JP2010073214A - マルチ呼処理スレッド処理方法及び呼処理装置 - Google Patents
マルチ呼処理スレッド処理方法及び呼処理装置 Download PDFInfo
- Publication number
- JP2010073214A JP2010073214A JP2009260064A JP2009260064A JP2010073214A JP 2010073214 A JP2010073214 A JP 2010073214A JP 2009260064 A JP2009260064 A JP 2009260064A JP 2009260064 A JP2009260064 A JP 2009260064A JP 2010073214 A JP2010073214 A JP 2010073214A
- Authority
- JP
- Japan
- Prior art keywords
- event
- call processing
- processing
- call
- scheduler
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000012545 processing Methods 0.000 title claims abstract description 305
- 238000003672 processing method Methods 0.000 claims abstract description 11
- 239000000284 extract Substances 0.000 claims abstract description 6
- 238000000034 method Methods 0.000 claims description 46
- 238000000605 extraction Methods 0.000 claims description 5
- 238000007726 management method Methods 0.000 description 16
- 238000012544 monitoring process Methods 0.000 description 12
- 230000002159 abnormal effect Effects 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 230000006870 function Effects 0.000 description 3
- 230000004044 response Effects 0.000 description 3
- 238000004891 communication Methods 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 238000012790 confirmation Methods 0.000 description 1
- 230000008034 disappearance Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
Images







Landscapes
- Telephonic Communication Services (AREA)
Abstract
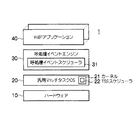
【解決手段】 呼処理プログラムは、VoIPアプリに加え、カーネル上位の呼処理イベントエンジンを有する。このエンジンにおいて、各パケット受信部は、呼制御パケットを受信すると、カーネルのTSSスケジューラにキューイング制御を実行させた後、第1のスケジューラに呼処理イベントをキューイングする。第1のスケジューラは、イベント処理用のスレッドを生成し、このイベント処理スレッドにより、呼処理イベントがキューから取り出されて実行される。この実行では、各種の呼処理サービスに係る各イベントキュー管理オブジェクトが生成され、呼処理イベントを振り分けてキューイングさせる。第2のスケジューラは、イベント処理スレッドを生成し、各イベントキュー管理オブジェクトから呼処理イベントを抽出して実行させる。
【選択図】 図7
Description
以下、本発明によるマルチ呼処理スレッド処理方法及び呼処理装置の一実施形態を、図面を参照しながら詳述する。
本発明によるマルチ呼処理スレッド処理装置及び方法は、その適用対象が、上記実施形態のようなコールエージェントに限定されるものではなく、メディアゲートウェイコントローラ(MGC)などの他の電話交換装置にも適用できる。
Claims (4)
- シングルCPUがメモリ上に展開された呼処理プログラムに従い、輻輳的に発生する呼処理イベントを実行するマルチ呼処理スレッド処理方法において、
上記呼処理プログラムは、VoIPアプリケーションに加えて呼処理イベントエンジンを有し、OSに実装されているTSSスケジューラを含むカーネルの上位に上記呼処理イベントエンジンを位置させると共に、上位呼処理イベントエンジンの上位に上記VoIPアプリケーションを位置させ、
上記呼処理イベントエンジンによるコールエージェントプロセスは、1又は複数のパケット受信部と、第1の呼処理イベントスケジューラと、生成される1又は複数のイベントキュー管理オブジェクトと、第2の呼処理イベントスケジューラとを有し、
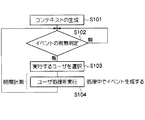
上記各パケット受信部は、呼制御に係るパケットを受信した際には、上記カーネルにその呼制御信号を引き渡して、上記TSSスケジューラにおけるキューイング制御を実行させた後、呼制御信号の返却を受けて、上記第1の呼処理イベントスケジューラに呼処理イベントをキューイングし、再びパケットの入力を待つように処理を戻し、
上記第1の呼処理イベントスケジューラは、呼処理イベントが入力されると、イベント処理を実行するためのスレッドを生成し、このイベント処理スレッドにより、呼処理イベントがキューから取り出されてイベント処理が実行され、
上記イベント処理の実行では、各種の呼処理サービスに係るそれぞれの呼処理イベントをキューイングしておくための上記各イベントキュー管理オブジェクトが生成され、呼処理イベントを振り分け、生成した上記各イベントキュー管理オブジェクト内のキュー配列へキューイングし、
上記第2の呼処理イベントスケジューラは、イベント処理スレッドを生成し、グルーピングされた上記各イベントキュー管理オブジェクトから呼処理イベントを抽出し、この抽出の際には、イベントキュー管理オブジェクトとイベント処理スレッドをバインドさせ、ステートフルエリアをアクセスしながら呼処理イベントを実行させる
ことを特徴とするマルチ呼処理スレッド処理方法。 - 上記第1及び第2の呼処理イベントスケジューラが、1又は複数の処理時間が短い呼処理イベントを、上記TSSスケジューラが呼処理イベントの1回の処理に割り当てている最大のCPU時間を使用して処理させることを特徴とする請求項1に記載のマルチ呼処理スレッド処理方法。
- シングルCPUがメモリ上に展開された呼処理プログラムに従い、輻輳的に発生する呼処理イベントを実行する呼処理装置において、
上記呼処理プログラムは、VoIPアプリケーションに加えて呼処理イベントエンジンを有し、OSに実装されているTSSスケジューラを含むカーネルの上位に上記呼処理イベントエンジンを位置させると共に、上位呼処理イベントエンジンの上位に上記VoIPアプリケーションを位置させ、
上記呼処理イベントエンジンによるコールエージェントプロセスは、1又は複数のパケット受信部と、第1の呼処理イベントスケジューラと、生成される1又は複数のイベントキュー管理オブジェクトと、第2の呼処理イベントスケジューラとを有し、
上記各パケット受信部は、呼制御に係るパケットを受信した際には、上記カーネルにその呼制御信号を引き渡して、上記TSSスケジューラにおけるキューイング制御を実行させた後、呼制御信号の返却を受けて、上記第1の呼処理イベントスケジューラに呼処理イベントをキューイングし、再びパケットの入力を待つように処理を戻し、
上記第1の呼処理イベントスケジューラは、呼処理イベントが入力されると、イベント処理を実行するためのスレッドを生成し、このイベント処理スレッドにより、呼処理イベントがキューから取り出されてイベント処理が実行され、
上記イベント処理の実行では、各種の呼処理サービスに係るそれぞれの呼処理イベントをキューイングしておくための上記各イベントキュー管理オブジェクトが生成され、呼処理イベントを振り分け、生成した上記各イベントキュー管理オブジェクト内のキュー配列へキューイングし、
上記第2の呼処理イベントスケジューラは、イベント処理スレッドを生成し、グルーピングされた上記各イベントキュー管理オブジェクトから呼処理イベントを抽出し、この抽出の際には、イベントキュー管理オブジェクトとイベント処理スレッドをバインドさせ、ステートフルエリアをアクセスしながら呼処理イベントを実行させる
ことを特徴とする呼処理装置。 - 上記第1及び第2の呼処理イベントスケジューラが、1又は複数の処理時間が短い呼処理イベントを、上記TSSスケジューラが呼処理イベントの1回の処理に割り当てている最大のCPU時間を使用して処理させることを特徴とする請求項3に記載の呼処理装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009260064A JP5029675B2 (ja) | 2009-11-13 | 2009-11-13 | マルチ呼処理スレッド処理方法及び呼処理装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009260064A JP5029675B2 (ja) | 2009-11-13 | 2009-11-13 | マルチ呼処理スレッド処理方法及び呼処理装置 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004379909A Division JP4609070B2 (ja) | 2004-12-28 | 2004-12-28 | マルチ呼処理スレッド処理方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010073214A true JP2010073214A (ja) | 2010-04-02 |
| JP5029675B2 JP5029675B2 (ja) | 2012-09-19 |
Family
ID=42204867
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009260064A Expired - Fee Related JP5029675B2 (ja) | 2009-11-13 | 2009-11-13 | マルチ呼処理スレッド処理方法及び呼処理装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5029675B2 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015136259A (ja) * | 2014-01-17 | 2015-07-27 | 株式会社東芝 | イベント管理装置、イベント管理方法およびモータシステム |
| CN114760530A (zh) * | 2020-12-25 | 2022-07-15 | 深圳Tcl新技术有限公司 | 事件处理方法、装置、电视机及计算机可读存储介质 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS61190633A (ja) * | 1985-02-20 | 1986-08-25 | Oki Electric Ind Co Ltd | プログラム運用管理方式 |
| JPH02166526A (ja) * | 1988-12-20 | 1990-06-27 | Fujitsu Ltd | 長時間使用資源検出方式 |
| JPH0357026A (ja) * | 1989-07-26 | 1991-03-12 | Hitachi Ltd | タスク制御方式 |
| JPH09319597A (ja) * | 1996-03-28 | 1997-12-12 | Hitachi Ltd | 周期的プロセスのスケジューリング方法 |
| JPH10155010A (ja) * | 1996-09-30 | 1998-06-09 | Oki Data:Kk | パケット処理方法とネットワ−クア−キテクチャ |
-
2009
- 2009-11-13 JP JP2009260064A patent/JP5029675B2/ja not_active Expired - Fee Related
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS61190633A (ja) * | 1985-02-20 | 1986-08-25 | Oki Electric Ind Co Ltd | プログラム運用管理方式 |
| JPH02166526A (ja) * | 1988-12-20 | 1990-06-27 | Fujitsu Ltd | 長時間使用資源検出方式 |
| JPH0357026A (ja) * | 1989-07-26 | 1991-03-12 | Hitachi Ltd | タスク制御方式 |
| JPH09319597A (ja) * | 1996-03-28 | 1997-12-12 | Hitachi Ltd | 周期的プロセスのスケジューリング方法 |
| JPH10155010A (ja) * | 1996-09-30 | 1998-06-09 | Oki Data:Kk | パケット処理方法とネットワ−クア−キテクチャ |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2015136259A (ja) * | 2014-01-17 | 2015-07-27 | 株式会社東芝 | イベント管理装置、イベント管理方法およびモータシステム |
| CN114760530A (zh) * | 2020-12-25 | 2022-07-15 | 深圳Tcl新技术有限公司 | 事件处理方法、装置、电视机及计算机可读存储介质 |
| CN114760530B (zh) * | 2020-12-25 | 2023-08-01 | 深圳Tcl新技术有限公司 | 事件处理方法、装置、电视机及计算机可读存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5029675B2 (ja) | 2012-09-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Tindell et al. | Holistic schedulability analysis for distributed hard real-time systems | |
| EP2701074B1 (en) | Method, device, and system for performing scheduling in multi-processor core system | |
| Tindell et al. | An extendible approach for analyzing fixed priority hard real-time tasks | |
| Tokuda et al. | Real-Time Mach: Towards a Predictable Real-Time System. | |
| US8166485B2 (en) | Dynamic techniques for optimizing soft real-time task performance in virtual machines | |
| Pyarali et al. | Evaluating and optimizing thread pool strategies for real-time CORBA | |
| Bangs et al. | Better operating system features for faster network servers | |
| JP4609070B2 (ja) | マルチ呼処理スレッド処理方法 | |
| CN111897637B (zh) | 作业调度方法、装置、主机及存储介质 | |
| Kaneko et al. | Integrated scheduling of multimedia and hard real-time tasks | |
| Lin et al. | {RingLeader}: efficiently offloading {Intra-Server} orchestration to {NICs} | |
| KR20070083460A (ko) | 다중 커널을 동시에 실행하는 방법 및 시스템 | |
| US20190042151A1 (en) | Hybrid framework of nvme-based storage system in cloud computing environment | |
| Kitayama et al. | RT-IPC: An IPC Extension for Real-Time Mach. | |
| CN116700901A (zh) | 基于微内核的容器构建与运行系统及方法 | |
| US7703103B2 (en) | Serving concurrent TCP/IP connections of multiple virtual internet users with a single thread | |
| Jia et al. | Skyloft: A General High-Efficient Scheduling Framework in User Space | |
| Nakajima et al. | Experiments with Real-Time Servers in Real-Time Mach. | |
| JP5029675B2 (ja) | マルチ呼処理スレッド処理方法及び呼処理装置 | |
| Tindell et al. | Guaranteeing Hard Real Time End-to-End Communications Deadlines | |
| Tsenos et al. | Amesos: a scalable and elastic framework for latency sensitive streaming pipelines | |
| Rocha et al. | A QoS aware non-work-conserving disk scheduler | |
| WO2024120118A1 (zh) | 中断请求处理方法、系统、设备及计算机可读存储介质 | |
| US8869171B2 (en) | Low-latency communications | |
| CN101349975A (zh) | 实现中断底半部机制的方法及嵌入式系统 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120529 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120611 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5029675 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150706 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |