JP2010019941A - 音声認識モデル作成装置とその方法、音声認識装置とその方法、プログラムとその記録媒体 - Google Patents
音声認識モデル作成装置とその方法、音声認識装置とその方法、プログラムとその記録媒体 Download PDFInfo
- Publication number
- JP2010019941A JP2010019941A JP2008178572A JP2008178572A JP2010019941A JP 2010019941 A JP2010019941 A JP 2010019941A JP 2008178572 A JP2008178572 A JP 2008178572A JP 2008178572 A JP2008178572 A JP 2008178572A JP 2010019941 A JP2010019941 A JP 2010019941A
- Authority
- JP
- Japan
- Prior art keywords
- speech recognition
- recognition model
- model
- updated
- initial value
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images






Abstract
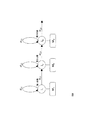
【解決手段】この発明の音声認識モデル作成装置は、初期値音声認識モデル記録部と、モデル更新部と、更新音声認識モデル記録部とを具備する。初期値音声認識モデル記録部は、複数の音声認識モデルを含む初期値音声認識モデルを記録する。モデル更新部は、複数の音声認識モデルの組み合わせから成る状態確率遷移を基に音声認識された単語列を入力として初期値音声認識モデルを1つのベクトルとして更新した更新音声認識モデルを生成する。更新音声認識モデル記録部は、更新音声認識モデルを記録する。
【選択図】図2
Description
Z.Wamg, U.Topkara, T.Schultz, and A.Waibel. Towards universal speech recognition.In Proc.ICMI2002,2002. 田熊竜太,岩野公司,古井貞煕「逐次話者適応を用いた並列処理型会議音声認識システムの検討」春季音響学会講演論文集、p105-106,2002.
この発明の音声認識モデルの作成方法の基本的な考えについて説明する。現在広く用いられる確率統計的音声認識方法は、確率モデルを用いて音声認識過程を音声データと単語(若しくは音素、HMM(Hidden Markov Model))の出現確率(尤度関数)として表現し、事後確率最大化や尤度最大化等の確率統計的評価規範を用いて音声認識のためのパラメータ推定を行う方法である。この発明の音声認識モデル作成方法も、この確率統計的評価規範を用いる部分では同じである。

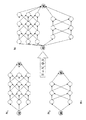
態で構成される音素モデルの概念図を一例として示す。図5に示す例は、left−to−r
ight型HMMと呼ばれるもので、3つの状態i1(第1状態)、i2(第2状態)、i3(第3状態)を並べたものであり、状態の確率連鎖(状態遷移)としては、自己遷移a11、a22、a33と、次状態へのa12、a23、a34からなる。図6に、状態iとフレームtとの時系列の関係を示す。横軸は時間経過でありフレーム番号で表す。縦軸は、各フレームの状態iである。各状態iは図4に示したように混合正規分布からなる。●は各フレーム内で出力確率スコアが最大になる最尤状態である。最尤状態●を時系列に並べたのが最尤状態系列である。この最尤状態系列が音声認識結果として出力される。
反復計算によって式(10)と(11)で計算される。
トルである。したがって以降の説明は、平均ベクトルについての適応学習について説明を
行う。音声認識モデルの平均ベクトルに焦点を当てた場合、補助関数Qは式(13)に示
す具体系に書き直すことができる。
ったものである。
ルμの2次形式(式(17)の右辺第1項)で表現することができるので、安定した解が
得られる。そして、この実施例の適応学習は、初期値音声認識モデルの平均ベクトルμ0
と推定すべきμに対して式(21)に示す線形変換を仮定する。
rgmaxを取る演算をすることにより、適応データからパラメータA,bを最尤推定法により推定する(ステップS122)。パラメータA,bは、式(4)と(17)に示したφに相当するものである。
モデル適応の代表的手法である最尤線形回帰法などでよく用いられるガウス分布共有木を
用いれば良い。ガウス分布共有木は、単一のガウス分布をリーフ、それらの集合をノード
とする木構造を用いてガウス分布の集合を表現する手法である。このとき、どのガウス分
布を一つの集合とするかについては、ユークリッド距離などの分布間距離が用いられる。
例えば2分木の場合は、分布間距離の近い2つのガウス分布を1つのノードとして表現す
る。複数音響モデルに対するガウス分布共有木の構築については、次の2種類がある。
構築し、それらのルートノードを小ノードとする共通の親ノードを用意することにより、
共有木を合成する。この場合、回帰行列は同一話者内で共有されるため、話者性情報を利
用した共有構造が構築される。
い共有木を構築する。この場合、回帰行列は複数話者にまたがって分布間距離の近いガウ
ス分布に対して共有される。つまり、話者性情報は直接的には考慮されず、音韻的に近い
ガウス分布が共有されることが想定される。
上記した(2)を用いた適応実験を行い、そのモデルを初期モデルにして上記した(1)
を用いた適応実験を行った。
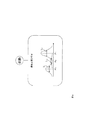
実施例1で説明した音声認識モデル作成装置100は、音声認識装置に利用することが可能である。音声認識モデル作成装置100を用いた音声認識装置200の機能構成例を図7に示す。その動作フローを図8に示す。音声認識装置200は、音声認識モデル作成装置100と、音声認識ネットワークデータベース22と、A/D変換部91と、特徴量抽出部92と、スコア計算部931と、音声認識ネットワーク選択部201とを備える。A/D変換部91、特徴量抽出部92、スコア計算部931は、従来技術で説明した音声認識装置900と同じものである。よって、音声認識ネットワークデータベース22と、音声認識ネットワーク選択部201とについて説明する。
この発明の音声認識モデル作成方法の有効性を確認する目的でシミュレーションを行っ
た。シミュレーション条件は、複数の音響環境として、性別依存音響モデル2種類(男性・女性)を用意した。音声認識の条件は、サンプリング周波数を16kHz、量子化数16bit、ウインドウタイプはハミング窓、フレーム長を25ms、フレームシフトを10msとした。言語モデルはトライグラム(新聞記事14年分)、語彙数は700,000個とした。
響モデルを用いた方法と比較した。その結果を表1に示す。
Claims (10)
- 複数の音声認識モデルを含む初期値音声認識モデルを記録した初期値音声認識モデル記録部と、
複数の音声認識モデルの組み合わせから成る状態確率遷移を基に音声認識された状態列の集合を入力としてフレーム毎の各状態の尤度と特徴量ベクトルとを計算する尤度計算部と、
上記尤度と特徴量ベクトルとを入力として、上記初期値音声認識モデルを1つのベクトルとして更新した更新音声認識モデルを生成するモデル更新部と、
上記更新音声認識モデルを記録する更新音声認識モデル記録部と、
を具備する音声認識モデル作成装置。 - 請求項1に記載した音声認識モデル作成装置において、
上記モデル更新部は、
上記尤度と特徴量ベクトルとを入力として上記状態を構成するガウス分布毎の事後確率値を計算する事後確率計算部と、
上記ガウス分布毎の事後確率値と上記初期値音声認識モデルとを入力とし、上記初期値音声認識モデルを1つのベクトルとして更新する関係パラメータを生成する関係パラメータ生成部と、
上記初期値音声認識モデルを上記関係パラメータで更新した更新音声認識モデルを出力する更新モデル生成部と、
を備えることを特徴とする音声認識モデル作成装置。 - 尤度計算部が、複数の音声認識モデルの組み合わせから成る状態確率遷移を基に音声認識された状態列の集合を入力としてフレーム毎の各状態の尤度を計算する尤度計算過程と、
モデル更新部が、上記尤度と特徴量ベクトルとを入力として上記複数の音声認識モデルを含む初期値音声認識モデルを1つのベクトルとして更新した更新音声認識モデルを生成するモデル更新過程と、
更新音声認識モデル記録部が、上記更新音声認識モデルを記録する更新音声認識モデル記録過程と、
を含む音声認識モデル作成方法。 - 請求項3に記載した音声認識モデル作成方法において、
上記モデル更新過程は、
事後確率計算部が、上記尤度を入力として上記状態を構成するガウス分布毎の事後確率値を計算する事後確率計算ステップと、
関係パラメータ生成部が、上記ガウス分布毎の事後確率値と上記初期値音声認識モデルと特徴量ベクトルとを入力とし、上記初期値音声認識モデルを1つのベクトルとして更新する関係パラメータを生成する関係パラメータ生成ステップと、
更新モデル生成部が、上記初期値音声認識モデルを上記関係パラメータで更新した更新音声認識モデルを出力する更新モデル生成ステップと、
を含むことを特徴とする音声認識モデル作成方法。 - 請求項1又は2に記載した音声認識モデル作成装置と、
複数の音声認識モデルの組み合わせから成る状態確率遷移を記録した音声認識ネットワークデータベースと、
離散値化された音声信号のフレーム毎に特徴量ベクトルを抽出する特徴量抽出部と、
上記特徴量ベクトルと、上記初期値音声認識モデルとを入力として、上記初期値音声認識モデルを音声認識結果で更新した更新音声認識モデルを用いてスコアを計算するスコア計算部と、
上記スコアが最も大きくなる上記状態確率遷移の音声認識ネットワークを、上記音声認識ネットワークデータベースから選択して上記音声認識結果として出力する音声認識ネットワーク選択部と、
を具備する音声認識装置。 - 請求項5に記載の音声認識装置において、
上記音声認識ネットワーク選択部は、上記選択した音声認識ネットワークから環境情報も出力するものであることを特徴とする音声認識装置。 - 請求項3又は4に記載した音声認識モデル作成方法を含み、
特徴量抽出部が、離散値化された音声信号のフレーム毎に特徴量ベクトルを抽出する特徴量抽出過程と、
スコア計算部が、上記特徴量ベクトルと上記更新音声認識モデルとを入力として上記特徴量ベクトルに対応したスコアを計算するスコア計算過程と、
上記スコアが最も大きくなる上記状態確率遷移の音声認識ネットワークを、上記音声認識ネットワークデータベースから選択して状態列の集合として出力する音声認識ネットワーク選択過程と、
を備える音声認識方法。 - 請求項3又は4に記載した音声認識モデル作成方法をコンピュータに機能させるための方法プログラム。
- 請求項7に記載した音声認識方法をコンピュータに機能させるための方法プログラム。
- 請求項8又は9に記載した方法プログラムを記録したコンピュータで読み取り可能な記録媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008178572A JP4964194B2 (ja) | 2008-07-09 | 2008-07-09 | 音声認識モデル作成装置とその方法、音声認識装置とその方法、プログラムとその記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008178572A JP4964194B2 (ja) | 2008-07-09 | 2008-07-09 | 音声認識モデル作成装置とその方法、音声認識装置とその方法、プログラムとその記録媒体 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2010019941A true JP2010019941A (ja) | 2010-01-28 |
| JP4964194B2 JP4964194B2 (ja) | 2012-06-27 |
Family
ID=41704936
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008178572A Expired - Fee Related JP4964194B2 (ja) | 2008-07-09 | 2008-07-09 | 音声認識モデル作成装置とその方法、音声認識装置とその方法、プログラムとその記録媒体 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4964194B2 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012103554A (ja) * | 2010-11-11 | 2012-05-31 | Advanced Telecommunication Research Institute International | 音声言語識別装置の学習装置、音声言語の識別装置、及びそれらのためのプログラム |
| CN104900230A (zh) * | 2014-03-03 | 2015-09-09 | 联想(北京)有限公司 | 一种信息处理方法及电子设备 |
| CN111243574A (zh) * | 2020-01-13 | 2020-06-05 | 苏州奇梦者网络科技有限公司 | 一种语音模型自适应训练方法、系统、装置及存储介质 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111696526B (zh) * | 2020-06-22 | 2021-09-10 | 北京达佳互联信息技术有限公司 | 语音识别模型的生成方法、语音识别方法、装置 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0660048A (ja) * | 1992-08-06 | 1994-03-04 | A T R Jido Honyaku Denwa Kenkyusho:Kk | 隠れマルコフモデル学習方法 |
| JPH0830289A (ja) * | 1994-07-12 | 1996-02-02 | Mitsubishi Electric Corp | 学習音声パタンモデル使用音声認識装置 |
| JP2002149185A (ja) * | 2000-09-27 | 2002-05-24 | Koninkl Philips Electronics Nv | 複数の学習用話者を表現する固有空間の決定方法 |
| JP2004004906A (ja) * | 1998-04-30 | 2004-01-08 | Matsushita Electric Ind Co Ltd | 固有声に基づいた最尤法を含む話者と環境の適合化方法 |
-
2008
- 2008-07-09 JP JP2008178572A patent/JP4964194B2/ja not_active Expired - Fee Related
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0660048A (ja) * | 1992-08-06 | 1994-03-04 | A T R Jido Honyaku Denwa Kenkyusho:Kk | 隠れマルコフモデル学習方法 |
| JPH0830289A (ja) * | 1994-07-12 | 1996-02-02 | Mitsubishi Electric Corp | 学習音声パタンモデル使用音声認識装置 |
| JP2004004906A (ja) * | 1998-04-30 | 2004-01-08 | Matsushita Electric Ind Co Ltd | 固有声に基づいた最尤法を含む話者と環境の適合化方法 |
| JP2002149185A (ja) * | 2000-09-27 | 2002-05-24 | Koninkl Philips Electronics Nv | 複数の学習用話者を表現する固有空間の決定方法 |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012103554A (ja) * | 2010-11-11 | 2012-05-31 | Advanced Telecommunication Research Institute International | 音声言語識別装置の学習装置、音声言語の識別装置、及びそれらのためのプログラム |
| CN104900230A (zh) * | 2014-03-03 | 2015-09-09 | 联想(北京)有限公司 | 一种信息处理方法及电子设备 |
| CN111243574A (zh) * | 2020-01-13 | 2020-06-05 | 苏州奇梦者网络科技有限公司 | 一种语音模型自适应训练方法、系统、装置及存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4964194B2 (ja) | 2012-06-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11315548B1 (en) | Method and system for performing domain adaptation of end-to-end automatic speech recognition model | |
| CN112435654B (zh) | 通过帧插入对语音数据进行数据增强 | |
| Lee | On stochastic feature and model compensation approaches to robust speech recognition | |
| JP4195428B2 (ja) | 多数の音声特徴を利用する音声認識 | |
| KR101415534B1 (ko) | 다단계 음성인식장치 및 방법 | |
| JP3933750B2 (ja) | 連続密度ヒドンマルコフモデルを用いた音声認識方法及び装置 | |
| CN107615376B (zh) | 声音识别装置及计算机程序记录介质 | |
| EP1447792A2 (en) | Method and apparatus for modeling a speech recognition system and for predicting word error rates from text | |
| JP2002366187A (ja) | 音声認識装置および音声認識方法、並びにプログラムおよび記録媒体 | |
| JP5249967B2 (ja) | 音声認識装置、重みベクトル学習装置、音声認識方法、重みベクトル学習方法、プログラム | |
| Chuangsuwanich | Multilingual techniques for low resource automatic speech recognition | |
| EP4068279B1 (en) | Method and system for performing domain adaptation of end-to-end automatic speech recognition model | |
| Weng et al. | Discriminative training using non-uniform criteria for keyword spotting on spontaneous speech | |
| JP4964194B2 (ja) | 音声認識モデル作成装置とその方法、音声認識装置とその方法、プログラムとその記録媒体 | |
| Wang et al. | Sequence teacher-student training of acoustic models for automatic free speaking language assessment | |
| JP6631883B2 (ja) | クロスリンガル音声合成用モデル学習装置、クロスリンガル音声合成用モデル学習方法、プログラム | |
| WO2020136948A1 (ja) | 発話リズム変換装置、モデル学習装置、それらの方法、およびプログラム | |
| JP6027754B2 (ja) | 適応化装置、音声認識装置、およびそのプログラム | |
| JP7423056B2 (ja) | 推論器および推論器の学習方法 | |
| JP6594251B2 (ja) | 音響モデル学習装置、音声合成装置、これらの方法及びプログラム | |
| Kurian | A review on technological development of automatic speech recognition | |
| Young | Acoustic modelling for large vocabulary continuous speech recognition | |
| JP2886118B2 (ja) | 隠れマルコフモデルの学習装置及び音声認識装置 | |
| JP5457999B2 (ja) | 雑音抑圧装置とその方法とプログラム | |
| JP4950600B2 (ja) | 音響モデル作成装置、その装置を用いた音声認識装置、これらの方法、これらのプログラム、およびこれらの記録媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20100726 |
|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20110810 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20111215 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20111227 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120224 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120321 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120327 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150406 Year of fee payment: 3 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |