JP2020160118A - Information processing device, information processing method and program - Google Patents
Information processing device, information processing method and program Download PDFInfo
- Publication number
- JP2020160118A JP2020160118A JP2019056140A JP2019056140A JP2020160118A JP 2020160118 A JP2020160118 A JP 2020160118A JP 2019056140 A JP2019056140 A JP 2019056140A JP 2019056140 A JP2019056140 A JP 2019056140A JP 2020160118 A JP2020160118 A JP 2020160118A
- Authority
- JP
- Japan
- Prior art keywords
- voice recognition
- dictionary
- recognition result
- word information
- registered
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 230000010365 information processing Effects 0.000 title claims description 84
- 238000003672 processing method Methods 0.000 title claims description 5
- 238000000605 extraction Methods 0.000 claims description 14
- 238000000034 method Methods 0.000 description 44
- 230000006870 function Effects 0.000 description 29
- 238000012545 processing Methods 0.000 description 13
- 239000000284 extract Substances 0.000 description 10
- 238000004891 communication Methods 0.000 description 7
- 230000008520 organization Effects 0.000 description 4
- 238000010586 diagram Methods 0.000 description 3
- 238000005401 electroluminescence Methods 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 230000000877 morphologic effect Effects 0.000 description 3
- 230000014509 gene expression Effects 0.000 description 2
- 239000004973 liquid crystal related substance Substances 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
Images





Landscapes
- Machine Translation (AREA)
- Telephonic Communication Services (AREA)
Abstract
Description
本発明は、情報処理装置、情報処理方法およびプログラムに関する。 The present invention relates to information processing devices, information processing methods and programs.
不特定者を対象とした音声認識装置では、汎用的かつ一般的な語彙を中心とした音声認識用の辞書が予め登録されており、当該音声認識装置は、登録されている音声認識用の辞書に基づいて音声を認識する。このような音声認識装置において、認識対象の語彙が設計時において規定可能な場合には、事前に作成した音声認識用辞書を用いるが、語彙が規定できない場合、あるいは動的に変更されるべきである場合においては、一般的に、人的作業による入力、または自動的に文字列情報から音声認識用の語彙を生成して辞書に登録する、などといったことが行われる。 In the voice recognition device for unspecified persons, a dictionary for voice recognition centering on general-purpose and general vocabulary is registered in advance, and the voice recognition device is a registered dictionary for voice recognition. Recognize voice based on. In such a speech recognition device, if the vocabulary to be recognized can be defined at the time of design, a pre-created speech recognition dictionary is used, but if the vocabulary cannot be defined, or it should be changed dynamically. In some cases, human input is generally performed, or a vocabulary for speech recognition is automatically generated from character string information and registered in a dictionary.
また、近年の音声認識装置では、例えば、省略語などの言い換え表現についても音声認識用の辞書に登録することによって、正式な単語の発声だけでなく、ユーザによる任意の省略的な発声にも対処している。 Further, in recent voice recognition devices, for example, by registering paraphrase expressions such as abbreviations in a dictionary for voice recognition, not only formal word utterances but also arbitrary abbreviations by users can be dealt with. are doing.
例えば特許文献1には、単語の省略的な言い換え表現に対しても高い認識率で認識することが可能な音声認識装置が開示されている。
For example,
しかしながら、特許文献1に開示されている音声認識装置では、例えば、企業特有の社内用語や今回の会議や講演会で登場するような特殊用語といった、汎用的かつ一般的ではない新規な単語(特殊用語)を音声認識用の辞書に登録する場合には、人的作業による入力が必要となり、登録すべき単語の選別や入力など、人的作業負担が大きかった。そのため、音声認識用の辞書を好適に生成するという観点からすると未だ十分でなかった。
However, in the speech recognition device disclosed in
本発明は、上述のような事情に鑑みてなされたものであり、音声認識用の辞書を好適に生成することができる情報処理装置、情報処理方法およびプログラムを提供することを目的としている。 The present invention has been made in view of the above circumstances, and an object of the present invention is to provide an information processing device, an information processing method, and a program capable of suitably generating a dictionary for voice recognition.
上記目的を達成するため、本発明の第1の観点に係る情報処理装置は、
第1の辞書に基づく第1音声認識結果と、前記第1の辞書とは異なる第2の辞書に基づく第2音声認識結果と、を受信する音声認識結果受信手段と、
予め定められた演算に基づいて算出された前記第1音声認識結果についての第1確信度と、前記演算に基づいて算出された前記第2音声認識結果についての第2確信度と、を受信する確信度受信手段と、
前記第1確信度と前記第2確信度とを比較し、予め定められた条件を満たす場合、前記第2音声認識結果に含まれる単語情報を登録する単語情報登録手段と、を備え、
前記第2の辞書には、前記第1の辞書に登録された単語情報に加え、ユーザにより指定された単語情報が含まれる、
ことを特徴とする。
In order to achieve the above object, the information processing device according to the first aspect of the present invention is
A voice recognition result receiving means for receiving a first voice recognition result based on the first dictionary and a second voice recognition result based on a second dictionary different from the first dictionary.
Receives the first certainty of the first voice recognition result calculated based on a predetermined calculation and the second certainty of the second voice recognition result calculated based on the calculation. Confidence receiving means and
A word information registration means for registering word information included in the second voice recognition result when the first certainty degree and the second certainty degree are compared and a predetermined condition is satisfied is provided.
The second dictionary includes word information specified by the user in addition to the word information registered in the first dictionary.
It is characterized by that.
前記予め定められた条件を満たす場合、前記第2音声認識結果から登録対象となる単語情報を、予め定められた基準に従って抽出する抽出手段をさらに備え、
前記単語情報登録手段は、前記抽出手段により抽出された単語情報を登録する、
ようにしてもよい。
When the predetermined conditions are satisfied, an extraction means for extracting word information to be registered from the second voice recognition result according to a predetermined standard is further provided.
The word information registration means registers the word information extracted by the extraction means.
You may do so.
前記抽出手段により抽出された単語情報を、出現頻度毎に予め定められた複数分類のいずれかに分類する分類手段をさらに備え、
前記単語情報登録手段は、前記分類手段により分類された単語情報を該分類毎に登録する、
ようにしてもよい。
Further provided with a classification means for classifying the word information extracted by the extraction means into one of a plurality of predetermined classifications for each occurrence frequency.
The word information registration means registers word information classified by the classification means for each classification.
You may do so.
前記単語情報には音声情報および文字情報が含まれ、
前記単語情報登録手段により登録された単語情報を前記第1の辞書に追加することで前記第1の辞書を更新する第1辞書更新手段、をさらに備え、
前記第2の辞書は、前記第1の辞書が更新される毎に前記ユーザの操作により新たに記憶される、
ようにしてもよい。
The word information includes voice information and character information.
A first dictionary update means for updating the first dictionary by adding the word information registered by the word information registration means to the first dictionary is further provided.
The second dictionary is newly stored by the operation of the user every time the first dictionary is updated.
You may do so.
上記目的を達成するため、本発明の第2の観点に係る情報処理方法は、
第1の辞書に基づく第1音声認識結果と、前記第1の辞書とは異なる第2の辞書に基づく第2音声認識結果と、を受信する音声認識結果受信ステップと、
予め定められた演算に基づいて算出された前記第1音声認識結果についての第1確信度と、前記演算に基づいて算出された前記第2音声認識結果についての第2確信度と、を受信する確信度受信ステップと、
前記第1確信度と前記第2確信度とを比較し、予め定められた条件を満たす場合、前記第2音声認識結果に含まれる単語情報を登録する単語情報登録ステップと、を備え、
前記第2の辞書には、前記第1の辞書に登録された単語情報に加え、ユーザにより指定された単語情報が含まれる、
ことを特徴とする。
In order to achieve the above object, the information processing method according to the second aspect of the present invention is
A voice recognition result receiving step for receiving a first voice recognition result based on the first dictionary and a second voice recognition result based on a second dictionary different from the first dictionary.
Receives the first certainty of the first voice recognition result calculated based on a predetermined calculation and the second certainty of the second voice recognition result calculated based on the calculation. Confidence reception step and
A word information registration step of comparing the first certainty degree and the second certainty degree and registering the word information included in the second voice recognition result when a predetermined condition is satisfied is provided.
The second dictionary includes word information specified by the user in addition to the word information registered in the first dictionary.
It is characterized by that.
上記目的を達成するため、本発明の第3の観点に係るプログラムは、
コンピュータを、
第1の辞書に基づく第1音声認識結果と、前記第1の辞書とは異なる第2の辞書に基づく第2音声認識結果と、を受信する音声認識結果受信手段、
予め定められた演算に基づいて算出された前記第1音声認識結果についての第1確信度と、前記演算に基づいて算出された前記第2音声認識結果についての第2確信度と、を受信する確信度受信手段、
前記第1確信度と前記第2確信度とを比較し、予め定められた条件を満たす場合、前記第2音声認識結果に含まれる単語情報を登録する単語情報登録手段、として機能させ、
前記第2の辞書には、前記第1の辞書に登録された単語情報に加え、ユーザにより指定された単語情報が含まれる、
ことを特徴とする。
In order to achieve the above object, the program according to the third aspect of the present invention is
Computer,
A voice recognition result receiving means for receiving a first voice recognition result based on the first dictionary and a second voice recognition result based on a second dictionary different from the first dictionary.
Receives the first certainty of the first voice recognition result calculated based on a predetermined calculation and the second certainty of the second voice recognition result calculated based on the calculation. Confidence receiving means,
When the first certainty degree and the second certainty degree are compared and a predetermined condition is satisfied, the word information included in the second voice recognition result is registered as a word information registration means.
The second dictionary includes word information specified by the user in addition to the word information registered in the first dictionary.
It is characterized by that.
本発明によれば、音声認識用の辞書を好適に生成することができる。 According to the present invention, a dictionary for voice recognition can be preferably generated.
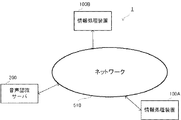
本発明における情報処理装置100を、図1に示す情報処理システム1に適用した例を用いて説明する。情報処理システム1では、図1に示すように、情報処理装置100Aおよび100Bと、音声認識サーバ200とがネットワーク510を介して通信可能に接続されている。なお、理解を容易にするため、この実施の形態では、情報処理装置100Aのユーザと情報処理装置100Bのユーザとが互いに会話を行う場合を例に、以下説明する。なお、情報処理装置100Aおよび情報処理装置100Bは、単に情報処理装置100とも言う。
An example in which the
情報処理装置100は、携帯電話やスマートフォン、タブレットやPC(Personal Computer)等の情報端末(所謂コンピュータ)であり、P2P(Peer to Peer)等の分散型のネットワーク510を構築している。なお、情報処理システム1は、P2P型のシステムに限られず、例えばクラウドコンピューティング型であってもよい。
The
情報処理装置100は、音声認識サーバ200から受信した、他の情報処理装置100のユーザの会話の音声データおよびテキストデータ(音声認識結果)を出力する機能を有している。また、情報処理装置100は、音声認識サーバ200から受信した確信度に基づいて、登録対象となる単語情報を音声認識結果から抽出し、音声認識用の辞書へ登録する機能を有している。
The
音声認識サーバ200は、例えばメインフレームやワークステーション、あるいはPC(Personal Computer)等の任意のコンピュータ装置である。音声認識サーバ200は、情報処理装置100から送信された音声(会話の内容)を、予め記憶された音声認識用の辞書に基づいて認識し、認識した音声データをテキストデータとともに(音声認識結果として)他の情報処理装置100へ送信する機能を有している。また、音声認識サーバ200は、音声認識結果として得られる語彙が実際に発話された語彙と一致している確率を示す確信度を算出し、他の情報処理装置100へ送信する機能も有している。
The
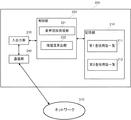
次に、図2を参照し、この実施の形態における情報処理装置100(図1に示す情報処理装置100Aおよび情報処理装置100B)の構成について説明する。なお、図示は省略しているが、ユーザの会話(音声)を送信用の音声データとして(アナログからデジタルへ)変換する機能(およびその逆の機能)を有する機能部が設けられているものとする。
Next, the configuration of the information processing device 100 (
図2に示すように、情報処理装置100は、記憶部110と、制御部120と、入出力部130と、通信部140と、これらを相互に接続するシステムバス(図示省略)と、を備えている。
As shown in FIG. 2, the
記憶部110は、ROM(Read Only Memory)やRAM(Random Access Memory)等を備える。ROMは制御部120のCPU(Central Processing Unit)が実行するプログラム及び、プログラムを実行する上で予め必要なデータを記憶する(図示省略)。
The
具体的に、この実施の形態における記憶部110は、登録用語一覧111として、音声認識用の辞書として登録すべき単語の音声データとそのテキストデータを記憶する。なお、音声データと当該音声データに対応するテキストデータを、合わせて単語情報とも言う。なお、登録用語一覧111は、登録対象の単語情報の一覧を示すものであり、複数の単語情報が含まれる。当該登録用語一覧111の単語情報は、後述する用語登録処理により、分類毎に記憶部110へ記憶される。また、記憶部110には、登録分類112として、ユーザによる指定に基づいて分類される登録分類の一覧と、その分類基準が記憶されている。登録分類としては、例えば、「普遍的に使用される社内用語」といった分類や、「特定の組織内で使用される組織内用語」などの分類が、ユーザによる指定に基づいて登録されている。分類基準としては、例えば、会話中における当該登録対象の単語情報の出現頻度を記憶しておき、5回以上出現している単語情報については「普遍的に使用される社内用語」と分類し、5回未満であれば「特定の組織内で使用される組織内用語」に分類するなど、ユーザによって任意に設定可能であればよい。
Specifically, the
制御部120は、CPUやASIC(Application Specific Integrated Circuit)等から構成される。制御部120は、記憶部110に記憶されたプログラムに従って動作し、当該プログラムに従った処理を実行する。制御部120は、記憶部110に記憶されたプログラムにより提供される主要な機能部として、確信度比較部121と、形態素抽出部122と、品詞推定部123と、用語分類部124と、用語登録部125と、を備える。
The
確信度比較部121は、音声認識サーバ200から送信された確信度を比較する機能部である。詳しくは後述するが、音声認識サーバ200からは、第1登録用語一覧211を音声認識用の辞書(第1の辞書)として用いた場合の音声認識結果(後述する第1登録用語一覧211に基づくテキストデータとその音声データ)とその確信度A(第1確信度)と、第2登録用語一覧212を音声認識用の辞書(第2の辞書)として用いた場合の音声認識結果(後述する第2登録用語一覧212に基づくテキストデータとその音声データ)とその確信度B(第2確信度)と、が送信される。確信度比較部121は、当該確信度Aと確信度Bとを比較する。具体的に、確信度比較部121は、確信度Bから確信度Aを減算した値が、予め定められた閾値以上であるか否かを判定することにより、確信度を比較する。閾値は、例えば、会議の内容や使用する言語などに応じて異なる値がユーザにより設定されていればよい。
The
形態素抽出部122は、例えば、第1登録用語一覧211を音声認識用の辞書として用いた場合の音声認識結果(第1音声認識結果)と、第2登録用語一覧212を音声認識用の辞書として用いた場合の音声認識結果(第2音声認識結果)と、のそれぞれを、形態素解析などにより形態素毎に分割し、異なる形態素を抽出する機能部である。具体的に、形態素抽出部122は、形態素毎に分割した第2音声認識結果から、形態素毎に分割した第1音声認識結果との共通部分の形態素を差し引くことで、異なる形態素を抽出する。
The morphological
品詞推定部123は、第1音声認識結果と第2音声認識結果とのそれぞれの形態素の品詞を比較することで、異なる品詞の形態素を抽出する機能部である。具体的に、品詞推定部123は、第1音声認識結果の形態素と第2音声認識結果の形態素を比較し、第2音声認識結果の形態素の品詞が名詞であるものの、第1音声認識結果の形態素が名詞以外である形態素を抽出する。すなわち、形態素抽出部122は、第2音声認識結果から、第1音声認識結果と異なる単語の形態素(異なる文字列)を抽出するのに対し、品詞推定部123は、第2音声認識結果から、第1音声認識結果と異なる品詞の形態素を抽出する。換言すると、形態素抽出部122は、文字列の観点から形態素を抽出する機能部であり、品詞推定部123は、品詞の観点から形態素を抽出する機能部であると言える。なお、「普遍的に使用される社内用語」や「特定の組織内で使用される組織内用語」などといった特殊用語は、通常名詞であることが多い。そのため、この実施の形態における品詞推定部123は、第2音声認識結果の形態素の品詞が名詞であるものの、第1音声認識結果の形態素が名詞以外である形態素を抽出する。これとは異なり、単に異なる品詞の形態素を入出力部130に出力し、ユーザにより抽出するか否かを選択させるようにしてもよい。
The part of
用語分類部124は、形態素抽出部122の機能により抽出した形態素と、品詞推定部123の機能により抽出した形態素と、が一致しているか否かを判定し、一致した場合に登録対象として認定し、当該認定した登録対象の形態素の単語情報を、登録分類112に基づく分類に基づいて分類する機能部である。具体的に、用語分類部124は、抽出したそれぞれの形態素が一致する場合、登録対象となる単語情報の出現頻度に基づいて、登録分類112として設定されている分類基準に従い、登録されているいずれかの分類に分類する。
The
用語登録部125は、用語分類部124で分類された単語情報を、当該分類毎に登録用語一覧111へ登録する機能部である。また、用語登録部125は、登録用語一覧111へ登録された単語情報の内容に基づいて、第1登録用語一覧211の内容を更新させる更新指示を音声認識サーバ200へ送信する機能も有している。なお、用語登録部125は、単語情報登録手段としての機能である。
The
これら各機能部が協働して、情報処理装置100において、登録対象となる単語情報を音声認識用の辞書へ登録する機能を実現している。
Each of these functional units cooperates to realize a function of registering word information to be registered in a speech recognition dictionary in the
入出力部130は、キーボード、マウス、カメラ、マイク、液晶ディスプレイ、有機EL(Electro−Luminescence)ディスプレイ等から構成され、データの入出力を行うための装置である。
The input /
通信部140は、他の情報処理装置100や音声認識サーバ200とネットワーク510を介して通信を行うためのデバイスである。
The communication unit 140 is a device for communicating with another
以上が、情報処理装置100の構成である。次に、図3を参照し、この実施の形態における音声認識サーバ200の構成について説明する。図3に示すように、音声認識サーバ200は、記憶部210と、制御部220と、入出力部230と、通信部240と、これらを相互に接続するシステムバス(図示省略)と、を備えている。
The above is the configuration of the
記憶部210は、ROMやRAM等を備える。ROMは制御部220のCPUが実行するプログラム及び、プログラムを実行する上で予め必要なデータを記憶する(図示省略)。
The
具体的に、この実施の形態における記憶部210は、音声認識用の辞書として、第1登録用語一覧211と、第2登録用語一覧212とを記憶する。第1登録用語一覧211は、単語情報の一覧であり、後述する用語登録処理が実行される度に、登録されている単語情報が更新される。なお、初期の第1登録用語一覧211は、汎用的かつ一般的な語彙を中心とした単語情報の一覧であればよく、例えば、ユーザにより生成されてもよいし、ネットワーク上に公開されているものをダウンロードすることで取得してもよい。
Specifically, the
一方、第2登録用語一覧212は、第1登録用語一覧211よりも、例えば「普遍的に使用される社内用語」や「特定の組織内で使用される組織内用語」などといった特殊用語の単語情報を多く含むよう、ユーザにより生成された単語情報の一覧である。なお、第2登録用語一覧212は、例えば、予定されている会議の資料や講演会の資料に基づいて、当該会議や講演会毎にユーザにより生成されればよい。この実施の形態における情報処理装置100では、例えば会議毎に(換言すると第1登録用語一覧211が更新される毎に)第2登録用語一覧212が新規に記憶されて、後述する用語登録処理が行われる。当該用語登録処理では、第2登録用語一覧212と第1登録用語一覧211との比較により、対象となる単語情報が登録される。したがって、「普遍的に使用される社内用語」などの特殊用語を音声認識用の辞書に好適に登録することができるとともに、繰り返し実行することで、当該音声認識用の辞書を更新することが可能となる。
On the other hand, the second
制御部220は、CPUやASIC等から構成される。制御部120は、記憶部110に記憶されたプログラムに従って動作し、当該プログラムに従った処理を実行する。制御部220は、記憶部210に記憶されたプログラムにより提供される主要な機能部として、音声認識処理部221と、確信度算出部222と、を備える。
The
音声認識処理部221は、例えば、情報処理装置100から受信した音声データについて、第1登録用語一覧211に基づくテキストデータと、第2登録用語一覧212に基づくテキストデータと、のそれぞれに変換する機能部である。なお、音声データからテキストデータへの変換は、第1登録用語一覧211および第2登録用語一覧212に基づいて、従来から用いられている音声認識技術により行われればよい。なお、音声認識処理部221は、変換したそれぞれのテキストデータを、音声データとともに他の情報処理装置100へと送信する機能も有している。
The voice
確信度算出部222は、音声認識処理部221にて変換されたテキストデータに対応する確信度を算出する機能部である。具体的に、確信度算出部222は、第1登録用語一覧211に基づくテキストデータの確信度Aと、第2登録用語一覧212に基づくテキストデータの確信度Bと、をそれぞれ算出する。確信度は、例えば、第1登録用語一覧211や第2登録用語一覧212に登録されている単語情報の音声特徴量(波形や周期等)と、受信した音声データによる音声特徴量の類似度に基づいて算出(予め定められた演算に基づいて算出)されればよい。なお、確信度算出部222は、算出したそれぞれの確信度を他の情報処理装置100へと送信する機能も有している。
The
これらの機能部が協働して、音声認識サーバ200において、情報処理装置100から受信した音声データをテキストデータにそれぞれ変換し(音声認識し)、当該音声データとともに音声認識結果として他の情報処理装置100へと送信する機能を実現している。また、確信度を他の情報処理装置100へと送信する機能を実現している。
These functional units work together to convert the voice data received from the
入出力部230は、キーボード、マウス、カメラ、マイク、液晶ディスプレイ、有機ELディスプレイ等から構成され、データの入出力を行うための装置である。
The input /
通信部240は、情報処理装置100とネットワーク510を介して通信を行うためのデバイスである。
The
以上が、音声認識サーバ200の構成である。続いて情報処理装置100の動作などについて、図4〜図7を参照して説明する。まず、情報処理システム1の動作として、全体的な処理の流れについて、図4を参照して説明する。なお、図示する例では、情報処理装置100Bのユーザが情報処理装置100Aのユーザに対して例文1の内容の発言した場合を例に、以下説明する。
The above is the configuration of the
図4に示すように、情報処理装置100Bのユーザが入出力部130に例文1の音声を入力すると、制御部120の機能により音声データに変換され、当該音声データが音声認識サーバ200へ送信される(図4の(1))。なお、図示する例では、理解を容易にするため、情報処理装置100Bから音声認識サーバ200へ当該音声データが送信される例を示しているが、例えば、情報処理装置100Bから情報処理装置100Aへと音声データが送信され、当該情報処理装置100Aにて抽出した特定の音声データが音声認識サーバ200へ送信されるようにしてもよい。
As shown in FIG. 4, when the user of the information processing apparatus 100B inputs the voice of the
音声認識サーバ200は、情報処理装置100Bから音声データを受信すると、音声認識処理部221の機能により、第1登録用語一覧211に基づいて音声認識を行い(テキストデータへ変換し)、音声データとテキストデータを、第1音声認識結果として情報処理装置100Aへ送信する(図4の(2))。また、音声認識サーバ200は、確信度算出部222の機能により、第1登録用語一覧211に基づく音声認識の確信度Aを算出し、情報処理装置100Aへ送信する(図4の(3))。
When the
また、音声認識サーバ200は、音声認識処理部221の機能により、第2登録用語一覧212に基づいて音声認識を行い(テキストデータへ変換し)、音声データとテキストデータを、第2音声認識結果として情報処理装置100Aへ送信する(図4の(4))。また、音声認識サーバ200は、確信度算出部222の機能により、第2登録用語一覧212に基づく音声認識の確信度Bを算出し、情報処理装置100Aへ送信する(図4の(5))。なお、図4の(2)〜(5)は、まとめて行われてもよい。
Further, the
情報処理装置100Aの側では、音声認識サーバ200から受信した、第2登録用語一覧212に基づく音声データとテキストデータを、入出力部130から出力する(図6(B)に示す内容が出力される)。また、情報処理装置100Aは、音声認識サーバ200から第1音声認識結果と第2音声認識結果(確信度Aおよび確信度Bも含む)を受信すると(音声認識結果受信手段および確信度受信手段に相当)、登録対象となる特殊用語を当該音声認識用の辞書に登録するための用語登録処理を行う。すなわち、情報処理装置100Aは、情報処理装置100Bのユーザの発言に含まれる特殊用語を音声認識用の辞書に登録するための処理を行う。なお、以下では、図6(A)に示す内容の音声データおよびテキストデータを第1音声認識結果として受信し、図6(B)に示す内容の音声データおよびテキストデータを第2音声認識結果として受信し、当該第2音声認識結果の「NTT」を、特殊用語として登録する場合について説明する(確信度についても図示する値であるとする)。
On the
図5は、用語登録処理の一例を示すフローチャートである。用語登録処理において、情報処理装置100Aは、確信度比較部121の機能により、確信度Bから確信度Aを減算した値が、予め定められた閾値以上であるか否か(予め定められた条件を満たすか否か)を判定する(ステップS101)。閾値未満である場合、情報処理装置100Aは、登録すべき対象が存在しないものとして、そのまま用語登録処理を終了する。具体的に、ステップS101の処理では、図6(B)に示す確信度0.89から図6(A)に示す確信度0.16を減算し、閾値以上であるか否かを判定する。なお、この例における閾値は、0.5として予めユーザにより設定されているものとする。
FIG. 5 is a flowchart showing an example of the term registration process. In the term registration process, the
閾値以上である場合(ステップS101;Yes)、情報処理装置100Aは、形態素抽出部122の機能により、音声認識サーバ200から受信した第1音声認識結果と第2音声認識結果のそれぞれを形態素毎に分割し、異なる形態素を第2音声認識結果から抽出する(ステップS102)。なお、ステップS102では、第1音声認識結果のうちのテキストデータを形態素毎に分割し、異なる形態素を抽出した上で、当該形態素に対応する部分の音声データを抽出してもよい。また、第1音声認識結果のうちのテキストデータと音声データの両方を形態素毎に分割し、それぞれについて異なる形態素を抽出してもよい。具体的に、ステップS102では、図6(A)および図7(A)に示す「Venditti」と図6(B)および図7(B)に示す「NTT」の形態素が異なるため、図6(B)および図7(B)に示す「NTT」の形態素を抽出する。なお、図6(A)および図7(A)に示す「Venditti」はこの実施の形態にて理解を容易にするために用いた造語であり、品詞が形容詞であるものとする。また、以下では、当該「NTT」の出現頻度が5回であり、今回の例文1にて6回の出現頻度となったものとする。
When the value is equal to or higher than the threshold value (step S101; Yes), the
ステップS102の処理を実行した後、情報処理装置100Aは、品詞推定部123の機能により、第1音声認識結果の形態素と第2音声認識結果の形態素を比較し、第2音声認識結果の形態素の品詞が名詞であるものの、第1音声認識結果の形態素が名詞以外である形態素を抽出する(ステップS103)。なお、上述したように、ステップS103では、単に異なる品詞の形態素を入出力部130に出力し、ユーザにより抽出するか否かを選択させるようにしてもよい。具体的に、ステップS103の処理では、図7(A)に示す「Venditti」の品詞が「形容詞」であり、図7(B)に示す「NTT」の品詞が「名詞」であることから、図7(B)に示す「NTT」の形態素を抽出する。また、この実施の形態では、図7に示すように「of」といった前置詞については、音声認識用の辞書への登録といった観点からすると不要な品詞であることから、比較対象外としている。
After executing the process of step S102, the
ステップS103の処理を実行した後、情報処理装置100Aは、用語分類部124の機能により、ステップS102で抽出した形態素とステップS103で抽出した形態素とが一致するか否かを判定する(ステップS104)。一致していない場合(ステップS104;No)、用語登録処理を終了する。なお、一致していない場合、ステップS102で抽出した形態素とステップS103で抽出した形態素のそれぞれに対応する単語情報ついて、登録用語一覧111へ登録するか否かをユーザに選択させ、いずれも登録しない場合に当該用語登録処理を終了し、少なくともいずれかを登録する場合には、ステップS105の処理に移行すればよい。なお、この実施の形態では、ステップS102の処理およびステップS103の処理で抽出した形態素同士が一致するか否かを判定したが、ステップS102の処理のみ、またはステップS103の処理のみ行い、ステップS105の処理に移行してもよい。さらに、ステップS102〜ステップS104の処理を実行せず、ステップS101にてYesと判定した場合には、ステップS105の処理へ移行してもよい。この場合、例えば、形態素毎の確信度が音声認識サーバ200から送信されればよい。
After executing the process of step S103, the
一致していると判定した場合(ステップS104;Yes)、情報処理装置100Aは、用語分類部124の機能により、抽出した形態素に対応する単語情報を登録対象として認定し、認定した登録対象の形態素の単語情報を、登録分類112に基づく分類に基づいて分類する(ステップS105)。具体的に、ステップS105の処理では、「NTT」の単語情報の出現頻度が6回であることから、当該「NTT」は「普遍的に使用される社内用語」の分類に分類する。なお、「普遍的に使用される社内用語」には、例えば、複数のプロジェクトにおいて共通して使用される用語が含まれる。
When it is determined that they match (step S104; Yes), the
ステップS105の処理を実行した後、情報処理装置100Aは、用語登録部125の機能により、ステップS104の処理にて分類された単語情報としての音声データおよびテキストデータを、当該分類に従い登録用語一覧111へ登録する(ステップS106)。具体的に、ステップS106の処理では、「普遍的に使用される社内用語」の分類に分類された「NTT」の音声データおよびテキストデータを、それぞれ対応付けて、登録用語一覧111における「普遍的に使用される社内用語」の分類として登録する。
After executing the process of step S105, the
ステップS106の処理を実行した後、情報処理装置100Aは、用語登録部125の機能により、登録用語一覧111へ登録された単語情報の内容に基づいて、第1登録用語一覧211の内容を更新させる更新指示を音声認識サーバ200へ送信し(ステップS107)、用語登録処理を終了する。具体的に、ステップS107の処理では、登録用語一覧111における「普遍的に使用される社内用語」の分類として登録した「NTT」の音声データおよびテキストデータを、更新指示とともに音声認識サーバ200へ送信し、音声認識サーバ200に記憶されている第1登録用語一覧211に、当該「NTT」の音声データおよびテキストデータを追加登録させる。これにより、第1登録用語一覧211の内容が更新されることとなる。
After executing the process of step S106, the
図4に戻り、音声認識サーバ200の側では、情報処理装置100Aから更新指示を受信したことに基づいて、第1登録用語一覧211の内容を更新する。なお、図示は省略しているが、この後に、情報処理装置100Aのユーザが情報処理装置100Bのユーザに対して発言した場合には、情報処理装置100Aの制御部120の機能により音声データに変換され、当該音声データが音声認識サーバ200へ送信される。そして情報処理装置100Bの側において用語登録処理が行われ、音声認識サーバ200における第1登録用語一覧211の内容が更新される。このような処理が、当該会議や講演会などの会話が終了するまで繰り返し実行されることとなる。このように、会話毎に用語登録処理が行われて第1登録用語一覧211の内容が更新されるため、リアルタイムで音声認識用の辞書が更新されることとなり、音声認識用の辞書を好適に生成することができる。なお、この実施の形態では、2者間での会話を例としたが、3者以上でも同様である。また、このようにして生成された辞書は、公知の日本語入力ソフトにおける辞書にも活用可能である。
Returning to FIG. 4, the
(変形例)
なお、この発明は、上記実施の形態に限定されず、様々な変形及び応用が可能である。例えば、情報処理装置100では、上記実施の形態で示した全ての技術的特徴を備えるものでなくてもよく、従来技術における少なくとも1つの課題を解決できるように、上記実施の形態で説明した一部の構成を備えたものであってもよい。また、下記の変形例それぞれについて、少なくとも一部を組み合わせてもよい。
(Modification example)
The present invention is not limited to the above embodiment, and various modifications and applications are possible. For example, the
上記実施の形態では、図5のステップS107の処理が用語登録処理の中で実行される例を示したが、例えば、会議の終了や講演会の終了などといった一連の会話が終了したタイミングで一度行われるようにしてもよい。例えば、会話が終了したタイミングでユーザによる入出力部130への操作が行われることで図5に示すステップS107の処理が実行されるようにしてもよい。また、例えば、「終了」など、予め定められた特定の音声(複数設定されていてよい)を受信した場合に、会話の終了と判定して図5のステップS107の処理を実行するようにしてもよい。また、これとは異なり、ユーザにより設定された数の単語情報が登録用語一覧111へ登録される毎に図5のステップS107の処理が実行されるようにしてもよい。これらによれば、第1登録用語一覧211の更新処理に対する負荷を軽減することができる。
In the above embodiment, an example is shown in which the process of step S107 in FIG. 5 is executed in the term registration process, but once at the timing when a series of conversations such as the end of a meeting or the end of a lecture are completed. It may be done. For example, the process of step S107 shown in FIG. 5 may be executed by the user performing an operation on the input /
また、例えば「PoC」という単語について、「ピーオーシー」と読むユーザや「ポック」と読むユーザなど、一の単語について、ユーザ毎に読み方が異なるような場合がある。このような単語について、第2登録用語一覧212として、一のテキストデータに対応して複数の音声データを予め登録しておき、図5のステップS106では、一のテキストデータに対応して複数の音声データを登録用語一覧111へ登録すればよい。そして、ステップS107の処理では、当該内容にて第1登録用語一覧211を更新させる指示を行えばよい。これによれば、一の単語について、ユーザ毎に読み方が異なるような場合についても、音声認識用の辞書を好適に生成することができる。
Further, for example, the word "PoC" may be read differently for each user, such as a user who reads "POC" or a user who reads "Pock". With respect to such words, a plurality of voice data corresponding to one text data are registered in advance as the second
また、上記実施の形態における音声認識サーバ200の構成を、情報処理装置100が備えていてもよい。この場合、図5のステップS107において、自身の記憶部110に記憶された第1登録用語一覧211を更新し、他の情報処理装置100に記憶された第1登録用語一覧211と同期をとるようにすればよい。
Further, the
なお、上述の機能を、OS(Operating System)とアプリケーションとの分担、またはOSとアプリケーションとの協同により実現する場合等には、OS以外の部分のみを媒体に格納してもよい。 In addition, when the above-mentioned function is realized by sharing the OS (Operating System) and the application, or by cooperating with the OS and the application, only the part other than the OS may be stored in the medium.
また、搬送波にプログラムを重畳し、通信ネットワークを介して配信することも可能である。例えば、通信ネットワーク上の掲示板(BBS、Bulletin Board System)に当該プログラムを掲示し、ネットワークを介して当該プログラムを配信してもよい。そして、これらのプログラムを起動し、オペレーティングシステムの制御下で、他のアプリケーションプログラムと同様に実行することにより、上述の処理を実行できるように構成してもよい。 It is also possible to superimpose a program on a carrier wave and distribute it via a communication network. For example, the program may be posted on a bulletin board system (BBS, Bulletin Board System) on a communication network, and the program may be distributed via the network. Then, by starting these programs and executing them in the same manner as other application programs under the control of the operating system, the above-mentioned processing may be executed.
1 情報処理システム、100、100A、100B 情報処理装置、110、210 記憶部、111 登録用語一覧、112 登録分類、120、220 制御部、121 確信度比較部、122 形態素抽出部、123 品詞推定部、124 用語分類部、125 用語登録部、130、230 入出力部、140、240 通信部、200 音声認識サーバ、211 第1登録用語一覧、212 第2登録用語一覧、221 音声認識処理部、222 確信度算出部、510 ネットワーク 1 Information processing system, 100, 100A, 100B Information processing device, 110, 210 Storage unit, 111 Registered term list, 112 Registration classification, 120, 220 Control unit, 121 Confidence comparison unit, 122 Morphological element extraction unit, 123 Part code estimation unit , 124 term classification unit, 125 term registration unit, 130, 230 input / output unit, 140, 240 communication unit, 200 voice recognition server, 211 first registered term list, 212 second registered term list, 221 voice recognition processing unit, 222 Confidence calculation unit, 510 network
Claims (6)
予め定められた演算に基づいて算出された前記第1音声認識結果についての第1確信度と、前記演算に基づいて算出された前記第2音声認識結果についての第2確信度と、を受信する確信度受信手段と、
前記第1確信度と前記第2確信度とを比較し、予め定められた条件を満たす場合、前記第2音声認識結果に含まれる単語情報を登録する単語情報登録手段と、を備え、
前記第2の辞書には、前記第1の辞書に登録された単語情報に加え、ユーザにより指定された単語情報が含まれる、
ことを特徴とする情報処理装置。 A voice recognition result receiving means for receiving a first voice recognition result based on the first dictionary and a second voice recognition result based on a second dictionary different from the first dictionary.
Receives the first certainty of the first voice recognition result calculated based on a predetermined calculation and the second certainty of the second voice recognition result calculated based on the calculation. Confidence receiving means and
A word information registration means for registering word information included in the second voice recognition result when the first certainty degree and the second certainty degree are compared and a predetermined condition is satisfied is provided.
The second dictionary includes word information specified by the user in addition to the word information registered in the first dictionary.
An information processing device characterized by this.
前記単語情報登録手段は、前記抽出手段により抽出された単語情報を登録する、
ことを特徴とする請求項1に記載の情報処理装置。 When the predetermined conditions are satisfied, an extraction means for extracting word information to be registered from the second voice recognition result according to a predetermined standard is further provided.
The word information registration means registers the word information extracted by the extraction means.
The information processing apparatus according to claim 1.
前記単語情報登録手段は、前記分類手段により分類された単語情報を該分類毎に登録する、
ことを特徴とする請求項2に記載の情報処理装置。 Further provided with a classification means for classifying the word information extracted by the extraction means into one of a plurality of predetermined classifications for each occurrence frequency.
The word information registration means registers word information classified by the classification means for each classification.
The information processing apparatus according to claim 2.
前記単語情報登録手段により登録された単語情報を前記第1の辞書に追加することで前記第1の辞書を更新する第1辞書更新手段、をさらに備え、
前記第2の辞書は、前記第1の辞書が更新される毎に前記ユーザの操作により新たに記憶される、
ことを特徴とする請求項1〜3のいずれか1項に記載の情報処理装置。 The word information includes voice information and character information.
A first dictionary update means for updating the first dictionary by adding the word information registered by the word information registration means to the first dictionary is further provided.
The second dictionary is newly stored by the operation of the user every time the first dictionary is updated.
The information processing apparatus according to any one of claims 1 to 3.
予め定められた演算に基づいて算出された前記第1音声認識結果についての第1確信度と、前記演算に基づいて算出された前記第2音声認識結果についての第2確信度と、を受信する確信度受信ステップと、
前記第1確信度と前記第2確信度とを比較し、予め定められた条件を満たす場合、前記第2音声認識結果に含まれる単語情報を登録する単語情報登録ステップと、を備え、
前記第2の辞書には、前記第1の辞書に登録された単語情報に加え、ユーザにより指定された単語情報が含まれる、
ことを特徴とする情報処理方法。 A voice recognition result receiving step for receiving a first voice recognition result based on the first dictionary and a second voice recognition result based on a second dictionary different from the first dictionary.
Receives the first certainty of the first voice recognition result calculated based on a predetermined calculation and the second certainty of the second voice recognition result calculated based on the calculation. Confidence reception step and
A word information registration step of comparing the first certainty degree and the second certainty degree and registering the word information included in the second voice recognition result when a predetermined condition is satisfied is provided.
The second dictionary includes word information specified by the user in addition to the word information registered in the first dictionary.
An information processing method characterized by this.
第1の辞書に基づく第1音声認識結果と、前記第1の辞書とは異なる第2の辞書に基づく第2音声認識結果と、を受信する音声認識結果受信手段、
予め定められた演算に基づいて算出された前記第1音声認識結果についての第1確信度と、前記演算に基づいて算出された前記第2音声認識結果についての第2確信度と、を受信する確信度受信手段、
前記第1確信度と前記第2確信度とを比較し、予め定められた条件を満たす場合、前記第2音声認識結果に含まれる単語情報を登録する単語情報登録手段、として機能させ、
前記第2の辞書には、前記第1の辞書に登録された単語情報に加え、ユーザにより指定された単語情報が含まれる、
ことを特徴とするプログラム。 Computer,
A voice recognition result receiving means for receiving a first voice recognition result based on the first dictionary and a second voice recognition result based on a second dictionary different from the first dictionary.
Receives the first certainty of the first voice recognition result calculated based on a predetermined calculation and the second certainty of the second voice recognition result calculated based on the calculation. Confidence receiving means,
When the first certainty degree and the second certainty degree are compared and a predetermined condition is satisfied, the word information included in the second voice recognition result is registered as a word information registration means.
The second dictionary includes word information specified by the user in addition to the word information registered in the first dictionary.
A program characterized by that.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019056140A JP7406921B2 (en) | 2019-03-25 | 2019-03-25 | Information processing device, information processing method and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019056140A JP7406921B2 (en) | 2019-03-25 | 2019-03-25 | Information processing device, information processing method and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2020160118A true JP2020160118A (en) | 2020-10-01 |
| JP7406921B2 JP7406921B2 (en) | 2023-12-28 |
Family
ID=72643073
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019056140A Active JP7406921B2 (en) | 2019-03-25 | 2019-03-25 | Information processing device, information processing method and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7406921B2 (en) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS63186298A (en) * | 1987-01-28 | 1988-08-01 | 富士通株式会社 | Word voice recognition equipment |
| JP2000250591A (en) * | 1999-02-25 | 2000-09-14 | Matsushita Electric Ind Co Ltd | Automatic retrieval system for television program |
| JP2003295893A (en) * | 2002-04-01 | 2003-10-15 | Omron Corp | System, device, method, and program for speech recognition, and computer-readable recording medium where the speech recognizing program is recorded |
| JP2011107251A (en) * | 2009-11-13 | 2011-06-02 | Ntt Docomo Inc | Voice recognition device, language model creation device and voice recognition method |
| JP2015215390A (en) * | 2014-05-08 | 2015-12-03 | 日本電信電話株式会社 | Speech recognition dictionary update device, speech recognition dictionary update method, and program |
| JP2018132626A (en) * | 2017-02-15 | 2018-08-23 | クラリオン株式会社 | Voice recognition system, voice recognition server, terminal device and word phrase management method |
-
2019
- 2019-03-25 JP JP2019056140A patent/JP7406921B2/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS63186298A (en) * | 1987-01-28 | 1988-08-01 | 富士通株式会社 | Word voice recognition equipment |
| JP2000250591A (en) * | 1999-02-25 | 2000-09-14 | Matsushita Electric Ind Co Ltd | Automatic retrieval system for television program |
| JP2003295893A (en) * | 2002-04-01 | 2003-10-15 | Omron Corp | System, device, method, and program for speech recognition, and computer-readable recording medium where the speech recognizing program is recorded |
| JP2011107251A (en) * | 2009-11-13 | 2011-06-02 | Ntt Docomo Inc | Voice recognition device, language model creation device and voice recognition method |
| JP2015215390A (en) * | 2014-05-08 | 2015-12-03 | 日本電信電話株式会社 | Speech recognition dictionary update device, speech recognition dictionary update method, and program |
| JP2018132626A (en) * | 2017-02-15 | 2018-08-23 | クラリオン株式会社 | Voice recognition system, voice recognition server, terminal device and word phrase management method |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7406921B2 (en) | 2023-12-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6484236B2 (en) | Online speech translation method and apparatus | |
| US20190164064A1 (en) | Question and answer interaction method and device, and computer readable storage medium | |
| US8909536B2 (en) | Methods and systems for speech-enabling a human-to-machine interface | |
| JP2021089705A (en) | Method and device for evaluating translation quality | |
| CN110019745A (en) | Conversational system with self study natural language understanding | |
| CN111967224A (en) | Method and device for processing dialog text, electronic equipment and storage medium | |
| CN111428010B (en) | Man-machine intelligent question-answering method and device | |
| CN107844470B (en) | Voice data processing method and equipment thereof | |
| CN108804427B (en) | Voice machine translation method and device | |
| CN111402861A (en) | Voice recognition method, device, equipment and storage medium | |
| CN111310440A (en) | Text error correction method, device and system | |
| CN110069624B (en) | Text processing method and device | |
| CN108345625B (en) | Information mining method and device for information mining | |
| CN112287085B (en) | Semantic matching method, system, equipment and storage medium | |
| US10529333B2 (en) | Command processing program, image command processing apparatus, and image command processing method | |
| JP6306376B2 (en) | Translation apparatus and translation method | |
| CN112579733A (en) | Rule matching method, rule matching device, storage medium and electronic equipment | |
| CN110232920B (en) | Voice processing method and device | |
| CN111444321B (en) | Question answering method, device, electronic equipment and storage medium | |
| KR20190074508A (en) | Method for crowdsourcing data of chat model for chatbot | |
| CN109002498B (en) | Man-machine conversation method, device, equipment and storage medium | |
| CN110781329A (en) | Image searching method and device, terminal equipment and storage medium | |
| CN109783677A (en) | Answering method, return mechanism, electronic equipment and computer readable storage medium | |
| JP7406921B2 (en) | Information processing device, information processing method and program | |
| US20200243092A1 (en) | Information processing device, information processing system, and computer program product |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220207 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20221216 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230104 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230301 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230627 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230824 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20231121 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20231218 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7406921 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |