JP2017016384A - Mixed coefficient parameter learning device, mixed occurrence probability calculation device, and programs thereof - Google Patents
Mixed coefficient parameter learning device, mixed occurrence probability calculation device, and programs thereof Download PDFInfo
- Publication number
- JP2017016384A JP2017016384A JP2015132347A JP2015132347A JP2017016384A JP 2017016384 A JP2017016384 A JP 2017016384A JP 2015132347 A JP2015132347 A JP 2015132347A JP 2015132347 A JP2015132347 A JP 2015132347A JP 2017016384 A JP2017016384 A JP 2017016384A
- Authority
- JP
- Japan
- Prior art keywords
- occurrence probability
- probability
- vector
- neural network
- mixed
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images





Abstract
Description
本願発明は、混合係数の算出に必要なパラメータを学習する混合係数パラメータ学習装置、ニューラルネットワーク確率モデルと他の確率モデルとの混合生起確率を算出する混合生起確率算出装置、及び、これらのプログラムに関する。 The present invention relates to a mixing coefficient parameter learning device that learns parameters necessary for calculating a mixing coefficient, a mixed occurrence probability calculation device that calculates a mixed occurrence probability between a neural network probability model and another probability model, and a program thereof. .
統計的言語モデル(以後、「言語モデル」)とは、ある言語又はドメインにおいて、単語系列w1w2…wnが生起する確率p(w1w2…wn)を計算する手段、及び、その手段によって計算するのに必要な各種統計量の一覧として定義される。言語モデルによって言語の生起を確率モデル化することは、統計的自然言語処理の最も基本的な技術の一つであり、音声認識、機械翻訳をはじめとする各種自然言語処理技術に用いられている。
Statistical language model (hereinafter, "language model") and comprises means for calculating in a language or domain, the
なお、言語モデルとは、ある言語、又は、その言語の特定分野における表現(単語系列)生起の確率モデルのことであり、一般的には予め与えられた当該言語又はその言語の当該分野のコーパスから学習する。
また、コーパスとは、ある言語又はその言語の特定分野で観測された単語系列の実例である。
また、w1,w2,wnは、単語を表す。
The language model is a probability model of occurrence of an expression (word sequence) in a specific language or a specific field of the language, and is generally a predetermined language or a corpus of the language in the field. To learn from.
A corpus is an example of a word sequence observed in a certain language or a specific field of the language.
In addition, w 1, w 2, w n represents the word.
単語系列の生起確率p(w1w2…wn)は、一般的には、系列の各単語がそれ以前の単語系を前文脈として生起する確率の積、すなわち、p(w1)×p(w2|w1)×p(w3|w1w2)×…×p(wn|w1w2…wn−1)としてモデル化される。つまり、言語モデルは、前文脈が与えられた条件下での次単語生起の予測モデルであると言える。 The occurrence probability p (w 1 w 2 ... W n ) of a word sequence is generally the product of the probabilities that each word of the sequence occurs with the previous word system as the previous context, that is, p (w 1 ) × It is modeled as p (w 2 | w 1 ) × p (w 3 | w 1 w 2 ) ×... × p (w n | w 1 w 2 ... w n−1 ). That is, it can be said that the language model is a prediction model for occurrence of the next word under the condition given the previous context.
言語モデルの最も一般的な実現手法は、n−gram言語モデルである。このn−gram言語モデルは、前記条件となる前文脈を直近のn−1単語に制限し(但し、nは1以上の整数)、学習コーパスから、n−1単語の列である前文脈の異なり毎に次単語生起頻度を収集した結果に基づき、各前文脈条件下の次単語生起確率を推定するものである。 The most common implementation method of the language model is an n-gram language model. This n-gram language model restricts the preceding context as the condition to the nearest n-1 words (where n is an integer equal to or greater than 1), and from the learning corpus, the previous context is a string of n-1 words. The next word occurrence probability under each previous context condition is estimated based on the result of collecting the next word occurrence frequency for each difference.
n−gram言語モデルでは、精度よく次単語の生起確率を推定するために長い前文脈を参照する(大きな値のnを用いる)必要がある。また、n−gram言語モデルでは、各前文脈に対して十分な実例を集める必要があるが、長い前文脈を用いるほど前文脈の異なりが増加するため、正確性を向上させるために非常に大きな学習コーパスを用意する必要がある。 In the n-gram language model, it is necessary to refer to a long previous context (using a large value of n) in order to accurately estimate the occurrence probability of the next word. Also, in the n-gram language model, it is necessary to collect sufficient examples for each previous context, but the longer the previous context, the more the difference in the previous context increases, so it is very large to improve accuracy. A learning corpus needs to be prepared.
近年、このn−gram言語モデルに対して、ニューラルネットワークを用いた言語モデル実現手法が提案されている。この手法は、ニューラルネットワークを用いて、各単語を表すものとして、固定次元で各次元が実数値である単語表現ベクトルへの写像を学習し、前文脈として単語列の各単語に対応する単語表現ベクトルの組み合わせを用いるものである。 In recent years, a language model realization method using a neural network has been proposed for this n-gram language model. This method uses a neural network to learn a mapping to a word expression vector with a fixed dimension and each dimension as a real value as representing each word, and the word expression corresponding to each word in the word sequence as the previous context A combination of vectors is used.
例えば、非特許文献1に記載のNNLM(Neural Network Language Model)は、図5のようなニューラルネットワークを構築する。以後、言語モデルについて、有限個|V|種類の単語のみを扱うものとし、各単語は1〜|V|の数値として表すことにする。このとき、|V|種類の単語の中には、必ず文頭を表す特殊な単語を含むものとする。ここで、各単語wに対応する予め定めた固定次元数mの単語表現ベクトルをC(w)とする。また、単語系列w1w2…wtの生起に関して、単語wtのn−1個の前文脈を表すn−1個の単語表現ベクトルを連結したn×m次元の入力ベクトルx(t)=[C(wt−n+1),…,C(wt−2),C(wt−1)]から予め定めた固有次元数hのベクトルへの線形写像をHx(t)とする。
なお、前文脈の長さがn−1未満である(すなわちt<nである)場合には、単語w1の前にn−t個の文頭を表す単語を補うことで入力ベクトルx(t)を作成するものとする。
For example, NNLM (Neural Network Language Model) described in
If the length of the previous context is less than n−1 (ie, t <n), the input vector x (t (t) is obtained by supplementing the word w 1 with the word representing the beginning of the sentence before the word w 1. ).
また、線形写像Hx(t)の各次元を非線形関数f(例えば、双曲線正接関数tanh)で変換した隠れ層ベクトルz(t)から|V|次元ベクトルy(t)への線形写像をUz(t)とする。
また、y(t)の各次元を式(1)に示す関数で変換した|V|次元ベクトルを出力ベクトルp(t)とする。この場合、次単語がwtである確率を以下の式(1)〜式(3)のように定義する(但し、yiはyのi次元の値)。
また、入力ベクトルx(t)の(t)は、前文脈w1w2…wt−1に後続する次単語wtの生起確率に関わる入力ベクトルxを意味する(他のベクトルも同様)。
また、図5の‘○’はベクトルの要素を表す。
Further, a linear mapping from a hidden layer vector z (t) obtained by converting each dimension of the linear mapping Hx (t) with a nonlinear function f (for example, a hyperbolic tangent function tanh) to a | V | -dimensional vector y (t) is expressed as Uz ( t).
Also, a | V | -dimensional vector obtained by converting each dimension of y (t) with the function shown in Expression (1) is set as an output vector p (t). In this case, the probability that the next word is w t is defined as in the following equations (1) to (3) (where y i is the i-dimensional value of y).
Further, (t) of the input vector x (t) means the input vector x related to the occurrence probability of the next word w t following the previous context w 1 w 2 ... W t−1 (the same applies to other vectors). .
Further, “◯” in FIG. 5 represents a vector element.
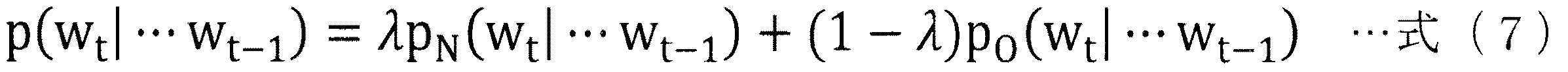
![]()
![]()
![]()
![]()
n,m,hを予め設定し、学習コーパスの各単語wtに対して、前文脈wt−n+1,…,wt−2,wt−1をニューラルネットワークに入力して次単語生起の確率分布を出力(順方向伝搬)し、出力ベクトルと正解ベクトルとの交差エントロピー誤差をニューラルネットワークに逆方向伝搬させながら、以下の式(4)〜式(6)のように単語表現ベクトルC、入力層から隠れ層への重みH、隠れ層から出力層への重みUを確率的勾配降下法により更新する(但し、εは更新率)。これを学習コーパス全体で何回か繰り返すことによって学習を実現する。
なお、正解ベクトルとは、単語wtの生起確率を1とし、それ以外の単語の生起確率を0としたベクトルである。
n, m, h are set in advance, and for each word w t in the learning corpus, the previous contexts w t−n + 1 ,..., w t−2 , w t−1 are input to the neural network to generate the next word occurrence. While outputting the probability distribution (forward propagation) and propagating the cross-entropy error between the output vector and the correct vector to the neural network in the backward direction, the word expression vector C as shown in the following equations (4) to (6): The weight H from the input layer to the hidden layer and the weight U from the hidden layer to the output layer are updated by the stochastic gradient descent method (where ε is the update rate). Learning is realized by repeating this several times in the entire learning corpus.
The correct vector is a vector in which the occurrence probability of the word w t is 1, and the occurrence probabilities of other words are 0.
![]()
![]()
![]()
![]()
![]()
![]()
単語表現ベクトルCの学習の結果、類似した単語が近い単語表現ベクトルに写像され、Hの学習の結果、類似した単語が近い隠れ層ベクトルに写像されるので、小規模な学習コーパスから学習した場合でも高い正確性を得ることができる。 As a result of learning the word expression vector C, similar words are mapped to the nearest word expression vector, and as a result of learning H, similar words are mapped to the nearest hidden layer vector, so when learning from a small learning corpus But you can get high accuracy.
また、NNLMとは異なる手法として、非特許文献2に記載のRNNLM(Recurrent Neural Network Language Model)が提案されている。前記したように、NNLMでは、単語wtに対して予め定めたn−1個の単語wt−n+1,…,wt−2,wt−1から前文脈を表す隠れ層ベクトルz(t)を計算する。一方、このRNNLMは、図6のように、隠れ層ベクトルz(t)を、1つ前の単語wt−1及びこの単語wt−1に対する前文脈を表す隠れ層ベクトルz(t−1)から計算する。これにより、RNNLMは、明示的な前文脈長nを与えることなく、長い前文脈を反映した次単語生起の予測を行うことを可能にする。
Further, as a method different from NNLM, RNNLM (Recurrent Neural Network Language Model) described in
一般的には、これらニューラルネットワーク言語モデルは、他の言語モデル(例えば、n−gram言語モデル)と組み合わせて用いられる。具体的には、ニューラルネットワーク言語モデルによる生起確率をpN、他の言語モデルによる生起確率をpO、混合比率をλとする。この場合、以下の式(7)のように、λ:1−λの比率で両言語モデルの生起確率pN,pOを混合したものを混合生起確率pとして算出する。 Generally, these neural network language models are used in combination with other language models (for example, n-gram language models). Specifically, the occurrence probability by the neural network language model is p N , the occurrence probability by another language model is p O , and the mixing ratio is λ. In this case, as shown in the following formula (7), a mixture of the occurrence probabilities p N and p O of the two language models at a ratio of λ: 1−λ is calculated as the mixed occurrence probability p.
![]()
![]()
なお、式(7)では、λが混合係数を表す。通常、混合係数λは、学習済みの両言語モデルを用意した上で、別途用意したテストコーパスに対して最も正確性が高くなる値を決定し、決定した値を固定的に用いる。 In Equation (7), λ represents a mixing coefficient. In general, the mixed coefficient λ is prepared by preparing a learned bilingual model, determining a value with the highest accuracy with respect to a separately prepared test corpus, and using the determined value in a fixed manner.
このように生起確率を混合するには、以下のような理由がある。
1)ニューラルネットワーク言語モデルでは学習コーパスに表れなかった単語(未知語)の生起確率を推定する一般的手法がないが、n−gram言語モデルでは未知語に適切な生起確率を割り当てることができる。
2)ニューラルネットワーク言語モデルは学習のための計算量がn−gram言語モデルと比較して非常に大きいため、ニューラルネットワーク言語モデルで小規模のドメインに特化した学習コーパスを用いて学習し、より広範囲の大規模な学習コーパスから学習したn−gram言語モデルと組み合わせることが現実的である。
There are the following reasons for mixing the occurrence probabilities in this way.
1) Although there is no general method for estimating the occurrence probability of a word (unknown word) that did not appear in the learning corpus in the neural network language model, an appropriate occurrence probability can be assigned to the unknown word in the n-gram language model.
2) Since the neural network language model has a very large amount of calculation for learning compared to the n-gram language model, the neural network language model learns using a learning corpus specialized for small domains in the neural network language model. It is realistic to combine with an n-gram language model learned from a wide range of large-scale learning corpora.
しかし、ニューラルネットワーク言語モデルでは、前文脈に関係なく固定的な混合係数を用いているため、混合生起確率の正確性が低くなるという問題がある。例えば、前文脈「私は」の次に表れる単語を正確に予測するためには巨大な学習コーパスで学習する必要がある。一方、前文脈「私は山にいきまし」の次に表れる単語は「た」「て」くらいしかあり得ず、小規模な学習コーパスで学習しても正確に予測可能である。すなわち、ニューラルネットワーク言語モデルでは、前文脈に応じて異なる混合係数を用いることで、混合生起確率の正確性を向上させることができる。 However, since the neural network language model uses a fixed mixing coefficient regardless of the previous context, there is a problem that the accuracy of the mixed occurrence probability is lowered. For example, in order to accurately predict the word appearing next to the previous context “I am”, it is necessary to learn with a huge learning corpus. On the other hand, the word that appears next to the previous context “I went to the mountain” can only be about “ta” and “te”, and can be accurately predicted even by learning with a small learning corpus. In other words, the neural network language model can improve the accuracy of the mixed occurrence probability by using different mixing coefficients depending on the previous context.
本願発明は、前記した課題に鑑みて、混合生起確率の正確性を向上させる混合係数パラメータ学習装置、混合生起確率算出装置、及び、これらのプログラムを提供することを課題とする。 This invention makes it a subject to provide the mixing coefficient parameter learning apparatus, the mixing occurrence probability calculation apparatus, and these programs which improve the precision of mixing occurrence probability in view of an above described subject.
前記した課題に鑑みて、本願発明に係る混合係数パラメータ学習装置は、ニューラルネットワーク確率モデルと前記ニューラルネットワーク確率モデル以外の他の確率モデルとのそれぞれで求めた前要素系列に対する次要素の生起確率を混合するときの混合係数の算出に必要なパラメータを学習する混合係数パラメータ学習装置であって、第1生起確率入力手段と、第2生起確率入力手段と、第1混合係数算出手段と、写像ベクトル更新手段と、更新率減少手段と、終了条件判定手段とを備える構成とした。 In view of the problems described above, the mixing coefficient parameter learning device according to the present invention determines the occurrence probability of the next element with respect to the previous element sequence obtained by each of the neural network probability model and the other probability models other than the neural network probability model. A mixing coefficient parameter learning device for learning parameters necessary for calculating a mixing coefficient when mixing, a first occurrence probability input means, a second occurrence probability input means, a first mixing coefficient calculation means, a mapping vector The update unit, the update rate reduction unit, and the end condition determination unit are provided.
かかる構成によれば、混合係数パラメータ学習装置は、第1生起確率入力手段によって、前記ニューラルネットワーク確率モデルの隠れ層ベクトルと、前記ニューラルネットワーク確率モデルで求めた生起確率とが入力される。 According to such a configuration, the mixed coefficient parameter learning apparatus receives the hidden layer vector of the neural network probability model and the occurrence probability obtained by the neural network probability model by the first occurrence probability input means.
すなわち、学習済みのニューラルネットワーク確率モデルに前要素系列を入力すると、ニューラルネットワーク確率モデルの隠れ層ベクトルとして、汎化された前要素の表現が得られる。従って、学習済みのニューラルネットワーク確率モデルの隠れ層ベクトルから混合係数への写像ベクトルを学習すれば、前要素系列に応じた混合係数を求めることが可能となる。 That is, when a previous element sequence is input to a learned neural network probability model, a generalized expression of the previous element is obtained as a hidden layer vector of the neural network probability model. Therefore, if a mapping vector from a hidden layer vector of a learned neural network probability model to a mixture coefficient is learned, a mixture coefficient corresponding to the previous element sequence can be obtained.
混合係数パラメータ学習装置は、第2生起確率入力手段によって、前記他の確率モデルで求めた生起確率が入力される。
混合係数パラメータ学習装置は、第1混合係数算出手段によって、予め設定された写像ベクトルにより前記隠れ層ベクトルを実数値のスカラに線形写像し、前記実数値のスカラをシグモイド関数で非線形変換することで、前記混合係数を算出する。
In the mixing coefficient parameter learning device, the occurrence probability obtained by the other probability model is input by the second occurrence probability input means.
The mixing coefficient parameter learning device linearly maps the hidden layer vector to a real-valued scalar according to a preset mapping vector by the first mixing coefficient calculation means, and nonlinearly converts the real-valued scalar by a sigmoid function. And calculating the mixing coefficient.
混合係数パラメータ学習装置は、写像ベクトル更新手段によって、前記ニューラルネットワーク確率モデルと前記他の確率モデルとのそれぞれで求めた生起確率、前記混合係数、及び、予め設定された更新率を用いた確率的勾配降下法により、前記パラメータとしての前記写像ベクトルを更新する。 The mixing coefficient parameter learning device uses the mapping vector update means to generate the probabilities of occurrence of the neural network probability model and the other probability models, the mixing coefficient, and a probabilistic value using a preset update rate. The mapping vector as the parameter is updated by a gradient descent method.
混合係数パラメータ学習装置は、更新率減少手段によって、予め設定された更新率減少規則に従って前記更新率を減少させる。
混合係数パラメータ学習装置は、終了条件判定手段によって、予め設定された終了条件を満たすか否かを判定し、前記終了条件を満たすまで、減少させた前記更新率で前記写像ベクトル更新手段に前記写像ベクトルを更新させる。例えば、この終了条件は、更新率を減少させても、生起確率が変化しないという条件である。
The mixing coefficient parameter learning device decreases the update rate according to a preset update rate decrease rule by the update rate decrease means.
The mixing coefficient parameter learning device determines whether or not a predetermined end condition is satisfied by an end condition determining unit, and the mapping vector updating unit reduces the update rate to the mapping vector update unit until the end condition is satisfied. Update the vector. For example, the termination condition is a condition that the occurrence probability does not change even if the update rate is decreased.
また、前記した課題に鑑みて、本願発明に係る混合生起確率算出装置は、ニューラルネットワーク確率モデルと前記ニューラルネットワーク確率モデル以外の他の確率モデルとのそれぞれで求めた前要素系列に対する次要素の生起確率を混合した混合生起確率を算出する混合生起確率算出装置であって、第3生起確率入力手段と、第4生起確率入力手段と、第2混合係数算出手段と、混合生起確率算出手段とを備える構成とした。 Further, in view of the above-described problems, the mixed occurrence probability calculation device according to the present invention provides the occurrence of the next element with respect to the previous element sequence obtained by each of the neural network probability model and another probability model other than the neural network probability model. A mixed occurrence probability calculating device for calculating a mixed occurrence probability in which probabilities are mixed, comprising: a third occurrence probability input means; a fourth occurrence probability input means; a second mixing coefficient calculation means; and a mixed occurrence probability calculation means. It was set as the structure provided.
かかる構成によれば、混合生起確率算出装置は、第3生起確率入力手段によって、前記ニューラルネットワークの隠れ層ベクトルと、前記ニューラルネットワーク確率モデルで求めた生起確率とが入力される。
混合生起確率算出装置は、第4生起確率入力手段によって、前記他の確率モデルで求めた生起確率が入力される。
According to such a configuration, the mixed occurrence probability calculation device receives the hidden layer vector of the neural network and the occurrence probability obtained by the neural network probability model by the third occurrence probability input unit.
In the mixed occurrence probability calculation device, the occurrence probability obtained by the other probability model is input by the fourth occurrence probability input means.
混合生起確率算出装置は、第2混合係数算出手段によって、本願発明に係る混合係数パラメータ学習装置が学習した写像ベクトルで前記隠れ層ベクトルを実数値のスカラに線形写像し、前記実数値のスカラをシグモイド関数で非線形変換することで、前要素系列に応じた混合係数を算出する。 The mixed occurrence probability calculating device linearly maps the hidden layer vector to a real-valued scalar with the mapping vector learned by the mixed-coefficient parameter learning device according to the present invention by the second mixing coefficient calculating means, and converts the real-valued scalar into the real-valued scalar. By performing non-linear transformation with a sigmoid function, a mixing coefficient corresponding to the previous element series is calculated.
混合生起確率算出装置は、混合生起確率算出手段によって、前要素系列に応じた前記混合係数を用いて、前記ニューラルネットワーク確率モデルと前記他の確率モデルとで求めた前記次要素の生起確率を混合することで、前記混合生起確率を算出する。 The mixed occurrence probability calculating device mixes the occurrence probabilities of the next element obtained by the neural network probability model and the other probability models by using the mixing coefficient corresponding to the previous element series by the mixed occurrence probability calculating means. Thus, the mixed occurrence probability is calculated.
本願発明は、以下のような優れた効果を奏する。
本願発明によれば、学習済みのニューラルネットワーク確率モデルの隠れ層ベクトルから混合係数への写像ベクトルを学習する。これにより、前要素系列に応じた混合係数が求められるので、混合生起確率の正確性を向上させることができる。
The present invention has the following excellent effects.
According to the present invention, a mapping vector from a hidden layer vector of a learned neural network probability model to a mixture coefficient is learned. Thereby, since the mixing coefficient according to the previous element series is obtained, the accuracy of the mixing occurrence probability can be improved.
以下、本願発明の実施形態に係る混合生起確率算出システム1について説明する。
最初に、図1を参照し、写像ベクトルの学習手順と、混合生起確率の算出手順とを説明する。その後、混合生起確率算出システム1の構成について説明する。
Hereinafter, the mixed occurrence
First, the mapping vector learning procedure and the mixed occurrence probability calculation procedure will be described with reference to FIG. Thereafter, the configuration of the mixed occurrence
ここで、前文脈(前要素系列)を表現したh次元の隠れ層ベクトルを持ち、この隠れ層ベクトルからの写像として次単語の生起確率を演算するニューラルネットワーク言語モデル演算装置10があることとする。このニューラルネットワーク言語モデル演算装置10は、生起確率の計算に必要な各統計量が学習コーパス等により学習済みであることとする。
Here, it is assumed that there is a neural network language
また、n−gram言語モデル等の他の言語モデルで次単語の生起確率を推定する他言語モデル演算装置20(図2)があることとする。この他言語モデル演算装置20では、生起確率の計算に必要な各統計量が学習コーパス等により学習済みであることとする。
なお、他言語モデル演算装置20の各統計量を学習するために用いる学習コーパス等は、前記のニューラルネットワーク言語モデル演算装置10の各統計量を学習するために用いた学習コーパスと同一である必要はない。
Further, it is assumed that there is another language model calculation device 20 (FIG. 2) that estimates the occurrence probability of the next word using another language model such as an n-gram language model. In this other language
The learning corpus used for learning each statistic of the other language
<写像ベクトルの学習手順>
ニューラルネットワーク言語モデル演算装置10に前文脈を入力すると、隠れ層ベクトルとして、汎化された前文脈の表現が得られる。そこで、本願発明は、図1のように、ニューラルネットワーク言語モデル演算装置10に、隠れ層ベクトルzから混合係数λへの写像を行う処理を追加し、この写像ベクトルSを学習することとする。
<Mapping vector learning procedure>
When the previous context is input to the neural network language
具体的には、ニューラルネットワーク言語モデルによる処理に以下の式(8)及び式(9)の処理を加えることで、前文脈…wt−1が与えられたときの次単語wtの生起確率の算出に必要な混合係数λ(t)を計算するようにする。 Specifically, by adding the processing of the following equations (8) and (9) to the processing by the neural network language model, the occurrence probability of the next word w t when the previous context... W t−1 is given. The mixing coefficient λ (t) necessary for calculating is calculated.
![]()
![]()
![]()
![]()
なお、式(8)は、実数値のスカラs(t)から混合係数λ(t)へのシグモイド関数による非線形変換を表している。
また、式(9)は、隠れ層ベクトルz(t)から実数値のスカラs(t)への線形写像Sz(t)を表している。また、式(9)では、bがバイアス値を表している。
Equation (8) represents a nonlinear conversion by a sigmoid function from a real-valued scalar s (t) to a mixing coefficient λ (t).
Equation (9) represents a linear mapping Sz (t) from a hidden layer vector z (t) to a real-valued scalar s (t). In Expression (9), b represents the bias value.
写像ベクトルS及びバイアス値bの学習は、何らかの学習コーパス中の各単語wtについて、生起確率pN(wt|…wt−1)と生起確率pO(wt|…wt−1)とを式(8)で定義される混合係数λ(t)を用いて、以下の式(10)に従って混合した混合生起確率p(wt|…wt−1)が最大となるように、以下の手順1〜手順3で行う。
Learning of the mapping vector S and the bias value b, for each word w t in some learning corpus, the occurrence probability p N (w t | ... w t-1) and the occurrence probability p O (w t | ... w t-1 ) And the mixing coefficient λ (t) defined by the equation (8) so that the mixed occurrence probability p (w t |... W t−1 ) is maximized according to the following equation (10). The following
![]()
![]()
なお、学習コーパスは、ニューラルネットワーク言語モデルや別の言語モデルの学習に用いたコーパスと同じもの、又は、そのコーパスと異なるものでもよい。
また、生起確率pN(wt|…wt−1)は、前文脈…wt−1をニューラルネットワーク言語モデルに与えて得られる次単語wtの生起確率である。
また、生起確率pO(wt|…wt−1)は、前文脈…wt−1を他の言語モデルに与えて得られる次単語wtの生起確率である。
Note that the learning corpus may be the same as or different from the corpus used to learn the neural network language model or another language model.
The occurrence probability p N (w t |... W t-1 ) is the occurrence probability of the next word w t obtained by giving the previous context... W t-1 to the neural network language model.
The occurrence probability p O (w t |... W t-1 ) is the occurrence probability of the next word w t obtained by giving the previous context ... w t-1 to another language model.
手順1.更新率εを予め設定する。
手順2.学習コーパス中の各単語wtに対して以下の(a)〜(c)の処理を実行する。
(a)ニューラルネットワーク言語モデル演算装置10に適宜(NNMLのように前文脈が固定されている場合、その長さで区切った)前文脈…wt−1を入力して順方向伝搬を行うことで、隠れ層ベクトルz(t)及び次単語wtの生起確率pN(wt|…wt−1)を求める。同様に、他の言語モデルの生起確率pO(wt|…wt−1)を求める。
(A) The forward context is input to the neural network language
(b)隠れ層から順方向伝搬を行うことで、混合係数λ(t)を求める。すなわち、式(8)及び式(9)を用いて、混合係数λ(t)を求める。 (B) The mixing coefficient λ (t) is obtained by performing forward propagation from the hidden layer. That is, the mixing coefficient λ (t) is obtained using the equations (8) and (9).
(c)確率的勾配降下法により写像ベクトルSを更新する。すなわち、h次元の写像ベクトルSの各次元Siを、以下の式(11)及び式(12)のように混合係数λ(t)が反映された確率的勾配降下法により更新する。 (C) Update the mapping vector S by the stochastic gradient descent method. That is, each dimension S i of the h-dimensional mapping vector S is updated by a probabilistic gradient descent method in which the mixing coefficient λ (t) is reflected as in the following expressions (11) and (12).
![]()
![]()
さらに、式(9)のバイアス値bも学習の対象となる。このため、以下の式(13)及び式(14)のようにバイアス値bも更新する。 Further, the bias value b in the equation (9) is also a learning target. For this reason, the bias value b is also updated as in the following equations (13) and (14).
![]()
![]()
手順2(c)において、写像ベクトルSを更新する際、ニューラルネットワーク言語モデルによる過学習を防止するため、一例として式(15)のように、正則化を行ってもよい。さらに、バイアス値bについても、写像ベクトルSと同様、正則化を行ってもよい。
なお、式(15)では、βが正則化係数を表す。例えば、正則化係数βは、更新率εより小さな値とする。
In the procedure 2 (c), when the mapping vector S is updated, regularization may be performed as shown in Expression (15) as an example in order to prevent over-learning by the neural network language model. Further, the bias value b may be regularized as with the mapping vector S.
In equation (15), β represents a regularization coefficient. For example, the regularization coefficient β is set to a value smaller than the update rate ε.
![]()
![]()
手順3.所定の終了条件に合致するまで、手順2に戻って処理を繰り返す。このとき、所定の更新率減少規則に従って、更新率εを減少させる。
なお、終了条件及び更新率減少規則の詳細は、後記する。
Details of the termination condition and the update rate reduction rule will be described later.
<混合生起確率の算出手順>
次単語wtの生起確率の計算は、前記した学習結果を用いて、以下の手順4〜手順6で行う。
<Procedure for calculating mixed occurrence probability>
The occurrence probability of the next word w t is calculated by the following procedure 4 to procedure 6 using the learning result described above.
手順4.ニューラルネットワーク言語モデル演算装置に適宜(NNMLのように前文脈が固定されている場合、その長さで区切った)前文脈…wt−1を入力して順方向伝搬を行うことで、隠れ層ベクトルz(t)及び次単語wtの生起確率pN(wt|…wt−1)を求める。同様に、他の言語モデルの生起確率pO(wt|…wt−1)を求める。
なお、この手順4は、写像ベクトルSの学習手順2(a)と同じ処理である。
Procedure 4. Hidden layer by inputting forward context ... w t-1 to the neural network language model arithmetic unit as appropriate (when the previous context is fixed like NNML, divided by its length) and performing forward propagation The occurrence probability p N (w t |... W t−1 ) of the vector z (t) and the next word w t is obtained. Similarly, occurrence probabilities p O (w t |... W t−1 ) of other language models are obtained.
This procedure 4 is the same process as the learning procedure 2 (a) of the mapping vector S.
手順5.隠れ層から順方向伝搬を行うことで、混合係数λ(t)を求める。すなわち、学習した写像ベクトルS及びバイアス値bを式(9)に代入して、混合係数λ(t)を求める。なお、この手順5は、写像ベクトルSの学習手順2(b)と同じ処理である。
手順6.式(16)を用いて、混合生起確率p(wt|…wt−1)を求める。
Procedure 5. By performing forward propagation from the hidden layer, the mixing coefficient λ (t) is obtained. That is, the learned mapping vector S and the bias value b are substituted into equation (9) to obtain the mixing coefficient λ (t). This procedure 5 is the same process as the learning procedure 2 (b) of the mapping vector S.
Procedure 6. The mixed occurrence probability p (w t |... W t−1 ) is obtained using Expression (16).
![]()
![]()
図2を参照し、本願発明の実施形態に係る混合生起確率算出システム1の構成について説明する。
With reference to FIG. 2, the structure of the mixed occurrence
混合生起確率算出システム1は、ニューラルネットワーク言語モデルで求めた生起確率pNと、他の言語モデルで求めた生起確率pOとを混合した混合生起確率Pを算出するものである。図2のように、混合生起確率算出システム1は、ニューラルネットワーク言語モデル演算装置10と、他言語モデル演算装置20と、混合係数パラメータ学習装置30と、混合生起確率算出装置40とを備える。
Mixed occurrence
[ニューラルネットワーク言語モデル演算装置の構成]
ニューラルネットワーク言語モデル演算装置10は、ニューラルネットワーク言語モデルにより、生起確率pNを演算するものである。例えば、ニューラルネットワーク言語モデル演算装置10は、隠れ層を用いるニューラルネットワーク(例えば、NNLM、RNNLM)を用いることができる。
[Configuration of Neural Network Language Model Calculation Device]
The neural network language
具体的には、ニューラルネットワーク言語モデル演算装置10は、前文脈w1,w2,…,wt−1が入力されると、当該前文脈に後続する単語wtの生起確率pN(wt|…wt−1)を演算する。また、ニューラルネットワーク言語モデル演算装置10は、ニューラルネットワークの出力層ベクトルp(t)を演算する際、ニューラルネットワークの入力層ベクトルx(t)から算出した隠れ層ベクトルz(t)を記憶し、記憶した隠れ層ベクトルz(t)を混合係数パラメータ学習装置30又は混合生起確率算出装置40に出力する。
Specifically, when the previous context w 1 , w 2 ,..., W t−1 is input, the neural network language
NNLMの場合、ニューラルネットワーク言語モデル演算装置10は、参照可能な前文脈の長さが、前文脈の末尾から所定の単語数n−1までに限定される(nは1以上の整数)。
例えば、前文脈がw1,w2,…,wt−1の場合、参照可能な前文脈がwt−n+1,wt-n+1,…,wt−1となる。
ニューラルネットワーク言語モデル演算装置10は、入力された前文脈の各単語に対応した単語表現ベクトルC(w)を記憶し、長さn−1の前文脈wt−n+1,wt-n+1,…,wt−1が入力されると、その各単語に応じた単語表現ベクトルC(w)を連結してニューラルネットワークの入力層ベクトルx(t)に設定する。そして、ニューラルネットワーク言語モデル演算装置10は、順方向伝搬を行い、ニューラルネットワークの隠れ層ベクトルz(t)及び出力層ベクトルp(t)を算出する。
出力層ベクトルp(t)は、単語の異なり数の次元を持つベクトルであり、ベクトルの各次元の値がその次元に対応した単語の生起確率を表す。なお、隠れ層ベクトルz(t)を「前文脈w1,w2,…,wt−1の隠れ層表現」と呼ぶ。
In the case of NNLM, the neural network language
For example, prior context w 1, w 2, ..., when the w t-1, referable prior context w t-n + 1, w
The neural network language
The output layer vector p (t) is a vector having a number of different dimensions of the word, and the value of each dimension of the vector represents the occurrence probability of the word corresponding to that dimension. It should be noted that the hidden layer vector z (t) is referred to as a "pre-context w 1, w 2, ..., hidden layer representation of w t-1".
RNNLMの場合、ニューラルネットワーク言語モデル演算装置10は、内部にこれまで順に入力された単語系列w1,w2,…を前文脈とする隠れ層ベクトルzを記憶している。初期状態において、隠れ層ベクトルzは、ニューラルネットワーク言語モデル演算装置10に固有の初期値に設定される。
ニューラルネットワーク言語モデル演算装置10は、i番目の単語wiを入力すると、当該単語wiに対応した次元のみが1で、他のすべての次元が0であるベクトルを入力層x(i)に設定する。そして、ニューラルネットワーク言語モデル演算装置10は、入力層x(i)及び記憶している前入力の隠れ層ベクトルz(i)から順方向伝搬を行い、ニューラルネットワークの隠れ層ベクトルz(i+1)及び出力層ベクトルp(i+1)を算出する。単語w1,w2,…,wt−1までの入力及び順方向伝搬が終了したとき、隠れ層ベクトルz(t)は、前記したNNLMを用いた場合の「前文脈w1,w2,…,wt−1の隠れ層表現」と同様のものになる。すなわち、ニューラルネットワーク言語モデル演算装置10は、隠れ層ベクトルz(t)を用いた順方向伝搬により出力層ベクトルp(t)を算出し、次単語の生起確率pNを求める。
In the case of RNNLM, the neural network language
When the i-th word w i is input, the neural network language
なお、ニューラルネットワーク言語モデル演算装置10は、学習済みであり(学習データにより順方向伝搬のための写像行列が適切な値に設定済みであり)、その学習結果が記憶されていることとする。
また、ニューラルネットワーク言語モデル演算装置10は、一般的な構成のため、これ以上の説明を省略する。
It is assumed that the neural network language
Further, since the neural network language
[他言語モデル演算装置の構成]
他言語モデル演算装置20は、ニューラルネットワーク言語モデル以外の他の言語モデル(例えば、n−gram言語モデル)により、生起確率pOを演算するものである。具体的には、他言語モデル演算装置20は、前文脈w1,w2,…,wt−1が入力されると、当該前文脈に後続する任意の単語wtの生起確率pO(wt|…wt−1)を演算して出力する。
[Configuration of other language model arithmetic unit]
The other language
なお、他言語モデル演算装置20は、確率値の計算に必要な各種パラメータが予め設定されていることとする。
また、他言語モデル演算装置20は、一般的な構成のため、これ以上の説明を省略する。
In the other language
Further, since the other language
[混合係数パラメータ学習装置の構成]
混合係数パラメータ学習装置30は、ニューラルネットワーク言語モデルと他の言語モデルとのそれぞれで求めた生起確率pN,pOを混合するときの混合係数λの算出に必要なパラメータを学習するものである。
[Configuration of mixing coefficient parameter learning device]
The mixing coefficient
図2のように、混合係数パラメータ学習装置30は、混合係数パラメータ記憶手段301と、学習パラメータ記憶手段302と、学習データ記憶手段303と、混合係数記憶手段304と、初期化手段311と、第1生起確率要求手段(第1生起確率入力手段)312と、第2生起確率要求手段(第2生起確率入力手段)313と、第1混合係数算出手段314と、写像ベクトル更新手段315と、終了条件判定手段316と、更新率減少手段317とを備える。
As shown in FIG. 2, the mixing coefficient
混合係数パラメータ記憶手段301は、混合係数λの算出に必要な混合係数パラメータを記憶するメモリ、ハードディスク等の記憶手段である。具体的には、混合係数パラメータ記憶手段301は、写像ベクトルS、バイアス値b等の混合係数パラメータを記憶する。この写像ベクトルSは、ニューラルネットワークの隠れ層ベクトルzの次元数hと同一次元数である。
The mixing coefficient
学習パラメータ記憶手段302は、写像ベクトルSの学習に必要なパラメータを記憶するメモリ、ハードディスク等の記憶手段である。具体的には、学習パラメータ記憶手段302は、更新率ε、正則化係数β等の学習パラメータを記憶する。
The learning
学習データ記憶手段303は、写像ベクトルSの学習に必要な学習データである単語列を記憶するメモリ、ハードディスク等の記憶手段である。この学習データは、ニューラルネットワーク言語モデル演算装置10及び他言語モデル演算装置20で学習に用いたものと同一でなくともよい。
混合係数記憶手段304は、混合係数λを記憶するメモリ、ハードディスク等の記憶手段である。
The learning
The mixing
初期化手段311は、混合係数パラメータ及び学習パラメータの初期化を行うものである。具体的には、初期化手段311は、混合係数パラメータ記憶手段301の写像ベクトルSの各次元の値、および、バイアス値bを乱数で初期化する。また、初期化手段311は、学習パラメータ記憶手段302の更新率ε及び正則化係数βを予め設定した値で初期化する。
The
第1生起確率要求手段312は、学習データ記憶手段303の前文脈をニューラルネットワーク言語モデル演算装置10に出力することで、隠れ層ベクトルz及び生起確率pNを要求するものである。この要求に応じて、第1生起確率要求手段312は、ニューラルネットワーク言語モデル演算装置10から、隠れ層ベクトルz及び生起確率pNが入力される。そして、第1生起確率要求手段312は、入力された隠れ層ベクトルz及び生起確率pNを第1混合係数算出手段314及び写像ベクトル更新手段315に出力する。
The first
第2生起確率要求手段313は、学習データ記憶手段303の前文脈を他言語モデル演算装置20に出力することで、生起確率pOを要求するものである。ここで、第2生起確率要求手段313は、第1生起確率要求手段312と同一の前文脈を他言語モデル演算装置20に出力する。この要求に応じて、第2生起確率要求手段313は、他言語モデル演算装置20から、生起確率pOが入力される。そして、第2生起確率要求手段313は、入力された生起確率pOを写像ベクトル更新手段315に出力する。
The second occurrence probability requesting unit 313 requests the occurrence probability p O by outputting the previous context of the learning
第1混合係数算出手段314は、式(9)を用いて、混合係数パラメータ記憶手段301の写像ベクトルSにより、第1生起確率要求手段312から入力された隠れ層ベクトルzを実数値のスカラsに線形写像するものである。また、第1混合係数算出手段314は、式(8)を用いて、実数値のスカラsをシグモイド関数で非線形変換することで、混合係数λを算出する。そして、第1混合係数算出手段314は、算出した混合係数λを混合係数記憶手段304に記憶する。
The first mixing coefficient calculating unit 314 uses the expression (9) to convert the hidden layer vector z input from the first occurrence
写像ベクトル更新手段315は、第1生起確率要求手段312からの生起確率pN、第2生起確率要求手段313からの生起確率pO、混合係数記憶手段304の混合係数λ、及び、学習パラメータ記憶手段302の更新率εを用いた確率的勾配降下法により、混合係数記憶手段304の写像ベクトルSを更新するものである。つまり、写像ベクトル更新手段315は、式(11)及び式(12)で表される確率的勾配降下法を用いて、写像ベクトルSを更新する。
The mapping vector update unit 315 includes an occurrence probability p N from the first occurrence
終了条件判定手段316は、予め設定された終了条件を満たすか否かを判定し、この終了条件を満たすまで、後記する更新率減少手段317が減少させた更新率εで写像ベクトル更新手段315に写像ベクトルSを更新させるものである。例えば、終了条件判定手段316は、予め設定した回数だけ更新率εを減少させて混合生起確率pの値が変化しなかった場合、終了条件を満たすと判定する。
The end
ここで、終了条件を満たしていない場合、終了条件判定手段316は、更新率減少手段317に更新率εの減少を指令する。その後、終了条件判定手段316は、第1生起確率要求手段312、第2生起確率要求手段313、第1混合係数算出手段314、及び、写像ベクトル更新手段315に処理の再実行を指令する。
一方、終了条件を満たしている場合、終了条件判定手段316は、処理を終了する。
なお、図2では、終了条件判定手段316からの指令信号を破線で図示した。
Here, when the end condition is not satisfied, the end
On the other hand, when the end condition is satisfied, the end
In FIG. 2, the command signal from the end
更新率減少手段317は、予め設定された更新率減少規則に従って、必要に応じて学習パラメータ記憶手段302の更新率εを減少させるものである。例えば、更新率減少規則としては、更新率εの値から予め設定した値を減算するという規則があげられる。 The update rate reduction means 317 reduces the update rate ε of the learning parameter storage means 302 as necessary according to a preset update rate reduction rule. For example, the update rate reduction rule includes a rule of subtracting a preset value from the value of the update rate ε.
[混合生起確率算出装置の構成]
混合生起確率算出装置40は、ニューラルネットワーク言語モデルと他の確率モデルとのそれぞれで求めた生起確率pN,pOを混合した混合生起確率pを算出するものである。図2のように、混合生起確率算出装置40は、対象データ記憶手段401と、混合生起確率記憶手段402と、第3生起確率要求手段(第3生起確率入力手段)411と、第4生起確率要求手段(第4生起確率入力手段)412と、第2混合係数算出手段413と、混合生起確率算出手段414とを備える。
[Configuration of mixed occurrence probability calculation device]
The mixed occurrence
対象データ記憶手段401は、混合生起確率pの算出対象となる前文脈及び次単語を表す単語列を記憶するメモリ、ハードディスク等の記憶手段である。この対象データ記憶手段401の単語列は、学習データ記憶手段303の単語列と異なるものである。
混合生起確率記憶手段402は、混合生起確率pを記憶するメモリ、ハードディスク等の記憶手段である。
The target
The mixed occurrence
第3生起確率要求手段411は、対象データ記憶手段401の前文脈をニューラルネットワーク言語モデル演算装置10に出力することで、隠れ層ベクトルz及び生起確率pNを要求するものである。この要求に応じて、第3生起確率要求手段411は、ニューラルネットワーク言語モデル演算装置10から、隠れ層ベクトルz及び生起確率pNが入力される。そして、第3生起確率要求手段411は、入力された隠れ層ベクトルz及び生起確率pNを第2混合係数算出手段413及び混合生起確率算出手段414に出力する。
Third probability requesting unit 411, by outputting the previous context object data storage means 401 in the neural network language
第4生起確率要求手段412は、対象データ記憶手段401の前文脈を他言語モデル演算装置20に出力することで、生起確率pOを要求するものである。ここで、第4生起確率要求手段412は、第3生起確率要求手段411と同一の前文脈を他言語モデル演算装置20に出力する。この要求に応じて、第4生起確率要求手段412は、他言語モデル演算装置20から、生起確率pOが入力される。そして、第4生起確率要求手段412は、入力された生起確率pOを混合生起確率算出手段414に出力する。
The fourth occurrence
第2混合係数算出手段413は、式(9)を用いて、混合係数パラメータ記憶手段301の写像ベクトルSにより、第3生起確率要求手段411から入力された隠れ層ベクトルzを実数値のスカラsに線形写像するものである。また、第2混合係数算出手段413は、式(8)を用いて、実数値のスカラsをシグモイド関数で非線形変換することで、混合係数λを算出する。そして、第2混合係数算出手段413は、算出した混合係数を混合係数記憶手段304に記憶する。
The second mixing
混合生起確率算出手段414は、混合係数記憶手段304の混合係数λを用いて、第3生起確率要求手段411から入力された生起確率pNと、第4生起確率要求手段412から入力された生起確率pOとを混合することで、混合生起確率pを算出するものである。そして、混合生起確率算出手段414は、算出した混合生起確率pを混合生起確率記憶手段402に記憶する。
The mixed occurrence probability calculation means 414 uses the mixing coefficient λ of the mixing coefficient storage means 304 and the occurrence probability p N input from the third occurrence probability request means 411 and the occurrence input input from the fourth occurrence probability request means 412. By mixing the probability p O , the mixed occurrence probability p is calculated. Then, the mixed occurrence
[混合係数パラメータ学習装置の動作]
図3を参照し、混合係数パラメータ学習装置30の動作について説明する(適宜図2参照)。
[Operation of mixing coefficient parameter learning device]
The operation of the mixing coefficient
混合係数パラメータ学習装置30は、初期化手段311によって、写像ベクトルS、バイアス値b等の混合係数パラメータを初期化する(ステップS1)。
混合係数パラメータ学習装置30は、初期化手段311によって、更新率ε、正則化係数β等の学習パラメータを初期化する(ステップS2)。
混合係数パラメータ学習装置30は、カウンタiの値を1に初期化する(ステップS3)。
The mixing coefficient
The mixing coefficient
The mixing coefficient
混合係数パラメータ学習装置30は、第1生起確率要求手段312によって、学習データ記憶手段303の単語列w1,w2,…,wNのうち、先頭からi−1個の単語列w1,w2,…,wi−1を前文脈としてニューラルネットワーク言語モデル演算装置10に出力する。
混合係数パラメータ学習装置30は、第1生起確率要求手段312によって、ニューラルネットワーク言語モデル演算装置10から、隠れ層ベクトルz(i)及び次単語wiの生起確率pN(wi|w1w2…wi−1)が入力される(ステップS4)。
Mixing coefficient
The mixing coefficient
混合係数パラメータ学習装置30は、第2生起確率要求手段313によって、ステップS4と同一の前文脈w1,w2,…,wi−1を他言語モデル演算装置20に出力する。
混合係数パラメータ学習装置30は、第2生起確率要求手段313によって、他言語モデル演算装置20から、次単語wiの生起確率pO(wi|w1w2…wi−1)が入力される(ステップS5)。
The mixed coefficient
The mixed coefficient
混合係数パラメータ学習装置30は、第1混合係数算出手段314によって、ステップS4で入力された隠れ層のベクトルz(i)及び写像ベクトルSを用いて、式(8)及び式(9)に従って混合係数λ(i)を算出する(ステップS6)
The mixing coefficient
混合係数パラメータ学習装置30は、写像ベクトル更新手段315によって、ステップS4で入力された生起確率pN(wi|w1w2…wi−1)と、ステップS5で入力された生起確率pO(wi|w1w2…wi−1)と、ステップS6で算出した混合係数λ(i)と、更新率εとを用いて、式(11)及び式(12)で写像ベクトルSを更新する(ステップS7)。
The mixing coefficient
混合係数パラメータ学習装置30は、カウンタiをインクリメントする(ステップS8)。
混合係数パラメータ学習装置30は、カウンタiが単語最大数N以下であるか否かを判定する(ステップS9)。
カウンタiが単語最大数N以下の場合(ステップS9でYes)、混合係数パラメータ学習装置30は、ステップS4の処理に戻る。
The mixing coefficient
The mixing coefficient
When the counter i is equal to or less than the maximum number N of words (Yes in step S9), the mixing coefficient
カウンタiが単語最大数N以下でない場合(ステップS9でNo)、混合係数パラメータ学習装置30は、終了条件判定手段316によって、終了条件を満たすか否かを判定する(ステップS10)。
終了条件を満たす場合(ステップS10でYes)、混合係数パラメータ学習装置30は、処理を終了する。
If the counter i is not equal to or less than the maximum number N of words (No in step S9), the mixture coefficient
If the end condition is satisfied (Yes in step S10), the mixing coefficient
終了条件を満たさない場合(ステップS10でNo)、混合係数パラメータ学習装置30は、更新率減少手段317によって、更新率減少規則に従って、必要に応じて更新率εを減少させ(ステップS11)、ステップS3の処理に戻る。
When the termination condition is not satisfied (No in step S10), the mixing coefficient
[混合生起確率算出装置の動作]
図4を参照し、混合生起確率算出装置40の動作について説明する(適宜図1参照)。
[Operation of mixed occurrence probability calculation device]
The operation of the mixed occurrence
混合生起確率算出装置40は、第3生起確率要求手段411によって、対象データ記憶手段401の単語列w1,w2,…,wt−1を前文脈としてニューラルネットワーク言語モデル演算装置10に出力する。
混合生起確率算出装置40は、第3生起確率要求手段411によって、ニューラルネットワーク言語モデル演算装置10から、隠れ層ベクトルz及び次単語wtの生起確率pN(wt|w1w2…wt−1)が入力される(ステップS21)。
The mixed occurrence
The mixed occurrence
混合生起確率算出装置40は、第4生起確率要求手段412によって、ステップS21と同一の前文脈w1,w2,…,wt−1を他言語モデル演算装置20に出力する。
混合生起確率算出装置40は、第4生起確率要求手段412によって、他言語モデル演算装置20から、次単語wiの生起確率pO(wt|w1w2…wt−1)が入力される(ステップS22)。
The mixed occurrence
The occurrence probability p O (w t | w 1 w 2 ... W t−1 ) of the next word w i is input to the mixed occurrence
混合生起確率算出装置40は、第2混合係数算出手段413によって、ステップS21で入力された隠れ層のベクトルz及び写像ベクトルSを用いて、式(8)及び式(9)に従って混合係数λ(t)を算出する(ステップS23)
The mixed occurrence
混合生起確率算出装置40は、混合生起確率算出手段414によって、ステップ21で入力された生起確率pN(wt|w1w2…wt−1)とステップ22で入力された生起確率pO(wt|w1,w2,…,wt−1)との混合生起確率p(wt|w1w2…wt−1)を、式(16)で算出する(ステップS24)。
The mixed occurrence
[作用・効果]
以上のように、混合生起確率算出システム1は、ニューラルネットワーク言語モデルにより写像ベクトルSを学習し、学習した写像ベクトルSにより前文脈に応じた混合係数を求めている。これにより、混合生起確率算出システム1は、n−gram言語モデル等の他の言語モデルと混合して混合生起確率pを算出する際、従来よりも混合生起確率pの正確性を向上させることができる。
[Action / Effect]
As described above, the mixed occurrence
(変形例)
以上、本願発明の各実施形態を詳述してきたが、本願発明は前記した実施形態に限られるものではなく、本願発明の要旨を逸脱しない範囲の設計変更等も含まれる。
(Modification)
As mentioned above, although each embodiment of this invention was explained in full detail, this invention is not limited to above-described embodiment, The design change etc. of the range which does not deviate from the summary of this invention are also included.
前記した実施形態では、混合係数パラメータ学習装置が混合係数パラメータ記憶手段及び混合係数記憶手段を備えることとして説明したが、本願発明は、これに限定されない。つまり、混合生起確率算出装置が混合係数パラメータ記憶手段及び混合係数記憶手段を備えてもよい。 In the embodiment described above, the mixing coefficient parameter learning device has been described as including the mixing coefficient parameter storage unit and the mixing coefficient storage unit, but the present invention is not limited to this. That is, the mixture occurrence probability calculation device may include a mixture coefficient parameter storage unit and a mixture coefficient storage unit.
前記した実施形態では、本願発明を言語モデルに適用する例を説明したが、本願発明が適用可能な確率モデルはこれに限定されず、何らかの記号系列に後続して生起する記号の生起確率モデル一般に適用することができる。 In the embodiment described above, an example in which the present invention is applied to a language model has been described. However, the probability model to which the present invention can be applied is not limited to this, and the occurrence probability model of a symbol that occurs following any symbol sequence in general. Can be applied.
前記した実施形態では、正則化を行うこととして説明したが、本願発明は、正則化を行わなくともよい。
前記した実施形態では、バイアス値bを用いることとして説明したが、本願発明は、バイアス値bを用いなくともよい。この場合、前記した式(9)の代わりに以下の式(17)を用いることになる。
In the above-described embodiment, it has been described that regularization is performed. However, the present invention may not be regularized.
In the above-described embodiment, the bias value b is used. However, the present invention may not use the bias value b. In this case, the following formula (17) is used instead of the above formula (9).
![]()
![]()
前記した実施形態では、混合係数パラメータ学習装置を独立したハードウェアとして説明したが、本願発明は、これに限定されない。例えば、混合係数パラメータ学習装置は、コンピュータが備えるCPU、メモリ、ハードディスク等のハードウェア資源を協調動作させる混合係数パラメータ学習プログラムで実現することもできる。このプログラムは、通信回線を介して配布してもよく、CD−ROMやフラッシュメモリ等の記録媒体に書き込んで配布してもよい。
また、混合生起確率算出装置は、混合係数パラメータ学習装置と同様、混合生起確率算出プログラムで実現することもできる。
In the above-described embodiment, the mixing coefficient parameter learning device has been described as independent hardware, but the present invention is not limited to this. For example, the mixing coefficient parameter learning device can also be realized by a mixing coefficient parameter learning program for cooperatively operating hardware resources such as a CPU, a memory, and a hard disk included in a computer. This program may be distributed through a communication line, or may be distributed by writing in a recording medium such as a CD-ROM or a flash memory.
Further, the mixed occurrence probability calculation device can also be realized by a mixed occurrence probability calculation program in the same manner as the mixing coefficient parameter learning device.
1 混合生起確率算出システム
10 ニューラルネットワーク言語モデル演算装置
20 他言語モデル演算装置
30 混合係数パラメータ学習装置
301 混合係数パラメータ記憶手段
302 学習パラメータ記憶手段
303 学習データ記憶手段
304 混合係数記憶手段
311 初期化手段
312 第1生起確率要求手段(第1生起確率入力手段)
313 第2生起確率要求手段(第2生起確率入力手段)
314 第1混合係数算出手段
315 写像ベクトル更新手段
316 終了条件判定手段
317 更新率減少手段
40 混合生起確率算出装置
401 対象データ記憶手段
402 混合生起確率記憶手段
411 第3生起確率要求手段(第3生起確率入力手段)
412 第4生起確率要求手段(第4生起確率入力手段)
413 第2混合係数算出手段
414 混合生起確率算出手段
DESCRIPTION OF
313 Second occurrence probability request means (second occurrence probability input means)
314 First mixture coefficient calculation means 315 Mapping vector update means 316 End condition determination means 317 Update rate reduction means 40 Mixed occurrence
412 Fourth occurrence probability request means (fourth occurrence probability input means)
413 Second mixing coefficient calculating means 414 Mixed occurrence probability calculating means
Claims (5)
前記ニューラルネットワーク確率モデルの隠れ層ベクトルと、前記ニューラルネットワーク確率モデルで求めた生起確率とが入力される第1生起確率入力手段と、
前記他の確率モデルで求めた生起確率が入力される第2生起確率入力手段と、
予め設定された写像ベクトルにより前記隠れ層ベクトルを実数値のスカラに線形写像し、前記実数値のスカラをシグモイド関数で非線形変換することで、前記混合係数を算出する第1混合係数算出手段と、
前記ニューラルネットワーク確率モデルと前記他の確率モデルとのそれぞれで求めた生起確率、前記混合係数、及び、予め設定された更新率を用いた確率的勾配降下法により、前記パラメータとしての前記写像ベクトルを更新する写像ベクトル更新手段と、
予め設定された更新率減少規則に従って前記更新率を減少させる更新率減少手段と、
予め設定された終了条件を満たすか否かを判定し、前記終了条件を満たすまで、減少させた前記更新率で前記写像ベクトル更新手段に前記写像ベクトルを更新させる終了条件判定手段と、
を備えることを特徴とする混合係数パラメータ学習装置。 A mixing coefficient parameter for learning parameters necessary for calculating the mixing coefficient when mixing the occurrence probabilities of the next element with respect to the previous element sequence obtained by the neural network probability model and other probability models other than the neural network probability model. A learning device,
First occurrence probability input means for inputting a hidden layer vector of the neural network probability model and an occurrence probability obtained by the neural network probability model;
A second occurrence probability input means for inputting the occurrence probability obtained by the other probability model;
A first mixing coefficient calculating means for calculating the mixing coefficient by linearly mapping the hidden layer vector to a real-valued scalar according to a preset mapping vector, and nonlinearly transforming the real-valued scalar with a sigmoid function;
The mapping vector as the parameter is obtained by a stochastic gradient descent method using an occurrence probability obtained by each of the neural network probability model and the other probability model, the mixing coefficient, and a preset update rate. Map vector updating means for updating;
Update rate reduction means for reducing the update rate according to a preset update rate reduction rule;
Determining whether or not a preset end condition is satisfied, and until the end condition is satisfied, an end condition determining unit that causes the map vector updating unit to update the mapping vector at the reduced update rate;
A mixing coefficient parameter learning apparatus comprising:
前記ニューラルネットワークの隠れ層ベクトルと、前記ニューラルネットワーク確率モデルで求めた生起確率とが入力される第3生起確率入力手段と、
前記他の確率モデルで求めた生起確率が入力される第4生起確率入力手段と、
請求項1に記載の混合係数パラメータ学習装置が学習した写像ベクトルで前記隠れ層ベクトルを実数値のスカラに線形写像し、前記実数値のスカラをシグモイド関数で非線形変換することで、混合係数を算出する第2混合係数算出手段と、
前記混合係数を用いて、前記ニューラルネットワーク確率モデルと前記他の確率モデルとで求めた前記次要素の生起確率を混合することで、前記混合生起確率を算出する混合生起確率算出手段と、
を備えることを特徴とする混合生起確率算出装置。 A mixed occurrence probability calculation device for calculating a mixed occurrence probability obtained by mixing the occurrence probabilities of the next element with respect to the previous element series obtained by the neural network probability model and other probability models other than the neural network probability model,
A third occurrence probability input means for inputting the hidden layer vector of the neural network and the occurrence probability obtained by the neural network probability model;
A fourth occurrence probability input means for inputting the occurrence probability obtained by the other probability model;
The mixture coefficient is calculated by linearly mapping the hidden layer vector to a real-valued scalar using the mapping vector learned by the mixing coefficient parameter learning apparatus according to claim 1 and performing nonlinear conversion on the real-valued scalar using a sigmoid function. Second mixing coefficient calculating means for
A mixed occurrence probability calculating means for calculating the mixed occurrence probability by mixing the occurrence probabilities of the next element obtained by the neural network probability model and the other probability model using the mixing coefficient;
A mixed occurrence probability calculation device comprising:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015132347A JP2017016384A (en) | 2015-07-01 | 2015-07-01 | Mixed coefficient parameter learning device, mixed occurrence probability calculation device, and programs thereof |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015132347A JP2017016384A (en) | 2015-07-01 | 2015-07-01 | Mixed coefficient parameter learning device, mixed occurrence probability calculation device, and programs thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2017016384A true JP2017016384A (en) | 2017-01-19 |
Family
ID=57829182
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015132347A Pending JP2017016384A (en) | 2015-07-01 | 2015-07-01 | Mixed coefficient parameter learning device, mixed occurrence probability calculation device, and programs thereof |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2017016384A (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018055670A (en) * | 2016-09-27 | 2018-04-05 | パナソニックIpマネジメント株式会社 | Similar sentence generation method, similar sentence generation program, similar sentence generation apparatus, and similar sentence generation system |
| JP2019046188A (en) * | 2017-09-01 | 2019-03-22 | 日本電信電話株式会社 | Sentence generation device, sentence generation learning device, sentence generation method, and program |
| JP2019139629A (en) * | 2018-02-14 | 2019-08-22 | 株式会社Nttドコモ | Machine translation device, translation learned model and determination learned model |
| WO2019171925A1 (en) * | 2018-03-08 | 2019-09-12 | 日本電信電話株式会社 | Device, method and program using language model |
| CN112771523A (en) * | 2018-08-14 | 2021-05-07 | 北京嘀嘀无限科技发展有限公司 | System and method for detecting a generated domain |
| CN114731171A (en) * | 2019-11-13 | 2022-07-08 | 美光科技公司 | Blending coefficient data for processing mode selection |
-
2015
- 2015-07-01 JP JP2015132347A patent/JP2017016384A/en active Pending
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018055670A (en) * | 2016-09-27 | 2018-04-05 | パナソニックIpマネジメント株式会社 | Similar sentence generation method, similar sentence generation program, similar sentence generation apparatus, and similar sentence generation system |
| JP2019046188A (en) * | 2017-09-01 | 2019-03-22 | 日本電信電話株式会社 | Sentence generation device, sentence generation learning device, sentence generation method, and program |
| JP2019139629A (en) * | 2018-02-14 | 2019-08-22 | 株式会社Nttドコモ | Machine translation device, translation learned model and determination learned model |
| JP7122835B2 (en) | 2018-02-14 | 2022-08-22 | 株式会社Nttドコモ | Machine translation device, translation trained model and judgment trained model |
| WO2019171925A1 (en) * | 2018-03-08 | 2019-09-12 | 日本電信電話株式会社 | Device, method and program using language model |
| JP2019159464A (en) * | 2018-03-08 | 2019-09-19 | 日本電信電話株式会社 | Device, method and program utilizing language model |
| CN112771523A (en) * | 2018-08-14 | 2021-05-07 | 北京嘀嘀无限科技发展有限公司 | System and method for detecting a generated domain |
| CN114731171A (en) * | 2019-11-13 | 2022-07-08 | 美光科技公司 | Blending coefficient data for processing mode selection |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3504666B1 (en) | Asychronous training of machine learning model | |
| JP2017016384A (en) | Mixed coefficient parameter learning device, mixed occurrence probability calculation device, and programs thereof | |
| US11081105B2 (en) | Model learning device, method and recording medium for learning neural network model | |
| BR112019014822B1 (en) | System, non-transient computer storage medium and attention-based sequence transduction neural network method | |
| KR20220005416A (en) | Method for training multivariate relationship generation model, electronic device and medium | |
| US11693854B2 (en) | Question responding apparatus, question responding method and program | |
| JP7179835B2 (en) | MODEL GENERATING DEVICE, MODEL GENERATING METHOD, AND PROGRAM | |
| US11380301B2 (en) | Learning apparatus, speech recognition rank estimating apparatus, methods thereof, and program | |
| US20180314978A1 (en) | Learning apparatus and method for learning a model corresponding to a function changing in time series | |
| CN112084301B (en) | Training method and device for text correction model, text correction method and device | |
| Wang et al. | Learning trans-dimensional random fields with applications to language modeling | |
| de Bézenac et al. | Optimal unsupervised domain translation | |
| CN115345169A (en) | Knowledge enhancement-based text generation model and training method thereof | |
| CN109858031B (en) | Neural network model training and context prediction method and device | |
| WO2019208564A1 (en) | Neural network learning device, neural network learning method, and program | |
| CN108475346A (en) | Neural random access machine | |
| JP7109071B2 (en) | Learning device, learning method, speech synthesizer, speech synthesis method and program | |
| WO2023061107A1 (en) | Language translation method and apparatus based on layer prediction, and device and medium | |
| Zhu et al. | A hybrid model for nonlinear regression with missing data using quasilinear kernel | |
| JP7349811B2 (en) | Training device, generation device, and graph generation method | |
| JP7425755B2 (en) | Conversion method, training device and inference device | |
| JP2019075003A (en) | Approximate calculation device, approximate calculation method, and program | |
| CN113536567A (en) | Method for multi-target vector fitting | |
| WO2023105596A1 (en) | Language processing device, image processing method, and program | |
| WO2022244216A1 (en) | Learning device, inference device, learning method, inference method, and program |