JP2013105207A - Information processing method and apparatus for retrieving concealed data - Google Patents
Information processing method and apparatus for retrieving concealed data Download PDFInfo
- Publication number
- JP2013105207A JP2013105207A JP2011246817A JP2011246817A JP2013105207A JP 2013105207 A JP2013105207 A JP 2013105207A JP 2011246817 A JP2011246817 A JP 2011246817A JP 2011246817 A JP2011246817 A JP 2011246817A JP 2013105207 A JP2013105207 A JP 2013105207A
- Authority
- JP
- Japan
- Prior art keywords
- value
- data
- numerical
- numerical value
- auxiliary
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






















Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
本技術は、秘匿化データの検索技術に関する。 The present technology relates to a concealed data search technology.
クラウドの広がりと共に、情報をクラウドに預けてクラウド本来の特徴を生かした情報共有及び活用が進んでいる。その中で、クラウドでの協業や分業における機密データの活用が期待されている。例えば、個人が健康に関する情報をクラウドに預け、これを信頼できる公的機関などに分析及び整理してもらうというような利用方法が考えられる。 With the spread of the cloud, information sharing and utilization utilizing the original features of the cloud is progressing by depositing information in the cloud. Among them, the utilization of confidential data in collaboration and division of labor in the cloud is expected. For example, there may be a usage method in which an individual deposits information on health in the cloud and has it analyzed and organized by a trusted public organization.
こういった場面では、数値を含むテキストデータが共有される。例えば、医療関係では体温や血圧など患者の検査データに数値が含まれることになる。このようなデータを共有することは、関係者には有用である。 In such situations, text data including numerical values is shared. For example, in medical relations, numerical values are included in patient examination data such as body temperature and blood pressure. Sharing such data is useful to those involved.
一方で、セキュリティとプライバシ保護のため、このようなデータは秘匿化してからクラウドに預けるのは一般的である。そうすると、セキュリティとプライバシが守られるが、データの活用という面では制限が生ずる。すなわち、秘匿化データは、従来の分析アプリケーションや検索サービスでは適切に処理できない。例えば、患者の症状と類似する診療例を検索したい場合であっても、診療データが秘匿化されていると、単純な検索では適切な診療例を見つけることが難しい。 On the other hand, for security and privacy protection, it is common to store such data in the cloud after concealing it. This protects security and privacy, but limits the use of data. That is, the concealment data cannot be appropriately processed by a conventional analysis application or search service. For example, even if it is desired to search for a medical treatment example similar to a patient's symptom, it is difficult to find an appropriate medical treatment example with a simple search if the medical treatment data is concealed.
なお、文書を検索キーワードで検索して、検索キーワードが出現すると当該文書内で検索キーワードに関連する数値と、検索キーワードと共に指定された数値とを比較するような技術が存在している。しかしながら、データを秘匿化することは考慮されていないので、秘匿化すると適切なデータを検索で抽出することは難しい。 There is a technique in which a document is searched with a search keyword, and when a search keyword appears, a numerical value related to the search keyword in the document is compared with a numerical value specified together with the search keyword. However, since it is not considered to conceal data, if it is concealed, it is difficult to extract appropriate data by searching.
また、検索対象のデータを秘匿化してサーバに保持しておき、検索時にも検索条件を同じように秘匿化して検索を行う技術も存在している。しかしながら、暗号化やハッシュ値算出を行うと、完全一致するデータのみしか抽出できないという問題がある。 There is also a technology in which data to be searched is concealed and held in a server, and the search condition is concealed in the same way during the search. However, when encryption or hash value calculation is performed, there is a problem that only data that completely matches can be extracted.
さらに、検索条件入力データとして、数値範囲を指定することができ、数値範囲に少なくとも一致するデータを抽出する技術も存在している。しかしながら、暗号化やハッシュ値算出を行うことは考慮されていない。 Further, there is a technique for specifying a numerical range as search condition input data and extracting data that at least matches the numerical range. However, it is not considered to perform encryption or hash value calculation.
また、秘匿化したデータを一旦安全な場所で復元し、検索条件とマッチング処理を行う技術も存在している。マッチング処理は平文の状態で行われるので、類似するデータをも抽出できるが、検索条件についても平文で入力するので、マッチング処理を行うサーバには検索条件は知られてしまう。 There is also a technique for restoring the concealed data once in a safe place and performing a search condition and matching processing. Since the matching process is performed in a plain text state, similar data can be extracted. However, since the search condition is also input in the plain text, the search condition is known to the server that performs the matching process.
従って、本技術の目的は、一側面としては、秘匿化したまま類似するデータを抽出できるようにするための技術を提供することである。 Therefore, an object of the present technology is to provide a technology for enabling extraction of similar data while keeping it secret in one aspect.
本技術の第1の形態に係る情報処理方法は、(A)データ格納部に格納されており且つ第1の数値を含むテキストデータから、第1の数値及び当該第1の数値の周辺に存在する複数個の特徴語を抽出するステップと、(B)抽出された第1の数値から、当該第1の数値と近似するか否かを判断する上で基準となる1又は複数の第2の数値を生成する生成ステップと、(C)1又は複数の第2の数値と複数個の特徴語との各々について秘匿化処理を行って秘匿化データを生成し、データ格納部に格納するステップとを含む。 The information processing method according to the first embodiment of the present technology is (A) from the text data stored in the data storage unit and including the first numeric value, the first numeric value and the vicinity of the first numeric value. A step of extracting a plurality of feature words, and (B) one or a plurality of second words that serve as a reference in determining whether to approximate the first numerical value from the extracted first numerical value A generation step of generating a numerical value; and (C) a step of generating concealment data by performing concealment processing for each of one or more second numerical values and a plurality of feature words, and storing the data in a data storage unit; including.
本技術の第2の技術に係る情報処理方法は、(A)第1の数値の第1の秘匿化データ値と複数個の第1の特徴語の第2の秘匿化データ値とを含む1又は複数の検索データブロックを含む検索要求を受信するステップと、(B)複数の第2の数値の第3の秘匿化データ値と複数個の第2の特徴語の第4の秘匿化データ値とを含む1又は複数のデータブロックと識別情報とを含む案件データブロックを複数格納するデータ格納部に格納されている案件データブロックの各々について、第1の秘匿化データ値と第3の秘匿化データ値とから算出される、数値についての第1の類似度と、第2の秘匿化データ値と一致する第4の秘匿化データ値の個数とから、処理対象の案件データブロックに含まれるデータブロックと検索データブロックとの各組み合わせについての第2の類似度の合計値である第3の類似度を算出する算出ステップと、(C)第3の類似度が閾値を超えた案件データブロックの識別情報又は第3の類似度が上位所定数の案件データブロックの識別情報を、検索要求の送信元に送信するステップとを含む。
The information processing method according to the second technique of the present technology includes (A) a first concealment data value of a first numerical value and a second concealment data value of a plurality of
本技術の一側面によれば、秘匿化したまま類似するデータを抽出できるようになる。 According to one aspect of the present technology, similar data can be extracted while being kept secret.
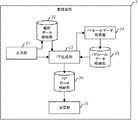
本技術の実施の形態に係るシステムの構成例を図1に示す。図1に示すように、例えばインターネットであるネットワーク1には、登録装置3と、管理装置5と、検索装置7とが接続されている。登録装置3は、以下で述べる処理を行って機密データを秘匿化して、管理装置5に登録する装置であり、登録装置3の数に制限はない。また、検索装置7は、以下で述べる処理を行って検索条件に係る機密データを秘匿化して、秘匿化データと他の検索条件とを含む検索要求を管理装置5に送信し、管理装置5から検索結果を受信する装置であり、検索装置7の数に制限はない。登録装置3と検索装置7は、専用の装置であっても良いし、秘匿化データを登録する際には登録装置3として機能し、検索を行う際には検索装置7として機能する装置であっても良い。
A configuration example of a system according to an embodiment of the present technology is illustrated in FIG. As shown in FIG. 1, a
図2に、登録装置3の機能ブロック図を示す。登録装置3は、入力部31と、機密データ格納部32と、FP(Finger Print)生成部33と、FPルールデータ取得部34と、FPルールデータ格納部35と、FPデータ格納部36と、送信部37とを有する。入力部31は、ユーザからの指示に応じて、機密データ格納部32に、管理装置5に格納すべきデータを格納したり、ユーザから機密データの選択指示を受け付け、当該選択指示をFP生成部33に出力する。FP生成部33は、FPルールデータ格納部35に格納されているFPルールデータに従ってFPデータを生成して、FPデータ格納部36に格納する。なお、FPルールデータ格納部35にFPルールデータが格納されていない場合には、FP生成部33は、FPルールデータ取得部34に対して管理装置5からFPルールデータを取得するように指示する。FPルールデータ取得部34は、FP生成部33からの指示に応じて、管理装置5からFPルールデータを取得して、FPルールデータ格納部35に格納する。送信部37は、FPデータ格納部36に格納されているFPデータを、管理装置5に送信する。
FIG. 2 shows a functional block diagram of the
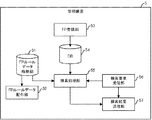
図3に、管理装置5の機能ブロック図を示す。管理装置5は、FPルールデータ格納部51と、FPルールデータ配布部52と、FP登録部53と、データベース(DB)54と、検索処理部55と、検索要求受信部56と、検索結果送信部57とを有する。FPルールデータ配布部52は、FPルールデータ格納部51に格納されているFPルールデータを、要求に応じて配信する。FP登録部53は、登録装置3からFPデータを受信し、DB54に格納する。検索要求受信部56は、検索装置7から、検索要求を受信し、受信した検索要求のデータを検索処理部55に出力する。検索結果送信部57は、検索処理部55から検索結果を受信すると、検索要求の送信元の検索装置7へ検索結果を送信する。検索処理部55は、FPルールデータに従って、検索要求受信部56から受け取った検索要求に含まれる秘匿化データ及び検索条件などを用いた検索処理を実施して、検索結果を検索結果送信部57に出力する。
FIG. 3 shows a functional block diagram of the
図4に、検索装置7の機能ブロック図を示す。検索装置7は、入力部71と、機密データ格納部72と、FP生成部73と、FPルールデータ取得部74と、FPルールデータ格納部75と、検索条件データ格納部76と、FPデータ格納部77と、検索要求部78と、出力部79とを有する。入力部71は、ユーザからの指示に応じて、機密データ格納部72に、検索のための機密データを格納したり、ユーザから機密データの選択指示を受け付け、当該選択指示をFP生成部73に出力する。また、入力部71は、ユーザから検索条件のデータを受け付け、検索条件データ格納部76に格納する。
FIG. 4 shows a functional block diagram of the
FP生成部73は、FPルールデータ格納部75に格納されているFPルールデータに従ってFPデータ等を生成して、FPデータ格納部77に格納する。なお、FPルールデータ格納部75にFPルールデータが格納されていない場合には、FP生成部73は、FPルールデータ取得部74に対して管理装置5からFPルールデータを取得するように指示する。FPルールデータ取得部74は、FP生成部73からの指示に応じて、管理装置5からFPルールデータを取得して、FPルールデータ格納部75に格納する。検索要求部78は、FPデータ格納部77に格納されているFPデータ等と、検索条件データ格納部76に格納されている検索条件データとを読み出して検索要求を生成して、管理装置5に送信する。また、検索要求部78は、管理装置5から検索結果を受信すると、出力部79に出力して、例えば表示装置などに検索結果を表示する。
The
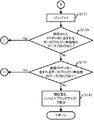
次に、図1乃至図4に示した装置の処理内容について説明する。まず、図5乃至図10を用いて、FPデータの登録処理について説明する。まず、入力部31は、FP生成対象の機密データの指定を受け付ける(図5:ステップS1)。例えば、機密データ格納部32に格納されている機密データを列挙して選択させるようにしても良いし、指定された機密データを他のコンピュータなどから取得して機密データ格納部32に格納するようにしても良い。そして、入力部31は、指定された機密データをFP生成部33に通知する。
Next, processing contents of the apparatus shown in FIGS. 1 to 4 will be described. First, the FP data registration process will be described with reference to FIGS. First, the input unit 31 receives designation of confidential data to be generated by FP (FIG. 5: step S1). For example, the confidential data stored in the confidential
FP生成部33は、FPルールデータ格納部35にFPルールデータが格納されているか確認する(ステップS3)。FPルールデータが格納されていない場合には(ステップS5:Noルート)、FP生成部33は、FPデータ取得部34に、FPルールデータを取得させ、FPルールデータ格納部35に格納させる(ステップS7)。
The
一方、FPルールデータがFPルールデータ格納部35に格納されている場合(ステップS5:Yesルート)、又はステップS7の後に、FP生成部33は、FPルールデータに従って、ユーザにより指定された機密データのFP生成処理を実施する(ステップS9)。FP生成処理については、後に詳しく述べる。これによって、生成されたFPデータは、FPデータ格納部36に格納される。
On the other hand, when the FP rule data is stored in the FP rule data storage unit 35 (step S5: Yes route), or after step S7, the
そして、送信部37は、FPデータ格納部36に格納されているFPデータを、管理装置5に送信する(ステップS11)。これに対して、管理装置5のFP登録部53は、登録装置3からFPデータを受信すると、当該受信したFPデータ及び識別情報などを、DB54に格納する(ステップS13)。識別情報は、例えば登録装置3の登録者IDと、登録日とを含み、FP登録部53が発行したFPIDをも含む。
Then, the
このような処理を繰り返すことで、DB54にFPデータが蓄積されてゆく。 By repeating such processing, FP data is accumulated in the DB 54.
次に、図6乃至図9を用いて、FP生成処理について説明する。FP生成部33は、指定された機密データに対して正規化処理を実施する(図6:ステップS21)。本実施の形態における機密データは、数値を含むテキストデータである。しかしながら、数値は、半角数字、全角数字、漢数字、アラビア数字などで表されている場合があり、さらに単位の違いも含まれる可能性がある。本実施の形態における正規化処理では、このような異なる表現を統一させる処理である。例えば、全角で「7000」を、半角の「7000」へ、「1万円」を半角数字の「10000」に変換する。この正規化処理についてはよく知られているので、これ以上述べない。
Next, the FP generation process will be described with reference to FIGS. The
その後、FP生成部33は、指定された機密データ中の数値及び特徴語を抽出し、例えばメインメモリなどの記憶装置に格納する(ステップS23)。例えば、機密データのテキストを形態素解析により形態素に分解し、さらにその中から数値及び特徴語(例えば一般名詞、固有名詞など)を抽出する。
Thereafter, the
例えば、図7に示すようなテキストを処理する場合を考える。この例では、「患者」「基本」「情報」「主訴」「朝」「体温」「38.5」「発熱」「症状」「検査」「心拍数」「測定」「結果」「85」「以上」「値」「血液検査」...「治療」「方針」などが抽出される。 For example, consider the case of processing text as shown in FIG. In this example, “patient” “basic” “information” “main complaint” “morning” “body temperature” “38.5” “fever” “symptom” “examination” “heart rate” “measurement” “result” “85” “ Above, "value", "blood test". . . “Treatment” and “policy” are extracted.
次に、FP生成部33は、抽出された数値のうち未処理の数値を1つ特定する(ステップS25)。そして、FP生成部33は、FPルールデータ格納部35に格納されているFPルールデータに従って、特定された数値から、FPのための数値を生成し、メインメモリなどの記憶装置に格納する(ステップS27)。本実施の形態では、数値の近似を判断できるようにするために、単純に数値を秘匿化するのではなく、例えば2つの方式のいずれかで、特定された数値を展開する。
Next, the
第1の方式では、複数の有効桁数で、特定された数値を表すようにする。例えば、「38.5」であれば、有効桁数が1であれば「3×101」、有効桁数が2であれば「3.8×101」、有効桁数が3であれば「3.82×101」というように表現を変更する。使用すべき有効桁数についてのデータは、FPルールデータに含まれている。これによって、近似判断の幅を表す数値を生成している。 In the first method, the specified numerical value is represented by a plurality of significant digits. For example, if “38.5”, the number of significant digits is “3 × 10 1 ”, if the number of significant digits is 2, “3.8 × 10 1 ”, and the number of significant digits is 3. For example, the expression is changed to “3.82 × 10 1 ”. Data on the number of significant digits to be used is included in the FP rule data. As a result, a numerical value indicating the width of the approximation determination is generated.
第2の方式では、予め定められた数値の範囲のいずれに、特定された数値が属するかを判断し、特定された数値が属する範囲の上限値及び下限値を特定する。なお、補助データとして、下限値からの差及び上限値からの差をさらに算出する。例えば、10刻みで範囲が規定されている場合には、「38.2」の場合、30乃至40という範囲に属するので、上限値「40」及び下限値「30」が特定される。補助データは、下限値からの差「8.2」と上限値からの差「−1.2」が算出される。FPルールデータには、数値の範囲についての定義が含まれる。このようにして、近似判断の幅を表す数値とその補助数値とが生成される。 In the second method, it is determined to which of the predetermined numerical ranges the specified numerical value belongs, and the upper limit value and the lower limit value of the range to which the specified numerical value belongs are specified. As auxiliary data, a difference from the lower limit value and a difference from the upper limit value are further calculated. For example, when the range is defined in increments of 10, the upper limit value “40” and the lower limit value “30” are specified because “38.2” belongs to the range of 30 to 40. For the auxiliary data, a difference “8.2” from the lower limit value and a difference “−1.2” from the upper limit value are calculated. The FP rule data includes a definition for a range of numerical values. In this way, a numerical value indicating the range of approximation determination and its auxiliary numerical value are generated.
そして、FP生成部33は、生成されたFPのための数値における秘匿部分に対するハッシュ値を生成し、メインメモリなどの記憶装置に格納する(ステップS29)。ハッシュ値ではなく、暗号化であっても良い。鍵を用いる場合には、登録装置3及び検索装置7で共通の鍵を用いる。第1の方式の場合には、有効桁数が1乃至3であれば、「3×101」、「3.8×101」及び「3.82×101」のそれぞれについてハッシュ値を算出する。第2の方式の場合には、特定された数値が属する範囲の上限値及び下限値のそれぞれについてハッシュ値を算出する。補助データについてはハッシュ値を算出しない。
Then, the
このように、FPデータの登録処理の場合には、複数の数値に対して複数のハッシュ値が算出される。単純に数値のハッシュ値を1つだけ算出するだけでは、数値が完全一致するか否かしか判断できない。しかしながら、第1の方式によれば、1桁一致、2桁一致、3桁一致といったように、有効桁数の範囲で一致不一致を判断できるため、近似する数値の有無を判断できる。第2の方式によれば、特定された数値が属する範囲の上限値又は下限値が一致する場合を特定でき、以下で述べるように実際に数値の差をも判断できるため、近似する数値の有無も判断できる。 Thus, in the case of FP data registration processing, a plurality of hash values are calculated for a plurality of numerical values. By simply calculating one numerical hash value, it can only be determined whether or not the numerical values completely match. However, according to the first method, it is possible to determine the coincidence / mismatch within the range of the effective digits, such as one-digit match, two-digit match, and three-digit match. According to the second method, it is possible to specify the case where the upper limit value or the lower limit value of the range to which the specified numerical value belongs, and to determine the difference between the numerical values as described below. Can also be judged.
FP生成部33は、特定された数値の周辺における特徴語を所定個数特定する(ステップS31)。所定個数は、例えばFPルールデータに規定されている。そして、FP生成部33は、特定された各特徴語についてハッシュ値を算出し、メインメモリなどの記憶装置に格納する(ステップS33)。
The
そして、FP生成部33は、数値のハッシュ値等(補助データがある場合には当該補助データ)と特徴語のハッシュ値とを含むデータブロックを、FPデータ格納部36に格納する(ステップS35)。
Then, the
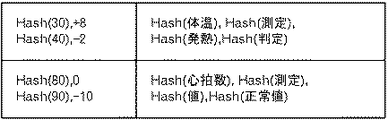
ここまで処理すると図8Aに示すようなデータブロックが、FPデータ格納部36に格納される。図8Aの例では、数値の周辺4個の特徴語についてハッシュ値を算出するようになっている。なお、図8Aは、第1の方式を採用した場合の例を示している。また、Hash(X)は、Xのハッシュ値を表す。一方、第2の方式を採用した場合には、図8Bに示すようなデータブロックが生成される。
When processing is performed so far, the data block as shown in FIG. 8A is stored in the FP
その後、FP生成部33は、機密データから抽出された数値の中で未処理の数値が存在するか判断する(ステップS37)。未処理の数値が存在している場合には処理はステップS25に戻る。一方、未処理の数値が存在していない場合には呼び出し元の処理に戻る。図7の機密データを第1の方式で処理すると、図9Aに示すようなもう一つデータブロックが生成される。一方、第2の方式で処理すると、図9Bに示すようなもう一つのデータブロックが生成される。このように、FPデータは、1又は複数のデータブロックを含む。
Thereafter, the
一般的には、管理装置5のDB54は、例えば図10に示すようなデータが蓄積される。図10の例では、FPIDと、登録者IDと、登録日と、FPデータとが登録されるようになっている。FPデータは、データブロックのIDであるブロック番号と、数値部分と、特徴語部分とを含む。各データブロックの数値部分には、複数の数値のハッシュ値(NUM(1,1),NUM(1,2)など)と、補助データがある場合には補助データ(AUX1など)とを含む。さらに特徴語部分には、複数の特徴語のハッシュ値(KW(1,1),KW(1,2)などM個の特徴語のハッシュ値)を含む。図10の例では、N個のデータブロックが含まれ、各データブロックの特徴語はM個である例を示している。
In general, the DB 54 of the
次に、検索時に行われる処理について図11乃至図21を用いて説明する。まず、検索装置7の入力部71は、ユーザから検索に係る機密データの指定を受け付け、FP生成部73に機密データの指定を出力する(図11:ステップS41)。機密データ格納部72に格納されていない場合には、例えば他のコンピュータから、指定された機密データを取得して、FP生成部73に出力するようにしても良い。
Next, processing performed at the time of search will be described with reference to FIGS. First, the
また、入力部71は、ユーザから検索条件の入力を受け付け、検索条件データ格納部76に格納する(ステップS43)。以下で具体的な検索処理において用いられるパラメータを、ユーザが指定する。例えば、類似度の閾値や結果の出力数などが指定される。どのパラメータを指定すべきかは、例えばFPルールデータに含まれる場合もある。また、FPデータを生成する上で用いられるパラメータについては、FP生成部73に出力される。
Further, the
そして、FP生成部73は、FPルールデータ格納部75に、FPルールデータが格納されているか判断する(ステップS45)。FPルールデータがFPルールデータ格納部75に格納されていない場合には(ステップS47:Noルート)、FP生成部73は、FPデータ取得部74に、FPルールデータを取得させ、FPルールデータ格納部75に格納させる(ステップS49)。
Then, the
一方、FPルールデータがFPルールデータ格納部75に格納されている場合(ステップS47:Yesルート)、又はステップS49の後に、FP生成部73は、FPルールデータに従って、ユーザにより指定された機密データの第2FP生成処理を実施する(ステップS51)。第2FP生成処理については、図12乃至図15Bを用いて説明する。
On the other hand, when the FP rule data is stored in the FP rule data storage unit 75 (step S47: Yes route), or after step S49, the
FP生成部73は、指定された機密データに対して正規化処理を実施する(図12:ステップS71)。ステップS21と同様である。
The
その後、FP生成部73は、指定された機密データ中の数値及び特徴語を抽出し、例えばメインメモリなどの記憶装置に格納する(ステップS73)。ステップS23と同様である。
Thereafter, the
例えば、図13に示すようなテキストを処理する場合を考える。この例では、「患者」「基本」「情報」「主訴」「体温」「38」「測定」「発熱」「判定」「検査」「心拍数」「測定」「値」「80」「正常値」...「治療」「方針」などが抽出される。 For example, consider the case of processing text as shown in FIG. In this example, “patient” “basic” “information” “main complaint” “body temperature” “38” “measurement” “fever” “determination” “examination” “heart rate” “measurement” “value” “80” “normal value” ". . . “Treatment” and “policy” are extracted.
次に、FP生成部73は、抽出された数値のうち未処理の数値を1つ特定する(ステップS75)。そして、FP生成部73は、FPルールデータ格納部75に格納されているFPルールデータに従って、特定された数値から、FPのための1又は複数の数値を生成し、メインメモリなどの記憶装置に格納する(ステップS77)。本ステップについてもステップS27と基本的には同様である。
Next, the
但し、本実施の形態では、第1の方式を採用する場合には、有効桁数の指定が検索条件に含まれる場合がある。その場合には、FPのための数値について、複数の数値を生成するのではなく、指定された有効桁数の数値を生成する。 However, in this embodiment, when the first method is adopted, designation of the number of significant digits may be included in the search condition. In that case, instead of generating a plurality of numerical values for the numerical value for the FP, a numerical value having a designated effective number of digits is generated.
図13の例の場合、「38」については、指定された有効桁数が「2」であれば、「3.8×101」というような表現の数値が生成される。 In the case of the example in FIG. 13, for “38”, if the designated number of significant digits is “2”, a numerical value with an expression such as “3.8 × 10 1 ” is generated.
また、第2の方式を採用する場合には、上で述べた方法と同様の方法を採用しても良い。例えば、10刻みで数値の範囲が規定されている場合には、「38」の場合、30乃至40という範囲に属するので、上限値「40」及び下限値「30」が特定される。補助データは、下限値からの差「8」と上限値からの差「−2」が算出される。この場合、下限値及び上限値が代表値としてハッシュ値の算出対象数値として取り扱われる。 When the second method is adopted, a method similar to the method described above may be adopted. For example, when the range of numerical values is defined in increments of 10, the value “38” belongs to the range of 30 to 40, so the upper limit value “40” and the lower limit value “30” are specified. For the auxiliary data, a difference “8” from the lower limit value and a difference “−2” from the upper limit value are calculated. In this case, the lower limit value and the upper limit value are treated as the calculation target numerical values of the hash value as representative values.
但し、第2の方式の場合、検索条件として近似と判断する範囲を指定するため、この近似と判断する範囲に基づき、特定された数値を展開してもよい。例えば、プラスマイナス1の範囲が近似と判断する範囲として指定された場合、特定された数値が「38」であれば「37」から「39」までであれば近似していると判断される。従って、特定された数値が属する数値の範囲を超えて近似と判断されることがないので、所属範囲の下限値「30」を代表値として特定し、当該代表値からの差「8」が補助データとして特定される。一方、特定された数値が「41」である場合に、プラスマイナス3の範囲が近似と判断する範囲として指定されると、「38」から「44」までであれば近似していると判断される。従って、代表値としては、所属する範囲の1つ下の範囲の下限値「30」と、所属する範囲の下限値「40」を代表値として特定し、補助データとして、第1の下限値からの差「11」と第2の下限値からの差「1」が算出される。
However, in the case of the second method, since a range that is determined to be approximate is designated as a search condition, a specified numerical value may be developed based on the range that is determined to be approximate. For example, when a range of plus or
上で述べた例では、数値の範囲の刻みを超えて近似と判断される範囲が規定されないという前提があるが、このような前提が成り立たない場合には、以下のようにする。例えば、10刻みで範囲が規定されているが、特定された数値が「123」で、プラスマイナス15が近似と判断する範囲と指定された場合、「108」乃至「138」が近似と判断される。従って、「100」「110」「120」「130」を代表値として特定し、それぞれとの差を補助データとして生成する。 In the example described above, there is a premise that the range that is determined to be approximate beyond the range of the numerical value range is not defined. If such a premise is not satisfied, the following is performed. For example, if the range is defined in increments of 10, but the specified numerical value is “123” and plus or minus 15 is designated as the range to be approximated, “108” to “138” are determined to be approximate. The Therefore, “100”, “110”, “120”, and “130” are specified as representative values, and the difference between them is generated as auxiliary data.
そして、FP生成部73は、生成された1又は複数の数値における秘匿部分に対するハッシュ値を生成し、メインメモリなどの記憶装置に格納する(ステップS79)。ステップS29と同様である。第2の方式の場合には、補助データはハッシュ値を算出しない。
Then, the
このように、検索を行う場合には、特定された数値に対して、FPのための数値として1又は複数の数値が生成される。但し、FP登録時と同様にFPデータを生成しても良い。上で述べたようなオプションについては、FPルールデータに規定されているものとする。 As described above, when a search is performed, one or a plurality of numerical values are generated as numerical values for the FP with respect to the specified numerical values. However, FP data may be generated as in FP registration. The options as described above are defined in the FP rule data.
FP生成部73は、特定された数値の周辺における特徴語を所定個数特定する(ステップS81)。所定個数は、例えばFPルールデータに規定されている。そして、FP生成部73は、特定された各特徴語についてハッシュ値を算出し、メインメモリなどの記憶装置に格納する(ステップS83)。
The
そして、FP生成部73は、数値のハッシュ値等(補助データがある場合には当該補助データ)と特徴語のハッシュ値とを含むデータブロックを、FPデータ格納部77に格納する(ステップS85)。ステップS35と同様である。
Then, the
その後、FP生成部73は、機密データから抽出された数値の中で未処理の数値が存在するか判断する(ステップS87)。未処理の数値が存在している場合には処理はステップS75に戻る。一方、未処理の数値が存在していない場合には呼び出し元の処理に戻る。
Thereafter, the
例えば、図13に示した機密データについて、単純な第1の方式を採用した場合には、図14Aに示すようなFPデータが生成される。また、第1の方式で有効桁数が「2」である場合には、例えば図14Bに示したようなFPデータが生成される。一方、単純な第2の方式によれば、図15Aに示したようなFPデータが生成される。さらに、検索条件で近似と判断される範囲がプラスマイナス3であれば、図15Bに示したようなFPデータが生成される。
For example, when the simple first method is adopted for the confidential data shown in FIG. 13, FP data as shown in FIG. 14A is generated. When the number of significant digits is “2” in the first method, for example, FP data as shown in FIG. 14B is generated. On the other hand, according to the simple second method, FP data as shown in FIG. 15A is generated. Furthermore, if the range determined to be approximate by the search condition is plus or
このようにすれば、完全一致だけではなく数値が近似しているか否かを判定できるようになる。 In this way, it is possible to determine whether the numerical values are approximated as well as exact matches.
図11の処理の説明に戻って、検索装置7の検索要求部78は、FPデータ格納部77に格納されているFPデータ(以下、区別するため検索FPデータと呼ぶ)と検索条件データ格納部76に格納されているデータとを含む検索要求を、管理装置5に送信する(ステップS53)。
Returning to the description of the processing in FIG. 11, the
管理装置5の検索要求受信部56は、検索装置7から、検索FPデータ及び検索条件を含む検索要求を受信すると(ステップS55)、検索要求のデータを検索処理部55に出力する。検索処理部55は、検索要求のデータを受け取ると、検索処理を実施する(ステップS57)。この検索処理については、図16乃至図21を用いて説明する。
When receiving the search request including the search FP data and the search condition from the search device 7 (step S55), the search
検索処理部55は、FPルールデータ格納部51からFPルールデータを読み出す(図16:ステップS91)。そして、検索処理部55は、類似すると判定されたFPについての識別情報を格納する類似FP配列を初期化する(ステップS93)。さらに、検索処理部55は、類似判定のための閾値Tを、FPルールデータ又は検索条件から設定する(ステップS95)。閾値は固定のこともあり、その場合にはFPルールデータに含まれる。
The
その後、検索処理部55は、DB54内の未処理のFPデータを特定する(ステップS97)。そして、検索処理部55は、特定されたFPデータと検索FPデータとについて類似度算出処理を実施する(ステップS99)。類似度算出処理については、図17乃至図21を用いて説明する。
Thereafter, the
まず、検索処理部55は、数値の類似度に応じた特徴語の共通度合いの累計値を算出するための変数c1及び特定されたFPデータに含まれるデータブロック数をカウントするための変数c2を0に初期化する(図17:ステップS111)。また、検索処理部55は、検索FPデータに含まれるデータブロックのうち未処理のデータブロックの数値データN1を特定する(ステップS113)。ハッシュ値が複数ある場合、補助データがある場合も、それらを含めてN1として特定する。
First, the
さらに、検索処理部55は、特定されたFPデータに含まれるデータブロックのうち未処理のデータブロックの数値データN2を特定する(ステップS115)。ここでも、ハッシュ値が複数ある場合、補助データがある場合も、それらも含めてN2として特定する。
Further, the
そして、検索処理部55は、数値データN1と数値データN2とを比較して、数値類似度Simを設定する(ステップS119)。本実施の形態では、上で述べた2つの方式が存在する。最初に、単純な比較方式について説明する。
Then, the
第1の方式の場合、数値データN1には1又は複数のハッシュ値が含まれ、数値データN2には複数のハッシュ値が含まれる。例えば、数値データN1に複数のハッシュ値が含まれる例を図18に示す。図18の例では、数値データN1の元の数値は38.2で、有効桁数1乃至3の場合のハッシュ値が数値データN1に含まれる。一方、図18には、元の数値が38.2であるデータブロック(A)の数値データN2と、元の数値が38であるデータブロック(B)の数値データN2と、元の数値が39であるデータブロック(C)の数値データN2とが比較対象として示されている。このように複数のハッシュ値が数値データN1に含まれる場合には、いずれかのハッシュ値が、比較対象の数値データN2に含まれるハッシュ値と一致すれば、Simに1を設定し、いずれのハッシュ値も、比較対象の数値データN2に含まれるハッシュ値と一致しなければ、Simに0を設定する。図18の例では、データブロック(A)乃至(C)のいずれも有効桁数「1」について一致するので、Sim=1と設定される。 In the case of the first method, the numerical data N1 includes one or a plurality of hash values, and the numerical data N2 includes a plurality of hash values. For example, FIG. 18 shows an example in which the numerical data N1 includes a plurality of hash values. In the example of FIG. 18, the original numerical value of the numerical data N1 is 38.2, and the hash value when the number of significant digits is 1 to 3 is included in the numerical data N1. On the other hand, FIG. 18 shows the numerical data N2 of the data block (A) whose original numerical value is 38.2, the numerical data N2 of the data block (B) whose original numerical value is 38, and the original numerical value of 39. Numerical data N2 of the data block (C) is shown as a comparison target. In this way, when a plurality of hash values are included in the numerical data N1, if any hash value matches the hash value included in the numerical data N2 to be compared, 1 is set in Sim, If the hash value does not match the hash value included in the numerical data N2 to be compared, 0 is set to Sim. In the example of FIG. 18, since all of the data blocks (A) to (C) match for the number of significant digits “1”, Sim = 1 is set.
一方、数値データN1に、指定された有効桁数のハッシュ値が1つだけ含まれる場合には、その1つのハッシュ値に一致するか否かを判断する。例えば、数値データN1について有効桁数2である「3.8×101」のみが含まれる場合には、データブロック(A)及び(B)については有効桁数2についてのハッシュ値が一致するが、データブロック(C)については一致するハッシュ値がないと判断される。
On the other hand, when the numerical data N1 includes only one hash value having the designated number of significant digits, it is determined whether or not it matches the one hash value. For example, when only the number of significant digits “3.8 × 10 1 ” is included for the numerical data N1, the hash values for the number of
第2の方式の場合、数値データN1には1又は複数のハッシュ値及び対応する補助データとが含まれ、数値データN2には複数のハッシュ値及び対応する補助データが含まれる。図19に、数値データN1と数値データN2との比較例を模式的に示す。例えば、元の数値「38.2」の数値データN2には、Hash(30)及び補助データ「8.2」とHash(40)及び補助データ「−1.8」とが含まれている。これに対して、元の数値「39.1」の数値データN1には、Hash(30)及び補助データ「9.1」とHash(40)及び補助データ「−0.9」とが含まれる。なお、検索条件として近似と判断する範囲のデータが指定され、ここではプラスマイナス1が指定されているものとする。
In the case of the second method, the numerical data N1 includes one or more hash values and corresponding auxiliary data, and the numerical data N2 includes a plurality of hash values and corresponding auxiliary data. FIG. 19 schematically shows a comparative example between the numerical data N1 and the numerical data N2. For example, the numerical data N2 of the original numerical value “38.2” includes Hash (30), auxiliary data “8.2”, Hash (40), and auxiliary data “−1.8”. On the other hand, the numerical data N1 of the original numerical value “39.1” includes Hash (30), auxiliary data “9.1”, Hash (40), and auxiliary data “−0.9”. . It should be noted that data in a range determined to be approximate is designated as a search condition, and here, plus or
この場合、数値データN1に含まれるハッシュ値と、数値データN2に含まれるハッシュ値とを比較して一致するものがあるか判断する。図19の例ではhash(30)及びhash(40)のいずれも一致すると判断される。そして、hash(30)の場合には、数値データN2の補助データ「8.2」と数値データN1の補助データ「9.1」との差が、指定された範囲内であるか否かを判断する。この場合、|9.1−8.2|=0.9であるから、指定された範囲内であるので、本実施の形態では、数値類似度Sim=1に設定する。もし、補助データの差が、指定された範囲を超えている場合には、数値類似度Sim=0に設定する。hash(40)については同じ値が得られるので、処理しなくとも良い。 In this case, the hash value included in the numerical data N1 and the hash value included in the numerical data N2 are compared to determine whether there is a match. In the example of FIG. 19, it is determined that both hash (30) and hash (40) match. In the case of hash (30), it is determined whether or not the difference between the auxiliary data “8.2” of the numerical data N2 and the auxiliary data “9.1” of the numerical data N1 is within a specified range. to decide. In this case, since | 9.1-8.2 | = 0.9, it is within the specified range, and therefore in this embodiment, the numerical similarity Sim = 1 is set. If the difference between the auxiliary data exceeds the designated range, the numerical similarity Sim = 0 is set. Since the same value is obtained for hash (40), it is not necessary to process it.
次に、数値の類似度合いに応じて数値類似度Simを0から1までの実数を設定する方式について説明する。第1の方式の場合には、図18に示すように、数値データN1に複数のハッシュ値が含まれ、数値データN2にも複数のハッシュ値が含まれる。従って、同一の有効桁数のハッシュ値同士を比較して、一致する回数をカウントする。例えばデータブロック(A)の場合、元の数値が一致するので、3回一致する。データブロック(B)の場合、有効桁数2まで一致するので、2回一致する。データブロック(C)については、有効桁数1まで一致するので、1回一致する。従って、データブロック(A)については、Sim=3回/3(=有効桁数の種類数)=1を設定し、データブロック(B)については、Sim=2回/3=0.67を設定し、データブロック(C)については、Sim=1回/3=0.33を設定する。 Next, a method for setting a real number from 0 to 1 as the numerical similarity Sim according to the numerical similarity will be described. In the case of the first method, as shown in FIG. 18, the numerical data N1 includes a plurality of hash values, and the numerical data N2 also includes a plurality of hash values. Therefore, hash values having the same number of significant digits are compared, and the number of times of matching is counted. For example, in the case of the data block (A), since the original numerical values match, they match three times. In the case of the data block (B), it matches up to 2 significant digits, so it matches twice. Since the data block (C) matches up to 1 significant digit, it matches once. Therefore, for data block (A), Sim = 3 times / 3 (= number of types of significant digits) = 1 is set, and for data block (B), Sim = 2 times / 3 = 0.67. For data block (C), Sim = 1 times / 3 = 0.33 is set.
一方、第2の方式の場合、上で述べたように補助データの差が算出されるので、(指定された範囲−補助データの差の絶対値)/(指定された範囲)で算出する。上で述べた例では、Sim=|1−0.9|/1=0.1と算出される。 On the other hand, in the case of the second method, since the difference between the auxiliary data is calculated as described above, it is calculated by (specified range-absolute value of auxiliary data difference) / (specified range). In the example described above, Sim = | 1-0.9 | /1=0.1 is calculated.
その後、検索処理部55は、数値類似度Simが0を超えているか判断する(ステップS121)。数値類似度Simが0である場合には、端子Bを介して図21のステップS137に移行する。これは、数値類似度Simとの乗算によってそのデータブロックについての類似度が決定されるので、数値類似度Sim=0であれば、当該データブロックについて比較を行っても全体で0となってしまうためである。一方、数値類似度Sim>0であれば、端子Aを介して図20のステップS123の処理に移行する。
After that, the
図20の処理の説明に移行して、検索処理部55は、数値データN1に対応するデータブロックに含まれる特徴語のうち未処理の特徴語のハッシュ値KW1を特定する(ステップS123)。また、検索処理部55は、数値データN2に対応するデータブロックに含まれる特徴語のうち未処理の特徴語のハッシュ値KW2を特定する(ステップS125)。そして、検索処理部55は、ハッシュ値KW1とハッシュ値KW2とを比較する(ステップS127)。
Shifting to the description of the processing in FIG. 20, the
なお、本実施の形態では同一のFPデータについて類似度を算出した場合には、1になることを前提としている。しかし、一般的には、数値について同一のハッシュ値が異なるデータブロックで出現する場合がある。この場合、異なる特徴語のハッシュ値が対応付けられている場合には特に問題ないが、同一の特徴語のハッシュ値が対応付けられている場合には同一のFPデータについて類似度を算出すると全体として類似度が1を超えてしまう。そこで、数値についてのハッシュ値と特徴語についてのハッシュ値との組み合わせが既に出現していたことが判明した場合には、その比較結果を類似度に反映しないようにする。 In this embodiment, it is assumed that the similarity is 1 when the similarity is calculated for the same FP data. However, in general, the same hash value may appear in different data blocks for numerical values. In this case, there is no particular problem when hash values of different feature words are associated with each other, but when hash values of the same feature words are associated with each other, the similarity is calculated for the same FP data as a whole. As a result, the degree of similarity exceeds 1. Therefore, when it is found that a combination of a hash value for a numerical value and a hash value for a feature word has already appeared, the comparison result is not reflected in the similarity.
従って、検索処理部55は、KW1=KW2であって且つ数値データN1とKW1の組み合わせが初出であるか判断する(ステップS129)。KW1とKW2とが一致しない場合、又は数値データN1とKW1の組み合わせが既出である場合には、ステップS133に移行する。
Therefore, the
一方、KW1=KW1であって且つ数値データN1とKW1の組み合わせが初出である場合、検索処理部55は、変数c1に数値類似度Simを加算して新たな変数c1の値として設定する(ステップS131)。数値類似度Simが0又は1の場合には、変数c1には、共通する特徴語の数が設定される。一方、数値類似度Simが0から1までの値で変化する場合には、変数c1には、データブロック毎に数値類似度Simで重み付けされた共通特徴語の数が累積される。
On the other hand, when KW1 = KW1 and the combination of the numerical data N1 and KW1 is the first appearance, the
そして、検索処理部55は、数値データN2に対応するデータブロックに未処理の特徴語のハッシュ値KW2が存在するか判断する(ステップS133)。未処理の特徴語のハッシュ値が存在する場合にはステップS125に戻る。一方、未処理の特徴語のハッシュ値が存在しない場合には、検索処理部55は、数値データN1に対応するデータブロックに未処理の特徴語が存在するか判断する(ステップS135)。未処理の特徴語のハッシュ値が存在する場合にはステップS123に戻る。一方、未処理の特徴語のハッシュ値が存在しない場合には、端子Bを介して図21のステップS137に移行する。
Then, the
図21の処理の説明に移行して、検索処理部55は、変数c2を1インクリメントする(ステップS137)。検索処理部55は、特定されたFPデータに含まれるデータブロックに未処理のデータブロックがあるか判断する(ステップS139)。特定されたFPデータに未処理のデータブロックが存在している場合には、処理は端子Cを介して図17のステップS115に戻る。一方、特定されたFPデータに未処理のデータブロックが存在しない場合には、検索処理部55は、検索FPデータに含まれるデータブロックに未処理のデータブロックが存在するか判断する(ステップS141)。検索FPデータに未処理のデータブロックが存在する場合には、処理は端子Dを介して図17のステップS113に戻る。一方、検索FPデータに未処理のデータブロックが存在しない場合には、検索処理部55は、c1/(c2×ブロックサイズ)により類似度を算出し、FPデータの識別情報に対応付けて例えばメインメモリなどの記憶装置に格納する(ステップS143)。ブロックサイズは、1データブロックに含まれる特徴語の数である。そして呼び出し元の処理に戻る。
Shifting to the description of the processing in FIG. 21, the
このような処理を実施することで、数値をベースに特徴語も類似する機密データを秘匿性を保持しつつ検索することができる。数値についても近似しているか否かを秘匿化したままで判断できる。さらに検索FPデータについても秘匿化されており、管理装置5に対しても、どのような検索を行っているのかについて秘密が保持されている。
By performing such processing, it is possible to search confidential data having similar feature words based on numerical values while maintaining confidentiality. Whether the numerical value is approximated or not can be determined while keeping it secret. Further, the search FP data is also concealed, and the
なお、ステップS143で計算される類似度については、特定されたFPデータにフォーカスし、そのデータに含まれるブロック数c2を類似度計算式に入れた。そのほかに、検索FPデータに含まれるブロック数NQをc2の代わりに使い、特徴語の共通度合いc1が検索FPデータのサイズ(ブロック数NQ×ブロックサイズ)のどの程度の割合を占めるかを表す類似度も考えられる。その計算式は以下の式で表される。同様に、利用場面によっては、c2とNQの大きい方max(c2, NQ)、または小さい方min(c2, NQ)をc2の代わりに使うことも考えられる。 Note that the similarity calculated in step S143 is focused on the specified FP data, and the number of blocks c2 included in the data is included in the similarity calculation formula. In addition, the number of blocks N Q included in the search FP data is used instead of c2, and the degree of commonness c1 of the feature word occupies the size of the search FP data size (number of blocks N Q × block size). The degree of similarity can also be considered. The calculation formula is represented by the following formula. Similarly, by the use scene it is also contemplated to use larger max of c2 and N Q (c2, N Q) , or the smaller min to (c2, N Q) instead of c2.

ここでQが検索FPデータを表し、Dが比較対象のFPデータを表す。そして、Block_sizeは、上で述べたブロックサイズであり、NQは、検索FPデータのデータブロック数を表す。NumQiは、検索FPデータにおけるi番目のデータブロックの数値データを表し、NumDjは、比較対象のFPデータにおけるj番目のデータブロックの数値データを表す。Sim(NumQi,NumDj)は、検索FPデータにおけるi番目のデータブロックの数値データと、比較対象のFPデータにおけるj番目のデータブロックの数値データとの類似度Simを表す。BQi∩BDjは、検索FPデータにおけるi番目のデータブロックに含まれる特徴語のハッシュ値と、比較対象のFPデータにおけるj番目のデータブロックに含まれる特徴語のハッシュ値とで共通するハッシュ値の個数を表す。 Here, Q represents search FP data, and D represents FP data to be compared. Block_size is the block size described above, and N Q represents the number of data blocks of the search FP data. Num Qi represents the numerical data of the i-th data block in the search FP data, and Num Dj represents the numerical data of the j-th data block in the FP data to be compared. Sim (Num Qi , Num Dj ) represents the similarity Sim between the numerical data of the i-th data block in the search FP data and the numerical data of the j-th data block in the FP data to be compared. B Qi ∩B Dj is a hash common to the hash value of the feature word included in the i-th data block in the search FP data and the hash value of the feature word included in the j-th data block in the FP data to be compared. Represents the number of values.
図16の処理の説明に戻って、検索処理部55は、算出した類似度が、検索条件で指定された閾値Tを超えているか判断する(ステップS101)。類似度が閾値Tを超えている場合には、検索処理部55は、特定されたFPデータの識別情報(図10におけるFPID、登録者ID及び登録日など)を含む書誌データを、類似FP配列に追加する(ステップS103)。検索者の参照のため、類似度の数値自体を書誌データに含めるようにしても良い。一方、類似度が閾値T以下である場合には、ステップS105に移行する。
Returning to the description of the processing in FIG. 16, the
ステップS101で類似度が閾値T以下であると判断された場合又はステップS103の後に、検索処理部55は、DB54内に未処理のFPデータが存在しているか判断する(ステップS105)。未処理のFPデータが存在している場合には処理はステップS97に戻る。一方、未処理のFPデータが存在していない場合には、検索処理部55は、類似FP配列のデータを検索結果送信部57に出力する(ステップS107)。そして呼び出し元の処理に戻る。なお、登録者の詳細データについて追加した形で、検索結果送信部57に出力するようにしても良い。
When it is determined in step S101 that the similarity is equal to or less than the threshold value T or after step S103, the
このようにして完全一致だけではなく類似するFPデータを特定して、当該FPデータに関連するデータが抽出される。 In this way, not only perfect matching but also similar FP data is specified, and data related to the FP data is extracted.
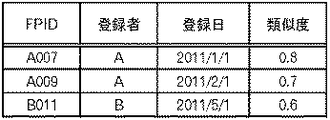
図11の処理の説明に戻って、検索結果送信部57は、検索処理部55から受け取った検索結果のデータを、検索要求の送信元である検索装置7に送信する(ステップS59)。検索装置7の検索要求部78は、検索結果を管理装置5から受信し、出力部79に出力する(ステップS61)。そして、出力部79は、検索結果を表示装置などに出力する。例えば、図22に示すようなデータが表示装置に表示される。図22の例では、FPIDと、登録者と、登録日と、類似度とが表示される。このように類似度が高い順にソートされた結果が提示されるようにしても良い。
Returning to the description of the processing in FIG. 11, the search
これによって、検索者は、類似するFPデータの登録者を特定できるので、当該登録者に具体的な情報提供を依頼することができるようになる。 As a result, the searcher can specify a registrant of similar FP data, and can request specific information from the registrant.
例えば、診療データについてFPデータを登録する場合には、診療データそのものを開示することがないので、プライバシ保護やセキュリティ保護の観点で問題が生じず、管理装置5へのFPデータ登録が促進される。一方、検索側でも患者のデータは秘匿化されたままであり、プライバシ保護やセキュリティ保護の観点で問題は無いので、利用の促進も図られる。そして、具体的に類似する症例の存在が確認できれば、別途問い合わせを行うことで、治療法などの情報を早期に取得でき、患者にも有効である。
For example, when registering FP data for medical data, since the medical data itself is not disclosed, there is no problem in terms of privacy protection and security protection, and registration of FP data in the
以上本技術の実施の形態を説明したが、本技術はこれに限定されるものではない。例えば、機密データから特徴語を特定するような処理を実施していたが、これに加えて、図23に示すような処理フローを実施しても良い。ステップS201乃至S205以外は、図6と同様である。FP生成部33は、特定された特徴語の同義語を辞書から抽出し(ステップS201)、各特徴語及び各同義語についてハッシュ値を算出する(ステップS203)。又、FP生成部33は、特徴語に加えて同義語のハッシュ値をも含むデータブロックをFPデータ格納部36に格納する(ステップS205)。このようにして、同義語についてのハッシュ値をもFPデータに含めるようにしても良い。
Although the embodiment of the present technology has been described above, the present technology is not limited to this. For example, processing for specifying a feature word from confidential data has been performed, but in addition to this, a processing flow as shown in FIG. 23 may be performed. Steps S201 to S205 are the same as in FIG. The
さらに、上では閾値Tを検索条件に含める例を示したが、例えば類似度が高い順で上位指定個数のFPデータを抽出するようにしても良い。 Furthermore, although the example in which the threshold value T is included in the search condition has been described above, for example, the upper designated number of FP data may be extracted in descending order of similarity.
さらに、上で示した機能ブロック図は一例であって、必ずしも実際のプログラムモジュール構成と一致しない場合もある。さらに、処理フローについても、処理結果が変わらない限り処理ステップの順番を入れ替えたり、並列実行するようにしても良い。 Furthermore, the functional block diagram shown above is an example, and may not necessarily match the actual program module configuration. Further, regarding the processing flow, as long as the processing result does not change, the order of the processing steps may be changed or may be executed in parallel.
また、FPルールデータは、管理装置5以外で管理しても良い。
The FP rule data may be managed by a device other than the
なお、上で述べた登録装置3、管理装置5及び検索装置7は、コンピュータ装置であって、図24に示すように、メモリ2501とCPU(Central Processing Unit)2503とハードディスク・ドライブ(HDD:Hard Disk Drive)2505と表示装置2509に接続される表示制御部2507とリムーバブル・ディスク2511用のドライブ装置2513と入力装置2515とネットワークに接続するための通信制御部2517とがバス2519で接続されている。オペレーティング・システム(OS:Operating System)及び本実施例における処理を実施するためのアプリケーション・プログラムは、HDD2505に格納されており、CPU2503により実行される際にはHDD2505からメモリ2501に読み出される。CPU2503は、アプリケーション・プログラムの処理内容に応じて表示制御部2507、通信制御部2517、ドライブ装置2513を制御して、所定の動作を行わせる。また、処理途中のデータについては、主としてメモリ2501に格納されるが、HDD2505に格納されるようにしてもよい。本技術の実施例では、上で述べた処理を実施するためのアプリケーション・プログラムはコンピュータ読み取り可能なリムーバブル・ディスク2511に格納されて頒布され、ドライブ装置2513からHDD2505にインストールされる。インターネットなどのネットワーク及び通信制御部2517を経由して、HDD2505にインストールされる場合もある。このようなコンピュータ装置は、上で述べたCPU2503、メモリ2501などのハードウエアとOS及びアプリケーション・プログラムなどのプログラムとが有機的に協働することにより、上で述べたような各種機能を実現する。
The
以上述べた本実施の形態をまとめると、以下のようになる。 The above-described embodiment can be summarized as follows.
本実施の形態の第1の形態に係る情報処理方法は、(A)データ格納部に格納されており且つ第1の数値を含むテキストデータから、第1の数値及び当該第1の数値の周辺に存在する複数個の特徴語を抽出する処理と、(B)抽出された第1の数値から、当該第1の数値と近似するか否かを判断する上で基準となる1又は複数の第2の数値を生成する生成処理と、(C)1又は複数の第2の数値と複数個の特徴語との各々について秘匿化処理を行って秘匿化データを生成し、データ格納部に格納する処理とを含む。 The information processing method according to the first embodiment of the present embodiment is based on (A) text data stored in the data storage unit and including the first numerical value, and the first numerical value and the surroundings of the first numerical value. A process of extracting a plurality of feature words existing in (B), and (B) one or a plurality of first reference values used as a reference in determining whether to approximate the first numerical value from the extracted first numerical value Generation processing for generating a numerical value of 2, and (C) concealment processing is performed on each of one or more second numerical values and a plurality of feature words to generate concealment data, and store the data in the data storage unit Processing.
このように第2の数値を生成して当該第2の数値の秘匿化データを生成すれば、完全一致だけではなく近似する数値についても検出できるようになる。なお、第2の数値を1つだけ生成するのではなく複数生成すれば、より近似する数値を検出し易くなる。これはデータ登録時でもデータ検索時でも同様である。なお、第1の数値と類似するか否かを判断する上で基準となる数値は、近似判断の幅を表す数値とも言える。 If the second numerical value is generated and the concealment data of the second numerical value is generated in this way, it is possible to detect not only a perfect match but also an approximate numerical value. If a plurality of second numerical values are generated instead of only one, it becomes easier to detect a more approximate numerical value. This is the same during data registration and data retrieval. In addition, it can be said that the numerical value used as a reference in determining whether or not the first numerical value is similar is a numerical value indicating the range of approximation determination.
また、上で述べた生成処理が、抽出された第1の数値を異なる有効桁数で表した複数の第2の数値を生成する処理である場合もある。このようにすれば、有効桁数によって近似の精度を調整できる。 In addition, the generation process described above may be a process of generating a plurality of second numerical values in which the extracted first numerical values are represented by different effective digits. In this way, the accuracy of approximation can be adjusted by the number of significant digits.
さらに、上で述べた生成処理が、抽出された第1の数値を含む所定の数値範囲の上限値及び下限値である複数の第2の数値を特定する処理と、第1の数値と下限値との差と、第1の数値と上限値との差とを算出し、データ格納部に格納する処理とを含むようにしても良い。このようにすれば、検索の際に、元の数値との差を計算しやすくなる。 Further, the generation processing described above specifies a plurality of second numerical values that are an upper limit value and a lower limit value of a predetermined numerical range including the extracted first numerical value, and the first numerical value and the lower limit value. And a process of calculating a difference between the first numerical value and the upper limit value and storing the difference in the data storage unit. In this way, it becomes easy to calculate the difference from the original numerical value during the search.
さらに、上で述べた生成処理が、抽出された第1の数値と、数値を分類するための数値範囲の設定とから、第1の数値を代表する1又は複数の第2の数値を特定する処理と、1又は複数の第2の数値と、第1の数値との差を算出し、データ格納部に格納する処理とを含むようにしても良い。例えば、検索のためのデータを生成する際には、近似と判断する範囲なども加味して第2の数値を生成すれば、検索時に近似する数値についての秘匿化データを正確に特定できるようになる。 Further, the generation process described above specifies one or more second numerical values representing the first numerical value from the extracted first numerical value and the setting of the numerical value range for classifying the numerical value. The process may include a process of calculating a difference between the first numerical value and the first numerical value and the first numerical value and storing the difference in the data storage unit. For example, when generating the data for search, if the second numerical value is generated in consideration of the range determined to be approximate, the concealment data for the numerical value approximated at the time of the search can be accurately specified. Become.
また、上で述べた生成処理が、抽出された第1の数値を、指示された有効桁数で表した第2の数値を1つ生成する処理である場合もある。検索時にはこのように有効桁数を指定することで、所望の精度で近似を判断できるようになる。 In addition, the generation process described above may be a process of generating one second numerical value in which the extracted first numerical value is represented by the designated effective number of digits. By specifying the number of significant digits in this way at the time of search, approximation can be determined with a desired accuracy.
さらに、本実施の形態の第1の形態に係る情報処理方法は、複数個の特徴語の同義語を抽出する処理と、同義語の秘匿化を行って秘匿化データを生成し、データ格納部に格納する処理とをさらに含むようにしても良い。これによれば、類似する秘匿化データを抽出し易くなる。 Furthermore, the information processing method according to the first embodiment of the present embodiment generates processing of extracting synonyms of a plurality of feature words and concealing synonyms to generate concealed data, and a data storage unit May further include a process of storing in. According to this, it becomes easy to extract similar concealment data.
本実施の形態の第2の態様に係る情報処理方法は、(A)第1の数値の第1の秘匿化データ値と複数個の第1の特徴語の第2の秘匿化データ値とを含む1又は複数の検索データブロックを含む検索要求を受信する処理と、(B)複数の第2の数値の第3の秘匿化データ値と複数個の第2の特徴語の第4の秘匿化データ値とを含む1又は複数のデータブロックと識別情報とを含む案件データブロックを複数格納するデータ格納部に格納されている案件データブロックの各々について、第1の秘匿化データ値と第3の秘匿化データ値とから算出される、数値についての第1の類似度と、第2の秘匿化データ値と一致する第4の秘匿化データ値の個数とから、処理対象の案件データブロックに含まれるデータブロックと検索データブロックとの各組み合わせについての第2の類似度の合計値である第3の類似度を算出する算出処理と、(C)第3の類似度が閾値を超えた案件データブロックの識別情報又は第3の類似度が上位所定数の案件データブロックの識別情報を、検索要求の送信元に送信する処理とを含む。 The information processing method according to the second aspect of the present embodiment includes (A) a first concealment data value of a first numerical value and a second concealment data value of a plurality of first feature words. Processing for receiving a search request including one or a plurality of search data blocks, and (B) a third concealment data value of a plurality of second numerical values and a fourth concealment of a plurality of second feature words For each of the case data blocks stored in the data storage unit for storing a plurality of case data blocks including one or more data blocks including the data value and identification information, the first concealed data value and the third Included in the case data block to be processed from the first similarity degree for the numerical value calculated from the concealment data value and the number of the fourth concealment data value that matches the second concealment data value Each set of data block and search data block A calculation process for calculating a third similarity that is a total value of the second similarities for the combination, and (C) identification information of the case data block whose third similarity exceeds the threshold or the third similarity Includes a process of transmitting the identification information of the upper predetermined number of item data blocks to the transmission source of the search request.
このようにすれば、データ格納部に格納されている案件データブロックも、検索要求に含まれるデータブロックについても秘匿された状態で、数値についての類似度も特定でき、全体としての類似度も算出できる。従って、より類似度の高い案件データブロックを特定できるようになる。 In this way, both the case data block stored in the data storage unit and the data block included in the search request are concealed, and the numerical similarity can be specified, and the overall similarity is calculated. it can. Therefore, it becomes possible to specify a case data block having a higher similarity.
なお、上で述べた算出処理が、第1の秘匿化データ値に一致する第3の秘匿化データ値が存在する場合には第1の類似度を1に設定し、第1の秘匿化データ値に一致する第3の秘匿化データ値が存在しない場合には第1の類似度を0に設定する処理を含むようにしても良い。例えば元の値の近似判断を表す複数の第2の数値について第3の秘匿化データ値を用意しておけば、近似する数値の存在を検出しやすくなる。 In addition, when the calculation process described above has the 3rd encryption data value which corresponds to a 1st encryption data value, a 1st similarity is set to 1 and the 1st encryption data If there is no third anonymized data value that matches the value, a process of setting the first similarity to 0 may be included. For example, if a third concealment data value is prepared for a plurality of second numerical values representing approximation of the original value, it is easy to detect the presence of the numerical value to be approximated.
また、上で述べた第1の秘匿化データ値が、第1の数値の元の数値についての代表値の秘匿化データ値である場合もある。そして、上で述べた検索要求には、第1の数値の元の数値についての代表値との差である第1の補助数値と、近似判定のための範囲のデータとをさらに含む場合もある。そして、複数の第2の数値が、元の数値が属する値域の下限値及び上限値であり、上で述べたデータブロックには、第2の数値の元の数値が属する値域の下限値と当該元の数値との差である第2の補助数値と当該元の数値と上記上限値との差である第3の補助数値とをさらに含むようにしてもよい。このような場合、上で述べた算出処理が、第1の秘匿化データ値に一致する第3の秘匿化データ値が存在する場合には、第1の秘匿化データ値についての第1の補助数値と、第1の秘匿化データ値に一致する第3の秘匿化データ値についての第2の補助数値又は第3の補助数値との差を算出する処理と、第1の補助数値と第2の補助数値又は第3の補助数値との差が、近似判定のための範囲内であれば、第1の類似度を1に設定し、第1の補助数値と第2の補助数値又は第3の補助数値との差が、近似判定のための範囲内でない場合には第1の類似度を0に設定する処理とを含むようにしても良い。 Further, the first concealment data value described above may be a concealment data value of a representative value for the original numerical value of the first numerical value. The search request described above may further include a first auxiliary numerical value that is a difference between the first numerical value and the representative value of the original numerical value, and range data for approximation determination. . The plurality of second numerical values are the lower limit value and upper limit value of the range to which the original numerical value belongs, and the data block described above includes the lower limit value of the range to which the original numerical value of the second numerical value belongs, A second auxiliary numerical value that is a difference from the original numerical value and a third auxiliary numerical value that is a difference between the original numerical value and the upper limit value may be further included. In such a case, if there is a third concealment data value that matches the first concealment data value, the calculation process described above is the first auxiliary for the first concealment data value. A process of calculating a difference between the numerical value and the second auxiliary value or the third auxiliary value for the third anonymized data value that matches the first anonymized data value; the first auxiliary value and the second If the difference between the auxiliary numerical value or the third auxiliary numerical value is within the range for approximation determination, the first similarity is set to 1, and the first auxiliary numerical value and the second auxiliary numerical value or third If the difference from the auxiliary numerical value is not within the range for approximation determination, the first similarity may be set to 0.
さらに、第1の数値の第1の秘匿化データ値が複数データブロックに含まれる場合には、上で述べた算出処理が、第1の秘匿化データ値に一致する第3の秘匿化データ値の個数に応じた類似度を第1の類似度に設定する処理を含むようにしても良い。このようにすれば、0又は1だけではない第1の類似度を設定できるようになる。 Furthermore, when the first concealment data value of the first numerical value is included in the plurality of data blocks, the calculation processing described above is performed by the third concealment data value that matches the first concealment data value. A process of setting the similarity according to the number of the first similarity as the first similarity may be included. In this way, the first similarity that is not only 0 or 1 can be set.
また、第1の秘匿化データ値が、第1の数値の元の数値についての代表値の秘匿化データ値であり、検索要求には、第1の数値の元の数値についての代表値との差である第1の補助数値と、近似判定のための範囲のデータとをさらに含むようにしても良い。さらに、上で述べた複数の第2の数値が、元の数値が属する値域の下限値及び上限値であり、上で述べたデータブロックには、第2の数値の元の数値が属する値域の下限値と当該元の数値との差である第2の補助数値と当該元の数値と上記上限値との差である第3の補助数値とをさらに含むようにしても良い。そして、上で述べた算出処理が、第1の秘匿化データ値に一致する第3の秘匿化データ値が存在する場合には、第1の秘匿化データ値についての第1の補助数値と、第1の秘匿化データ値に一致する第3の秘匿化データ値についての第2の補助数値又は第3の補助数値との差を算出する処理と、第1の補助数値と第2の補助数値又は第3の補助数値と、近似判定のための範囲を表す数値と、の差に応じた類似度を第1の類似度に設定する処理とを含むようにしても良い。このようにすれば0又は1だけではない第1の類似度が設定できるようになる。 Further, the first concealment data value is the concealment data value of the representative value for the original numerical value of the first numerical value, and the search request includes a representative value for the original numerical value of the first numerical value. You may make it further contain the 1st auxiliary | assistant numerical value which is a difference, and the data of the range for an approximation determination. Further, the plurality of second numerical values described above are the lower limit value and the upper limit value of the range to which the original numerical value belongs, and the data block described above includes the range of the range to which the original numerical value of the second numerical value belongs. A second auxiliary numerical value that is a difference between the lower limit value and the original numerical value, and a third auxiliary numerical value that is a difference between the original numerical value and the upper limit value may be further included. When the calculation process described above has a third concealed data value that matches the first concealed data value, the first auxiliary numerical value for the first concealed data value, A process of calculating a difference between the second auxiliary value or the third auxiliary value for the third anonymized data value that matches the first anonymized data value, and the first auxiliary value and the second auxiliary value Alternatively, a process of setting the similarity according to the difference between the third auxiliary numerical value and the numerical value representing the range for the approximate determination as the first similarity may be included. In this way, the first similarity that is not only 0 or 1 can be set.
なお、上で述べたような処理をコンピュータに実施させるためのプログラムを作成することができ、当該プログラムは、例えばフレキシブル・ディスク、CD−ROMなどの光ディスク、光磁気ディスク、半導体メモリ(例えばROM)、ハードディスク等のコンピュータ読み取り可能な記憶媒体又は記憶装置に格納される。 It is possible to create a program for causing a computer to carry out the processing described above, such as a flexible disk, an optical disk such as a CD-ROM, a magneto-optical disk, and a semiconductor memory (for example, ROM). Or a computer-readable storage medium such as a hard disk or a storage device.
以上の実施例を含む実施形態に関し、さらに以下の付記を開示する。 The following supplementary notes are further disclosed with respect to the embodiments including the above examples.
(付記1)
データ格納部に格納されており且つ第1の数値を含むテキストデータから、第1の数値及び当該第1の数値の周辺に存在する複数個の特徴語を抽出する処理と、
抽出された前記第1の数値から、当該第1の数値と近似するか否かを判断する上で基準となる1又は複数の第2の数値を生成する生成処理と、
前記1又は複数の第2の数値と前記複数個の特徴語との各々について秘匿化処理を行って秘匿化データを生成し、前記データ格納部に格納する処理と、
を含む処理を、コンピュータが実行する情報処理方法。
(Appendix 1)
A process of extracting a first numerical value and a plurality of feature words existing around the first numerical value from text data stored in the data storage unit and including the first numerical value;
A generation process for generating one or more second numerical values serving as a reference in determining whether to approximate the first numerical value from the extracted first numerical value;
A process of generating concealment data by performing concealment processing for each of the one or more second numerical values and the plurality of feature words, and storing the data in the data storage unit;
Processing method in which a computer executes a process including:
(付記2)
前記生成処理が、
抽出された前記第1の数値を異なる有効桁数で表した複数の第2の数値を生成する処理
である付記1記載の情報処理方法。
(Appendix 2)
The generation process is
The information processing method according to
(付記3)
前記生成処理が、
抽出された前記第1の数値を含む所定の数値範囲の上限値及び下限値である複数の第2の数値を特定する処理と、
前記第1の数値と前記下限値との差と、前記第1の数値と前記上限値との差とを算出し、前記データ格納部に格納する処理と、
を含む付記1記載の情報処理方法。
(Appendix 3)
The generation process is
A process of specifying a plurality of second numerical values that are an upper limit value and a lower limit value of a predetermined numerical value range including the extracted first numerical value;
A process of calculating a difference between the first numerical value and the lower limit value and a difference between the first numerical value and the upper limit value and storing the difference in the data storage unit;
The information processing method according to
(付記4)
前記生成処理が、
抽出された前記第1の数値と、数値を分類するための数値範囲の設定とから、前記第1の数値を代表する1又は複数の第2の数値を特定する処理と、
前記1又は複数の第2の数値と、前記第1の数値との差を算出し、前記データ格納部に格納する処理と、
を含む付記1記載の情報処理方法。
(Appendix 4)
The generation process is
A process of specifying one or a plurality of second numerical values representing the first numerical value from the extracted first numerical value and setting of a numerical value range for classifying the numerical value;
A process of calculating a difference between the one or more second numerical values and the first numerical value and storing the difference in the data storage unit;
The information processing method according to
(付記5)
前記生成処理が、
抽出された前記第1の数値を、指示された有効桁数で表した第2の数値を1つ生成する処理
である付記1記載の情報処理方法。
(Appendix 5)
The generation process is
The information processing method according to
(付記6)
前記複数個の特徴語の同義語を抽出する処理と、
前記同義語の秘匿化を行って秘匿化データを生成し、前記データ格納部に格納する処理と、
を前記処理がさらに含む付記1乃至5のいずれか1つ記載の情報処理方法。
(Appendix 6)
Processing to extract synonyms of the plurality of feature words;
Processing to generate concealment data by concealing the synonym and store in the data storage unit;
The information processing method according to any one of
(付記7)
第1の数値の第1の秘匿化データ値と複数個の第1の特徴語の第2の秘匿化データ値とを含む1又は複数の検索データブロックを含む検索要求を受信する処理と、
複数の第2の数値の第3の秘匿化データ値と複数個の第2の特徴語の第4の秘匿化データ値とを含む1又は複数のデータブロックと識別情報とを含む案件データブロックを複数格納するデータ格納部に格納されている前記案件データブロックの各々について、前記第1の秘匿化データ値と前記第3の秘匿化データ値とから算出される、数値についての第1の類似度と、前記第2の秘匿化データ値と一致する前記第4の秘匿化データ値の個数とから、処理対象の案件データブロックに含まれる前記データブロックと前記検索データブロックとの各組み合わせについての第2の類似度の合計値である第3の類似度を算出する算出処理と、
前記第3の類似度が閾値を超えた案件データブロックの識別情報又は前記第3の類似度が上位所定数の案件データブロックの識別情報を、前記検索要求の送信元に送信する処理と、
を含む処理を、コンピュータが実行する情報処理方法。
(Appendix 7)
A process of receiving a search request including one or more search data blocks including a first concealment data value of a first numerical value and a second concealment data value of a plurality of first feature words;
A case data block including one or a plurality of data blocks including a plurality of second concealed data values of a second numerical value and a fourth concealed data value of a plurality of second feature words and identification information; 1st similarity about the numerical value calculated from said 1st concealment data value and said 3rd concealment data value about each of said case data block stored in the data storage part to store two or more And the number of the fourth anonymized data values that coincide with the second anonymized data value, the number of each combination of the data block and the search data block included in the case data block to be processed A calculation process for calculating a third similarity that is a total value of two similarities;
A process of transmitting identification information of a case data block in which the third similarity exceeds a threshold or identification information of a case data block having a third highest degree of similarity to the transmission source of the search request;
Processing method in which a computer executes a process including:
(付記8)
前記算出処理が、
前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値が存在する場合には前記第1の類似度を1に設定し、前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値が存在しない場合には前記第1の類似度を0に設定する処理
を含む付記7記載の情報処理方法。
(Appendix 8)
The calculation process
If the third concealed data value that matches the first concealed data value exists, the first similarity is set to 1, and the first concealed data value matches the first concealed data value. The information processing method according to
(付記9)
前記第1の秘匿化データ値が、前記第1の数値の元の数値についての代表値の秘匿化データ値であり、
前記検索要求には、前記第1の数値の元の数値についての代表値との差である第1の補助数値と、近似判定のための範囲のデータとをさらに含み、
前記複数の第2の数値が、元の数値が属する値域の下限値及び上限値であり、
前記データブロックには、前記第2の数値の元の数値が属する値域の下限値と当該元の数値との差である第2の補助数値と当該元の数値と前記上限値との差である第3の補助数値とをさらに含み、
前記算出処理が、
前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値が存在する場合には、前記第1の秘匿化データ値についての前記第1の補助数値と、前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値についての前記第2の補助数値又は前記第3の補助数値との差を算出する処理と、
前記第1の補助数値と前記第2の補助数値又は前記第3の補助数値との差が、前記近似判定のための範囲内であれば、前記第1の類似度を1に設定し、前記第1の補助数値と前記第2の補助数値又は前記第3の補助数値との差が、前記近似判定のための範囲内でない場合には前記第1の類似度を0に設定する処理と、
を含む付記7記載の情報処理方法。
(Appendix 9)
The first concealment data value is a concealment concealment data value of a representative value for the original numerical value of the first numerical value;
The search request further includes a first auxiliary numerical value that is a difference from the representative value of the original numerical value of the first numerical value, and range data for approximation determination,
The plurality of second numerical values are a lower limit value and an upper limit value of a range to which the original numerical value belongs,
The data block is a difference between a second auxiliary value that is a difference between the lower limit value of the range to which the original value of the second value belongs and the original value, and the original value and the upper limit value. A third auxiliary numerical value,
The calculation process
If there is a third concealed data value that matches the first concealed data value, the first auxiliary value for the first concealed data value and the first concealment A process of calculating a difference between the second auxiliary value or the third auxiliary value for the third concealed data value that matches a data value;
If the difference between the first auxiliary value and the second auxiliary value or the third auxiliary value is within the range for the approximation determination, the first similarity is set to 1, A process of setting the first similarity to 0 when the difference between the first auxiliary numerical value and the second auxiliary numerical value or the third auxiliary numerical value is not within the range for the approximation determination;
The information processing method according to
(付記10)
前記第1の数値の第1の秘匿化データ値が複数前記データブロックに含まれ、
前記算出処理が、
前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値の個数に応じた類似度を前記第1の類似度に設定する処理
を含む付記7記載の情報処理方法。
(Appendix 10)
A plurality of first concealment data values of the first numerical value are included in the data block;
The calculation process
The information processing method according to
(付記11)
前記第1の秘匿化データ値が、前記第1の数値の元の数値についての代表値の秘匿化データ値であり、
前記検索要求には、前記第1の数値の元の数値についての代表値との差である第1の補助数値と、近似判定のための範囲のデータとをさらに含み、
前記複数の第2の数値が、元の数値が属する値域の下限値及び上限値であり、
前記データブロックには、前記第2の数値の元の数値が属する値域の下限値と当該元の数値との差である第2の補助数値と当該元の数値と前記上限値との差である第3の補助数値とをさらに含み、
前記算出処理が、
前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値が存在する場合には、前記第1の秘匿化データ値についての前記第1の補助数値と、前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値についての前記第2の補助数値又は前記第3の補助数値との差を算出する処理と、
前記第1の補助数値と前記第2の補助数値又は前記第3の補助数値と、前記近似判定のための範囲を表す数値と、の差に応じた類似度を前記第1の類似度に設定する処理と、
を含む付記7記載の情報処理方法。
(Appendix 11)
The first concealment data value is a concealment concealment data value of a representative value for the original numerical value of the first numerical value;
The search request further includes a first auxiliary numerical value that is a difference from the representative value of the original numerical value of the first numerical value, and range data for approximation determination,
The plurality of second numerical values are a lower limit value and an upper limit value of a range to which the original numerical value belongs,
The data block is a difference between a second auxiliary value that is a difference between the lower limit value of the range to which the original value of the second value belongs and the original value, and the original value and the upper limit value. A third auxiliary numerical value,
The calculation process
If there is a third concealed data value that matches the first concealed data value, the first auxiliary value for the first concealed data value and the first concealment A process of calculating a difference between the second auxiliary value or the third auxiliary value for the third concealed data value that matches a data value;
Similarity according to the difference between the first auxiliary numerical value, the second auxiliary numerical value or the third auxiliary numerical value, and the numerical value representing the range for the approximation determination is set as the first similarity. Processing to
The information processing method according to
(付記12)
データ格納部と、
前記データ格納部に格納されており且つ第1の数値を含むテキストデータから、第1の数値及び当該第1の数値の周辺に存在する複数個の特徴語を抽出し、抽出された前記第1の数値から、当該第1の数値と近似するか否かを判断する上で基準となる1又は複数の第2の数値を生成し、前記1又は複数の第2の数値と前記複数個の特徴語との各々について秘匿化処理を行って秘匿化データを生成し、第2のデータ格納部に格納する生成部と、
を有する情報処理装置。
(Appendix 12)
A data storage unit;
A first numerical value and a plurality of feature words existing around the first numerical value are extracted from text data stored in the data storage unit and including the first numerical value, and the extracted first 1 or a plurality of second numerical values serving as a reference in determining whether to approximate the first numerical value or not from the numerical values of the first numerical value, the one or more second numerical values and the plurality of characteristics Generating a concealment data by performing concealment processing for each word, and storing in a second data storage unit;
An information processing apparatus.
(付記13)
第1の数値の第1の秘匿化データ値と複数個の第1の特徴語の第2の秘匿化データ値とを含む1又は複数の検索データブロックを含む検索要求を受信する受信部と、
複数の第2の数値の第3の秘匿化データ値と複数個の第2の特徴語の第4の秘匿化データ値とを含む1又は複数のデータブロックと識別情報とを含む案件データブロックを複数格納するデータ格納部に格納されている前記案件データブロックの各々について、前記第1の秘匿化データ値と前記第3の秘匿化データ値とから算出される、数値についての第1の類似度と、前記第2の秘匿化データ値と一致する前記第4の秘匿化データ値の個数とから、処理対象の案件データブロックに含まれる前記データブロックと前記検索データブロックとの各組み合わせについての第2の類似度の合計値である第3の類似度を算出する検索処理部と、
前記第3の類似度が閾値を超えた案件データブロックの識別情報又は前記第3の類似度が上位所定数の案件データブロックの識別情報を、前記検索要求の送信元に送信する送信部と、
を有する情報処理装置。
(Appendix 13)
A receiving unit for receiving a search request including one or a plurality of search data blocks including a first concealment data value of a first numerical value and a second concealment data value of a plurality of first feature words;
A case data block including one or a plurality of data blocks including a plurality of second concealed data values of a second numerical value and a fourth concealed data value of a plurality of second feature words and identification information; 1st similarity about the numerical value calculated from said 1st concealment data value and said 3rd concealment data value about each of said case data block stored in the data storage part to store two or more And the number of the fourth anonymized data values that coincide with the second anonymized data value, the number of each combination of the data block and the search data block included in the case data block to be processed A search processing unit that calculates a third similarity that is a total value of two similarities;
A transmission unit that transmits identification information of a case data block in which the third similarity exceeds a threshold or identification information of a case data block having a third predetermined higher degree of similarity to the transmission source of the search request;
An information processing apparatus.
3 登録装置
31 入力部
32 機密データ格納部
33 FP生成部
34 FPルールデータ取得部
35 FPルールデータ格納部
36 PFデータ格納部
37 送信部
5 管理装置
51 FPルールデータ格納部
52 FPルールデータ配布部
53 PF登録部
54 DB
55 検索処理部
56 検索要求受信部
57 検索結果送信部
7 検索装置
71 入力部
72 機密データ格納部
73 FP生成部
74 FPルールデータ取得部
75 FPルールデータ格納部
76 検索条件データ格納部
77 FPデータ格納部
78 検索要求部
79 出力部
3 Registration Device 31
55
Claims (13)
抽出された前記第1の数値から、当該第1の数値と近似するか否かを判断する上で基準となる1又は複数の第2の数値を生成する生成処理と、
前記1又は複数の第2の数値と前記複数個の特徴語との各々について秘匿化処理を行って秘匿化データを生成し、前記データ格納部に格納する処理と、
を含む処理を、コンピュータが実行する情報処理方法。 A process of extracting a first numerical value and a plurality of feature words existing around the first numerical value from text data stored in the data storage unit and including the first numerical value;
A generation process for generating one or more second numerical values serving as a reference in determining whether to approximate the first numerical value from the extracted first numerical value;
A process of generating concealment data by performing concealment processing for each of the one or more second numerical values and the plurality of feature words, and storing the data in the data storage unit;
Processing method in which a computer executes a process including:
抽出された前記第1の数値を異なる有効桁数で表した複数の第2の数値を生成する処理
である請求項1記載の情報処理方法。 The generation process is
The information processing method according to claim 1, further comprising: generating a plurality of second numerical values representing the extracted first numerical values with different effective digits.
抽出された前記第1の数値を含む所定の数値範囲の上限値及び下限値である複数の第2の数値を特定する処理と、
前記第1の数値と前記下限値との差と、前記第1の数値と前記上限値との差とを算出し、前記データ格納部に格納する処理と、
を含む請求項1記載の情報処理方法。 The generation process is
A process of specifying a plurality of second numerical values that are an upper limit value and a lower limit value of a predetermined numerical range including the extracted first numerical value;
A process of calculating a difference between the first numerical value and the lower limit value and a difference between the first numerical value and the upper limit value and storing the difference in the data storage unit;
The information processing method according to claim 1 including:
抽出された前記第1の数値と、数値を分類するための数値範囲の設定とから、前記第1の数値を代表する1又は複数の第2の数値を特定する処理と、
前記1又は複数の第2の数値と、前記第1の数値との差を算出し、前記データ格納部に格納する処理と、
を含む請求項1記載の情報処理方法。 The generation process is
A process of specifying one or a plurality of second numerical values representing the first numerical value from the extracted first numerical value and setting of a numerical value range for classifying the numerical value;
A process of calculating a difference between the one or more second numerical values and the first numerical value and storing the difference in the data storage unit;
The information processing method according to claim 1 including:
抽出された前記第1の数値を、指示された有効桁数で表した第2の数値を1つ生成する処理
である請求項1記載の情報処理方法。 The generation process is
The information processing method according to claim 1, wherein the first numerical value is a process of generating one second numerical value representing the indicated effective number of digits.
前記同義語の秘匿化を行って秘匿化データを生成し、前記データ格納部に格納する処理と、
を前記処理がさらに含む請求項1乃至5のいずれか1つ記載の情報処理方法。 Processing to extract synonyms of the plurality of feature words;
Processing to generate concealment data by concealing the synonym and store in the data storage unit;
The information processing method according to any one of claims 1 to 5, wherein the processing further includes:
複数の第2の数値の第3の秘匿化データ値と複数個の第2の特徴語の第4の秘匿化データ値とを含む1又は複数のデータブロックと識別情報とを含む案件データブロックを複数格納するデータ格納部に格納されている前記案件データブロックの各々について、前記第1の秘匿化データ値と前記第3の秘匿化データ値とから算出される、数値についての第1の類似度と、前記第2の秘匿化データ値と一致する前記第4の秘匿化データ値の個数とから、処理対象の案件データブロックに含まれる前記データブロックと前記検索データブロックとの各組み合わせについての第2の類似度の合計値である第3の類似度を算出する算出処理と、
前記第3の類似度が閾値を超えた案件データブロックの識別情報又は前記第3の類似度が上位所定数の案件データブロックの識別情報を、前記検索要求の送信元に送信する処理と、
を含む処理を、コンピュータが実行する情報処理方法。 A process of receiving a search request including one or more search data blocks including a first concealment data value of a first numerical value and a second concealment data value of a plurality of first feature words;
A case data block including one or a plurality of data blocks including a plurality of second concealed data values of a second numerical value and a fourth concealed data value of a plurality of second feature words and identification information; 1st similarity about the numerical value calculated from said 1st concealment data value and said 3rd concealment data value about each of said case data block stored in the data storage part to store two or more And the number of the fourth anonymized data values that coincide with the second anonymized data value, the number of each combination of the data block and the search data block included in the case data block to be processed A calculation process for calculating a third similarity that is a total value of two similarities;
A process of transmitting identification information of a case data block in which the third similarity exceeds a threshold or identification information of a case data block having a third highest degree of similarity to the transmission source of the search request;
Processing method in which a computer executes a process including:
前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値が存在する場合には前記第1の類似度を1に設定し、前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値が存在しない場合には前記第1の類似度を0に設定する処理
を含む請求項7記載の情報処理方法。 The calculation process
If the third concealed data value that matches the first concealed data value exists, the first similarity is set to 1, and the first concealed data value matches the first concealed data value. The information processing method according to claim 7, further comprising: a process of setting the first similarity to 0 when there is no 3 concealed data value.
前記検索要求には、前記第1の数値の元の数値についての代表値との差である第1の補助数値と、近似判定のための範囲のデータとをさらに含み、
前記複数の第2の数値が、元の数値が属する値域の下限値及び上限値であり、
前記データブロックには、前記第2の数値の元の数値が属する値域の下限値と当該元の数値との差である第2の補助数値と当該元の数値と前記上限値との差である第3の補助数値とをさらに含み、
前記算出処理が、
前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値が存在する場合には、前記第1の秘匿化データ値についての前記第1の補助数値と、前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値についての前記第2の補助数値又は前記第3の補助数値との差を算出する処理と、
前記第1の補助数値と前記第2の補助数値又は前記第3の補助数値との差が、前記近似判定のための範囲内であれば、前記第1の類似度を1に設定し、前記第1の補助数値と前記第2の補助数値又は前記第3の補助数値との差が、前記近似判定のための範囲内でない場合には前記第1の類似度を0に設定する処理と、
を含む請求項7記載の情報処理方法。 The first concealment data value is a concealment concealment data value of a representative value for the original numerical value of the first numerical value;
The search request further includes a first auxiliary numerical value that is a difference from the representative value of the original numerical value of the first numerical value, and range data for approximation determination,
The plurality of second numerical values are a lower limit value and an upper limit value of a range to which the original numerical value belongs,
The data block is a difference between a second auxiliary value that is a difference between the lower limit value of the range to which the original value of the second value belongs and the original value, and the original value and the upper limit value. A third auxiliary numerical value,
The calculation process
If there is a third concealed data value that matches the first concealed data value, the first auxiliary value for the first concealed data value and the first concealment A process of calculating a difference between the second auxiliary value or the third auxiliary value for the third concealed data value that matches a data value;
If the difference between the first auxiliary value and the second auxiliary value or the third auxiliary value is within the range for the approximation determination, the first similarity is set to 1, A process of setting the first similarity to 0 when the difference between the first auxiliary numerical value and the second auxiliary numerical value or the third auxiliary numerical value is not within the range for the approximation determination;
The information processing method according to claim 7.
前記算出処理が、
前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値の個数に応じた類似度を前記第1の類似度に設定する処理
を含む請求項7記載の情報処理方法。 A plurality of first concealment data values of the first numerical value are included in the data block;
The calculation process
The information processing method according to claim 7, further comprising: setting a similarity according to the number of the third concealed data values that matches the first concealed data value as the first similarity.
前記検索要求には、前記第1の数値の元の数値についての代表値との差である第1の補助数値と、近似判定のための範囲のデータとをさらに含み、
前記複数の第2の数値が、元の数値が属する値域の下限値及び上限値であり、
前記データブロックには、前記第2の数値の元の数値が属する値域の下限値と当該元の数値との差である第2の補助数値と当該元の数値と前記上限値との差である第3の補助数値とをさらに含み、
前記算出処理が、
前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値が存在する場合には、前記第1の秘匿化データ値についての前記第1の補助数値と、前記第1の秘匿化データ値に一致する前記第3の秘匿化データ値についての前記第2の補助数値又は前記第3の補助数値との差を算出する処理と、
前記第1の補助数値と前記第2の補助数値又は前記第3の補助数値と、前記近似判定のための範囲を表す数値と、の差に応じた類似度を前記第1の類似度に設定する処理と、
を含む請求項7記載の情報処理方法。 The first concealment data value is a concealment concealment data value of a representative value for the original numerical value of the first numerical value;
The search request further includes a first auxiliary numerical value that is a difference from the representative value of the original numerical value of the first numerical value, and range data for approximation determination,
The plurality of second numerical values are a lower limit value and an upper limit value of a range to which the original numerical value belongs,
The data block is a difference between a second auxiliary value that is a difference between the lower limit value of the range to which the original value of the second value belongs and the original value, and the original value and the upper limit value. A third auxiliary numerical value,
The calculation process
If there is a third concealed data value that matches the first concealed data value, the first auxiliary value for the first concealed data value and the first concealment A process of calculating a difference between the second auxiliary value or the third auxiliary value for the third concealed data value that matches a data value;
Similarity according to the difference between the first auxiliary numerical value, the second auxiliary numerical value or the third auxiliary numerical value, and the numerical value representing the range for the approximation determination is set as the first similarity. Processing to
The information processing method according to claim 7.
前記データ格納部に格納されており且つ第1の数値を含むテキストデータから、第1の数値及び当該第1の数値の周辺に存在する複数個の特徴語を抽出し、抽出された前記第1の数値から、当該第1の数値と近似するか否かを判断する上で基準となる1又は複数の第2の数値を生成し、前記1又は複数の第2の数値と前記複数個の特徴語との各々について秘匿化処理を行って秘匿化データを生成し、第2のデータ格納部に格納する生成部と、
を有する情報処理装置。 A data storage unit;
A first numerical value and a plurality of feature words existing around the first numerical value are extracted from text data stored in the data storage unit and including the first numerical value, and the extracted first 1 or a plurality of second numerical values serving as a reference in determining whether to approximate the first numerical value or not from the numerical values of the first numerical value, the one or more second numerical values and the plurality of characteristics Generating a concealment data by performing concealment processing for each word, and storing in a second data storage unit;
An information processing apparatus.
複数の第2の数値の第3の秘匿化データ値と複数個の第2の特徴語の第4の秘匿化データ値とを含む1又は複数のデータブロックと識別情報とを含む案件データブロックを複数格納するデータ格納部に格納されている前記案件データブロックの各々について、前記第1の秘匿化データ値と前記第3の秘匿化データ値とから算出される、数値についての第1の類似度と、前記第2の秘匿化データ値と一致する前記第4の秘匿化データ値の個数とから、処理対象の案件データブロックに含まれる前記データブロックと前記検索データブロックとの各組み合わせについての第2の類似度の合計値である第3の類似度を算出する検索処理部と、
前記第3の類似度が閾値を超えた案件データブロックの識別情報又は前記第3の類似度が上位所定数の案件データブロックの識別情報を、前記検索要求の送信元に送信する送信部と、
を有する情報処理装置。 A receiving unit for receiving a search request including one or a plurality of search data blocks including a first concealment data value of a first numerical value and a second concealment data value of a plurality of first feature words;
A case data block including one or a plurality of data blocks including a plurality of second concealed data values of a second numerical value and a fourth concealed data value of a plurality of second feature words and identification information; 1st similarity about the numerical value calculated from said 1st concealment data value and said 3rd concealment data value about each of said case data block stored in the data storage part to store two or more And the number of the fourth anonymized data values that coincide with the second anonymized data value, the number of each combination of the data block and the search data block included in the case data block to be processed A search processing unit that calculates a third similarity that is a total value of two similarities;
A transmission unit that transmits identification information of a case data block in which the third similarity exceeds a threshold or identification information of a case data block having a third predetermined higher degree of similarity to the transmission source of the search request;
An information processing apparatus.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011246817A JP5720536B2 (en) | 2011-11-10 | 2011-11-10 | Information processing method and apparatus for searching for concealed data |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011246817A JP5720536B2 (en) | 2011-11-10 | 2011-11-10 | Information processing method and apparatus for searching for concealed data |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2013105207A true JP2013105207A (en) | 2013-05-30 |
| JP5720536B2 JP5720536B2 (en) | 2015-05-20 |
Family
ID=48624723
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011246817A Expired - Fee Related JP5720536B2 (en) | 2011-11-10 | 2011-11-10 | Information processing method and apparatus for searching for concealed data |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5720536B2 (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016203555A1 (en) * | 2015-06-16 | 2016-12-22 | 株式会社日立製作所 | System for confidentially searching for similarity, and method for confidentially searching for similarity |
| JP2017091173A (en) * | 2015-11-09 | 2017-05-25 | Necソリューションイノベータ株式会社 | Information management device, information management method, and program |
| JP2017130017A (en) * | 2016-01-20 | 2017-07-27 | ヤフー株式会社 | Information processing apparatus, information processing method, and program |
| JP2018160285A (en) * | 2018-07-20 | 2018-10-11 | ヤフー株式会社 | Information processing device, information processing method, and program |
| US10673614B2 (en) | 2015-10-09 | 2020-06-02 | Mitsubishi Electric Corporation | Secret search system, management device, secret search method and computer readable medium |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH02105974A (en) * | 1988-10-14 | 1990-04-18 | Hitachi Ltd | Numeral comparison and retrieval system |
| JP2005326970A (en) * | 2004-05-12 | 2005-11-24 | Mitsubishi Electric Corp | Structured document ambiguity retrieving device and its program |
| JP2007328196A (en) * | 2006-06-08 | 2007-12-20 | Fuji Xerox Co Ltd | Image processing apparatus, image processing method, and image processing program |
| JP2008276449A (en) * | 2007-04-27 | 2008-11-13 | Albert:Kk | Recommendation system for commodity similar to desired commodity |
| WO2011013463A1 (en) * | 2009-07-29 | 2011-02-03 | 日本電気株式会社 | Range retrieval system, range retrieval method, and program for range retrieval |
-
2011
- 2011-11-10 JP JP2011246817A patent/JP5720536B2/en not_active Expired - Fee Related
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH02105974A (en) * | 1988-10-14 | 1990-04-18 | Hitachi Ltd | Numeral comparison and retrieval system |
| JP2005326970A (en) * | 2004-05-12 | 2005-11-24 | Mitsubishi Electric Corp | Structured document ambiguity retrieving device and its program |
| JP2007328196A (en) * | 2006-06-08 | 2007-12-20 | Fuji Xerox Co Ltd | Image processing apparatus, image processing method, and image processing program |
| JP2008276449A (en) * | 2007-04-27 | 2008-11-13 | Albert:Kk | Recommendation system for commodity similar to desired commodity |
| WO2011013463A1 (en) * | 2009-07-29 | 2011-02-03 | 日本電気株式会社 | Range retrieval system, range retrieval method, and program for range retrieval |
| US20120131355A1 (en) * | 2009-07-29 | 2012-05-24 | Nec Corporation | Range search system, range search method, and range search program |
Non-Patent Citations (6)
| Title |
|---|
| CSND200600345011; 鎌滝 雅久: '本格移行を応援! OpenOffice.org研究室 データベース活用グループ' UNIX USER 第14巻,第8号, 20050801, p.93-102, ソフトバンクパブリッシング株式会社 * |
| CSNG200300569001; 山田 洋志、外1名: 'インターネット多角的検索システムOTROS' 第57回(平成10年後期)全国大会講演論文集(3) , 19981007, p.3-141〜3-142, 社団法人情報処理学会 * |
| CSNG201000308099; 渡辺 知恵美、外2名: 'ブルームフィルタを用いたプライバシ保護検索における攻撃モデルとデータ撹乱法の一検討' 第1回データ工学と情報マネジメントに関するフォーラム-DEIMフォーラム-論文集 , 20091215, p.1-8, 電子情報通信学会データ工学研究専門委員会 * |
| JPN6015006983; 渡辺 知恵美、外2名: 'ブルームフィルタを用いたプライバシ保護検索における攻撃モデルとデータ撹乱法の一検討' 第1回データ工学と情報マネジメントに関するフォーラム-DEIMフォーラム-論文集 , 20091215, p.1-8, 電子情報通信学会データ工学研究専門委員会 * |
| JPN6015006984; 山田 洋志、外1名: 'インターネット多角的検索システムOTROS' 第57回(平成10年後期)全国大会講演論文集(3) , 19981007, p.3-141〜3-142, 社団法人情報処理学会 * |
| JPN6015006985; 鎌滝 雅久: '本格移行を応援! OpenOffice.org研究室 データベース活用グループ' UNIX USER 第14巻,第8号, 20050801, p.93-102, ソフトバンクパブリッシング株式会社 * |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016203555A1 (en) * | 2015-06-16 | 2016-12-22 | 株式会社日立製作所 | System for confidentially searching for similarity, and method for confidentially searching for similarity |
| JPWO2016203555A1 (en) * | 2015-06-16 | 2018-02-15 | 株式会社日立製作所 | Concealed similarity search system and similarity concealment search method |
| US10673614B2 (en) | 2015-10-09 | 2020-06-02 | Mitsubishi Electric Corporation | Secret search system, management device, secret search method and computer readable medium |
| JP2017091173A (en) * | 2015-11-09 | 2017-05-25 | Necソリューションイノベータ株式会社 | Information management device, information management method, and program |
| JP2017130017A (en) * | 2016-01-20 | 2017-07-27 | ヤフー株式会社 | Information processing apparatus, information processing method, and program |
| JP2018160285A (en) * | 2018-07-20 | 2018-10-11 | ヤフー株式会社 | Information processing device, information processing method, and program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5720536B2 (en) | 2015-05-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11487902B2 (en) | Systems and methods for computing with private healthcare data | |
| US9262584B2 (en) | Systems and methods for managing a master patient index including duplicate record detection | |
| CA2950676C (en) | Methods and systems for mapping data items to sparse distributed representations | |
| US9558264B2 (en) | Identifying and displaying relationships between candidate answers | |
| WO2020257783A1 (en) | Systems and methods for computing with private healthcare data | |
| US11062035B2 (en) | Secure document management using blockchain | |
| US10572461B2 (en) | Systems and methods for managing a master patient index including duplicate record detection | |
| CN106844723A (en) | medical knowledge base construction method based on question answering system | |
| CN111104511B (en) | Method, device and storage medium for extracting hot topics | |
| CN104346418A (en) | Anonymizing Sensitive Identifying Information Based on Relational Context Across a Group | |
| JP5720536B2 (en) | Information processing method and apparatus for searching for concealed data | |
| EP3097527A1 (en) | Dynamic document matching and merging | |
| CN112885478B (en) | Medical document retrieval method, medical document retrieval device, electronic device and storage medium | |
| CN110929125A (en) | Search recall method, apparatus, device and storage medium thereof | |
| US11775665B2 (en) | System and method for executing access transactions of documents related to drug discovery | |
| CN111695336A (en) | Disease name code matching method and device, computer equipment and storage medium | |
| WO2021178689A1 (en) | Systems and methods for computing with private healthcare data | |
| CN112115697A (en) | Method, device, server and storage medium for determining target text | |
| Wang et al. | Accelerating epidemiological investigation analysis by using NLP and knowledge reasoning: a case study on COVID-19 | |
| Raghav et al. | Bigdata fog based cyber physical system for classifying, identifying and prevention of SARS disease | |
| JP2018005633A (en) | Related content extraction device, related content extraction method, and related content extraction program | |
| CN112685389B (en) | Data management method, data management device, electronic device, and storage medium | |
| Panchenko et al. | Large-scale parallel matching of social network profiles | |
| Nair et al. | Advancements in Cyber Security and Information Systems in Healthcare from 2004 to 2022: A Bibliometric Analysis | |
| Mathew et al. | Federated named entity recognition |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20140704 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20150113 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20150224 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20150309 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5720536 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |