JP2011123794A - 情報抽出システム及び情報抽出プログラム - Google Patents
情報抽出システム及び情報抽出プログラム Download PDFInfo
- Publication number
- JP2011123794A JP2011123794A JP2009282686A JP2009282686A JP2011123794A JP 2011123794 A JP2011123794 A JP 2011123794A JP 2009282686 A JP2009282686 A JP 2009282686A JP 2009282686 A JP2009282686 A JP 2009282686A JP 2011123794 A JP2011123794 A JP 2011123794A
- Authority
- JP
- Japan
- Prior art keywords
- sentence
- predicate
- subject
- case slot
- word
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images













Landscapes
- Machine Translation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
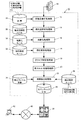
【解決手段】企業名、企業活動、活動対象物を示す具体的な表現文字列毎にその種類を示す抽象化文字列を登録した辞書記憶部26と、文を形態素単位に分解し、各形態素に対応の抽象化タグを関連付ける形態素解析処理部12と、企業活動の抽象化タグが付与された形態素を文の述語と認定すると共に、主語に付属する助詞毎及び目的語に付属する助詞毎に対応語の格納欄が設けられた格スロットに、文の述語単位で対応語を充填し、述語を関連付ける格スロット充填処理部20と、抽出すべき主語の抽象化タグ及び助詞を特定する条件と、抽出すべき述語の抽象化タグを特定する条件と、抽出すべき目的語の抽象化タグ及び助詞を特定する条件が規定された抽出フレーム定義を、対応語充填済みの格スロットに適用し、文の主語、述語、目的語に該当する情報要素を抽出する情報抽出処理部22を備えた情報抽出システム10。
【選択図】図1
Description
例えば、特許文献1に記載の情報抽出装置の場合、自然言語で記述された文書中の文字列と所定の文字パターンとを逐次照合し、一致が認められた文字列部分に対し固有名詞の種類を示すタグ情報を付与する文字パターン処理部と、上記タグ情報はそのままに、タグ情報を除く他の文字列部分を逐次単語情報に分割する形態素解析処理部と、形態素解析の結果得られた単語情報を文節単位にまとめ上げ、当該まとめ上げ後の単語情報を、文法上の構文規則と共に、ある種の情報の表現に特徴的に現れる構文パターンを用いて構文解析する構文解析部と、上記構文パターンに基づく解析により得られる係り受け関係及び当該係り受け関係に含まれるタグ情報から特定される情報を、必要な情報として抽出する情報抽出部を備えている。
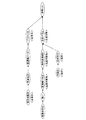
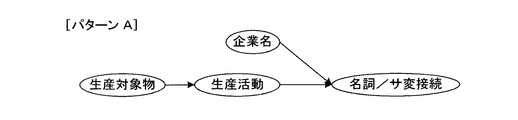
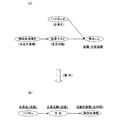
この構文パターンAを図15の構文解析結果に適用することにより、図17(a)に示す文節が文中より抽出され、これに必要な整形処理を施すことにより、図17(b)に示すように、主語、述語、目的語の組合せからなる構造化された企業情報が得られる。
(1) 先行する述語に関して対応語の充填が完了した格スロットを、後続の述語について継承させる。
(2) 後続の述語に係る対応語を上記格スロットの対応語格納欄に上書充填する。
(3)文の主語を表す助詞の対応語格納欄が後続の述語に係る有意思主体を表す語によって上書充填された場合には、先行する述語に関して充填された対応語を削除する。
(1)タイトル文中の主語となるべき種類の抽象化タグが付与された語については、助詞の有無を問わず主語に付属する助詞(「は」、「が」)の対応語格納欄に充填する。
(2)タイトル文中の目的語となるべき種類の抽象化タグが付与された語については、助詞の有無を問わず目的語に付属する助詞(「を」、「に」等)の対応語格納欄に充填する。
(1) 先行する述語に関して対応語の充填が完了した格スロットを、後続の述語について継承させる。
(2) 後続の述語に係る対応語を上記格スロットの対応語格納欄に上書充填する。
(3)文の主語を表す助詞の対応語格納欄が後続の述語に係る有意思主体を表す語によって上書充填された場合には、先行する述語に関して充填された対応語を削除する。
しかも、原則として前の述語に係る格スロットがつぎの述語に継承される仕組みを備えているため、後続の述語に関して主語や目的語の省略が存在したとしても、前の述語の主語や目的語で容易に補うことができる。
セマンティックDB24には、検索サーバ38が接続されており、通信ネットワーク40を介して接続されたクライアント端末42に対し検索サービスを提供する。
また、上記のセマンティックDB24、辞書記憶部26、複合語解析ルール記憶部28、抽象化ルール記憶部30、照応解析ルール記憶部32、抽出フレーム定義記憶部34、抽出制限ルール記憶部36は、同コンピュータのハードディスク内に設けられている。
まず、形態素解析処理部12により、外部から入力されたWebファイル等のテキストデータ44に対する形態素解析が実行される。ここで「形態素解析」とは、自然言語で記述された文を、意味を有する最小の言語単位である形態素に分解し、それぞれの品詞を同定する処理をいう。
この形態素解析自体は公知技術であり、例えば以下のようなフリーソフトを形態素解析エンジンとして用いることができる。
(1) MeCab(http://mecab.sourceforge.net/)
(2) ChaSen(http://chasen.naist.jp/hiki/ChaSen/)
図4はその一部を示すものであり、例えば、「東洋自動車」に関しては企業名辞書に登録例が存在していたため、形態素解析処理部12は「東洋(名詞-一般)」と「自動車(名詞-一般)」の形態素を結合した上で、<企業名>という抽象化タグを品詞項目に追記する。
また、「変速機」に関しては活動対象物辞書に生産対象物、販売対象物、開発対象物として登録されていたため、形態素解析処理部12は「変速(名詞-サ変接続)」と「機(名詞-接尾)」の形態素を結合した上で、<生産対象物><販売対象物><開発対象物>という抽象化タグを品詞項目に追記する。なお、<生産対象物>等の代わりに、上位概念である<活動対象物>の抽象化タグを用いることも当然に可能である。
また、「広州市」に関しては地域名辞書に登録例が存在していたため、「広州(名詞-固有名詞)」と「市(名詞-接尾)」の形態素を結合した上で、<地域>という抽象化タグが品詞項目に追記される。
さらに、「生産」に関しては企業活動辞書に登録例が存在していたため、<生産活動>という抽象化タグが品詞項目に追記される。<生産活動>の代わりに、上位概念である<企業活動>の抽象化タグを用いることも当然に可能である。
この複合語解析ルールは、図5(a)に示すように、品詞連結パターンと品詞決定基準のデータ項目を備えており、複合語解析処理部14は、文中において品詞連結パターンに合致する形態素の並びを発見すると、これらの形態素を複合語として連結すると共に、対応の品詞決定基準に従い、当該複合語の品詞を同定する。
上記のように、先に形態素解析処理部12が辞書記憶部26を参照し、辞書に収録された企業名や企業活動、生産対象物等に対して該当の抽象化タグが付与されているが、辞書の収録語数には自ずと限界があり、辞書ベースでの抽象化処理だけでは漏れが生じる可能性がある。
このため、抽象化処理部20は正規表現ルールによる抽象化処理を実行し、辞書に収録されていない企業名や活動対象物について、対応の抽象化タグを関連付ける機能を備えている。
このため、抽象化ルール記憶部28には、予め多数の抽象化ルールが格納されている。
この照応語解析ルールは、図7(a)に示すように、照応詞と先行詞決定基準のデータ項目を備えており、照応解析処理部18は、定義された照応詞を文中において発見すると、対応の先行詞決定基準に従い、当該照応詞の先行詞を同定する。
つぎに照応解析処理部18は、文中の「同製品」が照応解析ルール(3)の先行詞に該当することを検知し、その先行詞決定基準に従い直近の<生産対象物>タグが付された「新型パソコン」を先行詞と認定し、文中の「同製品」と置き換える。
また文タイプ判定処理部19は、各文の中で「倒置表現」を含むものに対して、倒置表現文であることを示す識別情報を付与する。倒置表現文の認定方法及び具体例については、後述する。
「タイトル文」または「倒置表現文」の識別情報が付与された文については、次段における格スロット充填処理において、これらの識別情報が付与されていない通常の文とは異なる扱いを受けることとなる。
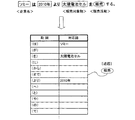
図8は、格スロットの一例を示すものであり、「助詞」と「対応語」の項目を備えている。また、助詞の項目には、予め(は)、(が)、(を)、(に)…等の必要な助詞(係助詞、格助詞)が設定されている。
一般的に「述語」といえば、主語の動作や状態、性質などを叙述する動詞、形容詞、名詞+判定詞を意味するが、格スロット充填処理部20が文中から抽出する「述語」は、最終的な抽出対象である企業情報の「述語」となるべき語であり、具体的には企業活動を示す<生産活動>、<販売活動>、<開発活動>等の抽象化タグが付された語が該当する。
この新たな格スロットに対しては、格スロット充填処理部20によって「研究開発」の述語が関連付けられる。
したがって、(は)には「ソミー」が、(に)には「研究開発」が、(より)には「2008年」が、(の)には「太陽電池技術」がそのまま保持されると共に、(へ)には「製品化」が、(で)には「約2年」が新たに充填される。
この新たな格スロットに対しては、格スロット充填処理部20によって「製品化」の述語が関連付けられる。
この新たな格スロットに対して格スロット充填処理部20は、「販売」の述語を関連付ける。
つぎに格スロット充填処理部20は、「次世代太陽電池部品」について、<販売対象物>の抽象化タグが付与されていることから、目的語を表す助詞である(を)が省略されているものと推定し、格スロットの(を)に「次世代太陽電池部品」を充填する。
つぎに格スロット充填処理部20は、「販売」について、企業活動を表す<販売活動>の抽象化タグが付与されているため述語であると認定し、格スロットに述語として「販売」を関連付ける。
また、格スロット充填処理部20は、この格スロットに対して「開発」の述語を関連付ける。
(1)格スロットの(が)または(は)に<企業名>の抽象化タグが付与された語が充填されていること。
(2)格スロットの述語として<販売活動>の抽象化タグが付与された語が関連付けられていること。
(3)格スロットの(を)に<生産対象物>の抽象化タグが付与された語が充填されていること。
このトリプルは、情報抽出処理部22により、RDF(Resource Description Framework)形式の企業情報としてセマンティックDB24に格納される。
例えば、企業の製品開発情報を収集したい場合には、「主語:<企業名>(が|は)」、「述語:<開発活動>」、「目的語:<開発対象物>」の抽出フレーム定義を用意しておけばよい。
ここで、抽出制限ルールとしては、「削除対象定義」と、「除外対象定義」が規定されている。以下、個別に説明する。
その一例として、「^(?:新型|次期|次世代)(.+)/ -> $1」という削除対象定義は、「新型」「次期」「次世代」という形容詞の削除を規定しているため、格スロットの(を)に「新型パソコン」や「次期ハイブリッド車」が充填されていた場合には、情報抽出処理部22によって「パソコン」や「ハイブリッド車」に整形された上で、トリプルの一部として抽出される。
情報抽出処理部22は、格スロット充填処理部20から渡された格スロットの(を)の対応語をチェックし、そこに「新製品」や「戦略車」などが充填されていた場合、当該格スロットからのトリプル抽出処理をキャンセルする。
例えば、抽出フレーム定義中に「オプション:<地域>で」の条件を加えておけば、格スロットの(で)の対応語格納欄に<地域>の抽象化タグが付与された語(例えば「広州市」)が充填されている場合、情報抽出処理部22は主語、述語、目的語に該当する文字列と共に、この地域を表す文字列を抽出する。
あるいは、抽出フレーム定義中に「オプション:<時間>より」の条件を加えておけば、格スロットの(より)の対応語格納欄に<時間>の抽象化タグが付与された語(例えば「2010年」)が充填されている場合、情報抽出処理部22は主語、述語、目的語に該当する文字列と共に、この時間を表す文字列を抽出する。
あるいは、クライアント端末42から「東北地方 AND 工場」という検索条件が送信された場合、検索サーバ38はセマンティック企業DB24を検索し、東北地方で工場に関する何らかの活動(例えば保有、建設、賃貸、閉鎖等)を行っている企業名のリストをクライアント端末42に送信する。より絞り込まれた情報を希望するユーザは、「東北地方 AND 工場 AND 保有」のように検索条件を変更すればよい。
また、「東洋自動車 AND 生産 AND 中国」の検索条件が送信された場合、検索サーバ38は東洋自動車が中国で生産している対象物のリストを生成し、クライアント端末42に送信することができる。
しかも、原則として前の文の格スロットがつぎの文に継承される仕組みを備えているため、後続の文中に主語や目的語の省略が存在したとしても、前の文の主語や目的語で容易に補うことができる。
すなわち、格スロット充填処理部20によって必要な語の充填が完了した格スロットを充填済み格スロット記憶部(図示省略)に蓄積しておき、これに対し情報抽出処理部22が多種多様な抽出フレーム定義を順次適用することにより、各種情報をまとめて抽出するように構成してもよい。
例えば、企業名辞書の代わりに人名辞書を、企業活動辞書の代わりに人間活動辞書を、企業の活動対象物辞書の代わりに人間の活動対象物辞書を用意し、人間の活動を抽出するための抽出フレーム定義を準備しておくことにより、「人名(主語)→人間活動(述語)→活動対象物(目的語)」のトリプル構造を備えた人物情報(芸能人情報等)を抽出することも可能となる。
12 形態素解析処理部
14 複合語解析処理部
16 抽象化処理部
18 照応解析処理部
19 文タイプ判定処理部
20 格スロット充填処理部
22 情報抽出処理部
24 セマンティック企業DB
26 辞書記憶部
28 複合語解析ルール記憶部
30 抽象化ルール記憶部
32 照応解析ルール記憶部
34 抽出フレーム定義記憶部
36 抽出制限ルール記憶部
38 検索サーバ
40 通信ネットワーク
42 クライアント端末
44 テキストデータ
Claims (7)
- 活動主体となる具体的な表現文字列と、その種類を示す抽象化文字列との対応関係を登録した辞書と、
上記活動主体の活動内容を示す具体的な表現文字列と、その種類を示す抽象化文字列との対応関係を登録した辞書と、
上記活動主体の活動対象物を示す具体的な表現文字列と、その種類を示す抽象化文字列との対応関係を登録した辞書と、
テキストデータ中の文を形態素単位に分解し、各形態素の品詞を同定する手段と、
上記の各辞書を参照し、文中において各辞書に収録されている形態素が存する場合には、当該形態素に対してその種類を示す抽象化タグを関連付ける手段と、
少なくとも主語に付属する助詞毎及び目的語に付属する助詞毎に対応語の格納欄が設けられた格スロットに、文中の対応語を充填すると共に、活動内容を示す抽象化タグが付与されている形態素を述語として当該格スロットに関連付ける格スロット充填手段と、
抽出すべき主語の抽象化タグ及び当該主語に付属する助詞を特定する条件と、抽出すべき述語の抽象化タグを特定する条件と、抽出すべき目的語の抽象化タグ及び当該目的語に付属する助詞を特定する条件が少なくとも規定された抽出フレーム定義を、複数格納しておく抽出フレーム定義記憶手段と、
対応語充填済みの上記格スロットに上記抽出フレーム定義を適用することにより、少なくとも文の主語、述語、目的語に該当する情報要素を抽出する情報抽出手段とを備えた情報抽出システムであって、
上記格スロット充填手段が、以下の処理を実行することを特徴とする情報抽出システム。
(1) 先行する述語に関して対応語の充填が完了した格スロットを、後続の述語について継承させる。
(2) 後続の述語に係る対応語を上記格スロットの対応語格納欄に上書充填する。
(3)文の主語を表す助詞の対応語格納欄が後続の述語に係る有意思主体を表す語によって上書充填された場合には、先行する述語に関して充填された対応語を削除する。 - 上記の文の中でタイトルに該当する文に対して、タイトル文であることを示す識別情報を予め付与する手段を備え、
この識別情報が付与されたタイトル文に対して、上記格スロット充填手段が以下の処理を実行することを特徴とする請求項1に記載の情報抽出システム。
(1)タイトル文中の主語となるべき種類の抽象化タグが付与された語については、助詞の有無を問わず主語に付属する助詞の対応語格納欄に充填する。
(2)タイトル文中の目的語となるべき種類の抽象化タグが付与された語については、助詞の有無を問わず目的語に付属する助詞の対応語格納欄に充填する。 - 文中における述語の前に目的語に付属する助詞が存在しない場合に、倒置表現文であることを示す識別情報を予め付与する手段を備え、
この識別情報が付与されたタイトル文に対して、上記格スロット充填手段が当該述語に後続する名詞を文の目的語と認定し、格スロットの目的語に付属する助詞の対応語格納欄に当該名詞を充填することを特徴とする請求項1または2に記載の情報抽出システム。 - 複合語となるべき複数の品詞の連結パターン毎に、当該複合語の品詞を決定するための基準が規定された複合語解析ルールを格納しておく複合語解析ルール記憶手段と、
この複合語解析ルールを参照し、文中に複合語解析ルールに規定された品詞の連結パターンに該当する形態素の組合せが存在している場合には、これらの形態素を複合語と認定する複合語解析手段とを備え、
上記の格スロット充填手段は、複合語と認定された形態素の組合せについては、複合語単位で格スロットへの充填処理を実行することを特徴とする請求項1〜3の何れかに記載の情報抽出システム。 - 形態素の種類を推定するための抽象化ルールを格納しておく抽象化ルール記憶手段と、
上記の抽象化ルールを文に対して適用し、当該抽象化ルールにマッチする形態素に対してその種類を示す抽象化タグを関連付ける手段と、
を備えたことを特徴とする請求項1〜4の何れかに記載の情報抽出システム。 - 照応詞毎に、その先行詞を決定するための基準を定めた照応解析ルールを格納しておく照応解析ルール記憶手段と、
この照応解析ルールを参照し、文中に存する照応詞に対して、対応の先行詞を決定すると共に、この先行詞によって照応詞を置き換える照応解析手段とを備えたことを特徴とする請求項1〜5の何れかに記載の情報抽出システム。 - コンピュータを、
活動主体となる具体的な表現文字列と、その種類を示す抽象化文字列との対応関係を登録した辞書、
上記活動主体の活動内容を示す具体的な表現文字列と、その種類を示す抽象化文字列との対応関係を登録した辞書、
上記活動主体の活動対象物を示す具体的な表現文字列と、その種類を示す抽象化文字列との対応関係を登録した辞書、
テキストデータ中の文を形態素単位に分解し、各形態素の品詞を同定する手段、
上記の各辞書を参照し、文中において各辞書に収録されている形態素が存する場合には、当該形態素に対してその種類を示す抽象化タグを関連付ける手段、
少なくとも主語に付属する助詞毎及び目的語に付属する助詞毎に対応語の格納欄が設けられた格スロットに、文中の対応語を充填すると共に、活動内容を示す抽象化タグが付与されている形態素を述語として当該格スロットに関連付ける格スロット充填手段、
抽出すべき主語の抽象化タグ及び当該主語に付属する助詞を特定する条件と、抽出すべき述語の抽象化タグを特定する条件と、抽出すべき目的語の抽象化タグ及び当該目的語に付属する助詞を特定する条件が少なくとも規定された抽出フレーム定義を、複数格納しておく抽出フレーム定義記憶手段、
対応語充填済みの上記格スロットに上記抽出フレーム定義を適用することにより、少なくとも文の主語、述語、目的語に該当する情報要素を抽出する情報抽出手段として機能させる情報抽出プログラムであって、
上記格スロット充填手段が、以下の処理を実行することを特徴とする情報抽出プログラム。
(1) 先行する述語に関して対応語の充填が完了した格スロットを、後続の述語について継承させる。
(2) 後続の述語に係る対応語を上記格スロットの対応語格納欄に上書充填する。
(3)文の主語を表す助詞の対応語格納欄が後続の述語に係る有意思主体を表す語によって上書充填された場合には、先行する述語に関して充填された対応語を削除する。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009282686A JP4625535B1 (ja) | 2009-12-14 | 2009-12-14 | 情報抽出システム及び情報抽出プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009282686A JP4625535B1 (ja) | 2009-12-14 | 2009-12-14 | 情報抽出システム及び情報抽出プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP4625535B1 JP4625535B1 (ja) | 2011-02-02 |
| JP2011123794A true JP2011123794A (ja) | 2011-06-23 |
Family
ID=43638510
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009282686A Expired - Fee Related JP4625535B1 (ja) | 2009-12-14 | 2009-12-14 | 情報抽出システム及び情報抽出プログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4625535B1 (ja) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9390117B2 (en) | 2012-05-31 | 2016-07-12 | International Business Machines Corporation | Method of transforming sets of input strings into at least one pattern expression that is string expressing sets of input strings, method of extracting transformation pattern as approximate pattern expression, and computer and computer program for the methods |
| JP2016532942A (ja) * | 2014-01-09 | 2016-10-20 | バイドゥ オンライン ネットワーク テクノロジー (ベイジン) カンパニー リミテッド | イベント知識データベースの構築方法および装置 |
| JP2021033804A (ja) * | 2019-08-28 | 2021-03-01 | 西日本電信電話株式会社 | 構造化文書作成装置とその方法 |
| JP2021117578A (ja) * | 2020-01-23 | 2021-08-10 | 株式会社リコー | 情報処理システム、情報補完方法、プログラム |
| US12135737B1 (en) * | 2023-06-21 | 2024-11-05 | Sas Institute Inc. | Graphical user interface and pipeline for text analytics |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110569494B (zh) * | 2018-06-05 | 2023-04-07 | 北京百度网讯科技有限公司 | 用于生成信息的方法、装置、电子设备及可读介质 |
| CN110309507A (zh) * | 2019-05-30 | 2019-10-08 | 深圳壹账通智能科技有限公司 | 测试语料生成方法、装置、计算机设备和存储介质 |
| CN111078947B (zh) * | 2019-11-19 | 2023-06-02 | 太极计算机股份有限公司 | 基于xml的领域要素提取配置语言系统 |
| CN111783460A (zh) * | 2020-06-15 | 2020-10-16 | 苏宁金融科技(南京)有限公司 | 一种企业简称提取方法、装置、计算机设备及存储介质 |
| CN117909559B (zh) * | 2024-02-06 | 2024-08-20 | 拓尔思信息技术股份有限公司 | 一种基于互联网公开数据的企业关联信息挖掘方法 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002197097A (ja) * | 2000-12-27 | 2002-07-12 | Nippon Telegr & Teleph Corp <Ntt> | 記事要約文生成装置,記事要約文生成処理方法および記事要約文生成処理プログラムの記録媒体 |
-
2009
- 2009-12-14 JP JP2009282686A patent/JP4625535B1/ja not_active Expired - Fee Related
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002197097A (ja) * | 2000-12-27 | 2002-07-12 | Nippon Telegr & Teleph Corp <Ntt> | 記事要約文生成装置,記事要約文生成処理方法および記事要約文生成処理プログラムの記録媒体 |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9390117B2 (en) | 2012-05-31 | 2016-07-12 | International Business Machines Corporation | Method of transforming sets of input strings into at least one pattern expression that is string expressing sets of input strings, method of extracting transformation pattern as approximate pattern expression, and computer and computer program for the methods |
| JP2016532942A (ja) * | 2014-01-09 | 2016-10-20 | バイドゥ オンライン ネットワーク テクノロジー (ベイジン) カンパニー リミテッド | イベント知識データベースの構築方法および装置 |
| US10282664B2 (en) | 2014-01-09 | 2019-05-07 | Baidu Online Network Technology (Beijing) Co., Ltd. | Method and device for constructing event knowledge base |
| JP2021033804A (ja) * | 2019-08-28 | 2021-03-01 | 西日本電信電話株式会社 | 構造化文書作成装置とその方法 |
| JP2021117578A (ja) * | 2020-01-23 | 2021-08-10 | 株式会社リコー | 情報処理システム、情報補完方法、プログラム |
| US12135737B1 (en) * | 2023-06-21 | 2024-11-05 | Sas Institute Inc. | Graphical user interface and pipeline for text analytics |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4625535B1 (ja) | 2011-02-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4625535B1 (ja) | 情報抽出システム及び情報抽出プログラム | |
| McCrae et al. | Linking lexical resources and ontologies on the semantic web with lemon | |
| US10839155B2 (en) | Text analysis of morphemes by syntax dependency relationship with determination rules | |
| JP5528787B2 (ja) | 株価影響企業検知システム | |
| Ide et al. | Standards for language resources | |
| WO2010038540A1 (ja) | テキストセグメントを有する文書から用語を抽出するためのシステム | |
| JP2007287134A (ja) | 情報抽出装置、及び情報抽出方法 | |
| US20080306726A1 (en) | Machine-processable global knowledge representation system and method using an extensible markup language consisting of natural language-independent BASE64-encoded words | |
| KR20140052328A (ko) | Rdf 기반의 문장 온톨로지 생성 장치 및 방법 | |
| Kumar et al. | Static UML model generator from analysis of requirements (SUGAR) | |
| KR102280028B1 (ko) | 빅데이터와 인공지능을 이용한 챗봇 기반 콘텐츠 관리 방법 및 장치 | |
| KR102206742B1 (ko) | 자연언어 텍스트의 어휘 지식 그래프 표현 방법 및 장치 | |
| JP5317922B2 (ja) | 情報抽出ルール作成支援システム | |
| Deeptimahanti et al. | An innovative approach for generating static UML models from natural language requirements | |
| Suh et al. | Extracting common sense knowledge from wikipedia | |
| Bimson et al. | The lexical bridge: A methodology for bridging the semantic gaps between a natural language and an ontology | |
| KR20170065417A (ko) | 자연 언어 처리 스키마 및 그 지식 데이터베이스 구축 방법 및 시스템 | |
| Haj et al. | Automatic extraction of SBVR based business vocabulary from natural language business rules | |
| Declerck et al. | Cross-linking Austrian dialectal Dictionaries through formalized Meanings | |
| Saadatfar et al. | Best Practice for DSDL-based Validation | |
| Dutkiewicz et al. | R2E: Rule-based Event Extractor. | |
| JP2006059049A (ja) | 情報検索システム、情報検索方法及び情報検索プログラム | |
| Panesar | An evaluation of a linguistically motivated conversational software agent framework | |
| Laporte | Lexicon management and standard formats | |
| Marciniak et al. | Toposław–a lexicographic framework for multi-word units |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20101102 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20101105 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20131112 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |