JP2013152595A - Information processing apparatus and method, and program - Google Patents
Information processing apparatus and method, and program Download PDFInfo
- Publication number
- JP2013152595A JP2013152595A JP2012012863A JP2012012863A JP2013152595A JP 2013152595 A JP2013152595 A JP 2013152595A JP 2012012863 A JP2012012863 A JP 2012012863A JP 2012012863 A JP2012012863 A JP 2012012863A JP 2013152595 A JP2013152595 A JP 2013152595A
- Authority
- JP
- Japan
- Prior art keywords
- learning
- feature amount
- unit
- recognition
- frame
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Abandoned
Links
Images







Abstract
Description
本技術は、情報処理装置および方法、並びにプログラムに関し、特に、認識物体を高速かつロバストに認識することができるようにする情報処理装置および方法、並びにプログラムに関する。 The present technology relates to an information processing device and method, and a program, and more particularly, to an information processing device and method, and a program that enable a recognition object to be recognized at high speed and robustly.
近年、ジェスチャコントロールや自動監視システム等を実現するため、物体を追跡する様々な手法が提案されている。 In recent years, various methods for tracking an object have been proposed in order to realize gesture control, an automatic monitoring system, and the like.
例えば、米国マサチューセッツ工科大学(MIT)の「SixthSense」や、米国Microsoft社の「Kinect」(商標)のように、色や深度等の特徴量を用いて、手や体等の形状やテクスチャが変化する物体追跡の実用例が存在する。 For example, as in Massachusetts Institute of Technology (MIT) "SixthSense" and Microsoft Corporation "Kinect" (trademark), shapes and textures of hands and bodies are changed using features such as color and depth. There are practical examples of tracking objects.
手ジェスチャを認識する技術としては、まず、手のみが撮像されている画像を用いるか、または、画像内における手の位置が指定されることにより、手のみが含まれている画像が抽出され、抽出されたその画像について、肌色情報、動き検出、およびパターンマッチングと言った手法により手ジェスチャを認識するものが提案されている(特許文献1参照)。 As a technique for recognizing a hand gesture, first, an image in which only the hand is captured is used, or an image including only the hand is extracted by specifying the position of the hand in the image. As for the extracted image, there has been proposed a technique for recognizing a hand gesture by a technique called skin color information, motion detection, and pattern matching (see Patent Document 1).
また、複数の手の形状等、姿勢やジェスチャを複数の辞書として事前学習により定義し、認識の際に、認識物体の状態や時系列変化に応じて、複数の辞書を切り替えて用いたり、同時に用いる手法も提案されている。 In addition, the posture and gestures such as multiple hand shapes are defined by prior learning as multiple dictionaries, and when recognizing, the multiple dictionaries can be switched and used at the same time depending on the state of the recognized object and time-series changes. A technique to be used has also been proposed.
しかしながら、特許文献1のような技術では、様々な状態の認識物体を事前学習する必要がある上に、事前学習したときの状態と同じ状態の認識物体しか認識できなかった。 However, in the technique such as Patent Document 1, it is necessary to previously learn recognition objects in various states, and only a recognition object in the same state as the state when learning in advance can be recognized.
すなわち、認識物体としての手の形状や色が大きく変化した場合には、認識性能に影響が出てしまい、また、認識物体の変化に対応できるように多数の辞書を定義しても、全ての状態空間(特徴量空間)を含めることには限界があった。 In other words, if the shape or color of the hand as a recognized object changes greatly, the recognition performance will be affected, and even if a large number of dictionaries are defined so as to cope with changes in the recognized object, There was a limit to including the state space (feature space).
特に、オンラインで、変化のある認識物体を認識する場合には、認識物体の様々な状態や時系列変化を事前学習した上で、認識物体を高速かつロバストに認識する必要があった。 In particular, when recognizing a recognized recognition object online, it is necessary to recognize the recognition object at high speed and robustly after learning in advance the various states and time-series changes of the recognition object.
本技術は、このような状況に鑑みてなされたものであり、認識物体を高速かつロバストに認識することができるようにするものである。 The present technology has been made in view of such a situation, and makes it possible to recognize a recognition object at high speed and robustly.
本技術の一側面の情報処理装置は、入力画像から認識物体を認識する認識部と、時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習する学習部とを備え、前記認識部は、前記学習部の学習結果として得られた前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識する。 An information processing apparatus according to an aspect of the present technology learns the feature amount of the recognition object for each frame using a recognition unit that recognizes a recognition object from an input image and a feature amount having a score that changes in time series. A learning unit, and the recognition unit recognizes the recognition object of the current frame based on the feature amount of the previous frame obtained as a learning result of the learning unit.
前記情報処理装置には、時系列で状態が変化する前記認識物体を含む学習用画像から、フレーム毎の前記認識物体の前記特徴量を事前に学習する事前学習部と、前記事前学習部の学習結果として得られたフレーム毎の前記特徴量の前記スコアを事前に計算する計算部をさらに設け、前記学習部には、前記計算部により事前に計算された前記スコアに応じた前記特徴量を用いて、前記入力画像のフレーム毎の前記認識物体の前記特徴量を学習させることができる。 The information processing apparatus includes: a pre-learning unit that learns in advance the feature amount of the recognized object for each frame from a learning image including the recognized object whose state changes in time series; and A calculation unit that pre-calculates the score of the feature amount for each frame obtained as a learning result is further provided, and the learning unit includes the feature amount corresponding to the score calculated in advance by the calculation unit. It is possible to learn the feature amount of the recognized object for each frame of the input image.
前記情報処理装置には、前記計算部により事前に計算された前記スコアを有する現フレームに対応する前記特徴量から、所定の閾値より高いスコアを有する前記特徴量を選択する選択部をさらに設け、前記学習部には、前記選択部により選択された前記特徴量を用いて、現フレームの前記認識物体の前記特徴量を学習させることができる。 The information processing apparatus further includes a selection unit that selects the feature amount having a score higher than a predetermined threshold from the feature amount corresponding to the current frame having the score calculated in advance by the calculation unit, The learning unit can learn the feature amount of the recognized object in the current frame using the feature amount selected by the selection unit.
前記情報処理装置には、前記学習部の学習結果として得られた前記特徴量を記憶する記憶部と、前記記憶部に記憶されている前記特徴量を、前記学習部の学習結果に応じてフレーム毎に更新する更新部をさらに設け、前記認識部には、前記更新部により更新された前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識させることができる。 The information processing apparatus includes a storage unit that stores the feature amount obtained as a learning result of the learning unit, and a frame that stores the feature amount stored in the storage unit according to the learning result of the learning unit. An update unit that updates each time is further provided, and the recognition unit can recognize the recognition object of the current frame based on the feature amount of the previous frame updated by the update unit.
前記選択部には、前記記憶部に記憶されている前フレームの前記特徴量から、他の閾値より低いスコアを有する前記特徴量を選択させ、前記学習部は、前記選択部により選択された前記特徴量を除いた前記特徴量を用いて、現フレームの前記認識物体の前記特徴量を学習させることができる。 The selection unit is configured to select the feature amount having a score lower than another threshold value from the feature amount of the previous frame stored in the storage unit, and the learning unit is selected by the selection unit The feature amount of the recognized object in the current frame can be learned using the feature amount excluding the feature amount.
前記更新部には、前記事前学習部の学習結果として得られた前記特徴量を、前記学習部の学習結果に応じてフレーム毎に更新させることができる。 The update unit can update the feature amount obtained as a learning result of the pre-learning unit for each frame according to the learning result of the learning unit.
本技術の一側面の情報処理方法は、入力画像から認識物体を認識する認識部と、時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習する学習部とを備える情報処理装置の情報処理方法であって、前記情報処理装置が、時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習し、前記学習部の学習結果として得られた前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識するステップを含む。 An information processing method according to an aspect of the present technology learns the feature amount of the recognized object for each frame using a recognition unit that recognizes a recognized object from an input image and a feature amount having a score that changes in time series. An information processing method of an information processing device comprising a learning unit, wherein the information processing device learns the feature amount of the recognized object for each frame using a feature amount having a score that changes in time series, Recognizing the recognized object of the current frame based on the feature amount of the previous frame obtained as a learning result of the learning unit.
本技術の一側面のプログラムは、入力画像から認識物体を認識する認識ステップと、
時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習する学習ステップとを含む処理をコンピュータに実行させ、前記認識ステップは、前記学習ステップの学習結果として得られた前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識する。
A program according to one aspect of the present technology includes a recognition step of recognizing a recognition object from an input image;
A learning step of learning the feature amount of the recognized object for each frame using a feature amount having a score that changes in time series, and the recognition step is a learning result of the learning step. The recognition object of the current frame is recognized based on the feature amount of the previous frame obtained as.
本技術の一側面においては、時系列で変化するスコアを有する特徴量を用いて、フレーム毎の認識物体の特徴量が学習され、学習部の学習結果として得られた前フレームの特徴量に基づいて、現フレームの認識物体が認識される。 In one aspect of the present technology, the feature amount of the recognition object for each frame is learned using the feature amount having a score that changes in time series, and the feature amount of the previous frame obtained as a learning result of the learning unit is used. Thus, the recognition object of the current frame is recognized.
本技術の一側面によれば、認識物体を高速かつロバストに認識することが可能となる。 According to one aspect of the present technology, a recognition object can be recognized at high speed and robustly.
以下、本技術の実施の形態について図を参照して説明する。なお、説明は以下の順序で行う。
1.情報処理装置の構成
2.パーソナルコンピュータの構成
3.オフライン学習処理
4.物体追跡処理
5.物体認識処理
6.学習処理
7.その他
Hereinafter, embodiments of the present technology will be described with reference to the drawings. The description will be given in the following order.
1. 1. Configuration of information processing apparatus 2. Configuration of personal computer Offline learning process Object tracking processing Object recognition processing Learning process Other
<1.情報処理装置の構成>
本技術を適用した情報処理装置の一実施の形態の構成を示すブロック図である。
<1. Configuration of information processing apparatus>
It is a block diagram which shows the structure of one Embodiment of the information processing apparatus to which this technique is applied.
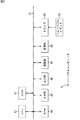
図1の情報処理装置1は、入力画像から認識対象である認識物体を認識し、その認識結果を出力する。情報処理装置1は、オフライン処理部2とオンライン処理部3とから構成されている。オフライン処理部2は、予め用意された学習用データを基に、認識物体の情報を事前に学習(オフライン学習)し、その学習結果をオンライン処理部3に供給する。オンライン処理部3は、オフライン処理部2からの学習結果を基に、入力画像から認識物体を認識するとともに、認識対象の情報を学習(オンライン学習)する。
The information processing apparatus 1 in FIG. 1 recognizes a recognition object that is a recognition target from an input image, and outputs the recognition result. The information processing apparatus 1 includes an offline processing unit 2 and an
オフライン処理部2は、学習用データ保存部11および学習処理部12を備え、オンライン処理部3は、オフライン辞書保存部13、入力部14、認識部15、および学習処理部16を備えている。
The offline processing unit 2 includes a learning
学習用データ保存部11には、認識物体の情報の学習のために事前に収集された学習用データが保存されている。学習用データは、認識物体を含む動画像(以下、学習用画像ともいう)である。
The learning
学習処理部12は、学習用データ保存部11に保存されている学習用画像から、フレーム毎の認識物体の情報として、認識物体の特徴量を事前に学習(オフライン学習)し、その学習結果をオフライン辞書保存部13に供給する。
The
また、学習処理部12は、学習部21および計算部22を備えている。学習部21は、フレーム毎の認識物体の特徴量を事前に学習し、計算部22は、フレーム毎の認識物体の特徴量のスコアを計算する。スコアは、その特徴量によっていかに認識物体が認識できるかの度合を表すパラメータであり、スコアの高い特徴量ほど、認識物体を精度よく認識するのに適した(良い)特徴量となる。
The
オフライン辞書保存部13には、学習処理部12からの学習結果が、辞書(オフライン辞書)として保存される。辞書は、認識物体の形状や状態の変化のパターン毎に与えられる認識器であり、学習結果としての特徴量やそのスコアを含むパラメータを有している。
The offline dictionary storage unit 13 stores the learning result from the
入力部14は、カメラ等により被写体を撮像することにより取得された動画像を入力し、その動画像(入力画像)を認識部15に出力する。なお、入力部14は、それ自体が被写体を撮像するカメラであってもよい。また、カメラは、撮影方向が固定の固定カメラであるものとする。
The
認識部15は、入力画像からフレーム毎に認識物体を認識し、その認識結果を学習処理部16に供給する。
The
学習処理部16は、オフライン辞書保存部13に保存されている辞書を用いて、認識部15からの認識結果に基づいて、入力画像における認識物体の特徴量を学習(オンライン学習)する。
The
また、学習処理部16は、選択部23、学習部24、記憶部25、および更新部26を備えている。選択部23は、オフライン辞書保存部13の辞書に含まれる特徴量をそのスコアに応じて選択する。スコアの詳細は後述する。学習部24は、選択部23により選択された特徴量を用いて、認識物体の特徴量を学習する。記憶部25は、学習部24の学習結果を辞書(オンライン辞書)として記憶する。更新部26は、記憶部25に記憶されているオンライン辞書を、学習部24の学習結果に応じて更新する。
The
また、この情報処理装置1は、図2に示されるような、ソフトウェアを実行することで所定の機能を実現するパーソナルコンピュータ31により構成することもできる。 The information processing apparatus 1 can also be configured by a personal computer 31 that realizes a predetermined function by executing software as shown in FIG.
<2.パーソナルコンピュータの構成>
図2は、本技術を適用したパーソナルコンピュータの一実施の形態の構成を示すブロック図である。
<2. Configuration of personal computer>
FIG. 2 is a block diagram illustrating a configuration of an embodiment of a personal computer to which the present technology is applied.
情報処理装置としてのパーソナルコンピュータ31は、バス41、CPU(Central Processing Unit)42、ROM(Read Only Memory)43、RAM(Random Access Memory)44、入力部45、出力部46、記憶部47、通信部48、ドライブ49、およびリムーバブルメディア50から構成されている。
A personal computer 31 as an information processing apparatus includes a
バス41は、CPU42、ROM43、RAM44、入力部45、出力部46、記憶部47、通信部48、ドライブ49をそれぞれ相互に接続する。
The
CPU42は、パーソナルコンピュータ31の各種の動作を制御することで、図1の情報処理装置1の各種の機能を実現する。
The
ROM43は、パーソナルコンピュータ31において実行される各種の処理プログラムや処理に必要なデータなどを記録する。RAM44は、各種の処理において得られたデータを一時的に記録保持するなどのように、各種の処理の作業領域として用いられる。
The
入力部45は、キーボード、マウス、マイクロフォンなどよりなる。出力部46は、ディスプレイ、スピーカなどよりなる。記憶部47は、ハードディスクや不揮発性のメモリなどよりなる。
The
通信部48は、ネットワークインタフェースなどよりなる。ドライブ49は、磁気ディスク、光ディスク、光磁気ディスク、或いは半導体メモリなどのリムーバブルメディア50を駆動する。
The
以上のように構成されるパーソナルコンピュータ31においては、CPU42が、例えば、ROM43や記憶部47に記憶されているプログラムを、バス41を介して、RAM44にロードして実行することにより、各種の処理が行われる。
In the personal computer 31 configured as described above, the
CPU42が実行するプログラムは、例えば、パッケージメディア等としてのリムーバブルメディア50に記録して提供される。
The program executed by the
なお、パッケージメディアとしては、磁気ディスク(フレキシブルディスクを含む)、光ディスク(CD-ROM(Compact Disc-Read Only Memory),DVD(Digital Versatile Disc)等)、光磁気ディスク、もしくは半導体メモリなどが用いられる。 As the package medium, a magnetic disk (including a flexible disk), an optical disk (CD-ROM (Compact Disc-Read Only Memory), DVD (Digital Versatile Disc), etc.), a magneto-optical disk, or a semiconductor memory is used. .
また、プログラムは、ローカルエリアネットワーク、インターネット、デジタル衛星放送といった、有線または無線の伝送媒体を介して提供することができる。 The program can be provided via a wired or wireless transmission medium such as a local area network, the Internet, or digital satellite broadcasting.
パーソナルコンピュータ31においては、プログラムは、リムーバブルメディア50をドライブ49に装着することにより、バス41を介して、記憶部47にインストールすることができる。
In the personal computer 31, the program can be installed in the
また、プログラムは、有線または無線の伝送媒体を介して、通信部48で受信し、記憶部47にインストールすることができる。その他、プログラムは、ROM43や記憶部47に、あらかじめインストールしておくことができる。
The program can be received by the
なお、パーソナルコンピュータ31が実行するプログラムは、本明細書で説明する順序に沿って時系列に処理が行われる処理であっても良いし、並列に、あるいは呼び出しが行われたとき等の必要なタイミングで処理が行われるプログラムであっても良い。 Note that the program executed by the personal computer 31 may be a process in which processing is performed in time series in the order described in this specification, or may be necessary in parallel or when a call is made. It may be a program that performs processing at timing.
<3.オフライン学習処理>
次に、図3のフローチャートを参照して、情報処理装置1のオフライン処理部2によるオフライン学習処理について説明する。
<3. Offline learning process>
Next, offline learning processing by the offline processing unit 2 of the information processing apparatus 1 will be described with reference to the flowchart of FIG.
ステップS11において、学習処理部12は、学習用データ保存部11に保存されている学習用画像を取得する。学習用画像は、時系列で形状や状態が変化する認識物体を含む動画像である。ここでは、認識物体は、手であるものとし、学習用画像は、時系列でその形状が変化する手を含む動画像であるものとする。具体的には、例えば、パーの形状から物を払うジェスチャをする手を複数人について複数回撮像した動画像が、学習用画像として用意される。
In step S <b> 11, the
ステップS12において、学習処理部12の学習部21は、学習用データ保存部11から取得した学習用画像から、認識対象の時系列状態を学習する。具体的には、学習部21は、学習用画像から、認識物体の特徴量の時系列変化を学習する。ここでの学習においては、認識物体の位置および(あるいは)大きさに応じた情報を含むラベル情報に基づいてクラスタリングや補間等を行うようにしてもよいし、HMM(Hidden Markov Model)等のモデリング手法を用いるようにしてもよい。
In step S <b> 12, the
ステップS13において、学習処理部12は、学習部21の学習結果を用いて、時系列で学習用画像を正規化する。
In step S <b> 13, the
ステップS14において、学習処理部12の計算部22は、正規化された学習用画像を用いて、フレーム毎に特徴量のスコアを計算する。
In step S14, the
図4は、特徴量のスコアの時系列変化の例を示している。 FIG. 4 shows an example of the time-series change of the feature amount score.
図4においては、n個の特徴量f1,f2,・・・,fnのうち、特徴量f1,f2,fnのスコアの時刻tに対する変化、すなわちフレーム毎の変化が示されている。 In FIG. 4, among n feature quantities f1, f2,..., Fn, changes in the scores of the feature quantities f1, f2, fn with respect to time t, that is, changes for each frame are shown.
図4に示されるように、特徴量f1のスコアは、特徴量f2,fnのスコアよりも常に高い。すなわち、特徴量f1は、特徴量f2,fnと比べて学習用画像における手形状変化を認識するのに好適であるということができる。 As shown in FIG. 4, the score of the feature quantity f1 is always higher than the scores of the feature quantities f2 and fn. That is, it can be said that the feature amount f1 is more suitable for recognizing a hand shape change in the learning image than the feature amounts f2 and fn.
ステップS15において、学習処理部12は、学習結果として得られたフレーム毎の認識物体の特徴量とそのスコアを、オフライン辞書保存部13に供給し、オフライン辞書(オフライン認識器)として保存する。
In step S <b> 15, the
このようにして、学習用画像を用いて、認識物体についてのオフライン学習が行われる。 In this way, offline learning is performed on the recognized object using the learning image.
なお、本実施の形態では、オフライン学習の学習結果を用いて、オンライン学習が行われるが、オンライン学習においても、オフライン学習で学習した手形状変化と同一の手形状変化を学習する。 In the present embodiment, online learning is performed using the learning result of offline learning. In online learning, the same hand shape change as that learned by offline learning is learned.
ここで、従来の学習においては、特徴量の学習(パラメータ調整)とスコアの計算(評価)とは、同フレームについて行われるのが一般的であったが、本実施の形態のオフライン学習においては、後述するオンライン学習の特徴を考慮して、現在注目している現フレームにおいて特徴量の学習を行い、現フレームより時間的に後の次フレームにおいてその特徴量のスコアを計算するものとする。 Here, in the conventional learning, the feature amount learning (parameter adjustment) and the score calculation (evaluation) are generally performed for the same frame, but in the offline learning of the present embodiment, Considering the feature of online learning described later, it is assumed that the feature amount is learned in the current frame of interest, and the feature amount score is calculated in the next frame temporally after the current frame.
なお、以上においては、オフライン学習は、特徴量毎に行われるものとしたが、複数の特徴量の組み合わせである特徴量組毎に行われるようにしてもよい。 In the above description, offline learning is performed for each feature amount, but may be performed for each feature amount group that is a combination of a plurality of feature amounts.
<4.物体追跡処理>
次に、図5のフローチャートを参照して、情報処理装置1のオンライン処理部3による物体追跡処理について説明する。物体追跡処理においては、オフライン学習処理で学習した認識物体の形状や状態の変化のパターンと同様の変化をする認識物体の追跡が行われる。具体的には、例えば、物体追跡処理においては、入力画像において、パーの形状から物を払うジェスチャをする手の追跡が行われる。
<4. Object tracking processing>
Next, the object tracking process by the
ステップS31において、入力部14は、認識物体を設定する。ここでは、認識物体である手の形状変化の初期状態である、パーの形状の手が設定される。
In step S31, the
ステップS32において、入力部14は、画像を取得する。すなわち、被写体を撮像して得られた入力画像が取得される。
In step S32, the
ステップS33において、入力部14は、認識物体を検出する。すなわち、ステップS31の処理で設定されたパーの形状の手が、ステップS32の処理により取得された入力画像から検出される。ここでの認識物体の検出は、ユーザの操作に応じて行われるようにしてもよいし、入力部14が物体検出手法を用いて行うようにしてもよい。
In step S33, the
ステップS34において、認識部15は、入力部14からの入力画像(フレーム)について、手形状の確率や手の色パターンを計算することで、物体認識処理を施す。この物体認識処理には、例えば特開2010−108475号公報のような、Steerable Filterの応答を特徴量としてBoostingを用いて認識器を構成する技術を用いることができる。また、SSD(Sum of Squared Difference)や、カラーヒストグラムのテンプレートマッチング手法等を用いるようにしてもよい。
In step S <b> 34, the
<5.物体認識処理の詳細>
ここで、図6のフローチャートを参照して、図5のフローチャートのステップS34における物体認識処理の詳細について説明する。
<5. Details of object recognition processing>
Here, the details of the object recognition processing in step S34 of the flowchart of FIG. 5 will be described with reference to the flowchart of FIG.
ステップS51において、認識部15は、学習処理部16の記憶部25から、前フレームについてのオンライン学習の学習結果であるオンライン辞書を取得する。なお、入力画像のフレームが1フレーム目の場合、認識部15は、オフライン辞書保存部13から、1フレーム目に対応するフレームについてのオフライン学習の学習結果(オフライン辞書)を取得する。
In step S <b> 51, the
ステップS52において、認識部15は、取得した辞書に基づいて、特徴量のスコアを計算することで認識物体を認識する。
In step S52, the
ステップS53において、認識部15は、計算した特徴量のスコアを基に認識結果を生成し、図5のステップS34の処理に戻る。
In step S53, the
図5のフローチャートに戻り、ステップS35において、学習処理部16は、認識部15により生成された認識結果を用いて、認識物体の学習処理を実行する。
Returning to the flowchart of FIG. 5, in step S <b> 35, the
<6.学習処理の詳細>
ここで、図7のフローチャートを参照して、図5のフローチャートのステップS35における学習処理の詳細について説明する。
<6. Details of the learning process>
Here, the details of the learning process in step S35 of the flowchart of FIG. 5 will be described with reference to the flowchart of FIG.
ステップS71において、学習処理部16の選択部23は、認識部15により生成された認識結果を取得する。
In step S <b> 71, the
ステップS72において、選択部23は、記憶部25に記憶されている、現フレームより時間的に前の前フレームのオンライン辞書(前フレームについてのオンライン学習結果)において、スコアが第1の閾値より低い特徴量を選択する。なお、現フレームが入力画像の1フレーム目である場合、ステップS72の処理はスキップされる。
In step S72, the
ステップS73において、選択部23は、オフライン辞書保存部13に保存されているオフライン辞書(オフライン学習結果)において、現フレームに対応する特徴量のうち、スコアが第2の閾値より高い特徴量を選択する。
In step S73, the
ここで、前フレームのオンライン学習結果において、ステップS72で選択された特徴量を除き、ステップS73で選択された特徴量を加えた特徴量を、学習用特徴量という。 Here, in the online learning result of the previous frame, the feature amount obtained by adding the feature amount selected in step S73 excluding the feature amount selected in step S72 is referred to as a learning feature amount.
なお、ステップS72で選択された特徴量と、ステップS73で選択された特徴量とを入れ替えることで、学習用特徴量を得るようにしてもよい。 Note that the feature quantity for learning may be obtained by exchanging the feature quantity selected in step S72 with the feature quantity selected in step S73.
具体的には、図8上段に示される、オフライン学習結果としての時系列変化する特徴量のスコアにおいて、現フレームに対応する時刻Tでのスコアが高い特徴量f1,f2を、図8中段に示される、前フレームのオンライン学習結果においてスコアが低い特徴量fy,fzと入れ替えるようにしてもよい。この結果、図8下段に示される、特徴量f1,f2を含み、特徴量fy,fzが除かれた学習用特徴量が得られるようになる。 Specifically, the feature quantities f1 and f2 having high scores at the time T corresponding to the current frame in the score of the feature quantity changing in time series as the offline learning result shown in the upper part of FIG. 8 are shown in the middle part of FIG. The feature values fy and fz having low scores in the online learning result of the previous frame shown may be replaced. As a result, the learning feature quantity including the feature quantities f1 and f2 and excluding the feature quantities fy and fz shown in the lower part of FIG. 8 is obtained.
ステップS74において、学習部24は、選択部23による選択の結果得られた学習用特徴量を用いて、認識物体の特徴量を学習する。学習は、オンラインブースティングの手法等を用いて実行される。オンラインブースティングの手法については、例えば次の文献に開示されている。
Helmut Grabner and Horst Bischof, "On-line Boosting and Vision", In Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR), volume 1, pages 260-267, 2006
In step S <b> 74, the
Helmut Grabner and Horst Bischof, "On-line Boosting and Vision", In Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR), volume 1, pages 260-267, 2006
ステップS75において、更新部26は、学習部24の学習結果により、記憶部25に記憶されているオンライン辞書を更新し、処理は図5のステップS35に戻る。
In step S75, the updating
図5のフローチャートに戻り、ステップS36において、更新部26は、学習部24の学習結果により、オフライン辞書保存部13に保存されているオフライン学習結果を更新する。これにより、特定の認識物体に対する認識性能の向上を図ることができる。なお、ステップS36の処理は、必要に応じて実行されなくともよい。
Returning to the flowchart of FIG. 5, in step S <b> 36, the
ステップS37において、認識部15は、例えば、図示せぬ表示装置に、認識結果を出力する。すなわち、ステップS34の処理により生成された認識結果が、図示せぬ表示装置に表示される。具体的には、表示装置により表示されている入力画像において、認識された手を囲むような枠が表示される。
In step S37, the
これにより、ユーザは、認識物体としての手の追跡を確認することができる。 Thereby, the user can confirm tracking of the hand as a recognition object.
なお、図5のステップS35,S36の処理とステップS37の処理は、並列に実行することができる。すなわち、ステップS35,S36の処理が終了するより前に、ステップS37の処理が実行されるようにしてもよい。 Note that the processes of steps S35 and S36 in FIG. 5 and the process of step S37 can be executed in parallel. That is, the process of step S37 may be executed before the processes of steps S35 and S36 are completed.
ステップS38において、入力部14は、画像を取得する。すなわち、新たな入力画像のフレームが取得される。
In step S38, the
なお、新たに取得される画像は、過去に取得された画像の次のフレームの画像でもよいし、過去に取得された画像から所定のフレーム数だけ後の画像でもよい。 Note that the newly acquired image may be an image of a frame next to an image acquired in the past, or may be an image after a predetermined number of frames from an image acquired in the past.
すなわち、新たな画像は、1フレーム毎に取得されてもよいし、所定のフレーム数ごとに取得されてもよい。 That is, a new image may be acquired for each frame or may be acquired for each predetermined number of frames.
ステップS38の処理の後、処理はステップS34に戻り、それ以降の処理が繰り返される。 After the process of step S38, the process returns to step S34, and the subsequent processes are repeated.
なお、以上においては、認識物体はユーザの体の一部である手であるものとしたが、手以外の体の一部や体全体、ユーザの体以外の物体等、時系列で形状や状態が変化するものであればよい。 In the above, the recognition object is assumed to be a hand that is a part of the user's body, but the shape and state in time series such as a part of the body other than the hand, the entire body, an object other than the user's body, As long as it changes.
以上の処理によれば、次のような効果を実現することができる。
(1)全特徴量空間についてオンライン学習を行うことは困難であるが、認識物体の事前知識を用いた学習(オフライン学習)を行うことで、形状や見えが大きく変化する認識物体を高速かつロバストに認識することができる。
(2)オフライン学習では、認識物体についての特徴量毎の良さ、または、複数の特徴量の組み合わせである特徴量組の良さであるスコアを、時間的な分布を用いて評価することができる。
(3)オンライン学習では、オフライン学習の学習結果に基づいて、学習に好適な特徴量が選択されて計算されるので高速に学習を行うことができ、また、認識対象に特化した特徴量が用いられるのでロバストに学習を行うことができる。
(4)オンライン学習の学習結果がオフライン学習結果(オフライン辞書)にフィードバックされるので、特定の認識物体についての辞書、すなわち、個人化された辞書を生成することができる。
(5)形状や見えが大きく変化する認識物体を高速かつロバストに認識することができるので、ジェスチャ認識におけるアプリケーションへの応用が容易となる。
According to the above processing, the following effects can be realized.
(1) Although it is difficult to perform online learning for the entire feature space, it is fast and robust to recognize objects whose shape and appearance change greatly by performing learning using prior knowledge of the recognized objects (offline learning). Can be recognized.
(2) In off-line learning, it is possible to evaluate a score, which is a goodness for each feature amount of a recognized object, or a goodness of a feature amount group which is a combination of a plurality of feature amounts, using a temporal distribution.
(3) In online learning, feature quantities suitable for learning are selected and calculated based on the learning results of offline learning, so that learning can be performed at high speed, and there are feature quantities specialized for recognition objects. Since it is used, it is possible to learn robustly.
(4) Since the learning result of online learning is fed back to the offline learning result (offline dictionary), a dictionary for a specific recognition object, that is, a personalized dictionary can be generated.
(5) Since a recognition object whose shape and appearance greatly change can be recognized at high speed and robustly, it can be easily applied to an application in gesture recognition.
本技術は、例えばテレビジョン受像器、パーソナルコンピュータなどの情報処理装置をジェスチャで遠隔操作する場合などに適用することができる。
<7.その他>
The present technology can be applied to a case where an information processing apparatus such as a television receiver or a personal computer is remotely operated with a gesture.
<7. Other>
本技術の実施の形態は、上述した実施の形態に限定されるものではなく、本技術の要旨を逸脱しない範囲において種々の変更が可能である。 Embodiments of the present technology are not limited to the above-described embodiments, and various modifications can be made without departing from the gist of the present technology.
例えば、本技術は、1つの機能をネットワークを介して複数の装置で分担、共同して処理するクラウドコンピューティングの構成をとることができる。 For example, the present technology can take a configuration of cloud computing in which one function is shared by a plurality of devices via a network and is jointly processed.
また、上述のフローチャートで説明した各ステップは、1つの装置で実行する他、複数の装置で分担して実行することができる。 In addition, each step described in the above flowchart can be executed by being shared by a plurality of apparatuses in addition to being executed by one apparatus.
さらに、1つのステップに複数の処理が含まれる場合には、その1つのステップに含まれる複数の処理は、1つの装置で実行する他、複数の装置で分担して実行することができる。 Further, when a plurality of processes are included in one step, the plurality of processes included in the one step can be executed by being shared by a plurality of apparatuses in addition to being executed by one apparatus.
また、本技術は以下のような構成をとることができる。
(1) 入力画像から認識物体を認識する認識部と、
時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習する学習部と
を備え、
前記認識部は、前記学習部の学習結果として得られた前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識する
情報処理装置。
(2) 時系列で状態が変化する前記認識物体を含む学習用画像から、フレーム毎の前記認識物体の前記特徴量を事前に学習する事前学習部と、
前記事前学習部の学習結果として得られたフレーム毎の前記特徴量の前記スコアを事前に計算する計算部をさらに備え、
前記学習部は、前記計算部により事前に計算された前記スコアに応じた前記特徴量を用いて、前記入力画像のフレーム毎の前記認識物体の前記特徴量を学習する
(1)に記載の情報処理装置。
(3) 前記計算部により事前に計算された前記スコアを有する現フレームに対応する前記特徴量から、所定の閾値より高いスコアを有する前記特徴量を選択する選択部をさらに備え、
前記学習部は、前記選択部により選択された前記特徴量を用いて、現フレームの前記認識物体の前記特徴量を学習する
(2)に記載の情報処理装置。
(4) 前記学習部の学習結果として得られた前記特徴量を記憶する記憶部と、
前記記憶部に記憶されている前記特徴量を、前記学習部の学習結果に応じてフレーム毎に更新する更新部をさらに備え、
前記認識部は、前記更新部により更新された前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識する
(1)乃至(3)のいずれかに記載の情報処理装置。
(5) 前記選択部は、前記記憶部に記憶されている前フレームの前記特徴量から、他の閾値より低いスコアを有する前記特徴量を選択し、
前記学習部は、前記選択部により選択された前記特徴量を除いた前記特徴量を用いて、現フレームの前記認識物体の前記特徴量を学習する
(1)乃至(4)のいずれかに記載の情報処理装置。
(6) 前記更新部は、前記事前学習部の学習結果として得られた前記特徴量を、前記学習部の学習結果に応じてフレーム毎に更新する
(4)または(5)に記載の情報処理装置。
(7) 入力画像から認識物体を認識する認識部と、
時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習する学習部とを備える情報処理装置の情報処理方法であって、
前記情報処理装置が、
時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習し、
前記学習部の学習結果として得られた前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識する
ステップを含む情報処理方法。
(8) 入力画像から認識物体を認識する認識ステップと、
時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習する学習ステップと
を含む処理をコンピュータに実行させ、
前記認識ステップは、前記学習ステップの学習結果として得られた前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識する
プログラム。
Moreover, this technique can take the following structures.
(1) a recognition unit that recognizes a recognition object from an input image;
A learning unit that learns the feature amount of the recognized object for each frame using a feature amount having a score that changes in time series, and
The recognition unit recognizes the recognition object of the current frame based on the feature amount of the previous frame obtained as a learning result of the learning unit.
(2) a pre-learning unit that learns in advance the feature amount of the recognized object for each frame from a learning image including the recognized object whose state changes in time series;
A calculation unit that calculates in advance the score of the feature amount for each frame obtained as a learning result of the pre-learning unit;
The information according to (1), wherein the learning unit learns the feature amount of the recognition object for each frame of the input image using the feature amount corresponding to the score calculated in advance by the calculation unit. Processing equipment.
(3) a selection unit that selects the feature amount having a score higher than a predetermined threshold from the feature amount corresponding to the current frame having the score calculated in advance by the calculation unit;
The information processing apparatus according to (2), wherein the learning unit learns the feature amount of the recognized object in the current frame using the feature amount selected by the selection unit.
(4) a storage unit that stores the feature amount obtained as a learning result of the learning unit;
An update unit that updates the feature amount stored in the storage unit for each frame according to a learning result of the learning unit;
The information processing apparatus according to any one of (1) to (3), wherein the recognition unit recognizes the recognition object of the current frame based on the feature amount of the previous frame updated by the update unit.
(5) The selection unit selects the feature amount having a score lower than another threshold from the feature amount of the previous frame stored in the storage unit,
The learning unit learns the feature amount of the recognized object in the current frame using the feature amount excluding the feature amount selected by the selection unit. (1) to (4) Information processing device.
(6) The update unit updates the feature amount obtained as a learning result of the pre-learning unit for each frame according to the learning result of the learning unit. (4) or (5) Processing equipment.
(7) a recognition unit that recognizes a recognition object from the input image;
An information processing method of an information processing apparatus including a learning unit that learns the feature amount of the recognized object for each frame using a feature amount having a score that changes in time series,
The information processing apparatus is
Using the feature amount having a score that changes in time series, learning the feature amount of the recognized object for each frame,
An information processing method including a step of recognizing the recognized object of the current frame based on the feature amount of the previous frame obtained as a learning result of the learning unit.
(8) a recognition step of recognizing a recognition object from the input image;
Using a feature amount having a score that changes in time series, causing a computer to execute a process including learning step for learning the feature amount of the recognized object for each frame,
The recognition step is a program for recognizing the recognition object of the current frame based on the feature amount of the previous frame obtained as a learning result of the learning step.
1 情報処理装置, 2 オフライン処理部, 3 オンライン処理部, 11 学習用データ保存部, 12 学習処理部, 13 オフライン辞書保存部, 14 入力部, 15 認識部, 16 学習処理部, 21 学習部, 22 計算部, 23 選択部, 24 学習部, 25 記憶部, 26 更新部 DESCRIPTION OF SYMBOLS 1 Information processing apparatus, 2 Offline processing part, 3 Online processing part, 11 Learning data storage part, 12 Learning processing part, 13 Offline dictionary preservation | save part, 14 Input part, 15 Recognition part, 16 Learning processing part, 21 Learning part, 22 calculation units, 23 selection units, 24 learning units, 25 storage units, 26 update units
Claims (8)
時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習する学習部と
を備え、
前記認識部は、前記学習部の学習結果として得られた前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識する
情報処理装置。 A recognition unit for recognizing a recognition object from an input image;
A learning unit that learns the feature amount of the recognized object for each frame using a feature amount having a score that changes in time series, and
The recognition unit recognizes the recognition object of the current frame based on the feature amount of the previous frame obtained as a learning result of the learning unit.
前記事前学習部の学習結果として得られたフレーム毎の前記特徴量の前記スコアを事前に計算する計算部をさらに備え、
前記学習部は、前記計算部により事前に計算された前記スコアに応じた前記特徴量を用いて、前記入力画像のフレーム毎の前記認識物体の前記特徴量を学習する
請求項1に記載の情報処理装置。 A pre-learning unit that learns in advance the feature amount of the recognized object for each frame from a learning image including the recognized object whose state changes in time series;
A calculation unit that calculates in advance the score of the feature amount for each frame obtained as a learning result of the pre-learning unit;
The information according to claim 1, wherein the learning unit learns the feature amount of the recognized object for each frame of the input image using the feature amount corresponding to the score calculated in advance by the calculation unit. Processing equipment.
前記学習部は、前記選択部により選択された前記特徴量を用いて、現フレームの前記認識物体の前記特徴量を学習する
請求項2に記載の情報処理装置。 A selection unit that selects the feature amount having a score higher than a predetermined threshold from the feature amount corresponding to the current frame having the score calculated in advance by the calculation unit;
The information processing apparatus according to claim 2, wherein the learning unit learns the feature amount of the recognized object in the current frame using the feature amount selected by the selection unit.
前記記憶部に記憶されている前記特徴量を、前記学習部の学習結果に応じてフレーム毎に更新する更新部をさらに備え、
前記認識部は、前記更新部により更新された前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識する
請求項3に記載の情報処理装置。 A storage unit for storing the feature amount obtained as a learning result of the learning unit;
An update unit that updates the feature amount stored in the storage unit for each frame according to a learning result of the learning unit;
The information processing apparatus according to claim 3, wherein the recognition unit recognizes the recognition object of the current frame based on the feature amount of the previous frame updated by the update unit.
前記学習部は、前記選択部により選択された前記特徴量を除いた前記特徴量を用いて、現フレームの前記認識物体の前記特徴量を学習する
請求項4に記載の情報処理装置。 The selection unit selects the feature amount having a score lower than another threshold from the feature amount of the previous frame stored in the storage unit,
The information processing apparatus according to claim 4, wherein the learning unit learns the feature amount of the recognized object in the current frame using the feature amount excluding the feature amount selected by the selection unit.
請求項4に記載の情報処理装置。 The information processing apparatus according to claim 4, wherein the update unit updates the feature amount obtained as a learning result of the pre-learning unit for each frame according to a learning result of the learning unit.
時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習する学習部とを備える情報処理装置の情報処理方法であって、
前記情報処理装置が、
時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習し、
前記学習部の学習結果として得られた前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識する
ステップを含む情報処理方法。 A recognition unit for recognizing a recognition object from an input image;
An information processing method of an information processing apparatus including a learning unit that learns the feature amount of the recognized object for each frame using a feature amount having a score that changes in time series,
The information processing apparatus is
Using the feature amount having a score that changes in time series, learning the feature amount of the recognized object for each frame,
An information processing method including a step of recognizing the recognized object of the current frame based on the feature amount of the previous frame obtained as a learning result of the learning unit.
時系列で変化するスコアを有する特徴量を用いて、フレーム毎の前記認識物体の前記特徴量を学習する学習ステップと
を含む処理をコンピュータに実行させ、
前記認識ステップは、前記学習ステップの学習結果として得られた前フレームの前記特徴量に基づいて、現フレームの前記認識物体を認識する
プログラム。 A recognition step for recognizing a recognition object from an input image;
Using a feature amount having a score that changes in time series, causing a computer to execute a process including learning step for learning the feature amount of the recognized object for each frame,
The recognition step is a program for recognizing the recognition object of the current frame based on the feature amount of the previous frame obtained as a learning result of the learning step.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012012863A JP2013152595A (en) | 2012-01-25 | 2012-01-25 | Information processing apparatus and method, and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012012863A JP2013152595A (en) | 2012-01-25 | 2012-01-25 | Information processing apparatus and method, and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2013152595A true JP2013152595A (en) | 2013-08-08 |
| JP2013152595A5 JP2013152595A5 (en) | 2015-02-19 |
Family
ID=49048890
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2012012863A Abandoned JP2013152595A (en) | 2012-01-25 | 2012-01-25 | Information processing apparatus and method, and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2013152595A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018198028A (en) * | 2017-05-25 | 2018-12-13 | 日本電信電話株式会社 | Movement state recognition model learning device, movement state recognition device, method, and program |
| JP2019095827A (en) * | 2017-11-17 | 2019-06-20 | 日本電気株式会社 | System, method, and program for processing information |
| WO2020021954A1 (en) * | 2018-07-26 | 2020-01-30 | ソニー株式会社 | Information processing device, information processing method, and program |
-
2012
- 2012-01-25 JP JP2012012863A patent/JP2013152595A/en not_active Abandoned
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018198028A (en) * | 2017-05-25 | 2018-12-13 | 日本電信電話株式会社 | Movement state recognition model learning device, movement state recognition device, method, and program |
| JP2019095827A (en) * | 2017-11-17 | 2019-06-20 | 日本電気株式会社 | System, method, and program for processing information |
| JP7119348B2 (en) | 2017-11-17 | 2022-08-17 | 日本電気株式会社 | Information processing system, information processing method and program |
| WO2020021954A1 (en) * | 2018-07-26 | 2020-01-30 | ソニー株式会社 | Information processing device, information processing method, and program |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11836932B2 (en) | Classifying motion in a video using detected visual features | |
| KR102425578B1 (en) | Method and apparatus for recognizing an object | |
| Molchanov et al. | Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network | |
| Wang et al. | Hidden-markov-models-based dynamic hand gesture recognition | |
| JP2018538631A (en) | Method and system for detecting an action of an object in a scene | |
| CN110959160A (en) | Gesture recognition method, device and equipment | |
| US11825278B2 (en) | Device and method for auto audio and video focusing | |
| US9811735B2 (en) | Generic object detection on fixed surveillance video | |
| Gupta et al. | Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural networks | |
| CN111860504A (en) | Visual multi-target tracking method and device based on deep learning | |
| JP2017523498A (en) | Eye tracking based on efficient forest sensing | |
| Ayral et al. | Temporal stochastic softmax for 3d cnns: An application in facial expression recognition | |
| Bisht et al. | Indian dance form recognition from videos | |
| KR20220059194A (en) | Method and apparatus of object tracking adaptive to target object | |
| JP2012203439A (en) | Information processing device, information processing method, recording medium, and program | |
| JP6103765B2 (en) | Action recognition device, method and program, and recognizer construction device | |
| JP2013152595A (en) | Information processing apparatus and method, and program | |
| JP2021015479A (en) | Behavior recognition method, behavior recognition device and behavior recognition program | |
| EP2781991B1 (en) | Signal processing device and signal processing method | |
| Nikpour et al. | Deep reinforcement learning in human activity recognition: A survey | |
| Kasaei et al. | An adaptive object perception system based on environment exploration and Bayesian learning | |
| Permana et al. | Hand movement identification using single-stream spatial convolutional neural networks | |
| US11218803B2 (en) | Device and method of performing automatic audio focusing on multiple objects | |
| US10917721B1 (en) | Device and method of performing automatic audio focusing on multiple objects | |
| Springstübe et al. | Continuous convolutional object tracking. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20141226 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20141226 |
|
| A762 | Written abandonment of application |
Free format text: JAPANESE INTERMEDIATE CODE: A762 Effective date: 20150402 |