JP2010068511A - データ圧縮及びデータ伸張 - Google Patents
データ圧縮及びデータ伸張 Download PDFInfo
- Publication number
- JP2010068511A JP2010068511A JP2009168779A JP2009168779A JP2010068511A JP 2010068511 A JP2010068511 A JP 2010068511A JP 2009168779 A JP2009168779 A JP 2009168779A JP 2009168779 A JP2009168779 A JP 2009168779A JP 2010068511 A JP2010068511 A JP 2010068511A
- Authority
- JP
- Japan
- Prior art keywords
- data
- stream
- group
- direct
- decompression
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 230000006837 decompression Effects 0.000 title claims abstract description 66
- 238000013144 data compression Methods 0.000 title claims abstract description 17
- 238000000034 method Methods 0.000 claims abstract description 57
- 230000008569 process Effects 0.000 claims description 15
- 238000007906 compression Methods 0.000 abstract description 17
- 230000006835 compression Effects 0.000 abstract description 12
- 239000000872 buffer Substances 0.000 description 43
- 230000008901 benefit Effects 0.000 description 4
- 239000000463 material Substances 0.000 description 3
- 230000008859 change Effects 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000007619 statistical method Methods 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000012804 iterative process Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
Images






















Classifications
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/3084—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction using adaptive string matching, e.g. the Lempel-Ziv method
- H03M7/3086—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction using adaptive string matching, e.g. the Lempel-Ziv method employing a sliding window, e.g. LZ77
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Memory System (AREA)
Abstract
【解決手段】前に復号されたデータアイテムの群の参照子の順序付けられたストリーム、復号されるデータアイテムの直接的表現の順序付けられたストリーム、及び各連続的な伸張オペレーションが参照子に作用すべきであるのか、又は直接的表現に作用すべきであるのかを示すフラグの順序付けられたストリームを備える圧縮データに作用するように構成されるデータ伸張装置が開示される。該装置は、出力メモリエリア、伸張オペレーションが直接的表現に作用すべきであることを示す個数nの連続したフラグを検出する検出器、及び前に復号されたデータの次の参照される群又は直接的表現の順序付けられたストリームからのn個の連続した直接的表現の群のいずれかを出力メモリエリアへコピーするためのデータコピー器を備える。
【選択図】図4
Description
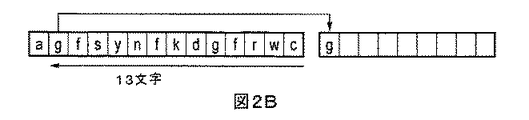
(a)現在のフラグがリテラルを示していた場合には、次の16個のリテラルが、リテラルストリームから出力バッファへコピーされる。
(b)現在のフラグが符号対を示していた場合には、検査バッファにおいて距離変数により示される位置の後に続く16文字が出力バッファへコピーされる。
// 必要とされるアラインされていない16バイトストリームを含む32バイト(16バイトにアラインされる)をフェッチする
lq b0to15,base,distance
lq b16to31,base16,distance
//16バイトのアラインされたストリームを、必要に応じて繰り返し生成する
shufb aligned,b0to15,b16to31,AlignRepeat
// アラインされた16書き込みブロックは、0〜14個の前に有効なバイトを含むことができる
lq write,dest
// ストリームをアラインされた終端まで挿入する
shufb write,write,aligned,insert0
sq write,dest
// 次の16バイトのアラインされたブロック内へのオーバーフローを生成する
shufb write,aligned,aligned,overflow
sq write,dest+16
]
すなわち、
距離7:16文字は{0,1,2,3,4,5,6,0,1,2,3,4,5,6,0,1}である。
距離9:16文字は{0,1,2,3,4,5,6,7,8,9,0,1,2,3,4,5}である。

Claims (10)
- 前に復号されたデータアイテムの群の参照子の順序付けられたストリーム、
復号されるデータアイテムの直接的表現の順序付けられたストリーム、及び
各連続的な伸張オペレーションが参照子に作用すべきであるのか、又は直接的表現に作用すべきであるのかを示すフラグの順序付けられたストリーム、
を備える圧縮データに作用するように構成されるデータ伸張装置であって、
該装置は、
出力メモリエリア、
伸張オペレーションが直接的表現に作用すべきであることを示す個数nの連続したフラグを検出する検出器、及び
前に復号されたデータの次の参照される群又は前記直接的表現の順序付けられたストリームからのn個の連続した直接的表現の群のいずれかを前記出力メモリエリアへコピーするためのデータコピー器、
を備える、装置。 - 前記データコピー器は、
前記出力メモリエリアへ既に書き込まれた有効に伸張されたデータの範囲を示す、前記出力メモリエリアに関するポインタを維持し、
前記参照される群のサイズ又は前記個数nに関わらず、m個の連続したデータアイテムの群をコピーし、且つ
前記参照される群のサイズ又は前記個数nに応じて前記ポインタを設定する、
ように構成される、請求項1に記載の装置。 - 前記伸張されるデータは、2つ以上の隣接したデータブロックのシリーズを含み、前記装置は、
前記出力メモリエリアとは別個のデータストアであって、前記シリーズにおける少なくとも最初のブロック以外のブロックに対応する最初に伸張されたデータアイテムの群を記憶するためのデータストアを備え、該データストアは、前記シリーズにおける先行ブロックの伸張が完了した後に、前記記憶されたデータアイテムの群をその元の位置へ再書き込みするように構成される、請求項1に記載の装置。 - 前記ブロックは、各ブロックが実質的に同じ量の伸張処理を必要とするようにサイズを構成される、請求項3に記載の装置。
- 前記ブロックは、並列に伸張される、請求項4に記載の装置。
- 前に復号されたデータアイテムの群の参照子の順序付けられたストリーム、
復号されるデータアイテムの直接的表現の順序付けられたストリーム、及び
各連続的な伸張オペレーションが参照子に作用すべきであるのか、又は直接的表現に作用すべきであるのかを示すフラグの順序付けられたストリーム、
を備える圧縮データに作用するように構成されるデータ伸張方法であって、
該方法は、
伸張オペレーションが直接的表現に作用すべきであることを示す個数nの連続したフラグを検出するステップ、及び
前に復号されたデータの次の参照される群又は前記直接的表現の順序付けられたストリームからのn個の連続した直接的表現の群のいずれかを出力メモリエリアへコピーするステップ、
を含む、方法。 - 入力データアイテムが、前に符号化されたデータアイテムの群の参照子として又は前記入力データアイテムの直接的表現としてのいずれかで符号化されるデータ圧縮方法であって、該方法は、
参照子の順序付けられたストリーム、
直接的表現の順序付けられたストリーム、及び
各連続的な伸張オペレーションが参照子に作用すべきであるのか、又は直接的表現に作用すべきであるのかを示すフラグの順序付けられたストリーム、
の、出力データの別個のストリームとして生成するステップを含む、データ圧縮方法。 - コンピュータによって実行されると、請求項7に記載の方法を該コンピュータに実行させるプログラムコードを含むコンピュータソフトウェアが記憶されているマシン可読媒体。
- 入力データアイテムが、前に符号化されたデータアイテムの群の参照子として又は前記入力データアイテムの直接的表現としてのいずれかで符号化されるデータ圧縮装置であって、該装置は、
参照子の順序付けられたストリーム、
直接的表現の順序付けられたストリーム、及び
各連続的な伸張オペレーションが参照子に作用すべきであるのか、又は直接的表現に作用すべきであるのかを示すフラグの順序付けられたストリーム、
の、出力データの別個のストリームとして生成するように構成される、データ圧縮装置。 - 入力データアイテムが、前に符号化されたデータアイテムの群の参照子として又は前記入力データアイテムの直接的表現としてのいずれかで符号化される、データ圧縮プロセスによって生成されるデータ信号であって、該データ信号は、
参照子の順序付けられたストリーム、
直接的表現の順序付けられたストリーム、及び
各連続的な伸張オペレーションが参照子に作用すべきであるのか、又は直接的表現に作用すべきであるのかを示すフラグの順序付けられたストリーム、
の、出力データの別個のストリームとして含む、データ信号。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP08252480A EP2148444B1 (en) | 2008-07-21 | 2008-07-21 | Data compression and decompression |
| EP08252480.2 | 2008-07-21 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010068511A true JP2010068511A (ja) | 2010-03-25 |
| JP5405930B2 JP5405930B2 (ja) | 2014-02-05 |
Family
ID=39877919
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009168779A Active JP5405930B2 (ja) | 2008-07-21 | 2009-07-17 | データ圧縮及びデータ伸張 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US8253608B2 (ja) |
| EP (1) | EP2148444B1 (ja) |
| JP (1) | JP5405930B2 (ja) |
| DE (1) | DE602008002583D1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9479194B2 (en) | 2013-08-09 | 2016-10-25 | Hitachi, Ltd. | Data compression apparatus and data decompression apparatus |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10430868B2 (en) * | 2010-06-18 | 2019-10-01 | Cox Communications, Inc. | Content purchases and rights storage and entitlements |
| US9852143B2 (en) | 2010-12-17 | 2017-12-26 | Microsoft Technology Licensing, Llc | Enabling random access within objects in zip archives |
| US8972967B2 (en) | 2011-09-12 | 2015-03-03 | Microsoft Corporation | Application packages using block maps |
| US8819361B2 (en) | 2011-09-12 | 2014-08-26 | Microsoft Corporation | Retaining verifiability of extracted data from signed archives |
| US8839446B2 (en) | 2011-09-12 | 2014-09-16 | Microsoft Corporation | Protecting archive structure with directory verifiers |
| US9337862B2 (en) * | 2014-06-09 | 2016-05-10 | Tidal Systems, Inc. | VLSI efficient Huffman encoding apparatus and method |
| US9634689B2 (en) * | 2014-08-20 | 2017-04-25 | Sunedison Semiconductor Limited (Uen201334164H) | Method and system for arranging numeric data for compression |
| CN107943424A (zh) * | 2017-12-18 | 2018-04-20 | 苏州蜗牛数字科技股份有限公司 | 一种网络游戏中方块地形信息的压缩方法 |
| US11509328B2 (en) * | 2018-05-31 | 2022-11-22 | Microsoft Technology Licensing, Llc | Computer data compression utilizing multiple symbol alphabets and dynamic binding of symbol alphabets |
| KR102868996B1 (ko) * | 2023-01-11 | 2025-10-13 | 삼성전자주식회사 | 압축 데이터 스트림의 디코딩 방법 및 장치 |
| CN115801019B (zh) * | 2023-02-08 | 2023-05-12 | 广州匠芯创科技有限公司 | 并行加速lz77解码方法及其装置、电子设备 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07261977A (ja) * | 1994-03-16 | 1995-10-13 | Fujitsu Ltd | データ圧縮方法および装置ならびにデータ復元方法および装置 |
| US5502439A (en) * | 1994-05-16 | 1996-03-26 | The United States Of America As Represented By The United States Department Of Energy | Method for compression of binary data |
| JPH10187410A (ja) * | 1996-12-24 | 1998-07-21 | Fujitsu Ltd | データ圧縮方法及び装置 |
| JP2003046392A (ja) * | 2001-06-30 | 2003-02-14 | Robert Bosch Gmbh | データ圧縮方法およびデータ伸長方法、該方法を実施するためのコンピュータプログラム製品と電子システム |
| JP2005269184A (ja) * | 2004-03-18 | 2005-09-29 | Seiko Epson Corp | データ圧縮方法及びプログラムならびにデータ復元方法及び装置 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4906991A (en) * | 1988-04-29 | 1990-03-06 | Xerox Corporation | Textual substitution data compression with finite length search windows |
| US5521597A (en) * | 1993-08-02 | 1996-05-28 | Mircosoft Corporation | Data compression for network transport |
| US7492290B1 (en) * | 2007-08-15 | 2009-02-17 | Red Hat, Inc. | Alternative encoding for LZSS output |
-
2008
- 2008-07-21 DE DE602008002583T patent/DE602008002583D1/de active Active
- 2008-07-21 EP EP08252480A patent/EP2148444B1/en active Active
-
2009
- 2009-07-17 US US12/504,815 patent/US8253608B2/en active Active
- 2009-07-17 JP JP2009168779A patent/JP5405930B2/ja active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07261977A (ja) * | 1994-03-16 | 1995-10-13 | Fujitsu Ltd | データ圧縮方法および装置ならびにデータ復元方法および装置 |
| US5502439A (en) * | 1994-05-16 | 1996-03-26 | The United States Of America As Represented By The United States Department Of Energy | Method for compression of binary data |
| JPH10187410A (ja) * | 1996-12-24 | 1998-07-21 | Fujitsu Ltd | データ圧縮方法及び装置 |
| JP2003046392A (ja) * | 2001-06-30 | 2003-02-14 | Robert Bosch Gmbh | データ圧縮方法およびデータ伸長方法、該方法を実施するためのコンピュータプログラム製品と電子システム |
| JP2005269184A (ja) * | 2004-03-18 | 2005-09-29 | Seiko Epson Corp | データ圧縮方法及びプログラムならびにデータ復元方法及び装置 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9479194B2 (en) | 2013-08-09 | 2016-10-25 | Hitachi, Ltd. | Data compression apparatus and data decompression apparatus |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2148444B1 (en) | 2010-09-15 |
| EP2148444A1 (en) | 2010-01-27 |
| JP5405930B2 (ja) | 2014-02-05 |
| US20100017424A1 (en) | 2010-01-21 |
| DE602008002583D1 (de) | 2010-10-28 |
| US8253608B2 (en) | 2012-08-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5405930B2 (ja) | データ圧縮及びデータ伸張 | |
| US7817069B2 (en) | Alternative encoding for LZSS output | |
| Lemire et al. | Stream VByte: Faster byte-oriented integer compression | |
| US9203887B2 (en) | Bitstream processing using coalesced buffers and delayed matching and enhanced memory writes | |
| CN114244373B (zh) | Lz系列压缩算法编解码速度优化方法 | |
| US5870036A (en) | Adaptive multiple dictionary data compression | |
| US6199064B1 (en) | Method and apparatus for sorting data blocks | |
| US8090027B2 (en) | Data compression using an arbitrary-sized dictionary | |
| JP6319740B2 (ja) | データ圧縮を高速化する方法、並びに、データ圧縮を高速化するためのコンピュータ、及びそのコンピュータ・プログラム | |
| US6597812B1 (en) | System and method for lossless data compression and decompression | |
| US7661102B2 (en) | Method for reducing binary image update package sizes | |
| RU2629440C2 (ru) | Устройство и способ для ускорения операций сжатия и распаковки | |
| US20200186165A1 (en) | Hardware friendly data compression | |
| CN1446404A (zh) | 操作码的双模数据压缩 | |
| CN112514270A (zh) | 数据压缩 | |
| US20200294629A1 (en) | Gene sequencing data compression method and decompression method, system and computer-readable medium | |
| JP6921936B2 (ja) | Simdエンジンを用いる汎用データ圧縮 | |
| US20180183462A1 (en) | Techniques for parallel data decompression | |
| CN101147325B (zh) | 用于霍夫曼代码的快速小型解码器和解码方法 | |
| US20200119747A1 (en) | Decompression Engine for Executable Microcontroller Code | |
| WO2015147912A1 (en) | Variable bit-length reiterative lossless compression system and method | |
| US9176973B1 (en) | Recursive-capable lossless compression mechanism | |
| US8537038B1 (en) | Efficient compression method for sorted data representations | |
| US8373584B2 (en) | Compressing and decompressing data | |
| JP4191438B2 (ja) | データ圧縮方法およびデータ伸長方法、該方法を実施するためのコンピュータプログラム製品と電子システム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20120619 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20130724 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20130730 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20130917 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20131008 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20131031 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5405930 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |