JP2017535809A - サウンド検出モデルを生成するためのサウンドサンプル検証 - Google Patents
サウンド検出モデルを生成するためのサウンドサンプル検証 Download PDFInfo
- Publication number
- JP2017535809A JP2017535809A JP2017521507A JP2017521507A JP2017535809A JP 2017535809 A JP2017535809 A JP 2017535809A JP 2017521507 A JP2017521507 A JP 2017521507A JP 2017521507 A JP2017521507 A JP 2017521507A JP 2017535809 A JP2017535809 A JP 2017535809A
- Authority
- JP
- Japan
- Prior art keywords
- sound
- acoustic feature
- sound sample
- sample
- electronic device
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images








Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
- G10L2015/022—Demisyllables, biphones or triphones being the recognition units
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
- G10L2015/025—Phonemes, fenemes or fenones being the recognition units
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
- G10L2015/027—Syllables being the recognition units
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Telephone Function (AREA)
Abstract
【選択図】 図3
Description
[0097] 以下に、本開示のいくつかの態様がさらに記載される。
以下に本願の出願当初の特許請求の範囲に記載された発明を付記する。
[C1]
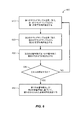
サウンド検出モデルを生成する際に使用される少なくとも1つのサウンドサンプルを検証するために、電子デバイスにおいて実行される方法であって、前記方法は、
第1のサウンドサンプルを受け取ることと、
前記第1のサウンドサンプルから第1の音響特徴を抽出することと、
第2のサウンドサンプルを受け取ることと、
前記第2のサウンドサンプルから第2の音響特徴を抽出することと、
前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定することと
を備える、方法。
[C2]
前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つに基づいて、前記サウンド検出モデルを生成することをさらに備える、C1に記載の方法。
[C3]
前記第1のサウンドサンプルの信号対雑音比(SNR)を決定することと、
前記第2のサウンドサンプルのSNRを決定することと、
前記第1および第2のサウンドサンプルの前記SNRに基づいて、前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つを選択することと、
前記第2の音響特徴が前記第1の音響特徴に類似することを決定すると、前記選択された少なくとも1つのサウンドサンプルに基づいて、前記サウンド検出モデルを生成することと、
選択されていないサウンドサンプルに基づいて、前記生成されたサウンド検出モデルを調整することと
をさらに備える、C1に記載の方法。
[C4]
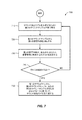
前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1の音響特徴および前記第2の音響特徴に基づいて、組み合わせられた音響特徴を決定することをさらに備える、C1に記載の方法。
[C5]
第3のサウンドサンプルを受け取ることと、
前記第3のサウンドサンプルから第3の音響特徴を抽出することと、
前記第3の音響特徴が前記組み合わせられた音響特徴に類似するかどうかを決定することと
をさらに備える、C4に記載の方法。
[C6]
前記第1の音響特徴および前記第2の音響特徴の各々は、スペクトル特徴または時間領域特徴のうちの少なくとも1つを含む、C1に記載の方法。
[C7]
前記第1の音響特徴および前記第2の音響特徴の各々は、サブワードのシーケンスを含む、C1に記載の方法。
[C8]
前記サブワードは、音、音素、トライフォン、または音節のうちの少なくとも1つを含む、C7に記載の方法。
[C9]
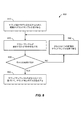
前記第2の音響特徴が前記第1の音響特徴に類似しないと決定することに応答して、新規のサウンドサンプルを受け取ることと、
前記新規のサウンドサンプルから新規の音響特徴を抽出することと、
前記新規の音響特徴が前記第1の音響特徴に類似するかどうかを決定することと
をさらに備える、C1に記載の方法。
[C10]
前記新規の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1のサウンドサンプルまたは前記新規のサウンドサンプルのうちの少なくとも1つに基づいて、前記サウンド検出モデルを生成することをさらに備える、C9に記載の方法。
[C11]
前記サウンド検出モデルを生成することは、
前記第1のサウンドサンプルまたは前記新規のサウンドサンプルのうちの少なくとも1つに基づいて、前記サウンド検出モデルの閾値を決定することと、
前記第2のサウンドサンプルに基づいて、前記閾値を調整することと
を備える、C10に記載の方法。
[C12]
前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定することに基づいて、前記第2のサウンドサンプルが前記第1のサウンドサンプルに類似するかどうかの指示を出力することと、
前記サウンド検出モデルを生成する際に使用される前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つを示す入力を受け取ることと
をさらに備える、C1に記載の方法。
[C13]
前記第1のサウンドサンプルおよび前記第2のサウンドサンプルの各々は、前記電子デバイスをアクティブ化するためのコマンド、あるいは前記電子デバイスにおけるアプリケーションまたは機能を制御するためのコマンドのうちの少なくとも1つを示す、C1に記載の方法。
[C14]
音声入力を受け取ることと、
前記サウンド検出モデルに基づいて、前記音声入力からキーワードまたはユーザのうちの少なくとも1つを認識することと
をさらに備える、C2に記載の方法。
[C15]
サウンド検出モデルを生成する際に使用される少なくとも1つのサウンドサンプルを検証するための電子デバイスであって、
第1のサウンドサンプルおよび第2のサウンドサンプルを受け取るように構成されたサウンドセンサと、
前記第1のサウンドサンプルから第1の音響特徴を抽出し、前記第2のサウンドサンプルから第2の音響特徴を抽出し、前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定するように構成されたサウンドサンプル検証ユニットと
を備える、電子デバイス。
[C16]
前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つに基づいて、前記サウンド検出モデルを生成するように構成されたサウンド検出モデル生成ユニットをさらに備える、C15に記載の電子デバイス。
[C17]
前記サウンドサンプル検証ユニットは、前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1の音響特徴および前記第2の音響特徴に基づいて、組み合わせられた音響特徴を決定するように構成される、C15に記載の電子デバイス。
[C18]
前記サウンドセンサは、第3のサウンドサンプルを受け取るように構成され、
前記サウンドサンプル検証ユニットは、前記第3のサウンドサンプルから第3の音響特徴を抽出し、前記第3の音響特徴が前記組み合わせられた音響特徴に類似するかどうかを決定するように構成される、
C17に記載の電子デバイス。
[C19]
前記サウンドセンサは、前記第2の音響特徴が前記第1の音響特徴に類似しないと決定することに応答して、新規のサウンドサンプルを受け取るように構成され、
前記サウンドサンプル検証ユニットは、前記新規のサウンドサンプルから新規の音響特徴を抽出し、前記新規の音響特徴が前記第1の音響特徴に類似するかどうかを決定するように構成される、
C15に記載の電子デバイス。
[C20]
前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定することに基づいて、前記第2のサウンドサンプルが前記第1のサウンドサンプルに類似するかどうかの指示を出力するように構成された出力ユニットと、
前記サウンド検出モデルを生成する際に使用される前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つを示す入力を受け取るための入力ユニットと
をさらに備える、C15に記載の電子デバイス。
[C21]
命令を備える非一時的コンピュータ可読記憶媒体であって、前記命令は、電子デバイスの少なくとも1つのプロセッサに、
第1のサウンドサンプルを受け取り、
前記第1のサウンドサンプルから第1の音響特徴を抽出し、
第2のサウンドサンプルを受け取り、
前記第2のサウンドサンプルから第2の音響特徴を抽出し、
前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定する
動作を実行させる、非一時的コンピュータ可読記憶媒体。
[C22]
前記電子デバイスの前記少なくとも1つのプロセッサに、前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つに基づいて、サウンド検出モデルを生成する動作を実行させる命令をさらに備える、C21に記載の非一時的コンピュータ可読記憶媒体。
[C23]
前記電子デバイスの前記少なくとも1つのプロセッサに、前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1の音響特徴および前記第2の音響特徴に基づいて、組み合わせられた音響特徴を決定する動作を実行させる命令をさらに備える、C21に記載の非一時的コンピュータ可読記憶媒体。
[C24]
前記電子デバイスの前記少なくとも1つのプロセッサに、
第3のサウンドサンプルを受け取り、
前記第3のサウンドサンプルから第3の音響特徴を抽出し、
前記第3の音響特徴が前記組み合わせられた音響特徴に類似するかどうかを決定する
動作を実行させる命令をさらに備える、C23に記載の非一時的コンピュータ可読記憶媒体。
[C25]
前記電子デバイスの前記少なくとも1つのプロセッサに、
前記第2の音響特徴が前記第1の音響特徴に類似しないと決定することに応答して、新規のサウンドサンプルを受け取り、
前記新規のサウンドサンプルから新規の音響特徴を抽出し、
前記新規の音響特徴が前記第1の音響特徴に類似するかどうかを決定する
動作を実行させる命令をさらに備える、C21に記載の非一時的コンピュータ可読記憶媒体。
[C26]
サウンド検出モデルを生成する際に使用される少なくとも1つのサウンドサンプルを検証するための電子デバイスであって、
第1のサウンドサンプルを受け取るための手段と、
前記第1のサウンドサンプルから第1の音響特徴を抽出するための手段と、
第2のサウンドサンプルを受け取るための手段と、
前記第2のサウンドサンプルから第2の音響特徴を抽出するための手段と、
前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定するための手段と
を備える、電子デバイス。
[C27]
前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つに基づいて、前記サウンド検出モデルを生成するための手段をさらに備える、C26に記載の電子デバイス。
[C28]
前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1の音響特徴および前記第2の音響特徴に基づいて、組み合わせられた音響特徴を決定するための手段をさらに備える、C26に記載の電子デバイス。
[C29]
第3のサウンドサンプルを受け取るための手段と、
前記第3のサウンドサンプルから第3の音響特徴を抽出するための手段と、
前記第3の音響特徴が前記組み合わせられた音響特徴に類似するかどうかを決定するための手段と
をさらに備える、C28に記載の電子デバイス。
[C30]
前記第2の音響特徴が前記第1の音響特徴に類似しないと決定することに応答して、新規のサウンドサンプルを受け取るための手段と、
前記新規のサウンドサンプルから新規の音響特徴を抽出するための手段と、
前記新規の音響特徴が前記第1の音響特徴に類似するかどうかを決定するための手段と
をさらに備える、C26に記載の電子デバイス。
Claims (30)
- サウンド検出モデルを生成する際に使用される少なくとも1つのサウンドサンプルを検証するために、電子デバイスにおいて実行される方法であって、前記方法は、
第1のサウンドサンプルを受け取ることと、
前記第1のサウンドサンプルから第1の音響特徴を抽出することと、
第2のサウンドサンプルを受け取ることと、
前記第2のサウンドサンプルから第2の音響特徴を抽出することと、
前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定することと
を備える、方法。 - 前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つに基づいて、前記サウンド検出モデルを生成することをさらに備える、請求項1に記載の方法。
- 前記第1のサウンドサンプルの信号対雑音比(SNR)を決定することと、
前記第2のサウンドサンプルのSNRを決定することと、
前記第1および第2のサウンドサンプルの前記SNRに基づいて、前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つを選択することと、
前記第2の音響特徴が前記第1の音響特徴に類似することを決定すると、前記選択された少なくとも1つのサウンドサンプルに基づいて、前記サウンド検出モデルを生成することと、
選択されていないサウンドサンプルに基づいて、前記生成されたサウンド検出モデルを調整することと
をさらに備える、請求項1に記載の方法。 - 前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1の音響特徴および前記第2の音響特徴に基づいて、組み合わせられた音響特徴を決定することをさらに備える、請求項1に記載の方法。
- 第3のサウンドサンプルを受け取ることと、
前記第3のサウンドサンプルから第3の音響特徴を抽出することと、
前記第3の音響特徴が前記組み合わせられた音響特徴に類似するかどうかを決定することと
をさらに備える、請求項4に記載の方法。 - 前記第1の音響特徴および前記第2の音響特徴の各々は、スペクトル特徴または時間領域特徴のうちの少なくとも1つを含む、請求項1に記載の方法。
- 前記第1の音響特徴および前記第2の音響特徴の各々は、サブワードのシーケンスを含む、請求項1に記載の方法。
- 前記サブワードは、音、音素、トライフォン、または音節のうちの少なくとも1つを含む、請求項7に記載の方法。
- 前記第2の音響特徴が前記第1の音響特徴に類似しないと決定することに応答して、新規のサウンドサンプルを受け取ることと、
前記新規のサウンドサンプルから新規の音響特徴を抽出することと、
前記新規の音響特徴が前記第1の音響特徴に類似するかどうかを決定することと
をさらに備える、請求項1に記載の方法。 - 前記新規の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1のサウンドサンプルまたは前記新規のサウンドサンプルのうちの少なくとも1つに基づいて、前記サウンド検出モデルを生成することをさらに備える、請求項9に記載の方法。
- 前記サウンド検出モデルを生成することは、
前記第1のサウンドサンプルまたは前記新規のサウンドサンプルのうちの少なくとも1つに基づいて、前記サウンド検出モデルの閾値を決定することと、
前記第2のサウンドサンプルに基づいて、前記閾値を調整することと
を備える、請求項10に記載の方法。 - 前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定することに基づいて、前記第2のサウンドサンプルが前記第1のサウンドサンプルに類似するかどうかの指示を出力することと、
前記サウンド検出モデルを生成する際に使用される前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つを示す入力を受け取ることと
をさらに備える、請求項1に記載の方法。 - 前記第1のサウンドサンプルおよび前記第2のサウンドサンプルの各々は、前記電子デバイスをアクティブ化するためのコマンド、あるいは前記電子デバイスにおけるアプリケーションまたは機能を制御するためのコマンドのうちの少なくとも1つを示す、請求項1に記載の方法。
- 音声入力を受け取ることと、
前記サウンド検出モデルに基づいて、前記音声入力からキーワードまたはユーザのうちの少なくとも1つを認識することと
をさらに備える、請求項2に記載の方法。 - サウンド検出モデルを生成する際に使用される少なくとも1つのサウンドサンプルを検証するための電子デバイスであって、
第1のサウンドサンプルおよび第2のサウンドサンプルを受け取るように構成されたサウンドセンサと、
前記第1のサウンドサンプルから第1の音響特徴を抽出し、前記第2のサウンドサンプルから第2の音響特徴を抽出し、前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定するように構成されたサウンドサンプル検証ユニットと
を備える、電子デバイス。 - 前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つに基づいて、前記サウンド検出モデルを生成するように構成されたサウンド検出モデル生成ユニットをさらに備える、請求項15に記載の電子デバイス。
- 前記サウンドサンプル検証ユニットは、前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1の音響特徴および前記第2の音響特徴に基づいて、組み合わせられた音響特徴を決定するように構成される、請求項15に記載の電子デバイス。
- 前記サウンドセンサは、第3のサウンドサンプルを受け取るように構成され、
前記サウンドサンプル検証ユニットは、前記第3のサウンドサンプルから第3の音響特徴を抽出し、前記第3の音響特徴が前記組み合わせられた音響特徴に類似するかどうかを決定するように構成される、
請求項17に記載の電子デバイス。 - 前記サウンドセンサは、前記第2の音響特徴が前記第1の音響特徴に類似しないと決定することに応答して、新規のサウンドサンプルを受け取るように構成され、
前記サウンドサンプル検証ユニットは、前記新規のサウンドサンプルから新規の音響特徴を抽出し、前記新規の音響特徴が前記第1の音響特徴に類似するかどうかを決定するように構成される、
請求項15に記載の電子デバイス。 - 前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定することに基づいて、前記第2のサウンドサンプルが前記第1のサウンドサンプルに類似するかどうかの指示を出力するように構成された出力ユニットと、
前記サウンド検出モデルを生成する際に使用される前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つを示す入力を受け取るための入力ユニットと
をさらに備える、請求項15に記載の電子デバイス。 - 命令を備える非一時的コンピュータ可読記憶媒体であって、前記命令は、電子デバイスの少なくとも1つのプロセッサに、
第1のサウンドサンプルを受け取り、
前記第1のサウンドサンプルから第1の音響特徴を抽出し、
第2のサウンドサンプルを受け取り、
前記第2のサウンドサンプルから第2の音響特徴を抽出し、
前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定する
動作を実行させる、非一時的コンピュータ可読記憶媒体。 - 前記電子デバイスの前記少なくとも1つのプロセッサに、前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つに基づいて、サウンド検出モデルを生成する動作を実行させる命令をさらに備える、請求項21に記載の非一時的コンピュータ可読記憶媒体。
- 前記電子デバイスの前記少なくとも1つのプロセッサに、前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1の音響特徴および前記第2の音響特徴に基づいて、組み合わせられた音響特徴を決定する動作を実行させる命令をさらに備える、請求項21に記載の非一時的コンピュータ可読記憶媒体。
- 前記電子デバイスの前記少なくとも1つのプロセッサに、
第3のサウンドサンプルを受け取り、
前記第3のサウンドサンプルから第3の音響特徴を抽出し、
前記第3の音響特徴が前記組み合わせられた音響特徴に類似するかどうかを決定する
動作を実行させる命令をさらに備える、請求項23に記載の非一時的コンピュータ可読記憶媒体。 - 前記電子デバイスの前記少なくとも1つのプロセッサに、
前記第2の音響特徴が前記第1の音響特徴に類似しないと決定することに応答して、新規のサウンドサンプルを受け取り、
前記新規のサウンドサンプルから新規の音響特徴を抽出し、
前記新規の音響特徴が前記第1の音響特徴に類似するかどうかを決定する
動作を実行させる命令をさらに備える、請求項21に記載の非一時的コンピュータ可読記憶媒体。 - サウンド検出モデルを生成する際に使用される少なくとも1つのサウンドサンプルを検証するための電子デバイスであって、
第1のサウンドサンプルを受け取るための手段と、
前記第1のサウンドサンプルから第1の音響特徴を抽出するための手段と、
第2のサウンドサンプルを受け取るための手段と、
前記第2のサウンドサンプルから第2の音響特徴を抽出するための手段と、
前記第2の音響特徴が前記第1の音響特徴に類似するかどうかを決定するための手段と
を備える、電子デバイス。 - 前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1のサウンドサンプルまたは前記第2のサウンドサンプルのうちの少なくとも1つに基づいて、前記サウンド検出モデルを生成するための手段をさらに備える、請求項26に記載の電子デバイス。
- 前記第2の音響特徴が前記第1の音響特徴に類似することを決定することに応答して、前記第1の音響特徴および前記第2の音響特徴に基づいて、組み合わせられた音響特徴を決定するための手段をさらに備える、請求項26に記載の電子デバイス。
- 第3のサウンドサンプルを受け取るための手段と、
前記第3のサウンドサンプルから第3の音響特徴を抽出するための手段と、
前記第3の音響特徴が前記組み合わせられた音響特徴に類似するかどうかを決定するための手段と
をさらに備える、請求項28に記載の電子デバイス。 - 前記第2の音響特徴が前記第1の音響特徴に類似しないと決定することに応答して、新規のサウンドサンプルを受け取るための手段と、
前記新規のサウンドサンプルから新規の音響特徴を抽出するための手段と、
前記新規の音響特徴が前記第1の音響特徴に類似するかどうかを決定するための手段と
をさらに備える、請求項26に記載の電子デバイス。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201462067322P | 2014-10-22 | 2014-10-22 | |
| US62/067,322 | 2014-10-22 | ||
| US14/682,009 US9837068B2 (en) | 2014-10-22 | 2015-04-08 | Sound sample verification for generating sound detection model |
| US14/682,009 | 2015-04-08 | ||
| PCT/US2015/053665 WO2016064556A1 (en) | 2014-10-22 | 2015-10-02 | Sound sample verification for generating sound detection model |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2017535809A true JP2017535809A (ja) | 2017-11-30 |
| JP2017535809A5 JP2017535809A5 (ja) | 2018-03-01 |
Family
ID=54291746
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017521507A Ceased JP2017535809A (ja) | 2014-10-22 | 2015-10-02 | サウンド検出モデルを生成するためのサウンドサンプル検証 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US9837068B2 (ja) |
| EP (1) | EP3210205B1 (ja) |
| JP (1) | JP2017535809A (ja) |
| CN (1) | CN106796785B (ja) |
| WO (1) | WO2016064556A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019176986A1 (ja) * | 2018-03-15 | 2019-09-19 | 日本電気株式会社 | 信号処理システム、信号処理装置、信号処理方法、および記録媒体 |
| JP2019219468A (ja) * | 2018-06-18 | 2019-12-26 | Zホールディングス株式会社 | 生成装置、生成方法及び生成プログラム |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9837068B2 (en) * | 2014-10-22 | 2017-12-05 | Qualcomm Incorporated | Sound sample verification for generating sound detection model |
| US10141010B1 (en) * | 2015-10-01 | 2018-11-27 | Google Llc | Automatic censoring of objectionable song lyrics in audio |
| CN105869637B (zh) * | 2016-05-26 | 2019-10-15 | 百度在线网络技术(北京)有限公司 | 语音唤醒方法和装置 |
| US10276161B2 (en) * | 2016-12-27 | 2019-04-30 | Google Llc | Contextual hotwords |
| US11250844B2 (en) * | 2017-04-12 | 2022-02-15 | Soundhound, Inc. | Managing agent engagement in a man-machine dialog |
| US10943573B2 (en) * | 2018-05-17 | 2021-03-09 | Mediatek Inc. | Audio output monitoring for failure detection of warning sound playback |
| US10249319B1 (en) * | 2017-10-26 | 2019-04-02 | The Nielsen Company (Us), Llc | Methods and apparatus to reduce noise from harmonic noise sources |
| KR102492727B1 (ko) * | 2017-12-04 | 2023-02-01 | 삼성전자주식회사 | 전자장치 및 그 제어방법 |
| CN108182937B (zh) * | 2018-01-17 | 2021-04-13 | 出门问问创新科技有限公司 | 关键词识别方法、装置、设备及存储介质 |
| CN108335694B (zh) * | 2018-02-01 | 2021-10-15 | 北京百度网讯科技有限公司 | 远场环境噪声处理方法、装置、设备和存储介质 |
| US10534515B2 (en) * | 2018-02-15 | 2020-01-14 | Wipro Limited | Method and system for domain-based rendering of avatars to a user |
| CN108847250B (zh) * | 2018-07-11 | 2020-10-02 | 会听声学科技(北京)有限公司 | 一种定向降噪方法、系统及耳机 |
| US11069334B2 (en) * | 2018-08-13 | 2021-07-20 | Carnegie Mellon University | System and method for acoustic activity recognition |
| CN109151702B (zh) * | 2018-09-21 | 2021-10-08 | 歌尔科技有限公司 | 音频设备的音效调节方法、音频设备及可读存储介质 |
| US11568731B2 (en) | 2019-07-15 | 2023-01-31 | Apple Inc. | Systems and methods for identifying an acoustic source based on observed sound |
| CN113450775A (zh) * | 2020-03-10 | 2021-09-28 | 富士通株式会社 | 模型训练装置、模型训练方法及存储介质 |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS584198A (ja) * | 1981-06-30 | 1983-01-11 | 株式会社日立製作所 | 音声認識装置における標準パタ−ン登録方式 |
| JPS62245295A (ja) * | 1986-04-18 | 1987-10-26 | 株式会社リコー | 特定話者音声認識装置 |
| JPH02210500A (ja) * | 1989-02-10 | 1990-08-21 | Ricoh Co Ltd | 標準パターン登録方式 |
| JPH0816186A (ja) * | 1994-06-27 | 1996-01-19 | Matsushita Electric Ind Co Ltd | 音声認識装置 |
| JPH09218696A (ja) * | 1996-02-14 | 1997-08-19 | Ricoh Co Ltd | 音声認識装置 |
| JPH10207483A (ja) * | 1997-01-16 | 1998-08-07 | Ricoh Co Ltd | 音声認識装置および標準パターン登録方法 |
| JP2004508593A (ja) * | 2000-09-01 | 2004-03-18 | スナップ − オン テクノロジーズ,インコーポレイテッド | コンピュータにより実現される音声認識システムトレーニング |
| JP2005196035A (ja) * | 2004-01-09 | 2005-07-21 | Nec Corp | 話者照合方法、話者照合用プログラム、及び話者照合システム |
| WO2007111197A1 (ja) * | 2006-03-24 | 2007-10-04 | Pioneer Corporation | 話者認識システムにおける話者モデル登録装置及び方法、並びにコンピュータプログラム |
| WO2010086925A1 (ja) * | 2009-01-30 | 2010-08-05 | 三菱電機株式会社 | 音声認識装置 |
Family Cites Families (32)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4994983A (en) * | 1989-05-02 | 1991-02-19 | Itt Corporation | Automatic speech recognition system using seed templates |
| US6134527A (en) * | 1998-01-30 | 2000-10-17 | Motorola, Inc. | Method of testing a vocabulary word being enrolled in a speech recognition system |
| US20040190688A1 (en) | 2003-03-31 | 2004-09-30 | Timmins Timothy A. | Communications methods and systems using voiceprints |
| US6879954B2 (en) * | 2002-04-22 | 2005-04-12 | Matsushita Electric Industrial Co., Ltd. | Pattern matching for large vocabulary speech recognition systems |
| US7013272B2 (en) | 2002-08-14 | 2006-03-14 | Motorola, Inc. | Amplitude masking of spectra for speech recognition method and apparatus |
| CN1547191A (zh) * | 2003-12-12 | 2004-11-17 | 北京大学 | 结合语义和声纹信息的说话人身份确认系统 |
| JP3955880B2 (ja) * | 2004-11-30 | 2007-08-08 | 松下電器産業株式会社 | 音声認識装置 |
| US20060215821A1 (en) | 2005-03-23 | 2006-09-28 | Rokusek Daniel S | Voice nametag audio feedback for dialing a telephone call |
| CN101154380B (zh) * | 2006-09-29 | 2011-01-26 | 株式会社东芝 | 说话人认证的注册及验证的方法和装置 |
| CN101465123B (zh) * | 2007-12-20 | 2011-07-06 | 株式会社东芝 | 说话人认证的验证方法和装置以及说话人认证系统 |
| US8983832B2 (en) * | 2008-07-03 | 2015-03-17 | The Board Of Trustees Of The University Of Illinois | Systems and methods for identifying speech sound features |
| US9253560B2 (en) * | 2008-09-16 | 2016-02-02 | Personics Holdings, Llc | Sound library and method |
| CN101714355A (zh) * | 2008-10-06 | 2010-05-26 | 宏达国际电子股份有限公司 | 语音辨识功能启动系统及方法 |
| US8635237B2 (en) * | 2009-07-02 | 2014-01-21 | Nuance Communications, Inc. | Customer feedback measurement in public places utilizing speech recognition technology |
| US20110004474A1 (en) * | 2009-07-02 | 2011-01-06 | International Business Machines Corporation | Audience Measurement System Utilizing Voice Recognition Technology |
| US20110320201A1 (en) * | 2010-06-24 | 2011-12-29 | Kaufman John D | Sound verification system using templates |
| US8802957B2 (en) * | 2010-08-16 | 2014-08-12 | Boardwalk Technology Group, Llc | Mobile replacement-dialogue recording system |
| CN102404287A (zh) * | 2010-09-14 | 2012-04-04 | 盛乐信息技术(上海)有限公司 | 用数据复用法确定声纹认证阈值的声纹认证系统及方法 |
| US9262612B2 (en) * | 2011-03-21 | 2016-02-16 | Apple Inc. | Device access using voice authentication |
| CN102237089B (zh) * | 2011-08-15 | 2012-11-14 | 哈尔滨工业大学 | 一种减少文本无关说话人识别系统误识率的方法 |
| US8290772B1 (en) * | 2011-10-03 | 2012-10-16 | Google Inc. | Interactive text editing |
| US9042867B2 (en) | 2012-02-24 | 2015-05-26 | Agnitio S.L. | System and method for speaker recognition on mobile devices |
| JPWO2013179464A1 (ja) * | 2012-05-31 | 2016-01-14 | トヨタ自動車株式会社 | 音源検出装置、ノイズモデル生成装置、ノイズ抑圧装置、音源方位推定装置、接近車両検出装置及びノイズ抑圧方法 |
| CN103680497B (zh) * | 2012-08-31 | 2017-03-15 | 百度在线网络技术(北京)有限公司 | 基于视频的语音识别系统及方法 |
| CN103685185B (zh) * | 2012-09-14 | 2018-04-27 | 上海果壳电子有限公司 | 移动设备声纹注册、认证的方法及系统 |
| CN103841248A (zh) * | 2012-11-20 | 2014-06-04 | 联想(北京)有限公司 | 一种信息处理的方法及电子设备 |
| CN106981290B (zh) * | 2012-11-27 | 2020-06-30 | 威盛电子股份有限公司 | 语音控制装置和语音控制方法 |
| CN103971689B (zh) * | 2013-02-04 | 2016-01-27 | 腾讯科技(深圳)有限公司 | 一种音频识别方法及装置 |
| US9865266B2 (en) | 2013-02-25 | 2018-01-09 | Nuance Communications, Inc. | Method and apparatus for automated speaker parameters adaptation in a deployed speaker verification system |
| US9785706B2 (en) * | 2013-08-28 | 2017-10-10 | Texas Instruments Incorporated | Acoustic sound signature detection based on sparse features |
| WO2015156775A1 (en) * | 2014-04-08 | 2015-10-15 | Empire Technology Development Llc | Sound verification |
| US9837068B2 (en) * | 2014-10-22 | 2017-12-05 | Qualcomm Incorporated | Sound sample verification for generating sound detection model |
-
2015
- 2015-04-08 US US14/682,009 patent/US9837068B2/en active Active
- 2015-10-02 JP JP2017521507A patent/JP2017535809A/ja not_active Ceased
- 2015-10-02 EP EP15778583.3A patent/EP3210205B1/en active Active
- 2015-10-02 CN CN201580054925.7A patent/CN106796785B/zh active Active
- 2015-10-02 WO PCT/US2015/053665 patent/WO2016064556A1/en not_active Ceased
Patent Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS584198A (ja) * | 1981-06-30 | 1983-01-11 | 株式会社日立製作所 | 音声認識装置における標準パタ−ン登録方式 |
| JPS62245295A (ja) * | 1986-04-18 | 1987-10-26 | 株式会社リコー | 特定話者音声認識装置 |
| JPH02210500A (ja) * | 1989-02-10 | 1990-08-21 | Ricoh Co Ltd | 標準パターン登録方式 |
| JPH0816186A (ja) * | 1994-06-27 | 1996-01-19 | Matsushita Electric Ind Co Ltd | 音声認識装置 |
| JPH09218696A (ja) * | 1996-02-14 | 1997-08-19 | Ricoh Co Ltd | 音声認識装置 |
| JPH10207483A (ja) * | 1997-01-16 | 1998-08-07 | Ricoh Co Ltd | 音声認識装置および標準パターン登録方法 |
| JP2004508593A (ja) * | 2000-09-01 | 2004-03-18 | スナップ − オン テクノロジーズ,インコーポレイテッド | コンピュータにより実現される音声認識システムトレーニング |
| JP2005196035A (ja) * | 2004-01-09 | 2005-07-21 | Nec Corp | 話者照合方法、話者照合用プログラム、及び話者照合システム |
| WO2007111197A1 (ja) * | 2006-03-24 | 2007-10-04 | Pioneer Corporation | 話者認識システムにおける話者モデル登録装置及び方法、並びにコンピュータプログラム |
| WO2010086925A1 (ja) * | 2009-01-30 | 2010-08-05 | 三菱電機株式会社 | 音声認識装置 |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019176986A1 (ja) * | 2018-03-15 | 2019-09-19 | 日本電気株式会社 | 信号処理システム、信号処理装置、信号処理方法、および記録媒体 |
| JPWO2019176986A1 (ja) * | 2018-03-15 | 2021-02-04 | 日本電気株式会社 | 信号処理システム、信号処理装置、信号処理方法、およびプログラム |
| US11842741B2 (en) | 2018-03-15 | 2023-12-12 | Nec Corporation | Signal processing system, signal processing device, signal processing method, and recording medium |
| JP2019219468A (ja) * | 2018-06-18 | 2019-12-26 | Zホールディングス株式会社 | 生成装置、生成方法及び生成プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3210205B1 (en) | 2020-05-27 |
| US9837068B2 (en) | 2017-12-05 |
| CN106796785A (zh) | 2017-05-31 |
| EP3210205A1 (en) | 2017-08-30 |
| US20160118039A1 (en) | 2016-04-28 |
| CN106796785B (zh) | 2021-05-25 |
| WO2016064556A1 (en) | 2016-04-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN106796785B (zh) | 用于产生声音检测模型的声音样本验证 | |
| CN106233374B (zh) | 用于检测用户定义的关键字的关键字模型生成 | |
| US10381004B2 (en) | Display apparatus and method for registration of user command | |
| CN106663430B (zh) | 使用用户指定关键词的说话者不相依关键词模型的关键词检测 | |
| EP2994911B1 (en) | Adaptive audio frame processing for keyword detection | |
| US20150302856A1 (en) | Method and apparatus for performing function by speech input | |
| KR102628211B1 (ko) | 전자 장치 및 그 제어 방법 | |
| CN105874732B (zh) | 用于识别音频流中的一首音乐的方法和装置 | |
| CN106233376A (zh) | 用于通过话音输入激活应用程序的方法和设备 | |
| KR102836970B1 (ko) | 전자 장치 및 이의 제어 방법 | |
| CN103035240A (zh) | 用于使用上下文信息的语音识别修复的方法和系统 | |
| CN105027574A (zh) | 在语音识别系统中控制显示装置的显示装置和方法 | |
| CN104123938A (zh) | 语音控制系统、电子装置及语音控制方法 | |
| WO2018047421A1 (ja) | 音声処理装置、情報処理装置、音声処理方法および情報処理方法 | |
| CN107977187B (zh) | 一种混响调节方法及电子设备 | |
| CN112863496B (zh) | 一种语音端点检测方法以及装置 | |
| KR102890420B1 (ko) | 사용자 명령어 등록을 위한 디스플레이 장치 및 방법 | |
| JP6571587B2 (ja) | 音声入力装置、その方法、及びプログラム | |
| CN120019356A (zh) | 基于语音的用户认证 | |
| JPWO2018043139A1 (ja) | 情報処理装置および情報処理方法、並びにプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170704 Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170705 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180118 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20180118 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20180118 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20180126 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20180206 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20180507 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20180717 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20181017 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20181218 |
|
| A045 | Written measure of dismissal of application [lapsed due to lack of payment] |
Free format text: JAPANESE INTERMEDIATE CODE: A045 Effective date: 20190507 |