JP2010092350A - 顔文字検出装置、その方法、プログラム及び記録媒体 - Google Patents
顔文字検出装置、その方法、プログラム及び記録媒体 Download PDFInfo
- Publication number
- JP2010092350A JP2010092350A JP2008262869A JP2008262869A JP2010092350A JP 2010092350 A JP2010092350 A JP 2010092350A JP 2008262869 A JP2008262869 A JP 2008262869A JP 2008262869 A JP2008262869 A JP 2008262869A JP 2010092350 A JP2010092350 A JP 2010092350A
- Authority
- JP
- Japan
- Prior art keywords
- html tag
- character
- text
- html
- emoticon
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images








Landscapes
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Abstract
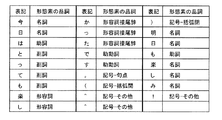
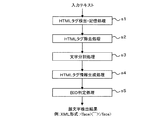
【解決手段】HTMLタグ検出部11により、テキスト中のHTMLタグをその出現位置とともに検出してHTMLタグ記憶部12に記憶し、HTMLタグが除去され、文字単位に分割された前記テキスト中の各文字の直前および直後にHTMLタグがあったかどうかを表すHTMLタグ情報を、HTMLタグ情報生成部13により、HTMLタグ記憶部12に記憶されたHTMLタグとその出現位置に基づいて生成し、これを当該テキスト中の各文字の表記とともに素性として用いて、BIO判定部15により、モデル記憶部14に記憶されたモデルを用いて顔文字を構成する最初の文字“B”、顔文字を構成する2番目以降の文字“I”、顔文字以外の文字“O”のいずれに当たるかを機械学習で判定する。
【選択図】図6
Description
田中裕紀、高村大也、奥村学、「文字ベースのコミュニケーションにおける顔文字に関する研究」、言語処理学会第10回年次大会、D4−3、2004
Claims (7)
- HTMLタグを含むテキスト中の顔文字を検出する装置であって、
テキスト中のHTMLタグをその出現位置とともに検出するHTMLタグ検出部と、
検出されたHTMLタグを前記テキストにおけるその出現位置とともに記憶するHTMLタグ記憶部と、
前記テキストからHTMLタグを除去するHTMLタグ除去部と、
HTMLタグが除去された前記テキストを文字単位に分割する文字分割部と、
HTMLタグが除去され、文字単位に分割された前記テキスト中の各文字の直前および直後にHTMLタグがあったかどうか、あった場合はどのようなHTMLタグかを表すHTMLタグ情報を、前記HTMLタグ記憶部に記憶された前記テキスト中のHTMLタグとその出現位置に基づいて生成するHTMLタグ情報生成部と、
少なくともテキスト中の各文字の表記並びにその直前および直後のHTMLタグ情報を素性として、当該テキスト中の各文字が顔文字を構成する文字列の最初の文字を意味する“B”、顔文字を構成する文字列の2番目以降の文字を意味する“I”、顔文字以外の文字を意味する“O”のいずれに当たるかを判定するためのモデルを記憶するモデル記憶部と、
HTMLタグが除去され、文字単位に分割された前記テキスト中の各文字の表記並びにその直前および直後のHTMLタグ情報を入力とし、前記モデル記憶部に記憶されたモデルを用いて、前記テキスト中の各文字が前記“B”、“I”、“O”のいずれに当たるかを判定するBIO判定部とを備えた
ことを特徴とする顔文字検出装置。 - HTMLタグ情報生成は、
HTMLタグが除去され、文字単位に分割された前記テキスト中の各文字の直前および直後の位置と、前記HTMLタグ記憶部に記憶された前記テキストにおけるHTMLタグの出現位置とを比較し、一致する場合はそのHTMLタグをHTMLタグ情報として、また、一致しない場合はタグ無しを意味するHTMLタグをHTMLタグ情報として、当該テキスト中の各文字の表記に対応させて出力することで行う
ことを特徴とする請求項1に記載の顔文字検出装置。 - HTMLタグを含むテキスト中の顔文字を検出する方法であって、
HTMLタグ検出部が、テキスト中のHTMLタグをその出現位置とともに検出し、HTMLタグ記憶部に記憶するステップと、
HTMLタグ除去部が、前記テキストからHTMLタグを除去するステップと、
文字分割部が、HTMLタグが除去された前記テキストを文字単位に分割するステップと、
HTMLタグ情報生成部が、HTMLタグが除去され、文字単位に分割された前記テキスト中の各文字の直前および直後にHTMLタグがあったかどうか、あった場合はどのようなHTMLタグかを表すHTMLタグ情報を、前記HTMLタグ記憶部に記憶された前記テキスト中のHTMLタグとその出現位置に基づいて生成するステップと、
BIO判定部が、HTMLタグが除去され、文字単位に分割された前記テキスト中の各文字の表記並びにその直前および直後のHTMLタグ情報を入力とし、少なくともテキスト中の各文字の表記並びにその直前および直後のHTMLタグ情報を素性として、当該テキスト中の各文字が顔文字を構成する文字列の最初の文字を意味する“B”、顔文字を構成する文字列の2番目以降の文字を意味する“I”、顔文字以外の文字を意味する“O”のいずれに当たるかを判定するためのモデルを用いて、前記テキスト中の各文字が前記“B”、“I”、“O”のいずれに当たるかを判定するステップとを含む
ことを特徴とする顔文字検出方法。 - HTMLタグ情報生成は、
HTMLタグが除去され、文字単位に分割された前記テキスト中の各文字の直前および直後の位置と、前記HTMLタグ記憶部に記憶された前記テキストにおけるHTMLタグの出現位置とを比較し、一致する場合はそのHTMLタグをHTMLタグ情報として、また、一致しない場合はタグ無しを意味するHTMLタグをHTMLタグ情報として、当該テキスト中の各文字の表記に対応させて出力することで行う
ことを特徴とする請求項3に記載の顔文字検出方法。 - コンピュータを、請求項1または2に記載の顔文字検出装置の各手段として機能させるためのプログラム。
- コンピュータに、請求項3または4に記載の顔文字検出方法の各処理ステップを実行させるためのプログラム。
- 請求項5または6に記載のプログラムを記録したことを特徴とするコンピュータ読み取り可能な記録媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008262869A JP5026384B2 (ja) | 2008-10-09 | 2008-10-09 | 顔文字検出装置、その方法、プログラム及び記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008262869A JP5026384B2 (ja) | 2008-10-09 | 2008-10-09 | 顔文字検出装置、その方法、プログラム及び記録媒体 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010092350A true JP2010092350A (ja) | 2010-04-22 |
| JP5026384B2 JP5026384B2 (ja) | 2012-09-12 |
Family
ID=42254983
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008262869A Expired - Fee Related JP5026384B2 (ja) | 2008-10-09 | 2008-10-09 | 顔文字検出装置、その方法、プログラム及び記録媒体 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5026384B2 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110020283A (zh) * | 2017-09-27 | 2019-07-16 | 北京国双科技有限公司 | 一种文本显示方法及装置 |
-
2008
- 2008-10-09 JP JP2008262869A patent/JP5026384B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP5026384B2 (ja) | 2012-09-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6251958B2 (ja) | 発話解析装置、音声対話制御装置、方法、及びプログラム | |
| CN107622054B (zh) | 文本数据的纠错方法及装置 | |
| US11031003B2 (en) | Dynamic extraction of contextually-coherent text blocks | |
| JP5071373B2 (ja) | 言語処理装置、言語処理方法および言語処理用プログラム | |
| Na | Conditional random fields for Korean morpheme segmentation and POS tagging | |
| CN114254643A (zh) | 文本纠错方法、装置、电子设备与存储介质 | |
| JP5323652B2 (ja) | 類似語決定方法およびシステム | |
| CN111310457B (zh) | 词语搭配不当识别方法、装置、电子设备和存储介质 | |
| JP5026384B2 (ja) | 顔文字検出装置、その方法、プログラム及び記録媒体 | |
| JP6055267B2 (ja) | 文字列分割装置、モデルファイル学習装置および文字列分割システム | |
| Namysl et al. | Empirical error modeling improves robustness of noisy neural sequence labeling | |
| JP5013539B2 (ja) | 顔文字検出装置、その方法、プログラム及び記録媒体 | |
| JP5031713B2 (ja) | 顔文字検出装置、その方法、プログラム及び記録媒体 | |
| KR101705228B1 (ko) | 전자문서생성장치 및 그 동작 방법 | |
| JP5026385B2 (ja) | 顔文字検出装置、その方法、プログラム及び記録媒体 | |
| JP5071986B2 (ja) | 顔文字検出装置、その方法、プログラム及び記録媒体 | |
| CN112231512A (zh) | 歌曲标注检测方法、装置和系统及存储介质 | |
| JP2010092351A (ja) | 顔文字検出装置、その方法、プログラム及び記録媒体 | |
| JP2010102564A (ja) | 感情特定装置、その方法、プログラム及び記録媒体 | |
| JP4941495B2 (ja) | ユーザ辞書作成システム、方法、及び、プログラム | |
| CN115577712A (zh) | 一种文本纠错方法及装置 | |
| Liu et al. | A Bambara tonalization system for word sense disambiguation using differential coding, segmentation and edit operation filtering | |
| Pari et al. | SLatAR-A Sign Language Translating Augmented Reality Application | |
| JPH0748217B2 (ja) | 文書要約装置 | |
| JP4407510B2 (ja) | 音声合成装置及び音声合成プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20101215 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20110613 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20110614 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20110615 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20110616 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120619 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120620 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150629 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |