JP2017146745A - Information processing apparatus, control method, information processing system, and program - Google Patents
Information processing apparatus, control method, information processing system, and program Download PDFInfo
- Publication number
- JP2017146745A JP2017146745A JP2016027352A JP2016027352A JP2017146745A JP 2017146745 A JP2017146745 A JP 2017146745A JP 2016027352 A JP2016027352 A JP 2016027352A JP 2016027352 A JP2016027352 A JP 2016027352A JP 2017146745 A JP2017146745 A JP 2017146745A
- Authority
- JP
- Japan
- Prior art keywords
- image data
- data
- information
- example data
- document
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 230000010365 information processing Effects 0.000 title claims abstract description 27
- 238000000034 method Methods 0.000 title claims description 48
- 230000008569 process Effects 0.000 claims description 21
- 230000005540 biological transmission Effects 0.000 claims 1
- 238000010276 construction Methods 0.000 abstract description 7
- 230000014509 gene expression Effects 0.000 description 14
- 238000010801 machine learning Methods 0.000 description 13
- 238000010586 diagram Methods 0.000 description 12
- WBMKMLWMIQUJDP-STHHAXOLSA-N (4R,4aS,7aR,12bS)-4a,9-dihydroxy-3-prop-2-ynyl-2,4,5,6,7a,13-hexahydro-1H-4,12-methanobenzofuro[3,2-e]isoquinolin-7-one hydrochloride Chemical compound Cl.Oc1ccc2C[C@H]3N(CC#C)CC[C@@]45[C@@H](Oc1c24)C(=O)CC[C@@]35O WBMKMLWMIQUJDP-STHHAXOLSA-N 0.000 description 6
- 230000006870 function Effects 0.000 description 4
- 238000003705 background correction Methods 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 239000000284 extract Substances 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 2
- 238000013500 data storage Methods 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 239000006185 dispersion Substances 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 238000000513 principal component analysis Methods 0.000 description 1
- 238000007637 random forest analysis Methods 0.000 description 1
- 238000012706 support-vector machine Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
Images











Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
本発明は、情報処理装置、制御方法、情報処理システム、およびプログラムに関する。 The present invention relates to an information processing device, a control method, an information processing system, and a program.
文書を扱うワークフローの効率化を実現する技術の1つとして、機械学習を利用した画像分類が提案されている。機械学習を利用した画像分類は、一般的に学習と分類(運用)の2つのプロセスを有し、画像データ群(教師データ、学習セット)を与えることで分類ルールを学習によって構築し、構築した分類ルールに基づいて入力画像を分類する。 Image classification using machine learning has been proposed as one technique for improving the efficiency of a workflow for handling documents. Image classification using machine learning generally has two processes, learning and classification (operation), and a classification rule is constructed by learning by providing an image data group (teacher data, learning set). The input image is classified based on the classification rule.
データを複数の種別に分類するには、データが学習セットとして与えた種別のいずれであるかを分類できればよい場合が多いが、文書を扱う場合には、学習したいずれの種別でもない文書を「該当なし」と分類したいというニーズがある。例えば、MFPのスキャナによって大量の文書が読み込まれた際に、特定の種別の文書のみをあらかじめ指定されたフォルダに格納し、その他の種別の文書は「該当なし」に分類し、まとめて一か所のフォルダに格納するようなケースが考えられる。 In order to classify data into a plurality of types, it is often only necessary to classify which type of data is given as a learning set. There is a need to classify as “not applicable”. For example, when a large number of documents are read by the scanner of the MFP, only specific types of documents are stored in a predetermined folder, and other types of documents are classified as “not applicable”. The case where it stores in the folder of the place can be considered.
機械学習では、学習セットとして与えられたデータに基づいて分類ルールを構築するため、学習セット内のデータは、運用時に入力されるデータと特徴量が近い方がよい。また、「該当なし」の分類を実現するには、本来分類したい種別のデータ(正例データ)に加えて、「その他」の種別であるデータ(負例データ)を用意した方がよく、負例データとしては、実際に分類時に入力される可能性の高い文書を用意することが望ましい。 In machine learning, a classification rule is constructed based on data given as a learning set. Therefore, it is preferable that the data in the learning set has a feature amount close to that of data input during operation. In addition, in order to realize the “not applicable” classification, it is better to prepare the data of the “other” type (negative example data) in addition to the data of the type to be originally classified (positive example data). As example data, it is desirable to prepare a document that is likely to be input at the time of classification.
しかし、ユーザが多くの種別の文書を扱っている場合に、本来分類したい種別のデータ(正例データ)以外の大量な文書データを負例データとして用意するのは、ユーザにとって大きな負担となってしまう。また、機械学習では正例データと負例データに同じ種別のデータが混在していると正しく分類ルールを構築することができない。そのため、初めて学習セットを用意する際だけでなく、正例データの種別を追加する度に、負例データの中に新しく追加した種別の正例データが混在していないかを確認する必要がある。 However, when a user handles many types of documents, it is a heavy burden on the user to prepare a large amount of document data other than the type of data (positive example data) that the user wants to classify as negative example data. End up. In machine learning, if the same type of data is mixed in the positive example data and the negative example data, the classification rule cannot be constructed correctly. Therefore, it is necessary not only to prepare the learning set for the first time, but also to check whether the positive example data of the newly added type is mixed in the negative example data every time the type of positive example data is added. .
特許文献1は、正例の文書(正例データ)から特徴語を抽出し、ファイルサーバから取り出した負例候補文書から、当該正例の特徴語をなるべく含まず、かつ当該正例の特徴語以外の特徴語を多く含む文書を負例として選択する文書分類システムを開示している。
しかしながら、特許文献1のように正例データと同じ種別である可能性の低い文書データを除くだけでは、効率よく高精度な分類器を構築することは困難である。一般に、学習セットのデータ量に応じて学習時間が増加する。このため、例えば、ユーザが用意したデータからその場で分類ルールを構築するシステムの場合には、学習セットを絞り込む必要がある。しかし、ファイルサーバからランダムに一定数のファイルを選ぶ等、学習に利用するデータを一律に削減してしまうと、実際に分類時に入力される可能性の高いデータも減り、分類精度が低下してしまう。
However, it is difficult to efficiently construct a highly accurate classifier only by removing document data that is unlikely to be the same type as the positive example data as in
本発明は、高精度な分類ルールの構築を可能とする高品質な教師データを効率的に生成する情報処理装置の提供を目的とする。 An object of the present invention is to provide an information processing apparatus that efficiently generates high-quality teacher data that enables construction of highly accurate classification rules.
本発明の一実施形態の情報処理装置は、分類する種別ごとの画像データを正例データとして受け付ける受付手段と、受け付けた前記画像データに付与されたファイル情報に含まれる情報のうち少なくとも1つが一致するファイル情報が付与された画像データを負例データとして取得する取得手段と、前記正例データ及び負例データを用いて、画像データを種別ごとに分類するために用いる分類ルールを生成する生成手段と、を備える。 An information processing apparatus according to an embodiment of the present invention includes a receiving unit that receives image data for each type to be classified as positive example data, and at least one of information included in file information attached to the received image data matches Acquisition means for acquiring image data to which file information to be assigned is provided as negative example data, and generation means for generating a classification rule used for classifying image data by type using the positive example data and the negative example data And comprising.
本発明の情報処理装置によれば、高精度な分類ルールの構築を可能とする高品質な教師データを生成することができる。 According to the information processing apparatus of the present invention, it is possible to generate high-quality teacher data that enables construction of a highly accurate classification rule.
以下、本発明を実施するための形態について図面などを参照して説明する。
(第1実施形態)
図1は、本実施形態における情報処理システム構成を示す図である。
第1実施形態における情報処理システムは、情報処理装置であるMFP101及びサーバ102を備える。
Hereinafter, embodiments for carrying out the present invention will be described with reference to the drawings.
(First embodiment)
FIG. 1 is a diagram showing a configuration of an information processing system in the present embodiment.
The information processing system in the first embodiment includes an
LAN103には、MFP101が接続されている。また、LAN103は、インターネット104を経由してサービスを提供するサーバ102と接続されている。MFP101及びサーバ102は、LAN103を介して互いに接続されており、画像データや各種情報の送受信を行う。なお、MFP101とサーバ102とは、互いに接続され、画像データや各種情報を送受信できればよく、有線により直接接続されていてもよく、また、無線通信により接続されていてもよい。
An MFP 101 is connected to the
サーバ102は、MFP101から入力された画像データを格納し、MFP101から指定された条件を満たす画像データをMFP101に送信するファイルサーバとして機能する。なお、本実施形態では、分類ルールを学習する際に使用する学習セットの生成や、当該学習セットを用いた分類ルールの構築はMFP101が実行するが、同様の処理をサーバ102が実行してもよい。
The
図2は、MFP101の構成例を示す図である。
図2(A)は、MFP101のハードウェア構成の一例を示す図である。図2(A)に示すように、MFP101は、コントローラ20、画像読取部201、画像出力部205、及び操作部207を備える。コントローラ20は、装置制御部200、画像処理部202、記憶部203、CPU204、及びネットワークI/F部206を備える。
FIG. 2 is a diagram illustrating a configuration example of the
FIG. 2A is a diagram illustrating an example of a hardware configuration of the
装置制御部200は、MFP101内およびネットワークI/F部206を経由した外部とのデータの受け渡しや、操作部207からの操作の受け付けを行う。画像読取部201は、原稿の画像を読み取り、画像データをコントローラ20に出力する。画像処理部202は、画像読取部201や外部から入力される画像データを含む印刷情報を中間情報(以下「オブジェクト」と呼ぶ)に変換し、記憶部203のオブジェクトバッファに格納する。
The
オブジェクトは、テキスト、グラフィック、イメージの属性を持つ。さらに、オブジェクトバッファに格納したオブジェクトに基づきビットマップデータを生成し、記憶部203のバッファに格納する。その際、色変換処理、濃度調整処理、トナー総量制御処理、ビデオカウント処理、プリンタガンマ補正処理、ディザなどの疑似中間調処理を行う。記憶部203は、ROM(Read Only Memory)、RAM(Random Access Memory)、HDD(Hard Disk Drive)などから構成される。
Objects have text, graphic, and image attributes. Further, bitmap data is generated based on the object stored in the object buffer and stored in the buffer of the
ROMは、CPU204が実行する各種の制御プログラムや画像処理プログラムを格納する。RAMは、CPU204がデータや各種情報を格納する参照領域や作業領域として用いられる。また、RAMおよびHDDは、上述したオブジェクトバッファなどに用いられる。コントローラ20は、RAMおよびHDD上で画像データを蓄積し、ページのソートや、ソートされた複数ページにわたる原稿を蓄積し、複数部プリント出力を行う。
The ROM stores various control programs and image processing programs executed by the
なお、記憶部203を構成するHDDは、ファイルサーバとして機能し、画像読取部201やネットワークI/F部206経由で入力された画像データが蓄積されているものとする。画像出力部205は、記録紙などの記録媒体にカラー画像を形成して出力する。ネットワークI/F部206は、MFP101をLAN103に接続し、インターネット104や他の装置との間で各種情報を送受信する。操作部207は、タッチパネルや操作ボタンを備え、ユーザからの操作を受け付けて装置制御部200へ該操作の情報を送信する。
Note that the HDD constituting the
図2(B)は、MFP101の外観の一例を示す図である。画像読取部201は、複数の受光画素を有している。各受光画素の感度が夫々異なっていると、たとえ原稿上の各画素の濃度が同じであったとしても、各画素が夫々違う濃度であると認識されてしまう。そのため、画像読取部201では、最初に白板(一様に白い板)を露光走査し、露光走査して得られた反射光の量を電気信号に変換してコントローラに出力している。
FIG. 2B is a diagram illustrating an example of the appearance of the
なお、画像処理部202内には、各受光画素から得られた電気信号を元に、各受光画素の感度の違いを認識し、その違いを利用して、原稿上の画像をスキャンして得られた電気信号の値を補正する、公知のシェーディング補正処理部を有する。さらに、シェーディング補正部は、コントローラ内のCPU204からゲイン調整の情報を受取ると、当該情報に応じたゲイン調整を行う。
The
ゲイン調整は、原稿を露光走査して得られた電気信号の値を、どのように0〜255の輝度信号値に割り付けるかを調整するために用いられる。このゲイン調整により、原稿を露光走査して得られた電気信号の値を高い輝度信号値に変換したり、低い輝度信号値に変換したりすることができるようになっている。すなわち、ゲイン調整により、読み取り信号のダイナミックレンジの調整が可能である。 The gain adjustment is used to adjust how an electric signal value obtained by exposing and scanning a document is assigned to a luminance signal value of 0 to 255. By this gain adjustment, the value of the electrical signal obtained by exposing and scanning the document can be converted into a high luminance signal value or converted into a low luminance signal value. That is, the dynamic range of the read signal can be adjusted by gain adjustment.
続いて、この原稿上の画像をスキャンする構成について説明する。
画像読取部201は、原稿上の画像を露光走査して得られた反射光を受光画素に入力することで画像の情報を電気信号に変換する。さらに電気信号をレッドR,グリーンG,およびブルーBの各色からなる輝度信号に変換し、当該輝度信号を画像としてコントローラ20に対して出力する。
Next, a configuration for scanning the image on the document will be described.
The
なお、原稿は原稿フィーダ211のトレイ212にセットされる。ユーザが操作部207から読み取り開始を指示すると、コントローラ20から画像読取部201に原稿読み取り指示が与えられる。画像読取部201は、この指示を受けると原稿フィーダ211のトレイ212から原稿を1枚ずつフィードして、原稿の読み取り動作を行う。なお、原稿の読み取り方法は、原稿フィーダ211による自動送り方式に限られるものではなく、原稿を不図示のガラス面上に載置し露光部を移動させることで原稿の走査を行う方法であってもよい。
The document is set on the
画像出力部205は、コントローラ20から受取った画像を用紙上に形成する画像形成デバイスである。なお、本実施形態では、画像形成方式は、感光体ドラムや感光体ベルトを用いた電子写真方式であるが、これに限られるものではない。例えば、微少ノズルアレイからインクを吐出して用紙上に印字するインクジェット方式などであっても本発明は適用可能である。また、画像出力部205には、異なる用紙サイズまたは異なる用紙向きを選択可能とする複数の用紙カセット213乃至215が設けられている。排紙トレイ216には印字後の用紙が排出される。
The
図3は、サーバのハードウェア構成の一例を示す図である。
サーバ102は、CPU301、RAM302、ROM303、ネットワークI/F部304、HDD305、及びデータバス306を備える。CPU301は、ROM303に記憶された制御プログラムを読み出してRAM302にロードし、各種制御処理を実行する。RAM302は、CPU301の実行するプログラムや、ワークメモリ等の一時記憶領域として用いられる。
FIG. 3 is a diagram illustrating an example of a hardware configuration of the server.
The
ネットワークI/F部304は、サーバ102をインターネット104に接続し、他の装置との間で各種情報を送受信する。HDD305は、画像データや特徴量データ、各種プログラム等を格納する。ネットワークI/F部304を介してMFP101から受信した画像データは、データバス306を介してCPU301、RAM302、及びROM303に送受信される。
A network I /
CPU301がROM303やHDD305に格納された画像処理プログラムを実行することによって、画像データに対する画像処理が実現される。また、HDD305は、ネットワークI/F部304を介してMFP101以外の外部装置からもデータの入力が可能であり、すでに文書の画像データを含む大量のファイルが格納されているものとする。
When the
<第1実施形態の詳細説明>
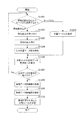
図4は、学習セットを生成し、分類ルールを学習する処理を説明するフローチャートである。
図4に示す処理は、MFP101およびサーバ102にて実行される。MFP101において実行される処理は、CPU204が記憶部203に格納されている処理プログラムをロードして実行することにより実現される。また、サーバ102において実行される処理は、CPU301がHDD305に格納されている処理プログラムをRAM302にロードして実行することにより実現される。
<Detailed Description of First Embodiment>
FIG. 4 is a flowchart for explaining processing for generating a learning set and learning classification rules.
The process shown in FIG. 4 is executed by the
なお、本実施形態では、ユーザがMFP101を用いて文書(原稿)をスキャンし、その種別毎に文書の画像データをサーバ102に格納するというワークフローの中で、同時にMFP101内で画像データの分類ルールを学習するシステムを想定している。このように、文書を扱うワークフローに機械学習を利用した分類ルールを応用すると、スキャナを備えたMFPなどの入力機器から入力された文書の格納先や配布先の自動決定、ファイル名の自動付与などが可能になる。また、ユーザ毎に用意した文書から学習することで、個別にカスタマイズされた分類ルールを構築することも可能になる。
In this embodiment, the user scans a document (original) using the
なお、文書のスキャン及びサーバへの格納と、分類ルールの学習を行うタイミングは上記のワークフローに限られるものではなく、文書のスキャン及びサーバへの格納と、分類ルールの学習が別々に実行されてもよい。第2実施形態では、すでにサーバ102に格納されたデータを分類ルールの学習時に取得する場合について説明する。また、分類ルールの学習は、データを読み込んだMFP101で必ずしも行う必要はなく、例えば画像データを格納したサーバで本実施形態の分類に係る処理を行ってもよい。
Note that the timing for scanning a document and storing it in the server and learning the classification rules is not limited to the above workflow, and the scanning of the document and storage in the server and the learning of the classification rules are performed separately. Also good. In the second embodiment, a case will be described in which data already stored in the
ステップS401において、MFP101は、ユーザから操作部207経由で画像データの保存設定を受付ける。なお、画像データの保存設定は、MFP101において読み込んだ画像データの保存先を示すフォルダのパスや、保存時のファイル名、ファイル形式などのことである。
In step S <b> 401, the
ステップS402において、MFP101は、操作部207からユーザの指示を受け付けると、原稿フィーダ211のトレイ212から原稿を1枚ずつフィードして、画像読取部201で原稿を読み取る。なお、本実施形態では、トレイ212にセットされる原稿は、同一種別の文書とする。また、同一種別の文書は、分類ルールにおいて同一のクラスに分類される文書とする。
In step S <b> 402, when the
ステップS403において、MFP101は、ステップS402で画像読取部201が読み込んだ画像データ群を、記憶部203に学習セットの正例データ候補群として格納する。画像データ群を格納する際には、各画像データに文書ファイル情報を付与する。文書ファイル情報は、後述する負例データ候補群の絞り込みに利用する。文書ファイル情報としては、タイトルや作成者名、ファイル形式、作成ツール、作成デバイス、変換ツール、キーワード、生成日時、更新日時など、アプリケーションで電子ファイルを作成する際に付与される一般的なメタ情報を利用する。
In step S403, the
キーワードとは、文書ファイルの特徴を表す文字列群であり、本実施形態では、原稿を読み込む際に文字認識を行い、その結果を利用する。例えば、タイトルとなる最初のページの上部中央や、ヘッダーやフッター、表内の項目など文書の特徴的な位置にある文字列、他の文字と比べてフォントの異なる文字列など、特徴的な文字列をキーワードとして利用する。 A keyword is a group of character strings representing the characteristics of a document file. In this embodiment, character recognition is performed when a document is read, and the result is used. For example, characteristic characters such as the upper center of the first page that becomes the title, a character string in a characteristic position of the document such as a header, footer, or an item in the table, or a character string with a different font compared to other characters Use columns as keywords.
また、文書ファイル情報用のキーワード群と対応する項目とを辞書として保持しておき、文字認識を行った結果、辞書内のキーワードに当てはまる文字列が含まれる場合に、当該キーワードに対応する項目を文書ファイル情報のキーワードとして付与してもよい。文書ファイル情報用のキーワード群としては、「決裁書」や「申請書」、「注文書」といった一般的に利用される文書のタイトルや、企業名リストを利用する。 In addition, if the keyword group for the document file information and the corresponding item are stored as a dictionary and character recognition is performed and character strings that match the keyword in the dictionary are included, the item corresponding to the keyword is displayed. You may give as a keyword of document file information. As a keyword group for document file information, commonly used document titles such as “decision document”, “application form”, “order form”, and company name list are used.
なお、文書ファイル情報は、上記のようなメタ情報に限定されるものではなく、文字認識の過程等で得られる文字列の位置情報やフォントサイズなどの文書構造情報を用いてもよい。また、MFP101での読み取り時に付与された読取解像度や色、割り当てなどのスキャン設定を用いてもよい。また、本実施形態では、文書ファイル情報と共に画像データ群が格納されるが、これに限定されるものではなく、例えば、読み込まれた画像データ群から算出される特徴量のデータを格納してもよい。
The document file information is not limited to the meta information as described above, and may be document structure information such as character string position information and font size obtained in the process of character recognition. In addition, scan settings such as reading resolution, color, and assignment assigned when reading with the
ステップS404において、MFP101は、ネットワークI/F部206を通じて画像読取部201で読み込まれた画像データ群をサーバ102に送信する。サーバ102は、LAN103およびインターネット104を経由してMFP101から画像データ群を受信する。サーバ102のCPU301は、ステップS401において設定された画像データの保存設定に基づき、受け付けた画像データをHDD305に記録する。
In step S <b> 404, the
ステップS405において、MFP101は、原稿の読み取りを続けるか否かの指示を、操作部207を介してユーザから受け付ける。原稿の読み取りを続ける場合には、処理はステップS401に戻る。原稿の読み取りを続けない場合には、処理はステップS406に進む。なお、原稿の読み取りを続けるか否かの判断は、上記の方法に限るものではない。例えば、ステップS401での原稿の読み取り回数をカウントし、あらかじめ操作部207を介してユーザによって設定された原稿の読み取り回数に達するまで原稿の読み取りを続けてもよい。
In step S <b> 405, the
ステップS406において、MFP101は、記憶部203に格納されている文書の画像データおよび、インターネット104およびLAN103を経由してサーバ102から取得した文書の画像データを、負例データ候補群として記憶部203に格納する。ステップS407において、MFP101は、ステップS406にて取得した負例データ候補群のファイルを抜粋する。負例データ候補群の抜粋処理の詳細については、図5を用いて後述する。
In step S <b> 406, the
ステップS408において、MFP101は、ステップS403にて格納した正例データ候補群、およびステップS407にて格納した負例データ候補群を学習セットとして機械学習を利用した分類ルールの学習に用いる。本実施形態において、分類ルールの学習については、図9〜11を用いて後述する。
In step S408, the
<負例データ候補群の抜粋処理に係る詳細説明(ステップS407)>
運用時に入力される可能性の低い文書データは、運用時の分類精度に寄与しない無駄なデータとなってしまう。例えば、サーバからランダムに選ばれた50個の文書データの中に使われていないデータが5個、別の業務で利用するデータが10個含まれていた場合、分類ルールの構築に有効なデータが35個となってしまう。このように、ランダムにデータを取得するだけでは、実際に分類時に入力される可能性の高い文書を減らしてしまう要因となる。
<Detailed Description of Extraction Process of Negative Example Data Candidate Group (Step S407)>
Document data that is unlikely to be input during operation becomes useless data that does not contribute to classification accuracy during operation. For example, if 50 pieces of document data randomly selected from the server contain 5 unused data and 10 pieces of data to be used in another job, this data is effective for constructing a classification rule. Will be 35. As described above, simply acquiring data at random can reduce the number of documents that are likely to be actually input during classification.
また、データの冗長性を考慮していない場合も、実際に分類時に入力される可能性の高い文書を減らしてしまう要因となる。例えば、負例データとして利用する文書データ50個が、5種類各10個の文書である場合と、50種類各1個の文書である場合には、前者の方が分類時に入力される可能性の高い文書を減らしてしまう。本実施形態では、負例データ候補群の抜粋処理により、高精度な分類を可能とする負例データを取得することが可能となる。 Even when data redundancy is not taken into account, it is a factor of reducing documents that are likely to be input at the time of classification. For example, when 50 pieces of document data used as negative example data are 10 documents for each of 5 types and 1 document for each of 50 types, the former may be input at the time of classification. Reduce the number of expensive documents. In the present embodiment, it is possible to acquire negative example data that enables highly accurate classification by extracting the negative example data candidate group.
図5は、負例データ候補群から負例データを構築する処理を示すフローチャートである。
詳細には、図5に示す処理は、分類ルールの構築に使用する学習セットの一部である負例データを、ステップS406にて取得した負例データ候補群から抜粋する処理である。図5に示す処理は、MFP101のCPU204が、記憶部203に格納されている処理プログラムをロードして実行することで実現される。
FIG. 5 is a flowchart showing a process of constructing negative example data from the negative example data candidate group.
Specifically, the process illustrated in FIG. 5 is a process of extracting negative example data that is a part of the learning set used for constructing the classification rule from the negative example data candidate group acquired in step S406. The processing shown in FIG. 5 is realized by the
ステップS501において、MFP101は、ステップS403で記憶部203に記録された正例データ候補群から、ステップS403で付与された文書ファイル情報およびユーザの指示に基づき、負例データ候補群の絞り込み条件を取得する。ステップS502において、MFP101は、ステップS501で取得した絞り込み条件に基づき、ステップS406で取得した負例データ候補群を絞り込む(抜粋する)。ステップS501およびステップS502の詳細については、図5〜図8を用いて後述する。
In step S501, the
ステップS503において、MFP101は、ステップS502で抜粋した負例データ候補群から、冗長なデータを削減する。冗長なデータの特定には、例えば、文書ファイル情報の1つであるキーワードを特徴量としたクラスタリングを利用する。これは、同じキーワードで構成される文書は、同じ種別の文書である可能性が高いため、同じ種別の文書であると判定するためである。
In step S503, the
なお、冗長なデータの特定は、上記の方法に限るものではない。例えば、キーワード以外の特徴量として文書構造情報に基づきタイトル文字列やタイトル文字列のフォントサイズ、タイトル文字列の位置等を特徴量としたクラスタリングを利用してもよく、また、それ以外の方法を用いてもよい。そして、同じ種別であると判定された文書が大量にある場合は、それらの中から一部を抜粋して、残りの文書は削除することにより冗長なデータを削減することができる。このとき、例えば、あらかじめ文書のデータ容量や個数の上限を決めておき、当該データ容量や個数が上限を超えた場合に、それらが上限の値以下となるように文書を削除すればよい。 The identification of redundant data is not limited to the above method. For example, as a feature amount other than a keyword, clustering with feature amounts such as a title character string, a font size of the title character string, a position of the title character string based on document structure information may be used, and other methods may be used. It may be used. If there are a large number of documents determined to be of the same type, redundant data can be reduced by extracting some of them and deleting the remaining documents. At this time, for example, the upper limit of the data capacity or the number of documents may be determined in advance, and when the data capacity or the number exceeds the upper limit, the document may be deleted so that they are less than the upper limit value.
ステップS504において、MFP101は、ステップS503で冗長なデータが削減された負例データ候補群から正例データ候補群に含まれる種別の可能性がある文書を削除する。正例データ候補群に含まれる種別であるか否かの判定は、正例データの文書とキーワードが一致する確率(一致率)に基づいて行う。なお、正例データ候補群に含まれる種別であるか否かの判定は、上記の方法に限るものではない。
In step S504, the
ここでの判定は、分類ルールを用いて「その他」に分類するか否かを判定する際の精度は必要としていない。文書構造情報の一致率や、画像特徴量の一致率を利用して、正例の種別であると疑わしい文書を削除できればよい。また、すでに分類ルールを一度構築しており、正例データの種別を追加する場合であれば、構築済みの分類ルールを適用して正例データの種別であるか否かを判定してもよい。 The determination here does not require accuracy when determining whether to classify as “others” using the classification rule. It is only necessary to delete a document that is suspected of being a positive type using the matching rate of document structure information and the matching rate of image feature amounts. Further, if the classification rule has already been constructed and the type of positive example data is to be added, it may be determined whether or not the type of positive example data is applied by applying the classification rule that has been constructed. .
なお、本実施形態では、サーバ102から取得した画像データ群をMFP101が絞り込む処理を実行することにより負例データを作成したが、これに限られるものではない。例えば、図6を用いて説明する絞り込み条件に従って、サーバ102がデータの絞り込みを行い、作成した負例データをMFP101に送信してもよい。
In this embodiment, the negative example data is created by the
<絞り込み条件の取得および絞り込み処理の詳細説明(ステップS501、S502)>
絞り込み条件の取得および絞り込みの処理は、MFP101のCPU204が実行する処理である。絞り込み条件の取得について、図6および図7を用いて説明する。
図6は、文書ファイル情報の一例を示す図である。正例データ候補群として与えられた3種別の文書に関して、文書ファイル情報を示している。図7は、正例データ候補群の文書ファイル情報による絞り込み条件をユーザが確認および編集するための画面の一例を示す図である。
<Detailed Description of Narrowing Condition Acquisition and Narrowing Processing (Steps S501 and S502)>
The process of obtaining and narrowing down the narrowing conditions is a process executed by the
FIG. 6 is a diagram illustrating an example of document file information. The document file information is shown for three types of documents given as the positive example data candidate group. FIG. 7 is a diagram showing an example of a screen for the user to confirm and edit the narrowing-down conditions based on the document file information of the positive example data candidate group.
図7の画面は、ラジオボタン701および702を有する。ラジオボタン701および702により、絞り込み条件を設定するか否かを切り替えることができる。ボタン703は、負例データ候補群の取得を指示(要求)するためのボタンであり、ラジオボタン701および702の状態に応じて取得する処理を切り替える。
The screen in FIG. 7 has
具体的には、ラジオボタン701が選択されている場合には、条件式フィールド705および条件フィールド706において設定された内容に基づいて、記憶部203およびHDD305内の文書を絞り込んで取得する。ラジオボタン702が選択されている場合には、記憶部203およびHDD305内の文書を絞り込まずにそのまま取得する。ボタン704は、絞り込み条件の自動取得を指示するためのボタンである。
Specifically, when the
ボタン704によって絞り込み条件の自動取得が指示されると、MFP101は、正例データ候補群の文書ファイル情報から絞り込み条件を取得して、条件式フィールド705および条件フィールド706に表示する。具体的には、条件式フィールド705および条件フィールド706には、図6に示した正例データ候補群の文書ファイル情報に基づいて、正例データ候補群の文書ファイル情報と1つでも共通の項目を含む文書が取得できる条件式が示される。条件フィールド706には、正例データ候補群の文書ファイル情報の各項目が条件として表示される。
When an automatic acquisition of the narrowing condition is instructed by the
また、条件式フィールド705には、条件フィールド706の各条件が、和集合を表す「+」で結合された条件式が入力されている。すなわち、正例データ候補群の文書ファイル情報の各項目と1つでも共通の項目を含む文書が抽出される。なお、条件式の自動取得では、上記のように文書ファイル情報の各項目の和集合を抽出する方法に限られるものではない。例えば、正例データ候補群の間で、文書ファイル情報の共起性を計算し、共起性の高い文書ファイル情報の項目の組み合わせを含む文書を絞り込むように条件を表示してもよい。すなわち、正例データ候補群において付与されている頻度が高い文書ファイル情報の項目の組み合わせを使用して、文書を絞り込むようにしてもよい。
In the
条件式フィールド705および条件フィールド706は、条件を表示するだけでなく、ユーザによる編集も受け付ける。ユーザは、ボタン704を用いて自動取得した条件を修正したい場合には編集すればよく、また、ユーザ所望の文書を絞り込むための条件を任意に設定することも可能である。ボタン709によって条件式フィールド705および条件フィールド706表示された条件をクリアすることも可能である。
The
また、図7に示す例では、条件フィールド706に条件番号7までの条件が一覧されているが、これらの数は可変であり、上限も現在表示されている10個に限られるものではない。ボタン710によって、条件の追加が指示されると、条件の数(行数)を増やすことが可能である。また、条件式フィールド705において、条件フィールド706に表示されている条件番号と括弧や演算子を用いて多項演算のように条件式を入力することも可能である。例えば、和集合であれば「+」の演算子で表記し、積集合であれば「*」の演算子で表記する。
In the example shown in FIG. 7, conditions up to
また、条件式フィールド705および条件フィールド706で表現される絞り込み条件は、ファイルに保存または読み込みが可能である。ボタン707は、絞り込み条件をファイルに保存するためのボタンであり、ボタン707が押下されると条件式フィールド705および条件フィールド706に表示されている絞り込み条件がテキストファイル形式にて保存される。
Further, the narrow-down conditions expressed in the
また、ボタン708は、絞り込み条件をファイルから読み込むためのボタンであり、ボタン708が押下されるとファイルから読み込んだ絞り込み条件が、条件式フィールド705および条件フィールド706に表示される。なお、絞り込み条件を保存するファイルの形式は、テキストファイル形式に限られるものではなく、条件を表現することができれば特に限定されない。例えば、XML形式に保存してもよい。
A
図8は、記憶部203およびHDD305内の文書ファイルを、上記の絞り込み条件によって絞り込んだ結果の一例を示す図である。
図7に示した条件によって絞り込んだ場合に、負例データとして採用されるデータの1つがデータ801である。
FIG. 8 is a diagram illustrating an example of a result of narrowing down the document files in the
文書ファイル情報の項目802(作成者名)、項目803(形式)、及び項目804(作成デバイス)が、それぞれ条件711、712、713と一致するため、採用される。一方、負例データとして採用されないデータの1つがデータ805である。文書ファイル情報の項目が、条件フィールド706に示す条件のいずれにも一致しないため、負例データとして採用されず、負例データ候補群から削除される。
The items 802 (name of creator), item 803 (format), and item 804 (creation device) of the document file information are adopted because they match the
<機械学習を利用した分類ルールの構築の詳細説明(ステップS408)>
次に、本実施形態で分類ルールの構築に利用する機械学習の手法について説明する。本実施形態では、機械学習の手法としてReal AdaBoostと呼ばれる公知の手法を利用する。Real AdaBoostは、大量の特徴量から、与えられた学習セットの分類に適した特徴量を選択して、その特徴量を組み合わせて分類器(分類ルール)を構成することが可能な手法である。
<Detailed Description of Construction of Classification Rule Using Machine Learning (Step S408)>
Next, a machine learning technique used for constructing a classification rule in this embodiment will be described. In the present embodiment, a known technique called Real AdaBoost is used as a machine learning technique. Real AdaBoost is a technique capable of selecting a feature amount suitable for classification of a given learning set from a large amount of feature amounts and combining the feature amounts to form a classifier (classification rule).
画像の分類時に大量の特徴量を利用すると、特徴量の計算負荷のためにパフォーマンスが低下する可能性がある。Real AdaBoostのように、分類に適した特徴量を選択して、一部の特徴量だけを利用し、分類器を構成できることは、大きな利点である。ただし、Real AdaBoostは、2クラス分類器であり、2種類のラベルがついたデータを分類するものである。つまり、このままでは、3種類以上の種別の画像データの分類には利用できない。 If a large amount of feature amount is used at the time of image classification, there is a possibility that the performance is lowered due to the calculation load of the feature amount. As in Real AdaBoost, it is a great advantage that a classifier can be configured by selecting feature quantities suitable for classification and using only some of the feature quantities. However, Real AdaBoost is a two-class classifier and classifies data with two types of labels. That is, as it is, it cannot be used for classification of three or more types of image data.
そこで、本実施形態では、2クラス分類器を多クラス分類器に拡張するOVA(One−Versus−All)と呼ばれる公知の方法を利用する。OVAは、1つのクラス(対象クラス)とそれ以外のクラスを分類する分類器をクラスの数だけ作成し、それぞれの分類器の出力を、対象クラスの信頼度とする。すなわち、1つの分類器では、その分類器が分類するクラスに属するデータを正例データとし、それ以外のクラスに属するデータを負例データとして分類ルールを学習する。 Therefore, in the present embodiment, a known method called OVA (One-Versus-All) that extends the two-class classifier to a multi-class classifier is used. OVA creates classifiers for classifying one class (target class) and other classes by the number of classes, and uses the output of each classifier as the reliability of the target class. That is, in one classifier, data belonging to a class classified by the classifier is used as positive example data, and data belonging to other classes is used as negative example data to learn a classification rule.
各分類器は、その分類器が対象とする1つのクラスのデータが入力された場合に、出力する信頼度が高くなるように学習を行う。分類の際には、分類したいデータをすべての分類器に入力し、信頼度が最大であったクラスを分類先とする。また、すべての分類器の出力する信頼度が小さい場合や、複数の分類器が出力する信頼度が高くなった場合には、「該当なし」や「不明」といった判定を行う。 Each classifier performs learning so as to increase the output reliability when data of one class targeted by the classifier is input. At the time of classification, data to be classified is input to all classifiers, and the class having the highest reliability is set as the classification destination. Further, when the reliability output from all the classifiers is low, or when the reliability output from a plurality of classifiers is high, the determination such as “not applicable” or “unknown” is performed.
図9は、学習セットを用いた機械学習の一例を示す図である。
この例では、学習セットとして、正例データ候補群の3つのクラス(種別)の文書(文書A、文書B、文書C)および負例データ候補群の「その他」の文書(文書A、文書B、文書Cではない文書)のそれぞれに対応する特徴量が用意されているものとする。この文書A、文書B、文書Cの3種類のクラスを分類するために、OVAでは3種類の分類器を用意する。3種類の分類器はそれぞれ、文書Aとそれ以外のクラスに文書を分類するための文書A分類器、文書Bとそれ以外のクラスに文書を分類するための文書B分類器、文書Cとそれ以外のクラスに文書を分類するための文書C分類器である。
FIG. 9 is a diagram illustrating an example of machine learning using a learning set.
In this example, three classes (types) of positive example data candidate groups (Document A, Document B, Document C) and “other” documents of negative example data candidate groups (Document A, Document B) are used as learning sets. , A feature amount corresponding to each of the documents (not the document C) is prepared. In order to classify the three types of documents A, B, and C, OVA prepares three types of classifiers. The three types of classifiers are document A classifier for classifying documents into document A and other classes, document B classifier for classifying documents into document B and other classes, document C and This is a document C classifier for classifying documents into classes other than.
