JP2004185306A - Dictionary construction supporting device and method - Google Patents
Dictionary construction supporting device and method Download PDFInfo
- Publication number
- JP2004185306A JP2004185306A JP2002351429A JP2002351429A JP2004185306A JP 2004185306 A JP2004185306 A JP 2004185306A JP 2002351429 A JP2002351429 A JP 2002351429A JP 2002351429 A JP2002351429 A JP 2002351429A JP 2004185306 A JP2004185306 A JP 2004185306A
- Authority
- JP
- Japan
- Prior art keywords
- dictionary
- expressions
- expression
- stored
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images












Abstract
Description
【0001】
【発明の属する技術分野】
本発明は、文書データを自動的に分類する文書分類システムにおいて利用される電子辞書をユーザによって構築可能とするための辞書構築支援装置および方法に関する。
【0002】
【従来の技術】
さまざまな場所で日々多様な電子データが利用されているが、それらデータの8割以上が文書データであると言われている。文書データは、用途に応じて、種々の電子辞書が利用される。例えば、日本語の文書データの作成時においては、かな漢字変換辞書が用いられ、また、日本語の文書データの形態素解析を行う場合には形態素解析辞書が、文書データの構文解析を行う際には構文解析辞書が用いられる。このような電子辞書においては、基本的には明確に定義された不変的な規則が存在しているため、予め製品メーカ側で作成されて供給されるものであり、ユーザはこのような電子辞書の内容を特に意識することなく利用している。
【0003】
ところで、多種多様な文書データのうち、特に自由な形式で記述された文書データからユーザにとって必要な情報を抽出する技術として、テキストマイニング技術が近年注目されてきている。
【0004】
本願出願人は、特許文献1において、テキストマイニング技術の一方法を提案している。これには、抽出したい概念と該概念を表す一つ以上の様々な表現とを対応づけて保持される情報抽出用辞書を利用して、対象となる文書データ中に含まれる重要な情報を抽出する文書データの解析方法が提案されている。なお、ここで言う表現とは、例えば、単語や、句や、共起関係にある単語の組、等のことを言い、また、ここで言う概念とは、このような表現それぞれに共通した上位の意味に相当する。例えば、「オーナー」、「トレーナー」、「バイヤー」等が個々の「表現」であり、「人」は、これら「オーナー」、「トレーナー」、「バイヤー」等の上位の意味を持つ「概念」である。
【0005】
このような情報抽出用辞書における概念と表現との対応付けは、明確に定義された不変的な規則が存在しているものではなく、分析対象とする文書データの分野や分析の視点に依存するものである。
【0006】
これら情報抽出用辞書においても、先に示した電子辞書と同様、製品メーカ側が、テキストマイニング技術を導入するユーザの利用形態を調査し、それに併せて情報抽出用辞書を作成して提供し、また、利用後の結果を検証してその情報抽出用辞書に登録、削除、修正などのメンテナンスを行っているのが現状であった。
【0007】
以上説明してきたように、テキストマイニング技術に用いられる従来の情報抽出用辞書は、その良し悪しにより、抽出精度に大きな影響を与えるにもかかわらず、利用者ではないメーカ側によって予め用意されているものであり、ユーザがその辞書を作成したり、作成した辞書を検証しながら編集する手段は提供されていなかった。なお、エディタなどを用いて、情報抽出用辞書を編集することは可能であったが、辞書の構造などを十分に把握し、プログラムレベルで編集する必要があり、通常のユーザにとって容易に編集できるものではなかった。
【0008】
また、これら情報抽出用辞書のメンテナンスにおいても、製品メーカ側が、利用後のユーザの不具合等を調査して、解決されると思われる箇所を経験などから判断し、情報抽出用辞書への追加、削除、修正などを行ってテキストマイニングの精度を向上するしかなかった。
【0009】
このような点に鑑み、本願出願人は、特許文献2において、テキストマイニングで用いられる情報抽出用辞書の作成およびメインテナンスを容易にする方法および装置を提案した。
【0010】
また、抽出したい概念が固有名詞など形態素解析を必要としない場合があることに鑑み、本願出願人は、特許文献3において、電子辞書中の表現と文書データとを照合する際、あらかじめ設定された条件に応じて形態素解析を行ってから照合するか形態素解析を行わずに照合するかを切り替えて表現を抽出する表現抽出手段を具備することを特徴とする情報抽出システムを提案した。これによれば、抽出すべき表現あるいは概念ごとに照合条件を設定できる。例えば、文字列照合だけでは他の単語の一部になってしまう表現を抽出したい場合、形態素解析を行えば単語の境界を正しく認識できるので、形態素解析を行わない場合よりも抽出精度が高くなる。具体的な例としては、「京都」を抽出したい場合、形態素解析を行わないと「東京都」という文字列中の「京都」にもマッチしてしまうが、形態素解析を行えばそのような誤りを防げる。
【0011】
逆に、例えば、形態素解析に失敗し未知語になるような場合、単語境界を誤る可能性が高いので、形態素解析を行うとマッチしなくなる場合がある。具体的な例としては、「コチジャン」を抽出しようとして1単語として抽出用辞書に登録したとしても、形態素解析すると「コチ/ジャン」のように2単語に分割されてしまう場合、形態素解析を行うとそのままではマッチしなくなる。
【0012】
一般に、形態素解析辞書には登録されていない製品名や記号列などを抽出したい場合には形態素解析を行わない方が適しており、形態素解析辞書に登録されているような一般的な語を抽出したい場合には形態素解析を行う方が適していると言える。
【0013】
【特許文献1】
特開2001−147937号公報
【0014】
【特許文献2】
特開2002−140338号公報
【0015】
【特許文献3】
特願2002−278421号
【0016】
【発明が解決しようとする課題】
ところが、上記条件設定を行うためには、テキストエディタ等を用いて情報抽出用辞書を編集することが必要であった。形態素解析を行わない場合の電子辞書の構築は、計算言語学上の知識を必要としないため、論理的には一般のユーザにも可能な作業であるが、プログラムレベルでの編集作業が必要であったため、実際にはプログラムレベルでの編集作業が必要であり、一般のユーザにとっては編集作業は極めて困難であった。
【0017】
本発明は、このような事情に鑑みてなされたものであり、ユーザが表現の照合において形態素解析をするかしないかを設定できる情報抽出用の辞書を作成・検証するための支援環境を提供することを目的とする。
【0018】
【課題を解決するための手段】
そこで、本発明の辞書構築支援装置は、複数の表現とそれら表現に共通する上位の表現である概念とを対応付けて格納される電子辞書を記憶する辞書記憶手段と、文書データから抽出された表現を記憶する表現記憶手段と、前記辞書記憶手段にて記憶される該電子辞書から少なくとも一部の概念と、前記表現記憶手段にて記憶される少なくとも一部の該抽出された表現とを同時に表示する表示手段と、前記表示手段によって表示された表現から一つ以上の表現の指定と、前記表示手段によって表示された概念から一つの概念の指定とを受けると、指定された表現を指定された概念に対応付けて前記電子辞書に追加登録する登録手段とに加え、概念毎に照合の際、形態素解析をするか否かを指定し、それを電子辞書に保存する手段を備えた。
【0019】
また、抽出結果を表示する際、形態素解析を用いて照合されたものとそうでないものを区別して表示する手段を備えた。
【0020】
これにより、文書データから抽出された表現を、簡単な操作で電子辞書内の所望の概念へ登録することができ、形態素解析をすべきか否かを含め電子辞書の良し悪しを容易に検証することができるようになった。
【0021】
すなわち、文書から抽出した重要な表現を参照しながら、必要な表現を選択して情報処理用の辞書に登録することができ、同時に、形態素解析を行うか否かも指定することができ、また、情報処理結果を見て辞書の性能を検証しながら辞書を編集することができるようになった。
【0022】
【発明の実施の形態】
以下、図面を参照して本発明に係る実施形態を説明する。
【0023】
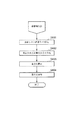
図1は、本発明の実施形態に係る辞書構築支援装置の構成を示した図である。
【0024】
本実施形態における辞書構築支援装置は、例えばパーソナルコンピュータ等のコンピュータにおいて、記憶装置50に格納された辞書構築支援プログラム100がメモリ40上へ読み込まれ、全体の制御を司るCPU10によって実行されることにより実現される。
【0025】
入力部20は、マウスやキーボードあるいは音声入力装置等から、文字列の挿入や削除などの編集指示、機能を選択するための操作指示、処理対象となる文書や辞書の指定などのコマンド入力等を受けるものである。出力部30は、例えばディスプレイ等の表示装置へ表示情報を供給するためのものである。
【0026】
メモリ40は、高速で揮発性の、例えばDRAM等から構成され、前記したとおりCPU10で実行される前記プログラム100等を記憶したり、該プログラム100が実行される際に一時的に保持される内部データ保持部110として利用される。
【0027】
この内部データ保持部110には、テキストバッファ110a、表現リストバッファ110b、処理結果バッファ110c、辞書バッファ110d、差分バッファ110eが設けられている。
【0028】
記憶装置50は、不揮発性の大容量記憶装置であり、例えば、HDD、CD−ROM、DVD−ROM等によって実現可能である。記憶装置50には、制御部101、表現抽出部102aを備えた表現登録部102、辞書編集部103、辞書検証部104、差分検出部105および条件設定部106からなる辞書構築支援プログラム100と、このプログラムによって構築される情報抽出用辞書109が格納されている。
【0029】
制御部101は、本プログラム100の起動時に最初に実行されるメインプログラムである。
【0030】
表現登録部102は、表現を情報抽出用辞書109へ登録するプログラムであり、制御部102からの所定の指示により起動され、後述する「表現」を情報抽出用辞書109へ登録する処理を行う。
【0031】
表現抽出部102aは、表現登録部102から、文書データの表現の抽出処理が必要になった際に起動されるプログラムである。表現抽出部102aは、テキストバッファ110aに記憶される内容を構文解析等を行って、文書中で使用される単語や句、あるいは共起関係等(以下、これらを表現と称す)をリスト化し、表現リストバッファ110bへ記憶する。なお、このリスト化されたものを、総称して表現リストと呼ぶ。この表現リストの作成方法については、たとえば特開昭62−99865号公報や特開平2−42572号公報で公開されており、説明を省略する。
【0032】
表現登録部102は、作成された表現リスト中からユーザによって指定された表現を、辞書バッファ110dへ登録する。
【0033】
辞書編集部103は、情報抽出用辞書109を編集するプログラムである。この辞書編集部103は、表現登録部102や辞書検証部104からも起動できる。
【0034】
辞書検証部104は、情報抽出用辞書109から読み出され格納した、辞書バッファ110dを用いて、ユーザによって指定された抽出処理を行い、抽出処理結果を処理結果バッファ110cに記憶する。また、ユーザの指示に基づき、処理結果バッファ110cに記憶される情報を表示する。
【0035】
差分検出部105は、2つの情報抽出用辞書109の差分を検出する。
【0036】
条件設定部106は、情報抽出の際の照合条件を設定する。設定された条件は、制御部101を通して情報抽出用辞書109に保存される。保存された条件は、辞書バッファ110dに読み出されることにより、辞書検証部104における情報抽出の動きを制御するほか、本情報抽出用辞書を用いる外部の情報抽出システムにおける情報抽出の動きを、たとえば特許文献3のように制御する。
【0037】
情報抽出用辞書109は、本プログラムで構築される電子辞書である。この情報抽出用辞書109の構成の一例を図2に示す。この情報抽出用辞書109は、3階層にて構成されており、最上位の階層をクラス、中位の階層を概念、下位の階層を表現と呼んでいる。なお、クラス、概念、表現の階層を特に意識することなく、これらの一つを指す場合には、以下では単にノードと呼ぶこととする。
【0038】
クラステーブル121は、クラスを示しており、ここには、「地名」、「人名」等を格納する。概念テーブル122は、クラスと概念を対応付けて格納している。表現テーブル123は、クラス、概念、表現とを対応付けて格納をしている。
【0039】
以上が本実施形態の辞書構築支援装置の構成である。
【0040】
次に、本実施形態の辞書構築支援装置の動作について情報抽出を例として、フローチャートを用いて説明する。
【0041】
図3は、辞書構築プログラム100のうち、制御部101のフローチャートを示している。
【0042】
ユーザが、辞書構築プログラム100の起動を要求すると、制御部101が起動される。
【0043】
制御部101は、自プログラム起動後、ユーザからのキー入力を待つ(S201)。キー入力を受けると、まず、ユーザの入力が終了指示であるか否か判定する(S202)。ここで終了指示と判定した場合には自プログラムを終了する。
【0044】
一方、ステップS202において、終了指示でないと判定した場合には、次に、ユーザの入力が文書指定であるか否か判定する(S204)。ここで文書指定である場合には、指定された文書データを、指定先の、例えばメモリや磁気ディスク、光ディスクなどから読み出して、メモリ40の内部データ保持部110内のテキストバッファ110aに記憶する(S204)。この処理が終了すると、ステップS201に戻り、ユーザからの次の入力を待つ。
【0045】
一方、ステップS203において、文書指定でないと判定した場合には、次に、ユーザの入力が辞書指定であるか否か判定する(S205)。ここで辞書指定である場合には、指定された辞書を、指定先の、例えばメモリや磁気ディスク、光ディスクなどから読み出して、メモリ40の内部データ保持部110内の辞書バッファ110dに記憶する(S206)。この処理が終了すると、ステップS201に戻り、ユーザからの次の入力を待つ。
【0046】
一方、ステップS205において、辞書指定でないと判定した場合には、次に、ユーザの入力が表現登録指示であるか否か判定する(S207)。ここで表現登録指示であると判断した場合には、表現登録部102を起動する(S208)。表現登録部102の動作については後述する。なお、表現登録部102の動作が終了すると、ステップS201に戻り、ユーザからの次の入力を待つ。
【0047】
一方、ステップS207において、表現登録指示でないと判断した場合には、次に、ユーザの入力が辞書検証指示であるか否か判定する(S209)。ここで辞書検証指示であると判定した場合には、辞書検証部104を起動する(S210)。辞書検証部104の動作については後述する。なお、辞書検証部104の動作が終了するとステップS201に戻り、ユーザからの次の入力を待つ。
【0048】
一方、ステップS209において、辞書検証指示でないと判断した場合には、次に、ユーザの入力が辞書編集指示であるか否か判定する(S211)。ここで辞書編集指示である場合には、辞書編集部103を起動する(S212)。辞書編集部103の動作については後述する。なお、辞書編集部103の動作が終了するとステップS201に戻り、ユーザからの次の入力を待つ。
【0049】
一方、ステップS211において、辞書編集指示でないと判断した場合には、次に、ユーザの入力が差分検出指示であるか否か判定する(S213)。ここで、差分検出指示である場合には、差分検出部105を起動する(S214)。差分検出部105の動作については後述する。なお、差分検出部105の動作が終了するとステップS201に戻り、ユーザからの次の入力を待つ。
【0050】
一方、ステップS213において、差分検出指示でないと判断した場合には、指定された他の処理、例えば環境設定処理等のユーザの入力指示に対応する処理を行って(S215)、ステップS201に戻り、ユーザからの次の入力を待つ。
【0051】
以上のように、制御部101は、ユーザの入力を解析して各種処理部を起動するとともに、ユーザの指示に基づき、処理対象の文書および辞書を内部データ保持部110に記憶する。
【0052】
図4は、制御部101が起動した直後の画面表示例を示している。上部には、登録、検証、編集、差分表示、環境設定、終了の各ボタンがあり、ユーザは、これらのボタンを押すことによって、次に行う処理を選択する。例えば、終了ボタンがクリックされると、ステップS202にて、ユーザの入力が終了指示であることを判定して、終了処理が行われる。また、例えば、登録ボタンがクリックされると、ステップS207にて、ユーザの入力が表現登録指示であることを判定し、表現登録部102が起動される処理が行われる。
【0053】
これらボタンの下部には、左に辞書名を入力する領域が、右に文書名を入力する領域が設けられており、ユーザは、これら領域に辞書名、文書名を入力し、実行することにより、該当する辞書あるいは文書を記憶装置50から読み出す。例えば、文書名を入力する領域にユーザが文書名を入力して実行すると、ステップS203にて、ユーザの入力が文書指定であると判定し、続くステップS204で、入力された文書名に基づいて、該当する文書を記憶装置50などから読み出して、テキストバッファ110aに記憶する。
【0054】
次に、表現登録部102の処理動作について説明する。図5は、表現登録部102の処理動作を示すフローチャートである。
【0055】
制御部101の動作中、ステップ207において表現登録指示であると判断した場合には、表現登録部102が起動される。起動された表現登録部102は、まず、表現抽出部102aを起動する。起動された表現抽出部102aは、テキストバッファ110aに記憶される文書データを所定の解析方法にて解析し、表現リストを作成する(S301)。この作成された表現リストを表現リストバッファ110bに保持する(S302)。なお、所定の解析方法は、例えば、単語の表現リストを作成する際には、文書データを形態素解析や、構文解析し、単語を抽出し、抽出した単語を羅列すればよく、またこの解析方法にとらわれることなく既知の様々な方法で作成すれば良い。抽出後、表現抽出部102aは、終了する。
【0056】
次に、辞書バッファ110dに記憶される辞書データと、表現リストバッファ110bに記憶される表現リストとを読み出して、同時に表示する(S303)。
【0057】
次に、ユーザの入力が辞書登録指示であるか否か判定する(S304)。ここで、辞書登録指示である場合には、次に、ユーザは、表示された表現リストの中から辞書に登録したい表現を指定する(S305)。これにより、表現登録部102は、ユーザによって指定された表現を得る。また、ユーザは、表示された辞書の概念の中から、得られた表現を登録したい概念を指定する(S306)。これにより、表現登録部102は、表現が登録される概念を得る。また、ユーザは、その概念が情報抽出時に形態素解析されるべきか否かを、チェックボックス等の入力手段を用いて条件設定部106に与える(S307)。そして、これら得た表現、概念、および情報抽出の条件を合成し、表現の辞書情報(下位のテーブル)として登録する(S308)。この登録は、辞書バッファ110dに追加される。
【0058】
一方、ステップS304において、辞書登録指示でない場合には、ユーザの入力が辞書編集指示であるか否か判定する(S309)。ここで、辞書編集指示である場合には、後述の辞書編集部103を起動し、辞書の編集を行う(S310)。辞書編集部103の処理が終了すると、ステップS304に戻る。
【0059】
一方、ステップS309において、辞書編集指示でない場合には、辞書バッファ110dに記憶される情報を磁気ディスク等に保存し(S311)、処理を終了する。
【0060】
このようにして、表現登録部102は、表現抽出部102aを起動して表現リストを作成し、表現リストから辞書109への辞書登録を行う。
【0061】
図6は、表現登録部102の処理時の画面表示例を示している。辞書名を入力する領域の下部には、登録ボタンがあり、このボタンをクリックすることによって辞書登録処理(図5のS305〜S308)が可能になる。この登録ボタンの下部には、辞書の内容を表示している。この例においては、辞書名「XXXXXXX」の辞書の内容の一部が表示されている。この表示では、クラス、概念、表現の3階層の形式で表示されている。また、各語の前部にはチェックボックスが設けられており、ユーザにてチェックボックスをクリックすることにより指定可能になる。また、概念には、情報抽出時の照合条件として形態素解析を使うかどうかを指定するためのチェックボックス(a1,a2,…)があり、ユーザによる条件の入力が可能となっている。そして、このチェックボックス(a1,a2,…)を設けて、形態素解析を行うか否かを指定できるようにした点が、この辞書構築支援装置の特徴の1つであり、これにより、プログラムレベルでの編集作業が不要となり、一般のユーザでも編集作業を簡単に行えるようになる。この例では、概念「仕事」のチェックボックス(a1)はオフ、概念「人」のチェックポイント(a2)はオンとなっているため、概念「仕事」に含まれる表現を抽出する際には形態素解析は用いられず、一方、概念「人」に含まれる表現を抽出する際には形態素解析が用いられることになる。
【0062】
一方、文書名を入力する領域の下部には、単語、共起、句の各ボタンがあり、これらボタンを押すことによって、表現リストの表示内容を選択できる。これらボタンの下部は、表現リストを表示する領域であり、この例においては、文書名「++++++」の単語の表現リストを表示している。この表現リストの各語(この場合は単語)の前部にはチェックボックスが設けられており、ユーザにてチェックボックスをクリックすることにより指定可能になっている。
【0063】
このように、この表現登録部102の処理時の画面は、辞書と表現リストが同時に表示可能となっており、また、辞書のクラス、概念、表現、および表現リストの各語は、簡単に指定可能になっており、ユーザにとって、簡単に辞書への登録が可能である。
【0064】
図7は、表現の登録処理を模式的に示した図である。この例では、表現リストから「社員」を選択し、「人」の概念の一つの表現として追加する際の内部データの処理について示している。
【0065】
表示された表現リストから「社員」が選択されると表現リストバッファ110bから「社員」を取得し、また、表示された辞書から概念「人」が選択されると辞書バッファ110dに記憶される概念テーブル122から「業界・人」を取得する。そして、これら取得した「業界、人」、「社員」を合成し、「業界・人・社員」を得て、これを辞書バッファ110dの表現テーブル123に登録する。その結果、表現テーブルは123’のようになる。
【0066】
これにより、文書データから抽出された表現を、簡単な操作で電子辞書内の所望の概念へ登録することができるようになった。
【0067】
次に、辞書検証部104の処理動作について説明する。図8は辞書検証部104の処理動作を示すフローチャートである。
【0068】
制御部101の動作中、ステップ209において辞書検証指示であると判断した場合には、辞書検証部104が起動される。起動された辞書検証部104は、辞書バッファ110dに記憶される辞書データを表示する(S401)。
【0069】
次に、辞書109を用いて情報抽出を行い、結果を処理結果バッファ110cに記憶する(S402)。そして、処理結果バッファ110dに記憶した情報を表示する(S403)。
【0070】
次に、ユーザの入力が情報抽出結果の検証指示であるか否か判定する(S404)。
【0071】
ここで、情報抽出結果の検証指示であると判定した場合には、検証したいノードを辞書中で指定する(S405)。そして、指定されたノードに対応する情報抽出結果を表示する(S406)。なお、この処理後、ステップS404に戻る。
【0072】
一方、ステップS404において、情報抽出結果の検証指示でないと判定した場合には、次に、ユーザの入力が辞書編集指示であるか否か判定する(S407)。ここで、辞書編集指示であると判定した場合には、辞書編集部103を起動し、辞書編集を行う。辞書編集部103が終了すると、ステップS404に戻る。
【0073】
一方、ステップS407において、辞書編集指示でないと判定した場合には、辞書バッファ110dに記憶される情報を磁気ディスク等に保存する(S409)。また、処理結果バッファ110cに記憶される情報を磁気ディスク等に保存し(S410)、辞書検証部104の処理を終了する。
【0074】
このようにして、辞書検証部104は、辞書109による情報抽出結果を表示しながら辞書の検証を行う。
【0075】
図9は、辞書検証部104の処理時の画面表示例を示している。
【0076】
表示上、左半分の表示内容は、図6の表現登録部102の左半分の表示内容と比較して、登録ボタンに代えて検証ボタンがあるのみで、その他は同じである。
【0077】
この検証ボタンを押すことによって結果検証処理(図8のS405〜S406)が可能になる。
【0078】
一方、図9の右半分の表示内容は、文書名の下部には、辞書109で処理された抽出結果が表示される。そして、図のように抽出結果の検証後にあたって、抽出結果上、指定された概念が持つ表現がある箇所には、ユーザへ明示可能なように、ここでは下線(b1,b2,b3,b4,…)で明示している。なお、下線以外に例えば、色などの十分識別ができる方法であれば良い。
【0079】
さらに、この際、情報抽出に当たって形態素解析を用いたかどうかにしたがって、下線の形状を変えたり、色を変えたりなどの表示方法の変化をつけることにより、情報抽出の条件をも同時に表示することができる。そして、この指定された概念が持つ表現がある箇所を、情報抽出に当たって形態素解析を用いたかどうかによってその表示方法に変化をつける点も、この辞書構築支援装置の特徴の1つである。
【0080】
これにより、階層化された電子辞書内の概念を、簡単な操作で指定でき、指定された概念に含まれる表現を電子辞書で抽出された抽出結果の中から容易に抽出して明示し、しかも照合条件も同時に表示するようにしたので、ユーザは、電子辞書の良し悪しを容易に検証することができるようになった。
【0081】
