JP2004347943A - Data processor, musical piece reproducing apparatus, control program for data processor, and control program for musical piece reproducing apparatus - Google Patents
Data processor, musical piece reproducing apparatus, control program for data processor, and control program for musical piece reproducing apparatus Download PDFInfo
- Publication number
- JP2004347943A JP2004347943A JP2003146099A JP2003146099A JP2004347943A JP 2004347943 A JP2004347943 A JP 2004347943A JP 2003146099 A JP2003146099 A JP 2003146099A JP 2003146099 A JP2003146099 A JP 2003146099A JP 2004347943 A JP2004347943 A JP 2004347943A
- Authority
- JP
- Japan
- Prior art keywords
- user
- voice
- question
- music
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images








Abstract
Description
【0001】
【発明の属する技術分野】
本発明は、ユーザの音声入力に基づいてデータ処理を実行するデータ処理装置、楽曲再生装置、および、これらの制御プログラムに関する。
【0002】
【従来の技術】
従来から、装置操作を、より簡便なものとすべく、ユーザの手操作に代えて音声入力による操作を可能にしたデータ処理装置が知られている。また、この種の装置としては、ユーザとの複数回の対話に基づいて、実行すべきデータ処理を絞り込むようになされたものが提案されている(例えば、特許文献1参照)。
【0003】
このような装置にあっては、対話中にユーザが、黙り込むなどして、ユーザからの応答が得られなくなった場合、対話を進めずに待機するのが一般的である。
【0004】
【特許文献1】
特開2003−108175号公報
【0005】
【発明が解決しようとする課題】
しかしながら、上記のように、対話の進行が止まってしまうと、操作性が悪くなるといった問題がある。具体的には、装置が対話を止めたままにしてしまうと、ユーザが操作を再開したい場合には、どこまで対話が進んでいたかを覚えておくか、その都度確認する必要がある。
【0006】
本発明は、上述した事情に鑑みてなされたものであり、より操作性の良いデータ処理装置、楽曲再生装置、データ処理装置の制御プログラムおよび楽曲再生装置の制御プログラムを提供することを目的とする。
【0007】
【課題を解決するための手段】
上記課題を解決するために、請求項1に記載の発明は、ユーザからの音声入力に基づいて複数のデータ処理のいずれか一を実行するデータ処理装置において、データ処理ごとに、ユーザに音声入力を促すための音声データを記憶する記憶手段とを備え、これらの音声データの中から1つを再生しユーザに音声入力を促した後、所定時間が経過しても、この促しに対してユーザから音声入力が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、前記音声データの中の他の音声データを再生し、ユーザに音声入力を促すことを特徴とする。
【0008】
請求項2に記載の発明は、請求項1に記載のデータ処理装置において、ユーザからの音声入力があるまで、先に再生した音声データと異なる音声データを再生し、ユーザに音声入力を促すことを特徴とする。
【0009】
請求項3に記載の発明は、ユーザからの音声入力に基づいて複数のデータ処理のいずれか一を実行するデータ処理装置において、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する記憶手段を備え、ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは他の階層に属する質問を音声により再生し、ユーザに応答を促すことを特徴とする。
【0010】
請求項4に記載の発明は、ユーザからの音声入力に基づいて複数のデータ処理のいずれか一を実行するデータ処理装置において、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する記憶手段を備え、ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、所定のあいまい言葉しか得られなかった場合に、当該階層あるいは当該階層から下に属する質問から特定され得るデータ処理を順次実行することを特徴とする。
【0011】
請求項5に記載の発明は、ユーザからの音声入力に基づいて楽曲を選曲し再生する楽曲再生装置において、楽曲ごとに、当該楽曲の再生を指示する旨の音声入力をユーザに促すための音声データを記憶する記憶手段を備え、これらの音声データの中の1つを再生して、ユーザに音声入力を促した後、所定時間が経過しても、この促しに対してユーザから音声入力が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、前記音声データの中の他の音声データを再生し、ユーザに音声入力を促すことを特徴とする。
【0012】
請求項6に記載の発明は、請求項5に記載の楽曲再生装置において、ユーザからの音声入力があるまで、先に再生した音声データと異なる音声データを再生することを特徴とする。
【0013】
請求項7に記載の発明は、ユーザからの音声入力に基づいて楽曲を選曲し再生する楽曲再生装置において、選曲すべき楽曲を特定すべく、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する記憶手段を備え、ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは他の階層に属する質問を音声により再生してユーザに応答を促すことを特徴とする。
【0014】
請求項8に記載の発明は、ユーザからの音声入力に基づいて楽曲を選曲し再生する楽曲再生装置において、選曲すべき楽曲を特定すべく、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する記憶手段を備え、ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは当該階層から下に属する質問から特定され得る楽曲を順次選曲し再生することを特徴とする。
【0015】
請求項9に記載の発明は、ユーザからの音声入力に基づいて複数のデータ処理のいずれか一を実行するデータ処理装置を、データ処理ごとに、ユーザに音声入力を促すための音声データを記憶する手段、および、これらの音声データの中から1つを再生しユーザに音声入力を促した後、所定時間が経過しても、この促しに対してユーザから音声入力が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、前記音声データの中の他の音声データを再生し、ユーザに音声入力を促す手段として機能させることを特徴とするデータ処理装置の制御プログラムを提供する。
【0016】
請求項10に記載の発明は、ユーザからの音声入力に基づいて複数のデータ処理のいずれか一を実行するデータ処理装置において、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する手段、および、ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは他の階層に属する質問を音声により再生し、ユーザに応答を促す手段として機能させることを特徴とするデータ処理装置の制御プログラムを提供する。
【0017】
請求項11に記載の発明は、ユーザからの音声入力に基づいて複数のデータ処理のいずれか一を実行するデータ処理装置を、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する手段、および、ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、所定のあいまい言葉しか得られなかった場合に、当該階層あるいは当該階層から下に属する質問から特定され得るデータ処理を順次実行する手段として機能させることを特徴とするデータ処理装置の制御プログラムを提供する。
【0018】
請求項12に記載の発明は、ユーザからの音声入力に基づいて楽曲を選曲し再生する楽曲再生装置を、楽曲ごとに、当該楽曲の再生を指示する旨の音声入力をユーザに促すための音声データを記憶する手段、および、これらの音声データの中の1つを再生して、ユーザに音声入力を促した後、所定時間が経過しても、この促しに対してユーザから音声入力が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、前記音声データの中の他の音声データを再生し、ユーザに音声入力を促す手段として機能させることを特徴とする楽曲再生装置の制御プログラムを提供する。
【0019】
請求項13に記載の発明は、ユーザからの音声入力に基づいて楽曲を選曲し再生する楽曲再生装置を、選曲すべき楽曲を特定すべく、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する手段、および、ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは他の階層に属する質問を音声により再生してユーザに応答を促す手段として機能させることを特徴とする楽曲再生装置の制御プログラムを提供する。
【0020】
請求項14に記載の発明は、ユーザからの音声入力に基づいて楽曲を選曲し再生する楽曲再生装置を、選曲すべき楽曲を特定すべく、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する手段、および、ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは当該階層から下に属する質問から特定され得る楽曲を順次選曲し再生する手段として機能させることを特徴とする楽曲再生装置の制御プログラムを提供する。
【0021】
【発明の実施の形態】
以下、図面を参照して本発明の実施の形態について説明する。本実施形態では、楽曲再生装置として自動車などの車両に搭載される車載用楽曲再生装置を例示する。
【0022】
<第1実施形態>
図1は、本実施形態にかかる車載用楽曲再生装置100の機能的構成を、この車載用楽曲再生装置100に楽曲データなどのマルチメディアデータを配信するための配信システム1と共に示す図である。この図に示すように、配信システム1は、配信サーバ10と、車載用楽曲再生装置100とを備え、これらがインターネット2および無線通信網3からなるネットワーク4を介して互いにデータ通信可能に接続されている。なお、同図には、配信サーバ10と車載用楽曲再生装置100とを、各々1台ずつ例示しているが、その台数は任意である。
【0023】
配信サーバ10は、一般的なコンピュータシステムから構成され、楽曲データや映像データ、テキストデータなどのマルチメディアデータをネットワーク4を介して車載用楽曲再生装置100に配信するものであり、多数のマルチメディアデータが格納されたデータベース11を備えている。
【0024】
車載用楽曲再生装置100は、自動車などの車両に搭載され、配信サーバ10から配信されたマルチメディアデータを再生するものである。図示のように、車載用楽曲再生装置100は、制御部110と、記憶部130とを備えている。この制御部110は、CPUや、ROM、RAMなどを備え、車載用楽曲再生装置100の各部を制御する。
【0025】
通信装置120は、制御部110の制御の下、ネットワーク4に接続された各種端末装置とデータ通信するものである。より具体的には、通信装置120は、例えば携帯電話機あるいは無線LAN通信装置(Local Area Network)などの移動通信装置に相当し、無線通信網3を介して当該無線通信網3あるいはインターネット2に接続された各種端末とデータ通信する。本実施形態では、この通信装置120は、特に配信サーバ10とデータ通信することで、この配信サーバ10から楽曲データや映像データなどのマルチメディアデータを受信する。
【0026】
記憶部130は、HDD(Hard Disk Drive)などの主記憶装置を備え、制御部110により実行される各種制御プログラムや、配信サーバ10から受信したマルチメディアデータ(楽曲データや映像データなど)、合成音声により出力されるテキストデータなどの各種データを記憶するものである。また、記憶部130は、マルチメディアの種類(楽曲、テキスト、映像など)ごとに、当該記憶部130に格納されているデータを管理するためのテーブルデータを記憶している。
【0027】
図2は、マルチメディアデータの1つである楽曲データを管理するための楽曲テーブル200の構成を模式的に示す図である。この図に示すように、楽曲テーブル200の1件のレコードには、楽曲IDと、ジャンル情報と、アーティスト情報と、曲名情報と、新曲フラグとが含まれている。
【0028】
楽曲IDは、楽曲データの識別子であり、ジャンル情報は、楽曲が属するジャンルを示すものであり、このジャンルとしては、例えばJPOP(日本のポピュラー音楽)、演歌、ロック、クラシックなどがある。アーティスト情報は、楽曲が歌であれば歌手の情報、クラシックのような演奏のみの楽曲であれば指揮者や演奏楽団の情報を示すものである。例えば楽曲が歌である場合には、アーティスト情報として、グループかソロかを示す情報、ボーカルが男性か女性かを示す情報、および、アーティスト名(もしくはグループ名)が含まれている。また、同図に示す曲名情報は、楽曲の曲目を示すものであり、新曲フラグは、楽曲を新曲として扱うか否かを示す情報であり、新曲であれば「YES」、新曲でなければ「NO」が示される。
【0029】
この楽曲テーブル200は、車載用楽曲再生装置100が配信サーバ10から楽曲データを受信し、記憶部130に格納するごとに、この楽曲データに対応するレコードを生成しレコードを追加することで更新される。楽曲データ以外のマルチメディアデータ(例えば、映像データなど)を管理するためのテーブルデータについても、楽曲テーブル200と同様に、配信サーバ10からデータを受信するごとに更新されるが、その詳細な説明については割愛することにする。
【0030】
なお、楽曲テーブル200には、上記の情報の他にも、例えばアーティスト情報として、作詞者あるいは作曲者名を含めるようにしても良いし、また、レコードに視聴人気ランキング情報や販売実績ランキング情報といった情報を含める構成としても良い。また、配信サーバ10が楽曲テーブル200などのマルチメディアデータを管理するためのテーブルデータを生成し、これらを車載用楽曲再生装置100がネットワーク4を介して受信する構成としても良い。
【0031】
さて、再び図1に戻り、楽曲再生部140は、制御部110の制御の下、マルチメディアデータの1つである楽曲データに基づいてアナログ信号を生成し、ミキサ141を介してアンプ142に出力するものである。アンプ142は、ミキサ141からのアナログ信号を増幅してスピーカ143に出力する。スピーカ143は、アンプ142から入力されたアナログ信号に応じて放音するものである。この構成の下、制御部110が記憶部130に記憶された楽曲データを楽曲再生部140に出力することで、スピーカ143から楽曲音が出力される。
【0032】
マイク150は、収音装置であり、本実施形態では、ユーザが発した音声を収音し、アナログ信号をアンプ151に出力する。アンプ151は、入力されたアナログ信号を増幅してA/D変換器152に出力するものである。A/D変換器152は、入力されたアナログ信号を所定ビットに量子化してデジタル信号に変換し、音声入力信号としてVR153に出力するものである。
【0033】
VR(Voice Recognition:音声認識部)153は、音声入力信号に基づいて音声認識処理を実行し、その認識結果を制御部110に出力するものであり、音声認識処理用の回路(例えばDSP(Digital Signal Processor))を備え、制御部110が音声認識処理を実行するよりも、高速処理が可能となっている。
【0034】
TTS(Text To Speech:音声変換部)160は、制御部110から入力されたテキストデータに基づいて、テキスト内容に即した合成音声を生成すべく、デジタル信号である合成音声データを生成し、D/A変換器161に出力するものである。D/A変換器161は、合成音声データをアナログ信号に変換し、ミキサ141を介してアンプ142に出力する。これにより、スピーカ143から合成音声が出力される。なお、上記のように、ミキサ141には、楽曲データに基づくアナログ信号と、合成音声データに基づくアナログ信号とが入力されており、両者が同時に入力されている場合には、楽曲と合成音声との音量比率が調整されスピーカ143から出力される。
【0035】
操作部154は、電源のオン/オフなどに用いられるものであり、押下式ボタンなどの複数の操作子を備え、ユーザによる操作子の操作を検出し、制御部110に出力する。また、車載用楽曲再生装置100は、この他にも、各種情報が表示される表示部(例えば液晶ディスプレイ)を備え、再生中の楽曲に関する情報や映像などが表示される。また、ユーザが音声により車載用楽曲再生装置100を操作している間、あたかも自然人と対話しているかの印象をユーザに与えることができるように、この表示部には、CG合成映像あるいは実写映像からなる人物映像が表示されるようになっている。
【0036】
さて上記のように、車載用楽曲再生装置100は、ユーザの音声を認識する構成を備え、音声指示による装置の各種操作が可能となっている。音声により操作されるものとしては、例えば、車載用楽曲再生装置100の初期設定(時刻設定など)や、楽曲選択操作などがある。以下では、説明が煩雑になるのを避けるべく、ユーザが音声を入力することによって楽曲を選択する際の操作について詳述する。
【0037】
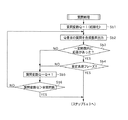
車載用楽曲再生装置100にあっては、音声入力による楽曲選択は、車載用楽曲再生装置100から出力される複数の質問音声に対して、ユーザが順次応答を音声により入力することで行われる構成となっている。この車載用楽曲再生装置100から出力される質問は、ユーザが所望する楽曲を特定するための質問であり、楽曲を絞り込むために、大項目から小項目の順にレイヤ(階層)に分けられている。
【0038】
図3は、楽曲選択操作の際に用いられる質問レイヤ構造の一例を示す図である。この図に示すように、質問は、その内容に応じて、第1レイヤ300〜第5レイヤ304に分けられている。具体的には、第1レイヤ300には、再生すべき楽曲のジャンルを特定するための質問が含まれ、これらの質問に対してユーザが応答することで所望する楽曲のジャンルが絞り込まれる。第2レイヤ301および第3レイヤ302には、アーティストを絞り込むための質問が含まれている。例えば第2レイヤ301には、ユーザが所望するアーティストがソロかグループかを特定するための質問が含まれ、第3レイヤ302には、ボーカルの性別を特定するための質問が含まれている。第4レイヤ303には、第1レイヤ300〜第3レイヤ302に含まれる質問に対する応答から特定されるアーティスト候補を順次ユーザに提示し、これらの候補の中から所望のアーティストをユーザに選択させるための質問が含まれる。また、第5レイヤ304には、第4レイヤ303の質問にてユーザが選択したアーティストに属する曲目を順次ユーザに提示し、これらの候補の中から所望の曲をユーザに選択させるための質問が含まれている。
【0039】
これら各レイヤ300〜304に属する質問は、楽曲選択用の質問テーブル(以下、単に「質問テーブル」と称する)400に予め登録されている。具体的には、質問テーブル400は、記憶部130に予め記憶され、図4に示すように、質問文を示すテキストデータを、当該質問が属するレイヤごとに記録するものである。例えば、この図に一例を示すように、ユーザが所望する楽曲のジャンルを特定するための質問が属する第1レイヤ300には、質問文として、「新曲を紹介しますか」や、「JPOPを聴きますか」、「演歌を聴きますか」といった内容のテキストデータが登録されている。
【0040】
また、質問に対してユーザが応答に使用するであろうフレーズは、応答テーブル500として登録されている。この応答テーブル500は、記憶部130に予め記憶されており、図5に示すように、応答フレーズが意味ごとに登録されている。本実施形態では、フレーズがとり得る意味として、肯定表現、否定表現、および、あいまい表現(あいまい言葉)が予め設定されている。肯定表現は、車載用楽曲再生装置100が出力した質問に対するユーザの同意を意味するフレーズであり、例えば、「はい」、「うん」、「そう」などがある。否定表現は、肯定表現とは逆に、ユーザの拒否を意味するフレーズであり、例えば、「いいえ」、「ちがう」、「だめ」などがある。また、あいまい表現は、質問に対して否定とは限らないが、肯定ではないということが明らかな応答を示すものであり、例えば「えーと」、「うーん」、「あれ」などがある。
【0041】
このような構成の下、車載用楽曲再生装置100は、ユーザに対して質問を、合成音声にて出力した後、ユーザの応答(音声)をマイク150から収音し、音声入力信号に対して音声認識を施して、ユーザの応答が肯定表現、否定表現、および、あいまい表現のいずれかを判断することとなる。
【0042】
次いで、このような車載用楽曲再生装置100からの質問と、この質問に対するユーザの応答とからなる対話によって楽曲が選択される際の動作について説明する。
【0043】
図6は、車載用楽曲再生装置100の制御部110が、楽曲選曲・再生のために実行する選曲・再生処理の処理手順を示すフローチャートである。この図に示すように、制御部110は、先ず、レイヤ変数Nを「1」に初期化する(ステップSa1)。レイヤ変数Nは、現在の質問がどのレイヤ(図3参照)に属しているかを識別するためのものである。次いで、制御部110は、レイヤ変数Nにて示される第Nレイヤに属する質問の各々をユーザに合成音声にて順次出力し、これらの質問に対するユーザの応答を識別する質問処理を実行する(ステップSa2)。なお、この質問処理の具体的な処理内容については、後に詳述する。
【0044】
次いで、制御部110は、ステップSa2にて、ユーザの応答として肯定表現の応答があったかを判別し(ステップSa3)、この判別結果がNOであれば、再度、同一のレイヤに属する質問をユーザに与えるべく、処理手順をステップSa2に戻す。
【0045】
一方、ステップSa3における判別結果がYESである場合には、制御部110は、レイヤ変数Nを「1」だけインクリメントし(ステップSa4)、レイヤ変数Nが全レイヤ数(本実施形態では「4」)より大であるかを判別する(ステップSa5)。この判別結果がNOであれば、制御部110は、レイヤ変数Nで指定された第Nレイヤに属する質問をユーザに与えるべく、処理手順をステップSa2に戻す。また、この判別結果がYESであれば、レイヤごとに、肯定表現の応答が得られたこととなり、ユーザが所望する楽曲データが特定されるから、制御部110は、この特定された楽曲データを再生する(ステップSa6)。
【0046】
次いで、上記ステップSa2における質問処理について図7に示すフローチャートを参照して、より詳細に説明する。
【0047】
この図に示すように、質問処理にあっては、第Nレイヤに属する質問が順番にユーザに対して合成音声出力される。具体的には、制御部110は、先ず、質問変数Qを「1」に初期化する(ステップSb1)。この質問変数Qは、レイヤに属する質問のうち、現在、どの質問まで出力が完了したかを示すものである。次いで、制御部110は、質問変数Qにて指定された質問をユーザに与えるべく、合成音声出力する(ステップSb2)。そして、制御部110は、質問を合成音声出力してから一定時間内にユーザから応答があったか(音声入力があったか)を判別する(ステップSb3)。
【0048】
具体的には、ステップSb3において、制御部110は、ステップSb2を実行した後に、タイマカウントを開始すると共に、音声入力を受付け続ける。そして、一定時間が経過してタイマカウントがタイムアウトする前に、制御部110がユーザからの音声入力を取得した場合、ステップSb3の判別結果がYESとなり、また、音声入力を取得せずにタイムアウトした場合には、ステップSb3の判別結果がNOとる。なお、より詳細には、制御部110は、タイマカウントがタイムアウトする前に、音声入力があったとしても、その音声入力に対して音声識別処理を施した結果、その音声が応答テーブル500(図5参照)に登録された各フレーズのいずれにも該当しない場合には、音声入力がなかったものとする。すなわち、このステップSb3にあっては、質問の応答として取り得る音声入力(応答テーブル500に登録されているフレーズ)があった場合にだけ、判別結果がYESとなる。
【0049】
ステップSb3の判別結果がYESである場合には、制御部110は、音声入力として得られた応答が肯定表現フレーズを含むものであるかを判別し(ステップSb4)、この判別結果がYESであれば、現在のレイヤに属する他の質問をユーザに与える必要が無いため、質問処理を終了し、処理手順をステップSa3に進める。また、制御部110は、音声入力として得られた応答が否定表現、あるいは、あいまい表現であれば(ステップSb4:NO)、現在のレイヤに属する次の質問をユーザに与えるべく、次の処理を実行する。すなわち、制御部110は、次の質問を指定すべく質問変数Qを「1」だけインクリメントした後(ステップSb5)、質問変数Qが全質問数より大きいかを判別し(ステップSb6)、この判別結果がNOである場合に、処理手順をステップSb2に戻し、次の質問をユーザに与える。また、ステップSb6の判別結果がYESである場合、すなわち、現在のレイヤに属する全ての質問がユーザに与えられている場合には、質問処理を終了し、処理手順をステップSa3に進める。そして、現在のレイヤにおいて肯定表現の応答が得られていないため、ステップSa3における判別結果がNOとなり、現在のレイヤに属する質問を最初からユーザに与えるべく、処理手順がステップSa2に戻る。
【0050】
さて、上記ステップSb3の判別結果がNOの場合、すなわち、質問をユーザに与えた後、一定時間が経過しても、ユーザから、肯定表現、否定表現およびあいまい表現のいずれかに属する音声入力が応答として得られなかった場合には、制御部110は、処理手順をステップSb5に進め、現在のレイヤに属する他の質問をユーザに与え、応答を促す。
【0051】
つまり、制御部110は、ユーザに質問を与えてから一定時間が経過した後、応答が得られなかった場合(ステップSb3:NO)、および、応答として、あいまい表現が得られた場合(ステップSb4:NO)には、現在のレイヤに属する他の質問をユーザに順次与えることとなる。
【0052】
これにより、質問に対してユーザが肯定的な応答をしなかった場合、車載用楽曲再生装置100が対話の進行をとめるのではなく、質問に応答することで明らかにすべき事項(例えば、所望する楽曲のジャンルやアーティストなど)に関した他の質問がユーザに与えられることで、あたかも、自然人と対話しているかのような自然な対話が実現される。
【0053】
また、一般的に、ユーザが質問の応答に思案する場合、すなわち、応答に対して黙り込んでしまうか、あるいは、あいまいな応答しかできない場合、ユーザが、その質問に同意していないことが大半である。そこで、上記のように、他の質問を順次与える構成とすることで、ユーザは、所望する質問に対してのみ応答すれば良く、操作性を向上させることができる。
【0054】
さらにまた、ユーザが車両の運転者であるような場合、車載用楽曲再生装置100の対話操作を、運転している最中に行うことがある。従って、運転の状況によっては、運転者は、対話操作の途中で、運転に集中することが多々あり、質問に対して一定時間応答しない場合がある。このような場合、対話の進行が止まったままであると、運転者は、再度、対話を再開する場合に、どこまで進行していたかを覚えておく必要があり、これを忘れてしまった場合には、結局最初から対話をやり直さなければならなくなる。これに対して、本実施形態によれば、車載用楽曲再生装置100は、ユーザからの応答が質問を出力してから一定時間得られなかった場合、質問を順次出力するから、ユーザは、対話操作を再開したい場合に、対話の進行を覚えておかなくとも、所望の質問が出力されたときに応答するだけで良く、操作が容易となる。
【0055】
<第2実施形態>
上述した実施形態では、車載用楽曲再生装置100は、質問を出力した後、一定時間が経過しても、ユーザから応答が得られなかった場合、あるいは、あいまい表現しか得られなかった場合に、同一のレイヤに属する他の質問を出力する構成について説明した。
【0056】
しかしながら、ユーザが質問に対する応答する際に、車載用楽曲再生装置100に現在のレイヤに属する処理ではなく、他のレイヤに属する処理させるべく、応答に思案して黙り込んでしまう、あるいは、あいまい表現を使用する場合がある。この場合の具体例としては、ユーザが、図3に示す第1レイヤ300に属する質問に応答することで所望の楽曲ジャンルとして「演歌」を選択した上で、第2レイヤ301、第3レイヤ302と対話を進めたものの、第3レイヤ302にて楽曲ジャンルを「JPOP」に変更したいと思った場合などがある。
【0057】
そこで、本実施形態では、図8に示すように、第1実施形態にて説明した質問処理において、車載用楽曲再生装置100の制御部110は、質問が出力されてから一定時間内に応答がなかった場合(ステップSb3:NO)、次に出力する質問を上位のレイヤに属する質問(すなわち、先の対話で確定した事項に関する質問)とすべく、レイヤ変数Nが「1」より大きいかを判別した後に(ステップSc1)、この判別結果がYESであれば、レイヤ変数Nを「1」だけデクリメントし(ステップSc2)、処理手順をステップSa3に進める。これにより、ユーザから一定時間応答がなかった場合の次の質問が、上位のレイヤに属する質問となる。
【0058】
なお、ステップSc1における判別結果がNOである場合には、それ以上上位のレイヤが無いことを示すため、現在のレイヤに属する質問を最初から繰り返すべく、処理手順をステップSa3に進める。
【0059】
また、質問から一定時間内に応答があった場合であっても、制御部110は、その応答が、あいまい表現であるかを判別し(ステップSb4)、この判別結果がYESであれば、一定時間応答が無かった場合と同様に、上位のレイヤに属する質問を次に出力すべく、処理手順をステップSc1に進める。
【0060】
このように、本実施形態によれば、他のレイヤに属する処理を所望するためにユーザが質問に対して沈黙、あるいは、あいまい表現を使用した場合に、次の質問が自動的に上位のレイヤに属するものとなるから、ユーザは、はじめから対話をやり直しするなどの操作をしなくとも、所望するレイヤの質問が出力されたときに応答すれば、所望の操作を装置に実行させることができる。
【0061】
なお、本実施形態では、質問を上位のレイヤに属するものにする構成について例示したが、下位のレイヤに属する質問としても良い。上位および下位のレイヤのどちらに移行するかは、質問のレイヤ構造に応じて適宜に選択可能である。
【0062】
<第3実施形態>
上述した第1あるいは第2実施形態にあっては、車載用楽曲再生装置100は、質問を出力してから一定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、他の質問を出力する構成について説明した。
【0063】
しかしながら、楽曲の選曲・再生操作のように、楽曲を特定するための対話がある程度進行しているような場合には、ユーザの所望する楽曲候補は、大まかに特定される。
【0064】
そこで、本実施形態にあっては、図9に示すように、車載用楽曲再生装置100の制御部110は、質問を出力してから一定時間が経過しても、この質問に対してユーザから応答が得られなかった場合(ステップSb3:NO)、あるいは、音声入力による応答として、あいまい言葉しか得られなかった場合に(ステップSc3:YES)、現在のレイヤから特定され得る全ての楽曲を順次再生する(ステップSd2)。
【0065】
このように、本実施形態では、車載用楽曲再生装置100は、質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合、対話の進行を止めるのではなく、現在までの対話にて確定した事項の中の処理(すなわち、特定され得る楽曲の再生)を順次実行するため、少なくとも、ユーザが所望する処理を含む各種処理が実行されることとなる。
【0066】
これにより、例えば、ユーザが楽曲のジャンルは特定するものの、その他はランダムに再生させたいといった場合に、質問にあえて一定時間応答しないようにするか、または、あいまいな表現をするといった操作の態様も可能となり、操作性が向上することとなる。
【0067】
<変形例>
上述した各実施形態は、あくまでも本発明の一態様にすぎず、本発明の範囲内で任意に変形可能である。
【0068】
例えば、上述した各実施形態では、本発明が車載用の楽曲再生装置を適用する場合について例示したが、車載用に限らず、家庭用のものであっても良いし、携帯用のものであっても良い。さらには、ユーザからの音声入力に基づいて複数のデータ処理のいずれか一を実行する装置であれば、任意の装置に適用することが可能である。
【0069】
また例えば、上述した各実施形態において、質問に対するユーザからの応答として、あいまい表現が得られた場合に、実際にユーザが、どのような処理を所望しているかを学習する構成としても良い。
【0070】
具体的には、第1および第2実施形態にて説明したように、車載用楽曲再生装置100は、質問に対するユーザの応答があいまい表現であった場合には、一定時間応答が得られなかった場合と同様に、他の質問を順次出力する構成となっている。そこで、車載用楽曲再生装置100が、ある質問に対する応答として、あいまい表現を得た場合、順次出力する質問のうち、ユーザが、どの質問に対して肯定したかを学習(対応付け)しておき、再度、同じ質問であいまい表現が使われた場合に、学習した質問を次に出力する構成としても良い。これにより、ユーザごとの趣向に合った質問を出力することが可能となる。
【0071】
【発明の効果】
以上説明したように、本発明によれば、より操作性の良いデータ処理装置、楽曲再生装置、データ処理装置の制御プログラムおよび楽曲再生装置の制御プログラムが提供される。
【図面の簡単な説明】
【図1】本発明の第1実施形態にかかる車載用楽曲再生装置の機能的構成を、当該車載用楽曲再生装置に楽曲データなどのマルチメディアデータを配信するための配信システムと共に示す図である。
【図2】楽曲テーブルの構成を模式的に示す図である。
【図3】楽曲選択操作の際に用いられる質問レイヤ構造の一例を示す図である。
【図4】質問テーブルの構成を模式的に示す図である。
【図5】応答テーブルの構成を模式的に示す図である。
【図6】第1実施形態にかかる選曲・再生処理の処理手順を示すフローチャートである。
【図7】第1実施形態にかかる質問処理の処理手順を示すフローチャートである。
【図8】本発明の第2実施形態にかかる質問処理の処理手順を示すフローチャートである。
【図9】本発明の第3実施形態にかかる質問処理の処理手順を示すフローチャートである。
【符号の説明】
100 車載用楽曲再生装置
110 制御部
130 記憶部
140 楽曲再生部
143 スピーカ
150 マイク
200 楽曲テーブル
300〜304 レイヤ
400 質問テーブル
500 応答テーブル[0001]
TECHNICAL FIELD OF THE INVENTION
The present invention relates to a data processing device that executes data processing based on a user's voice input, a music reproduction device, and a control program for these devices.
[0002]
[Prior art]
2. Description of the Related Art Conventionally, there has been known a data processing apparatus which enables an operation by voice input instead of a manual operation of a user in order to make the operation of the apparatus simpler. Further, as this type of device, there has been proposed a device in which data processing to be executed is narrowed down based on a plurality of dialogs with a user (for example, see Patent Document 1).
[0003]
In such an apparatus, when the user cannot obtain a response from the user due to, for example, silence during the dialog, the user generally waits without proceeding with the dialog.
[0004]
[Patent Document 1]
JP 2003-108175 A
[0005]
[Problems to be solved by the invention]
However, as described above, when the progress of the dialogue stops, there is a problem that operability deteriorates. Specifically, if the apparatus keeps the dialogue stopped, when the user wants to resume the operation, it is necessary to remember how far the dialogue has progressed or to confirm each time.
[0006]
The present invention has been made in view of the circumstances described above, and has as its object to provide a data processing device, a music reproduction device, a control program for a data processing device, and a control program for a music reproduction device, which have better operability. .
[0007]
[Means for Solving the Problems]
In order to solve the above-mentioned problem, an invention according to
[0008]
According to a second aspect of the present invention, in the data processing apparatus according to the first aspect, voice data different from the previously reproduced voice data is reproduced until the user inputs a voice, and the user is prompted to input a voice. It is characterized by.
[0009]
According to a third aspect of the present invention, in the data processing device which executes any one of a plurality of data processes based on a voice input from a user, a question for obtaining a voice input from the user as a response is provided in a plurality of layers. A storage means is provided for separately storing, and after reproducing a question belonging to a certain hierarchy by voice and prompting the user to respond, even if a predetermined time has elapsed, the user did not receive a response to this question. In this case, or when only a predetermined ambiguous word is obtained as a voice input, a question belonging to the hierarchy or another hierarchy is reproduced by voice to prompt the user to respond.
[0010]
According to a fourth aspect of the present invention, in the data processing device which executes any one of a plurality of data processes based on a voice input from a user, a question for obtaining a voice input from the user as a response is stored in a plurality of layers. A storage means is provided for separately storing, and after reproducing a question belonging to a certain hierarchy by voice and prompting the user to respond, even if a predetermined time has elapsed, the user did not receive a response to this question. In this case, or when only a predetermined ambiguous word is obtained, data processing that can be specified from the hierarchy or a question belonging to the hierarchy below is sequentially executed.
[0011]
According to a fifth aspect of the present invention, in a music reproducing apparatus for selecting and reproducing music based on a voice input from a user, a voice for urging the user to input a voice to instruct the reproduction of the music for each music. A storage means for storing data is provided, and one of these voice data is reproduced, and after prompting the user for voice input, even if a predetermined time has elapsed, the user receives voice input in response to the prompt. If not obtained, or if only a predetermined ambiguous word is obtained as a voice input, another voice data in the voice data is reproduced to prompt the user to input a voice.
[0012]
According to a sixth aspect of the present invention, in the music reproducing apparatus according to the fifth aspect, audio data different from the previously reproduced audio data is reproduced until there is a voice input from the user.
[0013]
According to a seventh aspect of the present invention, in a music reproducing apparatus for selecting and reproducing music based on a voice input from a user, a question for obtaining a voice input from the user as a response to specify a music to be selected is specified. A storage unit is provided for storing the information in a plurality of layers, and after reproducing a question belonging to a certain layer by voice and prompting the user to respond, even if a predetermined time has elapsed, the user receives a response to the question even if a predetermined time has elapsed. If not obtained, or if only a predetermined ambiguous word is obtained as a voice input, a question belonging to the hierarchy or another hierarchy is reproduced by voice to prompt the user to respond.
[0014]
In a music reproducing apparatus for selecting and reproducing music based on a voice input from a user, the invention according to claim 8 may include a question for obtaining a voice input from the user as a response in order to specify a music to be selected. A storage unit is provided for storing the information in a plurality of layers, and after reproducing a question belonging to a certain layer by voice and prompting the user to respond, even if a predetermined time has elapsed, the user receives a response to the question even if a predetermined time has elapsed. If not obtained, or if only a predetermined ambiguous word is obtained as a voice input, songs that can be specified from the hierarchy or questions belonging to the hierarchy below are sequentially selected and reproduced.
[0015]
According to a ninth aspect of the present invention, a data processing device that executes one of a plurality of data processes based on a voice input from a user stores voice data for prompting the user to perform a voice input for each data process. Means for reproducing, and prompting the user to input a voice by reproducing one of the voice data, and if no voice input is obtained from the user in response to the prompt even after a predetermined time has elapsed, Alternatively, when only a predetermined ambiguous word is obtained as a voice input, the other voice data in the voice data is reproduced, and the data processing device is made to function as means for prompting the user to input a voice. Provide a control program.
[0016]
According to a tenth aspect of the present invention, in the data processing device which executes any one of a plurality of data processes based on a voice input from a user, a question for obtaining a voice input from the user as a response is stored in a plurality of layers. Means for separately storing, and when a question belonging to a certain hierarchy is reproduced by voice, and after prompting the user for a response, even if a predetermined time has elapsed, the user does not receive a response to this question Alternatively, when only a predetermined ambiguous word is obtained as a voice input, a question belonging to the hierarchy or another hierarchy is reproduced by voice to function as a means for prompting a user to respond. Provide a control program.
[0017]
The invention according to
[0018]
According to a twelfth aspect of the present invention, there is provided a music reproducing apparatus for selecting and reproducing a music piece based on a voice input from a user, and a voice for urging the user to input a voice to instruct the reproduction of the music piece for each music piece. Means for storing data, and reproducing one of these voice data to prompt the user for voice input, and after a predetermined time elapses, the user receives a voice input in response to the prompt. If not, or if only a predetermined ambiguous word is obtained as a voice input, the other voice data in the voice data is reproduced to function as a means for prompting the user to voice input. The present invention provides a control program for a music playback device that performs
[0019]
According to a thirteenth aspect of the present invention, there is provided a music reproducing apparatus for selecting and reproducing music based on a voice input from a user, in order to specify a music to be selected, a question for obtaining a voice input from the user as a response. Means for storing the information in a plurality of layers, and reproducing a question belonging to a certain layer by voice and prompting the user for a response. If not, or if only a predetermined ambiguous word is obtained as a voice input, a question belonging to the hierarchy or another hierarchy is reproduced by voice to function as a means for prompting the user to respond. The present invention provides a control program for a music playback device that performs
[0020]
According to a fourteenth aspect of the present invention, there is provided a music reproducing apparatus for selecting and reproducing music based on a voice input from a user, in order to specify a music to be selected, a question for obtaining a voice input from the user as a response. Means for storing the information in a plurality of layers, and reproducing a question belonging to a certain layer by voice and prompting the user for a response. If not, or if only a predetermined ambiguous word is obtained as a voice input, it is made to function as a means for sequentially selecting and reproducing music that can be specified from the hierarchy or a question below the hierarchy. And a control program for the music reproducing apparatus.
[0021]
BEST MODE FOR CARRYING OUT THE INVENTION
Hereinafter, embodiments of the present invention will be described with reference to the drawings. In the present embodiment, an in-vehicle music reproducing device mounted on a vehicle such as an automobile will be exemplified as the music reproducing device.
[0022]
<First embodiment>
FIG. 1 is a diagram showing a functional configuration of an in-vehicle
[0023]
The
[0024]
The in-vehicle
[0025]
The
[0026]
The
[0027]
FIG. 2 is a diagram schematically showing a configuration of a music table 200 for managing music data, which is one of multimedia data. As shown in this figure, one record of the music table 200 includes a music ID, genre information, artist information, music name information, and a new music flag.
[0028]
The song ID is an identifier of the song data, and the genre information indicates the genre to which the song belongs. Examples of the genre include JPOP (Japanese popular music), enka, rock, and classical music. The artist information indicates information of a singer if the song is a song, and information of a conductor or a performance orchestra if the song is a performance-only song such as a classic. For example, when the song is a song, the artist information includes information indicating whether the song is a group or solo, information indicating whether the vocal is male or female, and an artist name (or group name). The song name information shown in the figure indicates the title of the song, and the new song flag is information indicating whether or not the song is treated as a new song. "NO" is indicated.
[0029]
The music table 200 is updated by generating and adding a record corresponding to the music data each time the in-vehicle
[0030]
In addition, in addition to the above-mentioned information, the song table 200 may include, for example, a songwriter or a composer name as artist information, or a record such as viewing popularity ranking information or sales performance ranking information. It may be configured to include information. Alternatively, the
[0031]
Now, returning to FIG. 1 again, under the control of the
[0032]
The
[0033]
The VR (Voice Recognition: voice recognition unit) 153 executes voice recognition processing based on a voice input signal, and outputs a recognition result to the
[0034]
A TTS (Text To Speech: voice conversion unit) 160 generates synthetic voice data, which is a digital signal, based on the text data input from the
[0035]
The
[0036]
As described above, the in-vehicle
[0037]
In the in-vehicle
[0038]
FIG. 3 is a diagram illustrating an example of a question layer structure used in a music selection operation. As shown in this figure, the question is divided into first to third layers 300 to 304 according to the content. Specifically, the first layer 300 includes questions for specifying the genre of the music to be reproduced, and the genre of the desired music is narrowed down by the user responding to these questions. The second layer 301 and the third layer 302 include a question for narrowing down artists. For example, the second layer 301 includes a question for specifying whether the artist desired by the user is a solo or a group, and the third layer 302 includes a question for specifying the gender of the vocal. On the fourth layer 303, artist candidates identified from responses to the questions included in the first to third layers 300 to 302 are sequentially presented to the user, and the user is allowed to select a desired artist from these candidates. Questions are included. Further, the fifth layer 304 sequentially presents the songs belonging to the artist selected by the user in the question of the fourth layer 303 to the user, and asks the user to select a desired song from these candidates. include.
[0039]
The questions belonging to each of the layers 300 to 304 are registered in advance in a music selection question table (hereinafter simply referred to as “question table”) 400. Specifically, the question table 400 is stored in the
[0040]
In addition, a phrase that the user will use for answering the question is registered as an answer table 500. This response table 500 is stored in the
[0041]
Under such a configuration, the in-vehicle
[0042]
Next, a description will be given of an operation when a music piece is selected by a dialogue including a question from the in-vehicle
[0043]
FIG. 6 is a flowchart showing a processing procedure of music selection / playback processing executed by the
[0044]
Next, in Step Sa2, the
[0045]
On the other hand, if the decision result in the step Sa3 is YES, the
[0046]
Next, the question processing in step Sa2 will be described in more detail with reference to the flowchart shown in FIG.
[0047]
As shown in this figure, in the question processing, the questions belonging to the N-th layer are sequentially output to the user as synthesized speech. Specifically, the
[0048]
Specifically, in step Sb3, after executing step Sb2,
[0049]
When the determined result in the step Sb3 is YES, the
[0050]
If the result of the determination in step Sb3 is NO, that is, even if a certain period of time has elapsed after the question was given to the user, a voice input belonging to any of the affirmative expression, the negative expression, and the ambiguous expression is received from the user. If a response has not been obtained, the
[0051]
That is, the
[0052]
Accordingly, when the user does not respond positively to the question, the in-vehicle
[0053]
Also, in general, when a user ponders in answering a question, that is, silently responds to the response or gives only an ambiguous response, the user often does not agree with the question. is there. Therefore, as described above, by adopting a configuration in which other questions are sequentially given, the user only has to respond to a desired question, and operability can be improved.
[0054]
Furthermore, when the user is the driver of the vehicle, the interactive operation of the in-vehicle
[0055]
<Second embodiment>
In the above-described embodiment, the in-vehicle
[0056]
However, when the user responds to the question, the in-vehicle
[0057]
Therefore, in the present embodiment, as shown in FIG. 8, in the question processing described in the first embodiment, the
[0058]
If the determination result in step Sc1 is NO, it indicates that there is no higher layer, and the process proceeds to step Sa3 to repeat the question belonging to the current layer from the beginning.
[0059]
Further, even if there is a response within a certain period of time from the question, the
[0060]
As described above, according to the present embodiment, when the user silences a question or uses an ambiguous expression in order to desire a process belonging to another layer, the next question is automatically transmitted to the upper layer. Therefore, the user can cause the apparatus to execute a desired operation by responding when a question of a desired layer is output, without performing an operation such as starting the dialog again from the beginning. .
[0061]
In the present embodiment, the configuration in which the question belongs to the upper layer has been described as an example, but the question may belong to the lower layer. Whether to shift to the upper layer or the lower layer can be appropriately selected according to the layer structure of the question.
[0062]
<Third embodiment>
In the above-described first or second embodiment, when the in-vehicle
[0063]
However, in the case where the dialogue for specifying the music has progressed to some extent, such as a music selection / playback operation, a music candidate desired by the user is roughly specified.
[0064]
Therefore, in the present embodiment, as shown in FIG. 9, the
[0065]
As described above, in the present embodiment, the in-vehicle
[0066]
Thereby, for example, when the user specifies the genre of the music but wants to play the others at random, the operation mode such as not responding to the question for a certain period of time or giving an ambiguous expression is also available. It becomes possible and operability is improved.
[0067]
<Modification>
Each of the above-described embodiments is merely an embodiment of the present invention, and can be arbitrarily modified within the scope of the present invention.
[0068]
For example, in each of the above-described embodiments, the case where the present invention is applied to an in-vehicle music reproducing device is illustrated. However, the present invention is not limited to the in-vehicle use and may be a home-use or portable one. May be. Furthermore, the present invention can be applied to any device as long as it performs any one of a plurality of data processes based on a voice input from a user.
[0069]
Further, for example, in each of the above-described embodiments, when an ambiguous expression is obtained as a response from the user to the question, a configuration may be employed in which the user actually learns what kind of processing the user desires.
[0070]
Specifically, as described in the first and second embodiments, when the user's response to the question is an ambiguous expression, the in-vehicle
[0071]
【The invention's effect】
As described above, according to the present invention, a data processing device, a music reproduction device, a control program for a data processing device, and a control program for a music reproduction device having better operability are provided.
[Brief description of the drawings]
FIG. 1 is a diagram showing a functional configuration of an in-vehicle music reproducing apparatus according to a first embodiment of the present invention, together with a distribution system for distributing multimedia data such as music data to the in-vehicle music reproducing apparatus. .
FIG. 2 is a diagram schematically showing a configuration of a music table.
FIG. 3 is a diagram showing an example of a question layer structure used in a music selection operation.
FIG. 4 is a diagram schematically showing a configuration of a question table.
FIG. 5 is a diagram schematically illustrating a configuration of a response table.
FIG. 6 is a flowchart illustrating a processing procedure of music selection / playback processing according to the first embodiment.
FIG. 7 is a flowchart illustrating a procedure of a question process according to the first embodiment;
FIG. 8 is a flowchart illustrating a procedure of a question process according to the second embodiment of the present invention.
FIG. 9 is a flowchart illustrating a processing procedure of a question process according to the third embodiment of the present invention.
[Explanation of symbols]
100 In-vehicle music playback device
110 control unit
130 storage unit
140 Music playback unit
143 Speaker
150 microphone
200 music table
300-304 layers
400 question table
500 response table
Claims (14)
データ処理ごとに、ユーザに音声入力を促すための音声データを記憶する記憶手段とを備え、
これらの音声データの中から1つを再生しユーザに音声入力を促した後、所定時間が経過しても、この促しに対してユーザから音声入力が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、前記音声データの中の他の音声データを再生し、ユーザに音声入力を促す
ことを特徴とするデータ処理装置。In a data processing device that executes any one of a plurality of data processes based on a voice input from a user,
Storage means for storing voice data for prompting the user to input voice for each data processing,
After reproducing one of these voice data and prompting the user to input a voice, if a voice input is not obtained from the user in response to the prompt even after a predetermined time has elapsed, or as a voice input. A data processing apparatus characterized in that when only a predetermined ambiguous word is obtained, another voice data in the voice data is reproduced to prompt the user to input a voice.
ことを特徴とする請求項1に記載のデータ処理装置。2. The data processing apparatus according to claim 1, wherein until data is input from the user, audio data different from the previously reproduced audio data is reproduced to prompt the user to input a voice.
ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する記憶手段を備え、
ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは他の階層に属する質問を音声により再生し、ユーザに応答を促す
ことを特徴とするデータ処理装置。In a data processing device that executes any one of a plurality of data processes based on a voice input from a user,
Storage means for storing a question for obtaining a voice input from the user as a response in a plurality of layers,
After playing a question belonging to a certain hierarchy by voice and prompting the user to respond, even if a predetermined time elapses, if the user does not receive a response to this question, A data processing apparatus characterized in that when only ambiguous words are obtained, a question belonging to the hierarchy or another hierarchy is reproduced by voice to prompt a user to respond.
ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する記憶手段を備え、
ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、所定のあいまい言葉しか得られなかった場合に、当該階層あるいは当該階層から下に属する質問から特定され得るデータ処理を順次実行する
ことを特徴とするデータ処理装置。In a data processing device that executes any one of a plurality of data processes based on a voice input from a user,
Storage means for storing a question for obtaining a voice input from the user as a response in a plurality of layers,
After playing a question belonging to a certain hierarchy by voice and prompting the user to respond, even if a predetermined time has elapsed, if the user has not received a response to this question, or only a predetermined vague word A data processing device which, when not obtained, sequentially executes data processing that can be specified from the hierarchy or a question belonging to the hierarchy below.
楽曲ごとに、当該楽曲の再生を指示する旨の音声入力をユーザに促すための音声データを記憶する記憶手段を備え、
これらの音声データの中の1つを再生して、ユーザに音声入力を促した後、所定時間が経過しても、この促しに対してユーザから音声入力が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、前記音声データの中の他の音声データを再生し、ユーザに音声入力を促す
ことを特徴とする楽曲再生装置。In a music playback device that selects and plays music based on a voice input from a user,
Storage means for storing voice data for prompting a user to input a voice to instruct reproduction of the music for each music,
After reproducing one of these voice data and prompting the user for voice input, if no voice input is obtained from the user even after a predetermined time has passed, or A music reproducing apparatus characterized in that, when only a predetermined ambiguous word is obtained as input, the other audio data in the audio data is reproduced to prompt the user to input a voice.
ことを特徴とする請求項5に記載の楽曲再生装置。6. The music reproducing apparatus according to claim 5, wherein audio data different from the previously reproduced audio data is reproduced until a user inputs a voice.
選曲すべき楽曲を特定すべく、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する記憶手段を備え、
ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは他の階層に属する質問を音声により再生してユーザに応答を促す
ことを特徴とする楽曲再生装置。In a music playback device that selects and plays music based on a voice input from a user,
In order to specify a song to be selected, a storage unit is provided for storing a question for obtaining a voice input from a user as a response in a plurality of layers,
After playing a question belonging to a certain hierarchy by voice and prompting the user to respond, even if a predetermined time elapses, if the user does not receive a response to this question, A music reproducing apparatus characterized in that, when only ambiguous words are obtained, a question belonging to the hierarchy or another hierarchy is reproduced by voice to prompt a user to respond.
選曲すべき楽曲を特定すべく、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する記憶手段を備え、
ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは当該階層から下に属する質問から特定され得る楽曲を順次選曲し再生する
ことを特徴とする楽曲再生装置。In a music playback device that selects and plays music based on a voice input from a user,
In order to specify a song to be selected, a storage unit is provided for storing a question for obtaining a voice input from a user as a response in a plurality of layers,
After playing a question belonging to a certain hierarchy by voice and prompting the user to respond, even if a predetermined time elapses, if the user does not receive a response to this question, A music reproducing apparatus characterized in that, when only ambiguous words are obtained, music that can be specified from the hierarchy or a question below the hierarchy is sequentially selected and reproduced.
データ処理ごとに、ユーザに音声入力を促すための音声データを記憶する手段、および、
これらの音声データの中から1つを再生しユーザに音声入力を促した後、所定時間が経過しても、この促しに対してユーザから音声入力が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、前記音声データの中の他の音声データを再生し、ユーザに音声入力を促す手段
として機能させることを特徴とするデータ処理装置の制御プログラム。A data processing device that executes any one of a plurality of data processes based on a voice input from a user,
Means for storing voice data for prompting the user to input voice for each data processing; and
After reproducing one of these voice data and prompting the user to input a voice, if a voice input is not obtained from the user in response to the prompt even after a predetermined time has elapsed, or as a voice input. A control program for a data processing device, wherein, when only a predetermined ambiguous word is obtained, another voice data in the voice data is reproduced, and the function is made to function as means for prompting a user to input a voice.
ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する手段、および、
ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは他の階層に属する質問を音声により再生し、ユーザに応答を促す手段
として機能させることを特徴とするデータ処理装置の制御プログラム。In a data processing device that executes any one of a plurality of data processes based on a voice input from a user,
Means for storing a question for obtaining a voice input from the user as a response in a plurality of layers, and
After playing a question belonging to a certain hierarchy by voice and prompting the user to respond, even if a predetermined time elapses, if the user does not receive a response to this question, A control program for a data processing device, characterized in that, when only ambiguous words are obtained, a question belonging to the hierarchy or another hierarchy is reproduced by voice and functions as means for prompting a user to respond.
ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する手段、および、
ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、所定のあいまい言葉しか得られなかった場合に、当該階層あるいは当該階層から下に属する質問から特定され得るデータ処理を順次実行する手段
として機能させることを特徴とするデータ処理装置の制御プログラム。A data processing device that executes any one of a plurality of data processes based on a voice input from a user,
Means for storing a question for obtaining a voice input from the user as a response in a plurality of layers, and
After playing a question belonging to a certain hierarchy by voice and prompting the user to respond, even if a predetermined time has elapsed, if the user has not received a response to this question, or only a predetermined vague word A control program for a data processing device, which, when not obtained, functions as means for sequentially executing data processing that can be specified from the hierarchy or a question below the hierarchy.
楽曲ごとに、当該楽曲の再生を指示する旨の音声入力をユーザに促すための音声データを記憶する手段、および、
これらの音声データの中の1つを再生して、ユーザに音声入力を促した後、所定時間が経過しても、この促しに対してユーザから音声入力が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、前記音声データの中の他の音声データを再生し、ユーザに音声入力を促す手段
として機能させることを特徴とする楽曲再生装置の制御プログラム。A music playback device that selects and plays music based on voice input from a user,
Means for storing voice data for prompting the user to input a voice to instruct reproduction of the music for each music, and
After reproducing one of these voice data and prompting the user for voice input, if no voice input is obtained from the user even after a predetermined time has passed, or When only a predetermined ambiguous word is obtained as an input, a control program for a music reproducing apparatus, which reproduces another audio data in the audio data and functions as a means for prompting a user to input a voice.
選曲すべき楽曲を特定すべく、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する手段、および、
ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは他の階層に属する質問を音声により再生してユーザに応答を促す手段
として機能させることを特徴とする楽曲再生装置の制御プログラム。A music playback device that selects and plays music based on voice input from a user,
Means for storing a question for obtaining a voice input from a user as a response in a plurality of layers in order to specify a music to be selected, and
After playing a question belonging to a certain hierarchy by voice and prompting the user to respond, even if a predetermined time elapses, if the user does not receive a response to this question, A control program for a music reproducing apparatus, characterized in that when only ambiguous words are obtained, a question belonging to the hierarchy or another hierarchy is reproduced by voice to function as means for prompting a user to respond.
選曲すべき楽曲を特定すべく、ユーザからの音声入力を応答として得るための質問を複数の階層に分けて記憶する手段、および、
ある階層に属する質問を音声により再生して、ユーザに応答を促した後、所定時間が経過しても、この質問に対してユーザから応答が得られなかった場合、あるいは、音声入力として所定のあいまい言葉しか得られなかった場合に、当該階層あるいは当該階層から下に属する質問から特定され得る楽曲を順次選曲し再生する手段
として機能させることを特徴とする楽曲再生装置の制御プログラム。A music playback device that selects and plays music based on voice input from a user,
Means for storing a question for obtaining a voice input from a user as a response in a plurality of layers in order to specify a music to be selected, and
After playing a question belonging to a certain hierarchy by voice and prompting the user to respond, even if a predetermined time elapses, if the user does not receive a response to this question, When only ambiguous words are obtained, a control program for a music reproducing apparatus, which functions as a means for sequentially selecting and reproducing music that can be identified from the hierarchy or a question below the hierarchy, and playing the selected music.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003146099A JP2004347943A (en) | 2003-05-23 | 2003-05-23 | Data processor, musical piece reproducing apparatus, control program for data processor, and control program for musical piece reproducing apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003146099A JP2004347943A (en) | 2003-05-23 | 2003-05-23 | Data processor, musical piece reproducing apparatus, control program for data processor, and control program for musical piece reproducing apparatus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2004347943A true JP2004347943A (en) | 2004-12-09 |
Family
ID=33533053
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003146099A Pending JP2004347943A (en) | 2003-05-23 | 2003-05-23 | Data processor, musical piece reproducing apparatus, control program for data processor, and control program for musical piece reproducing apparatus |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2004347943A (en) |
Cited By (68)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006189799A (en) * | 2004-12-31 | 2006-07-20 | Taida Electronic Ind Co Ltd | Voice inputting method and device for selectable voice pattern |
| JP2006202127A (en) * | 2005-01-21 | 2006-08-03 | Pioneer Electronic Corp | Recommended information presentation device and recommended information presentation method or the like |
| JP2010262147A (en) * | 2009-05-08 | 2010-11-18 | Toyota Central R&D Labs Inc | Response creating device and program |
| WO2017147081A1 (en) * | 2016-02-22 | 2017-08-31 | Sonos, Inc. | Voice control of a media playback system |
| US9794720B1 (en) | 2016-09-22 | 2017-10-17 | Sonos, Inc. | Acoustic position measurement |
| US9811314B2 (en) | 2016-02-22 | 2017-11-07 | Sonos, Inc. | Metadata exchange involving a networked playback system and a networked microphone system |
| US9942678B1 (en) | 2016-09-27 | 2018-04-10 | Sonos, Inc. | Audio playback settings for voice interaction |
| US9947316B2 (en) | 2016-02-22 | 2018-04-17 | Sonos, Inc. | Voice control of a media playback system |
| US9965247B2 (en) | 2016-02-22 | 2018-05-08 | Sonos, Inc. | Voice controlled media playback system based on user profile |
| US9978390B2 (en) | 2016-06-09 | 2018-05-22 | Sonos, Inc. | Dynamic player selection for audio signal processing |
| US10021503B2 (en) | 2016-08-05 | 2018-07-10 | Sonos, Inc. | Determining direction of networked microphone device relative to audio playback device |
| US10051366B1 (en) | 2017-09-28 | 2018-08-14 | Sonos, Inc. | Three-dimensional beam forming with a microphone array |
| US10075793B2 (en) | 2016-09-30 | 2018-09-11 | Sonos, Inc. | Multi-orientation playback device microphones |
| US10097939B2 (en) | 2016-02-22 | 2018-10-09 | Sonos, Inc. | Compensation for speaker nonlinearities |
| US10095470B2 (en) | 2016-02-22 | 2018-10-09 | Sonos, Inc. | Audio response playback |
| US10115400B2 (en) | 2016-08-05 | 2018-10-30 | Sonos, Inc. | Multiple voice services |
| US10134399B2 (en) | 2016-07-15 | 2018-11-20 | Sonos, Inc. | Contextualization of voice inputs |
| US10152969B2 (en) | 2016-07-15 | 2018-12-11 | Sonos, Inc. | Voice detection by multiple devices |
| US10181323B2 (en) | 2016-10-19 | 2019-01-15 | Sonos, Inc. | Arbitration-based voice recognition |
| US10264030B2 (en) | 2016-02-22 | 2019-04-16 | Sonos, Inc. | Networked microphone device control |
| US10445057B2 (en) | 2017-09-08 | 2019-10-15 | Sonos, Inc. | Dynamic computation of system response volume |
| US10446165B2 (en) | 2017-09-27 | 2019-10-15 | Sonos, Inc. | Robust short-time fourier transform acoustic echo cancellation during audio playback |
| US10466962B2 (en) | 2017-09-29 | 2019-11-05 | Sonos, Inc. | Media playback system with voice assistance |
| US10475449B2 (en) | 2017-08-07 | 2019-11-12 | Sonos, Inc. | Wake-word detection suppression |
| US10482868B2 (en) | 2017-09-28 | 2019-11-19 | Sonos, Inc. | Multi-channel acoustic echo cancellation |
| US10573321B1 (en) | 2018-09-25 | 2020-02-25 | Sonos, Inc. | Voice detection optimization based on selected voice assistant service |
| US10587430B1 (en) | 2018-09-14 | 2020-03-10 | Sonos, Inc. | Networked devices, systems, and methods for associating playback devices based on sound codes |
| US10586540B1 (en) | 2019-06-12 | 2020-03-10 | Sonos, Inc. | Network microphone device with command keyword conditioning |
| US10602268B1 (en) | 2018-12-20 | 2020-03-24 | Sonos, Inc. | Optimization of network microphone devices using noise classification |
| US10621981B2 (en) | 2017-09-28 | 2020-04-14 | Sonos, Inc. | Tone interference cancellation |
| US10681460B2 (en) | 2018-06-28 | 2020-06-09 | Sonos, Inc. | Systems and methods for associating playback devices with voice assistant services |
| US10692518B2 (en) | 2018-09-29 | 2020-06-23 | Sonos, Inc. | Linear filtering for noise-suppressed speech detection via multiple network microphone devices |
| CN111489749A (en) * | 2019-01-28 | 2020-08-04 | 丰田自动车株式会社 | Interactive apparatus, interactive method, and program |
| US10797667B2 (en) | 2018-08-28 | 2020-10-06 | Sonos, Inc. | Audio notifications |
| US10818290B2 (en) | 2017-12-11 | 2020-10-27 | Sonos, Inc. | Home graph |
| JP2020184060A (en) * | 2019-04-30 | 2020-11-12 | バイドゥ オンライン ネットワーク テクノロジー (ベイジン) カンパニー リミテッド | Interactive music request method, device, terminal, and storage medium |
| US10847178B2 (en) | 2018-05-18 | 2020-11-24 | Sonos, Inc. | Linear filtering for noise-suppressed speech detection |
| US10867604B2 (en) | 2019-02-08 | 2020-12-15 | Sonos, Inc. | Devices, systems, and methods for distributed voice processing |
| US10871943B1 (en) | 2019-07-31 | 2020-12-22 | Sonos, Inc. | Noise classification for event detection |
| US10878811B2 (en) | 2018-09-14 | 2020-12-29 | Sonos, Inc. | Networked devices, systems, and methods for intelligently deactivating wake-word engines |
| US10880650B2 (en) | 2017-12-10 | 2020-12-29 | Sonos, Inc. | Network microphone devices with automatic do not disturb actuation capabilities |
| US10959029B2 (en) | 2018-05-25 | 2021-03-23 | Sonos, Inc. | Determining and adapting to changes in microphone performance of playback devices |
| US11024331B2 (en) | 2018-09-21 | 2021-06-01 | Sonos, Inc. | Voice detection optimization using sound metadata |
| US11076035B2 (en) | 2018-08-28 | 2021-07-27 | Sonos, Inc. | Do not disturb feature for audio notifications |
| US11100923B2 (en) | 2018-09-28 | 2021-08-24 | Sonos, Inc. | Systems and methods for selective wake word detection using neural network models |
| US11120794B2 (en) | 2019-05-03 | 2021-09-14 | Sonos, Inc. | Voice assistant persistence across multiple network microphone devices |
| US11132989B2 (en) | 2018-12-13 | 2021-09-28 | Sonos, Inc. | Networked microphone devices, systems, and methods of localized arbitration |
| US11138975B2 (en) | 2019-07-31 | 2021-10-05 | Sonos, Inc. | Locally distributed keyword detection |
| US11138969B2 (en) | 2019-07-31 | 2021-10-05 | Sonos, Inc. | Locally distributed keyword detection |
| US11175880B2 (en) | 2018-05-10 | 2021-11-16 | Sonos, Inc. | Systems and methods for voice-assisted media content selection |
| US11183183B2 (en) | 2018-12-07 | 2021-11-23 | Sonos, Inc. | Systems and methods of operating media playback systems having multiple voice assistant services |
| US11183181B2 (en) | 2017-03-27 | 2021-11-23 | Sonos, Inc. | Systems and methods of multiple voice services |
| US11189286B2 (en) | 2019-10-22 | 2021-11-30 | Sonos, Inc. | VAS toggle based on device orientation |
| US11200900B2 (en) | 2019-12-20 | 2021-12-14 | Sonos, Inc. | Offline voice control |
| US11200894B2 (en) | 2019-06-12 | 2021-12-14 | Sonos, Inc. | Network microphone device with command keyword eventing |
| US11200889B2 (en) | 2018-11-15 | 2021-12-14 | Sonos, Inc. | Dilated convolutions and gating for efficient keyword spotting |
| US11308958B2 (en) | 2020-02-07 | 2022-04-19 | Sonos, Inc. | Localized wakeword verification |
| US11308962B2 (en) | 2020-05-20 | 2022-04-19 | Sonos, Inc. | Input detection windowing |
| US11315556B2 (en) | 2019-02-08 | 2022-04-26 | Sonos, Inc. | Devices, systems, and methods for distributed voice processing by transmitting sound data associated with a wake word to an appropriate device for identification |
| US11343614B2 (en) | 2018-01-31 | 2022-05-24 | Sonos, Inc. | Device designation of playback and network microphone device arrangements |
| US11361756B2 (en) | 2019-06-12 | 2022-06-14 | Sonos, Inc. | Conditional wake word eventing based on environment |
| US11482224B2 (en) | 2020-05-20 | 2022-10-25 | Sonos, Inc. | Command keywords with input detection windowing |
| US11551700B2 (en) | 2021-01-25 | 2023-01-10 | Sonos, Inc. | Systems and methods for power-efficient keyword detection |
| US11556307B2 (en) | 2020-01-31 | 2023-01-17 | Sonos, Inc. | Local voice data processing |
| US11562740B2 (en) | 2020-01-07 | 2023-01-24 | Sonos, Inc. | Voice verification for media playback |
| US11698771B2 (en) | 2020-08-25 | 2023-07-11 | Sonos, Inc. | Vocal guidance engines for playback devices |
| US11727919B2 (en) | 2020-05-20 | 2023-08-15 | Sonos, Inc. | Memory allocation for keyword spotting engines |
| US11899519B2 (en) | 2018-10-23 | 2024-02-13 | Sonos, Inc. | Multiple stage network microphone device with reduced power consumption and processing load |
-
2003
- 2003-05-23 JP JP2003146099A patent/JP2004347943A/en active Pending
Cited By (179)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006189799A (en) * | 2004-12-31 | 2006-07-20 | Taida Electronic Ind Co Ltd | Voice inputting method and device for selectable voice pattern |
| JP2006202127A (en) * | 2005-01-21 | 2006-08-03 | Pioneer Electronic Corp | Recommended information presentation device and recommended information presentation method or the like |
| JP2010262147A (en) * | 2009-05-08 | 2010-11-18 | Toyota Central R&D Labs Inc | Response creating device and program |
| US10264030B2 (en) | 2016-02-22 | 2019-04-16 | Sonos, Inc. | Networked microphone device control |
| US11042355B2 (en) | 2016-02-22 | 2021-06-22 | Sonos, Inc. | Handling of loss of pairing between networked devices |
| US9811314B2 (en) | 2016-02-22 | 2017-11-07 | Sonos, Inc. | Metadata exchange involving a networked playback system and a networked microphone system |
| US9820039B2 (en) | 2016-02-22 | 2017-11-14 | Sonos, Inc. | Default playback devices |
| US11832068B2 (en) | 2016-02-22 | 2023-11-28 | Sonos, Inc. | Music service selection |
| US9947316B2 (en) | 2016-02-22 | 2018-04-17 | Sonos, Inc. | Voice control of a media playback system |
| US9965247B2 (en) | 2016-02-22 | 2018-05-08 | Sonos, Inc. | Voice controlled media playback system based on user profile |
| US11750969B2 (en) | 2016-02-22 | 2023-09-05 | Sonos, Inc. | Default playback device designation |
| US11736860B2 (en) | 2016-02-22 | 2023-08-22 | Sonos, Inc. | Voice control of a media playback system |
| US11726742B2 (en) | 2016-02-22 | 2023-08-15 | Sonos, Inc. | Handling of loss of pairing between networked devices |
| US10097939B2 (en) | 2016-02-22 | 2018-10-09 | Sonos, Inc. | Compensation for speaker nonlinearities |
| US10095470B2 (en) | 2016-02-22 | 2018-10-09 | Sonos, Inc. | Audio response playback |
| US10097919B2 (en) | 2016-02-22 | 2018-10-09 | Sonos, Inc. | Music service selection |
| KR102095250B1 (en) * | 2016-02-22 | 2020-04-01 | 소노스 인코포레이티드 | Voice control method of media playback system |
| KR20200034839A (en) * | 2016-02-22 | 2020-03-31 | 소노스 인코포레이티드 | Voice control of a media playback system |
| US9772817B2 (en) | 2016-02-22 | 2017-09-26 | Sonos, Inc. | Room-corrected voice detection |
| JP2019514237A (en) * | 2016-02-22 | 2019-05-30 | ソノズ インコーポレイテッド | Audio control of media playback system |
| US10743101B2 (en) | 2016-02-22 | 2020-08-11 | Sonos, Inc. | Content mixing |
| US11513763B2 (en) | 2016-02-22 | 2022-11-29 | Sonos, Inc. | Audio response playback |
| US10142754B2 (en) | 2016-02-22 | 2018-11-27 | Sonos, Inc. | Sensor on moving component of transducer |
| US10847143B2 (en) | 2016-02-22 | 2020-11-24 | Sonos, Inc. | Voice control of a media playback system |
| US11514898B2 (en) | 2016-02-22 | 2022-11-29 | Sonos, Inc. | Voice control of a media playback system |
| KR20190014495A (en) * | 2016-02-22 | 2019-02-12 | 소노스 인코포레이티드 | Voice control method of media playback system |
| US10212512B2 (en) | 2016-02-22 | 2019-02-19 | Sonos, Inc. | Default playback devices |
| KR102234804B1 (en) | 2016-02-22 | 2021-04-01 | 소노스 인코포레이티드 | Voice control of a media playback system |
| WO2017147081A1 (en) * | 2016-02-22 | 2017-08-31 | Sonos, Inc. | Voice control of a media playback system |
| US10225651B2 (en) | 2016-02-22 | 2019-03-05 | Sonos, Inc. | Default playback device designation |
| US10970035B2 (en) | 2016-02-22 | 2021-04-06 | Sonos, Inc. | Audio response playback |
| US10764679B2 (en) | 2016-02-22 | 2020-09-01 | Sonos, Inc. | Voice control of a media playback system |
| US10971139B2 (en) | 2016-02-22 | 2021-04-06 | Sonos, Inc. | Voice control of a media playback system |
| US11405430B2 (en) | 2016-02-22 | 2022-08-02 | Sonos, Inc. | Networked microphone device control |
| US10365889B2 (en) | 2016-02-22 | 2019-07-30 | Sonos, Inc. | Metadata exchange involving a networked playback system and a networked microphone system |
| US10409549B2 (en) | 2016-02-22 | 2019-09-10 | Sonos, Inc. | Audio response playback |
| US11212612B2 (en) | 2016-02-22 | 2021-12-28 | Sonos, Inc. | Voice control of a media playback system |
| US11006214B2 (en) | 2016-02-22 | 2021-05-11 | Sonos, Inc. | Default playback device designation |
| US11184704B2 (en) | 2016-02-22 | 2021-11-23 | Sonos, Inc. | Music service selection |
| US11137979B2 (en) | 2016-02-22 | 2021-10-05 | Sonos, Inc. | Metadata exchange involving a networked playback system and a networked microphone system |
| US10555077B2 (en) | 2016-02-22 | 2020-02-04 | Sonos, Inc. | Music service selection |
| US10499146B2 (en) | 2016-02-22 | 2019-12-03 | Sonos, Inc. | Voice control of a media playback system |
| US10509626B2 (en) | 2016-02-22 | 2019-12-17 | Sonos, Inc | Handling of loss of pairing between networked devices |
| US11863593B2 (en) | 2016-02-22 | 2024-01-02 | Sonos, Inc. | Networked microphone device control |
| US11133018B2 (en) | 2016-06-09 | 2021-09-28 | Sonos, Inc. | Dynamic player selection for audio signal processing |
| US10332537B2 (en) | 2016-06-09 | 2019-06-25 | Sonos, Inc. | Dynamic player selection for audio signal processing |
| US10714115B2 (en) | 2016-06-09 | 2020-07-14 | Sonos, Inc. | Dynamic player selection for audio signal processing |
| US11545169B2 (en) | 2016-06-09 | 2023-01-03 | Sonos, Inc. | Dynamic player selection for audio signal processing |
| US9978390B2 (en) | 2016-06-09 | 2018-05-22 | Sonos, Inc. | Dynamic player selection for audio signal processing |
| US11184969B2 (en) | 2016-07-15 | 2021-11-23 | Sonos, Inc. | Contextualization of voice inputs |
| US10297256B2 (en) | 2016-07-15 | 2019-05-21 | Sonos, Inc. | Voice detection by multiple devices |
| US10152969B2 (en) | 2016-07-15 | 2018-12-11 | Sonos, Inc. | Voice detection by multiple devices |
| US10134399B2 (en) | 2016-07-15 | 2018-11-20 | Sonos, Inc. | Contextualization of voice inputs |
| US10593331B2 (en) | 2016-07-15 | 2020-03-17 | Sonos, Inc. | Contextualization of voice inputs |
| US11664023B2 (en) | 2016-07-15 | 2023-05-30 | Sonos, Inc. | Voice detection by multiple devices |
| US10699711B2 (en) | 2016-07-15 | 2020-06-30 | Sonos, Inc. | Voice detection by multiple devices |
| US11531520B2 (en) | 2016-08-05 | 2022-12-20 | Sonos, Inc. | Playback device supporting concurrent voice assistants |
| US10115400B2 (en) | 2016-08-05 | 2018-10-30 | Sonos, Inc. | Multiple voice services |
| US10354658B2 (en) | 2016-08-05 | 2019-07-16 | Sonos, Inc. | Voice control of playback device using voice assistant service(s) |
| US10565999B2 (en) | 2016-08-05 | 2020-02-18 | Sonos, Inc. | Playback device supporting concurrent voice assistant services |
| US10565998B2 (en) | 2016-08-05 | 2020-02-18 | Sonos, Inc. | Playback device supporting concurrent voice assistant services |
| US10021503B2 (en) | 2016-08-05 | 2018-07-10 | Sonos, Inc. | Determining direction of networked microphone device relative to audio playback device |
| US10847164B2 (en) | 2016-08-05 | 2020-11-24 | Sonos, Inc. | Playback device supporting concurrent voice assistants |
| US10034116B2 (en) | 2016-09-22 | 2018-07-24 | Sonos, Inc. | Acoustic position measurement |
| US9794720B1 (en) | 2016-09-22 | 2017-10-17 | Sonos, Inc. | Acoustic position measurement |
| US9942678B1 (en) | 2016-09-27 | 2018-04-10 | Sonos, Inc. | Audio playback settings for voice interaction |
| US11641559B2 (en) | 2016-09-27 | 2023-05-02 | Sonos, Inc. | Audio playback settings for voice interaction |
| US10582322B2 (en) | 2016-09-27 | 2020-03-03 | Sonos, Inc. | Audio playback settings for voice interaction |
| US10117037B2 (en) | 2016-09-30 | 2018-10-30 | Sonos, Inc. | Orientation-based playback device microphone selection |
| US11516610B2 (en) | 2016-09-30 | 2022-11-29 | Sonos, Inc. | Orientation-based playback device microphone selection |
| US10075793B2 (en) | 2016-09-30 | 2018-09-11 | Sonos, Inc. | Multi-orientation playback device microphones |
| US10313812B2 (en) | 2016-09-30 | 2019-06-04 | Sonos, Inc. | Orientation-based playback device microphone selection |
| US10873819B2 (en) | 2016-09-30 | 2020-12-22 | Sonos, Inc. | Orientation-based playback device microphone selection |
| US11308961B2 (en) | 2016-10-19 | 2022-04-19 | Sonos, Inc. | Arbitration-based voice recognition |
| US10181323B2 (en) | 2016-10-19 | 2019-01-15 | Sonos, Inc. | Arbitration-based voice recognition |
| US11727933B2 (en) | 2016-10-19 | 2023-08-15 | Sonos, Inc. | Arbitration-based voice recognition |
| US10614807B2 (en) | 2016-10-19 | 2020-04-07 | Sonos, Inc. | Arbitration-based voice recognition |
| US11183181B2 (en) | 2017-03-27 | 2021-11-23 | Sonos, Inc. | Systems and methods of multiple voice services |
| US10475449B2 (en) | 2017-08-07 | 2019-11-12 | Sonos, Inc. | Wake-word detection suppression |
| US11380322B2 (en) | 2017-08-07 | 2022-07-05 | Sonos, Inc. | Wake-word detection suppression |
| US11900937B2 (en) | 2017-08-07 | 2024-02-13 | Sonos, Inc. | Wake-word detection suppression |
| US11080005B2 (en) | 2017-09-08 | 2021-08-03 | Sonos, Inc. | Dynamic computation of system response volume |
| US11500611B2 (en) | 2017-09-08 | 2022-11-15 | Sonos, Inc. | Dynamic computation of system response volume |
| US10445057B2 (en) | 2017-09-08 | 2019-10-15 | Sonos, Inc. | Dynamic computation of system response volume |
| US10446165B2 (en) | 2017-09-27 | 2019-10-15 | Sonos, Inc. | Robust short-time fourier transform acoustic echo cancellation during audio playback |
| US11646045B2 (en) | 2017-09-27 | 2023-05-09 | Sonos, Inc. | Robust short-time fourier transform acoustic echo cancellation during audio playback |
| US11017789B2 (en) | 2017-09-27 | 2021-05-25 | Sonos, Inc. | Robust Short-Time Fourier Transform acoustic echo cancellation during audio playback |
| US10482868B2 (en) | 2017-09-28 | 2019-11-19 | Sonos, Inc. | Multi-channel acoustic echo cancellation |
| US11769505B2 (en) | 2017-09-28 | 2023-09-26 | Sonos, Inc. | Echo of tone interferance cancellation using two acoustic echo cancellers |
| US11302326B2 (en) | 2017-09-28 | 2022-04-12 | Sonos, Inc. | Tone interference cancellation |
| US10051366B1 (en) | 2017-09-28 | 2018-08-14 | Sonos, Inc. | Three-dimensional beam forming with a microphone array |
| US10880644B1 (en) | 2017-09-28 | 2020-12-29 | Sonos, Inc. | Three-dimensional beam forming with a microphone array |
| US11538451B2 (en) | 2017-09-28 | 2022-12-27 | Sonos, Inc. | Multi-channel acoustic echo cancellation |
| US10511904B2 (en) | 2017-09-28 | 2019-12-17 | Sonos, Inc. | Three-dimensional beam forming with a microphone array |
| US10621981B2 (en) | 2017-09-28 | 2020-04-14 | Sonos, Inc. | Tone interference cancellation |
| US10891932B2 (en) | 2017-09-28 | 2021-01-12 | Sonos, Inc. | Multi-channel acoustic echo cancellation |
| US11893308B2 (en) | 2017-09-29 | 2024-02-06 | Sonos, Inc. | Media playback system with concurrent voice assistance |
| US11175888B2 (en) | 2017-09-29 | 2021-11-16 | Sonos, Inc. | Media playback system with concurrent voice assistance |
| US10466962B2 (en) | 2017-09-29 | 2019-11-05 | Sonos, Inc. | Media playback system with voice assistance |
| US10606555B1 (en) | 2017-09-29 | 2020-03-31 | Sonos, Inc. | Media playback system with concurrent voice assistance |
| US11288039B2 (en) | 2017-09-29 | 2022-03-29 | Sonos, Inc. | Media playback system with concurrent voice assistance |
| US10880650B2 (en) | 2017-12-10 | 2020-12-29 | Sonos, Inc. | Network microphone devices with automatic do not disturb actuation capabilities |
| US11451908B2 (en) | 2017-12-10 | 2022-09-20 | Sonos, Inc. | Network microphone devices with automatic do not disturb actuation capabilities |
| US11676590B2 (en) | 2017-12-11 | 2023-06-13 | Sonos, Inc. | Home graph |
| US10818290B2 (en) | 2017-12-11 | 2020-10-27 | Sonos, Inc. | Home graph |
| US11343614B2 (en) | 2018-01-31 | 2022-05-24 | Sonos, Inc. | Device designation of playback and network microphone device arrangements |
| US11689858B2 (en) | 2018-01-31 | 2023-06-27 | Sonos, Inc. | Device designation of playback and network microphone device arrangements |
| US11797263B2 (en) | 2018-05-10 | 2023-10-24 | Sonos, Inc. | Systems and methods for voice-assisted media content selection |
| US11175880B2 (en) | 2018-05-10 | 2021-11-16 | Sonos, Inc. | Systems and methods for voice-assisted media content selection |
| US11715489B2 (en) | 2018-05-18 | 2023-08-01 | Sonos, Inc. | Linear filtering for noise-suppressed speech detection |
| US10847178B2 (en) | 2018-05-18 | 2020-11-24 | Sonos, Inc. | Linear filtering for noise-suppressed speech detection |
| US11792590B2 (en) | 2018-05-25 | 2023-10-17 | Sonos, Inc. | Determining and adapting to changes in microphone performance of playback devices |
| US10959029B2 (en) | 2018-05-25 | 2021-03-23 | Sonos, Inc. | Determining and adapting to changes in microphone performance of playback devices |
| US11696074B2 (en) | 2018-06-28 | 2023-07-04 | Sonos, Inc. | Systems and methods for associating playback devices with voice assistant services |
| US11197096B2 (en) | 2018-06-28 | 2021-12-07 | Sonos, Inc. | Systems and methods for associating playback devices with voice assistant services |
| US10681460B2 (en) | 2018-06-28 | 2020-06-09 | Sonos, Inc. | Systems and methods for associating playback devices with voice assistant services |
| US10797667B2 (en) | 2018-08-28 | 2020-10-06 | Sonos, Inc. | Audio notifications |
| US11563842B2 (en) | 2018-08-28 | 2023-01-24 | Sonos, Inc. | Do not disturb feature for audio notifications |
| US11482978B2 (en) | 2018-08-28 | 2022-10-25 | Sonos, Inc. | Audio notifications |
| US11076035B2 (en) | 2018-08-28 | 2021-07-27 | Sonos, Inc. | Do not disturb feature for audio notifications |
| US10587430B1 (en) | 2018-09-14 | 2020-03-10 | Sonos, Inc. | Networked devices, systems, and methods for associating playback devices based on sound codes |
| US10878811B2 (en) | 2018-09-14 | 2020-12-29 | Sonos, Inc. | Networked devices, systems, and methods for intelligently deactivating wake-word engines |
| US11778259B2 (en) | 2018-09-14 | 2023-10-03 | Sonos, Inc. | Networked devices, systems and methods for associating playback devices based on sound codes |
| US11551690B2 (en) | 2018-09-14 | 2023-01-10 | Sonos, Inc. | Networked devices, systems, and methods for intelligently deactivating wake-word engines |
| US11432030B2 (en) | 2018-09-14 | 2022-08-30 | Sonos, Inc. | Networked devices, systems, and methods for associating playback devices based on sound codes |
| US11024331B2 (en) | 2018-09-21 | 2021-06-01 | Sonos, Inc. | Voice detection optimization using sound metadata |
| US11790937B2 (en) | 2018-09-21 | 2023-10-17 | Sonos, Inc. | Voice detection optimization using sound metadata |
| US11727936B2 (en) | 2018-09-25 | 2023-08-15 | Sonos, Inc. | Voice detection optimization based on selected voice assistant service |
| US11031014B2 (en) | 2018-09-25 | 2021-06-08 | Sonos, Inc. | Voice detection optimization based on selected voice assistant service |
| US10573321B1 (en) | 2018-09-25 | 2020-02-25 | Sonos, Inc. | Voice detection optimization based on selected voice assistant service |
| US10811015B2 (en) | 2018-09-25 | 2020-10-20 | Sonos, Inc. | Voice detection optimization based on selected voice assistant service |
| US11100923B2 (en) | 2018-09-28 | 2021-08-24 | Sonos, Inc. | Systems and methods for selective wake word detection using neural network models |
| US11790911B2 (en) | 2018-09-28 | 2023-10-17 | Sonos, Inc. | Systems and methods for selective wake word detection using neural network models |
| US11501795B2 (en) | 2018-09-29 | 2022-11-15 | Sonos, Inc. | Linear filtering for noise-suppressed speech detection via multiple network microphone devices |
| US10692518B2 (en) | 2018-09-29 | 2020-06-23 | Sonos, Inc. | Linear filtering for noise-suppressed speech detection via multiple network microphone devices |
| US11899519B2 (en) | 2018-10-23 | 2024-02-13 | Sonos, Inc. | Multiple stage network microphone device with reduced power consumption and processing load |
| US11741948B2 (en) | 2018-11-15 | 2023-08-29 | Sonos Vox France Sas | Dilated convolutions and gating for efficient keyword spotting |
| US11200889B2 (en) | 2018-11-15 | 2021-12-14 | Sonos, Inc. | Dilated convolutions and gating for efficient keyword spotting |
| US11557294B2 (en) | 2018-12-07 | 2023-01-17 | Sonos, Inc. | Systems and methods of operating media playback systems having multiple voice assistant services |
| US11183183B2 (en) | 2018-12-07 | 2021-11-23 | Sonos, Inc. | Systems and methods of operating media playback systems having multiple voice assistant services |
| US11132989B2 (en) | 2018-12-13 | 2021-09-28 | Sonos, Inc. | Networked microphone devices, systems, and methods of localized arbitration |
| US11538460B2 (en) | 2018-12-13 | 2022-12-27 | Sonos, Inc. | Networked microphone devices, systems, and methods of localized arbitration |
| US11159880B2 (en) | 2018-12-20 | 2021-10-26 | Sonos, Inc. | Optimization of network microphone devices using noise classification |
| US10602268B1 (en) | 2018-12-20 | 2020-03-24 | Sonos, Inc. | Optimization of network microphone devices using noise classification |
| US11540047B2 (en) | 2018-12-20 | 2022-12-27 | Sonos, Inc. | Optimization of network microphone devices using noise classification |
| JP7135896B2 (en) | 2019-01-28 | 2022-09-13 | トヨタ自動車株式会社 | Dialogue device, dialogue method and program |
| JP2020119436A (en) * | 2019-01-28 | 2020-08-06 | トヨタ自動車株式会社 | Interactive device, interactive method and program |
| CN111489749A (en) * | 2019-01-28 | 2020-08-04 | 丰田自动车株式会社 | Interactive apparatus, interactive method, and program |
| US11315556B2 (en) | 2019-02-08 | 2022-04-26 | Sonos, Inc. | Devices, systems, and methods for distributed voice processing by transmitting sound data associated with a wake word to an appropriate device for identification |
| US11646023B2 (en) | 2019-02-08 | 2023-05-09 | Sonos, Inc. | Devices, systems, and methods for distributed voice processing |
| US10867604B2 (en) | 2019-02-08 | 2020-12-15 | Sonos, Inc. | Devices, systems, and methods for distributed voice processing |
| JP2020184060A (en) * | 2019-04-30 | 2020-11-12 | バイドゥ オンライン ネットワーク テクノロジー (ベイジン) カンパニー リミテッド | Interactive music request method, device, terminal, and storage medium |
| US11798553B2 (en) | 2019-05-03 | 2023-10-24 | Sonos, Inc. | Voice assistant persistence across multiple network microphone devices |
| US11120794B2 (en) | 2019-05-03 | 2021-09-14 | Sonos, Inc. | Voice assistant persistence across multiple network microphone devices |
| US10586540B1 (en) | 2019-06-12 | 2020-03-10 | Sonos, Inc. | Network microphone device with command keyword conditioning |
| US11200894B2 (en) | 2019-06-12 | 2021-12-14 | Sonos, Inc. | Network microphone device with command keyword eventing |
| US11361756B2 (en) | 2019-06-12 | 2022-06-14 | Sonos, Inc. | Conditional wake word eventing based on environment |
| US11501773B2 (en) | 2019-06-12 | 2022-11-15 | Sonos, Inc. | Network microphone device with command keyword conditioning |
| US11854547B2 (en) | 2019-06-12 | 2023-12-26 | Sonos, Inc. | Network microphone device with command keyword eventing |
| US11551669B2 (en) | 2019-07-31 | 2023-01-10 | Sonos, Inc. | Locally distributed keyword detection |
| US11138969B2 (en) | 2019-07-31 | 2021-10-05 | Sonos, Inc. | Locally distributed keyword detection |
| US11714600B2 (en) | 2019-07-31 | 2023-08-01 | Sonos, Inc. | Noise classification for event detection |
| US10871943B1 (en) | 2019-07-31 | 2020-12-22 | Sonos, Inc. | Noise classification for event detection |
| US11710487B2 (en) | 2019-07-31 | 2023-07-25 | Sonos, Inc. | Locally distributed keyword detection |
| US11354092B2 (en) | 2019-07-31 | 2022-06-07 | Sonos, Inc. | Noise classification for event detection |
| US11138975B2 (en) | 2019-07-31 | 2021-10-05 | Sonos, Inc. | Locally distributed keyword detection |
| US11189286B2 (en) | 2019-10-22 | 2021-11-30 | Sonos, Inc. | VAS toggle based on device orientation |
| US11862161B2 (en) | 2019-10-22 | 2024-01-02 | Sonos, Inc. | VAS toggle based on device orientation |
| US11869503B2 (en) | 2019-12-20 | 2024-01-09 | Sonos, Inc. | Offline voice control |
| US11200900B2 (en) | 2019-12-20 | 2021-12-14 | Sonos, Inc. | Offline voice control |
| US11562740B2 (en) | 2020-01-07 | 2023-01-24 | Sonos, Inc. | Voice verification for media playback |
| US11556307B2 (en) | 2020-01-31 | 2023-01-17 | Sonos, Inc. | Local voice data processing |
| US11961519B2 (en) | 2020-02-07 | 2024-04-16 | Sonos, Inc. | Localized wakeword verification |
| US11308958B2 (en) | 2020-02-07 | 2022-04-19 | Sonos, Inc. | Localized wakeword verification |
| US11482224B2 (en) | 2020-05-20 | 2022-10-25 | Sonos, Inc. | Command keywords with input detection windowing |
| US11727919B2 (en) | 2020-05-20 | 2023-08-15 | Sonos, Inc. | Memory allocation for keyword spotting engines |
| US11308962B2 (en) | 2020-05-20 | 2022-04-19 | Sonos, Inc. | Input detection windowing |
| US11698771B2 (en) | 2020-08-25 | 2023-07-11 | Sonos, Inc. | Vocal guidance engines for playback devices |
| US11551700B2 (en) | 2021-01-25 | 2023-01-10 | Sonos, Inc. | Systems and methods for power-efficient keyword detection |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2004347943A (en) | Data processor, musical piece reproducing apparatus, control program for data processor, and control program for musical piece reproducing apparatus | |
| US8046689B2 (en) | Media presentation with supplementary media | |
| EP1736961B1 (en) | System and method for automatic creation of digitally enhanced ringtones for cellphones | |
| CN104471512A (en) | Content customization | |
| JP4182613B2 (en) | Karaoke equipment | |
| JP4452643B2 (en) | Karaoke system | |
| JP2005285285A (en) | Content read system and musical piece reproduction apparatus | |
| JP2006208963A (en) | Karaoke system | |
| JP2006276560A (en) | Music playback device and music playback method | |
| JP2006276547A (en) | Karaoke system | |
| JP5098896B2 (en) | Playback apparatus and playback method | |
| JP3974069B2 (en) | Karaoke performance method and karaoke system for processing choral songs and choral songs | |
| JP5439994B2 (en) | Data collection / delivery system, online karaoke system | |
| JPH1091176A (en) | Musical piece retrieval device and musical piece reproducing device | |
| JP6587459B2 (en) | Song introduction system in karaoke intro | |
| US20220391438A1 (en) | Information processing apparatus, information processing method, and program | |
| JP2006018156A (en) | Karaoke machine, karaoke machine server, and karaoke machine system | |
| KR101576683B1 (en) | Method and apparatus for playing audio file comprising history storage | |
| JP7028942B2 (en) | Information output device and information output method | |
| JP6901955B2 (en) | Karaoke equipment | |
| JP4720858B2 (en) | Karaoke equipment | |
| JP6781636B2 (en) | Information output device and information output method | |
| JP2007172745A (en) | Music reproducing device, program and music selecting method | |
| JP4299747B2 (en) | Electronic sampler | |
| CN113703882A (en) | Song processing method, device, equipment and computer readable storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20060424 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20090402 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090414 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20090804 |