ここで、文書A分類器を構築する方法について説明する。まず、MFP101のCPU204は、分類ルールを学習するにあたって必要となる正例データおよび負例データを、学習セットの中から取得する。文書A用分類器では、正例データは文書Aのデータであり、負例データはそれ以外のクラスのデータである。したがって、CPU204は、正例データ候補群の中から、文書Aのラベルが付与された画像データを取得し、正例データとする。
Here, a method for constructing the document A classifier will be described. First, the
また、CPU204は、正例データ候補群の中から、文書A以外(文書B、文書C)のラベルの付与された画像データを、負例データとして取得する。さらに、CPU204は、負例データ候補群の中から、画像データを負例データとして取得する。このとき、負例データ候補群の中に、正例データである文書Aのデータが混ざっている場合には、正しく分類ルールを学習することができない。このため、上記のステップS504の処理により文書Aである可能性の高いものは取り除かれているものとする。
In addition, the
CPU204は、取得した正例データおよび負例データの特徴量に基づき、Real AdaBoostを利用して文書A分類器を構築する。文書A分類器では、文書Aの特徴量が入力された場合に、大きい出力値(信頼度)が出力され、それ以外のクラスの文書の特徴量が入力された場合に、小さい出力値(信頼度)が出力される。文書B分類器、文書C分類器についても同様である。
The
なお、本実施形態で利用可能な機械学習の手法は、上記の手法に限定されるものではない。Support Vector MachineやRandom Forest等の公知の手法を利用してもよい。また、特徴量選択の枠組みが機械学習の手法に含まれていない場合に、分類時の分類速度を向上させたい場合には、主成分分析や判別分析を利用した特徴量選択等の公知の特徴量選択を行ってもよい。機器学習の手法が2クラス分類器である場合は、OVA以外の、All−Versus−All(AVA)やError−Correcting Output−Coding(ECOC)等の公知の手法を用いてもよい。 Note that the machine learning technique that can be used in the present embodiment is not limited to the above technique. A known method such as Support Vector Machine or Random Forest may be used. In addition, if the feature selection framework is not included in the machine learning method and you want to improve the classification speed during classification, you can use known features such as feature selection using principal component analysis or discriminant analysis. Quantity selection may be performed. When the device learning method is a two-class classifier, a known method such as All-Versus-All (AVA) or Error- Correcting Output-Coding (ECOC) other than OVA may be used.
<分類ルールの構築に利用する特徴量の詳細>
本実施形態において分類ルールの構築に利用する特徴量について、図10および図11を用いて説明する。
<Details of features used to construct classification rules>
A feature amount used for constructing a classification rule in the present embodiment will be described with reference to FIGS. 10 and 11.
図10は、特徴量の算出方法について説明する図である。
本実施形態において特徴量は、入力画像1001内から切り出されたパッチ画像1002に対して勾配情報に基づき算出される9次元の特徴量である。MFP101のCPU204は、パッチ画像1002内の各画素について注目し、注目画素に隣接する画素の階調値から、勾配強度および勾配方向を算出する。
FIG. 10 is a diagram illustrating a feature amount calculation method.
In the present embodiment, the feature amount is a nine-dimensional feature amount calculated based on the gradient information for the
そして、CPU204は、勾配強度に基づいてエッジ判定を行うことで、勾配強度が一定値以上の画素をエッジ画素、一定値より小さい画素を非エッジ画素と判定する。エッジ判定の結果、画素1003は、非エッジ画素と判定された画素の一例であり、画素1004は、エッジ画素と判定された画素の一例である。エッジ画素である画素1004内の矢印は、勾配方向を表す。
Then, the
勾配方向は、文字や罫線の線の方向を表現するため、180度回転した角度は同一方向とみなして、0〜180度に正規化される。CPU204は、エッジ画素群から勾配方向を22.5度毎の8方向に量子化し、方向ごとの勾配強度積算値/パッチ画素数を計算して8ビンのヒストグラムを作成する。また、CPU204は、非エッジ画素群から、非エッジ画素数/パッチ画素数を計算し、エッジ画素群から作成したヒストグラムと合わせて、1つのパッチ画像から9次元の特徴量を算出する。
Since the gradient direction expresses the direction of the line of characters and ruled lines, the angle rotated by 180 degrees is regarded as the same direction and is normalized to 0 to 180 degrees. The
エッジ画素と非エッジ画素を利用することで、罫線や文字の情報だけでなく、文書画像の大きな特徴である余白部分を表現することが可能になる。これまでの説明は、1つのパッチ画像1002における特徴量の説明であるが、実際には、1つの入力画像から複数のパッチ画像を切り出して利用することにより、多数の特徴量を利用する。
By using edge pixels and non-edge pixels, it is possible to express not only ruled line and character information but also a margin part which is a major feature of a document image. Although the description so far has been a description of feature amounts in one
図11は、読み取った画像データからパッチ画像を切り出す方法について説明する図である。
CPU204は、入力画像1101から余白をカットし、ノイズが表れやすい画像端1102を削除する。CPU204は、余白カット後の画像1103を縮小することで、マルチスケール(複数の解像度の)画像を作成する。マルチスケールの画像を用意するのは、解像度ごとにエッジの構造が変わるためであり、画像読取部201の読取解像度や文書の解像度が多少異なっていても対応できるようにするためである。
FIG. 11 is a diagram illustrating a method for cutting out a patch image from read image data.
The
画像1104は、余白カット後の画像1103を1/4に縮小した画像である。余白カット後の画像1103および縮小した画像1104から、パッチサイズと切り出し位置を変えながら、パッチ画像を切り出す。具体的には、まず、縮小した画像1104から、均等に16分割して得られる1/16サイズのパッチ画像16枚と、均等に64分割して得られる1/64サイズのパッチ画像64枚から、合計80枚のパッチ画像を作成する。
An
また、余白カット後の画像1103から、同様に分割して80枚のパッチ画像を作成することで、1枚の入力画像1101から、合計160枚のパッチ画像が得られる。各パッチ画像から9次元の特徴量を算出するため、1枚の入力画像1101から9×160=1440次元の特徴量を算出することが可能となる。
Further, 80 patch images are similarly divided from the
なお、画像解像度、パッチサイズ、パッチ切り出し位置に関するパラメータは、上記の数字に限定されるものではない。また、算出する特徴量として、原稿の色の情報を利用するために、色ヒストグラムや色分散等を特徴量としてもよい。また、分類ルールの構築に利用する特徴量は、上記のような画像データに関する特徴量に限定されるものではない。例えば、負例データ候補群の絞り込みに利用するメタ情報や文書構造情報などの文書ファイル情報を利用してもよい。 Note that the parameters relating to the image resolution, patch size, and patch cutout position are not limited to the above numbers. In addition, a color histogram, color dispersion, or the like may be used as the feature amount in order to use the color information of the document as the feature amount to be calculated. Further, the feature amount used for the construction of the classification rule is not limited to the feature amount related to the image data as described above. For example, document file information such as meta information and document structure information used for narrowing down the negative example data candidate group may be used.
また、本実施形態では、文書をMFP101により画像データとして読み込み、当該画像データを分類する場合について説明したが、これに限られるものではない。例えば、テキスト形式のデータに対しても、本発明の正例データを用いた負例データの絞り込みは適用可能である。
In the present embodiment, a case has been described in which a document is read as image data by the
以上のように、本実施形態によれば、高精度な分類ルールの構築を可能とする高品質な負例データを効率的に生成することができる。 As described above, according to the present embodiment, it is possible to efficiently generate high-quality negative example data that enables construction of a highly accurate classification rule.
(第2実施形態)
第1実施形態では、トレイ212にセットされ画像読取部201により一度に読み取られる原稿を正例データとして利用することを想定していた。これに対して、本実施形態では、トレイ212にセットされ画像読取部201により一度に読み取られる原稿に加え、すでにサーバ102上に格納された文書を正例データとして利用する場合を想定する。以下、第1実施形態との差分についてのみ説明する。
(Second Embodiment)
In the first embodiment, it is assumed that a document set on the
<第2実施形態の詳細説明>
図12は、学習セットを生成し、分類ルールを学習する処理を説明するフローチャートである。
図12に示す処理は、MFP101およびサーバ102にて実行される。MFP101において実行される処理は、CPU204が記憶部203に格納されている処理プログラムをロードして実行することにより実現される。また、サーバ102において実行される処理は、CPU301がHDD305に格納されている処理プログラムをRAM302にロードして実行することにより実現される。
<Detailed Description of Second Embodiment>
FIG. 12 is a flowchart for explaining processing for generating a learning set and learning classification rules.
The process shown in FIG. 12 is executed by the
なお、本実施形態では、ユーザがMFP101を用いて文書(原稿)をスキャンし、その種別毎に文書の画像データをサーバ102に保存するという業務フローの中で、同時にMFP101内で画像データの分類ルールを学習するシステムを想定している。さらに、本実施形態では、分類ルールの学習に利用する文書をサーバ102から取得することを想定している。
In this embodiment, the user scans a document (original) using the
ステップS1201において、MFP101は、正例データとして利用する文書を、原稿フィーダ211から読み込むか、サーバ102から選択するかを受け付ける。原稿フィーダ211から読み込む場合には、処理はステップS1202に進み、サーバ102から選択する場合には、処理はステップS1205に進む。ステップS1202およびステップS1203は、図4のステップS401およびステップS402と同様である。また、ステップS1204は、図4のステップS404と同様である。
In step S <b> 1201, the
ステップS1205において、MFP101は、ユーザから操作部207経由でサーバ102のHDD305内のどの文書を利用するかの指示を受け付ける。サーバ102のCPU301は、ユーザの指示に基づきHDD305内の画像データ群を、インターネット104およびLAN103を経由してMFP101に送信する。ステップS1206において、MFP101は、ステップS1203にて画像読取部201で読み込まれた画像データ群、または、ステップS1205にてサーバ102から受信した画像データ群を、記憶部203に学習セットの正例データ候補群として格納する。
In step S <b> 1205, the
格納する際には、各画像データに負例データ候補群の絞り込みにて利用する文書ファイル情報を付与する。画像読取部201で読み込まれた画像データ群に付与する文書ファイル情報は、図4のステップS403で付与する文書ファイル情報と同様である。一方、サーバ102から受信した画像データ群には、すでに文書ファイル情報が付与されている場合にはその文書ファイル情報を利用する。また、文書ファイル情報が不足している場合には不足している項目について、図4のステップS403で付与する文書ファイル情報と同様の文書ファイル類情報を付与する。
When storing, document file information used for narrowing down the negative example data candidate group is assigned to each image data. The document file information added to the image data group read by the
ステップS1207において、MFP101は、正例データの登録を続けるか否かの指示を、操作部207を介してユーザから受け付ける。正例データの登録を続ける場合には、処理はステップS1201に戻る。正例データの登録を続けない場合には、処理はステップS1208に進む。なお、正例データの登録を続けるか否かの判断は、上記の方法に限られるものではない。例えば、ステップS1206における正例データの登録数をカウントし、あらかじめ操作部207を介してユーザによって設定された正例データの登録数に達するまで正例データの登録を続けてもよい。ステップS1208〜ステップS1210は、図4のステップS406〜ステップS408と同様である。
In step S <b> 1207, the
このように、本実施形態によれば、負例データを作成する際に、MFPから入力された画像データ(正例データ)から得られる文書ファイル情報に加えて、サーバから取得された画像データにすでに付与されている文書ファイル情報を利用することができる。これにより、大量の文書の中からデータの容量を抑えつつ、分類時に入力される可能性の高いデータを負例データとして収集することができ、高精度の分類ルールを効率よく生成することが可能となる。 As described above, according to this embodiment, when creating negative example data, in addition to document file information obtained from image data (positive example data) input from the MFP, image data obtained from the server is added. Document file information that has already been assigned can be used. This makes it possible to collect data that is highly likely to be input at the time of classification as negative example data while suppressing the volume of data from a large amount of documents, and can efficiently generate highly accurate classification rules. It becomes.
(その他の実施形態)
本発明は、上述の実施形態の1以上の機能を実現するプログラムを、ネットワーク又は記憶媒体を介してシステム又は装置に供給し、そのシステム又は装置のコンピュータにおける1つ以上のプロセッサーがプログラムを読出し実行する処理でも実現可能である。また、1以上の機能を実現する回路(例えば、ASIC)によっても実現可能である。
(Other embodiments)
The present invention supplies a program that realizes one or more functions of the above-described embodiments to a system or apparatus via a network or a storage medium, and one or more processors in a computer of the system or apparatus read and execute the program This process can be realized. It can also be realized by a circuit (for example, ASIC) that realizes one or more functions.
以上、本発明の好ましい実施形態について説明したが、本発明は、これらの実施形態に限定されず、その要旨の範囲内で種々の変形および変更が可能である。 As mentioned above, although preferable embodiment of this invention was described, this invention is not limited to these embodiment, A various deformation | transformation and change are possible within the range of the summary.
101 MFP
102 サーバ
101 MFP
102 servers
Claims (10)
受け付けた前記画像データに付与されたファイル情報に含まれる情報のうち少なくとも1つが一致するファイル情報が付与された画像データを負例データとして取得する取得手段と、
前記正例データ及び負例データを用いて、画像データを種別ごとに分類するために用いる分類ルールを生成する生成手段と、を備える
ことを特徴とする情報処理装置。 Receiving means for receiving image data for each type to be classified as positive example data;
Obtaining means for obtaining, as negative example data, image data provided with file information that matches at least one of the information included in the file information provided in the received image data;
An information processing apparatus comprising: generating means for generating a classification rule used for classifying image data for each type using the positive example data and the negative example data.
ことを特徴とする請求項1に記載の情報処理装置。 The information processing apparatus according to claim 1, wherein the file information includes at least meta information of image data.
ことを特徴とする請求項2に記載の情報処理装置。 The information processing according to claim 2, wherein the meta information includes at least one of a title of image data, a creator name, a file format, a creation device, a generation date and time, or a keyword included in the image data. apparatus.
ことを特徴とする請求項1乃至3のいずれか1項に記載の情報処理装置。 The acquisition unit acquires, as negative example data, image data to which file information including information having high co-occurrence in the positive example data is included among the information included in the file information assigned to the positive example data. The information processing apparatus according to any one of claims 1 to 3.
ことを特徴とする請求項1乃至4のいずれか1項に記載の情報処理装置。 The acquisition means includes image data to which file information having a high coincidence rate with information included in file information added to the positive example data among image data acquired as the negative example data is added to the negative example data. The information processing apparatus according to claim 1, wherein the information processing apparatus is not used as an information processing apparatus.
ことを特徴とする請求項1乃至5のいずれか1項に記載の情報処理装置。 The acquisition means classifies the image data acquired as the negative example data for each type based on the keyword of the image data, and when the number of image data classified in each type is greater than the upper limit value, The information processing apparatus according to any one of claims 1 to 5, wherein the image data is deleted so that the number of the classified image data is equal to or less than the upper limit value.
受け付けた前記画像データに付与されたファイル情報に含まれる情報を項目ごとに表示する画面を有し、
前記画面において指定された項目ごとの値が当該画面において指定された条件を満たす画像データを前記負例データとして取得する
ことを特徴とする請求項1乃至6のいずれか1項に記載の情報処理装置。 The acquisition means includes
A screen that displays information included in the file information attached to the received image data for each item;
The information processing according to any one of claims 1 to 6, wherein image data satisfying a value specified for each item specified on the screen satisfying a specified condition is acquired as the negative example data. apparatus.
前記情報処理装置は、
分類する種別ごとの画像データを正例データとして受け付ける受付手段と、
受け付けた前記画像データに付与されたファイル情報に含まれる情報のうち少なくとも1つが一致するファイル情報が付与された画像データを、前記サーバから負例データとして取得する取得手段と、
前記正例データ及び負例データを用いて、画像データを種別ごとに分類するために用いる分類ルールを生成する生成手段と、を備え、
前記サーバは、
前記情報処理装置の要求に応じて、画像データを前記情報処理装置に送信する送信手段を備える
ことを特徴とする情報処理システム。 A system comprising an information processing device and a server,
The information processing apparatus includes:
Receiving means for receiving image data for each type to be classified as positive example data;
Acquisition means for acquiring, as negative example data, image data to which file information that matches at least one of the information included in the file information provided to the received image data is assigned;
Using the positive example data and the negative example data, and generating means for generating a classification rule used for classifying the image data by type,
The server
An information processing system comprising: transmission means for transmitting image data to the information processing apparatus in response to a request from the information processing apparatus.
受け付けた前記画像データに付与されたファイル情報に含まれる情報のうち少なくとも1つが一致するファイル情報が付与された画像データを、負例データとして取得する取得工程と、
前記正例データ及び負例データを用いて、画像データを種別ごとに分類するために用いる分類ルールを生成する生成工程と、を備える
ことを特徴とする情報処理装置の制御方法。 A reception process for receiving image data for each type to be classified as positive example data;
An acquisition step of acquiring, as negative example data, image data provided with file information that matches at least one of the information included in the file information provided in the received image data;
And a generating step of generating a classification rule used for classifying image data for each type using the positive example data and the negative example data.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016027352A JP2017146745A (en) | 2016-02-16 | 2016-02-16 | Information processing apparatus, control method, information processing system, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016027352A JP2017146745A (en) | 2016-02-16 | 2016-02-16 | Information processing apparatus, control method, information processing system, and program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2017146745A true JP2017146745A (en) | 2017-08-24 |
Family
ID=59681393
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016027352A Pending JP2017146745A (en) | 2016-02-16 | 2016-02-16 | Information processing apparatus, control method, information processing system, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2017146745A (en) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019117553A (en) * | 2017-12-27 | 2019-07-18 | 富士フイルム株式会社 | Information presentation device, method and program |
| JP2019159824A (en) * | 2018-03-13 | 2019-09-19 | 富士通株式会社 | Learning program, learning method and learning device |
| JP2020149409A (en) * | 2019-03-14 | 2020-09-17 | セイコーエプソン株式会社 | Information processing equipment, machine learning equipment and information processing methods |
| JP2020166461A (en) * | 2019-03-29 | 2020-10-08 | 株式会社野村総合研究所 | Data wrangling work support device, data wrangling work support method and data wrangling work support program |
| WO2021152883A1 (en) * | 2020-01-31 | 2021-08-05 | 株式会社日立製作所 | Recommendation system, configuration method therefor, and recommendation method |
| JP2021131610A (en) * | 2020-02-18 | 2021-09-09 | 富士フイルムビジネスイノベーション株式会社 | Trail management device and trail management program |
| CN113676609A (en) * | 2020-05-15 | 2021-11-19 | 夏普株式会社 | Image forming apparatus and document data classifying method |
| WO2022065216A1 (en) * | 2020-09-23 | 2022-03-31 | 富士フイルム株式会社 | Feature quantity selecting method, feature quantity selecting program, feature quantity selecting device, multiclass classification method, multiclass classification program, multiclass classification device, and feature quantity set |
-
2016
- 2016-02-16 JP JP2016027352A patent/JP2017146745A/en active Pending
Cited By (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019117553A (en) * | 2017-12-27 | 2019-07-18 | 富士フイルム株式会社 | Information presentation device, method and program |
| US10929723B2 (en) | 2017-12-27 | 2021-02-23 | Fujifilm Corporation | Information presenting apparatus, information presenting method and program |
| JP7006401B2 (en) | 2018-03-13 | 2022-01-24 | 富士通株式会社 | Learning programs, learning methods and learning devices |
| JP2019159824A (en) * | 2018-03-13 | 2019-09-19 | 富士通株式会社 | Learning program, learning method and learning device |
| JP2020149409A (en) * | 2019-03-14 | 2020-09-17 | セイコーエプソン株式会社 | Information processing equipment, machine learning equipment and information processing methods |
| CN111695568A (en) * | 2019-03-14 | 2020-09-22 | 精工爱普生株式会社 | Information processing apparatus, machine learning apparatus, and information processing method |
| CN111695568B (en) * | 2019-03-14 | 2023-08-18 | 精工爱普生株式会社 | Information processing device, machine learning device, and information processing method |
| US11335107B2 (en) | 2019-03-14 | 2022-05-17 | Seiko Epson Corporation | Generating file name using machine-learned model that relearns |
| JP2020166461A (en) * | 2019-03-29 | 2020-10-08 | 株式会社野村総合研究所 | Data wrangling work support device, data wrangling work support method and data wrangling work support program |
| JP7253161B2 (en) | 2019-03-29 | 2023-04-06 | 株式会社野村総合研究所 | Data wrangling work support device, data wrangling work support method, and data wrangling work support program |
| JP2021121890A (en) * | 2020-01-31 | 2021-08-26 | 株式会社日立製作所 | Recommendation system, how to configure it, and how to recommend |
| JP7242585B2 (en) | 2020-01-31 | 2023-03-20 | 株式会社日立製作所 | Recommendation system and recommendation method |
| WO2021152883A1 (en) * | 2020-01-31 | 2021-08-05 | 株式会社日立製作所 | Recommendation system, configuration method therefor, and recommendation method |
| JP2021131610A (en) * | 2020-02-18 | 2021-09-09 | 富士フイルムビジネスイノベーション株式会社 | Trail management device and trail management program |
| CN113676609A (en) * | 2020-05-15 | 2021-11-19 | 夏普株式会社 | Image forming apparatus and document data classifying method |
| CN113676609B (en) * | 2020-05-15 | 2024-05-14 | 夏普株式会社 | Image forming apparatus and document data classification method |
| WO2022065216A1 (en) * | 2020-09-23 | 2022-03-31 | 富士フイルム株式会社 | Feature quantity selecting method, feature quantity selecting program, feature quantity selecting device, multiclass classification method, multiclass classification program, multiclass classification device, and feature quantity set |
| JP7551231B2 (en) | 2020-09-23 | 2024-09-17 | 富士フイルム株式会社 | FEATURE SELECTION METHOD, FEATURE SELECTION PROGRAM, FEATURE SELECTION DEVICE, MULTI-CLASS CLASSIFICATION METHOD, MULTI-CLASS CLASSIFICATION PROGRAM, MULTI-CLASS CLASSIFICATION DEVICE, AND RECORDING MEDIUM |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2017146745A (en) | Information processing apparatus, control method, information processing system, and program | |
| US7623259B2 (en) | Image processing apparatus and image processing method to store image data for subsequent retrieval | |
| US8726178B2 (en) | Device, method, and computer program product for information retrieval | |
| JP4574235B2 (en) | Image processing apparatus, control method therefor, and program | |
| JP4310356B2 (en) | Image processing method, image processing apparatus, image reading apparatus, image forming apparatus, computer program, and recording medium | |
| US9454696B2 (en) | Dynamically generating table of contents for printable or scanned content | |
| EP1752895A1 (en) | Image processing apparatus for image retrieval and control method therefor | |
| JP2017107455A (en) | Information processing apparatus, control method, and program | |
| JP2007042106A (en) | Document processing method, document processing medium, document management method, document processing system, and document management system | |
| US11341733B2 (en) | Method and system for training and using a neural network for image-processing | |
| US8090728B2 (en) | Image processing apparatus, control method thereof, and storage medium that stores program thereof | |
| US8223389B2 (en) | Information processing apparatus, information processing method, and program and storage medium therefor | |
| JP6672668B2 (en) | Image processing device and program | |
| US20200050405A1 (en) | Image processing apparatus, method for controlling the same and storage medium | |
| US20220350956A1 (en) | Information processing apparatus, information processing method, and storage medium | |
| US11521404B2 (en) | Information processing apparatus and non-transitory computer readable medium for extracting field values from documents using document types and categories | |
| JP4213112B2 (en) | Image search apparatus, image forming apparatus, image search apparatus control method, image search program, and computer-readable recording medium | |
| US8219594B2 (en) | Image processing apparatus, image processing method and storage medium that stores program thereof | |
| WO2017110640A1 (en) | Image-processing device, image-processing method, and computer program | |
| US8531717B2 (en) | Image processing enabling reduction of processing time for data conversion | |
| JP4811133B2 (en) | Image forming apparatus and image processing apparatus | |
| JP6494435B2 (en) | Information processing apparatus, control method thereof, and computer program | |
| US12266204B2 (en) | Information processing apparatus, image forming apparatus, and information processing method for automatically ordering page | |
| US20230419709A1 (en) | Information processing apparatus, image forming apparatus, and information processing method for easily setting rules for ordering page data | |
| US20230419707A1 (en) | Information processing apparatus, image forming apparatus, and information processing method for automatically dividing page data |