JP2013127750A - パーティション分割装置及び方法及びプログラム - Google Patents
パーティション分割装置及び方法及びプログラム Download PDFInfo
- Publication number
- JP2013127750A JP2013127750A JP2011277623A JP2011277623A JP2013127750A JP 2013127750 A JP2013127750 A JP 2013127750A JP 2011277623 A JP2011277623 A JP 2011277623A JP 2011277623 A JP2011277623 A JP 2011277623A JP 2013127750 A JP2013127750 A JP 2013127750A
- Authority
- JP
- Japan
- Prior art keywords
- partition
- cost
- partitioning
- division
- boundary line
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images











Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
【課題】 設定されたパーティション数に対し、範囲参照の並列アクセスの応答性能向上を目的とした適切なパーティション分割を行う。
【解決手段】 本発明は、入力データのキー項目に対してキー値の小さい順に境界線を決定し、取得した所定の行数を所定のパーティション数初期値で除した行数に各パーティションを等分割し、分割された各パーティション分割候補を格納する。境界線を一つ削除し、パーティション分割を生成し、並列スキャン処理の並列数を取得し、スレッド毎に割り当てられたIOコストうちで最大値を入力データのクエリに対するIOコストとし、削除できる境界線がなくなるまで行い、パーティション分割候補からパーティション数が所定のパーティション数以下のコスト値が最小となるパーティション分割を出力する。
【選択図】 図2
【解決手段】 本発明は、入力データのキー項目に対してキー値の小さい順に境界線を決定し、取得した所定の行数を所定のパーティション数初期値で除した行数に各パーティションを等分割し、分割された各パーティション分割候補を格納する。境界線を一つ削除し、パーティション分割を生成し、並列スキャン処理の並列数を取得し、スレッド毎に割り当てられたIOコストうちで最大値を入力データのクエリに対するIOコストとし、削除できる境界線がなくなるまで行い、パーティション分割候補からパーティション数が所定のパーティション数以下のコスト値が最小となるパーティション分割を出力する。
【選択図】 図2
Description
本発明は、パーティション分割装置及び方法及びプログラムに係り、特に、データベースにおいて大きなデータサイズを扱う場合に、テーブルのパーティション分割を行うことで検索対象データを分散させ、並列に同時にアクセスを行うことで応答性能を向上させるためのテーブルのパーティション分割装置及び方法及びプログラムに関する。
商用データベースでは与えられたワークロードに関するパーティションの分割の実施要否を推奨し、パフォーマンス向上を支援する機能やデータベース設計を支援する設計アドバイザが存在する(例えば、非特許文献1,2参照)。このようにデータサイズの大きなデータベース設計は大変複雑であり、それ自体ツールの支援やパーティション分割の自動実現方式が必要とされる分野である。
しかし、従来の技術は、パーティション分割の実施要否の推奨を行うものであって、具体的にパーティション分割を行うにあたり分割方法(境界線を指定する分割キーの値)の出力には対応していない。
これに対し、入力データの範囲参照検索区間の端点を抽出して境界線候補として境界線候補記憶手段に格納し、該境界線候補とデータアクセスに要するIOコストをゼロとしたパーティション分割を生成し、範囲参照検索区間の両端を除く境界線を一つ削除し、削除後のパーティション分割を生成する。そして、境界線削除後のIOコスト増分値を計算し、パーティション分割候補のパーティション数が所定の数N以下で、かつ、IOコスト増分値が最小となるパーティション分割候補をパーティション分割の結果として出力する範囲参照検索が考えられる。しかし、並列アクセスを考慮に入れていないため、並列アクセスの応答性能向上を目的としたパーティション分割技術としては効果を望むことができない。
Oracle Databaseパフォーマンス・チューニング・ガイド11gリリース(11.1) 18 SQLアクセス・アドバイザhttp://otndnld.oracle.co.jp/document/products/oracle11g/111/doc_dvd/server.111/E0574302/advisor.htm
DB2 V8.2 設計アドバイザの使用パート2:データウェアハウスを設計するのに有効なヘルプ情報http://www-06.ibm.com/jp/domino01/mkt/dminfo.nsf/499721c3388537bd49256b1a001aab28/4925722f004efcee492570d4005a65ef/$FILE/Using%20the%20DB2%20V8.pdf
しかしながら、上記の範囲参照検索において、テーブルのパーティション分割を行い並列アクセスを実行するにあたり、応答時間は複数の並列アクセス処理単位(以下、「スレッド」と記す)の中で応答時間が最大となるスレッドの応答時間のみにより決まるため、もし検索対象データが各パーティションに均等に分配されていなければ、並列アクセスの効果を享受することができない。具体的には、並列アクセス数(典型的にはCPUコア数に等しい)を、例えば4とした場合、いくら3スレッドの応答時間を小さくしても残り1スレッドの応答時間が変わらなければ、系全体の応答性能は変わらない。
並列アクセスの応答性能向上を目的としたパーティション分割方式を検討するにあたり、検索対象データを各パーティションに分散配置し、並列に同時にアクセスを行った場合に応答時間が最大となるスレッドの応答時間を小さく抑えることで系全体の応答性能向上を図ることができる。そこで各スレッドが分担するIOコストが均等になるように検索対象データを各スレッドに分配する。そこで、並列アクセス数(例えば並列アクセス数を4とする)に対し、パーティション数(例えばパーティション数を12とする)の各パーティションに対し、各スレッドが担当するアクセス先パーティションをラウンドロビンにより対応付け(実際には並列アクセスのアクセス先を決める処理は並列アクセス処理の実装に依存する)、各スレッドが扱うIOコストが均等になるように検索対象データの各パーティションへの分配を行う。この例を図1に示す。同図では、並列アクセス数が設定値(例えば、4、CPUコア数)、並列アクセス単位(以下「スレッド」と記す)のアクセス先パーティションへの対応付けをラウンドロビンにより決める場合を示す。図1では、スレッドiをパーティション(i mod 4)に対応付ける例を示すが、実際には並列アクセスの実装に依存する。ここでIOコストは全てのパーティション、ワークロード内の全てのクエリからの寄与の和として定義する。ワークロード内のクエリQに対するパーティションiのIOコストをXjとした場合、系のコストは、
ΣQmax (X0+X4+X8+…,X1+X5+X9+…,X2+X6+X10+…,X3+X7+X11+…)
となる。ただし、Xi=min[(1+p)×パーティションiの対象行数、パーティションi全行数]であり、1+pは、インデクススキャンの1行あたりIOコスト/シーケンススキャンの1行当りのIOコストである。各パーティションにおいては、インデックススキャンまたはシーケンシャルスキャンのうちでIOコストの小さい方を選択する。行数見積もりは行数分布のヒストグラムから線形補間で行う。
ΣQmax (X0+X4+X8+…,X1+X5+X9+…,X2+X6+X10+…,X3+X7+X11+…)
となる。ただし、Xi=min[(1+p)×パーティションiの対象行数、パーティションi全行数]であり、1+pは、インデクススキャンの1行あたりIOコスト/シーケンススキャンの1行当りのIOコストである。各パーティションにおいては、インデックススキャンまたはシーケンシャルスキャンのうちでIOコストの小さい方を選択する。行数見積もりは行数分布のヒストグラムから線形補間で行う。
上記のように、各スレッドが扱うIOコストが均等になるような分配方法のひとつは各行を各パーティションとして細分し、パーティション数を最大にすることである。しかし、その一方で、パーティション数を増大させすぎると、アクセス先のパーティションを決定する処理やパーティションごとの固有処理で必要なオーバヘッドが無視できない程大きくなるため適当といえない。結果的には応答性能向上を目的としたパーティション分割ではパーティション数はある有限な値を取らざるを得ない。
本発明は、上記の点に鑑みなされたもので、設定されたパーティション数に対し、範囲参照の並列アクセスの応答性能向上を目的とした適切なパーティション分割が可能なパーティション分割装置及び方法及びプログラムを提供することを目的とする。
上記の課題を解決するため、本発明(請求項1)は、並列処理のためのデータベースのテーブルのパーティション分割を行うパーティション分割装置であって、
境界線候補記憶手段を初期化し、入力データのキー項目に対してキー値の小さい順に境界線を決定し、取得した所定の行数を所定のパーティション数初期値で除した行数に各パーティションを等分割し、該境界線を該境界線候補記憶手段に格納し、分割された各パーティション分割候補をパーティション分割候補記憶手段に格納するパーティション初期分割手段と、
パーティション分割の境界線のうちで両端を除く境界線を一つ削除し、削除後のパーティション分割を生成し、並列スキャン処理の並列数を取得し、並列スキャン処理単位(スレッド)毎に割り当てられたIOコストうちで最大値を前記入力データのクエリに対するIOコストとし、前記パーティション分割候補記憶手段に格納する境界線削除手段と、
前記パーティション分割候補記憶手段のパーティション分割候補からパーティション数が所定のパーティション数以下のコスト値が最小となるパーティション分割を出力する評価手段と、を有する。
境界線候補記憶手段を初期化し、入力データのキー項目に対してキー値の小さい順に境界線を決定し、取得した所定の行数を所定のパーティション数初期値で除した行数に各パーティションを等分割し、該境界線を該境界線候補記憶手段に格納し、分割された各パーティション分割候補をパーティション分割候補記憶手段に格納するパーティション初期分割手段と、
パーティション分割の境界線のうちで両端を除く境界線を一つ削除し、削除後のパーティション分割を生成し、並列スキャン処理の並列数を取得し、並列スキャン処理単位(スレッド)毎に割り当てられたIOコストうちで最大値を前記入力データのクエリに対するIOコストとし、前記パーティション分割候補記憶手段に格納する境界線削除手段と、
前記パーティション分割候補記憶手段のパーティション分割候補からパーティション数が所定のパーティション数以下のコスト値が最小となるパーティション分割を出力する評価手段と、を有する。
また、本発明(請求項2)は、前記境界線削除手段において、前記並列数の前記スレッドに対して、各パーティションをラウンドロビンで対応付ける。
また、本発明(請求項3)は、前記境界線削除手段において、前記IOコストを、与えられた行当りのインデックススキャンのIOコストとシーケンシャルスキャンのIOコストの比を用いて計算する。
本発明によれば、入力データを利用し、与えられたワークロードに対して並列アクセスにおけるアクセスコストが各スレッドへより均等に分配されるようにパーティション分割を行うことで範囲参照検索の並列アクセスの応答性能向上を図ることができる。また、各スレッドのアクセスコストの分配が均等となるような適切なパーティション分割の分割方法(境界線を指定する分割キー値)を出力するアドバイザを実現できる。
以下図面と共に、本発明の実施の形態を説明する。
まず、本発明の概要を説明する。
以下に、本発明を具体的に説明する。
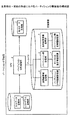
図2は、本発明の一実施の形態におけるパーティション分割装置の構成を示す。
同図に示すパーティション分割装置は、入力データ記憶部1、パーティション分割処理部2、出力データ記憶部3、境界線候補記憶部4、パーティション分割候補記憶部5、パーティション数記憶部6、IOコスト比設定値記憶部7、ヒストグラム記憶部8、並列数設定値記憶部9、パーティション数初期値記憶部10から構成される。
なお、同図では、入力データ記憶部1、出力データ記憶部3、境界線候補記憶部4、パーティション分割候補記憶部5、パーティション数記憶部6、IOコスト比設定値記憶部7、ヒストグラム記憶部8、並列数設定値記憶部9、パーティション数初期値記憶部10が、それぞれ異なる記憶媒体に格納されるように示されているが、この例に限定されることなく、個々の記憶媒体または、データベース等の複数の種類のデータを格納する記憶媒体に格納してもよい。
パーティション分割処理部2は、CPUで動作する処理部であり、データバスにより上記の記憶部と接続されている。
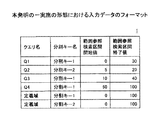
図3は、本発明の一実施の形態における入力データのフォーマットを示す。入力データは、クエリ名、分割キー名、範囲参照検索区間開始値、範囲参照検索区間終了値を含む。同図に示すように入力データは、分割キーの取り得る範囲(定義域)も登録する。当該入力データは入力されると入力データ記憶部1に格納される。
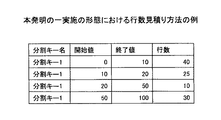
図4は、本発明の一実施の形態におけるヒストグラム記憶部のフォーマットであり、ヒストグラム記憶部8は、分割キー名、開始値、終了値、行数を格納する。
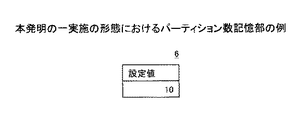
図5は、本発明の一実施の形態におけるパーティション数記憶部の例であり、パーティション記憶部6には、予めパーティション数設定値Nが格納される。
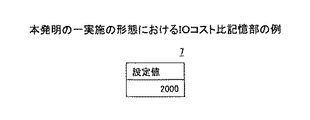
図6は、本発明の一実施の形態におけるIOコスト比記憶部の例であり、IOコスト比記憶部7には、運用者により設定された行当りのインデックススキャンのIOコストとシーケンシャルスキャンのIOコストの比が格納されている。例えば、図11のステップ100のIOコスト比p(設定値)を保持する。例えば、p=2000の場合は、「2000」を保持する。
上記のパーティション数記憶部6とIOコスト比設定値記憶部7のデータは、パーティション分割処理部2によるIOコスト増分値の計算に利用される。
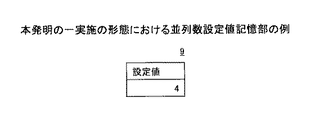
図7は、本発明の一実施の形態における並列数設定値記憶部の例であり、予め並列数が格納される。
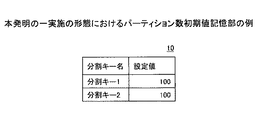
図8は、本発明の一実施の形態におけるパーティション数初期値記憶部の例であり、分割キーごとにパーティション数の初期値が格納される。
図9は、本発明の一実施の形態における境界線候補記憶部の例であり、境界線候補数が3の場合を示している。分割キーの追加、削除は分割キー値が昇順を保つような位置への挿入、削除により行う。
図10は、本発明の一実施の形態におけるパーティション分割候補記憶部の例であり、同図(a)は、初期生成時の例を示し、同図(b)は初期生成時以外の例を示す。同図(a)において、分割キー1の境界線数を3、分割キー2の境界線数3とすると、パーティション数は、(3−1)×(3−1)=4となる。
上記の構成における装置の動作を説明する。
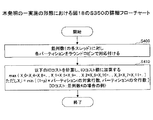
図11は、本発明の一実施の形態におけるパーティション分割装置の全体動作のフローチャートである。以下では、すでに入力データが入力され、入力データ記憶部1に格納されているものとする。
ステップ100) パーティション分割処理部2は、IOコスト比設定値記憶部7からIOコスト比pを取得する。
ステップ110) パーティション分割処理部2は、パーティション数記憶部6からパーティション数Nを取得する。
ステップ120) パーティション分割処理部2は、並列数設定値記憶部9から並列数を取得する。
ステップ125) パーティション分割処理部2は、パーティション数初期値記憶部10からパーティション数の初期値を取得する。
ステップ130) パーティション分割処理部2は、パーティション分割の初期生成を行う。
パーティション分割を行うにあたり、まず、パーティションの初期生成として検索対象データの行数が均等なパーティション分割(初期生成のパーティション分割数は設定値とする)を生成する。この例を図12に示す。同図に示すパーティション分割初期生成の例では、分割キーの定義域を分割数がパーティション数初期値(設定値、例えば、10)となるように行数で等分割したパーティション分割を初期候補とする。
パーティションの分割を行うにあたり、図3に示す入力データを入力データ記憶部1から読み込み、当該入力データを元に最も細分化されたパーティション分割を生成し、境界線候補記憶部4に格納する。具体的には、図9に示すように、入力データの範囲参照検索範囲の端点(開始値、終了値)を全て使用し、これを境界線としたパーティション分割を得る。これにより、図10(a)に示すような分割キー境界候補が得られる。同図の例において、「分割キー1」の境界線数を3、「分割キー2」の境界線数を3とすると、パーティション数=(3−1)×(3−1)=4となる。
ステップ140) パーティション分割処理部2は、図10に示すように分割キーの集合をパーティション分割候補としてパーティション分割候補記憶部5に格納する。なお、パーティション数は図10から導出可能である。
ステップ150) パーティション分割処理部2は、削除できる境界線が存在するかを判定する。なお、定義域の両端は削除不可である。具体的には、パーティション数>設定値Nであれば存在すると判定し、ステップ160に移行し、パーティション数≦設定値Nの場合は存在しないと判定し、ステップ170に移行する。
ステップ160) ステップ150で削除できる境界線があると判断された場合は、境界線数を1減少させた場合のパーティション分割を取得し、パーティション分割候補記憶部5に格納し、ステップ140に戻る。詳細な処理については図18で後述する。
ステップ170) パーティション分割処理部2は、上記で境界線を削除したことにより、アクセス範囲が大きくなり、パーティション分割を生成し、IOコスト増分値を計算し、パーティション分割候補からパーティション数≦Nを満たすIOコスト値が最小となるパーティション分割を出力データ記憶部3に出力する。入力データに対するパーティション分割の結果は図13のように出力される。
次に、上記のステップ130のパーティション分割の初期生成処理について説明する。
図17は、本発明の一実施の形態における図11のステップ130のパーティション分割の初期生成処理のフローチャートである。
ステップ200) パーティション分割処理部2は、境界線候補記憶部4の境界線候補を初期化する。
ステップ210) ヒストグラム記憶部8からヒストグラムを読み出して全行数を取得する。
ステップ220) パーティション分割候補記憶部5のパーティション数初期値から1行読み出す。
ステップ230) ステップ210で取得した全行数とステップ220で読み出したパーティション数初期値より
全行数÷パーティション数初期値
の計算を行う。
全行数÷パーティション数初期値
の計算を行う。
ステップ240)キー項目に対してキー値の小さい方から順に境界線を決定し、ステップ230で計算した行数に各パーティションを等分割する。
ステップ250) ステップ240で等分割されたパーティションを境界線候補記憶部4に保存する。パーティションの分割を行うにあたり、図3に示す入力データを入力データ記憶部1から読み込み、当該入力データを元に最も細分化されたパーティション分割を生成し、分割キー値の集合を境界線候補として境界線候補記憶部4に格納する。具体的には、図9に示すように、入力データの範囲参照検索範囲の端点(開始値、終了値)を全て使用し、これを境界線としたパーティション分割を得る。これにより、図10(a)に示すような分割キー境界候補が得られる。同図の例において、「分割キー1」の境界線数を3、「分割キー2」の境界線数を3とすると、パーティション数=(3−1)×(3−1)=4となる。
ステップ260) 読み出していないパーティション数初期値がある場合には、ステップ220に戻る。全て読み出している場合は処理を終了する。
次に、図11のステップ160の境界線数を1減少させた場合のパーティション分割の取得処理について説明する。
図18は、本発明の一実施の形態における図11のステップ160の詳細フローチャートである。
ステップ300) 境界線数Mが入力されると、パーティション分割処理部2は、一つ削除できる境界線がある場合に、パーティション分割候補記憶部5に一つの境界線を削除した後の境界線数Mと記述し、パーティション分割候補記憶部5の境界線数Mのパーティション分割候補を初期化する。
ステップ310) パーティション分割候補記憶部5の境界線数M+1のパーティション分割候補からIOコストが最小となるパーティション分割を一つ選択する。
ステップ315) 選択したパーティション分割のパーティション数が、パーティション数記憶部6から取得したパーティション数N以下(選択したパーティション分割のパーティション数≦N)であればステップ395に移行する。そうでない場合はステップ320に移行する。
ステップ320) パーティション分割候補記憶部5のパーティション分割候補の中で一つ境界線(ただし、定義域の両端は対象外)を選択する。
ステップ330) メモリ(図示せず)のIOコスト値を0に初期化する。
ステップ340) 入力データ記憶部1から入力データを1行読み出して、範囲参照検索区間を取り出す。
ステップ350) 入力データの範囲参照検索に対するIOコストを計算し、メモリ(図示せず)のIOコスト値に加算する。詳細は図19で後述する。
ステップ370) 入力データ記憶部1から読み出していないデータがある場合はステップ340に移行する。
ステップ380) パーティション分割候補記憶部5にパーティション分割候補を追加保存する。
ステップ390) パーティション分割候補記憶部5に選択していない境界線が存在する場合は、ステップ320に移行する。
ステップ395) パーティション分割候補記憶部5にIOコストの最小の選択していない境界線数M+1のパーティション分割候補が存在する場合には、ステップ310に移行する。
次に、上記の図18のステップ350の入力データの範囲参照検索に対するIOコストを計算処理について説明する。
図19は、本発明の一実施の形態における図18のステップ350の詳細フローチャートである。
ステップ400) パーティション分割処理部2は、図1に示すように、並列数の各スレッドに対し、各パーティションをラウンドロビンで対応付ける。図1に示す並列アクセス数が設定値(例えば、4、CPUコア数)とし、スレッドのアクセスをパーティションへの対応付けをラウンドロビンにより決める場合は、
max(X0+X4+X8+…,X1+X5+X9+…,X2+X6+X10+…,X3+X7+X11+…)
とする。ただし、Xi=min[(1+p)×パーティションiの対象行数、パーティションi全行数]である。
max(X0+X4+X8+…,X1+X5+X9+…,X2+X6+X10+…,X3+X7+X11+…)
とする。ただし、Xi=min[(1+p)×パーティションiの対象行数、パーティションi全行数]である。
ステップ410) 以下のIOコスト計算を行い、IOコスト値に加算する。
IOコスト値の計算にあたっては、図14に示すように、入力データの全ての範囲参照検索及び全てのパーティションにわたるIOコスト値からの寄与の総和とする。ここで、個々の範囲参照検索に対する個別のIOコスト値は、図15に示すように、行数の見積もり値及び行当りのインデックススキャンのIOコストとシーケンシャルスキャンのIOコストの比(運用者によるシステム設定値)を元に計算した、以下のうちでいずれか小さい値を元に算出する。
・行当りのインデックススキャンのIOコスト×対象行数;
・行当りのシーケンシャルスキャンのIOコスト×パーティション内の行数;
ただし、行数については、ヒストグラム記憶部8の図4に示すヒストグラムを使用した見積もり値を使用する。図16の例では、分割キー1の値が15と40の間の行数を見積もるには、線形補間を用いて、
見積もり行数=FLOOR [25×(20−15)/(20−10)+10×(40−20)/(50−20)]
ただし、FLOORは小数点以下切り下げを表す。こうしてパーティション分割をパーティション数が設定値以下に達するか、または、削除できる境界線がなくなるまで生成し(定義域の両端は削除負荷)、IOコスト値を評価した後、パーティション分割候補のうち、パーティション数が設定値以下の条件を満たすIOコスト値が最小となるパーティション分割の結果を出力する。
・行当りのシーケンシャルスキャンのIOコスト×パーティション内の行数;
ただし、行数については、ヒストグラム記憶部8の図4に示すヒストグラムを使用した見積もり値を使用する。図16の例では、分割キー1の値が15と40の間の行数を見積もるには、線形補間を用いて、
見積もり行数=FLOOR [25×(20−15)/(20−10)+10×(40−20)/(50−20)]
ただし、FLOORは小数点以下切り下げを表す。こうしてパーティション分割をパーティション数が設定値以下に達するか、または、削除できる境界線がなくなるまで生成し(定義域の両端は削除負荷)、IOコスト値を評価した後、パーティション分割候補のうち、パーティション数が設定値以下の条件を満たすIOコスト値が最小となるパーティション分割の結果を出力する。
上記のフローチャートに示したように、パーティション分割を行うにあたり、まず、パーティションの初期生成として検索対象データの行数が均等なパーティション分割(初期生成のパーティション分割数は設定値とする)を生成する。この例を図12に示す。同図に示すパーティション分割初期生成の例では、分割キーの定義域を分割数がパーティション数初期値となるように行数で等分割したパーティション分割を初期候補とする。
次に、一つの境界線を削除する処理を実行し、全ての可能なパーティション分割を生成し、IOコストを計算する。この処理では、各候補にわたって、IOコスト値を評価する。IOコスト値の計算にあたっては、図14に示すように、入力データの全ての範囲参照検索及び全てのパーティションにわたるIOコスト値からの寄与の総和とする。こうしてパーティション分割をパーティション数が設定値以下に達するか、または、削除できる境界線がなくなるまで生成し(定義域の両端は削除不可)、IOコスト値を評価した後、パーティション分割候補のうち、パーティション数が設定値以下の条件を満たすIOコスト値が最小となるパーティション分割の結果を出力する。
上述した処理の結果は、例えば、パーティション分割のテーブルの定義のために用いることができる。図20に、出力結果をテーブル定義として利用する例を示す。同図は、パーティション数3の場合を示している。テーブルpartitionをテーブルpartition0、partition1、partition2にパーティション分割する分割キーkeyの値の定義域0<key≦10に対して境界線をkey=2.5とした例である。
上記のように、入力データのワークロードに対して、並列アクセスにおけるアクセスコストが各スレッドへより均等に分配されるようにラウンドロビン方式でパーティションを割り当て、割り当てられたパーティションの大きさから各スレッドのIOコストを算出し、各スレッドのIOコストの最大値を系全体のコストとし、当該系全体のコストが最小となるように、パーティション分割候補のうち、パーティション数が所定の数以下の条件を満たすIOコストが最小となるパーティション分割を行う。これは、全体の応答時間はアクセスコストが最大のスレッドに対する応答時間のみにより決まるため、スレッドへのアクセスコストの分配が不均等なパーティション分割は応答性能向上を目的とした適切なパーティション分割とはいえないからである。
なお、上記の実施の形態におけるパーティション分割処理部2の処理をプログラムとして構築し、パーティション分割装置として利用されるコンピュータにインストールして実行させる、または、ネットワークを介して流通させることが可能である。
本発明は、上記の実施の形態に限定されることなく、特許請求の範囲内において、種々変更・応用が可能である。
1 入力データ記憶部
2 パーティション分割処理部
3 出力データ記憶部
4 境界線候補記憶部
5 パーティション分割候補記憶部
6 パーティション数記憶部
7 IOコスト比設定値記憶部
8 ヒストグラム記憶部
9 並列数設定値記憶部
10 パーティション数初期値記憶部
2 パーティション分割処理部
3 出力データ記憶部
4 境界線候補記憶部
5 パーティション分割候補記憶部
6 パーティション数記憶部
7 IOコスト比設定値記憶部
8 ヒストグラム記憶部
9 並列数設定値記憶部
10 パーティション数初期値記憶部
Claims (7)
- 並列処理のためのデータベースのテーブルのパーティション分割を行うパーティション分割装置であって、
境界線候補記憶手段を初期化し、入力データのキー項目に対してキー値の小さい順に境界線を決定し、取得した所定の行数を所定のパーティション数初期値で除した行数に各パーティションを等分割し、該境界線を該境界線候補記憶手段に格納し、分割された各パーティション分割候補をパーティション分割候補記憶手段に格納するパーティション初期分割手段と、
パーティション分割の境界線のうちで両端を除く境界線を一つ削除し、削除後のパーティション分割を生成し、並列スキャン処理の並列数を取得し、並列スキャン処理単位(スレッド)毎に割り当てられたIOコストうちで最大値を前記入力データのクエリに対するIOコストとし、前記パーティション分割候補記憶手段に格納する境界線削除手段と、
前記パーティション分割候補記憶手段のパーティション分割候補からパーティション数が所定のパーティション数以下のコスト値が最小となるパーティション分割を出力する評価手段と、
を有することを特徴とするパーティション分割装置。 - 前記境界線削除手段は、
前記並列数の前記スレッドに対して、各パーティションをラウンドロビンで対応付ける
請求項1記載のパーティション分割装置。 - 前記境界線削除手段は、
前記IOコストを、与えられた行当りのインデックススキャンのIOコストとシーケンシャルスキャンのIOコストの比を用いて計算する
請求項1記載のパーティション分割装置。 - 並列処理のためのデータベースのテーブルのパーティション分割を行うパーティション分割方法であって、
パーティション初期分割手段が、境界線候補記憶手段を初期化し、入力データのキー項目に対してキー値の小さい順に境界線を決定し、取得した所定の行数を所定のパーティション数初期値で除した行数に各パーティションを等分割し、該境界線を該境界線候補記憶手段に格納し、分割された各パーティション分割候補をパーティション分割候補記憶手段に格納するパーティション初期分割ステップと、
境界線削除手段が、パーティション分割の境界線のうちで両端を除く境界線を一つ削除し、削除後のパーティション分割を生成し、並列スキャン処理の並列数を取得し、並列スキャン処理単位(スレッド)毎に割り当てられたIOコストうちで最大値を前記入力データのクエリに対するIOコストとし、前記パーティション分割候補記憶手段に格納する処理を、削除できる境界線がなくなるまで行う境界線削除ステップと、
評価手段が、前記パーティション分割候補記憶手段のパーティション分割候補からパーティション数が所定のパーティション数以下のコスト値が最小となるパーティション分割を出力する評価ステップと、
を行うことを特徴とするパーティション分割方法。 - 前記境界線削除ステップにおいて、
前記並列数の前記スレッドに対して、各パーティションをラウンドロビンで対応付ける
請求項4記載のパーティション分割方法。 - 前記境界線削除ステップにおいて、
前記IOコストを、与えられた行当りのインデックススキャンのIOコストとシーケンシャルスキャンのIOコストの比を用いて計算する
請求項4記載のパーティション分割方法。 - コンピュータを、
請求項1乃至3のいずれか1項に記載のパーティション分割装置の各手段として機能させるためのパーティション分割プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011277623A JP2013127750A (ja) | 2011-12-19 | 2011-12-19 | パーティション分割装置及び方法及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011277623A JP2013127750A (ja) | 2011-12-19 | 2011-12-19 | パーティション分割装置及び方法及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2013127750A true JP2013127750A (ja) | 2013-06-27 |
Family
ID=48778235
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011277623A Pending JP2013127750A (ja) | 2011-12-19 | 2011-12-19 | パーティション分割装置及び方法及びプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2013127750A (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101833996B1 (ko) | 2017-08-18 | 2018-04-13 | 주식회사 마크베이스 | 데이터 검색 시스템 및 방법 |
| JP7466619B1 (ja) | 2022-12-23 | 2024-04-12 | 三菱電機インフォメーションネットワーク株式会社 | データベース管理システム、パーティション分割装置、パーティション分割方法およびパーティション分割プログラム |
| KR102679218B1 (ko) * | 2023-09-26 | 2024-06-28 | 쿠팡 주식회사 | 데이터 관리를 위한 테이블 분할 방법 및 이를 위한 전자 장치 |
-
2011
- 2011-12-19 JP JP2011277623A patent/JP2013127750A/ja active Pending
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101833996B1 (ko) | 2017-08-18 | 2018-04-13 | 주식회사 마크베이스 | 데이터 검색 시스템 및 방법 |
| JP7466619B1 (ja) | 2022-12-23 | 2024-04-12 | 三菱電機インフォメーションネットワーク株式会社 | データベース管理システム、パーティション分割装置、パーティション分割方法およびパーティション分割プログラム |
| KR102679218B1 (ko) * | 2023-09-26 | 2024-06-28 | 쿠팡 주식회사 | 데이터 관리를 위한 테이블 분할 방법 및 이를 위한 전자 장치 |
| WO2025070882A1 (ko) * | 2023-09-26 | 2025-04-03 | 쿠팡 주식회사 | 데이터 관리를 위한 테이블 분할 방법 및 이를 위한 전자 장치 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11194780B2 (en) | Early exit from table scans of loosely ordered and/or grouped relations using nearly ordered maps | |
| US10915528B2 (en) | Pluggable storage system for parallel query engines | |
| US11423082B2 (en) | Methods and apparatus for subgraph matching in big data analysis | |
| JP2019194882A (ja) | ファーストクラスデータベース要素としての半構造データの実装 | |
| US9262458B2 (en) | Method and system for dynamically partitioning very large database indices on write-once tables | |
| US10691696B2 (en) | Key-value storage using a skip list | |
| JP2019530068A (ja) | テーブルのインクリメンタルクラスタリング保守 | |
| US11074242B2 (en) | Bulk data insertion in analytical databases | |
| US10877973B2 (en) | Method for efficient one-to-one join | |
| JP2008225575A (ja) | 計算機負荷見積システム、計算機負荷見積方法 | |
| Karras et al. | Query optimization in NoSQL databases using an enhanced localized R-tree index | |
| JP2013127750A (ja) | パーティション分割装置及び方法及びプログラム | |
| Cahsai et al. | Scaling k-nearest neighbours queries (the right way) | |
| US11914740B2 (en) | Data generalization apparatus, data generalization method, and program | |
| JP2013080403A (ja) | テーブルパーティション分割装置及び方法及びプログラム | |
| CN111221814A (zh) | 二级索引的构建方法、装置及设备 | |
| Papadopoulos et al. | Grid file (and family) | |
| US20170300516A1 (en) | System and method for building a dwarf data structure | |
| JP2015045995A (ja) | 仮想データベースシステム管理装置、管理方法及び管理プログラム | |
| CN109388638B (zh) | 用于分布式大规模并行处理数据库的方法及系统 | |
| Al-Kateb et al. | Kassem Awada | |
| CN116383255A (zh) | 聚合查询方法、系统、设备及存储介质 | |
| Zhou et al. | WACO: Workload Aware Column Order for Scan Operator in Wide Table | |
| Suomi et al. | IT-enabled governance structures in health care | |
| JP2020052854A (ja) | 情報処理装置、情報処理システム、情報処理方法、及びプログラム。 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20131004 |