JP2010140407A - ソースコード検査装置 - Google Patents
ソースコード検査装置 Download PDFInfo
- Publication number
- JP2010140407A JP2010140407A JP2008318345A JP2008318345A JP2010140407A JP 2010140407 A JP2010140407 A JP 2010140407A JP 2008318345 A JP2008318345 A JP 2008318345A JP 2008318345 A JP2008318345 A JP 2008318345A JP 2010140407 A JP2010140407 A JP 2010140407A
- Authority
- JP
- Japan
- Prior art keywords
- source code
- node
- source
- ast
- annotation
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Landscapes
- Debugging And Monitoring (AREA)
- Stored Programmes (AREA)
Abstract
【課題】ソースコードの解析を支援する。
【解決手段】ソースコード処理装置は、検査対象となるソースコードを取得し、その構文解析を行いAST(抽象構文木)を生成する。ASTは、ソースコードの構成要素に対応するノードをその論理構造にしたがって構造化したモデルである。そしてASTにおける各ノードを走査し、ソースコードの構成要素についてあらかじめ設定されている検出条件に合致する箇所を特定し、注釈ノードを設定する。
【選択図】図7
【解決手段】ソースコード処理装置は、検査対象となるソースコードを取得し、その構文解析を行いAST(抽象構文木)を生成する。ASTは、ソースコードの構成要素に対応するノードをその論理構造にしたがって構造化したモデルである。そしてASTにおける各ノードを走査し、ソースコードの構成要素についてあらかじめ設定されている検出条件に合致する箇所を特定し、注釈ノードを設定する。
【選択図】図7
Description
本発明は、コンピュータプログラムの分析、特に、ソースコードの分析を支援するための技術に関する。
企業や公共施設などの運用を支える業務システム、いわゆるエンタープライズシステム(Enterprise System)は、今や、大小さまざまな組織の基盤として導入されている。業務システムは、ノード端末やデータベースから得られるデータを集計、蓄積、解析、加工した上でより付加価値の高い情報を出力する。業務システムを構成するプログラムファイルの数は、数十万、時には数百万にも及ぶことがある。業務システムは複雑化する組織マネジメントをより効率化するために発展を続けている。
特開2007−156791号公報
業務システムは、開発時だけでなく保守作業時・再構築時においてもソースコードの検査・修正を必要とする。特に、ソースコードの修正においては、修正作業自体よりも、膨大なソースコードの中から修正すべき箇所を特定するための作業の方が負荷が大きい。
また、複数のプログラマが関与する大規模な業務システムの開発においては、コーディングルールを制定することが多い。たとえば、関数や変数の命名、コメントの書き方等について統一性を持たせれば、ソースコードの可読性を高めたり修正ミスを防ぐことができる。しかし、コーディングルールの遵守は、プログラマの遵法意識に依存しているのが現状である。
本発明は、本発明者による上記課題認識に基づいて完成された発明であり、その主たる目的は、ソースコードの効率的な解析を支援するための技術を提供することにある。
本発明のある態様は、ソースコード検査装置に関する。
この装置は、ソースコードを取得し、ソースコードの構成要素に対応するノードを抽出し、構成要素の配置にしたがってノードを構造化することにより、ソースコードの論理構造をノードの集合体により示す構文モデルを生成する。そして、構文モデルにおける各ノードを走査し、ソースコードの構成要素についてあらかじめ設定されている検出条件に合致する箇所を特定し、注釈ノードを設定する。
この装置は、ソースコードを取得し、ソースコードの構成要素に対応するノードを抽出し、構成要素の配置にしたがってノードを構造化することにより、ソースコードの論理構造をノードの集合体により示す構文モデルを生成する。そして、構文モデルにおける各ノードを走査し、ソースコードの構成要素についてあらかじめ設定されている検出条件に合致する箇所を特定し、注釈ノードを設定する。
なお、以上に示した各構成要素の任意の組み合わせ、本発明を方法、システム、記録媒体、コンピュータプログラムにより表現したものもまた、本発明の態様として有効である。
本発明によれば、ソースコードの効率的に解析しやすくなる。
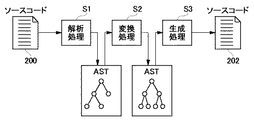
図1は、ソースコードの言語変換過程を示す模式図である。
本実施例においては、日立COBOLで記述されたソースコード(以下、「日立ソース200」とよぶ)をIBM・COBOLで記述されたソースコード(以下、「IBMソース202」とよぶ)に変換する過程を例として説明する。
本実施例においては、日立COBOLで記述されたソースコード(以下、「日立ソース200」とよぶ)をIBM・COBOLで記述されたソースコード(以下、「IBMソース202」とよぶ)に変換する過程を例として説明する。
ソースコードの言語変換を実現するための主たる機能は3つあり、それぞれ、パーサ(parser)、プロセッサ(processor)、ライタ(writer)とよぶ。各機能は、解析処理、変換処理、生成処理をそれぞれ担当する。
解析処理(S1):まず、第1ソースコードとして日立ソース200を取得し、パーサが構文解析し、第1の構文モデルとしての抽象構文木(以下、「AST(Abstract Syntax Tree)」とよぶ)を生成する。ASTは、演算子やそのオペランドといったソースコードの構成要素にノードを対応づけた木構造として形成される。ASTは、一般的なコンパイラやインタプリタで採用されている既存技術の応用により生成できる。日立ソース200のように変換元となるソースコードを「変換元ソース」、変換元ソースから生成されるASTを「変換元AST」、変換元ASTに含まれるノードを「基本ノード」、または、「変換元ノード」とよぶ。変換元ASTは、変換元ソースの言語構造に対応したASTであってもよいし、他のプログラミング言語、たとえば、標準的なCOBOLの言語構造に対応した標準モデルとしてのASTであってもよい。解析処理については、図3に関連して詳述する。
解析処理(S1):まず、第1ソースコードとして日立ソース200を取得し、パーサが構文解析し、第1の構文モデルとしての抽象構文木(以下、「AST(Abstract Syntax Tree)」とよぶ)を生成する。ASTは、演算子やそのオペランドといったソースコードの構成要素にノードを対応づけた木構造として形成される。ASTは、一般的なコンパイラやインタプリタで採用されている既存技術の応用により生成できる。日立ソース200のように変換元となるソースコードを「変換元ソース」、変換元ソースから生成されるASTを「変換元AST」、変換元ASTに含まれるノードを「基本ノード」、または、「変換元ノード」とよぶ。変換元ASTは、変換元ソースの言語構造に対応したASTであってもよいし、他のプログラミング言語、たとえば、標準的なCOBOLの言語構造に対応した標準モデルとしてのASTであってもよい。解析処理については、図3に関連して詳述する。
変換処理(S2):プロセッサは、変換元ASTを、第2ソースコードとしてのIBMソース202に対応したASTに変換する。IBMソース202のように変換先となるソースコードを「変換先ソース」、変換先ソースのために生成されるASTを「変換先AST」、変換先ASTに含まれるノードを「変換先ノード」とよぶ。第2構文モデルとしての変換先ASTは、変換先ソースの言語構造に対応する。変換処理については、図3および図4に関連して詳述する。
生成処理(S3):ライタは、変換先ASTから変換先ソースであるIBMソース202を生成する。生成処理については、図4に関連して詳述する。
以上に示したように、変換元ソースである日立ソース200から変換元ASTを生成し、変換元ASTから変換先ASTを生成し、変換先ASTから変換先ソースであるIBMソース202を生成することにより、日立ソース200がIBMソース202に変換される。
以上に示したように、変換元ソースである日立ソース200から変換元ASTを生成し、変換元ASTから変換先ASTを生成し、変換先ASTから変換先ソースであるIBMソース202を生成することにより、日立ソース200がIBMソース202に変換される。
言語変換処理を実現するためには、1.変換元ソースから変換元ASTを生成するためのルール(以下、「第1ASTルール」とよぶ)、2.変換元ASTから変換先ASTを生成するためのルール(以下、「第2ASTルール」とよぶ)、3.変換先ASTから変換先ソースを生成するためのルール(以下、「ソース生成ルール」とよぶ)の3種類のルールが必要である。各種のプログラミング言語についてこれらのルールをライブラリとして提供することにより、さまざまなプログラミング言語間における言語変換処理が実現される。
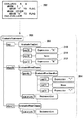
図2は、ソースコード処理装置100の機能ブロック図である。
ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組合せによっていろいろなかたちで実現できることは、当業者には理解されるところである。
ソースコード処理装置100は、図1に示したパーサ、プロセッサ、ライタの機能を担う装置である。本実施例においては、ソースコード処理装置100の主たる機能は、コンピュータ上のソフトウェアとして実現されるものとして説明する。より具体的には、本実施例におけるソースコード処理装置100の各機能は、主として、JAVA(登録商標)やScalaにより記述され、JVM(Java Virtual Machine)上において実行されるコンピュータプログラムにより実現される。
ここに示す各ブロックは、ハードウェア的には、コンピュータのCPUをはじめとする素子や機械装置で実現でき、ソフトウェア的にはコンピュータプログラム等によって実現されるが、ここでは、それらの連携によって実現される機能ブロックを描いている。したがって、これらの機能ブロックはハードウェア、ソフトウェアの組合せによっていろいろなかたちで実現できることは、当業者には理解されるところである。
ソースコード処理装置100は、図1に示したパーサ、プロセッサ、ライタの機能を担う装置である。本実施例においては、ソースコード処理装置100の主たる機能は、コンピュータ上のソフトウェアとして実現されるものとして説明する。より具体的には、本実施例におけるソースコード処理装置100の各機能は、主として、JAVA(登録商標)やScalaにより記述され、JVM(Java Virtual Machine)上において実行されるコンピュータプログラムにより実現される。
ソースコード処理装置100は、UI(ユーザインタフェース)部110、データ処理部120およびデータ保持部140を含む。
UI部110は、ユーザインタフェース処理を担当する。データ処理部120は、UI部110やデータ保持部140から取得されたデータを元にして各種のデータ処理を実行する。データ処理部120は、UI部110とデータ保持部140との間のインタフェースの役割も果たす。データ保持部140は、各種データを保持するための記憶領域である。
UI部110は、ユーザインタフェース処理を担当する。データ処理部120は、UI部110やデータ保持部140から取得されたデータを元にして各種のデータ処理を実行する。データ処理部120は、UI部110とデータ保持部140との間のインタフェースの役割も果たす。データ保持部140は、各種データを保持するための記憶領域である。
UI部110:
UI部110は、入力部112と出力部116を備える。入力部112は、ユーザの各種入力を検出したり、ファイル等のデータを外部装置から取得する。出力部116は、各種情報を表示したり、ファイル等のデータを外部装置に送信する。入力部112は、コード取得部114を含む。コード取得部114は、図1の日立ソース200のような変換元ソースを取得する。出力部116は、コード出力部118を含む。コード出力部118は、図1のIBMソース202のような変換先ソースを出力する。
UI部110は、入力部112と出力部116を備える。入力部112は、ユーザの各種入力を検出したり、ファイル等のデータを外部装置から取得する。出力部116は、各種情報を表示したり、ファイル等のデータを外部装置に送信する。入力部112は、コード取得部114を含む。コード取得部114は、図1の日立ソース200のような変換元ソースを取得する。出力部116は、コード出力部118を含む。コード出力部118は、図1のIBMソース202のような変換先ソースを出力する。
データ処理部120:
データ処理部120は、第1構文モデル生成部122、第2構文モデル生成部124、コード生成部126、検査部128および注釈ノード設定部130を含む。第1構文モデル生成部122は、第1ASTルール152を含む。第1構文モデル生成部122は、第1ASTルール152を参照して、変換元ソースから変換元ASTを生成する。第2構文モデル生成部124は、第2ASTルール154を含む。第2構文モデル生成部124は、第2ASTルール154を参照して、変換元ASTから変換先ASTを生成する。コード生成部126は、ソース生成ルール156を含む。コード生成部126は、ソース生成ルール156を参照して、変換先ASTから変換先ソースを生成する。
データ処理部120は、第1構文モデル生成部122、第2構文モデル生成部124、コード生成部126、検査部128および注釈ノード設定部130を含む。第1構文モデル生成部122は、第1ASTルール152を含む。第1構文モデル生成部122は、第1ASTルール152を参照して、変換元ソースから変換元ASTを生成する。第2構文モデル生成部124は、第2ASTルール154を含む。第2構文モデル生成部124は、第2ASTルール154を参照して、変換元ASTから変換先ASTを生成する。コード生成部126は、ソース生成ルール156を含む。コード生成部126は、ソース生成ルール156を参照して、変換先ASTから変換先ソースを生成する。
検査部128は、変換元AST、あるいは、変換先ASTのノードを走査して、所定の「検出条件」に合致する箇所を特定する。検査部128は、コーディングルール158を含む。検出条件の全部または一部は、コーディングルール158として定義される。検出条件については、図5以降に関連して詳述する。注釈ノード設定部130は、検出条件に合致する箇所が検出されたとき、「注釈ノード」をASTに設定する。注釈ノード設定部130は、注釈ノード設定ルール160を含む。注釈ノード設定ルール160には、検出条件と注釈ノードが対応づけられている。ある検出条件に合致する箇所が検出されたとき、どのような注釈ノードを設定すべきか、はこの注釈ノード設定ルール160に設定されている。注釈ノードの設定の詳細については、図6以降に関連して詳述する。検出条件と注釈ノードは、ASTを対象として所定のコーディングルールが守られているか、プログラミング構造的に不適切な記載箇所がないか、を判断するために導入される。
データ保持部140:
データ保持部140は、第1構文モデル保持部142と第2構文モデル保持部144を含む。第1構文モデル保持部142は、第1構文モデル生成部122が生成した変換元ASTを保持する。第2構文モデル保持部144は、第2構文モデル生成部124が生成した変換先ASTを保持する。
データ保持部140は、第1構文モデル保持部142と第2構文モデル保持部144を含む。第1構文モデル保持部142は、第1構文モデル生成部122が生成した変換元ASTを保持する。第2構文モデル保持部144は、第2構文モデル生成部124が生成した変換先ASTを保持する。
解析処理(S1)、すなわち、パーサとしての機能は、主として、入力部112と第1構文モデル生成部122により実現される。変換処理(S2)、すなわち、プロセッサとしての機能は、主として、第2構文モデル生成部124により実現される。生成処理(S3)、すなわち、ライタとしての機能は、主として、コード生成部126や出力部116により実現される。
ソースコード処理装置100は、変換元ソースを変換先ソースに言語変換する「ソースコード変換装置」としての機能のほかに、検出条件を設定することにより、ソースコードの記述内容を検査する「ソースコード検査装置」としての機能も備える。以下、「ソースコード変換装置」としての機能と「ソースコード検査装置」としての機能を分けて説明する。
[ソースコード変換装置としての機能]
図3は、日立ソース200から変換元ASTを生成する過程を説明するための模式図である。
同図に示す日立ソース200は、変数「A」と変数「B」を比較対象とし、「AとBが共に1」という条件が成立するときには、変数「FLAG」に文字列「Y」を設定し、それ以外のときには変数「FLAG」に文字列「N」を設定する、という内容を示している。1行目の構文「EVALUATE A B」は、「A」と「B」を比較対象とする、という処理内容を示している。
図3は、日立ソース200から変換元ASTを生成する過程を説明するための模式図である。
同図に示す日立ソース200は、変数「A」と変数「B」を比較対象とし、「AとBが共に1」という条件が成立するときには、変数「FLAG」に文字列「Y」を設定し、それ以外のときには変数「FLAG」に文字列「N」を設定する、という内容を示している。1行目の構文「EVALUATE A B」は、「A」と「B」を比較対象とする、という処理内容を示している。
コード取得部114が日立ソース200を取得すると、第1構文モデル生成部122は、まず、構文「EVALUATE A B」を取得する。この構文の構成要素は、「EVALUATE」、「A」、「B」である。第1構文モデル生成部122は、まず、第1ASTルールに基づき、「EVALUATE」に対応する変換元ノードEvaluateStatement206を設定し、「EVALUATE」の変数リスト宣言に対応する変換ノードEvaluateTagList208を設定する。構成要素とは、ソースコードに記述されている変数や定数、宣言や関数といったステートメントであり、ノードとはそれらの構成要素に対応づけられるASTの要素である。ノードの中には、EvaluateStatement206のように、ソースコード中において明示的に記述されている構成要素に対応して設定されるノードもあれば、EvaluateTagList208のように、EvaluateStatement206のような他ノードに付随して設定されるノードもある。
「EVALUATE」の引数「A」、「B」に対応して、Expression:"A"210とExpression:"B"212という2つのノードがEvaluateTagList208の子ノードとして設定される。更に、引数「A」、「B」の並置を示すためのノード「None214」も設定される。日立ソース200では、「EVALUATE A B」のように引数をそのまま並べて書くことができるが、IBMソース202では、「EVALUATE A ALSO B」のように引数「A」、「B」の間に「ALSO」という構成要素が記述される。日立ソース200から変換元AST204を生成するときには、Expression:"A"210とExpression:"B"212だけでなく、None214というノードも設定される。より具体的には、「EVALUATE」という表現に対しては、EvaluateStatement206、EvaluateTagList208および引数に対応するノードと引数をつなぐためのノード(None214)が第1ASTルールにおいて対応づけられている。第1構文モデル生成部122はこの第1ASTルールにしたがって、「EVALUATE」という表現に対応してしかるべき変換元ノードを組み立てる。
変換元AST204が標準的・統一的な構文モデルであるならば、変換元ソースのプログラミング言語ごとに第1ASTルールを用意すれば、任意の変換元ソースから標準的な構文モデルとしての変換元AST204を生成できる。
変換元AST204が標準的・統一的な構文モデルであるならば、変換元ソースのプログラミング言語ごとに第1ASTルールを用意すれば、任意の変換元ソースから標準的な構文モデルとしての変換元AST204を生成できる。
図4は、変換元ASTから変換先AST、IBMソース202を生成する過程を説明するための模式図である。
まず、第2構文モデル生成部124は、変換元AST204から変換先AST220を生成する。変換先ソースであるIBMソース202では、「EVALUATE A ALSO B」のように「EVALUATE」の引数は構成要素「ALSO」によってつなげられる。そこで、第2構文モデル生成部124は、変換元AST204の変換元ノードNone214を、変換先ノードALSO222に変換する。変換元ノードと変換先ノードの対応づけは、プログラミング言語ごとに第2ASTルールとして設定されている。第2構文モデル生成部124はこの第2ASTルールにしたがって変換元AST204から変換先AST220を生成する。
変換元AST204が標準的・統一的な構文モデルであるならば、変換先ソースのプログラミング言語ごとに第2ASTルールを用意すれば、任意の変換先ASTへの変換が可能となる。
まず、第2構文モデル生成部124は、変換元AST204から変換先AST220を生成する。変換先ソースであるIBMソース202では、「EVALUATE A ALSO B」のように「EVALUATE」の引数は構成要素「ALSO」によってつなげられる。そこで、第2構文モデル生成部124は、変換元AST204の変換元ノードNone214を、変換先ノードALSO222に変換する。変換元ノードと変換先ノードの対応づけは、プログラミング言語ごとに第2ASTルールとして設定されている。第2構文モデル生成部124はこの第2ASTルールにしたがって変換元AST204から変換先AST220を生成する。
変換元AST204が標準的・統一的な構文モデルであるならば、変換先ソースのプログラミング言語ごとに第2ASTルールを用意すれば、任意の変換先ASTへの変換が可能となる。
コード生成部126は、各変換先ノードごとにIBMソース202の該当構成要素を特定し、特定した構成要素を変換先AST220の構造にしたがって組み立てる。このようなルールは、ソース生成ルールとして定義されている。こうして、ALSO表現を含まない日立ソース200からALSO表現を含むIBMソース202が生成される。この結果、IBM・COBOL用の解析ツールにより日立ソース200を解析可能となる。
IBMソース202を変換元ソース、日立ソース200を変換先ソースとする場合にも基本的な考え方は同様である。IBMソース202から変換元ASTを作るときには、構成要素「ALSO」からノード「ALSO222」を設定する。変換元ASTを日立COBOL用の変換先ASTに変換するときには、ALSO222はNone214に変換される。あるいは、ALSO222に対応するノードを変換先ASTには設定しないとしてもよい。いずれにしても、変換先ASTにおいて、ALSO222に対応するノードが無効化されればよい。コード生成部126は、None214に対応する構成要素を日立ソース200に記述しない。このような処理方法により、IBMソース202の「EVALUATE A ALSO B」は、日立ソース200においては「EVALUATE A B」として表現されることになる。
ここでは、日立ソース200とIBMソース202の違いの例としてALSO222の有無を挙げたが、このほかのさまざまな言語間の差異についても、第1ASTルール、第2ASTルールおよびソース生成ルールを適切に定義することにより変換可能となる。
ここでは、日立ソース200とIBMソース202の違いの例としてALSO222の有無を挙げたが、このほかのさまざまな言語間の差異についても、第1ASTルール、第2ASTルールおよびソース生成ルールを適切に定義することにより変換可能となる。
[ソースコード検査装置としての機能]
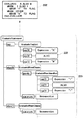
図5は、「int num,iNumber」という変数宣言文から生成されるASTを示す図である。
検査対象となるASTは、変換元ASTであっても変換先ASTであってもよい。ここでは、変換元ASTを対象として検査を実行するとして説明する。検査の内容はユーザが任意に設定できる。たとえば、業務システムの開発・保守について、以下のようなコーディングルールを設定したとする。
R1.int型の変数名は、文字「i」から始まること
R2.変数宣言においては、1回の型宣言で複数の変数を定義しないこと
R3.変数名は4文字以上であること
図5は、「int num,iNumber」という変数宣言文から生成されるASTを示す図である。
検査対象となるASTは、変換元ASTであっても変換先ASTであってもよい。ここでは、変換元ASTを対象として検査を実行するとして説明する。検査の内容はユーザが任意に設定できる。たとえば、業務システムの開発・保守について、以下のようなコーディングルールを設定したとする。
R1.int型の変数名は、文字「i」から始まること
R2.変数宣言においては、1回の型宣言で複数の変数を定義しないこと
R3.変数名は4文字以上であること
コーディングルールの制定は、ソースコードの可読性を高めたり、修正ミスを防ぐ上で重要である。特に、複数のソフトウェアエンジニアが関わる大規模な業務システムの開発において適切なコーディングルールを制定することは重要である。
同図の宣言文「int num,iNumber」において、変数「num」は、その先頭文字が「n」であるため、上記のルールR1を満たしていない。また、一つのint型宣言で「num」と「iNumber」という2つの変数をまとめて定義しているため、ルールR2も満たしていない。更に、変数「num」の文字数は3文字しかないため、ルールR3も満たしていない。ソースコード処理装置100は、コーディングルールが実際に守られているか、また、コーディングルールが守られていない箇所はどこか、を検査できる。
同図に示すAST230は、宣言文「int num,iNumber」に対応する。第1構文モデル生成部122は、変数の宣言文に出会うと、まず、第1ASTルールに基づき、LocalVariableDeclaration232をAST230に設定する。子ノードとして、int型を示すノードであるIntType234と変数リストを示すノードであるVariableDeclarators236が設定される。変数「num」、変数「iNumber」に対しては、VariableDeclarator238とIdentifier:"num"240、VariableDeclarator242とIdentifier:"iNumber"244がそれぞれ設定されている。
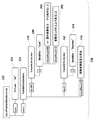
図6は、ルールR1に対応して注釈ノードが設定されたAST230を示す図である。
検査部128には、上述したルールR1〜R3が検出条件として設定される。検査部128は、まず、ルールR1「int型の変数名は、文字「i」から始まること」に違反している変数ノードをAST230から検索する。検査部128は、AST230を走査して、IntType234を見つけると、その親ノードであるLocalVariableDeclaration232の子ノードの中からidentifierノードを探し、変数名をチェックする。変数「num」はルールR1に違反している。注釈ノード設定部130はIdentifier:"num"240に注釈ノード250を設定する。
検査部128には、上述したルールR1〜R3が検出条件として設定される。検査部128は、まず、ルールR1「int型の変数名は、文字「i」から始まること」に違反している変数ノードをAST230から検索する。検査部128は、AST230を走査して、IntType234を見つけると、その親ノードであるLocalVariableDeclaration232の子ノードの中からidentifierノードを探し、変数名をチェックする。変数「num」はルールR1に違反している。注釈ノード設定部130はIdentifier:"num"240に注釈ノード250を設定する。
注釈ノード設定部130は、最終的に、AST230中の注釈ノード250を収集し、リスト化して出力部116に出力させる。また、コード生成部126は、注釈ノード250を含むAST230からソースコードを生成してもよい。コード生成部126はソースコード中において、注釈ノード250の対応する箇所に注釈内容を示すコメントを付記してもよい。
図7は、更に、ルールR2、R3に対応して注釈ノードが設定されたときのAST230を示す図である。
検査部128は、次に、ルールR2「変数宣言においては、1回の型宣言で複数の変数を定義しないこと」に違反している箇所を検索する。検査部128は、AST230を走査して、LocalVariableDeclaration232を見つけると、その子ノードの中からidentifierノードを探し、宣言されている変数の数をチェックする。ステートメント「int num,iNumber」はルールR2に違反している。注釈ノード設定部130はVariableDeclarators236に注釈ノード254を設定する。
検査部128は、次に、ルールR2「変数宣言においては、1回の型宣言で複数の変数を定義しないこと」に違反している箇所を検索する。検査部128は、AST230を走査して、LocalVariableDeclaration232を見つけると、その子ノードの中からidentifierノードを探し、宣言されている変数の数をチェックする。ステートメント「int num,iNumber」はルールR2に違反している。注釈ノード設定部130はVariableDeclarators236に注釈ノード254を設定する。
検査部128は、ルールR3「変数名は4文字以上であること」に違反している箇所を検索する。検査部128は、AST230を走査して、LocalVariableDeclaration232を見つけると、その子ノードの中からidentifierノードを探し、宣言されている変数の文字数をチェックする。変数「num」はルールR3に違反しているため、注釈ノード設定部130はIdentifier:"num"240に注釈ノード252を設定する。
検出条件は、コーディングルールに関わる条件に限らない。たとえば、コンピュータプログラムの構造として満たされるべき条件を検出条件として設定してもよい。以下、2例を示す。
例1.特定の処理の開始時に記載されるステートメントと終了時に記載されるべきステートメントの確認
たとえば、C++の場合、「new」演算子によりメモリの動的確保がなされる。メモリを解放する演算子は「delete」である。new演算子で確保したメモリは、使用後には、deleteによって解放しなければならない。また、「open」演算子によりファイルディスクリプタを開いたあとは、「close」演算子により同ファイルディスクリプタを閉じなければならない。このように、「メモリの動的確保」や「ファイルディスクリプタの使用」といった特定の処理の前後においては、所定のステートメントが一対として記述されなければならない。以下、newやopenのように特定の処理の開始時に記述されるべき構成要素を「開始要素」、終了時に記述されるべき構成要素を「終了要素」とよぶ。1つのソースファイルにおいては開始要素と終了要素の数は同数となるべきである。開始要素に対応するノードを「先端ノード」、終了要素に対応するノードを「終端ノード」とよぶことにすると、ASTにおいては、先端ノードの数と終端ノードの数は同数となるべきである。
このような観点から、ソースコード処理装置100は先端ノードと終端ノードに基づいてプログラム構造上の不備がないかを検査してもよい。
たとえば、C++の場合、「new」演算子によりメモリの動的確保がなされる。メモリを解放する演算子は「delete」である。new演算子で確保したメモリは、使用後には、deleteによって解放しなければならない。また、「open」演算子によりファイルディスクリプタを開いたあとは、「close」演算子により同ファイルディスクリプタを閉じなければならない。このように、「メモリの動的確保」や「ファイルディスクリプタの使用」といった特定の処理の前後においては、所定のステートメントが一対として記述されなければならない。以下、newやopenのように特定の処理の開始時に記述されるべき構成要素を「開始要素」、終了時に記述されるべき構成要素を「終了要素」とよぶ。1つのソースファイルにおいては開始要素と終了要素の数は同数となるべきである。開始要素に対応するノードを「先端ノード」、終了要素に対応するノードを「終端ノード」とよぶことにすると、ASTにおいては、先端ノードの数と終端ノードの数は同数となるべきである。
このような観点から、ソースコード処理装置100は先端ノードと終端ノードに基づいてプログラム構造上の不備がないかを検査してもよい。
ここでは、openを開始要素、closeを終端要素として説明する。まず、検査部128はASTを走査し、openに対応する先端ノードを検出すると、先端ノード数をインクリメントする。また、closeに対応する終端ノードを検出すると、終端ノード数をインクリメントする。ASTの全ノードを走査したとき、先端ノード数と終端ノード数が同数でなかったときには、ソースコードの記述に欠陥があるのかもしれない。先端ノード数が終端ノード数よりも多いときには、開いたまま閉じられていないファイルディスクリプタが存在する可能性がある。このような場合、注釈ノード設定部130その旨を警告するための注釈ノードを設定する。
例2.オーバーライドの範囲の確認
あるclassAにおいてそのメンバ関数method1()を定義したとする。このクラスを継承するclassBは、独自にメンバ関数method1()を定義しなくても、classAのメンバ関数method1()を自らのメンバ関数として提供できる。いわば、classBはclassAのメンバ関数を借用することになる。classA.method1()をコールしたときに実行される処理内容と、classB.method1()をコールしたときに実行される処理内容は全く同じとなる。したがって、classAに定義されているmethod1()の内容を修正すると、classA.method1()だけでなく、classB.method1()の挙動も変化する。
あるclassAにおいてそのメンバ関数method1()を定義したとする。このクラスを継承するclassBは、独自にメンバ関数method1()を定義しなくても、classAのメンバ関数method1()を自らのメンバ関数として提供できる。いわば、classBはclassAのメンバ関数を借用することになる。classA.method1()をコールしたときに実行される処理内容と、classB.method1()をコールしたときに実行される処理内容は全く同じとなる。したがって、classAに定義されているmethod1()の内容を修正すると、classA.method1()だけでなく、classB.method1()の挙動も変化する。
一方、classBにおいて、独自に、同名のmethod1()を再定義してもよい。これをオーバーライド(override)とよぶ。この場合、classA.method1()をコールしたときに実行される処理内容はclassAのmethod1()により定義され、classB.method1()をコールしたときに実行される処理内容はclassBのmethod1()により定義される。classAとclassBは、同名のインタフェースmethod1()を提供しつつ、その処理内容をclassAとclassBで異ならせることができる。オーバーライドというプログラミングテクニックは、classBのmethod1()と、classAのmethod1()の処理内容がほとんど同じでありながら若干異なる場合に利用されることが多い。
classBでmethod1()を再定義、すなわち、オーバーライドしている場合、classA.method1()の内容を修正すると、当然ながらclassA.method1()の挙動は変化するが、classB.method1()の挙動は変化しない。classA.method1()の内容の修正にあわせて、classB.method1()も変化させたい場合には、classB.method1()にも、同様の修正を忘れずに施す必要がある。
このような観点から、ソースコード処理装置100は、各クラスのメンバ関数について、そのオーバーライドされている箇所を特定することにより、ソースコード解析を支援する。
このような観点から、ソースコード処理装置100は、各クラスのメンバ関数について、そのオーバーライドされている箇所を特定することにより、ソースコード解析を支援する。
具体的には、検査部128は、まず、classAを継承しているサブクラス群を特定し、これらのサブクラスにおいて定義されるメンバ関数を検索する。そして、この中からmethod1()という名前のメンバ関数を特定する。classAのサブクラスにおいてmethod1()が定義されていれば、ここでオーバーライドとなっていることがわかる。注釈ノード設定部130は該当箇所に注釈ノードを設定する。classAのmethod1()を修正したときには、このようにして設定された注釈ノードを確認することにより、修正すべきかもしれないメンバ関数の場所を特定できる。
注釈ノード設定部130は、最終的に、注釈ノード群をリスト化する。このリストには、注釈ノードの内容、注釈ノードが所属するソースファイル名、行番号、桁位置、行テキスト、親ノード名等、注釈ノードの位置を示す情報も含まれることが好ましい。ユーザは、この注釈ノードのリストにより、膨大なソースコードの中から重点的に確認すべき箇所を把握できるため、ソースコードの開発・保守が容易となる。
以上、実施例に基づいて、ソースコード処理装置100を説明した。
ソースコード処理装置100は、「第1ASTルール」、「第2ASTルール」、「ソース生成ルール」を用意すれば、さまざまなプログラミング言語で記述されたソースコードを別のプログラミング言語で記述されたソースコードに変換できる。このため、さまざまなプログラミング言語が混在する業務システムにさまざまな解析ツールを適用しやすくなる。ソースコード同士を直接変換するのではなく、ソースコードの論理構造を反映させたAST同士の変換であるため、変換元ソースの論理構造を変換先ソースに反映させやすくなる。
ソースコード処理装置100は、「第1ASTルール」、「第2ASTルール」、「ソース生成ルール」を用意すれば、さまざまなプログラミング言語で記述されたソースコードを別のプログラミング言語で記述されたソースコードに変換できる。このため、さまざまなプログラミング言語が混在する業務システムにさまざまな解析ツールを適用しやすくなる。ソースコード同士を直接変換するのではなく、ソースコードの論理構造を反映させたAST同士の変換であるため、変換元ソースの論理構造を変換先ソースに反映させやすくなる。
また、検出条件にしたがってASTから該当箇所を特定し、注釈コードを設定することにより、ソースコードの解析が容易となる。ソースコードのテキスト検索ではなく、ソースコードの論理構造を反映するASTを対象とした検査であるため、膨大なソースコードの中から、コーディングルール違反をしている箇所やコーディングミスの可能性がある箇所を適確に見つけ出しやすくなる。
以上、本発明について実施例をもとに説明した。実施の形態は例示であり、それらの各構成要素や各処理プロセスの組み合わせにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。
100 ソースコード処理装置、 110 UI部、 112 入力部、 114 コード取得部、 116 出力部、 118 コード出力部、 120 データ処理部、 122 第1構文モデル生成部、 124 第2構文モデル生成部、 126 コード生成部、 128 検査部、 130 注釈ノード設定部、 140 データ保持部、 142 第1構文モデル保持部、 144 第2構文モデル保持部、 200 日立ソース、 202 IBMソース、 204 変換元AST、 220 変換先AST。
Claims (5)
- ソースコードを取得するコード取得部と、
前記ソースコードの構成要素に対応するノードを抽出し、前記ソースコードにおける前記構成要素の配置にしたがって前記ノードを構造化することにより、前記ソースコードの論理構造を前記ノードの集合体により示す構文モデルを生成する構文モデル生成部と、
前記構文モデルにおける各ノードを走査し、前記ソースコードの構成要素についてあらかじめ設定されている検出条件に合致する箇所を特定する検査部と、
前記特定された箇所に注釈を示すノードである注釈ノードを設定する注釈ノード設定部と、
を備えることを特徴とするソースコード検査装置。 - 前記検査部は、所定の命名規則に適合しない名称の変数に対応するノードに前記注釈ノードを設定することを特徴とする請求項1に記載のソースコード検査装置。
- 前記検査部は、更に、所定の処理の開始時に記述されるべき構成要素に対応する先端ノードと、前記所定の処理の終了時に記述されるべき構成要素に対応する終端ノードを特定し、先端ノードの数と終端ノードの数が同数となっているかを判定し、
前記注釈ノード設定部は、前記先端ノードの数と前記終端ノードの数が同数となっていないときには、更に、前記先端ノードと前記終端ノードに関するルールが満たされていない旨を示す注釈ノードを設定することを特徴とする請求項1または2に記載のソースコード検査装置。 - 前記検査部は、第1のクラスにおいて定義されている第1のメンバ関数が、前記第1のクラスを継承する第2のクラスにおいて定義されている第2のメンバ関数によりオーバーライド(override)されているかを判定し、
前記注釈ノード設定部は、前記第2のメンバ関数が前記第1のメンバ関数をオーバーライドしているとき、前記第2のメンバ関数に対応するノードに前記注釈ノードを設定することを特徴とする請求項1から3のいずれかに記載のソースコード検査装置。 - ソースコードを取得する処理と、
前記ソースコードの構成要素に対応するノードを抽出し、前記ソースコードにおける前記構成要素の配置にしたがって前記ノードを構造化することにより、前記ソースコードの論理構造を前記ノードの集合体により示す構文モデルを生成する処理と、
前記構文モデルにおける各ノードを走査し、前記ソースコードの構成要素についてあらかじめ設定されている検出条件に合致する箇所を特定する処理と、
前記特定された箇所に注釈を示すノードである注釈ノードを設定する処理と、
をコンピュータに実行させることを特徴とするソースコード検査プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008318345A JP2010140407A (ja) | 2008-12-15 | 2008-12-15 | ソースコード検査装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008318345A JP2010140407A (ja) | 2008-12-15 | 2008-12-15 | ソースコード検査装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2010140407A true JP2010140407A (ja) | 2010-06-24 |
Family
ID=42350477
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008318345A Pending JP2010140407A (ja) | 2008-12-15 | 2008-12-15 | ソースコード検査装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2010140407A (ja) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102799524A (zh) * | 2012-07-03 | 2012-11-28 | 天津大学 | 一种浏览器扩展的缺陷检测方法 |
| GB2506162A (en) * | 2012-09-24 | 2014-03-26 | Ibm | Searching source code |
| CN103927473A (zh) * | 2013-01-16 | 2014-07-16 | 广东电网公司信息中心 | 检测移动智能终端的源代码安全的方法、装置及系统 |
| CN110309050A (zh) * | 2019-05-22 | 2019-10-08 | 深圳壹账通智能科技有限公司 | 代码规范性的检测方法、装置、服务器及存储介质 |
| JP6854994B1 (ja) * | 2020-04-20 | 2021-04-07 | 三菱電機株式会社 | 動作確認支援装置、動作確認支援方法及び動作確認支援プログラム |
| CN114489664A (zh) * | 2021-12-24 | 2022-05-13 | 深圳技术大学 | 判题方法及系统 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05216681A (ja) * | 1991-10-22 | 1993-08-27 | American Teleph & Telegr Co <Att> | プログラムソースコード解析手法 |
| JPH08249193A (ja) * | 1995-03-15 | 1996-09-27 | Hitachi Ltd | プログラムの言語仕様範囲の検査方式 |
| JPH11296366A (ja) * | 1998-04-07 | 1999-10-29 | Nec Corp | エラー検出装置及びエラー検出方法及び記録媒体 |
| JP2000132387A (ja) * | 1998-10-22 | 2000-05-12 | Fujitsu Ltd | オブジェクト指向プログラム作成支援装置 |
| JP2005056183A (ja) * | 2003-08-05 | 2005-03-03 | Nec Corp | ルール検査システム、ルール検査装置、ルール検査方法、及びルール検査プログラム |
| JP2007122631A (ja) * | 2005-10-31 | 2007-05-17 | Internatl Business Mach Corp <Ibm> | プログラムの規約違反を判断する装置、およびその方法 |
-
2008
- 2008-12-15 JP JP2008318345A patent/JP2010140407A/ja active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05216681A (ja) * | 1991-10-22 | 1993-08-27 | American Teleph & Telegr Co <Att> | プログラムソースコード解析手法 |
| JPH08249193A (ja) * | 1995-03-15 | 1996-09-27 | Hitachi Ltd | プログラムの言語仕様範囲の検査方式 |
| JPH11296366A (ja) * | 1998-04-07 | 1999-10-29 | Nec Corp | エラー検出装置及びエラー検出方法及び記録媒体 |
| JP2000132387A (ja) * | 1998-10-22 | 2000-05-12 | Fujitsu Ltd | オブジェクト指向プログラム作成支援装置 |
| JP2005056183A (ja) * | 2003-08-05 | 2005-03-03 | Nec Corp | ルール検査システム、ルール検査装置、ルール検査方法、及びルール検査プログラム |
| JP2007122631A (ja) * | 2005-10-31 | 2007-05-17 | Internatl Business Mach Corp <Ibm> | プログラムの規約違反を判断する装置、およびその方法 |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102799524A (zh) * | 2012-07-03 | 2012-11-28 | 天津大学 | 一种浏览器扩展的缺陷检测方法 |
| GB2506162A (en) * | 2012-09-24 | 2014-03-26 | Ibm | Searching source code |
| US9268558B2 (en) | 2012-09-24 | 2016-02-23 | International Business Machines Corporation | Searching source code |
| CN103927473A (zh) * | 2013-01-16 | 2014-07-16 | 广东电网公司信息中心 | 检测移动智能终端的源代码安全的方法、装置及系统 |
| CN110309050A (zh) * | 2019-05-22 | 2019-10-08 | 深圳壹账通智能科技有限公司 | 代码规范性的检测方法、装置、服务器及存储介质 |
| JP6854994B1 (ja) * | 2020-04-20 | 2021-04-07 | 三菱電機株式会社 | 動作確認支援装置、動作確認支援方法及び動作確認支援プログラム |
| WO2021214843A1 (ja) * | 2020-04-20 | 2021-10-28 | 三菱電機株式会社 | 動作確認支援装置、動作確認支援方法及び動作確認支援プログラム |
| CN114489664A (zh) * | 2021-12-24 | 2022-05-13 | 深圳技术大学 | 判题方法及系统 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Schiewe et al. | Advancing static code analysis with language-agnostic component identification | |
| US8028276B1 (en) | Method and system for generating a test file | |
| US9122540B2 (en) | Transformation of computer programs and eliminating errors | |
| CN103336760B (zh) | 一种基于逆向工程自动生成软件文档的方法及装置 | |
| CN108845940B (zh) | 一种企业级信息系统自动化功能测试方法和系统 | |
| US8434062B2 (en) | Enhancing source code debugging and readability using visual symbols | |
| Rasool et al. | Design pattern recovery based on annotations | |
| US20070277163A1 (en) | Method and tool for automatic verification of software protocols | |
| CN114610640B (zh) | 一种面向物联网可信执行环境的模糊测试方法和系统 | |
| CN101866315B (zh) | 软件开发工具的测试方法及系统 | |
| CN108037913B (zh) | xUML4MC模型到MSVL语言程序的转换方法、计算机可读存储介质 | |
| CN103440196B (zh) | 一种操作系统资源问题检测方法 | |
| CN104035754A (zh) | 一种基于xml的自定义代码生成方法及生成器 | |
| CN102662825B (zh) | 一种面向堆操作程序的内存泄漏检测方法 | |
| CN106919612A (zh) | 一种上线结构化查询语言脚本的处理方法及装置 | |
| JP2010140408A (ja) | ソースコード変換装置 | |
| JP2010140407A (ja) | ソースコード検査装置 | |
| CN115080448A (zh) | 一种软件代码不可达路径自动检测的方法和装置 | |
| CN110543427A (zh) | 测试用例存储方法、装置、电子设备及存储介质 | |
| US8423971B2 (en) | Generating an application software library | |
| Liuying et al. | Test selection from UML statecharts | |
| CN119848841A (zh) | 一种代码分析方法及相关设备 | |
| CN117389518A (zh) | 一种针对Python开源生态的细粒度软件供应链构建方法 | |
| Gómez | Supporting integration activities in object-oriented applications | |
| EP2535813B1 (en) | Method and device for generating an alert during an analysis of performance of a computer application |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110310 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120904 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20120905 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20130108 |