EP2962300B1 - Method and apparatus for generating a speech signal - Google Patents
Method and apparatus for generating a speech signal Download PDFInfo
- Publication number
- EP2962300B1 EP2962300B1 EP14707461.1A EP14707461A EP2962300B1 EP 2962300 B1 EP2962300 B1 EP 2962300B1 EP 14707461 A EP14707461 A EP 14707461A EP 2962300 B1 EP2962300 B1 EP 2962300B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- speech
- microphone
- signal
- similarity
- reverberant
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims description 12
- 239000013598 vector Substances 0.000 claims description 42
- 230000004044 response Effects 0.000 claims description 29
- 238000004891 communication Methods 0.000 description 35
- 238000013459 approach Methods 0.000 description 33
- 238000012545 processing Methods 0.000 description 11
- 230000003595 spectral effect Effects 0.000 description 8
- 230000033001 locomotion Effects 0.000 description 5
- 238000012549 training Methods 0.000 description 5
- 238000007476 Maximum Likelihood Methods 0.000 description 4
- 230000006978 adaptation Effects 0.000 description 4
- 230000000694 effects Effects 0.000 description 4
- 238000001228 spectrum Methods 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 230000008901 benefit Effects 0.000 description 3
- 230000005540 biological transmission Effects 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 230000003321 amplification Effects 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 238000000354 decomposition reaction Methods 0.000 description 2
- 230000001934 delay Effects 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 230000002045 lasting effect Effects 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 101100228469 Caenorhabditis elegans exp-1 gene Proteins 0.000 description 1
- 230000002238 attenuated effect Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 238000011524 similarity measure Methods 0.000 description 1
- 230000005236 sound signal Effects 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
- G10L25/51—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use for comparison or discrimination
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/02—Casings; Cabinets ; Supports therefor; Mountings therein
- H04R1/025—Arrangements for fixing loudspeaker transducers, e.g. in a box, furniture
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/20—Arrangements for obtaining desired frequency or directional characteristics
- H04R1/32—Arrangements for obtaining desired frequency or directional characteristics for obtaining desired directional characteristic only
- H04R1/40—Arrangements for obtaining desired frequency or directional characteristics for obtaining desired directional characteristic only by combining a number of identical transducers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/20—Arrangements for obtaining desired frequency or directional characteristics
- H04R1/32—Arrangements for obtaining desired frequency or directional characteristics for obtaining desired directional characteristic only
- H04R1/40—Arrangements for obtaining desired frequency or directional characteristics for obtaining desired directional characteristic only by combining a number of identical transducers
- H04R1/406—Arrangements for obtaining desired frequency or directional characteristics for obtaining desired directional characteristic only by combining a number of identical transducers microphones
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R3/00—Circuits for transducers, loudspeakers or microphones
- H04R3/005—Circuits for transducers, loudspeakers or microphones for combining the signals of two or more microphones
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L2021/02082—Noise filtering the noise being echo, reverberation of the speech
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
- G10L2021/02161—Number of inputs available containing the signal or the noise to be suppressed
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2201/00—Details of transducers, loudspeakers or microphones covered by H04R1/00 but not provided for in any of its subgroups
- H04R2201/02—Details casings, cabinets or mounting therein for transducers covered by H04R1/02 but not provided for in any of its subgroups
- H04R2201/023—Transducers incorporated in garment, rucksacks or the like
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2420/00—Details of connection covered by H04R, not provided for in its groups
- H04R2420/07—Applications of wireless loudspeakers or wireless microphones
Definitions
- the invention relates to a method and apparatus for generating a speech signal, and in particular to generating a speech signal from a plurality of microphone signals, such as e.g. microphones in different devices.
- devices owned and used by a user has increased substantially.
- devices equipped with audio capture and typically wireless transmission are becoming increasingly common, such as e.g., mobile phones, tablet computers, notebooks, etc.
- Another approach is to use hands free communication based on a microphone being positioned further away from the user.
- conference systems have been developed which when positioned e.g. on a table will pick-up speakers located around the room.
- such systems tend to not always provide optimum speech quality, and in particular the speech from more distant users tends to be weak and noisy.
- the captured speech will in such scenarios tend to have a high degree of reverberation which may reduce the intelligibility of the speech substantially.
- Document US 381-4856 teaches an apparatus, which is analog in nature and uses the output of one of the microphones as a reference.More specifically, the document describes a system where the measuring reference microphone measures background noise and for each program microphone it is determined whether the signal is above the background noise level. If this is the case there is apparently desired activity and the microphone selected. Thus the document does not disclose a comparison between the microphone signal and non-reverberant speech. The document only discloses a comparison between the microphone signal and a background noise level.
- the document US 2011/038486 which is digital in nature, uses the output of the combined microphones as a reference.
- a beam-former output is compared with a single microphone signal (selected as one of the signals from the beam) and a distortion calculator (possibly based on a reverberation estimate) determines whether the single microphone is selected or the output of the beam-former .
- the document therefore does not disclose a comparison between the microphone signal and non-reverberant speech. In the document only a comparison is taught between the microphone and the beam-former output.
- an improved approach for capturing speech signals would be advantageous and in particular an approach allowing increased flexibility, improved speech quality, reduced reverberation, reduced complexity, reduced communication requirements, increased adaptability for different devices (including multifunction devices), reduced resource demand and/or improved performance would be advantageous.
- the Invention seeks to preferably mitigate, alleviate or eliminate one or more of the above mentioned disadvantages singly or in any combination.
- the invention may allow an improved speech signal to be generated in many embodiments.
- it may in many embodiments allow a speech signal to be generated with less reverberation and/or often less noise.
- the approach may allow improved performance of speech applications, and may in particular in many scenarios and embodiments provide improved speech communication.
- the comparison of at least one property derived from the microphone signals to a reference property for non-reverberant speech provides a particular efficient and accurate way of identifying the relative importance of the individual microphone signals to the speech signal, and may in particular provide a better evaluation than approaches based on e.g. signal level or signal-to-noise ratio measures. Indeed, the correspondence of the captured audio to non-reverberant speech signals may provide a strong indication of how much of the speech reaches the microphone via a direct path and how much reaches the microphone via reverberant paths.
- the at least one reference property may be one or more properties/ values which are associated with non-reverberant speech.
- the at least one reference property may be a set of properties corresponding to different samples of non-reverberant speech.
- the similarity indication may be determined to reflect a difference between the value of the at least one property derived from the microphone signal and the at least one reference property for non-reverberant speech, and specifically to at least one reference property of one non-reverberant speech sample.
- the at least one property derived from the microphone signal may be the microphone signal itself.
- the at least one reference property for non-reverberant speech may be a non-reverberant speech signal.
- the property may be an appropriate feature such as gain normalized spectral envelopes.
- the microphones providing the microphone signals may in many embodiments be microphones distributed in an area, and may be remote from each other.
- the approach may in particular provide improved usage of audio captured at different positions without requiring these positions to be known or assumed by the user or the apparatus/system.
- the microphones may be randomly distributed in an ad-hoc fashion around a room, and the system may automatically adapt to provide an improved speech signal for the specific arrangement.
- the non-reverberant speech samples may specifically be substantially dry or anechoic speech samples.
- the speech similarity indication may be any indication of a degree of difference or similarity between the individual microphone signal (or part thereof) and non-reverberant speech, such as e.g. a non-reverberant speech sample.
- the similarity indication may be a perceptual similarity indication.
- the apparatus comprises a plurality of separate devices, each device comprising a microphone receiver for receiving at least one microphone signal of the plurality of microphone signals.
- each device may comprise the microphone providing the microphone signal.
- the invention may allow improved and/or new user experiences with improved performance.
- a number of possible diverse devices may be positioned around a room.
- the individual devices may each provide a microphone signal, and these may be evaluated to find the most suited devices/ microphones to use for generating the speech signal.
- At least a first device of the plurality of separate devices comprises a local comparator for determining a first speech similarity indication for the at least one microphone signal of the first device.
- This may provide an improved operation in many scenarios, and may in particular allow a distributed processing which may reduce e.g. communication resources and/or spread computational resource demands.
- the separate devices may determine a similarity indication locally and may only transmit the microphone signal if the similarity criterion meets a criterion.
- the generator is implemented in a generator device separate from at least the first device; and wherein the first device comprises a transmitter for transmitting the first speech similarity indication to the generator device.
- the transmitter may be arranged to transmit the first speech similarity indication via a wireless communication link, such as a Bluetooth TM or Wi-Fi communication link.
- the generator device is arranged to receive speech similarity indications from each of the plurality of separate devices, and wherein the generator is arranged to generate the speech signal using a subset of microphone signals from the plurality of separate devices, the subset being determined in response to the speech similarity indications received from the plurality of separate devices.
- the subset may include only a single microphone.
- the generator may be arranged to generate the speech signal from a single microphone signal selected from the plurality of microphone signals based on the similarity indications.
- At least one device of the plurality of separate devices is arranged to transmit the at least one microphone signal of the at least one device to the generator device only if the at least one microphone signal of the at least one device is comprised in the subset of microphone signals.
- the transmitter may be arranged to transmit the at least one microphone signal via a wireless communication link, such as a Bluetooth TM or Wi-Fi communication link.
- the generator device comprises a selector arranged to determine the subset of microphone signals, and a transmitter for transmitting an indication of the subset to at least one of the plurality of separate devices.
- the generator may determine the subset and may be arranged to transmit an indication of the subset to at least one device of the plurality of devices. For example, for the device or devices of microphone signals comprised in the subset, the generator may transmit an indication that the device should transmit the microphone signal to the generator.
- the transmitter may be arranged to transmit the indication via a wireless communication link, such as a Bluetooth TM or Wi-Fi communication link.
- a wireless communication link such as a Bluetooth TM or Wi-Fi communication link.
- the comparator is arranged to determine the similarity indication for a first microphone signal in response to a comparison of at least one property derived from the microphone signal to reference properties for speech samples of a set of non-reverberant speech samples.
- the comparison of microphone signals to a large set of non-reverberating speech samples provides a particular efficient and accurate way of identifying the relative importance of the individual microphone signals to the speech signal, and may in particular provide a better evaluation than approaches based on e.g. signal level or signal-to-noise ratio measures.
- the correspondence of the captured audio to non-reverberant speech signals may provide a strong indication of how much of the speech reaches the microphone via a direct path and how much reaches the microphone via reverberant/ reflected paths.
- the comparison to the non-reverberant speech samples includes a consideration of the shape of impulse response of the acoustic paths rather than just an energy or level consideration.
- the approach may be speaker independent and in some embodiments the set of non-reverberant speech samples may include samples corresponding to different speaker characteristics (such as a high or low voice).
- the processing may be segmented, and the set of non-reverberant speech samples may for example comprise samples corresponding to the phonemes of human speech
- the comparator may for each microphone signal determine an individual similarity indication for each speech sample of the set of non-reverberant speech samples.
- the similarity indication for the microphone signal may then be determined from the individual similarity indications, e.g. by selecting the individual similarity indication which is indicative of the highest degree of similarity. In many scenarios, the best matching speech sample may be identified and the similarity indication for the microphone signal may be determined with respect to this speech sample.
- the similarity indication may provide an indication of a similarity of the microphone signal (or part thereof) to the non-reverberant speech sample of the set of non-reverberant speech samples for which the highest similarity is found.
- the similarity indication for a given speech signal sample may reflect the likelihood that the microphone signal resulted from a speech utterance corresponding to the speech sample.
- the speech samples of the set of non-reverberating speech samples are represented by parameters for a non-reverberating speech model.
- the approach may in many embodiments reduce the computational and/or memory resource requirements.
- the comparator may in some embodiments evaluate the model for the different sets of parameters and compare the resulting signals to the microphone signal(s). For example, frequency representations of the microphone signals and the speech samples may be compared.
- model parameters for the speech model may be generated from the microphone signal, i.e. the model parameters which would result in a speech sample matching the microphone signal may be determined. These model parameters may then be compared to the parameters of the set of non-reverberant speech samples.
- the non-reverberating speech model may specifically be a Linear Prediction model, such as a CELP (Code-Excited Linear Prediction) model.
- a Linear Prediction model such as a CELP (Code-Excited Linear Prediction) model.
- the comparator is arranged to determine a first reference property for a first speech sample of the set of non-reverberating speech samples from a speech sample signal generated by evaluating the non-reverberating speech model using the parameters for the first speech sample, and to determine the similarity indication for a first microphone signal of the plurality of microphone signals in response to a comparison of the property derived from the first microphone signal and the first reference property.
- the similarity indication for the first microphone signal may be determined by comparing a property determined for the first microphone signal to reference properties determined for each of the non-reverberant speech samples, the reference properties being determined from a signal representation generated by evaluating the model.
- the comparator may compare a property of the microphone signal to a property of the signal samples resulting from evaluating the non-reverberating speech model using the stored parameters for the non-reverberant speech samples.
- the comparator is arranged to decompose a first microphone signal of the plurality of microphone signals into a set of basis signal vectors; and to determine the similarity indication in response to a property of the set of basis signal vectors.
- the reference property may be related to a set of basis vectors in an appropriate feature domain, from which a non-reverberant feature vector can be generated as a weighted sum of basis vectors.
- This set can be designed such that a weighted sum with only a few basis vectors is sufficient to accurately describe the non-reverberant feature vector, i.e., the set of basis vectors provides a sparse representation for non-reverberant speech.
- the reference property may be the number of basis vectors that appear in the weighted sum.
- the property may be the number of basis vectors that receive a non-zero weight (or a weight above a given threshold) when used to describe a feature vector extracted from the microphone signal.
- the similarity indication may indicate an increasing similarity to non-reverberant speech for a reducing number of basic signal vectors.
- the comparator is arranged to determine speech similarity indications for each segment of a plurality of segments of the speech signal, and the generator is arranged to determine combination parameters for the combining for each segment.
- the apparatus may utilize segmented processing.
- the combination may be constant for each segment but may be varied from one segment to the next.
- the speech signal may be generated by selecting one microphone signal in each segment.
- the combination parameters may for example be combination weights for the microphone signal or may e.g. be a selection of a subset of microphone signals to include in the combination.
- the approach may provide improved performance and/or facilitated operation.
- the generator is arranged to determine combination parameters for one segment in response to similarity indications of at least one previous segment.
- This may provide improved performance in many scenarios. For example, it may provide a better adaptation to slow changes, and may reduce disruptions in the generated speech signal.
- the combination parameters may be determined only based on segments containing speech and not on segments during quiet periods or pauses.
- the generator is arranged to determine combination parameters for a first segment in response to a user motion model.
- the generator is arranged to select a subset of the microphone signals to combine in response to the similarity indications.
- the combining may specifically be selection combining.
- the generator may specifically select only microphone signals for which the similarity indication meets an absolute or relative criterion.
- the subset of microphone signals comprise only one microphone signal.
- the generator is arranged to generate the speech signal as a weighted combination of the microphone signals, a weight for a first of the microphone signals depending on the similarity indication for the microphone signal.
- This may allow improved and/or facilitated operation in many embodiments.
- a method of generating a speech signal comprising: receiving microphone signals from a plurality of microphones; for each microphone signal, determining a speech similarity indication indicative of a similarity between the microphone signal and non-reverberant speech, the similarity indication being determined in response to a comparison of at least one property derived from the microphone signal to at least one reference property for non-reverberant speech; and generating the speech signal by combining the microphone signals in response to the similarity indications.
- the comparator may be arranged to determine the similarity indication in response to a comparison performed in the feature domain.
- the comparator may be arranged to determine some features/parameters from the microphone signal and compare these to stored features/ parameters for non-reverberant speech. For example, as will be described in more detail later, the comparison may be based on parameters for a speech model, such as coefficients for a linear prediction model. Corresponding parameters may then be determined for the microphone signal and compared to stored parameters corresponding to various utterances in an anechoic environment.
- the apparatus of FIG. 1 utilizes an approach that allows the speech reverberation characteristic for the individual microphones to be assessed such that this can be taken into consideration. Indeed, the Inventor has realized not only that considerations of speech reverberation characteristics for individual microphone signals when generating a speech signal may improve quality substantially, but also how this can feasibly be achieved without requiring dedicated test signals and measurements. Indeed, the Inventor has realized that by comparing a property of the individual microphone signals with a reference property associated with non-reverberant speech, and specifically with sets of non-reverberant speech samples, it is possible to determine suitable parameters for combining the microphone signals to generate an improved speech signal.
- the speech signal may be communicated to a remote user, e.g. via a telephone network, a wireless connection, the Internet or any other communication network or link.
- the communication of the speech signal may typically include a speech encoding as well as potentially other processing.
- a similarity indication may be generated for each microphone signal in a given segment. For example, a microphone signal segment of, say, 50 msec duration may be generated for each of the microphone signals. The segment may then be compared to the set of non-reverberant speech samples which itself may be comprised of speech segment samples. The similarity indications may be determined for this 50 msec segment, and the generator 107 may proceed to generate a speech signal segment for the 50 msec interval based on the microphone signal segments and the similarity indications for the segment/ interval. Thus, the combination may be updated for each segment, e.g. by in each segment selecting the microphone signal which has the highest similarity to a speech segment sample of the non-reverberant speech samples.
- the combination parameters such as a selection of a subset of microphone signals to use, or weights for a linear summation, may be determined for a time interval of the speech signal.
- the speech signal may be determined in segments from a combination which is based on parameters that are constant for the segment but which may vary between segments.
- the determination of combination parameters is independent for each time segment, i.e. the combination parameters for the time segment may be calculated based only on similarity indications that are determined for that time segment.
- the combination parameters may alternatively or additionally be determined in response to similarity indications of at least one previous segment.
- the similarity indications may be filtered using a low pass filter that extends over several segments. This may ensure a slower adaptation which may e.g. reduce fluctuations and variations in the generated speech signal.
- a hysteresis effect may be applied which prevents e.g. quick ping-pong switching between two microphones positioned at roughly the same distance from a speaker.
- the generator 107 may be arranged to determine combination parameters for a first segment in response to a user motion model. Such an approach may be used to track the relative position of the user relative to the microphone devices 201, 203, 205.
- the user model need not explicitly track positions of the user or the microphone devices 201, 203, 205 but may directly track the variations of the similarity indications.
- a state-space representation may be employed to describe a human motion model and a Kalman filter may be applied to the similarity indications of the individual segments of one microphone signal in order to track the variations of the similarity indications due to movement. The resulting output of the Kalman filter may then be used as the similarity indication for the current segment.
- each of the microphones 103 may be part of or connected to a different device, and thus the microphone receivers 101 may be comprised in different devices.
- the similarity processor 105 and generator 107 are implemented in a single device.
- a number of different remote devices may transmit a microphone signal to a generator device which is arranged to generate a speech signal from the received microphone signals.
- This generator device may implement the functionality of the similarity processor 105 and the generator 107 as previously described.
- each of the devices may comprise a (sub)similarity processor 105 which is arranged to determine a similarity indication for the microphone signal of that device.
- the similarity indications may then be transmitted to the generator device which may determine parameters for the combination based on the received similarity indications. For example, it may simply select the microphone signal/ device which has the highest similarity indication.
- the devices may not transmit microphone signals to the generator device unless the generator device requests this. Accordingly, the generator device may transmit a request for the microphone signal to the selected device which in return provides this signal to the generator device. The generator device then proceeds to generate the output signal based on the received microphone signal.
- the generator 107 may be considered to be distributed over the devices with the combination being achieved by the process of selecting and selectively transmitting the microphone signal.
- the approach may use microphones of devices distributed in an area of interest in order to capture a user's speech.
- a typical modern living room typically has a number of devices equipped with one or more microphones and wireless transmission capabilities. Examples include cordless fixed-line phones, mobile phones, video chat-enabled televisions, tablet PCs, laptops, etc.
- These devices may in some embodiments be used to generate a speech signal, e.g. by automatically and adaptively selecting the speech captured by the microphone closest to the speaker. This may provide captured speech which typically will be of high quality and free from reverberation.
- the signal captured by a microphone will tend to be affected by reverberation, ambient noise and microphone noise with the impact depending on its location with respect to the sound source, e.g., to the user's mouth.
- the system may seek to select the microphone which is closest to that which would be recorded by a microphone close to the user's mouth.
- the generated speech signal can be applied where hands-free speech capture is desirable such as e.g., home/office telephony, tele-conferencing systems, front-end for voice control systems, etc.
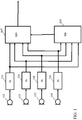
- FIG. 2 illustrates an example of a distributed speech generating/capturing apparatus/system.
- the example includes a plurality of microphone devices 201, 203, 205 as well as a generator device 207.
- the similarity processor 105 of each microphone device 201, 203, 205 specifically performs the operation of the similarity processor 105 of FIG. 1 for the specific microphone signal of the individual microphone device 201, 203, 205.
- the similarity processor 105 of each of the microphone devices 201, 203, 205 specifically proceeds to compare the microphone signal to a set of non-reverberant speech samples which are locally stored in each of the devices.
- the similarity processor 105 may specifically compare the microphone signal to each of the non-reverberant speech samples and for each speech sample determine an indication of how similar the signals are.
- the microphone devices 201, 203, 205 and the generator device 207 may be arranged to communicate data both directions. However, it will be appreciated that in some embodiments, only one-way communication from the microphone devices 201, 203, 205 to the generator device 207 may be applied.
- the devices may communicate via a wireless communication network such as a local Wi-Fi communication network.
- a wireless communication network such as a local Wi-Fi communication network.
- the wireless transceiver 207 of the microphone devices 201, 203, 205 may specifically be arranged to communicate with other devices (and specifically with the generator device 207) via Wi-Fi communications.
- other communication methods may be used including for example communication over e.g. a wired or wireless Local Area Network, Wide Area Network, the Internet, Bluetooth TM communication links etc.
- the wireless transceiver 211 of the generator device 207 is coupled to a controller 213 and a speech signal generator 215.
- the controller 213 is fed the similarity indications from the wireless transceiver 211 and in response to these it determines a set of combination parameters which control how the speech signal is generated from the microphone signals.
- the controller 213 is coupled to the speech signal generator 215 which is fed the combination parameters.
- the speech signal generator 215 is fed the microphone signals from the wireless transceiver 211, and it may accordingly proceed to generate the speech signal based on the combination parameters.
- the controller 213 may compare the received similarity indications and identify the one indicating the highest degree of similarity. An indication of the corresponding device/ microphone signal may then be passed to the speech signal generator 215 which can proceed to select the microphone signal from this device. The speech signal is then generated from this microphone signal.
- the microphone devices 201, 203, 205 transmits a microphone signal.
- Such an approach may substantially reduce the communication resource usage as well as reduce e.g. power consumption of the individual devices. It may also substantially reduce the complexity of the generator device 207 as this only needs to deal with e.g. one microphone signal at a time.
- the selection combining functionality used to generate the speech signal is thus distributed over the devices.
- the non-reverberating speech model may be a linear prediction model, such as specifically a CELP (Code Excited Linear Prediction) model.
- each speech sample of the non-reverberant speech samples may be represented by a codebook entry which specifies an excitation signal that may be used to excite a synthesis filter (which may also be represented by the stored parameters).
- K microphones may be distributed in an area.
- the impulse response h k ( n ) corresponds to a pure delay, corresponding to the time taken for the signal to propagate from the point of generation to the microphone at the speed of sound. Consequently, the PSD of the signal x k ( n ) is identical to that of s ( n ).
- h k ( n ) models not only the direct path of the signal from the sound source to the microphone but also signals arriving at the microphone as a result of being reflected by walls, ceiling, furniture, etc. Each reflection delays and attenuates the signal.
- the covariance matrices can be described as circulant and are diagonalized by the Fourier transform.
- the logarithm of the likelihood in the above equation, corresponding to the i th speech codebook vector a i can then be written using frequency domain quantities as (refer e.g. U. Grenander and G. Szego, "Toeplitz forms and their applications", 2nd ed.
- the noisy PSD P y k ( ⁇ ) and the noise PSD P w k ( ⁇ ) can be estimated from the microphone signal, and Ai ( ⁇ ) is specified by the i th codebook vector.
- Ai ( ⁇ ) is specified by the i th codebook vector.
- L k * max 1 ⁇ i ⁇ I L k i , 1 ⁇ k ⁇ K , where I is the number of vectors in the speech codebook. This maximum likelihood value is then used as the similarity indication for the specific microphone signal.
- the codebook size was fixed at 256 entries.
- the impulse response between the location of the speaker and each of the three microphones was recorded and then convolved with a dry speech signal to obtain the microphone data.
- the microphone noise at each microphone was 40 dB below the speech level.
- a particular advantage of the approach is that it inherently compensates for signal level differences between the different microphones.
- the approach selects the appropriate microphone during speech activity.
- non-speech segments such as e.g. pauses in the speech or when the speaker changes
- a speech activity detector such as a simple level detector
- the system may simply proceed using the combination parameters determined for the last segment which included a speech component.
- a set of properties may be derived by analyzing the microphone signals and these properties may then be compared to expected values for non-reverberant speech.
- the comparison may be performed in the parameter or property domain without consideration of specific non-reverberant speech samples.
- the similarity processor 105 may be arranged to decompose the microphone signals using a set of basis signal vectors.
- a decomposition may specifically use a sparse overcomplete dictionary that contains signal prototypes, also called atoms.
- a signal is then described as a linear combination of a subset of the dictionary.
- each atom may in this case correspond to a basis signal vector.
- the property derived from the microphone signals and used in the comparison may be the number of basis signal vectors, and specifically the number of dictionary atoms, that are needed to represent the signal in an appropriate feature domain.
- the property may then be compared to one or more expected properties for non-reverberant speech.
- the values for the set of basis vectors may be compared to samples of values for sets of basis vector corresponding to specific non-reverberant speech samples.
- the one that can be described using fewer dictionary atoms is more similar to non-reverberant speech (where the dictionary has been trained on non-reverberant speech).
- the number of basis vectors for which the value (specifically the weight of each basis vector in a combination of basis vectors approximating the signal) exceeds a given threshold may be used to determine the similarity indication.
- the number of basis vectors which exceed the threshold may simply be calculated and directly used as the similarity indication for a given microphone signal, with an increasing number of basis vectors indicating a reduced similarity.
- the property derived from the microphone signal may be the number of basis vector values that exceed a threshold, and this may be compared to a reference property for non-reverberant speech of zero or one basis vectors having values above the threshold.
- the invention can be implemented in any suitable form including hardware, software, firmware or any combination of these.
- the invention may optionally be implemented at least partly as computer software running on one or more data processors and/or digital signal processors.
- the elements and components of an embodiment of the invention may be physically, functionally and logically implemented in any suitable way. Indeed the functionality may be implemented in a single unit, in a plurality of units or as part of other functional units. As such, the invention may be implemented in a single unit or may be physically and functionally distributed between different units, circuits and processors.
Landscapes
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Physics & Mathematics (AREA)
- Otolaryngology (AREA)
- Human Computer Interaction (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Quality & Reliability (AREA)
- General Health & Medical Sciences (AREA)
- Circuit For Audible Band Transducer (AREA)
- Measurement Of Mechanical Vibrations Or Ultrasonic Waves (AREA)
Description
- The invention relates to a method and apparatus for generating a speech signal, and in particular to generating a speech signal from a plurality of microphone signals, such as e.g. microphones in different devices.
- Traditionally, speech communication between remote users has been provided through a direct two way communication using dedicated devices at each end. Specifically, traditional communication between two users has been via a wired telephone connection or a wireless radio connection between two radio transceivers. However, in the last decades, the variety and possibilities for capturing and communicating speech has increased substantially and a number of new services and speech applications have been developed, including more flexible speech communication applications.
- For example, the widespread acceptance of broadband Internet connectivity has led to new ways of communication. Internet telephony has significantly lowered the cost of communication. This, combined with the trend of families and friends to be spread around the globe, has resulted in phone conversations lasting for long durations. VoIP (Voice over Internet Protocol) calls lasting for longer than an hour are not uncommon, and user comfort during such long calls is now more important than ever.
- In addition, the range of devices owned and used by a user has increased substantially. Specifically, devices equipped with audio capture and typically wireless transmission are becoming increasingly common, such as e.g., mobile phones, tablet computers, notebooks, etc.
- The quality of most speech applications is highly dependent on the quality of the captured speech. Accordingly, most practical applications are based on positioning a microphone close to the mouth of the speaker. For example, mobile phones include a microphone which when in use is positioned close the user's mouth by the user. However, such an approach may be impractical in many scenarios and may provide a user experience which is less than optimal. For example, it may be impractical for a user to have to hold a tablet computer close to the head.
- In order to provide a freer and more flexible user experience, various hands free solutions have been proposed. These include wireless microphones which are comprised in very small enclosures that may be worn and e.g. attached to the user's clothes. However, this is still perceived to be inconvenient in many scenarios. Indeed, enabling hands-free communication with the freedom to move and multi-task during a call, but without having to be close to a device or to wear a headset, is an important step towards improved user experience.
- Another approach is to use hands free communication based on a microphone being positioned further away from the user. For example, conference systems have been developed which when positioned e.g. on a table will pick-up speakers located around the room. However, such systems tend to not always provide optimum speech quality, and in particular the speech from more distant users tends to be weak and noisy. Also, the captured speech will in such scenarios tend to have a high degree of reverberation which may reduce the intelligibility of the speech substantially.
- It has been proposed to use more than one microphone for e.g. such teleconferencing systems. However, a problem in such cases is that of how to combine the plurality of microphone signals. A conventional approach is to simply sum the signals together. However, this tends to provide suboptimal speech quality. Various more complex approaches have been proposed, such as performing a weighted summation based on the relative signal levels of the microphone signals. However, the approaches tend to provide suboptimal performance in many scenarios, such as e.g. still including a high degree of reverberation, being sensitive to absolute levels, being complex, requiring centralized access to all microphone signals, being relatively impractical, requiring dedicated devices etc.
- Document
US 381-4856 teaches an apparatus, which is analog in nature and uses the output of one of the microphones as a reference.More specifically, the document describes a system where the measuring reference microphone measures background noise and for each program microphone it is determined whether the signal is above the background noise level. If this is the case there is apparently desired activity and the microphone selected. Thus the document does not disclose a comparison between the microphone signal and non-reverberant speech. The document only discloses a comparison between the microphone signal and a background noise level. The documentUS 2011/038486 , which is digital in nature, uses the output of the combined microphones as a reference. More specifically, in the document a beam-former output is compared with a single microphone signal (selected as one of the signals from the beam) and a distortion calculator (possibly based on a reverberation estimate) determines whether the single microphone is selected or the output of the beam-former . The document therefore does not disclose a comparison between the microphone signal and non-reverberant speech. In the document only a comparison is taught between the microphone and the beam-former output. - Hence, an improved approach for capturing speech signals would be advantageous and in particular an approach allowing increased flexibility, improved speech quality, reduced reverberation, reduced complexity, reduced communication requirements, increased adaptability for different devices (including multifunction devices), reduced resource demand and/or improved performance would be advantageous.
- Accordingly, the Invention seeks to preferably mitigate, alleviate or eliminate one or more of the above mentioned disadvantages singly or in any combination.
- According to an aspect of the invention there is provided an apparatus according to claim 1.
- The invention may allow an improved speech signal to be generated in many embodiments. In particular, it may in many embodiments allow a speech signal to be generated with less reverberation and/or often less noise. The approach may allow improved performance of speech applications, and may in particular in many scenarios and embodiments provide improved speech communication.
- The comparison of at least one property derived from the microphone signals to a reference property for non-reverberant speech provides a particular efficient and accurate way of identifying the relative importance of the individual microphone signals to the speech signal, and may in particular provide a better evaluation than approaches based on e.g. signal level or signal-to-noise ratio measures. Indeed, the correspondence of the captured audio to non-reverberant speech signals may provide a strong indication of how much of the speech reaches the microphone via a direct path and how much reaches the microphone via reverberant paths.
- The at least one reference property may be one or more properties/ values which are associated with non-reverberant speech. In some embodiments, the at least one reference property may be a set of properties corresponding to different samples of non-reverberant speech. The similarity indication may be determined to reflect a difference between the value of the at least one property derived from the microphone signal and the at least one reference property for non-reverberant speech, and specifically to at least one reference property of one non-reverberant speech sample. In some embodiments the at least one property derived from the microphone signal may be the microphone signal itself. In some embodiments the at least one reference property for non-reverberant speech may be a non-reverberant speech signal. Alternatively, the property may be an appropriate feature such as gain normalized spectral envelopes.
- The microphones providing the microphone signals may in many embodiments be microphones distributed in an area, and may be remote from each other. The approach may in particular provide improved usage of audio captured at different positions without requiring these positions to be known or assumed by the user or the apparatus/system. For example, the microphones may be randomly distributed in an ad-hoc fashion around a room, and the system may automatically adapt to provide an improved speech signal for the specific arrangement.
- The non-reverberant speech samples may specifically be substantially dry or anechoic speech samples.
- The speech similarity indication may be any indication of a degree of difference or similarity between the individual microphone signal (or part thereof) and non-reverberant speech, such as e.g. a non-reverberant speech sample. The similarity indication may be a perceptual similarity indication.
- In accordance with an optional feature of the invention, the apparatus comprises a plurality of separate devices, each device comprising a microphone receiver for receiving at least one microphone signal of the plurality of microphone signals.
- This may provide a particularly efficient approach for generating a speech signal. In many embodiments, each device may comprise the microphone providing the microphone signal. The invention may allow improved and/or new user experiences with improved performance.
- For example, a number of possible diverse devices may be positioned around a room. When executing a speech application, such as a speech communication, the individual devices may each provide a microphone signal, and these may be evaluated to find the most suited devices/ microphones to use for generating the speech signal.
- In accordance with an optional feature of the invention, at least a first device of the plurality of separate devices comprises a local comparator for determining a first speech similarity indication for the at least one microphone signal of the first device.
- This may provide an improved operation in many scenarios, and may in particular allow a distributed processing which may reduce e.g. communication resources and/or spread computational resource demands.
- Specifically, in many embodiments, the separate devices may determine a similarity indication locally and may only transmit the microphone signal if the similarity criterion meets a criterion.
- In accordance with an optional feature of the invention, the generator is implemented in a generator device separate from at least the first device; and wherein the first device comprises a transmitter for transmitting the first speech similarity indication to the generator device.
- This may allow advantageous implementation and operation in many embodiments. In particular, it may in many embodiments allow one device to evaluate the speech quality at all other devices without requiring communication of any audio or speech signals. The transmitter may be arranged to transmit the first speech similarity indication via a wireless communication link, such as a Bluetooth™ or Wi-Fi communication link.
- In accordance with an optional feature of the invention, the generator device is arranged to receive speech similarity indications from each of the plurality of separate devices, and wherein the generator is arranged to generate the speech signal using a subset of microphone signals from the plurality of separate devices, the subset being determined in response to the speech similarity indications received from the plurality of separate devices.
- This may allow a highly efficient system in many scenarios where a speech signal can be generated from microphone signals being picked up by different devices, with only the best subset of devices being used to generate the speech signal. Thus, communication resources are reduced substantially, typically without significant impact on the resulting speech signal quality.
- In many embodiments, the subset may include only a single microphone. In some embodiments, the generator may be arranged to generate the speech signal from a single microphone signal selected from the plurality of microphone signals based on the similarity indications.
- In accordance with an optional feature of the invention, at least one device of the plurality of separate devices is arranged to transmit the at least one microphone signal of the at least one device to the generator device only if the at least one microphone signal of the at least one device is comprised in the subset of microphone signals.
- This may reduce communication resource usage, and may reduce computational resource usage for devices for which the microphone signal is not included in the subset. The transmitter may be arranged to transmit the at least one microphone signal via a wireless communication link, such as a Bluetooth™ or Wi-Fi communication link.
- In accordance with an optional feature of the invention, the generator device comprises a selector arranged to determine the subset of microphone signals, and a transmitter for transmitting an indication of the subset to at least one of the plurality of separate devices.
- This may provide advantageous operation in many scenarios.
- In some embodiments, the generator may determine the subset and may be arranged to transmit an indication of the subset to at least one device of the plurality of devices. For example, for the device or devices of microphone signals comprised in the subset, the generator may transmit an indication that the device should transmit the microphone signal to the generator.
- The transmitter may be arranged to transmit the indication via a wireless communication link, such as a Bluetooth™ or Wi-Fi communication link.
- In accordance with an optional feature of the invention, the comparator is arranged to determine the similarity indication for a first microphone signal in response to a comparison of at least one property derived from the microphone signal to reference properties for speech samples of a set of non-reverberant speech samples.
- The comparison of microphone signals to a large set of non-reverberating speech samples (e.g. in an appropriate feature domain) provides a particular efficient and accurate way of identifying the relative importance of the individual microphone signals to the speech signal, and may in particular provide a better evaluation than approaches based on e.g. signal level or signal-to-noise ratio measures. Indeed, the correspondence of the captured audio to non-reverberant speech signals may provide a strong indication of how much of the speech reaches the microphone via a direct path and how much reaches the microphone via reverberant/ reflected paths. Indeed, it may be considered that the comparison to the non-reverberant speech samples includes a consideration of the shape of impulse response of the acoustic paths rather than just an energy or level consideration.
- The approach may be speaker independent and in some embodiments the set of non-reverberant speech samples may include samples corresponding to different speaker characteristics (such as a high or low voice). In many embodiments, the processing may be segmented, and the set of non-reverberant speech samples may for example comprise samples corresponding to the phonemes of human speech
- The comparator may for each microphone signal determine an individual similarity indication for each speech sample of the set of non-reverberant speech samples. The similarity indication for the microphone signal may then be determined from the individual similarity indications, e.g. by selecting the individual similarity indication which is indicative of the highest degree of similarity. In many scenarios, the best matching speech sample may be identified and the similarity indication for the microphone signal may be determined with respect to this speech sample. The similarity indication may provide an indication of a similarity of the microphone signal (or part thereof) to the non-reverberant speech sample of the set of non-reverberant speech samples for which the highest similarity is found.
- The similarity indication for a given speech signal sample may reflect the likelihood that the microphone signal resulted from a speech utterance corresponding to the speech sample.
- In accordance with an optional feature of the invention, the speech samples of the set of non-reverberating speech samples are represented by parameters for a non-reverberating speech model.
- This may provide efficient yet reliable and/or accurate operation. The approach may in many embodiments reduce the computational and/or memory resource requirements.
- The comparator may in some embodiments evaluate the model for the different sets of parameters and compare the resulting signals to the microphone signal(s). For example, frequency representations of the microphone signals and the speech samples may be compared.
- In some embodiments, model parameters for the speech model may be generated from the microphone signal, i.e. the model parameters which would result in a speech sample matching the microphone signal may be determined. These model parameters may then be compared to the parameters of the set of non-reverberant speech samples.
- The non-reverberating speech model may specifically be a Linear Prediction model, such as a CELP (Code-Excited Linear Prediction) model.
- In accordance with an optional feature of the invention, the comparator is arranged to determine a first reference property for a first speech sample of the set of non-reverberating speech samples from a speech sample signal generated by evaluating the non-reverberating speech model using the parameters for the first speech sample, and to determine the similarity indication for a first microphone signal of the plurality of microphone signals in response to a comparison of the property derived from the first microphone signal and the first reference property.
- This may provide advantageous operation in many scenarios. The similarity indication for the first microphone signal may be determined by comparing a property determined for the first microphone signal to reference properties determined for each of the non-reverberant speech samples, the reference properties being determined from a signal representation generated by evaluating the model. Thus, the comparator may compare a property of the microphone signal to a property of the signal samples resulting from evaluating the non-reverberating speech model using the stored parameters for the non-reverberant speech samples.
- In accordance with an optional feature of the invention, the comparator is arranged to decompose a first microphone signal of the plurality of microphone signals into a set of basis signal vectors; and to determine the similarity indication in response to a property of the set of basis signal vectors.
- This may provide advantageous operation in many scenarios. The approach may allow reduced complexity and/or resource usage in many scenarios. The reference property may be related to a set of basis vectors in an appropriate feature domain, from which a non-reverberant feature vector can be generated as a weighted sum of basis vectors. This set can be designed such that a weighted sum with only a few basis vectors is sufficient to accurately describe the non-reverberant feature vector, i.e., the set of basis vectors provides a sparse representation for non-reverberant speech. The reference property may be the number of basis vectors that appear in the weighted sum. Using a set of basis vectors that has been designed for non-reverberant speech to describe a reverberant speech feature vector will result in a less-sparse decomposition. The property may be the number of basis vectors that receive a non-zero weight (or a weight above a given threshold) when used to describe a feature vector extracted from the microphone signal. The similarity indication may indicate an increasing similarity to non-reverberant speech for a reducing number of basic signal vectors.
- In accordance with an optional feature of the invention, the comparator is arranged to determine speech similarity indications for each segment of a plurality of segments of the speech signal, and the generator is arranged to determine combination parameters for the combining for each segment.
- The apparatus may utilize segmented processing. The combination may be constant for each segment but may be varied from one segment to the next. For example, the speech signal may be generated by selecting one microphone signal in each segment. The combination parameters may for example be combination weights for the microphone signal or may e.g. be a selection of a subset of microphone signals to include in the combination. The approach may provide improved performance and/or facilitated operation.
- In accordance with an optional feature of the invention, the generator is arranged to determine combination parameters for one segment in response to similarity indications of at least one previous segment.
- This may provide improved performance in many scenarios. For example, it may provide a better adaptation to slow changes, and may reduce disruptions in the generated speech signal.
- In some embodiments, the combination parameters may be determined only based on segments containing speech and not on segments during quiet periods or pauses.
- In some embodiments, the generator is arranged to determine combination parameters for a first segment in response to a user motion model.
- In accordance with an optional feature of the invention, the generator is arranged to select a subset of the microphone signals to combine in response to the similarity indications.
- This may allow improved and/or facilitated operation in many embodiments. The combining may specifically be selection combining. The generator may specifically select only microphone signals for which the similarity indication meets an absolute or relative criterion.
- In some embodiments, the subset of microphone signals comprise only one microphone signal.
- In accordance with an optional feature of the invention, the generator is arranged to generate the speech signal as a weighted combination of the microphone signals, a weight for a first of the microphone signals depending on the similarity indication for the microphone signal.
- This may allow improved and/or facilitated operation in many embodiments.
- According to an aspect of the invention there is provided a method of generating a speech signal, the method comprising: receiving microphone signals from a plurality of microphones; for each microphone signal, determining a speech similarity indication indicative of a similarity between the microphone signal and non-reverberant speech, the similarity indication being determined in response to a comparison of at least one property derived from the microphone signal to at least one reference property for non-reverberant speech; and generating the speech signal by combining the microphone signals in response to the similarity indications.
- These and other aspects, features and advantages of the invention will be apparent from and elucidated with reference to the embodiment(s) described hereinafter.
- Embodiments of the invention will be described, by way of example only, with reference to the drawings, in which
-
FIG. 1 is an illustration of a speech capture apparatus in accordance with some embodiments of the invention; -
FIG. 2 is an illustration of a speech capture system in accordance with some embodiments of the invention; -
FIG. 3 illustrates an example of spectral envelopes corresponding to a segment of speech recorded at three different distances in a reverberant room; and -
FIG. 4 illustrates an example of a likelihood of a microphone being the closest microphone to a speaker determined in accordance with some embodiments of the invention. - The following description focuses on embodiments of the invention applicable to the capture of speech in order to generate a speech signal for telecommunication. However, it will be appreciated that the invention is not limited to this application but may be applied to many other services and applications.
-
FIG. 1 illustrates an example of elements of a speech capture apparatus in accordance with some embodiments of the invention. - In the example, the speech capture apparatus comprises a plurality of
microphone receivers 101 which are coupled to a plurality of microphones 103 (which may be part of the apparatus or may be external to the apparatus). - The set of
microphone receivers 101 thus receive a set of microphone signals from themicrophones 103. In the example, themicrophones 103 are distributed around a room at various and unknown positions. Thus, different microphones may pick up sound from different areas, may pick up the same sound with different characteristics, or may indeed pick up the same sound with similar characteristics if they are close to each other. The relationship between themicrophones 103 and between themicrophones 103 and different sound sources are typically not known by the system. - The speech capture apparatus is arranged to generate a speech signal from the microphone signals. Specifically, the system is arranged to process the microphone signals to extract a speech signal from the audio captured by the
microphones 103. The system is arranged to combine the microphone signals depending on how closely each of them corresponds to a non-reverberant speech signal thereby providing a combined signal which is most likely to correspond to such a signal. The combination may specifically be a selection combining wherein the apparatus selects the microphone signal most closely resembling a non-reverberant speech signal. The generation of the speech signal may be independent of the specific position of the individual microphones and does not rely on any knowledge of the position of themicrophones 103 or of any speakers. Rather, themicrophones 103 may for example be randomly distributed around a room, and the system may automatically adapt to e.g. predominantly use the signal from the closest microphone to any given speaker. This adaptation may happen automatically and the specific approach for identifying such a closest microphone 103 (as will be described in the following) will result in a particularly suitable speech signal in most scenarios. - In the speech capture apparatus of
FIG. 1 themicrophone receivers 103 are coupled to a comparator orsimilarity processor 105 which is fed the microphone signals. - For each microphone signal, the
similarity processor 105 determines a speech similarity indication (henceforth just referred to as a similarity indication) which is indicative of a similarity between the microphone signal and non-reverberant speech. Thesimilarity processor 105 specifically determines the similarity indication in response to a comparison of at least one property derived from the microphone signal to at least one reference property for non-reverberant speech. The reference property may in some embodiments be a single scalar value and in other embodiments may be complex set of values or functions. The reference property may in some embodiments be derived from specific non-reverberant speech signals, and may in other embodiments be a generic characteristic associated with non-reverberant speech. The reference property and/or property derived from the microphone signal may for example be a spectrum, a power spectral density characteristic, a number of non-zero basis vectors etc. In some embodiments, the properties may be signals, and specifically the property derived from the microphone signal may be the microphone signal itself. Similarly, the reference property may be a non-reverberant speech signal. - Specifically, the
similarity processor 105 may be arranged to generate a similarity indication for each of the microphone signals where the similarity indication is indicative of a similarity of the microphone signal to a speech sample from a set of non-reverberant speech samples. Thus, in the example, thesimilarity processor 105 comprises a memory storing a (typically large) number of speech samples where each speech sample corresponds to speech in a non-reverberant, and specifically substantially anechoic, room. As an example, thesimilarity processor 105 may compare each microphone signal to each of the speech samples and for each speech sample determine a measure of the difference between the stored speech sample and the microphone signal. The difference measures for the speech samples may then be compared and the measure indicative of the smallest difference may be selected. This measure may then be used to generate (or as) the similarity indication for the specific microphone signal. The process is repeated for all microphone signals resulting in a set of similarity indications. Thus, the set of similarity indications may indicate how much each of the microphone signals resembles non-reverberant speech. - In many embodiments and scenarios, such a signal sample domain comparison may not be sufficiently reliable due to uncertainty relating to variations in microphone levels, noise etc. Therefore, in many embodiments, the comparator may be arranged to determine the similarity indication in response to a comparison performed in the feature domain. Thus, in many embodiments, the comparator may be arranged to determine some features/parameters from the microphone signal and compare these to stored features/ parameters for non-reverberant speech. For example, as will be described in more detail later, the comparison may be based on parameters for a speech model, such as coefficients for a linear prediction model. Corresponding parameters may then be determined for the microphone signal and compared to stored parameters corresponding to various utterances in an anechoic environment.
- Non-reverberant speech is typically achieved when the acoustic transfer function from a speaker is dominated by the direct path and with the reflected and reverberant parts being substantially attenuated. This also typically corresponds to situations where the speaker is relatively close to the microphone and may correspond most closely to a traditional arrangement where the microphone is positioned close to a speaker's mouth. Non-reverberant speech may also often be considered the most intelligible, and indeed is that which most closely corresponds to the actual speech source.
- The apparatus of
FIG. 1 utilizes an approach that allows the speech reverberation characteristic for the individual microphones to be assessed such that this can be taken into consideration. Indeed, the Inventor has realized not only that considerations of speech reverberation characteristics for individual microphone signals when generating a speech signal may improve quality substantially, but also how this can feasibly be achieved without requiring dedicated test signals and measurements. Indeed, the Inventor has realized that by comparing a property of the individual microphone signals with a reference property associated with non-reverberant speech, and specifically with sets of non-reverberant speech samples, it is possible to determine suitable parameters for combining the microphone signals to generate an improved speech signal. In particular, the approach allows the speech signal to be generated without necessitating any dedicated test signals, test measurements, or indeed a priori knowledge of the speech. Indeed, the system may be designed to operate with any speech and does not require e.g. specific test words or sentences to be spoken by the speaker. - In the system of
FIG. 1 , thesimilarity processor 105 is coupled to agenerator 107 which is fed the similarity indications. Thegenerator 107 is further coupled to themicrophone receivers 101 from which it receives the microphone signals. Thegenerator 107 is arranged to generate an output speech signal by combining the microphone signals in response to the similarity indications. - As a low complexity example, the
generator 107 may implement a selection combiner wherein e.g. a single microphone signal is selected from the plurality of microphone signals. Specifically, thegenerator 107 may select the microphone signal which most closely matches a non-reverberant speech sample. The speech signal is then generated from this microphone signal which is typically most likely to be the cleanest and clearest capture of the speech. Specifically, it is likely to be the one that much closely corresponds to the speech uttered by the listener. Typically, it will also correspond to the microphone which is closest to the speaker. - In some embodiments, the speech signal may be communicated to a remote user, e.g. via a telephone network, a wireless connection, the Internet or any other communication network or link. The communication of the speech signal may typically include a speech encoding as well as potentially other processing.
- The apparatus of
FIG. 1 may thus automatically adapt to the positions of the speaker and microphones, as well as to the acoustic environment characteristics, in order to generate a speech signal that most closely corresponds to the original speech signal. Specifically, the generated speech signal will tend to have reduced reverberation and noise, and will accordingly sound less distorted, cleaner, and more intelligible. - It will be appreciated that the processing may include various other processing, including typically amplification, filtering, conversion between the time domain and the frequency domain, etc. as is typically done in audio and speech processing. For example, the microphone signals may often be amplified and filtered prior to being combined and/or used to generate the similarity indications. Similarly the
generator 107 may include filtering, amplification etc. as part of the combining and/or generation of the speech signal. - In many embodiments, the speech capture apparatus may use segmented processing. Thus, the processing may be performed in short time intervals, such as in segments of less than 100msec duration, and often in around 20 msec segments.
- Thus, in some embodiments, a similarity indication may be generated for each microphone signal in a given segment. For example, a microphone signal segment of, say, 50 msec duration may be generated for each of the microphone signals. The segment may then be compared to the set of non-reverberant speech samples which itself may be comprised of speech segment samples. The similarity indications may be determined for this 50 msec segment, and the
generator 107 may proceed to generate a speech signal segment for the 50 msec interval based on the microphone signal segments and the similarity indications for the segment/ interval. Thus, the combination may be updated for each segment, e.g. by in each segment selecting the microphone signal which has the highest similarity to a speech segment sample of the non-reverberant speech samples. This may provide a particularly efficient processing and operation, and may allow a continuous and dynamic adaptation to the specific environment. Indeed, an adaption to dynamic movement in the speaker sound source and/or microphone positions can be achieved with low complexity. For example, if speech switches between two sources (speakers) the system may adapt to correspondingly switch between two microphones. - In some embodiments, the non-reverberant speech segment samples may have a duration which matches those of the microphone signal segments. However, in some embodiments, they may be longer. For example, each non-reverberant speech segment sample may correspond to a phoneme or specific speech sound which has a longer duration. In such embodiments, the determination of a similarity measure for each non-reverberant speech segment sample may include an alignment of the microphone signal segment to the speech segment samples. For example, a correlation value may be determined for different time offsets and the highest value may be selected as the similarity indication. This may allow a reduced number of speech segment samples to be stored.
- In some examples, the combination parameters, such as a selection of a subset of microphone signals to use, or weights for a linear summation, may be determined for a time interval of the speech signal. Thus, the speech signal may be determined in segments from a combination which is based on parameters that are constant for the segment but which may vary between segments.
- In some embodiments, the determination of combination parameters is independent for each time segment, i.e. the combination parameters for the time segment may be calculated based only on similarity indications that are determined for that time segment.
- However, in other embodiments, the combination parameters may alternatively or additionally be determined in response to similarity indications of at least one previous segment. For example, the similarity indications may be filtered using a low pass filter that extends over several segments. This may ensure a slower adaptation which may e.g. reduce fluctuations and variations in the generated speech signal. As another example, a hysteresis effect may be applied which prevents e.g. quick ping-pong switching between two microphones positioned at roughly the same distance from a speaker.
- In some embodiments, the
generator 107 may be arranged to determine combination parameters for a first segment in response to a user motion model. Such an approach may be used to track the relative position of the user relative to themicrophone devices microphone devices - In many embodiments, the functionality of
FIG. 1 may be implemented in a distributed fashion, and in particular the system may be spread over a plurality of devices. Specifically, each of themicrophones 103 may be part of or connected to a different device, and thus themicrophone receivers 101 may be comprised in different devices. - In some embodiments, the
similarity processor 105 andgenerator 107 are implemented in a single device. For example, a number of different remote devices may transmit a microphone signal to a generator device which is arranged to generate a speech signal from the received microphone signals. This generator device may implement the functionality of thesimilarity processor 105 and thegenerator 107 as previously described. - However, in many embodiments, the functionality of the
similarity processor 105 is distributed over a plurality of separate devices. Specifically, each of the devices may comprise a (sub)similarity processor 105 which is arranged to determine a similarity indication for the microphone signal of that device. The similarity indications may then be transmitted to the generator device which may determine parameters for the combination based on the received similarity indications. For example, it may simply select the microphone signal/ device which has the highest similarity indication. In some embodiments, the devices may not transmit microphone signals to the generator device unless the generator device requests this. Accordingly, the generator device may transmit a request for the microphone signal to the selected device which in return provides this signal to the generator device. The generator device then proceeds to generate the output signal based on the received microphone signal. Indeed, in this example, thegenerator 107 may be considered to be distributed over the devices with the combination being achieved by the process of selecting and selectively transmitting the microphone signal. An advantage of such an approach is that only one (or at least a subset) of the microphone signals need to be transmitted to the generator device, and thus that a substantially reduced communication resource usage can be achieved. - As an example, the approach may use microphones of devices distributed in an area of interest in order to capture a user's speech. A typical modern living room typically has a number of devices equipped with one or more microphones and wireless transmission capabilities. Examples include cordless fixed-line phones, mobile phones, video chat-enabled televisions, tablet PCs, laptops, etc. These devices may in some embodiments be used to generate a speech signal, e.g. by automatically and adaptively selecting the speech captured by the microphone closest to the speaker. This may provide captured speech which typically will be of high quality and free from reverberation.
- Indeed, generally the signal captured by a microphone will tend to be affected by reverberation, ambient noise and microphone noise with the impact depending on its location with respect to the sound source, e.g., to the user's mouth. The system may seek to select the microphone which is closest to that which would be recorded by a microphone close to the user's mouth. The generated speech signal can be applied where hands-free speech capture is desirable such as e.g., home/office telephony, tele-conferencing systems, front-end for voice control systems, etc.
- In more detail
FIG. 2 illustrates an example of a distributed speech generating/capturing apparatus/system. The example includes a plurality ofmicrophone devices generator device 207. - Each of the
microphone devices microphone receiver 101 which receives a microphone signal from amicrophone 103 which in the example is part of themicrophone device microphone devices microphone receiver 101 in eachmicrophone device similarity processor 105 which determines a similarity indication for the microphone signal. - The
similarity processor 105 of eachmicrophone device similarity processor 105 ofFIG. 1 for the specific microphone signal of theindividual microphone device similarity processor 105 of each of themicrophone devices similarity processor 105 may specifically compare the microphone signal to each of the non-reverberant speech samples and for each speech sample determine an indication of how similar the signals are. For example, if thesimilarity processor 105 includes memory for storing a local database comprising a representation of each of the phonemes of human speech, thesimilarity processor 105 may proceed to compare the microphone signal to each phoneme. Thus a set of indications indicating how closely the microphone signal resembles each of the phonemes that do not include any reverberation or noise is determined. The indication corresponding to the closest match is thus likely to correspond to an indication of how closely the captured audio corresponds to the sound generated by a speaker speaking that phoneme. Thus, the indication of the closest similarity is chosen as the similarity indication for the microphone signal. This similarity indication accordingly reflects how much the captured audio corresponds to noise-free and reverberation-free speech. For a microphone (and thus typically device) positioned far from the speaker the captured audio is likely to include only low relative levels of the original projected speech compared to the contribution from various reflections, reverberation and noise. However, for a microphone (and thus device) positioned close to the speaker, the captured sound is likely to comprise a significantly higher contribution from the direct acoustic path and relatively lower contributions from reflections and noise. Accordingly, the similarity indication provides a good indication of how clean and intelligible the speech of the captured audio of the individual device is. - Each of the
microphone devices wireless transceiver 209 which is coupled to thesimilarity processor 105 and themicrophone receiver 101 of each device. Thewireless transceiver 209 is specifically arranged to communicate with thegenerator device 207 over a wireless connection. - The
generator device 207 also comprises awireless transceiver 211 which may communicate with themicrophone devices - In many embodiments, the
microphone devices generator device 207 may be arranged to communicate data both directions. However, it will be appreciated that in some embodiments, only one-way communication from themicrophone devices generator device 207 may be applied. - In many embodiments, the devices may communicate via a wireless communication network such as a local Wi-Fi communication network. Thus, the
wireless transceiver 207 of themicrophone devices - In some embodiments, each of the
microphone devices generator device 207. It will be appreciated that the skilled person is well aware of how data, such as parameter data and audio data, may be communicated between devices. Specifically, the skilled person will be well aware of how audio signal transmission may include encoding, compression, error correction etc. - In such embodiments, the
generator device 207 may receive the microphone signals and the similarity indications from all themicrophone devices - Specifically, the
wireless transceiver 211 of thegenerator device 207 is coupled to acontroller 213 and aspeech signal generator 215. Thecontroller 213 is fed the similarity indications from thewireless transceiver 211 and in response to these it determines a set of combination parameters which control how the speech signal is generated from the microphone signals. Thecontroller 213 is coupled to thespeech signal generator 215 which is fed the combination parameters. In addition, thespeech signal generator 215 is fed the microphone signals from thewireless transceiver 211, and it may accordingly proceed to generate the speech signal based on the combination parameters. - As a specific example, the
controller 213 may compare the received similarity indications and identify the one indicating the highest degree of similarity. An indication of the corresponding device/ microphone signal may then be passed to thespeech signal generator 215 which can proceed to select the microphone signal from this device. The speech signal is then generated from this microphone signal. - As another example, in some embodiments, the
speech signal generator 215 may proceed to generate the output speech signal as a weighted combination of the received microphone signals. For example, a weighted summation of the received microphone signals may be applied where the weights for each individual signal is generated from the similarity indications. For example, the similarity indications may directly be provided as a scalar value within a given range, and the individual weights may directly be proportional to the scalar value (with e.g. a proportionality factor ensuring that the signal level or accumulated weight value is constant). - Such an approach may be particularly attractive in scenarios where the available communication bandwidth is not a constraint. Thus, instead of selecting a device closest to the speaker, a weight may be assigned to each device/microphone signal, and the microphone signals from the various microphones may be combined as a weighted sum. Such an approach may provide robustness and mitigate the impact of an erroneous selection in highly reverberant or noisy environments.
- It will also be appreciated that the combination approaches can be combined. For example, rather than using a pure selection combining, the
controller 213 may select a subset of microphone signals (such as e.g. the microphone signals for which the similarity indication exceeds a threshold) and then combine the microphone signals of the subset using weights that are dependent on the similarity indications. - It will also be appreciated that in some embodiments, the combination may include an alignment of the different signals. For example, time delays may be introduced to ensure that the received speech signals add coherently for a given speaker.
- In many embodiments, the microphone signals are not transmitted to the
generator device 207 from allmicrophone devices microphone devices - For example, the
microphone devices generator device 207 with thecontroller 213 evaluating the similarity indications to select a subset of microphone signals. For example, thecontroller 213 may select the microphone signal from themicrophone device controller 213 may then transmit a request message to the selectedmicrophone device wireless transceiver 211. Themicrophone devices generator device 207 when a request message is received, i.e. the microphone signal is only transmitted to thegenerator device 207 when it is included in the selected subset. Thus, in the example where only a single microphone signal is selected, only one of themicrophone devices generator device 207 as this only needs to deal with e.g. one microphone signal at a time. In the example, the selection combining functionality used to generate the speech signal is thus distributed over the devices. - Different approaches for determining the similarity indications may be used in different embodiments, and specifically the stored representations of the non-reverberant speech samples may be different in different embodiments, and may be used differently in different embodiments.
- In some embodiments, the stored non-reverberant speech samples are represented by parameters for a non-reverberating speech model. Thus, rather than storing e.g. a sampled time or frequency domain representation of the signal, the set of non-reverberant speech samples may comprise a set of parameters for each sample which may allow the sample to be generated.
- For example, the non-reverberating speech model may be a linear prediction model, such as specifically a CELP (Code Excited Linear Prediction) model. In such a scenario, each speech sample of the non-reverberant speech samples may be represented by a codebook entry which specifies an excitation signal that may be used to excite a synthesis filter (which may also be represented by the stored parameters).
- Such an approach may substantially reduce the storage requirements for the set of non-reverberant speech samples and this may be particularly important for distributed implementations where the determination of the similarity indications is performed locally in the individual devices. Furthermore, by using a speech model which directly synthesizes speech from a speech source (without consideration of the acoustic environment), a good representation of non-reverberant, anechoic speech is achieved.
- In some embodiments, the comparison of a microphone signal to a specific speech sample may be performed by evaluating the speech model for the specific set of stored speech model parameters for that signal. Thus, a representation of the speech signal which will be synthesized by the speech model for that set of parameters may be derived. The resulting representation may then be compared to the microphone signal and a measure of the difference between these may be calculated. The comparison may for example be performed in the time domain or in the frequency domain, and may be a stochastic comparison. For example, the similarity indication for one microphone signal and one speech sample may be determined to reflect the likelihood that the captured microphone signal resulted from a sound source radiating the speech signal resulting from a synthesis by the speech model. The speech sample resulting in the highest likelihood may then be selected, and the similarity indication for the microphone signal may be determined as the highest likelihood.
- In the following, a detailed example of a possible approach for determining similarity indications based on a LP speech model will be provided.
- In the example K microphones may be distributed in an area. The observed microphone signals may be modeled as


- In an anechoic environment, the impulse response hk (n) corresponds to a pure delay, corresponding to the time taken for the signal to propagate from the point of generation to the microphone at the speed of sound. Consequently, the PSD of the signal xk (n) is identical to that of s(n). In a reverberant environment, hk (n) models not only the direct path of the signal from the sound source to the microphone but also signals arriving at the microphone as a result of being reflected by walls, ceiling, furniture, etc. Each reflection delays and attenuates the signal.
- The PSD of xk (n) in this case could vary significantly from that of s(n), depending on the level of reverberation.
FIG. 3 illustrates an example of spectral envelopes corresponding to a 32 ms segment of speech recorded at three different distances in a reverberant room, with a T60 of 0.8 seconds. Clearly, the spectral envelopes of speech recorded at 5 cm and 50 cm distance from the speaker are relatively close whereas the envelope at 350 cm is significantly different. - When the signal of interest is speech, as in hands-free communication applications, the PSD may be modeled using a codebook trained offline using a large dataset. For example, the codebook may contain linear prediction (LP) coefficients, which model the spectral envelope.
- The training set typically consists of LP vectors extracted from short segments (20 - 30 ms) of a large set of phonetically balanced speech data. Such codebooks have been successfully employed in speech coding and enhancement. A codebook trained on speech recorded using a microphone located close to the user's mouth can then be used as a reference measure of how reverberant the signal received at a particular microphone is.
- The spectral envelope corresponding to a short-time segment of a microphone signal captured at a microphone close to the speaker will typically find a better match in the codebook than that captured at a microphone further away (and thus relatively more affected by reverberation and noise). This observation can then be used e.g. to select an appropriate microphone signal in a given scenario.
- Assuming that the noise is Gaussian, and given a vector of LP coefficients a, we have at the k th microphone (ref. e.g. S. Srinivasan, J. Samuelsson, and W. B. Kleijn, "Codebook driven short-term predictor parameter estimation for speech enhancement," IEEE Trans. Speech, Audio and Language Processing, vol. 14, no. 1, pp. 163-176, Jan. 2006):


- If we let the frame length approach infinity, the covariance matrices can be described as circulant and are diagonalized by the Fourier transform. The logarithm of the likelihood in the above equation, corresponding to the i th speech codebook vector a i , can then be written using frequency domain quantities as (refer e.g. U. Grenander and G. Szego, "Toeplitz forms and their applications", 2nd ed. New York: Chelsea, 1984):



k (ω) are set to zero. It should be noted that all the quantities in this equation are available. The noisy PSD Pyk (ω) and the noise PSD Pwk (ω) can be estimated from the microphone signal, and Ai(ω) is specified by the i th codebook vector.
For each sensor, a maximum likelihood value is computed over all codebook vectors, i.e.,
- Finally, the microphone for the largest value of the maximum likelihood value t is determined as the microphone closest to the speaker, i.e. the microphone signal resulting in the largest maximum likelihood value is determined:

- Experiments been performed for this specific example. A codebook of speech LP coefficients were generated using training data from the Wall Street Journal (WSJ) speech database (CSR-II (WSJ1) Complete," Linguistic Data Consortium,
- Philadelphia, 1994). 180 distinct training utterances of duration around 5 sec each from 50 different speakers, 25 male and 25 female, were used as the training data. Using the training utterances, around 55000 LP coefficients were extracted from Hann-windowed segments of size 256 samples, with a 50 percent overlap at a sampling frequency of 8 kHz. The codebooks were trained using LBG algorithm (Y. Linde, A. Buzo, and R. M. Gray, "An algorithm for vector quantizer design," IEEE Trans. Communications, vol. COM-28, no. 1, pp. 84-95, Jan. 1980.) with the Itakura-Saito distortion (S. R. Quackenbush, T. P. Barnwell, and M. A. Clements, Objective "Measures of Speech Quality". New Jersey: Prentice-Hall, 1988.) as the error criterion. The codebook size was fixed at 256 entries. A three microphone setup was considered and the microphones were located at 50 cm, 150 cm and 350 cm from the speaker in a reverberant room (T60 = 800 ms). The impulse response between the location of the speaker and each of the three microphones was recorded and then convolved with a dry speech signal to obtain the microphone data. The microphone noise at each microphone was 40 dB below the speech level.
-
FIG. 4 shows the likelihood p(y1) for a microphone located 50 cm away from the speaker. In the speech dominated regions, this microphone (which is located closest to the speaker) receives a value close to unity and the likelihood values at the other two microphones are close to zero. The closest microphone is thus correctly identified. - A particular advantage of the approach is that it inherently compensates for signal level differences between the different microphones.
- It should be noted that the approach selects the appropriate microphone during speech activity. However, during non-speech segments (such as e.g. pauses in the speech or when the speaker changes) will not allow such a selection to be determined. However, this may simply be addressed by the system including a speech activity detector (such as a simple level detector) to identify the non-speech periods. During these periods, the system may simply proceed using the combination parameters determined for the last segment which included a speech component.
- In the previous embodiments, the similarity indications have been generated by comparing properties of the microphone signals to properties of non-reverberant speech samples, and specifically comparing properties of the microphone signals to properties of speech signals that result from evaluating a speech model using the stored parameters.
- However, in other embodiments, a set of properties may be derived by analyzing the microphone signals and these properties may then be compared to expected values for non-reverberant speech. Thus, the comparison may be performed in the parameter or property domain without consideration of specific non-reverberant speech samples.
- Specifically, the
similarity processor 105 may be arranged to decompose the microphone signals using a set of basis signal vectors. Such a decomposition may specifically use a sparse overcomplete dictionary that contains signal prototypes, also called atoms. A signal is then described as a linear combination of a subset of the dictionary. Thus, each atom may in this case correspond to a basis signal vector. - In such embodiments, the property derived from the microphone signals and used in the comparison may be the number of basis signal vectors, and specifically the number of dictionary atoms, that are needed to represent the signal in an appropriate feature domain.
- The property may then be compared to one or more expected properties for non-reverberant speech. For example, in many embodiments, the values for the set of basis vectors may be compared to samples of values for sets of basis vector corresponding to specific non-reverberant speech samples.
- However, in many embodiments a simpler approach may be used. Specifically, if the dictionary is trained on non-reverberant speech, then a microphone signal that contains less reverberant speech can be described using a relatively low number of dictionary atoms. As the signal is increasingly exposed to reverberation and noise, an increasing number of atoms will be required, i.e. the energy will tend to be spread more equally over more basis vectors.
- Accordingly, in many embodiments, the distribution of the energy across the basis vectors may be evaluated and used to determine the similarity indication. The more the distribution is spread, the lower is the similarity indication.
- As a specific example, when comparing signals from two microphones, the one that can be described using fewer dictionary atoms is more similar to non-reverberant speech (where the dictionary has been trained on non-reverberant speech).
- As a specific example, the number of basis vectors for which the value (specifically the weight of each basis vector in a combination of basis vectors approximating the signal) exceeds a given threshold may be used to determine the similarity indication. Indeed, the number of basis vectors which exceed the threshold may simply be calculated and directly used as the similarity indication for a given microphone signal, with an increasing number of basis vectors indicating a reduced similarity. Thus, the property derived from the microphone signal may be the number of basis vector values that exceed a threshold, and this may be compared to a reference property for non-reverberant speech of zero or one basis vectors having values above the threshold. Thus, the higher the number of basis vectors the lower will the similarity indication be.
- It will be appreciated that the above description for clarity has described embodiments of the invention with reference to different functional circuits, units and processors. However, it will be apparent that any suitable distribution of functionality between different functional circuits, units or processors may be used without detracting from the invention. For example, functionality illustrated to be performed by separate processors or controllers may be performed by the same processor or controllers. Hence, references to specific functional units or circuits are only to be seen as references to suitable means for providing the described functionality rather than indicative of a strict logical or physical structure or organization.
- The invention can be implemented in any suitable form including hardware, software, firmware or any combination of these. The invention may optionally be implemented at least partly as computer software running on one or more data processors and/or digital signal processors. The elements and components of an embodiment of the invention may be physically, functionally and logically implemented in any suitable way. Indeed the functionality may be implemented in a single unit, in a plurality of units or as part of other functional units. As such, the invention may be implemented in a single unit or may be physically and functionally distributed between different units, circuits and processors.
- Although the present invention has been described in connection with some embodiments, it is not intended to be limited to the specific form set forth herein. Rather, the scope of the present invention is limited only by the accompanying claims. Additionally, although a feature may appear to be described in connection with particular embodiments, one skilled in the art would recognize that various features of the described embodiments may be combined in accordance with the invention. In the claims, the term comprising does not exclude the presence of other elements or steps.
- Furthermore, although individually listed, a plurality of means, elements, circuits or method steps may be implemented by e.g. a single circuit, unit or processor. Additionally, although individual features may be included in different claims, these may possibly be advantageously combined, and the inclusion in different claims does not imply that a combination of features is not feasible and/or advantageous. Also the inclusion of a feature in one category of claims does not imply a limitation to this category but rather indicates that the feature is equally applicable to other claim categories as appropriate. Furthermore, the order of features in the claims do not imply any specific order in which the features must be worked and in particular the order of individual steps in a method claim does not imply that the steps must be performed in this order. Rather, the steps may be performed in any suitable order. In addition, singular references do not exclude a plurality. Thus references to "a", "an", "first", "second" etc. do not preclude a plurality. Reference signs in the claims are provided merely as a clarifying example shall not be construed as limiting the scope of the claims in any way.
Claims (14)
- An apparatus for generating a speech signal, the apparatus comprising:microphone receivers (101) for receiving microphone signals from a plurality ofmicrophones (103);a comparator (105) arranged to, for each microphone signal, determine a speech similarity indication indicative of a similarity between the microphone signal and non-reverberant speech, the comparator (105) being arranged to determine the similarity indication in response to a comparison of at least one property derived from the microphone signal to at least one reference property for non-reverberant speech; anda generator (107) for generating the speech signal by combining the microphone signals in response to the similarity indications,characterized in that
the comparator (105) is further arranged to determine the similarity indication for a first microphone signal in response to a comparison of at least one property derived from the microphone signal to reference properties for speech samples of a set of non-reverberant speech samples. - The apparatus of claim 1 comprising a plurality of separate devices (201, 203, 205), each device comprising a microphone receiver for receiving at least one microphone signal of the plurality of microphone signals.
- The apparatus of claim 2 wherein at least a first device of the plurality of separate devices (201, 203, 205) comprises a local comparator (105) for determining a first speech similarity indication for the at least one microphone signal of the first device.
- The apparatus of claim 3 wherein the generator (107) is implemented in a generator device (207) separate from at least the first device; and wherein the first device comprises a transmitter (209) for transmitting the first speech similarity indication to the generator device (207).
- The apparatus of claim 4 wherein the generator device (207) is arranged to receive speech similarity indications from each of the plurality of separate devices (201, 203, 205), and wherein the generator (107, 207) is arranged to generate the speech signal using a subset of microphone signals from the plurality of separate devices (201, 203, 205), the subset being determined in response to the speech similarity indications received from the plurality of separate devices (201, 203, 205).
- The apparatus of claim 5 wherein at least one device of the plurality of separate devices (201, 203, 205) is arranged to transmit the at least one microphone signal of the at least one device to the generator device (207) only if the at least one microphone signal of the at least one device is comprised in the subset of microphone signals.
- The apparatus of claim 5 wherein the generator device (207) comprises a selector (213) arranged to determine the subset of microphone signals, and a transmitter (211) for transmitting an indication of the subset to at least one of the plurality of separate devices (201,203,205).
- The apparatus of claim 1 wherein the speech samples of the set of non-reverberating speech samples are represented by parameters for a non-reverberating speech model.
- The apparatus of claim 8 wherein the comparator (105) is arranged to determine a first reference property for a first speech sample of the set of non-reverberating speech samples from a speech sample signal generated by evaluating the non-reverberating speech model using the parameters for the first speech sample, and to determine the similarity indication for a first microphone signal of the plurality of microphone signals in response to a comparison of the property derived from the first microphone signal and the first reference property.
- The apparatus of claim 1 wherein the comparator (105) is arranged to decompose a first microphone signal of the plurality of microphone signals into a set of basis signal vectors; and to determine the similarity indication in response to a property of the set of basis signal vectors.
- The apparatus of claim 1 wherein the comparator (105) is arranged to determine speech similarity indications for each segment of a plurality of segments of the speech signal, and the generator is arranged to determine combination parameters for the combining for each segment.
- The apparatus of claim 10 wherein the generator (107) is arranged to determine combination parameters for one segment in response to similarity indications of at least one previous segment.
- The apparatus of claim 1 wherein the generator (107) is arranged to select a subset of the microphone signals to combine in response to the similarity indications.
- A method of generating a speech signal, the method comprising:receiving microphone signals from a plurality of microphones (103);for each microphone signal, determining a speech similarity indication indicative of a similarity between the microphone signal and non-reverberant speech, the similarity indication being determined in response to a comparison of at least one property derived from the microphone signal to at least one reference property for non-reverberant speech; andgenerating the speech signal by combining the microphone signals in response to the similarity indications,characterized in that
the similarity indication is further determined for a first microphone signal in response to a comparison of at least one property derived from the microphone signal to reference properties for speech samples of a set of non-reverberant speech samples.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201361769236P | 2013-02-26 | 2013-02-26 | |
| PCT/IB2014/059057 WO2014132167A1 (en) | 2013-02-26 | 2014-02-18 | Method and apparatus for generating a speech signal |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP2962300A1 EP2962300A1 (en) | 2016-01-06 |
| EP2962300B1 true EP2962300B1 (en) | 2017-01-25 |
Family
ID=50190513
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP14707461.1A Active EP2962300B1 (en) | 2013-02-26 | 2014-02-18 | Method and apparatus for generating a speech signal |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US10032461B2 (en) |
| EP (1) | EP2962300B1 (en) |
| JP (1) | JP6519877B2 (en) |
| CN (1) | CN105308681B (en) |
| BR (1) | BR112015020150B1 (en) |
| RU (1) | RU2648604C2 (en) |
| WO (1) | WO2014132167A1 (en) |
Families Citing this family (84)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8971546B2 (en) | 2011-10-14 | 2015-03-03 | Sonos, Inc. | Systems, methods, apparatus, and articles of manufacture to control audio playback devices |
| KR101904423B1 (en) * | 2014-09-03 | 2018-11-28 | 삼성전자주식회사 | Method and apparatus for learning and recognizing audio signal |
| US9922643B2 (en) * | 2014-12-23 | 2018-03-20 | Nice Ltd. | User-aided adaptation of a phonetic dictionary |
| KR102387567B1 (en) * | 2015-01-19 | 2022-04-18 | 삼성전자주식회사 | Method and apparatus for speech recognition |
| JP6631010B2 (en) * | 2015-02-04 | 2020-01-15 | ヤマハ株式会社 | Microphone selection device, microphone system, and microphone selection method |
| CN105185371B (en) | 2015-06-25 | 2017-07-11 | 京东方科技集团股份有限公司 | A kind of speech synthetic device, phoneme synthesizing method, the osteoacusis helmet and audiphone |
| US10142754B2 (en) | 2016-02-22 | 2018-11-27 | Sonos, Inc. | Sensor on moving component of transducer |
| US10264030B2 (en) | 2016-02-22 | 2019-04-16 | Sonos, Inc. | Networked microphone device control |
| US9947316B2 (en) | 2016-02-22 | 2018-04-17 | Sonos, Inc. | Voice control of a media playback system |
| US9965247B2 (en) | 2016-02-22 | 2018-05-08 | Sonos, Inc. | Voice controlled media playback system based on user profile |
| US10097919B2 (en) | 2016-02-22 | 2018-10-09 | Sonos, Inc. | Music service selection |
| US9811314B2 (en) | 2016-02-22 | 2017-11-07 | Sonos, Inc. | Metadata exchange involving a networked playback system and a networked microphone system |
| US10095470B2 (en) | 2016-02-22 | 2018-10-09 | Sonos, Inc. | Audio response playback |
| DK3217399T3 (en) * | 2016-03-11 | 2019-02-25 | Gn Hearing As | Kalman filtering based speech enhancement using a codebook based approach |
| US9978390B2 (en) * | 2016-06-09 | 2018-05-22 | Sonos, Inc. | Dynamic player selection for audio signal processing |
| US10134399B2 (en) | 2016-07-15 | 2018-11-20 | Sonos, Inc. | Contextualization of voice inputs |
| US10152969B2 (en) | 2016-07-15 | 2018-12-11 | Sonos, Inc. | Voice detection by multiple devices |
| US10115400B2 (en) | 2016-08-05 | 2018-10-30 | Sonos, Inc. | Multiple voice services |
| US9693164B1 (en) | 2016-08-05 | 2017-06-27 | Sonos, Inc. | Determining direction of networked microphone device relative to audio playback device |
| GB201615538D0 (en) | 2016-09-13 | 2016-10-26 | Nokia Technologies Oy | A method , apparatus and computer program for processing audio signals |
| US9794720B1 (en) | 2016-09-22 | 2017-10-17 | Sonos, Inc. | Acoustic position measurement |
| US9942678B1 (en) | 2016-09-27 | 2018-04-10 | Sonos, Inc. | Audio playback settings for voice interaction |
| US9743204B1 (en) | 2016-09-30 | 2017-08-22 | Sonos, Inc. | Multi-orientation playback device microphones |
| US10181323B2 (en) | 2016-10-19 | 2019-01-15 | Sonos, Inc. | Arbitration-based voice recognition |
| US10621980B2 (en) * | 2017-03-21 | 2020-04-14 | Harman International Industries, Inc. | Execution of voice commands in a multi-device system |
| US11183181B2 (en) | 2017-03-27 | 2021-11-23 | Sonos, Inc. | Systems and methods of multiple voice services |
| GB2563857A (en) | 2017-06-27 | 2019-01-02 | Nokia Technologies Oy | Recording and rendering sound spaces |
| US10475449B2 (en) | 2017-08-07 | 2019-11-12 | Sonos, Inc. | Wake-word detection suppression |
| US10048930B1 (en) | 2017-09-08 | 2018-08-14 | Sonos, Inc. | Dynamic computation of system response volume |
| US10446165B2 (en) | 2017-09-27 | 2019-10-15 | Sonos, Inc. | Robust short-time fourier transform acoustic echo cancellation during audio playback |
| US10051366B1 (en) | 2017-09-28 | 2018-08-14 | Sonos, Inc. | Three-dimensional beam forming with a microphone array |
| US10482868B2 (en) | 2017-09-28 | 2019-11-19 | Sonos, Inc. | Multi-channel acoustic echo cancellation |
| US10621981B2 (en) | 2017-09-28 | 2020-04-14 | Sonos, Inc. | Tone interference cancellation |
| US10466962B2 (en) | 2017-09-29 | 2019-11-05 | Sonos, Inc. | Media playback system with voice assistance |
| CA3078420A1 (en) | 2017-10-17 | 2019-04-25 | Magic Leap, Inc. | Mixed reality spatial audio |
| US10880650B2 (en) | 2017-12-10 | 2020-12-29 | Sonos, Inc. | Network microphone devices with automatic do not disturb actuation capabilities |
| US10818290B2 (en) | 2017-12-11 | 2020-10-27 | Sonos, Inc. | Home graph |
| CN108174138B (en) * | 2018-01-02 | 2021-02-19 | 上海闻泰电子科技有限公司 | Video shooting method, voice acquisition equipment and video shooting system |
| US11343614B2 (en) | 2018-01-31 | 2022-05-24 | Sonos, Inc. | Device designation of playback and network microphone device arrangements |
| IL276510B2 (en) | 2018-02-15 | 2024-02-01 | Magic Leap Inc | Mixed reality virtual reverberation |
| US11175880B2 (en) | 2018-05-10 | 2021-11-16 | Sonos, Inc. | Systems and methods for voice-assisted media content selection |
| US10847178B2 (en) | 2018-05-18 | 2020-11-24 | Sonos, Inc. | Linear filtering for noise-suppressed speech detection |
| US10959029B2 (en) | 2018-05-25 | 2021-03-23 | Sonos, Inc. | Determining and adapting to changes in microphone performance of playback devices |
| US10681460B2 (en) | 2018-06-28 | 2020-06-09 | Sonos, Inc. | Systems and methods for associating playback devices with voice assistant services |
| US10461710B1 (en) | 2018-08-28 | 2019-10-29 | Sonos, Inc. | Media playback system with maximum volume setting |
| US11076035B2 (en) | 2018-08-28 | 2021-07-27 | Sonos, Inc. | Do not disturb feature for audio notifications |
| CN117319912A (en) * | 2018-09-13 | 2023-12-29 | 科利耳有限公司 | Hearing performance and rehabilitation and/or rehabilitation enhancement using normals |
| US10587430B1 (en) | 2018-09-14 | 2020-03-10 | Sonos, Inc. | Networked devices, systems, and methods for associating playback devices based on sound codes |
| US10878811B2 (en) | 2018-09-14 | 2020-12-29 | Sonos, Inc. | Networked devices, systems, and methods for intelligently deactivating wake-word engines |
| US11024331B2 (en) | 2018-09-21 | 2021-06-01 | Sonos, Inc. | Voice detection optimization using sound metadata |
| US10811015B2 (en) | 2018-09-25 | 2020-10-20 | Sonos, Inc. | Voice detection optimization based on selected voice assistant service |
| US11100923B2 (en) | 2018-09-28 | 2021-08-24 | Sonos, Inc. | Systems and methods for selective wake word detection using neural network models |
| US10692518B2 (en) | 2018-09-29 | 2020-06-23 | Sonos, Inc. | Linear filtering for noise-suppressed speech detection via multiple network microphone devices |
| US11899519B2 (en) | 2018-10-23 | 2024-02-13 | Sonos, Inc. | Multiple stage network microphone device with reduced power consumption and processing load |
| EP3654249A1 (en) | 2018-11-15 | 2020-05-20 | Snips | Dilated convolutions and gating for efficient keyword spotting |
| US11183183B2 (en) | 2018-12-07 | 2021-11-23 | Sonos, Inc. | Systems and methods of operating media playback systems having multiple voice assistant services |
| US11132989B2 (en) | 2018-12-13 | 2021-09-28 | Sonos, Inc. | Networked microphone devices, systems, and methods of localized arbitration |
| US10602268B1 (en) | 2018-12-20 | 2020-03-24 | Sonos, Inc. | Optimization of network microphone devices using noise classification |
| US10867604B2 (en) | 2019-02-08 | 2020-12-15 | Sonos, Inc. | Devices, systems, and methods for distributed voice processing |
| US11315556B2 (en) | 2019-02-08 | 2022-04-26 | Sonos, Inc. | Devices, systems, and methods for distributed voice processing by transmitting sound data associated with a wake word to an appropriate device for identification |
| KR20210145733A (en) * | 2019-03-27 | 2021-12-02 | 소니그룹주식회사 | Signal processing apparatus and method, and program |
| JP7170851B2 (en) * | 2019-04-26 | 2022-11-14 | 株式会社ソニー・インタラクティブエンタテインメント | Information processing system, information processing device, control method for information processing device, and program |
| US11880633B2 (en) | 2019-04-26 | 2024-01-23 | Sony Interactive Entertainment Inc. | Information processing system, information processing apparatus, control method for information processing apparatus, and program |
| US11120794B2 (en) | 2019-05-03 | 2021-09-14 | Sonos, Inc. | Voice assistant persistence across multiple network microphone devices |
| US11200894B2 (en) | 2019-06-12 | 2021-12-14 | Sonos, Inc. | Network microphone device with command keyword eventing |
| US10586540B1 (en) | 2019-06-12 | 2020-03-10 | Sonos, Inc. | Network microphone device with command keyword conditioning |
| US11361756B2 (en) | 2019-06-12 | 2022-06-14 | Sonos, Inc. | Conditional wake word eventing based on environment |
| JP7362320B2 (en) * | 2019-07-04 | 2023-10-17 | フォルシアクラリオン・エレクトロニクス株式会社 | Audio signal processing device, audio signal processing method, and audio signal processing program |
| US10871943B1 (en) | 2019-07-31 | 2020-12-22 | Sonos, Inc. | Noise classification for event detection |
| US11138975B2 (en) | 2019-07-31 | 2021-10-05 | Sonos, Inc. | Locally distributed keyword detection |
| US11138969B2 (en) | 2019-07-31 | 2021-10-05 | Sonos, Inc. | Locally distributed keyword detection |
| US11189286B2 (en) | 2019-10-22 | 2021-11-30 | Sonos, Inc. | VAS toggle based on device orientation |
| EP4049466A4 (en) | 2019-10-25 | 2022-12-28 | Magic Leap, Inc. | Reverberation fingerprint estimation |
| US11217235B1 (en) * | 2019-11-18 | 2022-01-04 | Amazon Technologies, Inc. | Autonomously motile device with audio reflection detection |
| US11200900B2 (en) | 2019-12-20 | 2021-12-14 | Sonos, Inc. | Offline voice control |
| US11562740B2 (en) | 2020-01-07 | 2023-01-24 | Sonos, Inc. | Voice verification for media playback |
| US11556307B2 (en) | 2020-01-31 | 2023-01-17 | Sonos, Inc. | Local voice data processing |
| US11308958B2 (en) | 2020-02-07 | 2022-04-19 | Sonos, Inc. | Localized wakeword verification |
| US11482224B2 (en) | 2020-05-20 | 2022-10-25 | Sonos, Inc. | Command keywords with input detection windowing |
| US11308962B2 (en) | 2020-05-20 | 2022-04-19 | Sonos, Inc. | Input detection windowing |
| US11727919B2 (en) | 2020-05-20 | 2023-08-15 | Sonos, Inc. | Memory allocation for keyword spotting engines |
| US11698771B2 (en) | 2020-08-25 | 2023-07-11 | Sonos, Inc. | Vocal guidance engines for playback devices |
| US11984123B2 (en) | 2020-11-12 | 2024-05-14 | Sonos, Inc. | Network device interaction by range |
| US11551700B2 (en) | 2021-01-25 | 2023-01-10 | Sonos, Inc. | Systems and methods for power-efficient keyword detection |
Family Cites Families (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3814856A (en) | 1973-02-22 | 1974-06-04 | D Dugan | Control apparatus for sound reinforcement systems |
| US5561737A (en) | 1994-05-09 | 1996-10-01 | Lucent Technologies Inc. | Voice actuated switching system |
| US5638487A (en) * | 1994-12-30 | 1997-06-10 | Purespeech, Inc. | Automatic speech recognition |
| JP3541339B2 (en) | 1997-06-26 | 2004-07-07 | 富士通株式会社 | Microphone array device |
| US6684185B1 (en) * | 1998-09-04 | 2004-01-27 | Matsushita Electric Industrial Co., Ltd. | Small footprint language and vocabulary independent word recognizer using registration by word spelling |
| US6243322B1 (en) * | 1999-11-05 | 2001-06-05 | Wavemakers Research, Inc. | Method for estimating the distance of an acoustic signal |
| GB0120450D0 (en) * | 2001-08-22 | 2001-10-17 | Mitel Knowledge Corp | Robust talker localization in reverberant environment |
| US7783063B2 (en) | 2002-01-18 | 2010-08-24 | Polycom, Inc. | Digital linking of multiple microphone systems |
| ATE324763T1 (en) * | 2003-08-21 | 2006-05-15 | Bernafon Ag | METHOD FOR PROCESSING AUDIO SIGNALS |
| WO2005024780A2 (en) * | 2003-09-05 | 2005-03-17 | Grody Stephen D | Methods and apparatus for providing services using speech recognition |
| CN1808571A (en) | 2005-01-19 | 2006-07-26 | 松下电器产业株式会社 | Acoustical signal separation system and method |
| US7260491B2 (en) * | 2005-10-27 | 2007-08-21 | International Business Machines Corporation | Duty cycle measurement apparatus and method |
| JP4311402B2 (en) | 2005-12-21 | 2009-08-12 | ヤマハ株式会社 | Loudspeaker system |
| EP1994791B1 (en) * | 2006-03-03 | 2015-04-15 | GN Resound A/S | Automatic switching between omnidirectional and directional microphone modes in a hearing aid |
| US8233353B2 (en) | 2007-01-26 | 2012-07-31 | Microsoft Corporation | Multi-sensor sound source localization |
| US8411880B2 (en) | 2008-01-29 | 2013-04-02 | Qualcomm Incorporated | Sound quality by intelligently selecting between signals from a plurality of microphones |
| US8660281B2 (en) * | 2009-02-03 | 2014-02-25 | University Of Ottawa | Method and system for a multi-microphone noise reduction |
| US8867754B2 (en) | 2009-02-13 | 2014-10-21 | Honda Motor Co., Ltd. | Dereverberation apparatus and dereverberation method |
| US8644517B2 (en) * | 2009-08-17 | 2014-02-04 | Broadcom Corporation | System and method for automatic disabling and enabling of an acoustic beamformer |
| US8447619B2 (en) * | 2009-10-22 | 2013-05-21 | Broadcom Corporation | User attribute distribution for network/peer assisted speech coding |
| EP2375779A3 (en) * | 2010-03-31 | 2012-01-18 | Fraunhofer-Gesellschaft zur Förderung der Angewandten Forschung e.V. | Apparatus and method for measuring a plurality of loudspeakers and microphone array |
| US9258429B2 (en) * | 2010-05-18 | 2016-02-09 | Telefonaktiebolaget L M Ericsson | Encoder adaption in teleconferencing system |
| US8908874B2 (en) * | 2010-09-08 | 2014-12-09 | Dts, Inc. | Spatial audio encoding and reproduction |
| SI3239979T1 (en) * | 2010-10-25 | 2024-09-30 | Voiceage Evs Llc | Coding generic audio signals at low bitrates and low delay |
| EP2458586A1 (en) * | 2010-11-24 | 2012-05-30 | Koninklijke Philips Electronics N.V. | System and method for producing an audio signal |
| SE536046C2 (en) | 2011-01-19 | 2013-04-16 | Limes Audio Ab | Method and device for microphone selection |
| WO2012175094A1 (en) * | 2011-06-20 | 2012-12-27 | Agnitio, S.L. | Identification of a local speaker |
| US8340975B1 (en) * | 2011-10-04 | 2012-12-25 | Theodore Alfred Rosenberger | Interactive speech recognition device and system for hands-free building control |
| US8731911B2 (en) * | 2011-12-09 | 2014-05-20 | Microsoft Corporation | Harmonicity-based single-channel speech quality estimation |
| US9058806B2 (en) * | 2012-09-10 | 2015-06-16 | Cisco Technology, Inc. | Speaker segmentation and recognition based on list of speakers |
| US20140170979A1 (en) * | 2012-12-17 | 2014-06-19 | Qualcomm Incorporated | Contextual power saving in bluetooth audio |
-
2014
- 2014-02-18 EP EP14707461.1A patent/EP2962300B1/en active Active
- 2014-02-18 US US14/766,567 patent/US10032461B2/en active Active
- 2014-02-18 WO PCT/IB2014/059057 patent/WO2014132167A1/en active Application Filing
- 2014-02-18 JP JP2015558579A patent/JP6519877B2/en active Active
- 2014-02-18 BR BR112015020150-4A patent/BR112015020150B1/en active IP Right Grant
- 2014-02-18 CN CN201480010600.4A patent/CN105308681B/en active Active
- 2014-02-18 RU RU2015140965A patent/RU2648604C2/en active
Non-Patent Citations (1)
| Title |
|---|
| None * |
Also Published As
| Publication number | Publication date |
|---|---|
| BR112015020150A2 (en) | 2017-07-18 |
| EP2962300A1 (en) | 2016-01-06 |
| JP2016511594A (en) | 2016-04-14 |
| CN105308681B (en) | 2019-02-12 |
| RU2648604C2 (en) | 2018-03-26 |
| US20150380010A1 (en) | 2015-12-31 |
| CN105308681A (en) | 2016-02-03 |
| BR112015020150B1 (en) | 2021-08-17 |
| WO2014132167A1 (en) | 2014-09-04 |
| JP6519877B2 (en) | 2019-05-29 |
| US10032461B2 (en) | 2018-07-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP2962300B1 (en) | Method and apparatus for generating a speech signal | |
| Parchami et al. | Recent developments in speech enhancement in the short-time Fourier transform domain | |
| JP4796309B2 (en) | Method and apparatus for multi-sensor speech improvement on mobile devices | |
| KR101726737B1 (en) | Apparatus for separating multi-channel sound source and method the same | |
| JP5102365B2 (en) | Multi-microphone voice activity detector | |
| KR101172180B1 (en) | Systems, methods, and apparatus for multi-microphone based speech enhancement | |
| US9269368B2 (en) | Speaker-identification-assisted uplink speech processing systems and methods | |
| US20090018826A1 (en) | Methods, Systems and Devices for Speech Transduction | |
| JP6169910B2 (en) | Audio processing device | |
| JP6545419B2 (en) | Acoustic signal processing device, acoustic signal processing method, and hands-free communication device | |
| US20090299742A1 (en) | Systems, methods, apparatus, and computer program products for spectral contrast enhancement | |
| JP2011511571A (en) | Improve sound quality by intelligently selecting between signals from multiple microphones | |
| Habets et al. | Joint dereverberation and residual echo suppression of speech signals in noisy environments | |
| CN108810778B (en) | Method for operating a hearing device and hearing device | |
| CN109257687A (en) | Hearing device and method with non-intrusive speech clarity | |
| JP2018046452A (en) | Signal processing apparatus, program, method, and communications device | |
| JP6179081B2 (en) | Noise reduction device, voice input device, wireless communication device, and noise reduction method | |
| Gamper et al. | Predicting word error rate for reverberant speech | |
| WO2013057659A2 (en) | Signal noise attenuation | |
| JP5958218B2 (en) | Noise reduction device, voice input device, wireless communication device, and noise reduction method | |
| Srinivasan | Using a remotewireless microphone for speech enhancement in non-stationary noise | |
| JP2002258899A (en) | Method and device for suppressing noise | |
| GB2580655A (en) | Reducing a noise level of an audio signal of a hearing system | |
| WO2020039597A1 (en) | Signal processing device, voice communication terminal, signal processing method, and signal processing program | |
| Pacheco et al. | Spectral subtraction for reverberation reduction applied to automatic speech recognition |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| 17P | Request for examination filed |
Effective date: 20150928 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| AX | Request for extension of the european patent |
Extension state: BA ME |
|
| DAX | Request for extension of the european patent (deleted) | ||
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| INTG | Intention to grant announced |
Effective date: 20160810 |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO RS SE SI SK SM TR |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: FG4D |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: EP |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: REF Ref document number: 864539 Country of ref document: AT Kind code of ref document: T Effective date: 20170215 |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FG4D |
|
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: PLFP Year of fee payment: 4 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R096 Ref document number: 602014006358 Country of ref document: DE |
|
| REG | Reference to a national code |
Ref country code: LT Ref legal event code: MG4D |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: BE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20170228 |
|
| REG | Reference to a national code |
Ref country code: NL Ref legal event code: MP Effective date: 20170125 |
|
| REG | Reference to a national code |
Ref country code: AT Ref legal event code: MK05 Ref document number: 864539 Country of ref document: AT Kind code of ref document: T Effective date: 20170125 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: NL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: HR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: LT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: NO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170425 Ref country code: IS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170525 Ref country code: FI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: GR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170426 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: AT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: BG Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170425 Ref country code: RS Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: PT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170525 Ref country code: LV Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: SE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: PL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: PL |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R097 Ref document number: 602014006358 Country of ref document: DE |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: RO Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: LI Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20170228 Ref country code: IT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: CZ Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: CH Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20170228 Ref country code: EE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: SK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: MM4A |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: MC Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: DK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: SM Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 |
|
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20170218 |
|
| 26N | No opposition filed |
Effective date: 20171026 |
|
| REG | Reference to a national code |
Ref country code: BE Ref legal event code: MM Effective date: 20170228 |
|
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: PLFP Year of fee payment: 5 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 Ref country code: IE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20170218 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: MT Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20170218 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: HU Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT; INVALID AB INITIO Effective date: 20140218 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R082 Ref document number: 602014006358 Country of ref document: DE Representative=s name: HOEFER & PARTNER PATENTANWAELTE MBB, DE Ref country code: DE Ref legal event code: R081 Ref document number: 602014006358 Country of ref document: DE Owner name: MEDIATEK INC., TW Free format text: FORMER OWNER: KONINKLIJKE PHILIPS N.V., EINDHOVEN, NL |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: CY Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: MK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 |
|
| REG | Reference to a national code |
Ref country code: GB Ref legal event code: 732E Free format text: REGISTERED BETWEEN 20191114 AND 20191120 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: AL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20170125 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20240228 Year of fee payment: 11 Ref country code: GB Payment date: 20240227 Year of fee payment: 11 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: TR Payment date: 20240206 Year of fee payment: 11 Ref country code: FR Payment date: 20240226 Year of fee payment: 11 |