | Character and image segmentation device, character and image segmentation method, and program | |
| JP3210224B2 (en) | Character recognition device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20050324 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20050425 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20050624 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20050729 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20050809 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20080819 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20090819 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20090819 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100819 Year of fee payment: 5 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110819 Year of fee payment: 6 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120819 Year of fee payment: 7 |
|
| LAPS | Cancellation because of no payment of annual fees |