JP2005292770A6 - 音響モデル生成装置及び音声認識装置 - Google Patents
音響モデル生成装置及び音声認識装置 Download PDFInfo
- Publication number
- JP2005292770A6 JP2005292770A6 JP2004286082A JP2004286082A JP2005292770A6 JP 2005292770 A6 JP2005292770 A6 JP 2005292770A6 JP 2004286082 A JP2004286082 A JP 2004286082A JP 2004286082 A JP2004286082 A JP 2004286082A JP 2005292770 A6 JP2005292770 A6 JP 2005292770A6
- Authority
- JP
- Japan
- Prior art keywords
- acoustic model
- acoustic
- speech recognition
- speaker
- speakers
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images




Abstract
【課題】非ネイティブの話者の発話に対する音声認識精度を向上させる。
【解決手段】予め非ネイティブ話者グループごとに作成された複数の音響モデル34を用いて入力発話36に対する音声認識を行なう音声認識装置38は、入力発話36の音響的特徴に基づいて、入力発話36の音響的特徴に合致する音響モデル82を選択する話者グループ分類部80と、選択された音響モデル82を用いて入力発話36に対する音声認識を行なうデコード部84とを含む。複数の音響モデル34を用いて並列にデコードし、最も尤度の高い仮説を選択するようにしてもよい。
【選択図】 図3
【解決手段】予め非ネイティブ話者グループごとに作成された複数の音響モデル34を用いて入力発話36に対する音声認識を行なう音声認識装置38は、入力発話36の音響的特徴に基づいて、入力発話36の音響的特徴に合致する音響モデル82を選択する話者グループ分類部80と、選択された音響モデル82を用いて入力発話36に対する音声認識を行なうデコード部84とを含む。複数の音響モデル34を用いて並列にデコードし、最も尤度の高い仮説を選択するようにしてもよい。
【選択図】 図3
Description
この発明は音声認識のための音響モデル及びそうした音響モデルを用いた音声認識装置に関し、特に、ネイティブでない発話者(非ネイティブ話者)の発話を高精度に認識可能にするための音響モデルを生成する装置及びそうした音響モデルを使用して非ネイティブ話者の発話を高精度に認識可能な音声認識装置に関する。
非ネイティブ話者の音声認識のための主な方法として、二つのものが知られている。第1は発音モデルの適応であり、第2は音響モデルの適応である。従来の研究により、発音モデルを用いることによって母語の中での外国語由来のアクセントに対する音声認識の性能が向上することが明らかとなっている。なお、このように発話者が母語以外の発話を行なう場合、その外国語を以下「非ネイティブ言語」と呼ぶことにする。
そうした方法では、辞書内の各語に対して発音の変形を手操作で追加する必要がある。しかし、非ネイティブ話者の母語と、非ネイティブ言語との双方に関する深い知識がなければ、そのような作業はできない。また、自動的にそうした作業を行なおうとすれば、ラベル付けされた大量の発話データが必要となり、そうしたデータを準備するのは困難である。加えて、この方法では母語の音素に関する置換、削除及び挿入しか対象とすることができないという問題がある。
さらに、非特許文献1によれば、非ネイティブ話者は、母語の一部である発声特徴と、非ネイティブ言語の発声特徴とを融合させることにより、生成された発音を行なうように思われる。したがって、母語と非ネイティブ言語との双方の音響モデル又は発音モデルのみを用意しても、非ネイティブ話者の発声を十分に分析することは難しい。
J.E.フレーゲ、C.シル、及びI.R.A.マッケイ、「母語及び第二外国語の間の音素サブシステム間の相互作用」、スピーチ・コミュニケーション、40:pp.467−491、2003年 (Flege,J.E., Schirru,C., and MacKay,I.R.A., Interaction between the native and second language phonetic subsystems. Speech Communication, 40:467−491,2003.)
従来の研究から、非ネイティブ話者に対する音声認識の性能を向上させるためには、各音響−音素単位モデルの適応を行なうことが必要であり、発音のモデル化のみでは十分でないという結論が得られる。
したがって本発明は、音響モデルを適応化させることにより、非ネイティブ話者に対する音声認識の性能を向上させることを目的とする。
本発明はさらに、非ネイティブ話者の、ネイティブ話者と比較して異なる音響的特徴に対処することが可能な音声認識装置を提供することを目的とする。
本発明の第1の局面に係る音響モデル生成装置は、所定の音声の特徴にしたがって予め複数グループのいずれかに分類された複数話者の音声データを準備するための音声データ準備手段と、音声データ準備手段により準備された音声データに基づいて、各グループについてそれぞれ音響モデルを作成するための音響モデル群生成手段とを含む。
音声の特徴によって分類されたグループごとに音響モデルを作成することにより、各グループに属する話者に共通する特徴に適応した音響モデルが得られる。各グループに属する話者の音声認識などの際にその音響モデルを使用すると、全ての話者の音声データから作成した音響モデルを用いる場合と比較して、認識精度が向上する。
好ましくは、音声データ準備手段は、複数話者による発話データに基づき、複数話者を複数グループにクラスタリングするための話者クラスタリング手段を含み、音響モデル群生成手段は、話者クラスタリング手段により得られた複数グループに対し、各グループに属する話者の発話データに基づいてそれぞれ音響モデルを作成するための音響モデル群生成手段を含む。
発話データに基づいてクラスタリングを行なうことにより、複数話者を所定の基準にしたがって自動的に分類することができる。
好ましくは、話者クラスタリング手段は、複数話者の各々の発話データに基づき、話者依存の音響モデルを生成するための話者依存音響モデル生成手段と、音響モデルに基づいて、複数話者の各々の代表ベクトルを生成するための代表ベクトル生成手段と、複数話者について得られた複数の代表ベクトルに対して主成分分析を行なうことにより、複数の代表ベクトルをより低次の複数の代表ベクトルに変換するための手段と、低次の複数の代表ベクトルに対し予め定めるクラスタリング処理を実行することにより、複数の話者を複数のグループにクラスタリングするためのクラスタリング手段とを含む。
さらに好ましくは、予め定めるクラスタリング処理は、K平均クラスタリング処理である。
K平均クラスタリング処理を用いることにより、同程度の大きさのクラスタを作ることができる。クラスタごとに属する話者数を均等化でき、いずれの音響モデルも同程度の頑健さで構築できる。
音響モデル群生成手段は、話者クラスタリング手段により得られた複数グループの各々に対し、各グループに属する話者の発話データを用いて音響モデルを作成するための音響モデル群生成手段、又は話者クラスタリング手段により得られた複数グループの各々に対し、予め準備された話者に依存しない基本音響モデルを各グループに属する話者の発話データを用いた最大事後推定により適応させることにより音響モデルを作成するための音響モデル群生成手段のいずれを含んでもよい。
本発明の第2の局面に係る音声認識装置は、複数の音響モデルを用いて、入力発話に対する音声認識を行なう音声認識装置である。複数の音響モデルは、それぞれ互いに異なる音響的特徴を持つ発話データから生成されたものである。音声認識装置は、入力発話の音響的特徴に基づいて、複数の音響モデルのうちで入力発話の音響的特徴に合致する音響モデルを選択するための音響モデル選択手段と、音響モデル選択手段により選択された音響モデルを用いて入力発話に対する音声認識を行なうための音声認識手段とを含む。
互いに異なる音響的特徴に基づいて分類された発話データから構築された音響モデルの中から、入力発話の音響的特徴に合致する音響モデルを選択する。このようにして選択された音響モデルを用いると、入力発話に含まれる発音のバリエーションに対して頑健な音声認識を行なうことができる。その結果、音声認識の精度を高めることができる。
本発明の第3の局面に係る音声認識装置は、複数の音響モデルを用いて、入力発話に対する音声認識を行なう音声認識装置である。複数の音響モデルは、それぞれ互いに異なる音響的特徴を持つ発話データから生成されたものである。音声認識装置は、複数の音響モデルの各々を用いて入力発話に対する音声認識を行ない、複数の仮説を出力するための音声認識手段と、音声認識手段により出力される複数の仮説に基づいて、一つの仮説を出力するための仮説出力手段とを含む。
このように複数種類の音響モデルを用いて並列に音声認識を行なうと、それら音響モデルを用いて最も確率が高いと思われる仮説が得られる。それらの仮説の中で、一つの仮説を選択することにより、入力発話の音響的特徴にしたがって音響モデルを予め選択するということなしに、入力発話に対する音声認識を実現できる。
好ましくは、音声認識手段は、複数の仮説とともにそれぞれ尤度を出力し、仮説出力手段は、複数の仮説のうち、最も尤度の高いものを選択して出力するための手段を含む。
複数の仮説の中で認識時に音響モデルを用いて得られた尤度が最も高いものを選択することにより、入力発話の音響的特徴にしたがって音響モデルを予め選択するということなしに、入力音声に対する音声認識を高精度で実現できる。
また、音声認識手段は、複数の仮説に含まれる単語ごとにそれぞれ尤度を出力し、仮説出力手段は、複数の仮説を統合することにより形成可能な単語列のうちで、各単語の尤度に基づいて算出される尤度が最も高いものを出力する仮説統合手段を含むものであってもよい。
[第1の実施の形態]
<構成>
図1に、本発明の一実施の形態に係る英語発話の音声認識システム20の構成をブロック図形式で示す。図1を参照して、このシステム20は、複数の非ネイティブ話者の英語発話データ30を、それらの音響的特徴に基づいて複数のグループにクラスタリングし、グループ別音響モデル群34を生成するためのグループ別音響モデル生成装置32と、このグループ別音響モデル群34を用い、入力発話36に対する音声認識を行なって仮説40を出力するための非ネイティブ発話音声認識装置38とを含む。
<構成>
図1に、本発明の一実施の形態に係る英語発話の音声認識システム20の構成をブロック図形式で示す。図1を参照して、このシステム20は、複数の非ネイティブ話者の英語発話データ30を、それらの音響的特徴に基づいて複数のグループにクラスタリングし、グループ別音響モデル群34を生成するためのグループ別音響モデル生成装置32と、このグループ別音響モデル群34を用い、入力発話36に対する音声認識を行なって仮説40を出力するための非ネイティブ発話音声認識装置38とを含む。
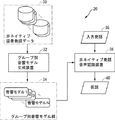
図2に、グループ別音響モデル生成装置32のより詳細な構成をブロック図形式で示す。図2を参照して、グループ別音響モデル生成装置32は、非ネイティブ話者発話データ30を、音響的特徴に基づいて複数のグループ62−1〜62−nにクラスタリングするための発話者クラスタリング処理部60と、各グループ62−1〜62−nについて、予め準備された音響モデルをトレーニングし、グループ別の音響モデル群34を生成するための音響モデルトレーニング部64とを含む。
発話者クラスタリング処理部60によるクラスタリングの詳細については後述する。音響モデルトレーニング部64による音響モデルのトレーニングは、使用する発話データが、発話者クラスタリング処理部60によってクラスタリングされた発話者グループ62−1〜62−nのいずれかである点を除き、通常のものと同様である。
図3は、このようにして生成されたグループ別音響モデル群34を用いて、非ネイティブ話者による入力発話36に対する音声認識を行なって仮説40を出力する非ネイティブ発話音声認識装置38のブロック図である。図3を参照して、この装置38は、入力発話36を受け、この入力発話36の発話者がグループ別音響モデル群34のどの話者グループに属するかを判定し、当該グループの音響モデル82をグループ別音響モデル群34から選択するための話者グループ分類部80と、選択された音響モデル82を用いて、入力発話36をデコード(音声認識)し仮説40を出力するためのデコード部84とを含む。
図2に示す発話者クラスタリング処理部60は、K平均クラスタリングアルゴリズムを用いて、データ自身の特徴に基づいて非ネイティブ話者発話データ30を複数のグループ62−1〜62−nにクラスタリングする。その手順は以下の通りである。
すなわち、各話者について、話者依存の音響モデル(以下「SD−AM(Speaker Dependent Acoustic Model)」と呼ぶ。)を作成する。次にSD−AMごとに、その平均ベクトルをつなぎ合わせることにより各話者を代表する統合ベクトル(以下「代表ベクトル」と呼ぶ。)を作成する。本実施の形態ではこのSD−AMは、HMM(隠れマルコフモデル)からなる、1状態あたり1ガウス分布を持つモノフォンモデルである。このSD−AMは、話者に依存しない基本AM(以下「SI−AM(Speaker Independent Acoustic Model)」と呼ぶ。)に対するMAP(最大事後推定)を行なうことによって得られる。
このようにして話者ごとに得られた代表ベクトルに対し、主成分分析(PCA)を行ない、15次元の固有空間の基底を得る。この場合、この基底によりサンプルの変動(分散)の95%がカバーされるように基底の次元を設定するのが望ましい。すなわち、主成分分析における固有値の和の比率をrkで表すと、

前述した各話者の代表ベクトルをこの固有空間に投射することにより、各話者をより低次のベクトルで表すことが可能になる。
K平均アルゴリズムでは、同程度の大きさのクラスタを作ることができる。本実施の形態ではクラスタ数は上記したグループ数n(例えばn=5)に設定した。nは、例えば、想定される非ネイティブ話者の母語の数に等しく選択すればよい。クラスタが疎にならないように、クラスタの数は十分小さくするとよい。各クラスタをそれぞれの母語グループの話者で初期化すると、話者の数のつりあったクラスタができやすくなる。
なお、種々の距離尺度(min,max,average,mean)を用いた階層的クラスタリングを使用してもよい。この場合、距離尺度としてmin、average、meanを使用すると一つの大きなクラスタができる傾向が高い。距離尺度としてmaxを使用するとクラスタが疎になる傾向が低い。
このクラスタリング処理により、複数の非ネイティブ話者の発話データがクラスタリングされ、結果として各話者は話者グループ62−1〜62−nに分類されることになる。各話者グループに対し一つの音響モデルが音響モデルトレーニング部64によりトレーニングされる。音響モデルのトレーニングでは、SI−AMに対するMAP適応処理を行なうか、モノフォンAMを最初から非ネイティブ発話データのみによりトレーニングするか、の二つの方法がある。いずれの方法をとってもよいが、AMを非ネイティブ話者データごとに最初からトレーニングする方が、基本AMに対するMAP適応処理を行なうより性能がよいという実験結果が得られている。したがって本実施の形態ではクラスタリングされた非ネイティブ話者グループごとに、音響モデルを最初からトレーニングする。
図3を参照して、話者グループ分類部80は、入力発話36の音響的特徴に基づいて、入力発話36の話者がグループ別音響モデル群34のどの話者グループに属するかを分類する機能を持つ。そして、その話者グループに対応する音響モデル82をグループ別音響モデル群34から選択する。
デコード部84による、音響モデル82を用いた入力発話36のデコードは、従来から行なわれているものと同様である。
<動作>
図1〜図3を参照して、この第1の実施の形態に係る音声認識システム20は以下のように動作する。このシステム20の動作は二つのフェーズに分けられる。第1のフェーズはグループ別音響モデル生成装置32による、オフラインでのグループ別音響モデル群34の生成処理である。第2のフェーズは、このようにして生成されたグループ別音響モデル群34を用い、非ネイティブ発話音声認識装置38が行なう入力発話36の音声認識である。以下順に説明する。
図1〜図3を参照して、この第1の実施の形態に係る音声認識システム20は以下のように動作する。このシステム20の動作は二つのフェーズに分けられる。第1のフェーズはグループ別音響モデル生成装置32による、オフラインでのグループ別音響モデル群34の生成処理である。第2のフェーズは、このようにして生成されたグループ別音響モデル群34を用い、非ネイティブ発話音声認識装置38が行なう入力発話36の音声認識である。以下順に説明する。
第1のフェーズでは、最初に非ネイティブ発話データ30の収集を行なう。ここでは、できれば同じ性の、様々な言語を母語とする話者による、同じ英語の文の発話を収集する。一つの母語につき、複数の話者が存在することが好ましい。ただし、それぞれの話者から収集する音声データが異なっていてもよい。この場合、それぞれの話者について、音素的につりあっている文による発話の収集が欠かせない。
図2を参照して、発話者クラスタリング処理部60は、前述した通りのクラスタリングを非ネイティブ発話データ30に対して行ない、話者を複数の話者グループ62−1〜62−nにクラスタリングする。音響モデルトレーニング部64は、話者グループ62−1〜62−nの各々について、それらに属する話者の発話データを用いてモノフォン音響モデルをトレーニングすることにより、グループ別音響モデル群34を生成する。
このグループ別音響モデル群34が生成されれば、図1に示す非ネイティブ発話音声認識装置38による音声認識が可能になる。
図3を参照して、入力発話36が非ネイティブ発話音声認識装置38に与えられたものとする。通常は、入力発話36の話者がどの言語グループに属するかについては不明である。話者グループ分類部80は、この入力発話36の音響的特徴に基づき、入力発話36がグループ別音響モデル群34のどのグループに属するものであるかを推定し、そのグループの音響モデル82を選択する。
デコード部84は、この音響モデル82を用い、入力発話36に対するデコードを行なって仮説40を出力する。
なお、上記したように固有空間でクラスタリングするのではなく、予め話者の母語が分かっているのであれば、その母語によって話者を別グループにし、各グループの話者の音声データを用いて音響モデルをトレーニングしても同様の効果が得られる。このように話者の母語により分類された音声データを用いてトレーニングされた音響モデルをアクセント依存の音響モデルと呼ぶ。これに対し、前述したように固有空間で基底を用いてクラスタリングされた音声データを用いてトレーニングされた音響モデルをクラスタ依存の音響モデルと呼ぶ。
<実験>
この第1の実施の形態に係るシステム20を用い、その効果を確認する実験を行なった。実験では、HTK(隠れマルコフモデルツールキット)を用いて全ての音響モデルおよび言語モデルの学習、ならびにデコーディングを行なった。非ネイティブの話者として、日本、中国、フランス(仏)、ドイツ(独)、およびインドネシアの話者をそれぞれ15人ずつ、合計75人を対象に実験を行なった。以下の実験では全ての話者が同じ文を発音した。トレーニングおよび適応データはそれぞれ88発話(約10分)を含み、検証データセットは10発話(約1分)、テストデータセットは23発話(約3分)を、それぞれ含む。
この第1の実施の形態に係るシステム20を用い、その効果を確認する実験を行なった。実験では、HTK(隠れマルコフモデルツールキット)を用いて全ての音響モデルおよび言語モデルの学習、ならびにデコーディングを行なった。非ネイティブの話者として、日本、中国、フランス(仏)、ドイツ(独)、およびインドネシアの話者をそれぞれ15人ずつ、合計75人を対象に実験を行なった。以下の実験では全ての話者が同じ文を発音した。トレーニングおよび適応データはそれぞれ88発話(約10分)を含み、検証データセットは10発話(約1分)、テストデータセットは23発話(約3分)を、それぞれ含む。
まず、比較対象とするために、6人のネイティブ英語話者によりベースラインモデルを以下のようにして作成した。ここで使用した文は非ネイティブ話者に対して使用した文と同じである。
−音響モデル−
LDC(Linguistic Data Consortium)のウォールストリートジャーナル(登録商標)コーパスに含まれる60時間以上(37,413発話)の音声データを発話者に依存しないネイティブ英語音響モデルの作成に用いた。音響モデルとして、以下の3通りの構成のものを作成した
(1)3状態・16混合分布からなるモノフォンの44個のHMM
(2)約3,000状態・10混合分布からなる、状態クラスタリングされたバイフォンモデル
(3)約9,600状態・12混合分布からなる状態クラスタリングされたクロスワード・トライフォンモデル
モデル作成の特徴量として、10ミリ秒間隔で39個の音響特徴量、12個のMFCC(メル周波数ケプストラム係数)、エネルギとその第1次および第2次微分とを抽出した。
LDC(Linguistic Data Consortium)のウォールストリートジャーナル(登録商標)コーパスに含まれる60時間以上(37,413発話)の音声データを発話者に依存しないネイティブ英語音響モデルの作成に用いた。音響モデルとして、以下の3通りの構成のものを作成した
(1)3状態・16混合分布からなるモノフォンの44個のHMM
(2)約3,000状態・10混合分布からなる、状態クラスタリングされたバイフォンモデル
(3)約9,600状態・12混合分布からなる状態クラスタリングされたクロスワード・トライフォンモデル
モデル作成の特徴量として、10ミリ秒間隔で39個の音響特徴量、12個のMFCC(メル周波数ケプストラム係数)、エネルギとその第1次および第2次微分とを抽出した。
これら3つの音響モデルの精度を調べるため、Hub2 5K評価タスクを行なった。その結果、モノフォンについては80.8%、バイフォンについては86.8%、トライフォンについては93.6%の精度を得た。
音声データのうち、男性のみの発話を用い、MAP適応によって話者に依存しないベースライン音響モデルを構築した。
−言語モデル−
6,460発話(65,839単語)を含む、ホテルの予約対話ドメインの235対話からなるデータベースから、nグラム確率を推定した。辞書は、複合語を含め7,300語に対する約8,800個の見出しを含んでいた。344単語評価タスク(23発話からなる二つの対話)により求めたパープレキシティは32であった。
6,460発話(65,839単語)を含む、ホテルの予約対話ドメインの235対話からなるデータベースから、nグラム確率を推定した。辞書は、複合語を含め7,300語に対する約8,800個の見出しを含んでいた。344単語評価タスク(23発話からなる二つの対話)により求めたパープレキシティは32であった。
−結果−
評価のため、75重リーブ・ワン・アウトクロス検定を話者グループ依存のモデルを用いた全ての実験に対して行ない、性能に関する実際的な評価を行なった。話者グループ依存のモデルは10混合分布からなる42個のHMMを含んでいる。各話者グループに対して別々に音声認識結果を調べた。
評価のため、75重リーブ・ワン・アウトクロス検定を話者グループ依存のモデルを用いた全ての実験に対して行ない、性能に関する実際的な評価を行なった。話者グループ依存のモデルは10混合分布からなる42個のHMMを含んでいる。各話者グループに対して別々に音声認識結果を調べた。
・話者に依存しないモデル
前述した話者に依存しないベースラインモデルを用いた場合、どのタイプの音響モデルを用いたか、および発話者がどのグループに属するか、によってその結果は大きく変わった。その結果を表1に示す。
前述した話者に依存しないベースラインモデルを用いた場合、どのタイプの音響モデルを用いたか、および発話者がどのグループに属するか、によってその結果は大きく変わった。その結果を表1に示す。
イフォンのいずれを用いても同程度の精度が得られた。しかし、他の話者グループの場合
には、モノフォン言語モデルを用いた場合に最も高い精度が得られ、バイフォン、トライフォンとなるにしたがい得られる精度が低くなるという興味深い結果が得られた。したがって、少なくとも英語の場合には、ネイティブ以外の話者の場合にはモノフォン音響モデルを用いるのが最も好ましいことが明確に分かる。これは、非ネイティブ話者の場合にはネイティブ話者と比較して発音のバリエーションが広いことが原因と思われる。非ネイティブ話者の発音のバリエーションが広くなるのは、英語以外の場合にも同様であろうから、英語に限らず、非ネイティブ話者の音声認識を行なう場合には、モノフォン音響モデルを用いることが望ましいと推定できる。
・話者クラスタリング
いくつかの距離尺度を用いて話者のクラスタリングについても実験を行なった。階層的クラスタリングを用いた場合、最長距離の点ではバランスのとれたクラスタが得られたが、重心距離および平均ベクトル間距離という点ではかなり疎なクラスタとなった。
いくつかの距離尺度を用いて話者のクラスタリングについても実験を行なった。階層的クラスタリングを用いた場合、最長距離の点ではバランスのとれたクラスタが得られたが、重心距離および平均ベクトル間距離という点ではかなり疎なクラスタとなった。
また、前述した主成分分析における固有空間の次元kが大きくなるとともに、クラスタが疎になる傾向が高くなる。次元が大きくてもよい結果を得られるのは、階層的クラスタリングで距離尺度としてmaxを使用した場合と、K平均を用いた場合とである。なお、主成分分析の結果得られるクラスタがあまりに疎である場合、次元の数kを、前述した値より低い値に設定してもよい。
クラスタリングの結果を表2に示す。
各テスト話者の母語、およびその属するクラスタについての知識を用い、選択したモデルが正しいものと想定した実験(オラクル実験)を行なって、最良の認識精度としてどのような値が得られるかを確認した。その結果を表3に示す。
大きく改善する。アクセント依存の音響モデルを用いた場合にも性能は高い。これは、共
通の母語を持つ話者についてはアクセントの特徴も共通していることを示唆している。クラスタ依存のモデルを用いた場合にもよい結果が得られるが、アクセント依存のモデルを用いた場合と比較するとやや精度が低くなっている。
以上のようにこの第1の実施の形態に係るシステム20によれば、非ネイティブ話者ごとに、音声認識のために最適と思われる音響モデルを選択し、その音響モデルを用いて入力発話のデコードを行なう。したがって、話者に依存しない音響モデルを用いた場合と比較して音声認識の精度がより高くなる可能性が高い。出願人において実験したところ、特に日本人による英語の発話に関し、単語認識精度に関して48%の相対的改善が見られた。
[第2の実施の形態]
<構成>
上記した第1の実施の形態のシステムでは、話者グループ分類部80が入力発話36の属するグループを推定し、そのグループに対応する音響モデル82を選択してデコードに用いた。しかし本発明はそのような実施の形態には限定されない。例えば、上記した複数のグループ別音響モデルをすべて用いて並列に入力発話に対するデコードを行ない、得られた複数の仮説のうち最も尤度の高いものを選択するようにしてもよい。図4にそのような非ネイティブ発話音声認識装置100のブロック図を示す。
<構成>
上記した第1の実施の形態のシステムでは、話者グループ分類部80が入力発話36の属するグループを推定し、そのグループに対応する音響モデル82を選択してデコードに用いた。しかし本発明はそのような実施の形態には限定されない。例えば、上記した複数のグループ別音響モデルをすべて用いて並列に入力発話に対するデコードを行ない、得られた複数の仮説のうち最も尤度の高いものを選択するようにしてもよい。図4にそのような非ネイティブ発話音声認識装置100のブロック図を示す。
図4を参照して、この非ネイティブ発話音声認識装置100は、グループ別音響モデル群34に含まれるグループ別の音響モデルを用い、入力発話36に対するデコードを並列に行ない、複数の仮説112をそれらの尤度とともに出力するためのデコード部110と、複数の仮説112の中で最も尤度の高い仮説を選択し仮説40として出力するための仮説選択部114とを含む。
音響モデルがk個あるものとし、得られるk個の仮説の尤度をそれぞれpi(x|w)(i=1〜k)(xは入力音声の音響特徴ベクトル列、wは単語列)とすると、仮説選択部114は~w=argmaxi=1…klogpi(x|w)となる仮説~w(本明細書では、符号の直前の「~」は、直後の符号の直上に記載されるべき記号をあらわすものとする。)を最終候補として選択する。これは以下の理由による。特徴ベクトルシーケンスxが観測されたときの、各音響モデルから得られる単語列wの事後確率がlogpi(w|x)であり、これを最大とする単語列~wを求める問題は、次のように定式化される。
<動作>
この非ネイティブ発話音声認識装置100の動作については明らかであるので、ここではその詳細については述べない。なお、仮説全体として最も尤度の高いものを選択する代わりに、仮説を構成する単語ごと、または単語ネットワークの経路ごとに、最も高い尤度を選択することにより仮説40を生成する、いわゆる仮説統合を行なうようにしてもよい。
この非ネイティブ発話音声認識装置100の動作については明らかであるので、ここではその詳細については述べない。なお、仮説全体として最も尤度の高いものを選択する代わりに、仮説を構成する単語ごと、または単語ネットワークの経路ごとに、最も高い尤度を選択することにより仮説40を生成する、いわゆる仮説統合を行なうようにしてもよい。
<実験>
この第2の実施の形態に係る非ネイティブ発話音声認識装置100を用いてアクセント依存モデルおよびクラスタ依存モデルを用いて実験を行なった。その結果を表4に示す。
この第2の実施の形態に係る非ネイティブ発話音声認識装置100を用いてアクセント依存モデルおよびクラスタ依存モデルを用いて実験を行なった。その結果を表4に示す。
クラスタ分類精度(64.6%)はアクセント分類精度(52.5%)よりも高かったが、より多くの話者のデータが利用可能になれば、クラスタ依存モデルを用いた並列デコードの方がアクセント依存モデルを用いたものよりもよい性能を示すのではないかと考えられる。各話者グループに対して得た結果を図5に示す。
以上のように、この発明の実施の形態によれば、ある言語について非ネイティブの話者による発話データ30に基づき、グループ別音響モデル群34が生成される。これらグループ別音響モデル群34を用い、入力発話36のうちで最も適切と思われる音響モデルを用いたデコードが行なわれる。または、複数の音響モデルを用いてデコードした結果得られた仮説の中で、最も尤度の高いものが選択される。その結果、当該言語を母語としない、母語の影響を受けた独特のアクセントで当該言語の発話を行なう非ネイティブ話者の発話を高い精度で認識することができる。
[単一の非ネイティブモデル]
今回考慮した5つのアクセントグループの全話者に対する発音のバリエーションを一つのモノフォン音響モデルを用いて的確に表すことができるかどうかを調べるため、各アクセントグループから10名、合計50名の非ネイティブ話者を用いて16混合分布の非ネイティブモノフォンモデル(NN)をトレーニングし、その評価を行なった。評価では、残りの25名の話者を用いて3重クロス検定を行なった。各トレーニングセットおよびテストセットのための話者はランダムに選択した。その際、各話者の母語が均一に分布するように配慮した。
今回考慮した5つのアクセントグループの全話者に対する発音のバリエーションを一つのモノフォン音響モデルを用いて的確に表すことができるかどうかを調べるため、各アクセントグループから10名、合計50名の非ネイティブ話者を用いて16混合分布の非ネイティブモノフォンモデル(NN)をトレーニングし、その評価を行なった。評価では、残りの25名の話者を用いて3重クロス検定を行なった。各トレーニングセットおよびテストセットのための話者はランダムに選択した。その際、各話者の母語が均一に分布するように配慮した。
このようにして作成した話者独立な非ネイティブモノフォンモデルを用いた音声認識の結果を、テスト話者の母語別に表5に示す。
この話者独立な非ネイティブモノフォンモデルを用いると、その精度に限界がある。しかし、非ネイティブ話者の音声コーパスが利用できない場合には、文脈依存の頑健な音響モデルをトレーニングにより得ることは困難である。各アクセントグループ内での非ネイティブ話者の発音のバリエーションがほぼ一致した傾向を示すことを仮定すれば、アクセントおよび文脈依存のモデルを用いることで、より精度を高めることが可能と思われる。
なお、上記した実施の形態では、英語発話に対する非ネイティブ話者の発話を音声認識する実施の形態を例にした。しかし本発明はそのような実施の形態に限定されない。任意の言語に対して、上記した非ネイティブ話者の音声認識を行なうようにしてもよい。
今回開示された実施の形態は単に例示であって、本発明が上記した実施の形態のみに制限されるわけではない。本発明の範囲は、発明の詳細な説明の記載を参酌した上で、特許請求の範囲の各請求項によって示され、そこに記載された文言と均等の意味および範囲内でのすべての変更を含む。
20 音声認識システム、30 非ネイティブ話者発話データ、32 グループ別音響モデル生成装置、34 グループ別音響モデル群、36 入力発話、38,100 非ネイティブ発話音声認識装置、40,112 仮説、60 発話者クラスタリング処理部、64 音響モデルトレーニング部、80 話者グループ分類部、82 音響モデル、84,110 デコード部、114 仮説選択部
Claims (5)
- 所定の音声の特徴にしたがって予め複数グループのいずれかに分類された複数話者の音声データを準備するための音声データ準備手段と、
前記音声データ準備手段により準備された音声データに基づいて、各グループについてそれぞれ音響モデルを作成するための音響モデル群生成手段とを含む、音響モデル生成装置。 - 前記音声データ準備手段は、複数話者による発話データに基づき、前記複数話者を複数グループにクラスタリングするための話者クラスタリング手段を含み、
前記音響モデル群生成手段は、前記話者クラスタリング手段により得られた複数グループに対し、各グループに属する話者の前記発話データに基づいてそれぞれ音響モデルを作成するための手段を含む、請求項1に記載の音響モデル生成装置。 - 前記話者クラスタリング手段は、
前記複数話者の各々の発話データに基づき、話者依存の音響モデルを生成するための話者依存音響モデル生成手段と、
前記音響モデルに基づいて、前記複数話者の各々の代表ベクトルを生成するための代表ベクトル生成手段と、
前記複数話者について得られた複数の代表ベクトルに対して主成分分析を行なうことにより、前記複数の代表ベクトルをより低次の複数の代表ベクトルに変換するための手段と、
前記低次の複数の代表ベクトルに対し予め定めるクラスタリング処理を実行することにより、前記複数の話者を複数のグループにクラスタリングするためのクラスタリング手段とを含む、請求項2に記載の音響モデル生成装置。 - 複数の音響モデルを用いて、入力発話に対する音声認識を行なう音声認識装置であって、前記複数の音響モデルは、それぞれ互いに異なる音響的特徴を持つ発話データから生成されたものであり、
入力発話の音響的特徴に基づいて、前記複数の音響モデルのうちで前記入力発話の音響的特徴に合致する音響モデルを選択するための音響モデル選択手段と、
前記音響モデル選択手段により選択された音響モデルを用いて前記入力発話に対する音声認識を行なうための音声認識手段とを含む、音声認識装置。 - 複数の音響モデルを用いて、入力発話に対する音声認識を行なう音声認識装置であって、前記複数の音響モデルは、それぞれ互いに異なる音響的特徴を持つ発話データから生成されたものであり、
前記複数の音響モデルの各々を用いて入力発話に対する音声認識を行ない、複数の仮説を出力するための音声認識手段と、
前記音声認識手段により出力される複数の仮説に基づいて、一つの仮説を出力するための仮説出力手段とを含む、音声認識装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004286082A JP2005292770A (ja) | 2004-03-10 | 2004-09-30 | 音響モデル生成装置及び音声認識装置 |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004066529 | 2004-03-10 | ||
| JP2004066529 | 2004-03-10 | ||
| JP2004286082A JP2005292770A (ja) | 2004-03-10 | 2004-09-30 | 音響モデル生成装置及び音声認識装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005292770A JP2005292770A (ja) | 2005-10-20 |
| JP2005292770A6 true JP2005292770A6 (ja) | 2006-04-13 |
Family
ID=35325713
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004286082A Pending JP2005292770A (ja) | 2004-03-10 | 2004-09-30 | 音響モデル生成装置及び音声認識装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2005292770A (ja) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5112978B2 (ja) * | 2008-07-30 | 2013-01-09 | Kddi株式会社 | 音声認識装置、音声認識システムおよびプログラム |
| US8788256B2 (en) * | 2009-02-17 | 2014-07-22 | Sony Computer Entertainment Inc. | Multiple language voice recognition |
| US9734819B2 (en) * | 2013-02-21 | 2017-08-15 | Google Technology Holdings LLC | Recognizing accented speech |
| JP6546070B2 (ja) * | 2015-11-10 | 2019-07-17 | 日本電信電話株式会社 | 音響モデル学習装置、音声認識装置、音響モデル学習方法、音声認識方法、およびプログラム |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2965537B2 (ja) * | 1997-12-10 | 1999-10-18 | 株式会社エイ・ティ・アール音声翻訳通信研究所 | 話者クラスタリング処理装置及び音声認識装置 |
-
2004
- 2004-09-30 JP JP2004286082A patent/JP2005292770A/ja active Pending
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP2192575B1 (en) | Speech recognition based on a multilingual acoustic model | |
| KR20050082253A (ko) | 모델 변이 기반의 화자 클러스터링 방법, 화자 적응 방법및 이들을 이용한 음성 인식 장치 | |
| Oh et al. | Acoustic model adaptation based on pronunciation variability analysis for non-native speech recognition | |
| JP4836076B2 (ja) | 音声認識システム及びコンピュータプログラム | |
| Juan et al. | Using resources from a closely-related language to develop ASR for a very under-resourced language: A case study for Iban | |
| Soltau et al. | Advances in Arabic speech transcription at IBM under the DARPA GALE program | |
| Yeh et al. | An improved framework for recognizing highly imbalanced bilingual code-switched lectures with cross-language acoustic modeling and frame-level language identification | |
| De Wet et al. | Speech recognition for under-resourced languages: Data sharing in hidden Markov model systems | |
| Liu et al. | State-dependent phonetic tied mixtures with pronunciation modeling for spontaneous speech recognition | |
| Liu et al. | Modeling partial pronunciation variations for spontaneous Mandarin speech recognition | |
| Zhang et al. | Reliable accent-specific unit generation with discriminative dynamic Gaussian mixture selection for multi-accent Chinese speech recognition | |
| He et al. | Model complexity optimization for nonnative English speakers. | |
| He et al. | Fast model selection based speaker adaptation for nonnative speech | |
| JP2005292770A6 (ja) | 音響モデル生成装置及び音声認識装置 | |
| JP2005292770A (ja) | 音響モデル生成装置及び音声認識装置 | |
| Liu et al. | Pronunciation modeling for spontaneous Mandarin speech recognition | |
| Seman et al. | Acoustic Pronunciation Variations Modeling for Standard Malay Speech Recognition. | |
| Garud et al. | Development of hmm based automatic speech recognition system for Indian english | |
| Ungureanu et al. | Establishing a baseline of romanian speech-to-text models | |
| Yang et al. | Unsupervised prosodic phrase boundary labeling of Mandarin speech synthesis database using context-dependent HMM | |
| Vancha et al. | Word-level speech dataset creation for sourashtra and recognition system using kaldi | |
| Oh et al. | A hybrid acoustic and pronunciation model adaptation approach for non-native speech recognition | |
| Yang et al. | Automatic phrase boundary labeling for Mandarin TTS corpus using context-dependent HMM | |
| Do et al. | Speaker recognition with small training requirements using a combination of VQ and DHMM | |
| Wiesler et al. | The RWTH English lecture recognition system |