この例では、「サービス」、「開発」、「営業」に付された下線(b1,b2,b3)は単線なのに対して、「バイヤー」に付された下線(b4)は2重線となっているが、これは、「サービス」、「開発」、「営業」は、情報抽出に当たって形態素解析が用いられておらず、一方、「バイヤー」は、形態素解析が用いられていることを示している。つまり、先に図6で示した、「サービス」、「開発」、「営業」を含む概念「仕事」については、形態素解析を使わず、「バイヤー」を含む概念「人」については、形態素解析を使うように設定した情報抽出時の照合条件を、この下線により簡単に認識することができる。
【0082】
次に、辞書編集部103の処理動作について説明する。図10は、辞書編集部103の処理動作を示すフローチャートである。
【0083】
制御部101の動作中、ステップS211において辞書編集指示であると判断した場合、表現登録部102の動作中、ステップS308において辞書編集指示であると判断した場合、および辞書検証部104の動作中、ステップS407において辞書編集指示であると判断した場合に、辞書編集部103が起動される。
【0084】
起動された辞書編集部103は、辞書バッファ110dに記憶される辞書データを表示する(S501)。
【0085】
次に、ユーザの入力がノードの追加指示であるか否か判定する(S502)。ここで、追加指示である場合には、追加ノードを指定する(S503)。そして、指定されたノードに子ノードを追加する(S504)。追加の内容は、ユーザが直接入力する。そして、ステップS502に戻る。
【0086】
一方、ステップS502において追加指示でない場合には、次にユーザの入力がノードの削除指示であるか否か判定する(S505)。ここで、削除指示である場合には、削除ノードを指定する(S506)。そして、指定されたノードとそのノードの子ノードを全て削除する(S507)。そして、ステップS502に戻る。
【0087】
一方、ステップS505において削除指示でない場合には、次にユーザの入力がノードの変更指示であるか否か判定する(S508)。ここで、変更指示である場合には、変更ノードを指定する(S509)。そして、指定されたノードの文字列や値などを変更する(S510)。そして、ステップS502に戻る。
【0088】
一方、ステップS508において変更指示でない場合には、次にユーザの入力がノードの複写指示であるか否か判定する(S511)。ここで、複写指示である場合には、複写元ノードを指定する(S512)。そして、複写先ノードを指定する(S513)。そして、指定された複写元ノードとその子ノード全てを複写先ノードの子ノードに追加する(S514)。そして、ステップS502に戻る。
【0089】
一方、ステップS511において、複写指示でない場合には、ユーザの入力がノードの移動指示であるか否か判定する(S515)。ここで、移動指示である場合には、移動元ノードを指定する(S516)。そして、移動先ノードを指定する(S517)。そして、指定された移動元ノードとその子ノード全てを移動先ノードの子ノードに移動する(S518)。そして、ステップS502に戻る。
【0090】
一方、ステップS515において、移動指示でない場合には、辞書バッファ110dに記憶される情報を磁気ディスク等に保存し(S519)、処理を終了する。
【0091】
このようにして、辞書編集部108は、辞書109のノードに対して、追加、削除、変更、複写、移動などを行い、辞書編集を行う。
【0092】
図11は、辞書編集部103の処理時の画面表示例を示している。
【0093】
この例では、図6の表現登録部102の左半分の表示内容と比較して、登録ボタンに変えて、追加、削除、変更、移動、複写の各ボタンが配置されている点が異なり、他は同じである。各ボタンをクリックすることにより、上記したようなクリックされたボタンの各種編集機能が実施される。
【0094】
以上のように、電子辞書の編集を扱いやすいユーザインターフェースにしたので、ユーザにとって辞書の編集が容易に実現できる。
【0095】
次に、差分検出部105の処理動作について説明する。図12は差分検証部105の処理動作を示すフローチャートである。
【0096】
制御部101の動作中、ステップS213において差分検出指示であると判断した場合に、差分検出部105が起動される。
【0097】
起動された差分検出部105は、ユーザの入力によって、比較したい辞書を2つ指定する(S601)。そして、指定された辞書の差分を作成して差分バッファ110eに記憶する(S602)。
【0098】
次に、差分バッファ110eに記憶される差分を表示する(S603)。差分バッファ110eに記憶される差分を磁気ディスク等に保存し(S604)、処理を終了する。
【0099】
このようにして、差分検出部105は、辞書109同士を比較して、差分を作成・表示する。
【0100】
図13は、差分検出部105の処理時の画面表示例を示している。
【0101】
この例では、上部には、比較したい辞書を入力する2つの領域を備える。この領域の下部には、比較結果を表示する領域であり、ここでは、概念毎の比較結果を表示している。
【0102】
これにより、2つの電子辞書を容易に指定可能となり、それら電子辞書間の差分を検出し、概念の単位でユーザへ提示可能となった。
【0103】
以上説明した本実施形態においては、文書データから抽出された表現を、簡単な操作で電子辞書内の所望の概念へ登録することができるようになった。
【0104】
また、階層化された電子辞書内の概念を、簡単な操作で指定でき、指定された概念に含まれる表現を電子辞書で抽出された抽出結果の中から容易に抽出して明示するようにしたので、ユーザは、電子辞書の良し悪しを容易に検証することができるようになった。
【0105】
また、2つの電子辞書を容易に指定可能となり、それら電子辞書間の差分を検出し、概念の単位でユーザへ提示可能となった。
【0106】
また、文書から抽出した重要な表現を参照しながら、必要な表現を選択して情報抽出用の辞書に登録することができ、また、情報抽出結果を見て辞書の性能を検証しながら辞書を編集することができるようになった。
【0107】
なお、本願発明は、前記実施形態に限定されるものではなく、実施段階ではその要旨を逸脱しない範囲で種々に変形することが可能である。更に、前記実施形態には種々の段階の発明が含まれており、開示される複数の構成要件における適宜な組み合わせにより種々の発明が抽出され得る。たとえば、実施形態に示される全構成要件から幾つかの構成要件が削除されても、発明が解決しようとする課題の欄で述べた課題が解決でき、発明の効果の欄で述べられている効果が得られる場合には、この構成要件が削除された構成が発明として抽出され得る。
【0108】
【発明の効果】
以上説明したように、本発明によれば、ユーザが表現の照合において形態素解析をするかしないかを設定できる情報抽出用の辞書を作成・検証するための支援環境を提供することができる。
【図面の簡単な説明】
【図1】本発明の実施形態に係る辞書構築支援装置の構成を示す図。
【図2】同実施形態における情報抽出用辞書109の構成の一例。
【図3】同実施形態における制御部101の処理動作を示すフローチャート。
【図4】同実施形態における制御部101が起動した直後の画面表示例。
【図5】同実施形態における表現登録部102の処理動作を示すフローチャート。
【図6】同実施形態における表現登録部102の処理時の画面表示例。
【図7】同実施形態における表現の登録処理を模式的に示した図。
【図8】同実施形態における辞書検証部104の処理動作を示すフローチャート。
【図9】同実施形態における辞書検証部104の処理時の画面表示例。
【図10】同実施形態における辞書編集部103の処理動作を示すフローチャート。
【図11】同実施形態における辞書編集部103の処理時の画面表示例。
【図12】同実施形態における差分検出部105の処理動作を示すフローチャート。
【図13】同実施形態における差分検出部105の処理時の画面表示例。
【符号の説明】
10…CPU
20…入力部
30…出力部
40…メモリ
50…記憶装置
100…辞書構築プログラム
101…制御部
102…表現登録部
102a…表現抽出部
103…辞書編集部
104…辞書検証部
105…差分検出部
106…条件設定部
109…情報抽出用辞書
110…内部データ保持部
110a…テキストバッファ
110b…表現リストバッファ
110c…処理結果バッファ
110d…辞書バッファ
110e…差分バッファ
121…クラステーブル
122…概念テーブル
123…表現テーブル[0001]
TECHNICAL FIELD OF THE INVENTION
The present invention relates to a dictionary construction support apparatus and method for enabling a user to construct an electronic dictionary used in a document classification system for automatically classifying document data.
[0002]
[Prior art]
A variety of electronic data is used every day in various places, and it is said that more than 80% of the data is document data. Various electronic dictionaries are used for the document data depending on the application. For example, a kana-kanji conversion dictionary is used when creating Japanese document data, a morphological analysis dictionary is used when performing morphological analysis on Japanese document data, and a morphological analysis dictionary is used when performing syntax analysis on document data. A parsing dictionary is used. In such electronic dictionaries, there are basically invariable rules that are clearly defined, and are created and supplied in advance by the product maker. Is used without any particular awareness.
[0003]
In recent years, a text mining technique has attracted attention as a technique for extracting information necessary for a user from document data described in a free format, among various kinds of document data.
[0004]
The applicant of the present application has proposed a method of text mining technology in Patent Document 1. This involves extracting important information contained in the target document data using an information extraction dictionary that holds the concept to be extracted and one or more various expressions representing the concept in association with each other. A method of analyzing document data has been proposed. The expression referred to here means, for example, a word, a phrase, a set of words having a co-occurrence relation, and the like, and the concept referred to herein is a higher order common to each of such expressions. Corresponds to the meaning of For example, “owner”, “trainer”, “buyer”, etc. are individual “expressions”, and “person” is a “concept” having a higher meaning such as “owner”, “trainer”, “buyer”, etc. It is.
[0005]
The correspondence between concepts and expressions in such an information extraction dictionary does not have a clearly defined invariant rule, but depends on the field of document data to be analyzed and the viewpoint of analysis. Things.
[0006]
In these information extraction dictionaries, similarly to the electronic dictionary described above, the product manufacturer investigates the usage form of the user who introduces the text mining technology, and creates and provides the information extraction dictionary in accordance with the survey. At present, the results after use are verified, and maintenance such as registration, deletion, and correction in the information extraction dictionary is performed.
[0007]
As described above, the conventional information extraction dictionary used for the text mining technique is prepared in advance by a manufacturer other than the user, despite the fact that the quality of the dictionary greatly affects the extraction accuracy. No means has been provided for the user to create the dictionary or to edit the dictionary while verifying the created dictionary. Although it was possible to edit the dictionary for information extraction using an editor or the like, it was necessary to fully understand the structure of the dictionary and to edit at the program level, and it could be easily edited by ordinary users. It was not something.
[0008]
In the maintenance of these information extraction dictionaries, the product manufacturer investigates the user's problems after use, judges from the experience, etc., the parts that are considered to be resolved, and adds them to the information extraction dictionaries. There was no choice but to improve the accuracy of text mining by deleting or modifying.
[0009]
In view of such points, the applicant of the present application has proposed a method and an apparatus in Patent Literature 2 that facilitate creation and maintenance of an information extraction dictionary used in text mining.
[0010]
In addition, in view of the fact that a concept to be extracted may not require a morphological analysis such as a proper noun, the applicant of the present application disclosed in Patent Literature 3 when collating an expression in an electronic dictionary with document data is set in advance. We have proposed an information extraction system characterized by comprising an expression extracting means for extracting expressions by switching between collation after performing morphological analysis and collation without performing morphological analysis according to conditions. According to this, matching conditions can be set for each expression or concept to be extracted. For example, if you want to extract an expression that becomes a part of another word only by string matching, you can perform morphological analysis to correctly recognize word boundaries, so the extraction accuracy is higher than without morphological analysis . As a specific example, if you want to extract "Kyoto", it will match "Kyoto" in the character string "Tokyo" unless you perform morphological analysis. Can be prevented.
[0011]
Conversely, for example, when the morphological analysis fails and becomes an unknown word, there is a high possibility that the word boundary is erroneous. As a specific example, if a word is registered in the dictionary for extraction as one word in an attempt to extract “Kochijan”, if the word is divided into two words such as “Kochi / Jan” by morphological analysis, morphological analysis is performed. Will not match as it is.
[0012]
In general, if you want to extract product names or symbol strings that are not registered in the morphological analysis dictionary, it is more appropriate not to perform morphological analysis, and extract general words that are registered in the morphological analysis dictionary. It can be said that it is more appropriate to perform morphological analysis.
[0013]
[Patent Document 1]
JP 2001-147937 A
[0014]
[Patent Document 2]
JP-A-2002-140338
[0015]
[Patent Document 3]
Japanese Patent Application No. 2002-278421
[0016]
[Problems to be solved by the invention]
However, in order to set the above conditions, it was necessary to edit the information extraction dictionary using a text editor or the like. The construction of an electronic dictionary without morphological analysis does not require knowledge of computational linguistics, so it is logically possible for ordinary users, but editing work at the program level is required. Therefore, editing work at the program level is actually required, and the editing work is extremely difficult for ordinary users.
[0017]
The present invention has been made in view of such circumstances, and provides a support environment for creating and verifying an information extraction dictionary that allows a user to set whether or not to perform morphological analysis in expression matching. The purpose is to:
[0018]
[Means for Solving the Problems]
Therefore, the dictionary construction support apparatus of the present invention provides a dictionary storage unit that stores an electronic dictionary that stores a plurality of expressions and a concept that is a higher-level expression common to those expressions, and that is extracted from the document data. Expression storage means for storing expressions, at least some concepts from the electronic dictionary stored in the dictionary storage means, and at least some of the extracted expressions stored in the expression storage means simultaneously Display means for displaying, designation of one or more expressions from the expressions displayed by the display means, and designation of one concept from the concepts displayed by the display means, the designated expression is designated. In addition to a registration unit for additionally registering the concept in the electronic dictionary in association with the concept, a unit for designating whether or not to perform morphological analysis at the time of matching for each concept and storing it in the electronic dictionary is provided.
[0019]
Further, when displaying the extraction result, a means is provided for distinguishing and displaying those that have been collated using morphological analysis and those that have not.
[0020]
This makes it possible to register expressions extracted from document data to desired concepts in the electronic dictionary with a simple operation, and to easily verify the quality of the electronic dictionary, including whether or not morphological analysis should be performed. Is now available.
[0021]
That is, while referring to the important expressions extracted from the document, necessary expressions can be selected and registered in the dictionary for information processing, and at the same time, whether or not to perform morphological analysis can be specified. The dictionary can be edited while verifying the performance of the dictionary by viewing the information processing results.
[0022]
BEST MODE FOR CARRYING OUT THE INVENTION
Hereinafter, embodiments of the present invention will be described with reference to the drawings.
[0023]
FIG. 1 is a diagram showing a configuration of a dictionary construction support device according to an embodiment of the present invention.
[0024]
The dictionary construction support apparatus according to the present embodiment is configured such that, for example, in a computer such as a personal computer, a dictionary
[0025]
The
[0026]
The
[0027]
The internal
[0028]
The
[0029]
The
[0030]
The
[0031]
The
[0032]
The
[0033]
The
[0034]
The
[0035]
The
[0036]
The
[0037]
The
[0038]
The class table 121 indicates a class, and stores “place name”, “person name”, and the like. The concept table 122 stores classes and concepts in association with each other. The expression table 123 stores classes, concepts, and expressions in association with each other.
[0039]
The above is the configuration of the dictionary construction support device of the present embodiment.
[0040]
Next, the operation of the dictionary construction support apparatus of the present embodiment will be described with reference to a flowchart, taking information extraction as an example.
[0041]
FIG. 3 shows a flowchart of the
[0042]
When the user requests activation of the
[0043]
After starting the own program, the
[0044]
On the other hand, if it is determined in step S202 that the input is not an end instruction, it is next determined whether or not the user input is a document designation (S204). If the document is designated, the designated document data is read from the designated destination, for example, a memory, a magnetic disk, an optical disk, or the like, and stored in the
[0045]
On the other hand, if it is determined in step S203 that the input is not a document specification, it is next determined whether or not the user input is a dictionary specification (S205). If the dictionary is specified, the specified dictionary is read from the specified destination, for example, a memory, a magnetic disk, an optical disk, or the like, and stored in the
[0046]
On the other hand, if it is determined in step S205 that the dictionary is not specified, it is determined whether the user input is an expression registration instruction (S207). If it is determined that the instruction is an expression registration instruction, the
[0047]
On the other hand, if it is determined in step S207 that the input is not an expression registration instruction, it is next determined whether or not the user input is a dictionary verification instruction (S209). If it is determined that the instruction is a dictionary verification instruction, the
[0048]
On the other hand, if it is determined in step S209 that the input is not a dictionary verification instruction, then it is determined whether the user input is a dictionary edit instruction (S211). If the input is a dictionary editing instruction, the
[0049]
On the other hand, if it is determined in step S211 that the input is not a dictionary editing instruction, then it is determined whether the user input is a difference detection instruction (S213). If the instruction is a difference detection instruction, the
[0050]
On the other hand, if it is determined in step S213 that the received instruction is not a difference detection instruction, another designated process, for example, a process corresponding to a user input instruction such as an environment setting process is performed (S215), and the process returns to step S201. Wait for the next input from the user.
[0051]
As described above, the
[0052]
FIG. 4 shows a screen display example immediately after the
[0053]
Below these buttons, an area for inputting a dictionary name is provided on the left, and an area for inputting a document name is provided on the right. The user inputs a dictionary name and a document name in these areas and executes the The corresponding dictionary or document is read from the
[0054]
Next, the processing operation of the
[0055]
If it is determined in
[0056]
Next, the dictionary data stored in the
[0057]
Next, it is determined whether or not the user input is a dictionary registration instruction (S304). If the instruction is a dictionary registration instruction, the user specifies an expression to be registered in the dictionary from the displayed expression list (S305). Thus, the
[0058]
On the other hand, if it is not a dictionary registration instruction in step S304, it is determined whether or not the user input is a dictionary editing instruction (S309). If the instruction is a dictionary editing instruction, the
[0059]
On the other hand, if it is not a dictionary editing instruction in step S309, the information stored in the
[0060]
In this way, the
[0061]
FIG. 6 shows an example of a screen display at the time of processing of the
[0062]
On the other hand, below the area for inputting the document name, there are buttons for word, co-occurrence, and phrase. By pressing these buttons, the display contents of the expression list can be selected. The lower part of these buttons is an area for displaying an expression list. In this example, an expression list of a word having a document name “++++++” is displayed. A check box is provided in front of each word (word in this case) in the expression list, and can be specified by the user by clicking the check box.
[0063]
As described above, the screen at the time of processing of the
[0064]
FIG. 7 is a diagram schematically illustrating expression registration processing. This example shows processing of internal data when "employee" is selected from the expression list and added as one expression of the concept of "person".
[0065]
When "employee" is selected from the displayed expression list, "employee" is obtained from the
[0066]
Thereby, the expression extracted from the document data can be registered to a desired concept in the electronic dictionary by a simple operation.
[0067]
Next, the processing operation of the
[0068]
If it is determined in
[0069]
Next, information is extracted using the
[0070]
Next, it is determined whether or not the user input is a verification instruction of the information extraction result (S404).
[0071]
If it is determined that the instruction is a verification instruction of the information extraction result, the node to be verified is specified in the dictionary (S405). Then, the information extraction result corresponding to the designated node is displayed (S406). After this processing, the process returns to step S404.
[0072]
On the other hand, if it is determined in step S404 that the instruction is not a verification instruction of the information extraction result, it is next determined whether or not the user input is a dictionary editing instruction (S407). If it is determined that the instruction is a dictionary editing instruction, the
[0073]
On the other hand, if it is determined in step S407 that the instruction is not a dictionary editing instruction, the information stored in the
[0074]
In this way, the
[0075]
FIG. 9 shows an example of a screen display at the time of processing by the
[0076]
On the display, the display content of the left half is the same as the display content of the left half of the
[0077]
By pressing this verification button, the result verification processing (S405 to S406 in FIG. 8) becomes possible.
[0078]
On the other hand, in the display content in the right half of FIG. 9, the extraction result processed by the
[0079]
Furthermore, at this time, depending on whether or not morphological analysis was used for information extraction, by changing the display method such as changing the shape of the underline or changing the color, it is possible to simultaneously display the conditions for information extraction. it can. One of the features of this dictionary construction support device is that the display method is changed depending on whether or not a morphological analysis is used for extracting information at a location where an expression of the designated concept exists.
[0080]
In this way, the concepts in the hierarchical electronic dictionary can be specified by a simple operation, and the expressions included in the specified concept can be easily extracted and specified from the extraction results extracted by the electronic dictionary. Since the matching condition is also displayed at the same time, the user can easily verify the quality of the electronic dictionary.
[0081]
In this example, the underline (b1, b2, b3) added to "service", "development", and "sales" is a single line, whereas the underline (b4) added to "buyer" is a double line. However, this indicates that “service”, “development”, and “sales” do not use morphological analysis in extracting information, while “buyers” indicate that morphological analysis is used. I have. In other words, the concept “work” including “service”, “development” and “sales” shown in FIG. 6 is not used for morphological analysis, and the concept “person” including “buyer” is not analyzed by morphological analysis. The matching condition at the time of information extraction set to use is easily recognized by the underline.
[0082]
Next, the processing operation of the
[0083]
During the operation of the
[0084]
The activated
[0085]
Next, it is determined whether or not the user input is a node addition instruction (S502). If the instruction is an addition instruction, an additional node is specified (S503). Then, a child node is added to the designated node (S504). Additional content is entered directly by the user. Then, the process returns to step S502.
[0086]
On the other hand, if it is not an addition instruction in step S502, it is next determined whether or not the user input is an instruction to delete a node (S505). If the instruction is a deletion instruction, a deletion node is designated (S506). Then, the designated node and all child nodes of the node are deleted (S507). Then, the process returns to step S502.
[0087]
On the other hand, if it is not a deletion instruction in step S505, it is next determined whether or not the user input is a node change instruction (S508). Here, if it is a change instruction, a change node is designated (S509). Then, the character string and value of the designated node are changed (S510). Then, the process returns to step S502.
[0088]
On the other hand, if it is not a change instruction in step S508, then it is determined whether or not the user input is a node copy instruction (S511). If the instruction is a copy instruction, a copy source node is designated (S512). Then, a copy destination node is designated (S513). Then, the specified copy source node and all of its child nodes are added to the child nodes of the copy destination node (S514). Then, the process returns to step S502.
[0089]
On the other hand, if it is not a copy instruction in step S511, it is determined whether or not the user input is a node move instruction (S515). Here, in the case of a move instruction, a move source node is designated (S516). Then, the destination node is specified (S517). Then, the designated source node and all of its child nodes are moved to child nodes of the destination node (S518). Then, the process returns to step S502.
[0090]
On the other hand, if it is not a move instruction in step S515, the information stored in the
[0091]
In this way, the dictionary editing unit 108 performs addition, deletion, change, copying, movement, and the like on the nodes of the
[0092]
FIG. 11 shows an example of a screen display at the time of processing by the
[0093]
This example is different from the display content of the left half of the
[0094]
As described above, since the editing of the electronic dictionary is made to be a user interface which is easy to handle, the dictionary editing can be easily realized for the user.
[0095]
Next, the processing operation of the
[0096]
During the operation of the
[0097]
The activated
[0098]
Next, the difference stored in the
[0099]
In this way, the
[0100]
FIG. 13 shows an example of a screen display at the time of processing of the
[0101]
In this example, the upper part is provided with two areas for inputting a dictionary to be compared. The lower part of this area is an area for displaying the comparison result. Here, the comparison result for each concept is displayed.
[0102]
This makes it possible to easily designate two electronic dictionaries, detect a difference between the electronic dictionaries, and present the difference to the user in units of concepts.
[0103]
In the present embodiment described above, an expression extracted from document data can be registered in a desired concept in the electronic dictionary by a simple operation.
[0104]
In addition, the concept in the hierarchical electronic dictionary can be specified by a simple operation, and the expressions included in the specified concept can be easily extracted from the extraction results extracted by the electronic dictionary and specified. Therefore, the user can easily verify the quality of the electronic dictionary.
[0105]
Further, two electronic dictionaries can be easily specified, and a difference between the electronic dictionaries can be detected and presented to the user in units of concepts.
[0106]
In addition, it is possible to select necessary expressions and register them in the dictionary for information extraction while referring to important expressions extracted from the document. You can now edit it.
[0107]
It should be noted that the present invention is not limited to the above-described embodiment, and can be variously modified in an implementation stage without departing from the scope of the invention. Furthermore, the embodiments include inventions at various stages, and various inventions can be extracted by appropriately combining a plurality of disclosed constituent elements. For example, even if some components are deleted from all the components shown in the embodiment, the problem described in the column of the problem to be solved by the invention can be solved, and the effects described in the column of the effect of the invention can be solved. Is obtained, a configuration from which this configuration requirement is deleted can be extracted as an invention.
[0108]
【The invention's effect】
As described above, according to the present invention, it is possible to provide a support environment for creating and verifying an information extraction dictionary in which a user can set whether or not to perform morphological analysis in expression matching.
[Brief description of the drawings]
FIG. 1 is a diagram showing a configuration of a dictionary construction support device according to an embodiment of the present invention.
FIG. 2 is an example of a configuration of an
FIG. 3 is a flowchart showing a processing operation of a
FIG. 4 is a screen display example immediately after the
FIG. 5 is a flowchart showing a processing operation of the
FIG. 6 is a screen display example during processing of the
FIG. 7 is an exemplary view schematically showing registration processing of expressions in the embodiment.
FIG. 8 is a flowchart showing a processing operation of the
FIG. 9 is an example of a screen display during processing of the
FIG. 10 is an exemplary flowchart illustrating the processing operation of the
FIG. 11 is a screen display example during processing of the
FIG. 12 is a flowchart showing a processing operation of a
FIG. 13 is a screen display example during processing of the
[Explanation of symbols]
10 ... CPU
20 ... input section
30 ... Output unit
40 ... Memory
50 ... Storage device
100: Dictionary construction program
101 ... Control unit
102 ... Expression registration unit
102a ... Expression extraction unit
103 ... Dictionary editor
104: Dictionary verification unit
105: Difference detection unit
106: Condition setting section
109: Information extraction dictionary
110: Internal data holding unit
110a ... text buffer
110b ... Expression list buffer
110c: Processing result buffer
110d: Dictionary buffer
110e ... difference buffer
121 ... Class table
122 ... Concept table
123 ... Expression table
Claims (12)
文書データから抽出された表現を記憶する表現記憶手段と、
前記辞書記憶手段にて記憶される該電子辞書から少なくとも一部の概念と、前記表現記憶手段にて記憶される少なくとも一部の該抽出された表現とを同時に表示する表示手段と、
前記表示手段によって表示された表現から一つ以上の表現の指定と、前記表示手段によって表示された概念から一つの概念の指定とを受けると、指定された表現を指定された概念に対応付けて前記電子辞書に追加登録する登録手段と
を備えた辞書構築支援装置であって、
前記辞書記憶手段にて記憶される電子辞書中の表現と文書データとを照合する際、該文書データを形態素解析してから照合するか、または形態素解析せずに照合するかを前記電子辞書中の概念ごとに設定する設定手段を具備することを特徴とする辞書構築支援装置。Dictionary storage means for storing an electronic dictionary stored in association with a plurality of expressions and concepts which are higher-level expressions common to those expressions,
An expression storage means for storing an expression extracted from the document data;
Display means for simultaneously displaying at least some of the concepts from the electronic dictionary stored in the dictionary storage means and at least some of the extracted expressions stored in the expression storage means;
Upon receiving designation of one or more expressions from the expressions displayed by the display means and designation of one concept from the concepts displayed by the display means, the specified expression is associated with the specified concept. A dictionary construction support device comprising a registration unit for additionally registering in the electronic dictionary,
When matching the expression in the electronic dictionary stored in the dictionary storage unit with the document data, it is determined whether the document data is subjected to morphological analysis and then collated or collated without morphological analysis. A dictionary construction support device comprising a setting means for setting each concept.
文書データから抽出された表現を記憶する表現記憶手段と、
前記辞書記憶手段にて記憶される該電子辞書から少なくとも一部の概念と、前記表現記憶手段にて記憶される少なくとも一部の該抽出された表現とを同時に表示する表示手段と
を備えた辞書構築支援装置であって、
前記表示手段にて一部の該抽出された表現を表示する際、照合時に用いられた形態素解析を用いるか否かの照合条件の違いにより、表示の方法を変化させる表示制御手段を具備することを特徴とする辞書構築支援装置。Dictionary storage means for storing an electronic dictionary stored in association with a plurality of expressions and concepts which are higher-level expressions common to those expressions,
An expression storage means for storing an expression extracted from the document data;
A dictionary comprising display means for simultaneously displaying at least some concepts from the electronic dictionary stored in the dictionary storage means and at least some of the extracted expressions stored in the expression storage means A construction support device,
When displaying a part of the extracted expressions on the display unit, the display unit includes a display control unit that changes a display method according to a difference in a matching condition whether or not to use a morphological analysis used at the time of matching. A dictionary construction support device characterized by the following.
文書データから抽出された表現を記憶する表現記憶手段と、
前記辞書記憶手段にて記憶される該電子辞書から少なくとも一部の概念と、前記表現記憶手段にて記憶される少なくとも一部の該抽出された表現とを同時に表示する表示手段と、
前記表示手段によって表示された表現から一つ以上の表現の指定と、前記表示手段によって表示された概念から一つの概念の指定とを受けると、指定された表現を指定された概念に対応付けて前記電子辞書に追加登録する登録手段と
を備えた辞書構築支援装置の辞書構築支援方法であって、
前記辞書記憶手段にて記憶される電子辞書中の表現と文書データとを照合する際、該文書データを形態素解析してから照合するか、または形態素解析せずに照合するかを前記電子辞書中の概念ごとに設定するステップを具備することを特徴とする辞書構築支援方法。Dictionary storage means for storing an electronic dictionary stored in association with a plurality of expressions and concepts which are higher-level expressions common to those expressions,
An expression storage means for storing an expression extracted from the document data;
Display means for simultaneously displaying at least some of the concepts from the electronic dictionary stored in the dictionary storage means and at least some of the extracted expressions stored in the expression storage means;
Upon receiving designation of one or more expressions from the expressions displayed by the display means and designation of one concept from the concepts displayed by the display means, the specified expression is associated with the specified concept. A dictionary construction support method of a dictionary construction support device comprising: a registration unit for additionally registering in the electronic dictionary;
When matching the expression in the electronic dictionary stored in the dictionary storage unit with the document data, it is determined whether the document data is subjected to morphological analysis and then collated or collated without morphological analysis. A dictionary construction supporting method, comprising a step of setting for each concept of:
文書データから抽出された表現を記憶する表現記憶手段と、
前記辞書記憶手段にて記憶される該電子辞書から少なくとも一部の概念と、前記表現記憶手段にて記憶される少なくとも一部の該抽出された表現とを同時に表示する表示手段と
を備えた辞書構築支援装置の辞書構築支援方法であって、
前記表示手段にて一部の該抽出された表現を表示する際、照合時に用いられた形態素解析を用いるか否かの照合条件の違いにより、表示の方法を変化させる表示制御ステップを具備することを特徴とする辞書構築支援方法。Dictionary storage means for storing an electronic dictionary stored in association with a plurality of expressions and concepts which are higher-level expressions common to those expressions,
An expression storage means for storing an expression extracted from the document data;
A dictionary comprising display means for simultaneously displaying at least some concepts from the electronic dictionary stored in the dictionary storage means and at least some of the extracted expressions stored in the expression storage means A dictionary construction support method of a construction support device,
When displaying a part of the extracted expressions on the display unit, a display control step of changing a display method depending on a difference in a matching condition whether or not to use a morphological analysis used at the time of matching is provided. A dictionary construction support method characterized by the following.
文書データから抽出された表現を記憶する表現記憶手段と、
前記辞書記憶手段にて記憶される該電子辞書から少なくとも一部の概念と、前記表現記憶手段にて記憶される少なくとも一部の該抽出された表現とを同時に表示する表示手段と、
前記表示手段によって表示された表現から一つ以上の表現の指定と、前記表示手段によって表示された概念から一つの概念の指定とを受けると、指定された表現を指定された概念に対応付けて前記電子辞書に追加登録する登録手段と
を備えたコンピュータを、
前記辞書記憶手段にて記憶される電子辞書中の表現と文書データとを照合する際、該文書データを形態素解析してから照合するか、または形態素解析せずに照合するかを前記電子辞書中の概念ごとに設定する設定手段
として機能させるためのプログラム。Dictionary storage means for storing an electronic dictionary stored in association with a plurality of expressions and concepts which are higher-level expressions common to those expressions,
An expression storage means for storing an expression extracted from the document data;
Display means for simultaneously displaying at least some of the concepts from the electronic dictionary stored in the dictionary storage means and at least some of the extracted expressions stored in the expression storage means;
Upon receiving designation of one or more expressions from the expressions displayed by the display means and designation of one concept from the concepts displayed by the display means, the specified expression is associated with the specified concept. A computer comprising a registration unit for additionally registering in the electronic dictionary,
When matching the expression in the electronic dictionary stored in the dictionary storage unit with the document data, it is determined whether the document data is subjected to morphological analysis and then collated or collated without morphological analysis. A program for functioning as setting means for setting each concept.
文書データから抽出された表現を記憶する表現記憶手段と、
前記辞書記憶手段にて記憶される該電子辞書から少なくとも一部の概念と、前記表現記憶手段にて記憶される少なくとも一部の該抽出された表現とを同時に表示する表示手段と
を備えたコンピュータを、
前記表示手段にて一部の該抽出された表現を表示する際、照合時に用いられた形態素解析を用いるか否かの照合条件の違いにより、表示の方法を変化させる表示制御手段
として機能させるためのプログラム。Dictionary storage means for storing an electronic dictionary stored in association with a plurality of expressions and concepts which are higher-level expressions common to those expressions,
An expression storage means for storing an expression extracted from the document data;
A computer including a display unit for simultaneously displaying at least some of the concepts from the electronic dictionary stored in the dictionary storage unit and at least some of the extracted expressions stored in the expression storage unit To
When displaying a part of the extracted expressions on the display unit, the display unit may function as a display control unit that changes a display method depending on a difference in a matching condition whether or not to use a morphological analysis used at the time of matching. Program.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2002351429A JP3774431B2 (en) | 2002-12-03 | 2002-12-03 | Dictionary construction support device and dictionary construction support method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2002351429A JP3774431B2 (en) | 2002-12-03 | 2002-12-03 | Dictionary construction support device and dictionary construction support method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2004185306A true JP2004185306A (en) | 2004-07-02 |
| JP3774431B2 JP3774431B2 (en) | 2006-05-17 |
Family
ID=32753347
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2002351429A Expired - Fee Related JP3774431B2 (en) | 2002-12-03 | 2002-12-03 | Dictionary construction support device and dictionary construction support method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP3774431B2 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10558756B2 (en) | 2016-11-03 | 2020-02-11 | International Business Machines Corporation | Unsupervised information extraction dictionary creation |
| US10558747B2 (en) | 2016-11-03 | 2020-02-11 | International Business Machines Corporation | Unsupervised information extraction dictionary creation |
| KR20200050620A (en) * | 2018-11-02 | 2020-05-12 | 한국전자통신연구원 | Apparatus and method for constructing new named entity dictionary with allomorph based on online encyclopedia |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07219962A (en) * | 1994-02-01 | 1995-08-18 | Dainippon Printing Co Ltd | Key word preparing device |
| JPH1145268A (en) * | 1997-07-28 | 1999-02-16 | Just Syst Corp | Document retrieval device and computer-readable recording medium where eprogram making computer funtion as same device is recorded |
| JPH11272701A (en) * | 1998-03-23 | 1999-10-08 | Oki Electric Ind Co Ltd | Information extraction device |
| JP2002140338A (en) * | 2000-10-31 | 2002-05-17 | Toshiba Corp | Device and method for supporting construction of dictionary |
| JP2004118378A (en) * | 2002-09-25 | 2004-04-15 | Toshiba Corp | Information extraction system and information extraction method |
-
2002
- 2002-12-03 JP JP2002351429A patent/JP3774431B2/en not_active Expired - Fee Related
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07219962A (en) * | 1994-02-01 | 1995-08-18 | Dainippon Printing Co Ltd | Key word preparing device |
| JPH1145268A (en) * | 1997-07-28 | 1999-02-16 | Just Syst Corp | Document retrieval device and computer-readable recording medium where eprogram making computer funtion as same device is recorded |
| JPH11272701A (en) * | 1998-03-23 | 1999-10-08 | Oki Electric Ind Co Ltd | Information extraction device |
| JP2002140338A (en) * | 2000-10-31 | 2002-05-17 | Toshiba Corp | Device and method for supporting construction of dictionary |
| JP2004118378A (en) * | 2002-09-25 | 2004-04-15 | Toshiba Corp | Information extraction system and information extraction method |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10558756B2 (en) | 2016-11-03 | 2020-02-11 | International Business Machines Corporation | Unsupervised information extraction dictionary creation |
| US10558747B2 (en) | 2016-11-03 | 2020-02-11 | International Business Machines Corporation | Unsupervised information extraction dictionary creation |
| KR20200050620A (en) * | 2018-11-02 | 2020-05-12 | 한국전자통신연구원 | Apparatus and method for constructing new named entity dictionary with allomorph based on online encyclopedia |
| KR102479043B1 (en) * | 2018-11-02 | 2022-12-20 | 한국전자통신연구원 | Apparatus and method for constructing new named entity dictionary with allomorph based on online encyclopedia |
Also Published As
| Publication number | Publication date |
|---|---|
| JP3774431B2 (en) | 2006-05-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5040925B2 (en) | Information extraction rule creation support system, information extraction rule creation support method, and information extraction rule creation support program | |
| JPH11175527A (en) | Output controller and output control method | |
| JP2003248676A (en) | Solution data compiling device and method, and automatic summarizing device and method | |
| WO2006046523A1 (en) | Document analysis system and document adaptation system | |
| JP3573501B2 (en) | Index creation device | |
| JP2005038395A (en) | Database retrieval device | |
| JP3774431B2 (en) | Dictionary construction support device and dictionary construction support method | |
| JP2002140338A (en) | Device and method for supporting construction of dictionary | |
| JP2007279978A (en) | Document retrieval device and document retrieval method | |
| JP2003308314A (en) | Device for supporting document preparation | |
| JP2006276912A (en) | Device, method, and program for editing document | |
| JP6114090B2 (en) | Machine translation apparatus, machine translation method and program | |
| JP6807201B2 (en) | Information processing device | |
| JPH07134720A (en) | Method and device for presenting relative information in sentence preparing system | |
| JP2003173338A (en) | Dictionary construction support device, dictionary construction support method, and dictionary construction support program | |
| JP2007018158A (en) | Character processor, character processing method, and recording medium | |
| JP4043176B2 (en) | Natural language processing device | |
| US7613709B2 (en) | System and method for editing operations of a text object model | |
| JP4206266B2 (en) | Full-text search device, processing method, processing program, and recording medium | |
| JP2008171109A (en) | Information retrieval system, information retrieval method and program | |
| JP2021128618A (en) | Display device and program | |
| JPH0981581A (en) | Data base generation method | |
| JPWO2016046988A1 (en) | Document processing apparatus and item extraction method | |
| JPH11232270A (en) | Variable document preparation system, variable document output device and variable original preparing device | |
| JP5564932B2 (en) | Document proofreading support apparatus, program and method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20050831 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20050906 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20051107 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20060214 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20060217 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100224 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20100224 Year of fee payment: 4 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20110224 Year of fee payment: 5 |
|
| LAPS | Cancellation because of no payment of annual fees |