JP2010060809A - Method of calculating identification score posterior probability classified for each number of errors, identification learning device and method with the number of errors weight using the method, voice recognition device using the device, program and recording medium - Google Patents
Method of calculating identification score posterior probability classified for each number of errors, identification learning device and method with the number of errors weight using the method, voice recognition device using the device, program and recording medium Download PDFInfo
- Publication number
- JP2010060809A JP2010060809A JP2008225998A JP2008225998A JP2010060809A JP 2010060809 A JP2010060809 A JP 2010060809A JP 2008225998 A JP2008225998 A JP 2008225998A JP 2008225998 A JP2008225998 A JP 2008225998A JP 2010060809 A JP2010060809 A JP 2010060809A
- Authority
- JP
- Japan
- Prior art keywords
- errors
- score
- lattice
- error
- identification
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images










Abstract
Description
この発明は、音声、静止画像、動画像等の時間軸上や空間軸上の概念情報を表現する信号の特徴量情報系列を用いて、予め定められた離散値で表現したシンボル系列としてパターン認識するためのモデルパラメータ学習に用いる誤り数別識別スコア・事後確率計算方法と、その方法を用いた誤り数重み付き識別学習装置とその方法と、その装置を用いた音声認識装置と、プログラムと記録媒体に関する。 This invention uses a feature amount information sequence of a signal expressing conceptual information on a time axis or a space axis such as a voice, a still image, and a moving image to recognize a pattern as a symbol sequence expressed by a predetermined discrete value. Error number-specific identification score / posterior probability calculation method used for model parameter learning, error number weighted identification learning device using the method, method thereof, speech recognition device using the device, program, and recording It relates to the medium.
パターン認識の誤りを少なくするためには、誤り数をモデルパラメータの関数(損失関数)として推定し、この損失関数値が小さくなるようにモデルパラメータの学習を行うことが有効である。このような学習を行う代表的な従来技術として、MPE/MWE(Minimum Phone Error/Minimum Word Error)学習方法が知られている(非特許文献1)。この学習方法を、パターン認識の代表的な例である連続音声認識に適用した場合を例に説明する。 In order to reduce pattern recognition errors, it is effective to estimate the number of errors as a model parameter function (loss function) and to learn model parameters so that the loss function value becomes small. As a typical conventional technique for performing such learning, an MPE / MWE (Minimum Phone Error / Minimum Word Error) learning method is known (Non-Patent Document 1). A case where this learning method is applied to continuous speech recognition, which is a typical example of pattern recognition, will be described as an example.
図7に音声認識装置800の機能構成例を示す。音声認識装置800は、MPE/MWE学習方法を用いた音響モデル学習装置700と、音声特徴量抽出部80と、単語系列探索部81と、音響モデルパラメータ記録部82とを備える。音響モデル学習装置700は、局所スコア・局所誤り計算部70、誤り数平均値計算部71、前向き・後ろ向きスコア計算部72、事後確率計算部73、損失関数値計算部74、偏微分係数値計算部75、モデルパラメータ更新部76を備える。
FIG. 7 shows a functional configuration example of the speech recognition apparatus 800. The speech recognition device 800 includes an acoustic model learning device 700 using the MPE / MWE learning method, a speech feature
音声特徴量抽出部80は、離散値で形成される音声情報列を入力として音声情報列の音声特徴量情報系列Xrを算出する。音声特徴量情報系列Xrは、例えばメル周波数ケプストラム係数(MFCC)分析によって抽出される。単語系列探索部81は、その音声特徴量情報系列Xrに応じて、音響モデルパラメータ記録部82内に記録された特徴量情報系列を探索して複数のシンボル系列で表現される単語ラティスを出力する。図8に「今日の北海道」に対応した単語ラティスの一例を示す。単語ラティスは単語グラフとも呼ばれ、複数の節点を、単語あるいは部分単語系列に対応する有向弧qで結んだ構造を持っている。
The voice feature
また、有向弧qは、音声特徴量情報系列Xrに含まれる部分特徴量系列にも対応している。ラティスに含まれる有向弧qの各々と単語あるいは部分単語系列との対応、及びラティスに含まれる有向弧qの各々と部分特徴量系列との対応は、単語列探索の結果として得られるものである。 The directed arc q also corresponds to a partial feature quantity sequence included in the speech feature quantity information series Xr . The correspondence between each directed arc q included in the lattice and the word or partial word sequence, and the correspondence between each directed arc q included in the lattice and the partial feature amount sequence are obtained as a result of word string search. It is.
局所スコア・局所誤り計算部70は、正解系列単語列Srと、音声特徴量情報系列Xrと、モデルパラメータλ(t)と、単語ラティスとを入力として、有向弧qの局所的なスコアである局所スコアpqと、局所的な誤り数である局所誤り数eqを計算する。局所スコアpqは、式(1)で計算できる。局所スコアpqと局所誤り数eqは、ラティスに含まれる有効弧qの各々について計算されるので、有効弧qについての集合を成している。これを図7では{pq},{eq}と表記している。他の信号についても同様である。
The local score / local
![]()
![]()
ここでPΛG(sq)は、有向弧qに割り付けられた局所言語スコアである。pΛA(xq|sq)は、有向弧qに割り付けられた局所音響スコアである。局所言語スコアと局所音響スコアの積が局所スコアとなる。ηとψは制御係数であり、ηが大きいほど局所スコアにおける局所言語スコアPΛG(sq)の寄与率が大きくなる係数である。ψが局所スコアpqを計算する際の部分単語系列sq毎のバラツキを抑制(ψ→小)、又は強調(ψ→大)する係数である。また、局所スコア・局所誤り計算部70は、局所誤り数eqを計数する。局所誤り数eqの計数例を図9に示す。図9(a)は単語単位の誤り数の例を示す。図9(b)は音素単位の誤り数、図9(c)は時間フレーム単位の誤り数の例を示す。全て、正解文を「今日の北海道の天気は晴れです」としたときのそれぞれの単位毎の誤り数の例である。例えば、単語単位では誤り数が2、音素単位では誤り数が5、フレーム単位では誤り数が35である。この局所誤り数eqは、正解単語系列Srと、音声特徴量情報系列Xrと、単語ラティスQとを対比させることで計数する。ここでQとは、有向弧qの接続関係を含む集合である。
Here, P ΛG (s q ) is a local language score assigned to the directed arc q. p ΛA (x q | s q ) is a local acoustic score assigned to the directed arc q. The product of the local language score and the local acoustic score is the local score. η and ψ are control coefficients, and the larger the η, the larger the contribution ratio of the local language score P ΛG (s q ) in the local score. ψ is a coefficient that suppresses (ψ → small) or emphasizes (ψ → large) variations for each partial word sequence s q when calculating the local score p q . Also, the local score local
誤り数平均値計算部71は、有向弧qを通る全ての単語系列について式(2)に示す誤り数の平均値c(q)を計算する。
The error number average
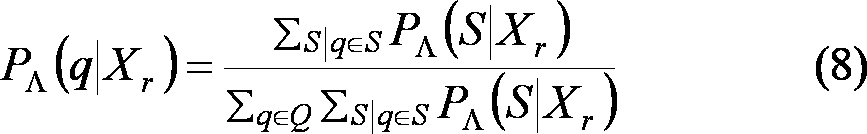
誤り数の平均値c(q)は、前向き・後ろ向きアルゴリズムと、平均誤り数伝播アルゴリズムとの組み合わせによって効率的に計算することができる。つまり、式(3)に示すように局所誤り数eqに、前向き平均誤り数α′qと後ろ向き平均誤り数β′qとを加えた値で求めることができる。 The average value c (q) of the number of errors can be efficiently calculated by a combination of a forward / backward algorithm and an average error number propagation algorithm. That is, as shown in Expression (3), the local error number e q can be obtained by adding the forward average error number α ′ q and the backward average error number β ′ q .
![]()
![]()
前向き平均誤り数α′qの求め方の概念図を10に示す。前向き平均誤り数α′qを求める前に有向弧qの前向き累積確率αqを式(4)の計算により求める。有向弧qの前向き累積確率αqは、有向弧qの始端に終端を接続している先行有向弧q−(i)(i=1,…,Nq)のそれぞれの前向き向き累積確率αq−(i)に、それぞれの局所確率pq(i)を乗じた値の累積である。 A conceptual diagram of how to obtain the forward average error number α ′ q is shown in FIG. Before obtaining the forward average error number α ′ q , the forward cumulative probability α q of the directed arc q is obtained by calculation of Equation (4). The forward cumulative probability α q of the directed arc q is the forward cumulative of each of the preceding directed arcs q − (i) (i = 1,..., N q ) whose end is connected to the start end of the directed arc q. This is the accumulation of values obtained by multiplying the probability α q− (i) by the respective local probabilities p q (i) .
![]()
![]()
有向弧qの前向き累積確率αqと後述する後ろ向き累積確率βqは、前向き・後ろ向きスコア計算72で、局所スコアpqを入力として計算される。前向き累積確率αqと後述する後ろ向き累積確率βqは、誤り数平均値計算部71と事後確率計算部73に出力される。
Backward cumulative probability beta q to be described later with forward cumulative probability alpha q of directed arcs q is the forward-
誤り数平均値計算部71は、局所スコアpqと、局所誤り数eqと、単語ラティスqを入力として式(3)の計算によって有向弧qを通る全ての単語系列についての誤り数の平均値c(q)を計算する。式(3)の計算に当たって、必要な前向き平均誤り数α′qは式(5)で計算される。
The error number average
同様に後ろ向き累積確率βqと、後ろ向き平均誤り数β′qは、式(6)と式(7)で計算できる。 Similarly, the backward cumulative probability β q and the backward average error number β ′ q can be calculated by the equations (6) and (7).
誤り数の平均値c(q)の求め方の概念図を図11に示す。有向弧qに割り付けられた部分単語系列sqが例えば「東海道」であり、その有向弧の誤り数の平均値c(q)は式(3)で与えられる。 FIG. 11 shows a conceptual diagram of how to obtain the average value c (q) of the number of errors. The partial word sequence s q assigned to the directed arc q is, for example, “Tokaido”, and the average value c (q) of the number of errors in the directed arc is given by Equation (3).
単語ラティスの始節点を始端とする有向弧から順に漸化的に式(4)、式(5)を適用し、さらに単語ラティスの終節点を終端とする有向弧から順に漸化的に式(6)、式(7)を適用すれば全ての有向弧qについて、式(3)の計算により誤り数の平均値c(q)を求めることができる。有向弧qは((q,{q−(i)},{q+(i)})∈Q)である。以降、簡単にq∈Qと表記する。 Equations (4) and (5) are applied recursively in order from the directional arc starting from the start node of the word lattice, and further recursively from the directional arc starting from the end node of the word lattice. If Expressions (6) and (7) are applied, the average value c (q) of the number of errors can be obtained for all directed arcs q by calculation of Expression (3). The directed arc q is ((q, {q − (i)}, {q + (i)}) ∈Q). Hereinafter, qεQ is simply written.
事後確率計算部73は、前向き累積確率αqと後ろ向き累積確率βqとを入力として、認識候補単語系列が有向弧qを通ることの事後確率PΛ(q|Xr)を式(8)で計算する。
The posterior
損失関数値計算部74は、誤り数の平均値c(q)と、事後確率PΛ(q|Xr)とを入力として式(9)の計算を行って単語ラティスに対する損失関数FMPE(Xr)を求める。
The loss function
![]()
![]()
損失関数FMPE(Xr)を、最適化手法を用いてモデルパラメータλについて最小化することにより、認識誤りを少なくする。具体的な最適化手法としては、確率的降下(PD: Probabilistic Descent)法、Quickprop法、Rprop法、拡張Baum-Welch(EBW: Extended Baum-Welch)法等を用いることができる。何れの最適化手法においてもモデルパラメータλ(∈Λ)についてのFMPE(Xr)の偏微分係数値∂FMPE(Xr)/∂λの計算が必要となる。偏微分係数値∂FMPE(Xr)/∂λは、logpΛ(Xr,q)≒log(PΛG(q)ηψpΛA(Xr,|q)ψ)と置いたとき、式(10)に示すように分解できる。 Recognition errors are reduced by minimizing the loss function F MPE (X r ) with respect to the model parameter λ using an optimization method. As a specific optimization method, a probabilistic descent (PD) method, a Quickprop method, an Rprop method, an extended Baum-Welch (EBW) method, or the like can be used. In any optimization method, it is necessary to calculate the partial differential coefficient value ∂F MPE (X r ) / ∂λ of F MPE (X r ) for the model parameter λ (∈Λ). When the partial differential coefficient value ∂F MPE (X r ) / ∂λ is set as logp Λ (X r , q) ≈log (P ΛG (q) ηψ p ΛA (X r , | q) ψ ), It can be disassembled as shown in (10).
式(10)の中で特に、Xrが有向弧qに対応する部分単語系列を含む単語列を意図して発声された音声の特徴量情報系列であることの尤もらしさを表す識別スコアlogpΛ(Xr,q)についての偏微分係数値が重要である。 Among the formula (10), the identification score logp representing the likelihood that X r is characteristic amount information sequence of speech uttered with the intention of word string including partial word sequence corresponding to the directed arcs q The partial derivative value for Λ (X r , q) is important.
偏微分係数値計算部75は、誤り数の平均値c(q)と、事後確率PΛ(q|Xr)と、損失関数FMPE(Xr)とを入力として、有向弧qでの偏微分係数値を式(11)の計算で求める。
The partial differential coefficient
つまり、単語ラティスに適用されるMPE/MWE学習法では、有向弧qの誤り数の平均値c(q)と、認識誤り数の平均値FMPE(Xr)との差、つまり認識誤り数の平均値FMPE(Xr)を基準にして学習を行う。関数FMPE(Xr)よりも小さな誤り数の平均値c(q)を持つ場合は、識別スコアlogpΛ(Xr,q)を高くするように学習を進める。逆に有向弧qがFMPE(Xr)よりも大きな誤り数の平均値c(q)を持つ場合は、識別スコアlogpΛ(Xr,q)を低くするように学習を進める。これを繰り返すことで、損失関数FMPE(Xr)を最小化することができる。モデルパラメータ更新部76は損失関数が低くなるように音響モデルパラメータ記録部82に記録されたモデルパラメータλ(t)を、モデルパラメータλ(t+1)に更新する。
従来のMPE/MWE学習法では、対象とするシンボル系列集合内での認識誤り数の平均値と、ラティス全体としての認識誤り数の平均値との差と、対象とする単語系列集合の事後確率の大きさとを基準にしてモデルパラメータの学習を行っている。そのため、次のような問題点が生じる。 In the conventional MPE / MWE learning method, the difference between the average value of the number of recognition errors in the target symbol sequence set and the average value of the number of recognition errors as the entire lattice, and the posterior probability of the target word sequence set The model parameters are learned based on the size of. Therefore, the following problems arise.
学習データの量が十分でない場合、或いは、学習データと認識対象とする特徴量情報系列とが異なる統計的性質を有している場合には、認識対象とする特徴量情報系列の誤り数を十分削減する学習効果が得られない。特に認識対象とする特徴量情報系列を初期モデルで認識した結果と、学習データを認識した結果とで、誤り数毎のシンボル系列数の分布が大きく異なる場合には学習効果が得られない。 If the amount of learning data is not enough, or if the learning data and the feature quantity information sequence to be recognized have different statistical properties, the number of errors in the feature quantity information sequence to be recognized is sufficient. The learning effect to reduce cannot be obtained. In particular, if the distribution of the number of symbol sequences for each number of errors differs greatly between the result of recognizing a feature quantity information sequence to be recognized by the initial model and the result of recognizing learning data, the learning effect cannot be obtained.
また、探索部の認識結果出力特性によるが、探索部から出力されるラティスは、同じシンボルの並びでもシンボル境界の時刻のみが異なるシンボル系列が多数含まれることがある。このような場合には、誤り数毎のシンボル系列数の分布の偏りが大きくなり学習の効果は限定的になる。 Further, depending on the recognition result output characteristics of the search unit, the lattice output from the search unit may include a large number of symbol sequences that differ only in the time of symbol boundaries even with the same symbol arrangement. In such a case, the bias of the distribution of the number of symbol sequences for each number of errors becomes large, and the learning effect is limited.
この発明は、このような問題点に鑑みてなされたものであり、学習データの偏りやシンボル系列の出現傾向の偏りによる悪影響が小さく、より高い認識精度が得られるパラメータの学習に用いる誤り数別識別スコア・事後確率計算方法とその方法を用いた誤り数重み付き識別学習装置とその方法と、その装置を用いた音声認識装置と、そのプログラムと記録媒体を提供することを目的とする。 The present invention has been made in view of such problems, and has a small adverse effect due to a bias in learning data and a bias in the appearance tendency of symbol sequences, and is classified by the number of errors used for learning parameters that can provide higher recognition accuracy. It is an object of the present invention to provide an identification score / posterior probability calculation method, an error number weighted identification learning device using the method, a speech recognition device using the device, a program, and a recording medium.
この発明の誤り数別識別スコア・事後確率計算方法は、局所スコア・局所誤り計算過程と、誤り数別識別スコア計算過程と、誤り数別事後確率計算過程とを含む。局所スコア・局所誤り計算過程は、特徴量情報系列と、上記特徴量情報系列に対応した正解シンボル系列と、上記特徴量情報系列を複数の認識シンンボル系列で表現したラティスと、モデルパラメータとを入力として、上記ラティスに含まれる各々の有向弧に対する局所スコアと有向弧に含まれる局所誤り数とを計算する。誤り数別識別スコア計算過程は、上記局所スコアと、上記局所誤り数と、上記ラティスとを入力として、上記ラティスの誤り数別の識別スコアと誤り数別前向き累積スコアと誤り数別後ろ向き累積スコアとを計算する。誤り数別事後確率計算過程は、上記ラティスの誤り数別の識別スコアと、上記誤り数別前向き累積スコアと、上記誤り数別後ろ向き累積スコアと、上記局所スコアとを入力として、上記正解シンボル系列が上記ラティスに含まれる各々の有向弧を含むことの事後確率を誤り数別に計算する。 The number-of-errors identification score / posterior probability calculation method of the present invention includes a local score / local error calculation process, an error number-specific identification score calculation process, and an error number-specific posterior probability calculation process. In the local score / local error calculation process, a feature quantity information series, a correct symbol series corresponding to the feature quantity information series, a lattice representing the feature quantity information series as a plurality of recognition symbol sequences, and a model parameter are input. As described above, the local score for each directed arc included in the lattice and the number of local errors included in the directed arc are calculated. The error score identification score calculation process is performed by using the local score, the local error count, and the lattice as input, the discrimination score by error count of the lattice, a forward cumulative score by error count, and a backward cumulative score by error count. And calculate. The posterior probability calculation process according to the number of errors includes the identification symbol for each number of errors in the lattice, the forward cumulative score by the number of errors, the backward cumulative score by the number of errors, and the local score, and the correct symbol series. Calculates the a posteriori probability of including each directed arc included in the lattice according to the number of errors.
また、この発明の誤り数重み付き識別学習方法は、この発明の誤り数別識別スコア・事後確率計算方法を用いる。また、この発明の音声認識装置は、この発明の誤り数重み付き識別学習方法を用いる。 In addition, the error number weighted identification learning method of the present invention uses the error number-specific identification score / posterior probability calculation method of the present invention. The speech recognition apparatus of the present invention uses the error number weighted identification learning method of the present invention.
この発明の誤り数別識別スコア・事後確率計算方法は、誤り数別識別スコア計算過程でラティスの誤り数別の識別スコアと、誤り数別前向き累積スコアと、誤り数別後ろ向き累積スコアとを計算し、誤り数別事後確率計算過程で正解シンボル系列がラティスに含まれる各々の有向弧を含むことの事後確率を誤り数別に計算する。つまり、誤り数別に識別スコアと事後確率を計算するので、学習データの偏りや認識シンボル系列の出現傾向の偏りの影響を受け難いモデルパラメータの学習装置に用いることができる誤り数別識別スコア・事後確率計算方法とすることができる。 The method of calculating the identification score / posterior probability according to the number of errors of the present invention calculates the identification score by the number of errors of the lattice, the forward cumulative score by the number of errors, and the backward cumulative score by the number of errors in the process of calculating the identification score by the number of errors. Then, the posterior probability that the correct symbol sequence includes each directed arc included in the lattice is calculated for each error number. In other words, since the identification score and the posterior probability are calculated for each error number, the identification score for each error number and the posterior can be used in a model parameter learning device that is not easily affected by the bias of the learning data and the bias of the appearance tendency of the recognition symbol series. It can be a probability calculation method.
また、この発明の誤り数別識別スコア・事後確率計算方法を用いた誤り数重み付き識別学習方法は、認識性能を向上させる学習方法とすることができる。更に、その誤り数重み付き識別学習方法を用いた音声認識装置は、認識率を向上させたものにすることができる。 Further, the error number weighted identification learning method using the error number-specific identification score / posterior probability calculation method of the present invention can be a learning method for improving recognition performance. Furthermore, the speech recognition apparatus using the error number weighted discrimination learning method can improve the recognition rate.
以下、この発明の実施の形態を図面を参照して説明する。複数の図面中同一のものには同じ参照符号を付し、説明は繰り返さない。 Embodiments of the present invention will be described below with reference to the drawings. The same reference numerals are given to the same components in a plurality of drawings, and the description will not be repeated.
図1にこの発明の誤り数重み付き識別学習装置100の機能構成例を示す。その動作フローを図2に示す。誤り数重み付き識別学習装置100は、局所スコア・局所誤り計算部12と、誤り数別識別スコア計算部13と、誤り数別事後確率計算部14と、損失関数値計算部15と、偏微分係数値計算部16と、モデルパラメータ更新部17とを備える。 誤り数重み付き識別学習装置100の外部に設けられたシンボル系列探索部10とモデルパラメータ記録部11とは、従来技術で説明した音響モデル学習装置700の外部に設けられた単語系列探索部81と音響モデルパラメータ記録部82と、基本的に同じものである。また、誤り数重み付き識別学習装置100内部の局所スコア・局所誤り計算部12とモデルパラメータ更新部17とは、従来技術の音響モデル学習装置700の局所スコア・局所誤り計算部70とモデルパラメータ更新部76と、基本的に同じものである。つまり、これらの部分については、モデルパラメータが音声認識用であるか否かの違いしかない。
FIG. 1 shows an example of the functional configuration of an error number weighted
以降の説明では異なる部分のみを説明する。図2のステップS10とステップS12までの動作は、従来の音響モデル学習装置700と同じである。なお、誤り数重み付き識別学習装置100、及び音響モデル学習装置700は、例えばROM、RAM、CPU等で構成されるコンピュータに所定のプログラムが読み込まれて、CPUがそのプログラムを実行することで実現される。
In the following description, only different parts will be described. The operations up to step S10 and step S12 in FIG. 2 are the same as those of the conventional acoustic model learning apparatus 700. The error number weighted
誤り数別識別スコア計算部13は、局所スコア・局所誤り計算部12で計算された局所スコアpqと、局所誤り数eqと、特徴量情報系列を複数の認識シンボル系列で表現したラティスとを入力として、式(12)に示すラティスの誤り数別の識別スコアGj(Xr)(以降、識別スコアGj(Xr)と略す)を求める(ステップS13)。
The number-of-errors identification
![]()
![]()
識別スコアGj(Xr)は、誤り数別の前向き・後ろ向きアルゴリズムによって効率的に計算することができる。今、有向弧qでの局所的なスコアを局所スコアpq、有向弧qでの局所的な誤り数を局所誤り数eqとする。連続パターン認識の結果として有向弧qに割り付けられた部分特徴量情報系列をxq、部分単語系列をsqとすると、有向弧qの局所スコアpqは従来技術と同じように式(1)で計算することができる。有向弧qの局所スコアと、先行有向弧の全てq−(i)(i=1,…,Nq−)の前向き累積スコアαq−(i)とで、前向き確率の総和αq,jを式(13)で計算する。 The identification score G j (X r ) can be efficiently calculated by a forward / backward algorithm for each number of errors. Now, local score p q local scores in directed arcs q, and local error count e q local errors Number of directed arcs q. Assuming that the partial feature quantity information sequence assigned to the directed arc q as a result of continuous pattern recognition is x q , and the partial word sequence is s q , the local score p q of the directed arc q is the same as the formula ( It can be calculated in 1). The sum of forward probabilities α q with the local score of the directed arc q and the forward cumulative score α q- (i) of all the preceding directed arcs q − (i) (i = 1,..., N q− ). , J is calculated by equation (13).
つまり、有向弧q(i)と先行有向弧以前の累積誤り数kの全ての組み合わせにおいて、先行有向弧以前の累積誤り数kと、先行有向弧q−(i)の局所誤り数eq−(i)との和であるj毎に、前向き確率の総和を求める。 That is, in all combinations of the directed arc q (i) and the cumulative error number k before the preceding directional arc, the cumulative error number k before the preceding directional arc and the local error of the preceding directional arc q − (i). For each j that is the sum of the number e q− (i), the sum of forward probabilities is obtained.
単語ラティスの始節点を始端とする有向弧から順に、先行有向弧を漏れなく用いて漸化的に式(13)を適用すれば、全ての有向弧q∈Qについて前向き累積誤り数別の前向き確率αq,j(以降、誤り数別前向き累積スコアと称する)を求めることができる。なお、先頭の有向弧については、始節点を終端としたpq−(1)=1、αq−(1),j=1(全てのjについて)、eq−=0の仮想の先行有向弧q−(1)=qstartを考える。 If the formula (13) is applied recursively using the preceding directed arc without omission in order from the directed arc starting from the starting node of the word lattice, the number of forward accumulated errors for all the directed arcs q∈Q Another forward probability α q, j (hereinafter referred to as a forward cumulative score by number of errors) can be obtained. As for the headed directional arc, the virtual nodes of p q− (1) = 1, α q− (1), j = 1 (for all j) and e q− = 0 with the start node as the end Consider the leading directed arc q − (1) = q start .
同様に、単語ラティスの終節点を終端とする有向弧から順に後続有向弧を漏れなく用いて漸化的に式(14)を適用すれば、全ての有向弧q∈Qについて後ろ向き累積誤り数別の後ろ向き確率の総和βq,j(以降、誤り数別後ろ向き累積スコアと称する)を求めることができる。 Similarly, if Equation (14) is applied recursively using the subsequent directed arc without omission in order from the directed arc that ends at the end of the word lattice, backward accumulation is performed for all directed arcs q∈Q. A total sum β q, j of backward probabilities by number of errors (hereinafter referred to as backward cumulative score by number of errors) can be obtained.
全ての有向弧q∈Qについて、誤り数別前向き累積スコアαq,j、又は誤り数別後ろ向き累積スコアβq,jを計算すれば、識別スコアGj(Xr)は式(15)で得られる。 If the forward cumulative score α q, j by number of errors or the backward cumulative score β q, j by number of errors is calculated for all directional arcs q∈Q, the identification score G j (X r ) can be expressed by the equation (15). It is obtained by.
![]()
![]()
つまり識別スコアGj(Xr)は、終端の有向弧の誤り数別前向き累積スコアαfinal j=Gj(Xr)又は、始端の有向弧の誤り数別後ろ向き累積スコアβstart j=Gj(Xr)で表すことができる。 That is, the identification score G j (X r ) is the forward cumulative score α final j = G j (X r ) by the number of errors in the terminal directed arc or the backward cumulative score β start j by the number of errors in the start directed arc. = G j (X r ).
誤り数別事後確率計算部14は、識別スコアGj(Xr)と、誤り数別前向き累積スコアαq,jと、誤り数別後ろ向き累積スコアβq,jと、有向弧qの局所スコアpqとを入力として、誤り数jの認識シンボル系列が有向弧qを通ることの事後確率γq,jを式(16)で計算する(ステップS14)。
The posterior
式(13)〜式(16)の動作の概念図を図3に示す。局所誤りeq=2の有向弧qの前向き/後ろ向き累積スコア統合ζq,j(以降、は累積スコア統合ζq,jと略す)式(17)で計算できる。つまり、式(16)の分子である。 FIG. 3 shows a conceptual diagram of the operations of the equations (13) to (16). The forward / backward cumulative score integration ζ q, j (hereinafter abbreviated as cumulative score integration ζ q, j ) of the directed arc q with the local error e q = 2 can be calculated by the equation (17). That is, the numerator of formula (16).
![]()
![]()
累積スコア統合ζq,jは、累積誤り数別の先行有向弧以前の累積スコアαq,kと、後続有向弧までの累積スコアβq,uと、事後確率を求めたい有向弧qの局所スコアpqとの積の累積である。この累積スコア統合ζq,jを識別スコアGj(Xr)で除した値が、誤り数jの認識シンボル系列が有向弧qを通ることの事後確率γq,jである。αq,k、βq,j、γq,jは、有向弧qと誤り数j毎のそれぞれの値である。 The cumulative score integration ζ q, j is a cumulative score α q, k before the preceding directed arc for each cumulative error number, a cumulative score β q, u until the subsequent directed arc, and a directed arc for which the posterior probability is to be obtained. It is the cumulative product of q and the local score p q . A value obtained by dividing the cumulative score integration ζ q, j by the identification score G j (X r ) is the posterior probability γ q, j that the recognition symbol sequence having the error number j passes through the directed arc q. α q, k , β q, j , and γ q, j are the respective values for the directed arc q and the number of errors j.
損失関数値計算部15は、誤り数別の識別スコアGj(Xr)を入力として、例えば式(18)に示す損失関数値を計算する(ステップS15)。
The loss function
ここでφは、誤り数別の識別スコアGj(Xr)の誤り数j毎のバラツキを抑制(φ→小)、又は強調(φ→大)するための制御係数である。 Here, φ is a control coefficient for suppressing (φ → small) or emphasizing (φ → large) the variation of the identification score G j (X r ) for each error number for each error number j.
偏微分係数値計算部16は、モデルパラメータについての式(18)の損失関数を最小化する偏微分係数値(式(19))を計算する(ステップS16)。
The partial differential coefficient
式(19)の右辺第一項の値が重要であって、偏微分係数値計算部16は、その右辺第一項を、誤り数別の識別スコアGj(Xr)と、損失関数値FMGE1(Xr)と、事後確率γq,jとを入力として式(20)で計算する。
The value of the first term on the right side of Equation (19) is important, and the partial differential coefficient
式(18)と式(19)とを用いて最適化手法を適用することで、損失関数値を最小化
することができる。最適化の収束を判定するのに特徴量情報系列の総損失ΓMGE1(Z)(式
21)とその偏微分係数値(式(22))を用いる。Zは様々な部分特徴量情報系列Xr1,
…,Xrmを含む全体の特徴量情報系列(Z∈{Xr(m)|m=1,…,M})である。Xr(m)
は式中の表記が正しい。
By applying the optimization method using Equation (18) and Equation (19), the loss function value can be minimized. The total loss Γ MGE1 (Z) (formula 21) and the partial differential coefficient value (formula (22)) of the feature amount information series are used to determine the convergence of the optimization. Z represents various partial feature amount information series X r1 ,
.., X rm is an entire feature amount information series (Zε {X r (m) | m = 1,..., M}). Xr (m)
Is correct in the expression.
モデルパラメータ更新部17は、式(18)の偏微分係数値と、損失関数値FMGE1(Xr)と、モデルパラメータ記録部11に記録されたモデルパラメータλ(t)とを入力として、最適化手法を用いて損失関数を最小化するモデルパラメータλ(t+1)に更新する(ステップS17)。
The model
以上のように誤り数別の識別スコアを用いてモデルパラメータを更新するので学習データの偏りや認識シンボル系列の出現傾向の偏りの影響を受け難いモデルパラメータの学習装置が実現できる。学習データの偏りや認識シンボル系列の出現傾向の偏りの影響を受け難い理由を図4と図5に示す。図4と図5は、単語シンボル系列当りの誤り数と、事後確率と偏微分係数値との関係を示したものである。横軸が単語シンボル系列当りの誤り数、図4(a)、図4(c)、図5(a)、図5(c)の縦軸が事後確率、図4(b)、図4(d)、図5(b)、図5(d)の縦軸が偏微分係数値である。 As described above, since the model parameters are updated using the identification score for each error number, it is possible to realize a model parameter learning apparatus that is hardly affected by the bias of the learning data and the bias of the appearance tendency of the recognition symbol series. The reason why it is difficult to be influenced by the bias of the learning data and the bias of the appearance tendency of the recognition symbol series is shown in FIGS. 4 and 5 show the relationship between the number of errors per word symbol sequence, the posterior probability, and the partial differential coefficient value. The horizontal axis represents the number of errors per word symbol sequence, the vertical axes in FIGS. 4 (a), 4 (c), 5 (a), and 5 (c) represent posterior probabilities, and FIGS. 4 (b) and 4 (c). d), the vertical axis of FIGS. 5B and 5D is the partial differential coefficient value.
部分単語系列毎のバラツキを調整するパラメータψは全て0.1に固定されている。誤り数j毎のバラツキを調整するパラメータφは図4(a),(b)と図5(a),(b)が1.0、図4(c),(d)と図5(c),(d)がφ=0.25に設定されている。ここでφ=1に設定すると、事後確率と偏微分係数値は、単語シンボル系列の平均値となる。これは式(18)から明らかである。つまり、図4(a),(b)と図5(a),(b)とは、従来技術の特性を示している。したがって、図4(c),(d)と図5(c),(d)の特性が実施例1で得られる事後確率と偏微分係数値である。 All the parameters ψ for adjusting the variation for each partial word sequence are fixed to 0.1. Parameters φ for adjusting the variation for each error number j are 1.0 in FIGS. 4A, 4B, 5A, and 5B, and FIGS. 4C, 4D, and 5C. ), (D) are set to φ = 0.25. When φ = 1 is set here, the posterior probability and the partial differential coefficient value are average values of the word symbol series. This is clear from equation (18). That is, FIGS. 4A and 4B and FIGS. 5A and 5B show the characteristics of the prior art. Therefore, the characteristics shown in FIGS. 4C and 4D and FIGS. 5C and 5D are the posterior probabilities and partial differential coefficient values obtained in the first embodiment.
図4(a)と図4(c)、図4(b)と図4(d)とを比較すると、従来技術の特性は、単語シンボル系列当りの誤り数が30を超えるまで変化がない。それに対して実施例1の特性には変化が見られる。図5(a)と図5(c)、図5(b)と図5(d)との比較も同じである。図5(c),(d)の特性は、式(22)と式(23)に示す損失関数と偏微分係数値を用いたもので、パラメータν=0.25、ε=10としたものである。このように変化が有るということは、学習に寄与することを意味する。 Comparing FIG. 4 (a) with FIG. 4 (c), FIG. 4 (b) and FIG. 4 (d), the characteristics of the prior art do not change until the number of errors per word symbol sequence exceeds 30. On the other hand, there is a change in the characteristics of Example 1. The comparison between FIG. 5 (a) and FIG. 5 (c) and FIG. 5 (b) and FIG. 5 (d) is the same. The characteristics shown in FIGS. 5C and 5D are obtained by using the loss function and the partial differential coefficient values shown in the equations (22) and (23), and the parameters ν = 0.25 and ε = 10. It is. This change means that it contributes to learning.
損失関数値と偏微分係数値を求める式には、上記したもの以外の式を適用することが可能である。例えば、式(23)と式(24)に示すように、誤り数に閾値εを設け、閾値εを境界として損失関数値に重み付けするようにしてもよい。 Expressions other than those described above can be applied to the expressions for obtaining the loss function value and the partial differential coefficient value. For example, as shown in Equation (23) and Equation (24), a threshold value ε may be provided for the number of errors, and the loss function value may be weighted using the threshold value ε as a boundary.
ここでνは、閾値εを境界としてバラツキを制御するパラメータである。また、式(25)と式(26)に示すような損失関数値と偏微分係数値を用いてもよい。 Here, ν is a parameter for controlling variation with the threshold ε as a boundary. Moreover, you may use a loss function value and a partial differential coefficient value as shown to Formula (25) and Formula (26).
ここで、σは誤り数が大きくなるほど指数的に識別スコアを減衰させる減衰係数である。〔応用例〕
この発明の誤り数重み付き識別学習装置100を音声認識に応用した例を説明する。図6にこの発明の誤り数重み付き識別学習装置100を用いて音声認識装置600を構成した機能構成例を示す。音声認識装置600は、従来技術で説明した音声認識装置800の音声認識用学習装置700をこの発明の誤り数重み付き識別学習装置100に置き換えたものである。
Here, σ is an attenuation coefficient that exponentially attenuates the identification score as the number of errors increases. [Application example]
An example in which the error number weighted
この発明の音声認識装置600は、音響モデルを誤り数別に学習するので、認識スコアの精度を高められる。よって、誤認識の少ない音声認識装置を実現することができる。 Since the speech recognition apparatus 600 according to the present invention learns the acoustic model according to the number of errors, the accuracy of the recognition score can be improved. Therefore, it is possible to realize a voice recognition device with few erroneous recognitions.
〔実験結果〕
この発明の誤り数重み付き識別学習方法の効果を確認する目的で実験を行った。この発明による学習方法、損失関数値を式(22)、偏微分係数値を式(23)で求め、ψ=0.04、φ=0.25、ν=0.65、ε=20の条件で、日本語の学会講演約230時間分の音声を学習した。その後、上記学習データとは別の約130分の長さの評価音声を、この発明の音声認識装置700で音声認識した結果の単語誤り率は18.8%であった。従来技術の音声認識装置800で評価音声を音声認識した結果の単語誤り率は19.3%であった。また、初期値のモデルパラメータで音声認識した結果の単語誤り率は21.6%であった。したがって、初期の誤り率を100とした相対誤り削減率はこの発明の方法が13.0%、従来法の削減率が10.6%であり、この発明の学習方法の方が優れた認識性能を示すことが確認できた。
〔Experimental result〕
An experiment was conducted for the purpose of confirming the effect of the error number weighted discriminative learning method of the present invention. According to the learning method of the present invention, the loss function value is obtained by the equation (22), the partial differential coefficient value is obtained by the equation (23), and the conditions of ψ = 0.04, φ = 0.25, ν = 0.65, ε = 20. So, I learned about 230 hours of speech in a Japanese conference. After that, the word error rate as a result of speech recognition of the evaluation speech having a length of about 130 minutes different from the learning data by the speech recognition apparatus 700 of the present invention was 18.8%. The word error rate as a result of speech recognition of the evaluation speech by the speech recognition apparatus 800 of the prior art was 19.3%. The word error rate as a result of speech recognition using the initial model parameters was 21.6%. Therefore, the relative error reduction rate with an initial error rate of 100 is 13.0% for the method of the present invention and 10.6% for the conventional method, and the recognition performance of the learning method of the present invention is superior. It was confirmed that
なお、この発明の技術思想に基づく誤り数別識別スコア・事後確率計算方法とその方法を用いた誤り数重み付き識別学習装置とその方法は、上述の実施形態に限定されるものではなく、この発明の趣旨を逸脱しない範囲で適宜変更が可能である。上記した装置及び方法において説明した処理は、記載の順に従って時系列に実行されるのみならず、処理を実行する装置の処理能力あるいは必要に応じて並列的にあるいは個別に実行されるとしてもよい。 The number-of-errors identification score / a posteriori probability calculation method based on the technical idea of the present invention, and the number-of-errors weighted identification learning apparatus and method using the method are not limited to the above-described embodiment. Modifications can be made as appropriate without departing from the spirit of the invention. The processes described in the above-described apparatus and method are not only executed in time series according to the order described, but may be executed in parallel or individually as required by the processing capability of the apparatus that executes the process. .
また、上記装置における処理手段をコンピュータによって実現する場合、各装置が有すべき機能の処理内容はプログラムによって記述される。そして、このプログラムをコンピュータで実行することにより、各装置における処理手段がコンピュータ上で実現される。 Further, when the processing means in the above apparatus is realized by a computer, the processing contents of functions that each apparatus should have are described by a program. Then, by executing this program on the computer, the processing means in each apparatus is realized on the computer.
この処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。コンピュータで読み取り可能な記録媒体としては、例えば、磁気記録装置、光ディスク、光磁気記録媒体、半導体メモリ等どのようなものでもよい。具体的には、例えば、磁気記録装置として、ハードディスク装置、フレキシブルディスク、磁気テープ等を、光ディスクとして、DVD(Digital Versatile Disc)、DVD-RAM(Random Access Memory)、CD-ROM(Compact Disc Read Only Memory)、CD-R(Recordable)/RW(ReWritable)等を、光磁気記録媒体として、MO(Magneto Optical disc)等を、半導体メモリとしてフラッシュメモリー等を用いることができる。 The program describing the processing contents can be recorded on a computer-readable recording medium. As the computer-readable recording medium, for example, any recording medium such as a magnetic recording device, an optical disk, a magneto-optical recording medium, and a semiconductor memory may be used. Specifically, for example, as a magnetic recording device, a hard disk device, a flexible disk, a magnetic tape, or the like, and as an optical disk, a DVD (Digital Versatile Disc), a DVD-RAM (Random Access Memory), a CD-ROM (Compact Disc Read Only) Memory), CD-R (Recordable) / RW (ReWritable), etc. can be used as magneto-optical recording media, MO (Magneto Optical disc) can be used, and flash memory can be used as semiconductor memory.
また、このプログラムの流通は、例えば、そのプログラムを記録したDVD、CD−ROM等の可搬型記録媒体を販売、譲渡、貸与等することによって行う。さらに、このプログラムをサーバコンピュータの記録装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することにより、このプログラムを流通させる構成としてもよい。 The program is distributed by selling, transferring, or lending a portable recording medium such as a DVD or CD-ROM in which the program is recorded. Further, the program may be distributed by storing the program in a recording device of a server computer and transferring the program from the server computer to another computer via a network.
また、各手段は、コンピュータ上で所定のプログラムを実行させることにより構成することにしてもよいし、これらの処理内容の少なくとも一部をハードウェア的に実現することとしてもよい。 Each means may be configured by executing a predetermined program on a computer, or at least a part of these processing contents may be realized by hardware.
Claims (10)
誤り数別識別スコア計算部が、上記局所スコアと、上記局所誤り数と、上記ラティスとを入力として、上記ラティスの誤り数別の識別スコアと誤り数別前向き累積スコアと誤り数別後ろ向き累積スコアとを計算する誤り数別識別スコア計算過程と、
誤り数別事後確率計算部が、上記ラティスの誤り数別の識別スコアと、上記誤り数別前向き累積スコアと、上記誤り数別後ろ向き累積スコアと、上記局所スコアとを入力として、上記正解シンボル系列が上記ラティスに含まれる各々の有向弧を含むことの事後確率を誤り数別に計算する誤り数別事後確率計算過程と、
を含む誤り数別識別スコア・事後確率計算方法。 The local score / local error calculation unit inputs a feature quantity information series, a correct symbol series corresponding to the feature quantity information series, a lattice representing the feature quantity information series as a plurality of recognition symbol series, and model parameters. A local score for each directed arc included in the lattice and a local score / local error calculation process for calculating the number of local errors included in the directed arc;
The number-of-errors identification score calculation unit receives the local score, the number of local errors, and the lattice as input, and the identification score for each number of errors of the lattice, the forward cumulative score by the number of errors, and the backward cumulative score by the number of errors. And an identification score calculation process according to the number of errors for calculating
The posterior probability calculation unit by number of errors receives the identification score by number of errors of the lattice, the forward cumulative score by number of errors, the backward cumulative score by number of errors, and the local score, and the correct symbol series A posterior probability calculation process according to the number of errors for calculating the posterior probability of each including the directed arc included in the lattice, according to the number of errors,
A method of calculating the identification score and posterior probability according to the number of errors including.
上記誤り数別識別スコア計算過程は、
上記誤り数別前向き累積スコアを、上記有向弧の先行有向弧の局所スコアと上記先行有向弧までの誤り数別前向き累積スコアの誤り数の和毎に累積した前向き確率総和として求める前向き確率総和算出ステップと、
上記誤り数別後ろ向き累積スコアを、上記有向弧の後続有向弧の局所スコアと上記後続有効弧までの誤り数別後ろ向き累積スコアの誤り数の和毎に累積した後ろ向き確率総和として求める後ろ向き確率総和算出ステップと、
上記ラティスの誤り数別の識別スコアを、上記有向弧の局所スコアと上記前向き確率総和と上記後ろ向き確率総和との誤り数の和毎の事後確率として求める事後確率算出ステップと、
を含むことを特徴とする誤り数別識別スコア・事後確率計算方法。 In the identification score / posterior probability calculation method according to the number of errors described in claim 1,
The identification score calculation process according to the number of errors is as follows:
Forward finding the forward cumulative score by the number of errors as the sum of forward probabilities accumulated for each sum of the local score of the preceding directed arc of the directed arc and the number of errors of the forward cumulative score by the number of errors up to the preceding directed arc Total probability calculation step;
Backward probabilities for obtaining the backward cumulative score by the number of errors as the sum of backward probabilities accumulated for each sum of the local score of the subsequent directed arc of the directed arc and the number of errors of the backward cumulative score by the number of errors up to the subsequent effective arc A sum calculation step;
A posteriori probability calculation step for obtaining an identification score for each number of errors of the lattice as a posterior probability for each sum of the number of errors of the local score of the directed arc, the forward probability sum, and the backward probability sum;
An error-specific identification score / posterior probability calculation method characterized by including:
パターン認識部が、特徴量情報系列を入力として複数のシンボル系列を表現するラティスを上記モデルパラメータ記録部から探索して出力するパターン認識過程と、
損失関数値計算部が、上記ラティスの誤り数別の識別スコアを入力として損失関数値を計算する損失関数値計算過程と、
偏微分係数値計算部が、上記ラティスの誤り数別の識別スコアと、上記損失関数値と、上記誤り数別事後確率とを入力として有向弧での偏微分係数値を計算する偏微分係数値計算過程と、
モデルパラメータ更新部が、上記偏微分係数値と、上記損失関数と、上記モデルパラメータとを入力として上記モデルパラメータを更新するモデルパラメータ更新過程と、
を含む誤り数重み付き識別学習方法。 The identification score / posterior probability calculation method according to the number of errors according to claim 1 or 2,
A pattern recognition process in which a pattern recognition unit searches and outputs a lattice representing a plurality of symbol sequences from the model parameter recording unit by inputting a feature amount information sequence;
A loss function value calculation process in which the loss function value calculation unit calculates a loss function value using the discrimination score for each number of errors of the lattice as an input,
The partial differential coefficient value calculation unit calculates a partial differential coefficient value in a directed arc with the identification score for each number of errors of the lattice, the loss function value, and the posterior probability for each error number as inputs. Numerical calculation process,
A model parameter update unit updates the model parameter with the partial differential coefficient value, the loss function, and the model parameter as inputs, and
An error-weighted discriminative learning method including:
上記損失関数値計算過程は、上記ラティスの誤り数別の識別スコアを制御係数でべき乗した値を、全ての有向弧の識別スコアを上記制御係数でべき乗した値の累積値で除し、更にその値に上記誤り数を乗算した値を上記誤り数で累積して上記損失関数とする過程であることを特徴とする誤り数重み付き識別学習方法。 In the error-weighted discriminative learning method according to claim 3,
The loss function value calculation process divides a value obtained by raising the identification score for each number of errors of the lattice by a control coefficient, and dividing by an accumulated value of values obtained by raising the identification scores of all directed arcs by the power of the control coefficient. An error number weighted discriminative learning method, characterized in that a value obtained by multiplying the value by the error number is accumulated in the error number to obtain the loss function.
特徴量情報系列を入力として複数のシンボル系列を表現するラティスを上記モデルパラメータ記録部から探索して出力するパターン認識部と、
上記特徴量情報系列と、上記特徴量情報系列に対応した正解シンボル系列と、上記特徴量情報系列を複数の認識シンンボル系列で表現したラティスと、モデルパラメータとを入力として、上記ラティスに含まれる各々の有向弧に対する局所スコアと、有向弧に含まれる局所誤り数とを計算する局所スコア・局所誤り計算部と、
上記局所スコアと、上記局所誤り数と、上記ラティスとを入力として上記ラティスの誤り数別の識別スコアと、誤り数別前向き累積スコアと、誤り数別後ろ向き累積スコアとを計算する誤り数別識別スコア計算部と、
上記ラティスの誤り数別の識別スコアと、上記誤り数別前向き累積スコアと、上記誤り数別後ろ向き累積スコアと、上記局所スコアとを入力として上記正解シンボル系列が上記ラティスに含まれる各々の有向弧を含むことの事後確率を誤り数別に計算する誤り数別事後確率計算部と、
上記ラティスの誤り数別の識別スコアを入力として損失関数値を計算する損失関数値計算部と、
上記ラティスの誤り数別の識別スコアと、上記損失関数値と、上記誤り数別事後確率とを入力として有向弧での偏微分係数値を計算する偏微分係数値計算部と、
上記偏微分係数値と、上記損失関数と、上記モデルパラメータとを入力として上記モデルパラメータを更新するモデルパラメータ更新部と、
を具備する誤り数重み付き識別学習装置。 A model parameter recording unit for recording model parameters;
A pattern recognizing unit that searches the model parameter recording unit for a lattice that represents a plurality of symbol sequences with a feature amount information sequence as an input;
The feature quantity information series, a correct symbol series corresponding to the feature quantity information series, a lattice that represents the feature quantity information series as a plurality of recognition symbol sequences, and model parameters as inputs, are included in the lattice. A local score for the directed arc of, and a local score / local error calculation unit for calculating the number of local errors included in the directed arc;
Discriminating by error number, using the local score, the local error number, and the lattice as inputs, and calculating an identification score by error number, a forward cumulative score by error number, and a backward cumulative score by error number A score calculator,
Each of the correct symbol sequences included in the lattice by inputting the identification score for each number of errors of the lattice, the forward cumulative score by the number of errors, the backward cumulative score by the number of errors, and the local score. An a posteriori probability calculation unit for each error number that calculates the a posteriori probability of including an arc for each error number;
A loss function value calculation unit for calculating a loss function value by using the discrimination score according to the number of errors of the lattice as an input;
A partial differential coefficient value calculation unit that calculates a partial differential coefficient value in a directed arc by using the discrimination score for each error number of the lattice, the loss function value, and the posterior probability for each error number as input,
A model parameter updating unit that updates the model parameter with the partial differential coefficient value, the loss function, and the model parameter as inputs;
An error-weighted identification learning device comprising:
上記損失関数値計算部は、上記ラティスの誤り数別の識別スコアを制御係数でべき乗した値を、上記ラティスの誤り数別の識別スコアの累積値を上記制御係数でべき乗した値で除し、更に上記誤り数を乗算した値を、誤り数で累積して上記損失関数とするものであることを特徴とする誤り数重み付き識別学習装置。 In the error number weighted identification learning device according to claim 5,
The loss function value calculation unit divides a value obtained by raising the identification score for each number of errors of the lattice by a control coefficient, and a value obtained by dividing a cumulative value of the identification score for each number of errors of the lattice by a power of the control coefficient, Further, an error number weighted identification learning apparatus characterized in that a value obtained by multiplying the number of errors is accumulated by the number of errors to form the loss function.
音声情報列を入力として音声情報列の音声特徴量情報系列を算出する音声特徴量抽出部と、
上記誤り数重み付き識別学習装置で学習した音響モデルを記録する音響モデル記録部と、
上記音声特徴量情報系列に応じて、上記音響モデルパラメータ記録部内に記録された特徴量情報系列を探索して複数のシンボル系列で表現される単語ラティスを出力する単語列探索部と、
を具備する音声認識装置。 An error number weighted identification learning device according to claim 5 or 6,
A voice feature quantity extraction unit that calculates a voice feature quantity information sequence of the voice information string using the voice information string as an input;
An acoustic model recording unit for recording an acoustic model learned by the error number weighted identification learning device;
A word string search unit for searching a feature amount information sequence recorded in the acoustic model parameter recording unit and outputting a word lattice represented by a plurality of symbol sequences in accordance with the speech feature amount information sequence;
A speech recognition apparatus comprising:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008225998A JP5308102B2 (en) | 2008-09-03 | 2008-09-03 | Identification score / posterior probability calculation method by number of errors, error number weighted identification learning device using the method, method thereof, speech recognition device using the device, program, and recording medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008225998A JP5308102B2 (en) | 2008-09-03 | 2008-09-03 | Identification score / posterior probability calculation method by number of errors, error number weighted identification learning device using the method, method thereof, speech recognition device using the device, program, and recording medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010060809A true JP2010060809A (en) | 2010-03-18 |
| JP5308102B2 JP5308102B2 (en) | 2013-10-09 |
Family
ID=42187690
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008225998A Active JP5308102B2 (en) | 2008-09-03 | 2008-09-03 | Identification score / posterior probability calculation method by number of errors, error number weighted identification learning device using the method, method thereof, speech recognition device using the device, program, and recording medium |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5308102B2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150012183A1 (en) * | 2012-03-09 | 2015-01-08 | Ntn Corporation | Control device for steer-by-wire steering mechanism |
| CN112166567A (en) * | 2018-04-03 | 2021-01-01 | 诺基亚技术有限公司 | Learning in a communication system |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0990975A (en) * | 1995-09-22 | 1997-04-04 | Nippon Telegr & Teleph Corp <Ntt> | Model learning method for pattern recognition |
| WO2007105409A1 (en) * | 2006-02-27 | 2007-09-20 | Nec Corporation | Reference pattern adapter, reference pattern adapting method, and reference pattern adapting program |
-
2008
- 2008-09-03 JP JP2008225998A patent/JP5308102B2/en active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0990975A (en) * | 1995-09-22 | 1997-04-04 | Nippon Telegr & Teleph Corp <Ntt> | Model learning method for pattern recognition |
| WO2007105409A1 (en) * | 2006-02-27 | 2007-09-20 | Nec Corporation | Reference pattern adapter, reference pattern adapting method, and reference pattern adapting program |
Non-Patent Citations (8)
| Title |
|---|
| CSNG200600193001; 南條 浩輝 Hiroaki NANJO: '音声理解のための音声認識評価尺度とベイズリスク最小化デコーディング ASR Evaluation Measure and Minim' 電子情報通信学会技術研究報告 Vol.104 No.540 IEICE Technical Report p.1-6, 200412, 社団法人電子情報通信学会 The Institute of Electro * |
| CSNG200700238017; 南條 浩輝 Hiroaki NANJO: '単語グラフを利用したベイズリスク最小化音声認識とそれに基づく重要文抽出 Minimum Bayes-Risk Decoding' 情報処理学会研究報告 Vol.2006 No.136 IPSJ SIG Technical Reports , 20061221, p.125-130, 社団法人情報処理学会 Information Processing Socie * |
| CSNG200800063102; 鈴木 潤: '学習誤り最小化に基づく条件付き確率場の学習:言語解析への適用' 言語処理学会第12回年次大会発表論文集 Proceedings of The Twelfth Annual Meeting of The Association , 200603, p.548-551, 言語処理学会 The Association for Natural Language * |
| CSNJ201110010422; マクダーモット エリック Erik McDermott: 日本音響学会 2010年 春季研究発表会講演論文集CD-ROM [CD-ROM] , 201003, p.271-274 * |
| JPN6012002055; 鈴木 潤: '学習誤り最小化に基づく条件付き確率場の学習:言語解析への適用' 言語処理学会第12回年次大会発表論文集 Proceedings of The Twelfth Annual Meeting of The Association , 200603, p.548-551, 言語処理学会 The Association for Natural Language * |
| JPN6012002059; 南條 浩輝 Hiroaki NANJO: '単語グラフを利用したベイズリスク最小化音声認識とそれに基づく重要文抽出 Minimum Bayes-Risk Decoding' 情報処理学会研究報告 Vol.2006 No.136 IPSJ SIG Technical Reports , 20061221, p.125-130, 社団法人情報処理学会 Information Processing Socie * |
| JPN6012002060; マクダーモット エリック Erik McDermott: 日本音響学会 2010年 春季研究発表会講演論文集CD-ROM [CD-ROM] , 201003, p.271-274 * |
| JPN6012002062; 南條 浩輝 Hiroaki NANJO: '音声理解のための音声認識評価尺度とベイズリスク最小化デコーディング ASR Evaluation Measure and Minim' 電子情報通信学会技術研究報告 Vol.104 No.540 IEICE Technical Report p.1-6, 200412, 社団法人電子情報通信学会 The Institute of Electro * |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20150012183A1 (en) * | 2012-03-09 | 2015-01-08 | Ntn Corporation | Control device for steer-by-wire steering mechanism |
| US9771100B2 (en) * | 2012-03-09 | 2017-09-26 | Ntn Corporation | Control device for steer-by-wire steering mechanism |
| CN112166567A (en) * | 2018-04-03 | 2021-01-01 | 诺基亚技术有限公司 | Learning in a communication system |
| CN112166567B (en) * | 2018-04-03 | 2023-04-18 | 诺基亚技术有限公司 | Learning in a communication system |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5308102B2 (en) | 2013-10-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6637078B2 (en) | Acoustic model learning device, acoustic model learning method and program | |
| JP6222821B2 (en) | Error correction model learning device and program | |
| JP4860265B2 (en) | Text processing method / program / program recording medium / device | |
| JP5294086B2 (en) | Weight coefficient learning system and speech recognition system | |
| US20160180839A1 (en) | Voice retrieval apparatus, voice retrieval method, and non-transitory recording medium | |
| JP6831343B2 (en) | Learning equipment, learning methods and learning programs | |
| CN108346436A (en) | Speech emotional detection method, device, computer equipment and storage medium | |
| WO2008001485A1 (en) | Language model generating system, language model generating method, and language model generating program | |
| JP7209330B2 (en) | classifier, trained model, learning method | |
| JP2017058877A (en) | Learning device, voice detection device, learning method, and program | |
| US20100100379A1 (en) | Voice recognition correlation rule learning system, voice recognition correlation rule learning program, and voice recognition correlation rule learning method | |
| JP6646337B2 (en) | Audio data processing device, audio data processing method, and audio data processing program | |
| JP6027754B2 (en) | Adaptation device, speech recognition device, and program thereof | |
| JP6366166B2 (en) | Speech recognition apparatus and program | |
| JP5308102B2 (en) | Identification score / posterior probability calculation method by number of errors, error number weighted identification learning device using the method, method thereof, speech recognition device using the device, program, and recording medium | |
| JP4964194B2 (en) | Speech recognition model creation device and method thereof, speech recognition device and method thereof, program and recording medium thereof | |
| JP5288378B2 (en) | Acoustic model speaker adaptation apparatus and computer program therefor | |
| JP4950600B2 (en) | Acoustic model creation apparatus, speech recognition apparatus using the apparatus, these methods, these programs, and these recording media | |
| JP5738216B2 (en) | Feature amount correction parameter estimation device, speech recognition system, feature amount correction parameter estimation method, speech recognition method, and program | |
| JP2004117503A (en) | Method, device, and program for generating acoustic model for voice recognition, recording medium, and voice recognition device using the acoustic model | |
| JP5113797B2 (en) | Dissimilarity utilization type discriminative learning apparatus and method, and program thereof | |
| JP5694976B2 (en) | Distributed correction parameter estimation device, speech recognition system, dispersion correction parameter estimation method, speech recognition method, and program | |
| JP5161174B2 (en) | Route search device, speech recognition device, method and program thereof | |
| JP4533160B2 (en) | Discriminative learning method, apparatus, program, and recording medium on which discriminative learning program is recorded | |
| JP5104732B2 (en) | Extended recognition dictionary learning device, speech recognition system using the same, method and program thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20100726 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20110810 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20111116 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120124 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120323 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20121002 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20121128 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20130618 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130628 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 Ref document number: 5308102 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |