JP2014016584A - データ分割装置、データ復元装置、データ分割方法、データ復元方法、及びプログラム - Google Patents
データ分割装置、データ復元装置、データ分割方法、データ復元方法、及びプログラム Download PDFInfo
- Publication number
- JP2014016584A JP2014016584A JP2012155882A JP2012155882A JP2014016584A JP 2014016584 A JP2014016584 A JP 2014016584A JP 2012155882 A JP2012155882 A JP 2012155882A JP 2012155882 A JP2012155882 A JP 2012155882A JP 2014016584 A JP2014016584 A JP 2014016584A
- Authority
- JP
- Japan
- Prior art keywords
- data
- dividing
- series
- divided
- division
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images





Abstract
【解決手段】 データ分割装置は、複数の記憶装置にデータを分散して保存するための分割データを生成するデータ分割装置であって、保存対象データを所定のサイズで分割して第1のデータ系列を生成すると共に、第1のデータ系列のそれぞれが保存対象データのどの部分に対応するかを示す識別情報をそれぞれ生成し、第1のデータ系列を、所定の鍵とその第1のデータ系列に対応する識別情報とに基づいて第2のデータ系列へ置換し、第2のデータ系列を記憶装置の数に応じた数に分割して分割データを生成する。
【選択図】 図2
Description
(システム構成)
本実施形態に係るデータ分割保存システムの一例を図1に示す。データ分割保存システムは、データ分割サーバ101と複数の外部ストレージサーバ102とを含む。また、データ分割サーバ101と外部ストレージサーバ102のそれぞれは、ネットワーク103を介して互いに接続される。
図2に、本実施形態に係るデータ分割サーバ101の機能構成例を示す。図2のデータ分割サーバ101は、上半分に示すように分割に関する機能部と、下半分に示すように復元に関する機能部とを有する。上述のように、これらの機能部は1つの装置に実装されてもよいし、2つ又はそれ以上の装置に分離して実装されてもよい。また、例えば、分割又は復元に関する1つ以上の機能ブロックを1つの装置により実装し、他の機能ブロックを他の装置により実装してもよい。
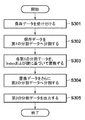
次に、図3を用いて、データ分割サーバにおける保存対象データの分割処理の動作を説明する。まず、受付部201は保存対象データを受け付ける(S301)。次に、第1の分割部202は保存対象データをあらかじめ定められたサイズに分割し、分割したデータと共にIndexを出力する(S302)。置換部203は、Indexと鍵とに基づいて、第1の分割データ(第1のデータ系列)を置換して、第2のデータ系列(置換データ)を生成する(S303)。第2の分割部204は、置換後の第2のデータ系列をさらに分割して、第2の分割データを生成する(S304)。出力部205は、第2の分割データを外部ストレージサーバへ順に出力する(S305)。
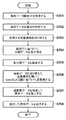
次に、図4を用いて、データ分割サーバにおける保存対象データの復元処理の動作を説明する。まず、読取部206は、保存対象データの識別子を読み取って取得する(S401)。保存対象データの一部だけを復元する場合は、読取部206は、復元箇所を指定する識別情報としてIndexも取得する。読取部206は、N個の外部ストレージサーバへ順にアクセスして、保存対象データの識別子に対応する全ての分割データを読み取って取得する(S402)。第1の結合部207は、N個のストレージサーバから読み取った分割データを、所定の順序で並べて結合し、結合データ(第3のデータ系列)を生成する(S403)。なお、第3のデータ系列は、データ分割処理における、置換処理を施した後の第2のデータ系列に対応する。逆置換部208は、Indexと鍵とに基づいて、第3のデータ系列を逆置換し、データ分割処理における第1の分割データに対応する逆置換データ(第4のデータ系列)を生成する(S404)。第2の結合部209は、逆置換により得られた複数の第4のデータ系列を結合して保存対象データを復元する(S405)。なお、復元箇所を特定する識別情報としてIndexを取得した場合は、S405における結合処理は不要である。第2の出力部210は、復元した保存対象データを出力する(S406)。
続いて、置換処理および逆置換処理について説明する。置換処理および逆置換処理は、鍵を知らないユーザが逆置換する困難さ(安全性)と処理速度のトレードオフの関係でいくつかの方法がある。置換部203と逆置換部208とは、例えば以下に示す方法の中からシステム内で定められた1つの方式をあらかじめ選択し、第1の分割データの置換と逆置換とをそれぞれ実行する。
実施形態1では、システム内であらかじめ定められた方法による置換と逆置換とを実行する場合について説明した。一方、保存対象データに適用すべき機密レベルは全て同一でなく、異なる場合がある。そこで本実施形態では、保存対象データの機密レベルに応じて置換と逆置換を実行する方法を適応的に選択できる手法について説明する。なお、データ分割保存システムの構成は実施形態1と同様であるため、説明を省略する。
図5は、本実施形態に係るデータ分割サーバ101の機能構成を示すブロック図である。図5では、図2と同様に、上段には分割に関する機能構成を、下段には復元に関する機能構成を、それぞれ示している。図5に示すように、データ分割サーバ101は、データ分割に関して、図2と同様に、受付部201、第1の分割部202、複数の置換部203、第2の分割部204、第1の出力部205とを有する。ただし、データ分割において、さらに、種別判定部501、および切替部502が用いられる。さらに、第1の実施形態では単一の置換部203を有していたが、本実施形態では複数の置換部203を有する。また、図5に示すように、データ分割サーバ101は、データ復元に関して、図2と同様に読取部206、第1の結合部207、複数の逆置換部208、第2の結合部209、第2の出力部210を有する。ただし、データ復元においても、さらに種別判定部501、および切替部502が使用される。また、第1の実施形態では単一の逆置換部208を有していたが、本実施形態では複数の逆置換部208を有する。
次に、図6を用いて、本実施形態に係る保存対象データの分割処理の動作について説明する。まず、受付部201は保存対象データを受け付ける(S601)。次に、種別判定部501は、保存対象データの種別を判定して、機密度のレベル付けを行う(S602)。そして、切替部502は、機密度のレベルに応じて使用する置換部を選択して切り替える(S603)。次に、第1の分割部202は、保存対象データを所定のサイズに分割して第1の分割データ(第1のデータ系列)を生成し、第1の分割データと共にIndexを出力する(S604)。機密度のレベルに応じて選択された置換部203は、Indexと鍵とに基づいて第1の分割データを置換し、第2のデータ系列(置換データ)を生成する(S605)。第2の分割部204は、第2のデータ系列をさらに分割して、第2の分割データを生成する(S606)。出力部205は、第2の分割データを外部ストレージサーバへ順に出力する(S607)。なお、本実施形態においては、第2の分割データに、機密度情報を付与してもよい。または、置換後のデータに機密度情報を付加し、それを分割して第2の分割データを生成してもよい。
次に、図7を用いて、本実施形態に係る保存対象データの復元処理の動作について説明する。まず、読取部206は、保存対象データの識別子を取得する(S701)。読取部206は、保存対象データの一部だけを復元する場合は、復元箇所を特定するIndexも併せて取得する。種別判定部501は、保存対象データの種別を判定して機密度のレベル付けを行う(S702)。なお、ここでの機密度のレベル付けは、例えば、分割データ又は第1の結合処理後のデータに付与された機密度情報や、外部から取得する機密度情報に基づいて行われてもよい。切替部502は、レベルに応じて利用する逆置換部を選択して切り替える(S703)。
また、本発明は、以下の処理を実行することによっても実現される。即ち、上述した実施形態の機能を実現するソフトウェア(プログラム)を、ネットワーク又は各種記憶媒体を介してシステム或いは装置に供給し、そのシステム或いは装置のコンピュータ(またはCPUやMPU等)がプログラムを読み出して実行する処理である。
Claims (16)
- 複数の記憶装置にデータを分散して保存するための分割データを生成するデータ分割装置であって、
保存対象データを所定のサイズで分割して第1のデータ系列を生成すると共に、前記第1のデータ系列のそれぞれが前記保存対象データのどの部分に対応するかを示す識別情報をそれぞれ生成する第1の分割手段と、
前記第1のデータ系列を、所定の鍵と当該第1のデータ系列に対応する前記識別情報とに基づいて第2のデータ系列へ置換する置換手段と、
前記第2のデータ系列を前記記憶装置の数に応じた数に分割して前記分割データを生成する第2の分割手段と、
を有することを特徴とするデータ分割装置。 - 前記置換手段は、前記鍵を共通鍵暗号方式の鍵とし、前記識別情報を暗号利用モードの初期ベクタとして、前記第1のデータ系列を暗号化することにより、前記第2のデータ系列へ置換する、
ことを特徴とする請求項1に記載のデータ分割装置。 - 前記鍵は所定の数を示し、
前記置換手段は、前記第1のデータ系列を前記記憶装置の数に応じた数で分割して部分データを生成して、前記鍵と前記識別情報とに基づいて特定される並べ替え方のパターンに従って当該部分データを並べ替えることにより、前記第1のデータ系列を前記第2のデータ系列へ置換する、
ことを特徴とする請求項1に記載のデータ分割装置。 - それぞれ異なる複雑度を有する置換を行う複数の前記置換手段と、
前記保存対象データの機密度に関する情報を取得する取得手段と、
前記機密度に関する情報に応じて、複数の前記置換手段のうち1つを選択する選択手段と、
をさらに有し、
前記選択手段により選択された1つの前記置換手段が、前記第1のデータ系列を前記第2のデータ系列へ置換する、
ことを特徴とする請求項1から3のいずれか1項に記載のデータ分割装置。 - 前記選択手段は、前記保存対象データの機密度が高いほど、複雑度の高い置換を行う前記置換手段を選択する、
ことを特徴とする請求項4に記載のデータ分割装置。 - 前記第2の分割手段は、前記第2のデータ系列を分割したデータをさらに暗号化し、その暗号化したデータを前記分割データとして生成する、
ことを特徴とする請求項1から5のいずれか1項に記載のデータ分割装置。 - 前記第2の分割手段は、前記第2のデータ系列を前記記憶装置の数に応じた数に分割したデータについて、当該分割したデータごとに異なる暗号化の鍵または暗号化アルゴリズムを用いて暗号化したデータを前記分割データとして生成する、
ことを特徴とする請求項6に記載のデータ分割装置。 - 前記所定のサイズは、前記保存対象データへのアクセスのための単位サイズに応じて定められる、
ことを特徴とする請求項1から7のいずれか1項に記載のデータ分割装置。 - 請求項1から8のいずれか1項に記載のデータ分割装置により分割され、複数の記憶装置に分散して保存された分割データから保存対象データの少なくとも一部を復元するデータ復元装置であって、
前記複数の記憶装置から前記分割データを読み取る読取手段と、
前記複数の記憶装置に保存された前記分割データを所定の順序で並べて結合し、第3のデータ系列を生成する結合手段と、
所定の鍵と、前記第3のデータ系列が前記保存対象データのどの部分に対応するかを示す識別情報とに基づいて、当該第3のデータ系列を前記保存対象データの一部へと逆置換する逆置換手段と、
を有することを特徴とするデータ復元装置。 - 前記読取手段は、前記保存対象データのうち、読み出す対象となる部分を特定する前記識別情報を受け付け、前記保存対象データのうち、取得した前記識別情報に対応する前記分割データのみを前記複数の記憶装置から読み込む、
ことを特徴とする請求項9に記載のデータ復元装置。 - 複数の前記識別情報に対応する前記第3のデータ系列から逆置換されて得られる、前記保存対象データの複数の部分を結合する第2の結合手段、
をさらに有することを特徴とする請求項9に記載のデータ復元装置。 - それぞれ異なる複雑度を有する逆置換を行う複数の前記逆置換手段と、
前記保存対象データの機密度に関する情報を取得する取得手段と、
前記機密度に関する情報に応じて、複数の前記逆置換手段のうち1つを選択する選択手段と、
をさらに有し、
前記選択手段により選択された1つの前記逆置換手段が、前記第3のデータ系列を前記保存対象データの一部へと逆置換する、
ことを特徴とする請求項9から11のいずれか1項に記載のデータ復元装置。 - 複数の記憶装置にデータを分散して保存するための分割データを生成するデータ分割装置におけるデータ分割方法であって、
第1の分割手段が、保存対象データを所定のサイズで分割して第1のデータ系列を生成すると共に、前記第1のデータ系列のそれぞれが前記保存対象データのどの部分に対応するかを示す識別情報をそれぞれ生成する第1の分割工程と、
置換手段が、前記第1のデータ系列を、所定の鍵と当該第1のデータ系列に対応する前記識別情報とに基づいて第2のデータ系列へ置換する置換工程と、
第2の分割手段が、前記第2のデータ系列を前記記憶装置の数に応じた数に分割して前記分割データを生成する第2の分割工程と、
を有することを特徴とするデータ分割方法。 - 請求項13に記載のデータ分割方法により分割され、複数の記憶装置に分散して保存された分割データから保存対象データの少なくとも一部を復元するデータ復元装置におけるデータ復元方法であって、
読取手段が、前記複数の記憶装置から前記分割データを読み取る読取工程と、
結合手段が、前記複数の記憶装置に保存された前記分割データを所定の順序で並べて結合し、第3のデータ系列を生成する結合工程と、
逆置換手段が、所定の鍵と、前記第3のデータ系列が前記保存対象データのどの部分に対応するかを示す識別情報とに基づいて、当該第3のデータ系列を前記保存対象データの一部へと逆置換する逆置換工程と、
を有することを特徴とするデータ復元方法。 - コンピュータを請求項1から8のいずれか1項に記載のデータ分割装置が備える各手段として機能させるためのプログラム。
- コンピュータを請求項9から12のいずれか1項に記載のデータ復元装置が備える各手段として機能させるためのプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012155882A JP2014016584A (ja) | 2012-07-11 | 2012-07-11 | データ分割装置、データ復元装置、データ分割方法、データ復元方法、及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012155882A JP2014016584A (ja) | 2012-07-11 | 2012-07-11 | データ分割装置、データ復元装置、データ分割方法、データ復元方法、及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2014016584A true JP2014016584A (ja) | 2014-01-30 |
Family
ID=50111288
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2012155882A Pending JP2014016584A (ja) | 2012-07-11 | 2012-07-11 | データ分割装置、データ復元装置、データ分割方法、データ復元方法、及びプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2014016584A (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017215518A (ja) * | 2016-06-01 | 2017-12-07 | 富士電機株式会社 | データ処理装置、データ処理方法及びプログラム |
| JP2018032908A (ja) * | 2016-08-22 | 2018-03-01 | 日本電気株式会社 | 情報送信方法、情報処理方法、プログラム、復号方法、プログラム |
| US10802888B2 (en) | 2014-09-19 | 2020-10-13 | Nec Corporation | Information processing device and cooperative distributed storage system |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH01122227A (ja) * | 1987-11-06 | 1989-05-15 | Konica Corp | 伝送装置 |
| JP2003223289A (ja) * | 2002-01-28 | 2003-08-08 | Internatl Business Mach Corp <Ibm> | データ処理方法、データ処理システムおよびプログラム |
| JP2005141529A (ja) * | 2003-11-07 | 2005-06-02 | Hitachi Ltd | 情報通信システム及び情報記憶媒体 |
| JP2005175605A (ja) * | 2003-12-08 | 2005-06-30 | Sony Corp | 情報処理装置、制御方法、プログラム、並びに記録媒体 |
| JP2006012192A (ja) * | 1999-12-20 | 2006-01-12 | Dainippon Printing Co Ltd | 分散型データアーカイブシステム |
| JP2006048158A (ja) * | 2004-07-30 | 2006-02-16 | Toshiba Corp | データ格納方法及びデータ処理装置 |
| JP2006279488A (ja) * | 2005-03-29 | 2006-10-12 | Toshiba Information Systems (Japan) Corp | 暗号文生成装置、暗号文復号装置、暗号文生成プログラム及び暗号文復号プログラム |
| WO2007111086A1 (ja) * | 2006-03-28 | 2007-10-04 | Tokyo Denki University | ディザスタリカバリ装置及びディザスタリカバリプログラム及びその記録媒体及びディザスタリカバリシステム |
-
2012
- 2012-07-11 JP JP2012155882A patent/JP2014016584A/ja active Pending
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH01122227A (ja) * | 1987-11-06 | 1989-05-15 | Konica Corp | 伝送装置 |
| JP2006012192A (ja) * | 1999-12-20 | 2006-01-12 | Dainippon Printing Co Ltd | 分散型データアーカイブシステム |
| JP2003223289A (ja) * | 2002-01-28 | 2003-08-08 | Internatl Business Mach Corp <Ibm> | データ処理方法、データ処理システムおよびプログラム |
| JP2005141529A (ja) * | 2003-11-07 | 2005-06-02 | Hitachi Ltd | 情報通信システム及び情報記憶媒体 |
| JP2005175605A (ja) * | 2003-12-08 | 2005-06-30 | Sony Corp | 情報処理装置、制御方法、プログラム、並びに記録媒体 |
| JP2006048158A (ja) * | 2004-07-30 | 2006-02-16 | Toshiba Corp | データ格納方法及びデータ処理装置 |
| JP2006279488A (ja) * | 2005-03-29 | 2006-10-12 | Toshiba Information Systems (Japan) Corp | 暗号文生成装置、暗号文復号装置、暗号文生成プログラム及び暗号文復号プログラム |
| WO2007111086A1 (ja) * | 2006-03-28 | 2007-10-04 | Tokyo Denki University | ディザスタリカバリ装置及びディザスタリカバリプログラム及びその記録媒体及びディザスタリカバリシステム |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10802888B2 (en) | 2014-09-19 | 2020-10-13 | Nec Corporation | Information processing device and cooperative distributed storage system |
| JP2017215518A (ja) * | 2016-06-01 | 2017-12-07 | 富士電機株式会社 | データ処理装置、データ処理方法及びプログラム |
| US10411881B2 (en) | 2016-06-01 | 2019-09-10 | Fuji Electric Co., Ltd. | Data processing apparatus, method for processing data, and medium |
| JP2018032908A (ja) * | 2016-08-22 | 2018-03-01 | 日本電気株式会社 | 情報送信方法、情報処理方法、プログラム、復号方法、プログラム |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11783056B2 (en) | Systems and methods for cryptographic-chain-based group membership content sharing | |
| US11586757B2 (en) | Systems and methods for a cryptographic file system layer | |
| Demertzis et al. | Fast searchable encryption with tunable locality | |
| US10581603B2 (en) | Method and system for secure delegated access to encrypted data in big data computing clusters | |
| KR101403745B1 (ko) | 데이터베이스 시스템에서 비-결정적으로 암호화된 데이터에대한 검색을 수행하는 방법 및 이를 위한 원격 데이터베이스를 제공하는 방법, 및 기계-판독가능 매체 | |
| Yang et al. | Achieving efficient and privacy-preserving cross-domain big data deduplication in cloud | |
| WO2006118171A1 (ja) | 電子情報保存方法及び装置、電子情報分割保存方法及び装置、電子情報分割復元処理方法及び装置並びにそれらのプログラム | |
| KR101979267B1 (ko) | 클라우드 저장 기반 암호화 시스템 및 방법 | |
| US11070357B2 (en) | Techniques for privacy-preserving data processing across multiple computing nodes | |
| US8189790B2 (en) | Developing initial and subsequent keyID information from a unique mediaID value | |
| Abdalwahid et al. | Enhancing approach using hybrid pailler and RSA for information security in bigdata | |
| WO2018208786A1 (en) | Method and system for secure delegated access to encrypted data in big data computing clusters | |
| KR101428649B1 (ko) | 맵 리듀스 기반의 대용량 개인정보 암호화 시스템 및 그의 동작 방법 | |
| Kim et al. | Survey on Data Deduplication in Cloud Storage Environments. | |
| JP2014016584A (ja) | データ分割装置、データ復元装置、データ分割方法、データ復元方法、及びプログラム | |
| CN105553661B (zh) | 密钥管理方法和装置 | |
| CN111786987A (zh) | 一种任务下发方法、装置、系统及设备 | |
| Yoosuf et al. | Fogdedupe: A fog-centric deduplication approach using multi-key homomorphic encryption technique | |
| Shin et al. | Efficient and secure file deduplication in cloud storage | |
| Dave et al. | Securing SQL with access control for database as a service model | |
| Sharma et al. | Privacy preserving on searchable encrypted data in cloud | |
| Kavade et al. | Secure De-Duplication using Convergent Keys (Convergent Cryptography) for Cloud Storage | |
| Guo et al. | High Efficient Secure Data Deduplication Method for Cloud Computing | |
| CN115549986A (zh) | 数据求交方法、装置和电子设备 | |
| Bharathi et al. | Secure Data Compression Scheme for Scalable Data in Dynamic Data Storage Environments |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20150702 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20160412 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20160520 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20160705 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20161205 |