EP2045736A1 - Erkennung von Wortgruppen nach Wortähnlichkeiten - Google Patents
Erkennung von Wortgruppen nach Wortähnlichkeiten Download PDFInfo
- Publication number
- EP2045736A1 EP2045736A1 EP08165809A EP08165809A EP2045736A1 EP 2045736 A1 EP2045736 A1 EP 2045736A1 EP 08165809 A EP08165809 A EP 08165809A EP 08165809 A EP08165809 A EP 08165809A EP 2045736 A1 EP2045736 A1 EP 2045736A1
- Authority
- EP
- European Patent Office
- Prior art keywords
- affinity
- word
- clusters
- words
- cluster
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/31—Indexing; Data structures therefor; Storage structures
- G06F16/316—Indexing structures
- G06F16/319—Inverted lists
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G06F16/355—Class or cluster creation or modification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
Definitions
- the present invention relates generally to lexigraphical analysis and, more particularly, to identifying clusters of words according to word affinities.
- Keyword searching is the primary technique for finding information. In certain situations, however, keyword searching is not effective in locating information.
- identifying clusters of words includes accessing a record that records affinities.
- An affinity between a first and second word describes a quantitative relationship between the first and second word.
- Clusters of words are identified according to the affinities.
- a cluster comprises words that are sufficiently affine with each other.
- a first word is sufficiently affine with a second word if the affinity between the first and second word satisfies one or more affinity criteria.
- a clustering analysis is performed using the clusters.
- creating and querying a domain ontology may include the following:
- the differential directional affinity (DiffDAff) between terms A and B may be defined as the directional affinity between terms A and B minus a factor that accounts for the common-ness of the term B in the corpus.
- the common-ness of the term B in the corpus may be a statistical value over the basic affinity or directional affinity values of the term B towards the other terms in the corpus.
- FIGURE 1 illustrates one embodiment of a system 10 that identifies clusters of words.
- system 10 identifies clusters of words from the affinities between the words.
- a cluster includes words that are sufficiently affine with each other, where sufficient affinity is determined according to one or more affinity criteria.
- system 10 performs a clustering analysis. Examples of clustering analyses include categorizing a page according to the clusters of the page, determining a character of a corpus from the clusters of the corpus, and analyzing users based on the clusters in the users' documents.
- directional affinity may be calculated on a specific inverted index II for a given subset of words and a dictionary D , where index II includes, for example, entries I ( w i ) and I ( w j ) for words w i and w j .
- index II includes, for example, entries I ( w i ) and I ( w j ) for words w i and w j .
- an inverted index is an index data structure that stores mappings from a term to its locations, that is, the co-occurrence contexts in which a term appears.
- DA(i,j) may be defined as the values in the conjunction of entries I ( w i ), I ( w j ) in II divided by the number of values in I ( w i ).
- DA(i,j) is not necessarily equal to DA(j,i).
- the results may be stored in any suitable manner, for example, row-wise, where the D(l,i) are stored, then the D(2,j) are stored, and so on. For each row i ,
- directional affinity may be calculated in three phases.
- each dictionary term is assigned a unique integer identifier.
- the entries of an inverted index correspond to the integer identifiers.
- the II entries corresponding to D are read.
- the element identifiers that are of the form ks + o are kept.
- the value ks+o defines a subset of the II entries to be examined.
- directional affinities can be computed in parallel.
- the result from parameters s,o (1,0) is equivalent to the one obtained from the merging of the computations with parameters (3,0), (3,1), (3,2). This step allows calculation of DA tables for very large inverted indices.
- Phase 1 the conjunctions are calculated row-wise only for DA ( i,j ) .
- Phase 2 the calculated upper-triangular UT DA array is read. From that, the lower-triangular part is obtained as the transpose of UT.
- multiple DA arrays of the same dimension may be merged into a single array.
- the DA may be stored row-wise, so the calculation of the AA entries may proceed in parallel with the calculation of the DA entries.
- AA may be generated by summing up the rows of the DA as they are read from the disk and, at the end, normalized by the number of the dictionary entries.
- system 10 includes a client 20, a server 22, and a memory 24.
- Client 20 allows a user to communicate with server 22 to generate ontologies of a language.
- Client 20 may send user input to server 22, and may provide (for example, display or print) server output to user.
- Server system 24 manages applications for generating ontologies of a language.
- Memory 24 stores data used by server system 24.
- memory 24 stores pages 50 and a record 54.
- a page 50 (or document or co-occurrence context) may refer to a collection of words. Examples of a page 50 include one or more pages of a document, one or more documents, one or more books, one or more web pages, correspondence (for example, email or instant messages), and/or other collections of words.
- a page 50 may be identified by a page identifier.
- a page 50 may be electronically stored in one or more tangible computer-readable media.
- a page 50 may be associated with any suitable content, for example, text (such as characters, words, and/or numbers), images (such as graphics, photographs, or videos), audio (such as recordings or computer-generated sounds), and/or software programs.
- a set of pages 50 may belong to a corpus.
- a corpus may be associated with a particular subject matter, community, organization, or other entity.
- Record 54 describes pages 50.
- record 54 includes an index 58, an inverted index 62, ontologies 66, and clusters 67.
- Index 58 includes index lists, where an index list for a page 50 indicates the words of the page 50.
- Inverted index 62 includes inverted index lists, where an inverted index list for a word (or set of words) indicates the pages 50 that include the word (or set of words).
- list W ⁇ includes page identifiers of pages 50 that include word w i .
- List W i & W j includes page identifiers of conjunction pages 50 that include both words w i and w j .
- List W ⁇ + W j includes page identifiers of disjunction pages 50 that include either word w i or w j .
- P(W i ) is the number of pages 50 of W i , that is, the number of pages 50 that include word w i .
- a list (such as an index list or an inverted index list) may be stored as a binary decision diagram (BDD).
- BDD binary decision diagram
- a binary decision diagram BDD( W i ) for set W i represents the pages 50 that have word w i .
- Ontologies 66 represent the words of a language and the relationships among the words.
- an ontology 66 represents the affinities between words.
- ontologies 66 include an affinity matrix and an affinity graph. Examples of affinity matrices are described with the reference to FIGURES 3 through 5 . An example of an affinity graph is described with reference to FIGURE 6 .
- Clusters 67 record clusters of words that are related to each other. Clusters are described in more detail with reference to FIGURE 7 .
- server 22 includes an affinity module 30 and a clustering module 31.
- Affinity module 30 may calculate affinities for word pairs, record the affinities in an affinity matrix, and/or report the affinity matrix. Affinity module 30 may also generate an affinity graph. Affinity module 30 is described in more detail with reference to FIGURE 2 .
- clustering module 31 may discover patterns in data sets by identifying clusters of related elements in the data sets.
- clustering module 31 may identify clusters of a set of words (for example, a language or a set of pages 50).
- words of a cluster are highly related to each other, but not to words outside of the cluster.
- a cluster of words may designate a theme (or topic) of the set of words.
- clustering module 31 identifies clusters of related words according to the affinities among the words.
- words of a cluster are highly affine to each other, but not to words outside of the cluster. Clustering module 31 is described in more detail with reference to FIGURE 7 .
- a component of system 10 may include an interface, logic, memory, and/or other suitable element.
- An interface receives input, sends output, processes the input and/or output, and/or performs other suitable operation.
- An interface may comprise hardware and/or software.
- Logic performs the operations of the component, for example, executes instructions to generate output from input.
- Logic may include hardware, software, and/or other logic.
- Logic may be encoded in one or more tangible media and may perform operations when executed by a computer.
- Certain logic, such as a processor, may manage the operation of a component. Examples of a processor include one or more computers, one or more microprocessors, one or more applications, and/or other logic.
- a memory stores information.
- a memory may comprise one or more tangible, computer-readable, and/or computer-executable storage medium. Examples of memory include computer memory (for example, Random Access Memory (RAM) or Read Only Memory (ROM)), mass storage media (for example, a hard disk), removable storage media (for example, a Compact Disk (CD) or a Digital Video Disk (DVD)), database and/or network storage (for example, a server), and/or other computer-readable medium.
- RAM Random Access Memory
- ROM Read Only Memory
- mass storage media for example, a hard disk
- removable storage media for example, a Compact Disk (CD) or a Digital Video Disk (DVD)
- database and/or network storage for example, a server
- system 10 may be integrated or separated. Moreover, the operations of system 10 may be performed by more, fewer, or other components. For example, the operations of generators 42 and 46 may be performed by one component, or the operations of affinity calculator 34 may be performed by more than one component. Additionally, operations of system 10 may be performed using any suitable logic comprising software, hardware, and/or other logic. As used in this document, "each" refers to each member of a set or each member of a subset of a set.
- a matrix may include more, fewer, or other values. Additionally, the values of the matrix may be arranged in any suitable order.
- FIGURE 2 illustrates one embodiment of affinity module 30 that may be used with system 10 of FIGURE 1 .
- Affinity module 30 may calculate an affinity for a word pair, record the affinity in an affinity matrix, and/or report the affinity matrix. Affinity module 30 may also generate an affinity graph.
- affinity module 30 includes an affinity calculator 34, ontology generators 38, and a word recommender 48.
- Affinity calculator 34 calculates any suitable type of affinity for a word w i or for a word pair comprising a first word w i and a second word w j .
- Examples of affinities include a basic, directional, average, differential, and/or other affinity.
- word recommender 48 receives a seed word and identifies words that have an affinity with the seed word that is greater than a threshold affinity.
- the threshold affinity may have any suitable value, such as greater than or equal to 0.25, 0.5, 0.75, or 0.95.
- the threshold affinity may be pre-programmed or user-designated.
- a basic affinity may be calculated from the amount (for example, the number) of pages 50 that include words w i and/or w j .
- the conjunction page amount represents the amount of pages 50 that include both word w i and word w j
- the disjunction page amount represents the amount of pages 50 that include either word w i or word w j .
- the basic affinity may be given by the conjunction page amount divided by the disjunction page amount.
- a number of conjunction pages indicates the number of pages comprising word w i and word w j
- a number of disjunction pages indicates the number of pages comprising either word w i or word w j .
- FIGURE 3 illustrates an example of an affinity matrix 110 that records basic affinities.
- affinity matrix 110 records the pairwise affinities of words w 1, ..., w 5 .
- the affinity between words w 0 and w 1 is 0.003
- between words w 0 and w 2 is 0.005, and so on.
- an affinity group includes word pairs that have high affinities towards each another, and may be used to capture the relationship between words w 1 and w 2 with respect to page content.
- a high affinity may be designated as an affinity over an affinity group threshold.
- a threshold may be set at any suitable value, such as greater than or equal to 0.50, 0.60, 0.75, 0.90, or 0.95.
- a word may belong to more than one affinity group.
- an affinity group may be represented as a BDD. The pointer for the BDD may be stored with each word of the group in inverted index 62.
- a directional affinity may be used to measure the importance of word w i with respect to word w j .
- Affinity calculator 34 calculates the directional affinity of word w i given word w j from the amount (for example, the number) of pages 50 that include words w i and w j .
- a word w j page amount represents the amount of pages 50 that include word w i .
- the directional affinity of word w i given word w j may be given by the conjunction page amount divided by word w j page amount. For example, a number of word w j pages indicates the number of pages 50 that include word w i .
- DAffinity( w i , w j ) is not the same as DAffinity( w j , w i ).
- a high directional affinity DAffinity( w i , w j ) between words w i and w j indicates a higher probability that a page 50 includes word w i given that the page 50 includes word w j .
- pages [1 2 3 4 5 6] include word w i
- pages [4 2] include word w j .
- the pages that include word w j also include word w i , so from the viewpoint of word w j , word w i is of high importance. Only in one-third the pages that include w i also include word w j , so from the viewpoint of word w i , word w j is of low importance.
- FIGURE 4 illustrates an example of an affinity matrix 120 that records the directional affinities for words w 0 , ..., w 5.
- words 124 are A words
- words 128 are B words.
- the rows of matrix 120 record the affinity of a B word given an A word
- the columns of affinity matrix 120 record the affinity of an A word given a B word.
- the average affinity of a word w i calculated with respect to the other words w j may be the average of the affinities between word w i and every other word w j .
- FIGURE 5 illustrates an example of an affinity matrix 140 that records average affinities.
- Rows 142 record basic affinities for word 1 through word 50,000.
- Row 144 records the average affinities of word 1 through word 50,000.
- the average affinity of a word may indicate the depth of the word.
- a word with a lower average affinity may be regarded as a deeper word, and a word with a higher average affinity may be regarded as a shallower word. Deeper words tend to be more technical, specific, and precise.
- a page 50 with a higher percentage of deeper words may be regarded as a deeper page, and a page 50 with a lower percentage of deeper words may be regarded as a shallower page.
- a user may specify the depth of word and/or pages 50 to be retrieved.
- the deeper words of a page 50 may form one or more clusters of highly related words.
- a cluster may represent a common idea, or theme.
- the number of themes of a page 50 may indicate the specificity of the page 50.
- a page 50 with fewer themes may be regarded as more specific, and a page 50 with more themes may be regarded as less specific.
- the differential affinity for word w i with respect to word w j is the directional affinity between words w i and w j minus the average affinity of word w j for all other words.
- Differential affinity removes the bias caused by the general tendency for word w j to occur in pages 50.
- differential affinity may provide a more accurate indication of the probability that a page includes word w i given that the page includes word w j .
- Differential affinities may be used in a variety of applications.
- differential affinities among people's names may be used to study social networking.
- differential affinities among language elements may be used to study natural language processing.
- differential affinities among products may be used to study marketing.
- Affinity calculator 34 may use any suitable technique to search inverted index lists to calculate affinities. For example, to identify pages that include both words w i , and w j , affinity calculator 34 may search list W ⁇ of word w i and list W j of word w j for common elements, that is, common page identifiers.
- an ontology generator 38 generates an ontology 66 of a language, such as an affinity matrix or an affinity graph.
- An ontology may be generated from any suitable affinity, such as a basic, directional, average, differential, and/or other affinity.
- Ontologies 66 may be generated from words selected from a language in any suitable manner. For example, words from a commonly used portion of the language or words related to one or more particular subject matter areas may be selected.
- ontology generators 38 include an affinity matrix generator 42 and an affinity graph generator 46.
- Affinity matrix generator 42 generates an affinity matrix that records affinities between words.
- Affinity graph generator 46 generates an affinity graph that represents affinities between words.
- a node represents a word
- the weight of the directed edge between nodes represents the affinity between the words represented by the nodes.
- An affinity graph may have any suitable number of dimensions.
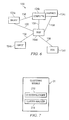
- FIGURE 6 illustrates an example of an affinity graph 150.
- Affinity graph 150 includes nodes 154 and links 158.
- a node 154 represents a word.
- node 154a represents the word "binary.”
- the weight of the directed edge between nodes between nodes 154 represents the affinity between the words represented by nodes 154. For example, a greater weight represents a greater affinity.
- a link 158 between the nodes indicates that the affinity between the words represented by the nodes 154 is above an affinity threshold.
- the affinity threshold may have any suitable value, for example, greater than or equal to 0.25, 0.5, 0.75, or 095.
- FIGURE 7 illustrates one embodiment of clustering module 31 that may be used with system 10 of FIGURE 1 .
- clustering module 31 discovers patterns in data sets by identifying clusters of related elements in the data sets.
- clustering module 31 may identify clusters of a set of words (for example, a language or a set of pages 50).
- words of a cluster are highly related to each other, but not to words outside of the cluster.
- a cluster of words may designate a theme (or topic) of the set of words.
- clustering module 31 identifies clusters of related words according to the affinities among the words.
- words of a cluster are highly affine to each other, but not to words outside of the cluster.
- words may be regarded as highly affine if they are sufficiently affine. Words may be sufficiently affine if they satisfy one or more affinity criteria (such as thresholds), examples of which are provided below.
- clustering module 31 uses directional affinity.
- the directional affinity of a word with respect to other words characterizes the word's co-occurrence.
- a cluster includes words with similar co-occurrence.
- clustering module 31 uses differential affinity. Differential affinity tends to removes bias caused by the general tendency of a word to occur in pages 50
- clustering module 31 includes a clustering engine 210 and a clustering analyzer 214.
- Clustering engine 210 identifies clusters of word according to affinity, and clustering analyzer 214 applies affinity clustering to analyze a variety of situations.
- Clustering engine 210 may identify clusters of words according to affinity in any suitable manner. Three examples of methods for identifying clusters are presented: building a cluster from a set of words, sorting words into clusters, and comparing affinity vectors of words. In one embodiment, clustering engine 210 builds a cluster from a set of words. In one example, clustering engine 210 builds a cluster S from a set W of words ⁇ w i ⁇ with affinities *Aff( w i , w j ).
- Affinity value *Aff( w i , w j ) represents any suitable type of affinity of word w i with respect to word w j , such as directional affinity DAffinity( w i , w j ) or differential affinity DiffAff ( w i , w j ). Certain examples of affinity values provided here may be regarded as normalized values. In the example, Aff for ( w i , w j ) represents forward affinity, and Aff back ( w j , w i ) represents backward affinity.
- cluster S starts with a seed word w q .
- the current word w x represents a word of cluster S that is being compared with a word from set W at the current iteration. Initially, current word w x is set to seed word w q .
- current word w x is set to a word of cluster S .
- Words w i of set Ware sorted according to their forward affinity Aff for ( w i , w x ) with current word w x .
- candidate words w c that meet affinity criteria are identified.
- the affinity criteria may comprise a forward affinity with the current word w x criterion: Aff for w c ⁇ w x > Th cf and a backward affinity with the seed word w q criterion: Aff back w q ⁇ w c > Th cb where Th cf represents a forward threshold for a candidate word, and Th cb represents a backward threshold for a candidate word.
- Th cf represents a forward threshold for a candidate word
- Th cb represents a backward threshold for a candidate word.
- the first words of an ordered set of candidate words ⁇ w c ⁇ are added to the cluster S, the number of added words given by the parameter Size c .
- Thresholds Th cf and Th cb may be floating point parameters with any suitable values ranging from a minimum value to a maximum value.
- suitable values of Th cf and Th cb may be determined from a rank-ordered list of actual affinities. For example, the 200 th value in the list may be used.
- Parameter Size c may be an integer parameter with any suitable value. Examples of suitable values include a default value of 1, 2, 3, or 4. In particular embodiments, the parameters may be varied at certain iterations.
- any suitable number of iterations may be performed.
- the number of iterations may be designated prior to initiation of the method.
- the number may be calculated during the performance of the method.
- the number may be calculated from the growth rate of the size of cluster S.
- clustering engine 210 identifies clusters by sorting words of a set of words into clusters.
- the words ⁇ w i ⁇ are sorted according to an aggregation function, such as the sum, of affinities of word w i to each member of a distinct set of words Q .
- Set W may be selected in any suitable manner.
- set W may be the X words most relevant to a query, where X may have any suitable value, such as a value in the range from 10 to 100, 100 to 200, or 200 or greater.
- the clusters are initially empty.
- a first word w i from set W is placed in a cluster.
- a current word w x is selected from set W .
- Current word w x is placed into a cluster if *Aff( w x , w f ) satisfies an affinity criterion given by an affinity threshold Th, where w f represents the first word placed in the cluster.
- Threshold Th may have any suitable value, for example, a value in the range of 0.1 to 0.5 for a minimum value of 0.0 and a maximum value of 1.0. If *Aff( w x , w f ) does not satisfy threshold Th, current word w x is placed into an empty cluster. The iterations are repeated for each word of set W .
- small clusters may be eliminated.
- clusters with less than Y words may be eliminated.
- Y may have any suitable value, such as a value in a range of 3 to 5, 5 to 10, 10 to 25, 25 to 50, or 50 or greater.
- the process may be repeated with a different value of threshold Th that yields a stricter or looser criterion for placement in a cluster.
- the satisfactory range may be given by a cluster number minimum and a cluster number maximum having any suitable values. Examples of suitable values include values in the range of 1 to 5, 5 to 10, or 10 or greater for the minimum, and values in the range of 10 to 15, 15 to 20, or 20 or greater for the maximum.
- the value of threshold Th may be increased to increase the number of clusters, and may be decreased to decrease the number of clusters.
- clustering engine 210 identifies clusters by comparing affinity vectors of words.
- Affinity value *Aff( w i , w j ) represents any suitable type of affinity of word w i with respect to word w j , for example, directional affinity or differential affinity.
- affinity vectors with similar affinity values may indicate a cluster.
- an affinity vector may be regarded as coordinates of the affinity of a word in affinity space. That is, each affinity value *Aff( w i , w j ) may be regarded as a coordinate for a particular dimension.
- Affinity vectors with similar affinity values indicate that the words with which the vectors are associated are close to each other in affinity space. That is, the vectors indicate that the words have similar affinity relationships with other words and thus may be suitable for membership in the same cluster.
- Affinity vectors may be similar if one affinity vector is proximate to the other affinity vector as determined by a suitable distance function.
- the distance function may be defined over the affinity vectors as, for example, the standard Euclidian distance for vectors of the given size, or as the cosine of vectors of the given size.
- the distance function may be designated by clustering engine 210 or by a user.
- clustering engine 210 applies a clustering algorithm to identify affinity vectors with values that are proximate to each other.
- clustering algorithms include direct, repeated bisection, agglomerative, biased agglomerative, and/or other suitable algorithms.
- clustering engine 210 may include clustering software, such as CLUTO.
- Clustering analyzer 214 may use affinity clustering for analysis in any suitable application.
- clustering analyzer 214 may use affinity clustering to categorize pages 50.
- a category may be associated with a cluster identifier or one or more members of a cluster.
- clusters of a page 50 may identified, and then the page 50 may be categorized according to the clusters.
- important words of a page 50 may be selected, and then clusters that include the words may be located. The page 50 may then be categorized according to the located clusters.
- clustering analyzer 214 may use affinity clustering to analyze corpuses of pages 50.
- a corpus may be associated with a particular subject matter, community of one or more individuals, organization, or other entity.
- clustering analyzer 214 may identify clusters of a corpus and determine a corpus character of the corpus from the clusters. The corpus character may indicate the words relevant to the entity associated with the corpus. If one or more pages 50 have clusters of the corpus character, the pages 50 may be relevant to the entity.
- clustering analyzer 214 may use affinity clustering for search query disambiguation and expansion.
- clustering analyzer 214 identifies clusters that include the search terms of a given search query. The clusters provide alternate words and/or categories relevant to the given search query.
- words from a cluster may be reported to a searcher to help with the next search query.
- clustering analyzer 214 may select words from the clusters and automatically form one or more new search queries. Clustering analyzer 214 may run the new queries in serial or parallel.
- clustering analyzer 214 may use affinity clustering to study a social network.
- pages 50 may provide insight into a social network. Examples of such pages include correspondence (such as letters, emails, and instant messages), memos, articles, and meeting minutes. These pages 50 may include words comprising user identifiers (such as names) of people of a social network. Clusters of names may be identified to analyze relationships among the people of the network. In one example, differential affinity clustering may be used to filter out names that appear most pages 50 without providing information, such as names of system administrators.
- clustering analyzer 214 may analyze data sets by combining and/or comparing the clusters of the data sets. In one embodiment, clusters of overlapping data sets are compared. Clusters from one data set may be mapped to clusters of the other data set, which may provide insight into the relationships between the data sets. For example, the data sets may be from an analysis of documents of a group of colleagues and from a social networking study of the group. A social network cluster may be mapped to a document subject matter cluster to analyze a relationship between the social network and the subject matter.
- a technical advantage of one embodiment may be that clusters of words are identified from the affinities between the words.
- a cluster includes words that are sufficiently affine with each other, where sufficient affinity is determined according to one or more affinity criteria.
- Another technical advantage of one embodiment may be that a clustering analysis may be performed. Examples of clustering analyses include categorizing a page according to the clusters of the page, determining a character of a corpus from the clusters of the corpus, and analyzing users based on the clusters in the users' documents.
- Certain embodiments of the invention may include none, some, or all of the above technical advantages.
- One or more other technical advantages may be readily apparent to one skilled in the art from the figures, descriptions, and claims included herein.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US97781107P | 2007-10-05 | 2007-10-05 | |
| US12/242,957 US8108392B2 (en) | 2007-10-05 | 2008-10-01 | Identifying clusters of words according to word affinities |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| EP2045736A1 true EP2045736A1 (de) | 2009-04-08 |
Family
ID=40184927
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP08165809A Ceased EP2045736A1 (de) | 2007-10-05 | 2008-10-03 | Erkennung von Wortgruppen nach Wortähnlichkeiten |
Country Status (1)
| Country | Link |
|---|---|
| EP (1) | EP2045736A1 (de) |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1705645A2 (de) * | 2005-03-21 | 2006-09-27 | AT&T Corp. | Vorrichtung und Verfahren zur Analyse von Sprachmodelländerungen |
-
2008
- 2008-10-03 EP EP08165809A patent/EP2045736A1/de not_active Ceased
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1705645A2 (de) * | 2005-03-21 | 2006-09-27 | AT&T Corp. | Vorrichtung und Verfahren zur Analyse von Sprachmodelländerungen |
Non-Patent Citations (5)
| Title |
|---|
| CHEN L ET AL: "Increasing the customer's choice: query expansion based on the layer-seeds method and its application in e-commerce", E-TECHNOLOGY, E-COMMERCE AND E-SERVICE, 2004. EEE '04. 2004 IEEE INTER NATIONAL CONFERENCE ON TAIPEI, TAIWAN 28-31 MARCH 2004, PISCATAWAY, NJ, USA,IEEE, 28 March 2004 (2004-03-28), pages 317 - 324, XP010697611, ISBN: 978-0-7695-2073-5 * |
| MOMTAZI S ET AL: "A POS-based fuzzy word clustering algorithm for continuous speech recognition systems", SIGNAL PROCESSING AND ITS APPLICATIONS, 2007. ISSPA 2007. 9TH INTERNATIONAL SYMPOSIUM ON, IEEE, PISCATAWAY, NJ, USA, 12 February 2007 (2007-02-12), pages 1 - 4, XP031280690, ISBN: 978-1-4244-0778-1 * |
| SCHUTZE H ET AL: "A cooccurrence-based thesaurus and two applications to information retrieval", INFORMATION PROCESSING & MANAGEMENT, ELSEVIER, BARKING, GB, vol. 33, no. 3, 1 May 1997 (1997-05-01), pages 307 - 318, XP004091803, ISSN: 0306-4573 * |
| SHUNTARO ISOGAI ET AL: "Multi-Class Composite N-gram Language Model Using Multiple Word Clusters and Word Successions", EUROSPEECH 2001, vol. 1, 2001, pages 25, XP007004901 * |
| TAMOTO M ET AL: "Clustering word category based on binomial posteriori co-occurrence distribution", ACOUSTICS, SPEECH, AND SIGNAL PROCESSING, 1995. ICASSP-95., 1995 INTER NATIONAL CONFERENCE ON DETROIT, MI, USA 9-12 MAY 1995, NEW YORK, NY, USA,IEEE, US, vol. 1, 9 May 1995 (1995-05-09), pages 165 - 168, XP010625195, ISBN: 978-0-7803-2431-2 * |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8108392B2 (en) | Identifying clusters of words according to word affinities | |
| US8543380B2 (en) | Determining a document specificity | |
| US8332439B2 (en) | Automatically generating a hierarchy of terms | |
| US8280886B2 (en) | Determining candidate terms related to terms of a query | |
| US8108405B2 (en) | Refining a search space in response to user input | |
| US9317593B2 (en) | Modeling topics using statistical distributions | |
| US8280892B2 (en) | Selecting tags for a document by analyzing paragraphs of the document | |
| US9081852B2 (en) | Recommending terms to specify ontology space | |
| US8171029B2 (en) | Automatic generation of ontologies using word affinities | |
| EP2045732A2 (de) | Bestimmung der Tiefen von Wörtern und Dokumenten | |
| EP2224361A1 (de) | Erstellung eines Domänencorpus und eines Wörterbuchs für automatische Ontologie | |
| EP2224360A1 (de) | Erstellung eines Wörterbuchs und Bestimmung des gemeinsamen Auftrittskontexts für automatische Ontologie | |
| US20170262528A1 (en) | System and method of content based recommendation using hypernym expansion | |
| US8554696B2 (en) | Efficient computation of ontology affinity matrices | |
| EP2090992A2 (de) | Bestimmung von Wörtern in Bezug auf einen vorgegebenen Satz von Wörtern | |
| EP2045736A1 (de) | Erkennung von Wortgruppen nach Wortähnlichkeiten |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MT NL NO PL PT RO SE SI SK TR |
|
| AX | Request for extension of the european patent |
Extension state: AL BA MK RS |
|
| 17P | Request for examination filed |
Effective date: 20091005 |
|
| AKX | Designation fees paid |
Designated state(s): DE FR GB |
|
| 17Q | First examination report despatched |
Effective date: 20130422 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: EXAMINATION IS IN PROGRESS |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN REFUSED |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN REFUSED |
|
| 18R | Application refused |
Effective date: 20180906 |