JP2005149014A - Method, device and program for obtaining document related word - Google Patents
Method, device and program for obtaining document related word Download PDFInfo
- Publication number
- JP2005149014A JP2005149014A JP2003384092A JP2003384092A JP2005149014A JP 2005149014 A JP2005149014 A JP 2005149014A JP 2003384092 A JP2003384092 A JP 2003384092A JP 2003384092 A JP2003384092 A JP 2003384092A JP 2005149014 A JP2005149014 A JP 2005149014A
- Authority
- JP
- Japan
- Prior art keywords
- document
- vocabulary
- word
- vector
- field vector
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Abstract
Description
本発明は、文書関連語彙獲得方法及び装置及びプログラムに係り、特に、文書から関連する語彙を獲得するための文書関連語彙獲得方法及び装置及びプログラムに関する。 The present invention relates to a document related vocabulary acquisition method, apparatus, and program, and more particularly, to a document related vocabulary acquisition method, apparatus, and program for acquiring related vocabulary from a document.
ある文書からそれに関連する文書を獲得する方法や、ある単語の集合からそれに関連する語彙を獲得する方法については従来から研究が行われているが、文書からそれに関連する語彙を獲得する方法についてはあまり研究が行われていない。 Research has been conducted on how to acquire a related document from a document and how to acquire a related vocabulary from a set of words, but how to acquire a related vocabulary from a document. Not much research has been done.
文書からそれに関連する語彙を獲得する方法としては、シソーラスを構築する目的で文書中に含まれる関連語を抽出する方法(例えば、特許文献1参照)や、ある文書に関連する文書を検索する目的でその文書中の関連キーワードを抽出する方法(例えば、特許文献2参照)がある。
しかしながら、上記に示した方法で得られた関連語や関連キーワードは、元の文書に必ず含まれていることが前提となっており、文書内を検索して語彙を抽出しているにすぎず、文書中に出現しない語彙を獲得することはできない。そのため、例えば、ある文書に関連する文書を検索する目的でその文書から語彙を抽出できたとしても、関連する文書中に抽出した語彙が含まれていなければその関連文書を検索することができない。 However, it is assumed that the related words and related keywords obtained by the above method are always included in the original document, and the vocabulary is only extracted by searching the document. Vocabulary that does not appear in the document cannot be acquired. Therefore, for example, even if a vocabulary can be extracted from a document for the purpose of searching for a document related to a certain document, the related document cannot be searched if the extracted vocabulary is not included in the related document.
また、文書を単語に分割して単語の集合を獲得し、単語の集合からそれに関連する語彙を獲得するという方法も考えられるが、単語の集合からそれに関連する語彙を獲得する方法を適用する場合には、その単語の集合は予め特定の分野の正しいキーワードが与えられることが前提となっているだけでなく、獲得できる語彙も特定の分野であることが前提となっているのに対し、文書を単語に分割してできる単語の集合には分野に無関係な単語が含まれていたり、もとの文書に誤りが含まれる場合には単語の集合にも誤りが含まれていたり、文書に複数の分野が関連していたりすることもあり得るため、文書を単語に分割してできる単語の集合をそのまま入力として関連する語彙を獲得する方法を適用することはできない。 In addition, it is possible to divide a document into words, acquire a set of words, and acquire the related vocabulary from the set of words, but when applying a method to acquire the related vocabulary from the set of words In addition to the premise that the set of words is given in advance a correct keyword of a specific field, the vocabulary that can be acquired is also premised on the specific field, whereas the document The set of words that can be divided into words includes words that are not related to the field, and if the original document contains errors, the set of words also contains errors, Therefore, it is impossible to apply a method of acquiring a related vocabulary by directly inputting a set of words obtained by dividing a document into words.
本発明は、上記の点に鑑みなされたもので、複数の分野に関連している文書や、音声認識結果のように多少の誤りを含むような文書であっても、その文書から関連する語彙を獲得することができ、さらに、獲得された語彙はもとの文書中に出現しないものを含むような文書関連語彙獲得方法及び装置及びプログラムを提供することを目的とする。 The present invention has been made in view of the above points, and even if a document is related to a plurality of fields or a document that includes some errors such as a speech recognition result, a vocabulary related to the document. It is another object of the present invention to provide a document-related vocabulary acquisition method, apparatus, and program that can acquire vocabulary, and that includes the acquired vocabulary that does not appear in the original document.
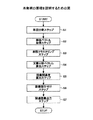
図1は、本発明の原理を説明するための図である。 FIG. 1 is a diagram for explaining the principle of the present invention.
文書から該文書に関連する語彙を獲得する文書関連語彙獲得方法であって、
入力された文書を単語に分割する単語分割ステップ(ステップ1)と、
単語の意味を表現するベクトルが格納されている概念ベースを検索することによって前記単語分割ステップで得られた各単語に対応するベクトルを取得する単語ベクトル取得ステップ(ステップ2)と、
単語ベクトル取得ステップで得られた各ベクトルをもとに単語のクラスタリングを行い、複数のクラスタを作成する単語クラスタリングステップ(ステップ3)と、
単語クラスタリングステップで得られた各クラスタをもとに文書の分野を表す文書分野ベクトルを求める文書分野ベクトル算出ステップ(ステップ4)と、
文書分野ベクトル算出ステップで得られた文書分野ベクトルと、予め作成しておいた語彙データベース中の各語彙の分野を表す語彙分野ベクトルから、入力された文書と各語彙との間の関連性を示す語彙関連度を求める語彙関連度算出ステップ(ステップ5)と、
語彙関連度算出ステップで得られた関連度をもとに語彙を順位付けする語彙順位付けステップ(ステップ6)と、
語彙順序付けステップで得られた語彙に関する順位をもとに関連語彙を出力する関連語彙出力ステップ(ステップ7)を行う。
A document related vocabulary acquisition method for acquiring a vocabulary related to a document from a document,
A word dividing step (step 1) for dividing the input document into words;
A word vector obtaining step (step 2) for obtaining a vector corresponding to each word obtained in the word dividing step by searching a concept base in which a vector expressing the meaning of the word is stored;
A word clustering step (step 3) for performing clustering of words based on each vector obtained in the word vector acquisition step and creating a plurality of clusters;
A document field vector calculation step (step 4) for obtaining a document field vector representing the field of the document based on each cluster obtained in the word clustering step;
The relationship between the input document and each vocabulary is shown from the document field vector obtained in the document field vector calculation step and the vocabulary field vector representing the vocabulary field in the vocabulary database created in advance. A vocabulary relevance calculating step for calculating a vocabulary relevance (step 5);
A vocabulary ranking step (step 6) for ranking vocabulary based on the relevance obtained in the vocabulary relevance calculation step;
A related vocabulary output step (step 7) for outputting related vocabulary based on the vocabulary rank obtained in the vocabulary ordering step is performed.
また、本発明は、文書分野ベクトル算出ステップ(ステップ4)において、単語が多く含まれている順に上位Q個以内のクラスタを選択し、
選択した各クラスタに対して該クラスタに含まれる各単語の単語ベクトルの重心をとることによってクラスタ毎に文書分野ベクトルを求める。
In the document field vector calculation step (step 4), the present invention selects the top Q clusters in the order in which many words are included,
For each selected cluster, the document field vector is obtained for each cluster by taking the centroid of the word vector of each word included in the cluster.
また、本発明は、文書分野ベクトル算出ステップ(ステップ4)において、
各単語の音声認識結果の信頼度を重みとして文書分野ベクトルを求める。
In the document field vector calculation step (step 4), the present invention
A document field vector is obtained using the reliability of the speech recognition result of each word as a weight.
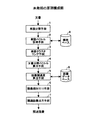
図2は、本発明の原理構成図である。 FIG. 2 is a principle configuration diagram of the present invention.
本発明は、文書から該文書に関連する語彙を獲得する文書間連語獲得装置であって、
単語の意味を表現するベクトルが格納されている概念ベース8と、
入力された文書を単語に分割する単語分割手段1と、
概念ベース8を検索することによって単語分割手段1で得られた各単語に対応するベクトルを取得する単語ベクトル取得手段2と、
単語ベクトル取得手段2で得られた各ベクトルをもとに単語のクラスタリングを行い、複数のクラスタを作成する単語クラスタリング手段3と、
単語クラスタリング手段3で得られた各クラスタをもとに文書の分野を表す文書分野ベクトルを求める文書分野ベクトル算出手段4と、
文書分野ベクトル算出手段4で得られた文書分野ベクトルと、予め作成しておいた語彙データベース9の中の各語彙の分野を表す語彙分野ベクトルから、入力された文書と各語彙との間の関連性を示す語彙関連度を求める語彙関連度算出手段5と、
語彙関連度算出手段5で得られた関連度をもとに語彙を順位付けする語彙順位付け手段6と、
語彙順位付け手段6で得られた語彙に関する順位をもとに、関連語彙を出力する関連語彙出力手段7と、を有する。
The present invention is an inter-document collocation acquisition device for acquiring a vocabulary related to a document from a document,
A concept base 8 in which vectors representing the meaning of words are stored;
Word dividing means 1 for dividing the input document into words;
Word vector acquisition means 2 for acquiring a vector corresponding to each word obtained by the word division means 1 by searching the concept base 8;
Word clustering means 3 for clustering words based on each vector obtained by the word vector acquisition means 2 to create a plurality of clusters;
A document field
The relationship between the input document and each vocabulary from the document field vector obtained by the document field vector calculating means 4 and the vocabulary field vector representing the field of each vocabulary in the vocabulary database 9 created in advance. Vocabulary relevance calculating means 5 for obtaining a lexical relevance indicating gender,
Vocabulary ranking means 6 for ranking the vocabulary based on the degree of association obtained by the vocabulary relation degree calculation means 5;
And a related vocabulary output means 7 for outputting a related vocabulary based on the vocabulary ranking obtained by the vocabulary ranking means 6.
また、本発明の文書分野ベクトル算出手段4は、
単語が多く含まれている順に上位Q個以内のクラスタを選択し、選択した各クラスタに対して該クラスタに含まれる各単語の単語ベクトルの重心をとることによってクラスタ毎に文書分野ベクトルを求める手段を有する。
The document field vector calculation means 4 of the present invention
Means for obtaining a document field vector for each cluster by selecting the top Q clusters in the order in which many words are included and taking the centroid of the word vector of each word included in the selected cluster. Have
また、本発明の文書分野ベクトル算出手段4は、
各単語の音声認識結果の信頼度を重みとして文書分野ベクトルを求める手段を有する。
The document field vector calculation means 4 of the present invention
Means for obtaining a document field vector with the reliability of the speech recognition result of each word as a weight.
本発明は、文書から該文書に関連する語彙を獲得することをコンピュータに実行させるための文書関連語獲得プログラムであって、
入力された文書を単語に分割する単語分割ステップと、
単語の意味を表現するベクトルが格納されている概念ベースを検索することによって単語分割ステップで得られた各単語に対応するベクトルを取得する単語ベクトル取得ステップと、
単語ベクトル取得ステップで得られた各ベクトルをもとに単語のクラスタリングを行い、複数のクラスタを作成する単語クラスタリングステップと、
単語クラスタリングステップで得られた各クラスタをもとに文書の分野を表す文書分野ベクトルを求める文書分野ベクトル算出ステップと、
文書分野ベクトル算出ステップで得られた文書分野ベクトルと、予め作成しておいた語彙データベース中の各語彙の分野を表す語彙分野ベクトルから、入力された文書と各語彙との間の関連性を示す語彙関連度を求める語彙関連度算出ステップと、
語彙関連度算出ステップで得られた関連度をもとに語彙を順位付けする語彙順位付けステップと、
語彙順序付けステップで得られた語彙に関する順位をもとに関連語彙を出力する関連語彙出力ステップと、をコンピュータに実行させる。
The present invention is a document related word acquisition program for causing a computer to acquire a vocabulary related to a document from a document,
A word splitting step for splitting the input document into words;
A word vector acquisition step of acquiring a vector corresponding to each word obtained in the word division step by searching a concept base in which a vector expressing the meaning of the word is stored;
A word clustering step of clustering words based on each vector obtained in the word vector acquisition step to create a plurality of clusters;
A document field vector calculation step for obtaining a document field vector representing the field of the document based on each cluster obtained in the word clustering step;
The relationship between the input document and each vocabulary is shown from the document field vector obtained in the document field vector calculation step and the vocabulary field vector representing the vocabulary field in the vocabulary database created in advance. A vocabulary relevance calculating step for obtaining a vocabulary relevance;
A vocabulary ranking step of ranking the vocabulary based on the relevance obtained in the vocabulary relevance calculation step;
The computer executes a related vocabulary output step of outputting a related vocabulary based on the vocabulary order obtained in the vocabulary ordering step.
また、本発明は、文書分野ベクトル算出ステップにおいて、単語が多く含まれている順に上位Q個以内のクラスタを選択するステップと、
選択した各クラスタに対して該クラスタに含まれる各単語の単語ベクトルの重心をとることによってクラスタ毎に文書分野ベクトルを求めるステップと、をコンピュータに実行させる。
In the document field vector calculation step, the present invention selects the top Q clusters in the order in which many words are included;
The computer is caused to execute a step of obtaining a document field vector for each cluster by taking the centroid of the word vector of each word included in the cluster for each selected cluster.
また、本発明は、文書分野ベクトル算出ステップにおいて、
各単語の音声認識結果の信頼度を重みとして文書分野ベクトルを求めるステップをコンピュータに実行させる。
Further, the present invention provides a document field vector calculation step,
The computer is caused to execute a step of obtaining a document field vector using the reliability of the speech recognition result of each word as a weight.
本発明は、入力された文書から得られた単語をクラスタリングして分野毎にクラスタを作成し、そのクラスタから文書の属する分野を推定するため、文書から得られた単語の中に誤りを含んでいたり、分野に関係のない単語が存在していたりしても、それらの単語は無視され、正しく分野を推定することができ、その結果適切な関連語彙を獲得することができる。 In the present invention, words obtained from an input document are clustered to create a cluster for each field, and the field to which the document belongs is estimated from the cluster. Therefore, an error is included in the word obtained from the document. Even if there are words that are not related to the field, those words are ignored and the field can be estimated correctly, and as a result, an appropriate related vocabulary can be obtained.
また、文書が複数の分野に属するような場合でも、複数のクラスタから複数の分野を推定することができる。さらに、予め大量の語彙を用意しておいき、その中から文書の分野に近い語彙を獲得するため、文書中に含まれていない語彙を獲得することができる。このようにして獲得した語彙は、文書検索における関連文書の検索などに役立てることができる。 Even when a document belongs to a plurality of fields, a plurality of fields can be estimated from a plurality of clusters. Furthermore, since a large amount of vocabulary is prepared in advance and vocabulary close to the field of the document is acquired from the vocabulary, vocabulary that is not included in the document can be acquired. The vocabulary acquired in this way can be used for searching related documents in document search.
以下、図面と共に本発明の実施の形態を説明する。 Hereinafter, embodiments of the present invention will be described with reference to the drawings.
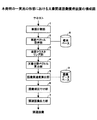
図3は、本発明の一実施の形態における文書関連語彙獲得装置の構成を示す。 FIG. 3 shows a configuration of a document-related vocabulary acquisition apparatus according to an embodiment of the present invention.
同図に示す関連文書語彙獲得装置は、単語分割部1、単語ベクトル取得部2、単語クラスタリング部3、文書分野ベクトル算出部4、語彙関連度算出部5、語彙順位付け部6、関連語彙出力部7、概念ベース8、語彙データベース9から構成される。
The related document vocabulary acquisition apparatus shown in FIG. 1 includes a
単語分割部1は、入力された文書を単語に分割する。
The
単語ベクトル取得部2は、単語の意味を表現するベクトルが格納されている概念ベース8を検索することによって単語分割部1で得られた各単語に対応するベクトルを取得する。
The word
単語クラスタリング部3は、単語ベクトル取得部2で得られた各ベクトルをもとに単語のクラスタリングを行い、複数のクラスタを作成する。
The
文書分野ベクトル算出部4は、単語クラスタリング部3で得られた各クラスタをもとに文書の分野を表す文書分野ベクトルを求める。
The document field
語彙関連度算出部5は、文書分野ベクトル算出部4で得られた文書分野ベクトルと、予め作成しておいた語彙データベース9中の各語彙の分野を表す語彙分野ベクトルから、入力された文書と各語彙との間の関連性を示す語彙関連度を求める。
The vocabulary
語彙順位付け部6は、語彙関連度算出部5で得られた関連度をもとに語彙を順位付けする。
The
関連語彙出力部7は、語彙順序付け部6で得られた語彙に関する順位を元に関連語彙を出力する。
The related
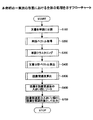
図4〜図8は、本発明の一実施の形態における文書関連語彙獲得装置の処理のフローチャートを示す。 4 to 8 show flowcharts of processing of the document-related vocabulary acquisition apparatus in one embodiment of the present invention.
図4は、本発明の一実施の形態における全体の処理を示すフローチャートである。 FIG. 4 is a flowchart showing overall processing in one embodiment of the present invention.
まず、単語分割部1により、文書を単語に分割する(ステップ100)。次に、単語ベクトル取得部2により、各単語の単語ベクトルを取得する(ステップ200)。
First, the
図5は、本発明の一実施の形態における単語ベクトル取得部の処理のフローチャートである。同図において、Nは、単語分割部1で得られた単語の数であり、Wは概念ベース8中に存在する単語数を表す。
FIG. 5 is a flowchart of the processing of the word vector acquisition unit in one embodiment of the present invention. In the figure, N is the number of words obtained by the
単語ベクトル取得部2は、単語分割部1で得られた各単語に対し、その単語が概念ベース8中に存在するかどうかを調べ(ステップ220)、存在すれば、概念ベース8から単語ベクトルを取得する(ステップ230、Yes,ステップ250)。存在しなければ(ステップ230、No)、その単語を削除する(ステップ240)。この処理を全単語について行う(ステップ260,270,280)。
The word
次に、単語クラスタリング部3により、単語のクラスタリングを行う(ステップ300)。 Next, word clustering is performed by the word clustering unit 3 (step 300).
図6は、本発明の一実施の形態における単語クラスタリング部の処理のフローチャートである。ここで、CIはI番目のクラスタ、Iはクラスタ数、Pはクラスタリングの終了条件として用いられるクラスタ数の閾値を表す。 FIG. 6 is a flowchart of the processing of the word clustering unit in one embodiment of the present invention. Here, C I is the I-th cluster, I is the number of clusters, P is represents a threshold value of the number of clusters to be used as the termination condition of the clustering.
単語クラスタリング部3は、単語ベクトル取得部2で得られたW個の単語について、それぞれ1単語からなるクラスタを作成する(ステップ310)。これらのW個のクラスタのうち、距離が最も近い二つのクラスタを求め(ステップ330)、この2つのクラスタを1つに併合してW−1個のクラスタを作成する(ステップ340,350)。このようにして二つのクラスタを1つに併合していく処理を、クラスタ数がP以下になるまで繰り返す(ステップ360)。
The
次に、文書分野ベクトル算出部4により、文書分野ベクトルの算出を行う(ステップ400)。
Next, the document field
図7は、本発明の一実施の形態における文書分野ベクトル算出部の処理のフローチャートである。ここで、Iはクラスタを単語数の多い順に並べたときの番号、Qは獲得する文書分野ベクトルの数を表す。 FIG. 7 is a flowchart of processing of the document field vector calculation unit according to the embodiment of the present invention. Here, I represents a number when clusters are arranged in descending order of the number of words, and Q represents the number of document field vectors to be acquired.
文書分野ベクトル算出部4は、I番目に単語数の多いクラスタの重心を求め、これをI番目の文書分野ベクトルとする(ステップ420)。この処理をQ回繰り返す(ステップ430,440)。
The document field
次に、語彙関連度算出部5により、語彙関連度の算出を行う(ステップ500)。
Next, the
図8は、本発明の一実施の形態における語彙関連度算出部の処理のフローチャートである。 FIG. 8 is a flowchart of processing of the vocabulary relevance calculating unit in the embodiment of the present invention.
語彙関連度算出部5は、語彙データベース9中の全ての語彙について、その語彙の語彙分野ベクトルと文書分野ベクトル算出部4で求めたQ個の文書分野ベクトルとの距離をそれぞれ求め、最も近い距離を語彙関連度とする(ステップ520,530)。この処理を全ての語彙について繰り返す。
The vocabulary
次に、語彙順位付け部6により、語彙を語彙関連度の大きい順にソートし、語彙に順位を付与する(ステップ600)。最後に、関連語彙出力部7により、語彙関連度の大きいものから順にV個の語彙を関連語彙として出力する(ステップ700)。
Next, the
以下では、具体的をあげて本実施の形態を説明する。 Hereinafter, the present embodiment will be described specifically.
入力に誤りがあっても適切な文書関連語彙が獲得できることを示すため、対象とする文書として、図9に示す文書を読み上げた音声を音声認識した結果である図10に示す文書を入力とする。 In order to show that an appropriate document-related vocabulary can be acquired even if there is an error in the input, the document shown in FIG. 10 which is the result of speech recognition of the speech read out from the document shown in FIG. .
まず、単語分割部1により、文書単語に分割する。分割した結果を図11に示す。
First, the
次に、単語ベクトル取得部2が、概念ベース8から各単語の単語ベクトルを取得する。表1に概念ベースの例を示す。
Next, the word
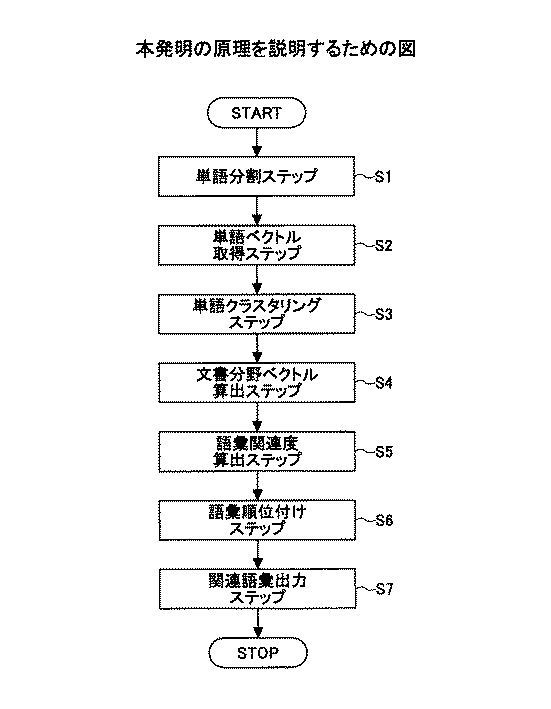
図11に示す単語のうち、概念ベース8中に存在する単語については、単語ベクトルを付与し、存在しない単語については削除する。単語ベクトル取得処理を行った結果、表2の単語の欄に記載された25個の単語について単語ベクトルが付与され、残りの単語については削除された。ここで、本実施の形態では、「ネットワーク部門」と「営業部門」という2箇所に出現する「部門」を別の単語として扱っているが、これを同一単語として一つにまとめてもよい。 Among words shown in FIG. 11, a word vector is assigned to a word that exists in the concept base 8, and a word that does not exist is deleted. As a result of the word vector acquisition processing, word vectors were assigned to the 25 words listed in the word column of Table 2, and the remaining words were deleted. Here, in this embodiment, “department” appearing in two places, “network department” and “sales department”, are treated as different words, but these may be combined into one as the same word.
これらの25個のクラスタのうち、距離が最も近い2つのクラスタを求め、この2つのクラスタを1つに併合して24個のクラスタを作成する。ここで、距離尺度としては、クラスタ間の類似性を表すものであれば、何を用いても構わないが、ここでは、クラスタに含まれる単語の単語ベクトルの重心間のコサイン距離を距離尺度として用いる。「NTT」、「サービス」、「部門」については、それぞれ2回ずつ出現しているが、同じ単語であれば、単語ベクトルも同じであるため、同じ単語を持つクラスタ同士の距離が1となり最も近くなる。ここでは、単語「NTT」を持つ6番目と14番目のクラスタを併合した。その結果を表3に示す。さらに、これらの24個のクラスタのうち、距離が最も近い2つのクラスタを求め、この2つのクラスタを1つに併合して23個のクラスタを作成する。このような処理を、クラスタ数が終了条件を満たすまで繰り返す。 Of these 25 clusters, two clusters having the shortest distance are obtained, and these two clusters are merged into one to create 24 clusters. Here, any distance scale may be used as long as it represents the similarity between the clusters, but here, the cosine distance between the centroids of the word vectors of the words included in the cluster is used as the distance scale. Use. “NTT”, “Service”, and “Department” each appear twice, but since the word vectors are the same for the same word, the distance between clusters having the same word is 1 and the most. Get closer. Here, the 6th and 14th clusters having the word “NTT” were merged. The results are shown in Table 3. Further, out of these 24 clusters, two clusters having the shortest distance are obtained, and these two clusters are merged into one to create 23 clusters. Such processing is repeated until the number of clusters satisfies the end condition.
クラスタに含まれる各単語の単語ベクトルの重心を文書分野ベクトルとする。本実施の形態では、文書分野ベクトルを求める際に、各単語の単語ベクトルの重みは均等であるとしたが、入力文書が音声認識結果であるような場合には、文書中の各単語に対し、その単語が正しく音声認識されているのかの程度を表す信頼度が付与されているので、クラスタ中の単語の信頼度を重みとした単語ベクトルの重心を文書分野ベクトルとしてもよい。信頼度を重みとすることで、認識誤りの単語がクラスタに含まれていても、一般に、認識誤りとなっている単語は信頼度が小さいため、重みも小さくなり、文書分野ベクトルへ及ぼす影響も小さくなる。よって、認識誤りの単語が文書分野ベクトルに及ぼす悪影響が軽減され、正しく分野を推定することができる。 The center of the word vector of each word included in the cluster is set as the document field vector. In the present embodiment, when the document field vector is obtained, the weight of the word vector of each word is equal. However, when the input document is a speech recognition result, for each word in the document, Since the reliability indicating the degree of whether or not the word is correctly recognized is given, the center of the word vector weighted by the reliability of the word in the cluster may be used as the document field vector. By using reliability as a weight, even if a word with a recognition error is included in the cluster, the word with a recognition error generally has a low reliability, so the weight is small and the influence on the document field vector is also reduced. Get smaller. Therefore, the adverse effect of the recognition error word on the document field vector is reduced, and the field can be estimated correctly.
次に、語彙関連度算出部5が、語彙データベース9から語彙関連度の算出を行う。語彙データベース9は、概念ベースの一種であり、意味的に類似している語彙間ほど距離が近く、意味的に類似していない語彙間ほど距離が遠くなるように語彙分野ベクトルが設定されたものである。語彙データベース9は単語ベクトル取得部2で使用した概念ベース8と整合性がとれているもの、つまり、語彙データベース9中の語彙の語彙分野ベクトルと概念ベース8中の単語の単語ベクトルにおいて、各次元が同じ意味を表しているものであればどのようなものでもよく、単語ベクトル取得部2で使用した概念ベース8そのものでもよいし、概念ベース8を利用して作成されたものでもよい。ここでは、ある語彙の語彙分野ベクトルは、大量の新聞記事などの文書中にその語彙が出現する文に対して文中に出現する単語の単語ベクトルの概念ベース8から求めてその単語ベクトルの重心を文毎の語彙分野ベクトルとし、文毎の語彙分野ベクトルの重心を語彙分野ベクトルとして求めた語彙データベース9を使用する。語彙データベース9中の全ての語彙について、その語彙の語彙分野ベクトルと文書分野ベクトル算出部4で求めた文書分野ベクトルとの距離をそれぞれ求め、最も近い距離を語彙関連度とする。本実施の形態では、文書分野ベクトルは1つであるから、単純に語彙分野ベクトルと文書分野ベクトルとの距離を語彙関連度とすればよい。語彙関連度を求めた結果を表5に示す。
Next, the vocabulary
最後に、関連語語彙出力部7により、語彙関連度の大きいものを関連語彙として出力する。ここでは、上位20個の語彙を関連語彙として獲得した。
Finally, the related word
本実施の形態では、順位に従ってそのまま上位のものを関連語彙として獲得したが、ここで、既知の語彙を取り除いてから上位の語彙を獲得しても構わない。獲得された関連語彙を表6に示す。これにより、文書に関連した語彙が獲得されていることがわかる。 In the present embodiment, the higher word is acquired as a related vocabulary as it is according to the ranking. However, the higher vocabulary may be acquired after removing the known vocabulary. Table 6 shows the acquired related vocabulary. Thereby, it is understood that the vocabulary related to the document is acquired.
また、構築されたプログラムを文書関連語彙獲得装置として利用されるコンピュータに接続されるハードディスク装置や、フレキシブルディスク、CD−ROM等の可搬記憶媒体に格納しておき、コンピュータにインストールして実行させることも可能である。 Further, the constructed program is stored in a hard disk device connected to a computer used as a document-related vocabulary acquisition device, a portable storage medium such as a flexible disk, a CD-ROM, etc., and installed and executed on the computer. It is also possible.
なお、本発明は、上記の実施の形態に限定されることなく、特許請求の範囲内において、種々変更・応用が可能である。 The present invention is not limited to the above-described embodiment, and various modifications and applications can be made within the scope of the claims.
本発明は、関連文書の検索等に適用可能である。 The present invention can be applied to retrieval of related documents.
1 単語分割手段、単語分割部
2 単語ベクトル取得手段、単語ベクトル取得部
3 単語クラスタリング手段、単語クラスタリング部
4 文書分野ベクトル算出手段、文書分野ベクトル算出部
5 語彙関連度算出手段、語彙関連度算出部
6 語彙順位付け手段、語彙順位付け部
7 関連語彙出力手段、関連語彙出力部
8 概念ベース
9 語彙データベース
DESCRIPTION OF
Claims (9)
入力された文書を単語に分割する単語分割ステップと、
単語の意味を表現するベクトルが格納されている概念ベースを検索することによって前記単語分割ステップで得られた各単語に対応するベクトルを取得する単語ベクトル取得ステップと、
前記単語ベクトル取得ステップで得られた各ベクトルをもとに単語のクラスタリングを行い、複数のクラスタを作成する単語クラスタリングステップと、
前記単語クラスタリングステップで得られた各クラスタをもとに文書の分野を表す文書分野ベクトルを求める文書分野ベクトル算出ステップと、
前記文書分野ベクトル算出ステップで得られた文書分野ベクトルと、予め作成しておいた語彙データベース中の各語彙の分野を表す語彙分野ベクトルから、入力された前記文書と各語彙との間の関連性を示す語彙関連度を求める語彙関連度算出ステップと、
前記語彙関連度算出ステップで得られた関連度をもとに語彙を順位付けする語彙順位付けステップと、
前記語彙順序付けステップで得られた語彙に関する順位をもとに関連語彙を出力する関連語彙出力ステップを有することを特徴とする文書関連語彙獲得方法。 A document related vocabulary acquisition method for acquiring a vocabulary related to a document from a document,
A word splitting step for splitting the input document into words;
A word vector acquisition step of acquiring a vector corresponding to each word obtained in the word division step by searching a concept base in which a vector expressing the meaning of the word is stored;
A word clustering step of performing clustering of words based on each vector obtained in the word vector acquisition step and creating a plurality of clusters,
A document field vector calculation step for obtaining a document field vector representing a field of the document based on each cluster obtained in the word clustering step;
The relationship between the input document and each vocabulary from the document field vector obtained in the document field vector calculation step and the vocabulary field vector representing the field of each vocabulary in the vocabulary database created in advance. A lexical relevance calculating step for obtaining a lexical relevance indicating
A vocabulary ranking step of ranking vocabularies based on the relevance obtained in the vocabulary relevance calculation step;
A document-related vocabulary acquisition method comprising a related vocabulary output step of outputting a related vocabulary based on the ranking of the vocabulary obtained in the vocabulary ordering step.
選択した各クラスタに対して該クラスタに含まれる各単語の単語ベクトルの重心をとることによってクラスタ毎に文書分野ベクトルを求める請求項1記載の文書関連語彙獲得方法。 In the document field vector calculation step, the top Q clusters are selected in the order in which many words are included,
2. The document related vocabulary acquisition method according to claim 1, wherein for each selected cluster, a document field vector is obtained for each cluster by taking the centroid of the word vector of each word included in the cluster.
前記各単語の音声認識結果の信頼度を重みとして文書分野ベクトルを求める請求項1または2記載の文書関連語彙獲得方法。 In the document field vector calculation step,
The document related vocabulary acquisition method according to claim 1 or 2, wherein a document field vector is obtained by using the reliability of the speech recognition result of each word as a weight.
単語の意味を表現するベクトルが格納されている概念ベースと、
入力された文書を単語に分割する単語分割手段と、
前記概念ベースを検索することによって前記単語分割手段で得られた各単語に対応するベクトルを取得する単語ベクトル取得手段と、
前記単語ベクトル取得手段で得られた各ベクトルをもとに単語のクラスタリングを行い、複数のクラスタを作成する単語クラスタリング手段と、
前記単語クラスタリング手段で得られた各クラスタをもとに文書の分野を表す文書分野ベクトルを求める文書分野ベクトル算出手段と、
前記文書分野ベクトル算出手段で得られた文書分野ベクトルと、予め作成しておいた語彙データベースの中の各語彙の分野を表す語彙分野ベクトルから、入力された文書と各語彙との間の関連性を示す語彙関連度を求める語彙関連度算出手段と、
前記語彙関連度算出手段で得られた関連度をもとに語彙を順位付けする語彙順位付け手段と、
前記語彙順位付け手段で得られた語彙に関する順位をもとに、関連語彙を出力する関連語彙出力手段と、を有することを特徴とする文書関連語彙獲得装置。 An inter-document collocation acquisition device for acquiring a vocabulary related to a document from a document,
A concept base that stores vectors representing the meaning of words;
Word dividing means for dividing the input document into words;
Word vector obtaining means for obtaining a vector corresponding to each word obtained by the word dividing means by searching the concept base;
Word clustering means for performing clustering of words based on each vector obtained by the word vector acquisition means and creating a plurality of clusters;
Document field vector calculation means for obtaining a document field vector representing the field of the document based on each cluster obtained by the word clustering means;
The relationship between the input document and each vocabulary from the document field vector obtained by the document field vector calculating means and the vocabulary field vector representing the vocabulary field in the vocabulary database prepared in advance. A lexical relevance calculating means for obtaining a lexical relevance indicating
Vocabulary ranking means for ranking vocabulary based on the relevance obtained by the vocabulary relevance calculation means;
A document-related vocabulary acquisition device comprising: related vocabulary output means for outputting related vocabulary based on the vocabulary ranking obtained by the vocabulary ranking means.
単語が多く含まれている順に上位Q個以内のクラスタを選択し、選択した各クラスタに対して該クラスタに含まれる各単語の単語ベクトルの重心をとることによってクラスタ毎に文書分野ベクトルを求める手段を有する請求項4記載の文書関連語彙獲得装置。 The document field vector calculating means includes:
Means for obtaining a document field vector for each cluster by selecting the top Q clusters in the order in which many words are included and taking the centroid of the word vector of each word included in the selected cluster. 5. The document-related vocabulary acquisition apparatus according to claim 4.
前記各単語の音声認識結果の信頼度を重みとして文書分野ベクトルを求める手段を有する請求項4または5記載の文書関連語彙獲得装置。 The document field vector calculating means includes:
6. The document related vocabulary acquisition apparatus according to claim 4 or 5, further comprising means for obtaining a document field vector using the reliability of the speech recognition result of each word as a weight.
入力された文書を単語に分割する単語分割ステップと、
単語の意味を表現するベクトルが格納されている概念ベースを検索することによって前記単語分割ステップで得られた各単語に対応するベクトルを取得する単語ベクトル取得ステップと、
前記単語ベクトル取得ステップで得られた各ベクトルをもとに単語のクラスタリングを行い、複数のクラスタを作成する単語クラスタリングステップと、
前記単語クラスタリングステップで得られた各クラスタをもとに文書の分野を表す文書分野ベクトルを求める文書分野ベクトル算出ステップと、
前記文書分野ベクトル算出ステップで得られた文書分野ベクトルと、予め作成しておいた語彙データベース中の各語彙の分野を表す語彙分野ベクトルから、入力された前記文書と各語彙との間の関連性を示す語彙関連度を求める語彙関連度算出ステップと、
前記語彙関連度算出ステップで得られた関連度をもとに語彙を順位付けする語彙順位付けステップと、
前記語彙順序付けステップで得られた語彙に関する順位をもとに関連語彙を出力する関連語彙出力ステップと、をコンピュータに実行させることを特徴とする文書関連語彙獲得プログラム。 A document related word acquisition program for causing a computer to acquire a vocabulary related to a document from a document,
A word splitting step for splitting the input document into words;
A word vector acquisition step of acquiring a vector corresponding to each word obtained in the word division step by searching a concept base in which a vector expressing the meaning of the word is stored;
A word clustering step of performing clustering of words based on each vector obtained in the word vector acquisition step and creating a plurality of clusters,
A document field vector calculation step for obtaining a document field vector representing a field of the document based on each cluster obtained in the word clustering step;
The relationship between the input document and each vocabulary from the document field vector obtained in the document field vector calculation step and the vocabulary field vector representing the field of each vocabulary in the vocabulary database created in advance. A lexical relevance calculating step for obtaining a lexical relevance indicating
A vocabulary ranking step of ranking vocabularies based on the relevance obtained in the vocabulary relevance calculation step;
A document-related vocabulary acquisition program that causes a computer to execute a related vocabulary output step of outputting a related vocabulary based on a rank related to the vocabulary obtained in the vocabulary ordering step.
選択した各クラスタに対して該クラスタに含まれる各単語の単語ベクトルの重心をとることによってクラスタ毎に文書分野ベクトルを求めるステップと、をコンピュータに実行させる請求項7記載の文書関連語彙獲得プログラム。 In the document field vector calculating step, selecting the top Q clusters in the order in which many words are included;
8. The document-related vocabulary acquisition program according to claim 7, wherein the computer executes a step of obtaining a document field vector for each cluster by taking the centroid of the word vector of each word included in the cluster for each selected cluster.
前記各単語の音声認識結果の信頼度を重みとして文書分野ベクトルを求めるステップをコンピュータに実行させる請求項7または8記載の文書関連語彙獲得プログラム。
In the document field vector calculation step,
9. The document related vocabulary acquisition program according to claim 7 or 8, wherein the computer executes a step of obtaining a document field vector by using the reliability of the speech recognition result of each word as a weight.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003384092A JP4325370B2 (en) | 2003-11-13 | 2003-11-13 | Document-related vocabulary acquisition device and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003384092A JP4325370B2 (en) | 2003-11-13 | 2003-11-13 | Document-related vocabulary acquisition device and program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005149014A true JP2005149014A (en) | 2005-06-09 |
| JP4325370B2 JP4325370B2 (en) | 2009-09-02 |
Family
ID=34692625
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003384092A Expired - Fee Related JP4325370B2 (en) | 2003-11-13 | 2003-11-13 | Document-related vocabulary acquisition device and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4325370B2 (en) |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2007066704A1 (en) * | 2005-12-09 | 2007-06-14 | Nec Corporation | Text mining device, text mining method, and text mining program |
| JP2008009671A (en) * | 2006-06-29 | 2008-01-17 | National Institute Of Information & Communication Technology | Data display device, data display method and data display program |
| JP2008123095A (en) * | 2006-11-09 | 2008-05-29 | Seiko Epson Corp | Retrieval terminal device, retrieval system, and program |
| JP2008268985A (en) * | 2007-04-16 | 2008-11-06 | Yahoo Japan Corp | Method for attaching tag |
| JP2009277100A (en) * | 2008-05-15 | 2009-11-26 | Nippon Telegr & Teleph Corp <Ntt> | Document feature representation computation device and program |
| JP2011059748A (en) * | 2009-09-07 | 2011-03-24 | Nippon Telegr & Teleph Corp <Ntt> | Keyword type determination apparatus, keyword type determination method and keyword type determination program |
| JP2011242850A (en) * | 2010-05-14 | 2011-12-01 | Nippon Telegr & Teleph Corp <Ntt> | Keyword type determination device and program |
| JP2013109125A (en) * | 2011-11-21 | 2013-06-06 | Nippon Telegr & Teleph Corp <Ntt> | Word addition device, word addition method and program |
| JP2017187828A (en) * | 2016-04-01 | 2017-10-12 | 京セラドキュメントソリューションズ株式会社 | Information processor and program |
| JP2018180937A (en) * | 2017-04-13 | 2018-11-15 | 日本電信電話株式会社 | Clustering apparatus, answer candidate generation apparatus, method, and program |
| JP2020074205A (en) * | 2020-01-27 | 2020-05-14 | 日本電信電話株式会社 | Answer candidate generation device, answer candidate generation method, and program |
| CN116226357A (en) * | 2023-05-09 | 2023-06-06 | 武汉纺织大学 | Document retrieval method under input containing error information |
-
2003
- 2003-11-13 JP JP2003384092A patent/JP4325370B2/en not_active Expired - Fee Related
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8229956B2 (en) | 2005-12-09 | 2012-07-24 | Nec Corporation | Text mining device, text mining method, and text mining program |
| WO2007066704A1 (en) * | 2005-12-09 | 2007-06-14 | Nec Corporation | Text mining device, text mining method, and text mining program |
| JP4868170B2 (en) * | 2005-12-09 | 2012-02-01 | 日本電気株式会社 | Text mining device, text mining method, and text mining program |
| JP2008009671A (en) * | 2006-06-29 | 2008-01-17 | National Institute Of Information & Communication Technology | Data display device, data display method and data display program |
| JP2008123095A (en) * | 2006-11-09 | 2008-05-29 | Seiko Epson Corp | Retrieval terminal device, retrieval system, and program |
| JP2008268985A (en) * | 2007-04-16 | 2008-11-06 | Yahoo Japan Corp | Method for attaching tag |
| JP2009277100A (en) * | 2008-05-15 | 2009-11-26 | Nippon Telegr & Teleph Corp <Ntt> | Document feature representation computation device and program |
| JP2011059748A (en) * | 2009-09-07 | 2011-03-24 | Nippon Telegr & Teleph Corp <Ntt> | Keyword type determination apparatus, keyword type determination method and keyword type determination program |
| JP2011242850A (en) * | 2010-05-14 | 2011-12-01 | Nippon Telegr & Teleph Corp <Ntt> | Keyword type determination device and program |
| JP2013109125A (en) * | 2011-11-21 | 2013-06-06 | Nippon Telegr & Teleph Corp <Ntt> | Word addition device, word addition method and program |
| JP2017187828A (en) * | 2016-04-01 | 2017-10-12 | 京セラドキュメントソリューションズ株式会社 | Information processor and program |
| JP2018180937A (en) * | 2017-04-13 | 2018-11-15 | 日本電信電話株式会社 | Clustering apparatus, answer candidate generation apparatus, method, and program |
| JP2020074205A (en) * | 2020-01-27 | 2020-05-14 | 日本電信電話株式会社 | Answer candidate generation device, answer candidate generation method, and program |
| CN116226357A (en) * | 2023-05-09 | 2023-06-06 | 武汉纺织大学 | Document retrieval method under input containing error information |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4325370B2 (en) | 2009-09-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11222167B2 (en) | Generating structured text summaries of digital documents using interactive collaboration | |
| US10025819B2 (en) | Generating a query statement based on unstructured input | |
| JP5346279B2 (en) | Annotation by search | |
| Zouaghi et al. | Combination of information retrieval methods with LESK algorithm for Arabic word sense disambiguation | |
| JP5710581B2 (en) | Question answering apparatus, method, and program | |
| US20070198511A1 (en) | Method, medium, and system retrieving a media file based on extracted partial keyword | |
| JP2007241888A (en) | Information processor, processing method, and program | |
| CN111414763A (en) | Semantic disambiguation method, device, equipment and storage device for sign language calculation | |
| US20150205860A1 (en) | Information retrieval device, information retrieval method, and information retrieval program | |
| JP2011118872A (en) | Method and device for determining category of unregistered word | |
| JP4325370B2 (en) | Document-related vocabulary acquisition device and program | |
| CN114880447A (en) | Information retrieval method, device, equipment and storage medium | |
| JP4333318B2 (en) | Topic structure extraction apparatus, topic structure extraction program, and computer-readable storage medium storing topic structure extraction program | |
| JP2006338342A (en) | Word vector generation device, word vector generation method and program | |
| JP2005301856A (en) | Method and program for document retrieval, and document retrieving device executing the same | |
| KR101860472B1 (en) | Apparatus and method of generation and classification for text classifier based on open directory project | |
| US20190095525A1 (en) | Extraction of expression for natural language processing | |
| CN113330430B (en) | Sentence structure vectorization device, sentence structure vectorization method, and recording medium containing sentence structure vectorization program | |
| JP2008152641A (en) | Similar example sentence retrieving device | |
| JP2009295052A (en) | Compound word break estimating device, method, and program for estimating break position of compound word | |
| JP5447368B2 (en) | NEW CASE GENERATION DEVICE, NEW CASE GENERATION METHOD, AND NEW CASE GENERATION PROGRAM | |
| JP2013222418A (en) | Passage division method, device and program | |
| US8745078B2 (en) | Control computer and file search method using the same | |
| JP6574469B2 (en) | Next utterance candidate ranking apparatus, method, and program | |
| JP6181890B2 (en) | Literature analysis apparatus, literature analysis method and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20060414 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090310 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090409 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090519 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090601 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120619 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130619 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140619 Year of fee payment: 5 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |