JP2016189158A - 画像処理装置、画像処理方法、プログラムおよび記録媒体 - Google Patents
画像処理装置、画像処理方法、プログラムおよび記録媒体 Download PDFInfo
- Publication number
- JP2016189158A JP2016189158A JP2015069473A JP2015069473A JP2016189158A JP 2016189158 A JP2016189158 A JP 2016189158A JP 2015069473 A JP2015069473 A JP 2015069473A JP 2015069473 A JP2015069473 A JP 2015069473A JP 2016189158 A JP2016189158 A JP 2016189158A
- Authority
- JP
- Japan
- Prior art keywords
- person
- character string
- image
- unit
- voice
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000012545 processing Methods 0.000 title claims abstract description 49
- 238000003672 processing method Methods 0.000 title claims description 18
- 239000002131 composite material Substances 0.000 claims abstract description 51
- 230000004044 response Effects 0.000 claims abstract description 27
- 239000000203 mixture Substances 0.000 claims abstract description 8
- 230000015572 biosynthetic process Effects 0.000 claims description 64
- 238000003786 synthesis reaction Methods 0.000 claims description 64
- 238000011156 evaluation Methods 0.000 claims description 51
- 238000000605 extraction Methods 0.000 claims description 40
- 230000002194 synthesizing effect Effects 0.000 claims description 36
- 238000012937 correction Methods 0.000 claims description 19
- 239000000284 extract Substances 0.000 claims description 16
- 238000001514 detection method Methods 0.000 claims description 9
- 239000003550 marker Substances 0.000 description 29
- 238000000034 method Methods 0.000 description 15
- 238000012546 transfer Methods 0.000 description 13
- 238000010586 diagram Methods 0.000 description 11
- 238000010191 image analysis Methods 0.000 description 9
- 238000005516 engineering process Methods 0.000 description 4
- 230000008921 facial expression Effects 0.000 description 4
- 230000003190 augmentative effect Effects 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000010079 rubber tapping Methods 0.000 description 2
- 206010011469 Crying Diseases 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 238000011895 specific detection Methods 0.000 description 1
- 230000007480 spreading Effects 0.000 description 1
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T11/00—2D [Two Dimensional] image generation
- G06T11/60—Editing figures and text; Combining figures or text
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/048—Interaction techniques based on graphical user interfaces [GUI]
- G06F3/0481—Interaction techniques based on graphical user interfaces [GUI] based on specific properties of the displayed interaction object or a metaphor-based environment, e.g. interaction with desktop elements like windows or icons, or assisted by a cursor's changing behaviour or appearance
- G06F3/04817—Interaction techniques based on graphical user interfaces [GUI] based on specific properties of the displayed interaction object or a metaphor-based environment, e.g. interaction with desktop elements like windows or icons, or assisted by a cursor's changing behaviour or appearance using icons
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/048—Interaction techniques based on graphical user interfaces [GUI]
- G06F3/0484—Interaction techniques based on graphical user interfaces [GUI] for the control of specific functions or operations, e.g. selecting or manipulating an object, an image or a displayed text element, setting a parameter value or selecting a range
- G06F3/04845—Interaction techniques based on graphical user interfaces [GUI] for the control of specific functions or operations, e.g. selecting or manipulating an object, an image or a displayed text element, setting a parameter value or selecting a range for image manipulation, e.g. dragging, rotation, expansion or change of colour
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
-
- A—HUMAN NECESSITIES
- A63—SPORTS; GAMES; AMUSEMENTS
- A63F—CARD, BOARD, OR ROULETTE GAMES; INDOOR GAMES USING SMALL MOVING PLAYING BODIES; VIDEO GAMES; GAMES NOT OTHERWISE PROVIDED FOR
- A63F2300/00—Features of games using an electronically generated display having two or more dimensions, e.g. on a television screen, showing representations related to the game
- A63F2300/80—Features of games using an electronically generated display having two or more dimensions, e.g. on a television screen, showing representations related to the game specially adapted for executing a specific type of game
- A63F2300/8064—Quiz
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/26—Recognition of special voice characteristics, e.g. for use in lie detectors; Recognition of animal voices
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/90—Pitch determination of speech signals
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Human Computer Interaction (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- User Interface Of Digital Computer (AREA)
- Processing Or Creating Images (AREA)
Abstract
【課題】フレーム画像と、フレーム画像に存在する人物の音声に対応する文字列の文字画像とを簡単に合成して、色々なバリエーションの合成画像を生成することができる画像処理装置等を提供する。【解決手段】画像処理装置では、表示部が、関連情報に基づいて、中心人物を示すアイコンと中心人物の音声に対応する文字列との関連情報を表示する。指示受付部が、ユーザにより選択されたアイコンに対応する中心人物を、合成の対象人物として指定する対象人物指定指示を受け付けると、合成部が、対象人物指定指示に応じて、対象人物が存在する任意の時刻のフレーム画像と、任意の時間帯の対象人物の音声に対応する文字列の文字画像とを合成して合成画像を生成する。【選択図】図2
Description
本発明は、動画像から抽出されたフレーム画像とフレーム画像に存在する人物の音声に対応する文字列の文字画像とを合成して合成画像を生成する画像処理装置、画像処理方法、プログラムおよび記録媒体に関するものである。
昨今、スマートフォンやタブレット端末等の携帯端末の普及が急速に進んでおり、携帯端末で撮影される静止画像(写真)の枚数が増えているが、それと同時に動画像が撮影される機会も多くなっている。現在では、動画像を利用したサービスとして、非特許文献1に示すように、写真等のプリント物を携帯端末で撮影(キャプチャ)すると、プリント物に関連付けられた動画像を、AR(Augmented Reality, 拡張現実)技術を使って、携帯端末の画面上に再生(AR再生)するシステムが提供されている。
このシステムでは、以下の(1)〜(6)のステップで、プリントに関連付けられた動画像のAR再生が行われる。
(1)ユーザにより、携帯端末上で動作する専用のアプリケーションを使用して、複数の動画像の中からプリントに使用したい動画像が選択されると、選択された動画像がサーバへアップロードされる。
(2)サーバにおいて、携帯端末からアップロードされた動画像から代表フレーム画像が抽出される。
(3)サーバで抽出された代表フレーム画像が携帯端末へダウンロードされる。
(4)ユーザにより、携帯端末の画面に一覧表示された代表フレーム画像の中からプリントしたいフレーム画像が選択され、プリントの注文が行われる。
(5)サーバにおいて、ユーザにより注文されたフレーム画像のプリント(以下、動画プリントともいう)が生成され、このフレーム画像に関連付けられた動画像がAR再生用に画像処理される。
(6)ユーザにより、配達されたプリントが携帯端末で撮影(キャプチャ)されると、このプリントに関連付けられたAR再生用の動画像がサーバからダウンロードされ、AR技術により、携帯端末の画面にAR再生される。
(2)サーバにおいて、携帯端末からアップロードされた動画像から代表フレーム画像が抽出される。
(3)サーバで抽出された代表フレーム画像が携帯端末へダウンロードされる。
(4)ユーザにより、携帯端末の画面に一覧表示された代表フレーム画像の中からプリントしたいフレーム画像が選択され、プリントの注文が行われる。
(5)サーバにおいて、ユーザにより注文されたフレーム画像のプリント(以下、動画プリントともいう)が生成され、このフレーム画像に関連付けられた動画像がAR再生用に画像処理される。
(6)ユーザにより、配達されたプリントが携帯端末で撮影(キャプチャ)されると、このプリントに関連付けられたAR再生用の動画像がサーバからダウンロードされ、AR技術により、携帯端末の画面にAR再生される。
上記のシステムのように、動画像から抽出されたフレーム画像をプリントするシステムでは、動画像から抽出されたままの状態のフレーム画像のプリントが生成される。
これに対し、特許文献1〜3には、動画像からフレーム画像および音声を抽出し、フレーム画像から人物を抽出するとともに、音声を文字列に変換し、フレーム画像と、フレーム画像に存在する人物の音声に対応する文字列とを吹き出しの形式によって合成して合成画像を生成することが記載されている。また、特許文献4、5には、音声から、性別および年齢を判別することが記載され、特許文献5には、さらに、映像から、性別および年齢を判別することが記載されている。
"動画フォト!サービス"、[online]、富士フイルム株式会社、[平成27年2月9日検索]、インターネット<URL: http://fujifilm.jp/personal/print/photo/dogaphoto/>
特許文献1〜3では、フレーム画像と、フレーム画像に存在する人物の音声に対応する文字列とを吹き出しの形式によって合成することにより、合成画像の魅力を向上させることができる。しかし、これらの文献では、フレーム画像と、フレーム画像が撮影された時刻の音声に対応する文字列とが合成され、例えば、それ以外の時刻の音声に対応する文字列を合成することができない。そのため、合成画像にバリエーションがないという問題があった。
一方、フレーム画像と、フレーム画像が撮影された時刻以外の時刻の音声に対応する文字列とを合成する場合、動画像から抽出された音声の中から、音声に対応する文字列を合成しようとするフレーム画像に存在する人物の音声を選択する必要がある。しかし、動画像に複数の人物が存在する場合、どの人物の音声なのかを判別したり、その人物の複数の音声の中から所望の音声を選択したりするために、手間がかかるという問題があった。
本発明の目的は、従来技術の問題点を解消し、フレーム画像と、フレーム画像に存在する人物の音声に対応する文字列の文字画像とを簡単に合成して、色々なバリエーションの合成画像を生成することができる画像処理装置、画像処理方法、プログラムおよび記録媒体を提供することにある。
上記目的を達成するために、本発明は、動画像から複数のフレーム画像を抽出するフレーム画像抽出部と、
フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出する人物領域検出部と、
検出された人物領域に対応する人物を特定する人物特定部と、
抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出する人物評価部と、
特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定する中心人物判定部と、
動画像から音声を抽出する音声抽出部と、
音声を音声認識により文字列データに変換する音声認識部と、
中心人物と中心人物の音声との関連情報を生成する関連付け部と、
関連情報に基づいて、中心人物を示すアイコンと中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示する表示部と、
ユーザにより入力された指示を受け付ける指示受付部と、
フレーム画像と文字列に対応する文字画像とを合成する合成部とを備え、
指示受付部は、さらに、アイコンのうちユーザにより選択されたアイコンに対応する中心人物を、合成の対象人物として指定する対象人物指定指示を受け付けるものであり、
合成部は、さらに、対象人物指定指示に応じて、対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における対象人物の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、合成用フレーム画像と合成用文字列に対応する文字画像とを合成して合成画像を生成するものである、画像処理装置を提供するものである。
フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出する人物領域検出部と、
検出された人物領域に対応する人物を特定する人物特定部と、
抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出する人物評価部と、
特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定する中心人物判定部と、
動画像から音声を抽出する音声抽出部と、
音声を音声認識により文字列データに変換する音声認識部と、
中心人物と中心人物の音声との関連情報を生成する関連付け部と、
関連情報に基づいて、中心人物を示すアイコンと中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示する表示部と、
ユーザにより入力された指示を受け付ける指示受付部と、
フレーム画像と文字列に対応する文字画像とを合成する合成部とを備え、
指示受付部は、さらに、アイコンのうちユーザにより選択されたアイコンに対応する中心人物を、合成の対象人物として指定する対象人物指定指示を受け付けるものであり、
合成部は、さらに、対象人物指定指示に応じて、対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における対象人物の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、合成用フレーム画像と合成用文字列に対応する文字画像とを合成して合成画像を生成するものである、画像処理装置を提供するものである。
指示受付部は、さらに、表示部に表示された関連情報に対して、関連情報を修正する修正指示を受け付けるものであり、
関連付け部は、さらに、修正指示に応じて、関連情報を修正するものであることが好ましい。
関連付け部は、さらに、修正指示に応じて、関連情報を修正するものであることが好ましい。
さらに、対象人物指定指示に応じて、対象人物が存在するフレーム画像の中から、代表フレーム画像を決定する代表フレーム画像決定部と、
対象人物指定指示に応じて、対象人物の音声の文字列データに対応する文字列の中から、代表文字列を決定する代表文字列決定部とを備え、
合成部は、代表フレーム画像と代表文字列に対応する文字画像とを合成するものであることが好ましい。
対象人物指定指示に応じて、対象人物の音声の文字列データに対応する文字列の中から、代表文字列を決定する代表文字列決定部とを備え、
合成部は、代表フレーム画像と代表文字列に対応する文字画像とを合成するものであることが好ましい。
また、代表フレーム画像決定部は、対象人物が存在するフレーム画像の中から、色味、明るさ、および、ボケブレのうちの少なくとも1つが一定範囲内であるフレーム画像を、代表フレーム画像に決定するものであることが好ましい。
また、代表フレーム画像決定部は、対象人物が存在するフレーム画像の中から、対象人物の顔の大きさおよび向きのうちの少なくとも1つが一定範囲内であり、かつ、対象人物の表情が笑顔であるフレーム画像を、代表フレーム画像に決定するものであることが好ましい。
また、代表フレーム画像決定部は、対象人物が存在するフレーム画像の中から、対象人物の発話シーン、動きが大きいシーンおよび音声が大きいシーンのうちの少なくとも1つのフレーム画像を、代表フレーム画像に決定するものであることが好ましい。
また、代表文字列決定部は、対象人物の音声の文字列データに対応する文字列の中から、対象人物の声の大きさおよび声の高さの少なくとも1つが一定範囲内である音声の文字列データに対応する文字列を、代表文字列に決定するものであることが好ましい。
また、代表文字列決定部は、対象人物の音声の文字列データに対応する文字列の中から、最も登場頻度の高い言葉の音声の文字列データに対応する文字列を、代表文字列に決定するものであることが好ましい。
表示部は、さらに、対象人物が存在する代表フレーム画像、および、対象人物が存在するフレーム画像であって代表フレーム画像以外のフレーム画像を表示するものであり、
指示受付部は、さらに、表示部に表示されたフレーム画像の中から、ユーザにより入力されたフレーム画像を指定するフレーム画像指定指示を受け付けるものであり、
代表フレーム画像決定部は、さらに、フレーム画像指定指示に応じて、ユーザにより指定されたフレーム画像を、代表フレーム画像に再決定するものであることが好ましい。
指示受付部は、さらに、表示部に表示されたフレーム画像の中から、ユーザにより入力されたフレーム画像を指定するフレーム画像指定指示を受け付けるものであり、
代表フレーム画像決定部は、さらに、フレーム画像指定指示に応じて、ユーザにより指定されたフレーム画像を、代表フレーム画像に再決定するものであることが好ましい。
表示部は、さらに、代表文字列、および、対象人物の音声の音声データに対応する文字列であって代表文字列以外の文字列を表示するものであり、
指示受付部は、さらに、表示部に表示された文字列の中から、ユーザにより入力された文字列を指定する文字列指定指示を受け付けるものであり、
代表文字列決定部は、さらに、文字列指定指示に応じて、ユーザにより指定された文字列を、代表文字列に再決定するものであることが好ましい。
指示受付部は、さらに、表示部に表示された文字列の中から、ユーザにより入力された文字列を指定する文字列指定指示を受け付けるものであり、
代表文字列決定部は、さらに、文字列指定指示に応じて、ユーザにより指定された文字列を、代表文字列に再決定するものであることが好ましい。
また、音声認識部は、動画像から抽出された音声のうち、対象人物の音声を優先して文字列データに変換するものであることが好ましい。
音声抽出部は、さらに、動画像から抽出された音声からノイズを除去するノイズキャンセリングを行うものであることが好ましい。
また、関連付け部は、中心人物が存在するフレーム画像の人物領域から、中心人物の性別および年齢を判定するとともに、中心人物の音声の高低から、音声に対応する人物の性別および年齢を判定し、中心人物の性別および年齢と音声に対応する人物の性別および年齢とが合致するように、関連情報を生成するものであることが好ましい。
また、関連付け部は、関連情報を生成する場合に、人間の声の音域以外の音域の音声を使用しないものであることが好ましい。
また、関連付け部は、動画像が、付帯情報として、動画像に存在する人物と動画像に存在する人物の音声との関連付けの指示データを有するか否かを判断し、動画像が関連付けの指示データを有すると判断したときに、関連付けの指示データに基づいて関連情報を生成するものであることが好ましい。
また、合成部は、文字列を、吹き出し、テロップおよび字幕のうちのいずれか1つの形式によって合成するものであることが好ましい。
また、合成部は、文字列の内容に応じて、文字列の書体を変更するものであることが好ましい。
また、合成部は、文字列の文字画像が合成された複数のフレーム画像を含む合成画像を生成するものであることが好ましい。
また、本発明は、動画像から複数のフレーム画像を抽出するフレーム画像抽出部と、
フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出する人物領域検出部と、
検出された人物領域に対応する人物を特定する人物特定部と、
抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出する人物評価部と、
特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定する中心人物判定部と、
動画像から音声を抽出する音声抽出部と、
音声を音声認識により文字列データに変換する音声認識部と、
中心人物と中心人物の音声との関連情報を生成し、さらに、フレーム画像に存在していない人物で、かつ、動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、非被写体人物と非被写体人物の音声との関連情報を生成する関連付け部と、
関連情報に基づいて、中心人物および非被写体人物を示すアイコンと中心人物および非被写体人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示する表示部と、
ユーザにより入力された指示を受け付ける指示受付部と、
フレーム画像と文字列に対応する文字画像とを合成する合成部とを備え、
指示受付部は、さらに、アイコンのうちユーザにより選択されたアイコンに対応する中心人物または非被写体人物を、合成の対象人物として指定する対象人物指定指示を受け付けるものであり、
合成部は、さらに、対象人物指定指示に応じて、対象人物の音声が存在する任意の時間帯における対象人物の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、中心人物が存在する任意の時刻における合成用フレーム画像を読み出し、合成用文字列に対応する文字画像と合成用フレーム画像とを合成して合成画像を生成するものである、画像処理装置を提供する。
フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出する人物領域検出部と、
検出された人物領域に対応する人物を特定する人物特定部と、
抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出する人物評価部と、
特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定する中心人物判定部と、
動画像から音声を抽出する音声抽出部と、
音声を音声認識により文字列データに変換する音声認識部と、
中心人物と中心人物の音声との関連情報を生成し、さらに、フレーム画像に存在していない人物で、かつ、動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、非被写体人物と非被写体人物の音声との関連情報を生成する関連付け部と、
関連情報に基づいて、中心人物および非被写体人物を示すアイコンと中心人物および非被写体人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示する表示部と、
ユーザにより入力された指示を受け付ける指示受付部と、
フレーム画像と文字列に対応する文字画像とを合成する合成部とを備え、
指示受付部は、さらに、アイコンのうちユーザにより選択されたアイコンに対応する中心人物または非被写体人物を、合成の対象人物として指定する対象人物指定指示を受け付けるものであり、
合成部は、さらに、対象人物指定指示に応じて、対象人物の音声が存在する任意の時間帯における対象人物の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、中心人物が存在する任意の時刻における合成用フレーム画像を読み出し、合成用文字列に対応する文字画像と合成用フレーム画像とを合成して合成画像を生成するものである、画像処理装置を提供する。
また、本発明は、動画像から複数のフレーム画像を抽出するフレーム画像抽出部と、
フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出する人物領域検出部と、
検出された人物領域に対応する人物を特定する人物特定部と、
抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出する人物評価部と、
特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定する中心人物判定部と、
動画像から音声を抽出する音声抽出部と、
音声を音声認識により文字列データに変換する音声認識部と、
中心人物と中心人物の音声との関連情報を生成し、さらに、フレーム画像に存在していない人物で、かつ、動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、非被写体人物と非被写体人物の音声との関連情報を生成する関連付け部と、
関連情報に基づいて、中心人物を示すアイコンと中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示する表示部と、
ユーザにより入力された指示を受け付ける指示受付部と、
フレーム画像と文字列に対応する文字画像とを合成する合成部とを備え、
指示受付部は、さらに、アイコンのうちユーザにより選択されたアイコンに対応する中心人物を、合成の対象人物として指定する対象人物指定指示を受け付けるものであり、
合成部は、さらに、対象人物指定指示に応じて、対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における中心人物と非被写体人物とのうちの任意の一人の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、合成用フレーム画像と合成用文字列に対応する文字画像とを合成して合成画像を生成するものである、画像処理装置を提供する。
フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出する人物領域検出部と、
検出された人物領域に対応する人物を特定する人物特定部と、
抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出する人物評価部と、
特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定する中心人物判定部と、
動画像から音声を抽出する音声抽出部と、
音声を音声認識により文字列データに変換する音声認識部と、
中心人物と中心人物の音声との関連情報を生成し、さらに、フレーム画像に存在していない人物で、かつ、動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、非被写体人物と非被写体人物の音声との関連情報を生成する関連付け部と、
関連情報に基づいて、中心人物を示すアイコンと中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示する表示部と、
ユーザにより入力された指示を受け付ける指示受付部と、
フレーム画像と文字列に対応する文字画像とを合成する合成部とを備え、
指示受付部は、さらに、アイコンのうちユーザにより選択されたアイコンに対応する中心人物を、合成の対象人物として指定する対象人物指定指示を受け付けるものであり、
合成部は、さらに、対象人物指定指示に応じて、対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における中心人物と非被写体人物とのうちの任意の一人の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、合成用フレーム画像と合成用文字列に対応する文字画像とを合成して合成画像を生成するものである、画像処理装置を提供する。
合成部は、さらに、合成用文字列を、合成画像の下方向を指し示す吹き出しの形式で合成するものであることが好ましい。
また、本発明は、フレーム画像抽出部が、動画像から複数のフレーム画像を抽出するステップと、
人物領域検出部が、フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出するステップと、
人物特定部が、検出された人物領域に対応する人物を特定するステップと、
人物評価部が、抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出するステップと、
中心人物判定部が、特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定するステップと、
音声抽出部が、動画像から音声を抽出するステップと、
音声認識部が、音声を音声認識により文字列データに変換するステップと、
関連付け部が、中心人物と中心人物の音声との関連情報を生成するステップと、
表示部が、関連情報に基づいて、中心人物を示すアイコンと中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示するステップと、
指示受付部が、表示部に表示された関連情報に対して、ユーザにより入力された関連情報を修正する修正指示を受け付けるステップと、
関連付け部が、さらに、修正指示に応じて、関連情報を修正するステップと、
指示受付部が、さらに、アイコンのうちユーザにより選択されたアイコンに対応する中心人物を、合成の対象人物として指定する対象人物指定指示を受け付けるステップと、
合成部が、対象人物指定指示に応じて、対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における対象人物の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、合成用フレーム画像と合成用文字列に対応する文字画像とを合成して合成画像を生成するステップとを含む、画像処理方法を提供する。
人物領域検出部が、フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出するステップと、
人物特定部が、検出された人物領域に対応する人物を特定するステップと、
人物評価部が、抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出するステップと、
中心人物判定部が、特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定するステップと、
音声抽出部が、動画像から音声を抽出するステップと、
音声認識部が、音声を音声認識により文字列データに変換するステップと、
関連付け部が、中心人物と中心人物の音声との関連情報を生成するステップと、
表示部が、関連情報に基づいて、中心人物を示すアイコンと中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示するステップと、
指示受付部が、表示部に表示された関連情報に対して、ユーザにより入力された関連情報を修正する修正指示を受け付けるステップと、
関連付け部が、さらに、修正指示に応じて、関連情報を修正するステップと、
指示受付部が、さらに、アイコンのうちユーザにより選択されたアイコンに対応する中心人物を、合成の対象人物として指定する対象人物指定指示を受け付けるステップと、
合成部が、対象人物指定指示に応じて、対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における対象人物の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、合成用フレーム画像と合成用文字列に対応する文字画像とを合成して合成画像を生成するステップとを含む、画像処理方法を提供する。
さらに、指示受付部が、表示部に表示された関連情報に対して、関連情報を修正する修正指示を受け付けるステップと、
関連付け部が、修正指示に応じて、関連情報を修正するステップとを含むことが好ましい。
関連付け部が、修正指示に応じて、関連情報を修正するステップとを含むことが好ましい。
さらに、代表フレーム画像決定部が、対象人物指定指示に応じて、対象人物が存在するフレーム画像の中から、代表フレーム画像を決定するステップと、
代表文字列決定部が、対象人物指定指示に応じて、対象人物の音声の文字列データに対応する文字列の中から、代表文字列を決定するステップとを含み、
合成部は、代表フレーム画像と代表文字列に対応する文字画像とを合成することが好ましい。
代表文字列決定部が、対象人物指定指示に応じて、対象人物の音声の文字列データに対応する文字列の中から、代表文字列を決定するステップとを含み、
合成部は、代表フレーム画像と代表文字列に対応する文字画像とを合成することが好ましい。
表示部が、さらに、対象人物が存在する代表フレーム画像、および、対象人物が存在するフレーム画像であって代表フレーム画像以外のフレーム画像を表示するステップと、
指示受付部が、さらに、表示部に表示されたフレーム画像の中から、ユーザにより入力されたフレーム画像を指定するフレーム画像指定指示を受け付けるステップと、
代表フレーム画像決定部が、さらに、フレーム画像指定指示に応じて、ユーザにより指定されたフレーム画像を、代表フレーム画像に再決定するステップとを含むことが好ましい。
指示受付部が、さらに、表示部に表示されたフレーム画像の中から、ユーザにより入力されたフレーム画像を指定するフレーム画像指定指示を受け付けるステップと、
代表フレーム画像決定部が、さらに、フレーム画像指定指示に応じて、ユーザにより指定されたフレーム画像を、代表フレーム画像に再決定するステップとを含むことが好ましい。
表示部が、さらに、代表文字列、および、対象人物の音声の音声データに対応する文字列であって代表文字列以外の文字列を表示するステップと、
指示受付部が、さらに、表示部に表示された文字列の中から、ユーザにより入力された文字列を指定する文字列指定指示を受け付けるステップと、
代表文字列決定部が、さらに、文字列指定指示に応じて、ユーザにより指定された文字列を、代表文字列に再決定するステップとを含むことが好ましい。
指示受付部が、さらに、表示部に表示された文字列の中から、ユーザにより入力された文字列を指定する文字列指定指示を受け付けるステップと、
代表文字列決定部が、さらに、文字列指定指示に応じて、ユーザにより指定された文字列を、代表文字列に再決定するステップとを含むことが好ましい。
また、本発明は、フレーム画像抽出部が、動画像から複数のフレーム画像を抽出するステップと、
人物領域検出部が、フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出するステップと、
人物特定部が、検出された人物領域に対応する人物を特定するステップと、
人物評価部が、抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出するステップと、
中心人物判定部が、特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定するステップと、
音声抽出部が、動画像から音声を抽出するステップと、
音声認識部が、音声を音声認識により文字列データに変換するステップと、
関連付け部が、中心人物と中心人物の音声との関連情報を生成し、さらに、フレーム画像に存在していない人物で、かつ、動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、非被写体人物と非被写体人物の音声との関連情報を生成するステップと、
表示部が、関連情報に基づいて、中心人物および非被写体人物を示すアイコンと中心人物および非被写体人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示するステップと、
指示受付部が、アイコンのうちユーザにより選択されたアイコンに対応する中心人物または非被写体人物を、合成の対象人物として指定する対象人物指定指示を受け付けるステップと、
合成部が、対象人物指定指示に応じて、対象人物の音声が存在する任意の時間帯における対象人物の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、中心人物が存在する任意の時刻における合成用フレーム画像を読み出し、合成用文字列に対応する文字画像と合成用フレーム画像とを合成して合成画像を生成するステップとを含む、画像処理方法を提供する。
人物領域検出部が、フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出するステップと、
人物特定部が、検出された人物領域に対応する人物を特定するステップと、
人物評価部が、抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出するステップと、
中心人物判定部が、特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定するステップと、
音声抽出部が、動画像から音声を抽出するステップと、
音声認識部が、音声を音声認識により文字列データに変換するステップと、
関連付け部が、中心人物と中心人物の音声との関連情報を生成し、さらに、フレーム画像に存在していない人物で、かつ、動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、非被写体人物と非被写体人物の音声との関連情報を生成するステップと、
表示部が、関連情報に基づいて、中心人物および非被写体人物を示すアイコンと中心人物および非被写体人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示するステップと、
指示受付部が、アイコンのうちユーザにより選択されたアイコンに対応する中心人物または非被写体人物を、合成の対象人物として指定する対象人物指定指示を受け付けるステップと、
合成部が、対象人物指定指示に応じて、対象人物の音声が存在する任意の時間帯における対象人物の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、中心人物が存在する任意の時刻における合成用フレーム画像を読み出し、合成用文字列に対応する文字画像と合成用フレーム画像とを合成して合成画像を生成するステップとを含む、画像処理方法を提供する。
また、本発明は、フレーム画像抽出部が、動画像から複数のフレーム画像を抽出するステップと、
人物領域検出部が、フレーム画像に存在する人物の少なくとも一部の領域を検出するステップと、
人物特定部が、検出された人物領域に対応する人物を特定するステップと、
人物評価部が、抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出するステップと、
中心人物判定部が、特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定するステップと、
音声抽出部が、動画像から音声を抽出するステップと、
音声認識部が、音声を音声認識により文字列データに変換するステップと、
関連付け部が、中心人物と中心人物の音声との関連情報を生成し、さらに、フレーム画像に存在していない人物で、かつ、動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、非被写体人物と非被写体人物の音声との関連情報を生成するステップと、
表示部が、関連情報に基づいて、中心人物を示すアイコンと中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示するステップと、
指示受付部が、表示部に表示された関連情報に対して、ユーザにより入力された関連情報を修正する修正指示を受け付けるステップと、
関連付け部が、さらに、修正指示に応じて、関連情報を修正するステップと、
指示受付部が、さらに、アイコンのうちユーザにより選択されたアイコンに対応する中心人物を、合成の対象人物として指定する対象人物指定指示を受け付けるステップと、
合成部が、対象人物指定指示に応じて、対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における中心人物と非被写体人物とのうちの任意の一人の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、合成用フレーム画像と合成用文字列に対応する文字画像とを合成して合成画像を生成するステップとを含む、画像処理方法を提供する。
人物領域検出部が、フレーム画像に存在する人物の少なくとも一部の領域を検出するステップと、
人物特定部が、検出された人物領域に対応する人物を特定するステップと、
人物評価部が、抽出された複数のフレーム画像の少なくとも一部における人物領域を特定された人物ごとに評価して、動画像における特定された人物の評価点を算出するステップと、
中心人物判定部が、特定された人物の評価点が一定値を超えた場合に、特定された人物が動画像における中心人物であると判定するステップと、
音声抽出部が、動画像から音声を抽出するステップと、
音声認識部が、音声を音声認識により文字列データに変換するステップと、
関連付け部が、中心人物と中心人物の音声との関連情報を生成し、さらに、フレーム画像に存在していない人物で、かつ、動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、非被写体人物と非被写体人物の音声との関連情報を生成するステップと、
表示部が、関連情報に基づいて、中心人物を示すアイコンと中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示するステップと、
指示受付部が、表示部に表示された関連情報に対して、ユーザにより入力された関連情報を修正する修正指示を受け付けるステップと、
関連付け部が、さらに、修正指示に応じて、関連情報を修正するステップと、
指示受付部が、さらに、アイコンのうちユーザにより選択されたアイコンに対応する中心人物を、合成の対象人物として指定する対象人物指定指示を受け付けるステップと、
合成部が、対象人物指定指示に応じて、対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における中心人物と非被写体人物とのうちの任意の一人の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、合成用フレーム画像と合成用文字列に対応する文字画像とを合成して合成画像を生成するステップとを含む、画像処理方法を提供する。
また、本発明は、上記に記載の画像処理方法の各々のステップをコンピュータに実行させるためのプログラムを提供する。
また、本発明は、上記に記載の画像処理方法の各々のステップをコンピュータに実行させるためのプログラムが記録されたコンピュータ読み取り可能な記録媒体を提供する。
本発明によれば、フレーム画像と、動画像内の人物の音声の文字列データに対応する文字列の文字画像とを合成することにより、合成画像の魅力を向上させることができる。また、関連情報を用いて人物と音声の関連付けが行われているので、人物と音声の対応を視認でき、フレーム画像と音声に対応する文字列データの選択を容易にかつ自由に行うことができる。
また、本発明では、中心人物とその中心人物の音声との関連付けが行われ、対象人物の代表フレーム画像および代表文字列が自動で決定される。ユーザは、自動で決定された対象人物の代表フレーム画像および代表文字列をそのまま選択することもできるし、あるいは、表示部に表示された、それ以外の対象人物のフレーム画像および文字列の中から、任意の時刻におけるフレーム画像および任意の時間帯における文字列を自由に選択することができる。
このように、対象人物が存在する任意の時刻におけるフレーム画像と、任意の時間帯における対象人物の音声の文字列データに対応する文字列の文字画像とを合成することができるため、本発明によれば、様々なバリエーションの合成画像を生成することができる。また、ユーザは、対象人物が存在する任意の時刻におけるフレーム画像と、フレーム画像に存在する人物の任意の時間帯における音声に対応する文字列の文字画像とを簡単に選択して合成することができる。
以下に、添付の図面に示す好適実施形態に基づいて、本発明の画像処理装置、画像処理方法、プログラムおよび記録媒体を詳細に説明する。
図1は、本発明の画像処理装置の構成を表す一実施形態のブロック図である。同図に示す画像処理装置10は、動画像から抽出されたフレーム画像と、フレーム画像に存在する人物の音声に対応する文字列の文字画像とを合成して合成画像を生成し、合成画像の出力画像(動画プリント)が撮影(キャプチャ)された場合に、出力画像に関連付けられた動画像を再生表示するものである。
画像処理装置10は、サーバ12と、携帯端末14と、プリンタ16とを備えている。サーバ12、携帯端末14およびプリンタ16は、インターネット等のネットワーク18を介して互いに接続されている。
図2は、図1に示すサーバの構成を表す一実施形態のブロック図である。図2に示すサーバ12は、フレーム画像抽出部20と、人物領域検出部22と、人物特定部23と、人物評価部24と、中心人物判定部26と、音声抽出部28と、音声認識部30と、関連付け部32と、代表フレーム画像決定部34と、代表文字列決定部36と、合成部38と、コンテンツ生成部40と、記憶部42と、撮影画像解析部44と、管理マーカ特定部46と、動画像処理部48と、第1転送部50とを備えている。
フレーム画像抽出部20は、動画像から複数のフレーム画像を抽出するものである。
ここで、動画像からフレーム画像を抽出する方法は何ら限定されない。例えば、動画像からユーザが手動で所望のフレーム画像を抽出してもよいし、動画像からあらかじめ設定された一定の時間間隔でフレーム画像を抽出してもよい。
あるいは、KFE(Key Frame Extraction)技術を利用して、シーンの変わり目などのキーとなるフレーム画像を抽出してもよい。KFEでは、例えば、動画像の各々のフレーム画像を解析し、フレーム画像の色味、明るさ、ボケやブレ等を検出し、色味や明るさが大きく変わる前後のフレーム画像や、適正露出によりボケやブレがないフレーム画像が抽出される。
また、動画像において人物の顔の大きさや向き、顔の表情(笑顔、泣き顔等)を検出し、それらに基づいてフレーム画像を抽出してもよい。さらに、動画像に音声が含まれる場合には、音声が大きくなった時刻(タイムコード)の前後の動画像からフレーム画像を抽出してもよい。上述の方法で動画像からフレーム画像を抽出することで、動画像の代表的なシーンをフレーム画像として抽出することができる。
人物領域検出部22は、フレーム画像抽出部20により動画像から抽出されたフレーム画像に存在する人物の少なくとも一部の領域、例えば、顔領域を人物領域として検出するものである。
なお、フレーム画像に存在する人物の領域を検出する方法は公知であり、その具体的な検出方法は何ら限定されない。また、顔領域は顔そのものでなくてもよい。例えば、顔を含む四角形の領域を切り取ったものでもよい。
人物特定部23は、人物領域検出部22により検出された人物領域に対応する人物を特定するものである。
人物特定部23は、人物領域に対応する人物が具体的に誰なのかを特定する必要はなく、異なる人物が人物領域に存在する場合に、人物領域に存在する人物毎に、異なる人物であるということを特定することができればよい。また、人物の特定について、内部では顔データそのものでなく、特徴量で管理してもよい。
人物特定部23は、人物領域に対応する人物が具体的に誰なのかを特定する必要はなく、異なる人物が人物領域に存在する場合に、人物領域に存在する人物毎に、異なる人物であるということを特定することができればよい。また、人物の特定について、内部では顔データそのものでなく、特徴量で管理してもよい。
なお、人物領域(静止画像)から、人物領域に対応する人物を特定する具体的な特定方法は何ら限定されない。
人物評価部24は、人物領域検出部22により検出された、複数のフレーム画像の少なくとも一部における人物領域を、人物特定部23により特定された人物ごとに評価して、動画像における特定された人物の評価点を算出するものである。
なお、人物領域を評価して、人物領域に存在する人物の評価点を算出する具体的な方法は何ら限定されないが、例えば、人物領域に含まれる人物の顔、人物領域のボケブレ、色味、明るさ等に基づいて評価を行うことができる。例えば、人物の顔のサイズが閾値以上である、人物の顔が正面を向いている、笑顔である場合、ボケブレの程度があらかじめ設定された閾値未満である場合、色味や明るさ、目の開き具合があらかじめ設定された一定範囲内である場合等に、人物の評価点を高くする。
中心人物判定部26は、人物特定部23により特定された人物の評価点が、あらかじめ設定された一定値を超えた場合に、その特定された人物が動画像における中心人物であると判定するものである。中心人物は、一人でも、複数人であっても構わない。
なお、中心人物の具体的な判定方法は、例えば、複数の人物領域に含まれる人物に対して同一人物判定処理が行われ、複数の人物領域が、同一人物の人物領域からなる複数の人物のグループに分類される。同一人物判定処理も公知であり、画像解析により、同一人物か否かの判定が行われる。そして、グループ内の人物領域に含まれる人物の評価点の合計値が算出され、合計値が一定値を超えた人物が中心人物であると判定される。
音声抽出部28は、動画像から音声を抽出するものである。
また、音声認識部30は、音声抽出部28により動画像から抽出された音声を音声認識により文字列データに変換するものである。
また、音声認識部30は、音声抽出部28により動画像から抽出された音声を音声認識により文字列データに変換するものである。
なお、特許文献4、5のように、動画像から音声を抽出する方法および音声を音声認識により文字列データに変換する具体的な方法は何ら限定されない。
続いて、音声認識部30は、得られた文字列データを、短い時間帯毎に区切って保存する。具体的には、文字列データの占める時刻を取得し、文字列データが存在しない時間が一定値(例えば1秒)を超えた場合、その時間の前後はそれぞれ異なる文字列データとして、記憶部42において保存する。
また、音声抽出部28は、動画像から抽出された音声からノイズを除去するノイズキャンセリングを行うことが望ましい。これにより、音声認識部30による音声認識の精度を向上させることができる。
続いて、音声認識部30は、得られた文字列データを、短い時間帯毎に区切って保存する。具体的には、文字列データの占める時刻を取得し、文字列データが存在しない時間が一定値(例えば1秒)を超えた場合、その時間の前後はそれぞれ異なる文字列データとして、記憶部42において保存する。
また、音声抽出部28は、動画像から抽出された音声からノイズを除去するノイズキャンセリングを行うことが望ましい。これにより、音声認識部30による音声認識の精度を向上させることができる。
関連付け部32は、中心人物判定部26により判定された中心人物と、音声抽出部28により動画像から抽出された、その中心人物の音声との関連付けを表す関連情報を生成するものである。
関連付け部32が、中心人物と、その中心人物の音声との関連情報を生成する方法は、例えば、中心人物が存在するフレーム画像の人物領域から、中心人物の性別および年齢を判定するとともに、中心人物の音声の高低から、音声に対応する人物の性別および年齢を判定する。そして、中心人物の性別および年齢と音声に対応する人物の性別および年齢とが合致するように、関連情報を生成することができる。
また、関連付け部32は、関連情報を生成する場合に、人間の声の音域、例えば、100Hz〜4000Hzの音域以外の音域の音声を使用しないことが望ましい。これにより、関連情報の精度を向上させることができる。
代表フレーム画像決定部34は、後述する、合成の対象人物を指定する対象人物指定指示に応じて、対象人物が存在するフレーム画像の中から、対象人物の代表的なシーンに対応する代表フレーム画像を決定するものである。
なお、対象人物が存在するフレーム画像の中から、対象人物の代表フレーム画像を決定する方法は、例えば、対象人物が存在するフレーム画像の中から、色味、明るさ、および、ボケブレのうちの少なくとも1つがあらかじめ設定された一定範囲内であるフレーム画像、対象人物の顔の大きさおよび向きのうちの少なくとも1つがあらかじめ設定された一定範囲内であり、かつ、対象人物の表情が笑顔であるフレーム画像、あるいは、代表人物の発話シーン、動きが大きいシーンおよび音声が大きいシーンのうちの少なくとも1つのフレーム画像を、対象人物の代表フレーム画像に決定することができる。
代表文字列決定部36は、対象人物指定指示に応じて、対象人物の音声の文字列データに対応する文字列の中から、対象人物の代表的な音声に対応する代表文字列を決定するものである。
代表文字列決定部36が、対象人物の音声の文字列データに対応する文字列の中から、対象人物の代表文字列を決定する方法は、例えば、対象人物の音声の文字列データに対応する文字列の中から、対象人物の声の大きさおよび声の高さのうちの少なくとも1つがあらかじめ設定された一定範囲内である音声の文字列データに対応する文字列、あるいは、最も登場頻度の高い言葉の音声の文字列データに対応する文字列を、代表文字列に決定することができる。
合成部38は、対象人物指定指示に応じて、対象人物のフレーム画像と、その音声の文字列データに対応する文字列の文字画像とを合成して合成画像を生成するものである。
例えば、合成部38は、フレーム画像抽出部20により動画像から抽出された複数のフレーム画像の中から、対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、音声抽出部28により動画像から抽出された音声の文字列データに対応する文字列の中から、任意の時間帯における対象人物の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、合成用フレーム画像と合成用文字列に対応する文字画像とを合成して合成画像を生成する。
また、合成部38は、代表フレーム画像決定部34により決定された対象人物の代表フレーム画像と、代表文字列決定部36により決定された対象人物の代表文字列に対応する文字画像とを合成する。
例えば、合成部38は、フレーム画像抽出部20により動画像から抽出された複数のフレーム画像の中から、対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、音声抽出部28により動画像から抽出された音声の文字列データに対応する文字列の中から、任意の時間帯における対象人物の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、合成用フレーム画像と合成用文字列に対応する文字画像とを合成して合成画像を生成する。
また、合成部38は、代表フレーム画像決定部34により決定された対象人物の代表フレーム画像と、代表文字列決定部36により決定された対象人物の代表文字列に対応する文字画像とを合成する。
ここで、合成用文字列を合成する時の形式は例えば、文字列を、吹き出し、テロップ、字幕のうちのいずれか1つの形式によって合成することができる。また、文字列の内容に応じて、文字列の書体を変更してもよい。さらに、4コマ漫画のように、文字列の文字画像が合成された複数のフレーム画像を含む合成画像を生成してもよい。これにより、様々なバリエーションの合成画像を生成することができる。
コンテンツ生成部40は、動画像と、合成部38により合成された合成画像またはその特定情報とが関連付けられたARコンテンツを生成するものである。
記憶部42は、各種のデータを記憶するものである。
記憶部42には、例えば、携帯端末14から送信されてきた動画像等の他、例えば、コンテンツ生成部40により生成されたARコンテンツ、つまり、合成画像またはその特定情報が、合成画像の管理マーカとして、動画像と関連付けて記憶される。
記憶部42には、例えば、携帯端末14から送信されてきた動画像等の他、例えば、コンテンツ生成部40により生成されたARコンテンツ、つまり、合成画像またはその特定情報が、合成画像の管理マーカとして、動画像と関連付けて記憶される。
ここで、管理マーカとは、あらかじめ決定されたアルゴリズムに基づいて静止画像の画像解析を行うことにより、静止画像から読み取られる画像の特徴量であり、例えば、静止画像に撮影された撮影対象のエッジ情報やエッジの位置情報等が含まれる。管理マーカは、静止画像そのものであってもよいし、静止画像を特定するための特定情報でもよい。静止画像の特定情報は、撮影画像から合成画像を特定することができる情報であれば、どのような情報であってもよい。
撮影画像解析部44は、後述するように、合成画像の出力画像(動画プリント)が撮影(キャプチャ)されて取得された撮影画像の画像解析を行って、撮影画像の管理マーカを得るものである。
管理マーカ特定部46は、記憶部42に記憶された合成画像の管理マーカの中から、撮影画像解析部44により得られた撮影画像の管理マーカに対応する合成画像の管理マーカを特定管理マーカとして特定するものである。管理マーカ特定部46は、例えば、撮影画像の管理マーカに基づいて、記憶部42に記憶された合成画像の管理マーカを検索することにより、撮影画像の管理マーカに対応する合成画像の管理マーカを特定する。
動画像処理部48は、特定管理マーカに関連付けられた関連動画像から、AR再生用の動画像を生成するものである。つまり、動画像処理部48は、特定管理マーカ、すなわち、合成画像またはその特定情報に基づいて、関連動画像からAR再生用の動画像を生成する。
動画像処理部48は、動画像のファイルサイズを小さくするために、例えば、動画像の解像度やビットレートを下げることにより、ファイルサイズが小さいAR再生用の動画像を生成する。
第1転送部50は、サーバ12と携帯端末14との間で、動画像、撮影画像などを含む、各種のデータを転送するものである。
続いて、図3は、図1に示す携帯端末の内部構成を表す一実施形態のブロック図である。携帯端末14は、ユーザが使用するスマートフォン、タブレット端末などであり、図3に示すように、画像撮影部52と、入力部54と、表示部56と、制御部58と、第2転送部60とを備えている。
画像撮影部52は、合成画像がプリンタ16により出力された出力画像(動画プリント)などを撮影(キャプチャ)して撮影画像を得るものである。
入力部54は、ユーザにより入力された各種の指示を受け付けるものであり、本発明の指示受付部に相当する。
表示部56は、各種の画像や情報等を表示するものである。
本実施形態では、タッチパネル62が、入力部54および表示部56を構成するものとする。
表示部56は、各種の画像や情報等を表示するものである。
本実施形態では、タッチパネル62が、入力部54および表示部56を構成するものとする。
制御部58は、表示部56の表示を制御するものである。制御部58は、例えば、画像撮影部52により出力画像が撮影(キャプチャ)された場合に、撮影画像に基づいて生成されたAR再生用の動画像が表示部56に再生して表示されるように制御する。
ここで、制御部58は、動画像を表示部56に再生させる場合、AR技術を使用して再生(AR再生)させてもよいし、AR技術を使用せず再生(通常再生)させてもよい。制御部58は、動画像をAR再生させる場合、撮影された出力画像を表示部56に表示し、表示部56に表示された出力画像の表示部分において動画像が再生されるように制御する。また、制御部58は、動画像を通常再生させる場合、表示部56の全面ないし任意のサイズのウィンドウ内において動画像が再生されるように制御する。
第2転送部60は、携帯端末14とサーバ12との間で、動画像、撮影画像などを含む、各種のデータを転送するものである。
次に、図4〜図6に示すフローチャートを参照しながら、ARコンテンツを生成し、合成画像の出力画像(動画プリント)を出力する場合の画像処理装置10の動作を説明する。
まず、ユーザにより、携帯端末14のタッチパネル62(入力部54)を操作して、動画像(動画像データ)が選択され、選択された動画像の送信(アップロード)の指示が入力される。
送信が指示された動画像は、第2転送部60により、携帯端末14からネットワーク18を介してサーバ12へ送信される。サーバ12では、第1転送部50により、携帯端末14から送信されてきた動画像が受信され、記憶部42に記憶される。
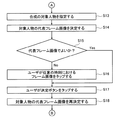
続いて、フレーム画像抽出部20により、記憶部42に記憶された動画像から複数のフレーム画像(画像データ)が抽出される(ステップS1)。
続いて、人物領域検出部22により、フレーム画像抽出部20により動画像から抽出されたフレーム画像に存在する人物の領域が人物領域として検出され(ステップS2)、人物特定部23により、人物領域検出部22により検出された人物領域に対応する人物が特定される(ステップS3)。
続いて、人物評価部24により、人物領域検出部22により検出された、複数のフレーム画像の人物領域が、人物特定部23により特定された人物ごとに評価されて、動画像における特定された人物の評価点が算出され(ステップS4)、中心人物判定部26により、人物特定部23により特定された人物の評価点が一定値を超えた場合に、その人物が動画像における中心人物であると判定される(ステップS5)。なお、ここでいう評価点が一定値を超えた場合とは、評価点が複数フレームのいずれか一つのフレームについて超えた場合、評価点の全てまたは所定数のフレームの平均値が超えた場合、あるいは動画像開始からのフレームの評価点の積分値が超えた場合のいずれでもよい。
続いて、音声抽出部28により、動画像から音声が抽出され(ステップS6)、音声抽出部28により動画像から抽出された音声が、音声認識部30により、音声認識により文字列データに変換される(ステップS7)。
続いて、関連付け部32により、中心人物判定部26により判定された中心人物と、音声抽出部28により動画像から抽出された、中心人物の音声との関連情報が生成される(ステップS8)。
関連付け部32により生成された関連情報は、サーバ12から携帯端末14へ送信される。
携帯端末14では、サーバ12から受信された関連情報に基づいて、中心人物を示すアイコンと中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報が、タッチパネル62(表示部56)に一覧表示される。
携帯端末14では、サーバ12から受信された関連情報に基づいて、中心人物を示すアイコンと中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報が、タッチパネル62(表示部56)に一覧表示される。
なお、中心人物のアイコンおよび中心人物の音声の文字列データに対応する文字列のデータ等は、サーバ12から携帯端末14へ送信してもよいし、あるいは、携帯端末14が備えるデータを使用してもよい。
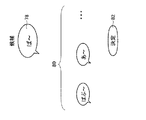
例えば、図8に示す例の場合、図中左側に、それぞれの中心人物の音声の文字列データに対応する文字列64が吹き出しの形式によって囲まれて時系列に並べられ、その右側に、それぞれの文字列に関連付けられた中心人物の候補として、父親、母親および赤ちゃんのアイコン66が表示されている。また、それぞれの人物と文字列が関連付けられていることを示す左向きの矢印が関連情報65として表示されている。この例では、父親の音声の文字列データに対応する文字列として、「お〜い」、「あっ」が、母親の音声の文字列データに対応する文字列として、「どこ?」が、赤ちゃんの音声の文字列データに対応する文字列として、「ば〜」が表示されている。なお、関連情報65は矢印として表示されている必要はなく、それぞれの人物と文字列がそれぞれ縦または横に配置されて表示されているなど、表示部56の表示によって関連付けされていることが視認できるものであればいかなる態様であってもよい。
なお、それぞれの中心人物の音声の文字列データに対応する文字列64は、表示されているもの以外にも時系列に並べられており、例えば、ユーザは、スクロールバー等を操作して閲覧したい文字列を適宜表示させることができる。
続いて、ユーザにより、タッチパネル62(入力部54)を操作して、タッチパネル62(表示部56)に一覧表示された関連情報に対して、関連情報を修正する修正指示が入力される。
図8に示す例の場合、中心人物と、中心人物の音声との関連情報を修正するための空白のアイコン68が、中心人物のアイコン66の右側に設けられている。
ここで、ユーザにより、中心人物と、中心人物の音声との関連情報が正しいか否かの判定が行われる(ステップS9)。
ユーザは、中心人物と、中心人物の音声との関連情報が正しいと考える場合(ステップS9でYes)、決定ボタン70をタップする(ステップS11)。この場合、関連情報は修正されない。
一方、ユーザは、関連情報が間違っていると考える場合(ステップS9でNo)、中心人物のアイコン66を、ユーザが正しいと考える空白のアイコン68のところへドラッグアンドドロップして関連情報を修正した後(ステップS10)、決定ボタン70をタップする(ステップS11)。この場合、関連情報は、ユーザが変更した通りに修正される。
ここで、ユーザにより、中心人物と、中心人物の音声との関連情報が正しいか否かの判定が行われる(ステップS9)。
ユーザは、中心人物と、中心人物の音声との関連情報が正しいと考える場合(ステップS9でYes)、決定ボタン70をタップする(ステップS11)。この場合、関連情報は修正されない。
一方、ユーザは、関連情報が間違っていると考える場合(ステップS9でNo)、中心人物のアイコン66を、ユーザが正しいと考える空白のアイコン68のところへドラッグアンドドロップして関連情報を修正した後(ステップS10)、決定ボタン70をタップする(ステップS11)。この場合、関連情報は、ユーザが変更した通りに修正される。
関連情報の修正指示は、携帯端末14からサーバ12へ送信される。
サーバ12では、関連付け部32により、さらに、関連情報の修正指示に応じて、関連情報が修正される(ステップS12)。
サーバ12では、関連付け部32により、さらに、関連情報の修正指示に応じて、関連情報が修正される(ステップS12)。
続いて、ユーザにより、タッチパネル62(入力部54)を操作して、タッチパネル62(表示部56)に一覧表示された中心人物のアイコンのうち、ユーザが合成画像(画像データ)を生成する処理を行いたい中心人物のアイコンが選択される。これにより、ユーザにより選択されたアイコンに対応する中心人物を、合成の対象人物として指定する対象人物指定指示が入力される(ステップS13)。
対象人物指定指示は、携帯端末14からサーバ12へ送信される。
サーバ12では、代表フレーム画像決定部34により、対象人物指定指示に応じて、対象人物が存在するフレーム画像の中から、代表フレーム画像が決定される(ステップS14)。
サーバ12では、代表フレーム画像決定部34により、対象人物指定指示に応じて、対象人物が存在するフレーム画像の中から、代表フレーム画像が決定される(ステップS14)。
代表フレーム画像決定部34により決定された代表フレーム画像は、対象人物が存在するフレーム画像であって代表フレーム画像以外のフレーム画像とともに、サーバ12から携帯端末14へ送信される。
携帯端末14では、サーバ12から受信された、対象人物の代表フレーム画像、および、それ以外の対象人物が存在するフレーム画像がタッチパネル62(表示部56)に一覧表示される。
続いて、ユーザにより、タッチパネル62(表示部56)に表示された、対象人物の代表フレーム画像、および、それ以外の対象人物が存在するフレーム画像の中から、ユーザが対象人物の代表フレーム画像として選択したい任意の時刻におけるフレーム画像が選択される。これにより、ユーザにより選択されたフレーム画像を指定するフレーム画像指定指示が入力される。
例えば、図9に示すように、図中上側に、対象人物の代表フレーム画像72の候補が表示され、その下側に、それ以外の対象人物が存在するフレーム画像74が表示される。この例では、赤ちゃんの代表フレーム画像が図中上側に表示され、それ以外の、赤ちゃんが存在するフレーム画像が図中下側に表示されている。
ここで、ユーザにより、代表フレーム画像72でよいか否かの判定が行われる(ステップS15)。
ユーザは、代表フレーム画像72でよいと考える場合(ステップS15でYes)、決定ボタン76をタップする(ステップS17)。この場合、代表フレーム画像は修正されない。
一方、ユーザは、代表フレーム画像72ではよくないと考える場合(ステップS15でNo)、それ以外の、対象人物が存在するフレーム画像74の中から、ユーザが対象人物の代表フレーム画像として選択したい任意の時刻におけるフレーム画像をタップした後(ステップS16)、決定ボタン76をタップする(ステップS17)。この場合、代表フレーム画像は、ユーザが変更した通りに修正される。
ユーザは、代表フレーム画像72でよいと考える場合(ステップS15でYes)、決定ボタン76をタップする(ステップS17)。この場合、代表フレーム画像は修正されない。
一方、ユーザは、代表フレーム画像72ではよくないと考える場合(ステップS15でNo)、それ以外の、対象人物が存在するフレーム画像74の中から、ユーザが対象人物の代表フレーム画像として選択したい任意の時刻におけるフレーム画像をタップした後(ステップS16)、決定ボタン76をタップする(ステップS17)。この場合、代表フレーム画像は、ユーザが変更した通りに修正される。
フレーム画像指定指示は、携帯端末14からサーバ12へ送信される。
サーバ12では、代表フレーム画像決定部34により、フレーム画像指定指示に応じて、ユーザにより指定された任意の時刻におけるフレーム画像が、対象人物の代表フレーム画像に再決定される(ステップS18)。
サーバ12では、代表フレーム画像決定部34により、フレーム画像指定指示に応じて、ユーザにより指定された任意の時刻におけるフレーム画像が、対象人物の代表フレーム画像に再決定される(ステップS18)。
続いて、代表文字列決定部36により、対象人物指定指示に応じて、対象人物の音声の文字列データに対応する文字列の中から、対象人物の代表文字列が決定される(ステップS19)。
代表文字列決定部36により決定された、対象人物の代表文字列の文字列データは、対象人物の音声の音声データに対応する文字列の文字列データであって代表文字列以外の文字列の文字列データとともに、サーバ12から携帯端末14へ送信される。
携帯端末14では、サーバ12から受信された、対象人物の代表文字列の文字列データに対応する代表文字列、および、対象人物の音声の音声データに対応する文字列であって代表文字列以外の文字列がタッチパネル62(表示部56)に一覧表示される。
続いて、ユーザにより、タッチパネル62(表示部56)に表示された、対象人物の代表文字列、および、それ以外の、対象人物の音声の文字列データに対応する文字列の中から、ユーザが対象人物の代表フレーム画像に対して合成したい任意の時間帯における文字列が選択される。これにより、ユーザにより選択された文字列を指定する文字列指定指示が入力される。
例えば、図10に示すように、図中上側に、対象人物の代表文字列78の候補が表示され、その下側に、それ以外の対象人物の音声の文字列データに対応する文字列80が表示される。この例では、赤ちゃんの代表文字列として、「ば〜」が図中上側に表示され、それ以外の、赤ちゃんの音声の文字列データに対応する文字列として、「ばぶ〜」、「あ〜」、…が図中下側に表示されている。
ここで、ユーザにより、対象人物の代表文字列78でよいか否かの判定が行われる(ステップS20)。
ユーザは、対象人物の代表文字列78でよいと考える場合(ステップS20でYes)、決定ボタン82をタップする(ステップS22)。この場合、代表文字列は修正されない。
一方、ユーザは、対象人物の代表文字列78ではよくないと考える場合(ステップS20でNo)、それ以外の、対象人物の音声の文字列データに対応する文字列80の中から、ユーザが対象人物の代表フレーム画像に対して合成したい任意の時間帯における文字列をタップした後(ステップS21)、決定ボタン82をタップする(ステップS22)。この場合、代表文字列は、ユーザにより変更された通りに修正される。
ユーザは、対象人物の代表文字列78でよいと考える場合(ステップS20でYes)、決定ボタン82をタップする(ステップS22)。この場合、代表文字列は修正されない。
一方、ユーザは、対象人物の代表文字列78ではよくないと考える場合(ステップS20でNo)、それ以外の、対象人物の音声の文字列データに対応する文字列80の中から、ユーザが対象人物の代表フレーム画像に対して合成したい任意の時間帯における文字列をタップした後(ステップS21)、決定ボタン82をタップする(ステップS22)。この場合、代表文字列は、ユーザにより変更された通りに修正される。
文字列指定指示は、携帯端末14からサーバ12へ送信される。
サーバ12では、代表文字列決定部36により、文字列指定指示に応じて、ユーザにより指定された任意の時間帯における文字列が、対象人物の代表文字列に再決定される(ステップS23)。
サーバ12では、代表文字列決定部36により、文字列指定指示に応じて、ユーザにより指定された任意の時間帯における文字列が、対象人物の代表文字列に再決定される(ステップS23)。
続いて、合成部38により、対象人物指定指示に応じて、関連情報に基づいて、対象人物の代表フレーム画像と、対象人物の代表文字列に対応する文字画像とが合成されて合成画像(画像データ)が生成される(ステップS24)。
例えば、図11に示すように、対象人物の代表フレーム画像と、対象人物の代表文字列の文字画像とが、対象人物がいる方向を指し示す吹き出しの形式によって合成される。この例では、赤ちゃんの代表フレーム画像と、赤ちゃんの代表文字列である「ば〜」の文字画像とが、赤ちゃんがいる方向を指し示す吹き出しの形式によって合成されている。
なお、吹き出しの形状や吹き出しの方向、色、大きさ、位置等は、ユーザが自由に修正してもよい。
このように、画像処理装置10では、フレーム画像と、フレーム画像に存在する人物の音声の文字列データに対応する文字列の文字画像とを合成することにより、合成画像の魅力を向上させることができる。また、関連情報を用いて人物と音声の関連付けが行われているので、中心人物とその中心人物の音声とが表示部56に列挙されるため、人物と音声の対応を視認でき、フレーム画像と音声に対応する文字列データの選択を容易にかつ自由に行うことができる。
また、中心人物とその中心人物の音声との関連付けが行われ、対象人物の代表フレーム画像および代表文字列が自動で決定される。ユーザは、自動で決定された対象人物の代表フレーム画像および代表文字列をそのまま選択することもできるし、あるいは、表示部56に表示された、それ以外の対象人物のフレーム画像および文字列の中から、任意の時刻におけるフレーム画像および任意の時間帯における文字列を自由に選択することができる。
このように、対象人物が存在する任意の時刻におけるフレーム画像と、任意の時間帯における対象人物の音声の文字列データに対応する文字列の文字画像とを合成することができるため、様々なバリエーションの合成画像を生成することができる。また、ユーザは、対象人物が存在する任意の時刻におけるフレーム画像と、フレーム画像に存在する人物の任意の時間帯における音声に対応する文字列の文字画像とを簡単に選択して合成することができる。
続いて、コンテンツ生成部40により、動画像と、合成部38により合成された合成画像またはその特定情報とが関連付けられたARコンテンツが生成される(ステップS25)。コンテンツ生成部40により生成されたARコンテンツ、つまり、合成画像またはその特定情報は、合成画像の管理マーカとして、対応する動画像と関連付けられて記憶部42に記憶される。
続いて、ユーザにより、タッチパネル62(入力部54)を操作して、プリントサイズやプリント枚数等が設定され、合成画像のプリント出力の指示が入力される。
プリント出力の指示は、携帯端末14からサーバ12へ送信される。
受信されたプリント出力の指示に対応する合成画像がサーバ12からプリンタ16へ送信され、プリンタ16により、合成画像の出力画像(動画プリント)が出力される(ステップS26)。
出力画像は、ユーザに配達される。
受信されたプリント出力の指示に対応する合成画像がサーバ12からプリンタ16へ送信され、プリンタ16により、合成画像の出力画像(動画プリント)が出力される(ステップS26)。
出力画像は、ユーザに配達される。
以上のようにして、動画像と、合成画像またはその特定情報とが関連付けられたARコンテンツが記憶部42に記憶されるとともに、合成画像の出力画像が出力される。
次に、図7に示すフローチャートを参照しながら、AR再生用の動画像を生成し、再生表示する場合の画像処理装置10の動作を説明する。
まず、画像撮影部52により、合成画像の出力画像が撮影(キャプチャ)され、撮影画像(画像データ)が取得される(ステップS27)。撮影された出力画像は、携帯端末14のタッチパネル62(表示部56)に表示される。
取得された撮影画像は、第2転送部60により、携帯端末14からネットワーク18を介してサーバ12へ送信される。サーバ12では、第1転送部50により、携帯端末14から送信されてきた撮影画像が受信される。
続いて、撮影画像解析部44により、撮影画像の画像解析が行われ、撮影画像の管理マーカが取得される(ステップS28)。
続いて、管理マーカ特定部46により、記憶部42に記憶された合成画像の管理マーカ中から、撮影画像の管理マーカに対応する合成画像の管理マーカが特定管理マーカとして特定される(ステップS29)。
続いて、動画像処理部48により、特定管理マーカに関連付けられた関連動画像から、AR再生用の動画像(動画像データ)が生成される(ステップS30)。
続いて、動画像処理部48により生成されたAR再生用の動画像は、サーバ12から携帯端末14へ送信される。携帯端末14では、サーバ12から送信されてきたAR再生用の動画像が受信される。
AR再生用の動画像が受信されると、制御部58の制御により、受信されたAR再生用の動画像が、携帯端末14のタッチパネル62(表示部56)に表示された出力画像の表示部分において再生して表示される(ステップS31)。
以上のようにして、合成画像の出力画像が撮影されると、撮影画像の管理マーカに対応する合成画像の管理マーカが特定され、特定管理マーカに関連付けられた関連動画像からAR再生用の動画像が生成され、携帯端末14で再生表示される。
なお、合成画像の出力画像を出力する場合、例えば、数字やアルファベットを含む文字列からなるアクセスキーを合成画像の出力画像に印刷してもよい。アクセスキーは、ユーザ毎に一意に決定されるものである。ユーザがアクセスキーを入力することにより、記憶部42に記憶された合成画像の管理マーカの中から特定管理マーカを特定する場合に、各々のユーザがサーバ12へ送信した動画像に関連付けられた合成画像の管理マーカの範囲に限定することができる。
また、対象人物のフレーム画像に対して、対象人物の音声の文字列データに対応する文字列を吹き出しの形式によって合成する場合、アクセスキーの文字列に応じて、吹き出しの形状や色等を変更することにより、吹き出しをアクセスキーの代わりに使用することもできる。この場合、アクセスキーを合成画像の出力画像に印刷する必要がなくなるため、美観が損なわれるのを防ぐことができるとともに、吹き出しの形状や色等を自動認識することにより、ユーザがアクセスキーを手入力する手間を省くことができる。
また、携帯端末14を使用することに限定されず、画像撮影部52、入力部54、表示部56、制御部58、第2転送部60を備えるパーソナルコンピュータ等の制御装置を使用することもできる。
また、前述のように、例えば、対象人物の代表フレーム画像と、対象人物の代表文字列とが合成される。従って、音声認識部30は、音声抽出部28により動画像から抽出された音声を文字列データに変換する場合に、動画像から抽出された音声のうち、対象人物の音声を時期的に優先して文字列データに変換することにより、変換効率を向上させることができる。
また、中心人物および非被写体人物の中から対象人物が指定された場合に、例えば、対象人物の音声の文字列データに対応する文字列の文字画像と、中心人物のフレーム画像とを組み合わせて合成してもよい。
この場合、関連付け部32は、さらに、フレーム画像に存在していない人物で、かつ、動画像から抽出された音声の登場頻度があらかじめ設定された一定値を超える人物が非被写体人物であると判定し、非被写体人物とその音声との関連情報を生成する。また、表示部56が、関連情報に基づいて、中心人物および非被写体人物を示すアイコンと中心人物および非被写体人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示し、入力部54が、アイコンのうちユーザにより選択されたアイコンに対応する中心人物および非被写体人物を、合成の対象人物として指定する対象人物指定指示を受け付ける。そして、合成部38は、対象人物指定指示に応じて、対象人物の音声が存在する任意の時間帯における対象人物の音声の文字列データに対応する合成用文字列を関連情報に基づいて読み出し、中心人物が存在する任意の時刻における合成用フレーム画像を読み出す。そして、合成用文字列に対応する文字画像と合成用フレーム画像とを合成して合成画像を生成する。これにより、対象人物を指定するだけで、対象人物の声が列挙されるため、対象人物の声のうち合成したい声を容易にかつ自由に選択できる。この際、非被写体人物の声も選択できる。また、全中心人物の顔が列挙されるため、合成すべき顔を容易にかつ自由に選択できる。
また、動画像には、中心人物以外の人物が発する音声も含まれている。中心人物以外の人物は、例えば撮影者あるいは動画像にわずかしか映っていない人物である。一般的に、動画像に撮影者の音声が含まれていても、撮影者は動画像に撮影されていない場合が多い。
この場合、関連付け部32は、さらに、中心人物以外の人物で、かつ、動画像から抽出された音声の登場頻度があらかじめ設定された一定値を超える人物が非被写体人物であると判定し、非被写体人物とその音声との関連情報を生成する。この場合、非被写体人物は、動画像に存在していないかわずかしか映っていないかのいずれかであるが、合成部38は、さらに、対象人物が存在する任意の時刻における合成用フレーム画像と、任意の時間帯における中心人物と非被写体人物とのうちの任意の一人の音声の文字列データに対応する合成用文字列とを、例えば、吹き出しの形式で合成して合成画像を生成する。これにより、動画像に存在しない非被写体人物や対象人物ではない他の中心人物の音声に対応する文字列の文字画像を容易にかつ自由に合成し、様々なバリエーションの合成画像を生成することができる。
なお、対象人物として非被写体人物を指定した場合においては、音声抽出部28が指向性を有する場合、合成用文字列が音声として発声された際の位置を推定し、その方向を指し示す吹き出しの形式で合成して合成画像を生成することができる。また、音声抽出部28に指向性がなく発声された際の位置が推定できない場合、および音声抽出部28に指向性があるが発声された際の位置が推定できない場合は、非被写体人物が撮影者であると推定し、文字画像を合成画像の下方向を指し示す吹き出しの形式で合成して合成画像を生成することができる。
なお、図12のように、表示部56において、非被写体人物に対応するアイコン(例えば、灰色のアイコン)を表示させ、非被写体人物の音声に対応する文字列との関連情報を表示することができる。
また、スマートフォンで動画像を撮像する場合、動画像に撮像された人物が音声を発したときに、例えば、撮影者がタッチパネル62(表示部56)に表示された、音声を発した人物をタップすることにより、音声を発した人物とその人物が発した音声とを関連付けることができる。この場合、動画像には、Exif(Exchangeable Image File Format)等による付帯情報として、動画像に存在する人物とその人物の音声との関連付けの指示データが添付される。
これに応じて、関連付け部32は、動画像が、付帯情報として、動画像に存在する人物とその音声との関連付けの指示データを有するか否かを判断する。そして、動画像が関連付けの指示データを有すると判断したときに、動画像が有する関連付けの指示データに基づいて、中心人物とその音声との関連情報を生成してもよい。これにより、関連情報の精度を向上させることができる。
また、動画像が再生して表示される場合、動画像の音声が再生されるのと同時に、音声認識部30により変換された文字列データに対応する文字列が携帯端末14のタッチパネル62(表示部56)に表示されるようにしてもよい。
上記実施形態では、動画像と、合成部38により合成された合成画像またはその特定情報とが関連付けられたARコンテンツが生成されることとしているが、本発明はこれに限定されず、合成画像のみを生成するものであってもよい。
本発明の装置は、装置が備える各々の構成要素を専用のハードウェアで構成してもよいし、各々の構成要素をプログラムされたコンピュータで構成してもよい。
本発明の方法は、例えば、その各々のステップをコンピュータに実行させるためのプログラムにより実施することができる。また、このプログラムが記録されたコンピュータ読み取り可能な記録媒体を提供することもできる。
本発明の方法は、例えば、その各々のステップをコンピュータに実行させるためのプログラムにより実施することができる。また、このプログラムが記録されたコンピュータ読み取り可能な記録媒体を提供することもできる。
以上、本発明について詳細に説明したが、本発明は上記実施形態に限定されず、本発明の主旨を逸脱しない範囲において、種々の改良や変更をしてもよいのはもちろんである。
10 画像処理装置
12 サーバ
14 携帯端末
16 プリンタ
18 ネットワーク
20 フレーム画像抽出部
22 人物領域検出部
23 人物特定部
24 人物評価部
26 中心人物判定部
28 音声抽出部
30 音声認識部
32 関連付け部
34 代表フレーム画像決定部
36 代表文字列決定部
38 合成部
40 コンテンツ生成部
42 記憶部
44 撮影画像解析部
46 管理マーカ特定部
48 動画像処理部
50 第1転送部
52 画像撮影部
54 入力部
56 表示部
58 制御部
60 第2転送部
62 タッチパネル
64、80 文字列
65 関連情報
78 代表文字列
66、68 アイコン
70、76、82 決定ボタン
72 代表フレーム画像
74 フレーム画像
12 サーバ
14 携帯端末
16 プリンタ
18 ネットワーク
20 フレーム画像抽出部
22 人物領域検出部
23 人物特定部
24 人物評価部
26 中心人物判定部
28 音声抽出部
30 音声認識部
32 関連付け部
34 代表フレーム画像決定部
36 代表文字列決定部
38 合成部
40 コンテンツ生成部
42 記憶部
44 撮影画像解析部
46 管理マーカ特定部
48 動画像処理部
50 第1転送部
52 画像撮影部
54 入力部
56 表示部
58 制御部
60 第2転送部
62 タッチパネル
64、80 文字列
65 関連情報
78 代表文字列
66、68 アイコン
70、76、82 決定ボタン
72 代表フレーム画像
74 フレーム画像
Claims (30)
- 動画像から複数のフレーム画像を抽出するフレーム画像抽出部と、
前記フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出する人物領域検出部と、
前記検出された人物領域に対応する人物を特定する人物特定部と、
前記抽出された複数のフレーム画像の少なくとも一部における前記人物領域を前記特定された人物ごとに評価して、前記動画像における前記特定された人物の評価点を算出する人物評価部と、
前記特定された人物の評価点が一定値を超えた場合に、前記特定された人物が前記動画像における中心人物であると判定する中心人物判定部と、
前記動画像から音声を抽出する音声抽出部と、
前記音声を音声認識により文字列データに変換する音声認識部と、
前記中心人物と前記中心人物の音声との関連情報を生成する関連付け部と、
前記関連情報に基づいて、前記中心人物を示すアイコンと前記中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示する表示部と、
ユーザにより入力された指示を受け付ける指示受付部と、
前記フレーム画像と前記文字列に対応する文字画像とを合成する合成部とを備え、
前記指示受付部は、さらに、前記アイコンのうち前記ユーザにより選択されたアイコンに対応する中心人物を、前記合成の対象人物として指定する対象人物指定指示を受け付けるものであり、
前記合成部は、さらに、前記対象人物指定指示に応じて、前記対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における前記対象人物の音声の文字列データに対応する合成用文字列を前記関連情報に基づいて読み出し、前記合成用フレーム画像と前記合成用文字列に対応する文字画像とを合成して合成画像を生成するものである、画像処理装置。 - 前記指示受付部は、さらに、前記表示部に表示された関連情報に対して、前記関連情報を修正する修正指示を受け付けるものであり、
前記関連付け部は、さらに、前記修正指示に応じて、前記関連情報を修正するものである請求項1に記載の画像処理装置。 - さらに、前記対象人物指定指示に応じて、前記対象人物が存在するフレーム画像の中から、代表フレーム画像を決定する代表フレーム画像決定部と、
前記対象人物指定指示に応じて、前記対象人物の音声の文字列データに対応する文字列の中から、代表文字列を決定する代表文字列決定部とを備え、
前記合成部は、前記代表フレーム画像と前記代表文字列に対応する文字画像とを合成するものである請求項1または2に記載の画像処理装置。 - 前記代表フレーム画像決定部は、前記対象人物が存在するフレーム画像の中から、色味、明るさ、および、ボケブレのうちの少なくとも1つが一定範囲内であるフレーム画像を、前記代表フレーム画像に決定するものである請求項3に記載の画像処理装置。
- 前記代表フレーム画像決定部は、前記対象人物が存在するフレーム画像の中から、前記対象人物の顔の大きさおよび向きのうちの少なくとも1つが一定範囲内であり、かつ、前記対象人物の表情が笑顔であるフレーム画像を、前記代表フレーム画像に決定するものである請求項3に記載の画像処理装置。
- 前記代表フレーム画像決定部は、前記対象人物が存在するフレーム画像の中から、前記対象人物の発話シーン、動きが大きいシーンおよび音声が大きいシーンのうちの少なくとも1つのフレーム画像を、前記代表フレーム画像に決定するものである請求項3に記載の画像処理装置。
- 前記代表文字列決定部は、前記対象人物の音声の文字列データに対応する文字列の中から、前記対象人物の声の大きさおよび声の高さの少なくとも1つが一定範囲内である音声の文字列データに対応する文字列を、前記代表文字列に決定するものである請求項3〜6のいずれか1項に記載の画像処理装置。
- 前記代表文字列決定部は、前記対象人物の音声の文字列データに対応する文字列の中から、最も登場頻度の高い言葉の音声の文字列データに対応する文字列を、前記代表文字列に決定するものである請求項3〜6のいずれか1項に記載の画像処理装置。
- 前記表示部は、さらに、前記対象人物が存在する代表フレーム画像、および、前記対象人物が存在するフレーム画像であって前記代表フレーム画像以外のフレーム画像を表示するものであり、
前記指示受付部は、さらに、前記表示部に表示されたフレーム画像の中から、前記ユーザにより入力されたフレーム画像を指定するフレーム画像指定指示を受け付けるものであり、
前記代表フレーム画像決定部は、さらに、前記フレーム画像指定指示に応じて、前記ユーザにより指定されたフレーム画像を、前記代表フレーム画像に再決定するものである請求項3〜8のいずれか1項に記載の画像処理装置。 - 前記表示部は、さらに、前記代表文字列、および、前記対象人物の音声の音声データに対応する文字列であって前記代表文字列以外の文字列を表示するものであり、
前記指示受付部は、さらに、前記表示部に表示された文字列の中から、前記ユーザにより入力された文字列を指定する文字列指定指示を受け付けるものであり、
前記代表文字列決定部は、さらに、前記文字列指定指示に応じて、前記ユーザにより指定された文字列を、前記代表文字列に再決定するものである請求項3〜9のいずれか1項に記載の画像処理装置。 - 前記音声認識部は、前記動画像から抽出された音声のうち、前記対象人物の音声を優先して文字列データに変換するものである請求項3〜10のいずれか1項に記載の画像処理装置。
- 前記音声抽出部は、さらに、前記動画像から抽出された音声からノイズを除去するノイズキャンセリングを行うものである請求項1〜11のいずれか1項に記載の画像処理装置。
- 前記関連付け部は、前記中心人物が存在するフレーム画像の人物領域から、前記中心人物の性別および年齢を判定するとともに、前記中心人物の音声の高低から、前記音声に対応する人物の性別および年齢を判定し、前記中心人物の性別および年齢と前記音声に対応する人物の性別および年齢とが合致するように、前記関連情報を生成するものである請求項1〜12のいずれか1項に記載の画像処理装置。
- 前記関連付け部は、前記関連情報を生成する場合に、人間の声の音域以外の音域の音声を使用しないものである請求項1〜13のいずれか1項に記載の画像処理装置。
- 前記関連付け部は、前記動画像が、付帯情報として、前記動画像に存在する人物と前記動画像に存在する人物の音声との関連付けの指示データを有するか否かを判断し、前記動画像が関連付けの指示データを有すると判断したときに、前記関連付けの指示データに基づいて前記関連情報を生成するものである請求項1〜14のいずれか1項に記載の画像処理装置。
- 前記合成部は、前記文字列を、吹き出し、テロップおよび字幕のうちのいずれか1つの形式によって合成するものである請求項1〜15のいずれか1項に記載の画像処理装置。
- 前記合成部は、前記文字列の内容に応じて、前記文字列の書体を変更するものである請求項1〜16のいずれか1項に記載の画像処理装置。
- 前記合成部は、前記文字列の文字画像が合成された複数のフレーム画像を含む合成画像を生成するものである請求項1〜17のいずれか1項に記載の画像処理装置。
- 動画像から複数のフレーム画像を抽出するフレーム画像抽出部と、
前記フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出する人物領域検出部と、
前記検出された人物領域に対応する人物を特定する人物特定部と、
前記抽出された複数のフレーム画像の少なくとも一部における前記人物領域を前記特定された人物ごとに評価して、前記動画像における前記特定された人物の評価点を算出する人物評価部と、
前記特定された人物の評価点が一定値を超えた場合に、前記特定された人物が前記動画像における中心人物であると判定する中心人物判定部と、
前記動画像から音声を抽出する音声抽出部と、
前記音声を音声認識により文字列データに変換する音声認識部と、
前記中心人物と前記中心人物の音声との関連情報を生成し、さらに、前記フレーム画像に存在していない人物で、かつ、前記動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、前記非被写体人物と前記非被写体人物の音声との関連情報を生成する関連付け部と、
前記関連情報に基づいて、前記中心人物および非被写体人物を示すアイコンと前記中心人物および非被写体人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示する表示部と、
ユーザにより入力された指示を受け付ける指示受付部と、
前記フレーム画像と前記文字列に対応する文字画像とを合成する合成部とを備え、
前記指示受付部は、さらに、前記アイコンのうち前記ユーザにより選択されたアイコンに対応する中心人物または非被写体人物を、前記合成の対象人物として指定する対象人物指定指示を受け付けるものであり、
前記合成部は、さらに、前記対象人物指定指示に応じて、前記対象人物の音声が存在する任意の時間帯における前記対象人物の音声の文字列データに対応する合成用文字列を前記関連情報に基づいて読み出し、前記中心人物が存在する任意の時刻における合成用フレーム画像を読み出し、前記合成用文字列に対応する文字画像と前記合成用フレーム画像とを合成して合成画像を生成するものである、画像処理装置。 - 動画像から複数のフレーム画像を抽出するフレーム画像抽出部と、
前記フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出する人物領域検出部と、
前記検出された人物領域に対応する人物を特定する人物特定部と、
前記抽出された複数のフレーム画像の少なくとも一部における前記人物領域を前記特定された人物ごとに評価して、前記動画像における前記特定された人物の評価点を算出する人物評価部と、
前記特定された人物の評価点が一定値を超えた場合に、前記特定された人物が前記動画像における中心人物であると判定する中心人物判定部と、
前記動画像から音声を抽出する音声抽出部と、
前記音声を音声認識により文字列データに変換する音声認識部と、
前記中心人物と前記中心人物の音声との関連情報を生成し、さらに、前記フレーム画像に存在していない人物で、かつ、前記動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、前記非被写体人物と前記非被写体人物の音声との関連情報を生成する関連付け部と、
前記関連情報に基づいて、前記中心人物を示すアイコンと前記中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示する表示部と、
ユーザにより入力された指示を受け付ける指示受付部と、
前記フレーム画像と前記文字列に対応する文字画像とを合成する合成部とを備え、
前記指示受付部は、さらに、前記アイコンのうち前記ユーザにより選択されたアイコンに対応する中心人物を、前記合成の対象人物として指定する対象人物指定指示を受け付けるものであり、
前記合成部は、さらに、前記対象人物指定指示に応じて、前記対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における前記中心人物と前記非被写体人物とのうちの任意の一人の音声の文字列データに対応する合成用文字列を前記関連情報に基づいて読み出し、前記合成用フレーム画像と前記合成用文字列に対応する文字画像とを合成して合成画像を生成するものである、画像処理装置。 - 前記合成部は、さらに、前記合成用文字列を、前記合成画像の下方向を指し示す吹き出しの形式で合成するものである請求項20に記載の画像処理装置。
- フレーム画像抽出部が、動画像から複数のフレーム画像を抽出するステップと、
人物領域検出部が、前記フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出するステップと、
人物特定部が、前記検出された人物領域に対応する人物を特定するステップと、
人物評価部が、前記抽出された複数のフレーム画像の少なくとも一部における前記人物領域を前記特定された人物ごとに評価して、前記動画像における前記特定された人物の評価点を算出するステップと、
中心人物判定部が、前記特定された人物の評価点が一定値を超えた場合に、前記特定された人物が前記動画像における中心人物であると判定するステップと、
音声抽出部が、前記動画像から音声を抽出するステップと、
音声認識部が、前記音声を音声認識により文字列データに変換するステップと、
関連付け部が、前記中心人物と前記中心人物の音声との関連情報を生成するステップと、
表示部が、前記関連情報に基づいて、前記中心人物を示すアイコンと前記中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示するステップと、
指示受付部が、前記表示部に表示された前記関連情報に対して、ユーザにより入力された前記関連情報を修正する修正指示を受け付けるステップと、
前記関連付け部が、さらに、前記修正指示に応じて、前記関連情報を修正するステップと、
前記指示受付部が、さらに、前記アイコンのうち前記ユーザにより選択されたアイコンに対応する中心人物を、前記合成の対象人物として指定する対象人物指定指示を受け付けるステップと、
合成部が、前記対象人物指定指示に応じて、前記対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における前記対象人物の音声の文字列データに対応する合成用文字列を前記関連情報に基づいて読み出し、前記合成用フレーム画像と前記合成用文字列に対応する文字画像とを合成して合成画像を生成するステップとを含む、画像処理方法。 - さらに、前記指示受付部が、前記表示部に表示された関連情報に対して、前記関連情報を修正する修正指示を受け付けるステップと、
前記関連付け部が、前記修正指示に応じて、前記関連情報を修正するステップとを含む請求項22に記載の画像処理方法。 - さらに、代表フレーム画像決定部が、前記対象人物指定指示に応じて、前記対象人物が存在するフレーム画像の中から、代表フレーム画像を決定するステップと、
代表文字列決定部が、前記対象人物指定指示に応じて、前記対象人物の音声の文字列データに対応する文字列の中から、代表文字列を決定するステップとを含み、
前記合成部は、前記代表フレーム画像と前記代表文字列に対応する文字画像とを合成する請求項22または23に記載の画像処理方法。 - 前記表示部が、さらに、前記対象人物が存在する代表フレーム画像、および、前記対象人物が存在するフレーム画像であって前記代表フレーム画像以外のフレーム画像を表示するステップと、
前記指示受付部が、さらに、前記表示部に表示されたフレーム画像の中から、前記ユーザにより入力されたフレーム画像を指定するフレーム画像指定指示を受け付けるステップと、
前記代表フレーム画像決定部が、さらに、前記フレーム画像指定指示に応じて、前記ユーザにより指定されたフレーム画像を、前記代表フレーム画像に再決定するステップとを含む請求項24に記載の画像処理方法。 - 前記表示部が、さらに、前記代表文字列、および、前記対象人物の音声の音声データに対応する文字列であって前記代表文字列以外の文字列を表示するステップと、
前記指示受付部が、さらに、前記表示部に表示された文字列の中から、前記ユーザにより入力された文字列を指定する文字列指定指示を受け付けるステップと、
前記代表文字列決定部が、さらに、前記文字列指定指示に応じて、前記ユーザにより指定された文字列を、前記代表文字列に再決定するステップとを含む請求項24または25に記載の画像処理方法。 - フレーム画像抽出部が、動画像から複数のフレーム画像を抽出するステップと、
人物領域検出部が、前記フレーム画像に存在する人物の少なくとも一部の領域を人物領域として検出するステップと、
人物特定部が、前記検出された人物領域に対応する人物を特定するステップと、
人物評価部が、前記抽出された複数のフレーム画像の少なくとも一部における前記人物領域を前記特定された人物ごとに評価して、前記動画像における前記特定された人物の評価点を算出するステップと、
中心人物判定部が、前記特定された人物の評価点が一定値を超えた場合に、前記特定された人物が前記動画像における中心人物であると判定するステップと、
音声抽出部が、前記動画像から音声を抽出するステップと、
音声認識部が、前記音声を音声認識により文字列データに変換するステップと、
関連付け部が、前記中心人物と前記中心人物の音声との関連情報を生成し、さらに、前記フレーム画像に存在していない人物で、かつ、前記動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、前記非被写体人物と前記非被写体人物の音声との関連情報を生成するステップと、
表示部が、前記関連情報に基づいて、前記中心人物および非被写体人物を示すアイコンと前記中心人物および非被写体人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示するステップと、
指示受付部が、前記アイコンのうち前記ユーザにより選択されたアイコンに対応する中心人物または非被写体人物を、前記合成の対象人物として指定する対象人物指定指示を受け付けるステップと、
合成部が、前記対象人物指定指示に応じて、前記対象人物の音声が存在する任意の時間帯における前記対象人物の音声の文字列データに対応する合成用文字列を前記関連情報に基づいて読み出し、前記中心人物が存在する任意の時刻における合成用フレーム画像を読み出し、前記合成用文字列に対応する文字画像と前記合成用フレーム画像とを合成して合成画像を生成するステップとを含む、画像処理方法。 - フレーム画像抽出部が、動画像から複数のフレーム画像を抽出するステップと、
人物領域検出部が、前記フレーム画像に存在する人物の少なくとも一部の領域を検出するステップと、
人物特定部が、前記検出された人物領域に対応する人物を特定するステップと、
人物評価部が、前記抽出された複数のフレーム画像の少なくとも一部における前記人物領域を前記特定された人物ごとに評価して、前記動画像における前記特定された人物の評価点を算出するステップと、
中心人物判定部が、前記特定された人物の評価点が一定値を超えた場合に、前記特定された人物が前記動画像における中心人物であると判定するステップと、
音声抽出部が、前記動画像から音声を抽出するステップと、
音声認識部が、前記音声を音声認識により文字列データに変換するステップと、
関連付け部が、前記中心人物と前記中心人物の音声との関連情報を生成し、さらに、前記フレーム画像に存在していない人物で、かつ、前記動画像から抽出された音声の登場頻度が一定値を超える人物が非被写体人物であると判定し、前記非被写体人物と前記非被写体人物の音声との関連情報を生成するステップと、
表示部が、前記関連情報に基づいて、前記中心人物を示すアイコンと前記中心人物の音声の文字列データの少なくとも一部に対応する文字列との関連情報を表示するステップと、
指示受付部が、前記表示部に表示された前記関連情報に対して、ユーザにより入力された前記関連情報を修正する修正指示を受け付けるステップと、
前記関連付け部が、さらに、前記修正指示に応じて、前記関連情報を修正するステップと、
前記指示受付部が、さらに、前記アイコンのうち前記ユーザにより選択されたアイコンに対応する中心人物を、前記合成の対象人物として指定する対象人物指定指示を受け付けるステップと、
合成部が、前記対象人物指定指示に応じて、前記対象人物が存在する任意の時刻における合成用フレーム画像を読み出し、任意の時間帯における前記中心人物と前記非被写体人物とのうちの任意の一人の音声の文字列データに対応する合成用文字列を前記関連情報に基づいて読み出し、前記合成用フレーム画像と前記合成用文字列に対応する文字画像とを合成して合成画像を生成するステップとを含む、画像処理方法。 - 請求項22〜28のいずれか1項に記載の画像処理方法の各々のステップをコンピュータに実行させるためのプログラム。
- 請求項22〜28のいずれか1項に記載の画像処理方法の各々のステップをコンピュータに実行させるためのプログラムが記録されたコンピュータ読み取り可能な記録媒体。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015069473A JP2016189158A (ja) | 2015-03-30 | 2015-03-30 | 画像処理装置、画像処理方法、プログラムおよび記録媒体 |
| US15/069,358 US9704279B2 (en) | 2015-03-30 | 2016-03-14 | Image processing device, image processing method, program, and recording medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015069473A JP2016189158A (ja) | 2015-03-30 | 2015-03-30 | 画像処理装置、画像処理方法、プログラムおよび記録媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2016189158A true JP2016189158A (ja) | 2016-11-04 |
Family
ID=57015989
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015069473A Pending JP2016189158A (ja) | 2015-03-30 | 2015-03-30 | 画像処理装置、画像処理方法、プログラムおよび記録媒体 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US9704279B2 (ja) |
| JP (1) | JP2016189158A (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020091431A1 (ko) * | 2018-11-02 | 2020-05-07 | 주식회사 모두앤모두 | 그래픽 객체를 이용한 자막 생성 시스템 |
| US11210525B2 (en) | 2017-09-15 | 2021-12-28 | Samsung Electronics Co., Ltd. | Method and terminal for providing content |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6942995B2 (ja) | 2017-03-31 | 2021-09-29 | ブラザー工業株式会社 | 情報処理プログラム、情報処理装置、および情報処理装置の制御方法 |
| CN109427341A (zh) * | 2017-08-30 | 2019-03-05 | 鸿富锦精密电子(郑州)有限公司 | 语音输入系统及语音输入方法 |
| CN108597522B (zh) * | 2018-05-10 | 2021-10-15 | 北京奇艺世纪科技有限公司 | 一种语音处理方法及装置 |
| JP2021009608A (ja) * | 2019-07-02 | 2021-01-28 | キヤノン株式会社 | 画像処理装置、画像処理方法、及びプログラム |
| CN113128399B (zh) * | 2021-04-19 | 2022-05-17 | 重庆大学 | 用于情感识别的语音图像关键帧提取方法 |
| CN116366933A (zh) * | 2021-12-23 | 2023-06-30 | 北京字跳网络技术有限公司 | 一种视频显示方法、装置及电子设备 |
| CN117197308A (zh) * | 2022-05-30 | 2023-12-08 | 中兴通讯股份有限公司 | 数字人驱动方法、数字人驱动设备及存储介质 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4226237B2 (ja) | 2001-09-11 | 2009-02-18 | 日本放送協会 | 漫画生成装置及び漫画生成プログラム |
| JP2005101931A (ja) * | 2003-09-25 | 2005-04-14 | Fuji Photo Film Co Ltd | 画像プリント装置 |
| KR101189765B1 (ko) | 2008-12-23 | 2012-10-15 | 한국전자통신연구원 | 음성 및 영상에 기반한 성별-연령 판별방법 및 그 장치 |
| JP5353835B2 (ja) * | 2010-06-28 | 2013-11-27 | ブラザー工業株式会社 | 情報処理プログラムおよび情報処理装置 |
| JP2012249211A (ja) | 2011-05-31 | 2012-12-13 | Casio Comput Co Ltd | 画像ファイル生成装置、画像ファイル生成プログラム及び画像ファイル生成方法 |
| JP6073649B2 (ja) | 2012-11-07 | 2017-02-01 | 株式会社日立システムズ | 音声自動認識・音声変換システム |
-
2015
- 2015-03-30 JP JP2015069473A patent/JP2016189158A/ja active Pending
-
2016
- 2016-03-14 US US15/069,358 patent/US9704279B2/en active Active
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11210525B2 (en) | 2017-09-15 | 2021-12-28 | Samsung Electronics Co., Ltd. | Method and terminal for providing content |
| WO2020091431A1 (ko) * | 2018-11-02 | 2020-05-07 | 주식회사 모두앤모두 | 그래픽 객체를 이용한 자막 생성 시스템 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20160292898A1 (en) | 2016-10-06 |
| US9704279B2 (en) | 2017-07-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2016189158A (ja) | 画像処理装置、画像処理方法、プログラムおよび記録媒体 | |
| US9685199B2 (en) | Editing apparatus and editing method | |
| US8416332B2 (en) | Information processing apparatus, information processing method, and program | |
| JP5120777B2 (ja) | 電子データ編集装置、電子データ編集方法及びプログラム | |
| US20110274406A1 (en) | Information processing method, information processing device, scene metadata extraction device, loss recovery information generation device, and programs | |
| JP2008276668A (ja) | 画像管理装置、画像表示装置、撮像装置、および、これらにおける処理方法ならびに当該方法をコンピュータに実行させるプログラム | |
| JP2016118991A (ja) | 画像生成装置、画像生成方法及びプログラム | |
| JP2016181808A (ja) | 画像処理装置、画像処理方法、プログラムおよび記録媒体 | |
| US20160292880A1 (en) | Image shooting device, image shooting method, and recording medium | |
| JP2007101945A (ja) | 音声付き映像データ処理装置、音声付き映像データ処理方法及び音声付き映像データ処理用プログラム | |
| US8872954B2 (en) | Image processing apparatus having feature extraction and stored image selection capability, method of controlling the apparatus, program thereof, and storage medium | |
| US10360221B2 (en) | Method, system, and client for content management | |
| JP2016189507A (ja) | 画像処理装置、画像処理方法、プログラムおよび記録媒体 | |
| JP6166070B2 (ja) | 再生装置および再生方法 | |
| JP2013197827A (ja) | 撮影補助装置、方法、並びに該撮影補助装置を搭載した撮影装置及びカメラ付き携帯端末 | |
| JP5389594B2 (ja) | 画像ファイル生成方法、そのプログラム、その記録媒体および画像ファイル生成装置 | |
| JP2005175839A (ja) | 画像表示装置、画像表示方法、プログラムおよび記憶媒体 | |
| JP6508635B2 (ja) | 再生装置、再生方法、再生プログラム | |
| JP5182507B2 (ja) | 撮影装置、撮影案内方法、及びプログラム | |
| JP2007049245A (ja) | 音声入力機能付撮影装置 | |
| US20240233770A1 (en) | Image processing apparatus, image processing method, and program | |
| JP6977847B2 (ja) | 画像管理装置、画像管理方法及びプログラム | |
| EP4443864A1 (en) | Image processing device, image processing method, and program | |
| JP2016189522A (ja) | 画像処理装置、画像処理方法、プログラムおよび記録媒体 | |
| KR20240078561A (ko) | 인물추적 기반 동영상 편집방법 |