JP2017194806A - Character recognition device, method and program - Google Patents
Character recognition device, method and program Download PDFInfo
- Publication number
- JP2017194806A JP2017194806A JP2016084081A JP2016084081A JP2017194806A JP 2017194806 A JP2017194806 A JP 2017194806A JP 2016084081 A JP2016084081 A JP 2016084081A JP 2016084081 A JP2016084081 A JP 2016084081A JP 2017194806 A JP2017194806 A JP 2017194806A
- Authority
- JP
- Japan
- Prior art keywords
- text
- likelihood
- output
- image recognition
- candidates
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images



Abstract
Description
本発明は、画像データの文字認識を行う文字認識装置、方法およびプログラムに関する。 The present invention relates to a character recognition apparatus, method, and program for character recognition of image data.
手書きで文字が記入された書類をイメージスキャナなどで読み取り、OCR(Optical Character Recognition)処理を行うことにより、入力情報を所定の文字コードに変換したデジタルデータを生成する技術が普及している。 2. Description of the Related Art A technique for generating digital data in which input information is converted into a predetermined character code by reading a handwritten document with an image scanner or the like and performing OCR (Optical Character Recognition) processing has become widespread.
例えば、特許文献1によれば、機械学習により文字認識を行う文字識別システムが開示されている。文字認識システムは、見本文字画像の入力を受け付ける文字画像入力受付部と、見本文字画像に基づいて文字部品を抽出する文字部品抽出と、文字部品に基づいて擬似文字モデルを生成する擬似文字モデル生成部と、擬似文字モデルに基づいて文字識別パターンを生成して識別辞書を生成する識別辞書生成と、により構成されている。
For example, according to
また、特許文献2によれば、文字認識後に形態素解析をして、品詞尤度と文字類似度の両方が含まれる特徴量ベクトルを用いて、尤もらしさを判定する情報処理装置が開示されている。情報処理装置は、文字認識結果に対して形態素解析を行う形態素解析手段と、文字認識結果の文字について、形態素解析手段による形態素解析結果である対象の文字が属する単語の品詞らしさから作成するP種の品詞それぞれの品詞尤度と、該文字認識結果の各文字の文字類似度によって構成されるP+1個の要素の特徴量ベクトルを作成する特徴量ベクトル作成手段と、特徴量ベクトル作成手段によって作成された特徴量ベクトルから、文字認識結果の各文字の確信度を算出する確信度算出手段とにより構成されている。 Patent Document 2 discloses an information processing apparatus that performs morphological analysis after character recognition and determines likelihood using a feature vector that includes both part-of-speech likelihood and character similarity. . The information processing apparatus includes: a morpheme analysis unit that performs morpheme analysis on a character recognition result; and a P type that is created based on a part of speech quality of a word to which a target character that is a morpheme analysis result by the morpheme analysis unit belongs A feature quantity vector creating means for creating a feature quantity vector of P + 1 elements composed of the part of speech likelihood of each part of speech and the character similarity of each character of the character recognition result, and a feature quantity vector creating means. The certainty factor calculating means for calculating the certainty factor of each character of the character recognition result from the feature amount vector.
上述した特許文献1,2によっても、様々な手書き文字(例えば、達筆な手書き文字や薄くて雑な手書き文字など)の認識を高精度に行うことは困難であり、さらに高精度に文字認識を行いたい要望がある。
According to
本発明では、様々な手書き文字が含まれている書類について、高精度に文字認識を行うことができる文字認識装置、方法およびプログラムを提供することを目的とする。 An object of the present invention is to provide a character recognition device, method, and program capable of performing character recognition with high accuracy on a document containing various handwritten characters.
上記目的を達成するために、本発明の一態様における文字認識装置は、多層のニューラルネットワークを用いて画像データから特徴点を抽出し、複数のテキスト候補と尤度を出力する第1画像認識部と、多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、前記テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する第2画像認識部と、前記第2画像認識部により出力されたテキスト候補に対して、隣接する素因子テキストの接合および切り離しを行って、組み合わせられる複数のパターンのテキストに形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する自然言語処理部と、前記第1画像認識部により出力されたテキスト候補と、前記自然言語処理部により出力されたテキスト候補とを対比する判断部とを備え、前記判断部は、所定以上の尤度のテキストを出力する。 In order to achieve the above object, a character recognition device according to an aspect of the present invention extracts a feature point from image data using a multilayer neural network, and outputs a plurality of text candidates and likelihoods. Extracting a feature point from the image data using a multi-layer neural network, and outputting a text candidate separated into a prime factor text that is a factor smaller than the text and a likelihood; and For the text candidates output by the second image recognizing unit, adjacent prime factor texts are joined and separated, morpheme analysis is performed on the texts of a plurality of patterns to be combined, and a plurality that is likely from a natural language viewpoint. A natural language processing unit for outputting a text candidate and likelihood, a text candidate output by the first image recognition unit, and the natural candidate And a determining section for comparing the text candidate output by the word processor, the determining unit outputs the text of a predetermined or more likelihoods.
また、本発明の一態様における文字認識装置では、前記第1画像認識部により出力された最も尤度の高いテキスト候補と、前記自然言語処理部により出力された最も尤度の高いテキスト候補とを対比し、所定以上の尤もらしさを得られなかった場合、所定以上の尤もらしさが得られるまで、尤度の高い順に他の候補同士の対比を行う構成でもよい。 In the character recognition device according to the aspect of the present invention, the most likely text candidate output by the first image recognition unit and the most likely text candidate output by the natural language processing unit In contrast, if a likelihood greater than or equal to a predetermined value is not obtained, another candidate may be compared in order of the likelihood until a likelihood greater than or equal to a predetermined value is obtained.
また、本発明の一態様における文字認識装置では、前記判断部は、前記自然言語処理部により出力されたテキスト候補の中で尤度の高いテキスト候補を、前記第1画像認識部により出力されたテキスト候補よりも優先的に扱う構成でもよい。 In the character recognition device according to an aspect of the present invention, the determination unit outputs a text candidate having a high likelihood among the text candidates output by the natural language processing unit, by the first image recognition unit. It may be configured to handle with priority over text candidates.
また、本発明の一態様における文字認識装置では、前記判断部は、対比した結果、2つのテキスト候補の差分が所定の閾値を超えない場合に、所定以上の尤度のテキストであると判断して出力する構成でもよい。 In the character recognition device according to an aspect of the present invention, the determination unit determines that the text has a likelihood greater than or equal to a predetermined value when the difference between the two text candidates does not exceed a predetermined threshold as a result of the comparison. May be configured to output.
また、本発明の一態様における文字認識装置では、処理にかかる時間を設定する設定部を備え、前記判断部は、前記第1画像認識部により出力された最も尤度の高いテキスト候補と、前記自然言語処理部により出力された最も尤度の高いテキスト候補とを対比し、所定以上の尤もらしさを得られなかった場合、前記設定部によって設定された時間以内において、所定以上の尤もらしさが得られるまで、尤度の高い順に他の候補同士の対比を行う構成でもよい。 In the character recognition device according to an aspect of the present invention, the character recognition device further includes a setting unit that sets a time required for the processing, and the determination unit includes the most likely text candidate output by the first image recognition unit, When the most likely text candidate output by the natural language processing unit is compared and a likelihood greater than or equal to a predetermined value is not obtained, a likelihood greater than or equal to a predetermined value is obtained within the time set by the setting unit. Until it is determined, another candidate may be compared in descending order of likelihood.
また、本発明の一態様における文字認識装置では、前記判断部は、所定以上の尤もらしさが得られなかったテキストを伏字にして出力する構成でもよい。 In the character recognition device according to an aspect of the present invention, the determination unit may be configured to output text in which the likelihood that the predetermined or higher likelihood is not obtained is converted to a buff.
また、本発明の一態様における文字認識装置では、前記第1画像認識部は、項目ごとに適した多層のニューラルネットワークを機械学習により有しており、前記画像データに含まれる項目を探索し、当該項目に適した多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、複数のテキスト候補と尤度を出力し、前記第2画像認識部は、項目ごとに適した多層のニューラルネットワークを機械学習により有しており、前記画像データに含まれる項目を探索し、当該項目に適した多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、前記テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する構成でもよい。 In the character recognition device according to an aspect of the present invention, the first image recognition unit has a multilayer neural network suitable for each item by machine learning, searches for an item included in the image data, A feature point is extracted from the image data using a multi-layer neural network suitable for the item, a plurality of text candidates and likelihoods are output, and the second image recognition unit is a multi-layer neural network suitable for each item. Is a factor that is smaller than the text by searching for an item included in the image data, extracting a feature point from the image data using a multilayer neural network suitable for the item A configuration may be adopted in which text candidates and likelihoods separated into prime factor texts are output.
上記目的を達成するために、本発明の一態様における文字認識方法は、多層のニューラルネットワークを用いて画像データから特徴点を抽出し、複数のテキスト候補と尤度を出力する第1画像認識工程と、多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、前記テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する第2画像認識工程と、前記第2画像認識工程により出力されたテキスト候補に対して、隣接する素因子テキストの接合および切り離しを行って、組み合わせられる複数のパターンのテキストに形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する自然言語処理工程と、前記第1画像認識工程により出力されたテキスト候補と、前記自然言語処理工程により出力されたテキスト候補とを対比する判断工程とを備え、前記判断工程は、所定以上の尤度のテキストを出力する。 To achieve the above object, a character recognition method according to an aspect of the present invention includes a first image recognition step of extracting feature points from image data using a multilayer neural network and outputting a plurality of text candidates and likelihoods. Extracting a feature point from the image data using a multi-layer neural network, and outputting a text candidate and likelihood separated into a prime factor text that is a factor smaller than the text; and For the text candidates output by the second image recognition process, adjacent prime factor texts are joined and separated, morpheme analysis is performed on a plurality of patterns of text to be combined, and a plurality that is likely from a natural language viewpoint. A natural language processing step for outputting a text candidate and likelihood, and a text candidate output by the first image recognition step; And a determination step of comparing the text candidate outputted by the natural language processing steps, said determining step outputs a text of a predetermined or more likelihoods.
上記目的を達成するために、本発明の一態様における文字認識プログラムは、多層のニューラルネットワークを用いて画像データから特徴点を抽出し、複数のテキスト候補と尤度を出力する第1画像認識工程と、多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、前記テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する第2画像認識工程と、前記第2画像認識工程により出力されたテキスト候補に対して、隣接する素因子テキストの接合および切り離しを行って、組み合わせられる複数のパターンのテキストに形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する自然言語処理工程と、前記第1画像認識工程により出力されたテキスト候補と、前記自然言語処理工程により出力されたテキスト候補とを対比する判断工程と、をコンピュータによって実現するための文字認識プログラムであって、前記判断工程は、所定以上の尤度のテキストを出力する文字認識プログラムである。 To achieve the above object, a character recognition program according to one aspect of the present invention extracts a feature point from image data using a multilayer neural network, and outputs a plurality of text candidates and likelihoods. Extracting a feature point from the image data using a multi-layer neural network, and outputting a text candidate and likelihood separated into a prime factor text that is a factor smaller than the text; and For the text candidates output by the second image recognition process, adjacent prime factor texts are joined and separated, morpheme analysis is performed on a plurality of patterns of text to be combined, and a plurality that is likely from a natural language viewpoint. A natural language processing step for outputting a text candidate and likelihood and a text output by the first image recognition step A character recognition program for realizing, by a computer, a determination step for comparing a complement and a text candidate output by the natural language processing step, wherein the determination step outputs a text having a predetermined likelihood or more It is a character recognition program.
本発明によれば、高精度に文字認識を行うことができる。 According to the present invention, character recognition can be performed with high accuracy.
以下、本発明の実施形態に係る文字認識装置、方法およびプログラムについて図面を参照しながら説明する。なお、実施形態を説明する全図において、共通の構成要素には同一の符号を付し、繰り返しの説明を省略する。 Hereinafter, a character recognition device, method, and program according to embodiments of the present invention will be described with reference to the drawings. In all the drawings for explaining the embodiments, common constituent elements are denoted by the same reference numerals, and repeated explanation is omitted.
以下では、一例として、手書き文字が含まれた帳票やアンケート用紙などの書類をスキャナ等で画像化し、画像化した画像データの文字を認識する文字認識装置の構成と動作について説明する。なお、手書き文字が含まれていない書類、いわゆる、書体データを利用してプリンタによって文字が印刷された書類であっても、印刷されている文字が掠れていたり、または、滲んでいたりすると、文字の認識率が低下する。本実施形態にかかる文字認識装置はこのような書類をスキャナ等で画像化し、画像化した画像データの文字の認識に適用されてもよい。 In the following, as an example, the configuration and operation of a character recognition apparatus that recognizes characters in imaged image data by imaging a document such as a form or a questionnaire sheet containing handwritten characters with a scanner or the like will be described. Even if a document does not contain handwritten characters, that is, a document in which characters are printed using a typeface data, if the printed characters are blurred or blurred, the characters The recognition rate decreases. The character recognition apparatus according to the present embodiment may be applied to the recognition of characters of image data obtained by imaging such a document with a scanner or the like.
文字認識装置1は、概念的には、バックプロパゲーション(誤差逆伝播法)によって、入力層、一または複数の中間層、および出力層から構成される多層のニューラルネットワークを学習させるアルゴリズムを利用して、文字認識を行う。
Conceptually, the
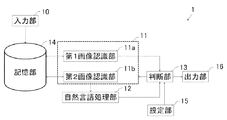
具体的には、文字認識装置1は、図1に示すように、画像データを入力する入力部10と、画像データを認識してテキストを生成する画像認識部11と、画像認識部11により生成されたテキストを自然言語処理する自然言語処理部12と、画像認識部11により生成されたテキストと自然言語処理部12により自然言語処理されたテキストを対比する判断部13とを備える。また、文字認識装置1は、判断部13から出力されるテキストを出力する出力部16を備える。出力部16は、テキストを項目に分けてcsvデータとして出力してもよい。また、文字認識装置1は、画像認識部11、自然言語処理部12および判断部13とを独立に機能させ、それぞれの出力結果が相互に出力結果に影響を与えることにより、所定以上の尤度のテキストを出力する。
Specifically, as shown in FIG. 1, the
入力部10は、例えば、スキャナ装置によって構成されており、書類を画像化して画像データを生成し、生成した画像データを記憶部14に入力する。
The
ここで、画像認識部11の動作について説明する。画像認識部11は、画像データに基づいて、例えば、罫線抽出、枠構造解析、読取対象枠の位置推定などの文書構造解析を行う。次に、画像認識部11は、文書構造解析の結果を受けて、読取対象である文字行を抽出する。次に、画像認識部11は、文字行画像から文字パターン候補の切出しと、各文字パターンの文字識別を行う。
Here, the operation of the
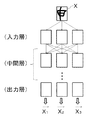
つぎに、文字識別の手順について説明する。画像認識部11は、図2に示すように、切出した1個の文字パターンの画像データに対して特徴抽出を行う。そして、画像認識部11は、文字のストロークの方向成分などを抽出して、画像データを1つのベクトルに変換する。図2に示す例では、画像データXが多層のニューラルネットワークに入力され、方向や位置等の特徴を捉えて特徴抽出をされている様子を模式的に示している。また、図2に示す例では、ベクトルX1と、ベクトルX2と、ベクトルX3とに変換された様子を模式的に示している。
Next, a character identification procedure will be described. As shown in FIG. 2, the
画像認識部11は、図3に示すように、変換されたベクトルに基づいて、字種が何であるかを判定する。画像認識部11は、当該判定において、事前に大量のパターンを使った分布の様子から、どの字種が特徴空間上のどの辺に分布しているかを保持している辞書データを参照し、未知の入力パターンでる画像データの候補を決定する。図3に示す例では、辞書データにおいて、字種「中」、字種「申」および字種「十」の情報が記憶されている様子を概念的に示している。
As shown in FIG. 3, the
画像認識部11は、以上のプロセスにより、複数のテキスト候補(例えば、中、申、十)と、各テキスト候補の尤度を取得する。なお、各テキスト候補の尤度は、特徴空間内における各候補の中心と、未知の入力パターンである画像データとの距離で算出することができる。
The
画像認識部11は、図1に示すように、第1画像認識部11aと、第2画像認識部11bとから構成されている。
As shown in FIG. 1, the
第1画像認識部11aは、記憶部15から画像データを読み出し、多層のニューラルネットワークを用いて当該画像データから特徴点を抽出し、複数のテキスト候補と尤度を出力する。
The first
第2画像認識部11bは、記憶部15から画像データを読み出し、多層のニューラルネットワークを用いて当該画像データから特徴点を抽出し、テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する。
The second image recognition unit 11b reads the image data from the
第1画像認識部11aと第2画像認識部11bとの主な違いは、画像認識の機械学習を行う際に利用する学習データの違いである。第1画像認識部11aは1文字を1文字として出力するように学習データが用意されているのに対し、第2画像認識部11bは1文字をより小さい因子である素因子テキストに分離して出力するように学習データが用意されている。
The main difference between the first
ここで、第1画像認識部11aによる画像認識と第2画像認識部11bによる画像認識の具体例について説明する。以下では、第1画像認識部11aおよび第2画像認識部11b、例えば、図4(a)に示すように、画像データA1について画像認識を行う場合について説明する。
Here, specific examples of image recognition by the first
第1画像認識部11aは、画像データA1を分割する処理を行う。本実施例では、分割する処理により、画像データA1は、図4(b)に示すように、4つの画像データa1,a2,a3,a4に分割できたものとする。
The first
第1画像認識部11aは、多層のニューラルネットワークを用いて画像データa1から特徴点を抽出し、複数の候補(例えば、「高」,「喬」,「富」,「畜」等)を生成し、各候補の尤度を計算する。
The first
第1画像認識部11aは、多層のニューラルネットワークを用いて画像データa2から特徴点を抽出し、複数の候補(例えば、「校」,「核」,「梓」,「検」等)を生成し、各候補の尤度を計算する。
The first
第1画像認識部11aは、多層のニューラルネットワークを用いて画像データa3から特徴点を抽出し、複数の候補(例えば、「時」,「暁」,「待」,「晤」等)を生成し、各候補の尤度を計算する。
The first
第1画像認識部11aは、多層のニューラルネットワークを用いて画像データa4から特徴点を抽出し、複数の候補(例えば、「代」,「付」,「何」,「仕」等)を生成し、各候補の尤度を計算する。
The first
第1画像認識部11aは、各候補の尤度に基づいて、例えば、「高校時代」、「喬核暁付」等をテキスト候補として判断部13に出力する。
Based on the likelihood of each candidate, the first
第2画像認識部11bは、第1画像認識部11aよりも小さい単位である素因子テキストを生成するように画像データA1を分割する処理を行う。素因子テキストとは、1文字をより小さい因子で表したテキストである。例えば、「校」という画像データから小さい因子で表した「木」と「交」が素因子テキストである。本実施例では、分割する処理により、画像データA1は、図4(c)に示すように、6つの画像データb1,b2,b3,b4,b5,b6に分割できたものとする。
The second image recognition unit 11b performs a process of dividing the image data A1 so as to generate a prime factor text that is a smaller unit than the first
第2画像認識部11bは、多層のニューラルネットワークを用いて画像データb1から特徴点を抽出し、複数の素因子テキストの候補(例えば、「高」,「喬」,「富」,「畜」等)を生成し、各候補の尤度を計算する。 The second image recognition unit 11b extracts feature points from the image data b1 using a multi-layer neural network, and a plurality of prime factor text candidates (for example, “high”, “喬”, “rich”, “livestock”). Etc.) and the likelihood of each candidate is calculated.
第2画像認識部11bは、多層のニューラルネットワークを用いて画像データb2から特徴点を抽出し、複数の素因子テキストの候補(例えば、「木」,「不」,「六」,「禾」等)を生成し、各候補の尤度を計算する。 The second image recognition unit 11b extracts feature points from the image data b2 using a multilayer neural network, and a plurality of prime factor text candidates (for example, “tree”, “not”, “six”, “禾”). Etc.) and the likelihood of each candidate is calculated.
第2画像認識部11bは、多層のニューラルネットワークを用いて画像データb3から特徴点を抽出し、複数の素因子テキストの候補(例えば、「交」,「定」,「気」,「充」等)を生成し、各候補の尤度を計算する。 The second image recognition unit 11b extracts feature points from the image data b3 using a multi-layer neural network, and a plurality of prime factor text candidates (for example, “intersection”, “fix”, “ki”, “fill”). Etc.) and the likelihood of each candidate is calculated.
第2画像認識部11bは、多層のニューラルネットワークを用いて画像データb4から特徴点を抽出し、複数の素因子テキストの候補(例えば、「日」,「曰」,「月」等)を生成し、各候補の尤度を計算する。 The second image recognition unit 11b extracts feature points from the image data b4 using a multilayer neural network, and generates a plurality of prime factor text candidates (for example, “day”, “,”, “month”, etc.). Then, the likelihood of each candidate is calculated.
第2画像認識部11bは、多層のニューラルネットワークを用いて画像データb5から特徴点を抽出し、複数の素因子テキストの候補(例えば、「寺」,「圭」,「茉」,「苦」等)を生成し、各候補の尤度を計算する。 The second image recognition unit 11b extracts feature points from the image data b5 using a multi-layer neural network, and a plurality of prime factor text candidates (for example, “Tera”, “圭”, “茉”, “bitter”). Etc.) and the likelihood of each candidate is calculated.
第2画像認識部11bは、多層のニューラルネットワークを用いて画像データb6から特徴点を抽出し、複数の素因子テキストの候補(例えば、「代」,「付」,「何」,「仕」等)を生成し、各候補の尤度を計算する。 The second image recognition unit 11b extracts feature points from the image data b6 using a multi-layer neural network, and a plurality of prime factor text candidates (for example, “price”, “addition”, “what”, “finish”). Etc.) and the likelihood of each candidate is calculated.
第2画像認識部11bは、各素因子テキストの尤度に基づいて、例えば、「高木交日寺代」、「喬不定曰圭付」等をテキスト候補として判断部13に出力する。
Based on the likelihood of each prime factor text, the second image recognition unit 11b outputs, for example, “Takagi Kyohichijiro”, “喬喬 不定 曰 圭” etc. to the
自然言語処理部13は、第2画像認識部11bにより出力されたテキスト候補に対して、隣接する素因子テキストの接合および切り離しを行って、組み合わせられる複数のパターンのテキストに形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する。
The natural
具体的には、自然言語処理部13は、「高木交日寺代」について、「高木」「交日寺代」に分離したり、「高」「木交」「日寺代」に分離したりして、それぞれに対して形態素解析を行って、それぞれの尤度を計算する。
Specifically, the natural
また、自然言語処理部13は、「高木」「交日寺代」について、「日」と「寺」を接合して「時」にし、「高木」「交時代」にして、形態素解析を行って、尤度を計算する。
Further, the natural
また、自然言語処理部13は、「高」「木交」「日寺代」について、「木」と「交」を接合して「校」にし、前のテキスト「高」と組み合わせて「高校」にし、「高校」「日寺代」にして、形態素解析を行って、尤度を計算する。
In addition, the natural
また、自然言語処理部13は、「高校」「日寺代」について、「日」と「寺」を接合して「時」にし、「高校」「時代」にして、形態素解析を行って、尤度を計算する。
The natural
このようにして、自然言語処理部13は、第2画像認識部11bから出力されたテキスト候補を、全てのパターンで接合、切り離しの処理を行う。例えば、「私の高木交日寺代は」というテキストについて形態素解析を行うと、「主語」「格助詞」「名詞(苗字)」「名詞」「名詞」「係助詞」となり、自然言語的な観点から不当な並びとなるため、当該テキストに対しては、尤度が低いという評価を行う。一方、「私の高校時代は」というテキストについて形態素解析を行うと、「主語」「格助詞」「名詞」「係助詞」となり、自然言語的な観点から適当な並びとなるため、当該テキストに対しては、尤度が高いという評価行う。素因子テキストに分離し、全てのパターンで組み合わせたテキスト候補に対して形態素解析による評価を行うことで、画像認識のエラーによる誤りを減らすことができる。
In this way, the natural
判断部14は、第1画像認識部11aにより出力されたテキスト候補(例えば、「高校時代」)と、自然言語処理部13により出力されたテキスト候補(例えば、「高木交日寺代」)とを対比する。
The
判断部14は、対比した結果に基づいて、所定以上の尤度のテキスト(例えば、「高校時代」)を出力する。
Based on the comparison result, the
画像認識を重視した第1画像認識部11aと、自然言語を重視した第2画像認識部11bという二つの異なる観点のテキストを対比することで、文字認識装置1は、より高精度に文字認識を行うことができる。
By comparing the text from two different viewpoints, the first
また、判断部14は、第1画像認識部11aにより出力された最も尤度の高いテキスト候補と、自然言語処理部13により出力された最も尤度の高いテキスト候補とを対比し、所定以上の尤もらしさ(例えば、一致率が98パーセント以上)を得られなかった場合、所定以上の尤もらしさが得られるまで、尤度の高い順に他の候補同士の対比を行う構成でもよい。
In addition, the
判断部14は、第1画像認識部11aと自然言語処理部13で得られたすべての出力パターンの中から、どの回答が尤もらしいかの重みを画像認識部11にフィードバックする。また、判断部14は、出力パターンには存在しない「Xという文字である可能性」をフィードバックする。画像認識部11は、当該フィードバックを受けて、再度重み付けに基づく画像認識を行う。
The
例えば、判断部14は、第1画像認識部11aにより出力された最も尤度の高いテキスト候補である「喬校時付」と、自然言語処理部13により出力された最も尤度の高いテキスト候補である「高木交時代」とを対比し、差分が大きく、所定以上の尤もらしさを得られなかった場合、第1画像認識部11aにより出力された次に尤度の高いテキスト候補である「高校時代」と、自然言語処理部13により出力された最も尤度の高いテキスト候補である「高校時代」とを対比し、所定以上の尤もらしさが得られた場合、「高校時代」を出力する。
For example, the
よって、文字認識装置1は、様々な手書き文字が含まれている書類について、所定以上の尤もらしさが得られるまで処理を繰り返すので、信頼性の高い高精度な文字認識を行うことができる。
Therefore, since the
また、判断部14は、自然言語処理部13により出力されたテキスト候補の中で、尤度の高いテキスト候補を第1画像認識部11aにより出力されたテキスト候補よりも優先的に扱う構成でもよい。
In addition, the
当該構成の場合には、文字認識装置1は、より自然言語処理部13による処理を優先するので、自然言語処理に適しているといえ、文章の文字認識に対して強みを発揮する。
In the case of this configuration, the
また、判断部14は、対比した結果、2つのテキスト候補の差分が所定の閾値を超えない場合に、所定以上の尤度のテキストであると判断して出力する構成でもよい。つまり、判断部14は、自然言語処理部13により出力されたテキスト候補と、第1画像認識部11aにより出力されたテキスト候補とがほぼ一致している場合に、所定以上の尤度のテキストであると判断する。
In addition, the
当該構成の場合には、文字認識装置1は、自然言語処理部13と第1画像認識部11aの二つの処理の結果を利用して文字認識を行っているので、高精度に文字認識を行うことができる。
In the case of this configuration, the
文字認識装置1は、図1に示すように、処理にかかる時間を設定する設定部15を備える構成でもよい。設定部15は、例えば、ユーザの指示にしたがって、処理時間を10分などに設定する。
As shown in FIG. 1, the
判断部14は、第1画像認識部11aにより出力された最も尤度の高いテキスト候補と、自然言語処理部13により出力された最も尤度の高いテキスト候補とを対比し、所定以上の尤もらしさを得られなかった場合、設定部15によって設定された時間以内において、所定以上の尤もらしさが得られるまで、尤度の高い順に他の候補同士の対比を行う。
The
よって、文字認識装置1は、設定された時間内において、所定以上の尤もらしさが得られるまで処理を繰り返すので、認識処理を何回行っても所定以上の尤もらしさが得られないような認識困難な画像データに対して何度も試行を繰り返すことがないメリットがある。
Therefore, since the
また、判断部14は、所定以上の尤もらしさが得られなかったテキストを伏字にして出力する構成でもよい。
Moreover, the
伏字とは、文字認識ができなかった箇所を示すものであり、例えば、「○」や「△」などである。具体的には、「高校時代」の「時」の箇所に対して所定以上の尤もらしさが得られなかった場合には、判断部14は、「高校○代」を出力する。
A prone character indicates a portion where character recognition could not be performed, such as “◯” and “Δ”. Specifically, when a likelihood greater than or equal to a predetermined value is not obtained for the “time” portion of “high school age”, the
よって、文字認識装置1は、文字識別できた箇所と文字識別ができなかった箇所を明示して出力することができる。なお、伏字にした箇所について、正しい文字(本実施例では、「○」の箇所は「時」である)を文字認識装置1にフィードバックしてもよい。当該フィードバックにより、文字認識装置1は、次回の文字認識において、前回「○」となった画像データを正しいテキスト「校」として出力することができる。
Therefore, the
また、第2画像認識部11bは、項目ごとに適した多層のニューラルネットワークを機械学習により有しており、画像データに含まれる項目を探索し、当該項目に適した多層のニューラルネットワークを用いて画像データから特徴点を抽出し、テキストよりも小さい因子である素因子テキストに分離されたテキスト候補を出力する構成でもよい。 The second image recognition unit 11b has a multilayer neural network suitable for each item by machine learning, searches for an item included in the image data, and uses the multilayer neural network suitable for the item. The configuration may be such that feature points are extracted from the image data, and text candidates separated into prime factor texts, which are factors smaller than the text, are output.
例えば、「申込日」のような項目には、「2015年5月1日」等の申込日に関する情報が入力されることが予想できる。つまり、「申込日」のような項目は、数字「0〜9」と、漢字「年」,「月」,「日」が入力され、他の文字は入力されない。よって、第2画像認識部11bは、認識する項目が「申込日」のような場合には、数字「0〜9」と、漢字「年」,「月」,「日」とを出力するようなニューラルネットワークを用いて画像データから特徴点を抽出し、テキストよりも小さい因子である素因子テキストに分離されたテキスト候補を出力する。 For example, information relating to an application date such as “May 1, 2015” can be expected to be input to an item such as “application date”. That is, for items such as “application date”, the numbers “0-9” and the kanji characters “year”, “month”, “day” are input, and no other characters are input. Therefore, when the recognized item is “application date”, the second image recognition unit 11b outputs the numbers “0-9” and the kanji characters “year”, “month”, “day”. A feature point is extracted from image data using a simple neural network, and text candidates separated into prime factor texts, which are factors smaller than the text, are output.
また、「氏名_フリガナ」のような項目には、「トッキョタロウ」等の氏名のカタカナに関する情報が入力されることが予想できる。つまり、「氏名_フリガナ」のような項目は、カタカナ「ア〜ン」等が入力され、他の文字(漢字、数字等)は入力されない。よって、第2画像認識部11bは、認識する項目が「氏名_フリガナ」のような場合には、カタカナを出力するようなニューラルネットワークを用いて画像データから特徴点を抽出し、テキストよりも小さい因子である素因子テキストに分離されたテキスト候補を出力する。 In addition, it can be expected that information related to a katakana of a name such as “Tokitataro” is input to an item such as “name_phonetic”. That is, for an item such as “name_reading”, katakana “A-N” or the like is input, and other characters (kanji, numbers, etc.) are not input. Therefore, the second image recognition unit 11b extracts feature points from the image data using a neural network that outputs katakana when the item to be recognized is “name_reading”, and is smaller than the text. Output text candidates separated into prime factor texts.
また、「電話番号(TEL)」のような項目には、「03−3581−1111」等の電話番号に関する情報が入力されることが予想できる。つまり、「電話番号(TEL)」のような項目は、数字「0〜9」とハイフン「−」が入力され、他の文字(漢字、ひらがな等)は入力されない。よって、第2画像認識部11bは、認識する項目が「電話番号(TEL)」のような場合には、数字「0〜9」とハイフン「−」を出力するようなニューラルネットワークを用いて画像データから特徴点を抽出し、テキストよりも小さい因子である素因子テキストに分離されたテキスト候補を出力する。 In addition, it is expected that information related to a telephone number such as “03-3581-1111” is input to an item such as “telephone number (TEL)”. That is, for items such as “telephone number (TEL)”, numbers “0-9” and hyphen “-” are input, and other characters (kanji, hiragana, etc.) are not input. Therefore, when the item to be recognized is “telephone number (TEL)”, the second image recognition unit 11b uses a neural network that outputs numbers “0-9” and a hyphen “-”. Feature points are extracted from the data, and text candidates separated into prime factor texts, which are factors smaller than the text, are output.
よって、文字認識装置1は、項目ごとに適した多層のニューラルネットワークを利用して画像データからテキスト候補を出力するので、効率的に高精度に文字認識を行うことができる。
Therefore, since the
ここで、文字認識装置1の動作の流れについて、図5に示すフローチャートを参照しながら説明する。
Here, the operation flow of the
ステップS1において、第1画像認識部11aは、多層のニューラルネットワークを用いて画像データから特徴点を抽出し、複数のテキスト候補と尤度を出力する。
In step S1, the first
ステップS2において、第2画像認識11bは、多層のニューラルネットワークを用いて画像データから特徴点を抽出し、テキストよりも小さい因子である素因子テキストに分離されたテキスト候補を出力する。 In step S2, the second image recognition 11b extracts feature points from the image data using a multilayer neural network, and outputs text candidates separated into prime factor text that is a factor smaller than the text.
ステップS3において、自然言語処理部12は、ステップS2の工程により出力されたテキスト候補に対して、隣接する素因子テキストを接合および切り離しを行って、組み合わせられる複数のパターンのテキストに形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する。
In step S3, the natural
ステップS4において、判断部13は、ステップS1の工程により出力されたテキスト候補と、ステップS3の工程により出力されたテキスト候補とを対比する。本工程において、判断部13は、所定以上の尤度(例えば、一致率が98パーセント以上)のテキストを出力する。
In step S4, the
よって、文字認識装置1は、様々な手書き文字が含まれている書類について、高精度に文字認識を行うことができる。
Therefore, the
また、本実施例では、主に、様々な手書き文字が含まれている書類について、高精度に文字認識を行うことができる文字認識装置1の構成と動作について説明したが、これに限られず、各構成要素を備え、様々な手書き文字が含まれている書類について、高精度に文字認識を行うための方法、およびプログラムとして構成されてもよい。
In the present embodiment, the configuration and operation of the
さらに、文字認識装置1を構成する各機能を実現するためのプログラムをコンピュータで読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータシステムに読み込ませ、指示することによって実現してもよい。
Further, it is realized by recording a program for realizing each function constituting the
具体的には、当該プログラムは、多層のニューラルネットワークを用いて画像データから特徴点を抽出し、複数のテキスト候補と尤度を出力する第1画像認識工程と、多層のニューラルネットワークを用いて画像データから特徴点を抽出し、テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する第2画像認識工程と、第2画像認識工程により出力されたテキスト候補に対して、隣接する素因子テキストの接合および切り離しを行って、組み合わせられる複数のパターンのテキストに形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する自然言語処理工程と、第1画像認識工程により出力されたテキスト候補と、自然言語処理工程により出力されたテキスト候補とを対比する判断工程と、をコンピュータによって実現するためのプログラムである。また、判断工程は、所定以上の尤度のテキストを出力する。 Specifically, the program extracts a feature point from image data using a multi-layer neural network, outputs a plurality of text candidates and likelihoods, and uses a multi-layer neural network to generate an image. A feature point is extracted from the data, a text candidate separated into a prime factor text that is a factor smaller than the text, a second image recognition step for outputting the likelihood, and a text candidate output by the second image recognition step A natural language processing step that combines and separates adjacent prime factor texts, performs morphological analysis on multiple patterns of combined text, and outputs multiple text candidates and likelihoods that are likely from a natural language perspective And the text candidate output by the first image recognition step and the text candidate output by the natural language processing step. A program for realizing the Hisuru determining step, the computer. In the determination step, text having a likelihood equal to or higher than a predetermined value is output.
さらに、ここでいう「コンピュータシステム」とは、OSや周辺機器等のハードウェアを含むものとする。また、「コンピュータで読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。 Furthermore, the “computer system” here includes an OS and hardware such as peripheral devices. The “computer-readable recording medium” refers to a storage device such as a portable medium such as a flexible disk, a magneto-optical disk, a ROM, and a CD-ROM, and a hard disk built in the computer system.
さらに「コンピュータで読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムを送信する場合の通信線のように、短時刻の間、動的にプログラムを保持するもの、その場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリのように、一定時刻プログラムを保持しているものも含んでもよい。また、上記プログラムは、前述した機能の一部を実現するためのものであってもよく、さらに前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるものであってもよい。 Furthermore, “computer-readable recording medium” means that a program is dynamically held for a short time, like a communication line when transmitting a program via a network such as the Internet or a communication line such as a telephone line. It is also possible to include one that holds a program for a certain time, such as a volatile memory inside a computer system that becomes a server or client in that case. Further, the program may be for realizing a part of the above-described functions, and may be capable of realizing the above-described functions in combination with a program already recorded in the computer system. .
1 文字認識装置、10 入力部、11 画像認識部、11a 第1画像認識部、11b 第2画像認識部、12 自然言語処理部、13 判断部、14 記憶部、15 設定部、16 出力部。
DESCRIPTION OF
上記目的を達成するために、本発明の一態様における文字認識装置は、多層のニューラルネットワークを用いて画像データから特徴点を抽出し、複数のテキスト候補と尤度を出力する第1画像認識部と、多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、前記テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する第2画像認識部と、前記第2画像認識部により出力されたテキスト候補に対して、隣接する素因子テキストの接合および切り離しを行って、組み合わせられる複数のパターンのテキストにそれぞれ形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する自然言語処理部と、前記第1画像認識部により出力されたテキスト候補と、前記自然言語処理部により出力されたテキスト候補とを対比する判断部とを備え、前記判断部は、所定以上の尤度のテキストを出力する。 In order to achieve the above object, a character recognition device according to an aspect of the present invention extracts a feature point from image data using a multilayer neural network, and outputs a plurality of text candidates and likelihoods. Extracting a feature point from the image data using a multi-layer neural network, and outputting a text candidate separated into a prime factor text that is a factor smaller than the text and a likelihood; and Adjacent prime factor texts are joined and separated from the text candidates output by the second image recognition unit, and morpheme analysis is performed on each of the combined patterns of text, which is plausible from a natural language perspective. A natural language processing unit that outputs a plurality of text candidates and likelihoods; a text candidate that is output by the first image recognition unit; Serial and a determining section for comparing the text candidate output by the natural language processing unit, wherein the determination unit outputs the text of a predetermined or more likelihoods.
上記目的を達成するために、本発明の一態様における文字認識方法は、多層のニューラルネットワークを用いて画像データから特徴点を抽出し、複数のテキスト候補と尤度を出力する第1画像認識工程と、多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、前記テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する第2画像認識工程と、前記第2画像認識工程により出力されたテキスト候補に対して、隣接する素因子テキストの接合および切り離しを行って、組み合わせられる複数のパターンのテキストにそれぞれ形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する自然言語処理工程と、前記第1画像認識工程により出力されたテキスト候補と、前記自然言語処理工程により出力されたテキスト候補とを対比する判断工程とを備え、前記判断工程は、所定以上の尤度のテキストを出力する。 To achieve the above object, a character recognition method according to an aspect of the present invention includes a first image recognition step of extracting feature points from image data using a multilayer neural network and outputting a plurality of text candidates and likelihoods. Extracting a feature point from the image data using a multi-layer neural network, and outputting a text candidate and likelihood separated into a prime factor text that is a factor smaller than the text; and Adjacent prime factor texts are joined to and separated from the text candidates output in the second image recognition process, and morpheme analysis is performed on each of the combined patterns of text, which is plausible from a natural language perspective. A natural language processing step for outputting a plurality of text candidates and likelihoods, and a text output by the first image recognition step. Comprising a candidate, and a judgment step of comparing the output text candidates by the natural language processing steps, said determining step outputs a text of a predetermined or more likelihoods.
上記目的を達成するために、本発明の一態様における文字認識プログラムは、多層のニューラルネットワークを用いて画像データから特徴点を抽出し、複数のテキスト候補と尤度を出力する第1画像認識工程と、多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、前記テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する第2画像認識工程と、前記第2画像認識工程により出力されたテキスト候補に対して、隣接する素因子テキストの接合および切り離しを行って、組み合わせられる複数のパターンのテキストにそれぞれ形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する自然言語処理工程と、前記第1画像認識工程により出力されたテキスト候補と、前記自然言語処理工程により出力されたテキスト候補とを対比する判断工程と、をコンピュータによって実現するための文字認識プログラムであって、前記判断工程は、所定以上の尤度のテキストを出力する文字認識プログラムである。 To achieve the above object, a character recognition program according to one aspect of the present invention extracts a feature point from image data using a multilayer neural network, and outputs a plurality of text candidates and likelihoods. Extracting a feature point from the image data using a multi-layer neural network, and outputting a text candidate and likelihood separated into a prime factor text that is a factor smaller than the text; and Adjacent prime factor texts are joined to and separated from the text candidates output in the second image recognition process, and morpheme analysis is performed on each of the combined patterns of text, which is plausible from a natural language perspective. A natural language processing step for outputting a plurality of text candidates and likelihoods, and the first image recognition step. A character recognition program for realizing, by a computer, a determination step for comparing a text candidate and a text candidate output by the natural language processing step, wherein the determination step includes text having a likelihood greater than or equal to a predetermined value. This is a character recognition program to output.
Claims (9)
多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、前記テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する第2画像認識部と、
前記第2画像認識部により出力されたテキスト候補に対して、隣接する素因子テキストの接合および切り離しを行って、組み合わせられる複数のパターンのテキストに形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する自然言語処理部と、
前記第1画像認識部により出力されたテキスト候補と、前記自然言語処理部により出力されたテキスト候補とを対比する判断部とを備え、
前記判断部は、所定以上の尤度のテキストを出力する文字認識装置。 A first image recognition unit for extracting feature points from image data using a multilayer neural network and outputting a plurality of text candidates and likelihoods;
A second image recognition unit that extracts feature points from the image data using a multi-layer neural network, and outputs a text candidate and likelihood separated into a prime factor text that is a factor smaller than the text;
For the text candidates output by the second image recognition unit, adjacent prime factor texts are joined and separated, morpheme analysis is performed on a plurality of patterns of text to be combined, and it is likely from a natural language viewpoint. A natural language processing unit that outputs a plurality of text candidates and likelihoods;
A determination unit that compares the text candidate output by the first image recognition unit with the text candidate output by the natural language processing unit;
The determination unit is a character recognition device that outputs text having a likelihood equal to or higher than a predetermined value.
前記判断部は、前記第1画像認識部により出力された最も尤度の高いテキスト候補と、前記自然言語処理部により出力された最も尤度の高いテキスト候補とを対比し、所定以上の尤もらしさを得られなかった場合、前記設定部によって設定された時間以内において、所定以上の尤もらしさが得られるまで、尤度の高い順に他の候補同士の対比を行う請求項1から4のいずれか一項に記載の文字認識装置。 It has a setting part that sets the time required for processing,
The determination unit compares the text candidate with the highest likelihood output by the first image recognition unit with the text candidate with the highest likelihood output by the natural language processing unit, and has a likelihood greater than or equal to a predetermined value. 5. If any of the candidates is not obtained, the other candidates are compared in descending order of likelihood until a likelihood greater than or equal to a predetermined value is obtained within the time set by the setting unit. The character recognition device according to item.
項目ごとに適した多層のニューラルネットワークを機械学習により有しており、
前記画像データに含まれる項目を探索し、当該項目に適した多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、複数のテキスト候補と尤度を出力し、
前記第2画像認識部は、
項目ごとに適した多層のニューラルネットワークを機械学習により有しており、
前記画像データに含まれる項目を探索し、当該項目に適した多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、前記テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する請求項1記載の文字認識装置。 The first image recognition unit
It has a multilayer neural network suitable for each item by machine learning,
Search for items included in the image data, extract feature points from the image data using a multilayer neural network suitable for the items, and output a plurality of text candidates and likelihoods,
The second image recognition unit
It has a multilayer neural network suitable for each item by machine learning,
Search for items included in the image data, extract feature points from the image data using a multilayer neural network suitable for the items, and separate text candidates into prime factor texts that are factors smaller than the text The character recognition device according to claim 1, wherein the likelihood is output.
多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、前記テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する第2画像認識工程と、
前記第2画像認識工程により出力されたテキスト候補に対して、隣接する素因子テキストの接合および切り離しを行って、組み合わせられる複数のパターンのテキストに形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する自然言語処理工程と、
前記第1画像認識工程により出力されたテキスト候補と、前記自然言語処理工程により出力されたテキスト候補とを対比する判断工程とを備え、
前記判断工程は、所定以上の尤度のテキストを出力する文字認識方法。 A first image recognition step of extracting feature points from image data using a multilayer neural network and outputting a plurality of text candidates and likelihoods;
A second image recognition step of extracting feature points from the image data using a multi-layer neural network, and outputting text candidates and likelihoods separated into prime factor text that is a factor smaller than the text;
For the text candidates output by the second image recognition process, adjacent prime factor texts are joined and separated, morpheme analysis is performed on a plurality of patterns of text to be combined, and it is plausible from a natural language viewpoint. A natural language processing step for outputting a plurality of text candidates and likelihood;
A determination step of comparing the text candidate output by the first image recognition step with the text candidate output by the natural language processing step;
The determination step is a character recognition method for outputting text having a likelihood equal to or greater than a predetermined value.
多層のニューラルネットワークを用いて前記画像データから特徴点を抽出し、前記テキストよりも小さい因子である素因子テキストに分離されたテキスト候補と尤度を出力する第2画像認識工程と、
前記第2画像認識工程により出力されたテキスト候補に対して、隣接する素因子テキストの接合および切り離しを行って、組み合わせられる複数のパターンのテキストに形態素解析を行い、自然言語的な観点から尤もらしい複数のテキスト候補と尤度を出力する自然言語処理工程と、
前記第1画像認識工程により出力されたテキスト候補と、前記自然言語処理工程により出力されたテキスト候補とを対比する判断工程と、をコンピュータによって実現するための文字認識プログラムであって、
前記判断工程は、所定以上の尤度のテキストを出力する文字認識プログラム。 A first image recognition step of extracting feature points from image data using a multilayer neural network and outputting a plurality of text candidates and likelihoods;
A second image recognition step of extracting feature points from the image data using a multi-layer neural network, and outputting text candidates and likelihoods separated into prime factor text that is a factor smaller than the text;
For the text candidates output by the second image recognition process, adjacent prime factor texts are joined and separated, morpheme analysis is performed on a plurality of patterns of text to be combined, and it is plausible from a natural language viewpoint. A natural language processing step for outputting a plurality of text candidates and likelihood;
A character recognition program for realizing, by a computer, a determination step of comparing the text candidates output by the first image recognition step with the text candidates output by the natural language processing step,
The determination step is a character recognition program that outputs text having a likelihood equal to or higher than a predetermined value.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016084081A JP6057112B1 (en) | 2016-04-19 | 2016-04-19 | Character recognition apparatus, method and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016084081A JP6057112B1 (en) | 2016-04-19 | 2016-04-19 | Character recognition apparatus, method and program |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016223844A Division JP2017194945A (en) | 2016-11-17 | 2016-11-17 | Character recognition device, method and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP6057112B1 JP6057112B1 (en) | 2017-01-11 |
| JP2017194806A true JP2017194806A (en) | 2017-10-26 |
Family
ID=57756118
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016084081A Active JP6057112B1 (en) | 2016-04-19 | 2016-04-19 | Character recognition apparatus, method and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6057112B1 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6635563B1 (en) * | 2018-07-09 | 2020-01-29 | ファーストアカウンティング株式会社 | Journal element analysis device, accounting processing system, journal element analysis method, journal element analysis program |
| JP2020149644A (en) * | 2019-03-15 | 2020-09-17 | 富士通株式会社 | Information processing method, information processing program, and information processing equipment |
| WO2020199730A1 (en) * | 2019-03-29 | 2020-10-08 | 北京市商汤科技开发有限公司 | Text recognition method and apparatus, electronic device and storage medium |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020203339A1 (en) * | 2019-03-29 | 2020-10-08 | Arithmer株式会社 | Printed character string recognition device, program, and method |
| JP7382544B2 (en) * | 2020-02-06 | 2023-11-17 | Arithmer株式会社 | String recognition device and string recognition program |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2682203B2 (en) * | 1990-06-14 | 1997-11-26 | 日本電気株式会社 | Character recognition method |
| JPH06251204A (en) * | 1993-02-26 | 1994-09-09 | Nec Corp | Character recognition device |
| JPH07262307A (en) * | 1994-03-22 | 1995-10-13 | N T T Data Tsushin Kk | Recognized result display method and display controller |
| JPH0991386A (en) * | 1995-09-28 | 1997-04-04 | Toshiba Corp | Document analyzing device and morpheme analyzing method |
| JPH09274645A (en) * | 1996-04-05 | 1997-10-21 | Ricoh Co Ltd | Method and device for recognizing character |
| JPH1185912A (en) * | 1997-09-08 | 1999-03-30 | Canon Inc | Device for character recognition and method therefor |
| JP2002366893A (en) * | 2001-06-08 | 2002-12-20 | Hitachi Ltd | Document recognizing method |
| JP4102153B2 (en) * | 2002-10-09 | 2008-06-18 | 富士通株式会社 | Post-processing device for character recognition using the Internet |
| JP2008117037A (en) * | 2006-11-01 | 2008-05-22 | Fujitsu Ltd | Program and method for creating character recognition dictionary |
-
2016
- 2016-04-19 JP JP2016084081A patent/JP6057112B1/en active Active
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6635563B1 (en) * | 2018-07-09 | 2020-01-29 | ファーストアカウンティング株式会社 | Journal element analysis device, accounting processing system, journal element analysis method, journal element analysis program |
| JP2020149644A (en) * | 2019-03-15 | 2020-09-17 | 富士通株式会社 | Information processing method, information processing program, and information processing equipment |
| JP7243333B2 (en) | 2019-03-15 | 2023-03-22 | 富士通株式会社 | Information processing method, information processing program, and information processing apparatus |
| WO2020199730A1 (en) * | 2019-03-29 | 2020-10-08 | 北京市商汤科技开发有限公司 | Text recognition method and apparatus, electronic device and storage medium |
| JP2021520002A (en) * | 2019-03-29 | 2021-08-12 | ベイジン センスタイム テクノロジー デベロップメント カンパニー, リミテッド | Text recognition methods and devices, electronic devices and storage media |
| JP7153088B2 (en) | 2019-03-29 | 2022-10-13 | ベイジン・センスタイム・テクノロジー・デベロップメント・カンパニー・リミテッド | Text recognition method and text recognition device, electronic device, storage medium, and computer program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6057112B1 (en) | 2017-01-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CA3129721C (en) | Pre-trained contextual embedding models for named entity recognition and confidence prediction | |
| JP6057112B1 (en) | Character recognition apparatus, method and program | |
| Rigaud et al. | ICDAR 2019 competition on post-OCR text correction | |
| Awal et al. | First experiments on a new online handwritten flowchart database | |
| Romero et al. | Multimodal interactive handwritten text transcription | |
| CN107229627B (en) | Text processing method and device and computing equipment | |
| GB2547068A (en) | Semantic natural language vector space | |
| KR20200055760A (en) | Image content recognition method and device | |
| Darwish et al. | Arabic pos tagging: Don’t abandon feature engineering just yet | |
| Nugraha et al. | Generating image description on Indonesian language using convolutional neural network and gated recurrent unit | |
| JP2006252333A (en) | Data processing method, data processor and its program | |
| Ma et al. | Tagging the web: Building a robust web tagger with neural network | |
| Romero et al. | Modern vs diplomatic transcripts for historical handwritten text recognition | |
| Kayal et al. | ICDAR 2021 competition on scientific table image recognition to LaTeX | |
| Engin et al. | Multimodal deep neural networks for banking document classification | |
| JP6172332B2 (en) | Information processing method and information processing apparatus | |
| US11379534B2 (en) | Document feature repository management | |
| JP2017194945A (en) | Character recognition device, method and program | |
| Sadaf et al. | Offline bangla handwritten text recognition: A comprehensive study of various deep learning approaches | |
| CN114528851B (en) | Reply sentence determination method, reply sentence determination device, electronic equipment and storage medium | |
| JP2009519547A (en) | Offline character recognition based on logical structure and layout | |
| Tannert et al. | FlowchartQA: the first large-scale benchmark for reasoning over flowcharts | |
| Das et al. | Survey of Pattern Recognition Approaches in Japanese Character Recognition | |
| Mollá et al. | Named entity recognition in question answering of speech data | |
| JP7322468B2 (en) | Information processing device, information processing method and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20161109 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20161122 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6057112 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |