FR3083355A1 - Procede, systeme et produit pour l'amelioration d'un processus industriel - Google Patents
Procede, systeme et produit pour l'amelioration d'un processus industriel Download PDFInfo
- Publication number
- FR3083355A1 FR3083355A1 FR1856007A FR1856007A FR3083355A1 FR 3083355 A1 FR3083355 A1 FR 3083355A1 FR 1856007 A FR1856007 A FR 1856007A FR 1856007 A FR1856007 A FR 1856007A FR 3083355 A1 FR3083355 A1 FR 3083355A1
- Authority
- FR
- France
- Prior art keywords
- industrial process
- relevant parameter
- prediction
- output values
- improving
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000004519 manufacturing process Methods 0.000 title claims abstract description 141
- 238000000034 method Methods 0.000 title claims abstract description 66
- 230000009471 action Effects 0.000 claims abstract description 43
- 230000008569 process Effects 0.000 claims abstract description 27
- 238000009776 industrial production Methods 0.000 claims abstract description 21
- 238000004590 computer program Methods 0.000 claims abstract description 5
- 238000010801 machine learning Methods 0.000 claims description 23
- 238000007405 data analysis Methods 0.000 claims description 21
- 238000004891 communication Methods 0.000 claims description 18
- 238000004458 analytical method Methods 0.000 claims description 14
- 238000013528 artificial neural network Methods 0.000 claims description 7
- 238000013459 approach Methods 0.000 claims description 6
- 230000002452 interceptive effect Effects 0.000 claims description 6
- 238000012706 support-vector machine Methods 0.000 claims description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 20
- 230000007774 longterm Effects 0.000 description 7
- 238000005259 measurement Methods 0.000 description 6
- 230000008901 benefit Effects 0.000 description 3
- 238000012544 monitoring process Methods 0.000 description 3
- 150000001875 compounds Chemical class 0.000 description 2
- 238000002790 cross-validation Methods 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 230000005611 electricity Effects 0.000 description 2
- 238000005070 sampling Methods 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 238000013019 agitation Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000008020 evaporation Effects 0.000 description 1
- 238000001704 evaporation Methods 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 239000008235 industrial water Substances 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 230000002688 persistence Effects 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 238000005096 rolling process Methods 0.000 description 1
- 238000004088 simulation Methods 0.000 description 1
- 239000002689 soil Substances 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/04—Manufacturing
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02P—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN THE PRODUCTION OR PROCESSING OF GOODS
- Y02P90/00—Enabling technologies with a potential contribution to greenhouse gas [GHG] emissions mitigation
- Y02P90/30—Computing systems specially adapted for manufacturing
Landscapes
- Business, Economics & Management (AREA)
- Engineering & Computer Science (AREA)
- Primary Health Care (AREA)
- Strategic Management (AREA)
- Economics (AREA)
- General Health & Medical Sciences (AREA)
- Human Resources & Organizations (AREA)
- Marketing (AREA)
- Manufacturing & Machinery (AREA)
- Health & Medical Sciences (AREA)
- Tourism & Hospitality (AREA)
- Physics & Mathematics (AREA)
- General Business, Economics & Management (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
L'invention concerne un procédé, un système et un programme d'ordinateur pour améliorer le rendement d'un processus industriel dans une infrastructure de production industrielle, le système comprenant au moins un ensemble de capteurs pour capturer au moins des valeurs de sortie d'au moins un paramètre pertinent du processus industriel, une base de données pour mémoriser lesdites valeurs de sortie capturées et au moins des données de longues séries chronologiques d'historique relatives au paramètre pertinent ou au processus industriel, au moins une infrastructure informatique comprenant au moins un processeur sur lequel sont exécutés un ensemble de programmes mémorisés dans une mémoire pour mettre en oeuvre ledit procédé comprenant au moins la prédiction et la mémorisation d'au moins une valeur de sortie d'un paramètre pertinent et le déclenchement d'un ensemble d'actions à appliquer au processus industriel et/ou à l'infrastructure sur laquelle ledit processus industriel s'exécute.
Description
Procédé, système et produit pour l’amélioration d’un processus industriel
DOMAINE TECHNIQUE DE L’INVENTION
La présente invention concerne le domaine de la surveillance de processus industriels et, plus précisément, un procédé, un système et un produit informatique pour améliorer le rendement desdits processus industriels. Ces procédé, système et produit informatique pourraient être appliqués à la surveillance d’un processus industriel se rapportant, par exemple, et de manière non limitative, à l’hydrologie et particulièrement à l’hydroélectricité.
ARRIERE-PLAN TECHNOLOGIQUE DE L’INVENTION
La prédiction d’une valeur de sortie future d’un processus physique tel que la génération d’énergie électrique par un dispositif ou une machine tel qu’un réacteur nucléaire, par exemple, est une clé pour l’élaboration d’un ensemble de stratégies en vue d’améliorer le rendement ou le taux de production du dispositif ou de la machine. Par exemple, la prédiction de l’intensité de la vitesse du vent peut être utile pour la gestion des risques climatiques.
Il existe, dans l’art antérieur, des procédés et un système pour prévoir les valeurs futures d’un paramètre physique donné, cependant, lesdits procédés sont souvent limités par leur capacité à ne prédire qu’un phénomène avec des données d’historique ou de mémoire courte. En effet, une prédiction de données d’historique ou de mémoire longue est souvent nécessaire pour capturer la variabilité ou la volatilité d’un paramètre physique pertinent pour améliorer un processus industriel.
DESCRIPTION GENERALE DE L’INVENTION
La présente invention a pour but de pallier certains inconvénients de
I art antérieur en proposant une procédure en vue d’augmenter au moins la productivité d’un processus industriel.
Ce but est atteint par un procédé pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle comprenant au moins une base de données comprenant des données de longues séries chronologiques d’historique du processus industriel ou d’au moins un paramètre pertinent dudit processus industriel, au moins une infrastructure informatique contenant au moins une mémoire pour mémoriser un ensemble de programmes, au moins un processeur pour exécuter ledit procédé comprenant au moins une étape consistant à :
• générer des premières valeurs de sortie prédites d’un paramètre pertinent du processus industriel avec un premier modèle de prédiction mémorisé et les erreurs associées, sur la base des données de longues séries chronologiques d’historique relatives audit paramètre pertinent mémorisées dans la base de données, le procédé étant caractérisé en ce qu’il comprend également au moins les étapes suivantes consistant à :
• construire une famille de H modèles d’apprentissage automatique (ML) de prédiction, constituant le deuxième modèle de prédiction, pour la prédiction de multiples valeurs de sortie du même paramètre pertinent sur la base des données de séries chronologiques d’historique mémorisées et des premières valeurs de sortie prédites mémorisées et générer, avec ledit deuxième modèle de prédiction, de multiples deuxièmes valeurs de sortie prédites dudit paramètre pertinent et les erreurs associées ;
• comparer les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent et les valeurs de sortie réelles mémorisées dudit paramètre pertinent ;
• déterminer l’ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute, sur la base de l’analyse de la comparaison, et mémoriser lesdites actions ;
• déclencher, automatiquement ou manuellement, l’ensemble d’actions mémorisé et surveiller la sortie du paramètre pertinent sur la base au moins des erreurs prédites obtenues à partir de la deuxième étape de prédiction.
Selon une autre particularité, le premier modèle de prédiction utilisé pour générer des premières valeurs de sortie prédites d’un paramètre pertinent est un modèle ARFIMA (modèle autorégressif à moyennes mobiles fractionnairement intégré).
Selon une autre particularité, chaque modèle de la famille de H modèles d’apprentissage automatique de prédiction utilisé pour prévoir les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent est construit au moyen d’une approche de stratégie directe élargie dans laquelle les premières valeurs de sortie prédites mémorisées sont incorporées en tant que variables d’entrée exogènes en plus des données de longues séries chronologiques d’historique mémorisées relatives au paramètre pertinent du processus industriel.
Selon une autre particularité, le modèle d’apprentissage automatique est un modèle ANN (réseau neuronal artificiel).
Selon une autre particularité, le modèle d’apprentissage automatique est un modèle k-NN (k voisins les plus proches).
Selon une autre particularité, te modèle d’apprentissage automatique est un modèle SVR (régression basée sur une machine à vecteur de support).
Selon une autre particularité, le nombre de jour minimum, D, des données d’historique mémorisées pour améliorer le rendement du processus industriel est compris dans un intervalle défini par 100 < D < 300.
Un autre but de la présente invention consiste à proposer une infrastructure pour augmenter au moins la productivité d’un processus industriel.
Cet but est atteint par un système pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle, le système comprenant au moins un ensemble de capteurs pour capturer au moins des valeurs de sortie d’au moins un paramètre pertinent du processus industriel, une base de données pour mémoriser lesdites données de sortie capturées et au moins des données de longues séries chronologiques d’historique relatives au paramètre pertinent ou au processus industriel, au moins une infrastructure informatique comprenant au moins un processeur sur lequel sont exécutés un ensemble de programmes mémorisés dans une mémoire pour prédire et mémoriser au moins de multiples valeurs de sortie d’un paramètre pertinent et déclencher, automatiquement ou manuellement, un ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle ledit processus industriel s’exécute, au moyen de la mise en œuvre du procédé pour améliorer le rendement d’un processus industriel tel que décrit dans la présente demande.
Selon une autre particularité, le système comprend un dispositif de prédiction contenant au moins :
• une première unité de prédiction comprenant au moins une première mémoire pour mémoriser des données, un processeur exécutant le premier modèle de prédiction pour calculer les premières valeurs de sortie prédites du paramètre pertinent et les mémoriser dans la première mémoire ;
• une unité de modélisation comprenant au moins une deuxième mémoire pour mémoriser des données, un processeur pour exécuter un ensemble de programmes pour construire le deuxième modèle de prédiction de H modèles d’apprentissage automatique et les mémoriser dans la deuxième mémoire ;
• une deuxième unité de prédiction comprenant une troisième mémoire pour mémoriser des données, un processeur pour exécuter le deuxième modèle de prédiction pour calculer les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent et les erreurs prédites associées, et mémoriser lesdites valeurs de sortie et les erreurs prédites dans la troisième mémoire.
Selon une autre particularité, le système comprend un dispositif d’analyse de données comprenant au moins un processeur, au moins une mémoire pour mémoriser des données et/ou un ensemble de programmes dont l’exécution sur le processeur met en oeuvre la comparaison des multiples deuxièmes valeurs de sortie prédites du paramètre pertinent et des valeurs de sortie réelles dudit paramètre pertinent et génère au moins un ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
Selon une autre particularité, le dispositif d’analyse de données transmet le résultat de l’analyse à une interface interactive d’un opérateur du processus industriel, ladite interface interactive comprenant au moins un agencement pour permettre à l’opérateur de générer, après avoir vérifié le résultat de l’analyse, un ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
Selon une autre particularité, le système comprend un dispositif de déclenchement, connecté à au moins une unité de commande du processus industriel, contenant au moins un processeur, au moins une mémoire pour mémoriser des données et/ou des instructions exécutables sur le processeur de manière à déclencher l’ensemble d’actions mémorisé à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
Selon une autre particularité, le dispositif de déclenchement comprend un agencement pour appliquer automatiquement l’ensemble d’actions au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
Selon une autre particularité, le dispositif de déclenchement comprend un agencement pour appliquer manuellement l’ensemble d’actions au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
Selon une autre particularité, le dispositif de déclenchement comprend également une alarme pour alerter un opérateur du fait qu’un ensemble d’actions doivent être appliquées audit processus.
Selon une autre particularité, la première unité de prédiction est connectée, par l’intermédiaire de moyens de communication, à l’unité de modélisation de manière à transmettre au moins les premières valeurs de sortie prédites du paramètre pertinent du processus industriel, lesdites valeurs de sortie prédites étant mémorisées dans la deuxième mémoire.
Selon une autre particularité, l’unité de modélisation est connectée, par l’intermédiaire de moyens de communication, à la deuxième unité de prédiction de manière à transmettre le deuxième modèle de prédiction de H modèles d’apprentissage automatique, ledit deuxième modèle de prédiction étant mémorisé dans la troisième mémoire.
Selon une autre particularité, la première unité de prédiction est connectée, par l’intermédiaire de moyens de connexion, à la deuxième unité de prédiction de manière à transmettre les premières valeurs de sortie prédites du paramètre pertinent du processus industriel utilisées en tant que variables d’entrée pour le deuxième modèle de prédiction, lesdites valeurs de sortie prédites étant mémorisées dans la troisième mémoire.
Selon une autre particularité, la deuxième unité de prédiction est connectée, par l’intermédiaire de moyens de communication, au dispositif d’analyse de données de manière à transmettre au moins les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent, et les erreurs prédites relatives auxdites multiples deuxièmes valeurs de sortie prédites.
Selon une autre particularité, le dispositif d’analyse de données est connecté, par l’intermédiaire de moyens de communication, au dispositif de déclenchement de manière à transmettre un résultat de l’analyse, et l’ensemble d’actions à appliquer.
Selon une autre particularité, la première unité de prédiction, la deuxième unité de prédiction, l’unité de modélisation et au moins le dispositif d’analyse de données sont connectés à la base de données de manière à récupérer les données d’historique et/ou les données réelles relatives au processus industriel ou au paramètre pertinent dudit processus industriel.
Selon une autre particularité, les moyens de communication de la première unité de prédiction, de la deuxième unité de prédiction, de l’unité de modélisation, du dispositif d’analyse de données et au moins du dispositif de déclenchement sont des moyens de communication sans fil/filaires.
Un autre but de la présente invention consiste à proposer au moins un ensemble d’instructions qui, lorsqu’elles sont exécutées sur au moins un processeur, permettent d’augmenter au moins la productivité d’un processus industriel.
Cet but est atteint par un produit-programme d’ordinateur, mémorisé sur un support pouvant être lu par des moyens informatiques et contenant des instructions exécutables par au moins un processeur de ces moyens informatiques pour mettre en œuvre le procédé tel que décrit dans la présente 5 demande.
DESCRIPTION DES FIGURES ILLUSTRATIVES
D’autres caractéristiques et avantages de la présente invention apparaîtront plus clairement à la lecture de la description ci-après, faite en 10 référence aux annexés, dans lesquels :
- la figure 1 est une représentation schématique des étapes du procédé pour améliorer le rendement du processus industriel, selon un mode de réalisation ;
-la figure 2 est une représentation schématique du système pour 15 améliorer le rendement du processus industriel, selon un mode de réalisation ;
- la figure 3 est une représentation schématique de tableaux comparant les approches de stratégie directe (DirStr) et de stratégie directe élargie (DirStrX) ;
- les figures 4a et 4b sont respectivement des représentations 20 schématiques des vrais (réels) rendements de l’indice CAC40 sur la période couvrant la crise de 2002 jusqu’à 2010 et du tableau des mesures d’erreurs et des performances de trading pour tous les procédés ;
- les figures 5a et 5b sont respectivement des représentations schématiques des vrais (réels) rendements de l’indice S&P 500 sur la période couvrant la crise de 2002 jusqu’à 2010, et du tableau des mesures d’erreurs et des performances de trading pour tous les procédés ;
- les figures 6a et 6b sont respectivement des représentations schématiques des vrais (réels) rendements de l’indice CAC40 sur la période post-crise de 2015 jusqu’à 2017 et du tableau des mesures d’erreurs et des performances de trading pour tous les procédés ;
- les figures 7a et 7b sont respectivement des représentations schématiques des vrais (réels) rendements de l’indice S&P 500 sur la période post-crise de 2015 jusqu’à 2017, et du tableau des mesures d’erreurs et des performances de trading pour tous les procédés.
DESCRIPTION DES MODES DE REALISATION PREFERES DE L'INVENTION
La présente invention concerne un procédé pour améliorer le rendement d’un processus industriel.
Dans certains modes de réalisation, le procédé (figure 1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle comprenant au moins une base de données comprenant des données de longues séries chronologiques d’historique du processus industriel ou d’au moins un paramètre pertinent dudit processus industriel, au moins une infrastructure informatique contenant au moins une mémoire pour mémoriser un ensemble de programmes, au moins un processeur pour exécuter ledit procédé comprenant au moins une étape consistant à :
• générer des premières valeurs de sortie prédites d’un paramètre pertinent du processus industriel avec un premier modèle de prédiction mémorisé et les erreurs associées, sur la base des données de longues séries chronologiques d’historique relatives audit paramètre pertinent mémorisées dans la base de données ;
le procédé étant caractérisé en ce qu’il comprend également au moins les étapes suivantes consistant à :
• construire une famille de H modèles d’apprentissage automatique (ML) de prédiction, constituant le deuxième modèle de prédiction, pour la prédiction de multiples valeurs de sortie du même paramètre pertinent sur la base des données de séries chronologiques mémorisées et des premières valeurs de sortie prédites mémorisées et générer, avec ledit deuxième modèle de prédiction, de multiples deuxièmes valeurs de sortie prédites dudit paramètre pertinent et les erreurs associées ;
• comparer les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent et les valeurs de sortie réelles mémorisées dudit paramètre pertinent ;
• déterminer l’ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute, sur la base de l’analyse de la comparaison et mémoriser lesdites actions ;
• déclencher, automatiquement ou manuellement, l’ensemble d’actions mémorisé et surveiller la sortie du paramètre pertinent sur la base au moins des erreurs prédites obtenues à partir de la deuxième étape de prédiction.
Par exemple, et de manière non limitative, le processus industriel peut être lié, dans certains modes de réalisation, au domaine de l’hydrologie. En effet, le procédé proposé peut être utilisé pour prévoir (prédire) l’approvisionnement en eau et les demandes d’eau, des jours, semaines, mois et années, en lien avec les données d’historiques hydrométéorologiques à mémoire longue ou mémorisées. Lesdites données d’historique hydrométéorologiques peuvent comprendre, par exemple, la pluviométrie, le débit, la température, l’humidité, l’équivalent en eau de la neige, l’épaisseur de neige, la couverture nuageuse, le rayonnement, l’évaporation ou l’évapotranspiration, les niveaux d’eau dans le sol et le vent. L’infrastructure mettant en œuvre le processus industriel d’alimentation (approvisionnement) en eau peut comprendre un ensemble de capteurs pour capturer en amont lesdites données hydrométéorologiques tels que, par exemple, et de manière non limitative, des pluviomètres, des oreillers de neige ou des coussins à grêlons, qui mesurent tous la quantité d’hydrométéores une fois qu’ils sont tombés sur le sol. Les oreillers de neige mesurent le poids de la neige tombée et le convertissent en un équivalent en liquide. Les coussins à grêlons montrent la taille approximative et la quantité représentative des grêlons qui sont tombés à un emplacement. Certains capteurs peuvent mesurer la quantité d’eau distribuée quotidiennement. Un paramètre pertinent dans le processus d’alimentation en eau, par exemple, peut être la quantité d’eau disponible quotidiennement en fonction d’un ensemble d’événements hydrométéorologiques tels que décrits ci-dessus. L’infrastructure mettant en oeuvre le processus industriel d’alimentation en eau peut comprendre un ensemble de capteurs capturant la quantité de l’eau disponible quotidiennement. Les données relatives audit paramètre pertinent peuvent être mémorisées dans une base de données pour le processus de prédiction conformément au procédé décrit ci-dessus. La deuxième valeur de sortie prédite de la quantité d’eau disponible quotidiennement peut être comparée à une valeur mesurée réelle de ladite quantité d’eau disponible quotidiennement. Ledit résultat de la comparaison est ainsi utilisé pour entreprendre certaines actions. Par exemple, et de manière non limitative, si la deuxième valeur de sortie prévue est supérieure à celle mesurée, une action peut ainsi être, par exemple, l’augmentation de la taille du réservoir stockant l’eau fournie. Si, au contraire, ladite deuxième valeur de sortie prévue est inférieure à celle mesurée, une action entreprise peut consister à construire un réservoir ou des cuves pour retenir, par exemple, davantage d’eau pendant les épisodes pluvieux.
Dans un autre mode de réalisation, le paramètre pertinent peut être la quantité d’eau tombée. Dans ce cas, les multiples deuxièmes valeurs de sortie prédites peuvent éviter l’inondation d’une région en les intégrant dans un système d’alerte pour entreprendre des actions concrètes, telles que la construction de digues, par exemple.
Dans certains modes de réalisation, le processus industriel peut concerner la production d’énergie dans un système hydroélectrique. Dans ce cas, les mêmes données d’historique hydrométéorologiques mémorisées peuvent être utilisées. Un paramètre pertinent est l’énergie de sortie dudit système hydroélectrique. La base de données peut également contenir des données relatives à l’écoulement d’eau utilisé pour produire les énergies de sortie, ou des données relatives au barrage hydroélectrique. Selon que les multiples deuxièmes valeurs de sortie prédites de l’énergie hydroélectrique sont inférieures ou supérieures aux valeurs de sortie mesurées réelles de l’énergie hydroélectrique, le flux d’eau pour produire ladite énergie de sortie peut être augmenté ou réduit.
Dans certains modes de réalisation, le premier modèle de prédiction utilisé pour générer des premières valeurs de sortie prédites d’un paramètre pertinent est un modèle ARFIMA (modèle autorégressif à moyennes mobiles fractionnairement intégré).
Le modèle ARFIMA tient compte d’un continuum de différences fractionnaires -0,5 < d < 0,5, tandis que la généralisation du modèle autorégressif à moyennes mobiles (ARMA) classique aux différences fractionnaires permet de rechercher des ruptures structurelles et cela a été utile dans des domaines aussi variés que l’hydrologie ou l’énergie par exemple. La forme générale d’un modèle ARFIMA(p,d,q) pour modéliser la valeur de sortie quotidienne du paramètre pertinent yt du processus industriel est donnée par
0(fî)(l-B)dyt= où le paramètre d est une valeur non entière comprise entre [-0,5;0,5], yt est la valeur de sortie quotidienne du paramètre pertinent à l’instant t, et est une composante stochastique normalement distribuée avec une moyenne 0 et une variance σ2, et φ(Β) et 0(B) représentent respectivement les composantes AR (autorégressives) et MA (de moyenne mobile) avec un opérateur de retard B. Dans un modèle fractionnaire, la puissance peut être fractionnaire, avec la signification du terme identifié utilisant le développement en série binomiale formelle suivant :
. d(d - 1) , (1 - B)d = 1 - dB + B2 - 13
De plus, Bk est l’opérateur de décalage ou de retard, c’est-à-dire, qu’étant donné yt, nous avons Bkyt = yt_k. La formulation de la valeur de sortie du paramètre pertinent yt par le modèle ARFIMA indiquée par yt /l peut être réécrite en tant que :
^ = 0^(5)(1-5)-^(5¼
Le modèle ARFIMA, ayant le paramètre d pour la technique d’ordre fractionnaire, pourrait capturer à la fois la dépendance à long terme et la dépendance à court terme. En général, les estimateurs de d peuvent être obtenus en utilisant la probabilité maximale.
Pour la prédiction des valeurs de sortie du paramètre pertinent du processus industriel, une prédiction de séries chronologiques a multiples pas (pas temporel) (également appelée à long terme) est utilisée. Ladite prédiction à multiples pas consiste, en général, à prédire les H valeurs suivantes [ym+i»-»ym+H] compte tenu d’une série chronologique à une variable comprenant m observations ou données d’historique mémorisées du processus industriel ou du paramètre pertinent dudit processus industriel.
Dans l’approche à multiples pas (multi-step ahead), une stratégie de prédiction récursive et une stratégie de prédiction directe peuvent être utilisées. Avec la stratégie récursive, des prédictions sont générées en utilisant un modèle avec à un pas, appliqué de manière itérative pour le nombre de pas souhaité. Avec la stratégie directe, un modèle spécifique à horizon est estimé et des prédictions sont calculées directement par le modèle estimé pour chaque horizon de prédiction.
La stratégie récursive itère, H fois, un modèle de prédiction à un pas pour obtenir les H prédictions. Après l’estimation de la série future, elle est renvoyée en tant qu’entrée pour la prédiction suivante. Dans cette stratégie, un modèle unique f est entraîné pour effectuer une prédiction à un pas. Ce modèle suppose une dépendance autorégressive de la valeur future de la série chronologique vis-à-vis des m valeurs (ordre de retard ou d’intégration) passées et d’un terme de bruit à moyenne nulle supplémentaire ω comme suit yt+i = f<Jt' -.yt-m+i) + ω
En fonction du bruit présent dans la série chronologique et de l’horizon de prédiction, la stratégie récursive peut présenter une faible performance dans les tâches de prédiction à multiples pas.
La stratégie directe (DirStr) estime un ensemble de H modèles de prédiction, renvoyant chacun une prédiction pour l’horizon h g [1,...,/7]. En d’autres termes, H modèles fh sont appris (un pour chaque horizon) à partir des données de série chronologique mémorisées [y1( ...,ym] où yt+h = fh(yt'->yt-m+i) + u avec t e [Ι,.,.,η- H] et h G [1,...,//]. Les prédictions estimées ÿt+h sont obtenues en utilisant les H modèles fh appris comme suit
Yt+h = fh(yt, · > Υί-τη+ΐ)
L’horizon de prédiction h peut être vu comme la durée dans le futur pendant laquelle la prédiction doit être faite. En résumé, la stratégie de prédiction directe est basée sur H apprenants (modèles d’apprentissage). Cela signifie un apprenant pour prédire la valeur à l’instant t+1, un autre à l’instant t+2, etc. Ainsi, par exemple, lorsque la prédiction concerne une prédiction sur cinq jours, cinq apprenants peuvent ainsi être utilisés avec la stratégie directe.
Dans certains modes de réalisation, chaque modèle de la famille de H modèles d’apprentissage automatique de prédiction fh utilisés pour prévoir les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent yt est construit au moyen d’une approche de stratégie directe élargie (DirStrX) dans laquelle les premières valeurs de sortie prédites mémorisées y[l sont incorporées en tant que variables d’entrée exogènes en plus des données de longues séries chronologiques d’historique mémorisées relatives au paramètre pertinent du processus industriel.
ÿt+h = fh(yt. ->yt f-m+i )
La stratégie directe réduit à un minimum les erreurs prédites avec h pas avant au lieu des erreurs avec un pas comme pour la stratégie récursive.
La figure 3 montre, par exemple et de manière non limitative, la différence entre la stratégie directe (DirStr) et la stratégie directe étendue (DirStrX) pour un ordre de modèle m = 3 et un horizon de prédiction h = 3.
Dans certains modes de réalisation, le modèle d’apprentissage automatique fh est un modèle ANN (réseau neuronal artificiel). Dans un autre mode de réalisation, le modèle d’apprentissage automatique fh est un modèle k-NN (k voisins les plus proches). Dans un autre mode de réalisation, le modèle d’apprentissage automatique fh est un modèle SVR (régression basée sur une machine à vecteur de support ou séparateurs à vaste marge).
Dans certains modes de réalisation, un procédé ANN, un procédé k-NN et un procédé SVR peuvent être construits simultanément pour la prédiction de la deuxième valeur de sortie du paramètre pertinent du processus industriel.
Dans certains modes de réalisation, le nombre minimum de jours, D, des données d’historique mémorisées pour améliorer le rendement du processus industriel est compris dans un intervalle défini par 100 < D < 300. De préférence, le nombre minimum de jours, D, est fixé à 250 jours. Un tel nombre minimum de jours est suffisant pour capturer la mémoire longue et la persistance du phénomène de variabilité d’un paramètre pertinent du processus industriel.
L’invention concerne également un système (1) pour améliorer le rendement d’un processus industriel.
Dans certains modes de réalisation, le système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle, comme illustré sur la figure 2, comprend au moins un ensemble de capteurs (10) pour capturer au moins des valeurs de sortie d’au moins un paramètre pertinent du processus industriel, une base de données (11) pour mémoriser lesdites données de sortie capturées et au moins des données de longues séries chronologiques d’historique relatives au paramètre pertinent ou au processus industriel, au moins une infrastructure informatique comprenant au moins un processeur sur lequel sont exécutés un ensemble de programmes mémorisés dans une mémoire pour prédire et mémoriser au moins de multiples valeurs de sortie d’un paramètre pertinent et déclencher, automatiquement ou manuellement, un ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle ledit processus industriel s’exécute, au moyen de la mise en œuvre du procédé pour améliorer le rendement d’un processus industriel tel que décrit dans les sections précédentes.
Dans certains modes de réalisation, le système (1) comprend un dispositif de prédiction (12) contenant au moins :
• une première unité de prédiction (120) comprenant au moins une première mémoire pour mémoriser des données, un processeur exécutant le premier modèle de prédiction pour calculer les premières valeurs de sortie prédites du paramètre pertinent et les mémoriser dans la première mémoire ;
• une unité de modélisation (121) comprenant au moins une deuxième mémoire pour mémoriser des données, un processeur pour exécuter un ensemble de programmes pour construire le deuxième modèle de prédiction de H modèles d’apprentissage automatique et les mémoriser dans la deuxième mémoire ;
• une deuxième unité de prédiction (122) comprenant une troisième mémoire pour mémoriser des données, un processeur pour exécuter le deuxième modèle de prédiction pour calculer les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent et les erreurs prédites associées, et mémoriser lesdites valeurs de sortie et les erreurs prédites dans la troisième mémoire.
Dans certains modes de réalisation, le système (1) comprend un dispositif d’analyse de données (13) comprenant au moins un processeur, au moins une mémoire pour mémoriser des données et/ou un ensemble de programmes dont l’exécution sur le processeur met en œuvre la comparaison des multiples deuxièmes valeurs de sortie prédites du paramètre pertinent et des valeurs de sortie réelles dudit paramètre pertinent et génère au moins un ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
Dans certains modes de réalisation, le dispositif d’analyse de données (13) transmet le résultat de l’analyse à une interface interactive d’un opérateur du processus industriel, ladite interface interactive comprenant au moins un agencement pour permettre à l’opérateur de générer, après avoir vérifié le résultat de l’analyse, un ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
Dans certains modes de réalisation, le système (1) comprend un dispositif de déclenchement (14), connecté au moins à une unité de commande du processus industriel, contenant au moins un processeur, au moins une mémoire pour mémoriser des données et/ou des instructions exécutables sur le processeur de manière à déclencher l’ensemble d’actions mémorisé à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
Dans certains modes de réalisation, le dispositif de déclenchement (14) peut comprendre un agencement pour appliquer automatiquement l’ensemble d’actions au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
Par exemple, le dispositif de déclenchement (14) peut être connecté à une unité de commande du processus industriel et, par exemple à un bouton d’alimentation qui peut arrêter le processus, l’agencement peut être un dispositif mécanique connecté au bouton d’alimentation. Si, après l’analyse du résultat de la prédiction de la deuxième valeur de sortie du paramètre pertinent, l’action choisie consiste à arrêter le processus industriel, le dispositif de déclenchement (14) peut actionner le dispositif mécanique qui, à son tour, enfoncera le bouton d’alimentation pour le désactiver.
Dans certains modes de réalisation, le dispositif de déclenchement (14) peut comprendre un agencement pour appliquer manuellement l’ensemble d’actions au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
Par exemple, et de manière non limitative, le dispositif de déclenchement (14) peut comprendre un ensemble de boutons qui peuvent commander le fonctionnement du processus industriel et/ou de l’infrastructure sur laquelle le processus industriel s’exécute. Ledit dispositif de déclenchement peut également comprendre une alarme pour alerter un opérateur du fait qu’un ensemble d’actions doivent être appliquées audit processus. L’opérateur peut ainsi, manuellement, pousser au moins un bouton parmi l’ensemble de boutons de manière à appliquer au moins une action parmi l’ensemble d’actions nécessaire pour surveiller le processus et/ou l’infrastructure sur laquelle le processus industriel s’exécute.
Dans certains modes de réalisation, la première unité de prédiction (120) est connectée, par l’intermédiaire de moyens de communication, à l’unité de modélisation (121) de manière à transmettre au moins les premières valeurs de sortie prédites du paramètre pertinent du processus industriel, lesdites valeurs de sortie prédites étant mémorisées dans la deuxième mémoire.
Dans certains modes de réalisation, l’unité de modélisation (121) est connectée, par l’intermédiaire de moyens de communication, à la deuxième unité de prédiction (122) de manière à transmettre le deuxième modèle de prédiction de H modèles d’apprentissage automatique, ledit deuxième modèle de prédiction étant mémorisé dans la troisième mémoire.
Dans certains modes de réalisation, la première unité de prédiction (120) est connectée, par l’intermédiaire de moyens de connexion, à la deuxième unité de prédiction (122) de manière à transmettre les premières valeurs de sortie prédites du paramètre pertinent du processus industriel utilisées en tantque variables d’entrée pour le deuxième modèle de prédiction, lesdites valeurs de sortie prédites étant mémorisées dans la troisième mémoire.
Dans certains modes de réalisation, la deuxième unité de prédiction (122) est connectée, par l’intermédiaire de moyens de communication, au dispositif d’analyse de données (13) de manière à transmettre au moins les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent et les erreurs prédites associées auxdites multiples deuxièmes valeurs de sortie prédites.
Dans certains modes de réalisation, le dispositif d’analyse de données (13) est connecté, par l’intermédiaire de moyens de communication, au dispositif de déclenchement (14) de manière à transmettre un résultat de l’analyse, et l’ensemble d’actions à appliquer.
Par exemple, et de manière non limitative, en ce qui concerne les systèmes hydroélectriques, le dispositif de déclenchement (14) peut être connecté au système surveillant le flux d’eau dans les turbines, qui convertissent l’énergie du flux d’eau en une rotation mécanique de manière à actionner des alternateurs pour produire l’énergie de sortie. Lors de la réception des instructions ou des informations contenant au moins l’ensemble d’actions à appliquer du dispositif d’analyse de données (13), ledit dispositif de déclenchement (14) peut actionner automatiquement l’ouverture du système contrôlant l’entrée d’eau dans les turbines de manière à réduire ou augmenter le flux d’eau dans les turbines.
Dans certains modes de réalisation, la première unité de prédiction (120), la deuxième unité de prédiction (122), l’unité de modélisation (121) et au moins le dispositif d’analyse de données (13) sont connectés à la base de données (11) de manière à récupérer des données d’historique et/ou des données réelles relatives au processus industriel ou au paramètre pertinent dudit processus industriel.
Dans certains modes de réalisation, les moyens de communication de la première unité de prédiction (120), de la deuxième unité de prédiction (122), de l’unité de modélisation (121), du dispositif d’analyse de données (13) et au moins du dispositif de déclenchement (14) consistent en des moyens de communication sans fil/filaires (Wifi, USB, Ethernet, etc.).
L’invention concerne également un produit programme d’ordinateur pour améliorer le rendement d’un processus industriel.
Dans certains modes de réalisation, le produit programme d’ordinateur est mémorisé sur un support pouvant être lu par des moyens informatiques et contenant des instructions exécutables par au moins un processeur de ces moyens informatiques pour mettre en œuvre le procédé tel que décrit cidessus.
Dans ce qui suit, nous présentons un exemple pour la compréhension du principe de la présente invention et particulièrement de son efficacité. Dans l’exemple, le paramètre pertinent peut ne pas être un paramètre physique, cependant, on doit comprendre que le but dudit exemple est simplement d’illustrer comment le système de la présente invention fonctionne.
Par exemple, et de manière non limitative, le paramètre à prédire dans cet exemple est le rendement composé en continu ou le rendement logarithmique (également appelé simplement rendement). Le but est d’évaluer la performance du procédé présenté dans la présente demande.
Dans la modélisation de série chronologique financière, par exemple, les quantités suivantes présentent un intérêt et sont souvent utilisées pour définir le rendement ou la volatilité: Pt (0), qui sont, respectivement, les cours des actions à l’ouverture, à la fermeture du jour de trading et les valeurs maximum et minimum pour chaque jour de trading. La disponibilité d’un ensemble d’apprentissage de T cours historiques est supposée. Le rendement pour le jour t calculé à partir des cours à la fermeture Pt (c) et est donné par rt = ln(Pt(c)/Pt(_cî)
Un premier estimateur σθ du proxy de volatilité peut être défini comme la valeur au carré du rendement tel que défini ci-dessus. Afin d’optimiser l’estimation dudit proxy de volatilité, une famille de proxies σ/ peut être déduite en incorporant des informations supplémentaires telles que les cours à l’ouverture, maximum et minimum pour un jour de trading donné en plus du cours à la fermeture. Dans ce cas, une estimation de la volatilité peut être donnée par σ/ = 0.511(u — d)2 — (2 ln2 — l)c2 avec u = ln(Pt (h)/Pt^), d = ln(Pt(z)/Pt(_°J), c = ln(Pt(c)/Pt(_°J] et où u, d et c sont respectivement le cours élevé normalisé, le cours bas normalisé et le cours à la fermeture normalisé.
Afin d’évaluer la performance de prédiction du procédé décrit dans la présente demande, une comparaison sera faite avec un modèle ARMAGARCH(P,Q) hybride (appelé ici GarchX), un modèle kNN, un modèle SVR, un modèle ANN et les modèles combinés ARFIMA-kNN, ARFIMA-NN et ARFIMA-SVR.
Dans le modèle GarchX, le rendement est généralement donné par
Σρ Q .-Wt-i + X ,_1 bj£t_j + £t avec une moyenne μ, des coefficients autorégressifs at et des coefficients de moyenne mobile bj. Le terme Et est une composante stochastique avec la forme st = atzt (zt~N(0,l)) où les zt sont des variables aléatoires indépendantes et identiquement distribuées avec une moyenne et une variance unitaire, et at est formulé en utilisant un prédicteur externe, a? représentant ledit prédicteur externe (ω + ζσ') + +
Les coefficients œ,ah β,,ζ sont ajustés conformément à une procédure à probabilité logarithmique maximum (ou la fonction logarithmique de la probabilité) estimée. Dans cette étude, P=Q=1. Généralement, une distribution d’erreurs à asymétrie généralisée est utilisée lors de l’estimation et de la prédiction de modèles GARCH.
Pour de nombreux traders et analystes, la direction du marché est plus importante que la valeur de la prédiction elle-même, étant donné que l’argent des marchés financiers peut être réalisé simplement en connaissant la direction dans laquelle les rendements iront. Le modèle de trading utilise les valeurs précédentes des rendements en tant que caractéristiques d’entrée et la direction du marché des jours suivants en tant que caractéristique cible. Trois stratégies de trading différentes sont définies : une stratégie « naïve », une stratégie « acheter et conserver » et une stratégie de trading « hybride ». Pour comparer les différentes stratégies de trading, plusieurs mesures de performances de trading sont utilisées telles que le ratio de Sharpe, le rendement et la volatilité annualisés et le rapport gain/perte moyen. Ces mesures de performances de trading sont analysées en examinant les périodes pré- et post-crise financière.
La stratégie de trading « naïve » est simpliste. En effet, une action est achetée au marché d’ouverture suivant, si le jour actuel t est haussier, c’està-dire, à la hausse où le cours de fermeture Pt (c) du jour actuel est supérieur à son cours d’ouverture Pt (o). Dans le trading, les investisseurs achètent une action ou continuent s’ils pensent que sa valeur va augmenter. De cette manière, ils peuvent la vendre à une valeur plus élevée que celle payée et récoltent un profit.
Par la même occasion, l’action est vendue à l’ouverture suivante, si le jour actuel t est baissier, c’est-à-dire, à la baisse où le cours de fermeture Pt (c) du jour actuel est inférieur au cours d’ouverture Pt (o). Dans ce cas, les investisseurs vendent d’abord dans l’espoir que la valeur du cours de l’action diminuera et qu’ils seront capables de racheter le bien ultérieurement à un cours plus bas.
La stratégie « acheter et conserver » est une stratégie d’investissement où un investisseur achète des actions et les conserve longtemps, avec pour but que la valeur des actions augmentera graduellement sur une longue période de temps. Celle-ci est basée sur l’idée qu’à long terme les marchés financiers donnent un bon taux de rendement même en prenant en compte un degré de volatilité.
La stratégie « acheter et conserver » dit que les investisseurs ne verront jamais ces rendements s’ils liquident après une baisse. Ce point de vue considère que la détermination du moment propice, c’est-à-dire, le concept qu’on peut entrer dans le marché à prix bas et vendre à prix hauts, ne fonctionne pas ; tenter cette détermination du moment propice donne des résultats négatifs, au moins pour les petits investisseurs et les investisseurs sans grande expérience, aussi il vaut mieux qu’ils achètent et conservent simplement.
Dans la stratégie de trading « hybride », la seule différence comparée à la stratégie « naïve », est qu’on considère la tendance à terme du rendement prédit. La direction du marché du jour suivant et la position à prendre sont déterminées comme suit : si le rendement prédit rt pour le jour suivant t est positif, acheter au marché d’ouverture le jour suivant t ; autrement, s’il est négatif, vendre au marché d’ouverture le jour suivant t. Toutes les positions sont liquidées au marché de fermeture.
Les rendements prédits sont les revenus basés sur les modèles d’apprentissage utilisant soit simplement GarchX, KNN et SVR, soit ARFIMAKNN, ARFIMA-SVR et ARFIMA-NN combinés. Les rendements prédits sont générés par deux catégories de stratégies de prédiction : récursive et directe décrites ci-dessus, avec une approche de validation croisée de série chronologique. Cette approche implique l’apprentissage du modèle sur une fenêtre de données et la prédiction du revenu de la période suivante, et ensuite le décalage de la fenêtre d’apprentissage en avant d’une période. Le modèle est ensuite réappris sur la nouvelle fenêtre et le revenu de la période suivante est prédit. Ce processus est répété sur la longueur de la série chronologique. La performance de la validation croisée du modèle est simplement la performance des prédictions du jour suivant utilisant certaines mesures de performance bien connues présentées ci-dessous.
Pour comparer la précision et la performance de trading, tous les modèles sont maintenus avec une période hors échantillonnage identique. Cette étude utilise 4 métriques statistiques généralement utilisées telles que l’erreur quadratique moyenne (MSE), l’erreur absolue moyenne (MAE) et la racine de l’erreur quadratique moyenne (RMSE). Plus les valeurs de ces mesures sont petites, plus les valeurs de rendement prédites sont proches des valeurs réelles.
On observe que ces mesures de précision statistiques ne sont pas suffisantes pour analyser les résultats concernant le critère financier. L’erreur de prédiction peut avoir été réduite à un minimum pendant l’estimation du modèle, mais l’évaluation du mérite réel devrait être basée sur la performance des stratégies de trading. Certaines des mesures de performance plus importantes utilisées comprennent le rendement annualisé, le ratio de Sharpe, et le rapport gain/perte moyen. Le ratio de Sharpe est une mesure ajustée au risque du rendement, les ratios plus élevés étant préférés aux ratios plus faibles. Le rapport gain/perte moyen est une mesure du gain global, pour lequel une valeur au-dessus de 1 est préférée. Nous examinons le rendement prédit rt à l’instant t, n est le nombre de prédictions et représente la moyenne des rendements sur la période {1, ...,n].
Le rendement annualisé est donné par
RA = 255RC où Rc, le rendement cumulatif, est donné par
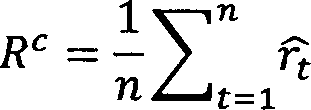
Le ratio de Sharpe est donné par
Sharpe ratio =
RA σΑ où σΑ, la volatilité annualisée, est donné par ,----- 1 x-171 255 ---T>
Le rapport de profit est donné par
Profit ratio =
Le rapport de profit est le rapport entre la somme des rendements rt positifs et la somme des rendements rt négatifs sur la période prédite t e {1.....n}.
L’étude est basée sur les cours de fermeture quotidiens Pt (c) pour les indices du CAC40 et du S&P500. Les deux séries couvrent la période du 1er janvier 2000 au 16 octobre 2017 totalisant 17 années avec 4476 jours de négociation. Ces séries ont été transformées en rendements rt comme l’équation définie ci-dessus du rendement composé. Pour évaluer notre étude du calme à I agitation, la série a été divisée en deux périodes : une historique de 9 années du 1er janvier 2000 au 31 décembre 2009 totalisant 2515 jours de négociation et couvrant une volatilité très faible avec une grande difficulté pendant la crise ; et une histoirique de 5 années du 1er janvier 2012 au 16 octobre 2017, la période post-crise totalisant 1457 jours de négociation.
Pour comparer la performance des modèles de prédiction proposés, il est nécessaire de les évaluer sur des données non vues précédemment. Cette situation est probablement la plus proche d’une situation de prédiction ou de négociation vraie. Pour réaliser cela, tous les modèles ont été maintenus avec une période hors échantillonnage identique permettant une comparaison directe de leur précision de prédiction et de leur performance de trading.
Pour chaque modèle de prédiction, nous avons effectué des prédictions de rendement à pas d’un jour ou directes à pas de deux jours sur la base d’une stratégie à origine roulante avec une fenêtre mobile fixée à 250 jours de négociation en tant qu échantillon de test. La performance moyenne est examinée parmi 30 exécutions indépendantes en débutant avec une fenêtre de 250 jours de trading prise de manière aléatoire dans les deux premières années des échantillons de données. Les différents modèles de prédiction GarchX, KNN, SVR et les modèles combinés ARFIMA-KNN, ARFIMA-SVR et ARFIMA-NN sont examinés pour tester les impacts sur la performance de trading et leur évaluation comparés à la référence de la stratégie « acheter et conserver ».
Les mesures d’erreurs utilisées sont l’erreur absolue moyenne, l’erreur quadratique moyenne, et la racine de l’erreur quadratique moyenne. Les mesures de performance de trading sont le rendement annualisé, la volatilité annualisée, le ratio de Sharpe et le rapport de profit tels que définis ci-dessus.
Nous commençons par analyser et examiner le résultat pendant la période couvrant la crise.
La figure 4a montre les vrais rendements de l’indice CAC40 sur la période couvrant la crise de 2002 jusqu’à 2010. De la même manière, la figure 5a montre les vrais rendements de l’indice S&P500 sur la période couvrant la crise de 2002 jusqu’à 2010. Sur ces figures, les procédés NN, ARFIMA-NN,
GarchX et ARFIMA-KNN montrent davantage de robustesse pendant la perturbation extrême pendant 2008-2009, tandis que les stratégies « acheter et conserver » et KNN présentent des pertes. Les tableaux 1 et 2, respectivement des figures 4b et 5b, donnent les détails des mesures d’erreurs et des performances de trading pour tous les procédés. Les trois meilleurs modèles sont NN-DirStr, ARFIMA-NN-DirStrX, GarchX. Dans le cas du CAC40, ARFIMA-NN-DirStrX et NN-DirStr montrent une haute performance avec un rendement annualisé d’environ 46 %, et un ratio de Sharpe supérieur à 1,90 et un rapport de profit supérieur à 44 %, tandis que la volatilité annualisée est similaire autour de 23_%. Pour le S&P500, avec une volatilité annualisée autour de -0,3 % comparé au CAC40, NN-DirStr, ARFIMA-NNDirStrX donnent tous deux un bon résultat de performance. On peut observer nettement, pour les deux indices, que le modèle hybride ARFIMA-KNN-DirStrX est plus performant que le simple KNN-DirStrX étant donné que, pour l’indice CAC40, le rendement prédit annualisé passe de -1,8 % à 22,36 %, le ratio de Sharpe passe de -0,08 à 0,96, et le rapport de profit passe de -0,015 % à 19,53 %. Et pour l’indice S&P500, le rendement annualisé passe de -15 % à 7 %, le ratio de Sharpe passe de -0,67 à 0,32, et le rapport de profit passe de -0,12 % à 0,06 %.
Enfin, tous les modèles proposés, à l’exception du KNN-DirStr, capturent bien l’effet asymétrique de la volatilité et la haute perturbation pendant la crise. Lorsqu’ils sont appliqués à l’indice CAC40, le rendement prédit annualisé va de 9,9 % à 46,25 %, avec un ratio de Sharpe de 0,42 à 1,99 et un rapport de profit de 0,08 % à 45,11 %, tandis que la stratégie « acheter et conserver » donne un rendement prédit annualisé de 2,5 % avec un ratio de Sharpe de 0,09 et un rapport de profit de 0,02. Lorsqu’ils sont appliqués à l’indice S&P500, le rendement prédit annualisé va de 1,5 % à 32 %, avec un ratio de Sharpe de 0,07 à 1,41 et un rapport de profit de 0,01 % à 331,2 %, tandis que la stratégie « acheter et conserver » donne un rendement annualisé de -0,3 % avec un ratio de Sharpe de -0,01 et un rapport de profit de -0,003 %.
Lors de l’analyse et de l’examen du résultat pendant la période postcrise, on peut voir que, similairement, la figure 6a montre les vrais rendements de l’indice CAC40 sur la période post-crise de 2015 jusqu’à 2017. De la même manière, la figure 7a montre les vrais rendements de l’indice S&P500 sur la période post-crise de 2015 jusqu’à 2017. Sur ces figures, les procédés NN, ARFIMA-NN, GarchX et ARFIMA-KNN montrent de plus hautes performances comparés à la stratégie « acheter et conserver » et à KNN. Sur les tableaux 3 et 4, respectivement des figures 6b et 7b, les trois meilleurs modèles sont NNDirStr, ARFIMA-NN-DirStrX et ARFIMA-KNN-DirStrX lorsqu’ils sont appliqués à l’indice CAC40, alors que la volatilité annualisée est d’environ 19,5 %. Dans le cas de l’indice S&P500, le tableau 4 montre que seuls ARFIMA-NN-DirStrX et NN-DirStr sont plus performants que la stratégie « acheter et conserver », alors que la volatilité annualisée est similaire autour de 13 %. Cela s’explique par le fait que la volatilité annualisée de l’indice S&P500 est plus faible comparé à I indice CAC40, illustrant une période calme où une simple stratégie « acheter et conserver » est couronnée de succès. Dans le cas de l’indice CAC40, davantage de perturbation est remarquée et capturée par les trois meilleurs modèles identifiés, et en première place le procédé ARFIMA-NNDirStr.
La même observation est faite pour l’indice CAC40 avec une volatilité et une perturbation plus élevées, le modèle hybride ARFIMA-KNN-DirStrX est nettement plus performant que le simple modèle KNN-DirStrX étant donné que, pour l’indice CAC40, le rendement prédit annualisé passe de 1,6 % à 20,2 %, le ratio de Sharpe passe de 0,08 à 1,04, et le rapport de profit passe de 0,02 % à 20,3 %.
Cette étude rapporte une tâche empirique qui recherche comment la performance de prédiction et de trading pourrait être améliorée en utilisant des modèles hybrides ARFIMA-apprentissage automatique couplés à une prédiction de stratégie directe à multiples pas. Ces modèles hybrides sont comparés avec de simples modèles d’apprentissage automatique utilisant une prédiction de stratégie directe, et également le modèle Garch classique avec un prédicteur externe (GarchX) basé sur une stratégie récursive. La performance des simulations de trading basées sur ces modèles est comparée avec la stratégie « acheter et conserver » bien connue. De plus, la performance de trading est estimée dans les périodes de crise lorsque le niveau de volatilité peut augmenter de façon spectaculaire en quelques jours.
Nous avons montré que, pendant les périodes de forte perturbation, la plupart des modèles examinés battent la stratégie « acheter et conserver » et réussissent à capturer le changement structurel avec l’effet de mémoire longue. A partir de l’analyse des résultats expérimentaux, il est nettement évident que les modèles proposés ARFIMA-NN-DirStrX, NN-DirStr et GarchX fournissent un meilleur rapport de profit avec une plus grande robustesse face aux agitations. Nous avons également remarqué l’avantage du modèle ARFIMA dans le modèle hybride ARFIMA-KNN-DirStrX étant donné qu’il augmente fortement le rapport de profit comparé au simple modèle KNNDirStr.
L’analyse montre également qu’il est difficile de battre la stratégie « acheter et conserver » dans une période calme et stable, caractérisée par une faible volatilité telle que rencontrée avec l’indice S&P500 dans la période post-crise.
Il a été montré, par cet exemple, combien le procédé décrit dans la présente demande peut être rentable.
Un autre exemple d’application du présent procédé et/ou du présent système, de manière non limitative, est la prédiction de l’intensité de la vitesse du vent pour la gestion des risques météorologiques. En effet, les producteurs d’électricité sont intéressés par les prédictions à long terme de la vitesse du vent pour au moins deux raisons principales :
. pour évaluer la profitabilité de la construction d’une ferme éolienne à un emplacement donné ; et . pour compenser les risques associés à la variabilité de la vitesse du vent pour une ferme éolienne déjà en fonctionnement.
Le procédé, tel que décrit dans la présente demande, peut être utilisé pour générer avec plus de précision une prédiction de l’évolution à long terme de l’intensité de la vitesse du vent (qui est, dans ce cas, le paramètre pertinent pour le processus de production d’électricité) et pourrait être utilisé pour alerter à temps de la nécessité d’entreprendre des actions contre un risque de dommages dus à une intensité de la vitesse du vent inattendue.
La présente demande décrit diverses caractéristiques techniques et avantages en référence aux figures et/ou à divers modes de réalisation. L’homme de métier comprendra que les caractéristiques techniques d’un mode de réalisation donné peuvent en fait être combinées avec des caractéristiques d’un autre mode de réalisation à moins que l’inverse ne soit explicitement mentionné ou qu’il ne soit évident que ces caractéristiques sont incompatibles ou que la combinaison ne fournisse pas une solution à au moins un des problèmes techniques mentionnés dans la présente demande. De plus, les caractéristiques techniques décrites dans un mode de réalisation donné peuvent être isolées des autres caractéristiques de ce mode à moins que l’inverse ne soit explicitement mentionné.
Il doit être évident pour les personnes versées dans l'art que la présente invention permet des modes de réalisation sous de nombreuses autres formes spécifiques sans l'éloigner du domaine d'application de l'invention comme revendiqué. Par conséquent, les présents modes de réalisation doivent être considérés à titre d'illustration, mais peuvent être modifiés dans le domaine défini par la protection demandée, et l'invention ne doit pas être limitée aux détails donnés ci-dessus.
Claims (23)
- REVENDICATIONS1. Procédé (2) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle comprenant au moins une base de données comprenant des données de longues séries chronologiques d’historique du processus industriel ou d’au moins un paramètre pertinent dudit processus industriel, au moins une infrastructure informatique contenant au moins une mémoire pour mémoriser un ensemble de programmes, au moins un processeur pour exécuter ledit procédé comprenant au moins une étape consistant à :• Générer, via un dispositif de prédiction, des premières valeurs de sortie prédites (20) d’un paramètre pertinent du processus industriel avec un premier modèle de prédiction mémorisé et les erreurs associées, sur la base des données de longues séries chronologiques d’historique relatives audit paramètre pertinent mémorisées dans la base de données, le procédé étant caractérisé en ce qu’il comprend également au moins les étapes suivantes consistant à :• construire (21), via le dispositif de prédiction, une famille de H modèles d’apprentissage automatique (ML) de prédiction, constituant le deuxième modèle de prédiction, pour la prédiction de multiples valeurs de sortie du même paramètre pertinent sur la base des données de séries chronologiques d’historique mémorisées et des premières valeurs de sortie prédites mémorisées et générer, avec ledit deuxième modèle de prédiction, de multiples deuxièmes valeurs de sortie prédites (22) dudit paramètre pertinent et les erreurs associées ;• comparer (23), via un dispositif d’analyse de données, les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent et les valeurs de sortie réelles mémorisées dudit paramètre pertinent ;• déterminer (24), via le dispositif d’analyses de données, l’ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute, sur la base de l’analyse de comparaison, et mémoriser lesdites actions ;• déclencher (25) automatiquement ou manuellement, via au moins un dispositif de déclenchement, l’ensemble d’actions mémorisé et surveiller la sortie du paramètre pertinent sur la base au moins des erreurs prédites obtenues à partir de la deuxième étape de prédiction.
- 2. Procédé pour améliorer le rendement d’un processus industriel selon la revendication 1, caractérisé en ce que le premier modèle de prédiction utilisé pour générer des premières valeurs de sortie prédites (20) d’un paramètre pertinent est un modèle ARFIMA (modèle autorégressif à moyennes mobiles fractionnairement intégré).
- 3. Procédé pour améliorer le rendement d’un processus industriel selon la revendication 1, caractérisé en ce que chaque modèle de la famille de H modèles d’apprentissage automatique de prédiction utilisé pour prévoir les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent est construit (21) au moyen d’une approche de stratégie directe élargie dans laquelle les premières valeurs de sortie prédites mémorisées sont incorporées en tant que variables d’entrée exogènes en plus des données de longues séries chronologiques d’historique mémorisées relatives au paramètre pertinent du processus industriel.
- 4. Procédé pour améliorer le rendement d’un processus industriel selon la revendication 1, caractérisé en ce que le modèle d’apprentissage automatique est un modèle ANN (réseau neuronal artificiel).
- 5. Procédé pour améliorer le rendement d’un processus industriel selon la revendication 1, caractérisé en ce que le modèle d’apprentissage automatique est un modèle k-NN (k voisins les plus proches).
- 6. Procédé pour améliorer le rendement d’un processus industriel selon la revendication 1, caractérisé en ce que le modèle d’apprentissage automatique est un modèle SVR (régression basée sur une machine à vecteur de support).
- 7. Procédé selon les revendications 1 à 6, caractérisé en ce que le nombre de jour minimum, D, des données d’historique mémorisées pour améliorer le rendement du processus industriel est compris dans un intervalle défini par 100 < D < 300.
- 8. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle, le système (1) comprenant au moins un ensemble de capteurs pour capturer au moins des valeurs de sortie d’au moins un paramètre pertinent du processus industriel, une base de données (11) pour mémoriser lesdites données de sortie capturées et au moins des données de longues séries chronologiques d’historique relatives au paramètre pertinent ou au processus industriel, au moins une infrastructure informatique comprenant au moins un ensemble de dispositifs comportant au moins un processeur sur lequel sont exécutés un ensemble de programmes mémorisés dans une mémoire pour prédire et mémoriser au moins de multiples valeurs de sortie d’un paramètre pertinent et déclencher, automatiquement ou manuellement, un ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle ledit processus industriel s’exécute, au moyen de la mise en œuvre du procédé pour améliorer le rendement d’un processus industriel selon la revendication 1.
- 9. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 8, caractérisé en ce qu’il comprend un dispositif de prédiction (12) contenant au moins :• une première unité de prédiction (120) comprenant au moins une première mémoire pour mémoriser des données, un processeur exécutant le premier modèle de prédiction pour calculer les premières valeurs de sortie prédites du paramètre pertinent et les mémoriser dans la première mémoire ;• une unité de modélisation (121) comprenant au moins une deuxième mémoire pour mémoriser des données, un processeur pour exécuter un ensemble de programmes pour construire le deuxième modèle de prédiction de H modèles d’apprentissage automatique et les mémoriser dans la deuxième mémoire ;• une deuxième unité de prédiction (122) comprenant une troisième mémoire pour mémoriser des données, un processeur pour exécuter le deuxième modèle de prédiction pour calculer les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent et les erreurs prédites associées, et mémoriser lesdites valeurs de sortie et erreurs prédites dans la troisième mémoire.
- 10. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 8, caractérisé en ce qu’il comprend un dispositif d’analyse de données (13) comprenant au moins un processeur, au moins une mémoire pour mémoriser des données et/ou un ensemble de programmes dont l’exécution sur le processeur met en œuvre la comparaison des multiples deuxièmes valeurs de sortie prédites du paramètre pertinent et des valeurs de sortie réelles dudit paramètre pertinent et génère au moins un ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
- 11. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 10, caractérisé en ce que le dispositif d’analyse de données (13) transmet le résultat de l’analyse à une interface interactive d’un opérateur du processus industriel, ladite interface interactive comprenant au moins un agencement pour permettre à l’opérateur de générer, après avoir vérifié le résultat de l’analyse, un ensemble d’actions à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
- 12. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 8, caractérisé en ce qu’il comprend un dispositif de déclenchement (14), connecté à au moins une unité de commande du processus industriel, contenant au moins un processeur, au moins une mémoire pour mémoriser des données et/ou des instructions exécutables sur le processeur de manière à déclencher l’ensemble d’actions mémorisé à appliquer au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
- 13. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 12, caractérisé en ce que le dispositif de déclenchement (14) comprend un agencement pour appliquer automatiquement l’ensemble d’actions au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
- 14. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 12, caractérisé en ce que le dispositif de déclenchement (14) comprend un agencement pour appliquer manuellement l’ensemble d’actions au processus industriel et/ou à l’infrastructure sur laquelle le processus industriel s’exécute.
- 15. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 12, caractérisé en ce que le dispositif de déclenchement (14) comprend également une alarme pour alerter un opérateur du fait qu’un ensemble d’actions doivent être appliquées audit processus.
- 16. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 9, caractérisé en ce que la première unité de prédiction (120) est connectée, par l’intermédiaire de moyens de communication, à l’unité de modélisation (121) de manière à transmettre au moins les premières valeurs de sortie prédites du paramètre pertinent du processus industriel, lesdites valeurs de sortie prédites étant mémorisées dans la deuxième mémoire.
- 17. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 9, caractérisé en ce que l’unité de modélisation (121) est connectée, par l’intermédiaire de moyens de communication, à la deuxième unité de prédiction (122) de manière à transmettre le deuxième modèle de prédiction de H modèles d’apprentissage automatique, ledit deuxième modèle de prédiction étant mémorisé dans la troisième mémoire.
- 18. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 9, caractérisé en ce que la première unité de prédiction (120) est connectée, par l’intermédiaire de moyens de connexion, à la deuxième unité de prédiction (122) de manière à transmettre les premières valeurs de sortie prédites du paramètre pertinent du processus industriel utilisées en tant que variables d’entrée pour le deuxième modèle de prédiction, lesdites valeurs de sortie prédites étant mémorisées dans la troisième mémoire.
- 19. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 9, caractérisé en ce que la deuxième unité de prédiction (122) est connectée, par l’intermédiaire de moyens de communication, au dispositif d’analyse de données (13) de manière à transmettre au moins les multiples deuxièmes valeurs de sortie prédites du paramètre pertinent et les erreurs prédites relatives auxdites multiples deuxièmes valeurs de sortie prédites.
- 20. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 10, caractérisé en ce que le dispositif d’analyse de données (13) est connecté, par l’intermédiaire de moyens de communication, au dispositif de déclenchement (14) de manière à transmettre un résultat de l’analyse, et l’ensemble d’actions à appliquer.
- 21. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon la revendication 9, caractérisé en ce que la première unité de prédiction (120), la deuxième unité de prédiction (122), l’unité de modélisation (121) et au moins le dispositif d’analyse de données (13) sont connectés à la base de données de manière à récupérer les données d’historique et/ou les données réelles relatives au processus industriel ou au paramètre pertinent dudit processus industriel.
- 22. Système (1) pour améliorer le rendement d’un processus industriel dans une infrastructure de production industrielle selon les revendications 16 à 20, caractérisé en ce que les moyens de communication de la première unité de prédiction (120), de la deuxième unité de prédiction5 (122), de l’unité de modélisation (121), du dispositif d’analyse de données (13) et au moins du dispositif de déclenchement (14) sont des moyens de communication sans fils/filaires.
- 23. Produit programme d’ordinateur, mémorisé sur un support pouvant être lu par des moyens informatiques et contenant des instructions10 exécutables par au moins un processeur de ces moyens informatiques pour mettre en œuvre le procédé selon la revendication 1.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR1856007A FR3083355B1 (fr) | 2018-06-29 | 2018-06-29 | Procede, systeme et produit pour l'amelioration d'un processus industriel |
| PCT/EP2019/067372 WO2020002622A1 (fr) | 2018-06-29 | 2019-06-28 | Procédé, système et produit pour l'amélioration d'un processus industriel |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR1856007 | 2018-06-29 | ||
| FR1856007A FR3083355B1 (fr) | 2018-06-29 | 2018-06-29 | Procede, systeme et produit pour l'amelioration d'un processus industriel |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| FR3083355A1 true FR3083355A1 (fr) | 2020-01-03 |
| FR3083355B1 FR3083355B1 (fr) | 2022-03-04 |
Family
ID=67514530
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| FR1856007A Active FR3083355B1 (fr) | 2018-06-29 | 2018-06-29 | Procede, systeme et produit pour l'amelioration d'un processus industriel |
Country Status (2)
| Country | Link |
|---|---|
| FR (1) | FR3083355B1 (fr) |
| WO (1) | WO2020002622A1 (fr) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11914599B2 (en) * | 2021-11-19 | 2024-02-27 | Hamilton Sundstrand Corporation | Machine learning intermittent data dropout mitigation |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6745169B1 (en) * | 1995-07-27 | 2004-06-01 | Siemens Aktiengesellschaft | Learning process for a neural network |
-
2018
- 2018-06-29 FR FR1856007A patent/FR3083355B1/fr active Active
-
2019
- 2019-06-28 WO PCT/EP2019/067372 patent/WO2020002622A1/fr active Application Filing
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6745169B1 (en) * | 1995-07-27 | 2004-06-01 | Siemens Aktiengesellschaft | Learning process for a neural network |
Non-Patent Citations (1)
| Title |
|---|
| YUAN XIAOHUI ET AL: "Wind power prediction using hybrid autoregressive fractionally integrated moving average and least square support vector machine", ENERGY, ELSEVIER, AMSTERDAM, NL, vol. 129, 19 April 2017 (2017-04-19), pages 122 - 137, XP085022905, ISSN: 0360-5442, DOI: 10.1016/J.ENERGY.2017.04.094 * |
Also Published As
| Publication number | Publication date |
|---|---|
| FR3083355B1 (fr) | 2022-03-04 |
| WO2020002622A1 (fr) | 2020-01-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3642647B1 (fr) | Procede d'acquisition et de modelisation par un capteur lidar d'un champ de vent incident | |
| US11151379B2 (en) | Method and system for crop type identification using satellite observation and weather data | |
| EP1281132A1 (fr) | Procede de simulation stochastique centralisee | |
| Terzago et al. | Sensitivity of snow models to the accuracy of meteorological forcings in mountain environments | |
| EP3688458B1 (fr) | Detection et caracterisation ameliorees d'anomalies dans un continuum d'eau | |
| EP1779149A1 (fr) | Systeme de previsions climatiques | |
| EP3080758A1 (fr) | Prediction d'une consommation de fluide effacee | |
| WO2020115431A1 (fr) | Procédé de détermination d'une vitesse de salissure d'une unité de production photovoltaïque | |
| WO2020002622A1 (fr) | Procédé, système et produit pour l'amélioration d'un processus industriel | |
| Allawi et al. | Monthly rainfall forecasting modelling based on advanced machine learning methods: Tropical region as case study | |
| Ehteram et al. | Read-First LSTM model: A new variant of long short term memory neural network for predicting solar radiation data | |
| WO2019063648A1 (fr) | Detection et caracterisation ameliorees d'anomalies dans un continuum d'eau | |
| Dahmani et al. | Etat de l’art sur les réseaux de neurones artificiels appliqués à l’estimation du rayonnement solaire | |
| FR3028114A1 (fr) | Procede de diagnostic d'un systeme photovoltaique | |
| Long et al. | Monthly precipitation modeling using Bayesian non-homogeneous hidden Markov chain | |
| Breckenfelder et al. | Asymmetry matters: A high-frequency risk-reward trade-off | |
| Panchanathan et al. | An overview of approaches for reducing uncertainties in hydrological forecasting: progress, and challenges | |
| CA2913250A1 (fr) | Estimation d'une consommation de fluide effacee | |
| Diodato et al. | Mixed nonlinear regression for modelling historical temperatures in Central–Southern Italy | |
| FR3135798A1 (fr) | Procédé de prévision d’une puissance produite par au moins un panneau photovoltaïque | |
| Msangi et al. | Ex post assessment methods of climate forecast impacts | |
| Chinchorkar et al. | Development of monsoon model for long range forecast rainfall explored for Anand (Gujarat-India) | |
| EP3380947B1 (fr) | Procédé et dispositif de prévision de nébulosité par traitement statistique de données sélectionnées par analyse spatiale | |
| Deschatre | Dependence modeling between continuous time stochastic processes: an application to electricity markets modeling and risk management | |
| Mabe et al. | The empirical evidence of climate change and its effects on rice production in the Northern region of Ghana |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PLFP | Fee payment |
Year of fee payment: 2 |
|
| PLSC | Publication of the preliminary search report |
Effective date: 20200117 |
|
| PLFP | Fee payment |
Year of fee payment: 3 |
|
| PLFP | Fee payment |
Year of fee payment: 4 |
|
| PLFP | Fee payment |
Year of fee payment: 5 |
|
| PLFP | Fee payment |
Year of fee payment: 6 |
|
| PLFP | Fee payment |
Year of fee payment: 7 |