EP1542206A1 - Vorrichtung und Verfahren zur automatischen Klassifizierung von Audiosignalen - Google Patents
Vorrichtung und Verfahren zur automatischen Klassifizierung von Audiosignalen Download PDFInfo
- Publication number
- EP1542206A1 EP1542206A1 EP03028573A EP03028573A EP1542206A1 EP 1542206 A1 EP1542206 A1 EP 1542206A1 EP 03028573 A EP03028573 A EP 03028573A EP 03028573 A EP03028573 A EP 03028573A EP 1542206 A1 EP1542206 A1 EP 1542206A1
- Authority
- EP
- European Patent Office
- Prior art keywords
- audio
- class
- fragments
- audio signals
- signal
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 230000005236 sound signal Effects 0.000 title claims abstract description 209
- 238000000034 method Methods 0.000 title claims abstract description 54
- 239000012634 fragment Substances 0.000 claims abstract description 146
- 238000000638 solvent extraction Methods 0.000 claims abstract description 5
- 230000011218 segmentation Effects 0.000 claims description 43
- 238000004458 analytical method Methods 0.000 claims description 16
- 238000012549 training Methods 0.000 claims description 12
- 230000003595 spectral effect Effects 0.000 claims description 10
- 230000004907 flux Effects 0.000 claims description 7
- 239000000203 mixture Substances 0.000 claims description 7
- 238000003066 decision tree Methods 0.000 claims description 6
- 230000001537 neural effect Effects 0.000 claims description 6
- 238000012545 processing Methods 0.000 claims description 6
- 238000001228 spectrum Methods 0.000 claims description 6
- 230000000694 effects Effects 0.000 description 13
- 238000013459 approach Methods 0.000 description 12
- 238000010586 diagram Methods 0.000 description 6
- 230000009286 beneficial effect Effects 0.000 description 3
- 238000005192 partition Methods 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 238000001514 detection method Methods 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000013473 artificial intelligence Methods 0.000 description 1
- ZYXYTGQFPZEUFX-UHFFFAOYSA-N benzpyrimoxan Chemical compound O1C(OCCC1)C=1C(=NC=NC=1)OCC1=CC=C(C=C1)C(F)(F)F ZYXYTGQFPZEUFX-UHFFFAOYSA-N 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 230000015654 memory Effects 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 235000020030 perry Nutrition 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
Images

Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
Definitions
- the present invention relates to an apparatus and a method for automatic classification of audio signals comprising the combination of features of independent claims 1 and 12, respectively.
- Said self-contained activities / important events might be the different notices mentioned in a newsmagazine or different pieces of music reproduced in a radio show, for example. If the programme is a certain football match, for example, said self-contained activities / important events might be kick-off, penalty kick, throw-in etc..
- the traditional audio / video tape recorder sample playback mode for browsing and skimming an analogue audio / video signal is cumbersome and inflexible.
- the reason for this problem is that the signal is treated as a linear block of samples. No searching functionality (except fast forward and fast reverse) is provided.
- indexes either manually or automatically each time a recording operation is started to allow automatic recognition of certain sequences of video signals. It is a disadvantage with said indexes that the indexes are not adapted to individually identify a certain sequence of audio / video signals.
- digital audio / video discs contain digital data (digitised audio / video signals), wherein tracks or chapters are added to the digital data during the production of the digital disc.
- Said tracks / chapters normally allow identification of separate portions of data / the story line, only.
- said chapters do not allow identification of certain important events / contents (self-contained activities / events having a certain minimum importance) contained in the data.
- said tracks / chapters are not neutral since they are provided by the manufacturer of the digital disc.
- Possible application areas for such an automatic segmentation of audio / video signals are digital libraries or the Internet, for example.
- the known approaches for the segmentation process comprise fragmenting, automatic classification and automatic segmentation of the raw signals.
- Framing is performed to partition the raw signals into fragments of a suitable length for further processing.
- the fragments comprise a suitable amount of signals, each.
- the accuracy of the following classification and segmentation process is depending on the length of said fragments.
- Classification stands for a raw discrimination of the signals comprised in the fragments with respect to the origin of the signals (e.g. speech, music, noise, silence and gender of speaker). Classification usually is performed by signal analysis techniques based on audio class classifying models. Thus, classification results in a sequence of fragments, which are discriminated with respect to the origin of the signals comprised in the fragments.
- Segmentation stands for segmenting the raw signal into individual sequences of cohesive fragments wherein each sequence contains a content (self-contained activity of a minimum importance) included in the signals of said sequence. Segmentation can be performed based on content classifying rules.
- Each content comprises all the fragments, which belong to the respective self-contained activity comprised in the raw signal (e.g. a goal, a penalty kick of a football match or different news during a news magazine or different pieces of music of a music sampler).
- a goal e.g. a goal, a penalty kick of a football match or different news during a news magazine or different pieces of music of a music sampler.
- a segmentation apparatus 40 for automatic segmentation of audio signals according to the prior art is shown in Fig. 5.
- the segmentation apparatus 40 comprises audio signal input means 42 for supplying a raw audio signal 50 via an audio signal entry port 41.
- said raw audio signal 50 is part of a video signal stored in a suitable video format in a hard disc 48.
- said raw audio signal might be a real time signal (e.g. an audio signal of a conventional television channel), for example.
- the audio signals 50 supplied by the audio signal input means 42 are transmitted to audio signal fragmenting means 43.
- the audio signal fragmenting means 43 partitions the audio signals 50 (and the respective video signals) into audio fragments 51 (and corresponding video fragments) of a predetermined length.
- the audio fragments 51 generated by the audio signal fragmenting means 43 are further transmitted to classifying means 44.
- the classifying means 44 discriminates the audio clips 51 into predetermined audio classes 52 based on predetermined audio class classifying models by analysing acoustic characteristics of the audio signal 50 comprised in the audio fragments 51, whereby each audio class identifies a kind of audio signals included in the respective audio fragment.
- Each of the audio class classifying models allocates a combination of certain acoustic characteristics of an audio signal to a certain kind of audio signal.
- the acoustic characteristics for the audio class classifying model identifying the kind of audio signals "silence” are "low energy level” and "low zero cross rate” of the audio signal comprised in the respective audio clip, for example.
- an audio class and a corresponding audio class classifying model for each "silence” (class 1), "speech” (class 2), “cheering/clapping” (class 3) and “music” (class 4) are provided.
- Said audio class classifying models are stored in the classifying means 44.
- the audio clips 52 discriminated into audio classes by the classifying means 44 are supplied to segmenting means 45.
- a plurality of predetermined content classifying rules is stored in the segmenting means 45.
- Each content classifying rule allocates a certain sequence of audio classes of consecutive audio clips to a certain content / important event.
- a content classifying rule for each a "free kick” (content 1), a “goal” (content 2), a “foul” (content 3) and “end of game” (content 4) are provided.
- the contents comprised in the audio signals are composed of a sequence of consecutive audio fragments, each. This is visualised by the segmented signal 53 of Fig. 6.
- each audio fragment can be discriminated into an audio class each content / important event comprised in the audio signals is composed of a sequence of corresponding audio classes of consecutive audio fragments, too.
- the segmenting means 45 detects a rule that meets the respective sequence of audio classes.
- the content allocated to said rule is allocated to the respective sequence of consecutive audio fragments that belongs to the audio signals.
- the segmenting means 45 segments the classified audio signals provided by the discrimination means 44 into a sequence of contents 53 (self-contained activities).
- an output file generation means 46 is used to generate a video output file containing the audio signals 50, the corresponding video signals and information regarding the corresponding sequence of contents 53.
- Said output file is stored via a signal output port 47 into a hard disc 48.
- the video output files stored in the hard disc 48 can be played back.
- the video playback apparatus 49 is a digital video recorder which is further capable to extract or select individual contents comprised in the video output file based on the information regarding the sequence of contents 53 comprised in the video output file.
- segmentation of audio signals with respect to its contents / important events is performed by the segmentation apparatus 40 shown in Fig. 5.
- HIDDEN MARKOV MODEL A stochastic signal model frequently used with classification of audio signals / data is the HIDDEN MARKOV MODEL, which is explained in detail in the essay "A tutorial on Hidden Markov Models and Selected Applications in Speech Recognition” by Lawrence R. RABINER published in the Proceedings of the IEEE, Vol. 77, No.2, February 1989.
- a “model-based approach” where models for each audio class are created, the models being based on low level features of the audio data such as cepstrum and MFCC.
- a “metric-based segmentation approach” uses distances between neighbouring windows for segmentation.
- a “rule-based approach” comprises creation of individual rules for each class wherein the rules are based on high and low level features.
- a “decoder-based approach” uses the hidden Makrov model of a speech recognition system wherein the hidden Makrov model is trained to give the class of an audio signal.
- this paper describes in detail speech, music and silence properties to allow generation of rules describing each class according to the "rule based approach" as well as gender detection to detect the gender of a speech signal.
- the audio data is divided into a plurality of clips, each clip comprising a plurality of frames.
- a set of low level audio features comprising analysis of volume contour, pitch contour and frequency domain features as bandwidth are proposed for classification of the audio data contained in each clip.
- a "low-level acoustic characteristics layer” low level generic features such as loudness, pitch period and bandwidth of an audio signal are analysed.
- an “intermediate-level acoustic signature layer” the object that produces a particular sound is determined by comparing the respective acoustic signal with signatures stored in a database.
- some ⁇ priori known semantic rules about the structure of audio in different scene types e.g. only speech in news reports and weather forecasts; speech together with noisy background in commercials
- sequences of audio classes of consecutive audio clips are used.
- a suitable number of consecutive audio clips e.g. 4 is allocated to a segment comprising one important event (e.g. "goal").
- the patent US 6,185,527 discloses a system and method for indexing an audio stream for subsequent information retrieval and for skimming, gisting and summarising the audio stream.
- the system and method includes use of special audio prefiltering such that only relevant speech segments that are generated by a speech recognition engine are indexed. Specific indexing features are disclosed that improve the precision and recall of an information retrieval system used after indexing for word spotting.
- the described method includes rendering the audio stream into intervals, with each interval including one or more segments. For each segment of an interval it is determined whether the segment exhibits one or more predetermined audio features such as a particular range of zero crossing rates, a particular range of energy, and a particular range of spectral energy concentration.
- the audio features are heuristically determined to represent respective audio events, including silence, music, speech, and speech on music. Also, it is determined whether a group of intervals matches a heuristically predefined meta pattern such as continuous uninterrupted speech, concluding ideas, hesitations and emphasis in speech, and so on, and the audio stream is then indexed based on the interval classification and meta pattern matching, with only relevant features being indexed to improve subsequent precision of information retrieval. Also, alternatives for longer terms generated by the speech recognition engine are indexed along with respective weights, to improve subsequent recall.
- Don KIMBER and Lynn WILCOX describe algorithms, which generate indices from automatic acoustic segmentation, in the essay "Acoustic Segmentation for Audio Browsers". These algorithms use hidden Markov models to segment audio into segments corresponding to different speakers or acoustic classes. Types of proposed acoustic classes include speech, silence, laughter, non-speech sounds and garbage, wherein garbage is defined as non-speech sound not explicitly modelled by the other class models.
- Music is a very general term that covers a huge variety of audio signals such as different instrumental sounds, singing voice with instrumental sound and also pure singing voice although in real life application, pure singing voice is not common.
- a robust speech/music classification should be able to distinguish speech from music regardless of the type of music, i.e. pure instrumental sound, singing voice etc..
- state-of-the-art speech/music classification system usually fail to classify an audio signal containing music correctly when there is only a singing voice, or a dominant singing voice in the signal.
- an apparatus for automatic classification of audio signals comprises signal input means for supplying audio signals, audio signal fragmenting means for partitioning audio signals supplied by the signal input means into audio fragments of a predetermined length, feature extracting means for analysing acoustic characteristics of the audio signals comprised in the audio fragments and classifying means for discriminating the audio fragments provided by the audio signal fragmenting means into a predetermined audio class based on predetermined audio class classifying models by using acoustic characteristics of the audio signals comprised in the audio fragments, wherein a predetermined audio class classifying model is provided for each audio class and each audio class represents a respective kind of audio signals comprised in the corresponding audio fragment, wherein an individual predetermined audio class classifying model is provided for at least each audio class "speech", "music” and "singing voice".
- an audio class classifying model specialised in singing voice included in the raw audio signal is provided.
- a singing voice can be identified in a raw audio signal with high accuracy.
- the inventive apparatus for automatic classification of audio signals further comprises a classifier database comprising the predetermined audio class classifying models, wherein the classifying means discriminates the audio fragments provided by the audio signal fragmenting means into predetermined audio classes based on the audio class classifying models stored in the classifier database.
- a classifier database comprising audio class classifying models
- audio class classifying models that are specialised (trained) for a certain kind of audio signal might be used.
- the usage of specialised audio class classifying models significantly enhances accuracy of the classification of the audio signals.
- the classifying means further allocates audio fragments discriminated into the audio class "singing voice" to the audio class "music".
- the accuracy of the inventive apparatus is significantly enhanced by further discriminating audio fragments allocated to the audio class "speech" into the audio classes "speech" and "singing voice".
- the acoustic characteristics analysed in the audio signals comprised in the audio fragments by the feature extracting means include volume standard deviation and/or volume dynamic range and/or high zero crossing rate ratio and/or low short-term energy ratio and/or spectral flux and/or zero crossing rate and/or energy/loudness and/or sub-band energy rate and/or mel-cepstral frequency components and/or frequency centroid and/or bandwidth and/or line spectrum frequencies and/or roll-off.
- the audio class classifying models are provided as hidden Markov models and/or Neuronal Networks and/or Gaussian Mixture Models and/or decision trees.
- the audio class model for the audio class "singing voice" is trained by a training audio signal comprising pure singing voice, only.
- a suitable audio class model for the audio class "singing voice" can be achieved in a very easy and reliable way.
- the apparatus for automatic classification of audio signals further comprises segmentation means for segmenting classified audio signals into individual audio windows consisting of sequences of cohesive audio fragments based on predetermined content classifying rules by analysing a sequence of audio classes of cohesive audio fragments provided by the classifying means, wherein each sequence of cohesive audio fragments segmented by the segmentation means corresponds to an individual content included in the audio signal.
- the segmentation means allocates a predefined number of audio fragments to an audio window, determines the number of audio fragments of each audio class comprised in the audio window and allocates the majority audio class to the respective audio window.
- the allocation of audio classes in the audio window is used to segment the audio signal.
- Complicated content classifying rules can be avoided.
- each audio fragment generated by the audio signal fragmenting means corresponds to a frame consisting of a predefined number N of signal samples.
- the inventive apparatus for automatic classification of audio signals further comprises signal output means for generating an output file, wherein the output file contains the raw audio signal supplied to the signal input means and an information signal comprising information regarding to the audio classes and / or the audio windows and / or contents included in the raw signal.
- Provision of such an information signal allows a distinct identification of the audio classes and audio windows extracted from the raw audio signals.
- Search engines and signal playback means can handle such an output file with ease. Therefore, a research for an audio window of a certain content comprised in the output file can be performed with ease.
- the method further comprises the step of providing a classifier database comprising the predetermined audio class classifying models, wherein the step of discriminating the audio fragments into a predetermined audio class is performed by using the audio class classifying models stored in the classifier database.
- the method further comprises the step of allocating the audio fragments discriminated into the audio class "singing voice" to the audio class "music".
- the method further comprises the step of discriminating the audio fragments allocated to the audio class "speech" into the audio classes "speech" and "singing voice".
- the step of analysing acoustic characteristics in the audio signals comprised in the audio fragments includes analysis of volume standard deviation and/or volume dynamic range and/or high zero crossing rate ratio and/or low short-term energy ratio and/or spectral flux and/or zero crossing rate and/or energy/loudness and/or sub-band energy rate and/or mel-cepstral frequency components and/or frequency centroid and/or bandwidth and/or line spectrum frequencies and/or roll-off.
- the audio class classifying models are provided as hidden Markov models and/or Neuronal Networks and/or Gaussian Mixture Models and/or decision trees.
- the method further comprises the step of training the audio class model for the audio class "singing voice" by a training audio signal comprising pure singing voice, only.
- the method further comprises the steps of analysing a sequence of audio classes of cohesive audio fragments and segmenting classified audio signals into individual audio windows consisting of sequences of cohesive audio fragments based on predetermined content classifying rules by using the analyses of said sequence of audio classes of cohesive audio fragments, wherein each sequence of cohesive audio fragments corresponds to an individual content included in the audio signal.
- the method further comprises the steps of allocating a predefined number of audio fragments to an audio window, determining the number of audio fragments of each audio class comprised in the audio window and allocating the majority audio class to the respective audio window.
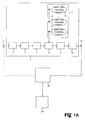
- Fig. 1A shows a block diagram of an apparatus for automatic classification of audio signals according to the one preferred embodiment of the present invention.
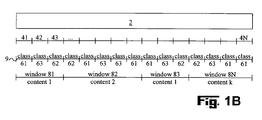
- Fig. 1B schematically shows the effect the inventive apparatus for automatic classification of audio signals has on audio signals.
- a raw audio signal 2 is supplied via an input port 12 to signal input means 3 of the inventive apparatus 1 for automatic classification of audio signals.
- the raw audio signal 2 provided to the signal input means 3 is a digital video data file which is stored on a suitable recording medium 48 (e.g. a hard disc or a digital video disc).
- a suitable recording medium 48 e.g. a hard disc or a digital video disc.
- the digital video data file is composed of at least an audio signal and a picture signal and an information signal.
- the raw signals 2 provided to the signal input means 3 might be real time video signals of a conventional television channel or audio signals of a radio broadcasting station.
- the inventive apparatus 1 for automatic classification of audio signals is included into a digital video recorder, which is not shown in the figures.
- the apparatus for automatic classification of audio signals might be included in a different digital audio / video apparatus, such as a personal computer or workstation or might even be provided as a separate equipment (e.g. a top set box).
- the signal input means 3 converts the raw signals 2 into a suitable format.
- Audio signals comprised in the raw signal 2 provided to signal input means 3 via the input port 12 are read out by the signal input means 3 and transmitted to audio signal fragmenting means 4.
- the audio signal fragmenting means 4 partitions said audio signals 2 into audio fragments 41, 42, 43, ..., 4N of a predetermined length.
- Said audio fragments 41, 42, 43, ..., 4N preferably are the smallest unit of audio signal analysis, respectively.
- one audio fragment comprises one frame of audio (video) signals and is about 10 milliseconds in length.
- the audio fragments alternatively might comprise more than one frame of audio (video) signals.
- one frame might comprise more or less than 10 milliseconds of audio signals (preferably between 4 and 20 milliseconds of audio signals, e.g. 6, 8, 12 or 14 milliseconds of audio signals).
- more than one frame is comprised in an audio fragment.
- the audio signals comprised in each audio fragment might be further divided into a plurality of frames of e.g. 512 samples. In this case it is profitable if consecutive frames are shifted by 180 samples with respect to the respective antecedent frame. This subdivision allows a precise and easy processing of the audio signals comprised in each audio fragment.
- the audio signal fragmenting means 4 do not necessarily subdivide the audio signals 2 into audio fragments 41, 42, 43, ..., 4N in a literal sense.
- the audio signal fragmenting means 4 defines fragments of audio signals comprising a suitable amount of audio signals within the audio signals, only.
- the audio signal fragmenting means 4 generates a meta data file defining audio fragments 41, 42, 43, ..., 4N in the audio signal 2 while the audio signal itself remains unamended.
- the audio fragments defined by the audio signal fragmenting means 4 are transmitted to feature extracting means 5.
- the feature extracting means 5 analyses acoustic characteristics of audio signals comprised in the audio fragments 41, 42, 43,..., 4N.
- volume standard deviation and volume dynamic range and high zero crossing rate ratio and low short-term energy ratio and spectral flux and zero crossing rate and energy/loudness and sub-band energy rate and mel-cepstral frequency components and frequency centroid and bandwidth and line spectrum frequencies and roll-off of the signals comprised in the audio fragments 41, 42, 43, ..., 4N are analysed by the feature extracting means 5.
- the acoustic characteristics of audio signals comprised in the audio fragments 41, 42, 43, ..., 4N are output to classifying means 6 by the feature extracting means 5.
- the classifying means 6 automatically discriminates the audio fragments 41, 42, 43 provided by the audio signal fragmenting means 4 into a predetermined audio class 61, 62, 63 by using the acoustic characteristics of the audio signals comprised in the audio fragments 41, 42, 43 analysed by the feature extracting means 5.
- Each audio class 61, 62, 63 represents a respective kind of audio signals comprised in the corresponding audio fragment 41, 42, 43.
- Discrimination is performed by the classifying means 6 based on predetermined audio class classifying models 71, 72, 73 which are stored in a classifier database 7.
- a predetermined audio class classifying model 71, 72, 73 is provided in the classifier database 7 for each audio class 61, 62, 63.
- an individual predetermined audio class classifying model 71, 72, 73 is provided for at least each audio class 61, 62, 63 "speech", "music” and “singing voice”.
- the audio class 63 "singing voice” alternatively might be referred to as "a capella music”.
- an audio class classifying model 73 specialised in singing voice included in the raw audio signal is provided.
- a singing voice can be identified in a raw audio signal 2 with high accuracy.
- a classifier database 7 comprising audio class classifying models 71, 72, 73
- audio class classifying models 71, 72, 73 that are specialised (trained) for a certain kind of audio signal 2 might be used.
- the usage of specialised audio class classifying models 71, 72, 73 significantly enhances accuracy of the classification of the audio signals 2.
- the predetermined audio class classifying models 71, 72, 73 are stored in the classifier database 7 as Gaussian Mixture Models (GMM).
- GMM Gaussian Mixture Models
- the audio class classifying models might even be provided e.g. as Neuronal Networks and/or hidden Markov models and/or decision trees.
- the audio class model 73 for the audio class 63 "singing voice” is trained by a training audio signal comprising pure singing voice, only.
- training is performed by analysing a plurality of raw signals consisting of "singing voice", only, and varying parameters of the audio class model 73 for the audio class "singing voice” till a satisfying accuracy for a correct identification of "singing voice” in the raw signal is achieved by the audio class model 73.
- the training signal might be provided by a large database (not shown in the Figures).
- the audio class models are Gaussian Mixture Models (GMM)
- GMM Gaussian Mixture Models
- pdf Gaussian probability density functions
- Component Gaussians can have full or diagonal covariance matrices.
- GMM parameters such as individual Gaussians and their weight factors are tuned to suit the training signals.
- a GMM can approximate well any continuous pdfs.
- the dimensions of the component Gaussians depend on the parametrization of the underlying acoustic signal.
- MFCC Mel Frequency Cepstral Coefficients
- said classifier database 7 is a convention hard disc.
- EEPROM electrically erasable programmable read-only memory
- FLASH-memory might be used.
- the discrimination of the audio fragments 41, 42, 43 is not necessarily performed in a literal sense, but might be performed e.g. by automatically generating a meta file (information signal) dedicated to the (raw) audio signal 2, the meta file comprising e.g. pointers to identify the audio fragments 41, 42, 43 and the corresponding audio classes 61, 62, 63 in the audio signal 2.
- said pointers contained in the meta file identify both the location and the audio class 61, 62, 63 of the fragments 41, 42, 43 comprised in the audio signals 2.
- the classifying means 6 allocates audio fragments 41, 42, 43 discriminated into the audio class 63 "singing voice" to the audio class 62 "music".
- the audio fragments allocated to the audio class 61 "speech” are further discriminated into the audio classes 61 “speech” and 63 “singing voice” to increase the accuracy of the inventive apparatus 1.
- a "singing voice” comprised in an audio signal 2 is very similar to the audio signal "speech”.
- a signal that seems to contain "speech” has to be further examined to detect whether the pretended "speech” is real “speech” or indeed a "singing voice”.
- the classified audio fragments 9 are transmitted to a segmentation means 8.
- Said segmentation means 8 segments the classified audio signals 9 into individual audio windows 81, 82, 83 consisting of sequences of cohesive audio fragments 41, 42, 43 based on predetermined content classifying rules by analysing a sequence of audio classes 61, 62, 63 of cohesive audio fragments 41, 42, 43 provided by the classifying means 6.
- Each sequence of cohesive audio fragments 41, 42, 43 segmented by the segmentation means 8 corresponds to an individual content included in the audio signal 2.
- Contents are self-contained activities comprised in the audio signals of a certain programme that meet a certain minimum importance.
- each content comprises a certain individual number of cohesive audio fragments 41, 42, 43.
- the contents are the different notices mentioned in the news. If the programme is football, for example, said contents are kick-off, penalty kick, throw-in, goal, etc. If the programme is a music sampler, said contents are the individual pieces of music, for example.
- the contents comprised in the audio signal are composed of a sequence of consecutive audio fragments 41, 42, 43, each. Since each audio fragment 41, 42, 43 is discriminated into an audio class 61, 62, 63 each content is composed of a sequence of corresponding audio classes 61, 62, 63 of consecutive the audio fragments 41, 42, 43, too.
- the sequence of audio classes of cohesive audio fragments 41, 42, 43 for the content classifying rule identifying the content "goal” might be "speech” 61, "singing voice” 63 and "music” 62.
- the segmentation means 8 allocates a predefined number of audio fragments 41, 42, 43, ..., 4N to an audio window 81, 82, 83, ..., 8N determines the number of audio fragments 41, 42, 43, ..., 4N of each audio class 61, 62, 63 comprised in the audio window and allocates the majority audio class to the respective audio window.
- the allocation of audio classes 61, 62, 63 in the audio window 81, 82, 83 is used to segment the audio signal. In consequence, complicated content classifying rule can be avoided.
- an audio window 8N comprises a sequence of audio fragments 4N-3, 4N-2, 4N-1, 4N of the audio classes 62, 63, 61, 61 the audio class 61 automatically will be determined as being the majority audio class by the segmentation means 8.
- the audio class 61 automatically will be allocated by the segmentation means 8 to the respective audio window 8N as content k (see Fig. 1B).
- the inventive apparatus 1 for automatic classification of audio signals 2 comprises signal output means 10.
- Said signal output means 10 automatically generates an output file 11 containing the raw signal 2 supplied by the signal input means 3 and an information signal (meta file) comprising information regarding to the fragments, audio classes, windows and contents included in the raw signal 2.
- Search engines and signal playback means can handle a correspondingly processed signal 11 with ease. Therefore, a research for the audio classes and contents comprised in the output file 11 is facilitated.
- the output file 11 is output by the signal output means 10 via an output port 13.
- the signal output via said output port 13 might be stored into a suitable recording medium 48 which might be a conventional hard disc or optical disc, for example.
- audio signals 2 automatically are partitioned into audio fragments 41, 42, 43 of a predetermined length.
- the length of the fragments 41, 42, 43 is one frame, each.
- step S2 acoustic characteristics of the audio signals comprised in the audio fragments 41, 42, 43 are analysed.
- Said acoustic characteristics include volume standard deviation and/or volume dynamic range and/or high zero crossing rate ratio and/or low short-term energy ratio and/or spectral flux and/or zero crossing rate and/or energy/loudness and/or sub-band energy rate and/or mel-cepstral frequency components and/or frequency centroid and/or bandwidth and/or line spectrum frequencies and/or roll-off.
- a classifier database 7 containing predetermined audio class classifying models 71, 72, 73 is provided in the following method step S4.
- a predetermined audio class classifying model 71, 72, 73 is provided for each audio class 61, 62, 63 and each audio class 61, 62, 63 represents a respective kind of audio signals comprised in the corresponding audio fragment 41, 42, 43 of the raw audio signal 2.
- an individual predetermined audio class classifying model 71, 72, 73 for at least each audio class 61, 62, 63 "speech", "music” and “singing voice” is provided.
- the audio class classifying models 71, 72, 73 are provided as hidden Markov models. Alternatively Neuronal Networks or Gaussian Mixture Models or decision trees might be used.
- the audio class model 73 for the audio class 63 "singing voice” has been trained by a training audio signal consisting of pure singing voice, only.
- the audio fragments 41, 42, 43 are discriminated into predetermined audio classes 61, 62, 63 based on predetermined audio class classifying models 71, 72, 73 stored in the classifier database 7 that has been provided in method step S4.
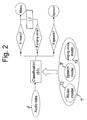
- step S3 In case an audio fragment 41, 42, 43 is discriminated in step S3 into the audio class 63 "singing voice", said audio fragment 41, 42, 43 is further allocated to the audio class 62 "music" in the following step S5 as it is shown in Fig. 2.
- step S3 in case an audio fragment 41, 42, 43 is discriminated in step S3 into the audio class 61 "speech", said audio fragment 41, 42, 43 is further discriminated into the audio classes 61 "speech” and 63 "singing voice” in the following step S6 as it is shown in Fig. 3.
- a sequence of audio classes 61, 62, 63 of cohesive audio fragments 41, 42, 43 is analysed in the following method step S8.
- step S9 classified audio signals 9 provided by method steps S3, S5 and S6 are segmented into individual audio windows 81, 82, 83 consisting of sequences of cohesive audio fragments 41, 42, 43 based on predetermined content classifying rules. Said segmentation is performed by using the sequence of audio classes 61, 62, 63 of cohesive audio fragments 41, 42, 43 analysed in method step S8. Each sequence of cohesive audio fragments 41, 42, 43 corresponds to an individual content included in the audio signal.
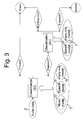
- said segmentation might be performed as follows:
- a predefined number of audio fragments 41, 42, 43 is allocated to an audio window 81, 82, 83.
- a second sub-step S11 the number of audio fragments 41, 42, 43 of each audio class 61, 62, 63 comprised in the audio window 81, 82, 83 is determined.
- a third sub-step S12 the majority audio class 61, 62, 63 is allocated to the respective audio window 81, 82, 83.
- a segmented audio signal is provided (see Fig. 4).
- a Viterbi algorithm is used for step 9 of segmenting classified audio signals.
- the steps S3, S5 and S6 of discriminating audio fragments and the steps S8 and S9 of analysing a sequence of audio classes and segmenting classified audio signals are combined into a joint optimisation of the best state sequence of audio fragments that explains the observation with the highest possible likelihood, given the model.
- one single microcomputer might be used to incorporate the signal input means, the audio signal fragmenting means, the feature extracting means, the classifying means, the segmentation means and the signal output means.
- the signal input means and the signal output means might be incorporated in one common microcomputer and the audio signal fragmenting means, the feature extracting means, the classifying means and the segmentation means might be incorporated in another common microcomputer.
- the inventive apparatus for automatic classification of audio signals might be integrated into a digital audio / video recorder or top set box or realised by use of a conventional personal computer or workstation.
- the above object is solved by a software product comprising a series of state elements that are adapted to be processed by a data processing means of a terminal such, that a method according to one of the claims 12 to 20 may be executed thereon.
- Said terminal might be a personal computer or video recording/reproducing apparatus, for example.
- the inventive apparatus and method for automatic classification of audio signals uses an easy and reliable way for classification of audio signals comprising a singing voice.
- an audio class classifying model specialised in singing voice included in the raw audio signal is provided.
- singing voice can be identified in a raw audio signal with high accuracy.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP03028573A EP1542206A1 (de) | 2003-12-11 | 2003-12-11 | Vorrichtung und Verfahren zur automatischen Klassifizierung von Audiosignalen |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP03028573A EP1542206A1 (de) | 2003-12-11 | 2003-12-11 | Vorrichtung und Verfahren zur automatischen Klassifizierung von Audiosignalen |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| EP1542206A1 true EP1542206A1 (de) | 2005-06-15 |
Family
ID=34486191
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP03028573A Withdrawn EP1542206A1 (de) | 2003-12-11 | 2003-12-11 | Vorrichtung und Verfahren zur automatischen Klassifizierung von Audiosignalen |
Country Status (1)
| Country | Link |
|---|---|
| EP (1) | EP1542206A1 (de) |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2007003505A1 (fr) * | 2005-07-01 | 2007-01-11 | France Telecom | Procédé et dispositif de segmentation et de labellisation du contenu d'un signal d'entrée se présentant sous la forme d'un flux continu de données d'entrée indifférenciées. |
| EP1847937A1 (de) * | 2006-04-21 | 2007-10-24 | CyberLink Corp. | System und Verfahren zur Erkennung interessanter Szenen in Sportvideos |
| WO2011007330A2 (en) * | 2009-07-15 | 2011-01-20 | Vijay Sathya | System and method of determining the appropriate mixing volume for an event sound corresuponding to an impact related event and determining the enhanced event audio |
| WO2011061361A2 (es) * | 2009-11-18 | 2011-05-26 | Universidad Carlos Iii De Madrid | Sistema y procedimiento de producción sonora multimicrofónica |
| CN104867492A (zh) * | 2015-05-07 | 2015-08-26 | 科大讯飞股份有限公司 | 智能交互系统及方法 |
| US9842605B2 (en) | 2013-03-26 | 2017-12-12 | Dolby Laboratories Licensing Corporation | Apparatuses and methods for audio classifying and processing |
| US10678828B2 (en) | 2016-01-03 | 2020-06-09 | Gracenote, Inc. | Model-based media classification service using sensed media noise characteristics |
| CN111768801A (zh) * | 2020-06-12 | 2020-10-13 | 瑞声科技(新加坡)有限公司 | 气流杂音消除方法、装置、计算机设备及存储介质 |
| CN111986655A (zh) * | 2020-08-18 | 2020-11-24 | 北京字节跳动网络技术有限公司 | 音频内容识别方法、装置、设备和计算机可读介质 |
| CN112400325A (zh) * | 2018-06-22 | 2021-02-23 | 巴博乐实验室有限责任公司 | 数据驱动的音频增强 |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2001016937A1 (en) * | 1999-08-30 | 2001-03-08 | Wavemakers Research, Inc. | System and method for classification of sound sources |
| US20020163533A1 (en) * | 2001-03-23 | 2002-11-07 | Koninklijke Philips Electronics N.V. | Synchronizing text/visual information with audio playback |
-
2003
- 2003-12-11 EP EP03028573A patent/EP1542206A1/de not_active Withdrawn
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2001016937A1 (en) * | 1999-08-30 | 2001-03-08 | Wavemakers Research, Inc. | System and method for classification of sound sources |
| US20020163533A1 (en) * | 2001-03-23 | 2002-11-07 | Koninklijke Philips Electronics N.V. | Synchronizing text/visual information with audio playback |
Non-Patent Citations (2)
| Title |
|---|
| WU CHOU ET AL: "Robust singing detection in speech/music discriminator design", 2001 IEEE INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH, AND SIGNAL PROCESSING. PROCEEDINGS (CAT. NO.01CH37221), 2001 IEEE INTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH, AND SIGNAL PROCESSING. PROCEEDINGS, SALT LAKE CITY, UT, USA, 7-11 MAY 2001, 2001, Piscataway, NJ, USA, IEEE, USA, pages 865 - 868 vol.2, XP002278343, ISBN: 0-7803-7041-4 * |
| ZHANG T ET AL: "Audio content analysis for online audiovisual data segmentation and classification", IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, IEEE INC. NEW YORK, US, vol. 9, no. 4, May 2001 (2001-05-01), pages 441 - 457, XP001164214, ISSN: 1063-6676 * |
Cited By (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2007003505A1 (fr) * | 2005-07-01 | 2007-01-11 | France Telecom | Procédé et dispositif de segmentation et de labellisation du contenu d'un signal d'entrée se présentant sous la forme d'un flux continu de données d'entrée indifférenciées. |
| EP1847937A1 (de) * | 2006-04-21 | 2007-10-24 | CyberLink Corp. | System und Verfahren zur Erkennung interessanter Szenen in Sportvideos |
| US8068719B2 (en) | 2006-04-21 | 2011-11-29 | Cyberlink Corp. | Systems and methods for detecting exciting scenes in sports video |
| WO2011007330A2 (en) * | 2009-07-15 | 2011-01-20 | Vijay Sathya | System and method of determining the appropriate mixing volume for an event sound corresuponding to an impact related event and determining the enhanced event audio |
| WO2011007330A3 (en) * | 2009-07-15 | 2011-03-31 | Vijay Sathya | System and method of determining the appropriate mixing volume for an event sound corresuponding to an impact related event and determining the enhanced event audio |
| US9426405B2 (en) | 2009-07-15 | 2016-08-23 | Vijay Sathya | System and method of determining the appropriate mixing volume for an event sound corresponding to an impact related events and determining the enhanced event audio |
| WO2011061361A2 (es) * | 2009-11-18 | 2011-05-26 | Universidad Carlos Iii De Madrid | Sistema y procedimiento de producción sonora multimicrofónica |
| ES2359902A1 (es) * | 2009-11-18 | 2011-05-30 | Manuel Universidad Carlos Iii De Madrid | Sistema y procedimiento de producción sonora multimicrofónica con seguimiento y localización de puntos de interés en un escenario. |
| WO2011061361A3 (es) * | 2009-11-18 | 2011-07-14 | Universidad Carlos Iii De Madrid | Sistema y procedimiento de producción sonora multimicrofónica |
| US10803879B2 (en) | 2013-03-26 | 2020-10-13 | Dolby Laboratories Licensing Corporation | Apparatuses and methods for audio classifying and processing |
| US9842605B2 (en) | 2013-03-26 | 2017-12-12 | Dolby Laboratories Licensing Corporation | Apparatuses and methods for audio classifying and processing |
| CN104867492A (zh) * | 2015-05-07 | 2015-08-26 | 科大讯飞股份有限公司 | 智能交互系统及方法 |
| CN104867492B (zh) * | 2015-05-07 | 2019-09-03 | 科大讯飞股份有限公司 | 智能交互系统及方法 |
| US10678828B2 (en) | 2016-01-03 | 2020-06-09 | Gracenote, Inc. | Model-based media classification service using sensed media noise characteristics |
| US10902043B2 (en) | 2016-01-03 | 2021-01-26 | Gracenote, Inc. | Responding to remote media classification queries using classifier models and context parameters |
| CN112400325A (zh) * | 2018-06-22 | 2021-02-23 | 巴博乐实验室有限责任公司 | 数据驱动的音频增强 |
| CN111768801A (zh) * | 2020-06-12 | 2020-10-13 | 瑞声科技(新加坡)有限公司 | 气流杂音消除方法、装置、计算机设备及存储介质 |
| CN111986655A (zh) * | 2020-08-18 | 2020-11-24 | 北京字节跳动网络技术有限公司 | 音频内容识别方法、装置、设备和计算机可读介质 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP1531458B1 (de) | Vorrichtung und Verfahren zur automatischen Extraktion von wichtigen Ereignissen in Audiosignalen | |
| EP1531478A1 (de) | Vorrichtung und Verfahren zur Klassifizierung eines Audiosignals | |
| US7058889B2 (en) | Synchronizing text/visual information with audio playback | |
| Tzanetakis et al. | Marsyas: A framework for audio analysis | |
| Kos et al. | Acoustic classification and segmentation using modified spectral roll-off and variance-based features | |
| US7521622B1 (en) | Noise-resistant detection of harmonic segments of audio signals | |
| US20100121637A1 (en) | Semi-Automatic Speech Transcription | |
| CN101685446A (zh) | 音频数据分析装置和方法 | |
| US20050228649A1 (en) | Method and apparatus for classifying sound signals | |
| KR20030070179A (ko) | 오디오 스트림 구분화 방법 | |
| Nwe et al. | Automatic Detection Of Vocal Segments In Popular Songs. | |
| US7962330B2 (en) | Apparatus and method for automatic dissection of segmented audio signals | |
| Jiang et al. | Video segmentation with the support of audio segmentation and classification | |
| KR20050082757A (ko) | 앵커 샷 검출 방법 및 장치 | |
| EP1542206A1 (de) | Vorrichtung und Verfahren zur automatischen Klassifizierung von Audiosignalen | |
| Jiang et al. | Video segmentation with the assistance of audio content analysis | |
| EP1531457B1 (de) | Vorrichtung und Verfahren zur Segmentation von Audiodaten in Metamustern | |
| Baillie et al. | An audio-based sports video segmentation and event detection algorithm | |
| Bugatti et al. | Audio classification in speech and music: a comparison between a statistical and a neural approach | |
| Zhang et al. | System and method for automatic singer identification | |
| Nitanda et al. | Accurate audio-segment classification using feature extraction matrix | |
| Razik et al. | Comparison of two speech/music segmentation systems for audio indexing on the web | |
| Nitanda et al. | Audio signal segmentation and classification using fuzzy c‐means clustering | |
| Tzanetakis et al. | Building audio classifiers for broadcast news retrieval | |
| Chaisorn et al. | Two-level multi-modal framework for news story segmentation of large video corpus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HU IE IT LI LU MC NL PT RO SE SI SK TR |
|
| AX | Request for extension of the european patent |
Extension state: AL LT LV MK |
|
| AKX | Designation fees paid | ||
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION IS DEEMED TO BE WITHDRAWN |
|
| 18D | Application deemed to be withdrawn |
Effective date: 20051216 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: 8566 |