EP3544005B1 - Codage audio avec de la quantification tramée - Google Patents
Codage audio avec de la quantification tramée Download PDFInfo
- Publication number
- EP3544005B1 EP3544005B1 EP18187597.2A EP18187597A EP3544005B1 EP 3544005 B1 EP3544005 B1 EP 3544005B1 EP 18187597 A EP18187597 A EP 18187597A EP 3544005 B1 EP3544005 B1 EP 3544005B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- spectral
- coding
- samples
- encoded
- encoding
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000013139 quantization Methods 0.000 title claims description 148
- 230000003595 spectral effect Effects 0.000 claims description 312
- 238000000034 method Methods 0.000 claims description 116
- 230000005236 sound signal Effects 0.000 claims description 58
- 239000013598 vector Substances 0.000 claims description 45
- 238000001228 spectrum Methods 0.000 claims description 42
- 239000011159 matrix material Substances 0.000 claims description 39
- 238000004590 computer program Methods 0.000 claims description 16
- 238000007493 shaping process Methods 0.000 claims description 3
- 238000009826 distribution Methods 0.000 description 113
- 238000013459 approach Methods 0.000 description 42
- 238000012360 testing method Methods 0.000 description 32
- 238000002474 experimental method Methods 0.000 description 26
- 238000004422 calculation algorithm Methods 0.000 description 22
- 238000013461 design Methods 0.000 description 16
- 230000006872 improvement Effects 0.000 description 16
- 230000008901 benefit Effects 0.000 description 12
- 238000001914 filtration Methods 0.000 description 11
- 238000012545 processing Methods 0.000 description 11
- 238000011049 filling Methods 0.000 description 10
- 230000000875 corresponding effect Effects 0.000 description 9
- 238000009792 diffusion process Methods 0.000 description 7
- 230000003993 interaction Effects 0.000 description 7
- 230000008569 process Effects 0.000 description 7
- 230000009467 reduction Effects 0.000 description 7
- 230000005540 biological transmission Effects 0.000 description 6
- 238000007796 conventional method Methods 0.000 description 6
- 230000000873 masking effect Effects 0.000 description 6
- 230000000694 effects Effects 0.000 description 5
- 238000011156 evaluation Methods 0.000 description 5
- 239000000463 material Substances 0.000 description 5
- 230000000717 retained effect Effects 0.000 description 5
- 238000005070 sampling Methods 0.000 description 5
- 238000004458 analytical method Methods 0.000 description 4
- 230000003247 decreasing effect Effects 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 230000003044 adaptive effect Effects 0.000 description 3
- 238000004891 communication Methods 0.000 description 3
- 230000002860 competitive effect Effects 0.000 description 3
- 230000002596 correlated effect Effects 0.000 description 3
- 230000007423 decrease Effects 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 238000009827 uniform distribution Methods 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000005284 excitation Effects 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 238000012805 post-processing Methods 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 238000004088 simulation Methods 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 230000002123 temporal effect Effects 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 238000011869 Shapiro-Wilk test Methods 0.000 description 1
- 238000001793 Wilcoxon signed-rank test Methods 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 230000004888 barrier function Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 238000003339 best practice Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 230000001427 coherent effect Effects 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 239000012141 concentrate Substances 0.000 description 1
- 239000013256 coordination polymer Substances 0.000 description 1
- 230000001186 cumulative effect Effects 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 238000013100 final test Methods 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 230000015654 memory Effects 0.000 description 1
- 230000003340 mental effect Effects 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 208000024891 symptom Diseases 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 238000012549 training Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 238000011179 visual inspection Methods 0.000 description 1
- 230000003936 working memory Effects 0.000 description 1
Images




















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G10L19/18—Vocoders using multiple modes
- G10L19/22—Mode decision, i.e. based on audio signal content versus external parameters
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/0017—Lossless audio signal coding; Perfect reconstruction of coded audio signal by transmission of coding error
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/032—Quantisation or dequantisation of spectral components
Definitions
- the present invention relates to audio encoding, audio processing and audio decoding, and in particular, to an audio encoder, an audio decoder, an audio encoding method and an audio decoding method for dithered quantization for frequency-domain speech and audio coding.
- Fig. 2 illustrates a mean energy of perceptually weighted and normalized MDCT-spectra over the TIMIT database, for original signal (thick line), conventional quantization (dotted), dithered (dashed), as well as dithered in combination with Wiener filtering (crosses) and energy matching (thin line). Quantization was scaled to match a bitrate of 13.2 kbit/s.
- noise filling With a method known as noise filling, one can insert noise in areas of the spectrum which have been quantized to zero such that absence of energy is avoided [64]. Both approaches thus aim to retain energy at a similar level as the original signal, but they do not optimize signal-to-noise ratio. A recent improvement, known as intelligent gap filling, combines these methods by using both noise filling and copy-up [65].
- Classical dithering algorithms however also include methods which can retain the signal distribution without reduction in signal to noise ratio [66].
- Common dithering methods such as Floyd-Steinberg, are based on error-diffusion or randomization of quantization levels, such that quantization errors can be diffused without loss in accuracy [67].
- WO2014161994 A2 discloses an audio encoding and decoding system and, in particular, to a transform-based audio codec system which is particularly well suited for voice encoding/decoding.
- a quantization unit configured to quantize a first coefficient of a block of coefficients is described.
- the block of coefficients comprises a plurality of coefficients for a plurality of corresponding frequency bins.
- the quantization unit is configured to provide a set of quantizers.
- the set of quantizers comprises a plurality of different quantizers associated with a plurality of different signal-to-noise ratios, respectively.
- the plurality of different quantizers includes a noise-filling quantizer; one or more dithered quantizers; and one or more un-dithered quantizers.
- the quantization unit is further configured to determine an SNR indication indicative of a SNR attributed to the first coefficient, and to select a first quantizer from the set of quantizers, based on the SNR indication. In addition, the quantization unit is configured to quantize the first coefficient using the first quantizer.
- BACKSTROM TOM ET AL "Arithmetic coding of speech and audio spectra using tcx based on linear predictive spectral envelopes", 2015 IEEE INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH AND SIGNAL PROCESSING (ICASSP), IEEE, (20150419), doi:10.1109/ICASSP.2015.7178948, pages 5127 - 5131 relates to unified speech and audio codecs, which often use a frequency domain coding technique of the transform coded excitation type, which is based on modeling the speech source with a linear predictor, spectral weighting by a perceptual model and entropy coding of the frequency components. It is disclosed to use the magnitude of the linear predictor to estimate the variance of spectral components.
- the object of the present invention is to provide improved concepts for audio encoding and audio decoding.
- the object of the present invention is solved by an audio encoder according to claim 1, by an audio decoder according to claim 7, by a system according to claim 13, by a method according to claim 14, by a method according to claim 15 and by a computer program according to claim 16.
- An audio encoder for encoding an audio signal, wherein the audio signal is represented in a spectral domain comprises a spectral envelope encoder configured for determining a spectral envelope of the audio signal and for encoding the spectral envelope. Moreover, the audio encoder comprises a spectral sample encoder configured for encoding a plurality of spectral samples of the audio signal. The spectral sample encoder is configured to estimate an estimated bitrate needed for encoding for each spectral sample of one or more spectral samples of the plurality of spectral samples depending on the spectral envelope.
- the spectral sample encoder is configured to encode each spectral sample of the plurality of spectral samples, depending on the estimated bitrate needed for encoding for the one or more spectral samples, according to a first coding rule or according to a second coding rule being different from the first coding rule.
- the second coding rule comprises using an entropy codec and conducting quantization, and wherein the first coding rule comprises using dithered coding.
- the spectral sample encoder is configured to encode the one or more spectral samples using dithered coding, if the estimated bitrate is smaller than or equal to a threshold value.
- the spectral sample encoder is configured to encode the one or more spectral samples using entropy coding and conducting quantization, if the estimated bitrate is greater than the threshold value.
- an audio decoder for decoding an encoded audio signal.
- the audio decoder comprises an interface configured for receiving an encoded spectral envelope of the audio signal and configured for receiving an encoded plurality of spectral samples of the audio signal.
- the audio decoder comprises a decoding unit configured for decoding the encoded audio signal by decoding the encoded spectral envelope and by decoding the encoded plurality of spectral samples.
- the decoding unit is configured to receive or to estimate an estimated bitrate needed for encoding for each spectral sample of one or more spectral samples of the encoded plurality of spectral samples.
- the decoding unit is configured to decode each spectral sample of the encoded plurality of spectral samples, depending on the estimated bitrate needed for encoding for the one or more spectral samples of the encoded plurality of spectral samples, according to a first coding rule or according to a second coding rule being different from the first coding rule.
- the second coding rule comprises using an entropy codec and conducting quantization, and wherein the first coding rule comprises using dithered coding.
- the decoding unit is configured to decode the one or more spectral samples using decoding of dithered encoding, if the estimated bitrate is smaller than or equal to a threshold value.
- the decoding unit is configured to decode the one or more spectral samples using entropy decoding and conducting dequantization, if the estimated bitrate is greater than the threshold value.
- a method for encoding an audio signal, wherein the audio signal is represented in a spectral domain comprises:
- Encoding the plurality of spectral samples of the audio signal is conducted by estimating an estimated bitrate needed for encoding for each spectral sample of one or more spectral samples of the plurality of spectral samples depending on the spectral envelope. Moreover, encoding the plurality of spectral samples of the audio signal is conducted by encoding each spectral sample of the plurality of spectral samples, depending on the estimated bitrate needed for encoding for the one or more spectral samples, according to a first coding rule or according to a second coding rule being different from the first coding rule.
- the second coding rule comprises using an entropy codec and conducting quantization, and wherein the first coding rule comprises using dithered coding.
- Encoding the one or more spectral samples using dithered coding is conducted, if the estimated bitrate is smaller than or equal to a threshold value. Moreover, encoding the one or more spectral samples using entropy coding and conducting quantization is conducted, if the estimated bitrate is greater than the threshold value.
- the method comprises:
- Decoding the encoded audio signal is conducted by receiving or by estimating an estimated bitrate needed for encoding for each spectral sample of one or more spectral samples of the encoded plurality of spectral samples. Moreover, decoding the encoded audio signal is conducted by decoding each spectral sample of the encoded plurality of spectral samples, depending on the estimated bitrate needed for encoding for the one or more spectral samples of the encoded plurality of spectral samples, according to a first coding rule or according to a second coding rule being different from the first coding rule.
- the second coding rule comprises using an entropy codec and conducting quantization, and wherein the first coding rule comprises using dithered coding.
- Decoding the one or more spectral samples using decoding of dithered encoding is conducted, if the estimated bitrate is smaller than or equal to a threshold value. Moreover, decoding the one or more spectral samples using entropy decoding and conducting dequantization is conducted, if the estimated bitrate is greater than the threshold value.
- each of the computer programs is configured to implement one of the above-described methods when being executed on a computer or signal processor.
- Embodiments are based on the following findings:
- frequency-domain codecs use uniform quantization and arithmetic coding to efficiently encode spectral components, and such entropy codec is near-optimal at high bitrates.
- Dithered coding concepts which use random rotations and 1-bit quantization are employed. In embodiments, such dithered coding concepts are applied in frequency-domain speech and audio coding.
- a hybrid coder which may, for example, apply a threshold at 1bit/sample to choose between the two codecs.
- An estimate of the bit-consumption for individual samples may, for example, be extracted from the LPC-based arithmetic codec which is used in 3GPP EVS [48].
- hybrid coding between uniform quantization with arithmetic coding (or other entropy codec, or other quantization) and dithered coding is conducted.
- randomization may, e.g., be based on orthonormal rotations and 1-bit coding (sign quantization), following [70].
- 1-bit coding where 1-bit coding (sign quantization) may e.g., be used on a select B samples of a vector length of N, to obtain a desired bit-consumption of B bits, which is equivalent with B/N bits per sample.
- hybrid coding is conducted such that the codec is chosen based on expected bit-rate of samples.
- a bit-rate may, e.g., be estimated from an envelope model such as the LPC, following [48].
- one may, e.g., have multiple thresholds on the bit-rate to split the samples into categories of different accuracy, to allow for noise shaping.
- dithered quantization and/or coding is conducted such that the output is post-filtered after reconstruction.
- post-filtering based on a minimum mean square error minimization, or based on scaling output energy to match the (estimated) original energy or based on other scaling or optimization or a combination of these may, e.g., be conducted.
- post-filtering may, e.g., be chosen to optimize a perceptual quality and/or a signal to noise ratio and/or another quality criteria.
- an audio encoder or a method of audio encoding or a computer program for implementing the method of audio coding using a hybrid coding as described in this application is provided.
- An audio decoder or a method of audio decoding or a computer program for implementing the method of audio decoding using a hybrid decoding as described in this application is provided.
- dithered quantization for frequency-domain speech and audio coding relating to a hybrid coding scheme for low-bitrate coding is employed, where low energy samples may, e.g., be quantized using dithering, instead of the conventional uniform quantizer. For dithering, one bit quantization in a randomized sub-space may, e.g., be applied.
- a hybrid coder which applies a threshold at 1bit/sample to choose between the two codecs.
- An estimate of the bit-consumption for individual samples may, e.g., be extracted from the LPC-based arithmetic codec which is used in 3GPP EVS [48].
- Some embodiments are based on using dithering instead of the conventional uniform quantizer. For dithering, one bit quantization in a randomized sub-space is applied.
- Embodiments of the present invention are based on particular combinations of first coding concepts and of second coding concepts.
- first coding concepts are described.
- One concept or two or more concepts or all concepts of the first coding concepts may be referred to as a first coding rule.
- the first coding concepts relate to arithmetic coding of speech and audio spectra using TCX based on linear predictive spectral envelopes.
- Unified speech and audio codecs often use a frequency domain coding technique of the transform coded excitation (TCX) type. It is based on modeling the speech source with a linear predictor, spectral weighting by a perceptual model and entropy coding of the frequency components. While previous approaches have used neighbouring frequency components to form a probability model for the entropy coder of spectral components, it is proposed to use the magnitude of the linear predictor to estimate the variance of spectral components.
- TCX transform coded excitation
- time-domain coding provides superior performance for signals with rapidly changing character and temporal events, such as spoken consonants, applause and percussive signals. Coding in the frequency-domain, on the other hand, is more effective for stationary signals such as harmonic music signals and sustained voiced speech sounds.
- AAC-type codecs use the perceptual masking model to scale the spectrum such that the detrimental effect of quantization on spectral components has perceptually the same expected magnitude in every part of the spectrum [22]. To allow efficient coding of the perceptual spectrum, these codecs then apply entropy coding of the frequency components. For higher efficiency, the arithmetic coder can use the neighbouring spectral components to determine the probability distribution of the spectral components, such as in USAC [57], [61].
- Speech codecs on the other hand use energy envelopes as a signal model and apply a perceptual weighting filter, much like the perceptual masking model, on top.
- the spectral envelope as described by the linear predictive model, provides information of the energy envelope of the spectrum. Since it thus describes the energy distribution of the spectral components, it can be used to describe their probability distributions. This distribution can, in turn, be used to design a highly efficient arithmetic coder for the spectral components. Since the linear predictive model is generally transmitted also for TCX frames, this spectral envelope information comes without additional side-information.
- an explicit source model may, e.g., be used in the form of the linear predictor, and in difference to TCX-type codecs, an adaptive probability distribution may, e.g., be used for the arithmetic codec derived from the magnitude of the linear predictor.
- a signal adaptive model of the probability distributions of spectral components is described based on the linear predictive model. The goal is to obtain a fixed bit-rate arithmetic coder applicable in speech and audio codecs which use linear predictive modeling. Moreover, the objective is to design a generic method which is efficient on a variety of bit-rates and bandwidths.
- the encoder of the first coding concepts may, e.g., be configured to conduct three steps.
- the perceptually weighted linear predictor may, e.g., be used as a model for the shape of the perceptually weighted spectrum. Since this envelope does not contain information of the signal magnitude, the envelope is scaled such that the expected bit-consumption of a signal, whose variance follows the envelope, matches the desired bit-rate.
- the actual perceptually weighted spectrum is scaled and quantized such that the bit-rate matches the desired bit-rate, when using the envelope model.
- a k ⁇ 1 be the samples of the discrete Fourier transform of hat linear predictive model which describes the short-time temporal structure and thus the spectral envelope of a signal spectrum S k .
- a k is an efficient model of S k
- This relation quantifies the relative energy of spectral components and can be used as an estimate of their relative variance in the design of models of the probability distribution of weighted spectral components.
- a probability distribution model for the individual spectral components can then be chosen.
- the most obvious candidates are either the normal or the Laplacian distribution, since they are both simple to implement and commonly known to be fairly accurate models of speech and audio signals. To determine which distribution fits the approach better, the following experiment has been conducted.
- the 16 critical items of speech, mixed and music material used in the standardization of MPEG USAC [57] were used.
- the material was resampled to 12.8kHz and windowed with sine-windows, and transformed to the frequency domain using the MDCT, with 256 frequency bands and full-overlap.
- Linear predictive models of order 16 were estimated for each frame using a Hamming window of length 30ms, centered to align with the MDCT windows.
- a Laplacian random variable with variance ⁇ 2 has a bit-consumption expectation of 1 + log 2 ( e ⁇ ), where e is Euler's number.
- the arithmetic coder of the first coding concepts is based on a Laplacian distribution, which is equivalent with a signed exponential distribution. To simplify the process, one can thus first encode the absolute magnitude of spectral lines and for non-zero values then also encode their sign with one bit.
- the decoder may, e.g., be set to decode the spectra until the maximal bit-consumption is reached and set any remaining spectral components to zero.
- the encoder thus encodes the spectrum up to the last non-zero frequency. Informal experiments showed that with this approach the number of encoded frequency components is often reduced by 30 to 40%.
- the spectrum must be scaled to obtain the highest accuracy which can be encoded with the available bits.
- the optimal scaling can then be determined in a rate-loop implemented as a binomial search. Informal experiments showed that the best scaling can usually be found within 5 iterations.
- the objective of the arithmetic coder is to encode the spectrum into the bit-stream as efficiently as possible.
- the numerical operations must be implemented with fixed-point operations such that differences in numerical accuracy across different platforms will not change the outcome.
- a 14 bit integer representation stored in a 16 bit integer variable can be chosen, which allows for a sign bit and avoids problems in the last bit due to differences in rounding.
- a related problem in implementation of the arithmetic coder is that when the standard deviation ⁇ k is small compared to the quantized magnitude
- the memory-lessness property of exponential distributions can be used. This principle states that p Y ⁇ k > r + s
- Y ⁇ k > r ) p Y ⁇ k > s .
- the probability p (
- bit-stream should be output only for the final scaling coefficient. To reduce computational complexity, it is then sufficient to only estimate bit-consumption in the rate-loop and invoke the arithmetic coder only with the optimal scaling.
- a logarithm of the product ⁇ k p ( ⁇ k ) can thus be calculated, and thereby, computational complexity can be reduced. It should be noted, however, that the product can become a very large number, whereby the calculation of the product shall be implemented in a representation where it can be guaranteed that an overflow cannot occur.
- a subjective AB comparison listening test [63] was performed.
- the codec was implemented according to the first coding concepts in a candidate version of the 3GPP Enhanced Voice Services speech and audio codec [2].
- an arithmetic coder derived from the MPEG Unified Speech and Audio Coder was used, which forms a probability model of spectral lines using neighbouring lines [57], [61].
- the codecs were operating at a fixed bit-rate of 8 kbps in the wide-band mode. Bandwidth extension was encoded normally but its output was disabled to concentrate on differences of the core bandwidth.
- the double-blind AB comparison test was performed by 7 expert listeners in a silent room with high-quality headphones.
- the test included 19 samples of mono speech, music, and mixed material.
- the differential results of the compare test are illustrated in Fig. 10 , where a positive score indicates a subjective improvement of the codec of the first coding concepts over the reference codec using the arithmetic coder of MPEG USAC.
- Fig. 10 illustrates differential AB scores and their 95% confidence intervals of a comparison listening test measuring the performance of the arithmetic coder in comparison to the coder from MPEG USAC at 8 kbps for wide-band signals.
- the first coding concepts provide concepts for modeling the probability distribution of perceptually weighted frequency components of speech and audio signals using a model of the spectral envelope and the perceptual weighting function.
- Frequency-domain codecs based on the TCX concept model the spectral envelope using linear prediction, from which an estimate of the perceptual masking curve can be obtained. Since the linear predictor is transmitted in any case, the first coding concepts can be applied without transmission of additional side-information.
- the first coding concepts use the spectral envelope model as a model of the speech source for construction of a probability model for the entropy coder.
- conventional methods have used preceding frequency components to predict the magnitude of the current component [57], [61].
- the conventional methods thus use an implicit source model, whereas the first coding concepts model the source explicitly.
- LTP long term prediction
- the long term predictor can be used to model the comb-structure of spectra with a dominant fundamental frequency.
- the presented results demonstrate that the first coding concepts improve perceptual quality at low bit-rates when the bit-consumption is kept constant. Specifically, subjective measurements with an AB test showed a statistically significant improvement.
- the coding scheme of the first coding concepts can thus be used to either increase quality at a given fixed bit-rate or decrease the bit-rate without losing perceptual quality.
- the presented approach is applicable in all speech and audio codecs which employ a frequency-domain coding of the TCX type, where a model of the spectral envelope is transmitted to the decoder.
- Such codecs include standards such as MPEG USAC, G.718 and AMR-WB+ [57], [58], [59]. In fact, the method has already been included in the ETSI 3GPP Enhanced Voice Services standard [2].
- One concept or two or more concepts or all concepts of the second coding concepts may be referred to as a second coding rule.
- the second coding concepts relate to fast randomization for distributed low-bitrate coding of speech and audio.
- the second coding concepts provide a distributed speech and audio codec design, which applies quantization in a randomized domain such that quantization errors are randomly rotated in the output domain. Similar to dithering, this ensures that quantization errors across nodes are uncorrelated and coding efficiency is retained.
- the second coding concepts achieve fast randomization with a computational complexity of O ( N log N ).
- the presented experiments demonstrate that the randomizations of the second coding concepts yield uncorrelated signals, that perceptual quality is competitive, and that the complexity of the second coding concepts is feasible for practical applications.
- the second coding concepts describe an alternative method using dithered quantization, where the input signal is multiplied with a random rotation before quantization such that the quantization levels are obscured when the rotation is inverted for the output signal [70].
- a similar approach is applied in the Opus codec [71], though only with Givens-rotations without permutations.
- a simple quantization such as 1 bit quantization is applied to obtain high performance at low complexity and very low bitrates [8].
- the randomized quantization methods of the second coding concepts are unique in the way they allow quantization and coding of signals without a lower limit on bitrate, while simultaneously providing the best SNR per bit ratio.
- the second coding concepts provide the benefits of vector coding by joint processing of multiple samples, without significant penalty on complexity.
- Speech coding Digital compression of speech signals for transmission and storage applications, known as speech coding, is a classic topic within speech processing and modern speech coding standards achieve high efficiency in their respective application scenarios [1], [2], [3], [4], [5]. Though these standards are high-fidelity products, they are constrained to configurations with a single encoder. Designs which would allow using the microphones of multiple independent devices could improve signal quality, and moreover, it would allow a more natural interaction with the user-interface as the speaker would no more be constrained to a single device. If the codec can flexibly use all available hardware, then the user does not need to know which devices are recording, releasing mental capacity from attention to devices to the communication at hand.
- the overall computational complexity increases linearly with both the encoder complexity as well as the number of nodes, whereby it is important to keep encoder complexity low to be able to use a large number of nodes. If one can move the main intelligence of the codec from the encoder to the decoder, then the overall complexity of the system would thus be much lower.
- CELP code-excited linear prediction
- high bit-rates say 100 kbits s
- very small differences in the signal such as variations in delay, background noise or sensor noise, would be sufficient to make quantization noise between nodes uncorrelated [7], whereby each node will provide unique information.
- An objective is to develop a distributed codec for speech and audio, where coding efficiency is optimized, but which can also be applied on any device, including simple mobile or even wearable devices with limited CPU and battery resources.
- the approach is based on randomizing the signal before quantization, such that quantization error expectations between devices are uncorrelated. It is assumed that the randomizer uses a random-number generator whose seed is communicated from the encoder to the decoder either offline or sufficiently seldom that it has a negligible effect on the bitrate. Overall, the randomizer in this context is similar to dithering and was inspired by the 1 bit quantization used in compressive sensing [10], [11].
- Randomization has several distinct benefits in the codec of the second coding concepts:
- Algorithmic complexity shall be improved, and the randomization properties and coding efficiency shall be retained or improved as much as feasible.
- randomization and decorrelation are used also in many other fields of speech, audio and signal processing in general. For example, in upmixing of audio signals from a low to a higher number of channels, concepts for generating uncorrelated source signals are needed [39].
- Randomization methods of the second coding concepts may find application in any such applications which require low-complexity methods for generation of uncorrelated signals.
- randomization can be used in single-channel codecs to diffuse unnaturally sparse quantization levels which appear at low bitrates.
- the main objective of coding is to quantize and encode an input signal x ⁇ R N ⁇ 1 , with a given number of bits B , such that it can be decoded with highest accuracy possible.
- the objective of randomization is to make sure that the resynthesized signal retains the continuous distribution of the original signal and that the quantization error is uncorrelated Gaussian noise.
- quantization by construction yields a signal with a discrete distribution, a signal which follows a similar distribution as the original signal shall be obtained.
- the aim is that if the signal is quantized and coded at multiple nodes, then the quantization errors of the outputs would be uncorrelated.
- Fig. 11 illustrates a flow diagram of the randomization process, where P is a random (orthogonal) matrix and Q [ ⁇ ] is a quantizer.
- the signal is multiplied with a random orthogonal matrix P before quantization.
- P a random orthogonal matrix
- multiplication with the inverse P T is conducted (see Fig. 11 ). It is important that the transform is orthonormal, since it preserves signal energy, such that the transform provides perfect reconstruction and a minimal white noise gain.
- Permutations are computationally fast operations which correspond to orthogonal matrices, whereby their use in randomization is interesting.
- ⁇ ⁇ be a diagonal matrix whose diagonal elements are randomly chosen as ⁇ 1.
- this matrix is also orthogonal.
- Random permutations can be easily generated at algorithmic complexity O ( N log N ) [41].
- a heuristic approach is for example to apply a sort algorithm, such as merge sort, on a vector of random uncorrelated samples. The sort operation then corresponds to a permutation, which is uniformly distributed over the length of the vector.
- Multiplication with matrices has in general an algorithmic complexity of O ( N 2 ).
- N ⁇ N matrix X with uncorrelated and normally distributed samples with zero mean and equal variance is generated.
- a simplification of the QR-algorithm is to apply Householder transformations with each of the columns of X [42]. While this approach is efficient for small matrices, in informal experiments it is found that for large matrices, the simplification does not provide a uniform distribution.
- the subgroup algorithm presented in [43], [44] has also been tried. Though this algorithm is faster than the Householder-based algorithm by a factor of 2, unfortunately however, it suffers from the same issues as the Householder based algorithm.
- the QR-algorithm applied on random matrices thus remains the high-quality and -complexity method for reference.
- the number of 2 ⁇ 2 blocks is N /2, whereby N /2 random scalars are needed to generate the matrix B.
- B involves N /2 multiplications by a 2 ⁇ 2 matrix at complexity O (2 N ), as well as N /2 evaluations of cos ⁇ and sin ⁇ at O ( N ), though evaluation of trigonometric functions can have a high constant multiplier for the complexity.
- permutations is straightforward; it is essentially a mapping of sample indices, whereby it does not involve computations other than moving operations, O ( N ).
- the permutation indices and the permuted vector have to be stored, whereby the storage requirements are O (2 N ).
- Generation of permutations can be applied by sorting a vector of random scalars ⁇ k with, for example, the merge sort algorithm [41]. It requires also a storage of O (2 N ), but not at the same time as the application of the permutation, whereby it does not add to the overall storage requirements.
- the algorithmic complexity for generating the permutation is O ( N log N ) [41].
- the QR-algorithm can be applied with arbitrary accuracy with an algorithmic complexity of O ( N 2 ) and storage O ( N 2 ) [38].
- Application of the randomization and its inverse are then simply multiplications by a matrix and its transpose, both at complexity O ( N 2 ). It however requires N 2 random scalars as input, whereby also the complexity of generating pseudo-random numbers becomes an issue.
- the random values at the input should have rotational symmetry, whereby the uniformly distributed scalars ⁇ k variables are not sufficient.
- a typical frequency domain codec will have no components which require a complexity more than O ( N log N ). Since the randomization of the second coding concepts is also O ( N log N ), in terms of algorithmic complexity, this corresponds to conventional TCX codecs. The complexity bottleneck thus returns to the rate-loop of the entropy codec [1], [48].
- the randomized quantizer was applied for coding of the fine-spectral structure in a distributed speech and audio codec.
- the overall structure is similar to that of the TCX mode in 3GPP EVS [2] and the implemented codec structure is illustrated in Fig. 12 .
- Fig. 12 illustrates a structure of the (a) encoder and (b) decoder of one node of the distributed speech and audio codec. Dashed boxes indicate modules which were not included in current experiments to facilitate isolated evaluation of randomization coefficients, while working memory must be always at least 2N coefficients.
- the MDCT time-frequency transform and half-sine windowing on the input signal [22] was applied to obtain spectral representations x k of each time-frame at a node k .
- the window length was 20 ms with 10 ms overlap, and the sampling rate was 12.8 kHz.
- the sampling rate was chosen to match the core-rate of EVS in wide-band mode [2].
- the remaining bandwidth is coded with bandwidth-extension methods, to obtain a total sampling rate of 16 kHz.
- the signal envelope and perceptual model is analyzed, using the LPC-based approach as in EVS [1], [2].
- the signal is then perceptually weighted and multiplied with random rotation matrices to obtain randomized vectors.
- the signal is quantized and coded.
- a fixed-bitrate entropy coder with 2 bits/sample was used as follows: the distribution was split into four quantization cells such that each cell had equal probability and each input sample was quantized to the nearest quantization cell. The quantization levels are thus fixed and the system does not require a rate-loop.
- the operations are reversed, with the exception of the perceptual model estimation, which is assumed to be transmitted.
- the perceptual model estimation which is assumed to be transmitted.
- the quality of the output signal could be further enhanced with noise attenuation techniques such as Wiener filtering [6], [49].
- noise attenuation was omitted such that tuning parameters can be avoided and the comparison of different methods can be kept fair.
- Fig. 13 illustrates an encoder/decoder structure of the distributed speech and audio codec with N encoder nodes and a single decoder node.
- the decoder can then contain the inverse randomizations and a "merge & enhance" -block can implement Wiener filtering independently from the randomization.
- a random orthogonal matrix is then obtained, which is defined as P o .
- K 1000 vectors x of length N are generated, whose samples are uncorrelated and follow the normal distribution.
- each of the vectors x o , x r and x re ⁇ were individually scaled for minimum error, and the quantization error energy for each vector was calculated.
- Table I illustrates a signal-to-noise ratio (SNR) of sign quantization with orthonormal randomization (Orth), randomization with a random matrix (Rand), and without randomization (None).
- SNR signal-to-noise ratio
- the dashed line indicates the theoretical distribution of normalized covariance between random Gaussian vectors, scaled to fit to each histogram.
- the theoretical distribution illustrated with a dashed line is used (see below for details).
- the third objective performance measure is the ability of randomization to diffuse the quantization levels in the output signal.
- Fig. 15 illustrates the output histogram when applying sign-quantization and the inverse rotation PTM for different values of M. The use of sign quantization has been chosen here, since it is the worst-case in terms of sparsity.
- Fig. 16 illustrates a convergence of distribution with increasing number of rotations M to (a) the normalized Gaussian and (b) the normalized Laplacian, as measured by the Kullback-Leibler divergence, for different vector lengths N .
- randomization with the QR-algorithm is depicted with crosses "x," representing a high-complexity and high-performance target level.
- the speech and audio codec was calculated according to the second coding concepts, whose generic structure was described above as follows.
- the LPC-based perceptual model was copied as-is from EVS [2].
- the perceptual SNR refers to the signal to noise ratio between the perceptually weighted original and quantized signals [22].
- Table II illustrates a perceptual SNRs of each evaluated method.
- MUSHRA listening test was conducted [52] (Regarding MUSHRA, see also [56]). Thirteen subjects, aged between 22 and 53, were asked to evaluate the quality of the different approaches. Seven of the thirteen test persons referred to themselves as expert listeners.
- Fig. 17 illustrates the results of the MUSHRA test, given for the different items, and an average over all items. The reference was omitted as it was always rated to 100.
- the QR approach has high scores.
- the coding quality of all methods is in the same range as the anchor, which is arguably low, even for a low bitrate codec.
- the perceptual results overall should be treated as preliminary.
- the 95% confidence intervals do not overlap, and there is a clear difference between all three conditions under test, where the second coding concepts perform on average about 20 MUSHRA points better than the conventional, and the QR approach can improve the quality by approximately 15 points.
- Fig. 18 illustrates the difference scores of the performed MUSHRA test, where the second coding concepts were used as a reference point. The lower anchor and the hidden reference were omitted.
- the low-complexity second coding concepts are always better than no randomization, which was a target.
- This argument also validates the choice of not using source modeling; by source modeling, quantization accuracy can be improved, but the experiments show that the perceptual quality of a codec can be improved by randomization even with a fixed quantization accuracy.
- Quality of speech and audio coding can be improved in terms of both signal quality and ease of interaction with the user-interface by including, in the coding process, all connected hardware which feature a microphone.
- a distributed speech and audio codec design may, e.g., be used which is based on randomization of the signal before quantization [8].
- the complexity bottle-neck of the codec of the second coding concepts, that is, the randomizer, is considered.
- the low-complexity randomizer of the second coding concepts may, e.g., be based on a sequence of random permutations and 2 ⁇ 2 block-rotations.
- high-accuracy decorrelation is obtained, such that the covariance of the original and the randomized signal behaves like uncorrelated signals, and such that the quantization levels of the output signal are diffused.
- the randomization of the second coding concepts has multiple benefits for low-bitrate coding, distributed coding, perceptual performance, robustness and encryption. Experiments confirm these benefits by showing that randomization improves perceptual SNR and subjective quality. Though inclusion of a randomizer shows here an SNR improvement of 2.4 dB, this benefit is expected to be reduced when a proper source model is included. However, it is shown that if quantization errors are randomized, taking the mean of signals improves SNR as much as 2.8 dB, whereby one can always improve quality by adding more microphones.
- a new random variable y x ⁇ x ⁇ p isobtained, which is closely related to x but does not follow the generalized normal distribution.
- Fig. 1a illustrates an audio encoder for encoding an audio signal, wherein the audio signal is represented in a spectral domain, according to an embodiment.
- the audio encoder comprises a spectral envelope encoder 110 configured for determining a spectral envelope of the audio signal and for encoding the spectral envelope.
- the audio encoder comprises a spectral sample encoder 120 configured for encoding a plurality of spectral samples of the audio signal.
- the spectral sample encoder 120 is configured to estimate an estimated bitrate needed for encoding for each spectral sample of one or more spectral samples of the plurality of spectral samples depending on the spectral envelope.
- the spectral sample encoder 120 is configured to encode each spectral sample of the plurality of spectral samples, depending on the estimated bitrate needed for encoding for the one or more spectral samples, according to a first coding rule or according to a second coding rule being different from the first coding rule.
- the second coding rule comprises using an entropy codec and conducting quantization, and wherein the first coding rule comprises using dithered coding.
- the spectral sample encoder 120 is configured to encode the one or more spectral samples using dithered coding, if the estimated bitrate is smaller than or equal to a threshold value. Moreover, the spectral sample encoder 120 is configured to encode the one or more spectral samples using entropy coding and conducting quantization, if the estimated bitrate is greater than the threshold value.
- the estimated bitrate may, e.g., be determined for each of the plurality of spectral samples.
- the spectral sample encoder 120 may, e.g., be configured to encode said spectral sample according to the first coding rule, and if said estimated bitrate needed for encoding said spectral samples is smaller than or equal to a threshold value, the spectral sample encoder 120 may, e.g., be configured to encode said spectral sample according to the second coding rule.
- the threshold value may, e.g., be 1 bit/sample (1 bit/spectral sample).
- the spectral sample encoder 120 may, e.g., be configured to estimate the estimated bitrate needed for encoding for each spectral sample of the one or more spectral samples depending on an estimated variance of said spectral sample which depends on the spectral envelope.
- the spectral sample encoder 120 may, e.g., be configured to encode the spectral samples that are encoded according to the second coding rule by quantizing said spectral samples that are encoded according to the second coding rule employing an orthogonal matrix. Moreover, the spectral sample encoder 120 may, e.g., be configured to encode the spectral samples that are encoded according to the first coding rule by quantizing said spectral samples that are encoded according to the first coding rule without employing the orthogonal matrix.
- Fig. 1b illustrates an audio decoder for decoding an encoded audio signal according to an embodiment.
- the audio decoder comprises an interface 130 configured for receiving an encoded spectral envelope of the audio signal and configured for receiving an encoded plurality of spectral samples of the audio signal.
- the audio decoder comprises a decoding unit 140 configured for decoding the encoded audio signal by decoding the encoded spectral envelope and by decoding the encoded plurality of spectral samples.
- the decoding unit 140 is configured to receive or to estimate an estimated bitrate needed for encoding for each spectral sample of one or more spectral samples of the encoded plurality of spectral samples.
- the decoding unit 140 is configured to decode each spectral sample of the encoded plurality of spectral samples, depending on the estimated bitrate needed for encoding for the one or more spectral samples of the encoded plurality of spectral samples, according to a first coding rule or according to a second coding rule being different from the first coding rule.
- the second coding rule comprises using an entropy codec and conducting quantization, and wherein the first coding rule comprises using dithered coding.
- the decoding unit 140 is configured to decode the one or more spectral samples using decoding of dithered encoding, if the estimated bitrate is smaller than or equal to a threshold value. Moreover, the decoding unit 140 is configured to decode the one or more spectral samples using entropy decoding and conducting dequantization, if the estimated bitrate is greater than the threshold value.
- the decoding unit 140 may, e.g., receive the estimated bitrate needed for encoding for each spectral sample of the one or more spectral samples from the audio encoder that encoded the plurality of spectral samples.
- the decoding unit 140 may, e.g., estimate the estimated bitrate needed for encoding for each spectral sample of the one or more spectral samples depending on the spectral envelope in a same way as the audio encoded that encoded the spectral samples has estimated the estimated bitrate.
- the decoding unit 140 may, e.g., be configured to decode said spectral sample according to the first coding rule, and if said estimated bitrate needed for encoding said spectral samples is smaller than or equal to a threshold value, the decoding unit 140 may, e.g., be configured to decode said spectral sample according to the second coding rule.
- the threshold value may, e.g., be 1 bit/sample (1 bit/spectral sample).
- the decoding unit 140 may, e.g., be configured to estimate the estimated bitrate needed for encoding for each spectral sample of the one or more spectral samples depending on an estimated variance of said spectral sample which depends on the spectral envelope.
- the decoding unit 140 may, e.g., be configured to decode the spectral samples that are decoded according to the second coding rule by employing an orthogonal matrix. Moreover, the decoding unit 140 is configured to decode the spectral samples that are decoded according to the first coding rule without employing the orthogonal matrix.
- the decoding unit 140 may, e.g., be configured to employ spectral noise shaping for decoding the encoded plurality of spectral samples.
- Fig. 1c illustrates a system according to an embodiment.
- the system comprises an audio encoder 105 according to Fig. 1a and an audio decoder 125 according to Fig.1b .
- the audio encoder 105 is configured to feed a encoded spectral envelope of an encoded audio signal and an encoded plurality of spectral samples of the encoded audio signal into the audio decoder.
- the audio decoder 125 is configured to decode the encoded audio signal by decoding the encoded spectral envelope and by decoding the encoded plurality of spectral samples.
- Dithering methods however provide an alternative approach, where both accuracy and energy are retained.
- a hybrid coding approach is provided where low-energy samples are quantized using dithering, instead of the conventional uniform quantizer. For dithering, 1 bit quantization is applied in a randomized sub-space. It is moreover demonstrated that the output energy can be adjusted to the desired level using a scaling parameter. Objective measurements and listening tests demonstrate the advantages of the provided concepts.
- ⁇ can be chosen according to a number of criteria, for example:
- ⁇ can thus be tuned according to perceptual criteria, for a balance between accuracy and how well the quantizer retains the signal distribution and variance.
- a state-of-the-art baseline system is implemented following the simplified structure of the 3GPP Enhanced Voice Services (EVS) [2], [1], [48] (see Fig. 3 ).
- EVS Enhanced Voice Services
- Fig. 3 illustrates a diagram of the speech and audio encoder.
- the gray box is modified in by embodiments.
- Quantization in the perceptually weighted domain is applied as in [1].
- a deadzone-quantizer was not implemented, even if it is known to improve signal-to-noise ratio [64], because it also amplifies the saturation effect at high frequencies. A deadzone-quantizer would therefore have unfairly penalized the baseline codec in terms low-rate performance.
- bitrate of the codec it was assumed that spectral envelope, gain and other parameters are encoded with 2.6 kbits/s, whereby the remaining bits can be used for encoding the spectrum. Further, for simplicity and reproducability, any other parameters of the signal were not quantized. It should be noted, however, that bitrate calculations here are provided only to assist the reader in getting a realistic impression of performance, as the bitrate of side-information can vary in particular implementations of codecs.
- the combination of uniform quantization and arithmetic coder saturates at low bitrates, whereby it is proposed to replace the conventional approach by dithered coding for spectral samples whose bitrate is below 1 bit/sample. It is thus a hybrid entropy coder, which uses uniform quantization and arithmetic coding following [48] in high-energy areas of the spectrum and dithered coding at the low-energy areas.
- Fig. 4 illustrates hybrid coding of spectral components.
- Random rotations between the non-zero and zeroed values could be readily used to reduce the computational complexity without effect on the statistics of the output signal.
- Fig. 6 depicts an illustration of performance for a typical speech spectrum at 13.2 kbits/s, wherein (a) depicts an input signal spectrum and its envelope, wherein (b) depicts the bitrate estimated from the envelope and the threshold where quantizers are switched, and wherein (c) the quantized spectra with conventional uniform quantization and entropy coding in comparison to the provided, dithered coder.
- the spectral magnitude envelope is estimated using linear predictive modelling in Fig. 6(a)
- the expected bit-rate for each frequency is estimated from the envelope using the method developed in [48] in Fig. 6(b) and a threshold is applied to determine the choice of quantizer.
- Fig. 6(c) the quantized output of the conventional method is compared with the provided concepts, where the gain factor was _2 . It can be clearly seen that whereas for the conventional approach, all frequencies above 2 kHz are quantized to zero, the provided concepts retain the spectral shape also at the higher frequencies.
- the entire TIMIT database (training and evaluation) was encoded with different combinations of quantization and entropy coding [51]. Namely, it was applied: 1. uniform quantization with arithmetic coding following [48] (Conventional), 2. a dithering simulation by adding white noise to obtain same signal to noise ratio as the conventional approach (Dithering), 3. the provided hybrid codec using ⁇ MMSE (1 bit MMSE) and 4. Using ⁇ 2 (1 bit EM). The mean output energy across frequencies for each method is illustrated in Fig. 2 .
- SNR signal to noise ratios
- Table III illustrates a mean signal to noise ratio in the perceptually weighted domain for the conventional and the two provided concepts.
- a MUSHRA listening test was performed [52]. In the test, 6 samples (3 male and 3 female) randomly chosen from the TIMIT corpus [51] were included. In addition to the above methods, Conventional, Dithered, 1 bit MMSE and 1 bit EM, also cases where the conventional uniform coder is enhanced by noise filling in post-processing were included. It was not included in the previous tests because it is a blind post-processing method in the sense that it adds noise without any transmitted information from the input signal, whereby it reduces accuracy even if it is designed to improve perceptual quality. In the listening test, 14 normal hearing subjects in the age-range 26 to 43 years attended. Fig. 7 illustrates the results.
- Fig. 7 depicts results of a subjective MUSHRA listening test, comparing the provided 1 bit dithered quantizers with conventional arithmetic coding, as well as a synthetic dithering serving as an anchor.
- the provided dithered 1 bit quantizers have a higher mean than the other methods. Moreover, in the mean over all items (the "All" column), the provided dithered 1 bit quantizers have a statistically significant difference to the antecedent methods. Conventional arithmetic coding without noisefill also shows a statistically significant reduction in quality in comparison to all other methdods. To further determine whether listeners have a preference among the two provided dithered quantizers, the differential MUSHRA scores with noisefill as a reference (see Fig. 8 ) was calculated.
- Fig. 8 illustrates differential scores of a subjective MUSHRA listening test, comparing the provided 1 bit dithered quantizers with conventional arithmetic coding, as well as a synthetic dithering serving as an anchor. Differences are calculated with the noisefill as reference.
- embodiments may, e.g., use a recently developed method for dithering and coding which is applicable to very low bitrates [70].
- the approach is based on a random rotation, sign-quantization in the randomized domain, and an inverse transform. It is proposed to apply it in combination with conventional uniform quantization and entropy coding, such that only frequency components where one can afford to use very little accuracy, are coded with the dithered quantizer.
- aspects have been described in the context of an apparatus, it is clear that these aspects also represent a description of the corresponding method, where a block or device corresponds to a method step or a feature of a method step. Analogously, aspects described in the context of a method step also represent a description of a corresponding block or item or feature of a corresponding apparatus.
- Some or all of the method steps may be executed by (or using) a hardware apparatus, like for example, a microprocessor, a programmable computer or an electronic circuit. In some embodiments, one or more of the most important method steps may be executed by such an apparatus.
- embodiments of the invention can be implemented in hardware or in software or at least partially in hardware or at least partially in software.
- the implementation can be performed using a digital storage medium, for example a floppy disk, a DVD, a Blu-Ray, a CD, a ROM, a PROM, an EPROM, an EEPROM or a FLASH memory, having electronically readable control signals stored thereon, which cooperate (or are capable of cooperating) with a programmable computer system such that the respective method is performed. Therefore, the digital storage medium may be computer readable.
- Some embodiments according to the invention comprise a data carrier having electronically readable control signals, which are capable of cooperating with a programmable computer system, such that one of the methods described herein is performed.
- embodiments of the present invention can be implemented as a computer program product with a program code, the program code being operative for performing one of the methods when the computer program product runs on a computer.
- the program code may for example be stored on a machine readable carrier.
- inventions comprise the computer program for performing one of the methods described herein, stored on a machine readable carrier.
- an embodiment of the inventive method is, therefore, a computer program having a program code for performing one of the methods described herein, when the computer program runs on a computer.
- a further embodiment of the inventive methods is, therefore, a data carrier (or a digital storage medium, or a computer-readable medium) comprising, recorded thereon, the computer program for performing one of the methods described herein.
- the data carrier, the digital storage medium or the recorded medium are typically tangible and/or nontransitory.
- a further embodiment of the inventive method is, therefore, a data stream or a sequence of signals representing the computer program for performing one of the methods described herein.
- the data stream or the sequence of signals may for example be configured to be transferred via a data communication connection, for example via the Internet.
- a further embodiment comprises a processing means, for example a computer, or a programmable logic device, configured to or adapted to perform one of the methods described herein.
- a processing means for example a computer, or a programmable logic device, configured to or adapted to perform one of the methods described herein.
- a further embodiment comprises a computer having installed thereon the computer program for performing one of the methods described herein.
- a further embodiment according to the invention comprises an apparatus or a system configured to transfer (for example, electronically or optically) a computer program for performing one of the methods described herein to a receiver.
- the receiver may, for example, be a computer, a mobile device, a memory device or the like.
- the apparatus or system may, for example, comprise a file server for transferring the computer program to the receiver.
- a programmable logic device for example a field programmable gate array
- a field programmable gate array may cooperate with a microprocessor in order to perform one of the methods described herein.
- the methods are preferably performed by any hardware apparatus.
- the apparatus described herein may be implemented using a hardware apparatus, or using a computer, or using a combination of a hardware apparatus and a computer.
- the methods described herein may be performed using a hardware apparatus, or using a computer, or using a combination of a hardware apparatus and a computer.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Claims (16)
- Codeur audio pour coder un signal audio, dans lequel le signal audio est représenté dans un domaine spectral, dans lequel le codeur audio comprend:un codeur d'enveloppe spectrale (110) configuré pour déterminer une enveloppe spectrale du signal audio et pour coder l'enveloppe spectrale, etun codeur d'échantillons spectraux (120) configuré pour coder une pluralité d'échantillons spectraux du signal audio,dans lequel le codeur d'échantillons spectraux (120) est configuré pour estimer un débit binaire estimé nécessaire pour coder chaque échantillon spectral parmi un ou plusieurs échantillons spectraux de la pluralité d'échantillons spectraux en fonction de l'enveloppe spectrale, etdans lequel le codeur d'échantillons spectraux (120) est configuré pour coder chaque échantillon spectral de la pluralité d'échantillons spectraux, en fonction du débit binaire estimé nécessaire pour le codage des un ou plusieurs échantillons spectraux, selon une première règle de codage ou selon une deuxième règle de codage qui est différente de la première règle de codage,dans lequel la deuxième règle de codage comprend le fait d'utiliser un codec entropique et de réaliser une quantification, et dans lequel la première règle de codage comprend le fait d'utiliser un codage tramé; etdans lequel le codeur d'échantillons spectraux (120) est configuré pour coder les un ou plusieurs échantillons spectraux à l'aide d'un codage tramé si le débit binaire estimé est inférieur ou égal à une valeur de seuil; et dans lequel le codeur d'échantillons spectraux (120) est configuré pour coder les un ou plusieurs échantillons spectraux à l'aide d'un codage entropique et pour réaliser une quantification si le débit binaire estimé est supérieur à la valeur de seuil.
- Codeur audio selon la revendication 1,
dans lequel la valeur de seuil est de 1 bit/échantillon. - Codeur audio selon la revendication 1 ou 2,
dans lequel le codeur d'échantillons spectraux (120) est configuré pour estimer le débit binaire estimé nécessaire pour coder chaque échantillon spectral des un ou plusieurs échantillons spectraux en fonction d'une variance estimée dudit échantillon spectral qui dépend de l'enveloppe spectrale. - Codeur audio selon la revendication 1 ou 2,dans lequel le codeur d'échantillons spectraux (120) est configuré pour estimer le débit binaire estimé nécessaire pour coder chaque échantillon spectral des un ou plusieurs échantillons spectraux en fonction de l'équation
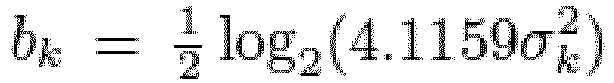 où bk est un k-ème échantillon spectral des un ou plusieurs échantillons spectraux,où
où bk est un k-ème échantillon spectral des un ou plusieurs échantillons spectraux,où
- Codeur audio selon l'une des revendications précédentes,dans lequel le codeur d'échantillons spectraux (120) est configuré pour coder les échantillons spectraux qui sont codés selon la deuxième règle de codage en quantifiant lesdits échantillons spectraux qui sont codés selon la deuxième règle de codage à l'aide d'une matrice orthogonale, etdans lequel le codeur d'échantillons spectraux (120) est configuré pour coder les échantillons spectraux qui sont codés selon la première règle de codage en quantifiant lesdits échantillons spectraux qui sont codés selon la première règle de codage sans utiliser la matrice orthogonale.
- Codeur audio selon la revendication 5,dans lequel le codeur d'échantillons spectraux (120) est configuré pour coder les échantillons spectraux qui sont codés selon la deuxième règle de codage à l'aide de:
 où x est un vecteur comprenant les échantillons spectraux, avec
où x est un vecteur comprenant les échantillons spectraux, avec où QB [·] est un quantificateur défini comme
où QB [·] est un quantificateur défini comme où y0, y1, yB-1 sont des valeurs quantifiées résultant de la quantification,où B indique un débit binaire total,où Υ est un coefficient de mise à échelle,où A est la matrice orthogonale, avec
où y0, y1, yB-1 sont des valeurs quantifiées résultant de la quantification,où B indique un débit binaire total,où Υ est un coefficient de mise à échelle,où A est la matrice orthogonale, avec
- Décodeur audio pour décoder un signal audio codé, dans lequel le décodeur audio comprend:une interface (130) configurée pour recevoir une enveloppe spectrale codée du signal audio et configurée pour recevoir une pluralité codée d'échantillons spectraux du signal audio, etune unité de décodage (140) configurée pour décoder le signal audio codé en décodant l'enveloppe spectrale codée et en décodant la pluralité codée d'échantillons spectraux,dans lequel l'unité de décodage (140) est configurée pour recevoir ou pour estimer un débit binaire estimé nécessaire pour le codage de chaque échantillon spectral des un ou plusieurs échantillons spectraux de la pluralité codée d'échantillons spectraux, etdans lequel l'unité de décodage (140) est configurée pour décoder chaque échantillon spectral de la pluralité codée d'échantillons spectraux, en fonction du débit binaire estimé nécessaire pour coder les un ou plusieurs échantillons spectraux de la pluralité codée d'échantillons spectraux, selon une première règle de codage ou selon une deuxième règle de codage qui est différente de la première règle de codage,dans lequel la deuxième règle de codage comprend le fait d"utiliser un codec entropique et de réaliser une quantification, et dans lequel la première règle de codage comprend le fait d'utiliser un codage tramé,dans lequel l'unité de décodage (140) est configurée pour décoder les un ou plusieurs échantillons spectraux à l'aide du décodage du codage tramé si le débit binaire estimé est inférieur ou égal à une valeur de seuil; et dans lequel l'unité de décodage (140) est configurée pour décoder les un ou plusieurs échantillons spectraux à l'aide d'un décodage entropique et pour effectuer une déquantification si le débit binaire estimé est supérieur à la valeur de seuil.
- Décodeur audio selon la revendication 7,
dans lequel la valeur de seuil est de 1 bit/échantillon. - Décodeur audio selon la revendication 7 ou 8,
dans lequel l'unité de décodage (140) est configurée pour estimer le débit binaire estimé nécessaire pour coder chaque échantillon spectral des un ou plusieurs échantillons spectraux en fonction d'une variance estimée dudit échantillon spectral qui dépend de l'enveloppe spectrale. - Décodeur audio selon la revendication 7 ou 8,dans lequel l'unité de décodage (140) est configurée pour estimer le débit binaire estimé nécessaire pour coder chaque échantillon spectral des un ou plusieurs échantillons spectraux en fonction de l'équation
 où bk est un k-ème échantillon spectral des un ou plusieurs échantillons spectraux,où
où bk est un k-ème échantillon spectral des un ou plusieurs échantillons spectraux,où
- Décodeur audio selon l'une des revendications 7 à 10,dans lequel l'unité de décodage (140) est configurée pour décoder les échantillons spectraux qui sont décodés selon la deuxième règle de codage à l'aide d'une matrice orthogonale, etdans lequel l'unité de décodage (140) est configurée pour décoder les échantillons spectraux qui sont décodés selon la première règle de codage sans utiliser la matrice orthogonale.
- Décodeur audio selon l'une des revendications 7 à 11,
dans lequel, si le débit binaire estimé nécessaire pour coder un échantillon spectral des un ou plusieurs échantillons spectraux est inférieur à une autre valeur de seuil, l'unité de décodage (140) est configurée pour utiliser une mise en forme spectrale de bruit pour décoder la pluralité codée d'échantillons spectraux. - Système comprenant:un codeur audio (105) selon l'une des revendications 1 à 6, etun décodeur audio (125) selon l'une des revendications 7 à 12,dans lequel le codeur audio (105) est configuré pour alimenter une enveloppe spectrale codée d'un signal audio codé et une pluralité codée d'échantillons spectraux du signal audio codé vers le décodeur audio, etdans lequel le décodeur audio (125) est configuré pour décoder le signal audio codé en décodant l'enveloppe spectrale codée et en décodant la pluralité codée d'échantillons spectraux.
- Procédé de codage d'un signal audio, dans lequel le signal audio est représenté dans un domaine spectral, dans lequel le procédé comprend le fait de:déterminer une enveloppe spectrale du signal audio et coder l'enveloppe spectrale, etcoder une pluralité d'échantillons spectraux du signal audio,dans lequel le codage de la pluralité d'échantillons spectraux du signal audio est effectué en estimant un débit binaire estimé nécessaire pour coder chaque échantillon spectral parmi un ou plusieurs échantillons spectraux de la pluralité d'échantillons spectraux en fonction de l'enveloppe spectrale, etdans lequel le codage de la pluralité d'échantillons spectraux du signal audio est effectué en codant chaque échantillon spectral de la pluralité d'échantillons spectraux, en fonction du débit binaire estimé nécessaire pour coder les un ou plusieurs échantillons spectraux, selon une première règle de codage ou selon une deuxième règle de codage qui est différente de la première règle de codage,dans lequel la deuxième règle de codage comprend le fait d"utiliser un codec entropique et de réaliser une quantification, et dans lequel la première règle de codage comprend le fait d"utiliser un codage tramé, etdans lequel le codage des un ou plusieurs échantillons spectraux à l'aide d'un codage tramé est effectué si le débit binaire estimé est inférieur ou égal à une valeur de seuil; et le codage des un ou plusieurs échantillons spectraux à l'aide du codage entropique et la réalisation d'une quantification sont effectués si le débit binaire estimé est supérieur à la valeur de seuil.
- Procédé de décodage d'un signal audio codé, dans lequel le procédé comprend le fait de:recevoir une enveloppe spectrale codée du signal audio et recevoir une pluralité codée d'échantillons spectraux du signal audio, etdécoder le signal audio codé en décodant l'enveloppe spectrale codée et en décodant la pluralité codée d'échantillons spectraux,dans lequel le décodage du signal audio codé est effectué en recevant ou en estimant un débit binaire estimé nécessaire pour coder chaque échantillon spectral parmi un ou plusieurs échantillons spectraux de la pluralité codée d'échantillons spectraux, etdans lequel le décodage du signal audio codé est effectué en décodant chaque échantillon spectral de la pluralité codée d'échantillons spectraux, en fonction du débit binaire estimé nécessaire pour coder les un ou plusieurs échantillons spectraux de la pluralité codée d'échantillons spectraux, selon une première règle de codage ou selon une deuxième règle de codage qui est différente de la première règle de codage,dans lequel la deuxième règle de codage comprend le fait d'utiliser un codec entropique et de réaliser une quantification, et dans lequel la première règle de codage comprend le fait d'utiliser un codage tramé,dans lequel le décodage des un ou plusieurs échantillons spectraux à l'aide du décodage du codage tramé est effectué si le débit binaire estimé est inférieur ou égal à une valeur de seuil; et dans lequel le décodage des un ou plusieurs échantillons spectraux à l'aide du décodage entropique et la réalisation d'une déquantification sont effectués si le débit binaire estimé est supérieur à la valeur de seuil.
- Programme d'ordinateur pour la réaliser le procédé selon la revendication 14 ou 15 lorsqu'il est exécuté sur un ordinateur ou un processeur de signal.
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP18163459 | 2018-03-22 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP3544005A1 EP3544005A1 (fr) | 2019-09-25 |
| EP3544005B1 true EP3544005B1 (fr) | 2021-12-15 |
Family
ID=61837513
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP18187597.2A Active EP3544005B1 (fr) | 2018-03-22 | 2018-08-06 | Codage audio avec de la quantification tramée |
Country Status (1)
| Country | Link |
|---|---|
| EP (1) | EP3544005B1 (fr) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11238554B2 (en) * | 2019-11-26 | 2022-02-01 | Ncr Corporation | Frictionless security monitoring and management |
| CN111681639B (zh) * | 2020-05-28 | 2023-05-30 | 上海墨百意信息科技有限公司 | 一种多说话人语音合成方法、装置及计算设备 |
| CN116959459B (zh) * | 2023-09-19 | 2023-12-22 | 国网江西省电力有限公司信息通信分公司 | 一种音频传输方法及系统 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7447631B2 (en) | 2002-06-17 | 2008-11-04 | Dolby Laboratories Licensing Corporation | Audio coding system using spectral hole filling |
| EP2981961B1 (fr) * | 2013-04-05 | 2017-05-10 | Dolby International AB | Quantificateur perfectionné |
-
2018
- 2018-08-06 EP EP18187597.2A patent/EP3544005B1/fr active Active
Non-Patent Citations (1)
| Title |
|---|
| None * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3544005A1 (fr) | 2019-09-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11416742B2 (en) | Audio signal encoding method and apparatus and audio signal decoding method and apparatus using psychoacoustic-based weighted error function | |
| JP6545748B2 (ja) | 低または中ビットレートに対する知覚品質に基づくオーディオ分類 | |
| EP3544005B1 (fr) | Codage audio avec de la quantification tramée | |
| US10460738B2 (en) | Encoding apparatus for processing an input signal and decoding apparatus for processing an encoded signal | |
| US11114110B2 (en) | Noise attenuation at a decoder | |
| Bäckström et al. | Blind Recovery of Perceptual Models in Distributed Speech and Audio Coding. | |
| Bäckström et al. | Fast randomization for distributed low-bitrate coding of speech and audio | |
| Van Kuyk et al. | On the information rate of speech communication | |
| RU2716911C2 (ru) | Способ и устройство для кодирования множественных аудиосигналов и способ и устройство для декодирования смеси множественных аудиосигналов с улучшенным разделением | |
| Salah-Eddine et al. | Robust coding of wideband speech immittance spectral frequencies | |
| Sugiura et al. | Optimal coding of generalized-Gaussian-distributed frequency spectra for low-delay audio coder with powered all-pole spectrum estimation | |
| Keser et al. | A subspace based progressive coding method for speech compression | |
| Moriya et al. | Progress in LPC-based frequency-domain audio coding | |
| Ohidujjaman et al. | Packet Loss Compensation for VoIP through Bone‐Conducted Speech Using Modified Linear Prediction | |
| US11295750B2 (en) | Apparatus and method for noise shaping using subspace projections for low-rate coding of speech and audio | |
| EP3008726B1 (fr) | Appareil et procédé pour codage d'enveloppe de signal audio, traitement et décodage par modélisation d'une représentation de sommes cumulatives au moyen d'une quantification et d'un codage par répartition | |
| Liu et al. | A High Fidelity and Low Complexity Neural Audio Coding | |
| Sugiura et al. | Resolution warped spectral representation for low-delay and low-bit-rate audio coder | |
| Vafin et al. | Rate-distortion optimized quantization in multistage audio coding | |
| Freiwald et al. | Loss Functions for Deep Monaural Speech Enhancement | |
| EP3629327A1 (fr) | Appareil et procédé de mise en forme du bruit à l'aide de projections de sous-espaces pour codage à faible débit de la parole et de l'audio | |
| Wang et al. | Critical band subspace-based speech enhancement using SNR and auditory masking aware technique | |
| Brendel et al. | Simple and Efficient Quantization Techniques for Neural Speech Coding | |
| Kim | KLT-based adaptive entropy-constrained vector quantization for the speech signals | |
| Ramírez | Prediction Transform GMM Vector Quantization for Wideband LSFs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN PUBLISHED |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| AX | Request for extension of the european patent |
Extension state: BA ME |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| 17P | Request for examination filed |
Effective date: 20200323 |
|
| RBV | Designated contracting states (corrected) |
Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| RAP1 | Party data changed (applicant data changed or rights of an application transferred) |
Owner name: FRAUNHOFER-GESELLSCHAFT ZUR FOERDERUNG DER ANGEWANDTEN FORSCHUNG E.V. |
|
| 17Q | First examination report despatched |
Effective date: 20200515 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| RIC1 | Information provided on ipc code assigned before grant |
Ipc: G10L 19/22 20130101AFI20210608BHEP Ipc: G10L 19/032 20130101ALN20210608BHEP Ipc: G10L 19/00 20130101ALN20210608BHEP |
|
| INTG | Intention to grant announced |
Effective date: 20210624 |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE PATENT HAS BEEN GRANTED |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: FG4D Ref country code: CH Ref legal event code: EP |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FG4D Ref country code: DE Ref legal event code: R096 Ref document number: 602018028108 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: REF Ref document number: 1456090 Country of ref document: AT Kind code of ref document: T Effective date: 20220115 |
|
| REG | Reference to a national code |
Ref country code: LT Ref legal event code: MG9D |
|
| RAP4 | Party data changed (patent owner data changed or rights of a patent transferred) |
Owner name: FRAUNHOFER-GESELLSCHAFT ZUR FOERDERUNG DER ANGEWANDTEN FORSCHUNG E.V. |
|
| REG | Reference to a national code |
Ref country code: NL Ref legal event code: MP Effective date: 20211215 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: RS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: LT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: FI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: BG Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220315 |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: MK05 Ref document number: 1456090 Country of ref document: AT Kind code of ref document: T Effective date: 20211215 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: NO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220315 Ref country code: LV Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: HR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: GR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220316 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: NL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SM Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: SK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: RO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: PT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220418 Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: EE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: CZ Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: PL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: AT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R097 Ref document number: 602018028108 Country of ref document: DE |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20220415 |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 Ref country code: AL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 |
|
| 26N | No opposition filed |
Effective date: 20220916 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: MC Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: PL |
|
| GBPC | Gb: european patent ceased through non-payment of renewal fee |
Effective date: 20220806 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220806 Ref country code: LI Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220831 Ref country code: CH Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220831 |
|
| REG | Reference to a national code |
Ref country code: BE Ref legal event code: MM Effective date: 20220831 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 |
|
| P01 | Opt-out of the competence of the unified patent court (upc) registered |
Effective date: 20230517 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220806 Ref country code: FR Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220831 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220831 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: GB Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20220806 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20230822 Year of fee payment: 6 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: HU Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT; INVALID AB INITIO Effective date: 20180806 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: CY Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20211215 |