JP2010096899A - 音響モデル作成方法、その装置、プログラム、その記録媒体 - Google Patents
音響モデル作成方法、その装置、プログラム、その記録媒体 Download PDFInfo
- Publication number
- JP2010096899A JP2010096899A JP2008266288A JP2008266288A JP2010096899A JP 2010096899 A JP2010096899 A JP 2010096899A JP 2008266288 A JP2008266288 A JP 2008266288A JP 2008266288 A JP2008266288 A JP 2008266288A JP 2010096899 A JP2010096899 A JP 2010096899A
- Authority
- JP
- Japan
- Prior art keywords
- phoneme
- appearance probability
- acoustic model
- learning data
- probabilities
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images








Abstract
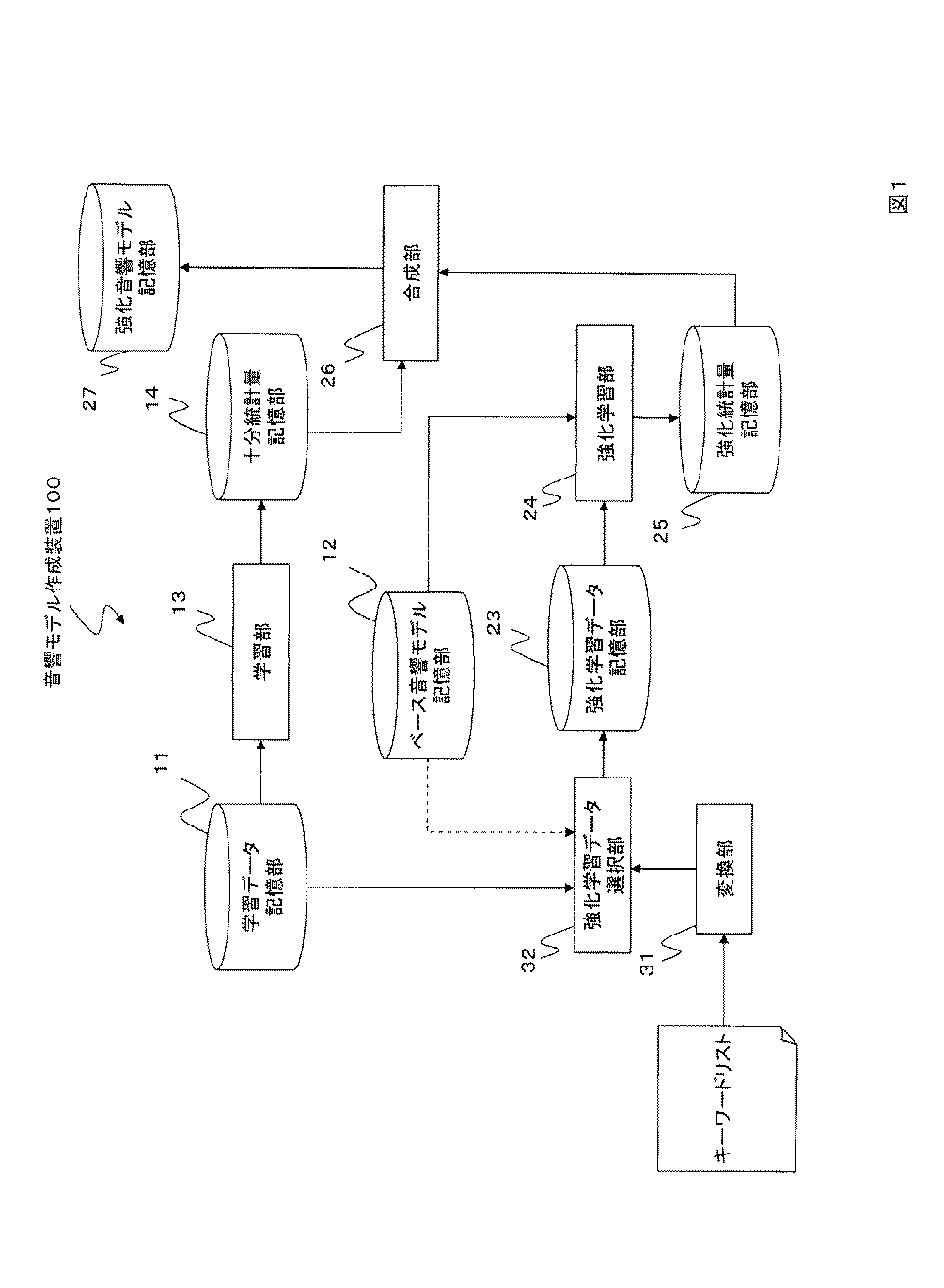
【解決手段】発音辞書記憶部に記憶されている発音辞書を用いて、言語モデル記憶部に記憶されている言語モデル中の単語を音素系列に変換し、全ての対象音素ごとに、当該対象音素を含む音素系列の出現確率の総和を当該対象音素の音素出現確率を求め、音素出現確率が高い高出現確率音素を選択し、学習データ記憶部から、高出現確率音素を含む音素系列についての学習データを抽出して、強化学習データとし、強化学習データとベース音響モデルから強化統計量を計算し、学習データ記憶部からの学習データについての十分統計量と強化統計量とから強化音響モデルを作成する。
【選択図】図2
Description
この発明は、キーワードリストを必要とすることなく、全体的な単語や音素の認識精度の向上を行う音響モデル作成方法、音響モデル作成装置、そのプログラム、記録媒体を提供するものである。
P(α)=w1Σuni(α)+w2Σbi(α)+w3Σtri(α) (1)
ここで、w1、w2、w3はそれぞれ、重み係数を示す。状況に応じて、重み係数w1、w2、w3を調整する。例えば、w1=1、w2=w3=0とすると、ユニグラム確率のみを使用して求めることができる。対象音素αを例えば音素「a」とし、重み係数をw1=1、w2=w3=0(つまり、ユニグラム確率のみ用いる)とし、図5記載の音素系列言語モデルを用いる場合を考える。そうすると、ユニグラム確率に記載されている「a」を含む単語は、図5記載の音素系列の単語では、
「watashi (出現確率は0.0001)」
「wa (出現確率は0.00025)」
「hatsumei(出現確率は0.00002)」
「shimasu (出現確率は0.00005)」
である。そして、これらの音素系列の出現確率の合計(つまり、0.0001+0.00025+0.00002+0.00005)が対象音素「a」の音素出現確率として、出現確率計算部44から出力される。このように、出現確率計算部44は、その他の全ての環境独立音素を対象音素として「i」「u」・・・の音素出現確率を求める。図7に出現確率計算部44から出力される音素出現確率の例を示す。図7に記載のように、全ての対象音素と、当該対象音素の音素出現確率と、が対応されたものが、音素選択部48に入力される。図7の記載では、「w−a+*」「h−a+t」の音素出現確率が記載されているが、これらは、それぞれ対象音素を両側環境依存音素、片側環境依存音素にした場合の音素出現確率である(それぞれ実施例3、実施例2で説明)。
P(α−β+γ)=w1Σuni(α−β+γ)+w2Σbi(α−β+γ)
+w3Σtri(α−β+γ) (4)
の例において、対象音素を「h−a+t」とした場合、対象音素「h−a+t」
を含む単語は「hatsumei」である。従って、図6に記載の単語のみで考
えると、対象音素「h−a+t」の音素出現確率P(h−a+t)は前記式(4
)を用いて以下のようになる。
P(h−a+t)=w1・0.00002
+w2(0.000001+0.000005)
+w3(0.0000004+0.0000002+0.0000005)になる。
そして、出現確率計算部44からは、図7記載の両側環境依存音素(図7の例では、「h−a+t」)と当該音素出現確率(図7の例では、0.00008)とが対応付けられ、出力される。
