EP3019957B1 - Verfahren zur optimierung der parallelen verarbeitung von daten auf einer hardwareplattform - Google Patents
Verfahren zur optimierung der parallelen verarbeitung von daten auf einer hardwareplattform Download PDFInfo
- Publication number
- EP3019957B1 EP3019957B1 EP14736856.7A EP14736856A EP3019957B1 EP 3019957 B1 EP3019957 B1 EP 3019957B1 EP 14736856 A EP14736856 A EP 14736856A EP 3019957 B1 EP3019957 B1 EP 3019957B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- processing
- data
- subset
- size
- criterion
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000012545 processing Methods 0.000 title claims description 180
- 238000000034 method Methods 0.000 title claims description 72
- 238000005457 optimization Methods 0.000 claims description 33
- 238000005259 measurement Methods 0.000 claims description 29
- 238000004590 computer program Methods 0.000 claims description 5
- 230000001976 improved effect Effects 0.000 claims description 3
- 238000005192 partition Methods 0.000 claims 14
- 238000000638 solvent extraction Methods 0.000 claims 1
- 238000004364 calculation method Methods 0.000 description 37
- 230000015556 catabolic process Effects 0.000 description 31
- 230000015654 memory Effects 0.000 description 28
- 238000011282 treatment Methods 0.000 description 23
- 230000008449 language Effects 0.000 description 21
- 238000012360 testing method Methods 0.000 description 6
- 230000008569 process Effects 0.000 description 5
- HPTJABJPZMULFH-UHFFFAOYSA-N 12-[(Cyclohexylcarbamoyl)amino]dodecanoic acid Chemical compound OC(=O)CCCCCCCCCCCNC(=O)NC1CCCCC1 HPTJABJPZMULFH-UHFFFAOYSA-N 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 4
- 239000011159 matrix material Substances 0.000 description 4
- 239000000872 buffer Substances 0.000 description 3
- 230000013016 learning Effects 0.000 description 3
- 238000003860 storage Methods 0.000 description 3
- 241000861223 Issus Species 0.000 description 2
- 238000005520 cutting process Methods 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000009826 distribution Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- 230000006978 adaptation Effects 0.000 description 1
- 238000012550 audit Methods 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 230000006854 communication Effects 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 230000005611 electricity Effects 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 230000017525 heat dissipation Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000000051 modifying effect Effects 0.000 description 1
- 230000002829 reductive effect Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000010187 selection method Methods 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5011—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resources being hardware resources other than CPUs, Servers and Terminals
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
- G06F9/4881—Scheduling strategies for dispatcher, e.g. round robin, multi-level priority queues
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5066—Algorithms for mapping a plurality of inter-dependent sub-tasks onto a plurality of physical CPUs
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/30—Monitoring
- G06F11/34—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment
- G06F11/3404—Recording or statistical evaluation of computer activity, e.g. of down time, of input/output operation ; Recording or statistical evaluation of user activity, e.g. usability assessment for parallel or distributed programming
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2209/00—Indexing scheme relating to G06F9/00
- G06F2209/50—Indexing scheme relating to G06F9/50
- G06F2209/5017—Task decomposition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G06F9/5044—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals considering hardware capabilities
Definitions
- the present invention relates to a method for optimizing parallel processing of data on a hardware platform comprising a plurality of processing units.
- the invention also relates to a computer program suitable for implementing the optimization method of parallel data processing.
- the invention relates more generally to the field of programming applications able to execute several tasks in parallel and to process data in parallel, on specific hardware architectures.
- multi-core architectures are considered in particular hardware architectures comprising a plurality of processing units or processing cores, or multi-cores (called “multi-core” architectures in English terminology), and / or multi-nodes.
- Examples of such hardware architectures are multi-core Central Processing Units (CPUs) or Graphics Processing Unit (GPU) graphics cards.
- a GPU graphics card includes a large number of calculation processors, typically hundreds, the term “many-cores” architecture or massively parallel architecture is then used. Initially dedicated to calculations relating to the processing of graphic data, stored in the form of two- or three-dimensional pixel arrays, GPU graphics cards are currently used more generally for any type of scientific calculation requiring great computing power and processing. data parallel.
- OpenMP Open Multi-Processing
- OpenCL Open Computing Language
- Parallel programming languages offer many possibilities, as for the distribution of the calculations to be performed, the number of tasks to be executed in parallel and the division of data into groups of data to be processed in parallel. Thus, the design of programming code optimized for parallel execution is difficult to obtain for the developer who uses the language.
- the optimization in terms of execution time is highly dependent on the architecture of the hardware platform on which the code of the programming application is executed. For example, typically, the number of executable tasks in parallel is dependent on the number of processing units available, but the speed of execution is also dependent on the speed of memory accesses and data transfers.
- the present invention also relates to a computer program product comprising programming code instructions able to be implemented by a processor.
- the program is capable of implementing an optimization method for parallel processing of data on a hardware platform as mentioned previously.
- a method for optimizing parallel processing of data on a hardware platform comprising at least one calculation unit comprising a plurality of processing units capable of executing a plurality of tasks in parallel. executable, and the data to be processed forming a set of data decomposable into subsets of data, the same sequence of operations being performed on each subset of data.
- the method comprises the steps of obtaining a maximum number of tasks executable in parallel by a unit for calculating the hardware platform, of determining the sizes of the data subsets to be processed by the same sequence of operations, and d optimization of the size of at least one subset of data to be processed so as to obtain an improvement in execution performance measurement compared to the size determined according to at least one chosen criterion, the measurement being associated with execution a program comprising program code instructions implementing a processing division corresponding to the division of the data set into a number of data groups, and to the assignment of at least one executable task, capable of execute said sequence of operations, for each subset of data in said data group, the total number of executable tasks per data group being equal to or equal to said number maximum number of tasks.
- the present invention also relates to a computer program comprising programming code instructions able to be implemented by a processor.
- the program is capable of implementing an optimization method for parallel processing of data on a hardware platform as mentioned previously.
- the invention will be described in its application for the optimization of programming code for a hardware platform comprising one or more GPU graphics cards, the programming code being in OpenCL language.
- the invention applies to any high-performance hardware platform with multiple processing units, in particular on heterogeneous platforms including both GPU graphics cards and general-purpose multi-core processors, and with other languages suitable for parallel programming.
- the invention also applies when the hardware platform consists of several high performance hardware platforms, these platforms being able to communicate via network communications, for example by using “message passing”.
- WO 2010/092483 teaches that, according to an embodiment of a method of the invention, at least part of the data to be processed is loaded into a capacity buffer memory (B).
- the buffer memory is accessible to N processing units of a computer system.
- the processing task is divided into processing execution threads.
- An optimal number (n) of processing execution threads is determined by a computer system optimization unit.
- the n processing execution threads are assigned to the processing task and executed by one or more of the N processing units.
- the processed data are stored on a disk defined by disk sectors, each disk sector having a storage capacity (S).
- the storage capacity (B) of the buffer memory is optimized to a multiple X of the sector storage capacity (S).
- the optimal number (n) is determined based, at least in part, on N, B and S.
- the system and method can be implemented in a multiprocessor multi-threaded computer system.
- the stored encrypted data can be recalled later and decrypted using the same system and method.
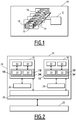
- an example of such a hardware platform 10 comprises a server machine 12 and a set of computing devices 14.
- the server machine 12 is adapted to receive the execution instructions and to distribute the execution on the set of calculation devices 14.
- the computing devices 14 are multiprocessors.
- the computing devices 14 are GPU graphics cards.
- the computing devices 14 are either physically inside the server machine 12, or inside other machines, or computing nodes, accessible either directly or via a communications network. According to the example of the figure 1 , the computing devices 14 are accessible via a communications network.
- the calculation devices 14 are suitable for implementing executable tasks transmitted by the server machine 12.
- the invention applies to a distributed calculation platform multi-nodes and / or multi calculation devices.
- Each calculation device 14 comprises one or more calculation units 16. In the case of the figure 1 , each calculation device 14 comprises three calculation units 16.
- Each computation unit 16 comprising a plurality of processing units 18, or processing cores, in a “multi-core” architecture.
- the server machine 12 comprises at least one processor and a memory capable of storing data and instructions.
- server machine 12 is suitable for executing a computer program comprising code instructions implementing an optimization method of parallel processing of proposed data.
- a program implementing the proposed parallel data processing optimization method is coded in a software programming language known as C or C ++.
- the program implements the optimization method for parallel data processing proposed in ISA (Instruction Set Architecture) type code instructions.
- ISA Instruction Set Architecture
- a programming language particularly suitable for this type of hardware platform with a so-called massively parallel architecture is the OpenCL language.
- OpenCL language has been designed more particularly for heterogeneous multi-core systems, comprising for example both a multi-core CPU and one or more GPU graphics cards.
- the OpenCL language makes it possible to manage both the parallelism of the executable tasks and the parallelism of the data.
- the OpenCL language thus makes it possible to manage the parallel execution of tasks on various available processing units and access to the data in separate memory spaces.
- the figure 2 illustrates the hierarchy of memory spaces defined by OpenCL, allowing parallel access to the data for the calculation device 14 considered.
- the memory model 20 illustrated in figure 2 comprises a first memory space 22 and a second memory space 24.
- the first memory space 22 is said to be “global” because the first memory space 22 is shared by the two calculation units 16 of the calculation device 14.
- the global memory space 22 is external to the calculation device 14.
- this is the case in an “off-chip” type memory of a GPU graphics card.
- the second memory space 24 comprises a constant memory space 26, two local memories 28 and four private memories 30.
- the second memory space 24 is located in the computing device 14.
- the constant memory space 26 is suitable for storing constant data for each read-only access for the two calculation units 16 of the calculation device 14 during the execution of a task performing a series of calculation operations.
- Each local memory 28 is associated with a calculation unit 16.
- Each local memory 28 is used by a task 32 of a group of tasks 34 executed by one of the two processing units 18 of the calculation unit 16 of the figure 2 .
- task 32 is also called by the English term "work-item” and task group 34 by the term "work-group”.
- Each calculation unit 16 comprises two of the four private memories 30. Each private memory 30 is associated with a processing unit 18 of the calculation unit 16.
- each private memory 30 operates in a manner similar to registers in a CPU with a single processing unit.
- An OpenCL processing space is a space comprising n dimensions, where n is an integer between 1 and 3.
- Each element of the multi-dimensional matrix corresponds to an executable task 32 or “work-item”, performing a series of computational operations on a subset of data of a set of data to be processed.
- the data to be processed are values of the digital image pixels.
- the set of data forms a two-dimensional table whose size is given by a first dimension p and a second dimension q. p and q are two non-zero natural integers.
- the first dimension p is greater than the second dimension q.
- the first dimension p is equal to 1024 and the second dimension q is equal to 768.
- This digital processing is an executable task 32.
- FFT Fast Fourier transform
- An FFT 1024 function makes it possible to obtain 1024 samples in the Fourier domain from a data subset of 1024 pixel values.
- a method used in practice to implement the FFT 1024 transformation is to perform the FFT 1024 transform for each of the 768 data subsets of the array comprising 1024 pixel values.
- the FFT 1024 transformation therefore constitutes a series of operations applied to the 768 data subsets independently and therefore parallelizable.
- the processing space defining the set of executable tasks to be performed on data subsets can be modeled as a one-dimensional array, each element of the array corresponding to a task 32 - calculation of the FFT 1024 transform - to execute on a subset of data, here a line of pixel values.
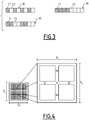
- FIG. 3 A schematic illustration of processing division with respect to a one-dimensional processing space table is given in figure 3 .
- the table includes eight “work-items” or subsets of data to be processed, and, for the simplicity of the explanation, only two processing units adapted to implement two executable tasks T1, T2 in parallel are considered.
- the figure 3 shows three treatment cutouts 36, 38 and 40.
- a hatched square represents a processing by the executable task T1 and a non-hatched square represents a processing by the executable task T2.
- the tasks executable in parallel available, T1 and T2 are distributed in a cyclic alternating manner.
- the tasks executable in parallel available are grouped by blocks of four consecutive subsets of data.
- the tasks T1 and T2 take care of blocks of two consecutive subsets of data, in a cyclical manner.
- OpenCL offers the possibility of defining the set of tasks that can be executed in parallel to be performed on the data, or "work-items", the dimensions of the "global work size” table being denoted Gx and Gy in this example.
- the elementary tasks or "work-items” are grouped into task groups “work-groups” each comprising the same number of tasks 32, defined by the "local work size”, here defined by Sx and Sy.
- the elementary tasks of a task group are able to communicate and synchronize for coordinated access to the local memory 28.
- Task groups 34 are executed in parallel, and the maximum number of tasks per task group 34 is limited by the limits of the hardware platform.
- the figure 5 is a flowchart of an optimization method for parallel data processing according to the invention, the optimization considered in this implementation example being an optimization in terms of execution time, the associated optimization criterion being the minimization of execution time.
- the processing is suitable for parallel implementation since the processing includes a repetition of the same sequence of operations, to be performed on subsets of input data.
- a series of operations can be limited to a single operation performed on a subset reduced to an input datum, for example a pixel of an image.
- repetition of a sequence of operations is expressed in number of turns of calculation loops, for example “for” loops in C language.
- a functional application can comprise several successive treatments, independent of each other.
- the proposed method is applied in a similar manner for each of the treatments included in the functional application.
- the method comprises a step 50 consisting in obtaining the context of the hardware platform 10 used.
- Step 50 is a preliminary step usually carried out only once.
- step 50 comprises obtaining the maximum number of tasks executable in parallel by a computing unit 16 of the hardware platform 10.
- NVIDIA® GTX graphics cards usually support a maximum number of 1024 tasks that can be executed simultaneously by a multiprocessor.
- the method includes a step 52 of determining the sizes of the data subsets to be processed by the same sequence of operations. As explained above, the sizes depend on the input data and the sequences of operations to be performed. In terms of the OpenCL specification, it's about determining the "global" sizes work size ”, according to its one, two or three dimensions, defining the multidimensional matrix processing space.
- step 52 of determining the sizes of the data subsets to be processed are envisaged.
- a program comprising code instructions written in a language suitable for the execution of parallel code.
- This program is, for example, written in the OpenCL language.
- This program is not optimized to provide a runtime configuration that makes the most of the hardware platform.
- the information corresponding to the sizes of the processing space is simply extracted from the code instructions of the non-optimized program supplied as input.
- the program supplied comprising non-optimized code instructions defines an initial "naive" unoptimized division, therefore an initial size for the "local work size”.
- the method receives as input an application graph defining a functional application, comprising one or more treatments to be carried out.
- Each treatment to be performed is defined via the application graph.
- Step 52 of determining the sizes of the data subsets to be processed then consists in analyzing the application graph and then breaking it down into processing. For each given processing, the sequence of operations to be performed repeatedly is identified as well as the number of calls or the number of loop turns to be calculated, which is directly linked to the number of data to be processed.
- the method also includes a step 54 of determining a set of divisions of the treatment space, or treatment divisions, D1 to DN.
- Each processing division corresponds to the division of the data set into a number of groups of data and the assignment of at least one executable task, suitable to execute the sequence of operations, for each subset of data in the data group.
- each group of the breakdown comprises the same number of data subsets, and the total number of tasks executable by group is less than or equal to the maximum number of tasks executable in parallel provided by the hardware platform, obtained in step 50 of context extraction.
- the determination of divisions consists of determining various possible “local work size” values.
- all of the possible treatment divisions are determined in step 54 of determining a set of treatment divisions.
- the set of divisions includes all the variants of division into groups of equal size of a three-dimensional matrix space of size 1999 ⁇ 32 ⁇ 16, which gives a fairly high combinatorial, but manageable by a automatic processing.
- a given number of processing splits D, D ⁇ 2 is determined, using one or more predetermined criteria, taking into account for example the maximum number of tasks executable in parallel by a computing unit 16 of the hardware platform 10.
- the method includes a step 56 of initializing values.
- an algorithmic parameter Tmin intended, in this embodiment, for memorize the minimum execution time, is initialized to a very large value, for example the maximum value available.
- a counter i is initialized at the value one.
- the method includes a step 58 of obtaining.
- a program comprising programming code instructions corresponding to the processing breakdown Di is generated and the execution of this program is launched on the hardware platform, in order to obtain a value of a measurement of execution performance, which in this embodiment is a measure of the effective execution time Ti associated with the processing breakdown Di.
- execution performance measures such as for example the consumption of electricity, or the heat dissipation associated with an execution or a combination of different criteria, are implemented in place of the measurement of time d 'execution.
- an associated predetermined optimization criterion is taken into account, making it possible to select the corresponding optimal processing division.
- the processing is preferably carried out with any input data, and not with actual data from a functional application, since the execution time should not be dependent on the values of the input data.
- the various address jumps being limited in the initial code, or even non-existent, the use of any input data therefore makes it possible to considerably reduce the impact of the input data on the execution of each application.
- the execution of the program corresponding to the processing breakdown Di is launched a given number of times, for example 10 times, and the time corresponding to the execution time is memorized for each of the executions. Then, the minimum execution time is retained in the variable Ti.
- the execution is launched a given number of times, and the measurement value Ti associated with the division Di is obtained by calculation of a statistic of the stored values, for example the minimum, the mean or a statistic of higher order.
- the calculated statistic is stored as a measurement value Ti of the execution performance associated with the breakdown Di.
- the method comprises a step 60 of selection of the processing breakdown making it possible to obtain an optimal measurement value according to the predetermined criterion.
- the selection step 60 includes a test 61 applied to determine whether the value of the execution time Ti associated with the processing breakdown Di is less than the value Tmin, the optimization criterion being the minimization of the execution time in this embodiment.
- the method includes a step 62 in which the value of Tmin is set to the value Ti and the processing split Di is recorded as the optimal processing split Dopt. Step 62 follows test 61.
- the method also includes a step 64 of incrementing the counter i by one, step 64 following step 62.
- the method comprises step 64 of incrementing the aforementioned counter i.
- the method then includes a test 66 whose purpose is to check whether the maximum number of processing splits has been reached.
- test 66 is followed by step 58 previously described.
- the method comprises a step 68 of obtaining information relating to the processing splitting having the shortest execution time, or optimal processing splitting Dopt.
- the breakdown information is retrieved, typically the information defining the "local work size" in the implementation with the OpenCL programming language.
- This information then makes it possible to generate programming code instructions implementing the optimal processing breakdown in terms of execution time in step 70.
- step 70 typically consists in replace the initial “local work size” values with the “local work size” values corresponding to the optimal processing split.
- step 70 consists in effectively generating a set of programming code instructions, in OpenCL language in this exemplary embodiment, implementing the optimal processing breakdown.
- step 70 consists in simply retrieving from memory the programming code instructions corresponding to the optimal processing division Dopt.
- step 70 on an NVIDIA GTX 480 architecture has been tested by the applicant for the example studied. An execution time of 1480 milliseconds was obtained.
- the method comprises a step 72 of optimizing the size of at least one subset of data to be processed.
- a subset of data having the optimized size makes it possible to obtain an improved execution performance compared to a subset of data having the size determined according to the chosen criteria.
- the optimized size is preferably the size for the data subset considered allowing an optimal execution performance to be obtained. Optimization is carried out on all sizes of the table (s) of input arbitrarily by the user via the various first higher multiples (2, 3, 4, etc.) or in relation to a database specific to the target with the various first multiples desired. The execution times are then retrieved for each value in the input table which allows us to compare them and deduce the minimum execution time.
- Step 72 includes a step 74 of selecting at least one integer N greater than the determined size of the subset considered.
- the integer N is less than or equal to twice the determined size of the considered subset. This avoids the calculation of too many possible combinations
- N is strictly greater than 1999.
- integer N is a multiple of numbers smaller than the determined size of the subset considered.
- the numbers smaller than the determined size of the subset considered are the prime numbers between 2 and 9, namely 2, 3, 5 and 7 and the integer N is the first multiple of one of the prime numbers.
- the whole number selected at the end of step 74 is 2000
- the whole number N is the first multiple of the different prime numbers 2, 3, 5 and 7.
- the whole number selected at the end of step 74 is 2100.
- the numbers smaller than the determined size of the subset considered are 2, 4 and 8. Choosing multiples of two is favorable since the architectures generally contain an even number of cores.
- the numbers smaller than the determined size of the subset considered come from a configurable file.
- this configurable file is suitable for implementing a selection method involving a learning technique.
- the learning criteria are defined following the choice of an expert.
- the expert identifies the divisions that he considers the most relevant.
- the learning technique makes it possible to obtain automatic selection criteria.
- step 74 one of the integers selected at the end of step 74 is 2000.
- Step 72 then comprises a step 76 of generating a calculation subset having for size the whole number selected from the subset and comprising all the data of the considered subset.
- Step 72 includes a step 78 of determining the optimal division for this new processing space.
- step 78 is implemented by applying steps 52 to 70 to the new three-dimensional processing space.
- This embodiment is indicated schematically by a dotted frame on the figure 5 .
- step 78 on an NVIDIA GTX 480 architecture was tested by the applicant for the example studied. An execution time of 170 milliseconds was obtained.
- step 72 it is possible to iterate step 72 as much as desired in an attempt to further reduce the execution time.
- the optimized size obtained at the end of step 72 will correspond to the size giving the lowest execution time.
- the step of selecting treatment cutouts making it possible to obtain an optimal measurement value according to the chosen criterion several cutouts meet the chosen criterion.
- the criterion chosen at the step of selection of divisions is a first criterion called the major criterion while the other criterion is a second criterion qualified as a secondary criterion.
- the method thus comprises a first selection step according to the first criterion making it possible to obtain a plurality of processing splits and a second selection step according to the second criterion making it possible to select a processing cutting.
- the first selection step is a less fine selection step than the second selection step.
- the second selection step is, for example, implemented by sorting the data. Any other embodiment making it possible to determine among the processing divisions selected in the first selection step is, however, conceivable.
- the first criterion is a performance criterion in execution time of the application and the second criterion chosen is then lower power consumption during execution .
- the resulting breakdown thus has a calculation time less than a given limit with lower consumption.
- the implementation of the method then makes it possible to obtain a division presenting a computation time respecting the given real time constraints and at least partially solving the problems called "greencomputing", English term corresponding to "eco-responsible computing".
- the application studied is an application embedded in non-real time.
- the first criterion is compliance with a given thermal envelope and the second criterion is a performance criterion in execution time of the application.
- the implementation of the method then makes it possible to obtain a breakdown which presents an optimal computation time while respecting implementation constraints.
- the implementation of the method then makes it possible to obtain a division respecting two criteria.
- This is particularly advantageous when the application of the first criterion gives a plurality of solutions.
- the first criterion can be modified so that a plurality of solutions exist.
- the application execution time may be longer than the optimum time if for the user there is no perceived difference.
- a division will be chosen which does not correspond to the optimal execution time but which remains fast enough with respect to the intended application to comply with another advantageous secondary criterion.
- a plurality of selection steps are carried out by modifying the criterion at each selection step.
- the method comprises a step of first selection of treatment divisions according to a first criterion, which is the major criterion, then a step of second selection of treatment divisions according to a second criterion from among the treatment divisions selected in step first selection, then a step of third selection of treatment splits according to a third criterion among the treatment splits selected in the second selection step and a step of fourth selection of a treatment splitting according to a fourth criterion among the splits selected during the third selection step.
- the four criteria are different.
- a division is obtained verifying the four criteria.
- the invention has been described more particularly in the case of the use of the parallel programming language OpenCL.
- the adaptation of the method of the invention applied to the CUDA language will vary the size of the "blocks” and the "grid”, so as to determine the optimal block / grid size within the meaning of a predetermined criterion, which allows '' achieve better performance in computing time or lower power consumption.
- the fact of varying the sizes of the “blocks” and “grid” elements amounts to carrying out a plurality of processing splits, these various processing splits then being tested to determine an optimal processing breakdown within the meaning of the predetermined criterion, as explained in the embodiment detailed above with reference to the figure 5 .
- the invention makes it possible to optimize the parallel processing of the data adaptively with respect to any available hardware platform.
- this property shows the modularity of the proposed process.
- the user of the method chooses to allocate a core of a quad-core architecture for another application, it is possible to implement the method by applying it to the architecture three-core available.
- this makes the method adaptable to the specific use of the cores of the architecture considered, by taking charge of the availability of these cores.
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Multi Processors (AREA)
- Stored Programmes (AREA)
- Advance Control (AREA)
Claims (8)
- Verfahren zum Optimieren der parallelen Verarbeitung von Daten auf einer Hardware-Plattform, wobei die Hardware-Plattform aufweist:- mindestens eine Recheneinheit, welche eine Mehrzahl von Verarbeitungseinheiten aufweist, welche imstande sind, parallel eine Mehrzahl von ausführbaren Aufgaben in einem Verarbeitungsraum auszuführen, wobei der Verarbeitungsraum ein Raum ist, in welchem eine gleiche Abfolge von Vorgängen an der Gruppe der Daten durchgeführt wird, wobei der Verarbeitungsraum in Verarbeitungsuntergruppen zerlegbar ist, wobei jede Untergruppe diese gleiche Verarbeitung an einer Datenuntergruppe realisiert,wobei das Verfahren dadurch gekennzeichnet ist, dass das Verfahren die Schritte aufweist des:- Erlangens einer maximalen Zahl von parallel ausführbaren Aufgaben mittels einer Recheneinheit der Hardware-Plattform,- Ermittelns von Größen der Datenuntergruppen des Verarbeitungsraums mittels einer gleichen Abfolge von Vorgängen, um ermittelte Größen zu erlangen,- Optimieren der Größe von mindestens einer Datenuntergruppe des Verarbeitungsraums, wobei das Optimieren aufweist einen Schritt des:- Auswählens, für mindestens eine in Betracht gezogene Untergruppe, mindestens einer ganzen Zahl, welche strikt größer ist als die ermittelte Größe, und mehrerer Zahlen, welche kleiner sind als die ermittelte Größe der in Betracht gezogenen Untergruppe, wobei die Zahl oder die Zahlen, welche kleiner sind als die vorbestimmte Größe der in Betracht gezogenen Untergruppe, vorzugsweise 2, 4 oder 8 sind,- Erzeugens, für jede im Schritt des Auswählens in Betracht gezogene Untergruppe, einer Rechenuntergruppe, welche als Größe die ausgehend von der Untergruppe ausgewählte ganze Zahl hat und alle Daten der in Betracht gezogenen Untergruppe aufweist, wobei die Rechenuntergruppe die in Betracht gezogene Datenuntergruppe im Verarbeitungsraum ersetzt, um einen neuen Verarbeitungsraum zu erlangen,wobei das Optimieren durchgeführt wird, um eine verbesserte Ausführungsleistungsmessung für den neuen Verarbeitungsraum im Vergleich zur Ausführungsleistungsmessung zu erlangen, welche für den Verarbeitungsraum erlangt wird, in welchem die in Betracht gezogene Datenuntergruppe die Größe hat, welche gemäß mindestens einem ausgewählten Kriterium ermittelt wird, wobei die Messung assoziiert ist mit dem Ausführen eines Programms, welches Programmcodeanweisungen aufweist, welche eine Verarbeitungsaufteilung durchführen, welche zur Aufteilung des in Betracht gezogenen Verarbeitungsraums in Datenuntergruppen korrespondiert, und mit dem Zuordnen mindestens einer ausführbaren Aufgabe, welche imstande ist, die besagte Abfolge von Vorgängen auszuführen, zu jeder Datenuntergruppe, wobei die Gesamtzahl an ausführbaren Aufgaben pro Datenuntergruppe kleiner oder gleich ist zur besagten maximalen Zahl an Aufgaben.
- Verfahren gemäß Anspruch 1, wobei die Zahlen, die kleiner sind als die ermittelte Größe der in Betracht gezogenen Untergruppe, aus einer parametrierbaren Datei stammen.
- Verfahren gemäß Anspruch 1 oder 2, wobei der Schritt des Optimierens aufweist, für jede Untergruppengröße, einen Schritt des:- Ermittelns der Verarbeitungsaufteilung, welche es erlaubt, die Ausführungsleitungsmessung zu minimieren, welche mit dem Ausführen eines Programms assoziiert ist, welches Programmcodeanweisungen aufweist, welche die Verarbeitungsaufteilung durchführen.
- Verfahren gemäß Anspruch 3, wobei der Schritt des Ermittelns der Verarbeitungsaufteilung ferner aufweist einen Schritt des:- Ermittelns mindestens zweier Verarbeitungsaufteilungen,- Erlangens eines Programms, welches Programmiercodeanweisungen aufweist, welche die besagte Verarbeitungsaufteilung durchführen,- Erlangens des Wertes einer Ausführungsleistungsmessung, welche mit dem ausgewählten Kriterium und der Ausführung des besagten Programms auf der besagten Hardware-Plattform assoziiert ist,- Auswählens der Verarbeitungsaufteilung, welche es erlaubt, einen optimalen Messwert zu erlangen, welcher das ausgewählte Kriterium einhält.
- Verfahren gemäß Anspruch 3, wobei die ausgewählten Kriterien ein erstes Kriterium und ein vom ersten Kriterium verschiedenes zweites Kriterium aufweisen, wobei der Schritt des Ermittelns der Verarbeitungsaufteilung ferner aufweist einen Schritt des:- Ermittelns mindestens zweier Verarbeitungsaufteilungen,- Erlangens eines Programms, welches Programmiercodeanweisungen aufweist, welche die besagte Verarbeitungsaufteilung durchführen,- Erlangens des Wertes von Ausführungsleistungsmessungen, welche jeweilig mit dem ersten Kriterium und dem zweiten Kriterium und mit der Ausführung des besagten Programms auf der besagten Hardware-Plattform assoziiert sind,- ersten Auswählens der Verarbeitungsaufteilungen, welche es erlauben, eine Mehrzahl von optimalen Messwerten zu erlangen, welche das erste ausgewählte Kriterium erfüllen,- zweiten Auswählens der Verarbeitungsaufteilung, welche es erlaubt, einen optimalen Messwert gemäß dem zweiten Kriterium, welches ausgewählt ist aus den Verarbeitungsaufteilungen, welche im Schritt des ersten Auswählens ausgewählt werden, zu erlangen.
- Verfahren gemäß Anspruch 4 oder 5, wobei das Verfahren ferner aufweist einen Schritt des:- Erlangens von Informationen, welche es erlauben, Programmiercodeanweisungen zu erzeugen, welche die besagte ausgewählte Verarbeitungsaufteilung durchführen.
- Verfahren gemäß Anspruch 5, wobei der besagte Wert einer Ausführungsleistungsmessung, welcher mit dem ersten Kriterium assoziiert ist, eine Ausführungszeit auf der besagten Hardware-Plattform ist.
- Computerprogrammprodukt, welches Programmiercodeanweisungen aufweist, welche, wenn sie mittels eines Prozessors durchgeführt werden, ein Verfahren zum Optimieren der parallelen Verarbeitung von Daten auf einer Hardware-Plattform gemäß irgendeinem der Ansprüche 1 bis 7 durchführen.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR1301633A FR3008505B1 (fr) | 2013-07-10 | 2013-07-10 | Procede d'optimisation de traitement parallele de donnees sur une plateforme materielle |
| PCT/EP2014/064758 WO2015004207A1 (fr) | 2013-07-10 | 2014-07-09 | Procede d'optimisation de traitement parallele de donnees sur une plateforme materielle |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP3019957A1 EP3019957A1 (de) | 2016-05-18 |
| EP3019957B1 true EP3019957B1 (de) | 2020-03-18 |
Family
ID=49378325
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP14736856.7A Active EP3019957B1 (de) | 2013-07-10 | 2014-07-09 | Verfahren zur optimierung der parallelen verarbeitung von daten auf einer hardwareplattform |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US10120717B2 (de) |
| EP (1) | EP3019957B1 (de) |
| FR (1) | FR3008505B1 (de) |
| WO (1) | WO2015004207A1 (de) |
Families Citing this family (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR3008505B1 (fr) * | 2013-07-10 | 2017-03-03 | Thales Sa | Procede d'optimisation de traitement parallele de donnees sur une plateforme materielle |
| US10496514B2 (en) * | 2014-11-20 | 2019-12-03 | Kevin D. Howard | System and method for parallel processing prediction |
| US9772852B2 (en) * | 2015-04-23 | 2017-09-26 | Google Inc. | Energy efficient processor core architecture for image processor |
| US10719350B2 (en) * | 2017-10-10 | 2020-07-21 | Sap Se | Worker thread manager |
| US10580190B2 (en) | 2017-10-20 | 2020-03-03 | Westghats Technologies Private Limited | Graph based heterogeneous parallel processing system |
| CN109359732B (zh) | 2018-09-30 | 2020-06-09 | 阿里巴巴集团控股有限公司 | 一种芯片及基于其的数据处理方法 |
| CN112631743B (zh) * | 2019-09-24 | 2023-08-04 | 杭州海康威视数字技术股份有限公司 | 任务调度方法、装置及存储介质 |
| CN113553039B (zh) * | 2020-04-23 | 2024-05-31 | 杭州海康威视数字技术股份有限公司 | 算子的可执行代码的生成方法及装置 |
| CN113687816B (zh) * | 2020-05-19 | 2023-09-01 | 杭州海康威视数字技术股份有限公司 | 算子的可执行代码的生成方法及装置 |
Family Cites Families (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002057946A1 (en) * | 2001-01-18 | 2002-07-25 | The Board Of Trustees Of The University Of Illinois | Method for optimizing a solution set |
| EP1515271A1 (de) * | 2003-09-09 | 2005-03-16 | STMicroelectronics S.r.l. | Verfahren und Vorrichtung zur Extrahierung eines Datenteilsatzes aus einem Datensatz |
| US7698451B2 (en) * | 2005-03-09 | 2010-04-13 | Vudu, Inc. | Method and apparatus for instant playback of a movie title |
| US7743087B1 (en) * | 2006-03-22 | 2010-06-22 | The Math Works, Inc. | Partitioning distributed arrays according to criterion and functions applied to the distributed arrays |
| US8127299B2 (en) * | 2006-03-28 | 2012-02-28 | Sap Ag | Landscape reorganization algorithm for dynamic load balancing |
| US8259321B2 (en) * | 2006-04-25 | 2012-09-04 | Xerox Corporation | Methods and systems for scheduling disturbance jobs |
| EP2030131A1 (de) * | 2006-06-06 | 2009-03-04 | Haskolinn I Reykjavik | Daten-mining unter verwendung eines durch rekursive projektion von datenpunkten auf zufallslinien erzeugten indexbaums |
| WO2008148624A1 (en) | 2007-06-05 | 2008-12-11 | Siemens Aktiengesellschaft | Method and device for providing a schedule for a predictable operation of an algorithm on a multi-core processor |
| US8127032B2 (en) * | 2007-10-18 | 2012-02-28 | International Business Machines Corporation | Performance sampling in distributed systems |
| EP2396730A4 (de) * | 2009-02-13 | 2013-01-09 | Alexey Raevsky | Vorrichtungen und verfahren für optimierte parallele datenverarbeitung in multicore-datenverarbeitungssystemen |
| US8935702B2 (en) * | 2009-09-04 | 2015-01-13 | International Business Machines Corporation | Resource optimization for parallel data integration |
| JP4967014B2 (ja) * | 2009-12-16 | 2012-07-04 | 株式会社日立製作所 | ストリームデータ処理装置及び方法 |
| US8707320B2 (en) * | 2010-02-25 | 2014-04-22 | Microsoft Corporation | Dynamic partitioning of data by occasionally doubling data chunk size for data-parallel applications |
| US8533423B2 (en) * | 2010-12-22 | 2013-09-10 | International Business Machines Corporation | Systems and methods for performing parallel multi-level data computations |
| US20120185867A1 (en) * | 2011-01-17 | 2012-07-19 | International Business Machines Corporation | Optimizing The Deployment Of A Workload On A Distributed Processing System |
| WO2013094156A1 (ja) * | 2011-12-19 | 2013-06-27 | 日本電気株式会社 | タスク配置最適化システム、タスク配置最適化方法、及びタスク配置最適化プログラム |
| US8996464B2 (en) * | 2012-06-11 | 2015-03-31 | Microsoft Technology Licensing, Llc | Efficient partitioning techniques for massively distributed computation |
| US9231721B1 (en) * | 2012-06-28 | 2016-01-05 | Applied Micro Circuits Corporation | System and method for scaling total client capacity with a standard-compliant optical transport network (OTN) |
| US8935222B2 (en) * | 2013-01-02 | 2015-01-13 | International Business Machines Corporation | Optimizing a partition in data deduplication |
| FR3008505B1 (fr) * | 2013-07-10 | 2017-03-03 | Thales Sa | Procede d'optimisation de traitement parallele de donnees sur une plateforme materielle |
-
2013
- 2013-07-10 FR FR1301633A patent/FR3008505B1/fr not_active Expired - Fee Related
-
2014
- 2014-07-09 US US14/903,321 patent/US10120717B2/en active Active
- 2014-07-09 WO PCT/EP2014/064758 patent/WO2015004207A1/fr active Application Filing
- 2014-07-09 EP EP14736856.7A patent/EP3019957B1/de active Active
Non-Patent Citations (1)
| Title |
|---|
| None * |
Also Published As
| Publication number | Publication date |
|---|---|
| FR3008505B1 (fr) | 2017-03-03 |
| FR3008505A1 (fr) | 2015-01-16 |
| WO2015004207A1 (fr) | 2015-01-15 |
| US20160147571A1 (en) | 2016-05-26 |
| EP3019957A1 (de) | 2016-05-18 |
| US10120717B2 (en) | 2018-11-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP3019957B1 (de) | Verfahren zur optimierung der parallelen verarbeitung von daten auf einer hardwareplattform | |
| EP2805234B1 (de) | Verfahren zur optimierung der parallelen verarbeitung von daten auf einer hardwareplattform | |
| WO2022037337A1 (zh) | 机器学习模型的分布式训练方法、装置以及计算机设备 | |
| FR3000578A1 (fr) | Systeme et procede de calcul partage utilisant une fourniture automatisee de ressources informatiques heterogenes | |
| US10402746B2 (en) | Computing instance launch time | |
| CN104123184B (zh) | 一种用于为构建过程中的任务分配资源的方法和系统 | |
| US20180052709A1 (en) | Dynamic usage balance of central processing units and accelerators | |
| FR2920899A1 (fr) | Structure de donnees en tranches et procede de chargement d'une simulation basee sur des particules utilisant une structure de donnees en tranches dans un gpu, etc | |
| US10846298B2 (en) | Record profiling for dataset sampling | |
| WO2021130596A1 (en) | Elastic execution of machine learning workloads using application based profiling | |
| TW202338668A (zh) | 用於神經網路訓練的稀疏性掩蔽方法 | |
| JP5560154B2 (ja) | モデルパラメータ推定装置およびそのプログラム | |
| CN116194934A (zh) | 模块化模型交互系统和方法 | |
| EP2956874B1 (de) | Vorrichtung und verfahren zur beschleunigung der aktualisierungsphase eines simulationskerns | |
| CA3188740C (fr) | Systeme et procede d'optimisation d'un outil de simulation | |
| Tesser et al. | Selecting efficient VM types to train deep learning models on Amazon SageMaker | |
| EP2756398B1 (de) | Verfahren, vorrichtung und computerprogramm zur dynamischen ressourcenzuweisung einer gruppe zur durchführung von anwendungsprozessen | |
| FR3074939A1 (fr) | Procede de gestion du systeme de fichiers d'un terminal informatique | |
| WO2019129958A1 (fr) | Procede de stockage de donnees et procede d'execution d'application avec reduction du temps d'acces aux donnees stockees | |
| EP3814893A1 (de) | Prozessorspeicherzugriff | |
| EP2953029B1 (de) | Leistungstest-methoden und -systeme mit konfigurierbarem durchsatz | |
| FR3069933B1 (fr) | Procede de validation de mutualisation de briques applicatives sur une infrastructure informatique | |
| FR2957435A1 (fr) | Systeme de test d'une architecture de calcul multitaches a partir de donnees de communication entre processeurs et procede de test correspondant | |
| FR3045863A1 (fr) | Procede et calculateur d'analyse predictive | |
| CN116011560A (zh) | 模型的训练方法、数据重构方法以及电子设备 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| 17P | Request for examination filed |
Effective date: 20160108 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| AX | Request for extension of the european patent |
Extension state: BA ME |
|
| DAX | Request for extension of the european patent (deleted) | ||
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: GRANT OF PATENT IS INTENDED |
|
| INTG | Intention to grant announced |
Effective date: 20191023 |
|
| RIN1 | Information on inventor provided before grant (corrected) |
Inventor name: LENORMAND, ERIC Inventor name: BARRERE, REMI Inventor name: BRELET, PAUL Inventor name: BARRETEAU, MICHEL |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE PATENT HAS BEEN GRANTED |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: FG4D Free format text: NOT ENGLISH |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R096 Ref document number: 602014062501 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: REF Ref document number: 1246725 Country of ref document: AT Kind code of ref document: T Effective date: 20200415 Ref country code: IE Ref legal event code: FG4D Free format text: LANGUAGE OF EP DOCUMENT: FRENCH |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: RS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: NO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200618 Ref country code: FI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 |
|
| REG | Reference to a national code |
Ref country code: NL Ref legal event code: MP Effective date: 20200318 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: HR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: LV Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: SE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: GR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200619 Ref country code: BG Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200618 |
|
| REG | Reference to a national code |
Ref country code: LT Ref legal event code: MG4D |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: NL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SM Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: EE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: RO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: SK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: IS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200718 Ref country code: CZ Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: LT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: PT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200812 |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: MK05 Ref document number: 1246725 Country of ref document: AT Kind code of ref document: T Effective date: 20200318 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R097 Ref document number: 602014062501 Country of ref document: DE |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: AT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: IT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: DK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 |
|
| 26N | No opposition filed |
Effective date: 20201221 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: MC Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: PL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: PL |
|
| GBPC | Gb: european patent ceased through non-payment of renewal fee |
Effective date: 20200709 |
|
| REG | Reference to a national code |
Ref country code: BE Ref legal event code: MM Effective date: 20200731 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20200709 Ref country code: CH Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20200731 Ref country code: GB Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20200709 Ref country code: LI Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20200731 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: BE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20200731 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20200709 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: TR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: MT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: CY Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: MK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 Ref country code: AL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20200318 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20240712 Year of fee payment: 11 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: FR Payment date: 20240725 Year of fee payment: 11 |