ES2950156T3 - Método implementado por ordenador para predecir el uso de energía para una ruta - Google Patents
Método implementado por ordenador para predecir el uso de energía para una ruta Download PDFInfo
- Publication number
- ES2950156T3 ES2950156T3 ES20187503T ES20187503T ES2950156T3 ES 2950156 T3 ES2950156 T3 ES 2950156T3 ES 20187503 T ES20187503 T ES 20187503T ES 20187503 T ES20187503 T ES 20187503T ES 2950156 T3 ES2950156 T3 ES 2950156T3
- Authority
- ES
- Spain
- Prior art keywords
- segment
- data
- energy
- segments
- trip
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 116
- 238000005265 energy consumption Methods 0.000 claims abstract description 123
- 238000004422 calculation algorithm Methods 0.000 claims abstract description 29
- 238000005259 measurement Methods 0.000 claims abstract description 17
- 238000005457 optimization Methods 0.000 claims description 33
- 230000000694 effects Effects 0.000 claims description 23
- 238000013528 artificial neural network Methods 0.000 claims description 16
- 230000015654 memory Effects 0.000 claims description 15
- 238000004590 computer program Methods 0.000 claims description 13
- 238000009499 grossing Methods 0.000 claims description 10
- 238000012545 processing Methods 0.000 claims description 10
- 238000004140 cleaning Methods 0.000 claims description 6
- 238000010248 power generation Methods 0.000 description 18
- 238000010586 diagram Methods 0.000 description 15
- 239000000543 intermediate Substances 0.000 description 14
- 230000006870 function Effects 0.000 description 11
- 238000012549 training Methods 0.000 description 11
- 230000007613 environmental effect Effects 0.000 description 10
- 238000004364 calculation method Methods 0.000 description 9
- 230000008859 change Effects 0.000 description 8
- 238000007781 pre-processing Methods 0.000 description 8
- 239000011159 matrix material Substances 0.000 description 7
- 238000003860 storage Methods 0.000 description 7
- 230000001133 acceleration Effects 0.000 description 6
- 238000013459 approach Methods 0.000 description 6
- 239000000470 constituent Substances 0.000 description 5
- 238000012360 testing method Methods 0.000 description 5
- 238000013500 data storage Methods 0.000 description 4
- 238000007637 random forest analysis Methods 0.000 description 4
- 230000002776 aggregation Effects 0.000 description 3
- 238000004220 aggregation Methods 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 238000004891 communication Methods 0.000 description 3
- 230000001186 cumulative effect Effects 0.000 description 3
- 238000009826 distribution Methods 0.000 description 3
- 230000005611 electricity Effects 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- 238000010801 machine learning Methods 0.000 description 3
- 239000000203 mixture Substances 0.000 description 3
- 230000036651 mood Effects 0.000 description 3
- 238000001556 precipitation Methods 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 238000013515 script Methods 0.000 description 3
- 230000007704 transition Effects 0.000 description 3
- 208000019901 Anxiety disease Diseases 0.000 description 2
- 230000036506 anxiety Effects 0.000 description 2
- 238000003491 array Methods 0.000 description 2
- 230000006399 behavior Effects 0.000 description 2
- 239000003086 colorant Substances 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 239000003814 drug Substances 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 239000010410 layer Substances 0.000 description 2
- 238000007726 management method Methods 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 238000013450 outlier detection Methods 0.000 description 2
- 238000011002 quantification Methods 0.000 description 2
- 238000013139 quantization Methods 0.000 description 2
- 238000012384 transportation and delivery Methods 0.000 description 2
- ORILYTVJVMAKLC-UHFFFAOYSA-N Adamantane Natural products C1C(C2)CC3CC1CC2C3 ORILYTVJVMAKLC-UHFFFAOYSA-N 0.000 description 1
- 238000006424 Flood reaction Methods 0.000 description 1
- 102000005717 Myeloma Proteins Human genes 0.000 description 1
- 108010045503 Myeloma Proteins Proteins 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 230000001353 anxiety effect Effects 0.000 description 1
- 230000001174 ascending effect Effects 0.000 description 1
- 230000004888 barrier function Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 238000004138 cluster model Methods 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 238000002790 cross-validation Methods 0.000 description 1
- 238000013135 deep learning Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000006866 deterioration Effects 0.000 description 1
- 238000001810 electrochemical catalytic reforming Methods 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 238000011176 pooling Methods 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 230000002787 reinforcement Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000013432 robust analysis Methods 0.000 description 1
- 238000010845 search algorithm Methods 0.000 description 1
- 230000011218 segmentation Effects 0.000 description 1
- 239000002356 single layer Substances 0.000 description 1
- 239000002689 soil Substances 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
Classifications
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01C—MEASURING DISTANCES, LEVELS OR BEARINGS; SURVEYING; NAVIGATION; GYROSCOPIC INSTRUMENTS; PHOTOGRAMMETRY OR VIDEOGRAMMETRY
- G01C21/00—Navigation; Navigational instruments not provided for in groups G01C1/00 - G01C19/00
- G01C21/26—Navigation; Navigational instruments not provided for in groups G01C1/00 - G01C19/00 specially adapted for navigation in a road network
- G01C21/34—Route searching; Route guidance
- G01C21/3453—Special cost functions, i.e. other than distance or default speed limit of road segments
- G01C21/3469—Fuel consumption; Energy use; Emission aspects
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01C—MEASURING DISTANCES, LEVELS OR BEARINGS; SURVEYING; NAVIGATION; GYROSCOPIC INSTRUMENTS; PHOTOGRAMMETRY OR VIDEOGRAMMETRY
- G01C21/00—Navigation; Navigational instruments not provided for in groups G01C1/00 - G01C19/00
- G01C21/26—Navigation; Navigational instruments not provided for in groups G01C1/00 - G01C19/00 specially adapted for navigation in a road network
- G01C21/28—Navigation; Navigational instruments not provided for in groups G01C1/00 - G01C19/00 specially adapted for navigation in a road network with correlation of data from several navigational instruments
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
Abstract
Un método implementado por computadora para predecir el uso de energía para una ruta que comprende: ingresar datos de mapas de carreteras incluidas en K viajes en un área geográfica e ingresar predictores de la tasa de uso de energía a lo largo de las carreteras; introducir datos de consumo de energía de los K viajes, indicando los datos de consumo de energía el uso total de energía T entre un punto inicial A y un punto final B de cada uno de los K viajes; dividir cada una de las carreteras en los datos del mapa para todos los viajes en segmentos de medida de longitud λi; agrupar los segmentos de los viajes en un número N de grupos, definiéndose los grupos de acuerdo con rangos de al menos uno de los predictores, definiéndose cada grupo con un peso Wj que está por determinar; utilizar un algoritmo para construir un modelo que prediga los pesos Wj basándose en la resolución de un sistema de ecuaciones, una por viaje, cada ecuación iguala el consumo de energía total conocido T del viaje con la suma de la medida de longitud conocida de cada segmento en el viaje multiplicada por el peso del grupo en el que se agrupó el segmento; para cada segmento, asignar el peso previsto aplicado al grupo en el que se agrupó el segmento como la tasa prevista de uso de energía Yi; y almacenar una ID de segmento con la ID de grupo correspondiente o tasa prevista de uso de energía Yi para permitir la predicción del uso de energía para una ruta en el área geográfica que incorpora uno o más de los segmentos. asignar el peso previsto aplicado al grupo en el que se agrupó el segmento como la tasa prevista de uso de energía Yi; y almacenar una ID de segmento con la ID de grupo correspondiente o tasa prevista de uso de energía Yi para permitir la predicción del uso de energía para una ruta en el área geográfica que incorpora uno o más de los segmentos. asignar el peso previsto aplicado al grupo en el que se agrupó el segmento como la tasa prevista de uso de energía Yi; y almacenar una ID de segmento con la ID de grupo correspondiente o tasa prevista de uso de energía Yi para permitir la predicción del uso de energía para una ruta en el área geográfica que incorpora uno o más de los segmentos. (Traducción automática con Google Translate, sin valor legal)
Description
DESCRIPCIÓN
Método implementado por ordenador para predecir el uso de energía para una ruta
Campo de la invención
La presente invención se refiere a la predicción del efecto de componentes individuales en una estadística agregada (una estadística que es la suma de otras variables aleatorias). En particular, puede relacionarse con la predicción del efecto de cada segmento de un viaje en el consumo total de energía de un vehículo eléctrico. La presente invención puede relacionarse además con la optimización de rutas energéticamente eficientes aplicando un algoritmo de optimización de rutas después de la estimación del consumo de energía para cada segmento del viaje, tal como un segmento de carretera.
Antecedentes de la invención
Una de las mayores barreras para la adopción a gran escala de vehículos eléctricos (EV) es la ansiedad por la autonomía. A pesar de las recientes mejoras en la tecnología de las baterías y la distribución cada vez más amplia de las estaciones de carga, muchos consumidores temen que una batería agotada los deje tirados debido a un cálculo erróneo de su autonomía restante.
El motivo de esta ansiedad es que el consumo energético de un vehículo eléctrico depende de muchos factores, por lo que la energía consumida durante el mismo trayecto o el mismo coche puede ser impredecible. Estos factores incluyen, por ejemplo, cualquier parámetro relevante como el estilo de conducción (pasivo o agresivo), el estado del vehículo, el estado de ánimo del conductor (por ejemplo, si el estado de ánimo de un conductor en un día en particular hace que su estilo de conducción se desvíe de su estilo habitual de conducción), las condiciones climáticas, las propiedades de la carretera, el tráfico y los eventos inesperados que ocurren durante el viaje. Esta falta de previsibilidad se ve agravada por los errores y el ruido en la medición de funciones importantes como la capacidad de la batería y la aceleración.
Se han realizado muchos intentos en la técnica anterior para disminuir el efecto de ansiedad de alcance. Los modelos de estimación de consumo de energía más notables se basan en datos de series de tiempo vinculados a cada segmento de carretera y un valor de verdad base del consumo de energía a nivel de enlace, es decir, para cada segmento de carretera. Esto se conoce como verdad de base a nivel de enlace, y la de verdad base se usa en este documento para denotar valores/medidas empíricas en oposición a medidas/valores derivados o valores conocidos. Se han utilizado registradores de GPS para vincular datos a segmentos de carreteras con el fin de predecir el consumo de energía para esos segmentos. Sin embargo, tales datos pueden ser costosos de obtener y, cuando se adquieren, requieren mucho tiempo de preprocesamiento antes de usarlos en el modelado.
El entrenamiento de modelos de aprendizaje automático para la predicción precisa del consumo de energía de manera supervisada se basa en valores de verdad base a nivel de enlace para el consumo de energía de cada segmento de carretera. Lo mismo ocurre con otros modelos.
El documento de estado de la técnica EE. UU. 2019/113354 A1 se refiere a un método para generar rutas de navegación para un vehículo, que incluye: recibir una posición de origen, en una red de carreteras, del vehículo; recibir una posición de destino, en la red de carreteras; recibir una preferencia de usuario desde un dispositivo de interfaz de usuario, indicando la preferencia de usuario un valor de compensación que tiene uno de una pluralidad de valores entre el tiempo de viaje y la eficiencia energética; calcular un valor de tiempo para cada uno de una pluralidad de segmentos de carretera de la red de carreteras utilizando un modelo de consumo de tiempo; calcular un consumo de energía para cada uno de la pluralidad de segmentos de carretera de la red de carreteras utilizando un modelo de consumo de energía; identificar una ruta ponderada desde la posición de origen hasta la posición de destino en base al valor del tiempo y el consumo de energía para los segmentos de carretera y con base en la preferencia del usuario; y suministrar la ruta ponderada identificada a un sistema de navegación del vehículo.
El documento de estado de la técnica EE. UU. 2012/232783 A1 se refiere a un método y sistema para determinar rutas energéticamente eficientes. Los datos de mapa representan segmentos de carretera. Los datos de consumo energético se obtienen mientras un vehículo circula por un primer segmento de carretera. Los datos de consumo de energía asociados con el primer segmento de carretera se pueden utilizar para predecir el consumo de energía esperado cuando se viaja en un segundo segmento de carretera que tiene atributos físicos similares a los del primer segmento de carretera. Los datos de consumo de energía pronosticados pueden usarse para determinar si el segundo segmento de carretera es parte de una ruta más eficiente energéticamente.
El documento de estado de la técnica EP 2690408 A1 se refiere a un método de operar un sistema de navegación de un vehículo. El método comprende determinar una cantidad actual de energía disponible del vehículo y determinar un costo de consumo de energía acumulado requerido para viajar a uno respectivo de una pluralidad de segmentos de carretera a lo largo de una ruta. El método comprende además, para una pluralidad de segmentos de carretera, comparar la cantidad actual de energía disponible con el coste de consumo de energía acumulado para obtener una cantidad de energía disponible al llegar al segmento de carretera respectivo. El método comprende además indicar gráficamente la ruta en
una vista de mapa, donde cada uno de la pluralidad de los segmentos de carretera se indica mediante colores, siendo los colores indicativos de la cantidad de energía disponible.
Declaraciones de invención
Los inventores se han dado cuenta de que sería ventajoso superar el desafío de predecir el consumo de energía de un segmento de carretera sin un valor de verdad base a nivel de enlace.
Por lo tanto, se han dado cuenta de que es deseable proporcionar una técnica de modelado para estimar el consumo de energía para cada segmento a partir de datos de viaje agregados, sin valor de verdad base a nivel de enlace para el consumo de energía en puntos intermedios del viaje. De manera más general, es deseable predecir una estadística agregada (por ejemplo, en cualquiera de los campos de consumo de energía, finanzas, gestión de producción o detección de anomalías) basada en el efecto de los componentes individuales modelados, pero sin conocimiento de la contribución de los componentes individuales.
De acuerdo con una realización de un primer aspecto de la invención, se proporciona un método implementado por computadora para predecir el uso de energía para una ruta. Los términos "carretera/camino", "vehículo" y "ruta" se utilizan aquí con carácter general, por lo que un vehículo puede ser un coche, camión, autobús, motocicleta que circule por una carretera, o cualquier vehículo que circule por vías u otros caminos y que utilice energía para viajar.
El uso de energía puede ser para un vehículo estándar o promedio o puede ajustarse para un vehículo en particular, después o durante el método. Igualmente, el uso de energía puede ajustarse para una velocidad predicha o basarse en una velocidad promedio o estandarizada.
En una primera fase, se construye un modelo. Hay dos tipos de entrada: datos de mapa y datos de consumo de energía, que pueden ser en paralelo o consecutivos, en cualquier orden. El método puede comprender la introducción de datos de mapa de carreteras incluidas en una pluralidad de viajes, o K viajes, en un área geográfica, y la introducción de predictores de la tasa de uso de energía a lo largo de las carreteras. El método también puede comprender la introducción de datos de consumo de energía (vehículo) de los K viajes, indicando los datos de consumo de energía el uso total de energía o el consumo T entre el punto de inicio A y el punto final B de cada viaje, medido por ejemplo como potencia en vatios o como una tasa por kilómetro en Wh/km. Estos últimos datos pueden promediarse entre una gama de vehículos o estandarizarse, por ejemplo, establecidos por un determinado vehículo. Las carreteras en los datos de mapa se pueden dividir en segmentos de (generalmente fraccionario pero potencialmente un valor real de) medida de longitud Ái, que pueden ser de diferentes medidas individuales de longitud. Por ejemplo, Ai puede ser la longitud del segmento i-ésimo dividida por la longitud total del viaje, es decir, un número en el intervalo [0, 1]. Los segmentos para los viajes se pueden agrupar en un número N de clústeres. Aquí, los clústeres pueden definirse de acuerdo con rangos de al menos uno de los predictores, definiéndose cada clúster con una ponderación/peso Wj que está por determinarse.
Luego, el método puede usar un algoritmo para construir un modelo que prediga las ponderaciones Wj basado en la solución de un sistema de ecuaciones, una por viaje, cada ecuación igualando el consumo total de energía conocido T del viaje con la suma de la medida de longitud conocida de cada segmento del viaje multiplicada por la ponderación del clúster en el que se agrupó el segmento. Para cada segmento, el método puede asignar la ponderación predicha aplicada al clúster en el que se agrupó el segmento como la tasa predicha de uso de energía Y; y almacenar una ID de segmento con una indicación de la tasa predicha de uso de energía Yi (como el ID de clúster correspondiente o el uso de energía total previsto del segmento o la tasa predicha de uso de energía Yi). Esto permite la predicción del uso de energía para una ruta en el área geográfica que incorpora uno o más de los segmentos. El último paso puede estar en una fase de consulta, que consulta el modelo para recuperar información que relaciona cada segmento con una tasa de uso de energía. La simple adición de esta información para cada segmento (potencialmente ampliada o reducida según un vehículo en particular y/o la velocidad predicha) proporcionará una idea del uso de energía de la ruta. La predicción del uso de energía puede ser comparativa (no adaptada para un vehículo específico), por ejemplo, para seleccionar una ruta de rutas potenciales entre un punto de inicio y final, con base en el consumo de energía.
El preprocesamiento opcional puede comprender, antes de ingresar los datos del mapa, para cada viaje en una base de datos, encontrar la ruta más corta entre el punto de inicio A y punto final B; comprobar la longitud en la base de datos entre el punto de inicio A y punto final B; e incluir los datos de la ruta más corta para un viaje si su longitud está dentro de un umbral de la ruta más corta entre A y B para formar los K viajes. El umbral puede expresarse en una longitud absoluta o una desviación porcentual, por ejemplo. La desviación porcentual puede ser del 10%, más preferiblemente entre el 1% y el 5%, lo más preferiblemente del 2%.
El preprocesamiento opcional puede comprender, antes de introducir los datos de mapa, la limpieza de datos que comprende preferiblemente suavizar los datos de elevación en mosaicos de elevación, cuando hay más de un punto en un mosaico, cambiar la elevación de uno o más puntos de borde en el mosaico adyacente a un mosaico de una elevación diferente para mover la elevación de los puntos de borde más cerca de la elevación del mosaico de la elevación diferente. Es decir, el preprocesamiento puede interpolar linealmente la elevación de los puntos intermedios teniendo en cuenta la elevación de los puntos que se encuentran en mosaicos de diferentes elevaciones.
El método puede extenderse para incluir todos los segmentos en el área geográfica al: dividir las partes de las carreteras en el área geográfica que no están incluidas en los viajes en segmentos no transitados; agrupar cualquier segmento no transitado en un clúster de acuerdo con el nivel de al menos uno de los predictores en ese segmento no transitado; y usar la tasa predicha de uso de energía y la medida de longitud de cada segmento no transitado para predecir el uso de energía para una ruta que también incorpora uno o más de los segmentos no transitados. Por lo tanto, se usa el mismo método que para los segmentos anteriores (no recorridos) en el modelo, para agrupar un segmento en un grupo una vez que se ha creado el modelo. Por lo tanto, el método puede cubrir todas las rutas en un mapa, formen o no parte de uno de los viajes que se utilizan para construir el modelo.
Puede usarse cualquier predictor adecuado. Por ejemplo, los predictores pueden incluir al menos uno de: gradientes en los segmentos, como un gradiente promedio positivo o negativo del segmento; y características que afectan el tráfico en los segmentos, como datos históricos de tráfico, señales de tráfico, cruces y tiendas, tipos de carreteras, temperatura meteorológica, velocidad del vehículo y/o efectos del viento. Las pendientes, las señales de tráfico, las tiendas y los tipos de carreteras pueden derivarse de datos de mapa (datos geográficos efectivos, que pueden ser, pero no necesariamente, los mismos que los datos de mapa que contienen las carreteras). Los datos restantes, como la temperatura meteorológica y la velocidad del vehículo y/o los efectos del viento, se pueden ingresar junto con los datos de consumo de energía relacionados con los viajes. Por ejemplo, la dirección del viento en un área geográfica puede consultarse a proveedores de datos de código abierto antes de que comience el viaje y la temperatura ambiente puede obtenerse de los datos meteorológicos de ese día. En cuanto a la velocidad, se puede tener en cuenta el historial del conductor en particular, así como los datos de tráfico históricos anteriores (si están disponibles); si no se dispone de historial, el método puede utilizar un valor de velocidad nominal para cada segmento de carretera proporcionado con los datos de consumo de energía. Otros datos del vehículo, como la temperatura de la batería, se pueden adquirir del vehículo y/o los datos de consumo de energía.
La generación de clústeres es una parte importante del método. Preferiblemente, los clústeres se definen de acuerdo con rangos de uno o más predictores que proporcionan un espacio de predictores de un número de dimensiones igual al número de predictores. Por ejemplo, dos predictores principales que se pueden usar juntos en un espacio de predictor bidimensional son el gradiente y un número de tiendas, o el gradiente y las señales de tráfico. El espacio predictor puede proporcionar, por ejemplo, un eje para cada predictor. Un predictor que tenga un mayor efecto sobre el uso de energía se divide preferiblemente en más divisiones de clústeres que un predictor que tenga un menor efecto sobre el uso de energía.
El método puede incluir, para cada dimensión, ordenar la división del clúster de modo que una división que represente un nivel de predictor que tenga un efecto menor sobre el consumo de energía se proporcione en una división más baja (y/o en una posición más baja a lo largo del eje para ese predictor) que una división que representa un nivel de predictor que tiene un mayor efecto sobre el consumo de energía, y Wj tiene un valor menor que Wj+1. Esto proporciona una agrupación natural y fácilmente comprensible en clústeres.
El método es especialmente ventajoso si el número de segmentos de carretera en la zona geográfica M es al menos un orden de magnitud mayor que el número N de clústeres y/o el número de viajes K
Se puede usar cualquier algoritmo adecuado para predecir las ponderaciones de los clústeres y construir así el modelo. En ejemplos, el algoritmo para construir el modelo puede ser un algoritmo de optimización cuadrática o desarrollado por una red neuronal.
Cuando el algoritmo es un algoritmo de optimización cuadrática, puede restringirse usando restricciones para las ponderaciones. En este caso, las ponderaciones pueden estar restringidas según los grupos a los que están asignadas (con una ponderación mayor para un grupo superior), y así ordenarse según el impacto que tiene cada predictor en la tasa de consumo de energía. El mismo viaje en los datos de consumo de energía de A a B puede tener diferentes valores según el comportamiento de conducción/estado de ánimo del conductor, las condiciones del tráfico ese día, el clima, etc. Por lo tanto, el mismo viaje puede estar relacionado con diferentes valores y tasas de consumo de energía no se promedian sobre los viajes (los predictores, por supuesto, tomarán valores diferentes). Se puede obtener una tasa de consumo de energía (por kilómetro, por ejemplo, a lo largo de una distancia) a partir de los datos de consumo de energía o usarse en lugar de este valor si la medida de longitud se da como una fracción de la longitud total).
Un método implementado por computadora para la optimización de rutas que no cae dentro del alcance de las reivindicaciones puede comprender usar el uso de energía previsto para posibles rutas en el área geográfica entre un punto de inicio y un punto final calculado de acuerdo con cualquiera de las definiciones anteriores e indicando al usuario el uso relativo de energía de las rutas posibles, por ejemplo, indicando la ruta de energía más baja. La ruta recomendada puede enviarse a una ayuda de navegación para el usuario. Según una realización de un segundo aspecto de la invención, se proporciona un programa de ordenador que comprende instrucciones que, cuando el programa es ejecutado por un ordenador, hacen que el ordenador lleve a cabo el método descrito anteriormente.
El programa puede ejecutarse localmente o en la nube para proporcionar el método de predicción del uso de energía en un dispositivo local.
Según una realización de un tercer aspecto de la invención, se proporciona un ordenador (aparato de procesamiento de datos) que comprende un procesador y una memoria configurados para llevar a cabo el método de cualquiera de las reivindicaciones anteriores. El procesador y la memoria pueden estar vinculados a una pantalla (para, por ejemplo, mostrar los campos de entrada y los resultados) y a un dispositivo de entrada (para que un desarrollador introduzca datos y parámetros para construir el modelo de uso de la energía y/o para que el usuario final pueda indicar el inicio y el final de una ruta).
Un sistema informático correspondiente puede comprender el ordenador como se define anteriormente, una pantalla y un dispositivo de entrada y cualquier otro componente necesario, como una interfaz de red.
Finalmente, en un ejemplo general útil para comprender la invención, pero que no cae dentro del alcance de las reivindicaciones, se proporciona un método implementado por computadora para estimar componentes individuales que contribuyen a una estadística agregada: ingresar datos en K ensayos e introducir predictores de la tasa general de contribución a la estadística agregada; introducir datos de contribución de los K ensayos, los datos de contribución que indican la contribución total T entre el inicio y el final de cada prueba; dividir cada una de las pruebas en segmentos de tiempo o espacio de medida de longitud (fraccional) Ai; agrupar los segmentos de los ensayos en un número N de clústeres, los clústeres definidos de acuerdo con rangos de al menos uno de los predictores, siendo definido cada clúster con una ponderación Wj que está por determinarse; usar un algoritmo para construir un modelo que prediga las ponderaciones Wj basado en la solución de un sistema de ecuaciones, uno por ensayo, cada ecuación igualando la contribución total conocida T de la prueba con la suma de la medida de longitud conocida de cada segmento en la prueba multiplicada por la ponderación para el grupo en el que se agrupó el segmento; para cada segmento, asignar la ponderación predicha aplicada al clúster en el que se agrupó el segmento como la tasa predicha de contribución Y; y almacenar un ID de segmento con el ID de clúster correspondiente o la tasa de contribución prevista Yi para permitir la predicción de la contribución de una estadística agregada que incorpora uno o más de los segmentos.
Un aparato (ordenador o sistema informático) o programa de ordenador según realizaciones preferidas de la presente invención puede comprender cualquier combinación de los aspectos del método. Igualmente, las características del aspecto uso de la energía podrán aplicarse al aspecto generalizado salvo que sean claramente incompatibles. Los métodos o programas de ordenador según realizaciones adicionales pueden describirse como implementados por ordenador porque requieren capacidad de procesamiento y memoria.
El aparato de acuerdo con las realizaciones preferidas puede describirse como configurado o dispuesto para, o simplemente "para" llevar a cabo ciertas funciones. Esta configuración o arreglo podría ser mediante el uso de hardware o middleware o cualquier otro sistema adecuado. En realizaciones preferidas, la configuración o arreglo es por software.
La invención puede implementarse en circuitos electrónicos digitales, o en hardware, firmware, software de computadora o en combinaciones de ellos. La invención puede implementarse como un programa de ordenador o un producto de programa de ordenador, es decir, un programa de ordenador con instrucciones incorporadas tangiblemente en un soporte de información no transitorio, por ejemplo, en un dispositivo de almacenamiento legible por máquina, o en una señal propagada, para su ejecución por o para controlar el funcionamiento de uno o más módulos de hardware.
Un programa de ordenador puede tener la forma de un programa independiente, una parte de un programa de ordenador o más de un programa de ordenador y puede estar escrito en cualquier forma de lenguaje de programación, incluidos los lenguajes compilados o interpretados, y puede implementarse en cualquier forma, incluido como programa independiente o como módulo, componente, subrutina u otra unidad adecuada para su uso en un entorno de procesamiento de datos. Un programa de ordenador puede implementarse para ejecutarse en un módulo o en múltiples módulos en un sitio o distribuirse en múltiples sitios e interconectarse mediante una red de comunicación.
Los pasos del método de la invención pueden ser realizados por uno o más procesadores programables que ejecutan un programa informático para realizar las funciones de la invención operando con datos de entrada y generando resultados. El aparato de la invención puede implementarse como hardware programado o como un circuito lógico de propósito especial, que incluye, por ejemplo, un FPGA (arreglo de compuertas programables en campo) o un ASIC (circuito integrado de aplicación específica).
Los procesadores adecuados para la ejecución de un programa de ordenador incluyen, a modo de ejemplo, microprocesadores de propósito tanto general como especial, y uno o más procesadores de cualquier tipo de ordenador digital. Generalmente, un procesador recibirá instrucciones y datos de una memoria de solo lectura o de una memoria de acceso aleatorio o de ambas. Los elementos esenciales de una computadora son un procesador para ejecutar instrucciones acoplado a uno o más dispositivos de memoria para almacenar instrucciones y datos.
La invención se describe en términos de realizaciones particulares. Se pueden editar e invocar varias versiones de scripts de prueba como una unidad sin usar tecnología de programación orientada a objetos; por ejemplo, los elementos de un objeto script pueden organizarse en una base de datos estructurada o un sistema de archivos, y las operaciones descritas como realizadas por el objeto script pueden ser realizadas por un programa de control de prueba.
Los elementos de la invención pueden describirse utilizando los términos "procesador", "dispositivo de entrada", etc. El experto apreciará que dichos términos funcionales y sus equivalentes pueden referirse a partes del sistema que están espacialmente separadas pero que se combinan para cumplir la función definida. Igualmente, las mismas partes físicas del sistema pueden proporcionar dos o más de las funciones definidas.
Por ejemplo, cualquier medio definido por separado puede implementarse utilizando la misma memoria y/o procesador, según corresponda.
Breve descripción de los dibujos
A continuación se describirán características preferentes de la presente invención, meramente a modo de ejemplo, con referencias a los dibujos adjuntos, en los que: -
Las Figuras 1a, 1b y 1c son diagramas generales que comparan una técnica anterior con el nuevo método.
la Figura 2 es un diagrama de flujo de un método en una realización general;
la Figura 3 es un diagrama de una base de datos para usar en el modelado del uso de energía;
la Figura 4 es un diagrama que ilustra un ajuste de peso utilizado para aproximarse al valor real de una predicción construida por un modelo;
la Figura 5 es un diagrama de flujo del proceso que representa las ideas subyacentes;
la Figura 6 es un ejemplo de un mapa que ilustra un viaje de A a B;
la Figura 7 es un diagrama que ilustra un viaje dividido en segmentos y los contenedores (clústeres) de segmentos; la Figura 8 es un gráfico de barras que representa la importancia de una gama de predictores;
la Figura 9 es una tabla de rangos de restricciones en un espacio predictor unidimensional;
la Figura 10 es una tabla de rangos de restricciones en un espacio predictor bidimensional;
la Figura 11 es una tabla de segmentos y predictores aplicados a ellos;
La Figura 12 muestra los segmentos de la figura 10 asignados a clústeres (contenedores);
la Figura 13 muestra la escala de las distribuciones de gradientes de temperatura promedio en una aplicación fotovoltaica durante la generación de clústeres;
la Figura 14 es una descripción general de los datos utilizados en el modelado y en el enrutamiento; y
La Figura 15 es un diagrama de hardware adecuado para la implementación de las realizaciones de la invención.
Descripción detallada
Estado de la técnica
Muchos artículos en la literatura están dedicados al problema de la estimación de rutas energéticamente eficientes para vehículos eléctricos. Para la estimación precisa del consumo de energía de la técnica anterior, es esencial adquirir información sobre el motor y el controlador, así como un valor de verdad base a nivel de enlace para el consumo de energía en ubicaciones intermedias durante un viaje. Esto se debe a que la agregación excesiva de información provoca la pérdida de variabilidad en los datos, lo que hace muy difícil estimar la contribución de cada segmento constituyente individual al consumo de energía en un viaje. Además, es ampliamente conocido que la velocidad y la aceleración del vehículo afectan en gran medida el consumo de energía. Por eso, los modelos más precisos del estado de la técnica intentan inferir el perfil de velocidad del conductor basándose en datos de series de tiempo vinculados a cada segmento de carretera.
Los sensores para enlazar los datos a cada segmento de carretera incluyen registradores GPS con una frecuencia de 1 Hz a 10 Hz que se utilizan para identificar las coordenadas de longitud/latitud y la velocidad instantánea. Entonces, las estimaciones de aceleración se pueden obtener utilizando diferencias finitas entre los valores de velocidad divididos por la distancia recorrida. Está claro que tener precisión en las coordenadas GPS da como resultado una mayor precisión en la estimación de la velocidad/aceleración y, por lo tanto, el consumo de energía. Además, sensores para el estado de la batería, el voltaje de la celda y la tasa de deterioro podrían ayudar a determinar anomalías que pueden alterar drásticamente el consumo de energía durante un viaje. Por último, no menos importante, la información sobre la marcha sobre las condiciones del tráfico y el clima (temperatura, viento, precipitación) permiten realizar estimaciones del comportamiento del conductor (perfil de velocidad) y de consumos auxiliares, lo cual es importante porque pueden tienen un gran impacto en el consumo de energía.
Existe una plétora de técnicas novedosas para estimar el consumo de energía de un vehículo eléctrico (como un coche, camión, furgoneta, autocaravana, o incluso un barco o tren u otro vehículo eléctrico o híbrido que no circule por carretera). Dichas técnicas incluyen regresores como regresión multilineal, regresores de vector de soporte, aumento de gradiente, etc., así como cadenas de Markov, modelos físicos, combinación de redes neuronales con modelos físicos, aprendizaje por refuerzo y muchos otros.
Para entrenar un modelo de aprendizaje automático para predecir el consumo de energía para cada segmento de carretera de manera supervisada, se ha considerado esencial adquirir un valor de verdad base del consumo de energía en las ubicaciones intermedias de un viaje, así como datos del motor y del conductor. Sin embargo, tal información
detallada puede ser difícil o costosa de obtener y también cuando se adquiere requiere mucho tiempo de preprocesamiento.
La Figura 1a muestra la curva de una carretera. Los puntos a lo largo de la curva representan datos proporcionados por un registrador de GPS que puede medir la ubicación y la velocidad instantánea. En este ejemplo de la técnica anterior, los valores de verdad base intermedios (verdad base a nivel de enlace, es decir, para los enlaces o segmentos entre cada punto registrado) para el consumo de energía facilitan la inferencia del consumo de energía para ese enlace o segmento de carretera.
Las realizaciones de la invención no tienen la información de GPS en ubicaciones intermedias. Este escenario se representa en la Figura 1 b. Por ello, el camino que seguirá el Vehículo Eléctrico (EV) es incierto. Además, solo se conoce el consumo total de energía (EC) para cada viaje. La Figura 1b muestra diferentes caminos que unen el principio y el final de la curva de la carretera. Para contrarrestar esta dificultad, en las realizaciones de la invención, no se consideran caminos cuyo kilometraje es superior a un cierto porcentaje, como 1-5%, preferiblemente 2%, diferente del camino más corto que une el punto de inicio y final. Es decir, los datos de estas rutas no se incluyen en el método, porque es poco probable que estas rutas sigan la ruta más corta que se considera en el método como la ruta del vehículo eléctrico.
La Figura 1c, nuevamente muestra puntos, los cuales se agregan en el método para delimitar los segmentos de camino. El software de optimización de rutas de código abierto, tal como OSRM (Open Source Routing Machine) o GraphHopper, se puede utilizar para dividir un viaje en segmentos de carretera (un mapa puede considerarse como un gráfico y un viaje por carretera como una ruta que une los nodos del gráfico; los segmentos de carretera son enlaces entre nodos adyacentes). Inferir el consumo de energía de cada segmento de carretera a partir de la información de conducción agregada (por ejemplo, velocidad promedio, sin información de aceleración) y sin un valor de verdad base de energía a nivel de enlace es mucho más difícil y desafiante. Esto se debe a que la agregación excesiva de información provoca la pérdida de variabilidad en los datos, lo que hace muy difícil estimar la contribución de cada segmento constituyente individual al consumo de energía en un viaje. Por ejemplo, en un caso con sólo dos segmentos de carretera con ECR de 200 Wh/km y 250 Wh/km, respectivamente, la ECR media es de 225 Wh/Km, que no es una mala estimación para cada segmento de carretera; pequeña cantidad de información perdida. Por el contrario, en un caso con veinte segmentos de carretera, de pendientes de carretera muy variables (tanto positivas como negativas): las ECR también variarán enormemente (por ejemplo, 200 Wh/km, 70 Wh/km, -90 Wh/km,...). La ECR promedio puede ser de 60 Wh/km, que es una mala estimación para cada segmento de carretera debido a la agregación excesiva. Las realizaciones de la invención resuelven estos problemas (y los problemas generales equivalentes en el modelado de datos agregados) como se explica con más detalle a continuación.
Por supuesto, la predicción de energía estándar puede modificarse para un automóvil específico y tener en cuenta las condiciones de conducción específicas. En la fase de modelado, los datos del fabricante para el consumo de energía pueden incluir un solo tipo de vehículo y velocidad total. En el motor de enrutamiento. Esperando comparar diferentes rutas de conducción, el motor de enrutamiento no tiene por qué basarse en tales datos (velocidad, viento, estilo de conducción, etc.). La ruta más eficiente energéticamente no cambia con estos predictores, por ejemplo, si hay más viento o la velocidad es diferente. La ruta más eficiente energéticamente debe ser la misma en todas las situaciones.
Por el contrario, para determinar el rango EV, se requieren más datos. Los métodos pueden utilizar dos modelos diferentes. El primer modelo utiliza solo gradientes, datos de tráfico, tiendas, etc. para crear un modelo para el motor de enrutamiento con el fin de encontrar la ruta más eficiente desde el punto de vista energético. El segundo modelo se utiliza para la estimación precisa de ECR de la ruta más eficiente energéticamente.
Después de encontrar la ruta más eficiente energéticamente utilizando el primer modelo, surgen dos preguntas:
A) ¿Cuánta energía utilizará, según el estilo de conducción, el clima, la velocidad, etc.? Para realizar una estimación precisa, se utilizan más predictores (velocidad, temperatura, viento, etc.) para construir un segundo modelo a partir de los datos del fabricante. Los predictores se cuantifican o agrupan en clústeres para resolver un sistema de ecuaciones para inferir un valor para cada grupo.
B) ¿Hay suficiente energía para realizar este camino? De lo contrario, el EV debe redirigir a la estación de carga más cercana, es decir, el método puede encontrar la ruta más eficiente energéticamente al punto de carga más cercano y luego redirigir nuevamente después de la carga.
La Figura 2 es un diagrama de flujo que ilustra una realización general de la invención.
S2 implica ingresar datos de mapa de carreteras incluidas en K viajes en un área geográfica, y la introducción de predictores de la tasa de uso de energía a lo largo de las carreteras. Algunos predictores del uso de energía pueden ser datos geográficos o de mapas, como el gradiente.
S4 comprende la introducción de datos de consumo de energía de los K viajes, los datos de consumo de energía que indican el uso total de energía T entre el punto de inicio A y el punto final B de cada viaje. Los datos de consumo de energía se pueden proporcionar en un conjunto de datos del vehículo con datos empíricos de viajes específicos del vehículo, por ejemplo, dando puntos de inicio y final de los viajes y el recorrido, que se compara con los datos de mapa
para derivar las carreteras utilizadas, así como opcionalmente la velocidad promedio (otro predictor) y otros factores relevantes.
En el paso S6, cada una de las carreteras en los datos de mapa para todos los viajes se divide en segmentos de medida de longitud Ai.
En el paso S8, los segmentos de los viajes se agrupan en un número N de clústeres, definiéndose los clústeres de acuerdo con rangos de al menos uno de los predictores, teniendo cada clúster una ponderación Wj que está por determinarse (usando un algoritmo).
En el paso S10, un algoritmo construye un modelo que predice las ponderaciones Wj resolviendo un sistema de ecuaciones, una por viaje. Cada ecuación iguala el consumo de energía total conocido T del viaje con la suma de la medida de longitud conocida de cada segmento del viaje multiplicada por la ponderación del grupo en el que se agrupó el segmento.
En el paso S12, para cada segmento, la ponderación predicha Wj aplicada al clúster en el que se agrupó el segmento se asigna como la tasa predicha de uso de energía Y; y el método almacena un ID de segmento con una indicación de la tasa predicha de uso de energía Yi para permitir la predicción del uso de energía para una ruta en el área geográfica que incorpora uno o más de los segmentos.
Por lo tanto, consultar el modelo permite determinar el uso de energía de una ruta. La consulta puede ser remota.
Las características clave del método descrito anteriormente pueden incluir:
• Predicción del consumo de energía para cada segmento de carretera a partir de estadísticas de conducción agregadas sin valor de verdad base a nivel de enlace para el consumo de energía. Además, no hay necesidad de datos de conducción intermedios (nivel de enlace) como velocidad, aceleración, etc.
• Generación de clústeres del espacio de predictores (que es el espacio multidimensional en el que se pueden trazar todos los valores posibles de los predictores de la tasa de uso de energía) en clústeres/contenedores
• El uso de técnicas algorítmicas como la optimización restringida o el descenso de gradiente proyectado para obtener ponderaciones naturales en el modelo. Esto da como resultado la interpretabilidad de las ponderaciones después del entrenamiento: representan la tasa de consumo de energía de cada segmento de la carretera.
• Método para recuperar la contribución de cada constituyente en una estadística agregada.
• No se basa en datos de series de tiempo históricas del mismo vehículo con fines de estimación. Por lo tanto, las realizaciones pueden evitar por completo el uso de datos de series de tiempo que mapean un viaje en segmentos.
Exposición de cálculos de ideas subyacentes
Las realizaciones presentan un método para estimar la contribución de componentes individuales a una estadística agregada. Una estadística agregada T se define como la suma de variables aleatorias Yi, de otras variables aleatorias, es decir:

dónde Ai se dan y pueden variar a través de los puntos de datos. Los datos consisten en valores de verdad base total 7^, ^(fc)
¿ para 7 y Ái, i = 1, ..., M respectivamente, donde k = 1, ..., K es el tamaño del conjunto de datos. K pueden ser considerados como caminos en un gráfico con un número total M de bordes (segmentos), y M >> K, significa que M es muchos órdenes de magnitudes mayor que K Por ejemplo, en el ejemplo de cálculo de energía, T es el consumo total de energía, que se conoce para cualquier viaje en el conjunto de datos, Yi es la tasa de consumo de energía del segmento de carretera i sobre la distancia en el segmento de la carretera, M es el número total de segmentos de carretera (bordes) en todo el mapa (el gráfico), K es el número de viajes en el conjunto de datos (cada viaje es una ruta en el gráfico), y Aj es una medida de longitud (conocida) para un segmento.
En consecuencia, para predecir la contribución a lo largo del tiempo a una estadística agregada, T es la contribución total, que se conoce para cualquier ensayo en el conjunto de datos, Yi es la tasa de contribución del segmento i en el tiempo, donde M es el número total posible de segmentos, K es el número de ensayos en el conjunto de datos, y Ai es una medida de longitud (conocida) de tiempo para un segmento.
El objetivo es inferir Y7s dados los valores de verdad base totales para 7 ^ y 1 en el siguiente sistema de ecuaciones:

Ecuación 1, Sistema subdeterminado de ecuaciones para resolver Yis
La dificultad para resolver el último sistema en la Ecuación 1 es que está muy subdeterminado y es probable que cualquier método basado en datos se sobreajuste. Esta sección introducirá un método para modelar la Ys usando la generación de clústeres del espacio de predictores para hacer manejable el sistema de ecuaciones de la Ecuación 1. Además, la optimización restringida (optimización de la función de energía con respecto a algunas variables en presencia de restricciones en esas variables) se puede utilizar en dominios donde existe la necesidad de adquirir un modelo con ponderaciones que representen cantidades físicas.
El método se puede utilizar para estimar el consumo de energía para cada segmento de carretera, sin un valor de verdad base a nivel de enlace para el consumo de energía o datos de motor/conducción. El objetivo en este problema es recuperar la 'contribución' de cada segmento de carretera Yi para el consumo total de energía T para cada viaje. La dificultad para hacerlo es la naturaleza de los datos: generalmente, hay muchos menos datos disponibles que el número de incógnitas Yi, resultando en un sistema de ecuaciones subdeterminado como en la Ecuación 1.
La idea principal es agrupar segmentos (de carretera) Yi, i = 1, ..., M usando, por ejemplo, una técnica de generación de clústeres en grupos de segmentos similares, denominados contenedores (“bins”) Wj, j = 1, ..., N con M >> N para reducir el número de incógnitas y hacer manejable el sistema de ecuaciones de la Ecuación 1. Luego, es posible utilizar una técnica como la optimización restringida para inferir los valores de los contenedores a fin de tener ponderaciones naturales en el modelo: las ponderaciones del modelo representan la tasa de consumo de energía de cada segmento de carretera.
Como se mencionó anteriormente, la tasa de consumo de energía Yi se ve afectada por diversos factores. Al menos algunos de estos pueden estar disponibles públicamente para cada segmento de carretera. Por ejemplo, los datos geográficos disponibles incluyen datos de elevación de malla de 30 metros, así como la ubicación de tiendas y señales de tráfico en el mapa que pueden ingresarse en el modelo desde fuentes públicas. En cuanto al clima, se puede utilizar información sobre la temperatura ambiente, el viento y la precipitación por hora. Finalmente (a) los fabricantes de automóviles y/u otra fuente pueden proporcionar datos de viajes por carretera que contengan el punto de inicio y fin de los viajes, la distancia de los viajes, la velocidad promedio, el consumo auxiliar, el tiempo de inactividad y los valores de verdad base total para el total consumo de energía (sin embargo, no se conocen valores de verdad base para el consumo de energía en ubicaciones intermedias, denominados verdad base a nivel de enlace). En la Figura 3 se presenta un diagrama de datos, que muestra una base de datos para usar en el modelado que puede contener cualquiera de los datos geográficos, meteorológicos y de fabricantes de automóviles agregados enumerados anteriormente.
Los predictores pueden inferirse de las fuentes de datos existentes. Por ejemplo, los cruces de carreteras se pueden usar como predictores, lo que se puede implementar, por ejemplo, agregando una variable booleana a cada nodo en un gráfico de carreteras (un segmento es la parte de la carretera entre 2 nodos) que describe si el nodo es un cruce o no. Por ejemplo, si al menos uno de los nodos del segmento de carretera es un cruce, entonces ponga el valor 1 en el segmento de carretera (que indica la presencia del cruce), de lo contrario ponga 0. Alternativamente, para cada segmento, el método puede encontrar el número total de segmentos vecinos, lo cual es simple de implementar usando OSRM o GraphHopper, por ejemplo. El predictor puede entonces definirse contando cuántos vecinos tiene un segmento de carretera (los segmentos que tienen vecinos >2 indican que existe un cruce). Cuanto más concurrido esté un segmento, más alto esperaríamos que sea la ECR (debido a la inactividad o avería).
Un objetivo es inferir el consumo de energía para cada segmento de carretera en un mapa, como el mapa de Japón, por ejemplo, potencialmente incluso para los segmentos de carretera que no están presentes en ninguno de los viajes en el conjunto de datos. Esto se puede lograr generando clústeres de segmentos que no están en ninguno de los viajes de acuerdo con los predictores y dándoles la ponderación del grupo en el que han sido asignados. Luego, los valores inferidos pueden usarse junto con un algoritmo de búsqueda de la ruta más corta (como el de Dijkstra o A*) para encontrar la ruta más eficiente energéticamente entre dos puntos en el mapa.
Este método introduce una forma robusta de modelar cada segmento de carretera e inferir el consumo de energía de cada uno de ellos. La agrupación de los predictores en un espacio predictor multidimensional se puede usar para hacer que el problema sea manejable y se puede usar la optimización restringida para que las ponderaciones de consumo de energía del modelo tengan valores naturales. Este método puede usarse para abordar cualquier problema que requiera modelado y estimación de componentes individuales que contribuyan a una estadística agregada. En muchas situaciones de la vida real, existe la necesidad de hacer predicciones de series de tiempo usando información agregada: el objetivo es inferir los valores de una variable de respuesta en pasos de tiempo intermedios (por hora, día, etc.) usando información agregada
en marcos de tiempo más grandes (por ejemplo, diario, mensual o anual). Esto sucede con frecuencia en campos como las finanzas, la gestión de la producción y la detección de anomalías.
Cálculos detallados
Como se describió anteriormente, el objetivo de este método es predecir el efecto de cada componente individual Y en y _ y M i y y M i _ -r
una estadística agregada 1 ¿ t= iA¿ í i, dónde ¿>¿=iA¿ 1 , y Mdenota el número de todos los componentes posibles (segmentos de carretera en nuestro ejemplo de consumo de energía). Los Ais (por ejemplo, medidas de longitud de segmento de carretera) son conocidos por el problema en cuestión pero, en general, no son constantes entre diferentes muestras. Por lo tanto, para la k-ésima muestra (por ejemplo, un solo viaje representativo en el conjunto de datos) tenemos,

dónde k = 1, ..., K es el número total de muestras en el conjunto de datos y T k denota el valor de verdad base total de la estadística T sobre la k-ésima muestra.
Obsérvese que la condición no es para nada restrictiva porque si la suma de A¡s no es igual a 1, la ecuación
no es para nada restrictiva porque si la suma de A¡s no es igual a 1, la ecuación
2 puede dividirse por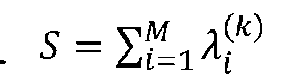 y ser convertida a la forma equivalente
y ser convertida a la forma equivalente 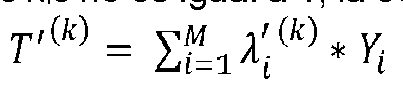 dónde
dónde

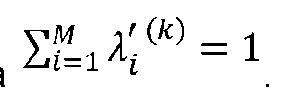
El objetivo es recuperar el efecto que cada Y tiene en T (es decir, encontrar el valor para cada Y) conociendo solo los valores de verdad base totales para T. Por lo tanto, el objetivo es resolver el sistema

^(fc)
para los Ys dados los valores verdaderos para T® y 1 para cada k = 1,2, ..., K La dificultad para resolver ese sistema (sin sobreajustar a los datos) es que generalmente está muy subeterminado con M >> k, es decir, el número de muestras (por ejemplo, viajes en el conjunto de datos) es mucho menor que el número de incógnitas (por ejemplo, tasa de consumo de energía para un segmento) Y,, i = 1, ..., M.
Tome el ejemplo que Tk) representa el valor de verdad base total para la tasa de consumo de energía en el k-ésimo viaje en los datos e Y representa la tasa de consumo de energía de un segmento de carretera en el mapa. La tasa de consumo de energía (ECR, por sus siglas en inglés) se define como el consumo de energía (diferencia entre la capacidad inicial y final de la batería) dividido por la duración total del viaje. Puede haber miles de millones (o incluso más) de segmentos de carretera (M) en el mapa para deducir, sin embargo, solo información para, por ejemplo, algunos miles dentro de los viajes
,0 0
K está presente. Al modelar cada viaje por carretera, * será cero si el segmento de carretera i-ésimo del mapa no está presente en el viaje. Por lo tanto, el sistema de ecuaciones también es muy escaso (“sparse”). Por eso, K es del orden de miles y M (el número total de diferentes segmentos de carretera en el mapa) es del orden de miles de millones (o más), y el sistema es muy subdeterminado. para denotar que M es muchos órdenes de magnitud mayor que k nosotros escribimos M >> k.
Para reducir el número de incógnitas M y hacer manejable la inferencia, una agrupación de segmentos Y se proporciona utilizando una técnica de agrupación en clústeres en W clústeres, cada uno con N segmentos Denotar por ponderaciones (fe)
Wi, ..., Wn con M >> N los N clústeres en los que Y cae y por d las fracciones acumuladas que cada tipo de clúster aparece en la k-ésima ecuación, es decir,
Inicializar d(k) = 0 = para k = 1,2,..,K y i=1,2,..,N
Para k = 1,2,...K: (para cada viaje en el conjunto de datos)
Para i = 1,2,...N: (para cada uno de los segmentos en un grupo)
Si (iésimo - tipo de clúster está presente en la k-ésima ecuación/viaje, entonces: d(k) = Á(k
Sino:
Continúe repitiendo, no agregue nada
Fin para
Fin para
Este bucle simplemente suma las medidas de longitud de los segmentos de cada tipo de grupo incluidos en el viaje para
dar una medida de longitud
d
i
(fc)
para el /c-ésimo clúster. Recuerde que esta es una medida de longitud fraccionaria en este caso.
Entonces, el sistema de ecuaciones en la Ecuación 2 se convierte en

Tenga en cuenta que i es cero si el y-ésimo contenedor no aparece en la /c-ésima muestra/viaje. Observe que ahora la suma es sobre todos los contenedores posibles N mientras que antes la suma era sobre todos los componentes posibles M (M >> N). La diferencia es que ahora este sistema es manejable porque el número total de ponderaciones desconocidas Wj (que es por supuesto N - el mismo que el número de contenedores) se puede elegir adecuadamente durante la agrupación en clústeres (N puede ser elegido cerca de K o menos de K por ejemplo) para ser del mismo orden (o menor que) el número de puntos de entrenamiento/ensayos K.
Recuerde que el objetivo ahora es encontrar los valores para Wi dado i y TrueValw = para cada k = 1,..., K Para resolver el sistema de ecuaciones anterior en la Ecuación 3, se podría usar cualquier algoritmo de optimización o arquitectura de red neuronal. El método recomendado aquí utiliza un algoritmo de optimización cuadrática con restricciones para las wjs de la biblioteca "cvxpy" (https://www.cvxpy.org/) en python y el solucionador "OSQP" con iteraciones máximas de 50K para ajustar los datos.
Usando una Red Neuronal, el entrenamiento es el siguiente: durante el entrenamiento el modelo hace predicciones

para cada k = 1, ..., K. El aprendizaje ocurre modificando las ponderaciones Wi con descenso de gradiente tal que Prediction(k) está cerca de la verdad base total TrueVal(k) para cada muestra K en el conjunto de datos en términos de una métrica apropiada. Usando la distancia L2 como métrica, es decir, el objetivo es encontrar ponderaciones W para minimizar

La Figura 4 es un diagrama que ilustra el ajuste de ponderaciones utilizado para aproximarse al valor real de la predicción construida por el modelo. La optimización restringida en redes neuronales se puede lograr con técnicas de descenso de gradiente proyectado. Es similar a la técnica de retropropagación estándar, con la única diferencia de proyectar la actualización del descenso del gradiente a la región factible del espacio restringido.
Después de encontrar las ponderaciones W (ponderaciones para cada contenedor-clúster) cada segmento de carretera en el mapa (incluidos los que no forman parte de ningún viaje) puede clasificarse en un clúster en particular, por lo que está relacionado con un valor de ponderación. Esta información se puede guardar en un diccionario {road_ID : contenedor
- clúster} y utilizarse en un motor de rutas que implemente algoritmos de optimización de rutas (como Dijkstras o A*) para encontrar la ruta con mayor eficiencia energética.
En la Figura 5 se presenta un diagrama de flujo de proceso que representa las ideas subyacentes en una realización. La base de datos proporciona datos para el preprocesamiento opcional (según el conjunto de datos de entrada), que utiliza un buscador de ruta óptimo para encontrar los viajes de distancia más corta (S100) y, opcionalmente, para llevar a cabo la limpieza de datos que incluye, por ejemplo, el suavizado de elevación y la detección de valores atípicos y para mantener solo viajes con distancia cercana al camino más corto (S110).
Los viajes seleccionados preprocesados se envían a una etapa de modelado de grupos, en la que un algoritmo de grupo asigna los viajes a contenedores/grupos (S120). Esto permite que las ecuaciones se conviertan en ecuaciones relacionadas con los contenedores (S130). La optimización restringida resuelve las ecuaciones convertidas en S140 y luego se puede consultar al sistema sobre la mejor ruta entre diferentes ubicaciones en S150.
Aplicación del método a la optimización de rutas energéticamente eficientes
Este ejemplo determina la contribución de cada segmento de carretera al consumo de energía total de un viaje, sin valores de verdad base a nivel de enlace para el consumo de energía (EC) (consulte la Figura 1c) y sin información de conducción/motor en puntos intermedios, usando solo información agregada.
Encontrar el consumo de energía es equivalente a encontrar la tasa de consumo de energía (ECR = EC/distancia), dada la distancia, por lo tanto, el objetivo será inferir la ECR de cada segmento de carretera, dado el valor de verdad base total de ECR para el viaje. La ECR puede establecerse de forma estandarizada/promediada, que luego puede compensarse para tener en cuenta las características específicas del EV/conductor.
Se proporcionan valores de verdad base totales para la tasa de consumo de energía para los viajes por carretera, así como la velocidad promedio y las estimaciones para el consumo auxiliar, por ejemplo, por parte de un importante fabricante de automóviles.
Se desconoce la ruta exacta que siguió el EV ya que no se utilizó GPS en ubicaciones intermedias de cada viaje en la base de datos de viajes. Para hacer frente a esta incertidumbre, el método mantuvo solo una pequeña fracción de los viajes: aquellos cuyo recorrido informado por el fabricante del automóvil no era más del 2% diferente del camino más corto que unía el punto de inicio y final de cada viaje. La ruta más corta que une el punto de inicio y el final de cada viaje se encontró utilizando el software de búsqueda de ruta de distancia más corta en gráficos y luego se comparó con el recorrido real. Si fue como máximo un 2% diferente del recorrido real, se supone que el conductor siguió la ruta más corta; de lo contrario, se descartó el viaje. Tenga en cuenta que todavía hay un 2% de incertidumbre en la ruta exacta seguida por el EV y esto se suma al error total de este enfoque de modelado. Por supuesto, si está presente un GPS para medir la ruta exacta, habrá un aumento del 2% en el rendimiento y no será necesario eliminar los viajes. Posteriormente, se realizan más pasos de limpieza, como suavizado de elevación, eliminación de datos corruptos y detección de valores atípicos.
La Figura 6 muestra un mapa con un viaje ilustrado desde A a B. El método primero filtra los viajes y mantiene aquellos con kilometraje cerca de la ruta más corta para el viaje desde A a B. Además, el método descompone los viajes filtrados en sus segmentos de ruta constituyentes utilizando los datos geográficos disponibles antes de agruparlos. Para cada viaje, el método puede utilizar la información representada en la figura: consumo de energía para todo el viaje (pero no para los puntos intermedios) y, para cada segmento de carretera, el gradiente, las señales de tráfico, las tiendas cercanas y cualquier otro dato geográfico útil. La tasa de consumo de energía de cada segmento de carretera puede considerarse como una función de dichos predictores.
Cada segmento de carretera es la porción del viaje entre 2 puntos como se muestra en la Figura. Para calcular el gradiente, los datos geográficos (por ejemplo, malla de 30 m de datos de elevación de mosaico) se pueden obtener de cualquier fuente disponible públicamente (como JAXA https://www.eorc.jaxa.jp/ALOS/en/aw3d30/index.htm) usando suavizado de elevación adicional.
Aquí, los segmentos de ruta son pequeñas partes del gráfico de ruta que pertenecen al viaje actual. Es posible (mediante el uso de motores de enrutamiento de código abierto como GraphHopper) recuperar los puntos geográficos intermedios en el gráfico de carreteras para el viaje más corto entre 2 puntos A y B. El mismo procedimiento podría utilizar alternativamente un registrador de GPS.
La tasa de consumo de energía (ECR) de cada segmento de carretera será Y, y la estadística agregada T es la ECR de
verdad base total de todo el viaje. Por lo tanto, T ' — = l ^ - =1 i 'Á Hi *Y i dónde ¿ v y™M4=1 1 = 1 , y M denota el número de todos los posibles segmentos de borde en el mapa. Los Á,s denotan la distancia de cada segmento de carretera dividida por la distancia total del viaje (para que su total sea 1). El objetivo es inferir los valores de Ys dados los valores de verdad base total T para la ECR de viaje y Ái se conocen a partir de los datos geográficos (Figura 3). Hay un sistema de tales ecuaciones, así que resuelva para Y, una ecuación por viaje por carretera en el conjunto de datos:

donde K denota el número total de viajes en el conjunto de datos. Observe que la mayoría de los segmentos de carretera aparecerán solo en unos pocos viajes, por lo tanto, el sistema en la Ecuación 4 está muy subdeterminado (M » k) y escaso ya que . la mayorí ,a AW f s sera , cero.
Para hacer manejable el sistema de ecuaciones, el método reduce el número de incógnitas agrupando Yi en contenedores o clústeres. Cualquier técnica de generación de clústeres para segmentos de caminos que minimice la pérdida de información puede usarse para hacer manejable el último sistema en la Ecuación 4. La persona experta elegirá cualquier enfoque de generación de clústeres adecuado según el dominio y el problema.
Después de la agrupación, cada Yi, i = 1, ... , m caerá en un contenedor-clúster particular Wj, j = 1, ... , N con M >> N. Estos grupos pueden representar agrupaciones de bordes con características que dan como resultado tasas de consumo de energía similares. Por ejemplo, un clúster puede contener segmentos de carretera con gradiente en el rango [0, 0,05], número de señales de tráfico en el rango [2, 5], número de tiendas en el rango [5, 10], etc. Estos clústeres definen de manera efectiva los tipos de segmentos de carretera y pueden imaginarse como volúmenes en un espacio predictor multidimensional. Podrían especificarse de antemano mediante un algoritmo de generación de clústeres, por ejemplo, utilizando el método en la solicitud en trámite junto con la copropiedad mencionada anteriormente o por expertos en el dominio, según el caso de uso. Cualquier enfoque de agrupación de cuantificación da como resultado la pérdida de información, por lo que es fundamental seleccionar agrupaciones que resulten en una pérdida de información mínima. Luego, para cada viaje en el conjunto de datos, la distancia acumulada para cada grupo de segmentos se guarda en un diccionario y se crea una tabla con las distancias correspondientes divididas por la duración total del viaje como columnas. Por ejemplo, la Figura 7 muestra un diagrama de un viaje de longitud 22, dividido en segmentos (bordes) y su asignación a grupos como "contenedor (número de contenedor)". El diagrama también muestra la longitud de cada segmento como L. En este caso, el siguiente diccionario realiza un seguimiento de las medidas de longitud de segmento acumuladas en cada uno de los clústeres 1 a N para el viaje en cuestión:
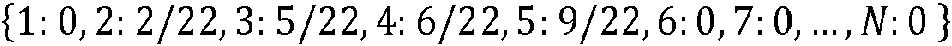
Por ejemplo, aquí no hay segmentos en los clústeres 1,6 y 7. La longitud total en el clúster 2 es 2 (de la longitud total de 22). La longitud total en el clúster 3 es 5, que se compone de 2 segmentos separados (de la longitud total de 22).
Del diccionario se obtiene la siguiente ecuación para tener en cuenta las longitudes de los segmentos (y por lo tanto las medidas de longitud) en cada grupo y las ponderaciones para cada clúster:

o, en general:

Además, este viaje se puede agregar a una tabla con columnas de clúster 1 hasta N usando el diccionario, creando una fila en la tabla y agregando valores para cada grupo como los valores de diccionario correspondientes.
El método procede como se indica arriba para cada viaje por carretera. k = 1, ..., K disponible en el conjunto de datos. Entonces, la tabla tendrá k filas y (N+ 1) columnas donde una columna es el total final por viaje representa la ECR de verdad base total y las otras N columnas son para los diferentes tipos de contenedores.
En una disposición, estos valores pueden ser las entradas de un modelo de aprendizaje automático para intentar predecir la tasa de consumo de energía (por lo tanto, el consumo de energía) para cada tipo o grupo de segmento de carretera. Por ejemplo, al entrenar una red neuronal de una capa, el modelo hace predicciones

y el objetivo es encontrar ponderaciones Wi para minimizar el error:

Después de encontrar las ponderaciones Wi (ECR para cada contenedor de segmento de carretera), se puede crear una tabla de búsqueda y esto, por ejemplo, se puede pasar a un motor de ruta que puede calcular la tasa de consumo de energía para una ruta determinada y, por ejemplo, implementar un algoritmo de optimización de ruta para optimización de rutas energéticamente eficientes.
El método puede utilizar alternativamente un algoritmo de optimización cuadrática con restricciones para los Ws de la biblioteca "cvxpy" en python y el solucionador "OSQP" con iteraciones máximas de 50K para ajustar los datos. Las restricciones se pueden elegir de modo que las ponderaciones resultantes (después del ajuste) reflejen el consumo de energía de cada segmento de la carretera y sean lo más naturales posible. Además, un ordenamiento de contenedores W[i] ≤ W[i + 1] se puede introducir de acuerdo con el impacto que cada predictor tiene en el problema (por ejemplo, si un contenedor tiene un gradiente de 0,2 y otro contenedor tiene un gradiente de 0,1 y todos los demás predictores son iguales, entonces el último contenedor se asociará con una ECR más baja, y por lo tanto menor W[i]). Este ordenamiento puede tener en cuenta tanto la importancia de los predictores como el ordenamiento natural dentro de cada predictor.
El objetivo del ordenamiento es que las ponderaciones del modelo representen el consumo de energía de un segmento de carretera. Esto aumenta la interpretabilidad del modelo y hace que los resultados sean más naturales. El impacto (y por lo tanto el orden) de cada predictor puede determinarse de forma automatizada mediante el uso de un algoritmo de bosque aleatorio (por lo tanto, evidente a partir de los datos). Por ejemplo, aproximadamente 2000 árboles pueden ser entrenados en datos (X, Y) dónde X son los predictores agregados a lo largo de todo el viaje (por ejemplo, gradiente promedio del viaje, número total de tiendas dividido por la distancia, número total de semáforos dividido por la distancia, etc.) e Y son los valores de verdad base del consumo de energía de cada viaje. Al trazar un diagrama de importancia de características después del entrenamiento, se puede medir la importancia de cada característica. Las características más importantes deben dividirse en más clústeres cuando los valores de generación de clústeres y sus valores divididos pueden determinarse como se describe en la solicitud en trámite junto con la propiedad mencionada anteriormente.
Como ejemplo: el gradiente podría dividirse en 8 divisiones de contenedor, cada una con un rango de gradiente dado:

y ordenar significa que la ponderación para la división de contenedores 1 es la más pequeña y que Wi ≤ W2 ≤ W3 ≤ ... ≤ Ws, dónde Wi es la 'ponderación', es decir, la tasa de consumo de energía prevista para el contenedor Bi, i = 1,2, ... ,8. El efecto de ordenar es hacer que los resultados del modelo sean interpretables y naturales: un gradiente más bajo debería tener un consumo de energía más bajo (W).
El número de tiendas podría dividirse en 4 divisiones de contenedores: [0,5), [5,10), [10, 20), [20, «). Nuevamente, el ordenamiento de las ponderaciones dice que el modelo debe ajustarse a la regla: un menor número de tiendas debe estar asociado con un menor consumo de energía.
El número total de divisiones de contenedores (8 para gradiente y 4 para tiendas) se puede seleccionar de acuerdo con la importancia de la característica después de entrenar el bosque aleatorio. El gradiente tenía más importancia, por lo tanto, se dividió en más divisiones de contenedores. El número total de contenedores es un hiperparámetro que el usuario debe ajustar teniendo en cuenta el número de datos disponibles y, por lo general, requiere una validación cruzada.
Un ejemplo de diagrama de importancia de características creado a partir de datos reales se puede ver en la Figura 8. En orden de importancia creciente, los predictores son: tipo de carretera promedio redondeado; efecto de viento por enlace (segmento); número de tiendas sobre el enlace; número de señales sobre el enlace; temperatura; AF (Factor y 1} (y. -). VU'E x S-Aerodinámico), que puede definirse como 1 iJ 1 dónde vi es la velocidad del vehículo en el i-ésimo segmento de carretera y wi, Si la velocidad del viento y la distancia en cada segmento, respectivamente. En ausencia de información sobre el enlace por carretera, el AF se puede estimar como (v w) x S dónde v, w son la velocidad media y la velocidad del viento y S la duración total del viaje; cambio de elevación por distancia y cambio de elevación promedio a lo largo de la distancia.
Las restricciones se imponen en forma de matriz para cada contenedor. Por ejemplo, usando solo como predictor el gradiente, las restricciones se resumen en una matriz unidimensional como se muestra en la Figura 9.
Los pesos reflejan la tasa de consumo de energía de los segmentos de carretera con pendientes en la posición de la fila correspondiente. Las restricciones toman la forma de un intervalo al especificar el límite inferior y superior para cada contenedor: por ejemplo, el consumo de energía debe estar entre -600 y -300 para gradientes inferiores a -0,25. Usando 2 predictores, por ejemplo, gradiente y número de tiendas, entonces las restricciones toman una forma de matriz 2D como se muestra en la Figura 10. En un sentido más general, se trata de un hipercubo con el orden adecuado. La Figura 10 ilustra bien este orden. Cada contenedor (en la matriz 2D de la Figura 10) está asociado con un rango de valores de ECR que tienen un valor medio (punto medio). El ordenamiento está implícitamente presente aquí. Los contenedores se pueden ordenar en orden ascendente o descendente según la ECR media.
Generalmente usando N predictores, las restricciones serán un arreglo N dimensional (hipercubo) cuyos valores se pueden establecer a través de un bucle 'for/para'. Tenga en cuenta que los valores para el límite superior e inferior de las ponderaciones son específicos del problema y pueden ser ajustados por el usuario (como hiperparámetros) o por un experto en el dominio. También se puede aplicar una búsqueda en cuadrícula que ajusta los rangos con avidez (“greedily”) uno a la vez. Por ejemplo, el usuario puede especificar un límite superior e inferior para el espacio de búsqueda, así como un paso. Luego, una búsqueda en cuadrícula probará todas las combinaciones posibles. En una dimensión, esto puede implicar especificar un límite inferior (por ejemplo, -400), un límite superior (por ejemplo, 400) y un tamaño de paso (por ejemplo, 100); la búsqueda en cuadrícula buscará todas las combinaciones [-400,-400], [-300,-200], ... , [300,400]). Habrá 4x3=12 combinaciones totales (ya que X1 puede tomar 4 intervalos diferentes [-200,-100],[-100,0],[0,100],[100,200] y X2 puede tomar 3 intervalos [10,20], [20,30], [30,40]). Las combinaciones son:
X1 en [-200,-100], X2 en [10,20]
X1 en [-200,-100], X2 en [20,30]
X1 en [-200,-100], X2 en [30,40]
X1 en [-100,0], X2 en [10,20]
X1 en [-100,0], X2 en [20,30]
X1 en [-100,0], X2 en [30,40]
X1 en [0.100], X2 en [10,20]
X1 en [0.100], X2 en [20,30]
X1 en [0.100], X2 en [30,40]
X1 en [100.200], X2 en [10,20]
X1 en [100.200], X2 en [20,30]
X1 en [100.200], X2 en [30,40]
El lector experto comprenderá que las búsquedas en cuadrículas de mayor dimensión funcionan de manera análoga.
Los grupos se crean dividiendo el espacio dimensional N en clústeres: cada clúster abarca un rango de cada uno de los predictores. En un ejemplo, en el que se usa un predictor, el número N puede ser igual al número de. En un ejemplo usando dos predictores, el primero puede dar N1 intervalos y el segundo puede dar N2 intervalos, resultando en N1 * N2 clústeres en total, por ejemplo, como se establece anteriormente.
La imposición de restricciones a las ponderaciones del modelo da como resultado un ajuste más natural. Observe que en la técnica de modelado anterior, las ponderaciones de la red neuronal tienen una interpretación física: representan la tasa de consumo de energía de cada grupo de contenedores de enlace de carretera. De esta forma es más fácil entender las predicciones hechas por la red neuronal e interpretar las ponderaciones después del aprendizaje. Comprender las predicciones de una red neuronal es mucho más crítico en otros dominios, como la medicina o la conducción autónoma.
A continuación, se puede utilizar un motor de enrutamiento para generar una ruta. El motor de enrutamiento puede usar dos modelos diferentes. El primer modelo puede usar solo, por ejemplo, gradiente, datos de tráfico, tiendas, etc. para hacer un modelo para el motor de enrutamiento con el fin de encontrar la ruta más eficiente energéticamente. El segundo modelo puede usarse para una estimación precisa de ECR de la ruta más eficiente energéticamente.
Después de encontrar la ruta más eficiente energéticamente utilizando el primer modelo, surgen dos preguntas: cuánta energía costará la ruta, según el estilo de conducción, el clima, la velocidad, etc.; y ¿el vehículo, en la actualidad, tiene suficiente energía (capacidad restante de la batería) para realizar este camino? Para realizar una estimación precisa, el método puede usar más predictores (velocidad, temperatura, viento, etc.) para construir un segundo modelo, por ejemplo, a partir de los datos del fabricante. El método puede cuantificar o agrupar en clústeres los predictores y resolver un sistema de ecuaciones (como se describe anteriormente) para inferir un valor para cada grupo. Si el vehículo no tiene suficiente energía, el vehículo debe ser redirigido a la estación de carga más cercana. Es decir, el método puede encontrar la ruta más eficiente energéticamente hasta el punto de carga más cercano y volver a enrutar una vez más después de la carga.
Suavizado de elevación
Algunas disposiciones utilizan suavizado de elevación, que puede funcionar de la siguiente manera: supongamos que las elevaciones, que se obtienen a partir de mosaicos de malla de 30 m de la elevación de una carretera incluida en un viaje, tienen la siguiente forma: [5, 5, 5,10, 20, 20, 20, 20, 0] donde los números representan la altitud en metros desde el nivel del mar. Los números constantes 5,5,5 al principio se producen debido a los puntos de viaje por carretera que pertenecen al mismo mosaico de elevación (el mosaico consta de puntos a la misma elevación). El algoritmo "suaviza" las elevaciones de la siguiente manera: el objetivo es cambiar la segunda y la tercera elevación en la lista de elevaciones para obtener una transición más suave desde el primer punto A con 5m de elevación hasta el cuarto punto B con una elevación de 10 m (suavizado similar desde el 5° punto de elevación 20m hasta el 9° punto de elevación 0m). Considere los puntos [A, X, Y, B] con elevaciones [5, 5, 5, 10] respectivamente que comprenden los primeros 4 puntos de la lista anterior. Denotamos por E(X) la elevación del punto X entonces en este momento [E(A)=5, E(X)=5, E(Y)=5, E(B)=10], Cambiando E(X) y E(Y) "suaviza" la transición de A a B. Por lo tanto, sea E(X) = X y E(Y) = y donde X, y se encuentran. La interpolación lineal da:

dónde (AX) denota la distancia entre puntos A y X y (AB) la distancia entre A y B. Ya que estas distancias se conocen del
mapa, X pueden ser calculadas. Por ejemplo, si (AX) = 15m y (AB) = 50m entonces altitud. Del mismo modo, para el punto Y:
altitud. Del mismo modo, para el punto Y:

e y puede calcularse ya que las distancias (AY) y (AB) se conocen. Si (AY) = 35m entonces y = 8,5m. Tenga en cuenta que la transición entre elevaciones [5,10,20] no necesita suavizarse ya que los puntos pertenecen a mosaicos de elevación diferentes. Finalmente, se realiza el mismo cálculo para el primer mosaico de 20m y el último mosaico de 0m, es decir, suavizado de elevación para los puntos con elevaciones [20,20,20,20,0] para obtener, por ejemplo, suavizado [20,13,7 ,3,0].
Parámetros algorítmicos para un arreglo de uso de energía
El consumo de energía se mide en Wh (vatios-hora) y se informa en el conjunto de datos. Dado que también se conoce la distancia total de cada uno de los viajes, es posible calcular la tasa de consumo de energía como el consumo de energía dividido por la distancia y medido en Wh/km.
Los arreglos pueden usar el solucionador OSQP de la biblioteca 'cvxpy' en python para la optimización con restricciones cuadráticas dispersas. Se pueden utilizar los parámetros predeterminados o la regularización de lazo y cresta. Los parámetros predeterminados (por ejemplo, especificando un límite superior de iteraciones de 50K, especificar la pérdida de L2 y usando una matriz de desigualdades (límites superior e inferior) para la optimización restringida) funcionan bien porque las ponderaciones después del ajuste tienen un significado natural: representan la tasa de consumo de energía de un segmento de carretera. Dado que OSQP se usa para la optimización restringida, se puede usar una matriz con valores mínimos y máximos para cada predictor (esto es específico del problema y depende del conjunto de datos) para obtener una tabla como la tabla en la Figura 10 para el caso bidimensional. Por lo tanto, para cada 'división de contenedores' se debe especificar el límite superior e inferior para el consumo de energía. Los clústeres se forman a partir de las divisiones de contenedores. Por ejemplo, cada celda de la tabla de la Figura 10 puede representar un grupo. Alternativamente, varias celdas (por ejemplo, los primeros tres grupos que se muestran en la parte superior izquierda de esta tabla) pueden fusionarse para formar un grupo, sin embargo, esto puede introducir una pérdida de precisión, lo que no siempre es deseable.
Los parámetros predeterminados del solucionador OSQP necesitan un número total de iteraciones (por ejemplo, un límite superior de 50 K), la pérdida (por ejemplo, L2 y el usuario puede elegir la regularización L2 cresta o L2 lazo) y una matriz de desigualdades (límites superior e inferior) para la optimización restringida. Ver https://osqp.org/docs/examples/least-squares.html
En una red neuronal, puede ser difícil aplicar una optimización restringida con un descenso de gradiente proyectado. Sin embargo, un sistema adecuado podría usar una arquitectura de red neuronal de alimentación-avance (“feed-forward”) (sin restricciones) usando de 2 a 4 capas ocultas con 200 unidades ocultas. Por supuesto, el lector experto comprenderá que este diseño y estos parámetros variarán entre diferentes conjuntos de datos. Por ejemplo, con más datos, uno puede encontrar una arquitectura más profunda con más capas y más unidades ocultas para ser más preciso. La entrada del conjunto de datos (también para otros algoritmos) podría incluir aproximadamente 61000 viajes después de la limpieza y los hiperparámetros pueden usar un optimizador Adam con una tasa de aprendizaje de 0,001, nuevamente de acuerdo con el conjunto de datos (por supuesto, tasas de aprendizaje de 0,0001,0,00001, etc. puede usarse; la convergencia es el objetivo). Las iteraciones totales podrían ser 20 épocas/repeticiones (“epochs”). El entrenamiento se puede realizar utilizando el marco de aprendizaje profundo de PyTorch.
El hardware utilizado podría ser la GPU: 1080Ti GeForce 11GB
Como ejemplo: cada viaje se descompone en segmentos de carretera después de consultar el motor GraphHopper y los valores de cada predictor almacenados en una tabla. Cada columna de la tabla de la Figura 11 corresponde a cada predictor y cada fila corresponde a cada segmento de carretera que está presente en el viaje por carretera. Los parámetros fromID y tolD corresponden a puntos en el gráfico (cada ID está relacionado con (Ion, lat), un par de longitud y latitud). Aquí, los segmentos 0 a 3, con sus ID de ubicación inicial y final, se muestran junto con: señales de tráfico en el segmento, tiendas en el segmento, AF en el segmento (promediado a partir de los datos del viaje completo), el tipo de carretera, tal como desconocido, residencial, sin clasificar, terciario, secundario, primario, troncal o autopista (determinado a partir de datos de mapa); la temperatura meteorológica y el efecto del viento (obtenidos a partir de datos meteorológicos); y la distancia y la elevación cambian por la distancia, lo que da el gradiente en la columna final. Los segmentos tienen una longitud diferente porque los nodos en graphHopper representan principalmente cruces o regiones importantes (como puntos de referencia). Si esto es de su interés, el usuario puede consultar un viaje por carretera con GraphHopper y ver los diferentes nodos y dónde se encuentran.
Posteriormente, se utiliza un módulo de cuantificación para clasificar cada fila (es decir, cada segmento de carretera) en el grupo correspondiente, como se muestra en la Figura 12. Finalmente, el solucionador OSQP ajusta los datos con restricciones de desigualdad como se muestra en la tabla de la Figura 10. La suma de la contribución de los clústeres en el viaje debe ser igual al consumo de energía del viaje, es decir

dónde EC es el consumo de energía y el EC(viaje) se conoce a partir de los datos disponibles. Por lo tanto, el objetivo es inferir los valores de EC (contenedor) para cada contenedor mediante la optimización de un sistema de ecuaciones:

para todos los ^-viajes presentes en el conjunto de datos.
Aplicación del método a datos de series de tiempo para la estimación de generación de energía
Las realizaciones se pueden usar para estimar la energía generada a partir de células fotovoltaicas (PV) en períodos de tiempo más precisos a partir de datos de series de tiempo agregados de una manera basada en datos. Existen muchos modelos teóricos de energía en la literatura que intentan estimar con precisión la generación de energía de los PV con base en ecuaciones de energía.
Suponga que es deseable encontrar/predecir la energía generada a partir de los PV por minuto (o por hora) dados los valores de verdad base diarios de la energía generada. Por ejemplo, se puede saber que al final del día, el panel producido X Wh (vatios hora), pero aún se desconoce cuánta energía producirá el panel por minuto en un día específico en el futuro. La estimación X/1440 (ya que un día tiene 1440 minutos) es inexacto, ya que la generación de energía depende de muchas variables ambientales, así como de factores específicos del panel. Por ejemplo, durante un día nublado o de noche, esperamos que la generación de energía sea cercana a cero, pero durante un período soleado la generación será muy alta. Además, las variables ambientales cambian dinámicamente dentro de un día, ya que un día que podría comenzar soleado puede terminar nublado y, por lo tanto, diferentes períodos de tiempo tendrán una generación de energía diferente (generación de energía diferente en vatios, por lo tanto, generación de energía diferente en vatios-hora).
Las realizaciones utilizadas para la aplicación de EV descrita anteriormente difieren de las realizaciones utilizadas para la aplicación de PV en el dominio (espacio para EV y tiempo de PV): La realización adecuada de EV estima el consumo de energía de los segmentos de carretera conociendo el consumo de energía total del viaje y, para hacerlo, divide los predictores con respecto al dominio del espacio. Por el contrario, las realizaciones adecuadas de PV estiman la generación de energía en un intervalo de tiempo, con valores de verdad base para la generación de energía al final de un día o para la generación de energía acumulada durante un período de tiempo prolongado (una acumulación de ensayos de datos). Por lo tanto, es necesario particionar los predictores con respecto al dominio del tiempo. Además de esta diferencia léctica, el cambio del dominio del espacio al tiempo hace uso de la misma formulación matemática de realizaciones descrita anteriormente. Como antes, el total puede ser una tasa (a lo largo del tiempo en este caso) o un valor absoluto.
Indique la tasa de generación de energía (EGR) dentro de un período de tiempo t como Yt, es decir, Yt = EG/t donde EG
representa la energía generada en Wh. Sea T la tasa de generación de energía total de verdad base. Por ejemplo, si la energía total generada en un día es de 2880 Wh, entonces la tasa de generación de energía es de 2 Wh/min (o, de manera equivalente, 120 W). Tenga en cuenta que esta tasa de generación de energía agregada no es un buen estimador para un intervalo de tiempo particular del día: durante los intervalos soleados, la generación puede ser de 300 W, mientras que durante los intervalos nublados, el valor puede ser de 20 W (estos valores son hipotéticos por el bien del ejemplo).
Por lo tanto, similar a la formulación de EV anterior, t 1 = L y . M i= in x i * y J(,donde y M x = 1 ^ y Mdenota el numero de todos los intervalos de tiempo en los que se divide el día. Por ejemplo, si dividimos el día en 24 intervalos iguales (por hora) entonces M=24 si solo se tiene en cuenta un día o, en general, 24 veces el número de días muestreados. Aquí, k denota el número de muestras realmente tomadas, que es menor que el número total posible de 24 muestras.
La división en intervalos de tiempo puede ser desigual según las necesidades de la aplicación: por ejemplo, las realizaciones pueden dividir los períodos de la mañana y la tarde en 10 intervalos de tiempo, mientras que la tarde puede dividirse en 5 intervalos y la noche en 2 intervalos, etc., la lógica es crear más contenedores para intervalos de tiempo con mayor variación con respecto a las condiciones ambientales que afectan la generación de energía o cualquier otra estrategia de acuerdo con la aplicación prevista por el usuario. Es decir, cada intervalo o segmento tiene una longitud única (en el tiempo).
El objetivo es inferir los valores de Ys dados los valores de verdad base totales T para la EGR del día y Ái se conocen a partir de los datos ambientales. Uno puede imaginar que Ái describe la fracción de tiempo que una variable ambiental se cumple: por ejemplo, si hay un día soleado con una temperatura de 24 °C durante 174 minutos, podemos decir Á1 = 174/1440, donde la primera variable describe esta situación ambiental. Entonces, la energía total generada T será el promedio ponderado de las generaciones de energía Yi para todas las diferentes condiciones ambientales que se cumplen para i-ésimas fracciones Ái en el día.
Por lo tanto, de manera similar a la aplicación de EV, el objetivo es resolver un sistema:

que es, en general, muy subdeterminado ya que hay una enorme cantidad de condiciones ambientales diferentes (si considera valores continuos de temperatura, dirección e intensidad del viento, precipitación, etc.) La idea es cuantificar el espacio de predictores agrupando 'similares' condiciones ambientales en el mismo contenedor, donde 'similar' significa que tiene un efecto equivalente o similar en la generación de energía. Por ejemplo, podemos decir que en un día soleado a 30 °C, esperamos la misma o similar generación de energía que en otro día soleado a 32 °C. Este es un ejemplo muy simple para enfatizar el punto de cuantificación: el objetivo es agrupar valores que tienen el mismo efecto o un efecto similar en la generación en el mismo contenedor. Esta cuantificación se puede realizar automáticamente usando la solicitud de patente en copropiedad mencionada anteriormente o de cualquier otra manera adecuada, como se estableció anteriormente para el ejemplo de dominio espacial de los vehículos eléctricos.
Siguiendo la formulación utilizada en las realizaciones adecuadas de EV anteriores, consideramos la tasa de generación de energía Y como una función de algunos predictores X 1, ..., Xn, es decir,
Yi - F(X i - ca, ...,Xn - cin) ,
dónde cij son valores reales constantes que cada predictor Xi alcanza en el i-ésimo punto de datos de los datos disponibles. Algunos predictores X pueden permanecer constantes a lo largo del tiempo (es decir, el área de superficie y el ángulo del panel solar, así como su ubicación), mientras que otros predictores cambian dinámicamente durante el día, es decir, factores ambientales como la temperatura del cielo, la temperatura del suelo, el ángulo del sol, etc. Si los datos contienen solo un tipo de panel solar (la misma área de superficie y la misma relación de conversión de electricidad a energía, por ejemplo), que puede colocarse en una ubicación específica, entonces no hay necesidad de cuantificar esas variables (ya que son constantes a través de los datos, ya se encuentran o pueden clasificarse en el mismo contenedor). Por lo tanto, en la última situación, cuantificamos solo los factores ambientales dinámicos que cambian a lo largo del tiempo. Si los datos contienen diferentes tipos de paneles solares (diferente área de superficie y relación de conversión de electricidad), que pueden colocarse en diferentes ubicaciones, estos predictores también deben cuantificarse.
Cualquier técnica de agrupamiento adecuada para datos ambientales y datos específicos del panel solar, que minimice la pérdida de información, puede usarse para hacer el sistema en la Ecuación 4 (aplicada a realizaciones adecuadas para la estimación de generación de energía PV). Por ejemplo, se puede utilizar el siguiente método de generación de clústeres (agrupación de segmentos de los ensayos).
1. A partir de datos geográficos y tipo de panel solar, adquiera predictores agregados construidos, por ejemplo:
a) Temperatura media del cielo
b) Temperatura media del suelo
c) Temperatura promedio del vidrio PV
d) Ángulo medio del sol
e) Porción de tiempo que el día estuvo soleado
f) Parte del día que estuvo nublado (etc. para otras condiciones como lluvia - nieve)
g) Área promedio del panel solar
h) Relación media de conversión de electricidad a energía
i) Etc. dependiendo de los datos disponibles
2. Entrene al bosque aleatorio con los datos agregados para predecir la tasa de consumo de energía total del viaje. 3. Realice un seguimiento de los valores de características utilizados para dividir los nodos de cada árbol dentro del bosque aleatorio en una estructura de datos como una lista. Por ejemplo:
- Temperatura media: [32, 15, 2, 8, 21, ...]
- Porción del día que estuvo soleado [0,2, 0,05, 0,15, 0,3, 0,5, ...]
- Porción del día que estuvo nublado [0,1,0,4, 0,05, 0,2, ...]
4. Cree un histograma para valores divididos para cada predictor.
5. Encuentra los picos del histograma.
6. Transporte paralelo por la diferencia de medias y escala por la razón de las desviaciones estándar de las distribuciones (ver Figura 13, por ejemplo):

7. Cuantifique de acuerdo con los valores máximos de la escala. Entonces, el sistema (Ecuación 1) se transformará en (Ecuación 3):

8. Resuelva el sistema utilizando, por ejemplo, el solucionador OSQP de la biblioteca cvxpy (si desea imponer restricciones) o una arquitectura de red neuronal de avance (si no se imponen restricciones). La arquitectura dependerá del tipo y tamaño del conjunto de datos y del número de predictores. Se pueden utilizar técnicas de regularización como abandono, cresta (si tiene sentido que las ponderaciones sean pequeñas en el problema) o lazo (si se desea imponer escasez). Estas técnicas de regularización también se pueden imponer para la optimización restringida.
De manera análoga a las realizaciones de EV descritas en las secciones anteriores, el sistema de ecuaciones transformado (paso 7 anterior), cuando se resuelve, proporciona ponderaciones de clústeres pronosticadas, que pueden usarse en la previsión de generación de energía PV.
Aplicación general para inferir valores de una cantidad en períodos de tiempo/espacio más precisos usando datos agregados
En general, los métodos se pueden aplicar a cualquier problema que abarque datos de tiempo/espacio agregados y, en los que el objetivo sea predecir el efecto de algunos predictores en períodos de tiempo/espacio más precisos. Por ejemplo, en contextos relacionados con las finanzas, la energía generada (Eg ) podría reemplazarse por ingresos, luego la tasa de generación de energía (EGR) podría reemplazarse por la tasa de ingresos (IR).
Supongamos que uno tiene valores para el ingreso diario y desea estimar el ingreso en períodos de tiempo más precisos (ingreso por minuto o por hora, por ejemplo) usando algunos predictores X 1, ..., Xn (los predictores pueden ser cualquier cosa que el usuario piense o sepa que influye en los ingresos). Indique la tasa de ingresos dentro de un período de tiempo t por Yt, es decir, Yt = l/t dónde / representa los ingresos. Sea T la verdad base total para la tasa de ingresos. Entonces T = V " A- * Y y M- 2 = 1
¿Jl=1 1 l , dónde Zj1_1 ( y M indica el número de todos los intervalos de tiempo en los que se divide el día. De manera similar a los ejemplos descritos anteriormente, el objetivo es resolver un sistema (Ecuación 1):

y, debido a que esto está muy subdeterminado, la tasa de ingreso Y se considera como una función de algunos predictores Xi, ..., Xn es decir,
Yl = F ( X 1 = ca ............ Xn = cin)
dónde cij son valores reales constantes que cada predictor Xj alcanza en el /-ésimo punto de datos de los datos disponibles. Posteriormente, el espacio del espacio predictor se cuantifica (por ejemplo, usando el método como en los pasos 1) - 7) anteriores) para resolver el sistema de ecuaciones transformado (Ecuación 3):

con cualquier solucionador de optimización restringida o red neuronal (o cualquier otro enfoque que prefiera el usuario).
Breve descripción de la invención
En una definición, se proporciona un método implementado por ordenador para la optimización de rutas, que comprende: recopilar datos de segmentos de ruta agregados, donde los datos de segmentos de ruta agregados incluyen datos geográficos y datos del vehículo, donde los datos del vehículo incluyen la tasa de consumo de energía del vehículo para los viajes del vehículo; y generar clústeres de los segmentos de viajes en una pluralidad de contenedores, donde los segmentos de viajes en cada contenedor comparten características de datos que dan como resultado tasas de consumo de energía similares; y estimar la tasa de consumo de energía del vehículo de al menos un segmento de ruta individual en comparación con los segmentos de viajes agrupados.
El método puede proporcionar una estimación robusta con un enfoque de modelado que utiliza la agrupación para hacer manejable un sistema de ecuaciones inaccesible y recuperar el efecto de cada segmento de carretera en el consumo total de energía de un viaje. Además, al usar la optimización restringida opcional, el método puede imponer valores de ponderación natural para el modelo que representan la tasa de consumo de energía de cada segmento de carretera. Esto hace que el modelo sea más interpretable y facilita la comprensión de las predicciones realizadas.
Este método puede superar la necesidad de adquirir costosos datos de nivel de enlace y también puede ahorrar tiempo, ya que no se requieren pasos de preprocesamiento para datos de series de tiempo. Después de predecir la contribución de cada segmento de carretera al consumo de energía, se puede aplicar un algoritmo de optimización de rutas para el cálculo de rutas energéticamente eficientes.
Los mismos pasos del método se pueden aplicar para pronosticar la generación de energía fotovoltaica o en el pronóstico financiero.
En general, el método predice el impacto de cada constituyente en una estadística agregada, ya sea en el dominio del tiempo o en el dominio del espacio. Por lo tanto, la solución propuesta se puede aplicar a muchos dominios en los que existe la necesidad de recuperar el efecto de las variables individuales en una estadística agregada.
Beneficios de las realizaciones de la invención
• Las realizaciones presentan un método para estimar las ponderaciones de los segmentos de carretera para un buscador de ruta óptimo en un gráfico como el algoritmo Dijkstra o A*. En el contexto de los vehículos eléctricos, óptimo significa más eficiente energéticamente.
• Las realizaciones pueden transformar un sistema de ecuaciones inaccesible en un sistema manejable. Esto es posible si los componentes de la estadística agregada forman clústeres.
• Las realizaciones se pueden aplicar a cualquier problema en el que exista la necesidad de encontrar la contribución de cada componente individual a una estadística agregada. Por ejemplo, las realizaciones pueden permitir una estimación
robusta del consumo de energía para cada segmento de carretera a partir de estadísticas agregadas a lo largo de un viaje sin la necesidad de un valor de verdad base a nivel de enlace para el consumo de energía o la información del motor/conductor.
• Los datos agregados requeridos pueden ser medidos por sensores de bajo costo. Esto ahorra tiempo y dinero para una empresa:
° Ahorro de tiempo de procesamiento porque los datos agregados son más rápidos de procesar.
° Ahorro de dinero porque no hay necesidad de adquirir costosos datos detallados en puntos intermedios de la cantidad agregada que se mide.
• Las realizaciones pueden ser escalables y, por lo tanto, pueden usarse para el cálculo de energía preciso sobre la marcha y, opcionalmente, también para la optimización de rutas. Solo se requiere una búsqueda en un diccionario para obtener el valor de clúster apropiado para un componente en particular.
• Las realizaciones tienen transferibilidad de dominio, es decir, entrenar el modelo en una región es suficiente para hacer inferencias en cualquier otra región. Esto se debe a la generación de clústeres del espacio predictor: para obtener el consumo de energía para otro dominio, los viajes se agrupan en clústeres en consecuencia (el número total de clústeres debe ser el mismo) y luego se consulta el modelo previamente entrenado en cada grupo. No se requiere entrenamiento del modelo desde cero.
• Las ponderaciones del modelo después del ajuste pueden tener un significado físico después de la optimización restringida: representan la tasa de consumo de energía de los segmentos de carretera. Esto facilita la comprensión e interpretación de las predicciones realizadas por la red neuronal. Tal comprensión es útil, por ejemplo, cuando las redes neuronales tienen que tomar decisiones importantes (por ejemplo, en medicina o conducción autónoma).
Áreas de aplicación
Un área de aplicación puede ser parte del cálculo de energía para un viaje planificado, por ejemplo, la distancia hasta el vacío (DTE) de un vehículo eléctrico o el software de optimización de rutas de eficiencia energética, que también puede predecir la ruta más eficiente energéticamente, así como el consumo de energía y la autonomía restante. Las realizaciones pueden ser utilizadas por vehículos comerciales para ahorrar dinero mediante la aplicación de una estimación de ruta eficiente en energía, así como también por vehículos de flota de entrega para minimizar costos mientras se completan las entregas a tiempo. Además, pueden ser utilizados por empresas de viajes compartidos (taxi compartido) para optimizar los lugares de recogida y maximizar las ganancias.
Las realizaciones también se pueden usar en escenarios en los que la capacidad de la batería es limitada (por ejemplo, EV de segunda mano con menor capacidad de batería). Los conductores tienden a comprar vehículos eléctricos con gran capacidad de batería, debido a las incertidumbres sobre el consumo de energía durante el viaje (por ejemplo, debido al clima, atascos de tráfico). Si se reducen esas incertidumbres, es posible que una mayor muestra representativa de conductores compre vehículos eléctricos porque los vehículos eléctricos con capacidades de batería más pequeñas son menos costosos.
Otro ámbito en el que pueden aplicarse las realizaciones es el de vehículo a red (“Vehicle-to-Grid”, V2G) en escenarios de apagón. Con el aumento de los desastres naturales (por ejemplo, fuertes vientos, inundaciones, terremotos), las áreas afectadas a veces tienen impactos secundarios debido a los apagones. Los EV se pueden utilizar como generadores móviles en estas situaciones. Dado que un EV utiliza electricidad para trasladarse al área afectada, es importante elegir las rutas más eficientes desde el punto de vista energético para un uso eficaz de los EV como generador móvil.
Las realizaciones pueden estar destinadas a datos de series de tiempo, en lugar de datos espaciales. Las realizaciones adecuadas de series de tiempo se pueden aplicar, por ejemplo, a la estimación de la generación de energía fotovoltaica (PV) o a la previsión financiera utilizando estadísticas agregadas.
De manera más general, el enfoque de modelado se puede utilizar para cualquier problema que necesite la estimación de componentes individuales que contribuyan a una estadística agregada.
Implementación de hardware
La Figura 14 es un diagrama general de cómo se utilizan los datos en los arreglos. Una base de datos con datos geográficos y datos de fabricantes sirve tanto para los clústeres de modelado (que puede llevarse a cabo, por ejemplo, en la nube) como para un motor de enrutamiento para sugerir rutas de energía más baja/menor (esto podría usar un ordenador portátil o un dispositivo móvil y consultar los datos formado por el modelado. En un ejemplo, el usuario del motor de enrutamiento introduce un punto de inicio y un punto final y el motor de enrutamiento divide las diversas rutas posibles entre los puntos en segmentos y consulta una tabla de diccionario/búsqueda proporcionada por el modelo de clúster para encontrar la tasa de uso de energía para cada segmento o un uso de energía total. El motor de enrutamiento puede entonces comparar las diferentes rutas para encontrar la más eficiente. Alternativamente, la segmentación puede realizarse de forma remota desde el motor de enrutamiento. El experto en la materia apreciará que existen varias formas de llevar a cabo el método en la nube, fuera de la nube o parcialmente localmente y parcialmente en la nube.
Por ejemplo, para crear el modelo (y, por lo tanto, los clústeres), el método requiere datos geográficos y datos del fabricante. Este modelado se realiza fuera de línea y las ponderaciones de los grupos se pueden almacenar en una tabla de búsqueda, como se muestra en las flechas que conectan la unidad de 'Datos geográficos' y la unidad de 'Base de datos de fabricantes' con la unidad de 'clústeres de modelado' en la Figura 14. Además, la unidad de 'Datos geográficos' se puede utilizar sobre la marcha cuando hay datos de tráfico en tiempo real disponibles.
Como paso de preprocesamiento, el método puede consultar las rutas más cortas entre los puntos inicial y final de cada viaje y mantener los viajes con una desviación de no más del 2% de la ruta más corta. Para ello, el método puede utilizar los datos del fabricante para el viaje (longitud y latitud inicial y final del viaje) y un motor de enrutamiento, como se muestra con la flecha que conecta la unidad de 'Base de datos de fabricantes' con la unidad de 'Motor de enrutamiento' en la Figura 14.
Finalmente, la unidad de 'clústeres de modelado' y la unidad 'Motor de enrutamiento' pueden comunicarse de dos maneras diferentes. Primero, diccionarios sin conexión con asignaciones de {segmentos de carretera ^ clústeres} y {clústeres ^ ponderaciones} se almacenan en la memoria. Luego, después de que un usuario ingresa una consulta (punto de inicio y final de un viaje) sobre la marcha, la unidad 'Motor de enrutamiento' puede usar los clústeres formados por el método para obtener ponderaciones para cada segmento de carretera en el mapa y, luego, usar un algoritmo de gráfico más corto (como Dijkstras o A*) para encontrar la ruta con mayor eficiencia energética. Por lo tanto, la unidad 'Motor de enrutamiento' primero puede consultar la base de datos con clústeres y ponderaciones (flecha de la unidad 'Motor de enrutamiento' a la unidad de 'clústeres de modelado') y luego recibir información (flecha de la unidad de 'clústeres de modelado' a la unidad de 'Motor de enrutamiento) para realizar una optimización de ruta eficiente energéticamente.
La Figura 15 es un diagrama de bloques de un dispositivo informático, como un servidor de almacenamiento de datos, que representa la presente invención y que puede usarse para implementar un método de una realización para predecir el uso de energía para una ruta como se define en las reivindicaciones y descrito en la descripción, o un método de clústeres de modelado, y/o un método para encontrar una ruta de energía optimizada como se muestra en la Figura 2. También se puede usar en otras implementaciones para estimar componentes individuales que contribuyen a una estadística agregada como se explica aquí. El dispositivo informático comprende un procesador 993 y una memoria 994. Opcionalmente, el dispositivo informático también incluye una interfaz de red 997 para la comunicación con otros dispositivos informáticos, por ejemplo, con otros dispositivos informáticos de realizaciones de la invención.
Por ejemplo, una realización puede estar compuesta por una red de dichos dispositivos informáticos. Opcionalmente, el dispositivo informático también incluye uno o más mecanismos de entrada, como un teclado y un ratón 996, y una unidad de pantalla/visualización como uno o más monitores 995. Los componentes se pueden conectar entre sí a través de un bus 992.
La memoria 994 puede incluir un medio legible por ordenador, un término que puede referirse a un solo medio o a múltiples medios (por ejemplo, una base de datos centralizada o distribuida y/o cachés y servidores asociados) configurado para transportar instrucciones ejecutables por ordenador o tener estructuras de datos almacenadas en el mismo. Las instrucciones ejecutables por computadora pueden incluir, por ejemplo, instrucciones y datos accesibles por un ordenador de propósito general, un ordenador de propósito especial o un dispositivo de procesamiento de propósito especial (por ejemplo, uno o más procesadores) para realizar una o más funciones u operaciones. Por lo tanto, el término "medio de almacenamiento legible por ordenador" también puede incluir cualquier medio que sea capaz de almacenar, codificar o transportar un conjunto de instrucciones para que las ejecute la máquina y que haga que la máquina realice uno o más de los métodos del presente revelación. En consecuencia, la expresión "medio de almacenamiento legible por ordenador" puede incluir, entre otros, memorias de estado sólido, medios ópticos y medios magnéticos. A modo de ejemplo, y sin limitación, dichos medios legibles por ordenador pueden incluir medios de almacenamiento legibles por ordenador no transitorios, que incluyen memoria de acceso aleatorio (RAM), memoria de solo lectura (ROM), memoria de solo lectura programable borrable eléctricamente (EEPROM), memoria de solo lectura de disco compacto (CD-ROM) u otro almacenamiento de disco óptico, almacenamiento de disco magnético u otros dispositivos de almacenamiento magnético, dispositivos de memoria flash (por ejemplo, dispositivos de memoria de estado sólido).
El procesador 993 está configurado para controlar el dispositivo informático y ejecutar operaciones de procesamiento, por ejemplo, ejecutar código almacenado en la memoria para implementar las distintas funciones descritas aquí y en las reivindicaciones. Por ejemplo, el procesador puede llevar a cabo los pasos que hacen coincidir un segmento de carretera con un grupo correspondiente y, por lo tanto, con una tasa predicha de uso de energía. Adicional o alternativamente, el procesador puede llevar a cabo los pasos que predicen el uso de energía de una nueva ruta sumando la tasa predicha de uso de energía multiplicada por la longitud del segmento para cada segmento de la ruta.
La memoria 994 almacena datos que el procesador 993 lee y escribe, por ejemplo, puede incluir la base de datos a la que se hace referencia aquí, o simplemente puede almacenar parámetros tales como niveles de predicción y tablas de información, por ejemplo, como se muestra en las Figuras 9, 10, 11 y 12. Como se menciona aquí, un procesador puede incluir uno o más dispositivos de procesamiento de uso general, como un microprocesador, una unidad central de procesamiento o similar. El procesador puede incluir un microprocesador de cálculos de conjunto de instrucciones complejo (CISC), un microprocesador de cálculos de conjunto de instrucciones reducido (RISC), un microprocesador de
palabra de instrucción muy larga (VLIW) o un procesador que implementa otros conjuntos de instrucciones o procesadores que implementan una combinación de conjuntos de instrucciones. El procesador también puede incluir uno o más dispositivos de procesamiento para fines especiales, como un circuito integrado de aplicación específica (ASIC), un arreglo de compuertas programables en campo (FPGA), un procesador de señal digital (DSP), un procesador de red o similar. En una o más realizaciones, un procesador está configurado para ejecutar instrucciones para realizar las operaciones y pasos discutidos aquí.
La unidad de pantalla 995 puede mostrar una representación de los datos almacenados por el dispositivo informático y también puede mostrar un cursor y cuadros de diálogo y pantallas que permitan la interacción entre un usuario y los programas y datos almacenados en el dispositivo informático. Los mecanismos de entrada 996 pueden permitir que un usuario introduzca datos e instrucciones en el dispositivo informático. En un ejemplo, la pantalla se puede utilizar para mostrar la construcción del modelo y la entrada utilizada para los hiperparámetros. Además o alternativamente, la pantalla puede mostrar un mapa con una ruta sugerida y potencialmente otras rutas menos eficientes energéticamente y la entrada puede ser un punto de inicio y final para una ruta. En una realización más general, la pantalla puede mostrar una o más predicciones de contribución para estadísticas agregadas que incorporan uno o más segmentos de los K ensayos.
La interfaz de red (red I/F) 997 se puede conectar a una red, como Internet, y se puede conectar a otros dispositivos informáticos a través de la red, lo que permite que el dispositivo informático acceda a la base de datos del fabricante o a la base de datos de K ensayos en una realización más general, por ejemplo. La red I/F 997 puede controlar la entrada/salida de datos desde/hacia otro aparato a través de la red. Otros dispositivos periféricos como micrófono, altavoces, impresora, fuente de alimentación, ventilador, carcasa, etc. pueden estar incluidos en el dispositivo informático.
Los métodos que incorporan la presente invención pueden llevarse a cabo en un dispositivo informático como el ilustrado en la Figura 15. Dicho dispositivo informático no necesita tener todos los componentes ilustrados en la Figura 15 y puede estar compuesto por un subconjunto de esos componentes. Un método que incorpora la presente invención puede ser llevado a cabo por un solo dispositivo informático en comunicación con uno o más servidores de almacenamiento de datos a través de una red. El dispositivo informático puede ser un almacenamiento de datos en sí mismo que almacene el uso de energía previsto para una ruta.
Un método que incorpora la presente invención puede ser llevado a cabo por una pluralidad de dispositivos informáticos que funcionan en cooperación entre sí. Uno o más de las pluralidades de dispositivos informáticos pueden ser un servidor de almacenamiento de datos que almacene al menos una parte de los datos, como la tasa predicha de uso de energía para grupos o el uso de energía previsto para una ruta.
Claims (12)
1. Un método implementado por computadora para predecir el uso de energía para una ruta que comprende:
introducir (S2) datos de mapa de las carreteras incluidas en K viajes en un área geográfica, e introducir predictores de tasa de uso de energía a lo largo de las carreteras;
introducir (S4) datos de consumo de energía de los K viajes, los datos de consumo de energía que indican el uso total de energía T entre un punto inicial A y un punto final B de cada uno de los K viajes;
dividir (S6) cada una de las carreteras en los datos de mapa para todos los K viajes en segmentos de medida de longitud Aí;
agrupar (S8) los segmentos de los viajes en un número N de clústeres, los clústeres definidos de acuerdo con rangos de al menos uno de los predictores, siendo definido cada clúster como teniendo una ponderación Wj que está por determinarse;
usar (S10) un algoritmo para construir un modelo que prediga las ponderaciones Wj con base en la solución de un sistema de ecuaciones, una por viaje, cada ecuación igualando el uso de energía total conocido T del viaje con la suma de la medida de longitud conocida de cada segmento en el viaje multiplicada por la ponderación del clúster en el que se agrupó el segmento;
para cada segmento, asignar (S12) la ponderación predicha Wj aplicada al clúster en el que se agrupó el segmento como la tasa predicha de uso de energía Y ; y
almacenar (S14) un ID de segmento con una indicación de la tasa predicha de uso de energía Y para permitir la predicción del uso de energía para una ruta en el área geográfica que incorpora uno o más de los segmentos.
2. El método de conformidad con la reivindicación 1, que comprende además:
antes de introducir (S2) los datos de mapa, para cada viaje en una base de datos, encontrar (S100) la ruta más corta entre el punto inicial A y el punto final B;
verificar la longitud en la base de datos entre el punto inicial A y el punto final B; y
incluir los datos de la ruta más corta para un viaje cuando su longitud está dentro de un umbral de la ruta más corta entre A y B para formar los K viajes.
3. El método de conformidad con cualquiera de las reivindicaciones anteriores, que comprende además:
limpieza de datos (S110) antes de introducir (S2) los datos de mapa, donde la limpieza de datos comprende suavizar los datos de elevación en mosaicos de elevación, cuando hay más de un punto en un mosaico, cambiar la elevación de uno o más puntos de borde en el mosaico adyacente a un mosaico de una elevación diferente para mover la elevación de los puntos de borde más cerca de la elevación del mosaico de la elevación diferente.
4. El método de conformidad con cualquiera de las reivindicaciones anteriores, donde el método se amplía para incluir todos los segmentos en el área geográfica al:
dividir las partes de las carreteras en el área geográfica que no están incluidas en los viajes en segmentos no transitados; agrupar cualquier segmento no transitado en un clúster de acuerdo con el nivel de al menos uno de los predictores en ese segmento no transitado; y
usar la tasa predicha de uso de energía y la longitud de la medida de cada segmento no transitado para permitir la predicción del uso de energía para una ruta que también incorpora uno o más de los segmentos no transitados.
5. El método de conformidad con cualquiera de las reivindicaciones anteriores, donde
los predictores incluyen al menos uno de: gradientes en los segmentos, tal como un gradiente promedio positivo o negativo del segmento; y características que afectan el tráfico en los segmentos, como datos históricos de tráfico, señales de tráfico, cruces y tiendas.
6. El método de conformidad con cualquiera de las reivindicaciones anteriores, donde
los clústeres se definen de acuerdo con rangos de uno o más predictores que proporcionan un espacio predictor de un número de dimensiones igual al número de predictores, el espacio predictor proporcionando, por ejemplo, un eje para cada predictor, un predictor que tiene un mayor efecto sobre el uso de energía preferiblemente se divide en más divisiones de clúster que un predictor que tiene un efecto menor sobre el uso de energía.
7. El método de conformidad con la reivindicación 6, que comprende además:
para cada dimensión, ordenar la división de clúster de modo que una división que represente un nivel de predictor que tenga un efecto menor en el consumo de energía se proporcione en una división más baja y/o en una posición más baja a lo largo del eje para ese predictor que una división que represente un nivel de predictor que tiene un mayor efecto sobre el consumo de energía, y Wj tiene un valor menor que W +i.
8. El método de conformidad con cualquiera de las reivindicaciones anteriores, donde
el número de segmentos de carretera en el área geográfica M es al menos un orden de magnitud mayor que el número N de clústeres y/o el número de viajes K
9. El método de conformidad con cualquiera de las reivindicaciones anteriores, donde el algoritmo para construir el modelo es un algoritmo de optimización cuadrática o desarrollado por una red neuronal.
10. El método de conformidad con la reivindicación 9, donde el algoritmo es un algoritmo de optimización cuadrática, que se restringe usando restricciones para las ponderaciones, restringiéndose las ponderaciones según los clústeres y ordenadas según el impacto que tiene cada predictor en la tasa de consumo de energía.
11. Un programa de ordenador que comprende instrucciones que, cuando el programa es ejecutado por un ordenador, hacen que la computadora lleve a cabo el método de la reivindicación 1.
12. Un aparato de procesamiento de datos que comprende un procesador (993) y una memoria (994) configurados para llevar a cabo el método de conformidad con cualquiera de las reivindicaciones anteriores.
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP20187503.6A EP3943890B1 (en) | 2020-07-23 | 2020-07-23 | A computer-implemented method of predicting energy use for a route |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2950156T3 true ES2950156T3 (es) | 2023-10-05 |
Family
ID=71786765
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES20187503T Active ES2950156T3 (es) | 2020-07-23 | 2020-07-23 | Método implementado por ordenador para predecir el uso de energía para una ruta |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US11913795B2 (es) |
| EP (1) | EP3943890B1 (es) |
| JP (1) | JP2022022106A (es) |
| ES (1) | ES2950156T3 (es) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112258268B (zh) * | 2020-10-16 | 2023-11-07 | 百度国际科技(深圳)有限公司 | 确定推荐模型和确定物品价格的方法、装置、设备和介质 |
| US11906315B2 (en) * | 2021-12-27 | 2024-02-20 | GM Global Technology Operations LLC | Electric vehicle trip energy prediction based on baseline and dynamic driver models |
| US11867521B2 (en) * | 2022-02-16 | 2024-01-09 | GM Global Technology Operations LLC | Adaptive in-drive updating of vehicle energy consumption prediction |
| CN114719880B (zh) * | 2022-06-01 | 2022-09-23 | 阿里巴巴(中国)有限公司 | 模型训练方法、装置及电子设备 |
| US20240078851A1 (en) * | 2022-09-01 | 2024-03-07 | Ford Global Technologies, Llc | Systems and methods for predicting energy consumption in vehicles |
| CN116978259B (zh) * | 2023-06-19 | 2024-01-26 | 武汉大海信息系统科技有限公司 | 一种船舰航行轨迹预测方法、装置及存储介质 |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7680749B1 (en) * | 2006-11-02 | 2010-03-16 | Google Inc. | Generating attribute models for use in adaptive navigation systems |
| US20110205359A1 (en) * | 2010-02-19 | 2011-08-25 | Panasonic Corporation | Video surveillance system |
| US8346772B2 (en) * | 2010-09-16 | 2013-01-01 | International Business Machines Corporation | Systems and methods for interactive clustering |
| US8755993B2 (en) * | 2011-03-08 | 2014-06-17 | Navteq B.V. | Energy consumption profiling |
| EP2690408B1 (en) * | 2012-07-26 | 2017-02-22 | Harman Becker Automotive Systems GmbH | Method of operating a navigation system and navigation system |
| EP3214406A1 (en) | 2016-03-04 | 2017-09-06 | Volvo Car Corporation | Method and system for utilizing a trip history |
| US20190114909A1 (en) * | 2016-04-05 | 2019-04-18 | Tomtom Traffic B.V. | Method and Apparatus for Identifying Congestion Bottlenecks |
| US11327475B2 (en) | 2016-05-09 | 2022-05-10 | Strong Force Iot Portfolio 2016, Llc | Methods and systems for intelligent collection and analysis of vehicle data |
| WO2019026180A1 (ja) * | 2017-08-01 | 2019-02-07 | 日産自動車株式会社 | 情報提供方法及び情報提供装置 |
| US10890459B2 (en) * | 2017-10-13 | 2021-01-12 | John Matsumura | Systems and methods for variable energy routing and tracking |
| EP3877235A4 (en) | 2018-11-09 | 2023-07-19 | Iocurrents, Inc. | MACHINE LEARNING-BASED PREDICTION, PLANNING AND OPTIMIZATION OF TRAVEL TIME, TRAVEL COSTS AND/OR POLLUTANT EMISSION DURING NAVIGATION |
| US11287272B2 (en) | 2018-11-19 | 2022-03-29 | International Business Machines Corporation | Combined route planning and opportunistic searching in variable cost environments |
| EP3767236B1 (en) * | 2019-07-15 | 2023-04-26 | Bayerische Motoren Werke Aktiengesellschaft | Energy map reconstruction by crowdsourced data |
-
2020
- 2020-07-23 EP EP20187503.6A patent/EP3943890B1/en active Active
- 2020-07-23 ES ES20187503T patent/ES2950156T3/es active Active
-
2021
- 2021-06-21 JP JP2021102131A patent/JP2022022106A/ja active Pending
- 2021-06-23 US US17/355,754 patent/US11913795B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2022022106A (ja) | 2022-02-03 |
| EP3943890A1 (en) | 2022-01-26 |
| US11913795B2 (en) | 2024-02-27 |
| US20220026228A1 (en) | 2022-01-27 |
| EP3943890B1 (en) | 2023-05-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2950156T3 (es) | Método implementado por ordenador para predecir el uso de energía para una ruta | |
| Ullah et al. | Electric vehicle energy consumption prediction using stacked generalization: An ensemble learning approach | |
| Cheng et al. | Research on travel time prediction model of freeway based on gradient boosting decision tree | |
| US11378411B2 (en) | Method and system for utilizing a trip history to predict a destination | |
| Guo et al. | GPS-based citywide traffic congestion forecasting using CNN-RNN and C3D hybrid model | |
| Cheng et al. | A big data based deep learning approach for vehicle speed prediction | |
| CN110816549B (zh) | 能源管理装置、模型管理方法以及计算机程序 | |
| Jiang et al. | Short-term speed prediction using remote microwave sensor data: machine learning versus statistical model | |
| Zeng et al. | Exploring trip fuel consumption by machine learning from GPS and CAN bus data | |
| Yi et al. | Inferencing hourly traffic volume using data-driven machine learning and graph theory | |
| Li et al. | Prediction of electric bus energy consumption with stochastic speed profile generation modelling and data driven method based on real-world big data | |
| CN103745110B (zh) | 纯电动公交车营运续驶里程估算方法 | |
| CN110501020B (zh) | 一种多目标三维路径规划方法 | |
| Chen et al. | A multiscale-grid-based stacked bidirectional GRU neural network model for predicting traffic speeds of urban expressways | |
| Foiadelli et al. | Energy consumption prediction of electric vehicles based on big data approach | |
| Gao et al. | Traffic speed forecast in adjacent region between highway and urban expressway: based on MFD and GRU model | |
| CN108510130A (zh) | 一种智能无人驾驶车辆极限里程智能多源评估方法及装置 | |
| Nadeem et al. | Performance analysis of a real-time adaptive prediction algorithm for traffic congestion | |
| Rasaizadi et al. | Short-term prediction of traffic state for a rural road applying ensemble learning process | |
| Modi et al. | A system for electric vehicle’s energy-aware routing in a transportation network through real-time prediction of energy consumption | |
| AlKheder et al. | Urban traffic prediction using metrological data with fuzzy logic, long short-term memory (LSTM), and decision trees (DTs) | |
| Sarker et al. | Vehicle routing trifecta: Data-driven route recommendation system | |
| Shenghua et al. | Road traffic congestion prediction based on random forest and DBSCAN combined model | |
| Abbas et al. | Scaling deep learning models for large spatial time-series forecasting | |
| Ajani et al. | Dynamic path planning approaches based on artificial intelligence and machine learning |