JP2005292958A - 教師データ作成装置およびプログラム、言語解析処理装置およびプログラム、ならびに要約処理装置およびプログラム - Google Patents
教師データ作成装置およびプログラム、言語解析処理装置およびプログラム、ならびに要約処理装置およびプログラム Download PDFInfo
- Publication number
- JP2005292958A JP2005292958A JP2004103862A JP2004103862A JP2005292958A JP 2005292958 A JP2005292958 A JP 2005292958A JP 2004103862 A JP2004103862 A JP 2004103862A JP 2004103862 A JP2004103862 A JP 2004103862A JP 2005292958 A JP2005292958 A JP 2005292958A
- Authority
- JP
- Japan
- Prior art keywords
- tag
- classification
- data
- range
- user
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images















Abstract
【解決手段】 タグ付与手段14は、コーパス入力手段11が入力したコーパス2のテキストデータ上でユーザが指定した箇所の前後に分類タグを挿入し、分類タグの付与箇所が含まれた教師データとして使用する範囲の前後に範囲指定タグを挿入し、コーパス記憶手段15に記憶する。ユーザ範囲抽出手段16は、タグが付与されたコーパスから範囲指定タグで囲まれたデータを抽出する。教師データ変換手段17は、抽出したデータを所定の単位に切り出し、分類タグに囲まれた単位に分類タグに対応する分類先を付与して教師データとする。
【選択図】 図1
Description
「…日本の首相は小泉さんです。小泉さんはいつも思いきったことをしています。…」
ユーザは、コーパス中の文「日本の首相は小泉さんです。」だけをチェックし、文中の単語「日本」に分類ラベル「地名」を、単語「小泉」に分類ラベル「人名」を付与する作業をしたとする。作業後の文は、以下のような状態になる。
「…”日本(地名)”の首相は”小泉(人名)”さんです。小泉さんはいつも思いきったことをしています。…」
このような言語情報(分類ラベル)を部分的にのみ付与したコーパスを教師データとして機械学習し、その学習結果を用いて固有表現抽出処理を行うとする。学習処理段階では、コーパス内の個々の単語の所定の素性を抽出し、付与された分類ラベルをもとに、その単語が「どのような素性の場合にどのような分類先になりやすいか」を学習する。素性とは、所定の解析処理のために用いる情報(例えば、品詞情報、字種情報、係り受け関係のような統語情報など)の一単位であって、文字や形態素などの所定の単位が備える性質を意味する。
〔第1の実施例〕
第1の実施例として、言語解析処理装置4で機械学習法を用いて固有表現抽出処理を行う場合に、教師データ作成装置1で言語解析処理装置4が使用する教師データを作成する処理を説明する。
<LOCATION></LOCATION >:分類先=地名、
<ORGANIZATION></ORGANIZATION >:分類先=組織名、
<ARTIFACT></ARTIFACT >:分類先=固有物名、
<DATE></DATE >:分類先=日付表現、
<TIME></TIME >:分類先=時間表現、
<MONEY ></MONEY>:分類先=金額表現、
<PERCENT ></PERCENT>:分類先=割合表現、…。
<KATAKANA></KATAKANA >:分類先=カタカナ、
<ALPHABETIC></ALPHABETIC >:分類先=英字、
<NUMERIC ></NUMERIC>:分類先=数字。
「…<LOCATION>日本</LOCATION >の首相は<PERSON>小泉</PERSON >さんです。小泉さんはいつも思いきったことをしています。…」
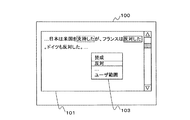
さらに、ユーザによって、指定項目101で分類先を付与する作業を行い教師データとして使用する範囲が指定されると(ステップS15)、タグ付与手段14は、タグ付与画面100で指定された範囲に対応するテキストデータの文字列の前後に範囲指定タグの開始タグおよび終了タグを付加する(ステップS16)。例えば、図3(B)に示すように、ユーザが、マウスドラッグにより文「日本の首相は小泉さんです。」を範囲として指定したとする。タグ付与手段14は、指定された範囲に対応するテキストデータの文字列の前後に範囲指定タグを挿入する。範囲指定タグが付与されたテキストデータは以下のようになる。
「…<UC><LOCATION>日本</LOCATION >の首相は<PERSON>小泉</PERSON >さんです。</UC >小泉さんはいつも思いきったことをしています。…」
一方、ユーザが、分類先を付与した後、教師データとして使用する範囲を指定しなかった場合には、タグ付与手段14は、指定項目101で分類先が付与された箇所を含む所定の箇所をユーザが選択した範囲とみなし、その範囲の前後に範囲指定タグを付加する(ステップS17)。例えば、タグ付与手段14は、テキストデータ中の分類タグが付与された文字列に単語の前後に連なる所定の文字数や単語数などの範囲を、ユーザが選択した範囲とみなし、みなした範囲の前後に範囲指定タグを付加する。
「学校:ガッコウ, 学校,名詞−一般;
へ: ヘ,へ, 助詞−格助詞−一般;
行く:イク,行く, 動詞−自立 五段・カ行促音便 基本形;
EOS」
なお、素性抽出手段110として、既知の他の形態素解析処理装置を用いてもよい。

sgn(x)=1 (x≧0)
−1(otherwise) 式(2)
であり、また、各αi は式(4)と式(5)の制約のもと、式(3)のL(α)を最大にする場合のものである。
なお、サポートベクトルマシンは、正例・負例の二値分類であるため、ワン・バーサス・レスト(One v.s. Rest )法、ペア・ワイズ(Pair Wise )法などの手法を用いて二値分類を多値分類に拡張する。
「賛成語」:支持した、賛成した、同意した、了承した、…、
「反対語」:反対した、同調しなかった、…。
<APPROVAL></APPROVAL >:分類先=賛成語
<DISAPPROVAL ></DISAPPROVAL>:分類先=反対語
なお、各分類ラベルに単位内での先頭文字を示す「B-」または先頭以外の文字を示す「I-」の区別を付け、分類先に該当しない旨の分類ラベルとして「OTHER 」を登録する。
「<UC>日本は米国を<APPROVAL>支持した</APPROVAL >が、フランスは<DISAPPROVAL >反対した</DISAPPROVAL>。</UC >ドイツも反対した。」
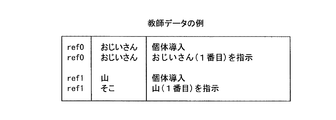
ユーザ範囲抽出手段16が、タグ付きコーパスから範囲指定タグに囲まれた部分「<UC>日本は米国を<APPROVAL>支持した</APPROVAL >が、フランスは<DISAPPROVAL >反対した</DISAPPROVAL>。」を抽出すると、教師データ変換手段17は、抽出されたテキストデータの各文字に分類タグに対応する分類ラベルを付与して教師データとする。図10は、教師データの例を示す図である。
〔第2の実施例〕
第2の実施例として、言語解析処理装置4で機械学習法を用いて照応解析処理を行う場合に、教師データ作成装置1で言語解析処理装置4が使用する教師データを作成する処理を説明する。
1)指示先となる対象(個体)の最初の出現(「固体導入」)であるか、否か、
2)前方の一番目に近い名詞句が指示先(「名詞(1番目)を指示」)であるか、否か、
3)前方の二番目に近い名詞句が指示先(「名詞(2番目)を指示」)であるか、否か。
「おじいさんがすんでいました。おじいさんは山にいきました。そこには大きな木がたっていました。木には小鳥の巣がありました。…」。
「<ref 0 >おじいさん</ref>がすんでいました。<ref 0 >おじいさん</ref>は<ref 1 >山</ref>にいきました。<ref 1 >そこ</ref>には大きな木がたっていました。木には小鳥の巣がありました。…」。
「<UC><ref 0 >おじいさん</ref>がすんでいました。<ref 0 >おじいさん</ref>は<ref 1 >山</ref>にいきました。<ref 1 >そこ</ref>には大きな木がたっていました。</UC >木には小鳥の巣がありました。…」。
「<UC><ref 0 >おじいさん</ref>がすんでいました。<ref 0 >おじいさん</ref>は<ref 1 >山</ref>にいきました。<ref 1 >そこ</ref>には大きな木がたっていました。</UC >」。
また、抽出する素性の種類は、以下のとおりである。
素性(1) :指示表現、
素性(2) :指示先の表現、もしくは、個体導入か、
素性(3) :指示表現と指示先との距離、何文節離れているか
(個体導入の場合「0文節離れている」とする)
素性(4) :指示表現と指示先の意味的整合性があっているかどうか、もしくは、
個体導入か、
素性(5) :指示表現が係る動詞がその指示表現のある格にとりうる意味と指示先の意味的整合性があっているかどうか、もしくは、個体導入か、
素性(6) :前方に同一名詞があるか、否か
図13および図14に、教師データの各単語の素性(1) 〜素性(6) として抽出された素性を示す。図13は、教師データのうち<ref 0 >および<ref 1 >に関するデータについて、前出の「1)指示先となる対象(個体という)の最初の出現である固体導入であるか、否か」という分類先の学習を行う場合の素性と分類ラベルの組の例を示す。図14は、同じデータについて前出の「2)前方の一番目に近い名詞句が指示先であるか、否か」という分類先の学習を行う場合の素性と分類ラベルの組の例である。
「1)指示表現と指示先の表現が完全に一致する場合、または、
2)指示先の表現が指示表現を含む場合、または、
3)指示先の表現が指示表現の下位語の場合、または、
4)指示表現に対して予め作成した表現の語のリストの中に指示先の表現がある場合に、 → 指示表現と指示先の意味的整合性がある」
下位語とは、他の概念に包括される関係にある概念の語をいう。「鳥」の下位語として、例えば「にわとり」、「からす」、「つる」などが該当する。
「いく:が−動物、に−場所; たつ:が−もの、に−場所、…」。
「おじいさん:人、動物、もの; 山:場所、もの、…。」
この例では、おじいさんは、人、動物、ものを意味し、山は、場所、ものをそれぞれ意味することを示す。
1)「固体導入」、それ以外か、
2)「前方の1番目に近い名詞句が指示先(名詞(1番目)を指示)」、それ以外か、
3)「前方の2番目に近い名詞句が指示先(名詞(2番目)を指示)」、それ以外か、
のそれぞれについて二値分類を推定し、その結果をもとに指示先を推定する。
「おばあさん:おばあさん、固体導入、0個、固体導入、固体導入、なし;
畑(1番目):畑、固体導入、0個、固体導入、固体導入、なし;
畑(2番目):畑、固体導入、0個、固体導入、固体導入、あり;
大根:大根、固体導入、0個、固体導入、固体導入、なし;」
機械学習手段42は、おばあさん、畑(1番目)、大根の分類ラベルを「固体導入」と推定し、畑(2番目)の分類ラベルを「それ以外」と推定する。
「畑(2番目):畑、畑、2個、整合性有り、整合性有り、同一名詞あり」
機械学習手段42は、「畑(2番目)」の分類ラベルは「前方の1番目に近い名詞句が指示先」であると推定し、最終的に、各単語の分類ラベルを以下のように推定する。
「おばあさん(1番目):個体導入、
畑(1番目):個体導入、
畑(2番目):畑(1番目)を指示、
大根(1番目):個体導入」
そして、機械学習手段42は、各単語の推定した分類ラベルから、「畑(1番目)」と「畑(2番目)」とが照応関係であると解析する。
「おばあさんは<ref 0 >畑</ref>へいきました。<ref 0 >畑</ref>には大根がいっぱいうわっていました。」
その後、解析結果表示処理手段48は、所定の表示規則に従って、同じ数字の照応タグに囲まれた名詞を同じ色で表示するなどして入力データを表示装置49に表示する。これにより、同一の指示対象についての照応関係を分かりやすく表示することができる。
〔第3の実施例〕
第3の実施例として、言語解析処理の一つである要約処理について、機械学習法を用いてユーザの指向に適応する要約処理を説明する。要約処理とは、文章データを、その内容を表わすために重要と考えられる文(重要文という)を用いて要約する処理をいう。
「…さらに、名詞の修飾語や所有者の情報を用い、より確実に指示対象の推定を行う。
この結果、学習サンプルにおいて適合率82%、再現率85%の精度で、テストサンプルにおいて適合率79%、再現率77%の精度で、照応する名詞の指示対象の推定をすることができた。また、対照実験を行って名詞の指示性や修飾語や所有者を用いることが有効であるこを示した。…」
タグ付与手段62は、コーパス7のテキストデータを表示しユーザにタグ付与操作を促すタグ付与画面200を表示装置615に表示する(ステップS31)。
「この結果、学習サンプルにおいて、適合率82%、再現率85%の精度で、テストサンプルにおいて適合率79%、再現率77%の精度で、照応する名詞の指示対象の推定をすることができた。」
タグ付与手段62は、以下のように、タグ付与画面200で指定された文に対応する文字列の前後に選択された重要文タグ<IMP _SENT></IMP_SENT>を挿入する。
「<IMP _SENT>この結果、学習サンプルにおいて、適合率82%、再現率85%の精度で、テストサンプルにおいて適合率79%、再現率77%の精度で、照応する名詞の指示対象の推定をすることができた。</IMP_SENT>」
さらに、ユーザが、以下の範囲を要約の対象とする範囲として指定する。例えば、図18(B)に示すように、ユーザが、指定項目201のテキストデータの以下の文をマウスドラッグ操作などにより、ユーザ範囲データ(段落データ)として選択し、マウス右ボタンクリック操作などにより、選択項目203からユーザ範囲を選択する。
「さらに、名詞の修飾語や所有者の情報を用い、より確実に指示対象の推定を行う。…
この結果、学習サンプルにおいて適合率82%、再現率85%の精度で、テストサンプルにおいて適合率79%、再現率77%の精度で、照応する名詞の指示対象の推定をすることができた。また、対照実験を行って名詞の指示性や修飾語や所有者を用いることが有効であるこを示した。」
タグ付与手段62は、以下のように、指定された範囲に対応するテキストデータの文字列の前後に範囲指定タグ<UC></UC >を付加する。
「<UC>さらに、名詞の修飾語や所有者の情報を用い、より確実に指示対象の推定を行う。…
<IMP _SENT>この結果、学習サンプルにおいて、適合率82%、再現率85%の精度で、テストサンプルにおいて適合率79%、再現率77%の精度で、照応する名詞の指示対象の推定をすることができた。</IMP_SENT>また、対照実験を行って名詞の指示性や修飾語や所有者を用いることが有効であるこを示した。</UC >」
なお、タグ付与手段62は、ユーザが重要文により要約される範囲を指定しなかった場合には、重要文タグが付与された文を含む所定の範囲、例えば、重要文タグが付与された文を含む段落の範囲をユーザが指定した範囲とみなして、その範囲の前後に範囲指定タグを付加する( ステップS36)。範囲の指定とみなす法としては、予め、同一文、同一の段落、前後所定数の文などと決めておく。
「<UC><LOCATION>日本</LOCATION >の首相は<PERSON>小泉</PERSON >さんです。</UC >小泉さんはいつも思いきったことをしています。」
しかし、ユーザが、分類先の「人名」は多く指定したが、「地名」はあまり多く指定していなかった場合には、分類先「地名」の指定だけをさらに増やしたいと考えることがある。
「<UC-LOCATION ><LOCATION> 大阪</LOCATION >の知事は太田さんです。</UC-LOCATION>大阪は古くは商業の中心地でした。」
そして、以降の処理においては分類先「地名」についてのみ処理を行うようにする。
11 コーパス入力手段
12 タグ登録手段
13 タグ記憶手段
14 タグ付与手段
15 コーパス記憶手段
16 ユーザ範囲抽出手段
17 教師データ変換手段
18 規則登録手段
19 規則記憶手段
110 素性抽出手段
21 表示装置
22 入力装置
2 コーパス(テキストデータ)
4 言語解析処理装置
42 機械学習手段
43 学習結果記憶手段
44 データ入力手段
45 素性抽出手段
46 解推定手段
47 タグ付与手段
48 解析結果表示処理手段
49 表示装置
6 要約処理装置
61 コーパス入力手段
62 タグ付与手段
63 コーパス記憶手段
64 ユーザ範囲抽出手段
65 教師データ変換手段
66 素性抽出手段
67 機械学習手段
68 学習結果記憶手段
69 データ入力手段
610 素性抽出手段
611 要約推定手段
612 タグ付与手段
613 要約出力処理手段
615 表示装置
616 入力装置
7 コーパス(テキストデータ)
Claims (17)
- 機械学習法を用いた所定の言語解析処理において使用する教師データをコーパスから作成する教師データ作成装置であって、
テキストデータで構成されるコーパスを入力するコーパス入力手段と、
前記コーパスのテキストデータにおいて、ユーザによって選択された文字列の前後に、所定の言語解析の結果となる言語情報の個々の分類先を示すタグであってマークアップ言語の形式で記述された分類タグを挿入する分類タグ付与手段と、
前記分類タグが挿入されたテキストデータにおいて、前記分類タグが挿入された箇所を含む所定の範囲の前後に、教師データとして使用する範囲を示すタグであってマークアップ言語の形式で記述された範囲指定タグを挿入する範囲指定タグ付与手段と、
前記分類タグおよび前記範囲指定タグが挿入されたテキストデータから、前記範囲指定タグに囲まれたデータをユーザ範囲データとして抽出するユーザ範囲抽出手段とを、備える
ことを特徴とする教師データ作成装置。 - ユーザによって入力された分類タグをタグ記憶手段に記憶するタグ登録手段を備え、
前記分類タグ付与手段は、前記タグ記憶手段に記憶された分類タグを前記コーパスのテキストデータに挿入する
ことを特徴とする請求項1記載の教師データ作成装置。 - 前記範囲指定タグ付与手段は、前記分類タグが挿入されたテキストデータにおいて、ユーザによって指定された前記分類タグが挿入された箇所を含む範囲の前後に前記範囲指定タグを挿入する
ことを特徴とする請求項1記載の教師データ作成装置。 - 前記範囲指定タグ付与手段は、前記分類タグが挿入されたテキストデータにおいて、前記分類タグが挿入された箇所を含む所定の範囲を所定の範囲指定規則にもとづいて指定し、前記指定された範囲の前後に前記範囲指定タグを挿入する
ことを特徴とする請求項1記載の教師データ作成装置。 - ユーザによって定義されたユーザ範囲指定規則を規則記憶手段に記憶する規則登録手段を備え、
前記範囲指定タグ付与手段は、前記規則記憶手段に記憶されたユーザ範囲指定規則に従って前記範囲指定タグを挿入する
ことを特徴とする請求項4記載の教師データ作成装置。 - 前記分類タグ付与手段は、前記テキストデータにおいて、前記分類タグが挿入された箇所を含む所定の範囲の前後に、前記分類タグのうちユーザによって指定された特定の分類先だけに対する教師データとして使用する範囲を示すタグであってマークアップ言語の形式で記述されたユーザ指定分類タグ用範囲指定タグを付与し、
前記ユーザ範囲抽出手段は、前記ユーザ指定分類タグ用範囲指定タグが挿入されたテキストデータから、前記ユーザ指定分類タグ用範囲指定タグに囲まれたデータを、前記特定の分類先に対する教師データを生成するためのユーザ範囲データとして抽出する
ことを特徴とする請求項1記載の教師データ作成装置。 - さらに、前記ユーザ範囲データを所定の単位ごとに分割し、前記ユーザ範囲データから前記分類タグに囲まれた文字列を検出し、前記分割した単位のうち前記検出した文字列に対応する部分に前記分類タグに対応する分類先を前記単位ごとに付与し、各単位のデータを、解を前記分類先とする教師データに変換する教師データ変換手段を備える
ことを特徴とする請求項1記載の教師データ作成装置。 - 前記教師データ変換手段は、前記検出した文字列が複数の単位である場合に、前記分類先に前記文字列における単位の位置を示す情報を付加したものを、単位ごとに付与する
ことを特徴とする請求項7記載の教師データ作成装置。 - さらに、前記教師データから所定の種類の素性を抽出し、前記単位について、前記素性の集合と前記付与された分類先との組を生成する素性抽出手段を備える
ことを特徴とする請求項7記載の教師データ作成装置。 - 前記素性抽出手段は、前記教師データに対して形態素解析を行い所定の種類の素性を抽出する
ことを特徴とする請求項9記載の教師データ作成装置。 - 前記素性抽出手段は、前記教師データから所定の文字または文字列を切り出して素性とする
ことを特徴とする請求項9記載の教師データ作成装置。 - 教師データを用いた機械学習法により所定の言語解析処理を行う言語解析処理装置であって、
テキストデータで構成されるコーパスであって、所定の言語解析の結果となる言語情報の個々の分類先を示すタグであってマークアップ言語の形式で記述された分類タグと、前記分類タグが挿入された箇所を含む所定の範囲の前後に、教師データとして使用する範囲を示すタグであってマークアップ言語の形式で記述された範囲指定タグとが付与されたものを入力し、前記コーパスから、前記範囲指定タグに囲まれたデータをユーザ範囲データとして抽出するユーザ範囲抽出手段と、
前記ユーザ範囲データを所定の単位ごとに切り出し、前記ユーザ範囲データから前記分類タグに囲まれた文字列を検出し、前記切り出した単位のうち前記検出した文字列に対応するものに前記分類タグに対応する分類先を付与し、前記切り出した単位のうち前記検出した文字列に対応しないものに分類先がないことを示す分類先を付与し、単位ごとのデータを教師データとする教師データ変換手段と、
前記教師データから所定の種類の素性を抽出し、前記単位について、前記素性の集合と前記付与された分類先との組を生成する素性抽出手段と、
前記素性の集合と前記分類先との組を利用して、前記単位について、前記素性の集合の場合にどのような分類先になりやすいかを学習し、前記学習の結果を記憶しておく機械学習手段と、
言語解析処理の対象とするテキストデータを入力するデータ入力手段と、
前記入力データから所定の解析処理または切り出し処理により素性を抽出する所定の種類の素性を抽出する素性抽出手段と、
前記学習結果を利用して、前記入力データの所定の単位のデータについて、前記素性の場合になりやすい分類先を推定する解推定手段と、
前記推定された分類先に対応する分類タグを、前記入力データの前記推定の対象となった単位に対応する文字列の前後に挿入するタグ付与手段とを、備える
ことを特徴とする言語解析処理装置。 - さらに、分類タグが挿入された前記入力データから、前記分類タグに囲まれた文字列を、前記分類タグに囲まれていない文字列と異なる表示態様で表示する解析結果表示処理手段を備える
ことを特徴とする請求項12記載の言語解析処理装置。 - 教師データを用いた機械学習法により文章の要約を行う要約処理装置であって、
複数の文で構成される教師用のテキストデータを入力する教師用データ入力手段と、
前記テキストデータにおいて、ユーザによって選択された文の前後に、要約処理において重要な文であることを示すタグであってマークアップ言語の形式で記述された重要文タグを挿入する重要文タグ付与手段と、
前記重要文タグが挿入されたテキストデータにおいて、前記重要文タグが挿入された文が含まれる要約する対象となる文章の範囲の前後に、教師データとして使用する範囲を示すタグであってマークアップ言語の形式で記述された範囲指定タグを挿入する範囲指定タグ付与手段と、
前記重要文タグおよび前記範囲指定タグが挿入されたテキストデータから、前記範囲指定タグに囲まれたデータをユーザ範囲データとして抽出するユーザ範囲抽出手段と、
前記ユーザ範囲データを文単位に分割し、前記ユーザ範囲データから前記重要文タグに囲まれた文を検出し、前記分割した文のうち前記検出した文に重要文であることを示す分類先を付与し、前記分割した文のうち前記検出した文以外の文に重要文でないことを示す分類先を付与し、各文を教師データとする教師データ変換手段と、
前記教師データから所定の種類の素性を抽出し、前記文について、前記素性の集合と前記付与された分類先との組を生成する素性抽出手段と、
前記文についての前記素性と前記分類先との組を利用して、前記各文について、前記素性の集合の場合にどのような分類先になりやすいかを学習し、前記学習の結果を記憶しておく機械学習手段と、
要約の対象とするテキストデータを入力するデータ入力手段と、
前記入力データから所定の解析処理または切り出し処理により、所定の種類の素性を抽出する素性抽出手段と、
前記学習結果を利用して、前記入力データの各文について、前記素性の集合の場合になりやすい分類先を推定する解推定手段と、
前記推定された分類先が重要文である文の前後に重要文タグを挿入するタグ付与手段と、
前記入力データの前記重要文タグで囲まれた文を要約として出力する要約出力処理手段とを、備える
ことを特徴とする要約処理装置。 - 請求項1記載の教師データ生成装置として、コンピュータを機能させるための教師データ生成プログラム。
- 請求項12記載の言語解析処理装置として、コンピュータを機能させるための言語解析処理プログラム。
- 請求項14記載の要約処理装置として、コンピュータを機能させるための要約処理プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004103862A JP3899414B2 (ja) | 2004-03-31 | 2004-03-31 | 教師データ作成装置およびプログラム、ならびに言語解析処理装置およびプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004103862A JP3899414B2 (ja) | 2004-03-31 | 2004-03-31 | 教師データ作成装置およびプログラム、ならびに言語解析処理装置およびプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005292958A true JP2005292958A (ja) | 2005-10-20 |
| JP3899414B2 JP3899414B2 (ja) | 2007-03-28 |
Family
ID=35325856
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004103862A Expired - Lifetime JP3899414B2 (ja) | 2004-03-31 | 2004-03-31 | 教師データ作成装置およびプログラム、ならびに言語解析処理装置およびプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP3899414B2 (ja) |
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2008225907A (ja) * | 2007-03-13 | 2008-09-25 | Nippon Telegr & Teleph Corp <Ntt> | 言語解析モデル学習装置、言語解析モデル学習方法、言語解析モデル学習プログラムならびにその記録媒体 |
| JP2009187048A (ja) * | 2008-02-01 | 2009-08-20 | Yahoo Japan Corp | 評価表現抽出方法、評価表現抽出装置、および、評価表現抽出プログラム |
| JP2010514019A (ja) * | 2006-12-22 | 2010-04-30 | インテル コーポレイション | 企業情報管理共有装置、方法、企業システム及び製品 |
| JP2010140263A (ja) * | 2008-12-11 | 2010-06-24 | Fuji Xerox Co Ltd | 自然言語処理装置及びプログラム |
| WO2011008862A2 (en) * | 2009-07-14 | 2011-01-20 | Zoomii, Inc. | Markup language-based authoring and runtime environment for interactive content platform |
| JP2012150586A (ja) * | 2011-01-18 | 2012-08-09 | Toshiba Corp | 学習装置、判定装置、学習方法、判定方法、学習プログラム及び判定プログラム |
| US8638319B2 (en) | 2007-05-29 | 2014-01-28 | Livescribe Inc. | Customer authoring tools for creating user-generated content for smart pen applications |
| JP2017058816A (ja) * | 2015-09-15 | 2017-03-23 | 株式会社東芝 | 情報抽出装置、方法およびプログラム |
| JP2018010532A (ja) * | 2016-07-14 | 2018-01-18 | 株式会社レトリバ | 情報処理装置、プログラム及び情報処理方法 |
| JP2019016181A (ja) * | 2017-07-07 | 2019-01-31 | 株式会社野村総合研究所 | テキスト要約システム |
| JP2020030408A (ja) * | 2018-08-20 | 2020-02-27 | ベイジン バイドゥ ネットコム サイエンス アンド テクノロジー カンパニー リミテッド | オーディオにおける重要語句を認識するための方法、装置、機器及び媒体 |
| WO2020059506A1 (ja) * | 2018-09-19 | 2020-03-26 | 日本電信電話株式会社 | 学習装置、抽出装置及び学習方法 |
| WO2020059469A1 (ja) * | 2018-09-19 | 2020-03-26 | 日本電信電話株式会社 | 学習装置、抽出装置及び学習方法 |
| JP2020160974A (ja) * | 2019-03-27 | 2020-10-01 | 大日本印刷株式会社 | 情報処理装置、情報処理方法及びプログラム |
-
2004
- 2004-03-31 JP JP2004103862A patent/JP3899414B2/ja not_active Expired - Lifetime
Cited By (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010514019A (ja) * | 2006-12-22 | 2010-04-30 | インテル コーポレイション | 企業情報管理共有装置、方法、企業システム及び製品 |
| JP2008225907A (ja) * | 2007-03-13 | 2008-09-25 | Nippon Telegr & Teleph Corp <Ntt> | 言語解析モデル学習装置、言語解析モデル学習方法、言語解析モデル学習プログラムならびにその記録媒体 |
| US8638319B2 (en) | 2007-05-29 | 2014-01-28 | Livescribe Inc. | Customer authoring tools for creating user-generated content for smart pen applications |
| US8842100B2 (en) | 2007-05-29 | 2014-09-23 | Livescribe Inc. | Customer authoring tools for creating user-generated content for smart pen applications |
| JP2009187048A (ja) * | 2008-02-01 | 2009-08-20 | Yahoo Japan Corp | 評価表現抽出方法、評価表現抽出装置、および、評価表現抽出プログラム |
| JP2010140263A (ja) * | 2008-12-11 | 2010-06-24 | Fuji Xerox Co Ltd | 自然言語処理装置及びプログラム |
| WO2011008862A2 (en) * | 2009-07-14 | 2011-01-20 | Zoomii, Inc. | Markup language-based authoring and runtime environment for interactive content platform |
| WO2011008862A3 (en) * | 2009-07-14 | 2011-05-05 | Zoomii, Inc. | Markup language-based authoring and runtime environment for interactive content platform |
| JP2012150586A (ja) * | 2011-01-18 | 2012-08-09 | Toshiba Corp | 学習装置、判定装置、学習方法、判定方法、学習プログラム及び判定プログラム |
| US9141601B2 (en) | 2011-01-18 | 2015-09-22 | Kabushiki Kaisha Toshiba | Learning device, determination device, learning method, determination method, and computer program product |
| JP2017058816A (ja) * | 2015-09-15 | 2017-03-23 | 株式会社東芝 | 情報抽出装置、方法およびプログラム |
| JP2018010532A (ja) * | 2016-07-14 | 2018-01-18 | 株式会社レトリバ | 情報処理装置、プログラム及び情報処理方法 |
| JP2019016181A (ja) * | 2017-07-07 | 2019-01-31 | 株式会社野村総合研究所 | テキスト要約システム |
| JP7100747B2 (ja) | 2017-07-07 | 2022-07-13 | 株式会社野村総合研究所 | 学習データ生成方法および装置 |
| JP2021180003A (ja) * | 2017-07-07 | 2021-11-18 | 株式会社野村総合研究所 | 学習データ生成方法および装置 |
| KR102316063B1 (ko) * | 2018-08-20 | 2021-10-22 | 베이징 바이두 넷컴 사이언스 앤 테크놀로지 코., 엘티디. | 오디오 중의 키 프레이즈를 인식하기 위한 방법과 장치, 기기 및 매체 |
| KR20200021429A (ko) * | 2018-08-20 | 2020-02-28 | 베이징 바이두 넷컴 사이언스 앤 테크놀로지 코., 엘티디. | 오디오 중의 키 프레이즈를 인식하기 위한 방법과 장치, 기기 및 매체 |
| JP2020030408A (ja) * | 2018-08-20 | 2020-02-27 | ベイジン バイドゥ ネットコム サイエンス アンド テクノロジー カンパニー リミテッド | オーディオにおける重要語句を認識するための方法、装置、機器及び媒体 |
| US11308937B2 (en) | 2018-08-20 | 2022-04-19 | Beijing Baidu Netcom Science And Technology Co., Ltd. | Method and apparatus for identifying key phrase in audio, device and medium |
| WO2020059469A1 (ja) * | 2018-09-19 | 2020-03-26 | 日本電信電話株式会社 | 学習装置、抽出装置及び学習方法 |
| JP2020046907A (ja) * | 2018-09-19 | 2020-03-26 | 日本電信電話株式会社 | 学習装置、抽出装置及び学習方法 |
| JP2020046909A (ja) * | 2018-09-19 | 2020-03-26 | 日本電信電話株式会社 | 学習装置、抽出装置及び学習方法 |
| WO2020059506A1 (ja) * | 2018-09-19 | 2020-03-26 | 日本電信電話株式会社 | 学習装置、抽出装置及び学習方法 |
| JP7135640B2 (ja) | 2018-09-19 | 2022-09-13 | 日本電信電話株式会社 | 学習装置、抽出装置及び学習方法 |
| JP7135641B2 (ja) | 2018-09-19 | 2022-09-13 | 日本電信電話株式会社 | 学習装置、抽出装置及び学習方法 |
| JP2020160974A (ja) * | 2019-03-27 | 2020-10-01 | 大日本印刷株式会社 | 情報処理装置、情報処理方法及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| JP3899414B2 (ja) | 2007-03-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11551567B2 (en) | System and method for providing an interactive visual learning environment for creation, presentation, sharing, organizing and analysis of knowledge on subject matter | |
| US10157171B2 (en) | Annotation assisting apparatus and computer program therefor | |
| US20180366013A1 (en) | System and method for providing an interactive visual learning environment for creation, presentation, sharing, organizing and analysis of knowledge on subject matter | |
| CN106650943B (zh) | 基于人工智能的辅助写作方法和装置 | |
| US7627562B2 (en) | Obfuscating document stylometry | |
| US7234942B2 (en) | Summarisation representation apparatus | |
| US11210468B2 (en) | System and method for comparing plurality of documents | |
| US9483460B2 (en) | Automated formation of specialized dictionaries | |
| JP3899414B2 (ja) | 教師データ作成装置およびプログラム、ならびに言語解析処理装置およびプログラム | |
| US10042880B1 (en) | Automated identification of start-of-reading location for ebooks | |
| US9262400B2 (en) | Non-transitory computer readable medium and information processing apparatus and method for classifying multilingual documents | |
| JP2008287517A (ja) | 強調表示装置及びプログラム | |
| Nassiri et al. | Arabic readability assessment for foreign language learners | |
| Thomas | Natural language processing with spark NLP: learning to understand text at scale | |
| van der Lee et al. | Neural data-to-text generation based on small datasets: Comparing the added value of two semi-supervised learning approaches on top of a large language model | |
| CN111274354B (zh) | 一种裁判文书结构化方法及装置 | |
| JP5366179B2 (ja) | 情報の重要度推定システム及び方法及びプログラム | |
| KR102552811B1 (ko) | 클라우드 기반 문법 교정 서비스 제공 시스템 | |
| Pakray et al. | An hmm based pos tagger for pos tagging of code-mixed indian social media text | |
| JP2007323238A (ja) | 強調表示装置及びプログラム | |
| WO2010103916A1 (ja) | 文書の特徴語提示装置及び特徴語の優先度付与プログラム | |
| Eyecioglu et al. | Knowledge-lean paraphrase identification using character-based features | |
| JP4831737B2 (ja) | キーワード強調装置及びプログラム | |
| JP6976585B2 (ja) | 照応・省略解析装置及びコンピュータプログラム | |
| JP2006227914A (ja) | 情報検索装置、情報検索方法、プログラム、記憶媒体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20060905 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20061101 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20061128 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |