JP2009059215A - Structured document processor, and structured document processing method - Google Patents
Structured document processor, and structured document processing method Download PDFInfo
- Publication number
- JP2009059215A JP2009059215A JP2007226694A JP2007226694A JP2009059215A JP 2009059215 A JP2009059215 A JP 2009059215A JP 2007226694 A JP2007226694 A JP 2007226694A JP 2007226694 A JP2007226694 A JP 2007226694A JP 2009059215 A JP2009059215 A JP 2009059215A
- Authority
- JP
- Japan
- Prior art keywords
- structured document
- xml
- format
- type
- parser
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images














Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/221—Parsing markup language streams
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/14—Tree-structured documents
- G06F40/143—Markup, e.g. Standard Generalized Markup Language [SGML] or Document Type Definition [DTD]
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Document Processing Apparatus (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
本発明は、構造化文書を処理する技術に関するものである。 The present invention relates to a technique for processing a structured document.
現在、コンピュータ上で扱う様々なデータのフォーマットとしてXML(Extensible Markup Language:http://www.w3.org/TR/2004/REC-xml-20040204/)が使用されている。XMLは、コンピュータやオペレーティングシステムなどに依存しないという特徴を持っている。これにより、ネットワーク上の異なる種類のコンピュータや機器間での通信が容易になるため、特に、ネットワーク上での通信データとして広く普及している。 Currently, XML (Extensible Markup Language: http://www.w3.org/TR/2004/REC-xml-20040204/) is used as a format of various data handled on a computer. XML has a feature that it does not depend on a computer or an operating system. This facilitates communication between different types of computers and devices on the network, and is particularly widespread as communication data on the network.
また、最近は携帯電話や複写機、デジタルカメラなどといった、パーソナルコンピュータやサーバ以外のさまざまな機器のネットワーク化が進んでいる。このため、これらの機器でもXMLを扱うことが増えている。 Recently, various devices other than personal computers and servers such as mobile phones, copiers, and digital cameras have been networked. For this reason, these devices are increasingly handling XML.
このような中で、XMLの処理速度や効率性が大きな問題となっている。XMLのフォーマットは、処理速度の向上を優先させた書式にはなっていないため、解析処理に時間がかかる。また、記述に冗長性があるために、そのデータサイズが大きくなる。これらの問題は、処理速度が遅くメモリ資源の少ない小型機器では大きな問題となる。また、サーバなどリソースの多い機器であっても、非常に多くのXML形式の文書を処理する場合には、XMLの解析時間が大きな問題となっている。 Under such circumstances, the processing speed and efficiency of XML become a big problem. Since the XML format is not a format that prioritizes the improvement of the processing speed, it takes time for the analysis process. Moreover, since the description has redundancy, the data size becomes large. These problems become a serious problem in small devices with a slow processing speed and a small memory resource. Further, even if a device having many resources such as a server is used, when processing a very large number of XML documents, the XML analysis time is a big problem.
そのため、XMLフォーマットと意味的に等価で、かつ、より効率的な処理が可能なフォーマットが使われるようになってきた。このようなフォーマットは一般に「バイナリXML」と呼ばれている。これに対し、XMLの仕様に従った、テキスト形式のXMLのことを本明細書では「テキストXML」と呼ぶ。 Therefore, a format that is semantically equivalent to the XML format and capable of more efficient processing has been used. Such a format is generally called “binary XML”. On the other hand, XML in a text format according to the XML specification is referred to as “text XML” in this specification.
バイナリXMLのフォーマット仕様は一つではなく、いくつかある。多くのフォーマットは、冗長性の排除とデータ型に応じたエンコーディングを行うことによってサイズの低減や処理の効率化を図っている。 There are several binary XML format specifications. Many formats attempt to reduce size and increase processing efficiency by eliminating redundancy and performing encoding according to the data type.
冗長性の排除とは、終了タグ名を省略したり、頻繁に登場する要素名や属性名、属性値などの文字列を整数に置き換えることである。終了タグは必ず直前に記述された開始タグと同じ名前でなければならないため、終了タグの名前は省くことが可能である。また、例えば画像を多く含むXHTML文書では、「img」という文字列が頻繁に出現する。これら頻出文字列をできるだけ小さな整数に置き換えることで、文書サイズの削減が行われている。 Eliminating redundancy means omitting end tag names or replacing character strings such as frequently appearing element names, attribute names, and attribute values with integers. Since the end tag must have the same name as the start tag described immediately before, the name of the end tag can be omitted. For example, in an XHTML document containing many images, the character string “img” frequently appears. The document size is reduced by replacing these frequent character strings with integers as small as possible.
データ型に応じたエンコーディングとは、要素の内容や属性値等に対するエンコーディング方法を、その型(整数、浮動小数、日付など)に応じて変えることである。例えば、テキストXMLでは、<x>12345</x>という要素における”12345”が整数の12345を表していたとしても、文書中には”12345”という文字列として記述される。よって、文書の文字エンコーディングがUTF−8の場合、0x30、0x31、0x32、0x33、0x45というデータになる。 Encoding according to the data type is to change the encoding method for element contents, attribute values, etc., according to the type (integer, float, date, etc.). For example, in text XML, even if “12345” in the element <x> 12345 </ x> represents the integer 12345, it is described as a character string “12345” in the document. Therefore, when the character encoding of the document is UTF-8, the data is 0x30, 0x31, 0x32, 0x33, 0x45.
このように、XML文書中に記述される書式とコンピュータ内部で扱うための書式が異なるため、XML文書を読み込んでコンピュータ内部で処理する際に、書式の変換を行わなければならない。例えば、ある構造化文書処理装置の内部で、整数がビッグエンディアンの4バイトで扱われている場合、整数12345は0x00、0x00、0x30、0x2Eというバイト列になる。このような型の変換は、特に浮動小数の場合に多くの時間を要する。 Thus, since the format described in the XML document is different from the format to be handled inside the computer, the format must be converted when the XML document is read and processed inside the computer. For example, when an integer is handled with 4 bytes of big endian inside a structured document processing apparatus, the integer 12345 becomes a byte string of 0x00, 0x00, 0x30, and 0x2E. This type of conversion takes a lot of time, especially for floating point numbers.
これに対しバイナリXMLでは、整数や浮動小数の値を、コンピュータ内部で扱う書式と同じ形式で記述する。このため、書式の変換を行う必要が無く、より高速に処理することが可能である。 On the other hand, in binary XML, integers and floating point values are described in the same format as the format handled inside the computer. For this reason, it is not necessary to convert the format, and processing can be performed at higher speed.
インデックス化による冗長性の除去とデータ型に応じたエンコーディングを行う例としては、Fast Infoset(ITU-T Rec. X.891 | ISO/IEC24824-1)が挙げられる。 As an example of performing redundancy removal by indexing and encoding according to the data type, Fast Infoset (ITU-T Rec. X.891 | ISO / IEC24824-1) can be given.
バイナリXMLを扱う場合は通常、バイナリXMLデータ専用の解析器(以下バイナリXMLパーサ)を使うのが普通である。また、バイナリXMLパーサのインターフェースはテキストXMLパーサと同じものになっていることが多い。なぜなら、インターフェースを揃えておくことで、テキストXMLパーサを使用するアプリケーションを改変せずにバイナリXMLパーサに対応させることができるからである。テキストXMLパーサと同じインターフェースを持つバイナリXMLパーサとして、Sun Microsystems Inc.のFast Infoset Projectのパーサがある。 When handling binary XML, it is usual to use an analyzer dedicated to binary XML data (hereinafter referred to as a binary XML parser). Further, the interface of the binary XML parser is often the same as that of the text XML parser. This is because by arranging the interfaces, it is possible to correspond to the binary XML parser without modifying the application that uses the text XML parser. As a binary XML parser having the same interface as the text XML parser, Sun Microsystems Inc. There is a parser for Fast Infoset Project.
特許文献1には、XMLデータを利用したシステムと、レガシーファイルデータを利用したシステムの、どちらでもデータを処理することができるように、それぞれをデータ変換することが記載されている。
しかしながら、テキストXMLパーサと同じインターフェースを持つバイナリXMLパーサでは、データ型に応じたエンコーディングを行うバイナリXMLフォーマットのメリットを生かすことができないという欠点があった。 However, the binary XML parser having the same interface as the text XML parser has a drawback that it cannot take advantage of the binary XML format that performs encoding according to the data type.
なぜなら、テキストXMLパーサのインターフェースでは、データはすべて文字列型として受け渡しが行われるため、インターフェースを同じにすると文字列型のデータしか扱えなくなってしまうからである。このため、バイナリXML文書中にIEEE754形式の浮動小数データがある場合も、バイナリXMLパーサが文字列型に変換して渡し、さらにアプリケーションがまたIEEE754形式に戻す、という無駄な変換が行われてしまう。 This is because, in the text XML parser interface, all data is transferred as a character string type, so if the interface is the same, only character string type data can be handled. For this reason, even if there is IEEE 754 format floating point data in the binary XML document, the binary XML parser converts it to a character string type and passes it, and further, the application converts it back to the IEEE 754 format. .
また、バイナリXMLパーサのインターフェースをテキストXMLパーサと異なるものにしてしまうと、バイナリXMLパーサ用アプリケーションはテキストXMLパーサを扱えないことになる。つまり、テキストXML文書に対応できなくなるという問題が起きてしまう。 If the interface of the binary XML parser is different from that of the text XML parser, the binary XML parser application cannot handle the text XML parser. That is, a problem that the text XML document cannot be handled occurs.
本発明は以上の問題に鑑みてなされたものであり、一つのアプリケーションで複数種のフォーマットのXML文書を扱うことを可能にするための技術を提供することを目的とする。 The present invention has been made in view of the above problems, and an object of the present invention is to provide a technique for making it possible to handle XML documents of a plurality of formats in one application.
更に、データ型に応じたエンコーディングで記述されたバイナリXMLの文書を効率的に扱う為の技術を提供することも目的とする。 It is another object of the present invention to provide a technique for efficiently handling a binary XML document described in an encoding according to a data type.
本発明の目的を達成するために、例えば、本発明の構造化文書処理装置は以下の構成を備える。 In order to achieve the object of the present invention, for example, a structured document processing apparatus of the present invention comprises the following arrangement.
即ち、構造化文書を処理する構造化文書処理装置であって、
構造化文書のフォーマットを取得する取得手段と、
前記取得手段が取得したフォーマットに応じた解析方法で、前記構造化文書を解析する解析手段と、
前記構造化文書中に記されている要素を、指定された型で取得する要求を受け付ける手段と、
前記要素について前記解析手段が解析した型と、前記指定された型とが一致しているか否かを判断する判断手段と、
前記判断手段が一致していると判断した場合には前記要素を要求元に出力し、前記判断手段が一致していないと判断した場合には前記要素の型を前記指定された型に変換してから当該要素を前記要求元に出力する出力手段と
を備えることを特徴とする。
That is, a structured document processing apparatus for processing a structured document,
An acquisition means for acquiring the format of the structured document;
Analysis means for analyzing the structured document by an analysis method according to the format acquired by the acquisition means;
Means for receiving a request for acquiring an element described in the structured document in a specified type;
Determining means for determining whether or not the type analyzed by the analyzing means for the element matches the specified type;
When the determination means determines that they match, the element is output to the request source. When the determination means determines that they do not match, the element type is converted to the specified type. And an output means for outputting the element to the request source.
本発明の目的を達成するために、例えば、本発明の構造化文書処理方法は以下の構成を備える。 In order to achieve the object of the present invention, for example, the structured document processing method of the present invention comprises the following arrangement.
即ち、構造化文書を処理する構造化文書処理装置が行う構造化文書処理方法であって、
構造化文書のフォーマットを取得する取得工程と、
前記取得工程で取得したフォーマットに応じた解析方法で、前記構造化文書を解析する解析工程と、
前記構造化文書中に記されている要素を、指定された型で取得する要求を受け付ける工程と、
前記要素について前記解析工程で解析した型と、前記指定された型とが一致しているか否かを判断する判断工程と、
前記判断工程で一致していると判断した場合には前記要素を要求元に出力し、前記判断工程で一致していないと判断した場合には前記要素の型を前記指定された型に変換してから当該要素を前記要求元に出力する出力工程と
を備えることを特徴とする。
That is, a structured document processing method performed by a structured document processing apparatus that processes a structured document,
An acquisition process for acquiring the format of the structured document;
In the analysis method according to the format acquired in the acquisition step, an analysis step of analyzing the structured document;
Receiving a request for acquiring an element described in the structured document in a specified type;
A determination step for determining whether or not the type analyzed in the analysis step for the element matches the designated type;
If it is determined in the determination step that the elements match, the element is output to the request source. If it is determined in the determination step that the elements do not match, the element type is converted to the specified type. And an output step for outputting the element to the request source.
本発明の構成によれば、一つのアプリケーションで複数種のフォーマットのXML文書を扱うことを可能にする。 According to the configuration of the present invention, it is possible to handle XML documents of a plurality of formats in one application.
更に、データ型に応じたエンコーディングで記述されたバイナリXMLの文書を効率的に扱うことができる。 Furthermore, it is possible to efficiently handle a binary XML document described in an encoding according to the data type.
以下、添付図面を参照し、本発明の好適な実施形態について詳細に説明する。 Hereinafter, preferred embodiments of the present invention will be described in detail with reference to the accompanying drawings.
[第1の実施形態]
図1は、本実施形態に係る構造化文書処理装置に適用可能なコンピュータのハードウェア構成例を示すブロック図である。なお、本実施形態に係る構造化文書処理装置に適用可能な装置が有する構成は、図1に示した構成に限定するものではなく、当業者であれば、種種の変形例が考え得る。更に、本実施形態に係る構造化文書処理装置を1台の装置で実現させることに限定するものではなく、複数台の装置による協調動作でもって、本実施形態に係る構造化文書処理装置を実現させても良い。この場合、複数台の装置間は、LANなどのネットワークを介して接続されていることになる。
[First Embodiment]
FIG. 1 is a block diagram illustrating a hardware configuration example of a computer applicable to the structured document processing apparatus according to the present embodiment. Note that the configuration of the apparatus applicable to the structured document processing apparatus according to the present embodiment is not limited to the configuration illustrated in FIG. 1, and various modifications can be considered by those skilled in the art. Further, the structured document processing apparatus according to the present embodiment is not limited to being realized by a single apparatus, and the structured document processing apparatus according to the present embodiment is realized by a cooperative operation by a plurality of apparatuses. You may let them. In this case, a plurality of devices are connected via a network such as a LAN.
図1において、CPU101は、ROM102やRAM103に格納されているプログラムやデータを用いて、コンピュータ100全体の制御を行うと共に、コンピュータ100が行うものとして説明する後述の各処理を実行する。
In FIG. 1, a
ROM102には、コンピュータ100の設定データやブートプログラム、変更を必要としないパラメータのデータなどが格納されている。
The
RAM103は、記憶装置104からロードされたプログラムやデータ、ネットワークインターフェース150を介して外部から受信したデータなどを一時的に記憶するためのエリアを有する。更には、RAM103は、CPU101が各種の処理を実行する際に用いるワークエリアも有する。
The
記憶装置104は、ハードディスクドライブ装置に代表される大容量情報記憶装置である。記憶装置104には、OS(オペレーティングシステム)や、コンピュータ100が行うものとして説明する後述の各処理をCPU101に実行させるためのプログラムやデータが保存されている。また、記憶装置104には、後述する処理の対象となる構造化文書としてのXML文書のデータが、ファイルとして保存されている。記憶装置104に保存されているプログラムやデータは、CPU101による制御に従って適宜RAM103にロードされ、CPU101による処理対象となる。
The
以下に、記憶装置104に保存されている各ソフトウェアについて説明する。
Below, each software preserve | saved at the memory |
テキストXMLパーサ105は、テキスト形式のXML文書(以下、テキストXML文書と呼称する)の解析依頼を受けると、このXML文書に対する解析処理を行い、その結果を返す。
When the
バイナリXMLパーサ106は、バイナリ形式のXML文書(以下、バイナリXML文書と呼称する)の解析依頼を受けると、このXML文書に対する解析処理を行い、その結果を返す。
When the
データ型変換部107は、変換前のデータの型、変換後のデータの型、変換対象データ、の3つを指定すると、変換対象データの型を変換後の型に変換して返す。
When the data
フォーマット判別部108は、与えられたデータのフォーマットを判別する。
The
共通XMLパーサ109は、テキストXMLパーサ105やバイナリXMLパーサ106を使い分けて、テキストXML文書やバイナリXML文書の解析処理を実現するものである。
The
レガシーアプリケーション110は、テキストXMLパーサ105のAPI(Application Programming Interface)を使用して処理を行う。
The
型対応アプリケーション111は、共通XMLパーサ109のAPIを使用して処理を行う。また、レガシーアプリケーション110と型対応アプリケーション111とは、両方ともネットワーク上から受信したXML文書を処理するサービスとして機能するものである。
The
なお、記憶装置104に保存されているものとして説明した各ソフトウェアによって実現される処理については後述する。
The processing realized by each software described as being stored in the
ネットワークインターフェース150は、コンピュータ100をLANやインターネット等に接続するためのものであり、コンピュータ100はこのネットワークインターフェース150を介して、外部機器とのデータ通信を行うことができる。
The
112は、上述の各部を繋ぐバスである。
A
図2は、上記コンピュータ100を適用したネットワークの構成例を示す図である。
FIG. 2 is a diagram illustrating a configuration example of a network to which the
図2に示す如く、コンピュータ100をサーバとしてネットワーク201に接続する。ネットワーク201は、LANやインターネット等により構成されている。202,203はそれぞれクライアント端末で、ネットワーク201に接続されている。
As shown in FIG. 2, a
ここで、クライアント端末202はバイナリXML文書を生成し、生成したバイナリXML文書をコンピュータ100に送信するものとする。一方、クライアント端末203はテキストXML文書を生成し、生成したテキストXML文書をコンピュータ100に送信するものとする。
Here, it is assumed that the
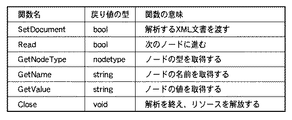
次に、テキストXMLパーサ105のAPIについて、図3を用いて説明する。図3は、テキストXMLパーサ105のAPIの一例を示す図である。
Next, the API of the
「SetDocument」は、解析対象のXML文書を開く為の関数である。 “SetDocument” is a function for opening an XML document to be analyzed.
「Read」は、解析対象のXML文書の先頭からノード1つ分読み進める為の関数である。ここで、ノードとはXML文書を構成する単位であり、開始タグ(StartElement)、終了タグ(EndElement)、要素の内容(Content)などがある。 “Read” is a function for reading one node from the beginning of the XML document to be analyzed. Here, a node is a unit that constitutes an XML document, and includes a start tag (StartElement), an end tag (EndElement), an element content (Content), and the like.
「GetNodeType」は、現在参照しているノードの型(ノード型)を返す為の関数であり、「StartElement」や「EndElement」といった値を返す。 “GetNodeType” is a function for returning the type (node type) of the currently referenced node, and returns a value such as “StartElement” or “EndElement”.
「GetName」は、現在参照しているノードの名前を返す為の関数である。つまり、現在参照しているノードが開始タグの場合には、開始タグのタグ名を返す。 “GetName” is a function for returning the name of the currently referenced node. In other words, if the currently referenced node is a start tag, the tag name of the start tag is returned.
「GetValue」は、現在参照しているノードの値を返す為の関数である。つまり、現在参照しているノードが「Content」の場合には、その要素の内容を返す。テキストXML文書はすべてテキスト形式で記述されているため、「GetValue」の戻り値もstring型である。 “GetValue” is a function for returning the value of the currently referenced node. That is, when the currently referenced node is “Content”, the content of the element is returned. Since all text XML documents are described in a text format, the return value of “GetValue” is also a string type.
「Close」は、解析処理を終了し、確保していたメモリ資源などを解放する為の関数である。 “Close” is a function for ending the analysis processing and releasing the reserved memory resources.
次に、バイナリXMLパーサ106のAPIについて、図4を用いて説明する。図4は、バイナリXMLパーサ106のAPIの一例を示す図である。
Next, the API of the
「SetDocument」、「Read」、「GetNodeType」、「GetName」、「Close」の各関数については図3に示したものと同じであり、その説明も上述の通りである。即ち、これらの関数は、テキストXMLパーサ105の同名のAPIと同じ役目を果たす。しかし、ノードの値を取得する為の関数については、テキストXMLパーサ105とバイナリXMLパーサ106とでは、大きく異なる。
The functions “SetDocument”, “Read”, “GetNodeType”, “GetName”, and “Close” are the same as those shown in FIG. 3, and the description thereof is also as described above. That is, these functions play the same role as the API of the same name in the
「GetValueType」は、現在参照しているノードの値の型を返す為の関数である。例えば、現在参照しているノードの値が、バイナリXML文書内に整数値として記述されている場合は「int」を返し、浮動小数として記述されている場合は「double」を返す。 “GetValueType” is a function for returning the value type of the currently referenced node. For example, if the value of the currently referenced node is described as an integer value in the binary XML document, “int” is returned, and if it is described as a floating point number, “double” is returned.
「GetStringValue」は、現在参照している文字列型のノードの値を取得する為の関数である。 “GetStringValue” is a function for acquiring the value of the currently referenced character string type node.
「GetIntValue」は、現在参照している整数型のノードの値を取得するための関数である。 “GetIntValue” is a function for obtaining the value of the currently referenced integer type node.
「GetDoubleValue」は、現在参照している浮動小数型のノードの値を取得する為の関数である。 “GetDoubleValue” is a function for acquiring the value of the currently referenced floating-point node.
つまり、バイナリXMLパーサ106のAPIは、現在参照しているノードの値を、XML文書内に記されている型で返す。
That is, the API of the
次に、共通XMLパーサ109のAPIについて、図5を用いて説明する。図5は、共通XMLパーサ109のAPIの一例を示す図である。
Next, the API of the
「SetDocument」、「Read」、「GetNodeType」、「GetName」、「Close」の各関数については図3に示したものと同じであり、その説明も上述の通りである。即ち、これらの関数は、テキストXMLパーサ105、バイナリXMLパーサ106の同名のAPIと同じ役目を果たす。
The functions “SetDocument”, “Read”, “GetNodeType”, “GetName”, and “Close” are the same as those shown in FIG. 3, and the description thereof is also as described above. That is, these functions play the same role as the API of the same name of the
「GetValueAsString」は、現在参照しているノードの値を、文字列として取得する関数である。 “GetValueAsString” is a function that acquires the value of the currently referenced node as a character string.
「GetValueAsInt」は、現在参照しているノードの値を、整数として取得する関数である。 “GetValueAsInt” is a function that acquires the value of the currently referenced node as an integer.
「GetValueAsDouble」は、現在参照しているノードの値を、浮動小数型として取得する関数である。 “GetValueAsDouble” is a function that acquires the value of the currently referenced node as a floating-point number type.
次に、図6に例示する構成を有するXML文書を処理対象とする場合における、コンピュータ100の動作について説明する。図6は、コンピュータ100による処理対象としてのXML文書の構成例を示す図である。図6に示す構成を有するXML文書は、人の名前(name)と身長(height)とを格納する個人情報データである。
Next, the operation of the
「<」と「>」で囲まれたものは開始タグを表す。図6では、602,603,606が開始タグに相当する。
What is surrounded by “<” and “>” represents a start tag. In FIG. 6,
「</>」は終了タグを表す。図6では、605,608,609が終了タグに相当する。
“</>” Represents an end tag. In FIG. 6,
要素の内容部分604,607はSやFといった記号から始まり、その後に実際の値が記されている。内容部分604における先頭の「S」は、それに後続する値がUTF−8で記されている文字列であることを示している。「F」は、それに後続する値がIEEE754形式の4バイト浮動小数形式で記されていることを示している。
The
IEEE754形式は、アプリケーションが扱う浮動小数型と同じ形式である。XML文書における先頭部分、即ち601で示す部分は、マジックナンバーと呼ばれており、XML文書の先頭付近の数バイトを見ることで、このXML文書のフォーマットが認識できるようになっている。本実施形態では、XML文書がバイナリXML文書であることを示すためには、マジックナンバー601として、「0x01、0x02、0x03」を用いる。
The IEEE 754 format is the same format as the floating point type handled by the application. The head portion in the XML document, that is, the portion indicated by 601 is called a magic number, and the format of the XML document can be recognized by looking at several bytes near the head of the XML document. In the present embodiment, “0x01, 0x02, 0x03” is used as the
次に、図6に示すXML文書のデータを記憶装置104からRAM103にロードした後に、コンピュータ100が行う処理について、図8を用いて説明する。図8は、CPU101が、型対応アプリケーション111のプログラムを実行することでなされる処理のフローチャートである。係る処理では、図6に示すXML文書、即ち、個人情報データから、名前と身長をそれぞれ文字列、整数として取得する。
Next, processing performed by the
先ず、ステップS802では、関数「SetDocument」を実行し、図6に示すXML文書を開く。なお、ステップS802における処理を行うと、図9に示したフローチャートに従った処理が開始される。図9のフローチャートについては後述する。 First, in step S802, the function “SetDocument” is executed to open the XML document shown in FIG. Note that when the processing in step S802 is performed, processing according to the flowchart shown in FIG. 9 is started. The flowchart of FIG. 9 will be described later.
次にステップS803では、最初の開始タグが「person」であることを確認する為に、関数「Read」を実行し、係る実行により進めた現在の参照位置に対して関数「GetNodeType」、関数「GetName」を実行する。そして、関数「GetNodeType」の返り値が開始タグ、且つ関数「GetName」による返り値が「person」となるまで、関数「Read」を実行する。 In step S803, in order to confirm that the first start tag is “person”, the function “Read” is executed, and the function “GetNodeType” and the function “ Execute "GetName". Then, the function “Read” is executed until the return value of the function “GetNodeType” is the start tag and the return value of the function “GetName” is “person”.
次にステップS804では、関数「Read」を実行し、係る実行により進めた現在の参照位置に対して関数「GetNodeType」、関数「GetName」を実行する。そして、関数「GetNodeType」の返り値がnameタグ、且つ関数「GetName」による返り値が「name」となるまで、関数「Read」を実行する。 In step S804, the function “Read” is executed, and the function “GetNodeType” and the function “GetName” are executed on the current reference position advanced by the execution. Then, the function “Read” is executed until the return value of the function “GetNodeType” becomes the name tag and the return value of the function “GetName” becomes “name”.
次にステップS805では、関数「GetValueAsString」を実行し、nameタグ(要素)の内容、即ち、「Alice」を文字列として取得する。ステップS805における処理の詳細については図10を用いて後述する。 In step S805, the function “GetValueAsString” is executed to acquire the contents of the name tag (element), that is, “Alice” as a character string. Details of the processing in step S805 will be described later with reference to FIG.
次にステップS806では、関数「Read」を実行し、係る実行により進めた現在の参照位置に対して関数「GetNodeType」、関数「GetName」を実行する。そして、関数「GetNodeType」の返り値がheightタグ、且つ関数「GetName」による返り値が「height」となるまで、関数「Read」を実行する。 In step S806, the function “Read” is executed, and the function “GetNodeType” and the function “GetName” are executed on the current reference position advanced by the execution. Then, the function “Read” is executed until the return value of the function “GetNodeType” is the height tag and the return value of the function “GetName” is “height”.
次にステップS807では、関数「GetValueAsDouble」を実行し、heightタグ(要素)の内容、即ち、「160.5」を浮動小数形式の値として取得する。ステップS807における処理の詳細については図10を用いて後述する。 In step S807, the function “GetValueAsDouble” is executed to acquire the content of the height tag (element), that is, “160.5” as a value in the floating-point format. Details of the processing in step S807 will be described later with reference to FIG.
次にステップS808では、関数「Close」を実行し、RAM103に対するメモリ資源等を解放する。
In step S808, the function “Close” is executed to release memory resources and the like for the
次に、上記ステップS802における処理が実行されると共に開始される処理について、同処理のフローチャートを示す図9を用いて以下説明する。図9のフローチャートに従った処理は、CPU101が共通XMLパーサ109のプログラムを実行することでなされる処理である。
Next, processing that is started when the processing in step S802 is executed will be described below with reference to FIG. 9 showing a flowchart of the processing. The process according to the flowchart of FIG. 9 is a process performed by the
ステップS902では、フォーマット判別部108を実行し、フォーマット判別部108に、上記ステップS802で開いたXML文書におけるマジックナンバー(図6における601)を取得させる。そして、フォーマット判別部108が取得したマジックナンバーを、共通XMLパーサ109が取得する。そしてこの取得したマジックナンバーを用いて、XML文書のフォーマットを判別する。即ち、XML文書がテキストXML文書であるのか、バイナリXML文書であるのかを判別する。
In step S902, the
ここで、係る判別では、マジックナンバーが「<?」という文字列で始まっている場合、テキストXML文書であると判別し、「0x01、0x02、0x03」という文字列で始まっている場合、バイナリXML文書であると判別する。図6に示したXML文書の場合、バイナリXML文書と判別されることになる。 In this determination, if the magic number starts with the character string “<?”, It is determined that the magic number is a text XML document. If the magic number starts with the character string “0x01, 0x02, 0x03”, binary XML is used. It is determined as a document. In the case of the XML document shown in FIG. 6, it is determined as a binary XML document.
しかし、XML文書のフォーマットを判別する方法はこれに限定するものではなく、様々な方法が考えられる。例えば、HTTPヘッダのContent−Typeフィールドの情報を参照することでフォーマットを判別したり、XML文書の拡張子を参照することでXML文書のフォーマットを判別しても良い。 However, the method for determining the format of the XML document is not limited to this, and various methods are conceivable. For example, the format may be determined by referring to the information in the Content-Type field of the HTTP header, or the format of the XML document may be determined by referring to the extension of the XML document.
そして、ステップS902における判別処理の結果、テキストXML文書であると判別された場合には、処理をステップS903を介してステップS904に処理を進める。一方、バイナリXML文書であると判別された場合には、処理をステップS903を介してステップS905に進める。 If it is determined as a text XML document as a result of the determination process in step S902, the process proceeds to step S904 via step S903. On the other hand, if it is determined that the document is a binary XML document, the process proceeds to step S905 via step S903.
ステップS904では、共通XMLパーサ109は、テキストXMLパーサ105の関数「SetDocument」を呼び出し、XML文書をテキストXMLパーサ105に渡す。これにより、テキストXMLパーサ105にこのXML文書の解析を行わせる。
In step S <b> 904, the
一方、ステップS905では、共通XMLパーサ109は、バイナリXMLパーサ106の関数「SetDocument」を呼び出し、XML文書をバイナリXMLパーサ106に渡す。これにより、バイナリXMLパーサ106にこのXML文書の解析を行わせる。
On the other hand, in
テキストXMLパーサ105、バイナリXMLパーサ106は何れも、XML文書中(構造化文書中)に記述されている要素に対する解析処理を行う。即ち、XML文書のフォーマットに応じた解析処理を実現する。
Both the
共通XMLパーサ109の関数「Read」、「GetNodeType」、「GetName」、「Close」は、テキストXMLパーサ105、バイナリXMLパーサ106の同名の関数をそのまま呼び出し、戻り値もそのまま渡すだけのラッパである。
The functions “Read”, “GetNodeType”, “GetName”, and “Close” of the
次に、上記ステップS805,S807における処理の詳細について、図10を用いて説明する。図10は、ステップS805,S807における処理の詳細を示すフローチャートである。 Next, details of the processing in steps S805 and S807 will be described with reference to FIG. FIG. 10 is a flowchart showing details of the processing in steps S805 and S807.
先ず、ステップS1002では、上記ステップS902における判別処理の結果として、テキストXMLパーサ105、バイナリXMLパーサ106の何れに解析処理を行わせているのかを判別する。係る判別の結果、現在テキストXMLパーサ105に解析処理を行わせている場合には、処理をステップS1008に進める。一方、現在バイナリXMLパーサ106に解析処理を行わせている場合には、処理をステップS1003に進める。図6に示したXML文書の場合、バイナリXMLパーサ106を用いてこのXML文書に対する解析処理を行わせていることになるので、処理はステップS1003に進むことになる。
First, in step S1002, it is determined which of the
ステップS1003以降の処理を、ステップS805において行う場合と、ステップS807において行う場合とに分けて説明する。 The processing after step S1003 will be described separately for the case where it is performed in step S805 and the case where it is performed in step S807.
先ず、ステップS805においてステップS1003以降の処理を行う場合について説明する。 First, the case where the process after step S1003 is performed in step S805 will be described.
ステップS1003では、関数「GetValueType」を実行することで、バイナリXMLパーサ106が解析した結果を取得する。ステップS805では、関数「GetValueAsString」が実行されるので、バイナリXMLパーサ106はnameタグの型を取得することになり、図6に示したXML文書の場合、string型を取得する。従って、ステップS1003では、このstring型を「型情報」として取得する。
In step S1003, the function “GetValueType” is executed to obtain a result analyzed by the
次に、ステップS1004では、関数「GetStringValue」を実行することで、バイナリXMLパーサ106が解析した結果を取得する。ステップS805では、関数「GetValueAsString」が実行されるので、バイナリXMLパーサ106はnameタグの内容を取得することになり、図6に示したXML文書の場合、文字列”Alice”を取得する。従って、ステップS1004では、この文字列”Alice”を取得する。
Next, in step S1004, the result of analysis by the
次にステップS1005では、ステップS805で実行した関数が要求する(受け付けた)データの型(依頼された型)と、ステップS1003で取得した型とが一致しているか否かを判断する。係る判断の結果、一致する場合には、処理をステップS1007に進める。図6に示したXML文書の場合、ステップS805で実行した関数が要求するデータの型はstring型であるし、ステップS1003で取得した型もまたstring型であるので、一致すると判断される。この場合、ステップS1007では、上記ステップS1004で取得したデータ(文字列)を、要求元(型対応アプリケーション111)に出力する。 Next, in step S1005, it is determined whether the data type requested (accepted) requested by the function executed in step S805 matches the type acquired in step S1003. As a result of the determination, if they match, the process proceeds to step S1007. In the case of the XML document shown in FIG. 6, since the data type requested by the function executed in step S805 is the string type, and the type acquired in step S1003 is also the string type, it is determined that they match. In this case, in step S1007, the data (character string) acquired in step S1004 is output to the request source (type-compatible application 111).
一方、ステップS1005における判断の結果、一致していない場合には、処理をステップS1006に進める。ステップS1006では、ステップS1004で取得したデータの型を、ステップS805で実行した関数が要求するデータの型に変換する。そして、その後、ステップS1007では、ステップS1006で型を変換したデータを、上記要求元に対して出力する。 On the other hand, if the result of determination in step S1005 is that they do not match, the process proceeds to step S1006. In step S1006, the data type acquired in step S1004 is converted into the data type required by the function executed in step S805. Thereafter, in step S1007, the data whose type has been converted in step S1006 is output to the request source.
次に、ステップS807においてステップS1003以降の処理を行う場合について説明する。 Next, the case where the process after step S1003 is performed in step S807 will be described.
ステップS1003では、関数「GetValueType」を実行することで、バイナリXMLパーサ106が解析した結果を取得する。ステップS807では、関数「GetValueAsDouble」が実行されるので、バイナリXMLパーサ106はheightタグの型を取得することになり、図6に示したXML文書の場合、double型を取得する。従って、ステップS1003では、このdouble型を「型情報」として取得する。
In step S1003, the function “GetValueType” is executed to obtain a result analyzed by the
次に、ステップS1004では、関数「GetStringValue」を実行することで、バイナリXMLパーサ106が解析した結果を取得する。ステップS807では、関数「GetValueAsDouble」が実行されるので、バイナリXMLパーサ106はheightタグの内容を取得することになり、図6に示したXML文書の場合、実数値”160.5”を取得する。従って、ステップS1004では、この実数値”160.5”を取得する。
Next, in step S1004, the result of analysis by the
次にステップS1005では、ステップS807で実行した関数が要求するデータの型(依頼された型)と、ステップS1003で取得した型とが一致しているか否かを判断する。係る判断の結果、一致する場合には、処理をステップS1007に進める。図6に示したXML文書の場合、ステップS807で実行した関数が要求するデータの型はdouble型であるし、ステップS1003で取得した型もまたdouble型であるので、一致すると判断される。この場合、ステップS1007では、上記ステップS1004で取得したデータ(実数値)を、要求元(型対応アプリケーション111)に出力する。 In step S1005, it is determined whether the data type requested by the function executed in step S807 (requested type) matches the type acquired in step S1003. As a result of the determination, if they match, the process proceeds to step S1007. In the case of the XML document shown in FIG. 6, since the data type requested by the function executed in step S807 is a double type, and the type acquired in step S1003 is also a double type, it is determined that they match. In this case, in step S1007, the data (real value) acquired in step S1004 is output to the request source (type-compatible application 111).
一方、ステップS1005における判断の結果、一致していない場合には、処理をステップS1006に進める。ステップS1006では、ステップS1004で取得したデータの型を、ステップS807で実行した関数が要求するデータの型に変換する。そして、その後、ステップS1007では、ステップS1006で型を変換したデータを、上記要求元に対して出力する。 On the other hand, if the result of determination in step S1005 is that they do not match, the process proceeds to step S1006. In step S1006, the data type acquired in step S1004 is converted into the data type required by the function executed in step S807. Thereafter, in step S1007, the data whose type has been converted in step S1006 is output to the request source.
次に、図6に示したXML文書の代わりに、図7に示した構成を有するXML文書を処理対象とした場合における、コンピュータ100の動作について説明する。図7は、コンピュータ100による処理対象としてのXML文書の構成例を示す図である。図7に示す構成を有するXML文書は、図6に示したXML文書と同様の内容が記述されている個人情報データであるが、図6に示したXML文書がバイナリXML文書であるのに対し、図7に示すXML文書は、テキストXML文書である。
Next, the operation of the
タグ701は、このXML文書がテキスト形式のものであることを示すものである。
A
タグ702,703,705,706,708,709はそれぞれ、図6のタグ602,603,605,606,608,609に対応するもので、テキスト形式固有の表現となっている。
704,705はそれぞれ、人の名前を示す文字列、身長を示す実数値、であり、内容が異なるのみで、実質的には図6の604,607と同じである。 704 and 705 are a character string indicating a person's name and a real value indicating height, respectively, and are substantially the same as 604 and 607 in FIG.
図7に示したXML文書を処理対象とする場合に図8〜図10に示したフローチャートに従った処理を行う場合、図8〜図10ついて説明した上記処理と異なる点は以下の通りである。 When processing the XML document shown in FIG. 7 according to the flowcharts shown in FIGS. 8 to 10 when the XML document shown in FIG. 7 is to be processed, the following points are different from those described with reference to FIGS. .
ステップS902では、フォーマット判別部108を実行し、フォーマット判別部108に、上記ステップS802で開いたXML文書におけるマジックナンバー(図7における701)を取得させる。そして、フォーマット判別部108が取得したマジックナンバーを、共通XMLパーサ109が取得する。そしてこの取得したマジックナンバーを用いて、XML文書のフォーマットを判別する。即ち、XML文書がテキストXML文書であるのか、バイナリXML文書であるのかを判別する。図7に示したXML文書の場合、テキストXML文書と判別されることになる。従って、処理はステップS903を介してステップS904に進み、ステップS904では、共通XMLパーサ109は、テキストXMLパーサ105の関数「SetDocument」を呼び出し、XML文書をテキストXMLパーサ105に渡す。これにより、テキストXMLパーサ105にこのXML文書の解析を行わせる。
In step S902, the
先ず、ステップS1002では、上記ステップS902における判別処理の結果として、テキストXMLパーサ105、バイナリXMLパーサ106の何れに解析処理を行わせているのかを判別する。図7に示したXML文書の場合、テキストXMLパーサ105を用いてこのXML文書に対する解析処理を行わせていることになるので、処理はステップS1008に進むことになる。
First, in step S1002, it is determined which of the
ステップS1008以降の処理を、ステップS805において行う場合と、ステップS807において行う場合とに分けて説明する。 The processing after step S1008 will be described separately for the case where it is performed in step S805 and the case where it is performed in step S807.
先ず、ステップS805においてステップS1008以降の処理を行う場合について説明する。 First, the case where the process after step S1008 is performed in step S805 will be described.
ステップS1008では、関数「GetValue」を実行することで、テキストXMLパーサ105が解析した結果を取得する。ステップS805では、関数「GetValueAsString」が実行されるので、テキストXMLパーサ105はnameタグの内容を取得することになり、図7に示したXML文書の場合、文字列”Bob”を取得する。従って、ステップS1008では、この文字列”Alice”を取得する。
In step S1008, the function “GetValue” is executed to obtain the result of analysis by the
次にステップS1009では、ステップS805で実行した関数が要求するデータの型(依頼された型)が、string型(文字列型)若しくは指定無しであるか否かを判断する。係る判断の結果、string型若しくは指定無しである場合には、処理をステップS1007に進める。図7に示したXML文書の場合、ステップS805で実行した関数が要求するデータの型はstring型であるので、処理をステップS1007に進める。ステップS1007では、上記ステップS1008で取得したデータ(文字列)を、要求元(型対応アプリケーション111)に出力する。 In step S1009, it is determined whether the data type requested by the function executed in step S805 (requested type) is a string type (character string type) or not specified. If the result of this determination is string or no designation, the process advances to step S1007. In the case of the XML document shown in FIG. 7, since the data type requested by the function executed in step S805 is the string type, the process advances to step S1007. In step S1007, the data (character string) acquired in step S1008 is output to the request source (type-compatible application 111).
一方、ステップS1009における判断の結果、string型若しくは指定無しではない場合には、処理をステップS1010に進める。ステップS1010では、上記ステップS1006と同様の処理を行う。そして、その後、ステップS1007では、ステップS1010で型を変換したデータを、上記要求元に対して出力する。 On the other hand, if the result of determination in step S1009 is not string type or no designation, processing proceeds to step S1010. In step S1010, the same processing as in step S1006 is performed. Thereafter, in step S1007, the data whose type has been converted in step S1010 is output to the request source.
次に、ステップS807においてステップS1008以降の処理を行う場合について説明する。 Next, the case where the process after step S1008 is performed in step S807 will be described.
ステップS1008では、関数「GetValue」を実行することで、テキストXMLパーサ105が解析した結果を取得する。ステップS807では、関数「GetValueAsDouble」が実行されるので、テキストXMLパーサ105はheightタグの内容を取得することになり、図7に示したXML文書の場合、文字列”175.3”を取得する。従って、ステップS1008では、この文字列”175.3”を取得する。
In step S1008, the function “GetValue” is executed to obtain the result of analysis by the
次にステップS1009では、ステップS807で実行した関数が要求するデータの型(依頼された型)が、string型(文字列型)若しくは指定無しであるか否かを判断する。係る判断の結果、string型若しくは指定無しである場合には、処理をステップS1007に進める。一方、ステップS1009における判断の結果、string型、指定無しの何れでもない場合には、処理をステップS1010に進める。 In step S1009, it is determined whether the data type requested by the function executed in step S807 (requested type) is a string type (character string type) or not specified. If the result of this determination is string or no designation, the process advances to step S1007. On the other hand, if the result of determination in step S1009 is neither string type nor designation, the process proceeds to step S1010.
図7に示したXML文書の場合、ステップS807で実行した関数が要求するデータの型はdouble型(浮動小数点型)であり、string型、指定無しの何れでもない。従ってこの場合、処理をステップS1010に進める。 In the case of the XML document shown in FIG. 7, the type of data requested by the function executed in step S807 is a double type (floating point type), which is neither a string type nor an unspecified type. Therefore, in this case, the process proceeds to step S1010.
ステップS1010では、ステップS1008で取得したデータの型を、ステップS807で実行した関数が要求するデータの型に変換する。その結果、IEEE754形式の175.3という浮動小数値を取得することができる。 In step S1010, the data type acquired in step S1008 is converted into the data type required by the function executed in step S807. As a result, a floating point value of 175.3 in the IEEE 754 format can be acquired.
そして、その後、ステップS1007では、ステップS1010で型を変換したデータを、上記要求元に対して出力する。 Thereafter, in step S1007, the data whose type has been converted in step S1010 is output to the request source.
次に、レガシーアプリケーション110の動作について説明する。レガシーアプリケーション110は元々、バイナリXML文書を対象としていなかったものであるため、テキストXMLパーサ105のAPIを使用して作られている。このレガシーアプリケーション110が個人情報データを扱う場合にコンピュータ100が行う処理は、図11に示したフローチャートに従ったものとなる。
Next, the operation of the
図11は、レガシーアプリケーション110が個人情報データを扱う場合にコンピュータ100が行う処理のフローチャートである。
FIG. 11 is a flowchart of processing performed by the
ステップS1102〜ステップS1104、ステップS1106、ステップS1108はそれぞれ、図8に示したステップS802〜ステップS804、ステップS806、ステップS808と同じである。以下では、ステップS1105,S1107における処理について説明する。 Step S1102 to step S1104, step S1106, and step S1108 are the same as step S802 to step S804, step S806, and step S808 shown in FIG. 8, respectively. Hereinafter, processing in steps S1105 and S1107 will be described.
ステップS1105,S1107において、ノードの値はすべて関数「GetValue」を用いて取得する。ステップS1105,S1107における処理の詳細は、図10に示したフローチャートに従ったものとなる。 In steps S1105 and S1107, the values of all nodes are acquired using the function “GetValue”. Details of the processing in steps S1105 and S1107 are according to the flowchart shown in FIG.
この場合、テキストXMLパーサ105を用いることになるので、ステップS1002からステップS1008に処理を進めることになる。
In this case, since the
ステップS1008では、関数「GetValue」を実行することで、テキストXMLパーサ105が解析した結果を取得するので、ステップS1105では、図6に示したXML文書の場合、文字列”Alice”を取得する。従って、ステップS1008では、この文字列”Alice”を取得する。
In step S1008, the function “GetValue” is executed to obtain the result of analysis by the
次に、ステップS1105で実行した関数が要求するデータの型(依頼された型)はstring型であるので、処理をステップS1009を介してステップS1007に進める。ステップS1007では、上記ステップS1008で取得したデータ(文字列)を、要求元(型対応アプリケーション111)に出力する。 Next, since the data type requested by the function executed in step S1105 (requested type) is the string type, the process proceeds to step S1007 via step S1009. In step S1007, the data (character string) acquired in step S1008 is output to the request source (type-compatible application 111).
また、ステップS1008では、関数「GetValue」を実行することで、テキストXMLパーサ105が解析した結果を取得するので、ステップS1107では、図6に示したXML文書の場合、文字列”160.5”を取得する。従って、ステップS1008では、この文字列”160.5”を取得する。
In step S1008, the function “GetValue” is executed to obtain the result of analysis by the
次に、ステップS1107で実行した関数が要求するデータの型(依頼された型)はdouble型(浮動小数点型)であり、string型ではないので、処理をステップS1009を介してステップS1010に進める。 Next, since the data type requested by the function executed in step S1107 (requested type) is a double type (floating point type) and not a string type, the process proceeds to step S1010 via step S1009.
ステップS1010では、ステップS1008で取得したデータの型を、ステップS1107で実行した関数が要求するデータの型に変換する。その結果、IEEE754形式の160.5という浮動小数値を取得することができる。 In step S1010, the data type acquired in step S1008 is converted to the data type required by the function executed in step S1107. As a result, a floating point value of 160.5 in the IEEE754 format can be acquired.
そしてその後、ステップS1007では、この浮動小数値160.5を上記要求元に対して出力する。 Thereafter, in step S1007, the floating point value 160.5 is output to the request source.
このようにして、レガシーアプリケーション110はバイナリXML文書から値を取得することができる。
In this way,
レガシーアプリケーション110に対してテキストXML文書が渡された場合、共通XMLパーサ109は特別な処理を行わず、テキストXMLパーサ105の単なるラッパとして振舞うことになるため、正常に値を取得することができる。
When a text XML document is passed to the
以上説明したように、本実施形態によれば、共通XMLパーサ109は、2種類のアプリケーションと2種類の形式のXML文書の組み合わせ、つまり計4つの場合のすべてにおいて正しく値を取得する機能を提供することができる。
As described above, according to the present embodiment, the
さらに、型対応アプリケーション111がバイナリXML文書を扱う場合は、途中で値の型の変換が行われないため、無駄のない高速な処理が可能となる。これにより、XML文書を使用するアプリケーションにおいて、バイナリXML文書を用いた高速な処理をサポートし、かつテキストXML文書も扱うことを可能にする。
Further, when the type-
また、テキストXML文書用に作成されたアプリケーションでバイナリXML文書を扱うことが可能になる。 In addition, a binary XML document can be handled by an application created for a text XML document.
[第2の実施形態]
図12は、本実施形態に係る構造化文書処理装置に適用可能なコンピュータ1200のハードウェア構成を示すブロック図である。図12において、図1に示したものと同じものについては同じ番号を付けており、その説明は省略する。即ち、図12に示した構成は、図1に示したバイナリXMLパーサ106の代わりに、Fast Infosetパーサ1206が記憶装置104内に保存されている構成となっている。
[Second Embodiment]
FIG. 12 is a block diagram showing a hardware configuration of a
Fast Infosetパーサ1206は、バイナリXMLフォーマットの一つであるFast Infoset形式のXML文書を解析するパーサである。
A
本実施形態において、型対応アプリケーション111による処理対象となるXML文書の一例を、図13,14に示す。図14は、テキストXML文書の構成例を示す図であり、図13は、図14に示したXML文書をFast Infoset形式で表現した場合の構成例を示す図である。
In this embodiment, an example of an XML document to be processed by the
図13において、1301で示す「E000」はマジックナンバーであり、係るXML文書がFast Infoset形式であることを示している。
In FIG. 13, “E000” indicated by
次の1302で示す「0001」はFast Infosetのバージョンであり、この例では1である。 Next, “0001” indicated by 1302 is the version of Fast Infoset, which is 1 in this example.
次の1303で示す「00」はオプションとなるデータの存在を示すものであり、「00」は存在しないことを意味する。 Next, “00” indicated by 1303 indicates the existence of optional data, and “00” means that there is no data.
次の1304で示す「3C00」は1ビットごとに意味を持つため多くの意味を持つが、主に次のノードが要素であることを意味している。他に、属性の有無や名前空間名の存在、要素名のバイト数などの情報も含まれているが、ここでの説明の本質とは関連が薄いため詳細な説明は省略する。 “3C00” indicated by the next 1304 has many meanings because it has a meaning for each bit, but it mainly means that the next node is an element. In addition, information such as presence / absence of attribute, existence of namespace name, number of bytes of element name, and the like are included.
次の1305で示す「61」はUTF−8でエンコードされた要素名「a」である。 Next, “61” indicated by 1305 is an element name “a” encoded by UTF-8.
次の1306で示す「9C1A」という2バイトも同様に多くの意味を持つが、主に次のノードが要素の内容であり、またその値が浮動小数型であることを意味している。その他にもバイト数などの情報も含まれている。 The next two bytes “9C1A” shown by 1306 have many meanings as well, but mainly the next node is the content of the element, and the value is a floating-point type. In addition, information such as the number of bytes is also included.
次の1307で示す「C2ED4000」はIEEE754形式でエンコードされた−118.625という浮動小数の値である。 Next, “C2ED4000” indicated by 1307 is a floating-point value of −118.625 encoded in the IEEE754 format.
最後の1308で示す「FF」は、はじめのFが要素の終端、次のFが文書の終端を表している。すなわち、図13に示したXML文書は、図14のテキストXML文書とほぼ同じ意味である。また文書の意味だけでなく、ノードの出現する順序も同じである。 “FF” shown at the last 1308 represents the end of the element, and the next F represents the end of the document. That is, the XML document shown in FIG. 13 has almost the same meaning as the text XML document shown in FIG. In addition to the meaning of the document, the order in which the nodes appear is the same.
ここで、型対応アプリケーション111が、図13に示したa要素の値を取得する場合は、図15に示したフローチャートに従った処理を、共通XMLパーサ109が行う。
Here, when the
図15は、型対応アプリケーション111が、図13に示したa要素の値を取得する場合に、コンピュータ1200が行う処理のフローチャートである。
FIG. 15 is a flowchart of processing performed by the
先ず、ステップS1502では、関数「SetDocument」を実行し、図13に示すXML文書を開く。なお、ステップS1502における処理を行うと、図9に示したフローチャートに従った処理が第1の実施形態と同様に開始される。なお、図9のフローチャートに従った処理において、フォーマットの判別処理は、Fast Infoset形式であるか否かを判断するのであるが、これは、マジックナンバーとして「E000」が記述されているのかを判断することで行う。マジックナンバーとして「E000」が記述されていれば、Fast Infosetパーサ1206を使用する。記述されていなければ、テキストXMLパーサ105を使用する。
First, in step S1502, the function “SetDocument” is executed to open the XML document shown in FIG. When the process in step S1502 is performed, the process according to the flowchart shown in FIG. 9 is started in the same manner as in the first embodiment. In the process according to the flowchart of FIG. 9, the format determination process determines whether or not the Fast Infoset format is used, and this determines whether or not “E000” is described as the magic number. To do. If “E000” is described as the magic number, the
次にステップS1503では、関数「Read」を実行し、係る実行により進めた現在の参照位置に対して関数「GetNodeType」、関数「GetName」を実行する。そして、関数「GetNodeType」の返り値が開始タグ、且つ関数「GetName」による返り値が「a」となるまで、関数「Read」を実行する。Fast Infoset形式もテキストXML形式と同様、まず要素の開始を表すバイト列と要素の名前を示すバイト列が現れるため、最初のノードは開始タグaとなる。 In step S1503, the function “Read” is executed, and the function “GetNodeType” and the function “GetName” are executed on the current reference position advanced by the execution. Then, the function “Read” is executed until the return value of the function “GetNodeType” is the start tag and the return value of the function “GetName” is “a”. Similarly to the text XML format in the Fast Infoset format, first, a byte sequence indicating the start of an element and a byte sequence indicating the name of the element appear, so the first node is a start tag a.
次にステップS1504では、関数「GetValueAsDouble」を実行し、aタグ(要素)の内容、即ち、「−118.625」を実数値として取得する。ステップS1504における処理の詳細については、図10に示したフローチャートに従ったものとなる。 In step S1504, the function “GetValueAsDouble” is executed to acquire the content of the a tag (element), that is, “−118.625” as a real value. Details of the processing in step S1504 are according to the flowchart shown in FIG.
即ち、Fast Infosetパーサ1206を使用しているため、先ず、ステップS1003では、Fast Infosetパーサ1206からデータの型情報を受け取る。Fast Infosetパーサ1206は図13の1306で示す「9C1A」の部分により、このデータの値が浮動小数であることを判断するので、double型を型情報として返す。そしてステップS1004では、その型で値、つまり「−118.625」を取得する。
That is, since the
次にステップS1005では、ステップS1504で実行した関数が要求するデータの型(依頼された型)と、ステップS1003で取得した型とが一致しているか否かを判断する。係る判断の結果、一致する場合には、処理をステップS1007に進める。図13に示したXML文書の場合、ステップS1504で実行した関数が要求するデータの型はdouble型であるし、ステップS1003で取得した型もまたdouble型であるので、一致すると判断される。この場合、ステップS1007では、上記ステップS1004で取得したデータ(実数値)を、要求元(型対応アプリケーション111)に出力する。 In step S1005, it is determined whether the data type requested by the function executed in step S1504 (requested type) matches the type acquired in step S1003. As a result of the determination, if they match, the process proceeds to step S1007. In the case of the XML document shown in FIG. 13, since the data type requested by the function executed in step S1504 is a double type, and the type acquired in step S1003 is also a double type, it is determined that they match. In this case, in step S1007, the data (real value) acquired in step S1004 is output to the request source (type-compatible application 111).
これにより、無駄な変換を行うことなく、アプリケーションにデータを渡すことができる。 As a result, data can be passed to the application without performing unnecessary conversion.
なお、図14に示したテキストXML文書を処理対象とする場合であっても、第1の実施形態と同様に処理すれば良い。 Even if the text XML document shown in FIG. 14 is a processing target, the processing may be performed in the same manner as in the first embodiment.
以上のようにして、従来のテキストXML形式のXML文書とFast Infoset形式の文書の両方に対応可能で、かつ無駄なデータ型変換を行わずに処理が可能な構造化文書処理装置が実現できる。 As described above, it is possible to realize a structured document processing apparatus that can handle both an XML document in the conventional text XML format and a Fast Infoset format document and that can perform processing without performing unnecessary data type conversion.
ここで、上記コンピュータ100、1200としては、携帯電話や複写機など、XML文書が使用可能な通信機器を用いることができる。
Here, as the
[その他の実施形態]
また、本発明の目的は、以下のようにすることによって達成されることはいうまでもない。即ち、前述した実施形態の機能を実現するソフトウェアのプログラムコードを記録した記録媒体(または記憶媒体)を、システムあるいは装置に供給する。係る記憶媒体は言うまでもなく、コンピュータ読み取り可能な記憶媒体である。そして、そのシステムあるいは装置のコンピュータ(またはCPUやMPU)が記録媒体に格納されたプログラムコードを読み出し実行する。この場合、記録媒体から読み出されたプログラムコード自体が前述した実施形態の機能を実現することになり、そのプログラムコードを記録した記録媒体は本発明を構成することになる。
[Other Embodiments]
Needless to say, the object of the present invention can be achieved as follows. That is, a recording medium (or storage medium) in which a program code of software that realizes the functions of the above-described embodiments is recorded is supplied to the system or apparatus. Needless to say, such a storage medium is a computer-readable storage medium. Then, the computer (or CPU or MPU) of the system or apparatus reads and executes the program code stored in the recording medium. In this case, the program code itself read from the recording medium realizes the functions of the above-described embodiment, and the recording medium on which the program code is recorded constitutes the present invention.
また、コンピュータが読み出したプログラムコードを実行することにより、そのプログラムコードの指示に基づき、コンピュータ上で稼働しているオペレーティングシステム(OS)などが実際の処理の一部または全部を行う。その処理によって前述した実施形態の機能が実現される場合も含まれることは言うまでもない。 Further, by executing the program code read by the computer, an operating system (OS) or the like running on the computer performs part or all of the actual processing based on the instruction of the program code. Needless to say, the process includes the case where the functions of the above-described embodiments are realized.
さらに、記録媒体から読み出されたプログラムコードが、コンピュータに挿入された機能拡張カードやコンピュータに接続された機能拡張ユニットに備わるメモリに書込まれたとする。その後、そのプログラムコードの指示に基づき、その機能拡張カードや機能拡張ユニットに備わるCPUなどが実際の処理の一部または全部を行い、その処理によって前述した実施形態の機能が実現される場合も含まれることは言うまでもない。 Furthermore, it is assumed that the program code read from the recording medium is written in a memory provided in a function expansion card inserted into the computer or a function expansion unit connected to the computer. After that, based on the instruction of the program code, the CPU included in the function expansion card or function expansion unit performs part or all of the actual processing, and the function of the above-described embodiment is realized by the processing. Needless to say.
本発明を上記記録媒体に適用する場合、その記録媒体には、先に説明したフローチャートに対応するプログラムコードが格納されることになる。 When the present invention is applied to the recording medium, program code corresponding to the flowchart described above is stored in the recording medium.
Claims (6)
構造化文書のフォーマットを取得する取得手段と、
前記取得手段が取得したフォーマットに応じた解析方法で、前記構造化文書を解析する解析手段と、
前記構造化文書中に記されている要素を、指定された型で取得する要求を受け付ける手段と、
前記要素について前記解析手段が解析した型と、前記指定された型とが一致しているか否かを判断する判断手段と、
前記判断手段が一致していると判断した場合には前記要素を要求元に出力し、前記判断手段が一致していないと判断した場合には前記要素の型を前記指定された型に変換してから当該要素を前記要求元に出力する出力手段と
を備えることを特徴とする構造化文書処理装置。 A structured document processing apparatus for processing a structured document,
An acquisition means for acquiring the format of the structured document;
Analysis means for analyzing the structured document by an analysis method according to the format acquired by the acquisition means;
Means for receiving a request for acquiring an element described in the structured document in a specified type;
Determining means for determining whether or not the type analyzed by the analyzing means for the element matches the specified type;
When the determination means determines that they match, the element is output to the request source. When the determination means determines that they do not match, the element type is converted to the specified type. A structured document processing apparatus, comprising: an output unit that outputs the element to the request source.
前記取得手段が取得したフォーマットがバイナリXMLである場合には、前記バイナリXMLパーサによって前記構造化文書を解析し、
前記取得手段が取得したフォーマットがテキストXMLである場合には、前記テキストXMLパーサによって前記構造化文書を解析する
ことを特徴とする請求項1に記載の構造化文書処理装置。 The analysis means is composed of a binary XML parser and a text XML parser,
If the format acquired by the acquisition unit is binary XML, the structured document is analyzed by the binary XML parser,
The structured document processing apparatus according to claim 1, wherein when the format acquired by the acquiring unit is text XML, the structured document is analyzed by the text XML parser.
前記取得手段が取得したフォーマットがFast Infoset形式である場合には、前記Fast Infosetパーサによって前記構造化文書を解析し、
前記取得手段が取得したフォーマットがテキストXMLである場合には、前記テキストXMLパーサによって前記構造化文書を解析する
ことを特徴とする請求項1に記載の構造化文書処理装置。 The analysis means includes a Fast Infoset parser and a text XML parser.
When the format acquired by the acquisition unit is a Fast Infoset format, the structured document is analyzed by the Fast Infoset parser,
The structured document processing apparatus according to claim 1, wherein when the format acquired by the acquiring unit is text XML, the structured document is analyzed by the text XML parser.
構造化文書のフォーマットを取得する取得工程と、
前記取得工程で取得したフォーマットに応じた解析方法で、前記構造化文書を解析する解析工程と、
前記構造化文書中に記されている要素を、指定された型で取得する要求を受け付ける工程と、
前記要素について前記解析工程で解析した型と、前記指定された型とが一致しているか否かを判断する判断工程と、
前記判断工程で一致していると判断した場合には前記要素を要求元に出力し、前記判断工程で一致していないと判断した場合には前記要素の型を前記指定された型に変換してから当該要素を前記要求元に出力する出力工程と
を備えることを特徴とする構造化文書処理方法。 A structured document processing method performed by a structured document processing apparatus for processing a structured document,
An acquisition process for acquiring the format of the structured document;
In the analysis method according to the format acquired in the acquisition step, an analysis step of analyzing the structured document;
Receiving a request to acquire an element described in the structured document with a specified type;
A determination step of determining whether or not the type analyzed in the analysis step for the element matches the designated type;
If it is determined in the determination step that the elements match, the element is output to the request source. If it is determined in the determination step that the elements do not match, the element type is converted to the specified type A structured document processing method comprising: an output step of outputting the element to the request source.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007226694A JP2009059215A (en) | 2007-08-31 | 2007-08-31 | Structured document processor, and structured document processing method |
| US12/196,565 US20090063954A1 (en) | 2007-08-31 | 2008-08-22 | Structured document processing apparatus and structured document processing method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007226694A JP2009059215A (en) | 2007-08-31 | 2007-08-31 | Structured document processor, and structured document processing method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2009059215A true JP2009059215A (en) | 2009-03-19 |
| JP2009059215A5 JP2009059215A5 (en) | 2010-07-08 |
Family
ID=40409412
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007226694A Withdrawn JP2009059215A (en) | 2007-08-31 | 2007-08-31 | Structured document processor, and structured document processing method |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US20090063954A1 (en) |
| JP (1) | JP2009059215A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012203819A (en) * | 2011-03-28 | 2012-10-22 | Toshiba Corp | Encoder compiler, program and communication apparatus |
| JP2012203826A (en) * | 2011-03-28 | 2012-10-22 | Toshiba Corp | Decoder compiler, program and communication apparatus |
| JP2013089183A (en) * | 2011-10-21 | 2013-05-13 | Toshiba Corp | Exi decoder and program |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IL286639B2 (en) * | 2015-01-29 | 2023-10-01 | Quantum Metric Inc | Techniques for compact data storage of network traffic and efficient search thereof |
| CN110309007A (en) * | 2019-07-02 | 2019-10-08 | 深圳市友华通信技术有限公司 | The display output method and device of D-Bus |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20040015840A1 (en) * | 2001-04-19 | 2004-01-22 | Avaya, Inc. | Mechanism for converting between JAVA classes and XML |
| US8695018B2 (en) * | 2003-10-07 | 2014-04-08 | Nokia Corporation | Extensible framework for handling different mark up language parsers and generators in a computing device |
| JP4916145B2 (en) * | 2005-08-08 | 2012-04-11 | キヤノン株式会社 | Information processing apparatus, information processing method, and program |
-
2007
- 2007-08-31 JP JP2007226694A patent/JP2009059215A/en not_active Withdrawn
-
2008
- 2008-08-22 US US12/196,565 patent/US20090063954A1/en not_active Abandoned
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012203819A (en) * | 2011-03-28 | 2012-10-22 | Toshiba Corp | Encoder compiler, program and communication apparatus |
| JP2012203826A (en) * | 2011-03-28 | 2012-10-22 | Toshiba Corp | Decoder compiler, program and communication apparatus |
| US8700680B2 (en) | 2011-03-28 | 2014-04-15 | Kabushiki Kaisha Toshiba | Decoder compiler, computer readable medium, and communication device |
| JP2013089183A (en) * | 2011-10-21 | 2013-05-13 | Toshiba Corp | Exi decoder and program |
Also Published As
| Publication number | Publication date |
|---|---|
| US20090063954A1 (en) | 2009-03-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP1038219B1 (en) | Apparatus and method for allowing object-oriented programs created with different framework versions to communicate | |
| JP5044942B2 (en) | System and method for determining acceptance status in document analysis | |
| JP2009059215A (en) | Structured document processor, and structured document processing method | |
| JP2012128853A (en) | System and method for processing xml documents | |
| US20110153531A1 (en) | Information processing apparatus and control method for the same | |
| JP2004341671A (en) | Information processing system, control method, control program and recording medium | |
| CN115796190B (en) | Front-end internationalization multi-language conversion method and system based on vue and weback | |
| CN117749899A (en) | Protocol conversion framework, device communication method, device and computer storage medium | |
| EP1677206B1 (en) | Methods and systems for preserving unknown markup in a strongly typed environment | |
| JP2007293548A (en) | Information processor and information processing method | |
| US20070239780A1 (en) | Simultaneous capture and analysis of media content | |
| CN113297425A (en) | Document conversion method, device, server and storage medium | |
| WO2001082121A2 (en) | Pre-computing and encoding techniques for an electronic document to improve run-time processing | |
| JP5168791B2 (en) | Acceptance status display system and method | |
| CN109358845A (en) | Method, tool and the storage medium of JS code are write based on XMPP protocol | |
| JP2009301538A (en) | Service flow processing apparatus and method | |
| CN111143310B (en) | Log recording method and device and readable storage medium | |
| WO2006104506A1 (en) | Methods and systems for transferring binary data | |
| JP5207886B2 (en) | Document encoding apparatus and document encoding method | |
| JP5409090B2 (en) | Information processing apparatus, information processing method, program, and storage medium | |
| JP2003196269A (en) | Method for analyzing document represented in markup language | |
| JPWO2005101210A1 (en) | Data analysis apparatus and data analysis program | |
| US8386922B2 (en) | Information processing apparatus and information processing method | |
| JP2004362343A (en) | Source code conversion apparatus, source code conversion method, and program | |
| JP2004234405A (en) | Protocol encoder/decoder |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20100520 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20100520 |
|
| A761 | Written withdrawal of application |
Free format text: JAPANESE INTERMEDIATE CODE: A761 Effective date: 20111212 |