P(α−β+*)=w1Σuni(α−β+*)+w2Σbi(α−β+*)
+w3Σtri(α−β+*) (5)
の例において、対象音素を「w−a+*」とした場合、対象音素「w−a+*」
を含む単語は「watashi」と「wa」である。従って、図6に記載の単語
のみで考えると、対象音素「w−a+*」の音素出現確率P(w−a+*)は上
記式(5)を用いて以下のようになる。
P(w−a+*)=w1(0.00002+0.00025)
+w2(0.000008+0.000001)
+w3(0.0000004+0.0000002)になる。
この実施例3のように、対象音素を片側環境依存音素とすることで、ベース音響モデルの片側環境依存音素についての全体的な認識精度の向上を図ることが出来る。
P’(α)=P(α)/Σ(x)
P’(α−β+γ)=P(α−β+γ)/Σ(x−y+z)
P’(α−β+*)=P(α−β+*)/Σ(x−y+*)
である。
このように、音素出現確率を正規化することで、音素出現確率の幅を0〜1にすることができ、結果として閾値Th1を定めやすくなるという効果を得ることができる。
W(P(α))=P(α)/ΣP(x)
ただし、ΣP(x)は、全ての対象音素xの音素出現確率の総和を示す。
r’(α、i、j、m)=W(P(α))・r(α、i、j、m)
そして、重み増強強化統計量は重み増強強化統計量記憶部52に記憶される。合成部26は、十分統計量と重み増強強化統計量とから強化音響モデルを作成する。
W’(S12+22)=W(S12)+W(S22)
本発明は上述の実施の形態に限定されるものではない。また、上述の各種の処理は、記載に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されてもよい。その他、本発明の趣旨を逸脱しない範囲で適宜変更が可能であることはいうまでもない。
また、上述の構成をコンピュータによって実現する場合、音響モデル作成装置200が有すべき機能の処理内容はプログラムによって記述される。そして、このプログラムをコンピュータで実行することにより、処理機能がコンピュータ上で実現される。
また、本実施例で説明した音響モデル作成装置200は、CPU(Central Processing Unit)、入力部、出力部、補助記憶装置、RAM(Random Access Memory)、ROM(Read Only Memory)及びバスを有している(何れも図示せず)。
本実施例の単語追加装置は、上述のようなハードウェアに所定のプログラムが読み込まれ、CPUがそれを実行することによって構築される。以下、このように構築される各装置の機能構成を説明する。
音響モデル作成装置200の図示しない入力部、出力部は、所定のプログラムが読み込まれたCPUの制御のもと駆動するLANカード、モデム等の通信装置である。その他の出現確率計算部44などは、所定のプログラムがCPUに読み込まれ、実行されることによって構築される演算部である。記憶部は前記補助記憶装置として機能する。
Claims (11)
- 発音辞書記憶部に記憶されている発音辞書を用いて、言語モデル記憶部に記憶されている言語モデル中の単語を音素系列に変換する変換過程と、
全ての対象音素ごとに、当該対象音素を含む音素系列の出現確率の総和を当該対象音素の出現確率(以下、「音素出現確率」という。)として求める出現確率計算過程と、
音素出現確率が高い対象音素(以下、「高出現確率音素」という。)を選択する音素選択過程と、
学習データ記憶部から、前記高出現確率音素を含む音素系列についての学習データを抽出して、強化学習データとする強化学習データ選択過程と、
前記強化学習データと前記ベース音響モデルから強化統計量を計算する強化学習過程と、
学習データ記憶部からの学習データについての十分統計量と前記強化統計量とから強化音響モデルを作成する合成過程と、
を備える音響モデル作成方法。 - 請求項1記載の音響モデル作成方法であって、
前記出現確率計算過程は、前記対象音素を環境独立音素として、前記音素系列中の全ての環境独立音素ごとに、当該環境独立音素を含む単語のユニグラム確率の総和、当該環境独立音素を含む単語のバイグラム確率の総和、当該環境独立音素を含む単語のトライグラム確率の総和、のうち少なくとも1つを用いて、音素出現確率を求める第1確率計算ステップを有するものであることを特徴とする音響モデル作成方法。 - 請求項1または2記載の音響モデル作成方法であって、
前記出現確率計算過程は、前記対象音素を片側環境依存音素として、前記音素系列中の全ての片側環境依存音素ごとに、当該片側環境依存音素を含む単語のユニグラム確率の総和、当該片側環境依存音素を含む単語のバイグラム確率の総和、当該片側環境依存音素を含む単語のトライグラム確率の総和、のうち少なくとも1つを用いて、音素出現確率を求める第2確率計算ステップを有するものであることを特徴とする音響モデル作成方法。 - 請求項1〜3何れかに記載の音響モデル作成方法であって、
前記出現確率計算過程は、前記対象音素を両側環境依存音素として、前記音素系列中の全ての両側環境依存音素ごとに、当該両側環境依存音素を含む単語のユニグラム確率の総和、当該両側環境依存音素を含む単語のバイグラム確率の総和、当該両側環境依存音素を含む単語のトライグラム確率の総和、のうち少なくとも1つを用いて、音素出現確率を求める第3確率計算ステップを有するものであることを特徴とする音響モデル作成方法。 - 請求項1〜4何れかに記載の音響モデル作成方法であって、
前記出現確率計算過程は、予め定められた閾値以上の音素数を持つ音素系列の出現確率の総和を演算することを特徴とする音響モデル作成方法。 - 請求項1〜5何れかに記載の音響モデル作成方法であって、
前記確率計算過程は、計算された音素出現確率を、対象音素の全ての出現確率で除算することで、正規化音素出現確率を求める正規化ステップを有し、
前記音素選択過程は、正規化音素出現確率が大きい対象音素を選択することを特徴とする音響モデル作成方法。 - 請求項1〜6何れかに記載の音響モデル作成方法であって、
更に、音素毎に、前記強化統計量に対して、当該音素の音素出現確率から求まる値を重み係数として、重み付けして、前記強化統計量として出力する統計量強化過程を有することを特徴とする音響モデル作成方法。 - 言語モデルを記憶する言語モデル記憶部と、
発音辞書記憶部に記憶されている発音辞書を用いて、前記言語モデル中の単語を音素系列に変換する変換部と、
全ての対象音素ごとに、当該対象音素を含む音素系列の出現確率の総和を当該対象音素の出現確率(以下、「音素出現確率」という。)として求める出現確率計算部と、
音素出現確率が高い対象音素(以下、「高出現確率音素」という。)を選択する音素選択部と、
学習データ記憶部から、前記高出現確率音素を含む音素系列についての学習データを抽出して、強化学習データとする強化学習データ選択部と、
前記強化学習データと前記ベース音響モデルから強化統計量を計算する強化学習部と、
学習データ記憶部からの学習データについての十分統計量と前記強化統計量とから強化音響モデルを作成する合成部と、
を備える音響モデル作成装置。 - 請求項8記載の音響モデル作成装置であって、
更に、音素毎に、前記強化統計量に対して、当該音素の音素出現確率から求まる値を重み係数として、重み付けして、前記強化統計量として出力する統計量強化部を有することを特徴とする音響モデル作成装置。 - 請求項1〜7何れかに記載の音響モデル作成方法の各過程をコンピュータに実行させるためのプログラム。
- 請求項10に記載のプログラムを記録したコンピュータ読み取り可能な記録媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008266288A JP5155811B2 (ja) | 2008-10-15 | 2008-10-15 | 音響モデル作成方法、その装置、プログラム、その記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008266288A JP5155811B2 (ja) | 2008-10-15 | 2008-10-15 | 音響モデル作成方法、その装置、プログラム、その記録媒体 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010096899A true JP2010096899A (ja) | 2010-04-30 |
| JP5155811B2 JP5155811B2 (ja) | 2013-03-06 |
Family
ID=42258637
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008266288A Expired - Fee Related JP5155811B2 (ja) | 2008-10-15 | 2008-10-15 | 音響モデル作成方法、その装置、プログラム、その記録媒体 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5155811B2 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105609100A (zh) * | 2014-10-31 | 2016-05-25 | 中国科学院声学研究所 | 声学模型训练构造方法、及声学模型和语音识别系统 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003099086A (ja) * | 2001-09-25 | 2003-04-04 | Nippon Hoso Kyokai <Nhk> | 言語・音響モデル作成方法および言語・音響モデル作成装置ならびに言語・音響モデル作成プログラム |
| JP2004317845A (ja) * | 2003-04-17 | 2004-11-11 | Nagoya Industrial Science Research Inst | モデルデータ生成装置、モデルデータ生成方法、およびこれらの方法 |
| JP2008129527A (ja) * | 2006-11-24 | 2008-06-05 | Nippon Telegr & Teleph Corp <Ntt> | 音響モデル生成装置、方法、プログラム及びその記録媒体 |
-
2008
- 2008-10-15 JP JP2008266288A patent/JP5155811B2/ja not_active Expired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003099086A (ja) * | 2001-09-25 | 2003-04-04 | Nippon Hoso Kyokai <Nhk> | 言語・音響モデル作成方法および言語・音響モデル作成装置ならびに言語・音響モデル作成プログラム |
| JP2004317845A (ja) * | 2003-04-17 | 2004-11-11 | Nagoya Industrial Science Research Inst | モデルデータ生成装置、モデルデータ生成方法、およびこれらの方法 |
| JP2008129527A (ja) * | 2006-11-24 | 2008-06-05 | Nippon Telegr & Teleph Corp <Ntt> | 音響モデル生成装置、方法、プログラム及びその記録媒体 |
Non-Patent Citations (2)
| Title |
|---|
| CSNJ201010091207; 小橋川 哲 Satoshi KOBASHIKAWA: 'キーワードに関する十分統計量増強による精度向上の検討' 日本音響学会 2008年 春季研究発表会講演論文集CD-ROM [CD-ROM] , 20080319, p.213-214, 社団法人日本音響学会 * |
| JPN6012011526; 小橋川 哲 Satoshi KOBASHIKAWA: 'キーワードに関する十分統計量増強による精度向上の検討' 日本音響学会 2008年 春季研究発表会講演論文集CD-ROM [CD-ROM] , 20080319, p.213-214, 社団法人日本音響学会 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105609100A (zh) * | 2014-10-31 | 2016-05-25 | 中国科学院声学研究所 | 声学模型训练构造方法、及声学模型和语音识别系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5155811B2 (ja) | 2013-03-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Toshniwal et al. | Multilingual speech recognition with a single end-to-end model | |
| JP3933750B2 (ja) | 連続密度ヒドンマルコフモデルを用いた音声認識方法及び装置 | |
| EP1447792B1 (en) | Method and apparatus for modeling a speech recognition system and for predicting word error rates from text | |
| CN113692616B (zh) | 用于在端到端模型中的跨语言语音识别的基于音素的场境化 | |
| EP1657650A2 (en) | System and method for compiling rules created by machine learning program | |
| JP2010170137A (ja) | 音声理解装置 | |
| JP5175325B2 (ja) | 音声認識用wfst作成装置とそれを用いた音声認識装置と、それらの方法とプログラムと記憶媒体 | |
| Ghai et al. | Using gaussian mixtures on triphone acoustic modelling-based punjabi continuous speech recognition | |
| Ming et al. | A light-weight method of building an LSTM-RNN-based bilingual TTS system | |
| Oba et al. | A comparative study on methods of weighted language model training for reranking LVCSR n-best hypotheses | |
| Li et al. | Hierarchical Phone Recognition with Compositional Phonetics. | |
| Gales et al. | Low-resource speech recognition and keyword-spotting | |
| JP2010139745A (ja) | 統計的発音変異モデルを記憶する記録媒体、自動音声認識システム及びコンピュータプログラム | |
| JP4705557B2 (ja) | 音響モデル生成装置、方法、プログラム及びその記録媒体 | |
| Liu et al. | Low-resource open vocabulary keyword search using point process models | |
| JP2002342323A (ja) | 言語モデル学習装置およびそれを用いた音声認識装置ならびに言語モデル学習方法およびそれを用いた音声認識方法ならびにそれらの方法を記憶した記憶媒体 | |
| JP5155811B2 (ja) | 音響モデル作成方法、その装置、プログラム、その記録媒体 | |
| JP2007078943A (ja) | 音響スコア計算プログラム | |
| Rybach et al. | Lexical prefix tree and WFST: A comparison of two dynamic search concepts for LVCSR | |
| WO2020166359A1 (ja) | 推定装置、推定方法、及びプログラム | |
| JP2005250071A (ja) | 音声認識方法及び装置及び音声認識プログラム及び音声認識プログラムを格納した記憶媒体 | |
| JP2002082690A (ja) | 言語モデル生成方法、音声認識方法及びそのプログラム記録媒体 | |
| JP2006107353A (ja) | 情報処理装置および方法、記録媒体、並びにプログラム | |
| Bayerl et al. | A comparison of hybrid and end-to-end models for syllable recognition | |
| JP4909318B2 (ja) | 音響モデル作成方法、音響モデル作成装置、そのプログラム、その記録媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20110106 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20110810 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20111219 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120306 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120423 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20121127 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20121207 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20151214 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5155811 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |