EP3422178A2 - Vector friendly instruction format and execution thereof - Google Patents
Vector friendly instruction format and execution thereof Download PDFInfo
- Publication number
- EP3422178A2 EP3422178A2 EP18177235.1A EP18177235A EP3422178A2 EP 3422178 A2 EP3422178 A2 EP 3422178A2 EP 18177235 A EP18177235 A EP 18177235A EP 3422178 A2 EP3422178 A2 EP 3422178A2
- Authority
- EP
- European Patent Office
- Prior art keywords
- field
- vector
- data element
- instruction
- bit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 239000013598 vector Substances 0.000 title claims abstract description 390
- 238000000034 method Methods 0.000 claims description 17
- 230000000873 masking effect Effects 0.000 claims description 10
- 239000003607 modifier Substances 0.000 abstract description 75
- 230000003416 augmentation Effects 0.000 abstract description 37
- 230000015654 memory Effects 0.000 description 325
- VOXZDWNPVJITMN-ZBRFXRBCSA-N 17β-estradiol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CCC2=C1 VOXZDWNPVJITMN-ZBRFXRBCSA-N 0.000 description 118
- 238000010586 diagram Methods 0.000 description 87
- 238000006073 displacement reaction Methods 0.000 description 73
- 238000007667 floating Methods 0.000 description 31
- 230000006870 function Effects 0.000 description 22
- 238000006243 chemical reaction Methods 0.000 description 21
- 235000019580 granularity Nutrition 0.000 description 16
- 230000002123 temporal effect Effects 0.000 description 16
- 238000012545 processing Methods 0.000 description 13
- 230000001343 mnemonic effect Effects 0.000 description 10
- 239000003795 chemical substances by application Substances 0.000 description 7
- 230000000295 complement effect Effects 0.000 description 7
- 238000005516 engineering process Methods 0.000 description 7
- 238000013507 mapping Methods 0.000 description 6
- 238000013461 design Methods 0.000 description 5
- 230000008901 benefit Effects 0.000 description 4
- 238000004891 communication Methods 0.000 description 4
- 239000000284 extract Substances 0.000 description 4
- 230000007246 mechanism Effects 0.000 description 4
- 239000000203 mixture Substances 0.000 description 4
- 230000003068 static effect Effects 0.000 description 4
- 230000006399 behavior Effects 0.000 description 3
- 238000005056 compaction Methods 0.000 description 3
- 230000002093 peripheral effect Effects 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 230000001629 suppression Effects 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 241000168096 Glareolidae Species 0.000 description 2
- 230000001133 acceleration Effects 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 230000006835 compression Effects 0.000 description 2
- 238000007906 compression Methods 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 238000004519 manufacturing process Methods 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 238000000638 solvent extraction Methods 0.000 description 2
- 101100285899 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) SSE2 gene Proteins 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 230000003190 augmentative effect Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 238000013500 data storage Methods 0.000 description 1
- 230000006837 decompression Effects 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 238000002789 length control Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000005065 mining Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000004088 simulation Methods 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images






































Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
- G06F9/30014—Arithmetic instructions with variable precision
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/80—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors
- G06F15/8053—Vector processors
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/3001—Arithmetic instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30018—Bit or string instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30025—Format conversion instructions, e.g. Floating-Point to Integer, decimal conversion
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30032—Movement instructions, e.g. MOVE, SHIFT, ROTATE, SHUFFLE
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30007—Arrangements for executing specific machine instructions to perform operations on data operands
- G06F9/30036—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations
- G06F9/30038—Instructions to perform operations on packed data, e.g. vector, tile or matrix operations using a mask
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/3004—Arrangements for executing specific machine instructions to perform operations on memory
- G06F9/30047—Prefetch instructions; cache control instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30145—Instruction analysis, e.g. decoding, instruction word fields
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30145—Instruction analysis, e.g. decoding, instruction word fields
- G06F9/30149—Instruction analysis, e.g. decoding, instruction word fields of variable length instructions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30181—Instruction operation extension or modification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30181—Instruction operation extension or modification
- G06F9/30185—Instruction operation extension or modification according to one or more bits in the instruction, e.g. prefix, sub-opcode
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30181—Instruction operation extension or modification
- G06F9/30192—Instruction operation extension or modification according to data descriptor, e.g. dynamic data typing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/34—Addressing or accessing the instruction operand or the result ; Formation of operand address; Addressing modes
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D30/00—Field-effect transistors [FET]
- H10D30/01—Manufacture or treatment
- H10D30/014—Manufacture or treatment of FETs having zero-dimensional [0D] or one-dimensional [1D] channels, e.g. quantum wire FETs, single-electron transistors [SET] or Coulomb blockade transistors
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D30/00—Field-effect transistors [FET]
- H10D30/40—FETs having zero-dimensional [0D], one-dimensional [1D] or two-dimensional [2D] charge carrier gas channels
- H10D30/43—FETs having zero-dimensional [0D], one-dimensional [1D] or two-dimensional [2D] charge carrier gas channels having 1D charge carrier gas channels, e.g. quantum wire FETs or transistors having 1D quantum-confined channels
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D30/00—Field-effect transistors [FET]
- H10D30/60—Insulated-gate field-effect transistors [IGFET]
- H10D30/611—Insulated-gate field-effect transistors [IGFET] having multiple independently-addressable gate electrodes influencing the same channel
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D30/00—Field-effect transistors [FET]
- H10D30/60—Insulated-gate field-effect transistors [IGFET]
- H10D30/67—Thin-film transistors [TFT]
- H10D30/6757—Thin-film transistors [TFT] characterised by the structure of the channel, e.g. transverse or longitudinal shape or doping profile
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D64/00—Electrodes of devices having potential barriers
- H10D64/01—Manufacture or treatment
- H10D64/018—Spacers formed inside holes at the prospective gate locations, e.g. holes left by removing dummy gates
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D84/00—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers
- H10D84/01—Manufacture or treatment
- H10D84/0123—Integrating together multiple components covered by H10D12/00 or H10D30/00, e.g. integrating multiple IGBTs
- H10D84/0126—Integrating together multiple components covered by H10D12/00 or H10D30/00, e.g. integrating multiple IGBTs the components including insulated gates, e.g. IGFETs
- H10D84/0135—Manufacturing their gate conductors
- H10D84/0142—Manufacturing their gate conductors the gate conductors having different shapes or dimensions
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D84/00—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers
- H10D84/01—Manufacture or treatment
- H10D84/0123—Integrating together multiple components covered by H10D12/00 or H10D30/00, e.g. integrating multiple IGBTs
- H10D84/0126—Integrating together multiple components covered by H10D12/00 or H10D30/00, e.g. integrating multiple IGBTs the components including insulated gates, e.g. IGFETs
- H10D84/0147—Manufacturing their gate sidewall spacers
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D84/00—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers
- H10D84/01—Manufacture or treatment
- H10D84/02—Manufacture or treatment characterised by using material-based technologies
- H10D84/03—Manufacture or treatment characterised by using material-based technologies using Group IV technology, e.g. silicon technology or silicon-carbide [SiC] technology
- H10D84/038—Manufacture or treatment characterised by using material-based technologies using Group IV technology, e.g. silicon technology or silicon-carbide [SiC] technology using silicon technology, e.g. SiGe
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D84/00—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers
- H10D84/80—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers characterised by the integration of at least one component covered by groups H10D12/00 or H10D30/00, e.g. integration of IGFETs
- H10D84/82—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers characterised by the integration of at least one component covered by groups H10D12/00 or H10D30/00, e.g. integration of IGFETs of only field-effect components
- H10D84/83—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers characterised by the integration of at least one component covered by groups H10D12/00 or H10D30/00, e.g. integration of IGFETs of only field-effect components of only insulated-gate FETs [IGFET]
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D88/00—Three-dimensional [3D] integrated devices
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D88/00—Three-dimensional [3D] integrated devices
- H10D88/01—Manufacture or treatment
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D48/00—Individual devices not covered by groups H10D1/00 - H10D44/00
- H10D48/30—Devices controlled by electric currents or voltages
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D84/00—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers
- H10D84/01—Manufacture or treatment
- H10D84/0123—Integrating together multiple components covered by H10D12/00 or H10D30/00, e.g. integrating multiple IGBTs
- H10D84/0126—Integrating together multiple components covered by H10D12/00 or H10D30/00, e.g. integrating multiple IGBTs the components including insulated gates, e.g. IGFETs
- H10D84/0165—Integrating together multiple components covered by H10D12/00 or H10D30/00, e.g. integrating multiple IGBTs the components including insulated gates, e.g. IGFETs the components including complementary IGFETs, e.g. CMOS devices
- H10D84/0172—Manufacturing their gate conductors
- H10D84/0179—Manufacturing their gate conductors the gate conductors having different shapes or dimensions
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D84/00—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers
- H10D84/01—Manufacture or treatment
- H10D84/0123—Integrating together multiple components covered by H10D12/00 or H10D30/00, e.g. integrating multiple IGBTs
- H10D84/0126—Integrating together multiple components covered by H10D12/00 or H10D30/00, e.g. integrating multiple IGBTs the components including insulated gates, e.g. IGFETs
- H10D84/0165—Integrating together multiple components covered by H10D12/00 or H10D30/00, e.g. integrating multiple IGBTs the components including insulated gates, e.g. IGFETs the components including complementary IGFETs, e.g. CMOS devices
- H10D84/0184—Manufacturing their gate sidewall spacers
-
- H—ELECTRICITY
- H10—SEMICONDUCTOR DEVICES; ELECTRIC SOLID-STATE DEVICES NOT OTHERWISE PROVIDED FOR
- H10D—INORGANIC ELECTRIC SEMICONDUCTOR DEVICES
- H10D84/00—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers
- H10D84/80—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers characterised by the integration of at least one component covered by groups H10D12/00 or H10D30/00, e.g. integration of IGFETs
- H10D84/82—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers characterised by the integration of at least one component covered by groups H10D12/00 or H10D30/00, e.g. integration of IGFETs of only field-effect components
- H10D84/83—Integrated devices formed in or on semiconductor substrates that comprise only semiconducting layers, e.g. on Si wafers or on GaAs-on-Si wafers characterised by the integration of at least one component covered by groups H10D12/00 or H10D30/00, e.g. integration of IGFETs of only field-effect components of only insulated-gate FETs [IGFET]
- H10D84/85—Complementary IGFETs, e.g. CMOS
Definitions
- Embodiments of the invention relate to the field of computers; and more specifically, to instruction sets supported by processors.
- instruction set or instruction set architecture (ISA) is the part of the computer architecture related to programming, including the native data types, instructions, register architecture, addressing modes, memory architecture, interrupt and exception handling, and external input and output (I/O).
- instruction generally refers herein to macro-instructions - that is instructions that are provided to the processor for execution - as opposed to micro-instructions or micro-ops - that is the result of a processor's decoder decoding macro-instructions).
- the instruction set architecture is distinguished from the microarchitecture, which is the set of processor design techniques used to implement the instruction set.
- Processors with different microarchitectures can share a common instruction set.
- Intel Pentium 4 processors, Intel Core processors, and Advanced Micro Devices, Inc. of Sunnyvale CA processors implement nearly identical versions of the x86 instruction set (with some extensions have been added with newer versions), but have different internal designs.
- the same register architecture of the ISA may be implemented in different ways in different microarchitectures using well known techniques, including dedicated physical registers, one or more dynamically allocated physical registers using a register renaming mechanism (e.g., the use of a Register Alias Table (RAT), a Reorder Buffer (ROB) and a retirement register file as described in U.S. Pat. No. 5,446,912 ; the use of multiple maps and a pool of registers as described in U.S. Pat. No. 5,207,132 ), etc.
- RAT Register Alias Table
- ROB Reorder Buffer
- a retirement register file as described in U.S. Pat. No. 5,446,912
- the phrases register architecture, register file, and register are used herein to that which is visible to the software/programmer and the manner in which instructions specify registers.
- the adjective logical, architectural, or software visible will be used to indicate registers/files in the register architecture, while different adjectives will be used to designation registers in a given microarchitecture (e.g., physical register, reorder buffer, retirement register, register pool).
- An instruction set includes one or more instruction formats.
- a given instruction format defines various fields (number of bits, location of bits) to specify, among other things, the operation to be performed and the operand(s) on which that operation is to be performed. Some instruction formats are further broken down though the definition of instruction templates (or subformats). For example, the instruction templates of a given instruction format may be defined to have different subsets of the instruction format's fields (the included fields are typically in the same order, but at least some have different bit positions because there are less fields included) and/or defined to have a given field interpreted differently.
- a given instruction is expressed using a given instruction format (and, if defined, in a given one of the instruction templates of that instruction format) and specifies the operation and the operands.
- An instruction stream is a specific sequence of instructions, where each instruction in the sequence is an occurrence of an instruction in an instruction format (and, if defined, a given one of the instruction templates of that instruction format).
- SIMD Single Instruction Multiple Data
- RMS recognition, mining, and synthesis
- multimedia applications e.g., 2D/3D graphics, image processing, video compression/decompression, voice recognition algorithms and audio manipulation
- SIMD technology is especially suited to processors that can logically divide the bits in a register into a number of fixed-sized data elements, each of which represents a separate value.
- the bits in a 64-bit register may be specified as a source operand to be operated on as four separate 16-bit data elements, each of which represents a separate 16-bit value.
- This type of data is referred to as the packed data type or vector data type, and operands of this data type are referred to as packed data operands or vector operands.
- a packed data item or vector refers to a sequence of packed data elements; and a packed data operand or a vector operand is a source or destination operand of a SIMD instruction (also known as a packed data instruction or a vector instruction).
- one type of SIMD instruction specifies a single vector operation to be performed on two source vector operands in a vertical fashion to generate a destination vector operand (also referred to as a result vector operand) of the same size, with the same number of data elements, and in the same data element order.
- the data elements in the source vector operands are referred to as source data elements, while the data elements in the destination vector operand are referred to a destination or result data elements.
- These source vector operands are of the same size and contain data elements of the same width, and thus they contain the same number of data elements.
- the source data elements in the same bit positions in the two source vector operands form pairs of data elements (also referred to as corresponding data elements).
- the operation specified by that SIMD instruction is performed separately on each of these pairs of source data elements to generate a matching number of result data elements, and thus each pair of source data elements has a corresponding result data element. Since the operation is vertical and since the result vector operand is the same size, has the same number of data elements, and the result data elements are stored in the same data element order as the source vector operands, the result data elements are in the same bit positions of the result vector operand as their corresponding pair of source data elements in the source vector operands.
- SIMD instructions there are a variety of other types of SIMD instructions (e.g., that has only one or has more than two source vector operands; that operate in a horizontal fashion; that generates a result vector operand that is of a different size, that has a different size data elements, and/or that has a different data element order).
- destination vector operand or destination operand is defined as the direct result of performing the operation specified by an instruction, including the storage of that destination operand at a location (be it a register or at a memory address specified by that instruction) so that it may be accessed as a source operand by another instruction (by specification of that same location by the another instruction).
- SIMD technology such as that employed by the Intel® CoreTM processors having an instruction set including x86, MMXTM, Streaming SIMD Extensions (SSE), SSE2, SSE3, SSE4.1, and SSE4.2 instructions, has enabled a significant improvement in application performance (CoreTM and MMXTM are registered trademarks or trademarks of Intel Corporation of Santa Clara, Calif.).
- SSE Streaming SIMD Extensions
- SSE2 SSE3, SSE4.1
- SSE4.2 instructions has enabled a significant improvement in application performance
- CoreTM and MMXTM are registered trademarks or trademarks of Intel Corporation of Santa Clara, Calif.
- An additional set of future SIMD extensions referred to the Advanced Vector Extensions (AVX) and using the VEX coding scheme, has been published.
- AVX Advanced Vector Extensions
- Coupled is used to indicate that two or more elements, which may or may not be in direct physical or electrical contact with each other, co-operate or interact with each other.
- Connected is used to indicate the establishment of communication between two or more elements that are coupled with each other.
- dashed lines have been used in the figures to signify the optional nature of certain items (e.g., features not supported by a given implementation of the invention; features supported by a given implementation, but used in some situations and not in others).
- a vector friendly instruction format is an instruction format that is suited for vector instructions (e.g., there are certain fields specific to vector operations). While embodiments are described in which both vector and scalar operations are supported through the vector friendly instruction format, alternative embodiments use only vector operations the vector friendly instruction format.
- Figure 1A is a block diagram illustrating an instruction stream having only instructions in the vector friendly instruction format according to one embodiment of the invention.
- the instruction stream includes a sequence of J instructions that are all in the vector friendly format 100A-100J.
- a processor supports only the vector instruction format and can execute this instruction stream.
- Figure 1B is a block diagram illustrating an instruction stream with instructions in multiple instruction formats according to one embodiment of the invention.
- Each instruction in the instruction stream is expressed in the vector friendly instruction format, a second format, or a third format.
- the instruction stream includes J instructions 110A-110J.
- a processor supports multiple instruction formats (including the formats shown in Figure 1B ) and can execute the instruction streams in both Figures 1A-1B .
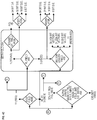
- Figures 2A-B are block diagrams illustrating a generic vector friendly instruction format and instruction templates thereof according to embodiments of the invention.
- Figure 2A is a block diagram illustrating a generic vector friendly instruction format and class A instruction templates thereof according to embodiments of the invention; while Figure 2B is a block diagram illustrating the generic vector friendly instruction format and class B instruction templates thereof according to embodiments of the invention.
- the term generic in the context of the vector friendly instruction format refers to the instruction format not being tied to any specific instruction set.
- a 64 byte vector operand length (or size) with 32 bit (4 byte) or 64 bit (8 byte) data element widths (or sizes) (and thus, a 64 byte vector consists of either 16 doubleword-size elements or alternatively, 8 quadword-size elements); a 64 byte vector operand length (or size) with 16 bit (2 byte) or 8 bit (1 byte) data element widths (or sizes); a 32 byte vector operand length (or size) with 32 bit (4 byte), 64 bit (8 byte), 16 bit (2 byte), or 8 bit (1 byte) data element widths (or sizes); and a 16 byte vector operand length (or size) with 32 bit (4 byte), 64 bit (8 byte), 16 bit (2 byte), or 8 bit (1 byte) data element widths (or sizes); alternative embodiments may support more, less and/or different vector operand sizes (e.g., 256 byte vector operands) with more, less, or different data
- the class A instruction templates in figure 2A include: 1) within the no memory access 205 instruction templates there is shown a no memory access, full round control type operation 210 instruction template and a no memory access, data transform type operation 215 instruction template; and 2) within the memory access 220 instruction templates there is shown a memory access, temporal 225 instruction template and a memory access, non-temporal 230 instruction template.
- the class B instruction templates in figure 2B include: 1) within the no memory access 205 instruction templates there is shown a no memory access, write mask control, partial round control type operation 212 instruction template and a no memory access, write mask control, vsize type operation 217 instruction template; and 2) within the memory access 220 instruction templates there is shown a memory access, write mask control 227 instruction template.
- the generic vector friendly instruction format 200 includes the following fields listed below in the order illustrated in Figures 2A-B .
- Format field 240 - a specific value (an instruction format identifier value) in this field uniquely identifies the vector friendly instruction format, and thus occurrences of instructions in the vector friendly instruction format in instruction streams.
- the content of the format field 240 distinguish occurrences of instructions in the first instruction format from occurrences of instructions in other instruction formats, thereby allowing for the introduction of the vector friendly instruction format into an instruction set that has other instruction formats.
- this field is optional in the sense that it is not needed for an instruction set that has only the generic vector friendly instruction format.
- Base operation field 242 its content distinguishes different base operations. As described later herein, the base operation field 242 may include and/or be part of an opcode field.
- PxQ e.g. 32x512
- Modifier field 246 its content distinguishes occurrences of instructions in the generic vector instruction format that specify memory access from those that do not; that is, between no memory access 205 instruction templates and memory access 220 instruction templates.
- Memory access operations read and/or write to the memory hierarchy (in some cases specifying the source and/or destination addresses using values in registers), while non-memory access operations do not (e.g., the source and destinations are registers). While in one embodiment this field also selects between three different ways to perform memory address calculations, alternative embodiments may support more, less, or different ways to perform memory address calculations.
- Augmentation operation field 250 its content distinguishes which one of a variety of different operations to be performed in addition to the base operation.
- This field is context specific. In one embodiment of the invention, this field is divided into a class field 268, an alpha field 252, and a beta field 254.
- the augmentation operation field allows common groups of operations to be performed in a single instruction rather than 2, 3 or 4 instructions. Below are some examples of instructions (the nomenclature of which are described in more detail later herein) that use the augmentation field 250 to reduce the number of required instructions.
- Scale field 260 - its content allows for the scaling of the index field's content for memory address generation (e.g., for address generation that uses 2 scale *index +base).
- Displacement Field 262A- its content is used as part of memory address generation (e.g., for address generation that uses 2 scale *index+base+displacement).
- Displacement Factor Field 262B (note that the juxtaposition of displacement field 262A directly over displacement factor field 262B indicates one or the other is used) - its content is used as part of address generation; it specifies a displacement factor that is to be scaled by the size of a memory access (N) - where N is the number of bytes in the memory access (e.g., for address generation that uses 2 scale *index+base+scaled displacement). Redundant low-order bits are ignored and hence, the displacement factor field's content is multiplied by the memory operands total size (N) in order to generate the final displacement to be used in calculating an effective address.
- N is determined by the processor hardware at runtime based on the full opcode field 274 (described later herein) and the data manipulation field 254C as described later herein.
- the displacement field 262A and the displacement factor field 262B are optional in the sense that they are not used for the no memory access 205 instruction templates and/or different embodiments may implement only one or none of the two.
- Data element width field 264 - its content distinguishes which one of a number of data element widths is to be used (in some embodiments for all instructions; in other embodiments for only some of the instructions). This field is optional in the sense that it is not needed if only one data element width is supported and/or data element widths are supported using some aspect of the opcodes.
- Write mask field 270 its content controls, on a per data element position basis, whether that data element position in the destination vector operand reflects the result of the base operation and augmentation operation.
- Class A instruction templates support merging-writemasking
- class B instruction templates support both merging- and zeroing-writemasking.
- any set of elements in the destination when zeroing vector masks allow any set of elements in the destination to be zeroed during the execution of any operation (specified by the base operation and the augmentation operation); in one embodiment, an element of the destination is set to 0 when the corresponding mask bit has a 0 value.
- a subset of this functionality is the ability to control the vector length of the operation being performed (that is, the span of elements being modified, from the first to the last one); however, it is not necessary that the elements that are modified be consecutive.
- the write mask field 270 allows for partial vector operations, including loads, stores, arithmetic, logical, etc.
- this masking can be used for fault suppression (i.e., by masking the destination's data element positions to prevent receipt of the result of any operation that may/will cause a fault - e.g., assume that a vector in memory crosses a page boundary and that the first page but not the second page would cause a page fault, the page fault can be ignored if all data element of the vector that lie on the first page are masked by the write mask).
- write masks allow for "vectorizing loops" that contain certain types of conditional statements.
- write mask field's 270 content selects one of a number of write mask registers that contains the write mask to be used (and thus the write mask field's 270 content indirectly identifies that masking to be performed)
- alternative embodiments instead or additional allow the mask write field's 270 content to directly specify the masking to be performed.
- zeroing allows for performance improvements when: 1) register renaming is used on instructions whose destination operand is not also a source (also call non-ternary instructions) because during the register renaming pipeline stage the destination is no longer an implicit source (no data elements from the current destination register need be copied to the renamed destination register or somehow carried along with the operation because any data element that is not the result of operation (any masked data element) will be zeroed); and 2) during the write back stage because zeros are being written.
- Immediate field 272 its content allows for the specification of an immediate. This field is optional in the sense that is it not present in an implementation of the generic vector friendly format that does not support immediate and it is not present in instructions that do not use an immediate.
- Class field 268 its content distinguishes between different classes of instructions. With reference to figures 2A-B , the contents of this field select between class A and class B instructions. In figures 2A-B , rounded corner squares are used to indicate a specific value is present in a field (e.g., class A 268A and class B 268B for the class field 268 respectively in figures 2A-B ).
- the alpha field 252 is interpreted as an RS field 252A, whose content distinguishes which one of the different augmentation operation types are to be performed (e.g., round 252A.1 and data transform 252A.2 are respectively specified for the no memory access, round type operation 210 and the no memory access, data transform type operation 215 instruction templates), while the beta field 254 distinguishes which of the operations of the specified type is to be performed.
- rounded corner blocks are used to indicate a specific value is present (e.g., no memory access 246A in the modifier field 246; round 252A. 1 and data transform 252A.2 for alpha field 252/rs field 252A).
- the scale field 260, the displacement field 262A, and the displacement scale field 262B are not present.
- the beta field 254 is interpreted as a round control field 254A, whose content(s) provide static rounding. While in the described embodiments of the invention the round control field 254A includes a suppress all floating point exceptions (SAE) field 256 and a round operation control field 258, alternative embodiments may support may encode both these concepts into the same field or only have one or the other of these concepts/fields (e.g., may have only the round operation control field 258).
- SAE suppress all floating point exceptions
- SAE field 256 its content distinguishes whether or not to disable the exception event reporting; when the SAE field's 256 content indicates suppression is enabled, a given instruction does not report any kind of floating-point exception flag and does not raise any floating point exception handler.
- Round operation control field 258 its content distinguishes which one of a group of rounding operations to perform (e.g., Round-up, Round-down, Round-towards-zero and Round-to-nearest).
- the round operation control field 258 allows for the changing of the rounding mode on a per instruction basis, and thus is particularly useful when this is required.
- the round operation control field's 250 content overrides that register value (Being able to choose the rounding mode without having to perform a save-modify-restore on such a control register is advantageous).
- the beta field 254 is interpreted as a data transform field 254B, whose content distinguishes which one of a number of data transforms is to be performed (e.g., no data transform, swizzle, broadcast).
- the alpha field 252 is interpreted as an eviction hint field 252B, whose content distinguishes which one of the eviction hints is to be used (in Figure 2A , temporal 252B.1 and non-temporal 252B.2 are respectively specified for the memory access, temporal 225 instruction template and the memory access, non-temporal 230 instruction template), while the beta field 254 is interpreted as a data manipulation field 254C, whose content distinguishes which one of a number of data manipulation operations (also known as primitives) is to be performed (e.g., no manipulation; broadcast; up conversion of a source; and down conversion of a destination).
- the memory access 220 instruction templates include the scale field 260, and optionally the displacement field 262A or the displacement scale field 262B.
- Vector Memory Instructions perform vector loads from and vector stores to memory, with conversion support. As with regular vector instructions, vector memory instructions transfer data from/to memory in a data element-wise fashion, with the elements that are actually transferred dictated by the contents of the vector mask that is selected as the write mask. In figure 2A , rounded corner squares are used to indicate a specific value is present in a field (e.g., memory access 246B for the modifier field 246; temporal 252B. 1 and non-temporal 252B.2 for the alpha field 252/eviction hint field 252B)
- a field e.g., memory access 246B for the modifier field 246; temporal 252B. 1 and non-temporal 252B.2 for the alpha field 252/eviction hint field 252B
- Temporal data is data likely to be reused soon enough to benefit from caching. This is, however, a hint, and different processors may implement it in different ways, including ignoring the hint entirely.
- Non-temporal data is data unlikely to be reused soon enough to benefit from caching in the 1st-level cache and should be given priority for eviction. This is, however, a hint, and different processors may implement it in different ways, including ignoring the hint entirely.
- the alpha field 252 is interpreted as a write mask control (Z) field 252C, whose content distinguishes whether the write masking controlled by the write mask field 270 should be a merging or a zeroing.
- part of the beta field 254 is interpreted as an RL field 257A, whose content distinguishes which one of the different augmentation operation types are to be performed (e.g., round 257A. 1 and vector length (VSIZE) 257A.2 are respectively specified for the no memory access, write mask control, partial round control type operation 212 instruction template and the no memory access, write mask control, VSIZE type operation 217 instruction template), while the rest of the beta field 254 distinguishes which of the operations of the specified type is to be performed.
- round 257A. 1 and vector length (VSIZE) 257A.2 are respectively specified for the no memory access, write mask control, partial round control type operation 212 instruction template and the no memory access, write mask control, VSIZE type operation 217 instruction template
- rounded corner blocks are used to indicate a specific value is present (e.g., no memory access 246A in the modifier field 246; round 257A.1 and VSIZE 257A.2 for the RL field 257A).
- the scale field 260, the displacement field 262A, and the displacement scale field 262B are not present.
- Round operation control field 259A just as round operation control field 258, its content distinguishes which one of a group of rounding operations to perform (e.g., Round-up, Round-down, Round-towards-zero and Round-to-nearest).
- the round operation control field 259A allows for the changing of the rounding mode on a per instruction basis, and thus is particularly useful when this is required.
- the round operation control field's 250 content overrides that register value (Being able to choose the rounding mode without having to perform a save-modify-restore on such a control register is advantageous).
- the rest of the beta field 254 is interpreted as a vector length field 259B, whose content distinguishes which one of a number of data vector length is to be performed on (e.g., 128, 256, or 512 byte).
- part of the beta field 254 is interpreted as a broadcast field 257B, whose content distinguishes whether or not the broadcast type data manipulation operation is to be performed, while the rest of the beta field 254 is interpreted the vector length field 259B.
- the memory access 220 instruction templates include the scale field 260, and optionally the displacement field 262A or the displacement scale field 262B.
- a full opcode field 274 is shown including the format field 240, the base operation field 242, and the data element width field 264. While one embodiment is shown where the full opcode field 274 includes all of these fields, the full opcode field 274 includes less than all of these fields in embodiments that do not support all of them.
- the full opcode field 274 provides the operation code.
- the augmentation operation field 250, the data element width field 264, and the write mask field 270 allow these features to be specified on a per instruction basis in the generic vector friendly instruction format.
- write mask field and data element width field create typed instructions in that they allow the mask to be applied based on different data element widths.
- the instruction format requires a relatively small number of bits because it reuses different fields for different purposes based on the contents of other fields. For instance, one perspective is that the modifier field's content chooses between the no memory access 205 instructions templates on figures 2A-B and the memory access 2250 instruction templates on figures 2A-B ; while the class field 268's content chooses within those non-memory access 205 instruction templates between instruction templates 210/215 of figure 2A and 212/217 of figure 2B ; and while the class field 268's content chooses within those memory access 220 instruction templates between instruction templates 225/230 of figure 2A and 227 of figure 2B .
- the class field 268's content chooses between the class A and class B instruction templates respectively of figures 2A and B; while the modifier field's content chooses within those class A instruction templates between instruction templates 205 and 220 of figure 2A ; and while the modifier field's content chooses within those class B instruction templates between instruction templates 205 and 220 of figure 2B .
- the content of the modifier field 246 chooses the interpretation of the alpha field 252 (between the rs field 252A and the EH field 252B.
- the contents of the modifier field 246 and the class field 268 chose whether the alpha field is interpreted as the rs field 252A, the EH field 252B, or the write mask control (Z) field 252C.
- the interpretation of the augmentation field's beta field changes based on the rs field's content; while in the case of the class and modifier fields indicating a class B no memory access operation, the interpretation of the beta field depends on the contents of the RL field.
- the interpretation of the augmentation field's beta field changes based on the base operation field's content; while in the case of the class and modifier fields indicating a class B memory access operation, the interpretation of the augmentation field's beta field's broadcast field 257B changes based on the base operation field's contents.
- the combination of the base operation field, modifier field and the augmentation operation field allow for an even wider variety of augmentation operations to be specified.
- Class B is useful when zeroing-writemasking or smaller vector lengths are desired for performance reasons. For example, zeroing allows avoiding fake dependences when renaming is used since we no longer need to artificially merge with the destination; as another example, vector length control eases store-load forwarding issues when emulating shorter vector sizes with the vector mask.
- Class A is useful when it is desirable to: 1) allow floating point exceptions (i.e., when the contents of the SAE field indicate no) while using rounding-mode controls at the same time; 2) be able to use upconversion, swizzling, swap, and/or downconversion; 3) operate on the graphics data type.
- upconversion, swizzling, swap, downconversion, and the graphics data type reduce the number of instructions required when working with sources in a different format; as another example, the ability to allow exceptions provides full IEEE compliance with directed rounding-modes.
- different processors or different cores within a processor may support only class A, only class B, or both classes.
- a high performance general purpose out-of-order core intended for general-purpose computing may support only class B
- a core intended primarily for graphics and/or scientific (throughput) computing may support only class A
- a core intended for both may support both (of course, a core that has some mix of templates and instructions from both classes but not all templates and instructions from both classes is within the purview of the invention).
- a single processor may include multiple cores, all of which support the same class or in which different cores support different class.
- one of the graphics cores intended primarily for graphics and/or scientific computing may support only class A, while one or more of the general purpose cores may be high performance general purpose cores with out of order execution and register renaming intended for general-purpose computing that support only class B.
- Another processor that does not have a separate graphics core may include one more general purpose in-order or out-of-order cores that support both class A and class B.
- features from one class may also be implement in the other class in different embodiments of the invention.
- Programs written in a high level language would be put (e.g., just in time compiled or statically compiled) into an variety of different executable forms, including: 1) a form having only instructions of the class(es) supported by the target processor for execution; or 2) a form having alternative routines written using different combinations of the instructions of all classes and having control flow code that selects the routines to execute based on the instructions supported by the processor which is currently executing the code.
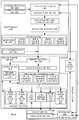
- Figure 3A is a block diagram illustrating an exemplary specific vector friendly instruction format according to embodiments of the invention.
- Figure 3A shows a specific vector friendly instruction format 300 that is specific in the sense that it specifies the location, size, interpretation, and order of the fields, as well as values for some of those fields.
- the specific vector friendly instruction format 300 may be used to extend the x86 instruction set, and thus some of the fields are similar or the same as those used in the existing x86 instruction set and extension thereof (e.g., AVX). This format remains consistent with the prefix encoding field, real opcode byte field, MOD R/M field, SIB field, displacement field, and immediate fields of the existing x86 instruction set with extensions.
- the fields from Figure 2 into which the fields from Figure 3A map are illustrated.
- the generic vector friendly instruction format 200 includes the following fields listed below in the order illustrated in Figure 3A .
- EVEX Prefix 302 - is encoded in a four-byte form.
- EVEX Byte 0 the first byte (EVEX Byte 0) is the format field 240 and it contains 0x62 (the unique value used for distinguishing the vector friendly instruction format in one embodiment of the invention).
- the second-fourth bytes include a number of bit fields providing specific capability.
- REX field 305 (EVEX Byte 1, bits [7-5]) - consists of a EVEX.R bit field (EVEX Byte 1, bit [7] - R), EVEX.X bit field (EVEX byte 1, bit [6] - X), and 257BEX byte 1, bit[5] - B).
- the EVEX.R, EVEX.X, and EVEX.B bit fields provide the same functionality as the corresponding VEX bit fields, and are encoded using Is complement form, i.e. ZMM0 is encoded as 1111B, ZMM15 is encoded as 0000B.
- Rrrr, xxx, and bbb may be formed by adding EVEX.R, EVEX.X, and EVEX.B.
- REX' field 310 - this is the first part of the REX' field 310 and is the EVEX.R' bit field (EVEX Byte 1, bit [4] - R') that is used to encode either the upper 16 or lower 16 of the extended 32 register set.
- this bit along with others as indicated below, is stored in bit inverted format to distinguish (in the well-known x86 32-bit mode) from the BOUND instruction, whose real opcode byte is 62, but does not accept in the MOD R/M field (described below) the value of 11 in the MOD field; alternative embodiments of the invention do not store this and the other indicated bits below in the inverted format.
- a value of 1 is used to encode the lower 16 registers.
- R'Rrrr is formed by combining EVEX.R', EVEX.R, and the other RRR from other fields.
- Opcode map field 315 (EVEX byte 1, bits [3:0] - mmmm) - its content encodes an implied leading opcode byte (0F, 0F 38, or 0F 3A).
- Data element width field 264 (EVEX byte 2, bit [7] - W) - is represented by the notation EVEX.W.
- EVEX.W is used to define the granularity (size) of the datatype (either 32-bit data elements or 64-bit data elements).
- EVEX.vvvv 320 (EVEX Byte 2, bits [6:3]-vvvv)- the role of EVEX.vvvv may include the following: 1) EVEX.vvvv encodes the first source register operand, specified in inverted (Is complement) form and is valid for instructions with 2 or more source operands; 2) EVEX.vvvv encodes the destination register operand, specified in 1s complement form for certain vector shifts; or 3) EVEX.vvvv does not encode any operand, the field is reserved and should contain 1111b.
- EVEX.vvvv field 320 encodes the 4 low-order bits of the first source register specifier stored in inverted (Is complement) form. Depending on the instruction, an extra different EVEX bit field is used to extend the specifier size to 32 registers.
- Prefix encoding field 325 (EVEX byte 2, bits [1:0]-pp) - provides additional bits for the base operation field. In addition to providing support for the legacy SSE instructions in the EVEX prefix format, this also has the benefit of compacting the SIMD prefix (rather than requiring a byte to express the SIMD prefix, the EVEX prefix requires only 2 bits).
- these legacy SIMD prefixes are encoded into the SIMD prefix encoding field; and at runtime are expanded into the legacy SIMD prefix prior to being provided to the decoder's PLA (so the PLA can execute both the legacy and EVEX format of these legacy instructions without modification).
- newer instructions could use the EVEX prefix encoding field's content directly as an opcode extension, certain embodiments expand in a similar fashion for consistency but allow for different meanings to be specified by these legacy SIMD prefixes.
- An alternative embodiment may redesign the PLA to support the 2 bit SIMD prefix encodings, and thus not require the expansion.
- Alpha field 252 (EVEX byte 3, bit [7] - EH; also known as EVEX.EH, EVEX.rs, EVEX.RL, EVEX.write mask control, and EVEX.N; also illustrated with ⁇ ) - as previously described, this field is context specific. Additional description is provided later herein.
- Beta field 254 (EVEX byte 3, bits [6:4]-SSS, also known as EVEX.s 2-0 , EVEX.r 2-0 , EVEX.rr1, EVEX.LL0, EVEX.LLB; also illustrated with ⁇ ) - as previously described, this field is context specific. Additional description is provided later herein.
- REX' field 310 - this is the remainder of the REX' field and is the EVEX.V' bit field (EVEX Byte 3, bit [3] - V') that may be used to encode either the upper 16 or lower 16 of the extended 32 register set. This bit is stored in bit inverted format. A value of 1 is used to encode the lower 16 registers.
- V'VVVV is formed by combining EVEX.V', EVEX.vvvv.
- Write mask field 270 (EVEX byte 3, bits [2:0]-kkk) - its content specifies the index of a register in the write mask registers as previously described.
- Modifier field 246 (MODR/M.MOD, bits [7-6] - MOD field 342) - As previously described, the MOD field's 342 content distinguishes between memory access and non-memory access operations. This field will be further described later herein.
- MODR/M.reg field 344 bits [5-3] - the role of ModR/M.reg field can be summarized to two situations: ModR/M.reg encodes either the destination register operand or a source register operand, or ModR/M.reg is treated as an opcode extension and not used to encode any instruction operand.
- ModR/M.r/m field 346 bits [2-0] -
- the role of ModR/M.r/m field may include the following: ModR/M.r/m encodes the instruction operand that references a memory address, or ModR/M.r/m encodes either the destination register operand or a source register operand.
- Scale field 260 (SIB.SS, bits [7-6] - As previously described, the scale field's 260 content is used for memory address generation. This field will be further described later herein.
- SIB.xxx 354 bits [5-3] and SIB.bbb 356 (bits [2-0]) - the contents of these fields have been previously referred to with regard to the register indexes Xxxx and Bbbb.
- Displacement field 262A (Bytes 7-10) - when MOD field 342 contains 10, bytes 7-10 are the displacement field 262A, and it works the same as the legacy 32-bit displacement (disp32) and works at byte granularity.
- Displacement factor field 262B (Byte 7) - when MOD field 342 contains 01, byte 7 is the displacement factor field 262B.
- the location of this field is that same as that of the legacy x86 instruction set 8-bit displacement (disp8), which works at byte granularity. Since disp8 is sign extended, it can only address between -128 and 127 bytes offsets; in terms of 64 byte cache lines, disp8 uses 8 bits that can be set to only four really useful values -128, -64, 0, and 64; since a greater range is often needed, disp32 is used; however, disp32 requires 4 bytes.
- the displacement factor field 262B is a reinterpretation of disp8; when using displacement factor field 262B, the actual displacement is determined by the content of the displacement factor field multiplied by the size of the memory operand access (N). This type of displacement is referred to as disp8*N. This reduces the average instruction length (a single byte of used for the displacement but with a much greater range). Such compressed displacement is based on the assumption that the effective displacement is multiple of the granularity of the memory access, and hence, the redundant low-order bits of the address offset do not need to be encoded. In other words, the displacement factor field 262B substitutes the legacy x86 instruction set 8-bit displacement.
- the displacement factor field 262B is encoded the same way as an x86 instruction set 8-bit displacement (so no changes in the ModRM/SIB encoding rules) with the only exception that disp8 is overloaded to disp8*N.
- Immediate field 272 operates as previously described.
- Figure 3B is a block diagram illustrating the fields of the specific vector friendly instruction format 300 that make up the full opcode field 274 according to one embodiment of the invention.
- the full opcode field 274 includes the format field 240, the base operation field 242, and the data element width (W) field 264.
- the base operation field 242 includes the prefix encoding field 325, the opcode map field 315, and the real opcode field 330.
- Figure 3C is a block diagram illustrating the fields of the specific vector friendly instruction format 300 that make up the register index field 244 according to one embodiment of the invention.
- the register index field 244 includes the REX field 305, the REX' field 310, the MODR/M.reg field 344, the MODR/M.r/m field 346, the VVVV field 320, xxx field 354, and the bbb field 356.
- Figure 3D is a block diagram illustrating the fields of the specific vector friendly instruction format 300 that make up the augmentation operation field 250 according to one embodiment of the invention.
- class (U) field 268 contains 0 it signifies EVEX.U0 (class A 268A); when it contains 1 it signifies EVEX.U1 (class B 268B).
- U 0 and the MOD field 342 contains 11 (signifying a no memory access operation)
- the alpha field 252 (EVEX byte 3, bit [7] - EH) is interpreted as the rs field 252A.
- the beta field 254 (EVEX byte 3, bits [6:4]- SSS) is interpreted as the round control field 254A.
- the round control field 254A includes a one bit SAE field 256 and a two bit round operation field 258.
- the beta field 254 (EVEX byte 3, bits [6:4]- SSS) is interpreted as a three bit data transform field 254B.
- the alpha field 252 (EVEX byte 3, bit [7] - EH) is interpreted as the eviction hint (EH) field 252B and the beta field 254 (EVEX byte 3, bits [6:4]- SSS) is interpreted as a three bit data manipulation field 254C.
- the alpha field 252 (EVEX byte 3, bit [7] - EH) is interpreted as the write mask control (Z) field 252C.
- the MOD field 342 contains 11 (signifying a no memory access operation)
- part of the beta field 254 (EVEX byte 3, bit [4]- S 0 ) is interpreted as the RL field 257A; when it contains a 1 (round 257A.1) the rest of the beta field 254 (EVEX byte 3, bit [6-5]- S 2-1 ) is interpreted as the round operation field 259A, while when the RL field 257A contains a 0 (VSIZE 257.A2) the rest of the beta field 254 (EVEX byte 3, bit [6-5]- S 2-1 ) is interpreted as the vector length field 259B (EVEX byte 3, bit [6-5]- L 1-0 ).
- the beta field 254 (EVEX byte 3, bits [6:4]- SSS) is interpreted as the vector length field 259B (EVEX byte 3, bit [6-5]- L 1-0 ) and the broadcast field 257B (EVEX byte 3, bit [4]- B).
- the vector format extends the number of registers to 32 (REX').
- Non-destructive source register encoding (applicable to three and four operand syntax): This is the first source operand in the instruction syntax. It is represented by the notation, EVEX.vvvv. This field is encoded using Is complement form (inverted form), i.e. ZMM0 is encoded as 1111B, ZMM15 is encoded as 0000B. Note that an extra bit field in EVEX is needed to extend the source to 32 registers.
- EVEX.W defines the datatype size (32-bits or 64-bits) for certain of the instructions.
- EVEX prefix provide additional bit field to encode 32 registers per source with the following dedicated bit fields: EVEX.R' and EVEX.V' (together with EVEX.X for register-register formats).
- Legacy SSE instructions effectively use SIMD prefixes (66H, F2H, F3H) as an opcode extension field.
- EVEX prefix encoding allows the functional capability of such legacy SSE instructions using 512 bit vector length.
- Compaction of two-byte and three-byte opcode More recently introduced legacy SSE instructions employ two and three-byte opcode.
- the one or two leading bytes are: 0FH, and 0FH 3AH/0FH 38H.
- the one-byte escape (0FH) and two-byte escape (0FH 3AH, 0FH 38H) can also be interpreted as an opcode extension field.
- the EVEX.mmm field provides compaction to allow many legacy instruction to be encoded without the constant byte sequence, 0FH, 0FH 3AH, 0FH 38H.
- Figures 4A - 4D illustrate a flow diagram showing the inter relationship of some of the fields of the vector friendly instruction format according to one embodiment of the invention; while figure 4E is an exploded view of each of blocks 415A-H according to one embodiment of the invention.
- block 400 it is determined whether the value of the initial field indicates the vector friendly instruction format (e.g., 0x62). If not, control passes to block 402 where the instruction is handled according to one of the other formats of the instruction set. If so, control passes to block 492.
- the vector friendly instruction format e.g., 0x62
- block 492 it is determined whether the content of the class (U) field indicates class A or class B instruction templates. In the case of class A, control passes to two separate blocks: block 404A and 490. Otherwise, control passes to through circled B to two separate blocks on figure 4C : block 404B and block 493.
- block 404A it is determined whether the content of the modifier field indicates a no memory access operation or a memory access operation.
- control passes to blocks 406 and 408.
- control passes to each of block 422, block 430, and block 440A (on figure 4B through the circled A).
- a rounded corner box labeled alpha field 252 encompasses block 408 and block 422 because they represent the different interpretations of the alpha field 252. Specifically, block 408 represents the alpha field's 252 interpretation as the rs field 252A, while block 422 represents when the alpha field's 252 interpretation as the eviction hint field 252B.
- control passes to each of block 410, block 412A, and block 414. In the latter case, control passes to block 416.
- a rounded corner box labeled beta (round control) field 254A encompasses block 410 and block 412A.
- Block 410 illustrates a decision regarding the SAE field's 256 content (whether or not to suppress floating point exceptions), while block 412A illustrates a decision based on the round operation field's 258 content (distinguishing one of the group of possible rounding operations). The decisions made in block 410 and 412A are illustrated in Figure 7A .
- Blocks 414, 416, 442, 448, 454, 460, 468, and 474 all illustrate a decision regarding the content of the data element width (w) field 264.
- the data element width field 264 is a 1 bit field in the specific vector friendly instruction format 300 of Figure 3A .
- these blocks decide whether the data element width is 64 bits (e.g., 1) or 32 bits (e.g., 0). With regard to block 414, this decision marks the end of this branch of the flow. In contrast, control passes from block 416 to block 418 or block 420 for the 64 bit and 32 bit data element widths, respectively.
- a rounded corner box labeled beta (data transform) field 254B encompasses both block 418 and block 420; and thus represents the case where the beta field 254 is interpreted as the data transform field 254B.
- the content of the data transform field 254B is used to distinguish which one of a number of data transform operations is to be performed.
- the groups of possible data transform operations for block 418 and block 420 are respectively shown in Figure 8A and Figure 8B .
- the content of the eviction hint field 252B is used to distinguish which one of the group of possible eviction hint options should be used.
- Figure 4 illustrates the use of a 1 bit eviction hint field 252B from the specific vector friendly instruction format 300. Specifically, the eviction hint options are non-temporal (1) and temporal (0). This marks the end of this branch of the flow diagram.
- the content of the base operation field 242 is used to distinguish which one of a group of different memory access operations is to be performed.
- the following table illustrates the group of supported memory access operations according to one embodiment of the invention, as well as the control flow from block 440A for each.
- Alternative embodiments of the invention may support more, less, or different memory access operations.
- Block Load/Operation Integer (load/op int) 442 Load/Operation Floating Point (load/op fp) 448 Load Integer (load int) 454 Load Floating Point (load fp) 460 Store Integer (store int) 468 Store Floating Point (store fp) 474 Load Graphics (load gr) 480 Load Packed Graphics (load p.gr) 482 Store Graphics (store gr) 484
- blocks 442, 448, 454, 460, 468, and 474 determine the change in control flow based on the data element width; the control flow is illustrated in the below table.
- a rounded corner box labeled beta (data manipulation) field 254C encompasses blocks 444A, 446A, 450A, 452A, 456, 458, 462, 464, 470, 472, 476, 478, 480, 482, and 484; thereby illustrating that the content of the data manipulation field 254C distinguishes which one of the group of possible data manipulation operations is to be performed.
- the content of the write mask (k) field 270 and the content of the data element width (w) field 264 are used to determine the write mask to be used in the operation.
- Figure 4 illustrates the embodiment in which there are eight right mask registers and the register 000 indicates that no write mask should be used. Where the write mask field's 270 content indicates other than 000, control passes to Figure 16A-D .
- block 404B it is determined whether the content of the modifier field indicates a no memory access operation or a memory access operation.
- control passes to blocks 406 (on figure 4A through the circled E) and 495.
- control passes to each of block 498, block 430 (on figure 4A through the circled D), and block 440B (on figure 4D through the circled C).
- a rounded corner box labeled part of beta field 254 encompasses block 495, block 412B, and block 498 because they represent the different interpretations of part of the beta field 254.
- block 495 represents part of the beta field's 254 interpretation as the RL field 257A
- a rounded corner box labeled broadcast field 257B on figure 4D represents this part of the beta field' 254 interpretation as the broadcast field 257B.
- control passes to each of block 412B and block 415A.
- control passes to each of block 498 and block 415B.
- Block 412B illustrates a decision based on the round operation field's 259B content (distinguishing one of the group of possible rounding operations). The decision made in block 412B is illustrated in Figure 7B .
- Blocks 415A-H all illustrate a decision regarding the width of data element on which to operate.
- the supported data elements for class B are 64 bit, 32 bit, 16 bit, and 8 bit. Exemplary manners of performing these blocks are describe later herein with reference to figure 4E .
- Blocks 415A-B respectively mark the end of these branches of the flow diagram.
- the lines to the 16 bit and 8 bit data element widths are shown as dashed because in one embodiment of the invention these are not supported; rather, if there is a no memory access type operation for class B that is operating on 16 bit or 8 bit data elements, then the content of RL field 257A is expected to be 0, and thus cause control to flow from block 495 to blocks 415B and 498 (in other words, the partial rounding is not available).
- the content of the vector length (LL) field 268 is used to determine the size of the vector to be operated on.
- Figure 4 illustrates the embodiment in which the following are supported: 1) 128 bit (00); 2) 256 bit (01); 512 bit (10); while (11) is reserved.
- the reserved 11 may be used for different purposes for different types of instructions or for different embodiments of the invention. For example, 11 could be used for the following exemplary purposes: 1) to designate a vector length of 1024 bits; or 2) to designate that a dynamic vector length register should be used.
- Different embodiments may implement the dynamic vector length register(s) differently, including a special register used to encode vector length that is readable and writable by programs.
- a dynamic vector length register stores a value to be used for the vector length of the instruction. While different embodiments may support a number of different vector lengths through a dynamic vector length register, one embodiment of the invention supports a multiple of 128-bit (e.g., 128, 256, 512, 1024, 2048). Where there is a set of one or more registers that function as dynamic vector length registers, different embodiments of the invention may select from those registers using different techniques (e.g., based on the type of instruction).
- the content of the base operation field 242 is used to distinguish which one of a group of different memory access operations is to be performed.
- the following table illustrates the group of supported memory access operations according to one embodiment of the invention, as well as the control flow from block 440B for each.
- Alternative embodiments of the invention may support more, less, or different memory access operations.
- Block Load/Operation Integer (load/op int) 415C Load/Operation Floating Point (load/op fp) 415D Load Integer (load int) 415E Load Floating Point (load fp) 415F Store Integer (store int) 415G Store Floating Point (store fp) 415H
- blocks 415C-H determine the change in control flow based on the data element width; the control flow is illustrated in the below table.
- one embodiment of the invention allows the content of the broadcast (b) field 257B select whether a broadcast operation is performed or not for the data element widths of 64 bit and 32 bit, that is not an option for the 16 bit and 8 bit data element widths; rather, if there is a memory access type operation for class B that is operating on 16 bit or 8 bit data elements, then the content of the broadcast (B) field 257B is expected to be 0.
- the content of the alpha field 252 (write make control (Z) field 252C), the content of the write mask (k) field 270, and a determination of the data element width are used to determine the write make operation to be performed (merging or zeroing) and the write mask to be used in the operation.
- the alpha field 252 (write mask control (Z field 252C) is expected to be zero (for zero-masking) on memory access operations that perform stores.
- the determination of the data element width is done in the same manner as block 415.
- Figure 4 illustrates the embodiment in which there are eight right mask registers and the register 000 indicates that no write mask should be used. Where the write mask field's 270 content indicates other than 000, control passes to Figure 16D-E .
- Figure 4E is an exploded view of each of blocks 415A-H according to one embodiment of the invention. Specifically, a single flow 415 is illustrated which represent the flow for each of blocks 415A-H.
- block 417A some or all of the content of the real opcode field 330 is used to select between two sets of data element widths: a first set 417A.1 (e.g., including 64 bit and 32 bit) and second set 417A.2 (e.g., 16 bit and 8 bit).
- While data element width is determine for the first set 417A.1 based on the data element width (w) field 264 as illustrated in block 417B; within the second set 471A.2, there are two manners of determining the data element width: 417A.2.1 (based just on the real opcode field 330) and 417A.2.2 (based on the data element width (w) field 264 as illustrated in block 417C).
- the data element width field 264 is a 1 bit field in the specific vector friendly instruction format 300 of Figure 3A .
- these block 417B decides whether the data element width is 64 bits (e.g., 1) or 32 bits (e.g., 0); while block 417C decides whether the data element width is 16 bits (e.g., 1) or 8 bits (e.g., 0). While figure 4E illustrates the involvement of the real opcode field 417A in determining the data element width, alternative embodiments may be implemented to use just the w field (e.g., have a one bit w field and support only two data element sizes; have a two bit w field and support the four data element sizes).
- alternative embodiment may not support different data element widths on one or more of the no-memory access round type operation and the no-memory access data transform type operation (in the former, blocks 414 and 415A would not be present; in the latter, block 415B would not be present, while block 416 would not be present and blocks 418 and 420 would be merged).
- different embodiments of the invention may not include the class (U) field 268 and support only one of the class A or B instruction templates; may include the SAE field 256 and not the round operation field 258; may not include the round operation field 259A; may not include the eviction hit field 252B; may not include the round type operation in either or both of class A and B instruction templates; may not include the data transform type operation; may not include the vector length field 259B in either or both of the no memory access 205 and memory access 220; support only one or the other of the load/op and load operations; may not include the mask write field 270; may not include the write mask control (Z) field 252C; and/or may not include the vector length field 268.
- the mask write field 270 may not include the write mask control (Z) field 252C; and/or may not include the vector length field 268.
- FIG. 5 is a block diagram of a register architecture 500 according to one embodiment of the invention.
- the register files and registers of the register architecture are listed below:
- the lower order 256 bits of the lower 16 zmm registers are overlaid on registers ymm0-16.
- the lower order 128 bits of the lower 16 zmm registers (the lower order 128 bits of the ymm registers) are overlaid on registers xmm0-15.
- the specific vector friendly instruction format 300 operates on these overlaid register file as illustrated in the below tables.
- the vector length field 259B selects between a maximum length and one or more other shorter lengths, where each such shorter length is half the length of the preceding length; and instructions templates without the vector length field 259B operate on the maximum vector length.
- the class B instruction templates of the specific vector friendly instruction format 300 operate on packed or scalar single/double-precision floating point data and packed or scalar integer data. Scalar operations are operations performed on the lowest order data element position in an zmm/ymm/xmm register; the higher order data element positions are either left the same as they were prior to the instruction or zeroed depending on the embodiment.
- Write mask registers 515 - in the embodiment illustrated there are 8 write mask registers (k0 through k7), each 64 bits in size.
- the vector mask register k0 cannot be used as a write mask; when the encoding that would normally indicate k0 is used for a write mask, it selects a hardwired write mask of 0xFFFF, effectively disabling write masking for that instruction.
- MXCSR Multimedia Extensions Control Status Register
- Extended flags (EFLAGS) register 530 in the embodiment illustrated, this 32 bit register is used to record the results of many instructions.
- FCW Floating Point Control Word
- FSW Floating Point Status Word
- Segment registers 555 - in the illustrated embodiment there are six 16 bit registers use to store data used for segmented address generation.
- Alternative embodiments of the invention may use wider or narrower registers. Additionally, alternative embodiments of the invention may use more, less, or different register files and registers.
- Figure 6A is a flow diagram for the register index field 244 for a no memory access type operation according to embodiments of the invention.
- bits are selected from the register index field 244 to address registers.
- the existing x86 instructions set with extensions allows for a wide variety of different register addressing options based upon the REX field 305, the reg field 344, the r/m field 346, the VVVV field 320, the xxx field 354, and the bbb field 356.
- the REX' field 310 extends these options. From block 605, control passes to block 610.
- register A is selected (e.g., zmm20) and control passes to block 615.
- register B is selected (e.g., zmm5) and control optionally passes to block 620.
- register C is selected (e.g., zmm7).
- Register A may be a source operand register;
- register B may be a source operand register, a destination operand register, or a source/destination operand register; and
- register C may be a source operand register, a destination operand register, or a source/destination operand.
- Figure 6B is a flow diagram illustrating the use of the register index field 244, the scale field 260, the displacement field 262A, and the displacement factor field 262B for a memory access type operation according to embodiments of the invention.
- bits are selected from the register index field to address registers and control passes to block 640.
- register A is selected (e.g., zmm20) and control optionally passes to block 645.
- register B is selected (e.g., zmm31) and control passes to block 650. In the case where block 645 is not used, control passes directly from block 640 to block 650.
- the contents of the REX field 305, the REX' field 310, the mod r/m field 340, the SIB byte 350, and the displacement field 262A or the displacement factor field 262B are used to address memory; specifically, the index and the base are pulled from the REX field 305 and the SIB byte 350, while the content of the scale field 260 (ss field 352) is pulled from the SIB byte 350. From block 650, control passes to block 660.
- control passes to block 675 in which the address is generated as follows: 2 ss * index + base + scaled displacement; where the scaled displacement (disp8*n) the content of the displacement factor field 262B multiplied by the memory access size (N), where N is dependent upon the contents of the full opcode field 274 (e.g., the base operation field and/or the data element width field) and the augmentation operation field 250 (e.g., the class field 268 and the data manipulation field 254C, the vector length field 259B, and/or the broadcast field 257B).
- the full opcode field 274 e.g., the base operation field and/or the data element width field
- the augmentation operation field 250 e.g., the class field 268 and the data manipulation field 254C, the vector length field 259B
- Figure 6C is a table illustrates the differences between disp8, disp32, and variations of the scaled displacement according to embodiments of the invention.
- the values in the rows in the "byte" column increase down the column.
- the second column, the third column, and each of the sub-columns include a blackened circle in the rows for address that can be generated by that field.
- Figure 7A is a table illustrating the group of possible operations that may be specified by the round control field 254A according to embodiments of the invention.
- Figure 7A shows a first column contains the possible content of the beta field 254 (which is acting as the round control field 254A and which is broken down into the SAE field 256 and the round operation field 258).
- figure 7B is a table illustrating the group of possible operations that may be specified by the round control field 259A according to embodiments of the invention.
- class B instruction templates there is no SAE field 256 and floating point exception suppression is always active.
- the immediate bits takes precedence over the rounding mode operation field 258 and 259A.
- UNORM indicates an unsigned normalized integer, meaning that for an n-bit number, all 0's means 0.0f, and all 1's means 1.0f
- a sequence of evenly spaced floating point values from 0.0f to 1.0f are represented, e.g. a 2-bit UNORM represents 0.0f, 1/3, 2/3, and 1.0f.
- SNORM indicates a signed normalized integer, meaning that for an n-bit 2's complement number, the maximum value means 1.0f (e.g. the 5-bit value 01111 maps to 1.0f), and the minimum value means -1.0f (e.g. the 5-bit value 10000 maps to -1.0f).
- the second-minimum number maps to -1.0f (e.g. the 5-bit value 10001 maps to -1.0f).
- -1.0f There are thus two integer representations for -1.0f.
- There is a single representation for 0.0f and a single representation for 1.0f. This results in a set of integer representations for evenly spaced floating point values in the range (-1.0f...0.0f), and also a complementary set of representations for numbers in the range (0.0f...1.0f).
- SIMD technology is especially suited to processors that can logically divide the bits in a register into a number of fixed/sized data elements, each of which represents a separate value.
- This type of data is referred to as the packed data type or vector data type, and operands of this data type are referred to as packed data operands or vector operands.
- the data elements of a vector operand are of the same data type; the data type of a given data element is referred to as the data element data type.
- the vector operand may be referred to as being of that data type (e.g., where all of the data elements of a vector operand are of the 32-bit floating-point data element data type, then the vector operand may be referred to as a 32-bit floating-point vector operand).
- Embodiments of the invention are described which support single value data element data types and multiple value data element data types.
- the single value data element data types store in each data element a single value; examples of single value data element data types used in some embodiments of the invention are 32-bit floating-point, 64-bit floating-point, 32-bit unsigned integer, 64-bit unsigned integer, 32-bit signed integer, and 64-bit signed integer.
- the multiple value data element data types store in each data element position a packet with multiple values contained therein; examples of multiple value data element data types used in some embodiments of the invention are the packed graphics data element data types described below:
- UNORM10A10B10C2D A 32-bit packet of three UNORM10 values and one UNORM2 value, begin with the last 2b (10b) field located in the most-significant bits of the 32b field (e.g., unorm2D [31-30] float 10C [29-20] float 10B [20-10] float 10A [9-0], where D-A signify slot position and the preceding names/numbers signify the format).
- FLOAT11A11B10C A 32-bit packet of two FLOAT11 values and one FLOAT10 value, begin the last one located in the higher order bits (e.g., float 10C [31-22] float 11B [21-11] float 11A [10-0]).
- Figures 8A-8B are tables illustrating the groups of possible data transform operations that may be specified by the data transform field according to embodiments of the invention.
- the first column in both tables illustrates the possible values of the content of the data transform field 254B; the second column the function, and the third column the usage.
- Figure 8A is a table illustrating the group of possible data transform operations that may be specified by the data transform field when the data element width is 64 bits according to embodiments of the invention.
- This table is referred to as the 64-bit Register SwizzUpConv swizzle primitives and it is representation of the block 418.
- dcba denotes the 64-bit elements that form one 256-bit block in the source (with 'a' least-significant and 'd' most-significant), so aaaa means that the least-significant element of the 256-bit block in the source is replicated to all four elements of the same 256-bit block in the destination; the depicted pattern is then repeated for the two 256-bit blocks in the source and destination.
- the notation 'hgfe dcba' is used to denote a full source register, where 'a' is the least-significant element and 'h' is the most-significant element. However, since each 256-bit block performs the same permutation for register swizzles, only the least-significant block is illustrated.
- Figure 8B is a table illustrating the group of possible data transform operations that may be specified by the data transform field when the data element width is 32 bits according to embodiments of the invention.
- This table is referred to as the 32-bit Register SwizzUpConv swizzle primitives and it is representation of the block 420.
- dcba denotes the 32-bit elements that form one 128-bit block in the source (with 'a' least-significant and 'd' most-significant), so aaaa means that the least-significant element of the 128-bit block in the source is replicated to all four elements of the same 128-bit block in the destination; the depicted pattern is then repeated for all four 128-bit blocks in the source and destination.
- Figure 8B calls out two exemplary operations to further illustrate the meaning of all of the operations shown in Figures 8A-8B : the cross-product swizzle 815 which is illustrated in Figure 9 and the broadcast an element across 4-element packets 820 illustrated in Figure 10A .
- Figure 9 is a block diagram illustrating the cross product swizzle 815 according to embodiments of the invention.
- Figure 9 shows a source operand 900 and a destination operand 910 that are both 512 bits wide and broken into consecutive 128 blocks (referred to as packet positions 3-0), where each block is broken into four 32 bit data elements (e.g., the contents of packet position 0 in the source operand 900 are D0 C0 B0 A0, while the contents of packet position 0 in the destination operand 910 are D0 A0 C0 B0.
- Figure 10A is a block diagram illustrating the broadcast of an element across 4-element packets 820 according to embodiments of the invention.
- Figure 10A shows a source operand 1000 and a destination operand 1010 that are both 512 bits wide and broken into consecutive 128 blocks (referred to as packet positions 3-0), where each block is broken into four 32 bit data elements (e.g., the contents of packet position 0 in the source operand 1000 are D0 C0 B0 A0, while the contents of packet position 0 in the destination operand 910 are A0 A0 A0 A0; the contents of packet position 1 in the source operand 1000 are D1 C1 B1 A1, while the contents of packet position 1 in the destination operand 1010 are A1 A1 A1 A1).
- Figure 10A is an example broadcast for a no memory access operation
- Figures 10B-10C are example broadcasts for memory access operations.
- the source memory operand contains fewer than the total number of elements, it can be broadcast (repeated) to form the full number of elements of the effective source operand (16 for 32-bit instructions, 8 for 64-bit instructions).
- These types of broadcast operations are referred to in Figures 12A-12D .
- Figure 10B is a block diagram illustrating the broadcast of 1-element granularity for a 32 bit data element width according to embodiments of the invention. An example of the operation is labeled 1210 in Figure 12B .
- Figure 10B shows a source operand 1020 sourced from memory having one 32 bit data element (A0) and a destination operand 1030 that is 512 bits wide and contains sixteen 32 bit data elements (all of the data elements are A0 in the destination operand 1030).
- FIG. 10C is a block diagram illustrating the broadcast 4-element granularity for 32 bit data elements according to embodiments of the invention. An example of the operation is labeled 1220 in Figure 12B .
- Figure 10C shows a source operand 1040 sourced from memory having four 32 bit data elements (D0 C0 B0 A0) and a destination operand 1050 that is 512 bits wide and broken into consecutive 128 blocks (referred to as packet positions 3-0), where each block is broken into four 32 bit data elements (e.g., the contents in each of the packet positions 3-0 of the destination operand 1050 are D0 C0 B0 A0).
- 4 to 16 broadcasts are very useful for AOS (array of structures) source code, where the computation is performed over an array of packed values (like color components RGBA); in this case, 4 to 16 is advantageous when there is a common packet used across the different operations of a vector instruction (a 16-element vector is considered an array of 4 packets of 4 elements each).
- Figure 11A is a table illustrating the group of possible opcode maps that may be specified by the opcode map field according to embodiments of the invention.
- the first column illustrates the possible values of the content of the opcode map field 315; the second column the implied leading opcode bytes, and the third column whether an immediate may be present.
- Figure 11B is a table illustrating the group of possible prefix encodings that may be specified by the opcode map field according to embodiments of the invention.
- the first column illustrates the possible values of the content of the prefix encoding field 325; and the second column the meaning of that prefix.
- Figures 12-15 are tables illustrating the groups of possible data manipulation operations and broadcast operation that may be respectively specified by the data manipulation field 254C and, for figures 12A-D the broadcast field 257B, according to embodiments of the invention.
- the first column in the tables illustrates the possible values of the content of the data manipulation field 254C; the second column the function, and the third column the usage.
- Figures 12A-12D are tables illustrating the groups of possible data manipulation operations and broadcast operation that may be respectively specified by the data manipulation field 254C and the broadcast field 257B for the load/op instructions according to embodiments of the invention.
- the data manipulation field 254C is a three bit field and the broadcast field 257B is a one bit field.
- the broadcast field's 257B content selects between the first two rows in the tables found in figures 12A-D ; in other words, its contents selects between the equivalent of 000 and 001 in the data manipulation field 254C. This is illustrated in figure 12A-D using bracket that includes only the first two rows of the tables.
- Figure 12A is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C and broadcast field 257B for a load/op int where the data element width is 64 bits according to embodiments of the invention.
- This table is referred to as the 64-bit Integer Load-op SwizzUpConv i 64 (Quadword) swizzle/convert primitives and it is a representation of the block 444A and block 444B.
- Figure 12B is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C and broadcast field 257B for a load/op int where the data element width is 32 bits according to embodiments of the invention.
- This table is referred to as the 32-bit Integer Load-op SwizzUpConv i 32 swizzle/convert primitives and it is a representation of the block 446A and block 446B.
- Figure 12C is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C and broadcast field 257B for a load/op fp where the data element width is 64 bits according to embodiments of the invention.
- This table is referred to as the 64-bit Floating-point Load-op SwizzUpConv f 64 swizzle/convert primitives and it is a representation of the block 450A and block 450B.
- Figure 12D is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C and broadcast field 257B for a load/op fp where the data element width is 32 bits according to embodiments of the invention.
- This table is referred to as the 32-bit Floating-point Load-op SwizzUpConv f 32 swizzle/convert primitives and it is a representation of the block 452A and block 452B.
- Figures 13A-13D are tables illustrating the groups of possible data manipulation operations that may be specified by the data manipulation field for the load instructions according to embodiments of the invention.
- Figure 13A is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C for a load int where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the UpConv i64 and it is a representation of the block 456.
- Figure 13B is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C for a load int where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the UpConv i32 and it is a representation of the block 458.
- Figure 13C is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C for a load fp where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the UpConv f64 and it is a representation of the block 462.
- Figure 13D is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C for a load fp where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the UpConv f32 and it is a representation of the block 464.
- the groups of possible data manipulation operations specified in each of Figures 13A-13D are a subset of those in the corresponding Figures 12A-12D (the load tables). Specifically, the subsets do not include broadcast operations. This is done because certain values in the full opcode field 274 (e.g., those that specify gather or broadcast operations) cannot be used in combination with broadcasts specified in the data manipulation field 254C, and thus such values in the full opcode field 274 can be used only with the loads of Figures 12A-12D (the load tables). By way of more specific example, if there is a value in the full opcode field 274 that specifies a broadcast operation, the data manipulation field 254C cannot also indicate a broadcast operation.
- the full opcode field 274 e.g., those that specify gather or broadcast operations
- While certain embodiments of the invention include the separate load/op and load operations with separate load/op and load tables, alternative embodiments need not have this enforcement mechanism (e.g., they may support only load/op, they may support only load, they may determine that a broadcast in the full opcode field 274 causes a broadcast in the data manipulation field 254C to be ignore).
- Figures 14A-14D are tables illustrating the groups of possible data manipulation operations that may be specified by the data manipulation field for the store instructions according to embodiments of the invention.
- Figure 14A is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C for a store int where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the DownConv i64 and it is a representation of the block 470.
- Figure 14B is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C for a store int where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the DownConv i32 and it is a representation of the block 472.
- Figure 14C is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C for a store fp where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the DownConv f64 and it is a representation of the block 476.
- Figure 14D is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C for a store fp where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the DownConv f32 and it is a representation of the block 478.
- Figures 15A-15C are tables illustrating the groups of possible data manipulation operations that may be specified by the data manipulation field for the instructions that operate on the graphics data types according to embodiments of the invention.
- Figure 15A is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C for a load graphics where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the UpConv g32 and it is a representation of the block 480.
- Figure 15B is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C for a load packed graphics where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the UpConv pg32 and it is a representation of the block 482.
- Figure 15C is a table illustrating the group of possible data manipulation operations that may be specified by the data manipulation field 254C for a store graphics where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the UpConv g32 and it is a representation of the block 484.
- Figures 16A-16B illustrate two merging operations performed with different write masks and with the second source and destination being the same according to embodiments of the invention.
- Figure 16A is a block diagram illustrating an exemplary operation 1600 that merges using the write mask in write mask register K1 where the data element width is 32 bits and where the second source and destination are the same according to embodiments of the invention.
- Figure 16A shows a source operand 1605; a source/destination operand 1610; the content of the mask register K1 1615 (with the lower 16 bits including a mix of ones and zeros); and the destination operand 1620.
- Each of the lower 16 bit positions in the mask register K1 corresponds to one of the data element positions (K1 [0] to data element position 0, K1 [1] to data element position 1, and so one).
- For each data element position in the destination operand 1620 it contains the content of that data element position in the source/destination 1610 or the result of the operation (illustrated as an add) depending on whether the corresponding bit position in the mask register K1 is a zero or 1, respectively.
- source/destination operand 1610 is replaced with a second source operand.
- the destination operand 1620 contains the contents of the destination operand 1620 from before the operation in those of the data element positions in which the corresponding bit positions of the mask register K1 are zero (if any) and contains the result of the operation in those of the data element positions in which of the corresponding bit positions of the mask register K1 are 1 (if any).
- Figure 16B is a block diagram illustrating an exemplary operation 1625 that merges using the hardwired mask of all ones (the hardwired write mask is used by instructions that specify write mask register k0) where the data element width is 32 bits and where the second source and destination are the same according to embodiments of the invention.
- Figure 16B is identical to Figure 16A , except that K1 1615 is replaced with hardwired mask 1630 and that destination operand 1620 is replaced with destination operand 1635.
- the hardwired mask 1630 is all ones, and thus the destination operand 1635 contains data elements representative of the result of the operation.
- Figure 16C is a block diagram illustrating the correspondence of bits in the write mask registers to the data element positions of a 512 bit vector for the 8, 16, 32, and 64 bit data element widths according to embodiments of the invention. Specifically, a 64 bit register K N 1640 is illustrated, where all 64 bits are used when the data element width is 8 bits, only the least significant 32 bits are used when the data element width is 16 bits, only the least significant 16 bits are used when the data element width is 32 bits, and only the least significant 8 bits are used when the data element width is 64 bits.
- only the least significant 32 bits are used when the data element width is 8 bits, only the least significant 16 bits are used when the data element width is 16 bits, only the least significant 8 bits are used when the data element width is 32 bits, and only the least significant 4 bits are used when the data element width is 64 bits.
- For a 128 bit vector only the least significant 16 bits are used when the data element width is 8 bits, only the least significant 8 bits are used when the data element width is 16 bits, only the least significant 2 bits are used when the data element width is 32 bits, and only the least significant 2 bits are used when the data element width is 64 bits.
- the value of a given mask register can be set up as a direct result of a vector comparison instruction, transferred from a GP register, or calculated as a direct result of a logical operation between two masks.
- Figure 16D is a block diagram illustrating an exemplary operation 1660 that merges using the write mask in writemask register K1 where the data element width is 32 bits and where the second source and destination are different according to embodiments of the invention.
- Figure 16E is a block diagram illustrating an exemplary operation 1666 that zeros using the write mask in writemask register K1 where the data element width is 32 bits and where the second source and destination are different according to embodiments of the invention. While the zeroing operation is illustrated only relative to an operation where the destination is different from the sources, zeroing also works where the second source and destination are the same.
- S i 32 ( zmm / m ) A vector integer 32-bit swizzle/conversion.
- S i 64 (zmm/m) A vector integer 64-bit swizzle/conversion.
- U f 32 ( m ) A floating-point 32-bit load Upconversion.
- U g 32 ( m ) A graphics floating-point 32-bit load Upconversion.
- U pg 32 ( m ) A packed graphics floating-point 32-bit load Upconversion.
- U i 32 ( m ) An integer 32-bit load Upconversion.
- U f 64 ( m ) A floating-point 64-bit load Upconversion.
- U i 64 (m) An integer 64-bit load Upconversion.
- D f 32 (zmm) A floating-point 32-bit store Downconversion.
- D g 32 (zmm) A graphics floating-point 32-bit store Downconversion.
- D i 32 (zmm) An integer 32-bit store Downconversion.
- D f 64 (zmm) A floating-point 64-bit store Downconversion.
- D i 64 (zmm) An integer 64-bit store Downconversion.
- m A memory operand.
- mv t A vector memory operand that may have a EH hint attribute. This memory operand is encoded using ModRM and VSIB bytes.
- each pointer is equal to BASE + V INDEX [ i ] ⁇ SCALE effective_address Used to denote the full effective address when dealing with a memory operand.
- imm8 An immediate byte value.
- SRC[a-b] A bit-field from an operand ranging from LSB b to MSB a.
- Vector Operand Value Notation Notation Meaning zmm1[i+31:i] The value of the element located between bit i and bit i +31 of the argument 1 vector operand.
- zmm2[i+31:i] The value of the element located between bit i and bit i+31 of the argument2 vector operand.
- k1[i] Specifies the i-th bit in the vector mask register k1.
- ⁇ k1 ⁇ A mask register operand in the write mask field of the instruction used with merging behavior.
- the 64 bit mask registers are: k0 through k7 ⁇ k1 ⁇ ⁇ z ⁇ A mask register operand in the write mask field of the instruction used with zeroing behavior.
- the 64 bit mask registers are: k0 through k7 SwizzUpConv, FullUpConv and DownConv function conventions Swizzle/conversion used Function used in operation description S f 32 (zmm/m) SwizzUpConvLoad f 32 (zmm/m) S f 64 (zmm/m) SwizzUpConvLoad f 64 (zmm/m) S i 32 (zmm/m) SwizzUpConvLoad i 32 (zmm/m) S i 64 (zmm/m) SwizzUpConvLoad i 64 (zmm/m) U f 32 (m) UpConvLoad f 32 (m) U g 32 ( m ) UpConvLoad g 32 (m) U pg 32 ( m ) UpConvLoad pg 32 (m) U i 32 ( m ) UpConvLoad i 32 (m) U f 64 (
- Figure 17A illustrates a subset of fields from an exemplary specific vector friendly instruction format according to embodiments of the invention. Specifically, Figure 17A shows an EVEX Prefix 302, a Real Opcode Field 330, and a MOD R/M Field 340. In this embodiment, the Format Field 240 contains 0x62 to indicate that the instruction format is the vector friendly instruction format.
- Figures 17B-17D each illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format of Figure 17A according to embodiments of the invention.
- the Format Field 240 contains 0x62 to indicate that the instruction is encoded in the vector friendly instruction format and the real opcode field 330 contains the VADDPS opcode.
- Figures 17B-17D each illustrates an encoding of the VADDPS instruction in the EVEX.U0 class according to embodiments of the invention
- Figure 17B and Figure 17C each illustrates an EXEV.U0 encoding of VADDPS in a no memory access 205 instruction template
- Figure 17D illustrates an EVEX.U0 encoding of VADDPS in a memory access 220 instruction template.
- the VADDPS instruction adds packed single-prevision floating-point values from a first register or memory operand (e.g. zmm3) to a second register (e.g. zmm2) and stores the result in a third register (e.g. zmm1) according to a writemask (e.g. k1).
- This instruction allows for various round operations, data transform operations, or data manipulation operations depending on the encoding of the instruction.
- This instruction may be described by the following instruction mnemonic: EVEX.U0.NDS.512.0F 58 /r VADDPS zmm1 ⁇ k1 ⁇ , zmm2, S f32 (zmm3/mV) ⁇ eh ⁇ .
- Figure 17B illustrates an encoding of the VADDPS instruction in the no memory access, full round control type operation 210 instruction template.
- the data element width field 264 is 0 to indicate 32 bit data element width.
- the class field 268 i.e. EVEX.U
- the alpha field 252 is interpreted as a RS field 252A (i.e. EVEX.rs) and is set to 1 (i.e. RS field 252A.1) to select the round control type operation. Since the alpha field 252 is acting as RS field 252A.1, the beta field 254 is interpreted as a round operation field 258 (i.e. EVEX.r 2-0 ).
- EVEX.r 2 is interpreted as a SAE field 256 while EVEX.r 1-0 act as the round control field 254A.
- the modifier field 246 i.e. MODR/M.MOD 342 is set to 11 to indicate no memory access (i.e. register zmm3 is the first source operand instead of a memory operand).
- Figure 17C illustrates an encoding of the VADDPS instruction in the no memory access, data transform type operation 215 instruction template.
- the encoding of Figure 17C is identical to Figure 17B except for the alpha field 252 and the beta field 254.
- the alpha field 252 is interpreted as a RS field 252A (i.e. EVEX.rs) and is set to 0 (i.e. RS field 252A.2) to select the data transform type operation. Since the alpha field 252 is acting as RS field 252A.2, the beta field 254 is interpreted as a data transform field 254B (i.e. EVEX.S 2-0 ).
- Figure 17D illustrates an encoding of the VADDPS instruction in the memory access 220 instruction template.
- the data element width field 264 is 0 to indicate 32 bit data element width.
- the class field 268 i.e. EVEX.U
- the alpha field 252 is interpreted as an eviction hint field 252B (i.e. EVEX.EH).
- the beta field 254 is interpreted as a data manipulation field 254C (i.e. EVEX.s 2-0 ).
- the modifier field 246 i.e. MODR/M.MOD 342 is set to either 00, 01, or 10 to indicate that the first source operand is a memory operand; this is shown in Figure 17D as 11 (i.e. any input except 11).
- Figure 18A illustrates a subset of fields from an exemplary specific vector friendly instruction format according to embodiments of the invention.
- Figure 1 *A shows an EVEX Prefix 302, a Real Opcode Field 330, and a MOD R/M Field 340.
- the Format Field 240 contains 0x62 to indicate that the instruction format is the vector friendly instruction format.
- Figures 18B-18F each illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format of Figure 18A according to embodiments of the invention.
- the specific uses of some fields are described to demonstrate possible encodings of those fields for various exemplary configurations of the VADDPS instruction.
- the Format Field 240 contains 0x62 to indicate that the instruction is encoded in the vector friendly instruction format and the real opcode field 330 contains the VADDPS opcode.
- Figures 18B-18F each illustrates an encoding of the VADDPS instruction in the EVEX.U1 class according to embodiments of the invention
- Figure 18B-18E each illustrates an EXEV.U1 encoding of VADDPS in a no memory access 205 instruction template
- Figure 18F illustrates an EVEX.U1 encoding of VADDPS in a memory access 220 instruction template.
- Figure 18B illustrates an encoding of the VADDPS instruction in the no memory access, write mask control, partial round control type operation 212 instruction template.
- the data element width field 264 is 0 to indicate 32 bit data element width.
- the class field 268 i.e. EVEX.U
- the alpha field 252 is interpreted as a write mask control field 252C (selecting between a merging or zeroing writemask).
- the least significant bit of the beta field 254 is interpreted as an RL field 257A and is set to 1 to indicate a partial round type operation (i.e. round 257A.1).
- the two most significant bits of the beta field 254 are interpreted as a round operation field 259A.
- the modifier field 246 (i.e. MODR/M.MOD 342) is set to 11 to indicate no memory access (i.e. register zmm3 is the first source operand instead of a memory operand).
- the VADDPS instruction adds a packed single-precision floating-point value from a first register (e.g. zmm3) to a second register (e.g. zmm2) and stores the rounded result in a third register (e.g. zmm1) according to a writemask (e.g. k1).
- Figures 18C-18E each illustrates an encoding of the VADDPS instruction in the no memory access, write mask control, VSIZE type operation 217 instruction template.
- the encoding of Figures 18C-18E are identical to Figure 17B except for the beta field.
- the least significant bit of the beta field 254 is interpreted as an RL field 257A and is set to 0 to indicate a VSIZE type operation 257A.2.
- the two most significant bits of the beta field 254 are interpreted as a vector length field 259B.
- the vector length field 259B is set to 10 to indicate a vector size of 512 bits.
- the vector length field 259B is set to 01 to indicate a vector size of 256 bits.
- the vector length field 259B is set to 00 to indicate a vector size of 128 bits.
- the VADDPS instruction adds a packed single-precision floating-point value from a first register (e.g. zmm3) to a second register (e.g. zmm2) and stores the result in a third register (e.g. zmm1) according to a writemask (e.g. k1).
- Figure 18C may be described by the following mnemonic: EVEX.U1.NDS.512.0F.W0 58 /r VADDPS zmm1 ⁇ k1 ⁇ ⁇ z ⁇ , zmm2, zmm3.
- Figure 18D may be described by the following mnemonic: EVEX.U1.NDS.256.0F.W0 58 /r VADDPS ymm1 ⁇ k1 ⁇ ⁇ z ⁇ , ymm2, ymm3.
- Figure 18E may be described by the following mnemonic: EVEX.U1.NDS.128.0F.W0 58 /r VADDPS xmm1 ⁇ k1 ⁇ ⁇ z ⁇ , xmm2, xmm3.
- Figure 18F illustrates an encoding of the VADDPS instruction in the memory access, write mask control 227 instruction template.
- the data element width field 264 is 0 to indicate 32 bit data element width.
- the class field 268 i.e. EVEX.U
- the alpha field 252 is interpreted as a write mask control field 252C (selecting between a merging or zeroing writemask).
- the least significant bit of the beta field 254 is interpreted as a broadcast field 257B.
- the two most significant bits of the beta field 254 are interpreted as a vector length field 259B.
- the modifier field 246 i.e.
- MODR/M.MOD 342 is set to either 00, 01, or 10 to indicate that the first source operand is a memory operand; this is shown in Figure 17D as 11 (i.e. any input except 11).
- the VADDPS instruction adds a packed single-precision floating-point value from a memory operand, that can be broadcast upon loading, to a first register (e.g. zmm2) and stores the result in a second register (e.g. zmm1) according to a writemask (e.g. kl).
- the vector length field indicates vectors of 512 bits, this may be described by the following mnemonic: EVEX.U1.NDS.512.0F.W0 58 /r VADDPS zmm1 ⁇ k1 ⁇ ⁇ z ⁇ , zmm2, B 32 (mV).
- the vector length field indicates vectors of 256 bits, this may be described by the following mnemonic: EVEX.U1.NDS.256.0F.W0 58/r VADDPS ymm1 ⁇ k1 ⁇ ⁇ z ⁇ , ymm2, B 32 (mV).
- the memory access size N is determined based on contents of two or more of the base operation field, the data element width field, and the augmentation operation field depending on the instruction template being used and other factors as described below.
- the below tables show the size of the vector (or element) being accessed in memory and, analogously, the displacement factor for compressed displacement (disp8*N). Note that some instructions work at element granularity instead of full vector granularity at the level of memory, and hence should use the "element level" column in the tables below.
- the function column's label (e.g., U/S i64 ) signifies the memory access type specified by the base operation field (e.g., U/S i signifies load int and load/op int) and data element width (e.g., 64 is a 64 bit data element width).
- the values in this column are the possible values of the data manipulation field 254C in the embodiment of Figure 3 .
- the various memory access types are shown flowing (in some cases through a data element width decision) to their data manipulation Figures 12A-15C ; the various tables 12A-15C drive the selection of N's value, and thus are placed on columns 2 and 3 as appropriate.
- a load/op int 64 bit data element width memory access operation flows to figure 12A , at which the data manipulation field's 254C content is used to both select the data manipulation operation (as indicted in figure 12A ) and the value of N (as indicated below).
- a load int 64 bit data element width memory access operation (which indicates a broadcast in the base operation field 242) flows to figure 13A , at which the data manipulation field's 254C content is used to both select the data manipulation operation (as indicted in figure 13A , which does not include broadcast data transforms) and the value of N (as indicated below).
- the second column is for instructions whose base operation field 242 does not specify a broadcast or element level memory access
- the third column's first sub-column is for instructions whose base operation field 242 specifies a broadcast but does not specify an element level memory access
- the third column's second sub-column is for instructions whose base operation field 242 specifies a broadcast or an element level memory access.
- various instructions have the ability to use a compressed displacement by using disp8 in conjunction with a memory access size N that is determined based on the vector length (determined by the content of the vector length field 259B), the type of vector operation and whether broadcast is being performed (the value of the base operation field 242 and/or the broadcast field 257B), and the data element width (determined by the content of the real opcode field 330 and/or the data element width field 264 as described in figure 4E ), for different types of instructions.
- the memory access size N corresponds to the number of bytes in the memory input (e.g., 64 when the accessing a full 512-bit memory vector).
- the first table below explains some of the terms use in the second table below, and the second table below gives the value of N for various types of instructions.
- a Tuple in the below tables is a packed structure of data in memory. Full Reads a full vector. Accepts broadcasts (load-op). e.g., VADDPS zmm1, zmm2, zmm3/B(mem) FullMem Reads a full vector. Does not accepts broadcasts (load only). e.g., VMOVAPS zmm1, m512 Scalar Reads a single element from memory to do an scalar operation: VADDSS xmm1, xmm2, m32 Tuple1 Reads a single element from memory.
- VBROADCASTSS zmm1 e.g., VBROADCASTSS zmm1, m32 Tuple2 Reads only 2 elements from memory.
- VBROADCASTF32X2 zmm1 m64 Tuple4 Reads only 4 elements from memory.
- VBROADCASTF32X4 zmm1 m128 Tuple 8 Reads only 8 elements from memory.
- VBROADCASTF32X8 zmm1 m256 Half Reads only half of the total elements from memory.
- different processors or different cores within a processor may support only class A, only class B, or both classes.
- a high performance general purpose out-of-order core intended for general-purpose computing may support only class B
- a core intended primarily for graphics and/or scientific (throughput) computing may support only class A
- a core intended for both may support both (of course, a core that has some mix of templates and instructions from both classes but not all templates and instructions from both classes is within the purview of the invention).
- a single processor may include multiple cores, all of which support the same class or in which different cores support different class.
- one of the graphics cores intended primarily for graphics and/or scientific computing may support only class A, while one or more of the general purpose cores may be high performance general purpose out-of-order cores intended for general-purpose computing that support only class B.
- Another processor that does not have a separate graphics core may include one more general purpose in-order or out-of-order cores that support both class A and class B.
- features from one class may also be implement in the other class in different embodiments of the invention.
- Programs written in a high level language would be put (e.g., just in time compiled or statically compiled) into an variety of different executable forms, including: 1) a form having only instructions of the class(es) supported by the target processor for execution; or 2) a form having alternative routines written using different combinations of the instructions of all classes and having control flow code that selects the routines to execute based on the instructions supported by the processor which is currently executing the code.
- Types of Instructions Write Mask Control Field 252C Broadcast Field 257B Loads/broadcast/inserts R Byte/Word operations with memory R Gather/scatter R R Extracts/stores R R Compares R
- one embodiment of the invention implements different versions of broadcast with the base operation field, and thus the broadcast field 257B is not needed.
- one embodiment of the invention does not support broadcasts with the broadcast field 257B because the hardware cost of supporting this feature was not currently justified.
- gather which is a type of load
- one embodiment of the invention implements different versions of broadcast with the base operation field, and thus the broadcast field 257B is not needed.
- scatter extracts and stores, one embodiment does not support broadcasts with the broadcast field 257B because these types of instructions have a register source (not a memory source) and a memory destination, and broadcast is only meaningful when memory is the source.
- the mask of a gather instruction is a completion mask; and thus a merging writemask operation is currently the desired operation.
- Performing zeroing writemask on a store, scatter, or extract would zero a location in memory - an operation for which a vector store, scatter, or extract is not typically used.
- zeroing writemasking would be unnatural since the compares already writes 0 if the comparison result is negative (e.g., the two elements compared are not equal in case of equality comparison), and thus might interfere with how the comparison result is interpreted.
- Figures 19-22 are block diagrams illustrating which fields of the instruction templates in figure 2A are utilized in different stages of four exemplary processor pipelines according to embodiments of the invention. It should be noted that at the level of understanding required, the illustrated pipeline stages and their function are well-known.
- Each of figures 19-22 include an A, B, and C figure respectively illustrating the no memory access, full round control type operation 210 instruction template; the no memory access, data transform type operation 215 instruction template; and the memory access 225/230 instruction templates. While each of the Figures 19-22 shows a different exemplary pipeline, the same pipeline is shown in each of the A-C figures for each figure number.
- Figure 19A shows the no memory access, full round control type operation 210 instruction template and a first exemplary instruction pipeline
- Figure 19B shows the no memory access data transform type operation 215 and the same exemplary pipeline as in Figure 19A
- Figure 20A shows the no memory access, full round type control operation 210 instruction template and the second exemplary processor pipeline.
- Figures 19-22 respectively illustrate processor pipeline 1900, processor pipeline 2000, processor pipeline 2100, and processor pipeline 2200.
- pipeline stage name is the same across the different exemplary pipelines, the same reference numeral was used for ease of understanding; however, this does not imply that the same name pipeline stages across the different exemplary pipelines are the same, just that they perform a similar operation (although it may include more or less sub operations).
- the processor pipeline 1900 is represents a generic processor pipeline, and thus it includes a fetch stage 1910, a decode stage 1920, a register read/memory read stage 1930, a data transform stage 1940, an execute stage 1950, and a write back/memory write stage 1960.
- Brackets and arrowed lines from the instruction templates to the processor pipeline stages illustrate the fields that are utilized by different ones of the pipeline stages.
- the decode stage 1920 the register index field 244 is utilized by the register read/memory read stage 1930; the rs field 252A (round 252A.1), the SAE field 256, the round operation field 258, and the data element width field 264 are utilized by the execute stage 1950; the data element width field 264 is also utilized by the write back/write memory stage 1960; and the write mask field 268 is used by the execute stage 1950 or the write back/memory write stage 1960 (The use of the write mask field 270 optionally in two different stages represents that the write mask field could disable the execution of the operation on the masked data elements in the execute stage 1950 (thereby preventing those data element positions from being updated in the write/memory write stage 1960), or the execution stage 1950 could perform the operation and the write mask be applied during the write/memory write stage 1960 to prevent
- the arrowed lines do not necessarily represent the only stage (s) utilized by the different fields, but do represent where that field will likely have the largest impact.
- the main difference is that the augmentation operation field 250 is utilized by the execute stage 1950 for the round operation; the augmentation operation field 250 is utilized by the data transform stage 1940 for the data transform type operation; and the line from the data element width field 264 to the execute stage 1950 is moved to the data transform stage 1940.
- Figure 19C shows the base operation field 242 instead going to the register read/memory read stage 1930; the EH field 252B of the augmentation operation field 250 being utilized by the register read/memory read stage 1930; the scale field 260, the displacement field 262A/displacement factor field 262B, the write mask field 270, and the data element width field 264 being optionally utilized by the register read/memory read stage 1930 or the write back/memory write 1960 depending on whether it is a memory read or memory write operation. Since it is well-known the pipeline stages that would utilize the immediate field 272, a mapping for that field is not represented in order not to obscure the invention.
- the processor pipeline 2000 represents an in order processor pipeline and has the same named pipeline stages as the processor pipeline 2000, but has a length decoding stage 2012 inserted between the fetch stage 1910 and the decode stage 1920.
- the processor pipeline 2100 represents an first exemplary out of order pipeline that has the same named pipeline stages as the processor pipeline 2000, but also has the following: 1) an allocate stage 2122, a renaming stage 2124, and a schedule stage 2126 inserted between the decode stage 1920 and the register read/memory read stage 1930; and 2) a reorder buffer (rob) read stage 2162, an exception handling stage 2164, and a commit stage 2166 added after the right back/memory right stage 1960.
- mappings are generally the same as the mappings in Figures 20A-20C , with the following exceptions: 1) that the register index field 244 and the modifier field 246 are utilized by the renaming stage 2142; 2) in only figure 21A , the write mask field 270 is also optionally used by the exception handling stage 2164 to suppress exceptions on masked data element positions; and 3) in only figure 21A , the SAE field 256 is used optionally by the execute stage 1950 and the exception handling stage 2164 depending on where floating point exceptions will be suppressed.
- the processor pipeline 2200 represents a second exemplary out of order pipeline that has the same named processor pipeline stages as the processor pipeline 2100, with the exception that the data transform and execution stages have been merged to form and an execute/data transform stage 2245.
- mappings in Figures 22A-22C are essentially the same as those in Figures 21A-21C , with the exception that the mappings that went separately to the data transform stage 1940 and the execute stage 1950 instead go to the execute/data transform stage 2245.
- FIG. 1 The below table illustrates how to modify figures 19-22 to accommodate the fields of the instruction templates in figure 2B according to embodiments of the invention.
- the decode unit may decode each macro instruction into a single wide micro instruction.
- the decode unit may decode some macro instructions into single wide micro instructions, but others into multiple wide micro instructions.
- the decode unit may decode each macro instruction into one or more micro-ops, where each of the micro-ops may be issued and execute out of order.
- a decode unit may be implemented with one or more decoders and each decoder may be implemented as a programmable logic array (PLA), as is well known in the art.
- PLA programmable logic array
- a given decode unit may: 1) have steering logic to direct different macro instructions to different decoders; 2) a first decoder that may decode a subset of the instruction set (but more of it than the second, third, and fourth decoders) and generate two micro-ops at a time; 3) a second, third, and fourth decoder that may each decode only a subset of the entire instruction set and generate only one micro-op at a time; 4) a micro-sequencer ROM that may decode only a subset of the entire instruction set and generate four micro-ops at a time; and 5) multiplexing logic feed by the decoders and the micro-sequencer ROM that determine whose output is provided to a micro-op queue.
- decoder unit may have more or less decoders that decode more or less instructions and instruction subsets.
- one embodiment may have a second, third, and fourth decoder that may each generate two micro-ops at a time; and may include a micro-sequencer ROM that generates eight micro-ops at a time.
- FIGS 23A-B illustrate a block diagram of an exemplary in-order processor architecture.
- This exemplary embodiment is designed around multiple instantiations of an in-order CPU core that is augmented with a wide vector processor (VPU).
- Cores communicate through a high-bandwidth interconnect network with some fixed function logic, memory I/O interfaces, and other necessary I/O logic, depending on the exact application.
- VPU wide vector processor
- Cores communicate through a high-bandwidth interconnect network with some fixed function logic, memory I/O interfaces, and other necessary I/O logic, depending on the exact application.
- an implementation of this embodiment as a stand-alone GPU would typically include a PCIe bus.
- Figure 23A is a block diagram of a single CPU core, along with its connection to the on-die interconnect network 2302 and with its local subset of the level 2 (L2) cache 2304, according to embodiments of the invention.
- An instruction decoder 2300 supports the x86 instruction set with an extension including the specific vector instruction format 300.
- a scalar unit 2308 and a vector unit 2310 use separate register sets (respectively, scalar registers 2312 and vector registers 2314) and data transferred between them is written to memory and then read back in from a level 1 (L1) cache 2306
- alternative embodiments of the invention may use a different approach (e.g., use a single register set or include a communication path that allow data to be transferred between the two register files without being written and read back).
- the L1 cache 2306 allows low-latency accesses to cache memory into the scalar and vector units. Together with load-op instructions in the vector friendly instruction format, this means that the L1 cache 2306 can be treated somewhat like an extended register file. This significantly improves the performance of many algorithms, especially with the eviction hint field 252B.
- the local subset of the L2 cache 2304 is part of a global L2 cache that is divided into separate local subsets, one per CPU core. Each CPU has a direct access path to its own local subset of the L2 cache 2304. Data read by a CPU core is stored in its L2 cache subset 2304 and can be accessed quickly, in parallel with other CPUs accessing their own local L2 cache subsets. Data written by a CPU core is stored in its own L2 cache subset 2304 and is flushed from other subsets, if necessary.
- the ring network ensures coherency for shared data.
- Figure 23B is an exploded view of part of the CPU core in figure 23A according to embodiments of the invention.
- Figure 23B includes an L1 data cache 2306A part of the L1 cache 2304, as well as more detail regarding the vector unit 2310 and the vector registers 2314.
- the vector unit 2310 is a 16-wide vector processing unit (VPU) (see the 16-wide ALU 2328), which executes integer, single-precision float, and double-precision float instructions.
- the VPU supports swizzling the register inputs with swizzle unit 2320, numeric conversion with numeric convert units 2322A-B, and replication with replication unit 2324 on the memory input.
- Write mask registers 2326 allow predicating the resulting vector writes.
- Register data can be swizzled in a variety of ways, e.g. to support matrix multiplication. Data from memory can be replicated across the VPU lanes. This is a common operation in both graphics and non-graphics parallel data processing, which significantly increases the cache efficiency.
- the ring network is bi-directional to allow agents such as CPU cores, L2 caches and other logic blocks to communicate with each other within the chip.
- Each ring data-path is 512-bits wide per direction.
- Figure 24 is a block diagram illustrating an exemplary out-of-order architecture according to embodiments of the invention. Specifically, Figure 24 illustrates a well-known exemplary out-of-order architecture that has been modified to incorporate the vector friendly instruction format and execution thereof. In Figure 24 arrows denotes a coupling between two or more units and the direction of the arrow indicates a direction of data flow between those units.
- Figure 24 includes a front end unit 2405 coupled to an execution engine unit 2410 and a memory unit 2415; the execution engine unit 2410 is further coupled to the memory unit 2415.
- the front end unit 2405 includes a level 1 (L1) branch prediction unit 2420 coupled to a level 2 (L2) branch prediction unit 2422.
- the L1 and L2 brand prediction units 2420 and 2422 are coupled to an L1 instruction cache unit 2424.
- the L1 instruction cache unit 2424 is coupled to an instruction translation lookaside buffer (TLB) 2426 which is further coupled to an instruction fetch and predecode unit 2428.
- the instruction fetch and predecode unit 2428 is coupled to an instruction queue unit 2430 which is further coupled a decode unit 2432.
- the decode unit 2432 comprises a complex decoder unit 2434 and three simple decoder units 2436, 2438, and 2440.
- the decode unit 2432 includes a micro-code ROM unit 2442.
- the decode unit 2432 may operate as previously described above in the decode stage section.
- the L1 instruction cache unit 2424 is further coupled to an L2 cache unit 2448 in the memory unit 2415.
- the instruction TLB unit 2426 is further coupled to a second level TLB unit 2446 in the memory unit 2415.
- the decode unit 2432, the micro-code ROM unit 2442, and a loop stream detector unit 2444 are each coupled to a rename/allocator unit 2456 in the execution engine unit 2410.
- the execution engine unit 2410 includes the rename/allocator unit 2456 that is coupled to a retirement unit 2474 and a unified scheduler unit 2458.
- the retirement unit 2474 is further coupled to execution units 2460 and includes a reorder buffer unit 2478.
- the unified scheduler unit 2458 is further coupled to a physical register files unit 2476 which is coupled to the execution units 2460.
- the physical register files unit 2476 comprises a vector registers unit 2477A, a write mask registers unit 2477B, and a scalar registers unit 2477C; these register units may provide the vector registers 510, the vector mask registers 515, and the general purpose registers 525; and the physical register files unit 2476 may include additional register files not shown (e.g., the scalar floating point stack register file 545 aliased on the MMX packed integer flat register file 550).
- the execution units 2460 include three mixed scalar and vector units 2462, 2464, and 2472; a load unit 2466; a store address unit 2468; a store data unit 2470.
- the load unit 2466, the store address unit 2468, and the store data unit 2470 are each coupled further to a data TLB unit 2452 in the memory unit 2415.
- the memory unit 2415 includes the second level TLB unit 2446 which is coupled to the data TLB unit 2452.
- the data TLB unit 2452 is coupled to an L1 data cache unit 2454.
- the L1 data cache unit 2454 is further coupled to an L2 cache unit 2448.
- the L2 cache unit 2448 is further coupled to L3 and higher cache units 2450 inside and/or outside of the memory unit 2415.
- the exemplary out-of-order architecture may implement the process pipeline 2200 as follows: 1) the instruction fetch and predecode unit 2428 perform the fetch and length decoding stages 1910 and 2012; 2) the decode unit 2432 performs the decode stage 1920; 3) the rename/allocator unit 2456 performs the allocation stage 2122 and renaming stage 2124; 4) the unified scheduler 2458 performs the schedule stage 2126; 5) the physical register files unit 2476, the reorder buffer unit 2478, and the memory unit 2415 perform the register read/memory read stage 1930; the execution units 2460 perform the execute/data transform stage 2245; 6) the memory unit 2415 and the reorder buffer unit 2478 perform the write back/memory write stage 1960; 7) the retirement unit 2474 performs the ROB read 2162 stage; 8) various units may be involved in the exception handling stage 2164; and 9) the retirement unit 2474 and the physical register files unit 2476 perform the commit stage 2166.
- Figure 29 is a block diagram of a single core processor and a multicore processor 2900 with integrated memory controller and graphics according to embodiments of the invention.
- the solid lined boxes in Figure 29 illustrate a processor 2900 with a single core 2902A, a system agent 2910, a set of one or more bus controller units 2916, while the optional addition of the dashed lined boxes illustrates an alternative processor 2900 with multiple cores 2902A-N, a set of one or more integrated memory controller unit(s) 2914 in the system agent unit 2910, and an integrated graphics logic 2908.
- the memory hierarchy includes one or more levels of cache within the cores, a set or one or more shared cache units 2906, and external memory (not shown) coupled to the set of integrated memory controller units 2914.
- the set of shared cache units 2906 may include one or more mid-level caches, such as level 2 (L2), level 3 (L3), level 4 (L4), or other levels of cache, a last level cache (LLC), and/or combinations thereof. While in one embodiment a ring based interconnect unit 2912 interconnects the integrated graphics logic 2908, the set of shared cache units 2906, and the system agent unit 2910, alternative embodiments may use any number of well-known techniques for interconnecting such units.
- the system agent 2910 includes those components coordinating and operating cores 2902A-N.
- the system agent unit 2910 may include for example a power control unit (PCU) and a display unit.
- the PCU may be or include logic and components needed for regulating the power state of the cores 2902A-N and the integrated graphics logic 2908.
- the display unit is for driving one or more externally connected displays.
- the cores 2902A-N may be homogenous or heterogeneous in terms of architecture and/or instruction set. For example, some of the cores 2902A-N may be in order (e.g., like that shown in figures 23A and 23B ) while others are out-of-order (e.g., like that shown in figure 24 ). As another example, two or more of the cores 2902A-N may be capable of executing the same instruction set, while others may be capable of executing only a subset of that instruction set or a different instruction set. At least one of the cores is capable of executing the vector friendly instruction format described herein.
- the processor may be a general-purpose processor, such as a CoreTM i3, i5, i7, 2 Duo and Quad, XeonTM, or Itanium processors, which are available from Intel Corporation, of Santa Clara, California. Alternatively, the processor may be from another company.
- the processor may be a special-purpose processor, such as, for example, a network or communication processor, compression engine, graphics processor, co-processor, embedded processor, or the like.
- the processor may be implemented on one or more chips.
- the processor 2900 may be a part of and/or may be implemented on one or more substrates using any of a number of process technologies, such as, for example, BiCMOS, CMOS, or NMOS.
- Figures 25-27 are exemplary systems suitable for including the processor 2900, while Figure 28 is an exemplary system on a chip (SoC) that may include one or more of the cores 2902..
- SoC system on a chip
- DSPs digital signal processors
- graphics devices video game devices, set-top boxes, micro controllers, cell phones, portable media players, hand held devices, and various other electronic devices, are also suitable.
- a huge variety of systems or electronic devices capable of incorporating a processor and/or other execution logic as disclosed herein are generally suitable.
- the system 2500 may include one or more processors 2510, 2515, which are coupled to graphics memory controller hub (GMCH) 2520.
- GMCH graphics memory controller hub
- the optional nature of additional processors 2515 is denoted in Figure 25 with broken lines.
- Each processor 2510, 2515 may be some version of processor 2900. However, it should be noted that it is unlikely that integrated graphics logic and integrated memory control units would exist in the processors 2510, 2515.
- Figure 25 illustrates that the GMCH 2520 may be coupled to a memory 2540 that may be, for example, a dynamic random access memory (DRAM).
- the DRAM may, for at least one embodiment, be associated with a non-volatile cache.
- the GMCH 2520 may be a chipset, or a portion of a chipset.
- the GMCH 2520 may communicate with the processor(s) 2510, 2515 and control interaction between the processor(s) 2510, 2515 and memory 2540.
- the GMCH 2520 may also act as an accelerated bus interface between the processor(s) 2510, 2515 and other elements of the system 2500.
- the GMCH 2520 communicates with the processor(s) 2510, 2515 via a multi-drop bus, such as a frontside bus (FSB) 2595.
- a multi-drop bus such as a frontside bus (FSB) 2595.
- GMCH 2520 is coupled to a display 2545 (such as a flat panel display).
- GMCH 2520 may include an integrated graphics accelerator.
- GMCH 2520 is further coupled to an input/output (I/O) controller hub (ICH) 2550, which may be used to couple various peripheral devices to system 2500.
- I/O controller hub ICH
- Shown for example in the embodiment of Figure 25 is an external graphics device 2560, which may be a discrete graphics device coupled to ICH 2550, along with another peripheral device 2570.
- additional processor(s) 2515 may include additional processors(s) that are the same as processor 2510, additional processor(s) that are heterogeneous or asymmetric to processor 2510, accelerators (such as, e.g., graphics accelerators or digital signal processing (DSP) units), field programmable gate arrays, or any other processor.
- accelerators such as, e.g., graphics accelerators or digital signal processing (DSP) units
- DSP digital signal processing
- multiprocessor system 2600 is a point-to-point interconnect system, and includes a first processor 2670 and a second processor 2680 coupled via a point-to-point interconnect 2650.
- processors 2670 and 2680 may be some version of the processor 2900.
- processors 2670, 2680 may be an element other than a processor, such as an accelerator or a field programmable gate array.
- processors 2670, 2680 While shown with only two processors 2670, 2680, it is to be understood that the scope of the present invention is not so limited. In other embodiments, one or more additional processing elements may be present in a given processor.
- Processor 2670 may further include an integrated memory controller hub (IMC) 2672 and point-to-point (P-P) interfaces 2676 and 2678.
- second processor 2680 may include a IMC 2682 and P-P interfaces 2686 and 2688.
- Processors 2670, 2680 may exchange data via a point-to-point (PtP) interface 2650 using PtP interface circuits 2678, 2688.
- PtP point-to-point
- IMC's 2672 and 2682 couple the processors to respective memories, namely a memory 2642 and a memory 2644, which may be portions of main memory locally attached to the respective processors.
- Processors 2670, 2680 may each exchange data with a chipset 2690 via individual P-P interfaces 2652, 2654 using point to point interface circuits 2676, 2694, 2686, 2698.
- Chipset 2690 may also exchange data with a high-performance graphics circuit 2638 via a high-performance graphics interface 2639.
- a shared cache (not shown) may be included in either processor outside of both processors, yet connected with the processors via P-P interconnect, such that either or both processors' local cache information may be stored in the shared cache if a processor is placed into a low power mode.
- first bus 2616 may be a Peripheral Component Interconnect (PCI) bus, or a bus such as a PCI Express bus or another third generation I/O interconnect bus, although the scope of the present invention is not so limited.
- PCI Peripheral Component Interconnect
- various I/O devices 2614 may be coupled to first bus 2616, along with a bus bridge 2618 which couples first bus 2616 to a second bus 2620.
- second bus 2620 may be a low pin count (LPC) bus.
- Various devices may be coupled to second bus 2620 including, for example, a keyboard/mouse 2622, communication devices 2626 and a data storage unit 2628 such as a disk drive or other mass storage device which may include code 2630, in one embodiment.
- an audio I/O 2624 may be coupled to second bus 2620.
- a system may implement a multi-drop bus or other such architecture.
- FIG. 27 shown is a block diagram of a third system 2700 in accordance with an embodiment of the present invention.
- Like elements in Figures 26 and 27 bear like reference numerals; and certain aspects of Figure 26 have been omitted from Figure 27 in order to avoid obscuring other aspects of Figure 27 .
- Figure 27 illustrates that the processing elements 2670, 2680 may include integrated memory and I/O control logic ("CL") 2672 and 2682, respectively.
- the CL 2672, 2682 may include memory controller hub logic (IMC) such as that described above in connection with Figures 29 and 26 .
- IMC memory controller hub logic
- CL 2672, 2682 may also include I/O control logic.
- Figure 27 illustrates that not only are the memories 2642, 2644 coupled to the CL 2672, 2682, but also that I/O devices 2714 are also coupled to the control logic 2672, 2682.
- Legacy I/O devices 2715 are coupled to the chipset 2690.
- an interconnect unit(s) 2802 is coupled to: an application processor 2810 which includes a set of one or more cores 2902A-N and shared cache unit(s) 2906; a system agent unit 2910; a bus controller unit(s) 2916; an integrated memory controller unit(s) 2914; a set or one or more media processors 2820 which may include integrated graphics logic 2908, an image processor 2824 for providing still and/or video camera functionality, an audio processor 2826 for providing hardware audio acceleration, and a video processor 2828 for providing video encode/decode acceleration; an static random access memory (SRAM) unit 2830; a direct memory access (DMA) unit 2832; and a display unit 2840 for coupling to one or more external displays.
- an application processor 2810 which includes a set of one or more cores 2902A-N and shared cache unit(s) 2906
- a system agent unit 2910 includes a bus controller unit(s) 2916; an integrated memory controller unit(s) 2914; a set or one or more media processors
- Embodiments of the mechanisms disclosed herein may be implemented in hardware, software, firmware, or a combination of such implementation approaches.
- Embodiments of the invention may be implemented as computer programs or program code executing on programmable systems comprising at least one processor, a storage system (including volatile and non-volatile memory and/or storage elements), at least one input device, and at least one output device.
- Program code such as code 2630 illustrated in Figure 26 , may be applied to input data to perform the functions described herein and generate output information.
- the output information may be applied to one or more output devices, in known fashion.
- a processing system includes any system that has a processor, such as, for example; a digital signal processor (DSP), a microcontroller, an application specific integrated circuit (ASIC), or a microprocessor.
- DSP digital signal processor
- ASIC application specific integrated circuit
- the program code may be implemented in a high level procedural or object oriented programming language to communicate with a processing system.
- the program code may also be implemented in assembly or machine language, if desired.
- the mechanisms described herein are not limited in scope to any particular programming language. In any case, the language may be a compiled or interpreted language.
- IP cores may be stored on a tangible, machine readable medium and supplied to various customers or manufacturing facilities to load into the fabrication machines that actually make the logic or processor.
- Such machine-readable storage media may include, without limitation, non-transitory, tangible arrangements of articles manufactured or formed by a machine or device, including storage media such as hard disks, any other type of disk including floppy disks, optical disks (compact disk read-only memories (CD-ROMs), compact disk rewritables (CD-RWs)), and magneto-optical disks, semiconductor devices such as read-only memories (ROMs), random access memories (RAMs) such as dynamic random access memories (DRAMs), static random access memories (SRAMs), erasable programmable read-only memories (EPROMs), flash memories, electrically erasable programmable read-only memories (EEPROMs), magnetic or optical cards, or any other type of media suitable for storing electronic instructions.
- storage media such as hard disks, any other type of disk including floppy disks, optical disks (compact disk read-only memories (CD-ROMs), compact disk rewritables (CD-RWs)), and magneto-optical disks
- embodiments of the invention also include non-transitoty, tangible machine-readable media containing instructions the vector friendly instruction format or containing design data, such as Hardware Description Language (HDL), which defines structures, circuits, apparatuses, processors and/or system features described herein.
- HDL Hardware Description Language
- Such embodiments may also be referred to as program products.
- an instruction converter may be used to convert an instruction from a source instruction set to a target instruction set.
- the instruction converter may translate (e.g., using static binary translation, dynamic binary translation including dynamic compilation), morph, emulate, or otherwise convert an instruction to one or more other instructions to be processed by the core.
- the instruction converter may be implemented in software, hardware, firmware, or a combination thereof.
- the instruction converter may be on processor, off processor, or part on and part off processor.
- Figure 30 is a block diagram contrasting the use of a software instruction converter to convert binary instructions in a source instruction set to binary instructions in a target instruction set according to embodiments of the invention.
- the instruction converter is a software instruction converter, although alternatively the instruction converter may be implemented in software, firmware, hardware, or various combinations thereof.
- Figure 30 shows a program in a high level language 3002 may be compiled using an x86 compiler 3004 to generate x86 binary code 3006 that may be natively executed by a processor with at least one x86 instruction set core 3016 (it is assume that some of the instructions that were compiled are in the vector friendly instruction format).
- the processor with at least one x86 instruction set core 3016 represents any processor that can perform substantially the same functions as a Intel processor with at least one x86 instruction set core by compatibly executing or otherwise processing (1) a substantial portion of the instruction set of the Intel x86 instruction set core or (2) object code versions of applications or other software targeted to run on an Intel processor with at least one x86 instruction set core, in order to achieve substantially the same result as an Intel processor with at least one x86 instruction set core.
- the x86 compiler 3004 represents a compiler that is operable to generate x86 binary code 3006 (e.g., object code) that can, with or without additional linkage processing, be executed on the processor with at least one x86 instruction set core 3016.
- Figure 30 shows the program in the high level language 3002 may be compiled using an alternative instruction set compiler 3008 to generate alternative instruction set binary code 3010 that may be natively executed by a processor without at least one x86 instruction set core 3014 (e.g., a processor with cores that execute the MIPS instruction set of MIPS Technologies of Sunnyvale, CA and/or that execute the ARM instruction set of ARM Holdings of Sunnyvale, CA).
- the instruction converter 3012 is used to convert the x86 binary code 3006 into code that may be natively executed by the processor without an x86 instruction set core 3014.
- the instruction converter 3012 represents software, firmware, hardware, or a combination thereof that, through emulation, simulation or any other process, allows a processor or other electronic device that does not have an x86 instruction set processor or core to execute the x86 binary code 3006.
- Certain operations of the instruction(s) in the vector friendly instruction format disclosed herein may be performed by hardware components and may be embodied in machine-executable instructions that are used to cause, or at least result in, a circuit or other hardware component programmed with the instructions performing the operations.
- the circuit may include a general-purpose or special-purpose processor, or logic circuit, to name just a few examples.
- the operations may also optionally be performed by a combination of hardware and software.
- Execution logic and/or a processor may include specific or particular circuitry or other logic responsive to a machine instruction or one or more control signals derived from the machine instruction to store an instruction specified result operand.
- embodiments of the instruction(s) disclosed herein may be executed in one or more the systems of Figures 25-28 and embodiments of the instruction(s) in the vector friendly instruction format may be stored in program code to be executed in the systems.
- the processing elements of these figures may utilize one of the detailed pipelines and/or architectures (e.g., the in-order and out-of-order architectures) detailed herein.
- the decode unit of the in-order architecture may decode the instruction(s), pass the decoded instruction to a vector or scalar unit, etc.
- embodiments have been described which would natively execute the vector friendly instruction format
- alternative embodiments of the invention may execute the vector friendly instruction format through an emulation layer running on a processor that executes a different instruction set (e.g., a processor that executes the MIPS instruction set of MIPS Technologies of Sunnyvale, CA, a processor that executes the ARM instruction set of ARM Holdings of Sunnyvale, CA).
- a processor that executes the MIPS instruction set of MIPS Technologies of Sunnyvale, CA e.g., a processor that executes the MIPS instruction set of MIPS Technologies of Sunnyvale, CA, a processor that executes the ARM instruction set of ARM Holdings of Sunnyvale, CA.
- the flow diagrams in the figures show a particular order of operations performed by certain embodiments of the invention, it should be understood that such order is exemplary (e.g., alternative embodiments may perform the operations in a different order, combine certain operations, overlap certain operations, etc.).
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Mathematical Analysis (AREA)
- Computational Mathematics (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Computer Hardware Design (AREA)
- Computing Systems (AREA)
- Executing Machine-Instructions (AREA)
- Advance Control (AREA)
- Complex Calculations (AREA)
- Stored Programmes (AREA)
- Insulated Gate Type Field-Effect Transistor (AREA)
- Image Processing (AREA)
Abstract
Description
- This application claims the benefit of
U.S. Provisional Application No. 61/471,043, filed April 1, 2011 - Embodiments of the invention relate to the field of computers; and more specifically, to instruction sets supported by processors.
- An instruction set, or instruction set architecture (ISA), is the part of the computer architecture related to programming, including the native data types, instructions, register architecture, addressing modes, memory architecture, interrupt and exception handling, and external input and output (I/O). It should be noted that the term instruction generally refers herein to macro-instructions - that is instructions that are provided to the processor for execution - as opposed to micro-instructions or micro-ops - that is the result of a processor's decoder decoding macro-instructions).
- The instruction set architecture is distinguished from the microarchitecture, which is the set of processor design techniques used to implement the instruction set. Processors with different microarchitectures can share a common instruction set. For example, Intel Pentium 4 processors, Intel Core processors, and Advanced Micro Devices, Inc. of Sunnyvale CA processors implement nearly identical versions of the x86 instruction set (with some extensions have been added with newer versions), but have different internal designs. For example, the same register architecture of the ISA may be implemented in different ways in different microarchitectures using well known techniques, including dedicated physical registers, one or more dynamically allocated physical registers using a register renaming mechanism (e.g., the use of a Register Alias Table (RAT), a Reorder Buffer (ROB) and a retirement register file as described in
U.S. Pat. No. 5,446,912 ; the use of multiple maps and a pool of registers as described inU.S. Pat. No. 5,207,132 ), etc. Unless otherwise specified, the phrases register architecture, register file, and register are used herein to that which is visible to the software/programmer and the manner in which instructions specify registers. Where a distinction is required, the adjective logical, architectural, or software visible will be used to indicate registers/files in the register architecture, while different adjectives will be used to designation registers in a given microarchitecture (e.g., physical register, reorder buffer, retirement register, register pool). - An instruction set includes one or more instruction formats. A given instruction format defines various fields (number of bits, location of bits) to specify, among other things, the operation to be performed and the operand(s) on which that operation is to be performed. Some instruction formats are further broken down though the definition of instruction templates (or subformats). For example, the instruction templates of a given instruction format may be defined to have different subsets of the instruction format's fields (the included fields are typically in the same order, but at least some have different bit positions because there are less fields included) and/or defined to have a given field interpreted differently. A given instruction is expressed using a given instruction format (and, if defined, in a given one of the instruction templates of that instruction format) and specifies the operation and the operands. An instruction stream is a specific sequence of instructions, where each instruction in the sequence is an occurrence of an instruction in an instruction format (and, if defined, a given one of the instruction templates of that instruction format).
- Scientific, financial, auto-vectorized general purpose, RMS (recognition, mining, and synthesis)/visual and multimedia applications (e.g., 2D/3D graphics, image processing, video compression/decompression, voice recognition algorithms and audio manipulation) often require the same operation to be performed on a large number of data items (referred to as "data parallelism"). Single Instruction Multiple Data (SIMD) refers to a type of instruction that causes a processor to perform the same operation on multiple data items. SIMD technology is especially suited to processors that can logically divide the bits in a register into a number of fixed-sized data elements, each of which represents a separate value. For example, the bits in a 64-bit register may be specified as a source operand to be operated on as four separate 16-bit data elements, each of which represents a separate 16-bit value. This type of data is referred to as the packed data type or vector data type, and operands of this data type are referred to as packed data operands or vector operands. In other words, a packed data item or vector refers to a sequence of packed data elements; and a packed data operand or a vector operand is a source or destination operand of a SIMD instruction (also known as a packed data instruction or a vector instruction).
- By way of example, one type of SIMD instruction specifies a single vector operation to be performed on two source vector operands in a vertical fashion to generate a destination vector operand (also referred to as a result vector operand) of the same size, with the same number of data elements, and in the same data element order. The data elements in the source vector operands are referred to as source data elements, while the data elements in the destination vector operand are referred to a destination or result data elements. These source vector operands are of the same size and contain data elements of the same width, and thus they contain the same number of data elements. The source data elements in the same bit positions in the two source vector operands form pairs of data elements (also referred to as corresponding data elements). The operation specified by that SIMD instruction is performed separately on each of these pairs of source data elements to generate a matching number of result data elements, and thus each pair of source data elements has a corresponding result data element. Since the operation is vertical and since the result vector operand is the same size, has the same number of data elements, and the result data elements are stored in the same data element order as the source vector operands, the result data elements are in the same bit positions of the result vector operand as their corresponding pair of source data elements in the source vector operands. In addition to this exemplary type of SIMD instruction, there are a variety of other types of SIMD instructions (e.g., that has only one or has more than two source vector operands; that operate in a horizontal fashion; that generates a result vector operand that is of a different size, that has a different size data elements, and/or that has a different data element order). It should be understood that the term destination vector operand (or destination operand) is defined as the direct result of performing the operation specified by an instruction, including the storage of that destination operand at a location (be it a register or at a memory address specified by that instruction) so that it may be accessed as a source operand by another instruction (by specification of that same location by the another instruction).
- The SIMD technology, such as that employed by the Intel® Core™ processors having an instruction set including x86, MMX™, Streaming SIMD Extensions (SSE), SSE2, SSE3, SSE4.1, and SSE4.2 instructions, has enabled a significant improvement in application performance (Core™ and MMX™ are registered trademarks or trademarks of Intel Corporation of Santa Clara, Calif.). An additional set of future SIMD extensions, referred to the Advanced Vector Extensions (AVX) and using the VEX coding scheme, has been published.
- The invention may best be understood by referring to the following description and accompanying drawings that are used to illustrate embodiments of the invention. In the drawings:
-
Figure 1A is a block diagram illustrating an instruction stream having only instructions in the vector friendly instruction format according to one embodiment of the invention; -
Figure 1B is a block diagram illustrating an instruction stream with instructions in multiple instruction formats according to one embodiment of the invention; -
Figure 2A is a block diagram illustrating a generic vector friendly instruction format and class A instruction templates thereof according to embodiments of the invention; -
Figure 2B is a block diagram illustrating the generic vector friendly instruction format and class B instruction templates thereof according to embodiments of the invention; -
Figure 3A is a block diagram illustrating an exemplary specific vector friendly instruction format according to embodiments of the invention; -
Figure 3B is a block diagram illustrating the fields of the specific vectorfriendly instruction format 300 that make up thefull opcode field 274 according to one embodiment of the invention; -
Figure 3C is a block diagram illustrating the fields of the specific vectorfriendly instruction format 300 that make up theregister index field 244 according to one embodiment of the invention; -
Figure 3D is a block diagram illustrating the fields of the specific vectorfriendly instruction format 300 that make up theaugmentation operation field 250 according to one embodiment of the invention; -
Figure 4A is part of a flow diagram showing the inter relationship of some of the fields of the vector friendly instruction format according to one embodiment of the invention; -
Figure 4B is a second part of the flow diagram showing the inter relationship of some of the fields of the vector friendly instruction format according to one embodiment of the invention; -
Figure 4C is a third part of the flow diagram showing the inter relationship of some of the fields of the vector friendly instruction format according to one embodiment of the invention -
Figure 4D is the rest of the flow diagram showing the inter relationship of some of the fields of the vector friendly instruction format according to one embodiment of the invention; -
Figure 4E is an exploded view of each ofblocks 415A-H according to one embodiment of the invention; -
Figure 5 is a block diagram of aregister architecture 500 according to one embodiment of the invention; -
Figure 6A is a flow diagram for theregister index field 244 for a no memory access type operation according to embodiments of the invention; -
Figure 6B is a flow diagram illustrating the use of theregister index field 244, thescale field 260, thedisplacement field 262A, and thedisplacement factor field 262B for a memory access type operation according to embodiments of the invention; -
Figure 6C is a table illustrating the differences between disp8, disp32, and variations of the scaled displacement according to embodiments of the invention; -
Figure 7A is a table illustrating the group of possible operations that may be specified by theround control field 254A according to embodiments of the invention; -
Figure 7B is a table illustrating the group of possible operations that may be specified by theround control field 259A according to embodiments of the invention; -
Figure 8A is a table illustrating the group of possible data transform operations that may be specified by thedata transform field 254B when the data element width is 64 bits according to embodiments of the invention; -
Figure 8B is a table illustrating the group of possible data transform operations that may be specified by thedata transform field 254B when the data element width is 32 bits according to embodiments of the invention; -
Figure 9 is a block diagram illustrating thecross product swizzle 815 according to embodiments of the invention; -
Figure 10A is a block diagram illustrating the broadcast of an element across 4-element packets 820 according to embodiments of the invention; -
Figure 10B is a block diagram illustrating the broadcast of 1-element granularity for a 32 bit data element width according to embodiments of the invention; -
Figure 10C is a block diagram illustrating the broadcast of 4-element granularity for 32 bit data elements according to embodiments of the invention; -
Figure 11A is a table illustrating the group of possible opcode maps that may be specified by the opcode map field according to embodiments of the invention; -
Figure 11B is a table illustrating the group of possible prefix encodings that may be specified by the opcode map field according to embodiments of the invention; -
Figure 12A is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C andbroadcast field 257B for a load/op int where the data element width is 64 bits according to embodiments of the invention; -
Figure 12B is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C andbroadcast field 257B for a load/op int where the data element width is 32 bits according to embodiments of the invention; -
Figure 12C is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C andbroadcast field 257B for a load/op fp where the data element width is 64 bits according to embodiments of the invention; -
Figure 12D is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C andbroadcast field 257B for a load/op fp where the data element width is 32 bits according to embodiments of the invention; -
Figure 13A is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load int where the data element width is 64 bits according to embodiments of the invention; -
Figure 13B is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load int where the data element width is 32 bits according to embodiments of the invention; -
Figure 13C is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load fp where the data element width is 64 bits according to embodiments of the invention; -
Figure 13D is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load fp where the data element width is 32 bits according to embodiments of the invention; -
Figure 14A is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a store int where the data element width is 64 bits according to embodiments of the invention; -
Figure 14B is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a store int where the data element width is 32 bits according to embodiments of the invention; -
Figure 14C is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a store fp where the data element width is 64 bits according to embodiments of the invention; -
Figure 14D is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a store fp where the data element width is 64 bits according to embodiments of the invention; -
Figure 15A is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load graphics where the data element width is 32 bits according to embodiments of the invention; -
Figure 15B is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load packed graphics where the data element width is 32 bits according to embodiments of the invention; -
Figure 15C is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a store graphics where the data element width is 32 bits according to embodiments of the invention; -
Figure 16A is a block diagram illustrating an exemplary operation 1600 that merges using the write mask in write mask register K1 where the data element width is 32 bits and where the second source and destination are the same according to embodiments of the invention; -
Figure 16B is a block diagram illustrating an exemplary operation 1625 that merges using the hardwired mask of all ones (the hardwired write mask is used by instructions that specify write mask register K0) where the data element width is 32 bits and where the second source and destination are the same according to embodiments of the invention; -
Figure 16C is a block diagram illustrating the correspondence of bits in the write mask registers to the data element positions of a 512 bit vector for the 8, 16, 32, and 64 bit data element widths according to embodiments of the invention; -
Figure 16D is a block diagram illustrating an exemplary operation 1660 that merges using the write mask in write mask register K1 where the data element width is 32 bits and where the second source and destination are different according to embodiments of the invention; -
Figure 16E is a block diagram illustrating an exemplary operation 1666 that zeros using the write mask in write mask register K1 where the data element width is 32 bits and where the second source and destination are different according to embodiments of the invention; -
Figure 17A illustrates a subset of fields from an exemplary specific vector friendly instruction format according to embodiments of the invention; -
Figure 17B illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format ofFigure 17A according to embodiments of the invention; -
Figure 17C illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format ofFigure 17A according to embodiments of the invention; -
Figure 17D illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format ofFigure 17A according to embodiments of the invention; -
Figure 18A illustrates a subset of fields from an exemplary specific vector friendly instruction format according to embodiments of the invention; -
Figure 18B illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format ofFigure 18A according to embodiments of the invention; -
Figure 18C illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format ofFigure 18A according to embodiments of the invention; -
Figure 18D illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format ofFigure 18A according to embodiments of the invention; -
Figure 18E illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format ofFigure 18A according to embodiments of the invention; -
Figure 18F illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format ofFigure 18A according to embodiments of the invention; -
Figure 19A is a block diagram illustrating which fields of the no memory access, full roundcontrol type operation 210 instruction template of class A are utilized in different stages of a first exemplary processor pipeline according to embodiments of the invention; -
Figure 19B is a block diagram illustrating which fields of the no memory access, data transformtype operation 215 instruction template of class A are utilized in different stages of a first exemplary processor pipeline according to embodiments of the invention; -
Figure 19C is a block diagram illustrating which fields of thememory access 220 instruction template of class A are utilized in different stages of a first exemplary processor pipeline according to embodiments of the invention; -
Figure 20A is a block diagram illustrating which fields of the no memory access, full roundcontrol type operation 210 instruction template of class A are utilized in different stages of a second exemplary processor pipeline according to embodiments of the invention; -
Figure 20B is a block diagram illustrating which fields of the no memory access, data transformtype operation 215 instruction template of class A are utilized in different stages of a second exemplary processor pipeline according to embodiments of the invention; -
Figure 20C is a block diagram illustrating which fields of thememory access 220 instruction template of class A are utilized in different stages of a second exemplary processor pipeline according to embodiments of the invention; -
Figure 21A is a block diagram illustrating which fields of the no memory access, full roundcontrol type operation 210 instruction template of class A are utilized in different stages of a third exemplary processor pipeline according to embodiments of the invention; -
Figure 21B is a block diagram illustrating which fields of the no memory access, data transformtype operation 215 instruction template of class A are utilized in different stages of a third exemplary processor pipeline according to embodiments of the invention; -
Figure 21C is a block diagram illustrating which fields of thememory access 220 instruction template of class A are utilized in different stages of a third exemplary processor pipeline according to embodiments of the invention; -
Figure 22A is a block diagram illustrating which fields of the no memory access, full roundcontrol type operation 210 instruction template of class A are utilized in different stages of a fourth exemplary processor pipeline according to embodiments of the invention; -
Figure 22B is a block diagram illustrating which fields of the no memory access, data transformtype operation 215 instruction template of class A are utilized in different stages of a fourth exemplary processor pipeline according to embodiments of the invention; -
Figure 22C is a block diagram illustrating which fields of thememory access 220 instruction template of class A are utilized in different stages of a fourth exemplary processor pipeline according to embodiments of the invention; -
Figure 23A is a block diagram of a single CPU core, along with its connection to the on-die interconnect network 2302 and with its local subset of the level 2 (L2)cache 2304, according to embodiments of the invention; -
Figure 23B is an exploded view of part of the CPU core infigure 23A according to embodiments of the invention; -
Figure 24 is a block diagram illustrating an exemplary out-of-order architecture according to embodiments of the invention; -
Figure 25 is a block diagram of asystem 2500 in accordance with one embodiment of the invention; -
Figure 26 is a block diagram of asecond system 2600 in accordance with an embodiment of the invention; -
Figure 27 is a block diagram of athird system 2700 in accordance with an embodiment of the invention; -
Figure 28 is a block diagram of aSoC 2800 in accordance with an embodiment of the invention; -
Figure 29 is a block diagram of a single core processor and amulticore processor 2900 with integrated memory controller and graphics according to embodiments of the invention; and -
Figure 30 is a block diagram contrasting the use of a software instruction converter to convert binary instructions in a source instruction set to binary instructions in a target instruction set according to embodiments of the invention. - In the following description, numerous specific details such as logic implementations, opcodes, ways to specify operands, resource partitioning/sharing/duplication implementations, types and interrelationships of system components, and logic partitioning/integration choices are set forth in order to provide a more thorough understanding of the present invention. It will be appreciated, however, by one skilled in the art that the invention may be practiced without such specific details. In other instances, control structures, gate level circuits and full software instruction sequences have not been shown in detail in order not to obscure the invention. Those of ordinary skill in the art, with the included descriptions, will be able to implement appropriate functionality without undue experimentation.
- It should also be appreciated that reference throughout this specification to "one embodiment", "an embodiment", or "one or more embodiments", for example, means that a particular feature may be included in the practice of embodiments of the invention, but every embodiment may not necessarily include the particular feature. Similarly, it should be appreciated that in the description various features are sometimes grouped together in a single embodiment, figure, or description thereof for the purpose of streamlining the disclosure and aiding in the understanding of various inventive aspects. Further, when a particular feature, structure, or characteristic is described in connection with an embodiment, it is submitted that it is within the knowledge of one skilled in the art to effect such feature, structure, or characteristic in connection with other embodiments whether or not explicitly described. This method of disclosure, however, is not to be interpreted as reflecting an intention that the invention requires more features than are expressly recited in each claim. Rather, as the following claims reflect, inventive aspects may lie in less than all features of a single disclosed embodiment. Thus, the claims following the Detailed Description are hereby expressly incorporated into this Detailed Description, with each claim standing on its own as a separate embodiment of the invention.
- In the following description and claims, the terms "coupled" and "connected," along with their derivatives, may be used. It should be understood that these terms are not intended as synonyms for each other. "Coupled" is used to indicate that two or more elements, which may or may not be in direct physical or electrical contact with each other, co-operate or interact with each other. "Connected" is used to indicate the establishment of communication between two or more elements that are coupled with each other.
- The operations of the flow diagrams will be described with reference to the exemplary embodiments of the block diagrams. However, it should be understood that the operations of flow diagrams can be performed by embodiments of the invention other than those discussed with reference to the block diagrams, and the embodiments discussed with reference to the block diagrams can perform operations different than those discussed with reference to the flow diagrams.
- To ease understanding, dashed lines have been used in the figures to signify the optional nature of certain items (e.g., features not supported by a given implementation of the invention; features supported by a given implementation, but used in some situations and not in others).
- A vector friendly instruction format is an instruction format that is suited for vector instructions (e.g., there are certain fields specific to vector operations). While embodiments are described in which both vector and scalar operations are supported through the vector friendly instruction format, alternative embodiments use only vector operations the vector friendly instruction format.
-
Figure 1A is a block diagram illustrating an instruction stream having only instructions in the vector friendly instruction format according to one embodiment of the invention. The instruction stream includes a sequence of J instructions that are all in the vectorfriendly format 100A-100J. In one embodiment of the invention a processor supports only the vector instruction format and can execute this instruction stream. -
Figure 1B is a block diagram illustrating an instruction stream with instructions in multiple instruction formats according to one embodiment of the invention. Each instruction in the instruction stream is expressed in the vector friendly instruction format, a second format, or a third format. The instruction stream includesJ instructions 110A-110J. In one embodiment of the invention a processor supports multiple instruction formats (including the formats shown inFigure 1B ) and can execute the instruction streams in bothFigures 1A-1B . -
Figures 2A-B are block diagrams illustrating a generic vector friendly instruction format and instruction templates thereof according to embodiments of the invention.Figure 2A is a block diagram illustrating a generic vector friendly instruction format and class A instruction templates thereof according to embodiments of the invention; whileFigure 2B is a block diagram illustrating the generic vector friendly instruction format and class B instruction templates thereof according to embodiments of the invention. Specifically, a generic vectorfriendly instruction format 200 for which are defined class A and class B instruction templates, both of which include nomemory access 205 instruction templates andmemory access 220 instruction templates. The term generic in the context of the vector friendly instruction format refers to the instruction format not being tied to any specific instruction set. While embodiments will be described in which instructions in the vector friendly instruction format operate on vectors that are sourced from either registers (nomemory access 205 instruction templates) or registers/memory (memory access 220 instruction templates), alternative embodiments of the invention may support only one of these. Also, while embodiments of the invention will be described in which there are load and store instructions in the vector instruction format, alternative embodiments instead or additionally have instructions in a different instruction format that move vectors into and out of registers (e.g., from memory into registers, from registers into memory, between registers). Further, while embodiments of the invention will be described that support two classes of instruction templates, alternative embodiments may support only one of these or more than two. - While embodiments of the invention will be described in which the vector friendly instruction format supports the following: a 64 byte vector operand length (or size) with 32 bit (4 byte) or 64 bit (8 byte) data element widths (or sizes) (and thus, a 64 byte vector consists of either 16 doubleword-size elements or alternatively, 8 quadword-size elements); a 64 byte vector operand length (or size) with 16 bit (2 byte) or 8 bit (1 byte) data element widths (or sizes); a 32 byte vector operand length (or size) with 32 bit (4 byte), 64 bit (8 byte), 16 bit (2 byte), or 8 bit (1 byte) data element widths (or sizes); and a 16 byte vector operand length (or size) with 32 bit (4 byte), 64 bit (8 byte), 16 bit (2 byte), or 8 bit (1 byte) data element widths (or sizes); alternative embodiments may support more, less and/or different vector operand sizes (e.g., 256 byte vector operands) with more, less, or different data element widths (e.g., 128 bit (16 byte) data element widths).
- The class A instruction templates in
figure 2A include: 1) within the nomemory access 205 instruction templates there is shown a no memory access, full roundcontrol type operation 210 instruction template and a no memory access, data transformtype operation 215 instruction template; and 2) within thememory access 220 instruction templates there is shown a memory access, temporal 225 instruction template and a memory access, non-temporal 230 instruction template. The class B instruction templates infigure 2B include: 1) within the nomemory access 205 instruction templates there is shown a no memory access, write mask control, partial roundcontrol type operation 212 instruction template and a no memory access, write mask control,vsize type operation 217 instruction template; and 2) within thememory access 220 instruction templates there is shown a memory access, writemask control 227 instruction template. - The generic vector
friendly instruction format 200 includes the following fields listed below in the order illustrated inFigures 2A-B . - Format field 240 - a specific value (an instruction format identifier value) in this field uniquely identifies the vector friendly instruction format, and thus occurrences of instructions in the vector friendly instruction format in instruction streams. Thus, the content of the
format field 240 distinguish occurrences of instructions in the first instruction format from occurrences of instructions in other instruction formats, thereby allowing for the introduction of the vector friendly instruction format into an instruction set that has other instruction formats. As such, this field is optional in the sense that it is not needed for an instruction set that has only the generic vector friendly instruction format. - Base operation field 242 - its content distinguishes different base operations. As described later herein, the
base operation field 242 may include and/or be part of an opcode field. - Register index field 244 - its content, directly or through address generation, specifies the locations of the source and destination operands, be they in registers or in memory. These include a sufficient number of bits to select N registers from a PxQ (e.g. 32x512) register file. While in one embodiment N may be up to three sources and one destination register, alternative embodiments may support more or less sources and destination registers (e.g., may support up to two sources where one of these sources also acts as the destination, may support up to three sources where one of these sources also acts as the destination, may support up to two sources and one destination). While in one embodiment P=32, alternative embodiments may support more or less registers (e.g., 16). While in one embodiment Q=512 bits, alternative embodiments may support more or less bits (e.g., 128, 1024).
- Modifier field 246 - its content distinguishes occurrences of instructions in the generic vector instruction format that specify memory access from those that do not; that is, between no
memory access 205 instruction templates andmemory access 220 instruction templates. Memory access operations read and/or write to the memory hierarchy (in some cases specifying the source and/or destination addresses using values in registers), while non-memory access operations do not (e.g., the source and destinations are registers). While in one embodiment this field also selects between three different ways to perform memory address calculations, alternative embodiments may support more, less, or different ways to perform memory address calculations. - Augmentation operation field 250 - its content distinguishes which one of a variety of different operations to be performed in addition to the base operation. This field is context specific. In one embodiment of the invention, this field is divided into a
class field 268, analpha field 252, and abeta field 254. The augmentation operation field allows common groups of operations to be performed in a single instruction rather than 2, 3 or 4 instructions. Below are some examples of instructions (the nomenclature of which are described in more detail later herein) that use theaugmentation field 250 to reduce the number of required instructions.Prior Instruction Sequences Instructions Sequences according to on Embodiment of the Invention vaddps ymm0, ymm1, ymm2 vaddps zmm0, zmm1, zmm2 vpshufd ymm2, ymm2, 0x55 vaddps ymm0, ymm1, ymm2 vaddps zmm0, zmm1, zmm2 {bbbb} vpmovsxbd ymm2, [rax] vcvtdq2ps ymm2, ymm2 vaddps ymm0, ymm1, ymm2 vaddps zmm0, zmm1, [rax]{sint8} vpmovsxbd ymm3, [rax] vcvtdq2ps ymm3, ymm3 vaddps ymm4, ymm2, ymm3 vblendvps ymm1, ymm5, ymm1, ymm4 vaddps zmm1 {k5}, zmm2, [rax] {sint8} vmaskmovps ymm1, ymm7, [rbx] vbroadcastss ymm0, [rax] vaddps ymm2, ymm0, ymm1 vblendvps ymm2, ymm2, ymm1, ymm7 vmovaps zmm1 {k7}, [rbx] vaddps zmm2{k7} {z}, zmm1, [rax]{1toN} - Scale field 260 - its content allows for the scaling of the index field's content for memory address generation (e.g., for address generation that uses 2scale*index +base).
-
Displacement Field 262A- its content is used as part of memory address generation (e.g., for address generation that uses 2scale*index+base+displacement). -
Displacement Factor Field 262B (note that the juxtaposition ofdisplacement field 262A directly overdisplacement factor field 262B indicates one or the other is used) - its content is used as part of address generation; it specifies a displacement factor that is to be scaled by the size of a memory access (N) - where N is the number of bytes in the memory access (e.g., for address generation that uses 2scale*index+base+scaled displacement). Redundant low-order bits are ignored and hence, the displacement factor field's content is multiplied by the memory operands total size (N) in order to generate the final displacement to be used in calculating an effective address. The value of N is determined by the processor hardware at runtime based on the full opcode field 274 (described later herein) and thedata manipulation field 254C as described later herein. Thedisplacement field 262A and thedisplacement factor field 262B are optional in the sense that they are not used for the nomemory access 205 instruction templates and/or different embodiments may implement only one or none of the two. - Data element width field 264 - its content distinguishes which one of a number of data element widths is to be used (in some embodiments for all instructions; in other embodiments for only some of the instructions). This field is optional in the sense that it is not needed if only one data element width is supported and/or data element widths are supported using some aspect of the opcodes.
- Write mask field 270 - its content controls, on a per data element position basis, whether that data element position in the destination vector operand reflects the result of the base operation and augmentation operation. Class A instruction templates support merging-writemasking, while class B instruction templates support both merging- and zeroing-writemasking. When merging, vector masks allow any set of elements in the destination to be protected from updates during the execution of any operation (specified by the base operation and the augmentation operation); in other one embodiment, preserving the old value of each element of the destination where the corresponding mask bit has a 0. In contrast, when zeroing vector masks allow any set of elements in the destination to be zeroed during the execution of any operation (specified by the base operation and the augmentation operation); in one embodiment, an element of the destination is set to 0 when the corresponding mask bit has a 0 value. A subset of this functionality is the ability to control the vector length of the operation being performed (that is, the span of elements being modified, from the first to the last one); however, it is not necessary that the elements that are modified be consecutive. Thus, the
write mask field 270 allows for partial vector operations, including loads, stores, arithmetic, logical, etc. Also, this masking can be used for fault suppression (i.e., by masking the destination's data element positions to prevent receipt of the result of any operation that may/will cause a fault - e.g., assume that a vector in memory crosses a page boundary and that the first page but not the second page would cause a page fault, the page fault can be ignored if all data element of the vector that lie on the first page are masked by the write mask). Further, write masks allow for "vectorizing loops" that contain certain types of conditional statements. While embodiments of the invention are described in which the write mask field's 270 content selects one of a number of write mask registers that contains the write mask to be used (and thus the write mask field's 270 content indirectly identifies that masking to be performed), alternative embodiments instead or additional allow the mask write field's 270 content to directly specify the masking to be performed. Further, zeroing allows for performance improvements when: 1) register renaming is used on instructions whose destination operand is not also a source (also call non-ternary instructions) because during the register renaming pipeline stage the destination is no longer an implicit source (no data elements from the current destination register need be copied to the renamed destination register or somehow carried along with the operation because any data element that is not the result of operation (any masked data element) will be zeroed); and 2) during the write back stage because zeros are being written. - Immediate field 272 - its content allows for the specification of an immediate. This field is optional in the sense that is it not present in an implementation of the generic vector friendly format that does not support immediate and it is not present in instructions that do not use an immediate.
- Class field 268 - its content distinguishes between different classes of instructions. With reference to
figures 2A-B , the contents of this field select between class A and class B instructions. Infigures 2A-B , rounded corner squares are used to indicate a specific value is present in a field (e.g.,class A 268A andclass B 268B for theclass field 268 respectively infigures 2A-B ). - In the case of the
non-memory access 205 instruction templates of class A, thealpha field 252 is interpreted as anRS field 252A, whose content distinguishes which one of the different augmentation operation types are to be performed (e.g., round 252A.1 and data transform 252A.2 are respectively specified for the no memory access,round type operation 210 and the no memory access, data transformtype operation 215 instruction templates), while thebeta field 254 distinguishes which of the operations of the specified type is to be performed. InFigure 2 , rounded corner blocks are used to indicate a specific value is present (e.g., nomemory access 246A in themodifier field 246; round 252A. 1 and data transform 252A.2 foralpha field 252/rs field 252A). In the nomemory access 205 instruction templates, thescale field 260, thedisplacement field 262A, and thedisplacement scale field 262B are not present. - In the no memory access full round
control type operation 210 instruction template, thebeta field 254 is interpreted as around control field 254A, whose content(s) provide static rounding. While in the described embodiments of the invention theround control field 254A includes a suppress all floating point exceptions (SAE)field 256 and a roundoperation control field 258, alternative embodiments may support may encode both these concepts into the same field or only have one or the other of these concepts/fields (e.g., may have only the round operation control field 258). - SAE field 256 - its content distinguishes whether or not to disable the exception event reporting; when the SAE field's 256 content indicates suppression is enabled, a given instruction does not report any kind of floating-point exception flag and does not raise any floating point exception handler.
- Round operation control field 258 - its content distinguishes which one of a group of rounding operations to perform (e.g., Round-up, Round-down, Round-towards-zero and Round-to-nearest). Thus, the round
operation control field 258 allows for the changing of the rounding mode on a per instruction basis, and thus is particularly useful when this is required. In one embodiment of the invention where a processor includes a control register for specifying rounding modes, the round operation control field's 250 content overrides that register value (Being able to choose the rounding mode without having to perform a save-modify-restore on such a control register is advantageous). - In the no memory access data transform
type operation 215 instruction template, thebeta field 254 is interpreted as adata transform field 254B, whose content distinguishes which one of a number of data transforms is to be performed (e.g., no data transform, swizzle, broadcast). - In the case of a
memory access 220 instruction template of class A, thealpha field 252 is interpreted as aneviction hint field 252B, whose content distinguishes which one of the eviction hints is to be used (inFigure 2A , temporal 252B.1 and non-temporal 252B.2 are respectively specified for the memory access, temporal 225 instruction template and the memory access, non-temporal 230 instruction template), while thebeta field 254 is interpreted as adata manipulation field 254C, whose content distinguishes which one of a number of data manipulation operations (also known as primitives) is to be performed (e.g., no manipulation; broadcast; up conversion of a source; and down conversion of a destination). Thememory access 220 instruction templates include thescale field 260, and optionally thedisplacement field 262A or thedisplacement scale field 262B. - Vector Memory Instructions perform vector loads from and vector stores to memory, with conversion support. As with regular vector instructions, vector memory instructions transfer data from/to memory in a data element-wise fashion, with the elements that are actually transferred dictated by the contents of the vector mask that is selected as the write mask. In
figure 2A , rounded corner squares are used to indicate a specific value is present in a field (e.g.,memory access 246B for themodifier field 246; temporal 252B. 1 and non-temporal 252B.2 for thealpha field 252/eviction hint field 252B) - Temporal data is data likely to be reused soon enough to benefit from caching. This is, however, a hint, and different processors may implement it in different ways, including ignoring the hint entirely.
- Non-temporal data is data unlikely to be reused soon enough to benefit from caching in the 1st-level cache and should be given priority for eviction. This is, however, a hint, and different processors may implement it in different ways, including ignoring the hint entirely.
- In the case of the instruction templates of class B, the
alpha field 252 is interpreted as a write mask control (Z)field 252C, whose content distinguishes whether the write masking controlled by thewrite mask field 270 should be a merging or a zeroing. - In the case of the
non-memory access 205 instruction templates of class B, part of thebeta field 254 is interpreted as anRL field 257A, whose content distinguishes which one of the different augmentation operation types are to be performed (e.g., round 257A. 1 and vector length (VSIZE) 257A.2 are respectively specified for the no memory access, write mask control, partial roundcontrol type operation 212 instruction template and the no memory access, write mask control,VSIZE type operation 217 instruction template), while the rest of thebeta field 254 distinguishes which of the operations of the specified type is to be performed. InFigure 2 , rounded corner blocks are used to indicate a specific value is present (e.g., nomemory access 246A in themodifier field 246; round 257A.1 and VSIZE 257A.2 for theRL field 257A). In the nomemory access 205 instruction templates, thescale field 260, thedisplacement field 262A, and thedisplacement scale field 262B are not present. - In the no memory access, write mask control, partial round
control type operation 210 instruction template, the rest of thebeta field 254 is interpreted as around operation field 259A and exception event reporting is disabled (a given instruction does not report any kind of floating-point exception flag and does not raise any floating point exception handler). - Round
operation control field 259A - just as roundoperation control field 258, its content distinguishes which one of a group of rounding operations to perform (e.g., Round-up, Round-down, Round-towards-zero and Round-to-nearest). Thus, the roundoperation control field 259A allows for the changing of the rounding mode on a per instruction basis, and thus is particularly useful when this is required. In one embodiment of the invention where a processor includes a control register for specifying rounding modes, the round operation control field's 250 content overrides that register value (Being able to choose the rounding mode without having to perform a save-modify-restore on such a control register is advantageous). - In the no memory access, write mask control,
VSIZE type operation 217 instruction template, the rest of thebeta field 254 is interpreted as avector length field 259B, whose content distinguishes which one of a number of data vector length is to be performed on (e.g., 128, 256, or 512 byte). - In the case of a
memory access 220 instruction template of class A, part of thebeta field 254 is interpreted as abroadcast field 257B, whose content distinguishes whether or not the broadcast type data manipulation operation is to be performed, while the rest of thebeta field 254 is interpreted thevector length field 259B. Thememory access 220 instruction templates include thescale field 260, and optionally thedisplacement field 262A or thedisplacement scale field 262B. - With regard to the generic vector
friendly instruction format 200, afull opcode field 274 is shown including theformat field 240, thebase operation field 242, and the dataelement width field 264. While one embodiment is shown where thefull opcode field 274 includes all of these fields, thefull opcode field 274 includes less than all of these fields in embodiments that do not support all of them. Thefull opcode field 274 provides the operation code. - The
augmentation operation field 250, the dataelement width field 264, and thewrite mask field 270 allow these features to be specified on a per instruction basis in the generic vector friendly instruction format. - The combination of write mask field and data element width field create typed instructions in that they allow the mask to be applied based on different data element widths.
- The instruction format requires a relatively small number of bits because it reuses different fields for different purposes based on the contents of other fields. For instance, one perspective is that the modifier field's content chooses between the no
memory access 205 instructions templates onfigures 2A-B and the memory access 2250 instruction templates onfigures 2A-B ; while theclass field 268's content chooses within thosenon-memory access 205 instruction templates betweeninstruction templates 210/215 offigure 2A and 212/217 offigure 2B ; and while theclass field 268's content chooses within thosememory access 220 instruction templates betweeninstruction templates 225/230 offigure 2A and 227 offigure 2B . From another perspective, theclass field 268's content chooses between the class A and class B instruction templates respectively offigures 2A and B; while the modifier field's content chooses within those class A instruction templates betweeninstruction templates figure 2A ; and while the modifier field's content chooses within those class B instruction templates betweeninstruction templates figure 2B . In the case of the class field's content indicating a class A instruction template, the content of themodifier field 246 chooses the interpretation of the alpha field 252 (between the rs field 252A and the EHfield 252B. In a related manner, the contents of themodifier field 246 and theclass field 268 chose whether the alpha field is interpreted as thers field 252A, the EHfield 252B, or the write mask control (Z)field 252C. In the case of the class and modifier fields indicating a class A no memory access operation, the interpretation of the augmentation field's beta field changes based on the rs field's content; while in the case of the class and modifier fields indicating a class B no memory access operation, the interpretation of the beta field depends on the contents of the RL field. In the case of the class and modifier fields indicating a class A memory access operation, the interpretation of the augmentation field's beta field changes based on the base operation field's content; while in the case of the class and modifier fields indicating a class B memory access operation, the interpretation of the augmentation field's beta field'sbroadcast field 257B changes based on the base operation field's contents. Thus, the combination of the base operation field, modifier field and the augmentation operation field allow for an even wider variety of augmentation operations to be specified. - The various instruction templates found within class A and class B are beneficial in different situations. Class B is useful when zeroing-writemasking or smaller vector lengths are desired for performance reasons. For example, zeroing allows avoiding fake dependences when renaming is used since we no longer need to artificially merge with the destination; as another example, vector length control eases store-load forwarding issues when emulating shorter vector sizes with the vector mask. Class A is useful when it is desirable to: 1) allow floating point exceptions (i.e., when the contents of the SAE field indicate no) while using rounding-mode controls at the same time; 2) be able to use upconversion, swizzling, swap, and/or downconversion; 3) operate on the graphics data type. For instance, upconversion, swizzling, swap, downconversion, and the graphics data type reduce the number of instructions required when working with sources in a different format; as another example, the ability to allow exceptions provides full IEEE compliance with directed rounding-modes. Also, in some embodiments of the invention, different processors or different cores within a processor may support only class A, only class B, or both classes. For instance, a high performance general purpose out-of-order core intended for general-purpose computing may support only class B, a core intended primarily for graphics and/or scientific (throughput) computing may support only class A, and a core intended for both may support both (of course, a core that has some mix of templates and instructions from both classes but not all templates and instructions from both classes is within the purview of the invention). Also, a single processor may include multiple cores, all of which support the same class or in which different cores support different class. For instance, in a processor with separate graphics and general purpose cores, one of the graphics cores intended primarily for graphics and/or scientific computing may support only class A, while one or more of the general purpose cores may be high performance general purpose cores with out of order execution and register renaming intended for general-purpose computing that support only class B. Another processor that does not have a separate graphics core, may include one more general purpose in-order or out-of-order cores that support both class A and class B. Of course, features from one class may also be implement in the other class in different embodiments of the invention. Programs written in a high level language would be put (e.g., just in time compiled or statically compiled) into an variety of different executable forms, including: 1) a form having only instructions of the class(es) supported by the target processor for execution; or 2) a form having alternative routines written using different combinations of the instructions of all classes and having control flow code that selects the routines to execute based on the instructions supported by the processor which is currently executing the code.
-
Figure 3A is a block diagram illustrating an exemplary specific vector friendly instruction format according to embodiments of the invention.Figure 3A shows a specific vectorfriendly instruction format 300 that is specific in the sense that it specifies the location, size, interpretation, and order of the fields, as well as values for some of those fields. The specific vectorfriendly instruction format 300 may be used to extend the x86 instruction set, and thus some of the fields are similar or the same as those used in the existing x86 instruction set and extension thereof (e.g., AVX). This format remains consistent with the prefix encoding field, real opcode byte field, MOD R/M field, SIB field, displacement field, and immediate fields of the existing x86 instruction set with extensions. The fields fromFigure 2 into which the fields fromFigure 3A map are illustrated. - It should be understand that although embodiments of the invention are described with reference to the specific vector
friendly instruction format 300 in the context of the generic vectorfriendly instruction format 200 for illustrative purposes, the invention is not limited to the specific vectorfriendly instruction format 300 except where claimed. For example, the generic vectorfriendly instruction format 200 contemplates a variety of possible sizes for the various fields, while the specific vectorfriendly instruction format 300 is shown as having fields of specific sizes. By way of specific example, while the dataelement width field 264 is illustrated as a one bit field in the specific vectorfriendly instruction format 300, the invention is not so limited (that is, the generic vectorfriendly instruction format 200 contemplates other sizes of the data element width field 264). - The generic vector
friendly instruction format 200 includes the following fields listed below in the order illustrated inFigure 3A . - Format Field 240 (
EVEX Byte 0, bits [7:0]) - the first byte (EVEX Byte 0) is theformat field 240 and it contains 0x62 (the unique value used for distinguishing the vector friendly instruction format in one embodiment of the invention). - The second-fourth bytes (EVEX Bytes 1-3) include a number of bit fields providing specific capability.
- REX field 305 (
EVEX Byte 1, bits [7-5]) - consists of a EVEX.R bit field (EVEX Byte 1, bit [7] - R), EVEX.X bit field (EVEX byte 1, bit [6] - X), and257BEX byte 1, bit[5] - B). The EVEX.R, EVEX.X, and EVEX.B bit fields provide the same functionality as the corresponding VEX bit fields, and are encoded using Is complement form, i.e. ZMM0 is encoded as 1111B, ZMM15 is encoded as 0000B. Other fields of the instructions encode the lower three bits of the register indexes as is known in the art (rrr, xxx, and bbb), so that Rrrr, Xxxx, and Bbbb may be formed by adding EVEX.R, EVEX.X, and EVEX.B. - REX' field 310 - this is the first part of the REX'
field 310 and is the EVEX.R' bit field (EVEX Byte 1, bit [4] - R') that is used to encode either the upper 16 or lower 16 of the extended 32 register set. In one embodiment of the invention, this bit, along with others as indicated below, is stored in bit inverted format to distinguish (in the well-known x86 32-bit mode) from the BOUND instruction, whose real opcode byte is 62, but does not accept in the MOD R/M field (described below) the value of 11 in the MOD field; alternative embodiments of the invention do not store this and the other indicated bits below in the inverted format. A value of 1 is used to encode the lower 16 registers. In other words, R'Rrrr is formed by combining EVEX.R', EVEX.R, and the other RRR from other fields. - Opcode map field 315 (
EVEX byte 1, bits [3:0] - mmmm) - its content encodes an implied leading opcode byte (0F, 0F 38, or 0F 3A). - Data element width field 264 (
EVEX byte 2, bit [7] - W) - is represented by the notation EVEX.W. EVEX.W is used to define the granularity (size) of the datatype (either 32-bit data elements or 64-bit data elements). - EVEX.vvvv 320 (
EVEX Byte 2, bits [6:3]-vvvv)- the role of EVEX.vvvv may include the following: 1) EVEX.vvvv encodes the first source register operand, specified in inverted (Is complement) form and is valid for instructions with 2 or more source operands; 2) EVEX.vvvv encodes the destination register operand, specified in 1s complement form for certain vector shifts; or 3) EVEX.vvvv does not encode any operand, the field is reserved and should contain 1111b. Thus,EVEX.vvvv field 320 encodes the 4 low-order bits of the first source register specifier stored in inverted (Is complement) form. Depending on the instruction, an extra different EVEX bit field is used to extend the specifier size to 32 registers. -
EVEX.U 268 Class field (EVEX byte 2, bit [2]-U) - If EVEX.U = 0, it indicates class A or EVEX.U0; if EVEX.U = 1, it indicates class B or EVEX.U1. - Prefix encoding field 325 (
EVEX byte 2, bits [1:0]-pp) - provides additional bits for the base operation field. In addition to providing support for the legacy SSE instructions in the EVEX prefix format, this also has the benefit of compacting the SIMD prefix (rather than requiring a byte to express the SIMD prefix, the EVEX prefix requires only 2 bits). In one embodiment, to support legacy SSE instructions that use a SIMD prefix (66H, F2H, F3H) in both the legacy format and in the EVEX prefix format, these legacy SIMD prefixes are encoded into the SIMD prefix encoding field; and at runtime are expanded into the legacy SIMD prefix prior to being provided to the decoder's PLA (so the PLA can execute both the legacy and EVEX format of these legacy instructions without modification). Although newer instructions could use the EVEX prefix encoding field's content directly as an opcode extension, certain embodiments expand in a similar fashion for consistency but allow for different meanings to be specified by these legacy SIMD prefixes. An alternative embodiment may redesign the PLA to support the 2 bit SIMD prefix encodings, and thus not require the expansion. - Alpha field 252 (
EVEX byte 3, bit [7] - EH; also known as EVEX.EH, EVEX.rs, EVEX.RL, EVEX.write mask control, and EVEX.N; also illustrated with α) - as previously described, this field is context specific. Additional description is provided later herein. - Beta field 254 (
EVEX byte 3, bits [6:4]-SSS, also known as EVEX.s2-0, EVEX.r2-0, EVEX.rr1, EVEX.LL0, EVEX.LLB; also illustrated with βββ) - as previously described, this field is context specific. Additional description is provided later herein. - REX' field 310 - this is the remainder of the REX' field and is the EVEX.V' bit field (
EVEX Byte 3, bit [3] - V') that may be used to encode either the upper 16 or lower 16 of the extended 32 register set. This bit is stored in bit inverted format. A value of 1 is used to encode the lower 16 registers. In other words, V'VVVV is formed by combining EVEX.V', EVEX.vvvv. - Write mask field 270 (
EVEX byte 3, bits [2:0]-kkk) - its content specifies the index of a register in the write mask registers as previously described. In one embodiment of the invention, the specific value EVEX.kkk=000 has a special behavior implying no write mask is used for the particular instruction (this may be implemented in a variety of ways including the use of a write mask hardwired to all ones or hardware that bypasses the masking hardware). - This is also known as the opcode byte. Part of the opcode is specified in this field.
- Modifier field 246 (MODR/M.MOD, bits [7-6] - MOD field 342) - As previously described, the MOD field's 342 content distinguishes between memory access and non-memory access operations. This field will be further described later herein.
- MODR/
M.reg field 344, bits [5-3] - the role of ModR/M.reg field can be summarized to two situations: ModR/M.reg encodes either the destination register operand or a source register operand, or ModR/M.reg is treated as an opcode extension and not used to encode any instruction operand. - MODR/M.r/m
field 346, bits [2-0] - The role of ModR/M.r/m field may include the following: ModR/M.r/m encodes the instruction operand that references a memory address, or ModR/M.r/m encodes either the destination register operand or a source register operand. - Scale field 260 (SIB.SS, bits [7-6] - As previously described, the scale field's 260 content is used for memory address generation. This field will be further described later herein.
- SIB.xxx 354 (bits [5-3] and SIB.bbb 356 (bits [2-0]) - the contents of these fields have been previously referred to with regard to the register indexes Xxxx and Bbbb.
-
Displacement field 262A (Bytes 7-10) - whenMOD field 342 contains 10, bytes 7-10 are thedisplacement field 262A, and it works the same as the legacy 32-bit displacement (disp32) and works at byte granularity. -
Displacement factor field 262B (Byte 7) - whenMOD field 342 contains 01,byte 7 is thedisplacement factor field 262B. The location of this field is that same as that of the legacy x86 instruction set 8-bit displacement (disp8), which works at byte granularity. Since disp8 is sign extended, it can only address between -128 and 127 bytes offsets; in terms of 64 byte cache lines, disp8 uses 8 bits that can be set to only four really useful values -128, -64, 0, and 64; since a greater range is often needed, disp32 is used; however, disp32 requires 4 bytes. In contrast to disp8 and disp32, thedisplacement factor field 262B is a reinterpretation of disp8; when usingdisplacement factor field 262B, the actual displacement is determined by the content of the displacement factor field multiplied by the size of the memory operand access (N). This type of displacement is referred to as disp8*N. This reduces the average instruction length (a single byte of used for the displacement but with a much greater range). Such compressed displacement is based on the assumption that the effective displacement is multiple of the granularity of the memory access, and hence, the redundant low-order bits of the address offset do not need to be encoded. In other words, thedisplacement factor field 262B substitutes the legacy x86 instruction set 8-bit displacement. Thus, thedisplacement factor field 262B is encoded the same way as an x86 instruction set 8-bit displacement (so no changes in the ModRM/SIB encoding rules) with the only exception that disp8 is overloaded to disp8*N. In other words, there are no changes in the encoding rules or encoding lengths but only in the interpretation of the displacement value by hardware (which needs to scale the displacement by the size of the memory operand to obtain a byte-wise address offset). -
Immediate field 272 operates as previously described. -
Figure 3B is a block diagram illustrating the fields of the specific vectorfriendly instruction format 300 that make up thefull opcode field 274 according to one embodiment of the invention. Specifically, thefull opcode field 274 includes theformat field 240, thebase operation field 242, and the data element width (W)field 264. Thebase operation field 242 includes theprefix encoding field 325, theopcode map field 315, and thereal opcode field 330. -
Figure 3C is a block diagram illustrating the fields of the specific vectorfriendly instruction format 300 that make up theregister index field 244 according to one embodiment of the invention. Specifically, theregister index field 244 includes theREX field 305, the REX'field 310, the MODR/M.reg field 344, the MODR/M.r/mfield 346, theVVVV field 320, xxxfield 354, and thebbb field 356. -
Figure 3D is a block diagram illustrating the fields of the specific vectorfriendly instruction format 300 that make up theaugmentation operation field 250 according to one embodiment of the invention. When the class (U)field 268 contains 0 it signifies EVEX.U0 (class A 268A); when it contains 1 it signifies EVEX.U1 (class B 268B). When U=0 and theMOD field 342 contains 11 (signifying a no memory access operation), the alpha field 252 (EVEX byte 3, bit [7] - EH) is interpreted as thers field 252A. When the rs field 252A contains a 1 (round 252A.1), the beta field 254 (EVEX byte 3, bits [6:4]- SSS) is interpreted as theround control field 254A. Theround control field 254A includes a onebit SAE field 256 and a two bitround operation field 258. When the rs field 252A contains a 0 (data transform 252A.), the beta field 254 (EVEX byte 3, bits [6:4]- SSS) is interpreted as a three bit data transformfield 254B. When U=0 and theMOD field 342 contains 00, 01, or 10 (signifying a memory access operation), the alpha field 252 (EVEX byte 3, bit [7] - EH) is interpreted as the eviction hint (EH)field 252B and the beta field 254 (EVEX byte 3, bits [6:4]- SSS) is interpreted as a three bitdata manipulation field 254C. - When U=1, the alpha field 252 (
EVEX byte 3, bit [7] - EH) is interpreted as the write mask control (Z)field 252C. When U=1 and theMOD field 342 contains 11 (signifying a no memory access operation), part of the beta field 254 (EVEX byte 3, bit [4]- S0) is interpreted as theRL field 257A; when it contains a 1 (round 257A.1) the rest of the beta field 254 (EVEX byte 3, bit [6-5]- S2-1) is interpreted as theround operation field 259A, while when theRL field 257A contains a 0 (VSIZE 257.A2) the rest of the beta field 254 (EVEX byte 3, bit [6-5]- S2-1) is interpreted as thevector length field 259B (EVEX byte 3, bit [6-5]- L1-0). When U=1 and theMOD field 342 contains 00, 01, or 10 (signifying a memory access operation), the beta field 254 (EVEX byte 3, bits [6:4]- SSS) is interpreted as thevector length field 259B (EVEX byte 3, bit [6-5]- L1-0) and thebroadcast field 257B (EVEX byte 3, bit [4]- B). - The vector format extends the number of registers to 32 (REX').
- Non-destructive source register encoding (applicable to three and four operand syntax): This is the first source operand in the instruction syntax. It is represented by the notation, EVEX.vvvv. This field is encoded using Is complement form (inverted form), i.e. ZMM0 is encoded as 1111B, ZMM15 is encoded as 0000B. Note that an extra bit field in EVEX is needed to extend the source to 32 registers.
- EVEX.W defines the datatype size (32-bits or 64-bits) for certain of the instructions.
- 32 extended register set encoding: EVEX prefix provide additional bit field to encode 32 registers per source with the following dedicated bit fields: EVEX.R' and EVEX.V' (together with EVEX.X for register-register formats).
- Compaction of SIMD prefix: Legacy SSE instructions effectively use SIMD prefixes (66H, F2H, F3H) as an opcode extension field. EVEX prefix encoding allows the functional capability of such legacy SSE instructions using 512 bit vector length.
- Compaction of two-byte and three-byte opcode: More recently introduced legacy SSE instructions employ two and three-byte opcode. The one or two leading bytes are: 0FH, and 0FH 3AH/0FH 38H. The one-byte escape (0FH) and two-byte escape (0FH 3AH, 0FH 38H) can also be interpreted as an opcode extension field. The EVEX.mmm field provides compaction to allow many legacy instruction to be encoded without the constant byte sequence, 0FH, 0FH 3AH, 0FH 38H.
-
Figures 4A - 4D illustrate a flow diagram showing the inter relationship of some of the fields of the vector friendly instruction format according to one embodiment of the invention; whilefigure 4E is an exploded view of each ofblocks 415A-H according to one embodiment of the invention. Inblock 400, it is determined whether the value of the initial field indicates the vector friendly instruction format (e.g., 0x62). If not, control passes to block 402 where the instruction is handled according to one of the other formats of the instruction set. If so, control passes to block 492. - In
block 492, it is determined whether the content of the class (U) field indicates class A or class B instruction templates. In the case of class A, control passes to two separate blocks: block 404A and 490. Otherwise, control passes to through circled B to two separate blocks onfigure 4C : block 404B and block 493. - In
block 404A, it is determined whether the content of the modifier field indicates a no memory access operation or a memory access operation. In the case of a no memory access operation (e.g.,MOD field 342 = 11), control passes toblocks 406 and 408. In the case of a memory access operation (e.g.,MOD field 342 = 00, 01, or 10), control passes to each ofblock 422, block 430, and block 440A (onfigure 4B through the circled A). - A rounded corner box labeled
alpha field 252 encompasses block 408 and block 422 because they represent the different interpretations of thealpha field 252. Specifically, block 408 represents the alpha field's 252 interpretation as thers field 252A, whileblock 422 represents when the alpha field's 252 interpretation as theeviction hint field 252B. - In block 406, the contents of the
register index field 244 are used as illustrated inFigure 6A . - In
block 408, it is determined whether the rs field's 252A content indicates a round type operation (e.g.,rs field 252A = 1) or a data transform type operation (e.g.,rs field 252A = 0). In the former, control passes to each ofblock 410, block 412A, and block 414. In the latter case, control passes to block 416. - A rounded corner box labeled beta (round control)
field 254A encompasses block 410 and block 412A.Block 410 illustrates a decision regarding the SAE field's 256 content (whether or not to suppress floating point exceptions), whileblock 412A illustrates a decision based on the round operation field's 258 content (distinguishing one of the group of possible rounding operations). The decisions made inblock Figure 7A . -
Blocks field 264. As illustrated inFigure 4 , the dataelement width field 264 is a 1 bit field in the specific vectorfriendly instruction format 300 ofFigure 3A . As such, these blocks decide whether the data element width is 64 bits (e.g., 1) or 32 bits (e.g., 0). With regard to block 414, this decision marks the end of this branch of the flow. In contrast, control passes fromblock 416 to block 418 or block 420 for the 64 bit and 32 bit data element widths, respectively. - A rounded corner box labeled beta (data transform)
field 254B encompasses both block 418 and block 420; and thus represents the case where thebeta field 254 is interpreted as the data transformfield 254B. In blocks 418 and 420, the content of the data transformfield 254B is used to distinguish which one of a number of data transform operations is to be performed. The groups of possible data transform operations forblock 418 and block 420 are respectively shown inFigure 8A and Figure 8B . - In
block 422, the content of theeviction hint field 252B is used to distinguish which one of the group of possible eviction hint options should be used.Figure 4 illustrates the use of a 1 biteviction hint field 252B from the specific vectorfriendly instruction format 300. Specifically, the eviction hint options are non-temporal (1) and temporal (0). This marks the end of this branch of the flow diagram. - In
block 430, the contents of theregister index field 244, thescale field 260, and thedisplacement field 262A or thedisplacement factor field 262B are used as indicated inFigure 6B . This marks the end of this branch of the flow diagram. - In
block 440A, the content of thebase operation field 242 is used to distinguish which one of a group of different memory access operations is to be performed. The following table illustrates the group of supported memory access operations according to one embodiment of the invention, as well as the control flow fromblock 440A for each. Alternative embodiments of the invention may support more, less, or different memory access operations.Memory Access Operation Type Block Load/Operation Integer (load/op int) 442 Load/Operation Floating Point (load/op fp) 448 Load Integer (load int) 454 Load Floating Point (load fp) 460 Store Integer (store int) 468 Store Floating Point (store fp) 474 Load Graphics (load gr) 480 Load Packed Graphics (load p.gr) 482 Store Graphics (store gr) 484 - As previously described, blocks 442, 448, 454, 460, 468, and 474 determine the change in control flow based on the data element width; the control flow is illustrated in the below table.
Block 64 bit 32 bit 442 444A as illustrated in Figure 12A 446A as illustrated in Figure 12B 448 450A as illustrated in Figure 12C 452A as illustrated in Figure 12D 454 456 as illustrated in Figure 13A 458 as illustrated in Figure 13B 460 462 as illustrated in Figure 13C 464 as illustrated in Figure 13D 468 470 as illustrated in Figure 14A 472 as illustrated in Figure 14B 474 476 as illustrated in Figure 14C 478 as illustrated in Figure 14D blocks Figures 15A, 15B, and 15C . A rounded corner box labeled beta (data manipulation)field 254C encompassesblocks data manipulation field 254C distinguishes which one of the group of possible data manipulation operations is to be performed. - In
block 490, the content of the write mask (k)field 270 and the content of the data element width (w)field 264 are used to determine the write mask to be used in the operation.Figure 4 illustrates the embodiment in which there are eight right mask registers and theregister 000 indicates that no write mask should be used. Where the write mask field's 270 content indicates other than 000, control passes toFigure 16A-D . - In
block 404B, it is determined whether the content of the modifier field indicates a no memory access operation or a memory access operation. In the case of a no memory access operation (e.g.,MOD field 342 = 11), control passes to blocks 406 (onfigure 4A through the circled E) and 495. In the case of a memory access operation (e.g.,MOD field 342 = 00, 01, or 10), control passes to each ofblock 498, block 430 (onfigure 4A through the circled D), and block 440B (onfigure 4D through the circled C). - A rounded corner box labeled part of
beta field 254 encompassesblock 495, block 412B, and block 498 because they represent the different interpretations of part of thebeta field 254. Specifically, block 495 represents part of the beta field's 254 interpretation as theRL field 257A, while a rounded corner box labeledbroadcast field 257B onfigure 4D represents this part of the beta field' 254 interpretation as thebroadcast field 257B. - In
block 495, it is determined whether the RL field's 257A content indicates a round type operation (e.g.,RL field 257A = 1) or a vector length type operation (e.g.,RL field 257A = 0). In the former, control passes to each ofblock 412B and block 415A. In the latter case, control passes to each ofblock 498 and block 415B. -
Block 412B illustrates a decision based on the round operation field's 259B content (distinguishing one of the group of possible rounding operations). The decision made inblock 412B is illustrated inFigure 7B . -
Blocks 415A-H all illustrate a decision regarding the width of data element on which to operate. As illustrated, the supported data elements for class B (when U=1) are 64 bit, 32 bit, 16 bit, and 8 bit. Exemplary manners of performing these blocks are describe later herein with reference tofigure 4E .Blocks 415A-B respectively mark the end of these branches of the flow diagram. With regard to figure 415A, the lines to the 16 bit and 8 bit data element widths are shown as dashed because in one embodiment of the invention these are not supported; rather, if there is a no memory access type operation for class B that is operating on 16 bit or 8 bit data elements, then the content ofRL field 257A is expected to be 0, and thus cause control to flow fromblock 495 toblocks 415B and 498 (in other words, the partial rounding is not available). - In
block 498, the content of the vector length (LL)field 268 is used to determine the size of the vector to be operated on.Figure 4 illustrates the embodiment in which the following are supported: 1) 128 bit (00); 2) 256 bit (01); 512 bit (10); while (11) is reserved. The reserved 11 may be used for different purposes for different types of instructions or for different embodiments of the invention. For example, 11 could be used for the following exemplary purposes: 1) to designate a vector length of 1024 bits; or 2) to designate that a dynamic vector length register should be used. Different embodiments may implement the dynamic vector length register(s) differently, including a special register used to encode vector length that is readable and writable by programs. A dynamic vector length register stores a value to be used for the vector length of the instruction. While different embodiments may support a number of different vector lengths through a dynamic vector length register, one embodiment of the invention supports a multiple of 128-bit (e.g., 128, 256, 512, 1024, 2048...). Where there is a set of one or more registers that function as dynamic vector length registers, different embodiments of the invention may select from those registers using different techniques (e.g., based on the type of instruction). - In
block 440B, the content of thebase operation field 242 is used to distinguish which one of a group of different memory access operations is to be performed. The following table illustrates the group of supported memory access operations according to one embodiment of the invention, as well as the control flow fromblock 440B for each. Alternative embodiments of the invention may support more, less, or different memory access operations.Memory Access Operation Type Block Load/Operation Integer (load/op int) 415C Load/Operation Floating Point (load/op fp) 415D Load Integer (load int) 415E Load Floating Point (load fp) 415F Store Integer (store int) 415G Store Floating Point (store fp) 415H - As previously described, blocks 415C-H determine the change in control flow based on the data element width; the control flow is illustrated in the below table.
Block 64 bit 32 bit 16 bit 8 bit 415C 444B as illustrated in Figure 12A 446B as illustrated in Figure 12B branch of the flow ends branch of the flow ends 415D 450B as illustrated in Figure 12C 452B as illustrated in Figure 12D branch of the flow ends branch of the flow ends 415E branch of the flow ends branch of the flow ends branch of the flow ends branch of the flow ends 415F branch of the flow ends branch of the flow ends branch of the flow ends branch of the flow ends 415G branch of the flow ends branch of the flow ends branch of the flow ends branch of the flow ends 415H branch of the flow ends branch of the flow ends branch of the flow ends branch of the flow ends broadcast field 257B encompassesblocks broadcast field 257B distinguishes whether a broadcast operation is to be performed. As illustrated, one embodiment of the invention allows the content of the broadcast (b)field 257B select whether a broadcast operation is performed or not for the data element widths of 64 bit and 32 bit, that is not an option for the 16 bit and 8 bit data element widths; rather, if there is a memory access type operation for class B that is operating on 16 bit or 8 bit data elements, then the content of the broadcast (B)field 257B is expected to be 0. - In
block 493, the content of the alpha field 252 (write make control (Z)field 252C), the content of the write mask (k)field 270, and a determination of the data element width are used to determine the write make operation to be performed (merging or zeroing) and the write mask to be used in the operation. In some embodiments of the invention, the alpha field 252 (write mask control (Z field 252C) is expected to be zero (for zero-masking) on memory access operations that perform stores. The determination of the data element width is done in the same manner asblock 415.Figure 4 illustrates the embodiment in which there are eight right mask registers and theregister 000 indicates that no write mask should be used. Where the write mask field's 270 content indicates other than 000, control passes toFigure 16D-E . -
Figure 4E is an exploded view of each ofblocks 415A-H according to one embodiment of the invention. Specifically, asingle flow 415 is illustrated which represent the flow for each ofblocks 415A-H. Inblock 417A, some or all of the content of thereal opcode field 330 is used to select between two sets of data element widths: a first set 417A.1 (e.g., including 64 bit and 32 bit) and second set 417A.2 (e.g., 16 bit and 8 bit). While data element width is determine for the first set 417A.1 based on the data element width (w)field 264 as illustrated inblock 417B; within the second set 471A.2, there are two manners of determining the data element width: 417A.2.1 (based just on the real opcode field 330) and 417A.2.2 (based on the data element width (w)field 264 as illustrated in block 417C). As illustrated inFigure 4 , the dataelement width field 264 is a 1 bit field in the specific vectorfriendly instruction format 300 ofFigure 3A . As such, theseblock 417B decides whether the data element width is 64 bits (e.g., 1) or 32 bits (e.g., 0); while block 417C decides whether the data element width is 16 bits (e.g., 1) or 8 bits (e.g., 0). Whilefigure 4E illustrates the involvement of thereal opcode field 417A in determining the data element width, alternative embodiments may be implemented to use just the w field (e.g., have a one bit w field and support only two data element sizes; have a two bit w field and support the four data element sizes). - While embodiments of the invention have been described with reference to
Figure 4 , alternative embodiments may use different flows. For example, as illustrated with theblocks block 416 would not be present and blocks 418 and 420 would be merged). As another example, different embodiments of the invention: may not include the class (U)field 268 and support only one of the class A or B instruction templates; may include theSAE field 256 and not theround operation field 258; may not include theround operation field 259A; may not include the eviction hitfield 252B; may not include the round type operation in either or both of class A and B instruction templates; may not include the data transform type operation; may not include thevector length field 259B in either or both of the nomemory access 205 andmemory access 220; support only one or the other of the load/op and load operations; may not include themask write field 270; may not include the write mask control (Z)field 252C; and/or may not include thevector length field 268. -
Figure 5 is a block diagram of aregister architecture 500 according to one embodiment of the invention. The register files and registers of the register architecture are listed below: - Vector register file 510 - in the embodiment illustrated, there are 32 vector registers that are 512 bits wide; these registers are referenced as zmm0 through zmm31. The
lower order 256 bits of the lower 16 zmm registers are overlaid on registers ymm0-16. Thelower order 128 bits of the lower 16 zmm registers (thelower order 128 bits of the ymm registers) are overlaid on registers xmm0-15. The specific vectorfriendly instruction format 300 operates on these overlaid register file as illustrated in the below tables.Adjustable Vector Length Class Operations Registers Instruction Templates that do not include the vector length field 259BA ( Figure 2A ; U=0)210, 215, 225, 230 zmm registers (the vector length is 64 byte) B ( Figure 2B ; U=1)212 zmm registers (the vector length is 64 byte) Instruction Templates that do include the vector length field 259BB ( Figure 2B ; U=1)217, 227 zmm, ymm, or xmm registers (the vector length is 64 byte, 32 byte, or 16 byte) depending on the vector length field 259B - In other words, the
vector length field 259B selects between a maximum length and one or more other shorter lengths, where each such shorter length is half the length of the preceding length; and instructions templates without thevector length field 259B operate on the maximum vector length. Further, in one embodiment, the class B instruction templates of the specific vectorfriendly instruction format 300 operate on packed or scalar single/double-precision floating point data and packed or scalar integer data. Scalar operations are operations performed on the lowest order data element position in an zmm/ymm/xmm register; the higher order data element positions are either left the same as they were prior to the instruction or zeroed depending on the embodiment. - Write mask registers 515 - in the embodiment illustrated, there are 8 write mask registers (k0 through k7), each 64 bits in size. As previously described, in one embodiment of the invention the vector mask register k0 cannot be used as a write mask; when the encoding that would normally indicate k0 is used for a write mask, it selects a hardwired write mask of 0xFFFF, effectively disabling write masking for that instruction.
- Multimedia Extensions Control Status Register (MXCSR) 520 - in the embodiment illustrated, this 32-bit register provides status and control bits used in floating-point operations.
- General-purpose registers 525 - in the embodiment illustrated, there are sixteen 64-bit general-purpose registers that are used along with the existing x86 addressing modes to address memory operands. These registers are referenced by the names RAX, RBX, RCX, RDX, RBP, RSI, RDI, RSP, and R8 through R15.
- Extended flags (EFLAGS) register 530 - in the embodiment illustrated, this 32 bit register is used to record the results of many instructions.
- Floating Point Control Word (FCW)
register 535 and Floating Point Status Word (FSW) register 540 - in the embodiment illustrated, these registers are used by x87 instruction set extensions to set rounding modes, exception masks and flags in the case of the FCW, and to keep track of exceptions in the case of the FSW. - Scalar floating point stack register file (x87 stack) 545 on which is aliased the MMX packed integer flat register file 550 - in the embodiment illustrated, the x87 stack is an eight-element stack used to perform scalar floating-point operations on 32/64/80-bit floating point data using the x87 instruction set extension; while the MMX registers are used to perform operations on 64-bit packed integer data, as well as to hold operands for some operations performed between the MMX and XMM registers.
- Segment registers 555 - in the illustrated embodiment, there are six 16 bit registers use to store data used for segmented address generation.
- RIP register 565 - in the illustrated embodiment, this 64 bit register that stores the instruction pointer.
- Alternative embodiments of the invention may use wider or narrower registers. Additionally, alternative embodiments of the invention may use more, less, or different register files and registers.
-
Figure 6A is a flow diagram for theregister index field 244 for a no memory access type operation according to embodiments of the invention.Figure 6A begins with an oval 600 which indicates that register to register addressing is being performed according to mod field 342 (= 11). From block 600, a control passes to block 605. - In
block 605, bits are selected from theregister index field 244 to address registers. With regard to the specific vectorfriendly instruction format 300, the existing x86 instructions set with extensions allows for a wide variety of different register addressing options based upon theREX field 305, thereg field 344, the r/mfield 346, theVVVV field 320, thexxx field 354, and thebbb field 356. The REX'field 310 extends these options. Fromblock 605, control passes to block 610. - In
block 610, register A is selected (e.g., zmm20) and control passes to block 615. Inblock 615, register B is selected (e.g., zmm5) and control optionally passes to block 620. In block 620, register C is selected (e.g., zmm7). Register A may be a source operand register; register B may be a source operand register, a destination operand register, or a source/destination operand register; and register C may be a source operand register, a destination operand register, or a source/destination operand. -
Figure 6B is a flow diagram illustrating the use of theregister index field 244, thescale field 260, thedisplacement field 262A, and thedisplacement factor field 262B for a memory access type operation according to embodiments of the invention.Figure 6B begins with an oval 630 indicating register-memory addressing (mod field 342 = 00, 01, or 10). From 630, control passes to block 635. - In
block 635, bits are selected from the register index field to address registers and control passes to block 640. - In
block 640, register A is selected (e.g., zmm20) and control optionally passes to block 645. Inblock 645, register B is selected (e.g., zmm31) and control passes to block 650. In the case where block 645 is not used, control passes directly fromblock 640 to block 650. - In block 650, the contents of the
REX field 305, the REX'field 310, the mod r/mfield 340, theSIB byte 350, and thedisplacement field 262A or thedisplacement factor field 262B are used to address memory; specifically, the index and the base are pulled from theREX field 305 and theSIB byte 350, while the content of the scale field 260 (ss field 352) is pulled from theSIB byte 350. From block 650, control passes to block 660. - In
block 660, the memory access mode is determined (e.g., based on the content of the mod field 342). Where the memory access mode is the no displacement mode (mod field 342 = 00), control passes to block 665 where the address is generated as follows: 2ss * index + base. - Where the memory access mode is the un-scaled displacement mode (
mod field 342 = 10), control passes to block 670 in which the address is generated as follows: 2ss * index + base + disp32. In the case where the memory access mode is the scaled displacement mode (mod field 342 = 01), control passes to block 675 in which the address is generated as follows: 2ss * index + base + scaled displacement; where the scaled displacement (disp8*n) = the content of thedisplacement factor field 262B multiplied by the memory access size (N), where N is dependent upon the contents of the full opcode field 274 (e.g., the base operation field and/or the data element width field) and the augmentation operation field 250 (e.g., theclass field 268 and thedata manipulation field 254C, thevector length field 259B, and/or thebroadcast field 257B). -
Figure 6C is a table illustrates the differences between disp8, disp32, and variations of the scaled displacement according to embodiments of the invention. The columns of the table are: 1) "byte" which indicates addresses incremented by bytes; 2) "disp8 field" which is a 1 byte field used to store from -128 to 127; 3) "disp32 field" which is a 4 byte field used to store from - 231 to 231-1; 4) "disp32*N field" which is a 1 byte field used to store from -128 to 127, which column has sub-columns with "N=1," "N=2," and "N=64." - The values in the rows in the "byte" column increase down the column. The second column, the third column, and each of the sub-columns include a blackened circle in the rows for address that can be generated by that field. It is worth nothing that the disp8 field, the disp32 field, and where N=1 have a blackened dot for every byte with their range signifying that these field increment on a byte granularity. In contrast, the N=2 column increments by two bytes and accordingly only has a blackened dot for every other byte within its range; as such, it has a wider range but a courser granularity as compared to the disp8 field, while at the same time it requires one fourth the bytes of the disp32 field. The N=64 column increments by 64 bytes and accordingly only has a blackened dot for every 64th byte within its range; as such, it has a wider range but a courser granularity as compared to the disp8 field and N=2, while at the same time it again requires one fourth the bytes of the disp32 field.
-
Figure 7A is a table illustrating the group of possible operations that may be specified by theround control field 254A according to embodiments of the invention.Figure 7A shows a first column contains the possible content of the beta field 254 (which is acting as theround control field 254A and which is broken down into theSAE field 256 and the round operation field 258). - Similarly,
figure 7B is a table illustrating the group of possible operations that may be specified by theround control field 259A according to embodiments of the invention. In the case of class B instruction templates, there is noSAE field 256 and floating point exception suppression is always active. - Note that in one embodiment in which some instructions already allow the specification of the rounding mode statically via immediate bits, the immediate bits takes precedence over the rounding
mode operation field - The following table lists some exemplary data types used herein (some of which are described in Microsoft's® DirectX® 10 (see Microsoft®, DirectX®, Data Conversion Rules (Aug. 17, 2010)):
FLOAT10 10-bit floating-point number (unsigned) FLOAT11 11-bit floating-point number (unsigned) FLOAT 16 16-bit floating-point number FLOAT16RZ a float 16 with the rounding mode being round toward zero (RZ) FLOAT32 32-bit floating-point number FLOAT64 64-bit floating-point number UINT8 8-bit value that maps to an integer number in the range [0, 255] UINT16 16-bit value that maps to an integer number in the range [0, 65535] UINT32 32-bit value that maps to an integer number in the range [0, 232 - 1] UINT64 64-bit value that maps to an integer number SINT8 8-bit value that maps to an integer number in the range [-128, 127] SINT16 16-bit value that maps to an integer number in the range [-32768, 32767] SINT32 32-bit value that maps to an integer number in the range [-231, 231 - 1] SINT64 64-bit value that maps to an integer number UNORM2 2-bit value that maps to a floating-point number in the range [0, 1] UNORM8 8-bit value that maps to a floating-point number in the range [0, 1] UNORM10 10-bit value that maps to a floating-point number in the range [0, 1] UNORM16 16-bit value that maps to a floating-point number in the range [0, 1] SNORM8 8-bit value that maps to a floating-point number in the range [-1, 1] SNORM16 16-bit value that maps to a floating-point number in the range [-1, 1] SRGB8 8-bit value that maps through a gamma correction function (generally implemented as a lookup table) to a floating-point number in the range [0, 1] - UNORM indicates an unsigned normalized integer, meaning that for an n-bit number, all 0's means 0.0f, and all 1's means 1.0f A sequence of evenly spaced floating point values from 0.0f to 1.0f are represented, e.g. a 2-bit UNORM represents 0.0f, 1/3, 2/3, and 1.0f.
- SNORM indicates a signed normalized integer, meaning that for an n-
bit 2's complement number, the maximum value means 1.0f (e.g. the 5-bit value 01111 maps to 1.0f), and the minimum value means -1.0f (e.g. the 5-bit value 10000 maps to -1.0f). In addition, the second-minimum number maps to -1.0f (e.g. the 5-bit value 10001 maps to -1.0f). There are thus two integer representations for -1.0f. There is a single representation for 0.0f, and a single representation for 1.0f. This results in a set of integer representations for evenly spaced floating point values in the range (-1.0f...0.0f), and also a complementary set of representations for numbers in the range (0.0f...1.0f). - As previously described, SIMD technology is especially suited to processors that can logically divide the bits in a register into a number of fixed/sized data elements, each of which represents a separate value. This type of data is referred to as the packed data type or vector data type, and operands of this data type are referred to as packed data operands or vector operands. Typically the data elements of a vector operand are of the same data type; the data type of a given data element is referred to as the data element data type. Where the data element data type of all of the data elements is the same, then the vector operand may be referred to as being of that data type (e.g., where all of the data elements of a vector operand are of the 32-bit floating-point data element data type, then the vector operand may be referred to as a 32-bit floating-point vector operand).
- Embodiments of the invention are described which support single value data element data types and multiple value data element data types. The single value data element data types store in each data element a single value; examples of single value data element data types used in some embodiments of the invention are 32-bit floating-point, 64-bit floating-point, 32-bit unsigned integer, 64-bit unsigned integer, 32-bit signed integer, and 64-bit signed integer. The multiple value data element data types store in each data element position a packet with multiple values contained therein; examples of multiple value data element data types used in some embodiments of the invention are the packed graphics data element data types described below:
- UNORM10A10B10C2D: A 32-bit packet of three UNORM10 values and one UNORM2 value, begin with the last 2b (10b) field located in the most-significant bits of the 32b field (e.g., unorm2D [31-30]
float 10C [29-20]float 10B [20-10]float 10A [9-0], where D-A signify slot position and the preceding names/numbers signify the format). - FLOAT11A11B10C: A 32-bit packet of two FLOAT11 values and one FLOAT10 value, begin the last one located in the higher order bits (e.g., float 10C [31-22]
float 11B [21-11]float 11A [10-0]). - It should be noted that while one the different values in a packet of the multiple value data element data types above is represented by different numbers of bits, alternative embodiments may have different configurations (e.g., more of the values represented by the different number of bits, all of the values represented by the same number of bits).
- While embodiments are described that support both a single value data element data type and a multiple value data element data type, alternative embodiments may support one or the other. In addition, while embodiments of the invention are described that utilize certain data types, alternative embodiments of the invention may utilize more, less, or different data types.
-
Figures 8A-8B are tables illustrating the groups of possible data transform operations that may be specified by the data transform field according to embodiments of the invention. The first column in both tables illustrates the possible values of the content of the data transformfield 254B; the second column the function, and the third column the usage. -
Figure 8A is a table illustrating the group of possible data transform operations that may be specified by the data transform field when the data element width is 64 bits according to embodiments of the invention. This table is referred to as the 64-bit Register SwizzUpConv swizzle primitives and it is representation of theblock 418. Notation: dcba denotes the 64-bit elements that form one 256-bit block in the source (with 'a' least-significant and 'd' most-significant), so aaaa means that the least-significant element of the 256-bit block in the source is replicated to all four elements of the same 256-bit block in the destination; the depicted pattern is then repeated for the two 256-bit blocks in the source and destination. The notation 'hgfe dcba' is used to denote a full source register, where 'a' is the least-significant element and 'h' is the most-significant element. However, since each 256-bit block performs the same permutation for register swizzles, only the least-significant block is illustrated. -
Figure 8B is a table illustrating the group of possible data transform operations that may be specified by the data transform field when the data element width is 32 bits according to embodiments of the invention. This table is referred to as the 32-bit Register SwizzUpConv swizzle primitives and it is representation of theblock 420. Notation: dcba denotes the 32-bit elements that form one 128-bit block in the source (with 'a' least-significant and 'd' most-significant), so aaaa means that the least-significant element of the 128-bit block in the source is replicated to all four elements of the same 128-bit block in the destination; the depicted pattern is then repeated for all four 128-bit blocks in the source and destination. The phrase 'ponm lkji hgfe dcba' is used to denote a source register, where 'a' is the least-significant element and 'p' is the most-significant element. However, since each 128-bit block performs the same permutation for register swizzles, only the least-significant block is shown. -
Figure 8B calls out two exemplary operations to further illustrate the meaning of all of the operations shown inFigures 8A-8B : thecross-product swizzle 815 which is illustrated inFigure 9 and the broadcast an element across 4-element packets 820 illustrated inFigure 10A . -
Figure 9 is a block diagram illustrating thecross product swizzle 815 according to embodiments of the invention.Figure 9 shows asource operand 900 and adestination operand 910 that are both 512 bits wide and broken into consecutive 128 blocks (referred to as packet positions 3-0), where each block is broken into four 32 bit data elements (e.g., the contents ofpacket position 0 in thesource operand 900 are D0 C0 B0 A0, while the contents ofpacket position 0 in thedestination operand 910 are D0 A0 C0 B0. -
Figure 10A is a block diagram illustrating the broadcast of an element across 4-element packets 820 according to embodiments of the invention.Figure 10A shows asource operand 1000 and adestination operand 1010 that are both 512 bits wide and broken into consecutive 128 blocks (referred to as packet positions 3-0), where each block is broken into four 32 bit data elements (e.g., the contents ofpacket position 0 in thesource operand 1000 are D0 C0 B0 A0, while the contents ofpacket position 0 in thedestination operand 910 are A0 A0 A0 A0; the contents ofpacket position 1 in thesource operand 1000 are D1 C1 B1 A1, while the contents ofpacket position 1 in thedestination operand 1010 are A1 A1 A1 A1). - While
Figure 10A is an example broadcast for a no memory access operation,Figures 10B-10C are example broadcasts for memory access operations. When the source memory operand contains fewer than the total number of elements, it can be broadcast (repeated) to form the full number of elements of the effective source operand (16 for 32-bit instructions, 8 for 64-bit instructions). These types of broadcast operations are referred to inFigures 12A-12D . There are two broadcast granularities: - 1-element granularity where the 1 element of the source memory operand is broadcast 16 times to form a full 16-element effective source operand (for 32-bit instructions), or 8 times to form a full 8-element effective source operand (for 64-bit instructions).
Figure 10B is a block diagram illustrating the broadcast of 1-element granularity for a 32 bit data element width according to embodiments of the invention. An example of the operation is labeled 1210 inFigure 12B .Figure 10B shows asource operand 1020 sourced from memory having one 32 bit data element (A0) and adestination operand 1030 that is 512 bits wide and contains sixteen 32 bit data elements (all of the data elements are A0 in the destination operand 1030). 1- element broadcasts useful for instructions that mix vector and scalar sources, where one of the sources is common across the different operations. - 4-element granularity where the 4 elements of the source memory operand is broadcast 4 times to form a full 16-element effective source operand (for 32-bit instructions), or 2 times to form a full 8-element effective source operand (for 64-bit instructions).
Figure 10C is a block diagram illustrating the broadcast 4-element granularity for 32 bit data elements according to embodiments of the invention. An example of the operation is labeled 1220 inFigure 12B .Figure 10C shows asource operand 1040 sourced from memory having four 32 bit data elements (D0 C0 B0 A0) and adestination operand 1050 that is 512 bits wide and broken into consecutive 128 blocks (referred to as packet positions 3-0), where each block is broken into four 32 bit data elements (e.g., the contents in each of the packet positions 3-0 of thedestination operand 1050 are D0 C0 B0 A0). 4 to 16 broadcasts are very useful for AOS (array of structures) source code, where the computation is performed over an array of packed values (like color components RGBA); in this case, 4 to 16 is advantageous when there is a common packet used across the different operations of a vector instruction (a 16-element vector is considered an array of 4 packets of 4 elements each). -
Figure 11A is a table illustrating the group of possible opcode maps that may be specified by the opcode map field according to embodiments of the invention. The first column illustrates the possible values of the content of theopcode map field 315; the second column the implied leading opcode bytes, and the third column whether an immediate may be present. -
Figure 11B is a table illustrating the group of possible prefix encodings that may be specified by the opcode map field according to embodiments of the invention. The first column illustrates the possible values of the content of theprefix encoding field 325; and the second column the meaning of that prefix. -
Figures 12-15 are tables illustrating the groups of possible data manipulation operations and broadcast operation that may be respectively specified by thedata manipulation field 254C and, forfigures 12A-D thebroadcast field 257B, according to embodiments of the invention. The first column in the tables illustrates the possible values of the content of thedata manipulation field 254C; the second column the function, and the third column the usage. -
Figures 12A-12D are tables illustrating the groups of possible data manipulation operations and broadcast operation that may be respectively specified by thedata manipulation field 254C and thebroadcast field 257B for the load/op instructions according to embodiments of the invention. In the case of the exemplary specific vector friendly instruction format infigures 3A-D , thedata manipulation field 254C is a three bit field and thebroadcast field 257B is a one bit field. In the illustrated embodiments, the broadcast field's 257B content selects between the first two rows in the tables found infigures 12A-D ; in other words, its contents selects between the equivalent of 000 and 001 in thedata manipulation field 254C. This is illustrated infigure 12A-D using bracket that includes only the first two rows of the tables. -
Figure 12A is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C andbroadcast field 257B for a load/op int where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the 64-bit Integer Load-op SwizzUpConv i64 (Quadword) swizzle/convert primitives and it is a representation of theblock 444A and block 444B. -
Figure 12B is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C andbroadcast field 257B for a load/op int where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the 32-bit Integer Load-op SwizzUpConv i32 swizzle/convert primitives and it is a representation of theblock 446A and block 446B. -
Figure 12C is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C andbroadcast field 257B for a load/op fp where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the 64-bit Floating-point Load-op SwizzUpConv f64 swizzle/convert primitives and it is a representation of theblock 450A and block 450B. -
Figure 12D is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C andbroadcast field 257B for a load/op fp where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the 32-bit Floating-point Load-op SwizzUpConv f32 swizzle/convert primitives and it is a representation of theblock 452A and block 452B. -
Figures 13A-13D are tables illustrating the groups of possible data manipulation operations that may be specified by the data manipulation field for the load instructions according to embodiments of the invention. -
Figure 13A is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load int where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the UpConvi64 and it is a representation of theblock 456. -
Figure 13B is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load int where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the UpConvi32 and it is a representation of theblock 458. -
Figure 13C is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load fp where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the UpConvf64 and it is a representation of theblock 462. -
Figure 13D is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load fp where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the UpConvf32 and it is a representation of theblock 464. - The groups of possible data manipulation operations specified in each of
Figures 13A-13D (the load/op tables) are a subset of those in the correspondingFigures 12A-12D (the load tables). Specifically, the subsets do not include broadcast operations. This is done because certain values in the full opcode field 274 (e.g., those that specify gather or broadcast operations) cannot be used in combination with broadcasts specified in thedata manipulation field 254C, and thus such values in thefull opcode field 274 can be used only with the loads ofFigures 12A-12D (the load tables). By way of more specific example, if there is a value in thefull opcode field 274 that specifies a broadcast operation, thedata manipulation field 254C cannot also indicate a broadcast operation. While certain embodiments of the invention include the separate load/op and load operations with separate load/op and load tables, alternative embodiments need not have this enforcement mechanism (e.g., they may support only load/op, they may support only load, they may determine that a broadcast in thefull opcode field 274 causes a broadcast in thedata manipulation field 254C to be ignore). -
Figures 14A-14D are tables illustrating the groups of possible data manipulation operations that may be specified by the data manipulation field for the store instructions according to embodiments of the invention. -
Figure 14A is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a store int where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the DownConvi64 and it is a representation of theblock 470. -
Figure 14B is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a store int where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the DownConvi32 and it is a representation of theblock 472. -
Figure 14C is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a store fp where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the DownConvf64 and it is a representation of theblock 476. -
Figure 14D is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a store fp where the data element width is 64 bits according to embodiments of the invention. This table is referred to as the DownConvf32 and it is a representation of theblock 478. -
Figures 15A-15C are tables illustrating the groups of possible data manipulation operations that may be specified by the data manipulation field for the instructions that operate on the graphics data types according to embodiments of the invention. -
Figure 15A is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load graphics where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the UpConvg32 and it is a representation of theblock 480. -
Figure 15B is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a load packed graphics where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the UpConvpg32 and it is a representation of theblock 482. -
Figure 15C is a table illustrating the group of possible data manipulation operations that may be specified by thedata manipulation field 254C for a store graphics where the data element width is 32 bits according to embodiments of the invention. This table is referred to as the UpConvg32 and it is a representation of theblock 484. -
Figures 16A-16B illustrate two merging operations performed with different write masks and with the second source and destination being the same according to embodiments of the invention.Figure 16A is a block diagram illustrating an exemplary operation 1600 that merges using the write mask in write mask register K1 where the data element width is 32 bits and where the second source and destination are the same according to embodiments of the invention.Figure 16A shows asource operand 1605; a source/destination operand 1610; the content of the mask register K1 1615 (with the lower 16 bits including a mix of ones and zeros); and thedestination operand 1620. Each of the lower 16 bit positions in the mask register K1 corresponds to one of the data element positions (K1 [0] todata element position 0, K1 [1] todata element position 1, and so one). For each data element position in thedestination operand 1620, it contains the content of that data element position in the source/destination 1610 or the result of the operation (illustrated as an add) depending on whether the corresponding bit position in the mask register K1 is a zero or 1, respectively. In other embodiments, source/destination operand 1610 is replaced with a second source operand. In those embodiments, thedestination operand 1620 contains the contents of thedestination operand 1620 from before the operation in those of the data element positions in which the corresponding bit positions of the mask register K1 are zero (if any) and contains the result of the operation in those of the data element positions in which of the corresponding bit positions of the mask register K1 are 1 (if any). - As previously described, one embodiment of the invention uses K0 to indicate no masking should be performed.
Figure 16B is a block diagram illustrating an exemplary operation 1625 that merges using the hardwired mask of all ones (the hardwired write mask is used by instructions that specify write mask register k0) where the data element width is 32 bits and where the second source and destination are the same according to embodiments of the invention.Figure 16B is identical toFigure 16A , except thatK1 1615 is replaced with hardwired mask 1630 and thatdestination operand 1620 is replaced withdestination operand 1635. The hardwired mask 1630 is all ones, and thus thedestination operand 1635 contains data elements representative of the result of the operation. -
Figure 16C is a block diagram illustrating the correspondence of bits in the write mask registers to the data element positions of a 512 bit vector for the 8, 16, 32, and 64 bit data element widths according to embodiments of the invention. Specifically, a 64bit register K N 1640 is illustrated, where all 64 bits are used when the data element width is 8 bits, only the least significant 32 bits are used when the data element width is 16 bits, only the least significant 16 bits are used when the data element width is 32 bits, and only the least significant 8 bits are used when the data element width is 64 bits. For a 256 bit vector, only the least significant 32 bits are used when the data element width is 8 bits, only the least significant 16 bits are used when the data element width is 16 bits, only the least significant 8 bits are used when the data element width is 32 bits, and only the least significant 4 bits are used when the data element width is 64 bits. For a 128 bit vector, only the least significant 16 bits are used when the data element width is 8 bits, only the least significant 8 bits are used when the data element width is 16 bits, only the least significant 2 bits are used when the data element width is 32 bits, and only the least significant 2 bits are used when the data element width is 64 bits. - The value of a given mask register can be set up as a direct result of a vector comparison instruction, transferred from a GP register, or calculated as a direct result of a logical operation between two masks.
-
Figure 16D is a block diagram illustrating an exemplary operation 1660 that merges using the write mask in writemask register K1 where the data element width is 32 bits and where the second source and destination are different according to embodiments of the invention. -
Figure 16E is a block diagram illustrating an exemplary operation 1666 that zeros using the write mask in writemask register K1 where the data element width is 32 bits and where the second source and destination are different according to embodiments of the invention. While the zeroing operation is illustrated only relative to an operation where the destination is different from the sources, zeroing also works where the second source and destination are the same. - The following notations are provided by way of introduction to
Figures 17-18 .Operand Notation Notation Meaning zmm1 A vector register operand in the argument1 field of the instruction. The 64 byte vector registers are: zmm0 through zmm31 zmm2 A vector register operand in the argument2 field of the instruction. The 64 byte vector registers are: zmm0 through zmm31 zmm3 A vector register operand in the argument3 field of the instruction. The 64 byte vector registers are: zmm0 through zmm31 S f32(zmm/m) A vector floating-point 32-bit swizzle/conversion. S f64(zmm/m) A vector floating-point 64-bit swizzle/conversion. S i32(zmm/m) A vector integer 32-bit swizzle/conversion. S i64(zmm/m) A vector integer 64-bit swizzle/conversion. U f32(m) A floating-point 32-bit load Upconversion. U g32(m) A graphics floating-point 32-bit load Upconversion. U pg32(m) A packed graphics floating-point 32-bit load Upconversion. U i32(m) An integer 32-bit load Upconversion. U f64(m) A floating-point 64-bit load Upconversion. U i64(m) An integer 64-bit load Upconversion. D f32(zmm) A floating-point 32-bit store Downconversion. D g32(zmm) A graphics floating-point 32-bit store Downconversion. D i32(zmm) An integer 32-bit store Downconversion. D f64(zmm) A floating-point 64-bit store Downconversion. D i64(zmm) An integer 64-bit store Downconversion. m A memory operand. mt A memory operand that may have a EH hint attribute. mvt A vector memory operand that may have a EH hint attribute. This memory operand is encoded using ModRM and VSIB bytes. It can be seen as a set of pointers where each pointer is equal to BASE + V INDEX[i] × SCALE effective_address Used to denote the full effective address when dealing with a memory operand. imm8 An immediate byte value. SRC[a-b] A bit-field from an operand ranging from LSB b to MSB a. Vector Operand Value Notation Notation Meaning zmm1[i+31:i] The value of the element located between bit i and bit i+31 of the argument 1 vector operand.zmm2[i+31:i] The value of the element located between bit i and bit i+31 of the argument2 vector operand. k1[i] Specifies the i-th bit in the vector mask register k1. {k1} A mask register operand in the write mask field of the instruction used with merging behavior. The 64 bit mask registers are: k0 through k7 {k1} {z} A mask register operand in the write mask field of the instruction used with zeroing behavior. The 64 bit mask registers are: k0 through k7 SwizzUpConv, FullUpConv and DownConv function conventions Swizzle/conversion used Function used in operation description S f32(zmm/m) SwizzUpConvLoad f32(zmm/m) S f64(zmm/m) SwizzUpConvLoad f64(zmm/m) S i32(zmm/m) SwizzUpConvLoad i32(zmm/m) S i64(zmm/m) SwizzUpConvLoad i64(zmm/m) U f32(m) UpConvLoad f32(m) U g32(m) UpConvLoad g32(m) U pg32(m) UpConvLoad pg32(m) U i32(m) UpConvLoad i32(m) U f64(m) UpConvLoad f64(m) U i64 (m) UpConvLoad i64(m) D f32(zmm) DownConvStore f32(zmm) or DownConvStore f32(zmm[xx:yy]) D g32(zmm) DownConvStore g32(zmm) or DownConvStore g32(zmm[xx:yy]) D i32(zmm) DownConvStore i32(zmm) or DownConvStore i32(zmm[xx:yy]) D f64(zmm) DownConvStore f64(zmm) or DownConvStore f64(zmm[xx:yy]) D i64(zmm) DownConvStore i64(zmm) or DownConvStore i64(zmm[xx:yy]) -
Figure 17A illustrates a subset of fields from an exemplary specific vector friendly instruction format according to embodiments of the invention. Specifically,Figure 17A shows anEVEX Prefix 302, aReal Opcode Field 330, and a MOD R/M Field 340. In this embodiment, theFormat Field 240 contains 0x62 to indicate that the instruction format is the vector friendly instruction format. -
Figures 17B-17D each illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format ofFigure 17A according to embodiments of the invention. In the description ofFigure 17B-17D , the specific uses of some fields are described to demonstrate possible encodings of those fields for various exemplary configurations of the VADDPS instruction. In each of theFigures 17B-17D , theFormat Field 240 contains 0x62 to indicate that the instruction is encoded in the vector friendly instruction format and thereal opcode field 330 contains the VADDPS opcode.Figures 17B-17D each illustrates an encoding of the VADDPS instruction in the EVEX.U0 class according to embodiments of the invention;Figure 17B and Figure 17C each illustrates an EXEV.U0 encoding of VADDPS in a nomemory access 205 instruction template whileFigure 17D illustrates an EVEX.U0 encoding of VADDPS in amemory access 220 instruction template. The VADDPS instruction adds packed single-prevision floating-point values from a first register or memory operand (e.g. zmm3) to a second register (e.g. zmm2) and stores the result in a third register (e.g. zmm1) according to a writemask (e.g. k1). This instruction allows for various round operations, data transform operations, or data manipulation operations depending on the encoding of the instruction. This instruction may be described by the following instruction mnemonic: EVEX.U0.NDS.512.0F 58 /r VADDPS zmm1 {k1}, zmm2, Sf32(zmm3/mV) {eh}. -
Figure 17B illustrates an encoding of the VADDPS instruction in the no memory access, full roundcontrol type operation 210 instruction template. The dataelement width field 264 is 0 to indicate 32 bit data element width. The class field 268 (i.e. EVEX.U) is set to 0 to indicate the EVEX.U0 class. Thealpha field 252 is interpreted as aRS field 252A (i.e. EVEX.rs) and is set to 1 (i.e. RS field 252A.1) to select the round control type operation. Since thealpha field 252 is acting as RS field 252A.1, thebeta field 254 is interpreted as a round operation field 258 (i.e. EVEX.r2-0). Specifically, EVEX.r2 is interpreted as aSAE field 256 while EVEX.r1-0 act as theround control field 254A. The modifier field 246 (i.e. MODR/M.MOD 342) is set to 11 to indicate no memory access (i.e. register zmm3 is the first source operand instead of a memory operand). -
Figure 17C illustrates an encoding of the VADDPS instruction in the no memory access, data transformtype operation 215 instruction template. The encoding ofFigure 17C is identical toFigure 17B except for thealpha field 252 and thebeta field 254. Thealpha field 252 is interpreted as aRS field 252A (i.e. EVEX.rs) and is set to 0 (i.e. RS field 252A.2) to select the data transform type operation. Since thealpha field 252 is acting as RS field 252A.2, thebeta field 254 is interpreted as adata transform field 254B (i.e. EVEX.S2-0). -
Figure 17D illustrates an encoding of the VADDPS instruction in thememory access 220 instruction template. The dataelement width field 264 is 0 to indicate 32 bit data element width. The class field 268 (i.e. EVEX.U) is set to 0 to indicate the EVEX.U0 class. Thealpha field 252 is interpreted as aneviction hint field 252B (i.e. EVEX.EH). Thebeta field 254 is interpreted as adata manipulation field 254C (i.e. EVEX.s2-0). The modifier field 246 (i.e. MODR/M.MOD 342) is set to either 00, 01, or 10 to indicate that the first source operand is a memory operand; this is shown inFigure 17D as11 (i.e. any input except 11). -
Figure 18A illustrates a subset of fields from an exemplary specific vector friendly instruction format according to embodiments of the invention. Specifically,Figure 1 *A shows anEVEX Prefix 302, aReal Opcode Field 330, and a MOD R/M Field 340. In this embodiment, theFormat Field 240 contains 0x62 to indicate that the instruction format is the vector friendly instruction format. -
Figures 18B-18F each illustrates a subset of fields from an exemplary specific vector friendly instruction encoded in the specific vector friend instruction format ofFigure 18A according to embodiments of the invention. In the description ofFigure 18B-18F , the specific uses of some fields are described to demonstrate possible encodings of those fields for various exemplary configurations of the VADDPS instruction. In each of theFigures 18B-18F theFormat Field 240 contains 0x62 to indicate that the instruction is encoded in the vector friendly instruction format and thereal opcode field 330 contains the VADDPS opcode.Figures 18B-18F each illustrates an encoding of the VADDPS instruction in the EVEX.U1 class according to embodiments of the invention;Figure 18B-18E each illustrates an EXEV.U1 encoding of VADDPS in a nomemory access 205 instruction template whileFigure 18F illustrates an EVEX.U1 encoding of VADDPS in amemory access 220 instruction template. -
Figure 18B illustrates an encoding of the VADDPS instruction in the no memory access, write mask control, partial roundcontrol type operation 212 instruction template. The dataelement width field 264 is 0 to indicate 32 bit data element width. The class field 268 (i.e. EVEX.U) is set to 1 to indicate the EVEX.U1 class. Thealpha field 252 is interpreted as a writemask control field 252C (selecting between a merging or zeroing writemask). The least significant bit of thebeta field 254 is interpreted as anRL field 257A and is set to 1 to indicate a partial round type operation (i.e. round 257A.1). The two most significant bits of thebeta field 254 are interpreted as around operation field 259A. The modifier field 246 (i.e. MODR/M.MOD 342) is set to 11 to indicate no memory access (i.e. register zmm3 is the first source operand instead of a memory operand). In this encoding, the VADDPS instruction adds a packed single-precision floating-point value from a first register (e.g. zmm3) to a second register (e.g. zmm2) and stores the rounded result in a third register (e.g. zmm1) according to a writemask (e.g. k1). This may be described by the following mnemonic: EVEX.U1.NDS.512.0F.W0 58 /r VADDPS zmml {k1} {z}, zmm2, zmm3 {er} for zeroing-writemasking and the same without the {z} for merging-writemasking. While the other mnemonics show below in this section all include {z}, it should be understood that the same mnemonic without the {z} is similarly also possible. -
Figures 18C-18E each illustrates an encoding of the VADDPS instruction in the no memory access, write mask control,VSIZE type operation 217 instruction template. The encoding ofFigures 18C-18E are identical toFigure 17B except for the beta field. In each ofFigures 18C-18E , the least significant bit of thebeta field 254 is interpreted as anRL field 257A and is set to 0 to indicate a VSIZE type operation 257A.2. The two most significant bits of thebeta field 254 are interpreted as avector length field 259B. - In
Figure 18C , thevector length field 259B is set to 10 to indicate a vector size of 512 bits. InFigure 18D , thevector length field 259B is set to 01 to indicate a vector size of 256 bits. InFigure 18E , thevector length field 259B is set to 00 to indicate a vector size of 128 bits. In this encoding, the VADDPS instruction adds a packed single-precision floating-point value from a first register (e.g. zmm3) to a second register (e.g. zmm2) and stores the result in a third register (e.g. zmm1) according to a writemask (e.g. k1).Figure 18C may be described by the following mnemonic: EVEX.U1.NDS.512.0F.W0 58 /r VADDPS zmm1 {k1} {z}, zmm2, zmm3.Figure 18D may be described by the following mnemonic: EVEX.U1.NDS.256.0F.W0 58 /r VADDPS ymm1 {k1} {z}, ymm2, ymm3.Figure 18E may be described by the following mnemonic: EVEX.U1.NDS.128.0F.W0 58 /r VADDPS xmm1 {k1} {z}, xmm2, xmm3. -
Figure 18F illustrates an encoding of the VADDPS instruction in the memory access, writemask control 227 instruction template. The dataelement width field 264 is 0 to indicate 32 bit data element width. The class field 268 (i.e. EVEX.U) is set to 1 to indicate the EVEX.U1 class. Thealpha field 252 is interpreted as a writemask control field 252C (selecting between a merging or zeroing writemask). The least significant bit of thebeta field 254 is interpreted as abroadcast field 257B. The two most significant bits of thebeta field 254 are interpreted as avector length field 259B. The modifier field 246 (i.e. MODR/M.MOD 342) is set to either 00, 01, or 10 to indicate that the first source operand is a memory operand; this is shown inFigure 17D as11 (i.e. any input except 11). In this encoding, the VADDPS instruction adds a packed single-precision floating-point value from a memory operand, that can be broadcast upon loading, to a first register (e.g. zmm2) and stores the result in a second register (e.g. zmm1) according to a writemask (e.g. kl). When the vector length field indicates vectors of 512 bits, this may be described by the following mnemonic: EVEX.U1.NDS.512.0F.W0 58 /r VADDPS zmm1 {k1} {z}, zmm2, B32(mV). When the vector length field indicates vectors of 256 bits, this may be described by the following mnemonic: EVEX.U1.NDS.256.0F.W0 58/r VADDPS ymm1 {k1} {z}, ymm2, B32(mV). When the vector length field indicates vectors of 128 bits, this may be described by the following mnemonic: EVEX.U1.NDS.128.0F.W0 58/r VADDPS xmm1 {k1} {z}, xmm2, B32(mV). - In one embodiment of the invention, the memory access size N is determined based on contents of two or more of the base operation field, the data element width field, and the augmentation operation field depending on the instruction template being used and other factors as described below. In one embodiment of the invention, with regard to U=0 (Class A), the below tables show the size of the vector (or element) being accessed in memory and, analogously, the displacement factor for compressed displacement (disp8*N). Note that some instructions work at element granularity instead of full vector granularity at the level of memory, and hence should use the "element level" column in the tables below. The function column's label (e.g., U/Si64) signifies the memory access type specified by the base operation field (e.g., U/Si signifies load int and load/op int) and data element width (e.g., 64 is a 64 bit data element width). The values in this column are the possible values of the
data manipulation field 254C in the embodiment ofFigure 3 . Referring toFigure 4B , the various memory access types are shown flowing (in some cases through a data element width decision) to their data manipulationFigures 12A-15C ; the various tables 12A-15C drive the selection of N's value, and thus are placed oncolumns op int 64 bit data element width memory access operation flows tofigure 12A , at which the data manipulation field's 254C content is used to both select the data manipulation operation (as indicted infigure 12A ) and the value of N (as indicated below). By way of another example, aload int 64 bit data element width memory access operation (which indicates a broadcast in the base operation field 242) flows tofigure 13A , at which the data manipulation field's 254C content is used to both select the data manipulation operation (as indicted infigure 13A , which does not include broadcast data transforms) and the value of N (as indicated below). Thus, the second column is for instructions whosebase operation field 242 does not specify a broadcast or element level memory access; the third column's first sub-column is for instructions whosebase operation field 242 specifies a broadcast but does not specify an element level memory access; and the third column's second sub-column is for instructions whosebase operation field 242 specifies a broadcast or an element level memory access.SwizzleUpConvert i64 and UpConvert i64 Function S/U i64 Figure 12A Figure 13A No broadcast or element level memory access specified by base operation field 4 to 16 broadcast specified by base operation field 1 to 16 broadcast or element level memory access specified by base operation field 000 64 32 8 001 8 NA NA 010 32 NA NA 011 NA NA NA 100 NA NA NA 101 NA NA NA 110 NA NA NA 111 NA NA NA SwizzleUpConvert i32 and UpConvert i32 Function S/U i32 Figure 12B Figure 13B No broadcast or element level memory access specified by base operation field 4tol6 broadcast specified by base operation field 1 to 16 broadcast or element level memory access specified by base operation field 000 64 16 4 001 4 NA NA 010 16 NA NA 011 NA NA NA 100 16 4 1 101 16 4 1 110 32 8 2 111 32 8 2 SwizzleUpConvert f64 and UpConvert f64 Function S/U f64 Figure 12C Figure 13C No broadcast or element level memory access specified by base operation field 4 to 16 broadcast specified by base operation field 1 to 16 broadcast or element level memory access specified by base operation field 000 64 32 8 001 8 NA NA 010 32 NA NA 011 NA NA NA 100 NA NA NA 101 NA NA NA 110 NA NA NA 111 NA NA NA SwizzleUpConvert f32 and UpConvert f32 Function S/U f32 Figure 12D Figure 13D No broadcast or element level memory access specified by base operation field 4 to 16 broadcast specified by base operation field 1 to 16 broadcast or element level memory access specified by base operation field 000 64 16 4 001 4 NA NA 010 16 NA NA 011 32 8 2 100 16 4 1 101 16 4 1 110 32 8 2 111 32 8 2 Down Conversion i64 Function D i64 Figure 14A Figure 14A Regular store specified by base operation field Not Applicable Element level memory access specified by base operation field 000 64 NA 8 001 NA NA NA 010 NA NA NA 011 NA NA NA 100 NA NA NA 101 NA NA NA 110 NA NA NA 111 NA NA NA Down Conversion i32 Function D i32 Figure 14B Figure 14B Regular store specified by base operation field Not Applicable Element level memory access specified by base operation field 1 000 64 NA 4 001 NA NA NA 010 NA NA NA 011 NA NA NA 100 16 NA 1 101 16 NA 1 110 32 NA 2 111 32 NA 2 Down Conversion f64 Function D f64 Figure 14C Figure 14C Regular store specified by base operation field Not Applicable Element level memory access specified by base operation field 000 64 NA 8 001 NA NA NA 010 NA NA NA 011 NA NA NA 100 NA NA NA 101 NA NA NA 110 NA NA NA 111 NA NA NA Down Conversion f32 Function D f32 Figure 14D Figure 14D Regular store specified by base operation field Not Applicable Element level memory access specified by base operation field 000 64 NA 4 001 NA NA NA 010 NA NA NA 011 32 NA 2 100 16 NA 1 101 16 NA 1 110 32 NA 2 111 32 NA 2 UpConvert g32 Function U g32 Figure 15A Figure 15A No broadcast or element level memory access specified by base operation field 4 to 16 broadcast specified by base operation field 1 to 16 broadcast or element level memory access specified by base operation field 000 64 16 4 001 NA NA NA 010 16 4 1 011 NA NA NA 100 16 4 1 101 16 4 1 110 32 8 2 111 32 8 2 UpConvert pg32 Function U pg32 Figure 15B Figure 15B No broadcast or element level memory access specified by base operation field 4 to 16 broadcast specified by base operation field 1 to 16 broadcast or element level memory access specified by base operation field 000 64 16 4 001 64 16 4 010 64 16 4 011 64 16 4 100 64 16 4 101 64 16 4 110 64 16 4 111 64 16 4 Down Conversion g32 Function D g32 Figure 15C Figure 15C Regular store specified by base operation field Not Applicable Element level memory access specified by base operation field 000 64 NA 4 001 NA NA NA 010 NA NA NA 011 32 NA 2 100 16 NA 1 101 16 NA 1 110 32 NA 2 111 32 NA 2 - In one embodiment of the invention, with regard to U=1 (Class B), various instructions have the ability to use a compressed displacement by using disp8 in conjunction with a memory access size N that is determined based on the vector length (determined by the content of the
vector length field 259B), the type of vector operation and whether broadcast is being performed (the value of thebase operation field 242 and/or thebroadcast field 257B), and the data element width (determined by the content of thereal opcode field 330 and/or the dataelement width field 264 as described infigure 4E ), for different types of instructions. In general, the memory access size N corresponds to the number of bytes in the memory input (e.g., 64 when the accessing a full 512-bit memory vector). In one embodiment of the invention, the first table below explains some of the terms use in the second table below, and the second table below gives the value of N for various types of instructions. A Tuple in the below tables is a packed structure of data in memory.Full Reads a full vector. Accepts broadcasts (load-op). e.g., VADDPS zmm1, zmm2, zmm3/B(mem) FullMem Reads a full vector. Does not accepts broadcasts (load only). e.g., VMOVAPS zmm1, m512 Scalar Reads a single element from memory to do an scalar operation: VADDSS xmm1, xmm2, m32 Tuple1 Reads a single element from memory. e.g., VBROADCASTSS zmm1, m32 Tuple2 Reads only 2 elements from memory. e.g., VBROADCASTF32X2 zmm1, m64 Tuple4 Reads only 4 elements from memory. e.g., VBROADCASTF32X4 zmm1, m128 Tuple 8 Reads only 8 elements from memory. e.g., VBROADCASTF32X8 zmm1, m256 Half Reads only half of the total elements from memory. e.g., VCVTPS2PD zmm1, B(mem) // only reads 8 SP input values to get 8 DP results HalfMem Same above, but memory only (it does not accept broadcasts), e.g., VPMOVZXBW zmm1, mem // only reads 32 byte input values to get to 32 Word results QuarterMem Reads only a quarter of the total elements from memory. e.g., VPMOVZXBD zmm1, mem // only reads 16 byte input values to get 16 Dword results EighthMem Reads only a quarter of the total elements from memory. e.g., VPMOVZXBQ zmm1, mem // only reads 8 byte input values to get 8 Qword results Mem128 Reads only a package of m128 bits from memory. It does not allow broadcasts. Disp8*N Format Broadcast Input Size Broadcast N (disp8*N) 128-bit N (disp8*N) 256-bit N (disp8*N) 512-bit Comment Full 0 32bit None 16 32 64 LoadOp 1 32bit {1toX} 4 4 4 0 64bit None 16 32 64 1 64bit {1toX} 8 8 8 FullMem 0 N/A None 16 32 64 Load/Store + SubDword 1 N/A N/A N/A N/A Tuple1/Scalar 0 8bit None 1 1 1 Broadcast/Extra ct/Insert (1 element) + Gather/Scatter + Scalar 1 8bit N/A N/A N/A N/A 0 16bit None 2 2 2 1 16bit N/A N/A N/A N/A 0 32bit None 4 4 4 1 32bit N/A N/A N/A N/A 0 64bit None 8 8 8 1 64bit N/A N/A N/A N/A Tuple2 0 32bit None 8 8 8 Broadcast (2 elements) 1 32bit N/A N/A N/A N/A 0 64bit None N/A 16 16 1 64bit N/A N/A N/A N/A Tuple4 0 32bit None N/A 16 16 Broadcast (4 elements) 1 32bit N/A N/A N/A N/A 0 64bit None N/A N/A 32 1 64bit N/A N/A N/A N/A Tuple8 0 32bit None N/A N/A 32 Broadcast (8 elements) 1 32bit N/A N/A N/A N/A 0 64bit N/A N/A N/A N/A 1 64bit N/A N/A N/A N/A Half 0 32bit None 8 16 32 LoadOp (Half mem size) 1 32bit {1toX} 4 4 4 0 64bit N/A N/A N/A N/A 1 64bit N/A N/A N/A N/A HalfMem 0 N/A None 8 16 32 Load/Store + SubDword (Half mem size) 1 N/A N/A N/A N/A QuarterMem 0 N/A None 4 8 16 Load/Store + SubDword (Quarter mem size) 1 N/A N/A N/A N/A EighthMem 0 N/A None 2 4 8 Load/Store + SubDword (Eighth mem size) 1 N/A N/A N/A N/A Mem128 0 N/A None 16 16 16 Shift with shift count from memory 1 N/A N/A N/A N/A - Also, in some embodiments of the invention, different processors or different cores within a processor may support only class A, only class B, or both classes. For instance, a high performance general purpose out-of-order core intended for general-purpose computing may support only class B, a core intended primarily for graphics and/or scientific (throughput) computing may support only class A, and a core intended for both may support both (of course, a core that has some mix of templates and instructions from both classes but not all templates and instructions from both classes is within the purview of the invention). Also, a single processor may include multiple cores, all of which support the same class or in which different cores support different class. For instance, in a processor with separate graphics and general purpose cores, one of the graphics cores intended primarily for graphics and/or scientific computing may support only class A, while one or more of the general purpose cores may be high performance general purpose out-of-order cores intended for general-purpose computing that support only class B. Another processor that does not have a separate graphics core, may include one more general purpose in-order or out-of-order cores that support both class A and class B. Of course, features from one class may also be implement in the other class in different embodiments of the invention. Programs written in a high level language would be put (e.g., just in time compiled or statically compiled) into an variety of different executable forms, including: 1) a form having only instructions of the class(es) supported by the target processor for execution; or 2) a form having alternative routines written using different combinations of the instructions of all classes and having control flow code that selects the routines to execute based on the instructions supported by the processor which is currently executing the code.
Types of Instructions Write Mask Control Field 252C Broadcast Field 257B Loads/broadcast/inserts R Byte/Word operations with memory R Gather/scatter R R Extracts/stores R R Compares R - With regard to loads, broadcast, and inserts, one embodiment of the invention implements different versions of broadcast with the base operation field, and thus the
broadcast field 257B is not needed. For byte/word operations, one embodiment of the invention does not support broadcasts with thebroadcast field 257B because the hardware cost of supporting this feature was not currently justified. As for gather (which is a type of load), one embodiment of the invention implements different versions of broadcast with the base operation field, and thus thebroadcast field 257B is not needed. With regard to scatter, extracts and stores, one embodiment does not support broadcasts with thebroadcast field 257B because these types of instructions have a register source (not a memory source) and a memory destination, and broadcast is only meaningful when memory is the source. The mask of a gather instruction is a completion mask; and thus a merging writemask operation is currently the desired operation. Performing zeroing writemask on a store, scatter, or extract would zero a location in memory - an operation for which a vector store, scatter, or extract is not typically used. For compares, in one embodiment of the invention, zeroing writemasking would be unnatural since the compares already writes 0 if the comparison result is negative (e.g., the two elements compared are not equal in case of equality comparison), and thus might interfere with how the comparison result is interpreted. -
Figures 19-22 are block diagrams illustrating which fields of the instruction templates infigure 2A are utilized in different stages of four exemplary processor pipelines according to embodiments of the invention. It should be noted that at the level of understanding required, the illustrated pipeline stages and their function are well-known. Each offigures 19-22 include an A, B, and C figure respectively illustrating the no memory access, full roundcontrol type operation 210 instruction template; the no memory access, data transformtype operation 215 instruction template; and thememory access 225/230 instruction templates. While each of theFigures 19-22 shows a different exemplary pipeline, the same pipeline is shown in each of the A-C figures for each figure number. For example,Figure 19A shows the no memory access, full roundcontrol type operation 210 instruction template and a first exemplary instruction pipeline;Figure 19B shows the no memory access data transformtype operation 215 and the same exemplary pipeline as inFigure 19A ; whereasFigure 20A shows the no memory access, full roundtype control operation 210 instruction template and the second exemplary processor pipeline. -
Figures 19-22 respectively illustrateprocessor pipeline 1900,processor pipeline 2000, processor pipeline 2100, andprocessor pipeline 2200. Where the pipeline stage name is the same across the different exemplary pipelines, the same reference numeral was used for ease of understanding; however, this does not imply that the same name pipeline stages across the different exemplary pipelines are the same, just that they perform a similar operation (although it may include more or less sub operations). - The
processor pipeline 1900 is represents a generic processor pipeline, and thus it includes a fetchstage 1910, adecode stage 1920, a register read/memory readstage 1930, adata transform stage 1940, an executestage 1950, and a write back/memory write stage 1960. - Brackets and arrowed lines from the instruction templates to the processor pipeline stages illustrate the fields that are utilized by different ones of the pipeline stages. For example, in
Figure 19A , all of the fields are utilized by thedecode stage 1920; theregister index field 244 is utilized by the register read/memory readstage 1930; the rs field 252A (round 252A.1), theSAE field 256, theround operation field 258, and the dataelement width field 264 are utilized by the executestage 1950; the dataelement width field 264 is also utilized by the write back/write memory stage 1960; and thewrite mask field 268 is used by the executestage 1950 or the write back/memory write stage 1960 (The use of thewrite mask field 270 optionally in two different stages represents that the write mask field could disable the execution of the operation on the masked data elements in the execute stage 1950 (thereby preventing those data element positions from being updated in the write/memory write stage 1960), or theexecution stage 1950 could perform the operation and the write mask be applied during the write/memory write stage 1960 to prevent the updating of the masked data element positions). - It should be noted that the arrowed lines do not necessarily represent the only stage (s) utilized by the different fields, but do represent where that field will likely have the largest impact. As between the A and B figures, it will be noted that the main difference is that the
augmentation operation field 250 is utilized by the executestage 1950 for the round operation; theaugmentation operation field 250 is utilized by the data transformstage 1940 for the data transform type operation; and the line from the dataelement width field 264 to the executestage 1950 is moved to the data transformstage 1940.Figure 19C shows thebase operation field 242 instead going to the register read/memory readstage 1930; the EHfield 252B of theaugmentation operation field 250 being utilized by the register read/memory readstage 1930; thescale field 260, thedisplacement field 262A/displacement factor field 262B, thewrite mask field 270, and the dataelement width field 264 being optionally utilized by the register read/memory readstage 1930 or the write back/memory write 1960 depending on whether it is a memory read or memory write operation. Since it is well-known the pipeline stages that would utilize theimmediate field 272, a mapping for that field is not represented in order not to obscure the invention. - The
processor pipeline 2000 represents an in order processor pipeline and has the same named pipeline stages as theprocessor pipeline 2000, but has alength decoding stage 2012 inserted between the fetchstage 1910 and thedecode stage 1920. - The mappings for
Figures 20A-20C are essentially identical to those inFigures 19A-19C . - The processor pipeline 2100 represents an first exemplary out of order pipeline that has the same named pipeline stages as the
processor pipeline 2000, but also has the following: 1) an allocatestage 2122, arenaming stage 2124, and aschedule stage 2126 inserted between thedecode stage 1920 and the register read/memory readstage 1930; and 2) a reorder buffer (rob) readstage 2162, anexception handling stage 2164, and a commitstage 2166 added after the right back/memoryright stage 1960. - In
Figures 21A-21C , the mappings are generally the same as the mappings inFigures 20A-20C , with the following exceptions: 1) that theregister index field 244 and themodifier field 246 are utilized by the renaming stage 2142; 2) in onlyfigure 21A , thewrite mask field 270 is also optionally used by theexception handling stage 2164 to suppress exceptions on masked data element positions; and 3) in onlyfigure 21A , theSAE field 256 is used optionally by the executestage 1950 and theexception handling stage 2164 depending on where floating point exceptions will be suppressed. - The
processor pipeline 2200 represents a second exemplary out of order pipeline that has the same named processor pipeline stages as the processor pipeline 2100, with the exception that the data transform and execution stages have been merged to form and an execute/data transform stage 2245. - The mappings in
Figures 22A-22C are essentially the same as those inFigures 21A-21C , with the exception that the mappings that went separately to the data transformstage 1940 and the executestage 1950 instead go to the execute/data transform stage 2245. - The below table illustrates how to modify
figures 19-22 to accommodate the fields of the instruction templates infigure 2B according to embodiments of the invention.Field Figure Pipeline Stage Write Mask Control Field (Z) 252C 19A-22C Write Back/ Memory Write 1960 and or Execute 1950/224521A- 22C Renaming 2124 Round 257A.1 19A, 20A, 21A Execute 1950 22A Execute/ Data Transform 224521A, 22A Exception Handling 2164 Round Operation Field 259A19A, 20A, 21A Execute 1950 22A Execute/ Data Transform 2245VSIZE Field 257A.2 19B, 20B, 21B, 22B Decode 1920 21B, 22B Renaming 2124 19B, 20B, 21B, 22B Register read/Memory read 1930 19B, 20B, 21B Execute 1950 22B Execute/ Data Transform 224519B, 20B, 21B, 22B Write Back/ Memory Write 1960Vector Length Field 259B19B-C, 20B-C, 21B-C, 22B- C Decode 1920 21B-C, 22B- C Renaming 2124 19B-C, 20B-C, 21B-C, 22B-C Register read/Memory read 1930 19B-C, 20B-C, 21B-C Execute 1950 22B-C Execute/ Data Transform 224519B-C, 20B-C, 21B-C, 22B-C Write Back/ Memory Write 1960Broadcast Field 257B19C, 20C, 21C Data Transform 1940 22C Execute/ Data Transform 224519C, 20C, 21C, 22C Memory Read 1930 - A variety of different well known decode units could be used in the decode stages 1920. For example, the decode unit may decode each macro instruction into a single wide micro instruction. As another example, the decode unit may decode some macro instructions into single wide micro instructions, but others into multiple wide micro instructions. As another example particularly suited for out of order processor pipelines, the decode unit may decode each macro instruction into one or more micro-ops, where each of the micro-ops may be issued and execute out of order.
- It should also be noted that a decode unit may be implemented with one or more decoders and each decoder may be implemented as a programmable logic array (PLA), as is well known in the art. By way of example, a given decode unit may: 1) have steering logic to direct different macro instructions to different decoders; 2) a first decoder that may decode a subset of the instruction set (but more of it than the second, third, and fourth decoders) and generate two micro-ops at a time; 3) a second, third, and fourth decoder that may each decode only a subset of the entire instruction set and generate only one micro-op at a time; 4) a micro-sequencer ROM that may decode only a subset of the entire instruction set and generate four micro-ops at a time; and 5) multiplexing logic feed by the decoders and the micro-sequencer ROM that determine whose output is provided to a micro-op queue. Other embodiments of the decoder unit may have more or less decoders that decode more or less instructions and instruction subsets. For example, one embodiment may have a second, third, and fourth decoder that may each generate two micro-ops at a time; and may include a micro-sequencer ROM that generates eight micro-ops at a time.
-
Figures 23A-B illustrate a block diagram of an exemplary in-order processor architecture. This exemplary embodiment is designed around multiple instantiations of an in-order CPU core that is augmented with a wide vector processor (VPU). Cores communicate through a high-bandwidth interconnect network with some fixed function logic, memory I/O interfaces, and other necessary I/O logic, depending on the exact application. For example, an implementation of this embodiment as a stand-alone GPU would typically include a PCIe bus. -
Figure 23A is a block diagram of a single CPU core, along with its connection to the on-die interconnect network 2302 and with its local subset of the level 2 (L2)cache 2304, according to embodiments of the invention. Aninstruction decoder 2300 supports the x86 instruction set with an extension including the specificvector instruction format 300. While in one embodiment of the invention (to simplify the design) ascalar unit 2308 and avector unit 2310 use separate register sets (respectively,scalar registers 2312 and vector registers 2314) and data transferred between them is written to memory and then read back in from a level 1 (L1)cache 2306, alternative embodiments of the invention may use a different approach (e.g., use a single register set or include a communication path that allow data to be transferred between the two register files without being written and read back). - The
L1 cache 2306 allows low-latency accesses to cache memory into the scalar and vector units. Together with load-op instructions in the vector friendly instruction format, this means that theL1 cache 2306 can be treated somewhat like an extended register file. This significantly improves the performance of many algorithms, especially with theeviction hint field 252B. - The local subset of the
L2 cache 2304 is part of a global L2 cache that is divided into separate local subsets, one per CPU core. Each CPU has a direct access path to its own local subset of theL2 cache 2304. Data read by a CPU core is stored in itsL2 cache subset 2304 and can be accessed quickly, in parallel with other CPUs accessing their own local L2 cache subsets. Data written by a CPU core is stored in its ownL2 cache subset 2304 and is flushed from other subsets, if necessary. The ring network ensures coherency for shared data. -
Figure 23B is an exploded view of part of the CPU core infigure 23A according to embodiments of the invention.Figure 23B includes anL1 data cache 2306A part of theL1 cache 2304, as well as more detail regarding thevector unit 2310 and the vector registers 2314. Specifically, thevector unit 2310 is a 16-wide vector processing unit (VPU) (see the 16-wide ALU 2328), which executes integer, single-precision float, and double-precision float instructions. The VPU supports swizzling the register inputs withswizzle unit 2320, numeric conversion withnumeric convert units 2322A-B, and replication withreplication unit 2324 on the memory input. Writemask registers 2326 allow predicating the resulting vector writes. - Register data can be swizzled in a variety of ways, e.g. to support matrix multiplication. Data from memory can be replicated across the VPU lanes. This is a common operation in both graphics and non-graphics parallel data processing, which significantly increases the cache efficiency.
- The ring network is bi-directional to allow agents such as CPU cores, L2 caches and other logic blocks to communicate with each other within the chip. Each ring data-path is 512-bits wide per direction.
-
Figure 24 is a block diagram illustrating an exemplary out-of-order architecture according to embodiments of the invention. Specifically,Figure 24 illustrates a well-known exemplary out-of-order architecture that has been modified to incorporate the vector friendly instruction format and execution thereof. InFigure 24 arrows denotes a coupling between two or more units and the direction of the arrow indicates a direction of data flow between those units.Figure 24 includes afront end unit 2405 coupled to anexecution engine unit 2410 and amemory unit 2415; theexecution engine unit 2410 is further coupled to thememory unit 2415. - The
front end unit 2405 includes a level 1 (L1)branch prediction unit 2420 coupled to a level 2 (L2) branch prediction unit 2422. The L1 and L2brand prediction units 2420 and 2422 are coupled to an L1instruction cache unit 2424. The L1instruction cache unit 2424 is coupled to an instruction translation lookaside buffer (TLB) 2426 which is further coupled to an instruction fetch andpredecode unit 2428. The instruction fetch andpredecode unit 2428 is coupled to aninstruction queue unit 2430 which is further coupled adecode unit 2432. Thedecode unit 2432 comprises acomplex decoder unit 2434 and threesimple decoder units decode unit 2432 includes amicro-code ROM unit 2442. Thedecode unit 2432 may operate as previously described above in the decode stage section. The L1instruction cache unit 2424 is further coupled to anL2 cache unit 2448 in thememory unit 2415. Theinstruction TLB unit 2426 is further coupled to a secondlevel TLB unit 2446 in thememory unit 2415. Thedecode unit 2432, themicro-code ROM unit 2442, and a loopstream detector unit 2444 are each coupled to a rename/allocator unit 2456 in theexecution engine unit 2410. - The
execution engine unit 2410 includes the rename/allocator unit 2456 that is coupled to aretirement unit 2474 and aunified scheduler unit 2458. Theretirement unit 2474 is further coupled toexecution units 2460 and includes areorder buffer unit 2478. Theunified scheduler unit 2458 is further coupled to a physicalregister files unit 2476 which is coupled to theexecution units 2460. The physicalregister files unit 2476 comprises avector registers unit 2477A, a writemask registers unit 2477B, and ascalar registers unit 2477C; these register units may provide the vector registers 510, the vector mask registers 515, and the general purpose registers 525; and the physicalregister files unit 2476 may include additional register files not shown (e.g., the scalar floating pointstack register file 545 aliased on the MMX packed integer flat register file 550). Theexecution units 2460 include three mixed scalar andvector units load unit 2466; astore address unit 2468; astore data unit 2470. Theload unit 2466, thestore address unit 2468, and thestore data unit 2470 are each coupled further to adata TLB unit 2452 in thememory unit 2415. - The
memory unit 2415 includes the secondlevel TLB unit 2446 which is coupled to thedata TLB unit 2452. Thedata TLB unit 2452 is coupled to an L1data cache unit 2454. The L1data cache unit 2454 is further coupled to anL2 cache unit 2448. In some embodiments, theL2 cache unit 2448 is further coupled to L3 andhigher cache units 2450 inside and/or outside of thememory unit 2415. - By way of example, the exemplary out-of-order architecture may implement the
process pipeline 2200 as follows: 1) the instruction fetch andpredecode unit 2428 perform the fetch andlength decoding stages decode unit 2432 performs thedecode stage 1920; 3) the rename/allocator unit 2456 performs theallocation stage 2122 andrenaming stage 2124; 4) theunified scheduler 2458 performs theschedule stage 2126; 5) the physicalregister files unit 2476, thereorder buffer unit 2478, and thememory unit 2415 perform the register read/memory readstage 1930; theexecution units 2460 perform the execute/data transform stage 2245; 6) thememory unit 2415 and thereorder buffer unit 2478 perform the write back/memory write stage 1960; 7) theretirement unit 2474 performs the ROB read 2162 stage; 8) various units may be involved in theexception handling stage 2164; and 9) theretirement unit 2474 and the physicalregister files unit 2476 perform the commitstage 2166. -
Figure 29 is a block diagram of a single core processor and amulticore processor 2900 with integrated memory controller and graphics according to embodiments of the invention. The solid lined boxes inFigure 29 illustrate aprocessor 2900 with asingle core 2902A, asystem agent 2910, a set of one or morebus controller units 2916, while the optional addition of the dashed lined boxes illustrates analternative processor 2900 withmultiple cores 2902A-N, a set of one or more integrated memory controller unit(s) 2914 in thesystem agent unit 2910, and anintegrated graphics logic 2908. - The memory hierarchy includes one or more levels of cache within the cores, a set or one or more shared
cache units 2906, and external memory (not shown) coupled to the set of integratedmemory controller units 2914. The set of sharedcache units 2906 may include one or more mid-level caches, such as level 2 (L2), level 3 (L3), level 4 (L4), or other levels of cache, a last level cache (LLC), and/or combinations thereof. While in one embodiment a ring basedinterconnect unit 2912 interconnects theintegrated graphics logic 2908, the set of sharedcache units 2906, and thesystem agent unit 2910, alternative embodiments may use any number of well-known techniques for interconnecting such units. - In some embodiments, one or more of the
cores 2902A-N are capable of multi-threading. Thesystem agent 2910 includes those components coordinating andoperating cores 2902A-N. Thesystem agent unit 2910 may include for example a power control unit (PCU) and a display unit. The PCU may be or include logic and components needed for regulating the power state of thecores 2902A-N and theintegrated graphics logic 2908. The display unit is for driving one or more externally connected displays. - The
cores 2902A-N may be homogenous or heterogeneous in terms of architecture and/or instruction set. For example, some of thecores 2902A-N may be in order (e.g., like that shown infigures 23A and 23B ) while others are out-of-order (e.g., like that shown infigure 24 ). As another example, two or more of thecores 2902A-N may be capable of executing the same instruction set, while others may be capable of executing only a subset of that instruction set or a different instruction set. At least one of the cores is capable of executing the vector friendly instruction format described herein. - The processor may be a general-purpose processor, such as a Core™ i3, i5, i7, 2 Duo and Quad, Xeon™, or Itanium processors, which are available from Intel Corporation, of Santa Clara, California. Alternatively, the processor may be from another company. The processor may be a special-purpose processor, such as, for example, a network or communication processor, compression engine, graphics processor, co-processor, embedded processor, or the like. The processor may be implemented on one or more chips. The
processor 2900 may be a part of and/or may be implemented on one or more substrates using any of a number of process technologies, such as, for example, BiCMOS, CMOS, or NMOS. -
Figures 25-27 are exemplary systems suitable for including theprocessor 2900, whileFigure 28 is an exemplary system on a chip (SoC) that may include one or more of the cores 2902.. Other system designs and configurations known in the arts for laptops, desktops, handheld PCs, personal digital assistants, engineering workstations, servers, network devices, network hubs, switches, embedded processors, digital signal processors (DSPs), graphics devices, video game devices, set-top boxes, micro controllers, cell phones, portable media players, hand held devices, and various other electronic devices, are also suitable. In general, a huge variety of systems or electronic devices capable of incorporating a processor and/or other execution logic as disclosed herein are generally suitable. - Referring now to
Figure 25 , shown is a block diagram of asystem 2500 in accordance with one embodiment of the invention. Thesystem 2500 may include one ormore processors additional processors 2515 is denoted inFigure 25 with broken lines. - Each
processor 2510, 2515may be some version ofprocessor 2900. However, it should be noted that it is unlikely that integrated graphics logic and integrated memory control units would exist in theprocessors -
Figure 25 illustrates that theGMCH 2520 may be coupled to amemory 2540 that may be, for example, a dynamic random access memory (DRAM). The DRAM may, for at least one embodiment, be associated with a non-volatile cache. - The
GMCH 2520 may be a chipset, or a portion of a chipset. TheGMCH 2520 may communicate with the processor(s) 2510, 2515 and control interaction between the processor(s) 2510, 2515 andmemory 2540. TheGMCH 2520 may also act as an accelerated bus interface between the processor(s) 2510, 2515 and other elements of thesystem 2500. For at least one embodiment, theGMCH 2520 communicates with the processor(s) 2510, 2515 via a multi-drop bus, such as a frontside bus (FSB) 2595. - Furthermore,
GMCH 2520 is coupled to a display 2545 (such as a flat panel display).GMCH 2520 may include an integrated graphics accelerator.GMCH 2520 is further coupled to an input/output (I/O) controller hub (ICH) 2550, which may be used to couple various peripheral devices tosystem 2500. Shown for example in the embodiment ofFigure 25 is anexternal graphics device 2560, which may be a discrete graphics device coupled toICH 2550, along with anotherperipheral device 2570. - Alternatively, additional or different processors may also be present in the
system 2500. For example, additional processor(s) 2515 may include additional processors(s) that are the same asprocessor 2510, additional processor(s) that are heterogeneous or asymmetric toprocessor 2510, accelerators (such as, e.g., graphics accelerators or digital signal processing (DSP) units), field programmable gate arrays, or any other processor. There can be a variety of differences between thephysical resources processing elements various processing elements - Referring now to
Figure 26 , shown is a block diagram of asecond system 2600 in accordance with an embodiment of the present invention. As shown inFigure 26 ,multiprocessor system 2600 is a point-to-point interconnect system, and includes afirst processor 2670 and asecond processor 2680 coupled via a point-to-point interconnect 2650. As shown inFigure 26 , each ofprocessors processor 2900. - Alternatively, one or more of
processors - While shown with only two
processors -
Processor 2670 may further include an integrated memory controller hub (IMC) 2672 and point-to-point (P-P) interfaces 2676 and 2678. Similarly,second processor 2680 may include aIMC 2682 andP-P interfaces Processors interface 2650 usingPtP interface circuits Figure 26 , IMC's 2672 and 2682 couple the processors to respective memories, namely a memory 2642 and a memory 2644, which may be portions of main memory locally attached to the respective processors. -
Processors chipset 2690 viaindividual P-P interfaces interface circuits Chipset 2690 may also exchange data with a high-performance graphics circuit 2638 via a high-performance graphics interface 2639. - A shared cache (not shown) may be included in either processor outside of both processors, yet connected with the processors via P-P interconnect, such that either or both processors' local cache information may be stored in the shared cache if a processor is placed into a low power mode.
-
Chipset 2690 may be coupled to afirst bus 2616 via aninterface 2696. In one embodiment,first bus 2616 may be a Peripheral Component Interconnect (PCI) bus, or a bus such as a PCI Express bus or another third generation I/O interconnect bus, although the scope of the present invention is not so limited. - As shown in
Figure 26 , various I/O devices 2614 may be coupled tofirst bus 2616, along with a bus bridge 2618 which couplesfirst bus 2616 to asecond bus 2620. In one embodiment,second bus 2620 may be a low pin count (LPC) bus. Various devices may be coupled tosecond bus 2620 including, for example, a keyboard/mouse 2622, communication devices 2626 and adata storage unit 2628 such as a disk drive or other mass storage device which may includecode 2630, in one embodiment. Further, an audio I/O 2624 may be coupled tosecond bus 2620. Note that other architectures are possible. For example, instead of the point-to-point architecture ofFigure 26 , a system may implement a multi-drop bus or other such architecture. - Referring now to
Figure 27 , shown is a block diagram of athird system 2700 in accordance with an embodiment of the present invention. Like elements inFigures 26 and27 bear like reference numerals; and certain aspects ofFigure 26 have been omitted fromFigure 27 in order to avoid obscuring other aspects ofFigure 27 . -
Figure 27 illustrates that theprocessing elements CL Figures 29 and26 . In addition.CL Figure 27 illustrates that not only are the memories 2642, 2644 coupled to theCL O devices 2714 are also coupled to thecontrol logic O devices 2715 are coupled to thechipset 2690. - Referring now to
Figure 28 , shown is a block diagram of aSoC 2800 in accordance with an embodiment of the present invention. Similar elements inFigure 29 bear like reference numerals. Also, dashed lined boxes are optional features on more advanced SoCs. InFigure 28 , an interconnect unit(s) 2802 is coupled to: anapplication processor 2810 which includes a set of one ormore cores 2902A-N and shared cache unit(s) 2906; asystem agent unit 2910; a bus controller unit(s) 2916; an integrated memory controller unit(s) 2914; a set or one ormore media processors 2820 which may includeintegrated graphics logic 2908, animage processor 2824 for providing still and/or video camera functionality, anaudio processor 2826 for providing hardware audio acceleration, and avideo processor 2828 for providing video encode/decode acceleration; an static random access memory (SRAM)unit 2830; a direct memory access (DMA)unit 2832; and adisplay unit 2840 for coupling to one or more external displays. - Embodiments of the mechanisms disclosed herein may be implemented in hardware, software, firmware, or a combination of such implementation approaches. Embodiments of the invention may be implemented as computer programs or program code executing on programmable systems comprising at least one processor, a storage system (including volatile and non-volatile memory and/or storage elements), at least one input device, and at least one output device.
- Program code, such as
code 2630 illustrated inFigure 26 , may be applied to input data to perform the functions described herein and generate output information. The output information may be applied to one or more output devices, in known fashion. For purposes of this application, a processing system includes any system that has a processor, such as, for example; a digital signal processor (DSP), a microcontroller, an application specific integrated circuit (ASIC), or a microprocessor. - The program code may be implemented in a high level procedural or object oriented programming language to communicate with a processing system. The program code may also be implemented in assembly or machine language, if desired. In fact, the mechanisms described herein are not limited in scope to any particular programming language. In any case, the language may be a compiled or interpreted language.
- One or more aspects of at least one embodiment may be implemented by representative instructions stored on a machine-readable medium which represents various logic within the processor, which when read by a machine causes the machine to fabricate logic to perform the techniques described herein. Such representations, known as "IP cores" may be stored on a tangible, machine readable medium and supplied to various customers or manufacturing facilities to load into the fabrication machines that actually make the logic or processor.
- Such machine-readable storage media may include, without limitation, non-transitory, tangible arrangements of articles manufactured or formed by a machine or device, including storage media such as hard disks, any other type of disk including floppy disks, optical disks (compact disk read-only memories (CD-ROMs), compact disk rewritables (CD-RWs)), and magneto-optical disks, semiconductor devices such as read-only memories (ROMs), random access memories (RAMs) such as dynamic random access memories (DRAMs), static random access memories (SRAMs), erasable programmable read-only memories (EPROMs), flash memories, electrically erasable programmable read-only memories (EEPROMs), magnetic or optical cards, or any other type of media suitable for storing electronic instructions.
- Accordingly, embodiments of the invention also include non-transitoty, tangible machine-readable media containing instructions the vector friendly instruction format or containing design data, such as Hardware Description Language (HDL), which defines structures, circuits, apparatuses, processors and/or system features described herein. Such embodiments may also be referred to as program products.
- In some cases, an instruction converter may be used to convert an instruction from a source instruction set to a target instruction set. For example, the instruction converter may translate (e.g., using static binary translation, dynamic binary translation including dynamic compilation), morph, emulate, or otherwise convert an instruction to one or more other instructions to be processed by the core. The instruction converter may be implemented in software, hardware, firmware, or a combination thereof. The instruction converter may be on processor, off processor, or part on and part off processor.
-
Figure 30 is a block diagram contrasting the use of a software instruction converter to convert binary instructions in a source instruction set to binary instructions in a target instruction set according to embodiments of the invention. In the illustrated embodiment, the instruction converter is a software instruction converter, although alternatively the instruction converter may be implemented in software, firmware, hardware, or various combinations thereof.Figure 30 shows a program in ahigh level language 3002 may be compiled using anx86 compiler 3004 to generatex86 binary code 3006 that may be natively executed by a processor with at least one x86 instruction set core 3016 (it is assume that some of the instructions that were compiled are in the vector friendly instruction format). The processor with at least one x86instruction set core 3016 represents any processor that can perform substantially the same functions as a Intel processor with at least one x86 instruction set core by compatibly executing or otherwise processing (1) a substantial portion of the instruction set of the Intel x86 instruction set core or (2) object code versions of applications or other software targeted to run on an Intel processor with at least one x86 instruction set core, in order to achieve substantially the same result as an Intel processor with at least one x86 instruction set core. Thex86 compiler 3004 represents a compiler that is operable to generate x86 binary code 3006 (e.g., object code) that can, with or without additional linkage processing, be executed on the processor with at least one x86instruction set core 3016. Similarly,Figure 30 shows the program in thehigh level language 3002 may be compiled using an alternativeinstruction set compiler 3008 to generate alternative instructionset binary code 3010 that may be natively executed by a processor without at least one x86 instruction set core 3014 (e.g., a processor with cores that execute the MIPS instruction set of MIPS Technologies of Sunnyvale, CA and/or that execute the ARM instruction set of ARM Holdings of Sunnyvale, CA). Theinstruction converter 3012 is used to convert thex86 binary code 3006 into code that may be natively executed by the processor without an x86 instruction set core 3014. This converted code is not likely to be the same as the alternative instructionset binary code 3010 because an instruction converter capable of this is difficult to make; however, the converted code will accomplish the general operation and be made up of instructions from the alternative instruction set. Thus, theinstruction converter 3012 represents software, firmware, hardware, or a combination thereof that, through emulation, simulation or any other process, allows a processor or other electronic device that does not have an x86 instruction set processor or core to execute thex86 binary code 3006. - Certain operations of the instruction(s) in the vector friendly instruction format disclosed herein may be performed by hardware components and may be embodied in machine-executable instructions that are used to cause, or at least result in, a circuit or other hardware component programmed with the instructions performing the operations. The circuit may include a general-purpose or special-purpose processor, or logic circuit, to name just a few examples. The operations may also optionally be performed by a combination of hardware and software. Execution logic and/or a processor may include specific or particular circuitry or other logic responsive to a machine instruction or one or more control signals derived from the machine instruction to store an instruction specified result operand. For example, embodiments of the instruction(s) disclosed herein may be executed in one or more the systems of
Figures 25-28 and embodiments of the instruction(s) in the vector friendly instruction format may be stored in program code to be executed in the systems. Additionally, the processing elements of these figures may utilize one of the detailed pipelines and/or architectures (e.g., the in-order and out-of-order architectures) detailed herein. For example, the decode unit of the in-order architecture may decode the instruction(s), pass the decoded instruction to a vector or scalar unit, etc. - The above description is intended to illustrate preferred embodiments of the present invention. From the discussion above it should also be apparent that especially in such an area of technology, where growth is fast and further advancements are not easily foreseen, the invention can may be modified in arrangement and detail by those skilled in the art without departing from the principles of the present invention within the scope of the accompanying claims and their equivalents. For example, one or more operations of a method may be combined or further broken apart.
- While embodiments have been described which would natively execute the vector friendly instruction format, alternative embodiments of the invention may execute the vector friendly instruction format through an emulation layer running on a processor that executes a different instruction set (e.g., a processor that executes the MIPS instruction set of MIPS Technologies of Sunnyvale, CA, a processor that executes the ARM instruction set of ARM Holdings of Sunnyvale, CA). Also, while the flow diagrams in the figures show a particular order of operations performed by certain embodiments of the invention, it should be understood that such order is exemplary (e.g., alternative embodiments may perform the operations in a different order, combine certain operations, overlap certain operations, etc.).
- In the description above, for the purposes of explanation, numerous specific details have been set forth in order to provide a thorough understanding of the embodiments of the invention. It will be apparent however, to one skilled in the art, that one or more other embodiments may be practiced without some of these specific details. The particular embodiments described are not provided to limit the invention but to illustrate embodiments of the invention. The scope of the invention is not to be determined by the specific examples provided above but only by the claims below.
The invention may be related to one or more of the following examples: - 1. An example of a processor to execute instructions in a first instruction format comprising:
a decode unit to decode the instructions in the first instruction format, the first instruction format including a base operation field and an augmentation operation field, the base operation field to specify different vector operations that each generate a destination vector operand having a plurality of data elements at different data element positions, wherein the decode unit is configured to distinguish for each of the instructions that specifies a memory access:- which one of the different vector operations to perform based on the base operation field's content; and
- which one of a plurality of different augmentation operations to perform based on both the vector operation to be performed and the augmentation field's content, wherein the plurality of augmentation operations for at least some of the vector operations are different types of broadcast operations and different types of conversion operations.
- 2. An example of an apparatus comprising: a processor configured to execute an instruction set, wherein the instruction set includes
a first instruction format, wherein the first instruction format has a plurality of fields including a base operation field, a modifier field, a class field, an alpha field, a beta field, and a data element width field, wherein the first instruction format supports different versions of base operations and different augmentation operations through placement of different values in the base operation field, the modifier field, the class field, the alpha field, the beta field, and the data element width field, and wherein only one of the different values may be placed in each of the base operation field, the modifier field, the class field, the alpha field, the beta field, and the data element width field on each occurrence of an instruction in the first instruction format in instruction streams, the processor including,
a decode unit to decode the occurrences of the instructions in the first instruction format with the class field's content specifying a first class as follows:- distinguish the occurrences that specify memory access from those that do not based on the modifier field's content in those different occurrences, wherein the alpha field and the beta field are respectively interpreted as an eviction hint field and a data manipulation field when the modifier field's content specifies memory access;
- distinguish, for each of the occurrences that does specify memory access through the modifier field's content, the following:
- whether the eviction hint is temporal or non-temporal based on the alpha field's content and its interpretation as the eviction hint field in that occurrence; and
- which one of a plurality of memory access operations to perform and which one of a plurality of data manipulations operations to apply based on the base operation field's content, the beta field's content, and the beta field's interpretation as the data manipulation field;
- distinguish, for each of the occurrences that does not specify memory access through the modifier field's content, whether to augment with a round type operation or with a data transform type operation based on the alpha field's content in that occurrence, wherein the beta field is interpreted as a round control field that comprises a round operation field when the alpha field's content indicates the round type operation, and wherein the beta field is instead interpreted as a data transform field when the alpha field's content indicates the data transform type operation;
- distinguish, for each of the occurrences that does not specify memory access through the modifier field's content and that does specify the round type operation through the alpha field's content, which one of a plurality of round operations to apply based on the beta field's content and its interpretation as the round operation field in that occurrence; and
- distinguish, for each of the occurrences that does not specify memory access through the modifier field's content and that does specify the data transform type operation through the alpha field's content, which one of a plurality of data element widths to use and which one of a plurality of different data transform operations to apply based on the data element width field's content, the beta field's content, and the beta field's interpretation as the data transform field in that occurrence.
- 3. An example of an apparatus comprising:
a processor configured to execute an instruction set, wherein the instruction set includes a first instruction format, wherein the first instruction format has a plurality of fields including a class field, an alpha field, and a beta field, wherein the first instruction format supports different augmentation operations through placement of different values in the alpha field and the beta field, wherein only one of the different values may be placed in each of the alpha field and the beta field on each occurrence of an instruction in the first instruction format in instruction streams, the processor including,
a decode unit to decode the occurrences of the instructions in the first instruction format with the class field's content specifying a first class as follows:- distinguish, for each of the occurrences that does not specify memory access, whether to augment with a round type operation or not based on the alpha field's content in that occurrence, wherein the beta field is interpreted as a suppress all floating point exceptions (SAE) field and a round operation field when the alpha field's content indicates the round type operation;
- distinguish, for each of the occurrences that does not specify memory access and that does specify the round type operation through the alpha field's content, whether floating point exceptions will be suppressed or not based on the SAE field's content in that occurrence; and
- distinguish, for each of the occurrences that does not specify memory access and that does specify the round type operation through the alpha field's content, which one of a plurality of round operations to apply based on the round type operation field's content in that occurrence.
- 4. An example of an apparatus comprising:
a processor configured to execute an instruction set, wherein the instruction set includes a first instruction format, wherein the first instruction format includes a first plurality of templates, wherein the first instruction format has a plurality of fields including a base operation field, a data element width (W) field, and a write mask field, wherein the first instruction format supports through different values in the base operation field the specification of different vector operations, wherein each of the vector operations generates a destination vector operand including a plurality of data elements at different data element positions, wherein the first instruction format supports through different values in the data element width field the specification of different data element widths, wherein the base operation field, the data element width field, and the write mask field may each store only one value on each occurrence of an instruction in the first instruction format in instruction streams, the processor including,
a decode unit to decode the occurrences of the instructions in the first plurality of templates as follows:- distinguish, for each of the occurrences, which one of the data element widths to use based on the data element width field's content; and
- distinguish, for each of the occurrences, which of the data elements resulting from the occurrence's vector operation is or is not to be reflected in the destination operand's corresponding data element positions based on the write mask field's content and the data element width for that occurrence, wherein one of the different values that may be placed in the write mask field is reserved for indicating that all of the results of the occurrence's vector operation are to be reflected in the destination vector operand's corresponding data element positions, wherein others of the different values that may be placed in the write mask field distinguish different write mask registers storing configurable write masks except for, and wherein the data element width for the occurrence distinguishes which data element positions correspond with which bits of the configurable write masks.
- 5. An example of an apparatus comprising:
a processor configured to execute an instruction set, wherein the instruction set includes a first instruction format, wherein the first instruction format includes a first plurality of templates that each include a plurality of fields including a base operation field, a data element width (W) field, a vector length field, and a write mask field, wherein the first instruction format supports through different values in the base operation field the specification of a plurality of different vector operations, wherein each of the plurality of vector operations requires an operation to be independently performed on each of a plurality of different data element positions of at least one source vector operand to generate at least one destination vector operand, wherein the first instruction format supports through different values in the data element width field the specification of a 32 bit and a 64 bit data element width, wherein the plurality of templates support through different values in the vector length field the specification of a plurality of different vector lengths, wherein the first instruction format supports through different values in the write mask field the specification of different write masks, wherein only one of the different values may be placed in each of the base operation field, the augmentation operation field, the data element width field, and the write mask field on each occurrence of an instruction in the first instruction format in instruction streams, the processor including,
a decode unit to decode the occurrences of the instructions in the first plurality of templates as follows:- distinguish, for each of the occurrences, which one of the different vector operations to perform based on the base operation field's content;
- distinguish, for each of the occurrences, which one of the data element widths to use based on the data element width field's content;
- distinguish, for each of the occurrences, which one of the vector lengths to use based on the vector length field's content; and
- distinguish, for each of the occurrences, which one of the different write masks to use based on the write mask field's content, wherein the data element width and the vector length for the occurrence distinguishes which data element positions correspond with which bits of the occurrence's write mask, and wherein the write mask for the occurrence specifies on a per data element position basis whether the results of the occurrence's vector operation is or is not to be reflected in the destination vector operand's corresponding data element positions.
- 6. An example of an apparatus comprising:
a processor configured to execute an instruction set, wherein the instruction set includes a first instruction format, wherein the first instruction format includes a first plurality of templates, wherein the first instruction format has a plurality of fields including a base operation field, a modifier field, an alpha field, and a beta field, wherein the first instruction format supports through different values in the base operation field the specification of a plurality of different vector operations, wherein each of the plurality of vector operations generates from a source operand a destination vector operand having a plurality of data elements at different data element positions, wherein the first instruction format supports through different values in the modifier field the specification of memory access and no memory access operations, wherein the first instruction format supports different interpretations of the contents of the alpha field and the beta field based on the modifier field's content, wherein the base operation field, the modifier field, the alpha field, the data element width field, and the beta field may store only one value on each occurrence of an instruction in the first instruction format in instruction streams, the processor including,
a decode unit to decode the occurrences of the instructions in the first plurality of templates as follows:- distinguish the occurrences that specify memory access from those that do not based on the modifier field's content in the different occurrences, wherein the alpha field and the beta field are respectively interpreted as an eviction hint field and a data manipulation field when the modifier field's content specifies memory access;
- distinguish, for each of the occurrences that specifies memory access through the modifier field's content, the following:
- whether the eviction hint is temporal or non-temporal based on the alpha field's content and its interpretation as the eviction hint field in that occurrence; and
- which one of a plurality of memory access operations to perform and which one of a plurality of data manipulations operations to apply based on the base operation field's content, the beta field's content, and the beta field's interpretation as the data manipulation field, wherein the plurality of data manipulation operations includes a no conversion and a conversion operation, wherein the conversion operation indicates the conversion from a data type of the source operand into a different data type of the destination vector operand.
- 7. An example of an apparatus comprising:
a processor configured to execute an instruction set, wherein the instruction set includes a first instruction format, wherein the first instruction format has a plurality of fields including a base operation field, a modifier field, a data element width field, and an augmentation operation field, wherein the first instruction format supports through different values in the base operation field the specification of a plurality of different vector operations, wherein each of the plurality of vector operations generates a destination vector operand having a plurality of data elements at different data element positions, wherein the first instruction format supports through different values in the modifier field the specification of memory access and no memory access operations, wherein the first instruction format includes a displacement factor field when the modifier field's content specifies a memory access operation with scaled displacement, wherein the base operation field, the modifier field, the data element width field, and the augmentation operation field may each stored only one value on each occurrence of an instruction in the first instruction format, the processor including,
a processor pipeline to execute the instructions in the first instruction format occurring in instruction streams, wherein the pipeline is configured to:- distinguish the occurrences of instructions in the first instruction format that specify memory access with scaled displacement from those that do not based on the modifier field's content in those different occurrences;
- distinguish, for the occurrences that specify memory access with scaled displacement through the modifier field's content, between a plurality of memory access sizes based on the contents of two or more of the base operation field, the data element width field, and the augmentation operation field; and
- determine, for each of the occurrences that specifies memory access with scaled displacement through the modifier field's content, a scaled displacement based on multiplying the size of the memory access by the displacement factor field's content, wherein the scaled displacement is to be used to generate an address.
- 8. An example of an apparatus comprising:
a processor configured to execute an instruction set, wherein the instruction set includes a first instruction format, wherein the first instruction format includes a first plurality of templates, wherein the first instruction format has a plurality of fields including a base operation field, a modifier field, an alpha field, a beta field, and a data element width field, wherein the first instruction format supports through different values in the base operation field the specification of a plurality of different vector operations, wherein each of the plurality of vector operations generates a destination vector operand having a plurality of data elements at different data element positions, wherein the first instruction format supports through different values in the modifier field the specification of memory access and no memory access operations, wherein the first instruction format supports through different values in the data element width field the specification of different data element widths, wherein the first instruction format supports different interpretations of the contents of the alpha field and the beta field based on the modifier field's content, wherein the base operation field, the modifier field, the alpha field, the beta field, and the data element width field may each store only one value on each occurrence of an instruction in the first instruction format in instruction streams, the processor including,
a decode unit to decode the occurrences of the instructions in the first plurality of templates as follows:- distinguish the occurrences that specify memory access from those that do not based on the modifier field's content in those different occurrences;
- distinguish, for each of the occurrences that does not specify memory access through the modifier field's content, whether to augment with a data transform type operation based on the alpha field's content in that occurrence, wherein the beta field is interpreted as a data transform field when the alpha field's content indicates the data transform type operation; and
- distinguish, for each of the occurrences that does not specify memory access and that does specify a data transform type operation, the following,
- which one of the data element widths to use based on the data element width field's content; and
- which one of a plurality of data transform operations to perform based on the data transform field's content, wherein the plurality of data transform operations include a no swizzle operation, a swizzle operation and a broadcast operation.
- 9. An example of an apparatus comprising:
- a processor including:
- a plurality of architectural vector registers that are each at least 512 bits in size,
- a plurality of architectural write mask registers that are at least 64 bits in size to store configurable write masks,
- wherein the processor is configured to execute an instruction set, wherein the instruction set includes a plurality of instruction formats including a vector friendly instruction format, wherein vector instructions in the vector friendly instruction format specify vector operations that generate a destination vector operand having a plurality of data elements at different data element positions, wherein the vector friendly instruction format includes the following fields of the following size and in the following order,
- a one byte format field to store a value that uniquely identifies the vector friendly instruction format;
- a one bit R field to store a bit that is combined with a first set of three lower order bits to address the architectural vector registers for certain instructions in the vector friendly instruction format;
- a one bit X field to store a bit that is combined with a second set of three lower order bits to address the architectural vector registers for certain instructions in the vector friendly instruction format;
- a one bit B field to store a bit that is combined with a third set of three lower order bits to address the architectural vector registers for certain instructions in the vector friendly instruction format;
- a one bit R' field to store a bit that is added as the most significant bit to the combination of the R field's bit and the first set of three lower order bits to address the architectural vector registers for certain instructions in the vector friendly instruction format;
- a four bit opcode map that is part of a base operation field;
- a one bit data element width (W) field to store a bit to distinguish between a 32 bit data element size and a 64 bit data element size for certain instructions in the vector friendly instruction format;
- a four bit V field to store a low order four bits used to address the architectural vector registers for certain instructions in the vector friendly instruction format;
- a one bit class (U) field to store a bit used to distinguish between two classes of instruction templates;
- a two bit prefix encoding field that is part of the base operation field;
- a one bit alpha field that is interpreted as a round type operation field, a data transform type operation field, an eviction hint field, a write mask control field, or reserved field, wherein the write mask control field's content selects between merging write mask and zeroing write mask;
- a three bit beta field that is interpreted as a full round control field, a data transform field, or a data manipulation field depending on the modifier field's content and the alpha field's content when the class field's content indicates a first class, and is interpreted to include a two bit round operation field, a two bit vector length field or a two bit vector length field followed by a broadcast field for certain instructions in the vector friendly instruction format when the class field's content indicate a second class;
- a one bit V' field to store a bit that is added as the most significant bit to the four bits of the V field to address the architectural vector registers for certain instructions in the vector friendly instruction format;
- a three bit write mask field to store different values that all address different ones of the architectural write mask registers with the exception of one that is reserved, wherein each of the configurable write masks specifies on a per data element position basis whether the results of the vector instruction's vector operation is or is not to be reflected in the destination vector operand's corresponding data element positions, whereas the one reserved value is for indicating that all of the results of the vector instruction's vector operation are to be reflected in the destination vector operand's corresponding data element positions;
- a one byte real opcode field to store a byte that is part of the base operation field, wherein in the base operation field's content distinguishes between different base operations; and
- the modifier field to store two bits used to distinguish between operations that require a memory access and operations that do not.
- a processor including:
- 10. The apparatus of example 9, wherein the full round control field includes,
a one bit suppress all floating point exceptions (SAE) field to store a bit used to distinguish between suppressing all floating point exceptions and not; and
a two bit round operation field to store two bits to distinguish between a plurality of different rounding operations. - 11. An example of an apparatus comprising:
- a processor configured to execute an instruction set, wherein the instruction set includes a first instruction format, wherein the first instruction format has a plurality of fields including a base operation field, a modifier field, a class field, an alpha field, and a beta field, wherein the first instruction format supports different versions of base operations and different augmentation operations through placement of different values in the base operation field, the modifier field, the class field, the alpha field, and the beta field, and wherein only one of the different values may be placed in each of the base operation field, the modifier field, the class field, the alpha field, and the beta field on each occurrence of an instruction in the first instruction format in instruction streams, wherein a first value in the class field specifies a first class and a second value specifies a second class, the processor including,
- a decode unit to decode the occurrences of the instructions in the first instruction format with the class field's content specifying the second class as follows:
- distinguish the occurrences of instructions in the first instruction format that specify memory access from those that do not based on the modifier field's content in those different occurrences, wherein the beta field is interpreted as a broadcast field and a vector length field when the modifier field's content specifies memory access, wherein part of the beta field is interpreted as an RL field when the modifier field's content do not specify memory access;
- distinguish, for each of the occurrences that specifies memory access through the modifier field's content, whether to broadcast or not and which one of a plurality of vector lengths to use based on the beta field's content and its interpretation as the broadcast field and the vector length field in that occurrence; and
- distinguish, for each of the occurrences that does not specify memory access through the modifier field's content, whether to augment with a round type operation or with a vector length type operation based on the RL field's content in that occurrence, wherein a remainder of the beta field is interpreted as a round operation field when the RL field's content indicates the round type operation, and wherein the remainder of the beta field is instead interpreted as the vector length field when the RL field's content indicates the vector length type operation;
- distinguish, for each of the occurrences that does not specify memory access through the modifier field's content and that does specify the round type operation through the RL field's content, which one of a plurality of round operations to apply based on the beta field's content and its interpretation as the round operation field in that occurrence; and
- distinguish, for each of the occurrences, whether to perform a merging write mask operation or a zeroing write mask operation based on the alpha field's content and its interpretation as a write mask control field in that occurrence.
- 12. An example of an apparatus comprising:
a processor configured to execute an instruction set, wherein the instruction set includes a first instruction format, wherein the first instruction format includes a first plurality of templates, wherein the first instruction format has a plurality of fields including a base operation field, an alpha field, a data element width (W) field, and a write mask field, wherein the first instruction format supports through different values in the base operation field the specification of different vector operations, wherein each of the vector operations generates a destination vector operand including a plurality of data elements at different data element positions, wherein the first instruction format supports through different values in the data element width field the specification of different data element widths, wherein the base operation field, the alpha field, the data element width field, and the write mask field may each store only one value on each occurrence of an instruction in the first instruction format in instruction streams, the processor including,
a decode unit to decode the occurrences of the instructions in the first plurality of templates as follows:- distinguish, for each of the occurrences, which one of the data element widths to use based on the data element width field's content,
- distinguish, for each of the occurrences, whether to perform a merge write mask operation or a zeroing write mask operation based on the alpha field's content and its interpretation as a write mask control field;
- distinguish, for each of the occurrences, which of the data elements resulting from the occurrence's vector operation is or is not to be reflected in the destination operand's corresponding data element positions based on the write mask field's content and the data element width for the occurrence, wherein one of the different values that may be placed in the write mask field is reserved for indicating that all of the results of the occurrence's vector operation are to be reflected in the destination vector operand's corresponding data element positions, wherein others of the different values that may be placed in the write mask field distinguish different write mask registers storing configurable write masks, and wherein the data element width for the occurrence distinguishes which data element positions correspond with which bits of the configurable write masks.
- 13. An example of an apparatus comprising:
a processor configured to execute an instruction set, wherein the instruction set includes a first instruction format, wherein the first instruction format has a plurality of fields including a base operation field, a modifier field, and a beta field, wherein the first instruction format supports different versions of base operations and different augmentation operations through placement of different values in the base operation field, the modifier field, and the beta field, and wherein only one of the different values may be placed in each of the base operation field, the modifier field, and the beta field on each occurrence of an instruction in the first instruction format, the processor including,
a decode unit to decode a plurality of instructions in the first instruction format, wherein the decode unit is configured to decode the plurality of instructions in the first instruction format as follows:- distinguish those of the plurality of instructions that specify memory access from those that do not based on the modifier field's content in those different instructions, wherein part of the beta field is interpreted as an RL field when the modifier field's content does not specify memory access;
- distinguish, for each of the plurality of instructions that does not specify memory access through the modifier field's content, whether to augment with a round type operation or with a vector length type operation based on the RL field's content in that instruction, wherein a remainder of the beta field is interpreted as a round operation field when the RL field's content indicates the round type operation, and wherein the remainder of the beta field is instead interpreted as the vector length field when the RL field's content indicates the vector length type operation;
- distinguish, for each of the plurality of instructions that does not specify memory access through the modifier field's content and that does specify the round type operation through the RL field's content, which one of a plurality of round operations to apply based on the beta field's content and its interpretation as the round operation field in that instruction; and
- distinguish, for each of the plurality of instructions that does not specify memory access through the modifier field's content and that does specify the vector length type operation through the RL field's content, which one of a plurality of vector lengths to use based on the beta field's content and its interpretation as the vector length field in that instruction.
- 14. An example of an apparatus comprising:
a processor configured to execute instructions, wherein a first instruction format has a plurality of fields including a base operation field, a class field, an alpha field, and a beta field, wherein the first instruction format supports different versions of base operations and different augmentation operations through placement of different values in the base operation field, the class field, the alpha field, and the beta field, wherein a first value in the class field specifies a first class of templates of the first instruction format and a second value specifies a second class of templates of the first instruction format, wherein a distinction between a full round control type operation template and a data transform type operation template in the first class of templates is based on the alpha field's content, wherein the beta field is interpreted as a round control field and a data transform field respectively in the full round control type operation template and the data transform type operation template, wherein the round control field's contents selects whether or not to suppress exceptions and a rounding mode to support IEEE compliance with direct rounding-modes, wherein the data transform field's contents selects from at least upconversion, swizzle, swap, and downconversion to reduce the number of instructions required when working with sources in different formats, wherein the alpha field's content is used to select between a zeroing write mask operation and a merging write mask operation for at least some instructions in the templates of the second class, wherein the beta field is interpreted to include a vector length field in at least a memory access template of the second class, and wherein the base operation field, the class field, the alpha field, and the beta field may each store only one value on each occurrence of an instruction in the first instruction format in instruction streams, the processor including,
a first core configured to execute at least one of,- instructions in the full round control type operation template of the first class,
- instructions in the data transform type operation template of the first class, instructions in the memory access template of the second class, and
- instructions where the alpha field's content is used to select between the zeroing write mask operation and the merging write mask operation in templates of the second class.
- 15. The apparatus of example 14, wherein the first core is configured to execute only instructions in the first class of templates, and wherein the processor includes a second core configured to execution only instructions in the second class of templates.
- 16. The apparatus of example 15, wherein the second core supports out of order execution and register renaming.
- 17. The apparatus of example 14, wherein the first core is configured to execute instructions in both the first class of templates and the second class of templates.
Claims (15)
- A computing apparatus comprising:
a processor configured to execute instructions in an instruction format, wherein the instruction format includes a plurality of fields including a data element width (W) field, a vector length field, and a write mask field, wherein the instruction format supports specification of a plurality of different vector operations, wherein each of the plurality of vector operations requires an operation to be independently performed on each of a plurality of different data element positions of at least one source vector operand to generate at least one destination vector operand, wherein the instruction format supports through different values in the data element width field specification of different data element widths, wherein the instruction format supports through different values in the vector length field specification of a plurality of different vector lengths, wherein the instruction format supports through different values in the write mask field specification of different write masks, wherein only one of the different values may be placed in each of the data element width field and the write mask field on each occurrence of an instruction in the instruction format, and wherein the data element width and the vector length for the occurrence distinguishes which data element positions correspond with which bits of the occurrence's write mask, and wherein the write mask for the occurrence specifies on a per data element position basis whether results of the occurrence's vector operation are or are not to be reflected in the destination vector operand's corresponding data element positions. - The computing apparatus of claim 1, wherein the plurality of different vector lengths includes 128, 256, and 512 bits.
- The computing apparatus of any one of claims 1 and 2, wherein the different data element widths include any one of a 8 bit, 16 bit, 32 bit, and a 64 bit data element width.
- The computing apparatus of claims 1 to 3, wherein the instruction format supports a zeroing-write masking operation.
- The computing apparatus of claims 1 to 4, wherein one of the different values that may be placed in the write mask field is reserved for indicating that all results of the occurrence's vector operation are to be reflected in the destination vector operand's corresponding data element positions.
- The computing apparatus of claims 1 to 5, wherein others of the different values that may be placed in the write mask field distinguish different write mask registers storing configurable write masks.
- The computing apparatus of claim 1, wherein the instruction format supports operations on two source vector operands and the destination vector operand does not overwrite either of the two source vector operands.
- The computing apparatus of claim 1, wherein the instruction format supports operations on two source vector operands and the destination vector operand overwrites one of the two source vector operands.
- A method for executing vector instructions in a vector friendly instruction format, comprising:fetching instructions of an instruction set for execution, wherein the instruction set includes an instruction format, wherein the instruction format includes a plurality of fields including a data element width (W) field, a vector length field, and a write mask field, wherein the instruction format supports specification of a plurality of different vector operations, wherein each of the plurality of vector operations requires an operation to be independently performed on each of a plurality of different data element positions of at least one source vector operand to generate at least one destination vector operand, wherein the instruction format supports through different values in the data element width field specification of different data element widths, wherein the instruction format supports through different values in the vector length field specification of a plurality of different vector lengths, wherein the instruction format supports through different values in the write mask field specification of different write masks, wherein only one of the different values may be placed in each of the data element width field and the write mask field on each occurrence of an instruction in the instruction format, and wherein the data element width and the vector length for the occurrence distinguishes which data element positions correspond with which bits of the occurrence's write mask, and wherein the write mask for the occurrence specifies on a per data element position basis whether results of the occurrence's vector operation are or are not to be reflected in the destination vector operand's corresponding data element positions; andperforming the operations specified by the fetched instructions as follows:distinguishing, for each of the occurrences, which one of the different vector operations to perform based on the base operation field's content;distinguishing, for each of the occurrences, which one of the data element widths to use based on the data element width field's content;distinguishing, for each of the occurrences, which one of the vector lengths to use based on the vector length field's content; anddistinguishing, for each of the occurrences, which one of the different write masks to use based on the write mask field's content, wherein the data element width and the vector length for the occurrence distinguishes which data element positions correspond with which bits of the occurrence's write mask, and wherein the write mask for the occurrence specifies on a per data element position basis whether the results of the occurrence's vector operation is or is not to be reflected in the destination vector operand's corresponding data element positions.
- The method of claim 9, wherein the plurality of different vector lengths includes 128, 256, and 512 bits, and wherein the different data element widths include any one of a 8 bit, 16 bit, 32 bit, and a 64 bit data element width.
- The method of claims 9 to 10, wherein the instruction format supports a zeroing-write masking operation.
- The method of claims 9 to 11, wherein one of the different values that may be placed in the write mask field is reserved for indicating that all results of the occurrence's vector operation are to be reflected in the destination vector operand's corresponding data element positions.
- The method of claims 9 to 12, wherein others of the different values that may be placed in the write mask field distinguish different write mask registers storing configurable write masks.
- The method of claims 9 to 13, wherein the instruction format supports operations on two source vector operands and the destination vector operand does not overwrite either of the two source vector operands.
- The method of claims 9 to 13, wherein the instruction format supports operations on two source vector operands and the destination vector operand overwrites one of the two source vector operands.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP20199439.9A EP3805921B1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
| EP23191570.3A EP4250101A3 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201161471043P | 2011-04-01 | 2011-04-01 | |
| EP11862801.5A EP2695054B1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
| PCT/US2011/054303 WO2012134532A1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
Related Parent Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP11862801.5A Division-Into EP2695054B1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
| EP11862801.5A Division EP2695054B1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
Related Child Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP23191570.3A Division EP4250101A3 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
| EP20199439.9A Division EP3805921B1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
| EP20199439.9A Division-Into EP3805921B1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| EP3422178A2 true EP3422178A2 (en) | 2019-01-02 |
| EP3422178A3 EP3422178A3 (en) | 2019-04-10 |
| EP3422178B1 EP3422178B1 (en) | 2023-02-15 |
Family
ID=46931820
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP18177235.1A Active EP3422178B1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
| EP20199439.9A Active EP3805921B1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
| EP23191570.3A Pending EP4250101A3 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
| EP11862801.5A Active EP2695054B1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
Family Applications After (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP20199439.9A Active EP3805921B1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
| EP23191570.3A Pending EP4250101A3 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
| EP11862801.5A Active EP2695054B1 (en) | 2011-04-01 | 2011-09-30 | Vector friendly instruction format and execution thereof |
Country Status (11)
| Country | Link |
|---|---|
| US (8) | US20130305020A1 (en) |
| EP (4) | EP3422178B1 (en) |
| JP (3) | JP5739055B2 (en) |
| KR (1) | KR101595637B1 (en) |
| CN (5) | CN104951277B (en) |
| DE (1) | DE102020102331A1 (en) |
| ES (1) | ES2943248T3 (en) |
| GB (1) | GB2502936A (en) |
| PL (1) | PL3422178T3 (en) |
| TW (2) | TWI506546B (en) |
| WO (1) | WO2012134532A1 (en) |
Families Citing this family (99)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104951277B (en) | 2011-04-01 | 2017-11-21 | 英特尔公司 | The friendly instruction format of vector and its execution |
| WO2013095553A1 (en) | 2011-12-22 | 2013-06-27 | Intel Corporation | Instructions for storing in general purpose registers one of two scalar constants based on the contents of vector write masks |
| CN107153524B (en) * | 2011-12-22 | 2020-12-22 | 英特尔公司 | Computing device and computer-readable medium for giving complex conjugates of respective complex numbers |
| CN104067224B (en) | 2011-12-23 | 2017-05-17 | 英特尔公司 | Instruction execution that broadcasts and masks data values at different levels of granularity |
| US9946540B2 (en) | 2011-12-23 | 2018-04-17 | Intel Corporation | Apparatus and method of improved permute instructions with multiple granularities |
| CN104081342B (en) | 2011-12-23 | 2017-06-27 | 英特尔公司 | The apparatus and method of improved inserting instruction |
| WO2013095612A1 (en) * | 2011-12-23 | 2013-06-27 | Intel Corporation | Apparatus and method for broadcasting from a general purpose register to a vector register |
| US9632980B2 (en) * | 2011-12-23 | 2017-04-25 | Intel Corporation | Apparatus and method of mask permute instructions |
| US9411739B2 (en) * | 2012-11-30 | 2016-08-09 | Intel Corporation | System, method and apparatus for improving transactional memory (TM) throughput using TM region indicators |
| US9189236B2 (en) * | 2012-12-21 | 2015-11-17 | Intel Corporation | Speculative non-faulting loads and gathers |
| US9823924B2 (en) | 2013-01-23 | 2017-11-21 | International Business Machines Corporation | Vector element rotate and insert under mask instruction |
| US9513906B2 (en) | 2013-01-23 | 2016-12-06 | International Business Machines Corporation | Vector checksum instruction |
| US9471308B2 (en) | 2013-01-23 | 2016-10-18 | International Business Machines Corporation | Vector floating point test data class immediate instruction |
| US9804840B2 (en) | 2013-01-23 | 2017-10-31 | International Business Machines Corporation | Vector Galois Field Multiply Sum and Accumulate instruction |
| US9715385B2 (en) | 2013-01-23 | 2017-07-25 | International Business Machines Corporation | Vector exception code |
| US9778932B2 (en) | 2013-01-23 | 2017-10-03 | International Business Machines Corporation | Vector generate mask instruction |
| US9207942B2 (en) * | 2013-03-15 | 2015-12-08 | Intel Corporation | Systems, apparatuses,and methods for zeroing of bits in a data element |
| US9817663B2 (en) * | 2013-03-19 | 2017-11-14 | Apple Inc. | Enhanced Macroscalar predicate operations |
| US9645820B2 (en) * | 2013-06-27 | 2017-05-09 | Intel Corporation | Apparatus and method to reserve and permute bits in a mask register |
| US9405539B2 (en) | 2013-07-31 | 2016-08-02 | Intel Corporation | Providing vector sub-byte decompression functionality |
| CN104346285B (en) * | 2013-08-06 | 2018-05-11 | 华为技术有限公司 | Internal storage access processing method, apparatus and system |
| US20150052330A1 (en) * | 2013-08-14 | 2015-02-19 | Qualcomm Incorporated | Vector arithmetic reduction |
| US10296334B2 (en) * | 2014-12-27 | 2019-05-21 | Intel Corporation | Method and apparatus for performing a vector bit gather |
| US10296489B2 (en) * | 2014-12-27 | 2019-05-21 | Intel Corporation | Method and apparatus for performing a vector bit shuffle |
| US11544214B2 (en) * | 2015-02-02 | 2023-01-03 | Optimum Semiconductor Technologies, Inc. | Monolithic vector processor configured to operate on variable length vectors using a vector length register |
| GB2540939B (en) * | 2015-07-31 | 2019-01-23 | Advanced Risc Mach Ltd | An apparatus and method for performing a splice operation |
| GB2540944B (en) * | 2015-07-31 | 2018-02-21 | Advanced Risc Mach Ltd | Vector operand bitsize control |
| WO2017074377A1 (en) * | 2015-10-29 | 2017-05-04 | Intel Corporation | Boosting local memory performance in processor graphics |
| US10691453B2 (en) | 2015-11-13 | 2020-06-23 | International Business Machines Corporation | Vector load with instruction-specified byte count less than a vector size for big and little endian processing |
| US10691456B2 (en) | 2015-11-13 | 2020-06-23 | International Business Machines Corporation | Vector store instruction having instruction-specified byte count to be stored supporting big and little endian processing |
| US9990317B2 (en) * | 2015-11-24 | 2018-06-05 | Qualcomm Incorporated | Full-mask partial-bit-field (FM-PBF) technique for latency sensitive masked-write |
| US10180829B2 (en) * | 2015-12-15 | 2019-01-15 | Nxp Usa, Inc. | System and method for modulo addressing vectorization with invariant code motion |
| US10338920B2 (en) * | 2015-12-18 | 2019-07-02 | Intel Corporation | Instructions and logic for get-multiple-vector-elements operations |
| US20170185402A1 (en) * | 2015-12-23 | 2017-06-29 | Intel Corporation | Instructions and logic for bit field address and insertion |
| US10019264B2 (en) * | 2016-02-24 | 2018-07-10 | Intel Corporation | System and method for contextual vectorization of instructions at runtime |
| GB2548602B (en) * | 2016-03-23 | 2019-10-23 | Advanced Risc Mach Ltd | Program loop control |
| CN111651205B (en) * | 2016-04-26 | 2023-11-17 | 中科寒武纪科技股份有限公司 | Apparatus and method for performing vector inner product operation |
| US10282204B2 (en) * | 2016-07-02 | 2019-05-07 | Intel Corporation | Systems, apparatuses, and methods for strided load |
| US10275243B2 (en) | 2016-07-02 | 2019-04-30 | Intel Corporation | Interruptible and restartable matrix multiplication instructions, processors, methods, and systems |
| US10176110B2 (en) | 2016-07-18 | 2019-01-08 | International Business Machines Corporation | Marking storage keys to indicate memory used to back address translation structures |
| US10761849B2 (en) | 2016-09-22 | 2020-09-01 | Intel Corporation | Processors, methods, systems, and instruction conversion modules for instructions with compact instruction encodings due to use of context of a prior instruction |
| US10268580B2 (en) * | 2016-09-30 | 2019-04-23 | Intel Corporation | Processors and methods for managing cache tiering with gather-scatter vector semantics |
| US11023231B2 (en) * | 2016-10-01 | 2021-06-01 | Intel Corporation | Systems and methods for executing a fused multiply-add instruction for complex numbers |
| EP3336692B1 (en) | 2016-12-13 | 2020-04-29 | Arm Ltd | Replicate partition instruction |
| EP3336691B1 (en) | 2016-12-13 | 2022-04-06 | ARM Limited | Replicate elements instruction |
| US10657126B2 (en) * | 2016-12-23 | 2020-05-19 | Cadreon LLC | Meta-join and meta-group-by indexes for big data |
| GB2560159B (en) * | 2017-02-23 | 2019-12-25 | Advanced Risc Mach Ltd | Widening arithmetic in a data processing apparatus |
| CN110312993B (en) | 2017-02-23 | 2024-04-19 | Arm有限公司 | Vector element-by-element operations in data processing devices |
| WO2018174932A1 (en) | 2017-03-20 | 2018-09-27 | Intel Corporation | Systems, methods, and apparatuses for tile store |
| WO2019009870A1 (en) | 2017-07-01 | 2019-01-10 | Intel Corporation | Context save with variable save state size |
| GB2564853B (en) * | 2017-07-20 | 2021-09-08 | Advanced Risc Mach Ltd | Vector interleaving in a data processing apparatus |
| CN108874444A (en) * | 2017-10-30 | 2018-11-23 | 上海寒武纪信息科技有限公司 | Machine learning processor and the method for executing Outer Product of Vectors instruction using processor |
| US11360930B2 (en) | 2017-12-19 | 2022-06-14 | Samsung Electronics Co., Ltd. | Neural processing accelerator |
| US11093247B2 (en) | 2017-12-29 | 2021-08-17 | Intel Corporation | Systems and methods to load a tile register pair |
| US11789729B2 (en) | 2017-12-29 | 2023-10-17 | Intel Corporation | Systems and methods for computing dot products of nibbles in two tile operands |
| US11669326B2 (en) | 2017-12-29 | 2023-06-06 | Intel Corporation | Systems, methods, and apparatuses for dot product operations |
| US11816483B2 (en) | 2017-12-29 | 2023-11-14 | Intel Corporation | Systems, methods, and apparatuses for matrix operations |
| US11809869B2 (en) | 2017-12-29 | 2023-11-07 | Intel Corporation | Systems and methods to store a tile register pair to memory |
| US11023235B2 (en) | 2017-12-29 | 2021-06-01 | Intel Corporation | Systems and methods to zero a tile register pair |
| CN108388446A (en) * | 2018-02-05 | 2018-08-10 | 上海寒武纪信息科技有限公司 | Computing module and method |
| US10664287B2 (en) | 2018-03-30 | 2020-05-26 | Intel Corporation | Systems and methods for implementing chained tile operations |
| US11093579B2 (en) | 2018-09-05 | 2021-08-17 | Intel Corporation | FP16-S7E8 mixed precision for deep learning and other algorithms |
| US11990137B2 (en) | 2018-09-13 | 2024-05-21 | Shanghai Cambricon Information Technology Co., Ltd. | Image retouching method and terminal device |
| US10970076B2 (en) | 2018-09-14 | 2021-04-06 | Intel Corporation | Systems and methods for performing instructions specifying ternary tile logic operations |
| US11579883B2 (en) | 2018-09-14 | 2023-02-14 | Intel Corporation | Systems and methods for performing horizontal tile operations |
| US10990396B2 (en) | 2018-09-27 | 2021-04-27 | Intel Corporation | Systems for performing instructions to quickly convert and use tiles as 1D vectors |
| US10866786B2 (en) | 2018-09-27 | 2020-12-15 | Intel Corporation | Systems and methods for performing instructions to transpose rectangular tiles |
| US10719323B2 (en) | 2018-09-27 | 2020-07-21 | Intel Corporation | Systems and methods for performing matrix compress and decompress instructions |
| US10896043B2 (en) | 2018-09-28 | 2021-01-19 | Intel Corporation | Systems for performing instructions for fast element unpacking into 2-dimensional registers |
| US10929143B2 (en) | 2018-09-28 | 2021-02-23 | Intel Corporation | Method and apparatus for efficient matrix alignment in a systolic array |
| US10963256B2 (en) | 2018-09-28 | 2021-03-30 | Intel Corporation | Systems and methods for performing instructions to transform matrices into row-interleaved format |
| US10963246B2 (en) | 2018-11-09 | 2021-03-30 | Intel Corporation | Systems and methods for performing 16-bit floating-point matrix dot product instructions |
| US11366663B2 (en) | 2018-11-09 | 2022-06-21 | Intel Corporation | Systems and methods for performing 16-bit floating-point vector dot product instructions |
| US10929503B2 (en) | 2018-12-21 | 2021-02-23 | Intel Corporation | Apparatus and method for a masked multiply instruction to support neural network pruning operations |
| US11294671B2 (en) | 2018-12-26 | 2022-04-05 | Intel Corporation | Systems and methods for performing duplicate detection instructions on 2D data |
| US11886875B2 (en) * | 2018-12-26 | 2024-01-30 | Intel Corporation | Systems and methods for performing nibble-sized operations on matrix elements |
| US20200210517A1 (en) | 2018-12-27 | 2020-07-02 | Intel Corporation | Systems and methods to accelerate multiplication of sparse matrices |
| US10942985B2 (en) | 2018-12-29 | 2021-03-09 | Intel Corporation | Apparatuses, methods, and systems for fast fourier transform configuration and computation instructions |
| US10922077B2 (en) | 2018-12-29 | 2021-02-16 | Intel Corporation | Apparatuses, methods, and systems for stencil configuration and computation instructions |
| US11016731B2 (en) | 2019-03-29 | 2021-05-25 | Intel Corporation | Using Fuzzy-Jbit location of floating-point multiply-accumulate results |
| US11269630B2 (en) | 2019-03-29 | 2022-03-08 | Intel Corporation | Interleaved pipeline of floating-point adders |
| US10990397B2 (en) | 2019-03-30 | 2021-04-27 | Intel Corporation | Apparatuses, methods, and systems for transpose instructions of a matrix operations accelerator |
| US11175891B2 (en) | 2019-03-30 | 2021-11-16 | Intel Corporation | Systems and methods to perform floating-point addition with selected rounding |
| US11403097B2 (en) | 2019-06-26 | 2022-08-02 | Intel Corporation | Systems and methods to skip inconsequential matrix operations |
| US11334647B2 (en) | 2019-06-29 | 2022-05-17 | Intel Corporation | Apparatuses, methods, and systems for enhanced matrix multiplier architecture |
| KR102720155B1 (en) * | 2019-09-17 | 2024-10-21 | 삼성전자주식회사 | Integrated circuit device and method of manufacturing the same |
| US11714875B2 (en) | 2019-12-28 | 2023-08-01 | Intel Corporation | Apparatuses, methods, and systems for instructions of a matrix operations accelerator |
| US11099848B1 (en) * | 2020-01-30 | 2021-08-24 | Arm Limited | Overlapped-immediate/register-field-specifying instruction |
| US12112167B2 (en) | 2020-06-27 | 2024-10-08 | Intel Corporation | Matrix data scatter and gather between rows and irregularly spaced memory locations |
| US11972230B2 (en) | 2020-06-27 | 2024-04-30 | Intel Corporation | Matrix transpose and multiply |
| KR20220018776A (en) * | 2020-08-07 | 2022-02-15 | 삼성전자주식회사 | Semiconductor memory device |
| US11941395B2 (en) | 2020-09-26 | 2024-03-26 | Intel Corporation | Apparatuses, methods, and systems for instructions for 16-bit floating-point matrix dot product instructions |
| US11379390B1 (en) * | 2020-12-14 | 2022-07-05 | International Business Machines Corporation | In-line data packet transformations |
| US12183739B2 (en) * | 2020-12-18 | 2024-12-31 | Intel Corporation | Ribbon or wire transistor stack with selective dipole threshold voltage shifter |
| US12001385B2 (en) | 2020-12-24 | 2024-06-04 | Intel Corporation | Apparatuses, methods, and systems for instructions for loading a tile of a matrix operations accelerator |
| US12001887B2 (en) | 2020-12-24 | 2024-06-04 | Intel Corporation | Apparatuses, methods, and systems for instructions for aligning tiles of a matrix operations accelerator |
| US12051697B2 (en) * | 2021-04-19 | 2024-07-30 | Samsung Electronics Co., Ltd. | Integrated circuit devices including stacked gate structures with different dimensions |
| US12107168B2 (en) * | 2021-08-25 | 2024-10-01 | International Business Machines Corporation | Independent gate length tunability for stacked transistors |
| US20250031444A1 (en) * | 2023-07-18 | 2025-01-23 | Samsung Electronics Co., Ltd. | 3d-stacked semiconductor device manufactured using channel spacer |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5207132A (en) | 1991-10-16 | 1993-05-04 | Textron Inc. | Elliptical lobed drive system |
| US5446912A (en) | 1993-09-30 | 1995-08-29 | Intel Corporation | Partial width stalls within register alias table |
Family Cites Families (84)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3189094A (en) * | 1963-01-03 | 1965-06-15 | Halliburton Co | Firing apparatus for gun perforators |
| JPS57209570A (en) | 1981-06-19 | 1982-12-22 | Fujitsu Ltd | Vector processing device |
| JP2539357B2 (en) * | 1985-03-15 | 1996-10-02 | 株式会社日立製作所 | Data processing device |
| US4945479A (en) * | 1985-07-31 | 1990-07-31 | Unisys Corporation | Tightly coupled scientific processing system |
| US4873630A (en) | 1985-07-31 | 1989-10-10 | Unisys Corporation | Scientific processor to support a host processor referencing common memory |
| JPH0724013B2 (en) | 1986-09-10 | 1995-03-15 | 株式会社日立製作所 | Vector processor |
| JPH04156613A (en) * | 1990-10-20 | 1992-05-29 | Fujitsu Ltd | instruction buffer device |
| JP2956707B2 (en) * | 1990-10-29 | 1999-10-04 | 富士通株式会社 | Information processing device |
| US5418973A (en) * | 1992-06-22 | 1995-05-23 | Digital Equipment Corporation | Digital computer system with cache controller coordinating both vector and scalar operations |
| WO1994003860A1 (en) * | 1992-08-07 | 1994-02-17 | Thinking Machines Corporation | Massively parallel computer including auxiliary vector processor |
| JP3248992B2 (en) * | 1993-07-13 | 2002-01-21 | 富士通株式会社 | Multiprocessor |
| US6049863A (en) * | 1996-07-24 | 2000-04-11 | Advanced Micro Devices, Inc. | Predecoding technique for indicating locations of opcode bytes in variable byte-length instructions within a superscalar microprocessor |
| US5903769A (en) | 1997-03-31 | 1999-05-11 | Sun Microsystems, Inc. | Conditional vector processing |
| US6505290B1 (en) | 1997-09-05 | 2003-01-07 | Motorola, Inc. | Method and apparatus for interfacing a processor to a coprocessor |
| US6189094B1 (en) * | 1998-05-27 | 2001-02-13 | Arm Limited | Recirculating register file |
| US6185670B1 (en) * | 1998-10-12 | 2001-02-06 | Intel Corporation | System for reducing number of opcodes required in a processor using an instruction format including operation class code and operation selector code fields |
| US7529907B2 (en) * | 1998-12-16 | 2009-05-05 | Mips Technologies, Inc. | Method and apparatus for improved computer load and store operations |
| US8127121B2 (en) * | 1999-01-28 | 2012-02-28 | Ati Technologies Ulc | Apparatus for executing programs for a first computer architechture on a computer of a second architechture |
| AU2743600A (en) | 1999-01-28 | 2000-08-18 | Ati International S.R.L. | Executing programs for a first computer architecture on a computer of a second architecture |
| US6625724B1 (en) | 2000-03-28 | 2003-09-23 | Intel Corporation | Method and apparatus to support an expanded register set |
| US6857061B1 (en) * | 2000-04-07 | 2005-02-15 | Nintendo Co., Ltd. | Method and apparatus for obtaining a scalar value directly from a vector register |
| US6788303B2 (en) * | 2001-02-27 | 2004-09-07 | 3Dlabs Inc., Ltd | Vector instruction set |
| US6986025B2 (en) * | 2001-06-11 | 2006-01-10 | Broadcom Corporation | Conditional execution per lane |
| US7529912B2 (en) * | 2002-02-12 | 2009-05-05 | Via Technologies, Inc. | Apparatus and method for instruction-level specification of floating point format |
| US7941651B1 (en) * | 2002-06-27 | 2011-05-10 | Intel Corporation | Method and apparatus for combining micro-operations to process immediate data |
| AU2003256870A1 (en) | 2002-08-09 | 2004-02-25 | Intel Corporation | Multimedia coprocessor control mechanism including alignment or broadcast instructions |
| US6986023B2 (en) * | 2002-08-09 | 2006-01-10 | Intel Corporation | Conditional execution of coprocessor instruction based on main processor arithmetic flags |
| US7917734B2 (en) | 2003-06-30 | 2011-03-29 | Intel Corporation | Determining length of instruction with multiple byte escape code based on information from other than opcode byte |
| US7734748B1 (en) * | 2003-10-03 | 2010-06-08 | Nortel Networks Limited | Method and apparatus for intelligent management of a network element |
| GB2409059B (en) * | 2003-12-09 | 2006-09-27 | Advanced Risc Mach Ltd | A data processing apparatus and method for moving data between registers and memory |
| US7302627B1 (en) * | 2004-04-05 | 2007-11-27 | Mimar Tibet | Apparatus for efficient LFSR calculation in a SIMD processor |
| US7052968B1 (en) * | 2004-04-07 | 2006-05-30 | Advanced Micro Devices, Inc. | Method and system for aligning IC die to package substrate |
| US7493474B1 (en) * | 2004-11-10 | 2009-02-17 | Altera Corporation | Methods and apparatus for transforming, loading, and executing super-set instructions |
| US7430207B2 (en) | 2005-02-07 | 2008-09-30 | Reti Corporation | Preemptive weighted round robin scheduler |
| US8218635B2 (en) | 2005-09-28 | 2012-07-10 | Synopsys, Inc. | Systolic-array based systems and methods for performing block matching in motion compensation |
| US7457938B2 (en) * | 2005-09-30 | 2008-11-25 | Intel Corporation | Staggered execution stack for vector processing |
| US7627735B2 (en) | 2005-10-21 | 2009-12-01 | Intel Corporation | Implementing vector memory operations |
| US20070157030A1 (en) * | 2005-12-30 | 2007-07-05 | Feghali Wajdi K | Cryptographic system component |
| US7725682B2 (en) * | 2006-01-10 | 2010-05-25 | International Business Machines Corporation | Method and apparatus for sharing storage and execution resources between architectural units in a microprocessor using a polymorphic function unit |
| US9710269B2 (en) * | 2006-01-20 | 2017-07-18 | Qualcomm Incorporated | Early conditional selection of an operand |
| US8010953B2 (en) * | 2006-04-04 | 2011-08-30 | International Business Machines Corporation | Method for compiling scalar code for a single instruction multiple data (SIMD) execution engine |
| US7676647B2 (en) * | 2006-08-18 | 2010-03-09 | Qualcomm Incorporated | System and method of processing data using scalar/vector instructions |
| US7779391B2 (en) * | 2006-09-05 | 2010-08-17 | International Business Machines Corporation | Method of employing instructions to convert UTF characters with an enhanced extended translation facility |
| KR100813533B1 (en) * | 2006-09-13 | 2008-03-17 | 주식회사 하이닉스반도체 | Semiconductor memory device and data mask method thereof |
| US9223751B2 (en) * | 2006-09-22 | 2015-12-29 | Intel Corporation | Performing rounding operations responsive to an instruction |
| US8572354B2 (en) * | 2006-09-28 | 2013-10-29 | 3Dlabs Inc., Ltd. | Programmable logic unit and method for translating and processing instructions using interpretation registers |
| US20080100628A1 (en) | 2006-10-31 | 2008-05-01 | International Business Machines Corporation | Single Precision Vector Permute Immediate with "Word" Vector Write Mask |
| US7996710B2 (en) * | 2007-04-25 | 2011-08-09 | Hewlett-Packard Development Company, L.P. | Defect management for a semiconductor memory system |
| US7836278B2 (en) * | 2007-07-25 | 2010-11-16 | Advanced Micro Devices, Inc. | Three operand instruction extension for X86 architecture |
| TWI351179B (en) | 2007-08-20 | 2011-10-21 | Lite On Technology Corp | Data processing method and computer system medium thereof |
| US8561037B2 (en) * | 2007-08-29 | 2013-10-15 | Convey Computer | Compiler for generating an executable comprising instructions for a plurality of different instruction sets |
| WO2009061547A1 (en) | 2007-11-05 | 2009-05-14 | Sandbridge Technologies, Inc. | Method of encoding register instruction fields |
| US20090172348A1 (en) | 2007-12-26 | 2009-07-02 | Robert Cavin | Methods, apparatus, and instructions for processing vector data |
| US8667250B2 (en) | 2007-12-26 | 2014-03-04 | Intel Corporation | Methods, apparatus, and instructions for converting vector data |
| US9529592B2 (en) | 2007-12-27 | 2016-12-27 | Intel Corporation | Vector mask memory access instructions to perform individual and sequential memory access operations if an exception occurs during a full width memory access operation |
| US8281109B2 (en) | 2007-12-27 | 2012-10-02 | Intel Corporation | Compressed instruction format |
| US8447962B2 (en) | 2009-12-22 | 2013-05-21 | Intel Corporation | Gathering and scattering multiple data elements |
| US7984273B2 (en) | 2007-12-31 | 2011-07-19 | Intel Corporation | System and method for using a mask register to track progress of gathering elements from memory |
| US8681173B2 (en) | 2007-12-31 | 2014-03-25 | Intel Corporation | Device, system, and method for improving processing efficiency by collectively applying operations |
| US8108614B2 (en) | 2007-12-31 | 2012-01-31 | Eric Sprangle | Mechanism for effectively caching streaming and non-streaming data patterns |
| GB2456775B (en) | 2008-01-22 | 2012-10-31 | Advanced Risc Mach Ltd | Apparatus and method for performing permutation operations on data |
| US8046400B2 (en) * | 2008-04-10 | 2011-10-25 | Via Technologies, Inc. | Apparatus and method for optimizing the performance of x87 floating point addition instructions in a microprocessor |
| US20100024183A1 (en) * | 2008-06-30 | 2010-02-04 | Cuprys Lawrence M | Removable tool for a display assembly |
| JP5357475B2 (en) * | 2008-09-09 | 2013-12-04 | ルネサスエレクトロニクス株式会社 | Data processor |
| US8326904B2 (en) * | 2009-01-27 | 2012-12-04 | International Business Machines Corporation | Trigonometric summation vector execution unit |
| US8838938B2 (en) * | 2009-05-19 | 2014-09-16 | Via Technologies, Inc. | Prefix accumulation for efficient processing of instructions with multiple prefix bytes |
| US8533438B2 (en) * | 2009-08-12 | 2013-09-10 | Via Technologies, Inc. | Store-to-load forwarding based on load/store address computation source information comparisons |
| US8996845B2 (en) | 2009-12-22 | 2015-03-31 | Intel Corporation | Vector compare-and-exchange operation |
| US8627042B2 (en) | 2009-12-30 | 2014-01-07 | International Business Machines Corporation | Data parallel function call for determining if called routine is data parallel |
| US9092213B2 (en) | 2010-09-24 | 2015-07-28 | Intel Corporation | Functional unit for vector leading zeroes, vector trailing zeroes, vector operand 1s count and vector parity calculation |
| US9141386B2 (en) | 2010-09-24 | 2015-09-22 | Intel Corporation | Vector logical reduction operation implemented using swizzling on a semiconductor chip |
| US8667042B2 (en) | 2010-09-24 | 2014-03-04 | Intel Corporation | Functional unit for vector integer multiply add instruction |
| US8972698B2 (en) | 2010-12-22 | 2015-03-03 | Intel Corporation | Vector conflict instructions |
| US20120185670A1 (en) | 2011-01-14 | 2012-07-19 | Toll Bret L | Scalar integer instructions capable of execution with three registers |
| US20120254588A1 (en) | 2011-04-01 | 2012-10-04 | Jesus Corbal San Adrian | Systems, apparatuses, and methods for blending two source operands into a single destination using a writemask |
| US20120254591A1 (en) | 2011-04-01 | 2012-10-04 | Hughes Christopher J | Systems, apparatuses, and methods for stride pattern gathering of data elements and stride pattern scattering of data elements |
| CN104951277B (en) | 2011-04-01 | 2017-11-21 | 英特尔公司 | The friendly instruction format of vector and its execution |
| US20120254593A1 (en) | 2011-04-01 | 2012-10-04 | Jesus Corbal San Adrian | Systems, apparatuses, and methods for jumps using a mask register |
| US20120254592A1 (en) | 2011-04-01 | 2012-10-04 | Jesus Corbal San Adrian | Systems, apparatuses, and methods for expanding a memory source into a destination register and compressing a source register into a destination memory location |
| US20120254589A1 (en) | 2011-04-01 | 2012-10-04 | Jesus Corbal San Adrian | System, apparatus, and method for aligning registers |
| WO2013095553A1 (en) | 2011-12-22 | 2013-06-27 | Intel Corporation | Instructions for storing in general purpose registers one of two scalar constants based on the contents of vector write masks |
| CN107092465B (en) | 2011-12-23 | 2021-06-29 | 英特尔公司 | Instruction and logic for providing vector blending and permutation functions |
| US9236476B2 (en) | 2011-12-28 | 2016-01-12 | Intel Corporation | Techniques and configuration for stacking transistors of an integrated circuit device |
| US9590089B2 (en) * | 2011-12-30 | 2017-03-07 | Intel Corporation | Variable gate width for gate all-around transistors |
-
2011
- 2011-09-30 CN CN201510464707.2A patent/CN104951277B/en active Active
- 2011-09-30 CN CN202011424482.5A patent/CN112463219A/en active Pending
- 2011-09-30 US US13/976,707 patent/US20130305020A1/en not_active Abandoned
- 2011-09-30 CN CN201180070598.6A patent/CN103502935B/en active Active
- 2011-09-30 PL PL18177235.1T patent/PL3422178T3/en unknown
- 2011-09-30 KR KR1020137029045A patent/KR101595637B1/en active IP Right Grant
- 2011-09-30 WO PCT/US2011/054303 patent/WO2012134532A1/en active Application Filing
- 2011-09-30 ES ES18177235T patent/ES2943248T3/en active Active
- 2011-09-30 EP EP18177235.1A patent/EP3422178B1/en active Active
- 2011-09-30 EP EP20199439.9A patent/EP3805921B1/en active Active
- 2011-09-30 JP JP2014502538A patent/JP5739055B2/en active Active
- 2011-09-30 EP EP23191570.3A patent/EP4250101A3/en active Pending
- 2011-09-30 CN CN201610804703.9A patent/CN106406817B/en active Active
- 2011-09-30 CN CN201710936456.2A patent/CN107608716B/en active Active
- 2011-09-30 GB GB1317902.3A patent/GB2502936A/en not_active Withdrawn
- 2011-09-30 EP EP11862801.5A patent/EP2695054B1/en active Active
- 2011-12-07 TW TW103135824A patent/TWI506546B/en active
- 2011-12-07 TW TW100145056A patent/TWI467477B/en active
-
2014
- 2014-01-31 US US14/170,397 patent/US9513917B2/en active Active
-
2015
- 2015-04-22 JP JP2015087178A patent/JP6058732B2/en active Active
-
2016
- 2016-12-07 JP JP2016237947A patent/JP6339164B2/en active Active
-
2019
- 2019-02-28 US US16/289,506 patent/US10795680B2/en active Active
- 2019-03-01 US US16/290,544 patent/US11573798B2/en active Active
-
2020
- 2020-01-30 DE DE102020102331.6A patent/DE102020102331A1/en active Pending
- 2020-08-27 US US17/004,711 patent/US11210096B2/en active Active
-
2021
- 2021-11-11 US US17/524,624 patent/US11740904B2/en active Active
-
2023
- 2023-08-28 US US18/239,106 patent/US12086594B2/en active Active
-
2024
- 2024-09-06 US US18/827,453 patent/US20240427600A1/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5207132A (en) | 1991-10-16 | 1993-05-04 | Textron Inc. | Elliptical lobed drive system |
| US5446912A (en) | 1993-09-30 | 1995-08-29 | Intel Corporation | Partial width stalls within register alias table |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12086594B2 (en) | Vector friendly instruction format and execution thereof | |
| US10908908B2 (en) | Instruction for determining histograms | |
| US12131154B2 (en) | Systems and methods for performing instructions to convert to 16-bit floating-point format | |
| US12008367B2 (en) | Systems and methods for performing 16-bit floating-point vector dot product instructions | |
| US20190042248A1 (en) | Method and apparatus for efficient matrix transpose | |
| US11321086B2 (en) | Instructions for fused multiply-add operations with variable precision input operands | |
| US10303471B2 (en) | Systems, apparatuses, and methods for performing a double blocked sum of absolute differences | |
| US10282204B2 (en) | Systems, apparatuses, and methods for strided load | |
| CN117130578A (en) | bit matrix multiplication | |
| US20170192789A1 (en) | Systems, Methods, and Apparatuses for Improving Vector Throughput |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN PUBLISHED |
|
| AC | Divisional application: reference to earlier application |
Ref document number: 2695054 Country of ref document: EP Kind code of ref document: P |
|
| AK | Designated contracting states |
Kind code of ref document: A2 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| PUAL | Search report despatched |
Free format text: ORIGINAL CODE: 0009013 |
|
| AK | Designated contracting states |
Kind code of ref document: A3 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| RIC1 | Information provided on ipc code assigned before grant |
Ipc: G06F 9/30 20180101AFI20190306BHEP |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: REQUEST FOR EXAMINATION WAS MADE |
|
| 17P | Request for examination filed |
Effective date: 20191002 |
|
| RBV | Designated contracting states (corrected) |
Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| 17Q | First examination report despatched |
Effective date: 20200131 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| INTG | Intention to grant announced |
Effective date: 20220908 |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE PATENT HAS BEEN GRANTED |
|
| AC | Divisional application: reference to earlier application |
Ref document number: 2695054 Country of ref document: EP Kind code of ref document: P |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: EP Ref country code: GB Ref legal event code: FG4D |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R096 Ref document number: 602011073675 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: REF Ref document number: 1548588 Country of ref document: AT Kind code of ref document: T Effective date: 20230315 Ref country code: IE Ref legal event code: FG4D |
|
| REG | Reference to a national code |
Ref country code: NL Ref legal event code: FP |
|
| REG | Reference to a national code |
Ref country code: LT Ref legal event code: MG9D Ref country code: ES Ref legal event code: FG2A Ref document number: 2943248 Country of ref document: ES Kind code of ref document: T3 Effective date: 20230612 |
|
| P01 | Opt-out of the competence of the unified patent court (upc) registered |
Effective date: 20230518 |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: MK05 Ref document number: 1548588 Country of ref document: AT Kind code of ref document: T Effective date: 20230215 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: RS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 Ref country code: PT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230615 Ref country code: NO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230515 Ref country code: LV Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 Ref country code: LT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 Ref country code: HR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 Ref country code: AT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 Ref country code: IS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230615 Ref country code: GR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230516 Ref country code: FI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SM Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 Ref country code: RO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 Ref country code: EE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 Ref country code: DK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 Ref country code: CZ Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R097 Ref document number: 602011073675 Country of ref document: DE |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed |
Effective date: 20231116 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: PL |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20230930 |
|
| REG | Reference to a national code |
Ref country code: BE Ref legal event code: MM Effective date: 20230930 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20230930 Ref country code: MC Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: MM4A |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20230930 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: CH Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20230930 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20230930 Ref country code: CH Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20230930 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20230930 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: NL Payment date: 20240826 Year of fee payment: 14 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20240820 Year of fee payment: 14 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 20240822 Year of fee payment: 14 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: FR Payment date: 20240821 Year of fee payment: 14 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: PL Payment date: 20240829 Year of fee payment: 14 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: IT Payment date: 20240830 Year of fee payment: 14 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BG Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BG Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20230215 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: ES Payment date: 20241004 Year of fee payment: 14 |