JP2009282903A - 知識抽出・検索装置およびその方法 - Google Patents
知識抽出・検索装置およびその方法 Download PDFInfo
- Publication number
- JP2009282903A JP2009282903A JP2008136620A JP2008136620A JP2009282903A JP 2009282903 A JP2009282903 A JP 2009282903A JP 2008136620 A JP2008136620 A JP 2008136620A JP 2008136620 A JP2008136620 A JP 2008136620A JP 2009282903 A JP2009282903 A JP 2009282903A
- Authority
- JP
- Japan
- Prior art keywords
- information
- search
- database
- unit
- expression
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images





Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Abstract
【課題】入力検索条件にダイレクトに対応する結果を、関連する情報を含めて検索可能とすること。
【解決手段】知識抽出部10において、テキスト文書を言語解析し、この言語解析情報を用いて、前記テキスト文書中の所定の表現に対し、その表現を特定するためのグラウンド情報を付与し、少なくとも前記言語解析情報を用いて前記テキスト文書から関係のある表現ペアを抽出し、前記言語解析情報およびグラウンド情報を用いて当該関係のある表現ペアに対する関係情報を関係DB20に出力して蓄積しておき、知識検索部30において、入力検索条件を解釈してデータベース用検索条件に変換し、前記データベース用検索条件に基づいて関係DB20を検索し、検索結果を集計して出力用検索結果を作成し、前記出力用検索結果を用いて予め定められた形式の検索結果を出力する。
【選択図】図1
【解決手段】知識抽出部10において、テキスト文書を言語解析し、この言語解析情報を用いて、前記テキスト文書中の所定の表現に対し、その表現を特定するためのグラウンド情報を付与し、少なくとも前記言語解析情報を用いて前記テキスト文書から関係のある表現ペアを抽出し、前記言語解析情報およびグラウンド情報を用いて当該関係のある表現ペアに対する関係情報を関係DB20に出力して蓄積しておき、知識検索部30において、入力検索条件を解釈してデータベース用検索条件に変換し、前記データベース用検索条件に基づいて関係DB20を検索し、検索結果を集計して出力用検索結果を作成し、前記出力用検索結果を用いて予め定められた形式の検索結果を出力する。
【選択図】図1
Description
本発明は、テキスト文書中の様々な表現間の関係を表す関係情報を抽出してデータベース化し、このデータベースを利用して情報検索を行う技術に関する。
従来の情報検索装置は、キーワードを入力すると、そのキーワードを含む文書を検索結果として出力するものがほとんどであった(非特許文献1)。このため、例えば「横浜にゆかりのある人物」について知りたい場合、まず「横浜」というキーワードで検索を行い、それぞれの文書を確認して「横浜」と関係する人名を探し出す必要があった。
北 研二、他「情報検索アルゴリズム」共立出版、2002年、p.1〜7
北 研二、他「情報検索アルゴリズム」共立出版、2002年、p.1〜7
前述した「横浜にゆかりのある人物」を知りたいような場合、「横浜」と関連する文書(「横浜」というキーワードを含む文書)ではなく、実際に「横浜」と関連する「人物(の情報)」を検索結果として出力する方が、ダイレクトに対応する結果を得ることができるので望ましい。
また、文書中に「横浜」という文字列が現れていなくても、「横浜のことを表している表現」と関連する人物を検索結果として出力するのが望ましい。例えば、「タレントの○○さんは神奈川県の磯子駅(注:神奈川県横浜市内に存在)の近くに住んでいる。」という文書が存在した場合、この「○○」さんも検索結果として出力する方が多くの情報を得ることができる。
さらに、同じ検索結果はまとめられて出力するのが望ましい。例えば、様々な文書において、前述の「○○」さんがフルネーム、姓のみ、名のみ、あだな等の様々な表現で書かれていたとしても、出力結果としては1つにまとめられている方が便利である。
本発明は、上記の点に鑑みなされたもので、文書中の様々な文字列表現が何を表しているかを特定し、それぞれの表現間の関係を抽出することにより、高精度に知識検索を行う装置およびその方法を提供することを目的とする。
本発明は、テキスト文書中の様々な表現間の関係を表す関係情報を抽出してデータベース化し、このデータベースを利用して情報検索を行う知識抽出・検索装置であって、テキスト文書に対して言語解析を行い、言語解析情報を出力するテキスト解析部と、前記言語解析情報を用いて、前記テキスト文書中の所定の表現に対し、その表現を特定するための情報であるグラウンド情報を付与するグラウンディング部と、少なくとも前記言語解析情報を用いて前記テキスト文書から関係のある表現ペアを抽出し、前記言語解析情報およびグラウンド情報を用いて当該関係のある表現ペアに対する関係情報を出力する関係抽出部とから構成される知識抽出部と、知識抽出部から出力された関係情報を蓄積する関係データベースと、入力検索条件を解釈してデータベース用検索条件に変換する条件入力部と、前記データベース用検索条件に基づいて前記関係データベースを検索し、検索結果を集計して出力用検索結果を作成する検索・集計部と、前記出力用検索結果を用いて、予め定められた形式の検索結果を出力する結果出力部とから構成される知識検索部とを備えたことを特徴とする。
本発明によれば、データベース化されていない大量のテキスト文書を対象として、様々な文字列表現が何を表しているかを特定し、それぞれの表現間の関係を抽出することにより知識をデータベース化し、そのデータベースを用いて広範囲に知識検索を行うことができる。
以下、本発明を図示の実施の形態により詳細に説明する。
本発明の知識抽出・検索装置は、コンピュータ装置からなり、キーボード等の入力手段、モニタ等の出力手段(表示手段)、ハードディスクやメモリ等の記億手段および外部ネットワークに接続可能な通信装置等(いずれも図示せず)を備えている。
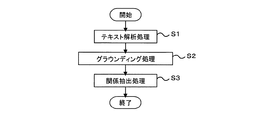
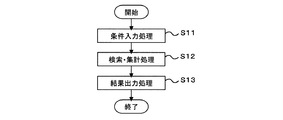
図1は本発明の知識抽出・検索装置の実施の形態の一例を示すもので、本発明の知識抽出・検索装置は、知識抽出部10、関係データベース(DB)20、知識検索部30、文書データベース(DB)40およびクラスデータベース(DB)50から構成される。また、図2は知識抽出部10における知識抽出処理の流れ図、図3は知識検索部30における知識検索処理の流れ図である。
知識抽出部10は、図1に示すように、テキスト解析部11、グラウンディング部12および関係抽出部13からなり、図示しない入力手段から直接入力され又は記憶手段から読み出されて入力され又は通信媒体を介して他の装置等から入力された文書(テキスト文書)の集合を入力とし、関係情報を関係DB20に出力する。
ここで、テキスト文書は、その文書を識別するための文書IDと、テキスト(テキストデータ)とを少なくとも有する。その他に、作成日時、文書種別(例:ブログ)等の文書メタ情報を備えていても良い。文書メタ情報として文書種別および作成日時を備えたテキスト文書の一例を図4(a)に示す。
テキスト解析部11は、前記テキスト文書のテキストに対して、周知の形態素解析処理(単語情報を生成)、固有表現抽出処理(固有表現情報を生成)および係り受け解析処理(係り受け情報を生成)からなる言語解析処理を行い、単語情報、固有表現情報および係り受け情報からなる言語解析情報を出力する(図2のステップS1)。
単語情報、固有表現情報および係り受け情報からなる言語解析情報の一例として、図4(a)のテキスト文書に対する言語解析情報を図4(b)に示す。
グラウンディング部12は、テキスト解析部11から出力された言語解析情報を用いて、前記テキスト文書中の固有表現等の所定の表現に対し、グラウンド情報を付与する(図2のステップS2)。
ここで、グラウンド情報とは、前記テキスト文書中の表現に対して、その表現が何であるかを特定(同定)するための情報を表す。例えば、人名ならば、人名データベース中の対応するIDやフルネーム、地名ならば、緯度・経度や住所等となる。これらグラウンド情報の付与は、平野 徹、他「地理的距離と有名度を用いた地名の曖昧性解消」情報処理学会第70回全国大会講演論文集、3D−7、2008年3月13日、等の技術を利用することにより可能である。
グラウンド情報の一例として、図4(a)のテキスト文書に対するグラウンド情報を図4(c)に示す。
関係抽出部13は、少なくとも前記言語解析情報を用いて前記テキスト文書から関係のある表現ペアを抽出し、前記言語解析情報およびグラウンド情報を用いて当該関係のある表現ペアに対する関係情報を出力し、関係DB20に書き込む(図2のステップS3)。
関係のある表現ペアの抽出は、平野 徹、他「テキストにおける固有表現間の意味的関係の抽出」自然言語処理学会第13回年次大会発表論文集、D1−5、2007年、等の技術を利用することにより可能である。ここで、関係抽出に利用する情報としては、言語解析情報に加えて、グラウンド情報も用いることで、多様な表現で記述されている同一実体をまとめて扱っても良い。
関係情報は複数のレコードからなり、各レコードは、レコードIDと、テキスト文書から抽出した関係のある2表現(表現ペア)の表記とを少なくとも有する。その他に、各表現のグラウンド情報(ID)、各表現の付加情報(例えば、固有表現(NE)クラス)、当該テキスト文書中の各表現の位置、2表現の関係の尤もらしさを表す関係スコア情報、2表現の関係が何であるかを表す関係ラベル情報、当該テキスト文書の文書ID、その他の文書メタ情報を備えていても良い。グラウンド情報のうち、最も標準的なものを標準表記(標準形)として扱っても良い。
図4(a)のテキスト文書に対する関係情報の一例を図4(d)に示す。ここで、「表現1情報」とは前述した表現ペアのうちの一方の表現に関する情報を、「表現2情報」とは前述した表現ペアのうちの他方の表現に関する情報をそれぞれ表す。
関係DB20は、知識抽出部10から出力された関係情報を蓄積・保持するデータベースであり、SQLのような各種検索条件によりレコード検索可能な周知のものを用いれば良い。
知識検索部30は、図1に示すように、条件入力部31、検索・集計部32および結果出力部33からなり、図示しない入力手段から直接入力され又は記憶手段から読み出されて入力され又は通信媒体を介して他の装置等から入力された入力検索条件を入力とし、関係DB20、文書DB40およびクラスDB50を用いて検索結果を出力する。
文書DB40は、知識抽出部10に入力されたテキスト文書をデータベース化したもので、各レコードが文書IDと、テキストデータとを少なくとも有する複数のレコードからなるデータベースであり、SQLのような各種検索条件によりレコード検索可能な周知のものを用いれば良い。また、各レコードは、前記に加え、作成日時等の文書メタ情報を備えていても良い。
クラスDB50は、前述した所定の表現の標準形とクラスとの対応関係をデータベース化したもので、各レコードがレコードIDと、標準形と、クラスとを少なくとも有する複数のレコードからなるデータベースであり、SQLのような各種検索条件によりレコード検索可能な周知のものを用いれば良い。このクラスDB50の作成は、例えば、有名人データベースや観光スポットデータベース等の既存のデータベースを流用したりすることで可能である。クラスDB50の一例を図5に示す。
条件入力部31は、前記入力検索条件を解釈して、関係DB用検索条件、クラスDB用検索条件および文書DB用検索条件等のデータベース用検索条件に変換する(図3のステップS11)。
ここで、検索条件の形式としては、様々なものが考えられる。以下、その形式を3例示すが、これ以外の形式を用いても良い。
(検索条件の形式例1)
関係DB20や文書DB40、クラスDB50がそのまま受け付け可能な、SQL等の検索条件を直接入力する。この場合は、入力検索条件をそのまま指定されたDB用検索条件とすれば良い。
関係DB20や文書DB40、クラスDB50がそのまま受け付け可能な、SQL等の検索条件を直接入力する。この場合は、入力検索条件をそのまま指定されたDB用検索条件とすれば良い。
(検索条件の形式例2)
グラフィカルユーザインタフェースを用いて、表現1情報、表現2情報のNEクラス条件を選択できるようにしたり、表現1情報、表現2情報、関係ラベル情報の表記に関する任意文字列や、クラス名(クラスDB用)に関する任意文字列を入力できるようにする。
グラフィカルユーザインタフェースを用いて、表現1情報、表現2情報のNEクラス条件を選択できるようにしたり、表現1情報、表現2情報、関係ラベル情報の表記に関する任意文字列や、クラス名(クラスDB用)に関する任意文字列を入力できるようにする。
表記に関する任意文字列は、それぞれの標準形と完全一致する条件にしても良いし、部分一致するものや前方一致するもの等、条件を緩めても良い。また、入力された標準形が関係DB20の標準形と一致するとは限らないため、表記に関する任意文字列を表記および標準形のいずれかと一致するという条件としたり、表記に関する任意文字列を入力すると関係DB20の標準形に変換する文字列変換フィルタを通しても良い。
入力されたクラス名に関する任意文字列は、クラスDB50のクラスと一致するとは限らないため、クラス名に関する任意文字列をクラスDB50のクラスに変換する文字列変換フィルタを通しても良い。
(検索条件の形式例3)
自然文(通常の日本語文)を入力として受け付け、DB用検索条件に変換する。自然文の質問解析は、永田 昌明、他「日本語自然文検索システム Web Answers」自然言語処理学会第12回年次大会発表論文集、B2−2、2006年、等の技術を利用することにより可能である。
自然文(通常の日本語文)を入力として受け付け、DB用検索条件に変換する。自然文の質問解析は、永田 昌明、他「日本語自然文検索システム Web Answers」自然言語処理学会第12回年次大会発表論文集、B2−2、2006年、等の技術を利用することにより可能である。
入力検索条件および関係DB用検索条件の一例、ここでは(検索条件の形式例2)の場合の例を図6に示す。
検索・集計部32は、条件入力部31で作成された関係DB用検索条件、クラスDB用検索条件、文書DB用検索条件(のうち、作成されたもの)を入力として、関係DB20、文書DB40およびクラスDB50に対する検索を行い、DB検索結果を得る。そして、前記DB検索結果を頻度や関係スコア情報等により集計し、さらに出力に必要な情報を取得して出力用検索結果を作成する(図3のステップS12)。
DB検索結果の集計は様々な方法が考えられるが、以下では、表現1情報、表現2情報、関係ラベル情報を指定された順に頻度集計して出力する例を示す。これ以外にも、表現1情報、表現2情報のみでの頻度集計を行っても良いし、関係スコア情報等を用いた集計を行っても良い。また、テキスト文書も出力する場合には、出力すべきレコードの文書IDを用いて文書DB40を検索し、テキスト(の抜粋)を取得しても良い。
ここでは、標準形を用いて、表現1情報、表現2情報、関係ラベル情報を指定された順に頻度集計する例を説明する。
表現1情報→表現2情報→関係ラベル情報の順に頻度集計する場合で説明する。
始めに、表現1情報の標準形を頻度でソートする。そして表現1情報の同一標準形のレコード単位で、表現2情報の標準形を頻度でソートする。さらに、表現2情報の同一標準形のレコード単位で関係ラベル情報の標準形を頻度でソートする。
最後に、結果出力部33は、出力用検索結果を用いて、予め定められた形式の検索結果をモニタの表示画面等に出力する(図3のステップS13)。
図6の検索条件を対象とし、上記の頻度集計例を用いて出力用検索結果を作成し、表現1情報、表現2情報、テキスト文書(抜粋)を出力した検索結果の例を図7に示す。
10:知識抽出部、11:テキスト解析部、12:グラウンディング部、13:関係抽出部、20:関係データベース(DB)、30:知識検索部、31:条件入力部、32:検索・集計部、33:結果出力部、40:文書データベース(DB)、50:クラスデータベース(DB)。
Claims (2)
- テキスト文書中の様々な表現間の関係を表す関係情報を抽出してデータベース化し、このデータベースを利用して情報検索を行う知識抽出・検索装置であって、
テキスト文書に対して言語解析を行い、言語解析情報を出力するテキスト解析部と、
前記言語解析情報を用いて、前記テキスト文書中の所定の表現に対し、その表現を特定するための情報であるグラウンド情報を付与するグラウンディング部と、
少なくとも前記言語解析情報を用いて前記テキスト文書から関係のある表現ペアを抽出し、前記言語解析情報およびグラウンド情報を用いて当該関係のある表現ペアに対する関係情報を出力する関係抽出部とから構成される知識抽出部と、
知識抽出部から出力された関係情報を蓄積する関係データベースと、
入力検索条件を解釈してデータベース用検索条件に変換する条件入力部と、
前記データベース用検索条件に基づいて前記関係データベースを検索し、検索結果を集計して出力用検索結果を作成する検索・集計部と、
前記出力用検索結果を用いて予め定められた形式の検索結果を出力する結果出力部とから構成される知識検索部とを備えた
ことを特徴とする知識抽出・検索装置。 - テキスト文書中の様々な表現間の関係を表す関係情報を抽出してデータベース化し、このデータベースを利用して情報検索を行う知識抽出・検索方法であって、
テキスト解析部が、テキスト文書に対して言語解析を行い、言語解析情報を出力するステップと、
グラウンディング部が、前記言語解析情報を用いて、前記テキスト文書中の所定の表現に対し、その表現を特定するための情報であるグラウンド情報を付与するステップと、
関係抽出部が、少なくとも前記言語解析情報を用いて前記テキスト文書から関係のある表現ペアを抽出し、前記言語解析情報およびグラウンド情報を用いて当該関係のある表現ペアに対する関係情報を関係データベースに出力するステップと、
条件入力部が、入力検索条件を解釈してデータベース用検索条件に変換するステップと、
検索・集計部が、前記データベース用検索条件に基づいて前記関係データベースを検索し、検索結果を集計して出力用検索結果を作成するステップと、
結果出力部が、前記出力用検索結果を用いて予め定められた形式の検索結果を出力するステップとを含む
ことを特徴とする知識抽出・検索方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008136620A JP2009282903A (ja) | 2008-05-26 | 2008-05-26 | 知識抽出・検索装置およびその方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008136620A JP2009282903A (ja) | 2008-05-26 | 2008-05-26 | 知識抽出・検索装置およびその方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2009282903A true JP2009282903A (ja) | 2009-12-03 |
Family
ID=41453265
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008136620A Pending JP2009282903A (ja) | 2008-05-26 | 2008-05-26 | 知識抽出・検索装置およびその方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2009282903A (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017058866A (ja) * | 2015-09-15 | 2017-03-23 | 株式会社東芝 | 情報抽出装置、情報抽出方法および情報抽出プログラム |
| JP2019511065A (ja) * | 2016-04-07 | 2019-04-18 | 北京百度网▲訊▼科技有限公司Beijing Baidu Netcom Science And Technology Co.,Ltd. | 情報検索方法及び装置 |
| JP7032582B1 (ja) | 2021-01-29 | 2022-03-08 | Kpmgコンサルティング株式会社 | 情報解析プログラム、情報解析方法及び情報解析装置 |
-
2008
- 2008-05-26 JP JP2008136620A patent/JP2009282903A/ja active Pending
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017058866A (ja) * | 2015-09-15 | 2017-03-23 | 株式会社東芝 | 情報抽出装置、情報抽出方法および情報抽出プログラム |
| JP2019511065A (ja) * | 2016-04-07 | 2019-04-18 | 北京百度网▲訊▼科技有限公司Beijing Baidu Netcom Science And Technology Co.,Ltd. | 情報検索方法及び装置 |
| JP7032582B1 (ja) | 2021-01-29 | 2022-03-08 | Kpmgコンサルティング株式会社 | 情報解析プログラム、情報解析方法及び情報解析装置 |
| JP2022117019A (ja) * | 2021-01-29 | 2022-08-10 | Kpmgコンサルティング株式会社 | 情報解析プログラム、情報解析方法及び情報解析装置 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9558264B2 (en) | Identifying and displaying relationships between candidate answers | |
| KR101431530B1 (ko) | 수학문장의 시맨틱거리 추출 및 시맨틱거리에 의한 수학문장의 분류방법과 그를 위한 장치 및 컴퓨터로 읽을 수 있는 기록매체 | |
| WO2017092337A1 (zh) | 评论标签提取方法和装置 | |
| US20200118022A1 (en) | Determining Comprehensiveness of Question Paper Given Syllabus | |
| KR101174057B1 (ko) | 인덱스 분석장치와 인덱스 검색장치 및 그 방법 | |
| WO2020248378A1 (zh) | 业务查询方法、装置及存储介质、计算机设备 | |
| JP2010250439A (ja) | 検索システム、データ生成方法、プログラムおよびプログラムを記録した記録媒体 | |
| JP2009282903A (ja) | 知識抽出・検索装置およびその方法 | |
| TWI636370B (zh) | Establishing chart indexing method and computer program product by text information | |
| CN109710844A (zh) | 基于搜索引擎的快速准确定位文件的方法和设备 | |
| US20080162165A1 (en) | Method and system for analyzing non-patent references in a set of patents | |
| JP5688754B2 (ja) | 情報検索装置及びコンピュータプログラム | |
| Kurmi et al. | Text summarization using enhanced MMR technique | |
| KR100837797B1 (ko) | 약어 생성 유형을 고려하는 약어 사전 자동 구축 방법, 그기록 매체 및 약어 생성 유형을 고려하는 약어 사전 자동구축 장치 | |
| KR101589626B1 (ko) | 어휘의미패턴 분석방법에 기반하여 빅데이터로부터 점포창업용 데이터 또는 운영지원용 데이터를 생성하는 방법 | |
| JP2011086156A (ja) | 漏洩情報追跡システムおよび漏洩情報追跡プログラム | |
| JPH10307837A (ja) | 検索装置並びに検索プログラムを記録した記録媒体 | |
| JP5308918B2 (ja) | キーワード抽出方法、キーワード抽出装置およびキーワード抽出プログラム | |
| Aksan et al. | The Turkish National Corpus (TNC): comparing the architectures of v1 and v2 | |
| JP5644087B2 (ja) | 構成要素ハイライト装置、プログラム、及び方法 | |
| JP4248828B2 (ja) | 文書処理装置、文書処理方法及び記録媒体 | |
| US20230409620A1 (en) | Non-transitory computer-readable recording medium storing information processing program, information processing method, information processing device, and information processing system | |
| JP2549745B2 (ja) | 文書検索装置 | |
| JP5137140B2 (ja) | 出現表記レコード同定装置、削除規則生成装置、その方法、プログラム及び記録媒体 | |
| JP2008130034A (ja) | 有名人の別表現の自動抽出装置、方法 |