JP2020052936A - Method, computer and program for generating training data - Google Patents
Method, computer and program for generating training data Download PDFInfo
- Publication number
- JP2020052936A JP2020052936A JP2018184242A JP2018184242A JP2020052936A JP 2020052936 A JP2020052936 A JP 2020052936A JP 2018184242 A JP2018184242 A JP 2018184242A JP 2018184242 A JP2018184242 A JP 2018184242A JP 2020052936 A JP2020052936 A JP 2020052936A
- Authority
- JP
- Japan
- Prior art keywords
- data
- training data
- conversion
- verification
- learned model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Landscapes
- Image Analysis (AREA)
Abstract
【課題】質の良い訓練データを自動的に生成することができる方法等を提供する。【解決手段】データ生成装置10は、検証データD1〜D3を用いて機械学習を行うことにより第1学習済みモデルM1を生成し、第1学習済みモデルM1を用いて検証データD1〜D3を分類し、正しく分類されなかった検証データのうちから基準データD1を選択し、基準データD1から変換済データT1〜T3を生成し、変換済データT1〜T3を分類し、正しく分類された変換データT3に係る変換の逆変換を訓練データK1,K2に対して施すことにより、新たな訓練データN2,N3を生成する。【選択図】図4PROBLEM TO BE SOLVED: To provide a method or the like capable of automatically generating high-quality training data. A data generation device 10 generates a first trained model M1 by performing machine learning using verification data D1 to D3, and classifies verification data D1 to D3 using the first trained model M1. Then, the reference data D1 is selected from the verification data that are not correctly classified, the converted data T1 to T3 are generated from the reference data D1, the converted data T1 to T3 are classified, and the correctly classified converted data T3. By applying the inverse conversion of the conversion according to the above to the training data K1 and K2, new training data N2 and N3 are generated. [Selection diagram] Fig. 4
Description
本発明は、訓練データを生成する方法等に関する。 The present invention relates to a method for generating training data and the like.
機械学習において、訓練データの質のみならず、量もまた重要である。とくに、データを高い精度で分類(クラスタリング)または予測するための学習済みモデルを生成するためには、正解が付与された学習データが大量に必要となる。 In machine learning, not only the quality but also the quantity of training data is important. In particular, in order to generate a trained model for classifying (clustering) or predicting data with high accuracy, a large amount of training data to which a correct answer is given is required.
このような訓練データを準備するためには、大量のデータを人手で分類して正解を付与したり、人手で予測値を準備したりする必要があり、多大な労力が必要となる。このために、訓練データを自動的に生成する方法の例が、特許文献1に記載されている。
In order to prepare such training data, it is necessary to classify a large amount of data manually to give a correct answer, or to prepare a predicted value manually, which requires a great deal of labor. For this purpose, an example of a method for automatically generating training data is described in
しかしながら、従来の技術では、質の良い学習データを生成することが困難であるという問題があった。 However, the conventional technique has a problem that it is difficult to generate high-quality learning data.
たとえば特許文献1の構成では訓練データそのものを生成することができず、元の訓練データとは無関係に特徴量のみに基づいて新たな訓練データを作成している。このため、実データ(たとえば写真)とはかけ離れたデータ(たとえば画像データ形式ではないデータや、人間が写真と認識できないようなデータ)が生成されてしまうおそれがある。同様の問題は、画像データだけでなく、たとえば音声データでも発生する可能性がある。
For example, in the configuration of
この発明は、このような問題点を解決するためになされたものであり、質の良い訓練データを自動的に生成することができる方法、コンピュータおよびプログラムを提供することを目的とする。 The present invention has been made to solve such a problem, and an object of the present invention is to provide a method, a computer, and a program capable of automatically generating high-quality training data.
上述の問題点を解決するため、この発明に係る方法は、機械学習に用いられる学習データに含まれる訓練データを生成する方法であって、
コンピュータが、訓練データを用いて機械学習を行うことにより、第1学習済みモデルを生成するステップと、
コンピュータが、前記第1学習済みモデルを用いて、少なくとも1つの検証データについて出力値を取得するステップと、
前記第1学習済みモデルによる出力値が不適切であった検証データのうちから、コンピュータが、少なくとも1つの基準データを選択するステップと、
コンピュータが、前記基準データに対して複数の異なる変換を施すことにより、複数の異なる変換済データを生成するステップと、
コンピュータが、前記第1学習済みモデルを用いて、各前記変換済データについて出力値を取得するステップと、
コンピュータが、前記変換済データのうち出力値が適切であったものに施されていた前記変換の逆変換を、少なくとも1つの訓練データに対して施すことにより、少なくとも1つの新たな訓練データを生成するステップと、
を備える。
また、この発明に係る方法は、機械学習に用いられる学習データに含まれる訓練データを生成する方法であって、
コンピュータが、訓練データを用いて機械学習を行うことにより、第1学習済みモデルを生成するステップと、
コンピュータが、前記第1学習済みモデルを用いて、少なくとも1つの検証データについて出力値を取得するステップと、
前記第1学習済みモデルによる出力値が適切であった検証データのうちから、コンピュータが、少なくとも1つの基準データを選択するステップと、
コンピュータが、前記基準データに対して複数の異なる変換を施すことにより、複数の異なる変換済データを生成するステップと、
コンピュータが、前記第1学習済みモデルを用いて、各前記変換済データについて出力値を取得するステップと、
コンピュータが、前記変換済データのうち出力値が不適切であったものに施されていた前記変換を、少なくとも1つの訓練データに対して施すことにより、少なくとも1つの新たな訓練データを生成するステップと、
を備える。
特定の態様によれば、前記学習データに含まれる訓練データおよび検証データは2次元画像データであり、前記変換は、幾何学的線形変換または色値の変換、ニューラルネットで抽出した特徴量の追加や削除、ニューラルネットで抽出した特徴量の強調や弱める変換を含む。
特定の態様によれば、前記学習データに含まれる訓練データおよび検証データは音声データであり、前記変換は、音の高さの変更、音声の再生スピードの変更、雑音の付加、雑音の除去、ローパスフィルタの適用、またはハイパスフィルタの適用、ニューラルネットで抽出した特徴量の追加や削除、ニューラルネットで抽出した特徴量の強調や弱める変換を含む。
また、この発明に係るコンピュータは、上述の方法を実行する。
また、この発明に係るプログラムは、コンピュータに上述の方法を実行させる。
In order to solve the above-described problems, a method according to the present invention is a method of generating training data included in learning data used for machine learning,
Generating a first learned model by the computer performing machine learning using the training data;
A step of: using the first learned model to obtain an output value for at least one verification data;
A step in which the computer selects at least one reference data from the verification data in which the output value of the first learned model is inappropriate;
A computer performing a plurality of different conversions on the reference data to generate a plurality of different converted data;
A step of: using the first learned model to obtain an output value for each of the converted data;
A computer generates at least one new training data by performing an inverse transformation of the transformation applied to the converted data having an appropriate output value to at least one training data. Steps to
Is provided.
Further, the method according to the present invention is a method of generating training data included in learning data used for machine learning,
Generating a first learned model by the computer performing machine learning using the training data;
A step of: using the first learned model to obtain an output value for at least one verification data;
A step in which the computer selects at least one reference data from the verification data whose output value by the first learned model is appropriate;
A computer performing a plurality of different conversions on the reference data to generate a plurality of different converted data;
A step of: using the first learned model to obtain an output value for each of the converted data;
A step of generating at least one new training data by performing, on the at least one training data, the conversion that has been performed on the converted data having an inappropriate output value among the converted data; When,
Is provided.
According to a specific mode, the training data and the verification data included in the learning data are two-dimensional image data, and the conversion is a geometric linear conversion or a color value conversion, and a feature amount extracted by a neural network is added. And deletion, and emphasizing and weakening the feature amount extracted by the neural network.
According to a specific mode, the training data and the verification data included in the learning data are audio data, and the conversion includes changing a pitch, changing a reproduction speed of a sound, adding noise, removing noise, This includes application of a low-pass filter or application of a high-pass filter, addition or deletion of a feature extracted by a neural network, and enhancement or weakening of a feature extracted by a neural network.
Further, a computer according to the present invention executes the above method.
Further, a program according to the present invention causes a computer to execute the above method.
この発明に係る方法等によれば、実際の学習データに変換を施すことで新たな学習データを生成するので、より質の良い学習データを生成することができる。 According to the method and the like according to the present invention, new learning data is generated by performing conversion on actual learning data, so that higher-quality learning data can be generated.
以下、この発明の実施の形態を添付図面に基づいて説明する。
実施の形態1.
図1に、本発明の実施の形態1に係るデータ生成装置10の構成の例を示す。データ生成装置10は、機械学習に用いられる学習データを生成する装置(コンピュータ)として機能する。
Hereinafter, embodiments of the present invention will be described with reference to the accompanying drawings.
FIG. 1 shows an example of the configuration of a data generation device 10 according to
図1に示すように、データ生成装置10は公知のコンピュータとしての構成を有し、演算を行う演算手段11と、情報を格納する記憶手段12とを備える。演算手段11はたとえばCPU(中央処理装置)を含み、記憶手段12はたとえば半導体メモリおよびHDD(ハードディスクドライブ)を含む。
As shown in FIG. 1, the data generation device 10 has a configuration as a known computer, and includes an
記憶手段12は、学習データを記憶する。学習データは、データについて出力値を取得する学習済みモデルを生成するための学習データである。学習済みモデルは、たとえばデータを複数のクラスのいずれかに分類するためのモデルであってもよい。その場合には、学習済みモデルの出力値は、たとえばそのデータがいずれのクラスに属するかを表す値となる。また、学習済みモデルは、未来のデータを予測するためのモデルであってもよい。その場合には、学習済みモデルの出力値は、たとえば未来のデータの予測値となる。以下では、データを分類するためのモデルについて説明するが、本発明はデータの予測を行うモデルにも応用が可能である。機械学習処理における学習データの具体的な利用方法は適宜設計可能であるが、訓練データと検証データを含んでいる。
The
学習データは、所定のデータ形式を有するデータ単位の集合である。各データ単位は、分類対象となるデータ部分と、正解ラベルとを含んでいる。なお、本明細書において、「データを分類する」という表現および「データを認識する」という表現は、いずれも、「データの正解ラベルを推定する」という意味である場合がある。以下では、データが画像データである場合について説明するが、本発明はデータが音声データである場合にも応用が可能である。 The learning data is a set of data units having a predetermined data format. Each data unit includes a data portion to be classified and a correct answer label. In this specification, the expressions “classify data” and “recognize data” may both mean “estimate the correct label of data”. Hereinafter, a case where the data is image data will be described. However, the present invention is also applicable to a case where the data is audio data.
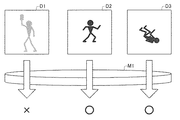
図2に、実施の形態1における検証データの例を示す。検証データは検証データD1〜D3を含む。本実施形態では、各データ単位において、分類対象となるデータ部分は2次元画像である。具体例として、あるデータ単位のデータ部分は人物の画像を表し、当該データ単位の正解ラベルは「人物」である。この場合には、当該データ単位は[人物]というクラスに属するということができる。図2の検証データD1〜D3はこれに該当する。また、別のデータ単位は人物でない物の画像を表し、当該データ単位の正解ラベルは「非人物」である。この場合には、当該データ単位は[非人物]というクラスに属するということができる。3個以上のクラスが定義されてもよい。 FIG. 2 shows an example of verification data according to the first embodiment. The verification data includes verification data D1 to D3. In the present embodiment, in each data unit, the data portion to be classified is a two-dimensional image. As a specific example, the data portion of a certain data unit represents an image of a person, and the correct label of the data unit is “person”. In this case, it can be said that the data unit belongs to the class of [person]. The verification data D1 to D3 in FIG. 2 correspond to this. Another data unit represents an image of an object that is not a person, and the correct label of the data unit is “non-person”. In this case, it can be said that the data unit belongs to the class [non-person]. Three or more classes may be defined.
訓練データも、検証データと同一の形式で定義される。この例では、これらの訓練データは、データを「人物」または「非人物」のクラスに分類する学習済みモデルを生成するための訓練データであるということができる。すなわち、これらの訓練データを用いた機械学習により生成される学習済みモデルは、画像が人物を表すものであるか否かを認識するためのモデルとなる。 The training data is also defined in the same format as the verification data. In this example, these training data can be said to be training data for generating a trained model that classifies the data into a "person" or "non-person" class. That is, the learned model generated by machine learning using these training data is a model for recognizing whether or not the image represents a person.
データ生成装置10の記憶手段12はプログラム(図示せず)も格納しており、演算手段11がこのプログラムを実行することによって、データ生成装置10は本明細書に記載される機能を実現する。すなわち、このプログラムは、本明細書に記載される方法を、コンピュータに実行させるものである。
The
データ生成装置10は、公知のコンピュータが通常備える他の構成要素を備えてもよい。たとえば、出力装置であるディスプレイおよびプリンタ、入力装置であるキーボードおよびマウス、通信ネットワークに対する入力装置と出力装置とを兼ねるネットワークインタフェース、等を備えてもよい。 The data generation device 10 may include other components that are commonly included in a known computer. For example, a display and a printer as output devices, a keyboard and a mouse as input devices, a network interface serving as an input device and an output device for a communication network, and the like may be provided.
図3は、実施の形態1においてデータ生成装置10が実行する処理の流れを説明するフローチャートである。図3の処理において、まずデータ生成装置10は、訓練データを用いて機械学習を行うことにより、第1学習済みモデルM1を生成する(ステップS1)。第1学習済みモデルM1は、データを複数のクラスのいずれかに分類するモデルである。すなわち、データについて、そのデータがいずれのクラスに属するかを表す値を、出力値として出力する。第1学習済みモデルM1はどのような形式のモデルであってもよいが、たとえばニューラルネットワークを用いて構成することができる。第1学習済みモデルM1の具体的な構造は当業者が適宜設計可能である。 FIG. 3 is a flowchart illustrating a flow of a process performed by data generation device 10 in the first embodiment. In the process of FIG. 3, first, the data generation device 10 generates a first learned model M1 by performing machine learning using the training data (step S1). The first learned model M1 is a model that classifies data into one of a plurality of classes. That is, for the data, a value indicating which class the data belongs to is output as an output value. The first learned model M1 may be any type of model, and may be configured using, for example, a neural network. The specific structure of the first learned model M1 can be appropriately designed by those skilled in the art.
次に、データ生成装置10は、第1学習済みモデルM1を用いて、検証データを分類する(ステップS2)。すなわち、検証データについて出力値を取得する。ステップS2は少なくとも1つの検証データ(たとえば検証データD1)に対して行われればよいが、すべての検証データに対して行ってもよい。 Next, the data generation device 10 classifies the verification data using the first learned model M1 (Step S2). That is, an output value is obtained for the verification data. Step S2 may be performed on at least one verification data (for example, verification data D1), but may be performed on all verification data.
ここでは、図2に示す検証データのうち、検証データD1は正しく分類されず(たとえば人物でないと認識され)、検証データD2およびD3は正しく分類された(たとえば人物であると認識された)とする。検証データD1の分類を誤った理由としては、たとえば画像中の人物が縦方向に長すぎ、かつ色が薄いためである、という理由が考えられるものとする。 Here, among the verification data shown in FIG. 2, verification data D1 is not correctly classified (for example, it is recognized as a person), and verification data D2 and D3 are correctly classified (for example, it is recognized as a person). I do. It is assumed that the reason why the classification of the verification data D1 is incorrect is that, for example, the person in the image is too long in the vertical direction and the color is light.
次に、データ生成装置10は、第1学習済みモデルM1を用いて正しく分類されなかった検証データ(すなわち第1学習済みモデルM1による出力値が不適切であった検証データ)のうちから、少なくとも1つの基準データを選択する(ステップS3)。ここで、「正しく分類されなかった」とは、たとえば誤ったクラスに分類されたもの(人物の画像であるのに[非人物]のクラスに分類された等)を意味するが、いずれのクラスにも分類されなかったものを含んでもよい。 Next, the data generation device 10 selects at least one of the verification data that is not correctly classified using the first learned model M1 (that is, the verification data whose output value by the first learned model M1 is inappropriate). One reference data is selected (step S3). Here, “not correctly classified” means, for example, an image that is classified into an incorrect class (eg, an image of a person but classified into a class of [non-person]). May also be included.
選択の基準は適宜設計可能であり、たとえば正しく分類されなかった検証データのうちからランダムに選択するようにしてもよいし、正しく分類されなかった検証データをすべて基準データとして選択するようにしてもよい。ここでは、検証データD1が基準データとして選択されたものとする。 The selection criterion can be designed as appropriate. For example, it is possible to randomly select verification data that has not been correctly classified, or to select all verification data that has not been correctly classified as reference data. Good. Here, it is assumed that the verification data D1 has been selected as the reference data.
次に、データ生成装置10は、基準データに対して複数の異なる変換を施すことにより、複数の異なる変換済データを生成する(ステップS4)。
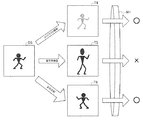
図4に、基準データに対する変換の例を示す。検証データD1に対してコントラストを強調する変換を施すことにより、変換済データT1が生成される。同様に、検証データD1に対して縦方向に圧縮する変換を施すことにより、変換済データT2が生成され、検証データD1に対してコントラストを強調する変換および縦方向への圧縮に圧縮する変換を施すことにより、変換済データT3が生成される。
Next, the data generation device 10 performs a plurality of different conversions on the reference data to generate a plurality of different converted data (step S4).
FIG. 4 shows an example of conversion for reference data. By performing a conversion for enhancing the contrast on the verification data D1, converted data T1 is generated. Similarly, by performing a conversion for compressing the verification data D1 in the vertical direction, converted data T2 is generated, and a conversion for enhancing the contrast and a conversion for compressing the verification data D1 to the compression in the vertical direction are generated. As a result, converted data T3 is generated.
このような変換に対応する具体的な演算処理は、公知の画像処理ソフトウェアまたは他の技術を用いて適宜設計可能である。 Specific arithmetic processing corresponding to such conversion can be appropriately designed using known image processing software or other techniques.
ここで、変換済データT1に係る変換と、変換済データT3に係る変換とは、その一部が共通している(いずれもコントラストを強調する変換を含む)が、全体として異なる変換となっている。このように、変換済データT1〜T3に対しては、互いに異なる変換が施されたということができる。このように、各変換済データは、基準データに対してそれぞれ異なる変換を施すことにより生成される。 Here, the conversion related to the converted data T1 and the conversion related to the converted data T3 have a part in common (both include the conversion for enhancing the contrast), but are different conversions as a whole. I have. Thus, it can be said that different conversions have been performed on the converted data T1 to T3. Thus, each converted data is generated by performing different conversions on the reference data.
次に、データ生成装置10は、第1学習済みモデルM1を用いて、変換済データT1〜T3を分類する(ステップS5)。すなわち、第1学習済みモデルM1を用いて、変換済データT1〜T3について出力値を取得する。ここでは、変換済データT1およびT2は正しく分類されず(たとえば人物でないと認識され)、変換済データT3は正しく分類された(たとえば人物であると認識された)ものとする。 Next, the data generation device 10 classifies the converted data T1 to T3 using the first learned model M1 (step S5). That is, using the first learned model M1, output values are obtained for the converted data T1 to T3. Here, it is assumed that converted data T1 and T2 are not correctly classified (for example, recognized as not being a person), and converted data T3 is correctly classified (for example, recognized as being a person).
なお、ここですべての変換済データが正しく分類された場合には、処理をステップS3に戻し、基準データの選択から処理をやり直してもよい。 Here, when all the converted data are correctly classified, the process may return to step S3, and the process may be repeated from the selection of the reference data.
ここで、検証データD1の分類は誤っていたにも関わらず、検証データD1から生成された変換済データT3の分類が正しく行われるようになった理由としては、変換済データT3のコントラストおよび縦横比率が、他の多くの訓練データと同程度に変更されていたため、第1学習済みモデルM1が正しく分類できるようになった、という理由が考えられるものとする。これを言い換えると、検証データD1のようにコントラストが薄く、かつ縦方向に長い画像が、学習データ中に不足していたものと考えられる。このため、検証データD1のようにコントラストが薄く、かつ縦方向に長い画像を訓練データ中に追加して新たに機械学習をやり直せば、検証データD1を正しく分類できる学習済みモデルが生成される可能性が高まることが期待される。 Here, the reason why the classification of the converted data T3 generated from the verification data D1 is correctly performed even though the classification of the verification data D1 is incorrect is that the contrast and the length and width of the converted data T3 are different. It is assumed that the reason is that the first learned model M1 can be correctly classified because the ratio has been changed to the same degree as many other training data. In other words, it is considered that an image having a low contrast and a long length in the vertical direction like the verification data D1 was insufficient in the learning data. For this reason, a trained model that can correctly classify the verification data D1 can be generated by adding an image having a low contrast and a long length in the vertical direction like the verification data D1 to the training data and newly performing machine learning again. It is expected that the nature will increase.
次に、データ生成装置10は、変換の内容に基づき、新たな訓練データを生成する(ステップS6)。より具体的には、変換済データのうち正しく分類されたもの(すなわち出力値が適切であったもの)に施されていた変換の逆変換を、全ての訓練データに施す。この例では、正しく分類された変換済データT3に施されていた変換は「コントラストを強調する変換および縦方向に圧縮する変換」であるので、これに対する逆変換は、たとえば「コントラストを緩和する変換および縦方向に伸長する変換」となる。なお、この例では変換を構成する要素の順序は可換であるが、そうでない場合には各要素の順序を逆転してもよい。 Next, the data generation device 10 generates new training data based on the content of the conversion (Step S6). More specifically, the inverse transformation of the transformation performed on correctly classified data (that is, the one whose output value is appropriate) among the converted data is performed on all the training data. In this example, since the conversion applied to the correctly classified converted data T3 is “conversion for enhancing contrast and conversion for compressing in the vertical direction”, the inverse conversion to this is, for example, “conversion for reducing contrast”. And a conversion that extends in the vertical direction ”. In this example, the order of the elements constituting the transformation is commutative, but if not, the order of the elements may be reversed.
なお、上述のように新たな学習データの元となる訓練データは、少なくとも1つであればよい。 As described above, at least one training data as a source of new learning data may be used.
図5に、新たな訓練データの例を示す。訓練データK1に対して「コントラストを緩和する変換および縦方向に伸長する変換」を施すことにより、新たな訓練データN2が生成される。同様に、訓練データK2に対して「コントラストを緩和する変換および縦方向に伸長する変換」を施すことにより、新たな訓練データN3が生成される。同様に、全ての訓練データに対して、変換が施される。 FIG. 5 shows an example of new training data. New training data N2 is generated by performing "conversion for reducing contrast and conversion for extending in the vertical direction" on training data K1. Similarly, new training data N3 is generated by performing "conversion for reducing contrast and conversion for extending in the vertical direction" on training data K2. Similarly, conversion is performed on all training data.
次に、データ生成装置10は、ステップS1で用いた訓練データと、ステップS6で生成された新たな訓練データとを用いて機械学習を行うことにより、第2学習済みモデルを生成する(ステップS7)。 Next, the data generation device 10 generates a second learned model by performing machine learning using the training data used in step S1 and the new training data generated in step S6 (step S7). ).
ここで、新たな訓練データN2およびN3は、検証データD1のようにコントラストが薄く、かつ縦方向に長い画像となっているので、これらを用いて生成された第2学習済みモデルは、検証データD1を正しく分類できる可能性が高いといえる。 Here, the new training data N2 and N3 are images having a low contrast and a long length in the vertical direction like the verification data D1, and the second trained model generated by using these images is the verification data D1. It can be said that there is a high possibility that D1 can be correctly classified.
以上説明するように、本発明の実施の形態1に係るデータ生成装置10によれば、検証データD1を正しく分類するための質の良い学習データを自動的に生成することができる。 As described above, the data generation device 10 according to the first embodiment of the present invention can automatically generate high-quality learning data for correctly classifying the verification data D1.
ステップS5では、検証データD1に異なる変換を施した変換済データT1〜T3を分類することにより、ステップS6で施す変換の内容を決定している。正しく分類されなかった検証データの全てまたは一部を選択し、ステップS5を実行する。ステップS6で施す変換は、ステップ5で正しく分類されるようになったデータが多い変換の逆変換を、施す変換の内容と決定するように構成してもよい。このとき、一番正しく分類されるようになったデータが多い変換の逆変換だけを施してもよいし、上位複数の変換の逆変換を施すように構成してもよい。
ステップS2で検証データD2、D3のように正しく分類されていた検証データが、ステップS5で正しく分類されなくなる場合はその検証データ数をカウントしてもよい。この検証データ数が一定値より多い場合は、ステップS6で変換の逆変換を施すことにより訓練データを増やしても、第1学習済みモデルM1の認識率が良くならない可能性がある。そこで、ステップS5で正しく分類されるようになった検証データ数と、ステップS5で正しく分類されなくなった検証データ数を比較して、ステップS5で正しく分類されるようになる検証データ数の差が大きい変換や、ステップS5で正しく分類されなくなる検証データがほとんど発生しない変換を優先して選択してもよい。
さらに、D1が正しく分類されるようになるほど大きな変化がない場合でも、正しいクラスである確率と正しくないクラスである確率が得られるので、それを比較するとD1の正しいクラスである確率が向上し、正しくないクラスである確率が低下する変換に着目し、逆に、D2、D3のように正しく分類されていた検証データについて、正しいクラスである確率が減少しないか減少が少ない変換を候補として選択してもよい。
In step S5, the contents of the conversion performed in step S6 are determined by classifying the converted data T1 to T3 obtained by performing different conversions on the verification data D1. All or a part of the verification data not correctly classified is selected, and step S5 is executed. The conversion performed in step S6 may be configured to determine the inverse conversion of the conversion having many data correctly classified in
If the verification data that has been correctly classified like the verification data D2 and D3 in step S2 is not correctly classified in step S5, the number of verification data may be counted. If the number of verification data is larger than a certain value, the recognition rate of the first learned model M1 may not be improved even if the training data is increased by performing the inverse transformation of the transformation in step S6. Therefore, by comparing the number of pieces of verification data correctly classified in step S5 with the number of pieces of verification data not correctly classified in step S5, the difference between the number of pieces of verification data that can be correctly classified in step S5 is determined. A large conversion or a conversion that hardly generates verification data that is not correctly classified in step S5 may be preferentially selected.
Furthermore, even if D1 does not change so much as to be correctly classified, the probability of being a correct class and the probability of being an incorrect class are obtained. Paying attention to the conversion in which the probability of being an incorrect class decreases, conversely, for verification data that has been correctly classified such as D2 and D3, a conversion in which the probability of being a correct class does not decrease or decreases is selected as a candidate. You may.
とくに、本実施形態では画像に対する変換を行うので、変換後のデータも画像として認識できる範囲のものであり、画像でないデータが生成されたり、人間が画像として認識できないようなデータが生成される可能性は低い。 In particular, in the present embodiment, since the conversion is performed on the image, the converted data is also in a range that can be recognized as an image, and data that is not an image or data that cannot be recognized as an image by humans may be generated. Sex is low.
なお、このような効果は、いかなる学習データセットに対しても必ず成り立つというものではないが、少なくとも多くの学習データセットについては効率的に質の良いデータを追加することが可能である。 Note that such an effect is not necessarily achieved for any learning data set, but high-quality data can be efficiently added to at least many learning data sets.
実施の形態2.
実施の形態2は、実施の形態1で説明した、基準データの選択方法および新たな訓練データの生成方法を変更するものである。以下、実施の形態1との相違点を説明する。
The second embodiment is a modification of the method of selecting reference data and the method of generating new training data described in the first embodiment. Hereinafter, differences from the first embodiment will be described.
図6に、実施の形態2における学習データの例を示す。検証データは検証データD4〜D6を含む。図6の検証データD4〜D6は[人物]のクラスに属するデータの例である。 FIG. 6 shows an example of learning data according to the second embodiment. The verification data includes verification data D4 to D6. The verification data D4 to D6 in FIG. 6 are examples of data belonging to the class of [person].
図7は、実施の形態2においてデータ生成装置10が実行する処理の流れを説明するフローチャートである。ステップS11およびS12は、図3のステップS1およびS2と同様である。 FIG. 7 is a flowchart illustrating a flow of a process performed by the data generation device 10 according to the second embodiment. Steps S11 and S12 are the same as steps S1 and S2 in FIG.
ここでは、図6に示す検証データのうち、検証データD4およびD6は正しく分類されず(たとえば人物でないと認識され)、検証データD5は正しく分類された(たとえば人物であると認識された)とする。 Here, of the verification data shown in FIG. 6, verification data D4 and D6 are not correctly classified (for example, recognized as a person), and verification data D5 is correctly classified (for example, recognized as a person). I do.
ステップS12の後、データ生成装置10は、第1学習済みモデルM1を用いて正しく分類された検証データのうちから、少なくとも1つの基準データを選択する(ステップS13)。実施の形態2では、実施の形態1と異なり、基準データは正しく分類された検証データのうちから選択される。ここでは、検証データD5が基準データとして選択されたものとする。
選択の基準は適宜設計可能であり、たとえば正しく分類された検証データのうちからランダムに選択するようにしてもよいし、正しく分類された検証データをすべて基準データとして選択するようにしてもよい。
After step S12, the data generation device 10 selects at least one reference data from the verification data correctly classified using the first learned model M1 (step S13). In the second embodiment, unlike the first embodiment, the reference data is selected from correctly classified verification data. Here, it is assumed that the verification data D5 has been selected as the reference data.
The selection criterion can be designed as appropriate. For example, the verification data may be randomly selected from the correctly classified verification data, or all the correctly classified verification data may be selected as the reference data.
次に、データ生成装置10は、ステップS4と同様に、基準データに対して複数の異なる変換を施すことにより、複数の異なる変換済データを生成する(ステップS14)。
図8に、基準データに対する変換の例を示す。検証データD5に対してコントラストを緩和する変換を施すことにより、変換済データT4が生成される。同様に、検証データD5に対して縦方向に伸長する変換を施すことにより、変換済データT5が生成され、検証データD5に対して左右反転する変換を施すことにより、変換済データT6が生成される。
Next, the data generation device 10 generates a plurality of different converted data by performing a plurality of different conversions on the reference data, similarly to step S4 (step S14).
FIG. 8 shows an example of conversion for reference data. The converted data T4 is generated by performing a conversion to reduce the contrast on the verification data D5. Similarly, converted data T5 is generated by performing a conversion that extends in the vertical direction on the verification data D5, and converted data T6 is generated by performing a conversion that inverts the verification data D5 from side to side. You.
次に、データ生成装置10は、ステップS5と同様に、第1学習済みモデルM1を用いて、変換済データT4〜T6を分類するステップ(ステップS15)。ここでは、変換済データT5は正しく分類されず(たとえば人物でないと認識され)、変換済データT4およびT6は正しく分類された(たとえば人物であると認識された)ものとする。 Next, the data generation device 10 classifies the converted data T4 to T6 using the first learned model M1, as in step S5 (step S15). Here, it is assumed that the converted data T5 is not correctly classified (for example, recognized as a person), and the converted data T4 and T6 are correctly classified (for example, recognized as a person).
ここで、変換済データT4およびT6の分類を正しく行えた理由としては、訓練データ中に、変換済データT4のようにコントラストが弱い画像や、変換済データT6のように左右反転されたものに類似した画像が、訓練データ中に多く存在していた、という理由が考えられるとする。また、それにも関わらず、これらと同じ検証データD5から生成された変換済データT5の分類を誤ってしまった理由としては、訓練データ中に、変換済データT5のような縦方向に長い画像が不足していた、という理由が考えられるとする。このため、変換済データT5のように縦方向に長い画像を訓練データ中に追加して新たに機械学習をやり直せば、変換済データT5に似た画像を正しく分類できる学習済みモデルが生成される可能性が高まることが期待される。 Here, the reason why the classification of the converted data T4 and T6 was correctly performed is that an image having a low contrast such as the converted data T4 or an image which is horizontally inverted such as the converted data T6 in the training data. Suppose that the reason may be that many similar images existed in the training data. Nevertheless, the reason why the classification of the converted data T5 generated from the same verification data D5 was erroneous was that a vertically long image such as the converted data T5 was included in the training data. Suppose that the reason was that there was a shortage. Therefore, if a vertically long image such as the converted data T5 is added to the training data and the machine learning is newly performed, a trained model that can correctly classify an image similar to the converted data T5 is generated. It is expected that the possibility will increase.
次に、データ生成装置10は、変換の内容に基づき、新たな訓練データを生成する(ステップS16)。より具体的には、変換済データのうち正しく分類されなかったものに施されていた変換を、少なくとも1つの訓練データに対して施すことにより、少なくとも1つの新たな訓練データを生成する。この例では、正しく分類されなかった変換済データT5に施されていた「縦方向に伸長する変換」という変換により、新たな訓練データを生成する。 Next, the data generation device 10 generates new training data based on the content of the conversion (Step S16). More specifically, at least one piece of new training data is generated by applying the transformation that has been performed on the converted data that is not correctly classified to at least one piece of training data. In this example, new training data is generated by the conversion “conversion that extends in the vertical direction” performed on the converted data T5 that has not been correctly classified.
なお、新たな訓練データの元となる訓練データは、上述のように少なくとも1つであればよいが、すべての訓練データについて同様に新たな訓練データを生成してもよい。 It should be noted that the training data serving as the basis of the new training data may be at least one as described above, but new training data may be similarly generated for all the training data.
図9に、新たな訓練データの例を示す。訓練データK3に対して「縦方向に伸長する変換」を施すことにより、新たな訓練データN4が生成される。同様に、訓練データK4に対して「縦方向に伸長する変換」を施すことにより、新たな訓練データN5が生成され、訓練データK5に対して「縦方向に伸長する変換」を施すことにより、新たな訓練データN6が生成される。 FIG. 9 shows an example of new training data. By performing "vertical expansion" on the training data K3, new training data N4 is generated. Similarly, by performing “vertical expansion” on the training data K4, new training data N5 is generated. By performing “vertical expansion” on the training data K5, New training data N6 is generated.
次に、データ生成装置10は、ステップS7と同様に、ステップS11で用いた訓練データと、ステップS16で生成された新たな訓練データとを用いて機械学習を行うことにより、第2学習済みモデルを生成する(ステップS17)。 Next, similarly to step S7, the data generation device 10 performs machine learning using the training data used in step S11 and the new training data generated in step S16, thereby obtaining the second learned model. Is generated (step S17).
ここで、新たな訓練データN4〜N6は、変換済データT5のように縦方向に長い画像となっているので、これらを用いて生成された第2学習済みモデルは、変換済データT4のようにコントラストが弱い画像や、変換済データT6のように左右反転したものに類似した画像のみならず、変換済データT5のように縦方向に長い画像についても、正しく分類できる可能性が高いといえる。すなわち、第2学習済みモデルは、より様々なデータを適切に分類できる頑強なモデルとなる。 Here, since the new training data N4 to N6 are vertically long images like the converted data T5, the second trained model generated using them is like the converted data T4. It can be said that there is a high possibility that not only an image having a low contrast and an image similar to an image which is inverted left and right like converted data T6, but also an image long in the vertical direction like converted data T5 can be correctly classified. . That is, the second learned model is a robust model that can appropriately classify more various data.
以上説明するように、本発明の実施の形態2に係るデータ生成装置10によれば、変換済データT5に類似する検証データ等を正しく分類するための質の良い訓練データを自動的に生成することができる。
As described above, according to the data generation device 10 according to
ステップS15では、検証データD5に異なる変換を施した変換済データT4〜T5を分類することにより、ステップS16で施す変換の内容を決定している。正しく分類された検証データの全てまたは一部を選択し、ステップS15を実行する。ステップS16で施す変換は、ステップ15で、正しく分類されないデータが多い変換を、施す変換の内容と決定するように構成してもよい。このとき、一番正しく分類されないデータが多い変換だけを施してもよいし、上位複数の変換を施すように構成してもよい。
ステップS12で検証データD4、D6のように正しく分類されていなかった検証データが、ステップS15で正しく分類される場合はその検証データ数をカウントしてもよい。この検証データ数が一定値より多い場合は、ステップS16で変換を施すことにより訓練データを増やしても、第1学習済みモデルM1の認識率が良くならない可能性がある。そこで、ステップS12で正しく分類されなかった検証データ数と、ステップS15で正しく分類された検証データ数を比較して、ステップS15で正しく分類されなくなる検証データ数の差が大きい変換や、ステップS15で正しく分類されるようになる検証データがほとんど発生しない変換が有力と考えられる。
さらに、D5が正しく分類されなくなるほど大きな変化がない場合でも、正しいクラスである確率と正しくないクラスである確率が得られるので、それを比較するとD5の正しくないクラスである確率が向上し、正しいクラスである確率が低下する変換に着目し、逆に、D4、D6のように正しく分類されていなかった検証データについて、正しくないクラスである確率が減少しないか減少が少ない変換を候補として選択してもよい。
In step S15, the contents of the conversion performed in step S16 are determined by classifying the converted data T4 to T5 obtained by performing different conversions on the verification data D5. All or part of the correctly classified verification data is selected, and step S15 is executed. The conversion performed in step S16 may be configured to determine, in
If the verification data that was not correctly classified like the verification data D4 and D6 in step S12 is correctly classified in step S15, the number of verification data may be counted. If the number of verification data is larger than a certain value, the recognition rate of the first learned model M1 may not be improved even if the training data is increased by performing the conversion in step S16. Therefore, the number of verification data that is not correctly classified in step S12 is compared with the number of verification data that is correctly classified in step S15, and the difference in the number of verification data that is not correctly classified in step S15 is large. A conversion that hardly generates verification data that can be correctly classified is considered to be effective.
Furthermore, even when D5 does not change so large that it is not correctly classified, the probability of being a correct class and the probability of being an incorrect class can be obtained. Focusing on the transformation in which the probability of being a class decreases, conversely, for the verification data that has not been correctly classified such as D4 and D6, a transformation in which the probability of being an incorrect class does not decrease or decreases little is selected as a candidate. You may.
実施の形態1で説明した処理を実行した後、実施の形態2で説明した処理を実行し、さらに実施の形態1で説明した処理に戻り実行する一連の流れを、基準データがなくなるまで繰り返してもよい。
実施の形態1および2において、以下のような変形を施すことができる。
ステップS1、S7、S11およびS17は、データ生成装置10以外のコンピュータが実行してもよい。また、ステップS7を実行せず、他の用途に新たな訓練データN2〜N6を用いてもよい。
After the processing described in the first embodiment is performed, the processing described in the second embodiment is performed, and a series of the flow of returning to the processing described in the first embodiment is repeated until there is no more reference data. Is also good.
In the first and second embodiments, the following modifications can be made.
Steps S1, S7, S11 and S17 may be executed by a computer other than the data generation device 10. Also, the new training data N2 to N6 may be used for other purposes without executing step S7.
データ変換の具体的内容は適宜設計可能であり、たとえば、任意の幾何学的線形変換を含むものであってもよい。幾何学的線形変換とは、たとえば直交2次元座標系において、座標に2×2行列を作用させる変換を意味する。幾何学的線形変換の例としては、回転、平行移動、拡大縮小、反転(たとえば左右反転)、これらの組み合わせ、等が挙げられる。拡大縮小は、1方向または2方向への拡大または縮小を含む。1方向への拡大または縮小は、縦方向の伸長、縦方向の圧縮、横方向の伸長、横方向の圧縮、斜め方向の伸長、斜め方向の圧縮、等を含む。2方向への拡大または縮小は、たとえば縦および横方向への伸長または圧縮(縦横で倍率が異なるものを含む)であるが、斜め方向への伸長または圧縮を含んでもよい。 The specific contents of the data conversion can be appropriately designed, and may include, for example, any geometric linear conversion. The geometric linear transformation means, for example, a transformation in which a 2 × 2 matrix acts on coordinates in an orthogonal two-dimensional coordinate system. Examples of the geometric linear transformation include rotation, translation, enlargement / reduction, inversion (for example, left / right inversion), a combination thereof, and the like. The enlargement / reduction includes enlargement / reduction in one or two directions. The enlargement or reduction in one direction includes vertical expansion, vertical compression, horizontal expansion, horizontal compression, diagonal expansion, diagonal compression, and the like. The expansion or contraction in two directions is, for example, expansion or compression in the vertical and horizontal directions (including those having different magnifications in the vertical and horizontal directions), but may also include expansion or compression in an oblique direction.
また、変換は、色値の変換を含むものであってもよい。色値の変換の例としては、明るさの変更、色調の変更、コントラストの強調または緩和、等が挙げられる。またニューラルネットで抽出した特徴量の追加や削除、ニューラルネットで抽出した特徴量の強調や弱める変換等であってもよい。 Further, the conversion may include a conversion of a color value. Examples of color value conversion include change in brightness, change in color tone, enhancement or mitigation of contrast, and the like. Further, addition or deletion of a feature extracted by a neural network, enhancement or weakening of a feature extracted by a neural network, or the like may be used.
学習データに含まれる訓練データと検証データは画像データ以外の種類のデータであってもよい。たとえば音声データであってもよい。この場合には、データの変換は、音の高さの変更を含んでもよく、音声の再生スピードの変更を含んでもよい。また、データの変換は、雑音の付加または雑音の除去を含んでもよい。雑音の付加および除去ならびにそれぞれの逆変換は、当業者が任意に設計可能であるが、たとえば、2018年9月12日において<https://tokyohappendix.com/audio-tips/audacity>で公開されている技術を用いて行うことができる。実施の形態2においては、さらに、データの変換は、ローパスフィルタの適用(すなわち所定周波数以上の周波数成分を除去する)、ハイパスフィルタの適用(すなわち所定周波数以下の周波数成分を除去する)、等を含んでもよい。ローパスフィルタおよびハイパスフィルタの適用ならびにそれぞれの逆変換は、当業者が任意に設計可能であるが、たとえば、2018年9月12日において<https://pianoforte32.com/blog/files/DSEE_performance_of_HAP-Z1ES_by_pure_sound_source.html>で公開されている技術を用いて行うことができる。
またデータ変換は、ニューラルネットで抽出した特徴量の追加や削除、ニューラルネットで抽出した特徴量の強調や弱める変換等を含んでもよい。
The training data and the verification data included in the learning data may be data of a type other than the image data. For example, it may be audio data. In this case, the data conversion may include a change in the pitch of the sound or a change in the reproduction speed of the sound. Also, converting the data may include adding or removing noise. The addition and removal of noise and their respective inverse transforms can be arbitrarily designed by those skilled in the art. This can be done using the techniques that are available. In the second embodiment, the data conversion further includes application of a low-pass filter (that is, removal of frequency components equal to or higher than a predetermined frequency), application of a high-pass filter (that is, removal of frequency components equal to or lower than a predetermined frequency), and the like. May be included. The application of the low-pass filter and the high-pass filter and their respective inverse transforms can be arbitrarily designed by those skilled in the art. .html>.
The data conversion may include addition or deletion of a feature extracted by a neural network, and enhancement or weakening of a feature extracted by a neural network.
機械学習を行わせるためのモデルとしては、任意の形式のモデルを用いることができる。たとえばニューラルネットワークを用いてもよいし、他のモデルを用いてもよい。 Any model can be used as a model for performing machine learning. For example, a neural network may be used, or another model may be used.
実施の形態1および2ではデータの分類を行うための学習済みモデル、訓練データおよび検証データについて説明したが、データの予測を行うための学習済みモデル、訓練データおよび検証データについても同様に実施が可能である。その場合には、学習済みモデルの出力値は予測値となる。また、出力値が適切であるか否かは、正しく分類されたか否かに代えて、予測精度が所定の閾値以上であったか否かに基づいて判定することができる。たとえば、予測された値と正解の値との間の二乗誤差を算出し、この二乗誤差が閾値未満であれば出力値が適切である(正しく予測された)と判定し、二乗誤差が閾値以上であれば出力値が不適切である(正しく予測されなかった)と判定してもよい。 In the first and second embodiments, the learned model, the training data, and the verification data for classifying the data have been described. However, the learning model, the training data, and the verification data for performing data prediction can be similarly performed. It is possible. In that case, the output value of the learned model is a predicted value. Also, whether or not the output value is appropriate can be determined based on whether or not the prediction accuracy is equal to or more than a predetermined threshold, instead of whether or not the classification is correctly performed. For example, a square error between a predicted value and a correct value is calculated, and if the square error is less than a threshold value, it is determined that the output value is appropriate (correctly predicted), and the square error is equal to or greater than the threshold value. Then, it may be determined that the output value is inappropriate (it was not correctly predicted).
ステップS7およびS17において、訓練データ全体ではなく、訓練データの一部を拡張した場合、データ全体の傾向に影響を与えないように、新たな訓練データと、その元となった訓練データとについては、学習する際の重みの変更量を通常より小さくしてもよい。たとえば、通常の重みの変更量(または係数)がηであり、1つの元の訓練データからn個の新たな訓練データが生成された場合には、その元の訓練データと、その新たな訓練データとについて、重みの変更量(または係数)はη/(n+1)としてもよい。具体例として、実施の形態1において、訓練データK1および訓練データK2と、これらから生成された新たな訓練データN2およびN3とについては、ステップS7においてこれらのデータを用いて学習する際の重みの変更量を通常の1/2としてもよい。 In Steps S7 and S17, if a part of the training data is expanded instead of the entire training data, the new training data and the training data based on the new training data are set so as not to affect the tendency of the entire data. Alternatively, the amount of change in weight at the time of learning may be smaller than usual. For example, when the normal weight change amount (or coefficient) is η and n new training data are generated from one original training data, the original training data and the new training data are generated. For the data, the weight change amount (or coefficient) may be η / (n + 1). As a specific example, in the first embodiment, with respect to the training data K1 and the training data K2 and the new training data N2 and N3 generated from the training data K1 and the training data K2, the weight at the time of learning using these data in step S7. The change amount may be 1 / of the normal amount.
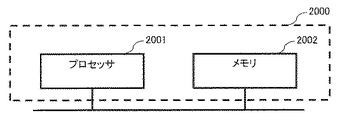
なお、上述した実施の形態1および2に係るデータ生成装置10における各機能は、処理回路によって実現される。各機能を実現する処理回路は、専用のハードウェアであってもよく、メモリに格納されるプログラムを実行するプロセッサであってもよい。図10は、本発明の実施の形態1および2に係るデータ生成装置10の各機能を専用のハードウェアである処理回路1000で実現する場合を示した構成図である。また、図11は、本発明の実施の形態1および2に係るデータ生成装置10の各機能をプロセッサ2001およびメモリ2002を備えた処理回路2000により実現する場合を示した構成図である。
Each function in the data generation device 10 according to the first and second embodiments is realized by a processing circuit. The processing circuit that realizes each function may be dedicated hardware or a processor that executes a program stored in a memory. FIG. 10 is a configuration diagram showing a case where each function of the data generation device 10 according to
処理回路が専用のハードウェアである場合、処理回路1000は、例えば、単一回路、複合回路、プログラム化したプロセッサ、並列プログラム化したプロセッサ、ASIC(Application Specific Integrated Circuit)、FPGA(Field Programmable Gate Array)、またはこれらを組み合わせたものが該当する。データ生成装置10の各部の機能それぞれを個別の処理回路1000で実現してもよいし、各部の機能をまとめて処理回路1000で実現してもよい。
When the processing circuit is dedicated hardware, the
一方、処理回路がプロセッサ2001の場合、データ生成装置10の各部の機能は、ソフトウェア、ファームウェア、またはソフトウェアとファームウェアとの組み合わせにより実現される。ソフトウェアおよびファームウェアは、プログラムとして記述され、メモリ2002に格納される。プロセッサ2001は、メモリ2002に記憶されたプログラムを読み出して実行することにより、各部の機能を実現する。すなわち、データ生成装置10は、処理回路2000により実行されるときに、ステップS1〜7またはS11〜S17が結果的に実行されることになるプログラムを格納するためのメモリ2002を備える。
On the other hand, when the processing circuit is the
これらのプログラムは、上述した各部の手順あるいは方法をコンピュータに実行させるものであるともいえる。ここで、メモリ2002とは、例えば、RAM(Random Access Memory)、ROM(Read Only Memory)、フラッシュメモリ、EPROM(Erasable Programmable Read Only Memory)、EEPROM(Electrically Erasable and Programmable Read Only Memory)等の、不揮発性または揮発性の半導体メモリが該当する。また、磁気ディスク、フレキシブルディスク、光ディスク、コンパクトディスク、ミニディスク、DVD等も、メモリ2002に該当する。
It can be said that these programs cause a computer to execute the procedures or methods of the above-described units. Here, the
なお、上述した各部の機能について、一部を専用のハードウェアで実現し、一部をソフトウェアまたはファームウェアで実現するようにしてもよい。 In addition, about the function of each part mentioned above, you may make it implement | achieve a part by exclusive hardware and implement | achieve a part by software or firmware.
このように、処理回路は、ハードウェア、ソフトウェア、ファームウェア、またはこれらの組み合わせによって、上述した各部の機能を実現することができる。 As described above, the processing circuit can realize the functions of the above-described units by hardware, software, firmware, or a combination thereof.
10 データ生成装置(コンピュータ)、D1〜D6 検証データ(D1,D5 基準データ)、M1 第1学習済みモデル、K1〜K5 訓練データ、N2〜N6 新たな訓練データ、T1〜T6 変換済データ。 10 Data generation device (computer), D1 to D6 verification data (D1, D5 reference data), M1 first learned model, K1 to K5 training data, N2 to N6 new training data, T1 to T6 converted data.
Claims (6)
コンピュータが、訓練データを用いて機械学習を行うことにより、第1学習済みモデルを生成するステップと、
コンピュータが、前記第1学習済みモデルを用いて、少なくとも1つの検証データについて出力値を取得するステップと、
前記第1学習済みモデルによる出力値が不適切であった検証データのうちから、コンピュータが、少なくとも1つの基準データを選択するステップと、
コンピュータが、前記基準データに対して複数の異なる変換を施すことにより、複数の異なる変換済データを生成するステップと、
コンピュータが、前記第1学習済みモデルを用いて、各前記変換済データについて出力値を取得するステップと、
コンピュータが、前記変換済データのうち出力値が適切であったものに施されていた前記変換の逆変換を、少なくとも1つの訓練データに対して施すことにより、少なくとも1つの新たな訓練データを生成するステップと、
を備える、方法。 A method for generating training data included in learning data used for machine learning,
Generating a first learned model by the computer performing machine learning using the training data;
A step of: using the first learned model to obtain an output value for at least one verification data;
A step in which the computer selects at least one reference data from the verification data in which the output value of the first learned model is inappropriate;
A computer performing a plurality of different conversions on the reference data to generate a plurality of different converted data;
A step of: using the first learned model to obtain an output value for each of the converted data;
A computer generates at least one new training data by applying an inverse transformation of the transformation applied to the converted data having an appropriate output value to at least one training data. Steps to
A method comprising:
コンピュータが、訓練データを用いて機械学習を行うことにより、第1学習済みモデルを生成するステップと、
コンピュータが、前記第1学習済みモデルを用いて、少なくとも1つの検証データについて出力値を取得するステップと、
前記第1学習済みモデルによる出力値が適切であった検証データのうちから、コンピュータが、少なくとも1つの基準データを選択するステップと、
コンピュータが、前記基準データに対して複数の異なる変換を施すことにより、複数の異なる変換済データを生成するステップと、
コンピュータが、前記第1学習済みモデルを用いて、各前記変換済データについて出力値を取得するステップと、
コンピュータが、前記変換済データのうち出力値が不適切であったものに施されていた前記変換を、少なくとも1つの訓練データに対して施すことにより、少なくとも1つの新たな訓練データを生成するステップと、
を備える、方法。 A method for generating training data included in learning data used for machine learning,
Generating a first learned model by the computer performing machine learning using the training data;
A step of: using the first learned model to obtain an output value for at least one verification data;
A step in which the computer selects at least one reference data from the verification data whose output value by the first learned model is appropriate;
A computer performing a plurality of different conversions on the reference data to generate a plurality of different converted data;
A step of: using the first learned model to obtain an output value for each of the converted data;
A step of generating at least one new training data by performing, on the at least one training data, the conversion that has been performed on the converted data having an inappropriate output value among the converted data; When,
A method comprising:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018184242A JP6622369B1 (en) | 2018-09-28 | 2018-09-28 | Method, computer and program for generating training data |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018184242A JP6622369B1 (en) | 2018-09-28 | 2018-09-28 | Method, computer and program for generating training data |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP6622369B1 JP6622369B1 (en) | 2019-12-18 |
| JP2020052936A true JP2020052936A (en) | 2020-04-02 |
Family
ID=68917280
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018184242A Expired - Fee Related JP6622369B1 (en) | 2018-09-28 | 2018-09-28 | Method, computer and program for generating training data |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6622369B1 (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022013919A (en) * | 2020-07-03 | 2022-01-18 | ローベルト ボツシユ ゲゼルシヤフト ミツト ベシユレンクテル ハフツング | Image classifier comprising non-injective transformation |
| WO2022177143A1 (en) * | 2021-02-22 | 2022-08-25 | 삼성전자 주식회사 | Electronic device for generating data, and operating method thereof |
| EP4141746A1 (en) * | 2021-08-23 | 2023-03-01 | Fujitsu Limited | Machine learning program, method of machine learning, and machine learning apparatus |
| DE112023000588T5 (en) | 2022-06-13 | 2024-11-21 | Hitachi Astemo, Ltd. | MACHINE LEARNING SYSTEM AND MACHINE LEARNING METHODS |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11803758B2 (en) * | 2020-04-17 | 2023-10-31 | Microsoft Technology Licensing, Llc | Adversarial pretraining of machine learning models |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04295898A (en) * | 1991-03-26 | 1992-10-20 | Sekisui Chem Co Ltd | Speaker collating system |
| JP2006004399A (en) * | 2004-05-20 | 2006-01-05 | Fujitsu Ltd | Information extraction program, recording medium thereof, information extraction apparatus, and information extraction rule creation method |
| JP2013125322A (en) * | 2011-12-13 | 2013-06-24 | Olympus Corp | Learning device, program and learning method |
| JP2016122336A (en) * | 2014-12-25 | 2016-07-07 | クラリオン株式会社 | Intention estimation device and intention estimation system |
| JP2016218995A (en) * | 2015-05-25 | 2016-12-22 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカPanasonic Intellectual Property Corporation of America | Machine translation method, machine translation apparatus and program |
-
2018
- 2018-09-28 JP JP2018184242A patent/JP6622369B1/en not_active Expired - Fee Related
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04295898A (en) * | 1991-03-26 | 1992-10-20 | Sekisui Chem Co Ltd | Speaker collating system |
| JP2006004399A (en) * | 2004-05-20 | 2006-01-05 | Fujitsu Ltd | Information extraction program, recording medium thereof, information extraction apparatus, and information extraction rule creation method |
| JP2013125322A (en) * | 2011-12-13 | 2013-06-24 | Olympus Corp | Learning device, program and learning method |
| JP2016122336A (en) * | 2014-12-25 | 2016-07-07 | クラリオン株式会社 | Intention estimation device and intention estimation system |
| JP2016218995A (en) * | 2015-05-25 | 2016-12-22 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカPanasonic Intellectual Property Corporation of America | Machine translation method, machine translation apparatus and program |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022013919A (en) * | 2020-07-03 | 2022-01-18 | ローベルト ボツシユ ゲゼルシヤフト ミツト ベシユレンクテル ハフツング | Image classifier comprising non-injective transformation |
| US12450891B2 (en) | 2020-07-03 | 2025-10-21 | Robert Bosch Gmbh | Image classifier comprising a non-injective transformation |
| WO2022177143A1 (en) * | 2021-02-22 | 2022-08-25 | 삼성전자 주식회사 | Electronic device for generating data, and operating method thereof |
| EP4141746A1 (en) * | 2021-08-23 | 2023-03-01 | Fujitsu Limited | Machine learning program, method of machine learning, and machine learning apparatus |
| DE112023000588T5 (en) | 2022-06-13 | 2024-11-21 | Hitachi Astemo, Ltd. | MACHINE LEARNING SYSTEM AND MACHINE LEARNING METHODS |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6622369B1 (en) | 2019-12-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6622369B1 (en) | Method, computer and program for generating training data | |
| JP6441980B2 (en) | Method, computer and program for generating teacher images | |
| CN112232346B (en) | Semantic segmentation model training method and device, and image semantic segmentation method and device | |
| US20190294661A1 (en) | Performing semantic segmentation of form images using deep learning | |
| WO2023050651A1 (en) | Semantic image segmentation method and apparatus, and device and storage medium | |
| JP6182242B1 (en) | Machine learning method, computer and program related to data labeling model | |
| JP6511986B2 (en) | PROGRAM GENERATION DEVICE, PROGRAM GENERATION METHOD, AND GENERATION PROGRAM | |
| WO2019026104A1 (en) | Information processing device, information processing program, and information processing method | |
| CN112396085B (en) | Method and device for recognizing image | |
| CN113450822B (en) | Speech enhancement method, device, equipment and storage medium | |
| CN115830054B (en) | Crack image segmentation method based on multi-window high-low frequency visual transformer | |
| CN111783935A (en) | Convolutional neural network construction method, device, equipment and medium | |
| JP7563241B2 (en) | Neural network and training method thereof | |
| CN111460355A (en) | A kind of page parsing method and device | |
| CN111079507A (en) | Behavior recognition method and device, computer device and readable storage medium | |
| JP7395960B2 (en) | Prediction model explanation method, prediction model explanation program, prediction model explanation device | |
| CN113055546B (en) | System and method for processing images | |
| US20210042550A1 (en) | Information processing device, information processing method, and computer-readable recording medium recording information processing program | |
| WO2024045319A1 (en) | Face image clustering method and apparatus, electronic device, and storage medium | |
| CN115631112A (en) | Building contour correction method and device based on deep learning | |
| CN114399639A (en) | Semantic segmentation model training method, electronic equipment and storage medium | |
| US11288534B2 (en) | Apparatus and method for image processing for machine learning | |
| CN113902001A (en) | Model training method and device, electronic equipment and storage medium | |
| CN111314706B (en) | A video transcoding method and device | |
| US20230385633A1 (en) | Training data generation device and method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20180928 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20191029 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20191112 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20191121 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6622369 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |