JP2007264718A - ユーザ興味分析装置、方法、プログラム - Google Patents
ユーザ興味分析装置、方法、プログラム Download PDFInfo
- Publication number
- JP2007264718A JP2007264718A JP2006085174A JP2006085174A JP2007264718A JP 2007264718 A JP2007264718 A JP 2007264718A JP 2006085174 A JP2006085174 A JP 2006085174A JP 2006085174 A JP2006085174 A JP 2006085174A JP 2007264718 A JP2007264718 A JP 2007264718A
- Authority
- JP
- Japan
- Prior art keywords
- user
- word
- file
- words
- influence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images








Landscapes
- Information Transfer Between Computers (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
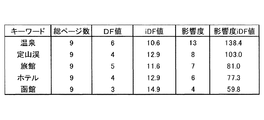
【解決手段】ユーザが閲覧した履歴から複数のファイルに含まれる語をファイル毎にテキストとして入力する手段と、そのテキストから言語単位に分割する手段と、ユーザが閲覧した複数のファイル間でユーザが参照した「伝播する語」を抽出する手段と、一または複数の前記「伝播する語」を記憶する手段と、前記「伝播する語」の全てのファイルに対する出現頻度から所定の「影響度」と、「伝播する語」の特定のファイル内に出現する程度を表す所定のiDF値を求める手段と、「影響度」と前記iDF値との関数である「影響度iDF値」に応じてユーザの興味ある語の集合をユーザプロファイル情報として抽出する手段と、を備える。
【選択図】図1
Description

tは伝播する語、
EDTは、伝播する語がユーザが所定の時間中に閲覧したファイル群の中に出現する頻度、
Nは、ユーザが所定の時間中に閲覧した全ファイル数、
DF(t)は、伝播する語tを含むファイル数、
を表す。
所定の時間とは、ユーザ分析装置が分析する対象期間を指し、分析対象やニーズに従って個別に定めることができる。例えば、数時間であっても、数ヶ月であってもよい。
プログラムメモリ25には、CPU21が実行する本装置の各機能を備えるプログラムが格納されている。すなわち、装置全体の制御部、入力したファイルからキーワードを抽出するキーワード抽出部、影響度iDF値を所定のアルゴリズムで求める影響度iDF値算出部、およびプロファイル作成部などのプログラムが格納されている。プログラムは機能別に分割されている必要はなく、単一のプログラムで構成されてもよい。
2 ファイルテキスト入力手段
3 形態素分割手段
4 伝播語抽出手段
5 影響度算出手段
5a、5b 影響度算出手段
6 iDF値算出手段
6a、6b iDF値算出手段
7 記憶手段
8 ユーザ興味語抽出手段
9 プロファイル情報出力手段
10 ユーザ興味分析装置(第一の実施形態)
11 類義語辞書
20 ユーザ興味分析装置(第二の実施形態)
21 CPU
22 入力部
24 出力部
24 通信部
25 プログラムメモリ
26 作業用メモリ
27 ユーザプロファイル
36 共通する語
37 伝播する語
41 新製品ニュース
42 製品情報サイト
43 価格比較サイト
44 Y社製品情報サイト(製品B仕様ページ)
45 Y社製品情報サイト(製品C仕様ページ)
46 価格比較サイト
47 ショプZサイト
48 購入ページ
61〜69 ページ1〜9
91〜93 ユーザ端末
94 インターネット
96 プロファイルサーバ
97〜99 プロファイルテーブル
Claims (9)
- ファイルを閲覧するユーザの興味のある語を抽出するユーザ興味分析装置であって、
前記ユーザが閲覧した前記ファイルの履歴から前記ファイルに含まれる複数の語を前記ファイル毎にテキストとして入力する手段と、
前記テキストから所定の単位に分割する手段と、
前記ユーザが閲覧した複数の前記ファイル間でユーザが参照した伝播する語を抽出する手段と、
一または複数の前記伝播する語を記憶する手段と、
前記伝播する語の複数の前記ファイルに対する出現頻度から、所定の影響度と前記伝播する語の特定の前記ファイル内に出現する程度を表す所定のiDF値を求める手段と、
前記影響度と前記iDF値との関数である影響度iDF値に応じて前記ユーザの興味ある語の集合をユーザプロファイル情報として抽出する手段と、
前記ユーザプロファイル情報を出力する手段と、
を備える、ユーザ興味分析装置。 - 前記ユーザプロファイル情報を他のユーザに公開する手段をさらに備える、請求項1に記載のユーザ興味分析装置。
- 前記伝播する語に関連する語を検出するための類似語辞書を更に備え、
前記影響度iDF値を前記伝播する語に関連する語に対しても算出する手段を備える、請求項1または2に記載のユーザ興味分析装置。 - 前記影響度iDF値が、次の数式で求められる、請求項1乃至3に記載のユーザ興味分析装置。
tは伝播する語、
EDTは、伝播する語tがユーザが閲覧したファイル群の中に出現する頻度、
Nは、ユーザが所定の時間中に閲覧した複数のファイル数、
DF(t)は、伝播する語tを含むファイル数。 - ファイルを閲覧するユーザの興味のある語を抽出するユーザ興味分析方法であって、
前記ユーザが閲覧した前記ファイルの履歴から前記ファイルに含まれる複数の語を前記ファイル毎にテキストとして入力するステップと、
前記テキストから所定の単位に形態素分割するステップと、
前記ユーザが閲覧した複数の前記ファイル間でユーザが参照した伝播する語を抽出するステップと、
一または複数の前記伝播する語を記憶するステップと、
前記伝播する語の複数の前記ファイルに対する出現頻度から、所定の影響度と前記伝播する語の特定の前記ファイル内に出現する程度を表す所定のiDF値を求めるステップと、
前記影響度と前記iDF値との積である影響度iDF値が高い順に前記ユーザの興味ある語の集合をユーザプロファイル情報として抽出するステップと、
前記ユーザプロファイル情報を出力するステップと、
を含む、ユーザ興味分析方法。 - ファイルを閲覧するユーザの興味のある語を抽出するユーザ興味分析コンピュータ・プログラムあって、
前記ユーザが閲覧した前記ファイルの履歴から前記ファイルに含まれる複数の語を前記ファイル毎にテキストとして入力するステップと、
前記テキストから意味を有する最小の言語単位に形態素分割するステップと、
前記ユーザが閲覧した複数の前記ファイル間でユーザが参照した伝播する語を抽出するステップと、
一または複数の前記伝播する語を記憶するステップと、
前記伝播する語の全ての前記ファイルに対する出現頻度から、所定の影響度と前記伝播する語の特定の前記ファイル内に出現する程度を表す所定のiDF値を求めるステップと、
前記影響度と前記iDF値との関数である影響度iDF値に応じて前記ユーザの興味ある語の集合をユーザプロファイル情報として抽出するステップと、
前記ユーザプロファイル情報を出力するステップと、
をコンピュータに実行させる、コンピュータ・プログラム。 - 前記ファイルが、WEBページである請求項1乃至4に記載のユーザ興味分析装置。
- 前記ファイルが、WEBページである請求項5に記載のユーザ興味分析方法。
- 前記ファイルが、WEBページである請求項6に記載のコンピュータ・プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006085174A JP2007264718A (ja) | 2006-03-27 | 2006-03-27 | ユーザ興味分析装置、方法、プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006085174A JP2007264718A (ja) | 2006-03-27 | 2006-03-27 | ユーザ興味分析装置、方法、プログラム |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011144495A Division JP2011198393A (ja) | 2011-06-29 | 2011-06-29 | ユーザ興味分析装置、方法、プログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2007264718A true JP2007264718A (ja) | 2007-10-11 |
Family
ID=38637697
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006085174A Pending JP2007264718A (ja) | 2006-03-27 | 2006-03-27 | ユーザ興味分析装置、方法、プログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2007264718A (ja) |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010128981A (ja) * | 2008-11-28 | 2010-06-10 | Nippon Telegr & Teleph Corp <Ntt> | 操作シーケンス抽出方法及び装置及びプログラム |
| JP2011146004A (ja) * | 2010-01-18 | 2011-07-28 | Zigsow Kk | Webコミュニティサイトを利用したユーザプロファイリングシステム |
| US8095652B2 (en) | 2008-02-29 | 2012-01-10 | International Business Machines Corporation | Analysis system, information processing apparatus, activity analysis method and program product |
| WO2012176317A1 (ja) * | 2011-06-23 | 2012-12-27 | サイバーアイ・エンタテインメント株式会社 | 画像認識システムを組込んだ関連性検索によるインタレスト・グラフ収集システム |
| JP2013105364A (ja) * | 2011-11-15 | 2013-05-30 | Nippon Telegr & Teleph Corp <Ntt> | 文書特徴抽出装置、文書特徴抽出方法、文書特徴抽出プログラム |
| WO2015190474A1 (ja) * | 2014-06-12 | 2015-12-17 | Emotion Intelligence株式会社 | 特典管理システム及び特典管理方法 |
| CN106506234A (zh) * | 2016-12-05 | 2017-03-15 | 深圳市彬讯科技有限公司 | 一种soa服务实时监控上报与服务性能度量方法 |
| US10198426B2 (en) | 2014-07-28 | 2019-02-05 | International Business Machines Corporation | Method, system, and computer program product for dividing a term with appropriate granularity |
| JP2020184151A (ja) * | 2019-05-07 | 2020-11-12 | 株式会社ビービット | ユーザ注目ワード分析装置、方法及びプログラム |
-
2006
- 2006-03-27 JP JP2006085174A patent/JP2007264718A/ja active Pending
Non-Patent Citations (6)
| Title |
|---|
| CSNG200600523002, 臼井 大介, "確率的手法を用いたWebページ推薦システム", 情報処理学会研究報告 Vol.2006 No.27, 20060317, 第2006巻 第27号, 25〜32, JP, 社団法人情報処理学会 * |
| CSNJ200610068089, 吉田 博哉, "ユーザの嗜好に基づいたRSSニュースリーダに関する基礎研究", 第68回(平成18年)全国大会講演論文集(3) データベースとメディア ネットワーク, 20060307, 3−185〜3−186, JP, 社団法人情報処理学会 * |
| CSNJ200910008075, 松井 一樹, "電子人格:サイバースペースにおけるコミュニティ形成支援", 第55回(平成9年後期)全国大会講演論文集(4) インタフェース コンピュータと人間社会, 19970924, 4−147〜4−148, JP, 社団法人情報処理学会 * |
| JPN6010073577, 臼井 大介, "確率的手法を用いたWebページ推薦システム", 情報処理学会研究報告 Vol.2006 No.27, 20060317, 第2006巻 第27号, 25〜32, JP, 社団法人情報処理学会 * |
| JPN6010073578, 松井 一樹, "電子人格:サイバースペースにおけるコミュニティ形成支援", 第55回(平成9年後期)全国大会講演論文集(4) インタフェース コンピュータと人間社会, 19970924, 4−147〜4−148, JP, 社団法人情報処理学会 * |
| JPN6010073579, 吉田 博哉, "ユーザの嗜好に基づいたRSSニュースリーダに関する基礎研究", 第68回(平成18年)全国大会講演論文集(3) データベースとメディア ネットワーク, 20060307, 3−185〜3−186, JP, 社団法人情報処理学会 * |
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8095652B2 (en) | 2008-02-29 | 2012-01-10 | International Business Machines Corporation | Analysis system, information processing apparatus, activity analysis method and program product |
| JP2010128981A (ja) * | 2008-11-28 | 2010-06-10 | Nippon Telegr & Teleph Corp <Ntt> | 操作シーケンス抽出方法及び装置及びプログラム |
| JP2011146004A (ja) * | 2010-01-18 | 2011-07-28 | Zigsow Kk | Webコミュニティサイトを利用したユーザプロファイリングシステム |
| US9600499B2 (en) | 2011-06-23 | 2017-03-21 | Cyber Ai Entertainment Inc. | System for collecting interest graph by relevance search incorporating image recognition system |
| JPWO2012176317A1 (ja) * | 2011-06-23 | 2015-02-23 | サイバーアイ・エンタテインメント株式会社 | 画像認識システムを組込んだ関連性検索によるインタレスト・グラフ収集システム |
| WO2012176317A1 (ja) * | 2011-06-23 | 2012-12-27 | サイバーアイ・エンタテインメント株式会社 | 画像認識システムを組込んだ関連性検索によるインタレスト・グラフ収集システム |
| JP2013105364A (ja) * | 2011-11-15 | 2013-05-30 | Nippon Telegr & Teleph Corp <Ntt> | 文書特徴抽出装置、文書特徴抽出方法、文書特徴抽出プログラム |
| WO2015190474A1 (ja) * | 2014-06-12 | 2015-12-17 | Emotion Intelligence株式会社 | 特典管理システム及び特典管理方法 |
| JP2016001422A (ja) * | 2014-06-12 | 2016-01-07 | Emotion Intelligence株式会社 | 特典管理システム及び特典管理方法 |
| US10198426B2 (en) | 2014-07-28 | 2019-02-05 | International Business Machines Corporation | Method, system, and computer program product for dividing a term with appropriate granularity |
| CN106506234A (zh) * | 2016-12-05 | 2017-03-15 | 深圳市彬讯科技有限公司 | 一种soa服务实时监控上报与服务性能度量方法 |
| CN106506234B (zh) * | 2016-12-05 | 2019-09-10 | 深圳市彬讯科技有限公司 | 一种soa服务实时监控上报与服务性能度量方法 |
| JP2020184151A (ja) * | 2019-05-07 | 2020-11-12 | 株式会社ビービット | ユーザ注目ワード分析装置、方法及びプログラム |
| JP7403735B2 (ja) | 2019-05-07 | 2023-12-25 | 株式会社ビービット | ユーザ注目ワード分析装置、方法及びプログラム |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10748164B2 (en) | Analyzing sentiment in product reviews | |
| Kim et al. | A scientometric review of emerging trends and new developments in recommendation systems | |
| Eickhoff et al. | Lessons from the journey: a query log analysis of within-session learning | |
| TW201944266A (zh) | 對話機器人檢索系統、對話機器人檢索方法、及程式 | |
| Zhang et al. | Mining users trust from e-commerce reviews based on sentiment similarity analysis | |
| US8713028B2 (en) | Related news articles | |
| Lewandowski | Understanding search engines | |
| KR101566616B1 (ko) | 빅데이터 처리를 통한 광고의사결정시스템 및 방법 | |
| CN105488697A (zh) | 一种基于客户行为特征的潜在客户挖掘方法 | |
| Akritidis et al. | Identifying the productive and influential bloggers in a community | |
| EP2188712A2 (en) | Recommendation systems and methods | |
| Vosecky et al. | Searching for quality microblog posts: Filtering and ranking based on content analysis and implicit links | |
| JPWO2009096523A1 (ja) | 情報分析装置、検索システム、情報分析方法及び情報分析用プログラム | |
| Huang et al. | A novel recommendation model with Google similarity | |
| Wang et al. | An approach to rank reviews by fusing and mining opinions based on review pertinence | |
| US20180089193A1 (en) | Category-based data analysis system for processing stored data-units and calculating their relevance to a subject domain with exemplary precision, and a computer-implemented method for identifying from a broad range of data sources, social entities that perform the function of Social Influencers | |
| Jansen et al. | Real time search on the web: Queries, topics, and economic value | |
| JP2007264718A (ja) | ユーザ興味分析装置、方法、プログラム | |
| Lin et al. | Blog popularity mining using social interconnection analysis | |
| Alghamdi et al. | The use and impact of Goodreads rating and reviews, for readers of Arabic books | |
| Guo et al. | An opinion feature extraction approach based on a multidimensional sentence analysis model | |
| JP2011198393A (ja) | ユーザ興味分析装置、方法、プログラム | |
| Chen et al. | A method of potential customer searching from opinions of network villagers in virtual communities | |
| Zhang et al. | Predicting temporary deal success with social media timing signals | |
| Tuma et al. | Online reviews as a source of marketing research data: a literature analysis |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20081224 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20101215 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20101221 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110221 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20110329 |
|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20120312 |