JP2022051113A - 情報出力装置、質問生成装置、及びプログラム - Google Patents
情報出力装置、質問生成装置、及びプログラム Download PDFInfo
- Publication number
- JP2022051113A JP2022051113A JP2020157394A JP2020157394A JP2022051113A JP 2022051113 A JP2022051113 A JP 2022051113A JP 2020157394 A JP2020157394 A JP 2020157394A JP 2020157394 A JP2020157394 A JP 2020157394A JP 2022051113 A JP2022051113 A JP 2022051113A
- Authority
- JP
- Japan
- Prior art keywords
- word
- user
- model
- target
- specific example
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/332—Query formulation
- G06F16/3329—Natural language query formulation or dialogue systems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3344—Query execution using natural language analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
- G06F18/2155—Generating training patterns; Bootstrap methods, e.g. bagging or boosting characterised by the incorporation of unlabelled data, e.g. multiple instance learning [MIL], semi-supervised techniques using expectation-maximisation [EM] or naïve labelling
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Databases & Information Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- Human Computer Interaction (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Machine Translation (AREA)
Abstract

【課題】アンケート等でユーザ既知語を調べる場合に比較して、ユーザ既知語を効率的に調べることを可能とする情報出力装置、質問生成装置及びプログラムを提供する。
【解決手段】質問生成装置は、プロセッサを備える。プロセッサは、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた特定のユーザ既知語の意味表現との差分を算出し、差分に基づいて、対象単語がユーザ既知語である可能性に関する情報を出力する。
【選択図】図7
【解決手段】質問生成装置は、プロセッサを備える。プロセッサは、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた特定のユーザ既知語の意味表現との差分を算出し、差分に基づいて、対象単語がユーザ既知語である可能性に関する情報を出力する。
【選択図】図7
Description
本発明は、情報出力装置、質問生成装置、及びプログラムに関する。
あるパターンが他のパターンを含意しているような2つの言語パターンのペアを生成する技術は、知られている(例えば、特許文献1参照)。
例えば、ユーザに単語を用いた質問を行い、その質問に対するユーザの回答を利用して何らかの処理を行うことがある。その際、ユーザがその単語の意味を知らないと、回答の質又は量が低下するので、その単語はユーザが意味を知っている単語(以下、「ユーザ既知語」という)であることが望ましい。ここで、ユーザ既知語を調べるには、アンケート等を行うことも考えられるが、時間やコスト等の観点から効率的な方法ではない。
本発明の目的は、アンケート等でユーザ既知語を調べる場合に比較して、ユーザ既知語を効率的に調べることを可能とすることにある。
請求項1に記載の発明は、プロセッサを備え、前記プロセッサは、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、当該特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた当該特定のユーザ既知語の意味表現との差分を算出し、前記差分に基づいて、前記対象単語がユーザ既知語である可能性に関する情報を出力することを特徴とする情報出力装置である。
請求項2に記載の発明は、前記プロセッサは、複数の対象単語の各対象単語について前記差分を算出することにより、複数の差分を算出し、前記対象単語がユーザ既知語である可能性に関する情報として、前記複数の対象単語の各対象単語についての前記差分に基づく順序で並べられた当該複数の対象単語を出力することを特徴とする請求項1に記載の情報出力装置である。
請求項3に記載の発明は、前記差分に基づく順序は、当該差分が大きい順序であることを特徴とする請求項2に記載の情報出力装置である。
請求項4に記載の発明は、前記第2のモデルは、前記特定の例文集合の前記対象単語を除く部分を用いて単語の意味表現を未学習モデルに新たに学習させたモデルであることを特徴とする請求項1に記載の情報出力装置である。
請求項5に記載の発明は、前記特定の例文集合の前記対象単語を除く部分は、当該特定の例文集合の前記特定のユーザ既知語及び当該対象単語の少なくとも何れか一方を含む構成要素の当該対象単語を除く部分であることを特徴とする請求項4に記載の情報出力装置である。
請求項6に記載の発明は、前記第2のモデルは、前記特定の例文集合の前記対象単語を除く部分を用いて単語の意味表現を学習済みモデルに更に学習させたモデルであることを特徴とする請求項1に記載の情報出力装置である。
請求項7に記載の発明は、前記特定の例文集合の前記対象単語を除く部分は、当該特定の例文集合の当該対象単語を含む構成要素の当該対象単語を除く部分であることを特徴とする請求項6に記載の情報出力装置である。
請求項8に記載の発明は、プロセッサを備え、前記プロセッサは、複数の対象単語の各対象単語について、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、当該特定の例文集合の当該各対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた当該特定のユーザ既知語の意味表現との差分を算出することにより、複数の差分を算出し、前記複数の差分に基づいて、前記複数の対象単語を用いた質問を生成することを特徴とする質問生成装置である。
請求項9に記載の発明は、前記プロセッサは、前記特定のユーザ既知語に代えて、前記質問に対するユーザの回答から把握される他のユーザ既知語を用いて、前記複数の差分を算出し、前記複数の差分に基づいて、前記複数の対象単語を用いた質問を再生成することを特徴とする請求項8に記載の質問生成装置である。
請求項10に記載の発明は、コンピュータに、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、当該特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた当該特定のユーザ既知語の意味表現との差分を算出する機能と、前記差分に基づいて、前記対象単語がユーザ既知語である可能性に関する情報を出力する機能とを実現させるためのプログラムである。
請求項2に記載の発明は、前記プロセッサは、複数の対象単語の各対象単語について前記差分を算出することにより、複数の差分を算出し、前記対象単語がユーザ既知語である可能性に関する情報として、前記複数の対象単語の各対象単語についての前記差分に基づく順序で並べられた当該複数の対象単語を出力することを特徴とする請求項1に記載の情報出力装置である。
請求項3に記載の発明は、前記差分に基づく順序は、当該差分が大きい順序であることを特徴とする請求項2に記載の情報出力装置である。
請求項4に記載の発明は、前記第2のモデルは、前記特定の例文集合の前記対象単語を除く部分を用いて単語の意味表現を未学習モデルに新たに学習させたモデルであることを特徴とする請求項1に記載の情報出力装置である。
請求項5に記載の発明は、前記特定の例文集合の前記対象単語を除く部分は、当該特定の例文集合の前記特定のユーザ既知語及び当該対象単語の少なくとも何れか一方を含む構成要素の当該対象単語を除く部分であることを特徴とする請求項4に記載の情報出力装置である。
請求項6に記載の発明は、前記第2のモデルは、前記特定の例文集合の前記対象単語を除く部分を用いて単語の意味表現を学習済みモデルに更に学習させたモデルであることを特徴とする請求項1に記載の情報出力装置である。
請求項7に記載の発明は、前記特定の例文集合の前記対象単語を除く部分は、当該特定の例文集合の当該対象単語を含む構成要素の当該対象単語を除く部分であることを特徴とする請求項6に記載の情報出力装置である。
請求項8に記載の発明は、プロセッサを備え、前記プロセッサは、複数の対象単語の各対象単語について、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、当該特定の例文集合の当該各対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた当該特定のユーザ既知語の意味表現との差分を算出することにより、複数の差分を算出し、前記複数の差分に基づいて、前記複数の対象単語を用いた質問を生成することを特徴とする質問生成装置である。
請求項9に記載の発明は、前記プロセッサは、前記特定のユーザ既知語に代えて、前記質問に対するユーザの回答から把握される他のユーザ既知語を用いて、前記複数の差分を算出し、前記複数の差分に基づいて、前記複数の対象単語を用いた質問を再生成することを特徴とする請求項8に記載の質問生成装置である。
請求項10に記載の発明は、コンピュータに、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、当該特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた当該特定のユーザ既知語の意味表現との差分を算出する機能と、前記差分に基づいて、前記対象単語がユーザ既知語である可能性に関する情報を出力する機能とを実現させるためのプログラムである。
請求項1の発明によれば、アンケート等でユーザ既知語を調べる場合に比較して、ユーザ既知語を効率的に調べることが可能となる。
請求項2の発明によれば、複数の対象単語についてのユーザ既知語である可能性に基づく順序を知ることができる。
請求項3の発明によれば、複数の対象単語についてのユーザ既知語である可能性が高い順序を知ることができる。
請求項4の発明によれば、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させるモデルとして学習済みモデルを用意しなくても、ユーザ既知語を調べることが可能となる。
請求項5の発明によれば、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させるモデルとして未学習モデルを用意した場合において、特定の例文集合を削減することができる。
請求項6の発明によれば、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させるモデルとして未学習モデルを用意する場合に比較して、単語の意味表現を学習させたモデルの精度を向上することができる。
請求項7の発明によれば、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させるモデルとして学習済みモデルを用意した場合において、特定の例文集合を削減することができる。
請求項8の発明によれば、アンケート等でユーザ既知語を調べてユーザ既知語を用いた質問を生成する場合に比較して、ユーザ既知語を用いた質問を効率的に生成することが可能となる。
請求項9の発明によれば、特定のユーザ既知語のみを用いて質問を生成する場合に比較して、ユーザ既知語を用いた質問が生成される可能性が高まる。
請求項10の発明によれば、アンケート等でユーザ既知語を調べる場合に比較して、ユーザ既知語を効率的に調べることが可能となる。
請求項2の発明によれば、複数の対象単語についてのユーザ既知語である可能性に基づく順序を知ることができる。
請求項3の発明によれば、複数の対象単語についてのユーザ既知語である可能性が高い順序を知ることができる。
請求項4の発明によれば、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させるモデルとして学習済みモデルを用意しなくても、ユーザ既知語を調べることが可能となる。
請求項5の発明によれば、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させるモデルとして未学習モデルを用意した場合において、特定の例文集合を削減することができる。
請求項6の発明によれば、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させるモデルとして未学習モデルを用意する場合に比較して、単語の意味表現を学習させたモデルの精度を向上することができる。
請求項7の発明によれば、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させるモデルとして学習済みモデルを用意した場合において、特定の例文集合を削減することができる。
請求項8の発明によれば、アンケート等でユーザ既知語を調べてユーザ既知語を用いた質問を生成する場合に比較して、ユーザ既知語を用いた質問を効率的に生成することが可能となる。
請求項9の発明によれば、特定のユーザ既知語のみを用いて質問を生成する場合に比較して、ユーザ既知語を用いた質問が生成される可能性が高まる。
請求項10の発明によれば、アンケート等でユーザ既知語を調べる場合に比較して、ユーザ既知語を効率的に調べることが可能となる。
以下、添付図面を参照して、本発明の実施の形態について詳細に説明する。
[本実施の形態の概要]
本実施の形態は、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた特定のユーザ既知語の意味表現との差分を算出し、その差分に基づいて、対象単語がユーザ既知語である可能性に関する情報を出力する情報出力装置である。
本実施の形態は、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた特定のユーザ既知語の意味表現との差分を算出し、その差分に基づいて、対象単語がユーザ既知語である可能性に関する情報を出力する情報出力装置である。
ここで、情報出力装置は、1つの対象単語について差分を算出し、この差分が閾値以上であれば、対象単語がユーザ既知語である可能性に関する情報として、対象単語がユーザ既知語と判断される旨の情報を出力するものでもよい。
或いは、情報出力装置は、複数の対象単語の各対象単語について差分を算出することにより、複数の差分を算出し、対象単語がユーザ既知語である可能性に関する情報として、複数の対象単語の各対象単語についての差分に基づく順序で並べられた複数の対象単語を出力するものでもよい。
情報出力装置は、これらの何れであってもよいが、以下では、後者であるものとして説明する。そして、単に複数の対象単語を出力するのではなく、複数の対象単語を用いた質問を生成するものとする。
その場合、本実施の形態は、複数の対象単語の各対象単語について、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、特定の例文集合の各対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた特定のユーザ既知語の意味表現との差分を算出することにより、複数の差分を算出し、複数の差分に基づいて、複数の対象単語を用いた質問を生成する質問生成装置となる。
従って、以下では、本実施の形態が質問生成装置である場合を例にとって説明する。
ここで、質問生成装置とは、ユーザに与える質問を生成する装置である。この装置は、例えば、質問に対するユーザの回答を利用して、目的のタスクを解くシステムにおいて、質問を生成する装置であってよい。タスクとしては、例えば、単語分類、単語間関連度予測がある。
システムが質問を与える方法としては、次のような方法が考えられる。
目的のタスクが単語分類タスクである場合は、システムが、単語と分類項目とを提示して、その単語に最も関連しそうな分類項目をユーザに質問する、という方法である。
目的のタスクが単語間関連度予測タスクである場合は、システムが、2つの単語を提示して、それらがどのくらい関連しているかをユーザに質問する、という方法である。
また、例文集合とは、何らかの例文を集めたものをいう。例文は、記事や書物等の一般に「文書」と呼ばれ得る比較的長い文であってもよいし、会話の文等の比較的短い文であってもよい。また、例文は、テキストデータとして記録された文だけでなく、例えば、音声データとして記録された文を含んでもよい。更に、例文は、自然言語処理の研究目的に限らず、如何なる目的で集められたものでもよい。以下では、例文集合としてコーパスを例にとって説明する。
更に、特定の例文集合の対象単語を除く部分とは、特定の例文集合に何らかの処理を行って対象単語が含まないようにされた部分のことをいう。この処理は、例えば、対象単語をマスクする処理でもよいし、対象単語を一時的に削除する処理でもよいが、以下では、前者の処理を例にとって説明する。
更に、単語の意味表現とは、単語の意味をベクトル化して表現したものをいう。但し、本実施の形態では、単語の意味表現により単語の意味の近さを計算できればよいので、単語の意味表現は、少なくとも単語の意味の近さを計算できる他の方法で表現したものであってもよい。
更にまた、差分に基づく順序とは、差分を用いて定められる順序をいう。差分に基づく順序は、例えば、差分が大きい順序でもよいし、差分が大きい順序を基本としつつ他の要素を加味した順序でもよい。ここで、他の要素は、他の複数のユーザ既知語を用いた場合の差分であってよい。例えば、特定のユーザ既知語のみを用いた場合の差分は小さいが、他の複数のユーザ既知語を用いた場合の差分の平均が大きい場合や分散が小さい場合に、順序を上げることが考えられる。或いは、他の要素は、対象単語の文法上の属性等であってもよい。以下では、差分に基づく順序として差分が大きい順序を用いた場合を例にとって説明する。
[質問生成装置のハードウェア構成]
図1は、本実施の形態における質問生成装置10のハードウェア構成例を示した図である。図示するように、質問生成装置10は、演算手段であるプロセッサ11と、記憶手段であるメインメモリ12及びHDD(Hard Disk Drive)13とを備える。ここで、プロセッサ11は、OS(Operating System)やアプリケーション等の各種ソフトウェアを実行し、後述する各機能を実現する。また、メインメモリ12は、各種ソフトウェアやその実行に用いるデータ等を記憶する記憶領域であり、HDD13は、各種ソフトウェアに対する入力データや各種ソフトウェアからの出力データ等を記憶する記憶領域である。更に、質問生成装置10は、外部との通信を行うための通信I/F(以下、「I/F」と表記する)14と、ディスプレイ等の表示デバイス15と、キーボードやマウス等の入力デバイス16とを備える。
図1は、本実施の形態における質問生成装置10のハードウェア構成例を示した図である。図示するように、質問生成装置10は、演算手段であるプロセッサ11と、記憶手段であるメインメモリ12及びHDD(Hard Disk Drive)13とを備える。ここで、プロセッサ11は、OS(Operating System)やアプリケーション等の各種ソフトウェアを実行し、後述する各機能を実現する。また、メインメモリ12は、各種ソフトウェアやその実行に用いるデータ等を記憶する記憶領域であり、HDD13は、各種ソフトウェアに対する入力データや各種ソフトウェアからの出力データ等を記憶する記憶領域である。更に、質問生成装置10は、外部との通信を行うための通信I/F(以下、「I/F」と表記する)14と、ディスプレイ等の表示デバイス15と、キーボードやマウス等の入力デバイス16とを備える。
[質問生成装置の機能構成]
図2は、本実施の形態における質問生成装置10の機能構成例を示したブロック図である。図示するように、質問生成装置10は、コーパス記憶部21と、第1学習部22と、第1学習済みモデル記憶部23と、第1出力部24と、第1出力情報記憶部25とを備えている。また、質問生成装置10は、マスキング処理部31を備えている。更に、質問生成装置10は、マスクコーパス記憶部41と、第2学習部42と、第2学習済みモデル記憶部43と、第2出力部44と、第2出力情報記憶部45とを備えている。更にまた、質問生成装置10は、出力差分算出部51と、出力差分情報記憶部52と、ランキング処理部53と、質問単語記憶部54とを備えている。
図2は、本実施の形態における質問生成装置10の機能構成例を示したブロック図である。図示するように、質問生成装置10は、コーパス記憶部21と、第1学習部22と、第1学習済みモデル記憶部23と、第1出力部24と、第1出力情報記憶部25とを備えている。また、質問生成装置10は、マスキング処理部31を備えている。更に、質問生成装置10は、マスクコーパス記憶部41と、第2学習部42と、第2学習済みモデル記憶部43と、第2出力部44と、第2出力情報記憶部45とを備えている。更にまた、質問生成装置10は、出力差分算出部51と、出力差分情報記憶部52と、ランキング処理部53と、質問単語記憶部54とを備えている。
コーパス記憶部21は、コーパスを記憶する。コーパスは、例えば、質問を行う分野における特定のコーパスである。コーパス記憶部21に記憶されたコーパスの具体例については後述する。
第1学習部22は、コーパス記憶部21に記憶されたコーパスを用いて単語の意味表現をモデルに学習させることにより第1学習済みモデルを生成する。本実施の形態では、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルの一例として、第1学習済みモデルを用いている。ここで、第1学習部22は、コーパス記憶部21に記憶されたコーパスを用いて、全く学習していないモデルを学習させることにより、第1学習済みモデルを生成してもよい。或いは、第1学習部22は、コーパス記憶部21に記憶されたコーパスを用いて、既に学習したモデルを更新することにより、第1学習済みモデルを生成してもよい。
第1学習済みモデル記憶部23は、第1学習部22が生成した第1学習済みモデルを記憶する。第1学習済みモデル記憶部23に記憶された第1学習済みモデルの具体例については後述する。
第1出力部24は、第1学習済みモデル記憶部23に記憶された第1学習済みモデルから得られた特定のユーザ既知語の意味表現を第1出力情報として出力する。本実施の形態では、第1のモデルから得られた特定のユーザ既知語の意味表現の一例として、第1出力情報を用いている。
第1出力情報記憶部25は、第1出力部24が出力した第1出力情報を記憶する。第1出力情報記憶部25に記憶された第1出力情報の具体例については後述する。
マスキング処理部31は、コーパス記憶部21に記憶されたコーパスに対し、特定のユーザ既知語に対する寄与を調べたい対象の単語(以下、「調査対象単語」という)をマスクするマスキング処理を行うことにより、マスクコーパスを作成する。本実施の形態では、対象単語の一例として、調査対象単語を用いており、特定の例文集合の対象単語を除く部分の一例として、マスクコーパスを用いている。
マスクコーパス記憶部41は、マスキング処理部31が作成したマスクコーパスを記憶する。マスクコーパス記憶部41に記憶されたマスクコーパスの具体例については後述する。
第2学習部42は、マスクコーパス記憶部41に記憶されたマスクコーパスを用いて単語の意味表現をモデルに学習させることにより第2学習済みモデルを生成する。本実施の形態では、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルの一例として、第2学習済みモデルを用いている。ここで、第2学習部42は、マスクコーパス記憶部41に記憶されたマスクコーパスを用いて、全く学習していないモデルを学習させることにより、第2学習済みモデルを生成してもよい。この場合、第2学習済みモデルは、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を未学習モデルに新たに学習させたモデルの一例である。或いは、第2学習部42は、マスクコーパス記憶部41に記憶されたマスクコーパスを用いて、既に学習したモデルを更新することにより、第2学習済みモデルを生成してもよい。この場合、第2学習済みモデルは、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習済みモデルに更に学習させたモデルの一例である。
第2学習済みモデル記憶部43は、第2学習部42が取得した第2学習済みモデルを記憶する。第2学習済みモデル記憶部43に記憶された第2学習済みモデルの具体例については後述する。
第2出力部44は、第2学習済みモデル記憶部43に記憶された第2学習済みモデルから得られた特定のユーザ既知語の意味表現を第2出力情報として出力する。本実施の形態では、第2のモデルから得られた特定のユーザ既知語の意味表現の一例として、第2出力情報を用いている。
第2出力情報記憶部45は、第2出力部44が出力した第2出力情報を記憶する。第2出力情報記憶部45に記憶された第2出力情報の具体例については後述する。
出力差分算出部51は、複数の調査対象単語のそれぞれについて、第1出力情報記憶部25に記憶された第1出力情報と、その調査対象単語を選択した場合に第2出力情報記憶部45に記憶された第2出力情報との差分である出力差分を算出する。本実施の形態では、第1のモデルから得られた特定のユーザ既知語の意味表現と、第2のモデルから得られた特定のユーザ既知語の意味表現との差分を算出する手段の一例として、出力差分算出部51を設けている。また、本実施の形態では、複数の対象単語の各対象単語について、第1のモデルから得られた特定のユーザ既知語の意味表現と、第2のモデルから得られた特定のユーザ既知語の意味表現との差分を算出することにより、複数の差分を算出する手段の一例としても、出力差分算出部51を設けている。
出力差分情報記憶部52は、複数の調査対象単語のそれぞれについて、その調査対象単語と、その調査対象単語を選択した場合に出力差分算出部51が算出した出力差分とを関連付けた出力差分情報を記憶する。
ランキング処理部53は、複数の調査対象単語を、ユーザに与える質問で用いる単語(以下、「質問単語」という)として、出力差分情報記憶部52に記憶された出力差分が大きい順、つまり、ユーザ既知語である可能性が高い順に並べて出力する。これは、コーパス内に調査対象単語がある場合とない場合とで特定のユーザ既知語の意味表現が大きくずれるのであれば、調査対象単語がないとその特定のユーザ既知語の意味表現が得られないと考えられるので、調査対象単語はユーザ既知語と判断できる、という考え方に基づくものである。本実施の形態では、差分に基づいて、対象単語がユーザ既知語である可能性に関する情報を出力する手段の一例として、ランキング処理部53を設けている。また、本実施の形態では、複数の差分に基づいて、複数の対象単語を用いた質問を生成する手段の一例としても、ランキング処理部53を設けている。
質問単語記憶部54は、ランキング処理部53が出力した質問単語を、ランキング処理部53が並べた順序で記憶する。そして、タスクを実行するシステムが、質問単語記憶部54に記憶された質問単語を、質問単語記憶部54に記憶された順序で取り出して、ユーザに与える質問で用いることになる。
尚、これらの機能部は、ソフトウェアとハードウェア資源とが協働することにより実現される。具体的には、これらの機能部は、プロセッサ11が、これらを実現するプログラムを例えばHDD13からメインメモリ12に読み込んで実行することにより実現される。
次に、本実施の形態における質問生成装置10で記憶されるコーパスの具体例について説明する。
図3(a)は、コーパス記憶部21に記憶されるコーパスの具体例を示した図である。図示するように、コーパス記憶部21に記憶されるコーパスは、文書211,212,213,…を含んでいる。そして、文書211は、文2111,2112,2113,…を含み、文書212は、文2121,2122,2123,…を含み、文書213は、文2131,2132,2133,…を含んでいる。ここで、ユーザ既知語n1,n2,n3は、それぞれ、文2111,2113,2132に存在するものとする。
図3(b)は、マスクコーパス記憶部41に記憶されるマスクコーパスの具体例を示した図である。図示するように、マスクコーパス記憶部41に記憶されるマスクコーパスは、コーパス記憶部21に記憶されるコーパスにおいて調査対象単語がマスクされたものになっている。ここでは、調査対象単語m1,m2,m3が、それぞれ、文4111,4123,4132に存在し、これらがマスクされているものとする。
ところで、図3(a),(b)では、マスクコーパス記憶部41に記憶されるデータの単位を文としたが、これには限らない。データの単位は、より一般化し、文書の構成要素としてよい。文書の構成要素には、文以外に、段落、章、節等が含まれる。
また、図3(b)では、ユーザ既知語しか含まない文や、ユーザ既知語及び調査対象単語の何れも含まない文も、マスクコーパス記憶部41に記憶したが、これには限らない。ユーザ既知語しか含まない文や、ユーザ既知語及び調査対象単語の何れも含まない文は、マスクコーパス記憶部41に記憶しないようにしてもよい。
具体的には、第2学習部42が、全く学習していないモデルを学習させる場合は、ユーザ既知語及び調査対象単語の何れかを含む文のみをフィルタリングして、マスクコーパス記憶部41に記憶するとよい。つまり、図3(b)の例で言えば、文4111,4113,4123,4132をマスクコーパス記憶部41に記憶するとよい。これは、特定の例文集合の対象単語を除く部分が、特定の例文集合の特定のユーザ既知語及び対象単語の少なくとも何れか一方を含む構成要素の対象単語を除く部分である場合の一例である。
一方、第2学習部42が、既に学習したモデルを更新する場合は、調査対象単語を含む文のみをフィルタリングして、マスクコーパス記憶部41に記憶するとよい。つまり、図3(b)の例で言えば、文4111,4123,4132をマスクコーパス記憶部41に記憶するとよい。更新前の学習済みモデルにユーザ既知語が含まれていると仮定できるからである。これは、特定の例文集合の対象単語を除く部分が、特定の例文集合の対象単語を含む構成要素の対象単語を除く部分である場合の一例である。
次に、本実施の形態における質問生成装置10で記憶される学習済みモデルの具体例について説明する。尚、以下では、Word2Vecを構成する2種類のモデルのうちCBOW(Continuous Bag-Of-Words)モデルにより単語の意味表現を学習させる場合を例にとって説明する。
図4(a)は、第1学習済みモデル記憶部23に記憶される第1学習済みモデルの具体例を示した図である。ここでは、コーパスXを入力としたCBOWモデルの出力である第1学習済みモデルをYと表記する。第1学習済みモデルYは、単語の意味表現を各行に持つV×Wの行列である。Vは単語の数であり、Wは意味表現の次元数である。以下、第1学習済みモデルYの単語vの行における次元wの意味表現をYv(w)と表すことにする。図において、第1学習済みモデルYの1行目は、単語v1の次元1,2,3,…の意味表現を表している。また、2行目は、単語v2の次元1,2,3,…の意味表現を表し、3行目は、単語v3の次元1,2,3,…における意味表現を表している。
図4(b)は、第2学習済みモデル記憶部43に記憶される第2学習済みモデルの具体例を示した図である。ここでは、マスキング処理部31が調査対象単語mjをマスキングしたコーパスXをコーパスXmjとし、このコーパスXmjを入力としたCBOWモデルの出力である第2学習済みモデルをYmjと表記する。第2学習済みモデルYmjも、単語の意味表現を各行に持つV×Wの行列である。以下、第2学習済みモデルYmjの単語vの行における次元wの意味表現をYv
mj(w)と表すことにする。図において、第2学習済みモデルYmjの1行目は、単語v1の次元1,2,3,…の意味表現を表している。また、2行目は、単語v2の次元1,2,3,…の意味表現を表し、3行目は、単語v3の次元1,2,3,…の意味表現を表している。
次に、本実施の形態における質問生成装置10で記憶される出力情報の具体例について説明する。
図5(a)は、第1出力情報記憶部25に記憶される第1出力情報の具体例を示した図である。図示するように、第1出力情報は、第1学習済みモデルYからユーザ既知語niに対応する行を抜き出したものである。ここでは、この抜き出された行である第1出力情報をYniと表記する。第1出力情報Yniは、単語の意味表現を要素に持つW次元のベクトルである。
図5(b)は、第2出力情報記憶部45に記憶される第2出力情報の具体例を示した図である。図示するように、第2出力情報は、第2学習済みモデルYmjからユーザ既知語niに対応する行を抜き出したものである。ここでは、この抜き出された行である第2出力情報をYni
mjと表記する。第2出力情報Yni
mjは、単語の意味表現を要素に持つW次元のベクトルである。
次に、本実施の形態における質問生成装置10で記憶される出力差分情報の具体例について説明する。
図6は、出力差分情報記憶部52に記憶される出力差分情報の具体例を示した図である。図示するように、出力差分情報は、調査対象単語と、出力差分とを対応付けたものである。調査対象単語はmjであり、出力差分はδ(ni,mj)である(j=1,2,3,…)。ここで、出力差分δ(ni,mj)は、第1出力情報Yniと、調査対象単語mjをマスクした場合の第2出力情報Ymj
niとの二乗距離として定義される。
尚、その後、ランキング処理部53が、調査対象単語mjを、出力差分δ(ni,mj)の大きい順に並べ替えて、質問単語記憶部54に記憶することになる。
[質問生成装置の動作]
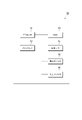
図7は、本実施の形態における質問生成装置10の動作例を示したフローチャートである。
図7は、本実施の形態における質問生成装置10の動作例を示したフローチャートである。
図示するように、質問生成装置10では、まず、第1学習部22が、コーパス記憶部21に記憶されたコーパスを用いて単語の意味表現を学習させて第1学習済みモデルを生成する(ステップ101)。この第1学習済みモデルは、第1学習済みモデル記憶部23に記憶される。
次に、第1出力部24が、第1学習済みモデル記憶部23に記憶された第1学習済みモデルからユーザ既知語の意味表現を抜き出して第1出力情報として出力する(ステップ102)。この第1出力情報は、第1出力情報記憶部25に記憶される。
一方、質問生成装置10では、マスキング処理部31が、コーパス記憶部21に記憶されたコーパスに対して調査対象単語をマスクするマスキング処理を行ってマスクコーパスを生成する(ステップ103)。このマスクコーパスは、マスクコーパス記憶部41に記憶される。
次に、第2学習部42が、マスクコーパス記憶部41に記憶されたコーパスを用いて単語の意味表現を学習させて第2学習済みモデルを生成する(ステップ104)。この第2学習済みモデルは、第2学習済みモデル記憶部43に記憶される。
次に、第2学習部42が、第2学習済みモデル記憶部43に記憶された第2学習済みモデルからユーザ既知語の意味表現を抜き出して第2出力情報として出力する(ステップ105)。この第2出力情報は、第2出力情報記憶部45に記憶される。
次いで、質問生成装置10では、第1出力情報記憶部25に記憶された第1出力情報と第2出力情報記憶部45に記憶された第2出力情報との出力差分を算出し、調査対象単語と関連付けて、出力差分情報として出力する(ステップ106)。この出力差分情報は、出力差分情報記憶部52に記憶される。
その後、質問生成装置10は、調査対象単語が終了したかどうかを判定する(ステップ107)。つまり、着目すべき調査対象単語がなくなったかどうかを判定する。
その結果、調査対象単語が終了していないと判定すれば、質問生成装置10は、処理をステップ103へ戻す。そして、他の調査対象単語に着目し、ステップ103~106の処理を行う。
一方、調査対象単語が終了したと判定すれば、質問生成装置10は、処理をステップ108へ進める。
そして、ランキング処理部53が、調査対象単語を出力差分が大きい順に並べ替えて、質問順に並べられた質問単語として出力する(ステップ108)。この質問単語は、質問単語記憶部54に記憶される。
[変形例]
上記実施の形態では言及しなかったが、システムは、ユーザから質問に対する回答が得られた時点で、新たなユーザ既知語を特定し、コーパス記憶部21に記憶されたコーパスにこれを反映させてもよい。ここで、新たなユーザ既知語は、ユーザがタスク中でその単語の意味を知っているかを明示的にシステムに伝えることで、特定されるようにするとよい。これにより、質問生成装置10では、出力差分算出部51が、この新たなユーザ既知語が反映されたコーパスを用いて新たに出力差分情報を生成することにより、ユーザ既知語を再度予測するようにしてよい。そして、ランキング処理部53が、質問に用いる単語の順序をリアルタイムに更新してよい。この場合、出力差分算出部51は、特定のユーザ既知語に代えて、質問に対するユーザの回答から把握される他のユーザ既知語を用いて、複数の差分を算出する手段の一例であり、ランキング処理部53は、複数の差分に基づいて、複数の対象単語を用いた質問を再生成する手段の一例である。
上記実施の形態では言及しなかったが、システムは、ユーザから質問に対する回答が得られた時点で、新たなユーザ既知語を特定し、コーパス記憶部21に記憶されたコーパスにこれを反映させてもよい。ここで、新たなユーザ既知語は、ユーザがタスク中でその単語の意味を知っているかを明示的にシステムに伝えることで、特定されるようにするとよい。これにより、質問生成装置10では、出力差分算出部51が、この新たなユーザ既知語が反映されたコーパスを用いて新たに出力差分情報を生成することにより、ユーザ既知語を再度予測するようにしてよい。そして、ランキング処理部53が、質問に用いる単語の順序をリアルタイムに更新してよい。この場合、出力差分算出部51は、特定のユーザ既知語に代えて、質問に対するユーザの回答から把握される他のユーザ既知語を用いて、複数の差分を算出する手段の一例であり、ランキング処理部53は、複数の差分に基づいて、複数の対象単語を用いた質問を再生成する手段の一例である。
[プロセッサ]
本実施の形態において、プロセッサとは広義的なプロセッサを指し、汎用的なプロセッサ(例えばCPU:Central Processing Unit等)や、専用のプロセッサ(例えばGPU:Graphics Processing Unit、ASIC:Application Specific Integrated Circuit、FPGA:Field Programmable Gate Array、プログラマブル論理デバイス等)を含むものである。
本実施の形態において、プロセッサとは広義的なプロセッサを指し、汎用的なプロセッサ(例えばCPU:Central Processing Unit等)や、専用のプロセッサ(例えばGPU:Graphics Processing Unit、ASIC:Application Specific Integrated Circuit、FPGA:Field Programmable Gate Array、プログラマブル論理デバイス等)を含むものである。
また、本実施の形態におけるプロセッサの動作は、1つのプロセッサによって成すのみでなく、物理的に離れた位置に存在する複数のプロセッサが協働して成すものであってもよい。また、プロセッサの各動作の順序は、本実施の形態において記載した順序のみに限定されるものではなく、変更してもよい。
[プログラム]
本実施の形態における質問生成装置10が行う処理は、例えば、アプリケーションソフトウェア等のプログラムとして用意される。
本実施の形態における質問生成装置10が行う処理は、例えば、アプリケーションソフトウェア等のプログラムとして用意される。
即ち、本実施の形態を実現するプログラムは、コンピュータに、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた特定のユーザ既知語の意味表現との差分を算出する機能と、差分に基づいて、対象単語がユーザ既知語である可能性に関する情報を出力する機能とを実現させるためのプログラムとして捉えられる。
尚、本実施の形態を実現するプログラムは、通信手段により提供することはもちろん、CD-ROM等の記録媒体に格納して提供することも可能である。
10…質問生成装置、21…コーパス記憶部、22…第1学習部、23…第1学習済みモデル記憶部、24…第1出力部、25…第1出力情報記憶部、31…マスキング処理部、41…マスクコーパス記憶部、42…第2学習部、43…第2学習済みモデル記憶部、44…第2出力部、45…第2出力情報記憶部、51…出力差分算出部、52…出力差分情報記憶部、53…ランキング処理部、54…質問単語記憶部
Claims (10)
- プロセッサを備え、
前記プロセッサは、
特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、当該特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた当該特定のユーザ既知語の意味表現との差分を算出し、
前記差分に基づいて、前記対象単語がユーザ既知語である可能性に関する情報を出力する
ことを特徴とする情報出力装置。 - 前記プロセッサは、
複数の対象単語の各対象単語について前記差分を算出することにより、複数の差分を算出し、
前記対象単語がユーザ既知語である可能性に関する情報として、前記複数の対象単語の各対象単語についての前記差分に基づく順序で並べられた当該複数の対象単語を出力することを特徴とする請求項1に記載の情報出力装置。 - 前記差分に基づく順序は、当該差分が大きい順序であることを特徴とする請求項2に記載の情報出力装置。
- 前記第2のモデルは、前記特定の例文集合の前記対象単語を除く部分を用いて単語の意味表現を未学習モデルに新たに学習させたモデルであることを特徴とする請求項1に記載の情報出力装置。
- 前記特定の例文集合の前記対象単語を除く部分は、当該特定の例文集合の前記特定のユーザ既知語及び当該対象単語の少なくとも何れか一方を含む構成要素の当該対象単語を除く部分であることを特徴とする請求項4に記載の情報出力装置。
- 前記第2のモデルは、前記特定の例文集合の前記対象単語を除く部分を用いて単語の意味表現を学習済みモデルに更に学習させたモデルであることを特徴とする請求項1に記載の情報出力装置。
- 前記特定の例文集合の前記対象単語を除く部分は、当該特定の例文集合の当該対象単語を含む構成要素の当該対象単語を除く部分であることを特徴とする請求項6に記載の情報出力装置。
- プロセッサを備え、
前記プロセッサは、
複数の対象単語の各対象単語について、特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、当該特定の例文集合の当該各対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた当該特定のユーザ既知語の意味表現との差分を算出することにより、複数の差分を算出し、
前記複数の差分に基づいて、前記複数の対象単語を用いた質問を生成する
ことを特徴とする質問生成装置。 - 前記プロセッサは、
前記特定のユーザ既知語に代えて、前記質問に対するユーザの回答から把握される他のユーザ既知語を用いて、前記複数の差分を算出し、
前記複数の差分に基づいて、前記複数の対象単語を用いた質問を再生成することを特徴とする請求項8に記載の質問生成装置。 - コンピュータに、
特定の例文集合を用いて単語の意味表現を学習させた第1のモデルから得られた特定のユーザ既知語の意味表現と、当該特定の例文集合の対象単語を除く部分を用いて単語の意味表現を学習させた第2のモデルから得られた当該特定のユーザ既知語の意味表現との差分を算出する機能と、
前記差分に基づいて、前記対象単語がユーザ既知語である可能性に関する情報を出力する機能と
を実現させるためのプログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020157394A JP2022051113A (ja) | 2020-09-18 | 2020-09-18 | 情報出力装置、質問生成装置、及びプログラム |
| US17/165,349 US20220092260A1 (en) | 2020-09-18 | 2021-02-02 | Information output apparatus, question generation apparatus, and non-transitory computer readable medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020157394A JP2022051113A (ja) | 2020-09-18 | 2020-09-18 | 情報出力装置、質問生成装置、及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2022051113A true JP2022051113A (ja) | 2022-03-31 |
Family
ID=80740495
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020157394A Pending JP2022051113A (ja) | 2020-09-18 | 2020-09-18 | 情報出力装置、質問生成装置、及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US20220092260A1 (ja) |
| JP (1) | JP2022051113A (ja) |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6583686B2 (ja) * | 2015-06-17 | 2019-10-02 | パナソニックIpマネジメント株式会社 | 意味情報生成方法、意味情報生成装置、およびプログラム |
| US10366108B2 (en) * | 2015-06-26 | 2019-07-30 | Sri International | Distributional alignment of sets |
| US10795902B1 (en) * | 2016-04-12 | 2020-10-06 | Tableau Software, Inc. | Applying natural language pragmatics in a data visualization user interface |
| KR102617717B1 (ko) * | 2016-10-18 | 2023-12-27 | 삼성전자주식회사 | 전자 장치 및 그 제어 방법 |
| US10482183B1 (en) * | 2018-09-27 | 2019-11-19 | Babylon Partners Limited | Device and method for natural language processing through statistical model comparison |
| US10831793B2 (en) * | 2018-10-23 | 2020-11-10 | International Business Machines Corporation | Learning thematic similarity metric from article text units |
| US11410031B2 (en) * | 2018-11-29 | 2022-08-09 | International Business Machines Corporation | Dynamic updating of a word embedding model |
| US11625534B1 (en) * | 2019-02-12 | 2023-04-11 | Text IQ, Inc. | Identifying documents that contain potential code words using a machine learning model |
| US11227298B2 (en) * | 2019-04-11 | 2022-01-18 | Prime Research Solutions LLC | Digital screening platform with open-ended association questions and precision threshold adjustment |
| FR3098000B1 (fr) * | 2019-06-27 | 2022-05-13 | Ea4T | Procédé et dispositif d’obtention d’une réponse à partir d’une question orale posée à une interface homme-machine. |
| US20220067486A1 (en) * | 2020-09-02 | 2022-03-03 | Sap Se | Collaborative learning of question generation and question answering |
-
2020
- 2020-09-18 JP JP2020157394A patent/JP2022051113A/ja active Pending
-
2021
- 2021-02-02 US US17/165,349 patent/US20220092260A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| US20220092260A1 (en) | 2022-03-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Arora et al. | Character level embedding with deep convolutional neural network for text normalization of unstructured data for Twitter sentiment analysis | |
| CN111444320B (zh) | 文本检索方法、装置、计算机设备和存储介质 | |
| Kutuzov et al. | Texts in, meaning out: neural language models in semantic similarity task for Russian | |
| US10678769B2 (en) | Artificial intelligence system and method for auto-naming customer tree nodes in a data structure | |
| CN106202010A (zh) | 基于深度神经网络构建法律文本语法树的方法和装置 | |
| US20190317986A1 (en) | Annotated text data expanding method, annotated text data expanding computer-readable storage medium, annotated text data expanding device, and text classification model training method | |
| EP3940582A1 (en) | Method for disambiguating between authors with same name on basis of network representation and semantic representation | |
| CN107436942A (zh) | 基于社交媒体的词嵌入方法、系统、终端设备及存储介质 | |
| Banik et al. | Gru based named entity recognition system for bangla online newspapers | |
| CN111400584A (zh) | 联想词的推荐方法、装置、计算机设备和存储介质 | |
| JP5235918B2 (ja) | テキスト要約装置、テキスト要約方法及びテキスト要約プログラム | |
| US20210133390A1 (en) | Conceptual graph processing apparatus and non-transitory computer readable medium | |
| JP5812534B2 (ja) | 質問応答装置、方法、及びプログラム | |
| CN114490926A (zh) | 一种相似问题的确定方法、装置、存储介质及终端 | |
| WO2022039803A1 (en) | Identifying noise in verbal feedback using artificial text from non-textual parameters and transfer learning | |
| Sanyal et al. | Natural language processing technique for generation of SQL queries dynamically | |
| WO2020263182A1 (en) | Method and system for conducting a brainstorming session with a virtual expert | |
| Liu | Python machine learning by example: implement machine learning algorithms and techniques to build intelligent systems | |
| JP2022051113A (ja) | 情報出力装置、質問生成装置、及びプログラム | |
| CN114661616A (zh) | 目标代码的生成方法及装置 | |
| JP4405542B2 (ja) | 音素モデルをクラスタリングする装置、方法およびプログラム | |
| JP2023544560A (ja) | 文字認識における制約条件を強制するためのシステムおよび方法 | |
| Mammadov et al. | Part-of-speech tagging for azerbaijani language | |
| Gudmundsson et al. | Swedish Natural Language Processing with Long Short-term Memory Neural Networks: A Machine Learning-powered Grammar and Spell-checker for the Swedish Language | |
| US10963501B1 (en) | Systems and methods for generating a topic tree for digital information |