JP2013164863A - Information processing device, information processing method, and program - Google Patents
Information processing device, information processing method, and program Download PDFInfo
- Publication number
- JP2013164863A JP2013164863A JP2013090989A JP2013090989A JP2013164863A JP 2013164863 A JP2013164863 A JP 2013164863A JP 2013090989 A JP2013090989 A JP 2013090989A JP 2013090989 A JP2013090989 A JP 2013090989A JP 2013164863 A JP2013164863 A JP 2013164863A
- Authority
- JP
- Japan
- Prior art keywords
- feature quantity
- information
- quantity extraction
- data
- feature
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images













Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
本開示は、情報処理装置、情報処理方法、およびプログラムに関し、特に、例えば、楽曲データなどの入力データから当該入力データの特徴を示す情報を高精度に抽出できる高精度情報抽出アルゴリズムを自動的に構築するようにした情報処理装置、情報処理方法、およびプログラムに関する。 The present disclosure relates to an information processing device, an information processing method, and a program, and in particular, a high-accuracy information extraction algorithm that can extract information indicating characteristics of the input data from input data such as music data with high accuracy automatically. The present invention relates to an information processing apparatus, an information processing method, and a program that are constructed.
従来、楽曲データや画像データなどを入力データとして、前記入力データの情報(入力データが楽曲データである場合、速さ、明るさ、にぎやかさ等)を出力することができるアルゴリズムを自動的に構築する発明が提案されている(例えば、特許文献1参照)。 Conventionally, an algorithm that can output information of the input data (speed, brightness, liveliness, etc. when the input data is music data) is automatically constructed using music data or image data as input data. An invention has been proposed (see, for example, Patent Document 1).
また、入力データから当該入力データの特徴を示す情報を高精度に抽出できるアルゴリズムを構築する方法として、アンサンブル学習と称する手法が知られている。 Also, a technique called ensemble learning is known as a method for constructing an algorithm that can extract information indicating the characteristics of input data from input data with high accuracy.
アンサンブル学習は、複数の教師データを用いて精度の低い情報抽出装置(以下、弱情報抽出部(weak learner)と称する)を複数生成し、生成した複数の弱情報抽出部による出力を組み合わせることによって高精度の情報抽出装置を得る手法である。 Ensemble learning involves generating multiple low-accuracy information extraction devices (hereinafter referred to as weak learners) using multiple teacher data, and combining the generated outputs from multiple weak information extraction units. This is a technique for obtaining a highly accurate information extraction apparatus.
アンサンブル手法の例としては、ブースティング(boosting)とバッギング(bagging)の2種類を挙げることができる。 As an example of the ensemble method, there are two types of boosting and bagging.
ブースティングでは、各教師データに重み付けを行い、全ての教師データを用いて1つの弱情報抽出部を生成する。そして生成した弱情報抽出部によって正しく情報が抽出された教師データについては重みを下げ、間違って情報が抽出された教師データについては重みを上げることにより、教師データの重みを更新する。また、重みが更新された全ての教師データを用いてさらにもう1つの弱情報抽出部を生成する。以下同様の処理を繰り返すことにより、複数の弱情報抽出部を生成し、生成した複数の弱情報抽出部の出力をそれぞれの重み付けで組み合わせることによって高精度の情報抽出装置を得る。 In boosting, each teacher data is weighted, and one weak information extraction unit is generated using all the teacher data. Then, the weight of the teacher data is updated by lowering the weight of the teacher data in which the information is correctly extracted by the weak information extraction unit, and increasing the weight of the teacher data from which the information is erroneously extracted. Further, another weak information extraction unit is generated using all the teacher data whose weights are updated. Thereafter, by repeating the same processing, a plurality of weak information extraction units are generated, and a high-precision information extraction device is obtained by combining the generated outputs of the plurality of weak information extraction units with respective weightings.
バッギングでは、全ての教師データから所定数をランダムにサンプリングして教師データ群を生成し、教師データ群を用いて1つの弱情報抽出部を生成する。この処理を繰り返すことにより、複数の弱情報抽出部を生成し、生成した複数の弱情報抽出部の出力を組み合わせることによって高精度の情報抽出装置を得る。 In bagging, a predetermined number is randomly sampled from all teacher data to generate a teacher data group, and one weak information extraction unit is generated using the teacher data group. By repeating this process, a plurality of weak information extraction units are generated, and a highly accurate information extraction device is obtained by combining the outputs of the generated plurality of weak information extraction units.
上述したブースティングやバッギングなどアンサンブル手法では、より多くの弱情報抽出部を生成して、その出力を組み合わせることによって、より高精度の情報抽出装置を得ることができる。 In the ensemble methods such as boosting and bagging described above, a more accurate information extraction device can be obtained by generating more weak information extraction units and combining their outputs.
しかしながら、入力データの種類に拘わらずアンサンブル学習における弱情報抽出部を自動的に生成する方法は従来確立されておらず、弱情報抽出部を人手によって生成する必要があった。したがって、弱情報抽出部の数を増やして情報抽出装置の精度を所望のレベルまで到達させることが困難であった。 However, a method for automatically generating a weak information extraction unit in ensemble learning regardless of the type of input data has not been established conventionally, and it has been necessary to manually generate a weak information extraction unit. Therefore, it is difficult to increase the number of weak information extraction units and reach the desired level of accuracy of the information extraction device.
本開示はこのような状況に鑑みてなされたものであり、入力データの種類に拘わらずアンサンブル学習における弱情報抽出部を自動的に生成することによって、より高精度の情報抽出装置を自動的に構築できるようにするものである。 The present disclosure has been made in view of such a situation, and by automatically generating a weak information extraction unit in ensemble learning regardless of the type of input data, a more accurate information extraction device is automatically created. It can be constructed.
本開示の第1の側面である情報処理装置は、入力データの特徴を示す情報を抽出する複数の情報抽出部の出力を合成して、前記情報抽出部よりも高精度で前記入力データの特徴を示す情報を抽出する高精度情報抽出部を構築するアンサンブル学習における前記情報抽出部を生成する情報処理装置において、複数の演算子から成る特徴量抽出式を複数含む特徴量抽出式リストを、前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新することにより生成する特徴量抽出式リスト生成手段と、前記特徴量抽出式リストに含まれる各特徴量抽出式に、実データ、前記実データの特徴を示す情報、および重みからなる教師データの実データを入力して、前記実データに対応する複数の特徴量を計算する特徴量計算手段と、計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記特徴量抽出式リストに含まれる各特徴量抽出式にそれぞれ対応する情報抽出部候補を生成するとともに、生成した前記情報抽出部候補によって正しく推定された教師データの重みを用いて各特徴量抽出式にそれぞれ対応する評価値を算出し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式に対応する前記情報抽出部候補を、前記アンサンブル学習における1つの前記情報抽出部に決定して、決定した前記情報抽出部によって間違って推定された教師データの重みを用いて、決定した前記情報抽出部の信頼度を算出する評価値算出手段と、決定された前記情報抽出部の前記信頼度を用いて、教師データの重みを更新する更新手段とを含むことを特徴とする。 An information processing apparatus according to a first aspect of the present disclosure synthesizes outputs of a plurality of information extraction units that extract information indicating characteristics of input data, and features the input data with higher accuracy than the information extraction unit. In the information processing apparatus that generates the information extraction unit in the ensemble learning that constructs a high-precision information extraction unit that extracts information indicating a feature amount, a feature amount extraction formula list including a plurality of feature amount extraction formulas including a plurality of operators A plurality of feature quantity extraction formulas included in the feature quantity extraction formula list of the generation is regarded as a gene, and the feature quantity extraction formula list of the previous generation is updated using a genetic algorithm based on the evaluation value of the feature quantity extraction formula A feature quantity extraction formula list generating means for generating the feature quantity, and each feature quantity extraction formula included in the feature quantity extraction formula list from real data, information indicating features of the real data, and weights. From the plurality of feature amounts corresponding to the actual data of the calculated teacher data, the feature amount calculation means for inputting the actual data of the teacher data and calculating a plurality of feature amounts corresponding to the actual data, The machine learning that estimates the information corresponding to the actual data of the teacher data generates information extraction unit candidates corresponding to the feature quantity extraction formulas included in the feature quantity extraction formula list, and the generated information An evaluation value corresponding to each feature quantity extraction formula is calculated using the weight of the teacher data correctly estimated by the extraction unit candidate, and among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation, The information extraction unit determined by determining the information extraction unit candidate corresponding to the feature quantity extraction formula having the best evaluation value as one information extraction unit in the ensemble learning Evaluation value calculation means for calculating the reliability of the determined information extraction unit using the weight of the teacher data erroneously estimated by the method, and using the reliability of the determined information extraction unit, And updating means for updating the weight.
本開示の第1の側面である情報処理装置は、複数の前記情報抽出部を、前記情報抽出部の前記信頼度に基づいて合成することにより、前記高精度情報抽出部を構築する合成手段をさらに含むことができる。 The information processing apparatus according to the first aspect of the present disclosure includes a synthesizing unit configured to construct the high-precision information extraction unit by synthesizing a plurality of the information extraction units based on the reliability of the information extraction unit. Further can be included.
本開示の第1の側面である情報処理方法は、入力データの特徴を示す情報を抽出する複数の情報抽出部の出力を合成して、前記情報抽出部よりも高精度で前記入力データの特徴を示す情報を抽出する高精度情報抽出部を構築するアンサンブル学習における前記情報抽出部を生成する情報処理装置の情報処理方法において、複数の演算子から成る特徴量抽出式を複数含む第1世代の特徴量抽出式リストをランダムに生成し、前記特徴量抽出式リストに含まれる各特徴量抽出式に、実データ、前記実データの特徴を示す情報、および重みからなる教師データの実データを入力して、前記実データに対応する複数の特徴量を計算し、計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記特徴量抽出式リストに含まれる各特徴量抽出式にそれぞれ対応する情報抽出部候補を生成するとともに、生成した前記情報抽出部候補によって正しく推定された教師データの重みを用いて各特徴量抽出式にそれぞれ対応する評価値を算出し、前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式に対応する前記情報抽出部候補を、前記アンサンブル学習における1つの前記情報抽出部に決定して、決定した前記情報抽出部によって間違って推定された教師データの重みを用いて、決定した前記情報抽出部の信頼度を算出し、決定された前記情報抽出部の前記信頼度を用いて、教師データの重みを更新するステップを含むことを特徴とする。 An information processing method according to a first aspect of the present disclosure is characterized by combining the outputs of a plurality of information extraction units that extract information indicating the characteristics of input data, with higher accuracy than the information extraction unit. In the information processing method of the information processing apparatus for generating the information extraction unit in ensemble learning for constructing a high-precision information extraction unit for extracting information indicating the first generation, A feature quantity extraction formula list is randomly generated, and actual data, information indicating the features of the actual data, and actual data of teacher data including weights are input to each feature quantity extraction formula included in the feature quantity extraction formula list And calculating a plurality of feature amounts corresponding to the actual data, and corresponding to the actual data of the teacher data from the plurality of feature amounts corresponding to the actual data of the calculated teacher data The information extraction unit candidate corresponding to each feature quantity extraction formula included in the feature quantity extraction formula list is generated by machine learning for estimating the information, and the teacher correctly estimated by the generated information extraction unit candidate An evaluation value corresponding to each feature quantity extraction formula is calculated using the weight of the data, a plurality of feature quantity extraction formulas included in the feature quantity extraction formula list of the previous generation are regarded as genes, and the feature quantity extraction formula The feature quantity extraction formula list of the previous generation is updated using a genetic algorithm based on the evaluation value, and the evaluation value is the best among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation The information extraction unit candidate corresponding to the feature quantity extraction formula is determined as one information extraction unit in the ensemble learning, and is erroneously estimated by the determined information extraction unit Calculating the reliability of the determined information extraction unit using the determined weight of the teacher data, and updating the weight of the teacher data using the determined reliability of the information extraction unit. Features.
本開示の第1の側面であるプログラムは、入力データの特徴を示す情報を抽出する複数の情報抽出部の出力を合成して、前記情報抽出部よりも高精度で前記入力データの特徴を示す情報を抽出する高精度情報抽出部を構築するアンサンブル学習における前記情報抽出部を生成する情報処理装置の制御用のプログラムであって、複数の演算子から成る特徴量抽出式を複数含む第1世代の特徴量抽出式リストをランダムに生成し、前記特徴量抽出式リストに含まれる各特徴量抽出式に、実データ、前記実データの特徴を示す情報、および重みからなる教師データの実データを入力して、前記実データに対応する複数の特徴量を計算し、計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記特徴量抽出式リストに含まれる各特徴量抽出式にそれぞれ対応する情報抽出部候補を生成するとともに、生成した前記情報抽出部候補によって正しく推定された教師データの重みを用いて各特徴量抽出式にそれぞれ対応する評価値を算出し、前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式に対応する前記情報抽出部候補を、前記アンサンブル学習における1つの前記情報抽出部に決定して、決定した前記情報抽出部によって間違って推定された教師データの重みを用いて、決定した前記情報抽出部の信頼度を算出し、決定された前記情報抽出部の前記信頼度を用いて、教師データの重みを更新するステップを含む処理を情報処理装置のコンピュータに実行させることを特徴とする。 The program according to the first aspect of the present disclosure combines the outputs of a plurality of information extraction units that extract information indicating the characteristics of input data, and indicates the characteristics of the input data with higher accuracy than the information extraction unit. A program for controlling an information processing apparatus for generating the information extraction unit in ensemble learning for constructing a high-precision information extraction unit for extracting information, the first generation including a plurality of feature quantity extraction expressions composed of a plurality of operators The feature quantity extraction formula list is randomly generated, and each feature quantity extraction formula included in the feature quantity extraction formula list includes real data, information indicating the characteristics of the real data, and actual data of teacher data including weights. Input, calculate a plurality of feature amounts corresponding to the actual data, and convert the calculated feature amounts corresponding to the actual data of the teacher data into the actual data of the teacher data Machine learning for estimating the corresponding information generates information extraction unit candidates corresponding to the respective feature quantity extraction formulas included in the feature quantity extraction formula list, and is correctly estimated by the generated information extraction unit candidates An evaluation value corresponding to each feature quantity extraction formula is calculated using the weight of the teacher data, a plurality of feature quantity extraction formulas included in the feature quantity extraction formula list of the previous generation are regarded as genes, and the feature quantity extraction formula The feature quantity extraction formula list of the previous generation is updated using a genetic algorithm based on the evaluation value, and the evaluation value is the highest among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation. The information extraction unit candidate corresponding to a good feature quantity extraction formula is determined as one information extraction unit in the ensemble learning, and the determined information extraction unit erroneously determines Processing including calculating the reliability of the determined information extraction unit using the determined weight of the teacher data and updating the weight of the teacher data using the determined reliability of the information extraction unit Is executed by a computer of the information processing apparatus.
本開示の第1の側面においては、複数の演算子から成る特徴量抽出式を複数含む第1世代の特徴量抽出式リストがランダムに生成され、前記特徴量抽出式リストに含まれる各特徴量抽出式に、実データ、前記実データの特徴を示す情報、および重みからなる教師データの実データが入力されて、前記実データに対応する複数の特徴量が計算される。また、計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記特徴量抽出式リストに含まれる各特徴量抽出式にそれぞれ対応する情報抽出部候補が生成されるとともに、生成された前記情報抽出部候補によって正しく推定された教師データの重みを用いて各特徴量抽出式にそれぞれ対応する評価値が算出される。さらに、前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストが更新される。そして、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式に対応する前記情報抽出部候補が、前記アンサンブル学習における1つの前記情報抽出部に決定され、決定された前記情報抽出部によって間違って推定された教師データの重みを用いて、決定された前記情報抽出部の信頼度が算出され、決定された前記情報抽出部の前記信頼度を用いて、教師データの重みが更新される。 In the first aspect of the present disclosure, a first generation feature quantity extraction formula list including a plurality of feature quantity extraction formulas including a plurality of operators is randomly generated, and each feature quantity included in the feature quantity extraction formula list Actual data, information indicating the characteristics of the actual data, and actual data of teacher data including weights are input to the extraction formula, and a plurality of feature amounts corresponding to the actual data are calculated. In addition, it is included in the feature quantity extraction formula list by machine learning for estimating the information corresponding to the actual data of the teacher data from the plurality of feature quantities corresponding to the actual data of the teacher data calculated. Information extraction unit candidates corresponding to the respective feature quantity extraction formulas are generated, and evaluation values corresponding to the respective feature quantity extraction formulas using the weights of the teacher data correctly estimated by the generated information extraction unit candidates Is calculated. Further, the feature quantity extraction formulas included in the feature quantity extraction formula list of the previous generation are regarded as genes, and the feature quantity extraction of the previous generation is performed using a genetic algorithm based on the evaluation value of the feature quantity extraction formula The expression list is updated. Then, the information extraction unit candidate corresponding to the feature quantity extraction formula having the best evaluation value among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation is one information extraction in the ensemble learning The reliability of the determined information extraction unit is calculated using the weight of the teacher data erroneously estimated by the determined information extraction unit, and the determined reliability of the information extraction unit is determined. The weight of the teacher data is updated using the degree.
本開示の第2の側面である情報処理装置は、入力データの特徴を示す情報を抽出する複数の情報抽出部の出力を合成して、前記情報抽出部よりも高精度で前記入力データの特徴を示す情報を抽出する高精度情報抽出部を構築するアンサンブル学習における前記情報抽出部を生成する情報処理装置において、実データ、および前記実データの特徴を示す情報からなる教師データをランダムに選択する選択手段と、複数の演算子から成る特徴量抽出式を複数含む特徴量抽出式リストを、前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新することにより生成する特徴量抽出式リスト生成手段と、前記特徴量抽出式リストに含まれる各特徴量抽出式に、前記教師データの実データを入力して、前記実データに対応する複数の特徴量を計算する特徴量計算手段と、各特徴量抽出式にそれぞれ対応する評価値として、各特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量を用いて、前記教師データの前記実データに対応する前記情報を推定した場合の精度を算出し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記アンサンブル学習における1つの前記情報抽出部を生成する評価値算出手段とを含むことを特徴とする。 An information processing apparatus according to a second aspect of the present disclosure synthesizes outputs of a plurality of information extraction units that extract information indicating characteristics of input data, and features the input data with higher accuracy than the information extraction unit. In the information processing apparatus for generating the information extraction unit in the ensemble learning that constructs a high-precision information extraction unit that extracts information indicating the actual data, teacher data consisting of actual data and information indicating the characteristics of the actual data are randomly selected The feature quantity extraction formula list including a plurality of feature quantity extraction formulas consisting of a selection means and a plurality of operators is regarded as a plurality of feature quantity extraction formulas included in the previous generation feature quantity extraction formula list, and the feature quantity Feature quantity extraction formula list generation means for generating the feature quantity extraction formula list generated by updating the feature quantity extraction formula list of the previous generation using a genetic algorithm based on the evaluation value of the extraction formula, and the feature quantity Each feature quantity extraction formula included in the output formula list is inputted with actual data of the teacher data, and a feature quantity calculation means for calculating a plurality of feature quantities corresponding to the actual data, and each feature quantity extraction formula As the corresponding evaluation value, the information corresponding to the actual data of the teacher data is estimated using the plurality of feature amounts corresponding to the actual data of the teacher data calculated using each feature amount extraction formula The actual data of the teacher data calculated using the feature quantity extraction formula having the best evaluation value among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation. An evaluation value calculation that generates one information extraction unit in the ensemble learning by machine learning that estimates the information corresponding to the actual data of the teacher data from the plurality of feature amounts corresponding to Characterized in that it comprises a means.
本開示の第2の側面である情報処理装置は、複数の前記情報抽出部を合成することにより、前記高精度情報抽出部を構築する合成手段をさらに含むことができる。 The information processing apparatus according to the second aspect of the present disclosure may further include a synthesizing unit that constructs the high-precision information extraction unit by synthesizing the plurality of information extraction units.
本開示の第2の側面である情報処理方法は、入力データの特徴を示す情報を抽出する複数の情報抽出部の出力を合成して、前記情報抽出部よりも高精度で前記入力データの特徴を示す情報を抽出する高精度情報抽出部を構築するアンサンブル学習における前記情報抽出部を生成する情報処理装置の情報処理方法において、実データ、および前記実データの特徴を示す情報からなる教師データをランダムに選択し、複数の演算子から成る特徴量抽出式を複数含む第1世代の特徴量抽出式リストをランダムに生成し、前記特徴量抽出式リストに含まれる各特徴量抽出式に、前記教師データの実データを入力して、前記実データに対応する複数の特徴量を計算し、各特徴量抽出式にそれぞれ対応する評価値として、各特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量を用いて、前記教師データの前記実データに対応する前記情報を推定した場合の精度を算出し、前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記アンサンブル学習における1つの前記情報抽出部を生成するステップを含むことを特徴とする。 The information processing method according to the second aspect of the present disclosure is characterized by combining the outputs of a plurality of information extraction units that extract information indicating the characteristics of the input data, with higher accuracy than the information extraction unit. In the information processing method of the information processing apparatus for generating the information extraction unit in the ensemble learning that constructs the high-precision information extraction unit for extracting the information indicating the real data, the teacher data including the information indicating the characteristics of the real data Randomly selecting and randomly generating a first generation feature quantity extraction formula list including a plurality of feature quantity extraction formulas composed of a plurality of operators, and for each feature quantity extraction formula included in the feature quantity extraction formula list, The actual data of the teacher data is input, a plurality of feature amounts corresponding to the actual data are calculated, and an evaluation value corresponding to each feature amount extraction formula is calculated using each feature amount extraction formula. Using the plurality of feature amounts corresponding to the actual data of the teacher data, the accuracy when the information corresponding to the actual data of the teacher data is estimated is calculated, and the feature amount extraction formula list of the previous generation is calculated A plurality of feature quantity extraction formulas included in the feature quantity are regarded as genes, and the feature quantity extraction formula list of the previous generation is updated using a genetic algorithm based on the evaluation value of the feature quantity extraction formula, and the feature of the last generation From the plurality of feature quantities corresponding to the actual data of the teacher data calculated using the feature quantity extraction formula having the best evaluation value among the feature quantity extraction formulas included in the quantity extraction formula list, the teacher data And generating one information extraction unit in the ensemble learning by machine learning for estimating the information corresponding to the actual data.
本開示の第2の側面であるプログラムは、入力データの特徴を示す情報を抽出する複数の情報抽出部の出力を合成して、前記情報抽出部よりも高精度で前記入力データの特徴を示す情報を抽出する高精度情報抽出部を構築するアンサンブル学習における前記情報抽出部を生成する情報処理装置の制御用のプログラムであって、実データ、および前記実データの特徴を示す情報からなる教師データをランダムに選択し、複数の演算子から成る特徴量抽出式を複数含む第1世代の特徴量抽出式リストをランダムに生成し、前記特徴量抽出式リストに含まれる各特徴量抽出式に、前記教師データの実データを入力して、前記実データに対応する複数の特徴量を計算し、各特徴量抽出式にそれぞれ対応する評価値として、各特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量を用いて、前記教師データの前記実データに対応する前記情報を推定した場合の精度を算出し、前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記アンサンブル学習における1つの前記情報抽出部を生成するステップを含む処理を情報処理装置のコンピュータに実行させることを特徴とする。 A program according to a second aspect of the present disclosure combines the outputs of a plurality of information extraction units that extract information indicating the characteristics of input data, and indicates the characteristics of the input data with higher accuracy than the information extraction unit. A program for controlling an information processing apparatus that generates the information extraction unit in ensemble learning that constructs a high-precision information extraction unit that extracts information, the teacher data comprising real data and information indicating characteristics of the real data Are randomly generated, a first generation feature quantity extraction formula list including a plurality of feature quantity extraction formulas composed of a plurality of operators is randomly generated, and each feature quantity extraction formula included in the feature quantity extraction formula list is Input actual data of the teacher data, calculate a plurality of feature quantities corresponding to the actual data, and calculate using each feature quantity extraction formula as an evaluation value corresponding to each feature quantity extraction formula The accuracy when the information corresponding to the actual data of the teacher data is estimated is calculated using the plurality of feature amounts corresponding to the actual data of the teacher data, and the feature amount extraction of the previous generation is performed. A plurality of feature quantity extraction formulas included in the formula list are regarded as genes, the previous generation generation feature quantity extraction formula list is updated using a genetic algorithm based on the evaluation value of the feature quantity extraction formula, and the last generation From the plurality of feature amounts corresponding to the actual data of the teacher data calculated using the feature amount extraction formula having the best evaluation value among the feature amount extraction formulas included in the feature amount extraction formula list, A process including a step of generating one of the information extraction units in the ensemble learning by machine learning that estimates the information corresponding to the actual data of the teacher data is performed by a control unit of the information processing apparatus. Characterized in that to execute the Yuta.
本開示の第2の側面においては、実データ、および前記実データの特徴を示す情報からなる教師データがランダムに選択され、複数の演算子から成る特徴量抽出式を複数含む第1世代の特徴量抽出式リストがランダムに生成され、前記特徴量抽出式リストに含まれる各特徴量抽出式に、前記教師データの実データが入力されて、前記実データに対応する複数の特徴量が計算される。また、各特徴量抽出式にそれぞれ対応する評価値として、各特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量を用いて、前記教師データの前記実データに対応する前記情報を推定した場合の精度が算出される。さらに、前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストが更新される。さらに、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記アンサンブル学習における1つの前記情報抽出部が生成される。 In the second aspect of the present disclosure, a first generation feature including a plurality of feature quantity extraction formulas including a plurality of feature data, in which teacher data including real data and information indicating features of the actual data is selected at random. A quantity extraction formula list is randomly generated, and the actual data of the teacher data is input to each feature quantity extraction formula included in the feature quantity extraction formula list, and a plurality of feature quantities corresponding to the actual data are calculated. The Further, as the evaluation value corresponding to each feature quantity extraction formula, using the plurality of feature quantities corresponding to the actual data of the teacher data calculated using each feature quantity extraction formula, the teacher data The accuracy when the information corresponding to the actual data is estimated is calculated. Further, the feature quantity extraction formulas included in the feature quantity extraction formula list of the previous generation are regarded as genes, and the feature quantity extraction of the previous generation is performed using a genetic algorithm based on the evaluation value of the feature quantity extraction formula The expression list is updated. Further, among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation, the plurality of the plurality of data corresponding to the actual data of the teacher data calculated using the feature quantity extraction formula having the best evaluation value One information extraction unit in the ensemble learning is generated by machine learning that estimates the information corresponding to the actual data of the teacher data from the feature amount.
本開示の第1および第2の側面によれば、入力データの種類に拘わらずアンサンブル学習における弱情報抽出部を自動的に生成することができる。 According to the first and second aspects of the present disclosure, a weak information extraction unit in ensemble learning can be automatically generated regardless of the type of input data.
また本開示の第1および第2の側面によれば、入力データの種類に拘わらずより高精度の情報抽出装置を自動的に構築できる。 Further, according to the first and second aspects of the present disclosure, it is possible to automatically construct a more accurate information extraction device regardless of the type of input data.
以下、本開示を適用した具体的な実施の形態について、図面を参照しながら詳細に説明する。 Hereinafter, specific embodiments to which the present disclosure is applied will be described in detail with reference to the drawings.
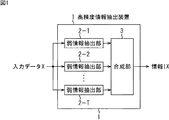
本開示を適用した高精度情報抽出装置構築システムは、図1に示すような、入力データXの特徴を示す情報を出力する複数の弱情報抽出部2−1乃至2−T、および、弱情報抽出部2−1乃至2−Tの出力を組み合わせることによって、入力データXの特徴を示す情報を高精度で出力する合成部3から成る高精度情報装置1を自動的に構築するものである。
The high-precision information extraction device construction system to which the present disclosure is applied includes a plurality of weak information extraction units 2-1 to 2-T that output information indicating the characteristics of the input data X as illustrated in FIG. By combining the outputs of the extraction units 2-1 to 2-T, the high-accuracy information device 1 including the
なお、入力データXは、多次元のデータであればよく、その種類は任意である。例えば、時間の次元とチャンネルの次元を有する楽曲データ、X次元とY次元と画素の次元を有する画像データ、画像データに時間の次元を加えた動画像データなどを入力データXとすることができる。 Note that the input data X may be multidimensional data, and the type thereof is arbitrary. For example, music data having a time dimension and a channel dimension, image data having an X dimension, a Y dimension, and a pixel dimension, moving image data obtained by adding a time dimension to image data, and the like can be used as the input data X. .
高精度情報装置1が出力する入力データXに対する情報としては、例えば、入力データXが楽曲データである場合、当該楽曲データの明暗(明るいか、明るくないかの2値情報)、または、明るさ(その値によって明るさの程度を示す数値情報。例えば、0から5までの値として、0は全く明るくない。5は非常に明るいとする)などを挙げることができる。勿論、上に挙げた例以外を入力データXとその情報とすることができる。 As information on the input data X output from the high-precision information device 1, for example, when the input data X is music data, the light and darkness (binary information indicating whether the music data is bright or not bright) or the brightness of the music data. (Numerical information indicating the degree of brightness according to the value. For example, as a value from 0 to 5, 0 is not bright at all, and 5 is very bright). Of course, the input data X and its information other than the examples given above can be used.
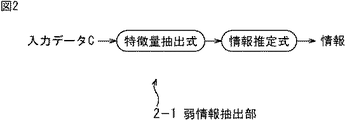
図1の弱情報抽出部2−1は、図2に示すように、特徴量抽出式と情報推定式から構成されている。特徴量抽出式は、入力データXに対して所定の演算を行い、演算結果として1次元の値を出力する。情報推定式は、特徴量抽出式の出力である1次元の値から、入力データXの特徴を示す情報を推定する。ここで、情報推定式は、例えば、その出力(すなわち、弱情報抽出部2-1の出力)を、+1または−1の2値情報とする場合には、特徴量抽出式の出力である1次元の値と比較するための閾値からなる判別式とすることができる。また例えば、その出力を、所定の範囲の数値とする場合には、特徴量抽出式の出力である1次元の値を入力とする線形結合式とすることができる。 As shown in FIG. 2, the weak information extraction unit 2-1 in FIG. 1 includes a feature amount extraction formula and an information estimation formula. The feature quantity extraction formula performs a predetermined calculation on the input data X and outputs a one-dimensional value as a calculation result. The information estimation formula estimates information indicating the feature of the input data X from the one-dimensional value that is the output of the feature quantity extraction formula. Here, the information estimation formula is, for example, the output of the feature quantity extraction formula when the output (that is, the output of the weak information extraction unit 2-1) is binary information of +1 or -1. It can be a discriminant consisting of a threshold value for comparison with a dimension value. For example, when the output is a numerical value in a predetermined range, it can be a linear combination formula with a one-dimensional value that is the output of the feature quantity extraction formula as an input.
図1の弱情報抽出部2−2乃至2−Tについても、弱情報抽出部2−1と同様である。 The weak information extraction units 2-2 to 2-T in FIG. 1 are the same as the weak information extraction unit 2-1.
次に、本開示の第1の実施の形態である高精度情報抽出装置構築システム10の構成例について、図3を参照して説明する。この高精度情報抽出装置構築システム10は、複数の教師データを用いたアンサンブル学習のブースティングによって高精度情報抽出装置1を構築するものである。 Next, a configuration example of the high-accuracy information extraction device construction system 10 according to the first embodiment of the present disclosure will be described with reference to FIG. The high-accuracy information extraction device construction system 10 constructs the high-accuracy information extraction device 1 by boosting ensemble learning using a plurality of teacher data.
この高精度情報抽出装置構築システム10は、m本の特徴量抽出式からなる特徴量抽出式リストを生成、更新する特徴量抽出式リスト生成部11、生成された各特徴量抽出式に教師データの実データを代入して特徴量を計算する特徴量計算部12、教師データを特徴量計算部12と評価値算出部15に供給する教師データ供給部13、特徴量計算部12によって計算された教師データに対応する特徴量と教師データとに基づいて情報抽出式を機械学習により生成するとともに特徴量抽出式リストを構成する各特徴抽出式の評価値を算出する評価値算出部15、および、評価値算出部15から出力されるT個の弱情報抽出部F(X)tとそれに対応する信頼度Ctを用いて高精度情報抽出装置1を構築する合成部16から構成される。
This high-accuracy information extraction device construction system 10 generates a feature quantity extraction formula list consisting of m feature quantity extraction formulas, updates a feature quantity extraction formula
特徴量抽出式リスト生成部11は、第1世代の特徴量抽出式リストを構成するm本の特徴量抽出式をランダムに生成し、生成した第1世代の特徴量抽出式リストを特徴量計算部12に供給する。
The feature quantity extraction formula
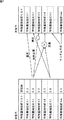
ここで、特徴量抽出式リスト生成部11によって生成される特徴量抽出式について、図4を参照して説明する。図4A乃至図4Dは、それぞれ特徴量抽出式の例を示している。
Here, the feature quantity extraction formula generated by the feature quantity extraction formula
特徴量抽出式には、左端に入力データの種類が記述され、入力データの種類の右側には、1種類以上のオペレータ(演算子)が演算される順序に従って記述される。各オペレータには、適宜、処理対称軸とパラメータが含まれる。 In the feature quantity extraction formula, the type of input data is described at the left end, and the right side of the type of input data is described according to the order in which one or more types of operators are calculated. Each operator includes a process symmetry axis and parameters as appropriate.
オペレータの種類としては、平均値(Mean)、高速フーリエ変換(FFT)、標準偏差(StDev)、出現率(Ratio)、ローパスフィルタ(LPF)、ハイパスフィルタ(HPF)、絶対値(ABS)、2乗(Sqr)、平方根(Sqrt)、正規化(Normalize)、微分(Differential)、積分(Integrate)、最大値(MaxIndex)、不偏分散(UVariance)、ダウンサンプリング(DownSampling)などを挙げることができる。なお、決定されたオペレータによっては処理対称軸が固定されていることがあるので、その場合、パラメータに固定されている処理対称軸を採用する。また、パラメータを必要とするオペレータが決定された場合、パラメータもランダムまたは予め設定されている値に決定する。 Operator types include mean value (Mean), fast Fourier transform (FFT), standard deviation (StDev), appearance rate (Ratio), low pass filter (LPF), high pass filter (HPF), absolute value (ABS), 2 Examples include power (Sqr), square root (Sqrt), normalization (Differential), integration (Integrate), maximum value (MaxIndex), unbiased variance (UVariance), and downsampling (DownSampling). Depending on the determined operator, the process symmetry axis may be fixed. In this case, the process symmetry axis fixed to the parameter is adopted. When an operator who needs a parameter is determined, the parameter is also determined to be a random value or a preset value.
例えば、図4Aに示された特徴量抽出式の場合、12TomesMが入力データであり、32#Differential,32#MaxIndex,16#LPF_1;O.861,16#UVarianceそれぞれがオペレータである。また、各オペレータ中の32#,16#などは処理対称軸を示している。 For example, in the case of the feature quantity extraction formula shown in FIG. 4A, 12TomesM is input data, and 32 # Differential, 32 # MaxIndex, 16 # LPF_1; O.861, 16 # UVariance are operators. In addition, 32 #, 16 #, etc. in each operator indicate processing symmetry axes.
ここで、12TomesMはモノラルのPCM(pulse coded modulation sound source)波形データを時間軸に沿って音程解析したものであることを示しており、48#はチャンネル軸、32#は周波数軸と音程軸、16#は時間軸を示している。オペレータ中の0.861はローパスフィルタ処理におけるパラメータであり、例えば透過させる周波数の閾値を示している。 Here, 12TomesM indicates that the pitch analysis of monaural PCM (pulse coded modulation sound source) waveform data along the time axis, 48 # is the channel axis, 32 # is the frequency axis and the pitch axis, 16 # indicates a time axis. 0.861 in the operator is a parameter in the low-pass filter process, and indicates, for example, a threshold value of the frequency to be transmitted.
なお、第1世代の特徴量抽出式リストを構成する各特徴量抽出式の入力データの種類は入力データXと同じもの、オペレータの数と種類はランダムに決定されるが、各特徴量抽出式を生成する際の制約として、図5に示すように、複数のオペレータに対応する演算が順次実行されるにつれて、演算結果の保有次元数が順次減少し、特徴量抽出式の最終的な演算結果がスカラになるか、あるいはその次元数が1となるようになされている。 Note that the type of input data of each feature quantity extraction formula constituting the first generation feature quantity extraction formula list is the same as that of the input data X, and the number and types of operators are randomly determined. As shown in FIG. 5, as the calculation corresponding to a plurality of operators is sequentially executed, the number of retained dimensions in the calculation result decreases sequentially, and the final calculation result of the feature quantity extraction formula is obtained. Is a scalar, or its dimensionality is 1.
図4A乃至図4Dに示された例から明らかなように、特徴量抽出式によって計算される特徴量は、例えば、楽曲データに対するテンポ、画像データに対する画素のヒストグラムなどのように、既存の概念で有意義と判断される値になるわけではない。すなわち、特徴量抽出式によって計算される特徴量は、単に入力データを特徴量抽出式に代入したときの演算結果に過ぎないものでよい。 As is clear from the examples shown in FIGS. 4A to 4D, the feature amount calculated by the feature amount extraction formula is an existing concept such as a tempo for music data and a pixel histogram for image data. It is not a value that is judged to be meaningful. That is, the feature quantity calculated by the feature quantity extraction formula may be merely a calculation result when the input data is substituted into the feature quantity extraction formula.
以下、特徴量抽出式リスト生成部11によって生成される特徴量抽出式リストは、図6に示すように、m本の特徴量抽出式f1乃至fmによって構成されているものとする。図6の例において、特徴量抽出式f1乃至fmの入力データであるWavMはモノラルのPCM波形データであり、保有次元は時間軸とチャンネル軸である。
Hereinafter, it is assumed that the feature quantity extraction formula list generated by the feature quantity extraction formula
図3に戻る。特徴量抽出式リスト生成部11はまた、第2世代以降の特徴量抽出式リストを、前世代の特徴量抽出式リストを遺伝的アルゴリズム(GA:genetic algorism)に従って更新することによって生成し、生成した特徴量抽出式リストを特徴量計算部12に供給する。
Returning to FIG. The feature quantity extraction formula
ここで、遺伝的アルゴリズムとは、現世代の遺伝子から、選択処理、交差処理、突然変異処理、およびランダム生成処理により、次世代の遺伝子を生成するアルゴリズムを指す。具体的には、特徴量抽出式リストを構成する複数の各特徴量抽出式を遺伝子とみなし、現世代の特徴量抽出式リストを構成する複数の特徴量抽出式の評価値に応じて選択処理、交差処理、突然変異処理、およびランダム生成処理を行い、次世代の特徴量抽出式リストを生成する。 Here, the genetic algorithm refers to an algorithm for generating the next generation gene from the current generation gene by selection processing, crossover processing, mutation processing, and random generation processing. Specifically, each of the plurality of feature quantity extraction formulas constituting the feature quantity extraction formula list is regarded as a gene, and selection processing is performed according to the evaluation values of the plurality of feature quantity extraction formulas constituting the current generation feature quantity extraction formula list Then, a cross process, a mutation process, and a random generation process are performed to generate a next generation feature quantity extraction formula list.
すなわち、例えば図7に示すように、選択処理では、現世代の特徴量抽出式リストを構成する複数の特徴量抽出式のうち、評価値の高い特徴量抽出式f2を選択して次世代の特徴量抽出式リストに含める。交差処理では、現世代の特徴量抽出式リストを構成する複数の特徴量抽出式のうち、評価値の高い複数の特徴量抽出式f2とf5を交差させて(組み合わせて)特徴量抽出式を生成し、次世代の特徴量抽出式リストに含める。 That is, for example, as shown in FIG. 7, in the selection process, a feature quantity extraction formula f2 having a high evaluation value is selected from a plurality of feature quantity extraction formulas constituting the current generation feature quantity extraction formula list to generate the next generation. Include in feature quantity extraction formula list. In the intersection processing, among the plurality of feature quantity extraction formulas constituting the current generation feature quantity extraction formula list, a plurality of feature quantity extraction formulas f2 and f5 having a high evaluation value are crossed (combined) to obtain a feature quantity extraction formula. Generate and include in the next generation feature quantity extraction formula list.
突然変異処理では、現世代の特徴量抽出式リストを構成する複数の特徴量抽出式のうち、評価値の高い特徴量抽出式f2を部分的に突然変異させて(変更して)特徴量抽出式を生成し、次世代の特徴量抽出式リストに含める。ランダム生成処理では、新たな特徴量抽出式をランダムに生成して次世代の特徴量抽出式リストに含める。 In the mutation processing, feature quantity extraction is performed by partially mutating (changing) a feature quantity extraction formula f2 having a high evaluation value among a plurality of feature quantity extraction formulas constituting the current generation feature quantity extraction formula list. Generate the formula and include it in the next generation feature extraction formula list. In the random generation process, a new feature quantity extraction formula is randomly generated and included in the next-generation feature quantity extraction formula list.
図3に戻る。特徴量計算部12は、特徴量抽出式リスト生成部11から供給された特徴量抽出式リストを構成する各特徴量抽出式f1乃至fmに、教師データ供給部13から供給される複数の教師データTiの実データDiを代入し、教師データTiに対する特徴量を計算し、計算した特徴量を評価値算出部15に供給する。
Returning to FIG. The feature
ここで、教師データ供給部13から供給される教師データTiについて説明する。図8は、教師データTiのデータ構造を示している。
Here, the teacher data Ti supplied from the teacher
総数L個の教師データTi(i=1,2,・・・,L)は、入力データXと同じ種類のデータである実データDi、実データDiに対応する情報Iiを有している。情報Iiは、例えば、実データDiの明るさを示すものであり、(明るいか(+1)、明るくないか(−1)の2値情報)であってもよいし、明るさ(その値によって明るさの程度を示す数値情報。例えば、0から5までの値として、0は全く明るくない。5は非常に明るいとする)であってもよい。以下、情報Iiは、+1または−1の2値情報であるとする。 The total number L of teacher data Ti (i = 1, 2,..., L) includes actual data Di that is the same type of data as the input data X, and information Ii corresponding to the actual data Di. The information Ii indicates, for example, the brightness of the actual data Di, and may be (binary information of whether bright (+1) or not bright (-1)) or brightness (depending on the value). Numerical information indicating the degree of brightness (for example, 0 to 5 is not bright at all, and 5 is very bright). Hereinafter, it is assumed that the information Ii is binary information of +1 or -1.
さらに、教師データTiには重みWiが設定されている。初期状態において、各教師データTiの重みWiは均一であり、L個の教師データTiの重みWiの合計が1と成るように正規化されている。 Further, a weight Wi is set for the teacher data Ti. In the initial state, the weight Wi of each teacher data Ti is uniform and is normalized so that the sum of the weights Wi of L teacher data Ti is 1.
教師データ供給部13は、重み設定部14を内蔵する。重み設定部14は、各教師データTiの重みWiを、評価値算出部15から供給される、構築された弱情報抽出部F(X)tによって各教師データTiが正しく判別されたか否かを示す情報と、弱情報抽出部F(X)tに対応する信頼度Ctに基づいて更新する。
The teacher
具体的には、弱情報抽出部F(X)tによって正しく判別された教師データTiについては現状の重みWiをEXP(−Ct)倍とし、弱情報抽出部F(X)tによって間違って判別された教師データTiについては、現状の重みWiをEXP(Ct)倍とする。さらに、L個の教師データTiの重みWiの合計が1と成るように正規化する。 Specifically, for the teacher data Ti correctly discriminated by the weak information extraction unit F (X) t , the current weight Wi is multiplied by EXP (−C t ), and the weak information extraction unit F (X) t makes a mistake. For the discriminated teacher data Ti, the current weight Wi is multiplied by EXP (C t ). Further, normalization is performed so that the sum of the weights Wi of the L pieces of teacher data Ti is 1.
図3に戻る。上述したように、教師データTiの数はL、特徴量抽出式リストを構成する特徴量抽出式の数はmであるので、特徴量計算部12では、図9に示すように、(L×m)個の特徴量が算出されることになる。以下、特徴量抽出式fj(j=1,2,・・・,m)に、教師データTi(i=1,2,・・・,L)の実データDiを代入して計算された特徴量をfj[Ti]と記述する。なお、図9には、特徴量fj[Ti]の具体的な値が記載されている。 Returning to FIG. As described above, since the number of teacher data Ti is L and the number of feature quantity extraction formulas constituting the feature quantity extraction formula list is m, the feature quantity calculation unit 12 (L × m) The feature amount is calculated. Hereinafter, the feature calculated by substituting the actual data Di of the teacher data Ti (i = 1, 2,..., L) into the feature quantity extraction formula fj (j = 1, 2,..., M). The quantity is described as fj [Ti]. FIG. 9 shows specific values of the feature quantity fj [Ti].
評価値算出部15は、L個の教師データTiとL個の特徴量f1[Ti]とに基づき、特徴量抽出式f1に対応する情報推定式を決定するとともに、特徴量抽出式f1の評価値を算出する。なお、ここで情報推定式は、その出力を2値情報とするので、情報推定式として、特徴量f1[Ti]と比較する閾値を有する判別式が決定される。
The evaluation
この判別式は、例えば、
特徴量f1[Ti]>閾値 → 情報=−1
特徴量f1[Ti]≦閾値 → 情報=+1
とする。
This discriminant is, for example,
Feature quantity f1 [Ti]> threshold value → information = −1
Feature amount f1 [Ti] ≦ threshold value → information = + 1
And
具体的には、図10に示すように、横軸には特徴量f1[Ti]の値、縦軸は重みWiをかけた教師データの分布を示すグラフに、L個の教師データTiを情報Iiの値(+1または−1)に応じて2つに分類してプロットする。そして、情報推定式(閾値による判別式)によって、情報Iiが正しく判別された教師データTiの重みWiの合計が最大となるように閾値を決定する。すなわち、図10に示された左側の山の分布(教師データTiの情報Iiの値が+1である分布)のうちの閾値よりも左側の面積と、図10に示された右側の山の分布(教師データTiの情報Iiの値が−1である分布)のうちの閾値よりも右側の面積との合計が最大となるように閾値を決定する。 Specifically, as shown in FIG. 10, the horizontal axis represents the value of the feature value f1 [Ti], and the vertical axis represents the distribution of the teacher data multiplied by the weight Wi. According to the value of Ii (+1 or −1), it is classified into two and plotted. Then, the threshold is determined so that the sum of the weights Wi of the teacher data Ti in which the information Ii is correctly determined is maximized by the information estimation equation (discriminant using the threshold). That is, the area on the left side of the threshold in the distribution of the left mountain shown in FIG. 10 (the distribution of the information Ii of the teacher data Ti is +1) and the distribution of the right mountain shown in FIG. The threshold value is determined so that the sum of the area with the area on the right side of the threshold value in the distribution (the distribution of the information Ii of the teacher data Ti is −1) becomes maximum.
そして、決定した情報推定式(閾値による判別式)によって、情報Iiが正しく判別された教師データTiの重みWiの合計を、特徴量抽出式f1の評価値とする。 Then, the sum of the weights Wi of the teacher data Ti in which the information Ii is correctly discriminated by the determined information estimation formula (discriminant using a threshold) is set as the evaluation value of the feature quantity extraction formula f1.
同様に、評価値算出部15は、特徴量抽出式f2乃至fmにそれぞれ対応する情報推定式を決定するとともに、特徴量抽出式f2乃至fmの評価値を算出する。
Similarly, the evaluation
ここで算出された特徴量抽出式f1乃至fmの評価値は、特徴量抽出式リスト生成部11に供給されて、次世代の特徴量抽出式リストの生成に利用される。
The evaluation values of the feature quantity extraction formulas f1 to fm calculated here are supplied to the feature quantity extraction formula
さらに、評価値算出部15は、所定の終了条件が満たされた数世代後(最終世代とする)の特徴量抽出式リストを構成する特徴量抽出式f1乃至fmのうち、最も評価値の良い特徴量抽出式fiとそれに対応する情報推定式から1つの弱情報抽出部F(X)tを構築する。さらに、構築した弱情報抽出部F(X)tの信頼度Ctを算出する。
信頼度Ct=1/2log((1−E)/E)
Further, the evaluation
Reliability C t = 1/2 log ((1-E) / E)
ここで、Eは構築した弱情報抽出部F(X)tのエラー率であり、弱情報抽出部F(X)tによって、情報Iiが間違って判別された教師データTiの重みWiの合計値(図10の例では、左側の山の分布(教師データTiの情報Iiの値が+1である分布)のうちの閾値よりも右側の面積と、図10に示された右側の山の分布(教師データTiの情報Iiの値が−1である分布)のうちの閾値よりも左側の面積との合計)である。 Here, E is the error rate of the constructed weak information extraction unit F (X) t , and the total value of the weights Wi of the teacher data Ti in which the information Ii is erroneously determined by the weak information extraction unit F (X) t (In the example of FIG. 10, the area on the right side of the threshold in the distribution of the left mountain (the distribution of the information Ii of the teacher data Ti is +1) and the distribution of the right mountain shown in FIG. The distribution of the information Ii of the teacher data Ti is a sum of the area on the left side of the threshold value in the distribution).
ここで構築された弱情報抽出部F(X)tとそれに対応する信頼度Ctは合成部16に供給される。また、構築された弱情報抽出部F(X)tによって各教師データTiが正しく判別されたか否かを示す情報と、弱情報抽出部F(X)t対応する信頼度Ctが教師データ供給部13の重み設定部14に供給される。
The weak information extraction unit F (X) t constructed here and the corresponding reliability C t are supplied to the
合成部16は、評価値算出部15から供給されている1個以上の弱情報抽出部F(X)tと、それぞれに対応する信頼度Ctを用いた次式に従い、高精度情報抽出装置1(図1)を構築する。
SignΣ(Ct・F(X)t)
The synthesizing
SignΣ (C t · F (X) t )
すなわち、合成部16では、複数の弱情報抽出部F(X)tの出力がそれの信頼度Ctによって重み付けられて加算される。そして、その総和の符号が正であるならば、入力データXの情報Iが+1、その総和の符号が負であるならば、入力データXの情報Iが−1とされる、高精度情報抽出装置1が構築される。
That is, the combining
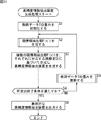
次に、高精度情報抽出装置構築システム10による動作について、図11のフローチャートを参照して説明する。 Next, the operation of the high-precision information extraction device construction system 10 will be described with reference to the flowchart of FIG.
ステップS1において、教師データ供給部13は、内蔵する重み設定部14により、予め用意されているL個の教師データTiの各重みWiを均等な値1/Lに初期化し、第1世代の教師データTiとして特徴量計算部12および評価値算出部15に供給する。
In step S1, the teacher
ステップS2において、第1世代の教師データTiに対応する弱情報抽出部F(X)1が生成される。ステップS2の処理について、図12のフローチャートを参照して詳述する。 In step S2, the weak information extraction unit F (X) 1 corresponding to the first generation teacher data Ti is generated. The process of step S2 will be described in detail with reference to the flowchart of FIG.
ステップS11において、特徴量抽出式リスト生成部11は、m本の特徴量抽出式をランダムに生成し、生成したm本の特徴量抽出式からなる第1世代の特徴量抽出式リストを特徴量計算部12に供給する。
In step S11, the feature quantity extraction formula
ステップS12において、特徴量計算部12は、特徴量抽出式リスト生成部11から供給された特徴量抽出式リストを構成するm本の特徴量抽出式f1乃至fmを順に1本ずつ注目する特徴量抽出式リストループを開始する。
In step S12, the feature
ステップS13において、特徴量計算部12は、注目している特徴量抽出式fjに、L個の教師データTiを代入してL個の特徴量fj[Ti]を計算し、評価値算出部15に出力する。ステップS14において、評価値算出部15は、L個の教師データTiとL個の特徴量fj[Ti]とに基づき、特徴量抽出式fjに対応する情報推定式を決定し、ステップS15において、特徴量抽出式fjの評価値を算出する。ステップS12乃至S15の処理により、注目している特徴量抽出式fjに対応する情報推定式と評価値が得られたことになる。
In step S13, the feature
ステップS16において、特徴量計算部12は、特徴量抽出式リスト生成部11から供給された特徴量抽出式リストを構成するm本の特徴量抽出式f1乃至fmのうち、注目してないものが残っているか否かを判定する。そして、注目していない特徴量抽出式が残っていると判定された場合、処理はステップS12に戻り、ステップS12乃至S16の処理が繰り返される。
In step S <b> 16, the feature
そして、ステップS16において、特徴量抽出式リスト生成部11から供給された特徴量抽出式リストを構成するm本の特徴量抽出式f1乃至fmのうち、注目してないものが残っていないと判定された場合、m本の特徴量抽出式f1乃至fmにそれぞれ対応する情報推定式と評価値が得られたことになるので、処理はステップS17に進められる。
In step S16, it is determined that there is no unfocused feature quantity extraction formula f1 to fm constituting the feature quantity extraction formula list supplied from the feature quantity extraction formula
ステップS17において、評価値算出部15は、所定の終了条件を満たしているか否かを判定する。ここで、所定の終了条件としては、例えば、m本の特徴量抽出式f1乃至fmにそれぞれ対応する評価値のうち、最も良い評価値の値が所定の数世代の間、向上していないことなどとすることができる。
In step S17, the evaluation
ステップS17において、所定の終了条件を満たしていないと判定された場合、処理はステップS18に進められる。 If it is determined in step S17 that the predetermined end condition is not satisfied, the process proceeds to step S18.
ステップS18において、評価値算出部15は、現世代の特徴量抽出式リストを構成するm本の特徴量抽出式f1乃至fmにそれぞれ対応する評価値を特徴量抽出式リスト生成部11に供給する。特徴量抽出式リスト生成部11は、現世代の特徴量抽出式リストを遺伝的アルゴリズムに従って更新することにより、次世代の特徴量抽出式リストを生成して特徴量計算部12に供給する。
In step S18, the evaluation
具体的には、遺伝的アルゴリズムの選択処理として、現世代の特徴量抽出式リストを構成する複数の特徴量抽出式のうち、評価値の良いms本の特徴量抽出式を選択して次世代の特徴量抽出式リストに含める。また、遺伝的アルゴリズムの交差処理として、現世代の特徴量抽出式リストを構成する複数の特徴量抽出式のうち、評価値の良いものほど選択され易いように重み付けをして2本の特徴量抽出式を選択し、選択した2本の特徴量抽出式を交差させる(組み合わせる)ことにより、mx本の特徴量抽出式を生成し、次世代の特徴量抽出式リストに含める。 Specifically, as a selection process of the genetic algorithm, the next generation is selected by selecting ms feature quantity extraction formulas having good evaluation values from a plurality of feature quantity extraction formulas constituting the current generation feature quantity extraction formula list. To the feature extraction formula list. In addition, as a crossover process of the genetic algorithm, two feature quantities are weighted so that the one with a better evaluation value among the plurality of feature quantity extraction formulas constituting the current generation feature quantity extraction formula list is easily selected. By selecting an extraction formula and intersecting (combining) the two selected feature quantity extraction formulas, mx feature quantity extraction formulas are generated and included in the next-generation feature quantity extraction formula list.
さらに、遺伝的アルゴリズムの突然変異処理として、現世代の特徴量抽出式リストを構成する複数の特徴量抽出式のうち、評価値の良いものほど選択され易いように重み付けをして1本の特徴量抽出式を選択し、選択した1本の特徴量抽出式を部分的に突然変異させる(変更する)ことにより、mm本の特徴量抽出式を生成し、次世代の特徴量抽出式リストに含める。さらにまた、遺伝的アルゴリズムのランダム生成処理として、新たにmr(=m−ms−mx−mm)本の特徴量抽出式をランダムに生成して次世代の特徴量抽出式リストに含める。 Further, as a genetic algorithm mutation process, one feature is weighted so that the better the evaluation value among the plurality of feature amount extraction formulas constituting the current generation feature quantity extraction formula list is selected. By selecting a quantity extraction formula and partially mutating (changing) one selected feature quantity extraction formula, mm feature quantity extraction formulas are generated and added to the next generation feature quantity extraction formula list. include. Furthermore, as a random generation process of the genetic algorithm, mr (= m−ms−mx−mm) new feature quantity extraction formulas are randomly generated and included in the next generation feature quantity extraction formula list.
以上のように、次世代の特徴量抽出式リストが生成されて特徴量計算部12に供給された後、処理はステップS12に戻り、ステップS12乃至S18の処理が繰り返される。そして、ステップS17において、所定の終了条件を満たしていると判定された場合、処理はステップS19に進められる。
As described above, after the next generation feature quantity extraction formula list is generated and supplied to the feature
ステップS19において、評価値算出部15は、現世代、すなわち、最終世代の特徴量抽出式リストを構成するm本の特徴量抽出式f1乃至fmのうち、評価値が最も良い特徴量抽出式fiとそれに対応する情報推定式から1つ目の弱情報抽出部F(X)1を構築し、構築した弱情報抽出部F(X)1の信頼度C1を算出する。さらに、評価値算出部15は、構築した1つ目の弱情報抽出部F(X)1とそれに対応する信頼度C1を合成部16に供給する。またさらに、評価値算出部15は、構築した弱情報抽出部F(X)1によって第1世代の各教師データTiが正しく判別されたか否かを示す情報と、弱情報抽出部F(X)1対応する信頼度C1を教師データ供給部13の重み設定部14に供給する。
In step S19, the evaluation
以上のように、第1世代の教師データTiに対応する1つ目の弱情報抽出部F(X)1が構築され、その信頼度C1が算出された後、処理は図11のステップS3に戻される。 As described above, after the first weak information extraction unit F (X) 1 corresponding to the first generation teacher data Ti is constructed and the reliability C 1 is calculated, the process proceeds to step S3 in FIG. Returned to
ステップS3において、合成部16は、現時点までに評価値算出部15から供給されている1個以上の弱情報抽出部F(X)tとそれに対応する信頼度Ctを合成することにより、高精度情報抽出装置1を構築する。
In step S3, the
ステップS4において、合成部16は、所定の終了条件を満たしているか否かを判定する。ここで、所定の終了条件としては、例えば、所定の数Tだけ弱情報抽出部F(X)tとそれに対応する信頼度Ctが評価値算出部15から供給されていること、高精度情報抽出装置1が所望の精度に達していること、またはユーザから終了が指示されたことのうち、少なくとも1つが満たされていることなどとすることができる。
In step S4, the
ステップS4において、所定の終了条件を満たしていないと判定された場合、処理はステップS5に進められる。 If it is determined in step S4 that the predetermined end condition is not satisfied, the process proceeds to step S5.
ステップS5において、教師データ供給部13の重み設定部14は、各教師データTiの重みWiを、ステップS19の処理で評価値算出部15から供給された、現世代の教師データTiに対応する弱情報抽出部F(X)tによって各教師データTiが正しく判別されたか否かを示す情報と、弱情報抽出部F(X)tに対応する信頼度Ctに基づいて更新する。
In step S5, the
ステップS5の処理について、図13のフローチャートを参照して詳述する。 The process of step S5 will be described in detail with reference to the flowchart of FIG.
ステップS41において、重み設定部14は、L個の教師データTiを順に1つずつ注目する教師データループを開始する。
In step S41, the
ステップS42において、重み設定部14は、注目する教師データTiが、現世代の教師データTiに対応する弱情報抽出部F(X)tによって正しく判別されたか否かを判定する。
In step S42, the
ステップS42において、正しく判別されたと判定された場合、処理はステップS43に進められる。ステップS43において、重み設定部14は、注目する教師データTiの現状の重みWiをEXP(−Ct)倍することにより更新する。この後、処理はステップS45に進められる。
If it is determined in step S42 that the determination is correct, the process proceeds to step S43. In step S43, the
反対に、ステップS42において、正しく判別されていない(間違って判別されている)と判定された場合、処理はステップS44に進められる。ステップS44において、重み設定部14は、注目する教師データTiの現状の重みWiをEXP(Ct)倍することにより更新する。この後、処理はステップS45に進められる。
On the other hand, if it is determined in step S42 that it is not correctly determined (incorrectly determined), the process proceeds to step S44. In step S44, the
ステップS45において、重み設定部14は、L個の教師データTiのうち、注目していないものが残っているか否かを判定し、注目していないものが残っていると判定した場合、ステップS41に戻って、ステップS41乃至45の処理を繰り返す。
In step S45, the
そして、ステップS45において、L個の教師データTiのうち、注目していないものが残っていないと判定された場合、L個の教師データTiにそれぞれ対応する重みWiを全て更新したので、処理はステップS46に進められる。 In step S45, when it is determined that there is no unfocused data among the L teacher data Ti, the weights Wi respectively corresponding to the L teacher data Ti are all updated. The process proceeds to step S46.
ステップS46において、重み設定部14は、L個の教師データTiにそれぞれ対応する更新した重みWiの合計が1となるように正規化する。
In step S46, the
以上のようにして重みWiが更新されたL個の教師データTiが、次世代の教師データTiとして評価値算出部15に供給される。なお、2世代以降の教師データTiは、実データDiおよび情報Iiに変更はなく、重みWiだけが更新されているので、次世代の教師データTiとして、更新された重みWiだけを評価値算出部15に供給するようにしてもよい。
The L pieces of teacher data Ti whose weights Wi are updated as described above are supplied to the evaluation
この後、処理は図11のステップS2に戻り、ステップS2乃至S5の処理が繰り返される。この繰り返しにより、教師データTiが更新された世代数と同じ数だけ、弱情報抽出部F(X)tとそれに対応する信頼度Ctが合成部16に供給され、合成部16により、徐々に制度が高められた高精度情報抽出装置1が構築されることになる。
Thereafter, the process returns to step S2 of FIG. 11, and the processes of steps S2 to S5 are repeated. Through this repetition, the weak information extraction unit F (X) t and the corresponding reliability C t are supplied to the
そして、ステップS4において、所定の終了条件を満たしていると判定された場合、処理はステップS5に進められる。ステップS5において、合成部16は、直前のステップS3の処理で構築した高精度情報抽出装置1を、最終的な高精度情報抽出装置1として出力する。
If it is determined in step S4 that the predetermined end condition is satisfied, the process proceeds to step S5. In step S <b> 5, the
以上で、本開示の第1の実施の形態である高精度情報抽出装置構築システム10の動作説明を終了する。 Above, operation | movement description of the high precision information extraction device construction system 10 which is 1st Embodiment of this indication is complete | finished.
次に、本開示の第2の実施の形態である高精度情報抽出装置構築システム50の構成例について、図14を参照して説明する。この高精度情報抽出装置構築システム50は、複数の教師データを用いたアンサンブル学習のバッギングによって高精度情報抽出装置1を構築するものである。 Next, a configuration example of the high-accuracy information extraction device construction system 50 according to the second embodiment of the present disclosure will be described with reference to FIG. The high-accuracy information extraction device construction system 50 constructs the high-accuracy information extraction device 1 by bagging of ensemble learning using a plurality of teacher data.
なお、この高精度情報抽出装置構築システム50と、図3に示された本開示の第1の実施の形態である、アンサンブル学習のブースティングによって高精度情報抽出装置1を構築する高精度情報抽出装置構築システム10との間で共通する構成要素については同一の符号を付しているので、その説明は適宜省略する。 Note that this high-precision information extraction device construction system 50 and high-precision information extraction that constructs the high-precision information extraction device 1 by boosting ensemble learning, which is the first embodiment of the present disclosure shown in FIG. Components common to the apparatus construction system 10 are denoted by the same reference numerals, and the description thereof is omitted as appropriate.
この高精度情報抽出装置構築システム50は、m本の特徴量抽出式からなる特徴量抽出式リストを生成、更新する特徴量抽出式リスト生成部11、生成された各特徴量抽出式に教師データの実データを代入して特徴量を計算する特徴量計算部12、教師データを特徴量計算部12と評価値算出部53に供給する教師データ供給部51、特徴量計算部12によって計算された教師データに対応する特徴量と教師データとに基づいて情報抽出式を機械学習により生成するとともに特徴量抽出式リストを構成する各特徴抽出式の評価値を算出する評価値算出部53、および、評価値算出部15から出力されるT個の弱情報抽出部F(X)tとそれに対応する信頼度Ctを用いて高精度情報抽出装置1を構築する合成部54から構成される。
This high-accuracy information extraction device construction system 50 generates a feature quantity extraction formula list including m feature quantity extraction formulas, updates a feature quantity extraction formula
特徴量抽出式リスト生成部11は、第1世代の特徴量抽出式リストをランダムに生成する。また、特徴量抽出式リスト生成部11は、第2世代以降の特徴量抽出式リストを、前世代の特徴量抽出式リストを遺伝的アルゴリズムにしたがって更新することにより生成する。生成された特徴量抽出式リストは特徴量計算部12に供給される。
The feature quantity extraction formula
特徴量計算部12は、特徴量抽出式リスト生成部11から供給された特徴量抽出式リストを構成する各特徴量抽出式f1乃至fmに、教師データ供給部51から供給される、教師データTi(i=1,2,・・・,J)の実データDiを代入し、教師データTiに対する特徴量を計算し、計算した特徴量を評価値算出部53に供給する。
The feature
ここで、教師データ供給部51から供給される教師データTiについて説明する。
Here, the teacher data Ti supplied from the teacher
教師データ供給部51は、内蔵するランダムサンプリング部52により、総数L個の教師データTiの中からJ個をランダムに選択して教師データ群を生成し、特徴量計算部12および評価値算出部53に供給する。なお、教師データTiは、入力データXと同じ種類のデータである実データDi、実データDiに対応する情報Iiを有している。情報Iiは、例えば、実データDiの明るさを示すものであり、(明るいか(+1)、明るくないか(−1)の2値情報)であってもよいし、明るさ(その値によって明るさの程度を示す数値情報。例えば、0から5までの値として、0は全く明るくない。5は非常に明るいとする)であってもよい。以下、情報Iiは、+1または−1の2値情報であるとする。
The teacher
さらに、教師データTiには重みWiが設定されている。初期状態において、各教師データTiの重みWiは均一であり、L個の教師データTiの重みWiの合計が1と成るように正規化されている。 Further, a weight Wi is set for the teacher data Ti. In the initial state, the weight Wi of each teacher data Ti is uniform and is normalized so that the sum of the weights Wi of L teacher data Ti is 1.
上述したように、教師データTiの数はJ、特徴量抽出式リストを構成する特徴量抽出式の数はmであるので、特徴量計算部12では、(J×m)個の特徴量が算出されることになる。
As described above, since the number of teacher data Ti is J and the number of feature quantity extraction formulas constituting the feature quantity extraction formula list is m, the feature
評価値算出部53は、J個の教師データTiとJ個の特徴量f1[Ti]とに基づき、特徴量抽出式f1の評価値を算出する。
The evaluation
なお、情報推定式によって推定しようとする情報Iiが2値情報である場合には、評価値として、J個の教師データTiとJ個の特徴量f1[Ti]とのFDR(fisher discriminant ratio)を算出する。
FDR=((Xの平均)−(Yの平均))2/((Xの標準偏差)−(Yの標準偏差))
ただし、Xは教師データTi、Yは特徴量f1[Ti]を示すものとする。
When the information Ii to be estimated by the information estimation formula is binary information, an FDR (fisher discriminant ratio) of J teacher data Ti and J feature quantity f1 [Ti] is used as an evaluation value. Is calculated.
FDR = ((average of X) − (average of Y)) 2 / ((standard deviation of X) − (standard deviation of Y))
However, X indicates teacher data Ti, and Y indicates a feature quantity f1 [Ti].
また、情報推定式によって推定しようとする情報Iiが数値情報である場合には、評価値として、J個の教師データTiとJ個の特徴量f1[Ti]とのPearsonの相関係数rを算出する。
r=(XとYの共分散)/((Xの標準偏差)×(Yの標準偏差))
ただし、Xは教師データTi、Yは特徴量f1[Ti]を示すものとする。
When the information Ii to be estimated by the information estimation formula is numerical information, Pearson's correlation coefficient r between the J teacher data Ti and the J feature quantity f1 [Ti] is used as an evaluation value. calculate.
r = (covariance of X and Y) / ((standard deviation of X) × (standard deviation of Y))
However, X indicates teacher data Ti, and Y indicates a feature quantity f1 [Ti].
同様に、評価値算出部53は、特徴量抽出式f2乃至fmの評価値も算出する。ここで算出された特徴量抽出式f1乃至fmの評価値は、特徴量抽出式リスト生成部11に供給されて、次世代の特徴量抽出式リストの生成に利用される。
Similarly, the evaluation
さらに、評価値算出部53は、所定の終了条件が満たされた数世代後(最終世代とする)の特徴量抽出式リストを構成するm本の特徴量抽出式f1乃至fmのうち、評価値が最も良い特徴量抽出式fiの計算結果であるJ個の特徴量f1[Ti]とJ個の教師データTiとを用いた機械学習により、評価値が最も良い特徴量抽出式fiに対応する情報推定式を決定する。
Further, the evaluation
なお、情報推定式は、その出力が2値情報である場合には線形判別などの機械学習によって判別式が決定される。また、その出力が数値情報である場合には線形回帰などの機械学習によって線形結合式が決定される。 The information estimation formula is determined by machine learning such as linear discrimination when the output is binary information. When the output is numerical information, a linear combination formula is determined by machine learning such as linear regression.
またさらに、評価値算出部53は、評価値が最も良い特徴量抽出式fiとそれに対応する情報推定式から1つの弱情報抽出部F(X)tを構築して合成部54に供給する。
Furthermore, the evaluation
合成部54は、評価値算出部53から供給されている1個以上の弱情報抽出部F(X)tから次式に従って高精度情報抽出装置1(図1)を構築する。
(ΣF(X)t)/t
The synthesizing
(ΣF (X) t ) / t
すなわち、合成部54では、複数の弱情報抽出部F(X)tの出力の平均値を出力とする高精度情報抽出装置1が構築されることになる。
That is, in the synthesizing
次に、高精度情報抽出装置構築システム50による動作について、図15のフローチャートを参照して説明する。 Next, the operation of the high-precision information extraction device construction system 50 will be described with reference to the flowchart of FIG.
ステップS61において、教師データ供給部51のランダムサンプリング部52は、予め用意されているL個の教師データTiの中から、ランダムにJ個の教師データTiを選択して教師データ群を生成し、第1世代の教師データ群として特徴量計算部12および評価値算出部53に供給する。
In step S61, the
ステップS62において、第1世代の教師データ群に対応する弱情報抽出部F(X)1が生成される。ステップS62の処理について、図16のフローチャートを参照して詳述する。 In step S62, the weak information extraction unit F (X) 1 corresponding to the first generation teacher data group is generated. The process of step S62 will be described in detail with reference to the flowchart of FIG.
ステップS71において、特徴量抽出式リスト生成部11は、m本の特徴量抽出式をランダムに生成し、生成したm本の特徴量抽出式からなる第1世代の特徴量抽出式リストを特徴量計算部12に供給する。
In step S <b> 71, the feature quantity extraction formula
ステップS72において、特徴量計算部12は、特徴量抽出式リスト生成部11から供給された特徴量抽出式リストを構成するm本の特徴量抽出式f1乃至fmを順に1本ずつ注目する特徴量抽出式リストループを開始する。
In step S72, the feature
ステップS73において、特徴量計算部12は、注目している特徴量抽出式fjに、現世代の教師データ群を構成するJ個の教師データTiを代入してJ個の特徴量fj[Ti]を計算し、評価値算出部53に出力する。ステップS74において、評価値算出部53は、J個の教師データTiとJ個の特徴量fj[Ti]とに基づき、特徴量抽出式fjに対応する評価値を算出する。ステップS73乃至S74の処理により、注目している特徴量抽出式fjの価値が得られたことになる。
In step S73, the feature
ステップS76において、特徴量計算部12は、特徴量抽出式リスト生成部11から供給された特徴量抽出式リストを構成するm本の特徴量抽出式f1乃至fmのうち、注目してないものが残っているか否かを判定する。そして、注目していない特徴量抽出式が残っていると判定された場合、処理はステップS72に戻り、ステップS72乃至S76の処理が繰り返される。
In step S <b> 76, the feature
そして、ステップS76において、特徴量抽出式リスト生成部11から供給された特徴量抽出式リストを構成するm本の特徴量抽出式f1乃至fmのうち、注目してないものが残っていないと判定された場合、m本の特徴量抽出式f1乃至fmにそれぞれ対応する評価値が得られたことになるので、処理はステップS76に進められる。
In step S76, it is determined that there are no unfocused feature quantity extraction formulas f1 to fm constituting the feature quantity extraction formula list supplied from the feature quantity extraction formula
ステップS76において、評価値算出部53は、所定の終了条件を満たしているか否かを判定する。ここで、所定の終了条件としては、例えば、m本の特徴量抽出式f1乃至fmにそれぞれ対応する評価値のうち、最も良い評価値の値が所定の数世代の間、向上していないことなどとすることができる。
In step S76, the evaluation
ステップS76において、所定の終了条件を満たしていないと判定された場合、処理はステップS77に進められる。 If it is determined in step S76 that the predetermined end condition is not satisfied, the process proceeds to step S77.
ステップS77において、評価値算出部53は、現世代の特徴量抽出式リストを構成するm本の特徴量抽出式f1乃至fmにそれぞれ対応する評価値を特徴量抽出式リスト生成部11に供給する。特徴量抽出式リスト生成部11は、現世代の特徴量抽出式リストを遺伝的アルゴリズムに従って更新することにより、次世代の特徴量抽出式リストを生成して特徴量計算部12に供給する。
In step S77, the evaluation
以上のように、生成された次世代の特徴量抽出式リストが特徴量計算部12に供給された後、処理はステップS72に戻り、ステップS72乃至S77の処理が繰り返される。そして、ステップS76において、所定の終了条件を満たしていると判定された場合、処理はステップS78に進められる。
As described above, after the generated next-generation feature quantity extraction formula list is supplied to the feature
ステップS78において、評価値算出部53は、現世代、すなわち、最終世代の特徴量抽出式リストを構成するm本の特徴量抽出式f1乃至fmのうち、評価値が最も良い特徴量抽出式fiの計算結果であるJ個の特徴量f1[Ti]とJ個の教師データTiとを用いた機械学習により、評価値が最も良い特徴量抽出式fiに対応する情報推定式を決定する。また、評価値算出部53は、評価値が最も良い特徴量抽出式fiとそれに対応する情報推定式から1つ目の弱情報抽出部F(X)1を構築して合成部54に供給する。
In step S78, the evaluation
以上のように、第1世代の教師データ群に対応する1つ目の弱情報抽出部F(X)1が構築され後、処理は図15のステップS63に戻される。 As described above, after the first weak information extraction unit F (X) 1 corresponding to the first generation teacher data group is constructed, the process returns to step S63 in FIG.
ステップS63において、合成部54は、現時点までに評価値算出部53から供給されている1個以上の弱情報抽出部F(X)tを合成する(出力の平均を演算する)ことにより、高精度情報抽出装置1を構築する。
In step S63, the
ステップS64において、合成部54は、所定の終了条件を満たしているか否かを判定する。ここで、所定の終了条件としては、例えば、所定の数Tだけ弱情報抽出部F(X)tが評価値算出部53から供給されていること、高精度情報抽出装置1が所望の精度に達していること、またはユーザから終了が指示されたことのうち、少なくとも1つが満たされていることなどとすることができる。
In step S64, the
ステップS64において、所定の終了条件を満たしていないと判定された場合、処理はステップS61に戻される。そして、ステップS61乃至64の処理が繰り返される。 If it is determined in step S64 that the predetermined termination condition is not satisfied, the process returns to step S61. And the process of step S61 thru | or 64 is repeated.
この繰り返し毎、順次、次世代以降の教師データ群が生成されて、それに対応する弱情報抽出部F(X)tが合成部54に供給され、合成部54により、徐々に制度が高められた高精度情報抽出装置1が構築されることになる。
For each repetition, a teacher data group from the next generation is generated sequentially, and the weak information extraction unit F (X) t corresponding thereto is supplied to the
そして、ステップS64において、所定の終了条件を満たしていると判定された場合、処理はステップS65に進められる。ステップS65において、合成部54は、直前のステップS63の処理で構築した高精度情報抽出装置1を、最終的な高精度情報抽出装置1として出力する。
If it is determined in step S64 that the predetermined end condition is satisfied, the process proceeds to step S65. In step S65, the
以上で、本開示の第2の実施の形態である高精度情報抽出装置構築システム50の動作説明を終了する。 Above, operation | movement description of the high precision information extraction device construction system 50 which is 2nd Embodiment of this indication is complete | finished.
以上説明したように、本開示を適用した高精度情報抽出装置構築システム10および50によれば、アンサンブル学習における弱情報抽出部を、遺伝的アルゴリズムを用いて生成することができる。 As described above, according to the high-accuracy information extraction device construction systems 10 and 50 to which the present disclosure is applied, the weak information extraction unit in the ensemble learning can be generated using the genetic algorithm.
また、本開示を適用した高精度情報抽出装置構築システム10および50によれば、任意の種類の入力データXから高い精度で情報を抽出することができる高精度情報抽出装置を構築することができる。 Moreover, according to the high-precision information extraction device construction systems 10 and 50 to which the present disclosure is applied, it is possible to construct a high-precision information extraction device that can extract information with high accuracy from any type of input data X. .
ところで、上述した一連の処理は、ハードウェアにより実行することもできるし、ソフトウェアにより実行することもできる。一連の処理をソフトウェアにより実行する場合には、そのソフトウェアを構成するプログラムが、専用のハードウェアに組み込まれているコンピュータ、または、各種のプログラムをインストールすることで、各種の機能を実行することが可能な、例えば汎用のパーソナルコンピュータなどに、プログラム記録媒体からインストールされる。 By the way, the above-described series of processing can be executed by hardware or can be executed by software. When a series of processing is executed by software, a program constituting the software may execute various functions by installing a computer incorporated in dedicated hardware or various programs. For example, it is installed from a program recording medium in a general-purpose personal computer or the like.
図13は、上述した一連の処理をプログラムにより実行するコンピュータのハードウェアの構成例を示すブロック図である。 FIG. 13 is a block diagram illustrating a hardware configuration example of a computer that executes the above-described series of processing by a program.
このコンピュータ100において、CPU(Central Processing Unit)101,ROM(Read Only Memory)102,RAM(Random Access Memory)103は、バス104により相互に接続されている。
In this computer 100, a CPU (Central Processing Unit) 101, a ROM (Read Only Memory) 102, and a RAM (Random Access Memory) 103 are connected to each other by a
バス104には、さらに、入出力インタフェース105が接続されている。入出力インタフェース105には、キーボード、マウス、マイクロホンなどよりなる入力部106、ディスプレイ、スピーカなどよりなる出力部107、ハードディスクや不揮発性のメモリなどよりなる記憶部108、ネットワークインタフェースなどよりなる通信部109、磁気ディスク、光ディスク、光磁気ディスク、或いは半導体メモリなどの着脱可能な記録媒体111を駆動するドライブ110が接続されている。
An input /
以上のように構成されるコンピュータでは、CPU101が、例えば、記憶部108に記憶されているプログラムを、入出力インタフェース105およびバス104を介して、RAM103にロードして実行することにより、上述した一連の処理が行われる。
In the computer configured as described above, the
なお、コンピュータが実行するプログラムは、本明細書で説明する順序に沿って時系列に処理が行われるプログラムであっても良いし、並列に、あるいは呼び出しが行われたとき等の必要なタイミングで処理が行われるプログラムであっても良い。 The program executed by the computer may be a program that is processed in time series in the order described in this specification, or in parallel or at a necessary timing such as when a call is made. It may be a program for processing.
また、プログラムは、1台のコンピュータにより処理されるものであってもよいし、複数のコンピュータによって分散処理されるものであってもよい。さらに、プログラムは、遠方のコンピュータに転送されて実行されるものであってもよい。 The program may be processed by a single computer, or may be distributedly processed by a plurality of computers. Furthermore, the program may be transferred to a remote computer and executed.
また、本明細書において、システムとは、複数の装置により構成される装置全体を表すものである。 Further, in this specification, the system represents the entire apparatus constituted by a plurality of apparatuses.
なお、本開示の実施の形態は、上述した実施の形態に限定されるものではなく、本開示の要旨を逸脱しない範囲において種々の変更が可能である。 The embodiment of the present disclosure is not limited to the above-described embodiment, and various modifications can be made without departing from the gist of the present disclosure.
10 高精度情報抽出装置構築システム, 11 特徴量抽出式リスト生成部, 12 特徴量計算部, 13 教師データ供給部, 14 重み設定部, 15 評価値算出部, 16 合成部, 50 高精度情報抽出装置構築システム, 51 教師データ供給部, 52 ランダムサンプリング部, 53 評価値算出部, 54 合成部, 101 CPU, 111 記録媒体 DESCRIPTION OF SYMBOLS 10 High precision information extraction apparatus construction system, 11 Feature quantity extraction formula list generation part, 12 Feature quantity calculation part, 13 Teacher data supply part, 14 Weight setting part, 15 Evaluation value calculation part, 16 Synthesis | combination part, 50 High precision information extraction Device construction system, 51 teacher data supply unit, 52 random sampling unit, 53 evaluation value calculation unit, 54 synthesis unit, 101 CPU, 111 recording medium
本開示の第一の側面である情報処理装置は、複数の次元軸を保有する入力データの特徴を示す情報を第一の精度で抽出する複数の第一の情報抽出部の出力を合成して、第二の精度で前記入力データの特徴を示す情報を抽出する第二の情報抽出部を構築するアンサンブル学習における前記第一の情報抽出部を生成する情報処理装置において、前記入力データに所定の演算を行う複数のオペレータを任意に組み合わせた特徴量抽出式を複数含む特徴量抽出式リストを、遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新することにより生成する特徴量抽出式リスト生成部と、前記特徴量抽出式リストに含まれる各特徴量抽出式に、教師データの実データを入力して、前記実データに対応する複数の特徴量を計算する特徴量計算部と、計算された前記複数の特徴量から、前記特徴量抽出式リストに含まれる各特徴量抽出式にそれぞれ対応する情報抽出部候補を生成するとともに、生成した前記情報抽出部候補によって正しく推定された教師データの重みを用いて各特徴量抽出式にそれぞれ対応する評価値を算出し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式に対応する前記情報抽出部候補を、前記アンサンブル学習における一つの前記第一の情報抽出部に決定して、決定した前記第一の情報抽出部によって間違って推定された教師データの重みを用いて、決定した前記第一の情報抽出部の信頼度を算出する算出部と、前記信頼度を用いて、教師データの重みを更新する更新部とを備え、前記オペレータは、前記入力データの保有する次元軸のうち、任意の次元軸を前記所定の演算処理の対象に指定するための処理対象軸指定情報を含む。 An information processing apparatus according to the first aspect of the present disclosure combines outputs of a plurality of first information extraction units that extract information indicating characteristics of input data having a plurality of dimension axes with a first accuracy. an information processing apparatus for generating the first information extraction unit in the ensemble learning to build a second information extraction unit for extracting information indicating characteristics of the input data in a second precision, the predetermined the input data multiple comprising feature quantity extraction formula list to any combination of feature quantity extraction formulas multiple operators performing operations, the feature produced by updating the characteristic amount extraction expression list of the previous generation using heritage Den algorithm an extraction formula list generation unit, to each feature quantity extraction formulas included in the feature quantity extraction formula list, and enter the actual data of the teacher data, the feature quantity calculation that calculates a plurality of feature amounts corresponding to the real data part , From the calculated pre-Symbol plurality of features, and generates each feature quantity extraction formula to the corresponding information extracting section candidates respectively included before Symbol feature quantity extraction formula list, correctly estimated by the generated the information extraction section candidate An evaluation value corresponding to each feature quantity extraction formula is calculated using the weights of the teacher data, and the feature with the best evaluation value among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation is calculated. the information extraction unit candidates corresponding to the amount extraction expression, determined to one of the first information extraction unit in the ensemble learning, the weights of the teacher data estimated incorrectly by determined the first information extraction portion using a calculation output section for calculating a reliability of the determined the first information extraction portion, using a pre-Symbol reliability, and a update unit for updating the weights of the teacher data, the operator, before Of the dimensions shaft held by the input data, including the processing target axis designation information for designating an arbitrary dimension axes subject to the predetermined arithmetic processing.
前記入力データは、時間の次元とチャンネルの次元を有する楽曲データ、X次元とY次元と画素の次元を有する画像データ、または画像データに時間の次元を加えた動画像データとすることができる。The input data may be music data having a time dimension and a channel dimension, image data having an X dimension, a Y dimension, and a pixel dimension, or moving image data obtained by adding a time dimension to image data.
前記入力データが楽曲データである場合、前記第二の情報抽出部は、前記楽曲データの特徴を示す情報として明暗または明るさを抽出することができる。When the input data is music data, the second information extraction unit can extract light and dark or brightness as information indicating the characteristics of the music data.
前記特徴量抽出式リスト生成部は、前記特徴量抽出式リストを構成する複数の各特徴量抽出式を遺伝子とみなし、現世代の特徴量抽出式リストを構成する複数の特徴量抽出式の評価値に応じて選択処理、交差処理、突然変異処理、およびランダム生成処理を行い、次世代の特徴量抽出式リストを生成することができる。The feature quantity extraction formula list generation unit regards each of the plurality of feature quantity extraction formulas constituting the feature quantity extraction formula list as a gene, and evaluates the plurality of feature quantity extraction formulas constituting the current generation feature quantity extraction formula list A selection process, a cross process, a mutation process, and a random generation process are performed according to the value, and a next-generation feature quantity extraction formula list can be generated.
前記特徴量抽出式リスト生成部は、前記突然変異処理として、現世代の特徴量抽出式リストを構成する複数の特徴量抽出式のうち、評価値の高い前記特徴量抽出式を部分的に突然変異させて特徴量抽出式を生成し、次世代の特徴量抽出式リストに含めることができる。The feature quantity extraction formula list generation unit, as the mutation process, partially extracts the feature quantity extraction formula having a high evaluation value from among a plurality of feature quantity extraction formulas constituting the current generation feature quantity extraction formula list. It is possible to generate a feature quantity extraction formula by mutating and include it in the next generation feature quantity extraction formula list.
本開示の第一の側面である情報処理方法は、複数の次元軸を保有する入力データの特徴を示す情報を第一の精度で抽出する複数の第一の情報抽出部の出力を合成して、第二の精度で前記入力データの特徴を示す情報を抽出する第二の情報抽出部を構築するアンサンブル学習における前記第一の情報抽出部を生成する情報処理装置の情報処理方法において、前記情報処理装置による、前記入力データに所定の演算を行う複数のオペレータを任意に組み合わせた特徴量抽出式を複数含む特徴量抽出式リストに含まれる各特徴量抽出式に、教師データの実データを入力して、前記実データに対応する複数の特徴量を計算する特徴量計算ステップと、計算された前記複数の特徴量から、前記特徴量抽出式リストに含まれる各特徴量抽出式にそれぞれ対応する情報抽出部候補を生成するとともに、生成した前記情報抽出部候補によって正しく推定された教師データの重みを用いて各特徴量抽出式にそれぞれ対応する評価値を算出する第一の算出ステップと、算出された前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新する更新ステップと、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式に対応する前記情報抽出部候補を、前記アンサンブル学習における一つの前記第一の情報抽出部に決定して、決定した前記第一の情報抽出部によって間違って推定された教師データの重みを用いて、決定した前記第一の情報抽出部の信頼度を算出する第二の算出ステップと、前記信頼度を用いて、教師データの重みを更新する更新ステップとを含み、前記オペレータは、前記入力データの保有する次元軸のうち、任意の次元軸を前記所定の演算処理の対象に指定するための処理対象軸指定情報を含む。 The information processing method according to the first aspect of the present disclosure includes combining outputs of a plurality of first information extraction units that extract information indicating characteristics of input data having a plurality of dimensional axes with a first accuracy. In the information processing method of the information processing apparatus for generating the first information extraction unit in ensemble learning that constructs a second information extraction unit that extracts information indicating the characteristics of the input data with second accuracy, the information by processing apparatus to each feature quantity extraction formulas included in the feature quantity extraction formula list including a plurality of any combination of feature quantity extraction formulas multiple operators performing a predetermined operation on the input data, the actual data of teacher data enter a feature quantity calculation step of calculating a plurality of feature amounts corresponding to the actual data, from the calculated pre-Symbol plurality of features, each feature quantity extraction formulas included in the prior SL feature quantity extraction formula list Each pair Generates the information extraction unit candidates, a first calculation step of calculating an evaluation value corresponding to each feature quantity extraction formula by using the weight of the generated supervisor data the information has been correctly estimated by the extracting unit candidates, An update step of updating the feature quantity extraction formula list of the previous generation using a genetic algorithm based on the calculated evaluation value, and a feature quantity extraction formula included in the feature quantity extraction formula list of the last generation the information extraction unit candidates the evaluation value corresponds to the best feature quantity extraction formula, to determine the one of the first information extraction unit in the ensemble learning, wrong by determined the first information extraction portion using the weight of the estimated teacher data, by using a second calculation step of calculating, the pre-Symbol reliability the reliability of the determined the first information extraction portion, teacher data And a updating step of updating the weights, the operator of the dimensions shaft held of the input data, including the processing target axis designation information for designating an arbitrary dimension axes subject to the predetermined arithmetic processing.
本開示の第一の側面であるプログラムは、複数の次元軸を保有する入力データの特徴を示す情報を第一の精度で抽出する複数の第一の情報抽出部の出力を合成して、第二の精度で前記入力データの特徴を示す情報を抽出する第二の情報抽出部を構築するアンサンブル学習における前記第一の情報抽出部を生成するコンピュータを、前記入力データに所定の演算を行う複数のオペレータを任意に組み合わせた特徴量抽出式を複数含む特徴量抽出式リストを、遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新することにより生成する特徴量抽出式リスト生成部と、前記特徴量抽出式リストに含まれる各特徴量抽出式に、教師データの実データを入力して、前記実データに対応する複数の特徴量を計算する特徴量計算部と、計算された前記複数の特徴量から、前記特徴量抽出式リストに含まれる各特徴量抽出式にそれぞれ対応する情報抽出部候補を生成するとともに、生成した前記情報抽出部候補によって正しく推定された教師データの重みを用いて各特徴量抽出式にそれぞれ対応する評価値を算出し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式に対応する前記情報抽出部候補を、前記アンサンブル学習における一つの前記第一の情報抽出部に決定して、決定した前記第一の情報抽出部によって間違って推定された教師データの重みを用いて、決定した前記第一の情報抽出部の信頼度を算出する算出部と、前記信頼度を用いて、教師データの重みを更新する更新部として機能させ、前記オペレータは、前記入力データの保有する次元軸のうち、任意の次元軸を前記所定の演算処理の対象に指定するための処理対象軸指定情報を含む。 A program according to a first aspect of the present disclosure combines outputs of a plurality of first information extraction units that extract information indicating characteristics of input data having a plurality of dimension axes with a first accuracy . A computer that generates the first information extraction unit in ensemble learning that constructs a second information extraction unit that extracts information indicating the characteristics of the input data with a second accuracy, and that performs a predetermined calculation on the input data of any combination of plurality comprising a feature quantity extraction formula list feature extraction equation operators, heritage feature quantity extraction formula list generation to generation by updating the characteristic amount extraction expression list of the previous generation using heat algorithm and parts, to each feature quantity extraction formulas included in the feature quantity extraction formula list, and enter the actual data of the teacher data, wherein a feature amount calculation unit for calculating a plurality of feature amounts corresponding to the actual data, calculates Before Symbol plurality of feature values, to generate a pre-Symbol feature quantity extraction formula corresponding information extracting unit candidate to each feature quantity extraction formulas included in the list have been correctly estimated by the generated the information extraction section candidate An evaluation value corresponding to each feature quantity extraction formula is calculated using the weight of the teacher data, and the feature quantity extraction having the best evaluation value among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation is calculated. the information extraction unit candidates corresponding to the formula, to determine the one of the first information extraction unit in the ensemble learning, using the weight of the teacher data estimated incorrectly by determined the first information extraction portion Te, a calculation output unit for calculating the reliability of the determined the first information extraction portion, using a pre-Symbol reliability, to function as an updating unit that updates the weights of the teacher data, the operator, the Of the dimensions shaft held by the force data, including the processing target axis designation information for designating an arbitrary dimension axes subject to the predetermined arithmetic processing.
本開示の第一の側面においては、入力データに所定の演算を行う複数のオペレータを任意に組み合わせた特徴量抽出式を複数含む特徴量抽出式リストに含まれる各特徴量抽出式に、教師データの実データが入力されて、前記実データに対応する複数の特徴量が計算される。また、計算された前記複数の特徴量から、前記特徴量抽出式リストに含まれる各特徴量抽出式にそれぞれ対応する情報抽出部候補が生成されるとともに、生成した前記情報抽出部候補によって正しく推定された教師データの重みを用いて各特徴量抽出式にそれぞれ対応する評価値が算出される。さらに、算出された前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストが更新される。そして、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式に対応する前記情報抽出部候補が、アンサンブル学習における一つの前記第一の情報抽出部に決定され、決定された前記第一の情報抽出部によって間違って推定された教師データの重みを用いて、決定された前記第一の情報抽出部の信頼度が算出され、前記信頼度を用いて、教師データの重みが更新される。 In the first aspect of the present disclosure, teacher data is included in each feature quantity extraction formula included in a feature quantity extraction formula list including a plurality of feature quantity extraction formulas that arbitrarily combine a plurality of operators that perform predetermined calculations on input data. actual data is input, a plurality of feature amounts corresponding to the actual data is calculated. Further, from the calculated pre-Symbol plurality of feature amounts, together with corresponding information extracting unit candidate, respectively, are generated for each feature quantity extraction formulas included in the prior SL feature quantity extraction formula list, the generated the information extraction section candidate An evaluation value corresponding to each feature amount extraction formula is calculated using the weight of the teacher data that is correctly estimated. Further, the feature quantity extraction formula list of the previous generation is updated using a genetic algorithm based on the calculated evaluation value. Then, the information extracting unit candidates the evaluation value among the feature quantity extraction formulas included in the feature amount extraction expression list of the final generation corresponds to the best feature quantity extraction formula, one of said at A Ensemble Learning first It is determined in the information extraction unit, using the weight of the teacher data estimated incorrectly by determined the first information extraction portion, the reliability of the determined the first information extraction portion is calculated, before The weight of the teacher data is updated using the writing reliability.
本開示の第二の側面である情報処理装置は、複数の次元軸を保有する入力データの特徴を示す情報を第一の精度で抽出する複数の第一の情報抽出部の出力を合成して、第二の精度で前記入力データの特徴を示す情報を抽出する第二の精度情報抽出部を構築するアンサンブル学習における前記第一の情報抽出部を生成する情報処理装置において、教師データをランダムに選択する選択部と、前記入力データに所定の演算を行う複数のオペレータを組み合わせた特徴量抽出式を複数含む特徴量抽出式リストを、遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新することにより生成する特徴量抽出式リスト生成部と、前記特徴量抽出式リストに含まれる各特徴量抽出式に、前記教師データの実データを入力して、前記実データに対応する複数の特徴量を計算する特徴量計算部と、各特徴量抽出式にそれぞれ対応する評価値として、各特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量を用いて、前記教師データの前記実データに対応する前記情報を推定した場合の精度を算出し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記アンサンブル学習における一つの前記第一の情報抽出部を生成する評価値算出部とを含む。 An information processing apparatus according to a second aspect of the present disclosure combines outputs of a plurality of first information extraction units that extract information indicating characteristics of input data having a plurality of dimension axes with a first accuracy. random in the information processing apparatus, the teacher data to generate the first information extraction unit in the ensemble learning to build a second accuracy information extractor for extracting information indicating characteristics of the input data in the second precision a selection unit that selects, the multiple including feature quantity extraction formula list a plurality of feature quantity extraction formula that combines the operator to perform a predetermined operation on the input data, the feature quantity extraction previous generation using heritage Den algorithm a feature quantity extraction formula list generation unit which generates by updating expression list, each feature quantity extraction formulas included in the feature quantity extraction formula list, and enter the actual data of the teacher data, the the actual data A feature quantity calculation unit that calculates a plurality of feature amounts response, as the evaluation value corresponding to each feature quantity extraction formula, the corresponding to the real data of the teacher data calculated by using each feature quantity extraction formula The accuracy when the information corresponding to the actual data of the teacher data is estimated is calculated using a plurality of feature quantities, and the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation are By machine learning for estimating the information corresponding to the actual data of the teacher data from the plurality of feature amounts corresponding to the actual data of the teacher data calculated using the feature amount extraction formula having the best evaluation value , including the evaluation value calculation unit that generates one of the first information extraction unit in the ensemble learning.
本開示の第二の側面である情報処理装置は、複数の前記第一の情報抽出部を合成することにより、前記第二の情報抽出部を構築する合成部をさらに含むことができる。 The information processing apparatus according to the second aspect of the present disclosure may further include a combining unit that constructs the second information extracting unit by combining a plurality of the first information extracting units.
本開示の第二の側面である情報処理方法は、複数の次元軸を保有する入力データの特徴を示す情報を第一の精度で抽出する複数の第一の情報抽出部の出力を合成して、第二の精度で前記入力データの特徴を示す情報を抽出する第二の精度情報抽出部を構築するアンサンブル学習における前記第一の情報抽出部を生成する情報処理装置の情報処理方法において、前記情報処理装置による、教師データをランダムに選択し、前記入力データに所定の演算を行う複数のオペレータを組み合わせた特徴量抽出式を複数含む第1世代の特徴量抽出式リストをランダムに生成し、前記特徴量抽出式リストに含まれる各特徴量抽出式に、前記教師データの実データを入力して、前記実データに対応する複数の特徴量を計算し、各特徴量抽出式にそれぞれ対応する評価値として、各特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量を用いて、前記教師データの前記実データに対応する前記情報を推定した場合の精度を算出し、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記アンサンブル学習における一つの前記第一の情報抽出部を生成するステップを含む。 The information processing method according to the second aspect of the present disclosure includes combining outputs of a plurality of first information extraction units that extract information indicating characteristics of input data having a plurality of dimension axes with a first accuracy. an information processing method for an information processing apparatus for generating the first information extraction unit in the ensemble learning to build a second accuracy information extractor for extracting information indicating characteristics of the input data in the second precision, wherein by the information processing apparatus, and select teacher data randomly, the feature amount extraction expression list of the first generation containing a plurality of feature quantity extraction formula by combining a plurality of operators to perform the predetermined operation on the input data generated at random The actual data of the teacher data is input to each feature quantity extraction formula included in the feature quantity extraction formula list, and a plurality of feature quantities corresponding to the actual data are calculated, and each feature quantity extraction formula is respectively supported. As the evaluation value, the information corresponding to the actual data of the teacher data is estimated using the plurality of feature amounts corresponding to the actual data of the teacher data calculated using each feature amount extraction formula calculating the accuracy of the case, to update the feature amount extraction expression list of the previous generation with a genetic algorithm based on the evaluation value before Symbol feature quantity extraction formulas, included in the feature amount extraction expression list of the final generation Corresponding to the actual data of the teacher data from the plurality of feature amounts corresponding to the actual data of the teacher data calculated using the feature amount extraction formula having the best evaluation value the machine learning for estimating the information, including the step of generating one of the first information extraction unit in the ensemble learning.
本開示の第二の側面であるプログラムは、複数の次元軸を保有する入力データの特徴を示す情報を第一の精度で抽出する複数の第一の情報抽出部の出力を合成して、第二の精度で前記入力データの特徴を示す情報を抽出する第二の精度情報抽出部を構築するアンサンブル学習における前記第一の情報抽出部を生成する情報処理装置の制御用のプログラムであって、教師データをランダムに選択し、前記入力データに所定の演算を行う複数のオペレータを組み合わせた特徴量抽出式を複数含む第1世代の特徴量抽出式リストをランダムに生成し、前記特徴量抽出式リストに含まれる各特徴量抽出式に、前記教師データの実データを入力して、前記実データに対応する複数の特徴量を計算し、各特徴量抽出式にそれぞれ対応する評価値として、各特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量を用いて、前記教師データの前記実データに対応する前記情報を推定した場合の精度を算出し、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記アンサンブル学習における一つの前記第一の情報抽出部を生成するステップを含む処理を情報処理装置のコンピュータに実行させる。 Program is a second aspect of the present disclosure combines the outputs of the first information extraction portion a plurality of extracting information indicating characteristics of the input data held multiple dimensions shaft at a first precision, the a second accuracy information extraction unit the first program for controlling an information processing apparatus for generating information extraction unit in the ensemble learning to build to extract information in two accuracy indicating characteristics of said input data, the teacher data randomly selected, to generate a first generation feature quantity extraction formula list including a plurality a plurality of feature quantity extraction formula that combines the operator to perform a predetermined operation on the input data at random, the feature quantity extraction The actual data of the teacher data is input to each feature quantity extraction formula included in the formula list, a plurality of feature quantities corresponding to the actual data are calculated, and evaluation values respectively corresponding to the feature quantity extraction formulas are as follows: each The accuracy when the information corresponding to the actual data of the teacher data is estimated is calculated using the plurality of feature amounts corresponding to the actual data of the teacher data calculated using a collection amount extraction formula. previous SL updates the feature amount extraction expression list of the previous generation with a genetic algorithm based on the evaluation value feature quantity extraction formulas, the feature amount extraction expressions included in the feature amount extraction expression list of the final generation The information corresponding to the actual data of the teacher data is estimated from the plurality of feature amounts corresponding to the actual data of the teacher data calculated using the feature amount extraction formula having the best evaluation value. the machine learning, Ru to execute the process including the step of generating one of the first information extraction unit in the ensemble learning by a computer in an information processing apparatus.
本開示の第二の側面においては、教師データがランダムに選択され、入力データに所定の演算を行う複数のオペレータを組み合わせた特徴量抽出式を複数含む第1世代の特徴量抽出式リストがランダムに生成され、前記特徴量抽出式リストに含まれる各特徴量抽出式に、前記教師データの実データが入力されて、前記実データに対応する複数の特徴量が計算される。また、各特徴量抽出式にそれぞれ対応する評価値として、各特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量を用いて、前記教師データの前記実データに対応する前記情報を推定した場合の精度が算出される。さらに、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストが更新される。さらに、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記アンサンブル学習における一つの前記第一の情報抽出部が生成される。 In a second aspect of the present disclosure, teachers data is randomly selected, the first generation feature quantity extraction formula list including a plurality a plurality of feature quantity extraction formula that combines the operator to perform a predetermined operation on the input data The actual data of the teacher data is input to each feature quantity extraction formula that is randomly generated and included in the feature quantity extraction formula list, and a plurality of feature quantities corresponding to the actual data are calculated. Further, as the evaluation value corresponding to each feature quantity extraction formula, using the plurality of feature quantities corresponding to the actual data of the teacher data calculated using each feature quantity extraction formula, the teacher data The accuracy when the information corresponding to the actual data is estimated is calculated. Further, the feature amount extraction expression list of the previous generation with a genetic algorithm based on the evaluation value before Symbol feature quantity extraction formula is updated. Further, among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation, the plurality of the plurality of data corresponding to the actual data of the teacher data calculated using the feature quantity extraction formula having the best evaluation value from the feature quantity, the machine learning for estimating the information corresponding to the real data of the teacher data, one of the first information extraction unit in the ensemble learning is generated.
Claims (8)
複数の演算子から成る特徴量抽出式を複数含む特徴量抽出式リストを、前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新することにより生成する特徴量抽出式リスト生成手段と、
前記特徴量抽出式リストに含まれる各特徴量抽出式に、実データ、前記実データの特徴を示す情報、および重みからなる教師データの実データを入力して、前記実データに対応する複数の特徴量を計算する特徴量計算手段と、
計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記特徴量抽出式リストに含まれる各特徴量抽出式にそれぞれ対応する情報抽出部候補を生成するとともに、生成した前記情報抽出部候補によって正しく推定された教師データの重みを用いて各特徴量抽出式にそれぞれ対応する評価値を算出し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式に対応する前記情報抽出部候補を、前記アンサンブル学習における1つの前記情報抽出部に決定して、決定した前記情報抽出部によって間違って推定された教師データの重みを用いて、決定した前記情報抽出部の信頼度を算出する評価値算出手段と、
決定された前記情報抽出部の前記信頼度を用いて、教師データの重みを更新する更新手段と
を含むことを特徴とする情報処理装置。 By combining outputs of a plurality of information extraction units that extract information indicating the characteristics of the input data, a high-precision information extraction unit that extracts information indicating the characteristics of the input data with higher accuracy than the information extraction unit is constructed. In an information processing apparatus that generates the information extraction unit in ensemble learning,
The feature quantity extraction formula list including a plurality of feature quantity extraction formulas composed of a plurality of operators is regarded as a plurality of feature quantity extraction formulas included in the feature quantity extraction formula list of the previous generation, and the feature quantity extraction formula is evaluated. A feature quantity extraction formula list generation means for generating the feature quantity extraction formula list by updating the previous generation feature quantity extraction formula list using a genetic algorithm based on a value;
Each feature quantity extraction formula included in the feature quantity extraction formula list is input with actual data, information indicating the characteristics of the actual data, and actual data of teacher data including weights, and a plurality of data corresponding to the actual data. A feature amount calculating means for calculating a feature amount;
Each feature included in the feature quantity extraction formula list by machine learning for estimating the information corresponding to the actual data of the teacher data from the plurality of feature quantities corresponding to the actual data of the teacher data calculated. Generating an information extraction unit candidate corresponding to each of the quantity extraction formulas, and calculating an evaluation value corresponding to each feature quantity extraction formula using the weight of the teacher data correctly estimated by the generated information extraction unit candidate, The information extraction unit candidate corresponding to the feature quantity extraction formula having the best evaluation value among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation is assigned to one information extraction unit in the ensemble learning. Evaluation to determine and calculate the reliability of the determined information extraction unit using the weight of the teacher data erroneously estimated by the determined information extraction unit A calculation means,
An information processing apparatus comprising: update means for updating weights of teacher data using the determined reliability of the information extraction unit.
さらに含むことを特徴とする請求項1に記載の情報処理装置。 2. The information according to claim 1, further comprising a combining unit configured to construct the high-precision information extracting unit by combining a plurality of the information extracting units based on the reliability of the information extracting unit. Processing equipment.
複数の演算子から成る特徴量抽出式を複数含む第1世代の特徴量抽出式リストをランダムに生成し、
前記特徴量抽出式リストに含まれる各特徴量抽出式に、実データ、前記実データの特徴を示す情報、および重みからなる教師データの実データを入力して、前記実データに対応する複数の特徴量を計算し、
計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記特徴量抽出式リストに含まれる各特徴量抽出式にそれぞれ対応する情報抽出部候補を生成するとともに、生成した前記情報抽出部候補によって正しく推定された教師データの重みを用いて各特徴量抽出式にそれぞれ対応する評価値を算出し、
前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新し、
最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式に対応する前記情報抽出部候補を、前記アンサンブル学習における1つの前記情報抽出部に決定して、
決定した前記情報抽出部によって間違って推定された教師データの重みを用いて、決定した前記情報抽出部の信頼度を算出し、
決定された前記情報抽出部の前記信頼度を用いて、教師データの重みを更新する
ステップを含むことを特徴とする情報処理方法。 By combining outputs of a plurality of information extraction units that extract information indicating the characteristics of the input data, a high-precision information extraction unit that extracts information indicating the characteristics of the input data with higher accuracy than the information extraction unit is constructed. In an information processing method of an information processing apparatus for generating the information extraction unit in ensemble learning,
Randomly generating a first generation feature quantity extraction formula list including a plurality of feature quantity extraction formulas composed of a plurality of operators;
Each feature quantity extraction formula included in the feature quantity extraction formula list is input with actual data, information indicating the characteristics of the actual data, and actual data of teacher data including weights, and a plurality of data corresponding to the actual data. Calculate features,
Each feature included in the feature quantity extraction formula list by machine learning for estimating the information corresponding to the actual data of the teacher data from the plurality of feature quantities corresponding to the actual data of the teacher data calculated. Generating an information extraction unit candidate corresponding to each of the quantity extraction formulas, and calculating an evaluation value corresponding to each feature quantity extraction formula using the weight of the teacher data correctly estimated by the generated information extraction unit candidate,
A plurality of feature quantity extraction formulas included in the feature quantity extraction formula list of the previous generation are regarded as genes, and the feature quantity extraction formula list of the previous generation using a genetic algorithm based on the evaluation value of the feature quantity extraction formula Update
The information extraction unit candidate corresponding to the feature quantity extraction formula having the best evaluation value among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation is assigned to one information extraction unit in the ensemble learning. Decide
Using the weight of the teacher data erroneously estimated by the determined information extraction unit, calculate the reliability of the determined information extraction unit,
An information processing method comprising a step of updating a weight of teacher data using the determined reliability of the information extraction unit.
複数の演算子から成る特徴量抽出式を複数含む第1世代の特徴量抽出式リストをランダムに生成し、
前記特徴量抽出式リストに含まれる各特徴量抽出式に、実データ、前記実データの特徴を示す情報、および重みからなる教師データの実データを入力して、前記実データに対応する複数の特徴量を計算し、
計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記特徴量抽出式リストに含まれる各特徴量抽出式にそれぞれ対応する情報抽出部候補を生成するとともに、生成した前記情報抽出部候補によって正しく推定された教師データの重みを用いて各特徴量抽出式にそれぞれ対応する評価値を算出し、
前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新し、
最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式に対応する前記情報抽出部候補を、前記アンサンブル学習における1つの前記情報抽出部に決定して、
決定した前記情報抽出部によって間違って推定された教師データの重みを用いて、決定した前記情報抽出部の信頼度を算出し、
決定された前記情報抽出部の前記信頼度を用いて、教師データの重みを更新する
ステップを含む処理を情報処理装置のコンピュータに実行させることを特徴とするプログラム。 By combining outputs of a plurality of information extraction units that extract information indicating the characteristics of the input data, a high-precision information extraction unit that extracts information indicating the characteristics of the input data with higher accuracy than the information extraction unit is constructed. A program for controlling an information processing apparatus that generates the information extraction unit in ensemble learning,
Randomly generating a first generation feature quantity extraction formula list including a plurality of feature quantity extraction formulas composed of a plurality of operators;
Each feature quantity extraction formula included in the feature quantity extraction formula list is input with actual data, information indicating the characteristics of the actual data, and actual data of teacher data including weights, and a plurality of data corresponding to the actual data. Calculate features,
Each feature included in the feature quantity extraction formula list by machine learning for estimating the information corresponding to the actual data of the teacher data from the plurality of feature quantities corresponding to the actual data of the teacher data calculated. Generating an information extraction unit candidate corresponding to each of the quantity extraction formulas, and calculating an evaluation value corresponding to each feature quantity extraction formula using the weight of the teacher data correctly estimated by the generated information extraction unit candidate,
A plurality of feature quantity extraction formulas included in the feature quantity extraction formula list of the previous generation are regarded as genes, and the feature quantity extraction formula list of the previous generation using a genetic algorithm based on the evaluation value of the feature quantity extraction formula Update
The information extraction unit candidate corresponding to the feature quantity extraction formula having the best evaluation value among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation is assigned to one information extraction unit in the ensemble learning. Decide
Using the weight of the teacher data erroneously estimated by the determined information extraction unit, calculate the reliability of the determined information extraction unit,
A program for causing a computer of an information processing apparatus to execute a process including a step of updating a weight of teacher data using the reliability of the determined information extraction unit.
実データ、および前記実データの特徴を示す情報からなる教師データをランダムに選択する選択手段と、
複数の演算子から成る特徴量抽出式を複数含む特徴量抽出式リストを、前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新することにより生成する特徴量抽出式リスト生成手段と、
前記特徴量抽出式リストに含まれる各特徴量抽出式に、前記教師データの実データを入力して、前記実データに対応する複数の特徴量を計算する特徴量計算手段と、
各特徴量抽出式にそれぞれ対応する評価値として、各特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量を用いて、前記教師データの前記実データに対応する前記情報を推定した場合の精度を算出し、最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記アンサンブル学習における1つの前記情報抽出部を生成する評価値算出手段と
を含むことを特徴とする情報処理装置。 By combining outputs of a plurality of information extraction units that extract information indicating the characteristics of the input data, a high-precision information extraction unit that extracts information indicating the characteristics of the input data with higher accuracy than the information extraction unit is constructed. In an information processing apparatus that generates the information extraction unit in ensemble learning,
Selection means for randomly selecting teacher data comprising real data and information indicating characteristics of the real data;
The feature quantity extraction formula list including a plurality of feature quantity extraction formulas composed of a plurality of operators is regarded as a plurality of feature quantity extraction formulas included in the feature quantity extraction formula list of the previous generation, and the feature quantity extraction formula is evaluated. A feature quantity extraction formula list generation means for generating the feature quantity extraction formula list by updating the previous generation feature quantity extraction formula list using a genetic algorithm based on a value;
A feature quantity calculation means for inputting actual data of the teacher data to each feature quantity extraction formula included in the feature quantity extraction formula list, and calculating a plurality of feature quantities corresponding to the actual data;
Using the plurality of feature amounts corresponding to the actual data of the teacher data calculated using the feature amount extraction formulas as evaluation values respectively corresponding to the feature amount extraction formulas, the actual data of the teacher data The accuracy when the information corresponding to is estimated is calculated, and the evaluation value is calculated using the best feature quantity extraction formula among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation Evaluation that generates one information extraction unit in the ensemble learning by machine learning that estimates the information corresponding to the actual data of the teacher data from the plurality of feature amounts corresponding to the actual data of the teacher data An information processing apparatus comprising: a value calculating means.
さらに含むことを特徴とする請求項5に記載の情報処理装置。 The information processing apparatus according to claim 5, further comprising a combining unit that combines the plurality of information extracting units to construct the high-precision information extracting unit.
実データ、および前記実データの特徴を示す情報からなる教師データをランダムに選択し、
複数の演算子から成る特徴量抽出式を複数含む第1世代の特徴量抽出式リストをランダムに生成し、
前記特徴量抽出式リストに含まれる各特徴量抽出式に、前記教師データの実データを入力して、前記実データに対応する複数の特徴量を計算し、
各特徴量抽出式にそれぞれ対応する評価値として、各特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量を用いて、前記教師データの前記実データに対応する前記情報を推定した場合の精度を算出し、
前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新し、
最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記アンサンブル学習における1つの前記情報抽出部を生成する
ステップを含むことを特徴とする情報処理方法。 By combining outputs of a plurality of information extraction units that extract information indicating the characteristics of the input data, a high-precision information extraction unit that extracts information indicating the characteristics of the input data with higher accuracy than the information extraction unit is constructed. In an information processing method of an information processing apparatus for generating the information extraction unit in ensemble learning,
Randomly select teacher data consisting of actual data and information indicating the characteristics of the actual data,
Randomly generating a first generation feature quantity extraction formula list including a plurality of feature quantity extraction formulas composed of a plurality of operators;
The actual data of the teacher data is input to each feature quantity extraction formula included in the feature quantity extraction formula list, and a plurality of feature quantities corresponding to the actual data are calculated.
Using the plurality of feature amounts corresponding to the actual data of the teacher data calculated using the feature amount extraction formulas as evaluation values respectively corresponding to the feature amount extraction formulas, the actual data of the teacher data Calculate the accuracy when estimating the information corresponding to
A plurality of feature quantity extraction formulas included in the feature quantity extraction formula list of the previous generation are regarded as genes, and the feature quantity extraction formula list of the previous generation using a genetic algorithm based on the evaluation value of the feature quantity extraction formula Update
The plurality of feature quantities corresponding to the actual data of the teacher data calculated using the feature quantity extraction formula having the best evaluation value among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation And generating one information extraction unit in the ensemble learning by machine learning for estimating the information corresponding to the actual data of the teacher data.
実データ、および前記実データの特徴を示す情報からなる教師データをランダムに選択し、
複数の演算子から成る特徴量抽出式を複数含む第1世代の特徴量抽出式リストをランダムに生成し、
前記特徴量抽出式リストに含まれる各特徴量抽出式に、前記教師データの実データを入力して、前記実データに対応する複数の特徴量を計算し、
各特徴量抽出式にそれぞれ対応する評価値として、各特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量を用いて、前記教師データの前記実データに対応する前記情報を推定した場合の精度を算出し、
前世代の前記特徴量抽出式リストに含まれる複数の特徴量抽出式を遺伝子とみなし、前記特徴量抽出式の前記評価値に基づいた遺伝的アルゴリズムを用いて前世代の前記特徴量抽出式リストを更新し、
最終世代の前記特徴量抽出式リストに含まれる特徴量抽出式のうちで前記評価値が最も良い特徴量抽出式を用いて計算された前記教師データの前記実データに対応する前記複数の特徴量から、前記教師データの前記実データに対応する前記情報を推定する機械学習により、前記アンサンブル学習における1つの前記情報抽出部を生成する
ステップを含む処理を情報処理装置のコンピュータに実行させることを特徴とするプログラム。 By combining outputs of a plurality of information extraction units that extract information indicating the characteristics of the input data, a high-precision information extraction unit that extracts information indicating the characteristics of the input data with higher accuracy than the information extraction unit is constructed. A program for controlling an information processing apparatus that generates the information extraction unit in ensemble learning,
Randomly select teacher data consisting of actual data and information indicating the characteristics of the actual data,
Randomly generating a first generation feature quantity extraction formula list including a plurality of feature quantity extraction formulas composed of a plurality of operators;
The actual data of the teacher data is input to each feature quantity extraction formula included in the feature quantity extraction formula list, and a plurality of feature quantities corresponding to the actual data are calculated.
Using the plurality of feature amounts corresponding to the actual data of the teacher data calculated using the feature amount extraction formulas as evaluation values respectively corresponding to the feature amount extraction formulas, the actual data of the teacher data Calculate the accuracy when estimating the information corresponding to
A plurality of feature quantity extraction formulas included in the feature quantity extraction formula list of the previous generation are regarded as genes, and the feature quantity extraction formula list of the previous generation using a genetic algorithm based on the evaluation value of the feature quantity extraction formula Update
The plurality of feature quantities corresponding to the actual data of the teacher data calculated using the feature quantity extraction formula having the best evaluation value among the feature quantity extraction formulas included in the feature quantity extraction formula list of the last generation And causing the computer of the information processing apparatus to execute a process including a step of generating one information extraction unit in the ensemble learning by machine learning that estimates the information corresponding to the actual data of the teacher data. Program.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013090989A JP2013164863A (en) | 2013-04-24 | 2013-04-24 | Information processing device, information processing method, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013090989A JP2013164863A (en) | 2013-04-24 | 2013-04-24 | Information processing device, information processing method, and program |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007281035A Division JP2009110212A (en) | 2007-10-29 | 2007-10-29 | Information processor, information processing method, and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2013164863A true JP2013164863A (en) | 2013-08-22 |
| JP2013164863A5 JP2013164863A5 (en) | 2014-02-13 |
Family
ID=49176130
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013090989A Pending JP2013164863A (en) | 2013-04-24 | 2013-04-24 | Information processing device, information processing method, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2013164863A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019009420A1 (en) | 2017-07-07 | 2019-01-10 | 国立大学法人大阪大学 | Pain determination using trend analysis, medical device incorporating machine learning, economic discriminant model, and iot, tailormade machine learning, and novel brainwave feature quantity for pain determination |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05108061A (en) * | 1991-10-15 | 1993-04-30 | Matsushita Electric Ind Co Ltd | Music classification device |
| JPH10187186A (en) * | 1996-12-26 | 1998-07-14 | Sony Corp | Device and method for recognition, and device and method for learning |
| JP2005044330A (en) * | 2003-07-24 | 2005-02-17 | Univ Of California San Diego | Weak hypothesis generation device and method, learning device and method, detection device and method, expression learning device and method, expression recognition device and method, and robot device |
| JP2006202127A (en) * | 2005-01-21 | 2006-08-03 | Pioneer Electronic Corp | Recommended information presentation device and recommended information presentation method or the like |
| JP2006251955A (en) * | 2005-03-09 | 2006-09-21 | Fuji Photo Film Co Ltd | Discriminator creating device, discriminator creating method and its program |
| JP2007121457A (en) * | 2005-10-25 | 2007-05-17 | Sony Corp | Information processor, information processing method, and program |
-
2013
- 2013-04-24 JP JP2013090989A patent/JP2013164863A/en active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05108061A (en) * | 1991-10-15 | 1993-04-30 | Matsushita Electric Ind Co Ltd | Music classification device |
| JPH10187186A (en) * | 1996-12-26 | 1998-07-14 | Sony Corp | Device and method for recognition, and device and method for learning |
| JP2005044330A (en) * | 2003-07-24 | 2005-02-17 | Univ Of California San Diego | Weak hypothesis generation device and method, learning device and method, detection device and method, expression learning device and method, expression recognition device and method, and robot device |
| JP2006202127A (en) * | 2005-01-21 | 2006-08-03 | Pioneer Electronic Corp | Recommended information presentation device and recommended information presentation method or the like |
| JP2006251955A (en) * | 2005-03-09 | 2006-09-21 | Fuji Photo Film Co Ltd | Discriminator creating device, discriminator creating method and its program |
| JP2007121457A (en) * | 2005-10-25 | 2007-05-17 | Sony Corp | Information processor, information processing method, and program |
Non-Patent Citations (4)
| Title |
|---|
| CSNG200400452011; 松井 和宏 外1名: '遺伝的特徴選択を取り入れたブースティング' 電子情報通信学会技術研究報告 Vol.102,No.708, 20030307, pp.87-92, 社団法人電子情報通信学会 * |
| CSNG200500701004; 上田 修功: 'アンサンブル学習' 電子情報通信学会技術研究報告 Vol.104,No.291, 20040904, pp.25-32, 社団法人電子情報通信学会 * |
| JPN6012048725; 上田 修功: 'アンサンブル学習' 電子情報通信学会技術研究報告 Vol.104,No.291, 20040904, pp.25-32, 社団法人電子情報通信学会 * |
| JPN6012048726; 松井 和宏 外1名: '遺伝的特徴選択を取り入れたブースティング' 電子情報通信学会技術研究報告 Vol.102,No.708, 20030307, pp.87-92, 社団法人電子情報通信学会 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019009420A1 (en) | 2017-07-07 | 2019-01-10 | 国立大学法人大阪大学 | Pain determination using trend analysis, medical device incorporating machine learning, economic discriminant model, and iot, tailormade machine learning, and novel brainwave feature quantity for pain determination |
| US11922277B2 (en) | 2017-07-07 | 2024-03-05 | Osaka University | Pain determination using trend analysis, medical device incorporating machine learning, economic discriminant model, and IoT, tailormade machine learning, and novel brainwave feature quantity for pain determination |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Mesaros et al. | Detection and classification of acoustic scenes and events: Outcome of the DCASE 2016 challenge | |
| Akhtar et al. | Signal processing in sequence analysis: advances in eukaryotic gene prediction | |
| JP4948118B2 (en) | Information processing apparatus, information processing method, and program | |
| JP4392620B2 (en) | Information processing device, information processing method, arithmetic device, arithmetic method, program, and recording medium | |
| JP4935047B2 (en) | Information processing apparatus, information processing method, and program | |
| CN111444967A (en) | Training method, generation method, device, equipment and medium for generating confrontation network | |
| CN109346043B (en) | Music generation method and device based on generation countermeasure network | |
| JPWO2019198306A1 (en) | Estimator, learning device, estimation method, learning method and program | |
| JP2011118786A (en) | Information processing apparatus, observation value prediction method, and program | |
| US10586519B2 (en) | Chord estimation method and chord estimation apparatus | |
| JP5007714B2 (en) | Information processing apparatus and method, program, and recording medium | |
| JP4591566B2 (en) | Information processing apparatus, information processing method, and program | |
| US8712936B2 (en) | Information processing apparatus, information processing method, and program | |
| CN111445922B (en) | Audio matching method, device, computer equipment and storage medium | |
| JP4433323B2 (en) | Information processing apparatus, information processing method, and program | |
| JP4987282B2 (en) | Information processing apparatus, information processing method, and program | |
| JP4392621B2 (en) | Information processing apparatus, information processing method, and program | |
| JP2009110212A (en) | Information processor, information processing method, and program | |
| JP2013164863A (en) | Information processing device, information processing method, and program | |
| JP2007122186A (en) | Information processor, information processing method and program | |
| JP4392622B2 (en) | Information processing apparatus, information processing method, and program | |
| Fu et al. | Generating high coherence monophonic music using monte-carlo tree search | |
| Tanji et al. | ConBreO: a music performance rendering system using hybrid approach of IEC and automated evolution | |
| Mahapatra et al. | Stationary Signal, Autocorrelation, and Linear and Discriminant Analysis | |
| CN116072090A (en) | Short video automatic music distribution method and system based on reinforcement learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130522 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20130522 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20131225 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20140318 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140512 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20140612 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140804 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20141021 |