JP2008511936A - Method and system for semantic identification in a data system - Google Patents
Method and system for semantic identification in a data system Download PDFInfo
- Publication number
- JP2008511936A JP2008511936A JP2007530351A JP2007530351A JP2008511936A JP 2008511936 A JP2008511936 A JP 2008511936A JP 2007530351 A JP2007530351 A JP 2007530351A JP 2007530351 A JP2007530351 A JP 2007530351A JP 2008511936 A JP2008511936 A JP 2008511936A
- Authority
- JP
- Japan
- Prior art keywords
- data
- item
- identifier
- semantic
- items
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images













Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Machine Translation (AREA)
Abstract
【課題】 機能の使用、再使用および変更を変化するビジネス環境において可能にするデータ統合システム・ツールを提供すること。
【解決手段】 追加のデータを必要とすることなく、他のアイテムとの関係に基づいてアイテムの識別を可能にする意味識別子と、データ、メタデータ、意味識別子その他のアイテムを、あるフォーマット、言語、および/またはデータ・モデルから他のものに変換することができる変換エンジンと、アイテムの多数のインスタンスまたは形式の区別を可能にする、ハブまたはデータベースの抽象化プロパティ・レベルとに関連する方法およびシステムが提供される。
【選択図】 図1PROBLEM TO BE SOLVED: To provide a data integration system tool that enables use, reuse, and change of functions in a changing business environment.
Semantic identifiers that enable identification of items based on their relationship to other items without the need for additional data, data, metadata, semantic identifiers and other items in a certain format, language , And / or methods associated with the conversion engine that can convert from the data model to the other, and the abstract property level of the hub or database that allows for the distinction of multiple instances or forms of items and A system is provided.
[Selection] Figure 1
Description
本発明は、情報技術の分野に関し、より特定的には、データ統合システムの分野に関する。 The present invention relates to the field of information technology, and more particularly to the field of data integration systems.
コンピュータ・アプリケーションの出現によって、多くのビジネス・プロセスがより速く、より効率的なものとなった。しかし、異なるデータ構造、通信プロトコル、言語およびプラットフォームを使用する異なるコンピュータ・アプリケーションが急増したことによって、一般的な企業のITインフラストラクチャが極めて複雑になってきている。典型的な企業内における異なるビジネス・プロセスにおいて、企業全体ではなく特定のビジネス・プロセスのために各々が開発され最適化されたコンピュータ・アプリケーションが使用されている場合がある。例えば、ある企業が、支払勘定を追跡するための特定のコンピュータ・アプリケーションと、顧客とのコンタクトの履歴を追跡するためのコンピュータ・アプリケーションを有している場合がある。実際、集中顧客コンタクト・データベースを保持するが、従業員は個人情報マネージャなどに彼ら自身のコンタクト情報を保持する場合などでは、企業は同一のビジネス・プロセスであっても2つ以上のコンピュータ・アプリケーションを使用する場合がある。 With the advent of computer applications, many business processes have become faster and more efficient. However, with the proliferation of different computer applications using different data structures, communication protocols, languages and platforms, the typical enterprise IT infrastructure has become extremely complex. Different business processes within a typical enterprise may use computer applications that are each developed and optimized for a specific business process rather than the entire enterprise. For example, a company may have a specific computer application for tracking payment accounts and a computer application for tracking the history of customer contacts. In fact, it maintains a centralized customer contact database, but when employees maintain their own contact information, such as in a personal information manager, a company may have more than one computer application, even in the same business process. May be used.
特定用途のコンピュータ・アプリケーションによれば顧客に適合したソリューションを提供することができるという利点を得ることができるが、特定用途のコンピュータ・アプリケーションが多くなると、同じデータを企業全体で何度も繰り返し入力して処理する必要が生じたり、企業が1つのプロセスと関連するデータから利益を受ける他のプロセスを実行するときにそのデータを利用できないというような非効率につながってしまう場合がある。例えば、支払勘定プロセスがサプライ・チェーンおよび注文プロセスから分離された場合には、企業は、その企業が注文を拒絶するであろう信用履歴をもつ顧客からの注文を受け付け、応じてしまう可能性がある。他にも、様々なコンピュータ・アプリケーション全体にわたるデータのすべてに対して矛盾のないアクセスから企業が利益を得ることになる数多くの例がある。 Special-purpose computer applications offer the advantage of being able to provide a tailored solution to the customer, but the more specific-use computer applications, the same data is repeatedly entered throughout the enterprise This may lead to inefficiencies such as the need to process, or when a company executes other processes that benefit from data associated with one process. For example, if the payment account process is separated from the supply chain and ordering process, the company may accept and respond to orders from customers with a credit history that the company will reject the order. is there. There are many other examples where companies can benefit from consistent access to all of the data across various computer applications.
多くの会社が、企業における異なるアプリケーション間でデータを共有する必要性を認識し、これに取り組んできた。このようにして、エンタープライズ・アプリケーション統合すなわちEAIが、異なるソースからのデータを処理するためのメッセージ・ベースの戦略として登場した。コンピュータ・アプリケーションの複雑さと数が増加するにつれて、EAIへの取り組みは、異なるプロトコルを処理する必要性、増え続けるデータおよびトランザクションを処理する必要性、ならびに、増え続けるデータのより高速な統合に対する要求を含む多くの課題に直面する。最小公分母アプローチ、アトミック・アプローチおよびブリッジ型アプローチを含む、EAIに対する様々なアプローチが実施されている。しかし、EAIは、個々のアプリケーション間の通信に基づくものである。重大な課題は、プラットフォームおよびアプリケーションの直線的な追加に応じて、EAIソリューションの複雑さが幾何学的に増大することである。 Many companies have recognized and addressed the need to share data between different applications in the enterprise. In this way, enterprise application integration or EAI has emerged as a message-based strategy for processing data from different sources. As the complexity and number of computer applications increase, EAI efforts address the need to handle different protocols, the need to handle increasing data and transactions, and the demand for faster integration of increasing data. Face many challenges, including Various approaches to EAI have been implemented, including the lowest common denominator approach, atomic approach and bridged approach. However, EAI is based on communication between individual applications. A significant challenge is that the complexity of the EAI solution increases geometrically with the linear addition of platforms and applications.
データ統合システムが企業の必要性に対処するための有用なツールをもたらす一方で、こうしたシステムが、典型的には、顧客ソリューションとして導入されている。このようなシステムは、長期にわたる開発サイクルを伴い、ビジネス構造および情報要求の変化に対応するために高度な技術的なトレーニングを必要とすることがある。変化するビジネス環境において、機能の使用、再使用および変更を可能にするデータ統合システム・ツールに対する必要性が残っている。こうしたツールの1つは、あるアイテムを、追加的なデータを必要とすることなく他のアイテムとの関係に基づいて一意的に識別することを可能にする意味識別子(semantic identifier)である。変換エンジンは、データ、メタデータ、意味識別子および他のアイテムを、あるフォーマット、言語、および/またはデータ・モデルから他のものに変換することができるツールである。最終的には、ハブまたはデータベースの抽象化プロパティ・レベルにより、アイテムの多数のインスタンスまたは形式の区別が可能になる。 While data integration systems provide useful tools to address enterprise needs, such systems are typically deployed as customer solutions. Such a system involves a long development cycle and may require advanced technical training to respond to changes in business structure and information requirements. There remains a need for data integration system tools that allow the use, reuse, and change of functionality in a changing business environment. One such tool is a semantic identifier that allows an item to be uniquely identified based on relationships with other items without requiring additional data. A conversion engine is a tool that can convert data, metadata, semantic identifiers, and other items from one format, language, and / or data model to another. Ultimately, the abstract property level of the hub or database allows the distinction between multiple instances or types of items.
アイテムについて意味識別子を存在させることができる。アイテムは、オブジェクト、データ・アイテム、データ、列、行、テーブル、データベース、インスタンス、属性、メタデータ、概念、トピック、主題、意味識別子、他の識別子、RFIDタグ、ベンダー、供給業者、顧客、人、チーム、組織、ユーザ、ネットワーク、システム、装置、家族、店、製品、製造ライン、製品特性、製品仕様、製品属性、価格、コスト、材料仕様書、出荷データ、税金データ、コース、教育プログラム、位置、地図、部門、組織、有機的組織体、プロセス、規則、法、評価システム、商品、サービスおよびサービス提供、あるいは他のアイテムまたは概念とすることができる。アイテムは、データ統合ジョブおよび/またはデータ統合プラットフォームに関連付けることができる。意味識別子は、アイテムと1以上の他のアイテムとの関係に基づいて、アイテムを識別することができる。関係は、関係の不存在とすることもできる。関係は、意味に基づくものとすることができる。関係は、関係階層におけるアイテムの位置を含むことができる。 There can be a semantic identifier for the item. Item is object, data item, data, column, row, table, database, instance, attribute, metadata, concept, topic, subject, semantic identifier, other identifier, RFID tag, vendor, supplier, customer, person Teams, organizations, users, networks, systems, equipment, families, stores, products, production lines, product characteristics, product specifications, product attributes, prices, costs, material specifications, shipping data, tax data, courses, educational programs, It can be a location, map, department, organization, organic organization, process, rule, law, rating system, product, service and service offering, or other item or concept. An item can be associated with a data integration job and / or a data integration platform. A semantic identifier can identify an item based on the relationship between the item and one or more other items. A relationship can also be the absence of a relationship. The relationship can be based on meaning. The relationship can include the position of the item in the relationship hierarchy.
意味識別子は、アイテムについての固有の識別子とすることができる。アイテムについての固有の意味識別子が、アイテムと他のアイテムとのすべての関係より少ない数の関係を考えることが可能である。一意性を確実にするために、最小数の関係に基づいた意味識別子を作成することが有利である。アイテムについての固有の意味識別子を作成するのに必要とされる関係の数は、コンテキストによって異なり得る。意味識別子は、コンテキスト依存のものとすることができる。意味識別子は、動的なものとすることができる。 The semantic identifier can be a unique identifier for the item. It is possible to consider a relationship where the number of unique semantic identifiers for an item is less than all relationships between the item and other items. In order to ensure uniqueness, it is advantageous to create semantic identifiers based on a minimum number of relationships. The number of relationships required to create a unique semantic identifier for an item can vary from context to context. The semantic identifier can be context dependent. The semantic identifier can be dynamic.
意味識別子は、文字列構造またはフォーマットで格納し、維持し、記録し、処理し、および/または解釈することができる構文の形で格納し、維持し、記録し、処理し、および/または解釈することができる。構文および/または文字列構造またはフォーマットは、構文解析可能である。構文および/または文字列構造またはフォーマットは、切り捨て、修正し、短縮し、構文解析し、または再配列することができる。構文および/または文字列を切り捨て、修正し、短縮し、または再配列し、依然として意味識別子を保持することが可能である。特定のコンテキストにおいて、より短い構文および/または文字列は有用であり、性能を増大させることができる。 Semantic identifiers are stored, maintained, recorded, processed, and / or interpreted in a syntax that can be stored, maintained, recorded, processed, and / or interpreted in a string structure or format. can do. The syntax and / or string structure or format can be parsed. The syntax and / or string structure or format can be truncated, modified, shortened, parsed, or rearranged. It is possible to truncate, modify, shorten, or rearrange the syntax and / or string and still retain the semantic identifier. In certain contexts, shorter syntaxes and / or strings are useful and can increase performance.
意味識別子は、企業の方法におけるステップ、データベース内のデータ、行または列内のデータ、テーブル内の行または列、データベース内の行または列、テーブル内のデータ、データ内のテーブル、データベース内のメタデータ、ハブまたはリポジトリ内のアイテム、データベース内のアイテム、テーブル内のアイテム、列内のアイテム、行内のアイテム、組織内の人、通信の送信者または受信者、ネットワーク上のユーザ、ネットワーク上のシステム、ネットワーク上の装置、家族内の人、店の中の品目、メニュー上の料理、製造ライン内の製品、製品提供における製品、教育プログラムまたは訓練プログラムにおけるコースまたはステップ、地図上の位置、アイテムの位置、組織の部門、チームの人、規則システムにおける規則、サービス・スイートにおけるサービス、企業の組織階層内のエンティティ、供給チェーン内のエンティティ、マーケットにおける顧客、購買決定における購入者、商品またはサービスの価格、商品またはサービスのコスト、製造またはシステムの構成部品、方法のステップ、および/またはグループのメンバーのような意味コンテキストと関連付けることができる。 A semantic identifier is a step in an enterprise method, data in a database, data in a row or column, row or column in a table, row or column in a database, data in a table, table in data, meta in database Data, items in the hub or repository, items in the database, items in the table, items in the column, items in the row, people in the organization, sender or receiver of the communication, users on the network, systems on the network Devices on the network, people in the family, items in the store, dishes on the menu, products in the production line, products in the product offering, courses or steps in the educational or training program, location on the map, item Location, organizational unit, team person, rules in the rules system, services Services in the business suite, entities in the corporate organizational hierarchy, entities in the supply chain, customers in the market, purchasers in purchase decisions, prices of goods or services, costs of goods or services, manufacturing or system components, methods And / or a semantic context such as a member of a group.
実施形態において、データベースは、列を持ったテーブルを有することができる。その列についての固有の意味識別子は、「データベース名のテーブル名の列名」とすることができる。この固有の意味識別子は、次の構文、すなわち「列名::テーブル名::データベース名」を用いて、格納され、維持され、記録され、処理され、および/または解釈される。構文および/または任意の関連した文字列を構文解析することができ、不必要な要素を除去することができる。例えば、1つのデータベースだけが存在する場合には、以下の構文は、列::列名::テーブル名についての固有の識別子を依然として生成することができる。固有の意味識別子を作成するのに、データベース関係は必要とされない。他の例において、データベースは、1つのテーブルしか有することができないので、以下の構文は、列::列名::データベース名についての固有の識別子とすることができる。固有の識別子を作成するのに、テーブル関係は必要とされない。より短い構文および/または文字列を使用することにより、処理の回数が減少し、効率が増大される。 In an embodiment, the database may have a table with columns. The unique semantic identifier for the column can be “column name of table name of database name”. This unique semantic identifier is stored, maintained, recorded, processed, and / or interpreted using the following syntax: “column name :: table name :: database name”. The syntax and / or any associated string can be parsed and unnecessary elements can be removed. For example, if there is only one database, the following syntax can still generate a unique identifier for the column :: column name :: table name. Database relationships are not required to create unique semantic identifiers. In another example, since the database can have only one table, the following syntax can be a unique identifier for column :: column name :: database name. Table relationships are not required to create unique identifiers. By using shorter syntax and / or strings, the number of operations is reduced and efficiency is increased.
変換エンジンは、1以上の意味識別子、データベース、意味識別子を含むデータベース、情報システム、意味識別子、または他のアイテムを含む情報システムに対して変換操作を行うことができる。変換操作は、意味識別子のフォーマット、言語、および/またはデータ・モデルを変換するか、または他の方法で修正することができる。変換操作は、1以上のデータ・ツール、言語、フォーマット、および/またはデータ・モデルとの間、少なくとも1つの他のデータ・ツール、言語、フォーマット、および/またはデータ・ツールとの間の変換またはマッピングを含むことができる。例えば、変換操作は、DataStage7、QualityStage、Business Object、IBM−DB2 Cube Views、UML1.1、UML1.3、ERStudio、ProfileStage、PowerDesigner(PackagesおよびExtended Attributesのためのサポートが付加された)、および/またはMicroStrategyとの間の変換、またはこれらへのマッピングを含むことができる。変換エンジンおよび/または変換操作は、随意的に、メタブローカにおいて実現することができる。変換エンジン、変換操作のマッピング、または変換操作は、操作の実行において、元の意味コンテキストと変換された意味コンテキストとの間で前後に変換されるデータをトレースすることができる。変換操作は、バッチで、リアルタイムに、または連続的に行い、実行し、および/または実施することができる。変換操作は、例えば、サービス指向アーキテクチャの一部としてなど、サービスとして提供すること、または利用可能にすることができる。 The conversion engine can perform conversion operations on one or more semantic identifiers, databases, databases containing semantic identifiers, information systems, semantic identifiers, or information systems including other items. The conversion operation may convert or otherwise modify the format, language, and / or data model of the semantic identifier. A conversion operation is a conversion or conversion between one or more data tools, languages, formats, and / or data models, and at least one other data tool, language, format, and / or data tools. Mapping can be included. For example, the conversion operation is DataStage7, QualityStage, BusinessObject, IBM-DB2 CubeViews, UML1.1, UML1.3, ERSStudio, ProfileStage, PowerDesigner (Packages and ExtendedAttached support) Conversions to and from MicroStrategies can be included. The conversion engine and / or the conversion operation can optionally be implemented in a metabroker. The conversion engine, mapping of the conversion operation, or conversion operation can trace data that is converted back and forth between the original semantic context and the converted semantic context in the execution of the operation. Conversion operations can be performed, performed, and / or performed in batch, in real time, or continuously. The conversion operation can be provided or made available as a service, eg, as part of a service-oriented architecture.
意味識別子、データベース、1以上の意味識別子を含むデータベース、情報システム、1以上の意味識別子を含む情報システム、または他のアイテムについての変換操作が存在すると、この変換操作を、いずれかの他の意味識別子、データベース、1以上の意味識別子を含むデータベース、情報システム、1以上の意味識別子、あるいは少なくとも1つの変換操作を共有する他のアイテムとの間で変換し、これにマッピングし、これに結合し、これとともに使用し、またはこれと関連付けることが可能になる。 If there is a conversion operation for a semantic identifier, a database, a database that includes one or more semantic identifiers, an information system, an information system that includes one or more semantic identifiers, or other items, this conversion operation may be designated as any other meaning. An identifier, a database, a database containing one or more semantic identifiers, an information system, one or more semantic identifiers, or other items that share at least one conversion operation, map to, and bind to Can be used with, or associated with, this.
アイテムは、物理モデリング活動および/または論理モデリング活動のような、多数の形式またはインスタンスで存在することができる。データベースおよび/またはハブにおいて、いずれかの関連したデータまたはメタデータを含むアイテムは、多数の形式またはインスタンスで存在することができる。アイテムの種々の形式またはインスタンスを区別するために、抽象化レベル、階層内の位置、他のアイテムとの関係、アイテムの1以上の区別属性、アイテムが見出されるコンテキスト、アイテムが見出される物理的位置等のような、いずれかの区別特性を使用されることができる。 Items can exist in many forms or instances, such as physical modeling activities and / or logical modeling activities. In a database and / or hub, items that contain any relevant data or metadata can exist in many forms or instances. To distinguish between different types or instances of an item, the level of abstraction, position in the hierarchy, relationship to other items, one or more distinct attributes of the item, the context in which the item is found, the physical location in which the item is found Any distinguishing property can be used, such as.
1つの実施形態において、「従業員」と名づけられたテーブルのようなアイテムをハブに入れることができる。ハブ・コレクタは、ハブ内に2つの形式またはインスタンスの「従業員」、すなわち1つは物理データベース・インスタンスに対応し、他のものは論理モデリング活動に対応するものを有することができる。ハブ・データ収集の抽象化プロパティ・レベルは、物理モデルと論理モデル・インスタンスまたは形式との間の区別を可能にする。 In one embodiment, an item such as a table named “employee” may be placed in the hub. A hub collector can have two types or instances of “employees” within the hub, one corresponding to a physical database instance and the other corresponding to a logical modeling activity. The abstract property level of hub data collection allows a distinction between a physical model and a logical model instance or form.
クエリに応答するものとすることができる変換操作を実行するとき、変換エンジンは、ハブまたはデータベースからアイテムのすべてをグラブし、ロードし、または獲得することができる。変換エンジンは、抽象化レベル、階層内の位置、他のアイテムとの関係、アイテムの属性、物理的位置等のような区別特性に基づいて、アイテムをフィルタリングし、選択し、格納し、変換し、修正し、または他の方法で操作することができる。代替的には、クエリに応答するものとすることができる変換操作を実行するとき、変換エンジンは、ハブまたはデータベースにおいて、任意のデータおよび/またはメタデータを含むアイテムをフィルタリングし、選択し、格納し、変換し、修正し、または他の方法で操作することができ、関連した抽象化レベルのアイテムまたは関連した属性、位置、関係、位置等を有するアイテムだけをグラブし、または獲得することができる。フィルタリング、選択、格納、変換、修正、または他の操作は、実行時および設計時に行うことができ、バッチで、リアルタイムで、または連続的に行うことができる。実施形態において、フィルタリング、選択、格納、変換、修正、または他の操作は、データ・モデル、データ・モデルのマッピング、識別子の構文の区別特性等といった、開発時、設計時、または実行時に変換エンジンおよび/またはシステムによって得られる情報または入力に基づくものとすることができる。情報は、リアルタイムで動的に更新することができる。したがって、1つの好ましい実施形態において、システムは、論理アイテムを選択し、物理アイテムを省くため、または物理アイテムを選択し、論理アイテムを省くためなどに、データベースの周知のマッピングに基づいて、データベースからデータを選択するための選択コマンドを精緻化することができる。 When performing a transformation operation that can be responsive to a query, the transformation engine can grab, load, or obtain all of the items from the hub or database. The transformation engine filters, selects, stores, and transforms items based on distinctive properties such as abstraction level, position in hierarchy, relationship to other items, item attributes, physical location, etc. Can be modified, manipulated, or otherwise manipulated. Alternatively, when performing a transformation operation that can be responsive to a query, the transformation engine filters, selects, and stores items that contain any data and / or metadata at the hub or database. Can be converted, modified, or otherwise manipulated to grab or acquire only items with an associated level of abstraction or with associated attributes, positions, relationships, positions, etc. it can. Filtering, selection, storage, conversion, modification, or other operations can be performed at run time and design time, and can be performed in batch, in real time, or continuously. In an embodiment, the filtering, selection, storage, transformation, modification, or other operation is a transformation engine at development time, design time, or runtime, such as a data model, data model mapping, identifier syntax distinguishing characteristics, etc. And / or based on information or input obtained by the system. Information can be updated dynamically in real time. Thus, in one preferred embodiment, the system selects from a database based on a well-known mapping of the database, such as selecting a logical item and omitting a physical item, or selecting a physical item and omitting a logical item. The selection command for selecting data can be refined.
場合によっては、プロセス全体において、フィルタリング、選択、または他の操作がハブまたはデータベースに近いほど、操作がより効率的かつ高速になる。変換エンジンは、クエリ自体に変換操作を行い、ハブまたはデータベースに直接送ることができる、改訂されたクエリまたは選択コマンドをもたらすことができる。改訂されたクエリまたは選択コマンドは、ハブまたはデータベースと直接互換性があるフォーマットにすることができる。 In some cases, the closer the filtering, selection, or other operation is to the hub or database, the more efficient and faster the operation is throughout the process. The transformation engine can perform a transformation operation on the query itself, resulting in a revised query or select command that can be sent directly to the hub or database. The revised query or select command can be in a format that is directly compatible with the hub or database.
他の態様において、コンピュータ・プログラム製品は、コンピュータ・プログラム・コードを含むコンピュータ使用可能媒体を含むことができ、コンピュータ可読プログラム・コードは、1以上のコンピュータ上で実行されるとき、1以上のコンピュータに、上記の方法のいずれか1以上を実行させる。 In other aspects, a computer program product can include a computer-usable medium that includes computer program code, where the computer-readable program code when executed on one or more computers. To perform any one or more of the above methods.
本明細書において用いられる「International Business Machines」または「IBM」は、ニューヨーク州アーモンク所在のインターナショナル・ビジネス・マシーンズ・コーポレーションを指している。 As used herein, “International Business Machines” or “IBM” refers to International Business Machines Corporation, Armonk, NY.
本明細書において用いられる「データ・ソース」または「データ・ターゲット」は、特定の意味が他に示されるかまたは語句の文脈を別に要求することがない限り、これらの用語と矛盾しない最も広範な意味を持つように意図されており、データベース、複数のデータベース、リポジトリ情報マネージャ、キュー、メッセージ・サービス、リポジトリ、データ機構、データ・ストレージ機構、データ・プロバイダ、ウェブサイト、サーバ、コンピュータ、コンピュータ・ストレージ機構、CD、DVD、モバイル・ストレージ機構、中央ストレージ機構、ハードディスク、複数の調整データ・ストレージ機構、RAM、ROM、フラッシュメモリ、メモリカード、一時メモリ機構、永続メモリ機構、磁気テープ、ローカル接続コンピューティング機構、遠隔接続コンピューティング機構、無線機構、有線機構、モバイル機構、中央機構、ウェブ・ブラウザ、クライアント、ラップトップ、携帯情報端末(「PDA」)、電話、携帯電話、移動電話、情報プラットフォーム、分析機構、処理機構、ビジネス・エンタープライズ・システムまたはデータを処理する他の機構もしくはデータまたは他の情報ならびに上記のシステムのいずれかに用いられる構造化データまたは非構造化データあるいはいずれかのストリーミング・データ、メッセージ化データ、イベント駆動データもしくはソース・データを保持するための何らかのファイルまたはファイル・タイプを格納するようになった他の機構、および、上記のいずれかの組み合わせを含むものとする。ストレージ機構とは、何らかの物理装置または論理装置、リソース、あるいは、データ・ソースもしくはデータ・ターゲットとして機能を果たすか、さもなければ検索可能な形式でデータを格納することができる機構である。 As used herein, “data source” or “data target” is the broadest consistent with these terms, unless a specific meaning is otherwise indicated or the context of the phrase is otherwise required. Intended to be meaningful, database, multiple databases, repository information manager, queue, message service, repository, data mechanism, data storage mechanism, data provider, website, server, computer, computer storage Mechanism, CD, DVD, mobile storage mechanism, central storage mechanism, hard disk, multiple coordinated data storage mechanism, RAM, ROM, flash memory, memory card, temporary memory mechanism, permanent memory mechanism, magnetic tape, local connection computing Networking mechanism, remote connection computing mechanism, wireless mechanism, wired mechanism, mobile mechanism, central mechanism, web browser, client, laptop, personal digital assistant ("PDA"), telephone, mobile phone, mobile phone, information platform, Analysis mechanism, processing mechanism, business enterprise system or other mechanism or data or other information processing data and structured or unstructured data or any streaming data used in any of the above systems , Other mechanisms adapted to store any file or file type to hold messaged data, event driven data or source data, and any combination of the above. A storage mechanism is a mechanism that can function as some physical or logical device, resource, or data source or data target, or otherwise store data in a searchable format.
「Enterprise Java(登録商標) Bean(EJB)」は、J2EEプラットフォームのためのサーバ側のコンポーネント・アーキテクチャを含む。EJBは、分散Java(登録商標)アプリケーション、トランザクションJava(登録商標)アプリケーション、セキュアおよびポータブルJava(登録商標)アプリケーションの迅速で簡単な開発をサポートする。EJBは、メッセージの並行処理を可能にするコンテナ・アーキテクチャをサポートし、分散トランザクションをサポートするため、J2EEアーキテクチャを使用するデータベース更新、メッセージ処理およびエンタープライズ・システムへの接続が、同一のトランザクション・コンテキストに関与することが可能になる。 “Enterprise Java® Bean (EJB)” includes a server-side component architecture for the J2EE platform. EJB supports fast and easy development of distributed Java applications, transactional Java applications, secure and portable Java applications. EJB supports a container architecture that allows concurrent processing of messages and supports distributed transactions, so database updates, message processing, and connections to enterprise systems using the J2EE architecture are in the same transaction context. It becomes possible to get involved.
「JMS」は、Java(登録商標)ベースのJ2EEエンタープライズ・アーキテクチャのためのエンタープライズ・メッセージ・サービスであるJava(登録商標) Message Serviceを意味する。「JCA」は、以下により詳細に説明されるJ2EEプラットフォームのJ2EE Connector Architectureを意味する。EJB、JMSおよびJCAは、現代の分散トランザクション環境において一般的に用いられるソフトウェア・ツールであるが、同様の機能を提供するいずれかのプラットフォーム、システムまたはアーキテクチャを本明細書において説明されるデータ統合システムとともに利用できることに留意されたい。 “JMS” refers to Java® Message Service, an enterprise message service for Java®-based J2EE enterprise architecture. “JCA” means J2EE Connector Architecture of the J2EE platform described in more detail below. EJB, JMS, and JCA are software tools commonly used in modern distributed transaction environments, but any platform, system, or architecture that provides similar functionality is described herein. Note that it can be used with.
本明細書において用いられる「リアルタイム」は、ビジネス・トランザクションまたはビジネスの継続時間に近い時間の間隔を含み、夜間に行われるバッチ処理操作のようなオフラインで行われるものとは対照的に、営業活動またはビジネス・プロセス中に行われるプロセスまたはサービスと含むものとする。ビジネス・プロセスの継続時間によって、リアルタイムは、秒、一瞬、分、時間、あるいはさらに日を含む場合がある。 As used herein, “real time” includes time intervals close to business transactions or business durations, as opposed to those performed offline, such as batch processing operations performed at night. Or with processes or services that take place during the business process. Depending on the duration of the business process, real time may include seconds, moments, minutes, hours, or even days.
本明細書において用いられる「ビジネス・プロセス」、「ビジネス・ロジック」および「ビジネス・トランザクション」は、販売、マーケティング、フルフィルメント、在庫管理、価格付け、製品設計、専門的サービス、金融サービス、管理、財務、引受業務、分析、契約、情報技術サービス、データ・ストレージ、データ・マイニング、情報配信、商品の経路指定、スケジューリング、通信、投資、トランザクション、提供、販売促進、広告、付け値、エンジニアリング、製造、サプライ・チェーン管理、人事管理、データ処理、データ統合、ワークフロー管理、ソフトウェア生成、ハードウェア生産、新製品の開発、研究、開発、戦略機能、品質管理および保証、パッケージ化、物流、顧客関係管理、リベートおよび返品処理、顧客サポート、製品保守、電話勧誘、企業広報、投資家向け広報活動を含むが、これらに限定されるものではなく、企業が行うことができるあらゆる方法、サービス、運用、プロセス、または取引を含むものとする。 As used herein, “business process”, “business logic” and “business transaction” include sales, marketing, fulfillment, inventory management, pricing, product design, professional services, financial services, management, Finance, underwriting, analysis, contracts, information technology services, data storage, data mining, information distribution, product routing, scheduling, communications, investment, transactions, provision, promotion, advertising, bids, engineering, manufacturing , Supply chain management, personnel management, data processing, data integration, workflow management, software generation, hardware production, new product development, research, development, strategic functions, quality control and assurance, packaging, logistics, customer relationship management , Rebates and returns processing, customer support Theft, product maintenance, telephone solicitation, corporate communications, including investor relations activities, the present invention is not limited to these, any method can be performed by the company, service, is intended to include operational, process, or the transaction.
本明細書において用いられる「サービス指向アーキテクチャ(SOA)」は、企業のインフラストラクチャの一部を形成するサービスを含む。SOAにおいては、サービスは、迅速なアプリケーション開発を可能とし、冗長なコードを避ける、アプリケーションの開発および導入のための構成単位となることがある。各々のサービスは、サービスについてのデータ入力のソース、またはサービスのデータ出力のターゲットといった、周囲環境に結合できるビジネス・ロジックまたはビジネス規則の組を具体化することができる。SOAの種々の例が、以下の説明において提供される。 As used herein, “service oriented architecture (SOA)” includes services that form part of an enterprise's infrastructure. In SOA, services can be a building block for application development and deployment that enables rapid application development and avoids redundant code. Each service can embody a set of business logic or business rules that can be coupled to the surrounding environment, such as a source of data input for the service or a target of data output for the service. Various examples of SOA are provided in the following description.
本明細書において用いられる「メタデータ」は、処理されるデータにコンテキストを導入するデータ、データに関するデータ、関連情報のコンテキストに関する情報、データの出所に関する情報、データの場所に関する情報、データの意味に関する情報、データの経過時間に関する情報、データの見出しに関する情報、データの単位に関する情報、データのフィールドに関する情報、および/または、データのコンテキストに関連する他のいずれかの情報に関する情報を含むものとする。 As used herein, “metadata” refers to data that introduces context into the data being processed, data about the data, information about the context of the related information, information about the origin of the data, information about the location of the data, and the meaning of the data Information, information about the elapsed time of the data, information about the headings of the data, information about the units of the data, information about the fields of the data, and / or information about any other information related to the context of the data.
本明細書において用いられる「WSDL」すなわち「ウェブ・サービス記述言語」は、文書指向情報または手続き指向情報のいずれかを含むメッセージ上で動作するエンドポイントの組としてネットワーク・サービス(多くの場合、ウェブ・サービス)を記述するためのXMLフォーマットを含む。動作およびメッセージは、抽象的に記述され、次いでエンドポイントを定めるために具体的なネットワーク・プロトコルおよびメッセージ・フォーマットに結合される。関連する具体的なエンドポイントは、抽象的なエンドポイント(サービス)に組み合わされる。WSDLは、どのメッセージ・フォーマットまたはネットワーク・プロトコルが通信に用いられるかにかかわらず、エンドポイントおよびそれらのメッセージの記述を可能にするように拡張可能である。 As used herein, “WSDL” or “Web Service Description Language” is a network service (often a web service) as a set of endpoints that operate on messages that contain either document-oriented or procedure-oriented information. XML format for describing (service). Operations and messages are described abstractly and then combined into a specific network protocol and message format to define the endpoint. Related concrete endpoints are combined into abstract endpoints (services). WSDL is extensible to allow the description of endpoints and their messages regardless of which message format or network protocol is used for communication.
本明細書において用いられる「メタブローカ」は、データまたはメタデータの変換操作その他の操作を行うための変換エンジンその他の手段を含むことができるシステムまたは方法を含むことができる。変換操作その他の操作は、1以上のフォーマット、言語、および/またはデータ・モデルから1以上のフォーマット、言語、および/またはデータ・モデルへのデータまたはメタデータの変換を含むことができる。 A “metabroker” as used herein can include a system or method that can include a conversion engine or other means for performing data or metadata conversion operations or other operations. Transformation operations and other operations can include the transformation of data or metadata from one or more formats, languages, and / or data models to one or more formats, languages, and / or data models.
以下の説明全体を通して、他に特に示されない限り、同様の要素に対する数字は同様の要素を指すことが意図されている。 Throughout the following description, unless otherwise indicated, numbers for like elements are intended to refer to like elements.
本明細書に開示される本発明は、全体がハードウェアの実施形態、全体がソフトウェアの実施形態、または、ハードウェア要素とソフトウェア要素の両方を含む実施形態の形式を取ることができる。好ましい実施形態においては、本発明は、これらに限定されるものではないが、ファームウェア、常駐型のソフトウェア、マイクロコード等を含むソフトウェアにおいて実装される。 The invention disclosed herein may take the form of an entirely hardware embodiment, an entirely software embodiment or an embodiment containing both hardware and software elements. In preferred embodiments, the present invention is implemented in software, including but not limited to firmware, resident software, microcode, and the like.
さらに、本発明は、コンピュータまたはいずれかの命令実行システムによって、またはこれらと接続して、使用されるためのプログラム・コードを提供するコンピュータ使用可能またはコンピュータ可読媒体からアクセス可能なコンピュータ・プログラム製品の形態を取ることができる。この説明のために、コンピュータ使用可能またはコンピュータ可読媒体は、命令実行システム、装置によって、またはこれらと接続して、使用されるためのプログラムを含み、格納し、通信し、伝搬し、または転送することが可能ないずれかの装置とすることができる。 Furthermore, the present invention provides a computer program product accessible from a computer usable or computer readable medium that provides program code for use by or in connection with a computer or any instruction execution system. Can take form. For purposes of this description, a computer usable or computer readable medium includes, stores, communicates, propagates, or transfers a program for use by or in connection with an instruction execution system, apparatus, or the like. It can be any device that can.
媒体は、電子システム、磁気システム、光システム、電磁システム、赤外線システム、もしくは半導体システム(または機器もしくは装置)または伝搬媒体とすることができる。コンピュータ可読媒体の例は、半導体メモリまたはソリッドステート・メモリ、磁気テープ、取り外し可能コンピュータ・ディスケット、ランダム・アクセス・メモリ(RAM)、読み取り専用メモリ(ROM)、磁気ハードディスクおよび光ディスクを含む。現時点における光ディスクの例は、CD−ROM、CD−R/WおよびDVDを含む。 The medium can be an electronic system, a magnetic system, an optical system, an electromagnetic system, an infrared system, or a semiconductor system (or apparatus or device) or a propagation medium. Examples of computer readable media include semiconductor memory or solid state memory, magnetic tape, removable computer diskette, random access memory (RAM), read only memory (ROM), magnetic hard disk and optical disk. Current examples of optical disks include CD-ROM, CD-R / W and DVD.
プログラム・コードを格納および/または実行するのに適したデータ処理システムは、システム・バスを通してメモリ要素に直接的にまたは間接的に結合された少なくとも1つのプロセッサを含む。メモリ要素は、プログラム・コードの実際の実行時に使用されるローカル・メモリと、大容量記憶装置と、実行時に大容量記憶装置からコードを取得しなければならない回数を減少させるように少なくともいくつかのプログラム・コードの一時的な記憶場所を提供するキャッシュ・メモリとを含むことができる。 A data processing system suitable for storing and / or executing program code will include at least one processor coupled directly or indirectly to memory elements through a system bus. The memory element has at least some local memory used during actual execution of the program code, mass storage, and at least some so as to reduce the number of times code must be obtained from the mass storage during execution. And cache memory providing a temporary storage location for program code.
入力/出力装置すなわちI/O装置(キーボード、ディスプレイ、ポインティング装置等を含むが、これらに限定されるものではない)を、直接的に、または介在するI/Oコントローラを通して、システムに結合することができる。 Coupling input / output devices or I / O devices (including but not limited to keyboards, displays, pointing devices, etc.) to the system either directly or through intervening I / O controllers Can do.
プライベート・ネットワークまたは公衆ネットワークを通じて、データ処理システムを他のデータ処理システムまたは遠隔プリンタもしくは記憶装置に結合できるように、ネットワーク・アダプタをシステムに結合することもできる。モデム、ケーブル・モデムおよびイーサネット(登録商標)・カードは、現時点で利用可能なタイプのネットワーク・アダプタのうちの一部である。 Network adapters can also be coupled to the system so that the data processing system can be coupled to other data processing systems or remote printers or storage devices through private or public networks. Modems, cable modems and Ethernet cards are some of the currently available types of network adapters.
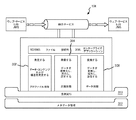
図1は、企業の様々なデータの統合を容易にするためのプラットフォーム100を表す。プラットフォームは、各々が複数の異なるコンピュータ・アプリケーションおよびデータ・ソースを含むことができる複数のビジネス・プロセスを含む。プラットフォームは、上述のようなデータ・ソースとすることができるいくつかのデータ・ソース102を含むことができる。これらのデータ・ソースは、様々な物理的場所からの様々なデータ・タイプを含むことができる。例えば、データ・ソースは、Sybase、Microsoft、Informix、Oracle、Inlomover、EMC、Trillium、First Logic、Siebel、PeopleSoft、IBM、Apache、またはNetscapeなどのプロバイダから提供されるシステムを含むことができる。データ・ソース102は、IMS、DB2、ADABAS、VSAM、MD Series、UDB、XML、複合フラット・ファイル、またはFTPファイルなどのデータベース製品または標準技術を使用するシステムを含むことができる。データ・ソース102は、Microsoft Outlook、Microsoft Word、Microsoft Excel、Microsoft Accessのようなアプリケーションによって作成または使用されるファイル、ならびに、ASCII、CSV、GIF、TIF、PNG等のような標準フォーマットのファイルを含むことができる。データ・ソース102は、様々な場所に配置することができ、または集中的に配置することもできる。データ・ソース102から供給されるデータは、様々な形式のものとすることができ、互換性があるか、または互換性のない異なるフォーマットを有することができる。
FIG. 1 represents a
データ・ターゲットは、本明細書の後半で説明されるが、一般的に、これらのデータ・ターゲットは、上述のデータ・ソース102のいずれかとすることができる。このような用語の使用方法の違いは、一般的には、データ統合プロセスにおいてデータ・システムがデータを提供するのか、またはデータを受け取るのかに起因するものである。しかし、通常のデータ統合システムにおいては、データ・ソースはデータを受け取ることもできるし、データ・ターゲットはデータを提供することもできるため、特に他に記述がない限り、この区別はデータ・ソースとデータ・ターゲットとの間の能力に関する違いを与えることを意図するものではないことに留意されたい。
Data targets are described later in this document, but in general, these data targets can be any of the
また、図1に示されたプラットフォームはデータ統合システム104も含む。データ統合システムは、例えば、データ統合システム104が受信するクエリまたは検索コマンドの結果としてのデータ・ソース102からのデータ収集を容易にすることができる。データ統合システム104は、データ・ソースがデータをデータ統合システム104に供給するように、1以上のデータ・ソース102に対してコマンドを送信することができる。受信されたデータは、様々なメタデータを含む多数のフォーマットのものであり得るため、データ統合システムは、統合処理のために後に結合することができるように、受信したデータを再構成することができる。データ統合システム104によって実現することができる機能は、以下により詳細に説明される。
The platform shown in FIG. 1 also includes a
また、プラットフォーム100は、検索システム108を含む。検索システム108は、データ統合システム104から送信されるデータをさらに操作するのに用いられるデータベースまたは処理プラットフォームを含むことができる。例えば、データ統合システム104は、検索システム108が、処理されたデータを用いてビジネスに有用なレポート110を生成することができるように、データ・ソース102から受信するデータを整理し、結合し、変換し、または、他の方法で操作することができる。レポート110は、データの関連性を報告し、複雑なクエリに回答し、単純なクエリに回答し、または、ビジネスもしくはユーザに有用な他の報告を作成するために使用することができる。レポート110は、生データ、テーブル、チャート、グラフ、および検索システム108からのデータの他のいずれかの表現を含むことができる。
The
また、プラットフォーム100は、データベースまたはデータベース管理システム112を含むこともできる。データベース112は、一時的または永続的もしくは長期的な記憶として、情報を格納するために使用することができる。例えば、データ統合システム104は、1以上のデータ・ソース102からデータを収集し、そのデータを、互いに互換性がある形式または互いに結合することができる形式に変換することができる。データが変換されると、データ統合システム104は、後で実施される検索のために、分解形式、結合形式その他の形式で、データをデータベース112に格納することができる。
The
図2は、企業の複数のエンティティおよびビジネス・プロセス間のデータ統合を示す概略図である。図示される実施形態においては、データ統合システム104は、ユーザ・インターフェース・システム202とデータ・ソース102との間の情報の流れを容易なものにする。データ統合システム104は、1以上のデータ・ソース102に存在するデータを抽出し、場合によっては変換するためのクエリを、インターフェース・システム202から受信することができる。インターフェース・システム202は、ラップトップ・コンピュータもしくはデスクトップ・コンピュータ、携帯電話、個人用情報端末(「PDA」)、ネットワーク化プラットフォーム、およびこれらに取り付けられる装置上で作動するウェブ・ブラウザといった、データ統合システム104と通信するためのいずれかの装置およびプログラム、または、データ統合システム104とインターフェース接続される他のいずれかの装置またはシステムを含むことができる。
FIG. 2 is a schematic diagram illustrating data integration between multiple entities and business processes in an enterprise. In the illustrated embodiment, the
例えば、ユーザは、PDAを操作して、WiFiまたはワイヤレス・アクセス・プロトコル/ワイヤレス・マークアップ言語(「WAP/WML」)インターフェースを介してデータ統合システム104に情報を要求することができる。データ統合システム104は、その要求を受信して、ウェブサイトまたはFTPファイル・サイト等の他のデータ・ソース102から情報にアクセスするために、必要ないずれかのクエリを生成することができる。データ・ソース102からのデータは、抽出され、要求するインターフェース・システム202(この例ではPDA)と互換性のあるフォーマットに変換され、次いで、ユーザが見て操作するためのインターフェース・システム202に送信することができる。他の実施形態においては、データは、データ・ソースから予め抽出され、データ統合システム104によって用いられるデータ・ウェアハウスその他のデータ機器であり得る別個のデータベース112に格納しておくことができる。データは、変換された状態で、またはその元の状態で、データベース112に格納することができる。例えば、データは、多くのデータ・ソース102からのデータを他の変換プロセスで結合することができるように、変換された状態で格納することができる。例えば、PDAからのクエリをデータ統合システム104に送信することができ、データ統合システム104は、データベース112から情報を抽出することができる。抽出後に、データ統合システム104は、そのデータをPDAに返信する前にPDAと互換性のある結合フォーマットに変換することができる。
For example, a user can operate a PDA to request information from the
図3は、企業の複数のデータ・ソース102についてのデータ統合を提供するためのアーキテクチャを示す概略図である。データ統合システム104の実施形態は、データ・ソースからのデータの抽出およびソース・データについての列の値およびテーブル構造の分析を(場合によっては他の処理の間に)実行するデータ発見段階302を含むことができる。また、データ発見段階302はデータ・ターゲットについてのテーブル構造、関係およびキーに関する推奨を生成することができる。より高度なプロファイリングおよび監査機能は、日付範囲の検証、計算の精度、if-then評価の精度等を含むことができる。データ発見段階302は、ソース・データの冗長な依存関係その他の変則的な部分を排除することなどによって、データを正規化することができる。データ発見段階302は、さらなる分析のためにデータ・ソース102内部の例外を掘り下げることまたはメインフレーム・データの直接プロファイリングを可能にするなどの付加的な機能を提供することができる。データ発見段階302の市販されている形態は、例えば、IBMのWebsphere ProfileStage製品があるがこれに限定されない。
FIG. 3 is a schematic diagram illustrating an architecture for providing data integration for a plurality of
データ統合システム104はまた、後に変換されることになる品質(クオリティ)データを生成するために、データを準備し、標準化し、照合し、または他の方法で操作する、データ準備段階304を含むこともできる。データ準備段階304は、データ内の不整合を調整すること、または(1対1の照合、1対多数の照合および重複排除を含む)正確な照合を行うことというような一般的なデータ品質機能を実行することができる。また、データ準備段階304は特定のデータ拡張機能を提供することもできる。例えば、データ準備段階304は、国際通信の改善のために、住所が多国間の郵便基準(multinational postal reference)に適合することを確実なものにすることができる。データ準備段階304は、空間情報の管理のために、位置データを多国間ジオコーディング標準(multinational geocoding standard)に適合させることができる。データ準備段階304は、住所情報が、米国政府に認証された合衆国アドレス修正(US address correction)によってアメリカ郵便公社の郵便料金の割引を受けることができることを保証するために、住所を変更または追加することができる。同様の分析およびデータ訂正を、適切に住所が記載された郵便について割引料金を提供する、カナダおよびオーストラリアの郵便システムに導入することができる。データ準備段階304の市販されている形態は、例えば、IBMのWebsphere QualityStage製品があるがこれに限定されない。
The
また、データ統合システムは、変換されたデータを変換し、質を高めて配信するデータ変換段階308を含むこともできる。データ変換段階308は、データの再構成および再フォーマットのような移行サービスを実行し、システム・ユーザのビジネス規則およびアルゴリズムに基づいて計算を実行することもできる。データ変換段階308はまた、特定の分析コンテキストにおけるデータのより高度な調整処理のために、ターゲット・データをデータマートまたはキューブとして知られるサブセットに編成することもできる。データ変換段階308は、データ統合システム104によって使用される様々なデータ・ソースおよびデータ・ターゲットの様々なソフトウェア・アーキテクチャおよびハードウェア・アーキテクチャの橋渡しをする、(以下に一般的に説明されるような)ブリッジ、トランスレータ、または他のインターフェースを使用することができる。データ変換段階308は、プラットフォーム100全体にわたるデータ統合ジョブを設計するために、グラフィカル・ユーザ・インターフェース、コマンドライン・インターフェース、またはこれらの組み合わせを含むことができる。データ変換段階308の市販されている形態は、例えば、IBMのWebsphere DataStage製品があるがこれに限定されない。
The data integration system may also include a
データ統合システム104の段階302、304、308は、該システム104の性能を最適化するために、並列実行システム310を連続的にまたは組み合わせて用いて実行することができる。
The
データ統合システム104は、データ・ソース102と関連するメタデータを管理するためのメタデータ管理システム312を含むこともできる。一般に、メタデータ管理システム312は、データ統合環境におけるツールの全体にわたって、メタデータの交換、統合、管理および分析を提供することができる。例えば、メタデータ管理システム312は、IBMのWebsphere ODBC MetaBroker、CA ERwin、IBM Websphere ProfileStage、IBM Websphere DataStage、IBM Websphere QualityStage、IBM DB2 Cube ViewsおよびCognos Impromptuのような、異なるソースにおけるデータの、広くアクセス可能な共通のビューを提供することができる。メタデータ管理システム312はまた、データ系統および影響分析のための分析ツールを提供することもできる。さらに、メタデータ管理システム312を用いて、データ統合システム104内のデータについてのデータ定義、アルゴリズムおよびビジネス・コンテキストのビジネス・データ用語集を作成することができ、この用語集は、企業全体で用いられるように公開することができる。メタデータ管理システム312の市販されている形態は、例えば、IBMのWebsphere MetaStage製品があるがこれに限定されない。
The
図4を参照すると、企業に関連するアイテムは、そのアイテムの意味コンテキストを取得するためといった、様々なコンテキストまたは階層の観点から記述することができる。このように、図4は、アイテムについての意味識別子を示す。アイテムは、オブジェクト、クラス、属性、データ・アイテム、データ・モデル、モデル、定義、識別、構造、言語、マッピング、関係、インスタンスその他の意味識別子を含む、他のアイテムまたは概念とすることができる。意味識別子は、アイテムの属性、アイテムの物理的位置、階層等におけるアイテムと1以上の他のアイテムとの関係等に基づいて、アイテムを識別することができる。場合によっては、何らかの特定の関係の不存在として関係を定義することができる。関係は、意味に基づくものとすることができる。関係は、関係階層におけるアイテムの位置を含むことができる。例えば、図4において、関連する他のアイテムとの関係に基づいて、アイテム1 5202を識別することができる。アイテム1 5202は、アイテム2 5204、アイテム3 5208およびアイテム4 5210に直接関連するものとして、アイテム5 5212に間接的に関連するものとして、およびアイテム5 5212およびアイテム4 5210を介してアイテム6 5214に間接的に関連するものとして、識別することができる。アイテム1はまた、アイテム2 5204、アイテム3 5208およびアイテム4 5210に直接関連するものとして識別することもできる。実施形態において、アイテム1 5202とアイテム5 5212およびアイテム6 5214の間の間接的な関係は、アイテム1 5202とアイテム4 5210との関係において取得することができる。この連結タイプまたは再帰タイプの識別は、静的な識別子に加えて、動的な識別子の実現を可能にする。例えば、アイテム4 5210とアイテム6 5214との間の関係が変化する場合、アイテム2 5204、アイテム3 5208およびアイテム4 5210を組み入れるアイテム1 5208についての意味識別子は、アイテム4 5210の組み入れを通してこの変更を組み入れ、アイテム6 5214が意味識別子内に直接含まれていた場合のように、アイテム6 5214の変更を説明するために更新を行う必要はない。
Referring to FIG. 4, items associated with a company can be described in terms of various contexts or hierarchies, such as to obtain the semantic context of the item. Thus, FIG. 4 shows the semantic identifier for the item. Items can be other items or concepts including objects, classes, attributes, data items, data models, models, definitions, identifications, structures, languages, mappings, relationships, instances and other semantic identifiers. A semantic identifier can identify an item based on the item's attributes, the physical location of the item, the relationship between the item and one or more other items in the hierarchy, and the like. In some cases, a relationship can be defined as the absence of some particular relationship. The relationship can be based on meaning. The relationship can include the position of the item in the relationship hierarchy. For example, in FIG. 4,
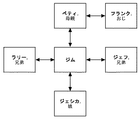
図5は、意味識別子のより具体的な例を示す。ジムは、米国某州、某町、某通り111に居住し、電話番号555−555−5555および社会保障番号012−34−5678を有するジムとして識別することができる。代替的に、ジムは、他者との関係の観点から識別することができる。図5に示されるように、ジムは、ベティの息子、ラリーとジェフの兄弟、ジェシカの父親およびフランクの甥として識別することができる。 FIG. 5 shows a more specific example of the semantic identifier. Jim can be identified as a Jim who resides in Sakai Street, Sakaimachi, U.S. 111, USA and has a telephone number 555-555-5555 and a social security number 012-34-5678. Alternatively, Jim can be identified in terms of relationships with others. As shown in FIG. 5, Jim can be identified as Betty's son, Larry and Jeff's brother, Jessica's father, and Frank's nephew.
意味識別子は、1つのアイテムについての固有の識別子とすることができる。図5の例においては、ベティの息子、ラリーとジェフの兄弟、ジェシカの父親およびフランクの甥であるジムが世界に一人しかいない場合には、この意味識別子は、ジムについての固有識別子となる。アイテムに対する固有の意味識別子が、そのアイテムと他のアイテムとの関係のすべてより少ない数である場合を考えることも可能である。ベティの息子、ラリーの兄弟、ジェシカの父親であるジムが世界に一人しかいない場合には、固有の意味識別子を作成するのに、これらの関係の存在だけで十分である。ジムとジェフおよびフランクとの関係を考慮する必要はない。一意性を保証する最小数の関係に基づいた意味識別子を作成することが有利である。例えば、意味識別子がデータベース112内に格納されるか、またはデータ統合システム104によって処理される場合には、複雑でない意味識別子は、必要とする空間が少なく、より高速な処理が可能になる。
The semantic identifier can be a unique identifier for one item. In the example of FIG. 5, if there is only one person in the world, Betty's son, Larry and Jeff's brother, Jessica's father, and Frank's nephew, this semantic identifier is a unique identifier for Jim. It is also possible to consider the case where the unique semantic identifier for an item is less than all of its relationships with other items. If there is only one Jim in the world, Betty's son, Larry's brother, and Jessica's father, the existence of these relationships is sufficient to create a unique semantic identifier. There is no need to consider the relationship between Jim and Jeff and Frank. It is advantageous to create semantic identifiers based on a minimum number of relationships that guarantee uniqueness. For example, if semantic identifiers are stored in the
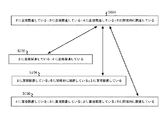
アイテムについての固有の意味識別子を作成するのに必要とされる関係の数は、コンテキストに基づいて異なり得る。図6は、2つの関心あるアイテム、すなわちアイテム1 5402およびアイテム7 5404を示す。コンテキストA 5408において、アイテム1 5402は、アイテム1 5402とアイテム5 5410およびアイテム6 5412との関係によって、アイテム7 5404と区別することができる。つまり、コンテキストAにおいて、アイテム1 5402についての固有の意味識別子は、アイテム2、3および4に直接関連し、アイテム4を通してアイテム5 5410に間接的に関連し、アイテム5 5410およびアイテム4を通してアイテム6 5412に間接的に関連するものとすることができる。コンテキストAにおいて、アイテム7 5404についての固有の意味識別子は、アイテム2および3だけに直接関連するものとすることができる。図7は、異なるコンテキスト、すなわちコンテキストB 5414内のアイテム1 5402を示す。コンテキストB 5414においてアイテム1 5402を一意的に識別するために、アイテム1 5402の、アイテム4との直接的な関係、アイテム6との直接的な関係の不存在、またはアイテム5との間接的な関係のいずれか1以上を考えることができる。コンテキストB 5414において、アイテム1 5402は、アイテム2および3に直接関連するが、アイテム6に直接関連していないものとして一意的にかつ意味的に識別することができる。したがって、アイテム1についての固有識別子は、コンテキストA 5408とコンテキストB 5414で異なる。このように、ここで説明されるデータ統合方法およびシステムの実施形態においては、データ統合ジョブまたはデータ統合プラットフォームに関連したアイテムのようなアイテムについての意味識別子に、そのアイテムについてのコンテキスト依存識別子を与えることができる。実施形態において、こうしたコンテキスト依存識別子は、データ・リポジトリ等の中に、アトミック・フォーマットの形で格納することができる。
The number of relationships required to create a unique semantic identifier for an item can vary based on context. FIG. 6 shows two items of interest,
他の実施形態において、コンテキストA 5408およびコンテキストB 5414は、2つの異なるインポート、マッピング、実行バージョン、モデル、メタブローカ・モデル、インスタンス、ツール、ビュー、オブジェクト、クラス、アイテム、関係、属性、または上記のいずれかの任意の組み合わせとすることができる。照合または比較機構は、異なるインポート、実行バージョン、モデル、メタブローカ・モデル、インスタンス、ツール、および/またはアイテムにおけるアイテムの識別の構文(シンタックス)を比較し、その比較に基づいてどの動作を取るべきかまたは動作を取るべきではないかについての判定を決定することができる。例えば、照合エンジンは、インポート・インスタンスAによって用いられるモデルを、メタブローカBによって用いられるモデルと比較することができる。この比較に基づいて、メタブローカBは、変換または修正なしに、インポート・インスタンスAのデータおよびメタデータにアクセスすることができ、比較機構が、メタブローカBの続行を命令することができることが決定される。他の例においては、ツールA 5408をツールB 5414と比較することができ、各々のツールが他のツールのオブジェクトにアクセスし、使用することができる、ツール間のオブジェクト併合の実行が決定される。実施形態においては、比較機構が、変換機構をトリガし、それぞれのツールの各々における特定のアイテムの識別の処理のための異なる構文に基づいた変換、あるいは、比較によって決定されるツール間の他の差異に基づいた変換のような変換を必要とするいずれかのオブジェクトを変換するのを助けるといった、ブリッジ、メタブローカ、ハブ等の確立のようなツール間のオブジェクト併合を助けることができる。
In other embodiments, Context A 5408 and
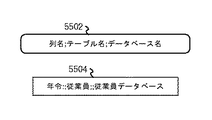
実施形態において、意味識別子は、文字列構造またはフォーマットで格納し、維持し、記録し、処理し、および/または解釈することができる構文の形で格納し、維持し、記録し、処理し、および/または解釈することができる。図8は、構文およびその構文内に構成された対応する文字列の例を示す。構文 5502は、列名::テーブル名::データベース名とすることができる。この構文は、例えば、データベース内のテーブルの列を識別する意味識別子に関連付けることができる。この構文 5504内に構成された文字列は、年齢::従業員::従業員データベースとすることができる。この文字列は、例えば、特定の従業員データベース内の従業員の年齢を識別する意味識別子に関連付けることができる。図7の例において、コンテキストBにおけるアイテム1 5402についての意味識別子に対応する文字列は、アイテム2との直接的な関係::アイテム3との直接的な関係::アイテム4との直接的な関係とすることができる。意味識別子および対応する文字列はまた、アイテム1 5402とアイテム6との間の直接的な関係の欠如を組み込むこともできる。
In an embodiment, the semantic identifier is stored, maintained, recorded, processed in a syntax that can be stored, maintained, recorded, processed, and / or interpreted in a string structure or format, And / or can be interpreted. FIG. 8 shows an example of a syntax and a corresponding character string constructed in the syntax. The syntax 5502 can be a column name :: table name :: database name. This syntax can be associated with, for example, a semantic identifier that identifies a column of a table in the database. The string constructed in this
図9において、アイテム9 5602についての、文字列フォーマットでの意味識別子は、アイテム2に直接関連している::アイテム4に直接関連している::アイテム5 5604に間接的に関連しているものとすることができる。文字列を構文解析することができる。構文および/または文字列を切り捨て、修正することができ、および/または、構文および/または文字列の要素を再配列することができる。図10において、文字列5702は、文字列5604を切り捨てたものであり、文字列5704は、文字列5604を切り捨て、修正し、および/または再配列したものであり、文字列5708は、文字列5606を修正し、および/または再配列したものである。変換エンジンによって、切り捨て、修正、および/または再配列を行うことができる。意味識別子の一意性のために、構文および/または文字列内に含まれるすべての関係を必要としないとき、構文および/または文字列を切り捨てることは有用である。文字列 5604の所定のコンテキストにおいて、すべてのアイテムがアイテム3に直接関連している、すなわち、例えば、アイテム3が、すべてのアイテムを格納するデータベースであったと想定する。アイテム3を含む関係を省略する文字列を作成するといったように、文字列 5604を切り捨て、依然として固有の意味識別子を残すことができる。構文および/または文字列の切り捨てにより、格納要件を減らし、処理の効率を増大させることができる。例えば、データ統合プロセスのための処理時間を減少させるために、構文および/または文字列における関係の順序を変えることも有用である。あまり共通性がない関係が先に処理された場合、システムは、アイテムを識別するために、アイテムとの関連付けられたより少ない関係にアクセスし、処理することが必要になる可能性が高い。例えば、アイテム3に関連するアイテムが殆どなく、アイテム4に関連するものはさらに少なく、多くのアイテムがアイテム2に関連する場合には、コンテキストによって、文字列5708が、文字列5604より短い時間でアイテム9を識別することが可能になる。コンテキストにおいてアイテム9を一意的に識別するために、文字列5708の最初の2要素だけを必要とし、文字列5604の最初の3要素を必要とするということもあり得る。
In FIG. 9, the semantic identifier in string format for
変換エンジンは、1以上の意味識別子、データベース112、意味識別子を含むデータベース112、情報システム、1以上の意味識別子を含む情報システム、または他のアイテムに対して変換操作を行うことができる。図11は、文字列5804として具体化される意味識別子、および、データベース5808内に配置された文字列として具体化される意味識別子に作用する変換エンジン5802を示す。変換操作は、意味識別子のフォーマット、言語、および/またはデータ・モデルを変換するか、または他の方法で修正することができる。変換操作は、1以上のデータ・ツール、言語、フォーマット、および/またはデータ・モデルとの間の変換またはマッピング、少なくとも1つの他のデータ・ツール、言語、フォーマット、および/またはデータ・ツールとの間の変換またはマッピングを含むことができる。例えば、変換操作は、IBMからのWebSphere DataStage7、IBMからのWebSphere QualityStage、Business Objectツール、IBM−DB2 Cube Views、UML1.1、UML1.3、ERStudio、IBMのWebSphere ProfileStage、PowerDesigner(PackagesおよびExtended Attributesのためのサポートが付加された)、および/またはMicroStrategyツールのような、周知のデータ統合ツールへの、これらからの、またはこれらの間の変換またはマッピングを含むことができる。変換エンジンおよび/または変換操作は、随意的に、メタブローカにおいて具体化することができる。変換操作は、バッチ、リアルタイムまたは連続的に行い、実行し、および/または実施することができる。変換操作は、例えば、サービス指向アーキテクチャの一部としてなど、サービスとして提供すること、または利用可能にすることができる。SOAは、ビジネス・エンタープライズのエンタープライズ・コンピュータ・システムのインフラストラクチャの一部とすることができる。SOAにおいて、サービスは、アプリケーション開発および導入のための基礎的要素になり、迅速なアプリケーション開発を可能とし、冗長なコードを避ける。各々のサービスは、サービスについてのデータ入力ソースまたはサービスについてのデータ出力ターゲットといった周囲環境に左右されない1組のビジネス・ロジックまたはビジネス規則を具体化する。その結果、適切な入力および出力がサービスとアプリケーションとの間に確立された場合、サービスを様々なアプリケーションとともに再使用することができる。サービス指向アーキテクチャは、環境の変化に対してサービスが保護されることを可能にするので、アーキテクチャは、周囲のコンピュータ環境が変わったとしても機能する。その結果、インフラストラクチャの変更の結果としてサービスを記録する必要はなくなり、そのことは、時間と労力の節約をもたらす。SOAは、ウェブ・サービスのためのものとすることができ、3つのエンティティ、すなわちサービス・プロバイダ、サービス・リクエスタおよびサービス・レジストリを含むことができる。レジストリは、公衆のものであっても、または私的なものであってもよい。サービス・リクエスタは、適切なサービスを探してレジストリをサーチすることができる。適切なサービスが発見されると、サービス・リクエスタは、サービスを呼び出すのに必要な、ウェブ・サービス記述言語(Web Services Description Language、「WSDL」)コードのようなコードを受け取ることができる。WSDLは、ウェブ・サービスを記述するために従来より用いられているプログラミング言語である。次に、サービス・リクエスタは、サービスを呼び出すために、適切なフォーマット(ウェブ・サービス・メッセージのためのシンプル・オブジェクト・アクセス・プロトコル(Simple Object Access Protocol、「SOAP」)フォーマットのような)のメッセージなどを通して、サービス・プロバイダと接続することができる。SOAPプロトコルは、ウェブ・サービスにおいてデータを転送するための好ましいプロトコルである。SOAPプロトコルは、ウェブ・サービス・クライアントとウェブ・サービス・サーバとの間のメッセージ交換フォーマットを定める。SOAPプロトコルは、eXtensible Markup Language(「XML」)スキーマを使用し、XMLは、データのタグ付けのためにウェブ・サービスにおいて通常用いられる一般的な言語仕様であるが、他のマークアップ言語を使用することもできる。
The conversion engine may perform a conversion operation on one or more semantic identifiers, a
意味識別子、データベース112、1以上の意味識別子を含むデータベース112、情報システム、1以上の意味識別子を含む情報システム、または他のアイテムについての変換操作が存在すると、この変換操作を、いずれかの他の意味識別子、データベース112、1以上の意味識別子を含むデータベース112、情報システム、1以上の意味識別子を含む情報システム、あるいは少なくとも1つの変換操作を共有する他のアイテムとの間で変換し、これにマッピングし、これに結合し、これとともに使用し、またはこれと関連付けることが可能になる。変換操作のために、ハブのようなアトミック・データ・リポジトリを使用されるような実施形態においては、変換操作のマッピングは、とりわけ、操作の実行において、元の意味コンテキストと変換された意味コンテキストとの間で前後に変換されるデータをトレースすることができる。コンテキストによって、構文および/または文字列を変えるかまたは切り捨ててより効率的な格納またはより高速な処理を可能することによって、あるいは、意味コンテキストが変化する固有識別子を形成するのに用いられる関係を変えることなどによって、データ・アイテムの適切な識別子が変化することがある。したがって、動的な識別子は、再トレース可能な変換の利点を、データ・アイテムが用いられる種々のコンテキストにおける高速処理、効率的なデータ処理および効率的な操作の利点と結び付けることができる。
If there is a conversion operation for the semantic identifier, the
モデル内に識別を有するアイテムのような所定のアイテムは、物理インスタンスおよび論理モデリング・インスタンスのような多数の形式またはインスタンスで存在することができる。図12は、アイテム、すなわち従業員情報5902のテーブルを示す。しかし、概念またはエンティティ「従業員」は、企業内で多数の異なる形式で存在する場合がある。例えば、従業員テーブル5902は、従業員に関連した値を物理データ・ストレージ機構に格納する物理テーブルとして存在することができる。他方、エンティティ従業員は、論理モデリング活動5908または種々の他の形式またはインスタンスにおける従業員を表すアイコンまたはテキストのような、論理エンティティとして表すこともできる。つまり、いずれかの関連したデータまたはメタデータを含む同じアイテムが、例えば、データベース、データ・リポジトリ、モデル、ハブ等におけるビュー、モデル、構造、またはデータ統合環境にわたる様々な形式またはインスタンスで存在することができる。図13は、データベース6002内の1つの形式または単一のインスタンス、および/または、データベース6004またはハブ6008内の2つ以上の形式またはインスタンスでの従業員テーブル5902を示す。
A given item, such as an item having an identity in the model, can exist in many forms or instances, such as physical instances and logical modeling instances. FIG. 12 shows a table of items, ie
アイテムの種々の形式またはインスタンスを区別するために、抽象化レベル、アイテムの物理プロパティ、階層内のアイテムの位置、データベース内のアイテムの位置、アイテムが見出されるコンテキスト、アイテムの構文、アイテムと他のアイテムの関係、アイテムの属性、アイテムのクラス、または他の特性といった、何らかの区別特性を使用されることができる。例えば、再び図5を参照すると、年齢、性別、髪の色、IQ、政治的所属、および/または過去3ヶ月に医者にかかった回数に基づいて、アイテムすなわちこの場合は個人を区別することができる。例えば、年齢が製品を区別化する要因として選択された場合には、ジェシカは唯一の10歳以下の個人であり、ベティは57歳から67歳までの唯一の個人であり、ジムは37歳である唯一の個人である。他の例において、アイテムの異なる形式またはインスタンスは、異なる抽象化レベルで、または異なるコンテキストで存在することができる。例えば、従業員テーブルは、従業員に関するデータに関連したデータベース内の値を格納するためなどに用いられる物理的な従業員テーブル5904、および従業員に関連するプロセスに鑑みて用いられるような論理的な従業員モデル5908といった、ハブ6102内の多数の形式またはインスタンスで存在することができる。
To distinguish between different types or instances of items, the level of abstraction, item physical properties, item location in the hierarchy, item location in the database, the context in which the item is found, item syntax, item and other Some distinguishing characteristics can be used, such as item relationships, item attributes, item classes, or other characteristics. For example, referring again to FIG. 5, it is possible to distinguish items, or individuals in this case, based on age, gender, hair color, IQ, political affiliation, and / or the number of times the doctor has been seen in the last three months. it can. For example, if age is selected as a product distinguishing factor, Jessica is the only individual under 10 years old, Betty is the only individual from 57 to 67 years old, Jim is 37 years old There is only one individual. In other examples, different types or instances of items can exist at different levels of abstraction or in different contexts. For example, the employee table may be a logical employee table 5904, such as used to store values in a database related to employee-related data, and logical processes such as those used in connection with employee-related processes. It can exist in numerous forms or instances within the hub 6102, such as a
識別された特定のアイテムの異なるインスタンス間で区別化を行うことによって、様々な他の方法およびプロセスが可能になる。例えば、1つの実施形態において、「従業員」と名づけられたテーブルのようなアイテムをハブに入れることができる。ハブ・コレクタは、ハブ内に2つの形式またはインスタンス(1つは物理データベース・インスタンスに対応し、他のものは論理モデリング活動に対応する)の「従業員」を有することができる。ハブ内のアイテムに帰属するアイテムのプロパティのような区別特性により、物理インスタンスと論理モデル・インスタンスまたは形式との間の区別が可能になる。実施形態において、その区別特性は、抽象化の論理レベルと物理レベルを区別するためといった、いわゆる抽象化レベルとすることができる。他の場合においては、ハブは、他の特性を、異なる形式の識別子、関係、クラス、属性、物理的位置、論理的位置、モデル等のようなアイテムと関連付けることができる。 Differentiating between different instances of a particular item identified allows for various other methods and processes. For example, in one embodiment, an item such as a table named “employee” may be placed in the hub. A hub collector can have two types or instances of “employees” within the hub, one corresponding to a physical database instance and the other corresponding to a logical modeling activity. Differentiating characteristics, such as the properties of items attributed to items in the hub, allow a distinction between physical instances and logical model instances or forms. In the embodiment, the distinction characteristic may be a so-called abstraction level, such as for distinguishing between a logical level and a physical level of abstraction. In other cases, the hub may associate other characteristics with items such as different types of identifiers, relationships, classes, attributes, physical locations, logical locations, models, and the like.
図15に示されるように、データベース内にロードされるデータの選択、データの変換、クエリの生成等のような操作を実行するとき、変換エンジン6204のようなシステムは、ハブ6208またはデータベース6210から、すべてのアイテムをグラブし、ロードし、または獲得することができる。システムは、何らかの区別特性に基づいて、アイテムを選択またはフィルタリングすることができる。例えば、システムは、物理的抽象化レベルを有する、他のアイテムと特定の関係を有する、論理的抽象化レベルを有する、指定された日および時間の前に作成された、またはいずれかの他の区別特性を有するインスタンスまたは形式を選択またはフィルタリングすることができる。したがって、ここで説明される方法およびシステムは、いずれかの区別特性に基づいた同じアイテムまたはエンティティのインスタンスの選択的な処理を提供する。
As shown in FIG. 15, when performing operations such as selecting data to be loaded into a database, transforming data, generating queries, etc., a system such as the
図16に示されるように、クエリ6202に応答するものとすることができる、変換操作のようなデータ統合操作を実行するとき、変換エンジン6204は、ハブ6208またはデータベース6210において、任意のデータおよび/またはメタデータを含むアイテムをフィルタリングまたは選択することができ、関連する抽象化レベルのそれらのアイテムだけをグラブし、ロードし、または獲得することができる。例えば、変換エンジンは、論理的抽象化レベルを有するインスタンスまたは形式をフィルタリングまたは選択し、物理的抽象化レベルを有するものだけを保持することができる。フィルタリングまたは選択は、実行時および設計時に行うことができ、バッチで、リアルタイムで、または連続的に行うことができる。実施形態において、フィルタリングおよび選択のこうした方法は、サービス指向アーキテクチャにおけるRTIサービスとして提供することができる。
As shown in FIG. 16, when performing a data integration operation, such as a conversion operation, that may be responsive to a
フィルタリングまたは選択は、開発時、設計時、または実行時に変換エンジンおよび/またはシステムによって獲得される、データ・モデルのマッピング、メタデータ・モデルのマッピング、区別特性、アイテムと他のアイテムの関係、アイテムの属性、または識別子の構文などの情報に基づくものとすることができる。実施形態において、情報は、リアルタイムで動的に更新することができる。 Filtering or selection is acquired by the transformation engine and / or system at development time, design time, or runtime, data model mapping, metadata model mapping, distinctive characteristics, relationship between items and other items, item Based on information such as the attribute or identifier syntax. In embodiments, the information can be updated dynamically in real time.
プロセス全体においてフィルタリングまたは選択がハブまたはデータベースにより近いほど、操作がより効率的かつ高速になる。図17に示されるように、変換エンジン6204は、クエリ6202自体の変換操作を行い、ハブ6208またはデータベース6210に直接送るなど、さらなる処理のために送ることができる改善されたクエリ6402を実現することができる。例えば、改訂されたクエリ6402は、ハブ6208またはデータベース6210の固有フォーマットと直接互換性のあるフォーマットにすることができる。例えば、クエリをデータベース6210の固有フォーマットにすることによって、システムは、クエリに対する処理効率を高めることができる。同様に、クエリ6402をフィルタリングすることができ、または物理エンティティではなく論理モデリング・エンティティを保持するために、選択コマンドのようなコマンドを生成することができ、この場合、クエリ5402は、データベースに適したフォーマットではなく、論理モデリング活動(グラフィカル・ユーザ・インターフェースのような)に適したフォーマットにすることができる。勿論、クエリのみならず他のメッセージおよび操作を、抽象化レベルに従ってフィルタリングし、同じエンティティが、データ統合プラットフォームにわたってトレースされ、特定のデータ統合活動の適切な操作環境に従って処理できるようにすることが可能である。
The closer the filtering or selection is to the hub or database throughout the process, the more efficient and faster the operation. As shown in FIG. 17, the
ここで説明される方法およびシステムを用いて、意味コンテキストを捕捉し、オブジェクト、データ・アイテム、データ、列、行、テーブル、データベース、インスタンス、属性、メタデータ、概念、トピック、主題、意味識別子、他の識別子、RFIDタグ、ベンダー、供給業者、顧客、人、チーム、組織、ユーザ、ネットワーク、システム、装置、家族、店、製品、製造ライン、製品特性、製品仕様、製品属性、価格、コスト、材料仕様書、出荷データ、税金データ、コース、教育プログラム、位置、地図、部門、組織、有機的組織体、プロセス、規則、法、評価システム、商品、サービス、および/またはサービス提供のような、企業に関連した広範囲のアイテムに対してデータ統合タスクを処理することができる。 Using the methods and systems described herein, semantic context is captured and objects, data items, data, columns, rows, tables, databases, instances, attributes, metadata, concepts, topics, subject matter, semantic identifiers, Other identifiers, RFID tags, vendors, suppliers, customers, people, teams, organizations, users, networks, systems, equipment, families, stores, products, production lines, product characteristics, product specifications, product attributes, prices, costs, Such as material specifications, shipping data, tax data, courses, educational programs, locations, maps, departments, organizations, organic organizations, processes, rules, laws, evaluation systems, goods, services, and / or service offerings, Data integration tasks can be handled for a wide range of items related to the enterprise.
ここで説明される方法およびシステムは、企業の方法におけるステップ、データベース内のデータ、行または列内のデータ、テーブル内の行または列、データベース内の行または列、テーブル内のデータ、データベース内のテーブル、データベース内のメタデータ、ハブまたはリポジトリ内のアイテム、データベース内のアイテム、テーブル内のアイテム、列内のアイテム、行内のアイテム、組織内の人、通信の送信者または受信者、ネットワーク上のユーザ、ネットワーク上のシステム、ネットワーク上の装置、家族内の人、店の中の品目、メニュー上の料理、製造ライン内の製品、製品提供における製品、教育プログラムまたは訓練プログラムにおけるコースまたはステップ、地図上の位置、アイテムの位置、組織の部門、チームの人、規則システムにおける規則、サービス・スイートにおけるサービス、企業の組織階層内のエンティティ、供給チェーン内のエンティティ、マーケットにおける顧客、購買決定における購入者、商品またはサービスの価格、商品またはサービスのコスト、製造またはシステムの構成部品、方法のステップ、グループのメンバー、または多くの他のものといった、様々な意味コンテキストにおいて使用されることができる。 The methods and systems described herein include steps in an enterprise method, data in a database, data in a row or column, rows or columns in a table, rows or columns in a database, data in a table, data in a database Table, metadata in database, item in hub or repository, item in database, item in table, item in column, item in row, person in organization, sender or receiver of communication, on network Users, systems on the network, devices on the network, people in the family, items in the store, dishes on the menu, products in the production line, products in the product offering, courses or steps in the educational or training program, maps Top position, item position, organizational department, team person, Rules in the law system, services in the service suite, entities in the corporate organizational hierarchy, entities in the supply chain, customers in the market, buyers in purchase decisions, prices of goods or services, costs of goods or services, manufacturing or systems Can be used in a variety of semantic contexts, such as components, method steps, group members, or many others.
本発明は、特定の好ましい実施形態に関連して説明されたが、他の実施形態が、当業者によって認識され、本発明の範囲内に含まれるように意図されていることに留意されたい。 Although the invention has been described with reference to certain preferred embodiments, it is noted that other embodiments are recognized by those skilled in the art and are intended to be included within the scope of the invention.
Claims (35)
データ・モデル内のアイテムについての前記意味識別子の判定を可能にするために、データ・モデルのマッピングを獲得するステップと、
前記マッピングを、マッピングおよび前記意味識別子のうちの少なくとも1つに基づいて実行されるデータ統合機能と関連付けるステップと、
を含む、
データ統合のための方法。 Providing a semantic identifier for identifying the item based on relationships with other items;
Obtaining a mapping of the data model to enable determination of the semantic identifier for an item in the data model;
Associating the mapping with a data integration function performed based on at least one of a mapping and the semantic identifier;
including,
A method for data integration.
モデルをデータ・セットと関連付けるステップと、
前記データ・セットからアイテムを選択するための選択コマンドを、前記モデルから判定される前記アイテムについての区別特性に基づいて形成するステップと、
を含む、
方法。 A method for performing a data integration process,
Associating a model with a data set;
Forming a selection command for selecting an item from the data set based on a distinguishing characteristic for the item determined from the model;
including,
Method.
モデルをデータ・セットと関連付けるステップと、
前記データ・セットを照会するためのクエリを、前記モデルから判定される前記アイテムについての区別特性に基づいて形成するステップと、
を含む、
方法。 A method for performing a data integration process,
Associating a model with a data set;
Forming a query for querying the data set based on a distinguishing characteristic for the item determined from the model;
including,
Method.
他のアイテムとの関係に基づいてアイテムを識別するための意味識別子と、
データ・モデル内のアイテムについての前記意味識別子の判定を可能にするためのデータ・モデルのマッピングと、
前記マッピングを、マッピングおよび前記意味識別子のうちの少なくとも1つに基づいて実行されるデータ統合機能と関連付けるための機構と、
を備える
、システム。 A system for data integration,
A semantic identifier to identify the item based on its relationship to other items,
Mapping of the data model to enable determination of the semantic identifier for items in the data model;
A mechanism for associating the mapping with a data integration function performed based on at least one of the mapping and the semantic identifier;
A system comprising:
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US60640704P | 2004-08-31 | 2004-08-31 | |
| PCT/US2005/031097 WO2006026702A2 (en) | 2004-08-31 | 2005-08-31 | Methods and systems for semantic identification in data systems |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2008511936A true JP2008511936A (en) | 2008-04-17 |
| JP2008511936A5 JP2008511936A5 (en) | 2008-07-17 |
Family
ID=36000723
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007530351A Pending JP2008511936A (en) | 2004-08-31 | 2005-08-31 | Method and system for semantic identification in a data system |
Country Status (4)
| Country | Link |
|---|---|
| EP (1) | EP1815349A4 (en) |
| JP (1) | JP2008511936A (en) |
| CN (1) | CN101044472A (en) |
| WO (1) | WO2006026702A2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011054168A (en) * | 2009-08-31 | 2011-03-17 | Sap Ag | Transforming service oriented architecture model to service oriented infrastructure model |
| KR20200089453A (en) * | 2019-01-17 | 2020-07-27 | 주식회사 쓰리데이즈 | Database management system |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7849090B2 (en) * | 2005-03-30 | 2010-12-07 | Primal Fusion Inc. | System, method and computer program for faceted classification synthesis |
| CN101226523B (en) | 2007-01-17 | 2012-09-05 | 国际商业机器公司 | Method and system for analyzing data general condition |
| JP5183150B2 (en) * | 2007-10-30 | 2013-04-17 | アズビル株式会社 | Information linkage window system and program |
| EP2112593A1 (en) | 2008-04-25 | 2009-10-28 | Facton GmbH | Domain model concept for developing computer applications |
| US8341099B2 (en) * | 2010-03-12 | 2012-12-25 | Microsoft Corporation | Semantics update and adaptive interfaces in connection with information as a service |
| CN102402507B (en) * | 2010-09-07 | 2014-07-09 | 重庆邮电大学 | Heterogeneous data integration system for service-oriented architecture (SOA) multi-message mechanism |
| US9076152B2 (en) | 2010-10-20 | 2015-07-07 | Microsoft Technology Licensing, Llc | Semantic analysis of information |
| CN102541861A (en) * | 2010-12-14 | 2012-07-04 | 金蝶软件(中国)有限公司 | Method, device and system for establishing mapping relation in system integration |
| US20140129533A1 (en) * | 2012-11-08 | 2014-05-08 | Microsoft Corporation | Intermediary model to handle web vocabulary conflicts |
| CN104461494B (en) * | 2014-10-29 | 2018-10-26 | 中国建设银行股份有限公司 | A kind of method and device for the data packet generating data processing tools |
| US10360201B2 (en) * | 2016-07-11 | 2019-07-23 | Investcloud Inc | Data exchange common interface configuration |
| CN111373365A (en) * | 2017-10-12 | 2020-07-03 | 惠普发展公司,有限责任合伙企业 | Pattern syntax |
| DE102018219173A1 (en) * | 2018-11-09 | 2020-05-14 | Phoenix Contact Gmbh & Co. Kg | Device and method for generating neutral data for a product specification |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5692184A (en) * | 1995-05-09 | 1997-11-25 | Intergraph Corporation | Object relationship management system |
| US6044374A (en) * | 1997-11-14 | 2000-03-28 | Informatica Corporation | Method and apparatus for sharing metadata between multiple data marts through object references |
| AU2001290646A1 (en) * | 2000-09-08 | 2002-03-22 | The Regents Of The University Of California | Data source integration system and method |
| US6937983B2 (en) * | 2000-12-20 | 2005-08-30 | International Business Machines Corporation | Method and system for semantic speech recognition |
-
2005
- 2005-08-31 JP JP2007530351A patent/JP2008511936A/en active Pending
- 2005-08-31 CN CNA2005800290342A patent/CN101044472A/en active Pending
- 2005-08-31 WO PCT/US2005/031097 patent/WO2006026702A2/en active Application Filing
- 2005-08-31 EP EP05794064A patent/EP1815349A4/en not_active Withdrawn
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2011054168A (en) * | 2009-08-31 | 2011-03-17 | Sap Ag | Transforming service oriented architecture model to service oriented infrastructure model |
| KR20200089453A (en) * | 2019-01-17 | 2020-07-27 | 주식회사 쓰리데이즈 | Database management system |
| KR102150335B1 (en) | 2019-01-17 | 2020-09-01 | 주식회사 쓰리데이즈 | Database management system |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2006026702A2 (en) | 2006-03-09 |
| EP1815349A2 (en) | 2007-08-08 |
| CN101044472A (en) | 2007-09-26 |
| EP1815349A4 (en) | 2008-12-10 |
| WO2006026702A3 (en) | 2006-04-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2008511936A (en) | Method and system for semantic identification in a data system | |
| Bernstein et al. | Information integration in the enterprise | |
| US8041760B2 (en) | Service oriented architecture for a loading function in a data integration platform | |
| US7814142B2 (en) | User interface service for a services oriented architecture in a data integration platform | |
| US7814470B2 (en) | Multiple service bindings for a real time data integration service | |
| US8060553B2 (en) | Service oriented architecture for a transformation function in a data integration platform | |
| US8176083B2 (en) | Generic data object mapping agent | |
| US7991800B2 (en) | Object oriented system and method for optimizing the execution of marketing segmentations | |
| US8234308B2 (en) | Deliver application services through business object views | |
| CN101084494B (en) | Method and device for managing workflow in computer environment | |
| US20050262193A1 (en) | Logging service for a services oriented architecture in a data integration platform | |
| US20050223109A1 (en) | Data integration through a services oriented architecture | |
| US20060010195A1 (en) | Service oriented architecture for a message broker in a data integration platform | |
| JP2008511928A (en) | Metadata management | |
| US20050262190A1 (en) | Client side interface for real time data integration jobs | |
| US20050228808A1 (en) | Real time data integration services for health care information data integration | |
| US20050222931A1 (en) | Real time data integration services for financial information data integration | |
| US20050235274A1 (en) | Real time data integration for inventory management | |
| US20050240354A1 (en) | Service oriented architecture for an extract function in a data integration platform | |
| US20050240592A1 (en) | Real time data integration for supply chain management | |
| US20060069717A1 (en) | Security service for a services oriented architecture in a data integration platform | |
| US20050232046A1 (en) | Location-based real time data integration services | |
| US20110313969A1 (en) | Updating historic data and real-time data in reports | |
| CN109033113B (en) | Data warehouse and data mart management method and device | |
| US20130166563A1 (en) | Integration of Text Analysis and Search Functionality |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070807 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A711 Effective date: 20070921 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080530 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080530 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110405 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20111004 |