EP1334485B1 - Speech codec and method for generating a vector codebook and encoding/decoding speech signals - Google Patents
Speech codec and method for generating a vector codebook and encoding/decoding speech signals Download PDFInfo
- Publication number
- EP1334485B1 EP1334485B1 EP01993000A EP01993000A EP1334485B1 EP 1334485 B1 EP1334485 B1 EP 1334485B1 EP 01993000 A EP01993000 A EP 01993000A EP 01993000 A EP01993000 A EP 01993000A EP 1334485 B1 EP1334485 B1 EP 1334485B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- speech
- vector
- codebook
- embedded
- speech signal
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images


Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/06—Determination or coding of the spectral characteristics, e.g. of the short-term prediction coefficients
- G10L19/07—Line spectrum pair [LSP] vocoders
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L2019/0001—Codebooks
- G10L2019/0004—Design or structure of the codebook
- G10L2019/0005—Multi-stage vector quantisation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L2019/0001—Codebooks
- G10L2019/0007—Codebook element generation
Definitions
- This invention relates to speech coding and methods of optimising the performance of speech codecs in communications systems.
- the invention is applicable to, but not limited to, speech codecs that accommodate wideband and narrowband speech signals without compromising the overall performance of the speech codec quantiser.
- GSM global system for mobile communications
- TETRA TErrestrial Trunked RAdio
- a primary objective in the use of speech coding techniques is to reduce the occupied capacity of the speech patterns as much as possible, by use of compression techniques, without losing fidelity.
- VQ vector quantisation
- the process of vector quantisation is to represent an input vector as a member of a set of fixed vectors.
- This set of fixed vectors is known as the VQ codebook.
- the fixed vector in the VQ codebook which best represents the input vector is found by exhaustively searching all members of the VQ codebook and selecting the fixed vector which gives the minimum distance measure (or Euclidean distance) between it and the input vector.
- VQ has been shown to be very attractive and efficient in many areas of speech coding, it is not without its drawbacks.
- Wideband speech codecs are likely to find application in telephone conferencing.
- Wideband speech codecs have an input speech bandwidth covering the 50Hz to 7KHz range, compared to narrowband or telephone-band codecs that have an input speech bandwidth of 250Hz to 3.3KHz.
- Tandemming is a term which is used to describe the situation where speech previously processed by one speech encoder/decoder is processed by a second speech encoder/decoder pair.
- the speech quality requirement of such tandemmed codecs is to achieve equivalence to the best narrowband codecs i.e. GSM Enhanced full-rate codec (EFR). It is therefore appropriate to consider the performance of any wideband line spectral frequency (LSF) VQ scheme in the presence of narrowband speech.
- GSM Global System for Mobile communications
- one option may be to use a classified VQ scheme with two sets of codebooks: one to represent the wideband speech and one to represent the narrowband speech.
- a respective codebook would be selected by a special "mode" bit, where the mode bit indicates whether the subsequent data bits represent a wideband or narrowband speech signal.
- the representative codecs have been simulated with each predictor of the speech codec arranged to be an 18 th order split vector quantiser, with the eighteen associated line spectral frequencies split into six groups of three bits each. 7KHz & 3KHz Spectral Distortion Results for the 1st order MA-PVQ 40 bit Quantisers.
- Table 1 details the wideband and narrowband spectral distortion figures for a 40-bit first order moving average quantiser trained on 50:50 wideband:narrowband speech.
- the configuration column denotes the number of bits allocated to each of six, moving-average predictive split-vector quantisers, applied to LSFs 1-3, 4-6, 7-9, 10-12, 13-15 and 16-18 respectively.
- a wideband speech codec would typically be represented by an even distribution of bits allocated to each of the six split-vector quantisers, to provide an approximately even frequency response across the full range of the line spectral frequencies.
- a narrowband speech codec would have an uneven distribution of bits associated with each quantiser, with more bits allocated to the lower frequencies of the LSFs.
- a compromise quantiser such as 8,9,8,7,6,2 provides substantially inferior performance to both of these.
- lsfs wideband line spectral frequencies
- the present invention aims to provide a speech codec and method of optimising a performance of the speech codec to at least alleviate some of the aforementioned disadvantages.
- a speech coder for a speech communications unit in accordance with claim 1 is provided.
- a speech communications unit adapted to include the speech coder of any one of claims 1 to 10 is provided.
- a method of generating a speech vector codebook in a speech communications unit in accordance with claim 12 is provided.
- a speech communications unit adapted to include a speech vector codebook generated, in accordance with any one of claims 12 to 20, is provided.
- a method of encoding a speech signal in accordance with claim 22, is provided.
- a speech communications unit adapted to employ a speech encoding method in accordance with any one of claims 22 to 26 is provided.
- a method of decoding a speech signal in accordance with claim 28, is provided.
- a speech communications unit adapted to employ a speech decoding method in accordance with any one of claims 28 to 31 is provided.
- FIG. 1 a block diagram of a code excited linear predictive speech encoder 100, according to a preferred embodiment of the present invention, is shown.
- An acoustic input signal to be analysed is applied to speech coder 100 at microphone 102.
- the input signal is then applied to filter 104.
- Filter 104 will generally exhibit band-pass filter characteristics. However, if the speech bandwidth is already adequate, filter 104 may comprise a direct wire connection.
- the analog speech signal from filter 104 is then converted into a sequence of N pulse samples, and the amplitude of each pulse sample is then represented by a digital code in analog-to-digital (A/D) converter 108, as known in the art.
- the sampling rate is determined by sample clock (SC).
- SC sample clock
- SC is generated along with the frame clock (FC) via clock 112.
- A/D 108 which may be represented as input speech vector s(n)
- coefficient analyser 110 The digital output of A/D 108, which may be represented as input speech vector s(n), is then applied to coefficient analyser 110.
- This input speech vector s(n) is repetitively obtained in separate frames, i.e., blocks of time, the length of which is determined by the frame clock (FC), as is known in the art.
- LPC linear predictive coding
- the generated speech coder parameters may include the following: LPC parameters, long-term predictor (LTP) parameters, excitation gain factor ( ⁇ ) (along with the best excitation codeword I).
- LPC parameters are applied to multiplexer 150 and sent over the channel 152 for use by the speech synthesizer at the decoder.
- the input speech vector s(n) is also applied to subtractor 130, the function of which is described later.
- coefficient analyser 110 has been adapted to incorporate the specially constructed family of embedded codebooks.
- the codebook search controller 140 selects the best indices and gains from the adaptive codebook within block 116 and the stochastic codebook within block 114 in order to produce a minimum weighted error in the summed chosen excitation vector used to represent the input speech sample.
- the output of the stochastic codebook 114 and the adaptive codebook 116 are input into respective gain functions 122 and 118.
- the gain-adjusted outputs are then summed in summer 120 and input into the LPC filter 124, as is known in the art.
- Gain block 122 For each individual excitation vector u i (n), a reconstructed speech vector s' i (n) is generated for comparison to the input speech vector s(n).
- Gain block 122 scales the excitation gain factor ' ⁇ '. Such gain may be pre-computed by coefficient analyser 110 and used to analyse all excitation vectors, or may be optimised jointly with the search for the best excitation codeword I, generated by codebook search controller 140.
- the scaled excitation signal ⁇ u i (n) is then filtered by the linear predictive coding filter 124, which preferably includes a long-term predictor (LTP) filter and a short-term predictor (STP) filter, to generate the reconstructed speech vector s' i (n).
- the reconstructed speech vector s' i (n) for the i-th excitation code vector is compared to the same block of input speech vector s(n) by subtracting these two signals in subtractor 130.
- the difference vector e i (n) represents the difference between the original and the reconstructed blocks of speech.
- the difference vector is perceptually-weighted by weighting filter 132, utilising the weighting filter parameters (WTP) generated by coefficient analyser 110. Perceptual weighting accentuates those frequencies where the error is perceptually more important to the human ear, and attenuates other frequencies.
- An energy calculator function inside the codebook search controller 140 computes the energy of the weighted difference vector e' i (n).
- the codebook search controller compares the i-th error signal for the present excitation vector u i (n) against previous error signals to determine the excitation vector producing the minimum error.
- the code of the i-th excitation vector having a minimum error is then output over the channel as the best excitation code I.
- codebook search controller 140 may determine a particular codeword that provides an error signal having some predetermined criteria, such as meeting a predefined error threshold.
- the coefficient analyzer 110 has also been adapted to employ at least some of the inventive concepts of the present invention. To accommodate vectors in either the wideband or narrowband vector space, the coefficient analyser 110 is used to train the quantisers and to determine whether the input speech comprises wideband or narrowband speech.
- the inventors of the present invention have recognised the opportunity to use the same training data, or at least very similar data, to train each of the quantisers.
- the different sized quantisers cover much the same signal vector space and hence a smaller quantiser is embedded within the larger quantiser leading to a more compact representation.
- the coefficient analyser 110 it is desirable for the coefficient analyser 110 to send an additional mode bit to indicate which quantiser set (i.e. which of the specially constructed family of embedded codebooks) is being used.
- the quantiser set will preferably refer to a wideband or narrowband arrangement.
- the codebook index transmission is structured in order to minimise the effect of errors to this mode bit, as described later with respect to FIG. 4. The consequence of such a careful structuring of the codebook index transmission means that any bit error(s) in the mode bit have much less impact than in any two or more independent-codebook prior art approach.
- FIG. 2 a block diagram of a code excited linear predictive speech decoder 200 is shown, according to a preferred embodiment of the present invention.
- the decoder functionality is substantially the reverse of that of the encoder.
- the received multiplexed signal is input into demultiplexer 202, which separates the excitation parameters 204 from the LPC parameters 206.
- LPC linear predictive coding
- the LPC parameters are input into an LPC de-quantiser, stability check and correction block 210 to obtain a local stable version of the synthesis filter even in the presence of channel bit errors.
- the LPC de-quantise, stability check and correction block 210 has been adapted to encompass the inventive concepts contained herein.
- the LPC de-quantise, stability check and correction block 210 receives the LPC parameters and mode bit sent from the corresponding encoder function.
- the LPC de-quantise function of block 210 includes the corresponding embedded codebook arrangement of the encoder, such that the determination of the at least one mode bit can select the embedded codebook arrangement that best describes the encoded and transmitted speech signal.
- the LPC de-quantise, stability check and correction block 210 also controls the filter co-efficients of the LPC synthesis filter 222 in order to reconstruct the transmitted speech vector s' i (n).
- the output from the LPC synthesis filter 222 is input to a post filter process 224, which subsequently outputs the reconstructed speech 226.
- the excitation parameters 204 may include: excitation gain factor ⁇ together with the best excitation codeword I, and are input into an adaptive non-linear smoothing function 208.
- the output from the adaptive non-linear smoothing function 208 provides the precise adaptive and stochastic codebook indices and gains that form the excitation for the synthesis filter. As such, the outputs from the adaptive non-linear smoothing function 208 are input to stochastic codebook 218 and adaptive codebook 212.
- the gain controls are input to adaptive codebook gain block 214, which receives an output from the adaptive codebook 212, and stochastic codebook gain block 220, which receives an output from the stochastic codebook 218.
- the output from the respective gain blocks 214, 220 are input to summing junction 216, whose output is fed into the LPC synthesis filter 222 and fed back to the adaptive codebook 212, as known in the art.
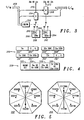
- FIG. 3 shows a 2-way split VQ codebook applied to eighteen wideband line spectral frequencies (LSFs).
- LSFs wideband line spectral frequencies
- the input LSFs (L1-L18) 250 are quantised by first quantiser 254 and second quantiser 268 to derive estimates and the two binary indices "I1" 270 and "I2" 272 using a respective first embedded codebook 256 and second embedded codebook 262.
- the LSFs (L1-L18) 250 are fed into a mode-bit detector 252, that selects the respective embedded codebook to provide the most appropriate one for the speech signal presented.
- the first embedded codebook 256 contains a first set of core entries, in this case appropriate for wideband speech 260, and additional entries appropriate for narrowband speech 258.
- the second embedded codebook 262 contains a second set of core entries, this time appropriate for narrowband speech 266, and additional wideband entries 264.
- the core entries are always searched in each quantiser and are indexed by a set of core bits. Additional entries are searched, depending upon the mode, and a set of "extra" bits are formed.
- the codebook is structured such that when the full codebook is searched, the "extra" bits are effectively zero for the core entries. This is depicted in FIG. 4.
- This arrangement of core bits provides for a constant sum of the bit allocations for each of the two modes, wideband or narrowband.
- FIG. 4 shows the preferred packing of bits for the 2-way split VQ of FIG. 3.
- the configuration of the bit stream 320 comprises the mode bit 322 (indicating a wideband or narrowband input signal) followed by the "I1" core bits 324 (either wideband or narrowband) and the "I2" core bits. Finally the "I1" narrowband extra bits or the "I2" wideband extra bits complete the preferred packing configuration.
- the mode bit and core bits are beneficially always in the same locations. Hence, the impact of a mode bit error can be arranged to result in much smaller errors in the two quantisers than in prior art arrangements.
- a series of "test" input speech signals may be used, to obtain the optimum set of vectors to represent all input speech signals.
- FIG. 5 shows two octagons 350 and 354, partitioned to reflect eight separate locations identified by a respective 3-bit address.
- the two octagons 350, 354 individually each represent one of the two split VQ codebooks of FIG. 3.
- the example shows the case where three "extra" LSBs are used.
- the xxxx & yyyy represent core entry bit patterns for each of the respective embedded codebooks.
- a potentially "non-zero extra” position will be appended instead of all zeros and the "extra" LSBs of the larger codebooks will be set to zero.
- the maximum error for a (WB/NB) mode bit is equivalent to that of several LSB errors in each codebook.
- the codebook entries of the embedded codebook trained using relevant and appropriately varied speech patterns, must be interlaced regularly within the large codebook.
- index reassignment of the combined codebook must be performed such that LSB errors in the indices result in small perceptual distances. This may be arranged using a simulated annealing method as is well known to those skilled in the art.
- a set of codebooks was derived and selectively searched. In order to determine which codebook configuration to search during each frame an appropriate narrowband speech indicator was employed.
- the graph 400 shown in FIG. 6 demonstrates the error resilience of the preferred embodiment of the invention in the presence of 10% bit errors, applied on a per-bit basis measured using an objective distortion measure, such as the perceptual speech quality measure (PSQM value), as defined by the ITU-T Recommendation P.861.
- PSQM value perceptual speech quality measure
- Graph 400 shows the bit error sensitivity profiles, this time for two 43-bit quantisers according to the embodiment.
- the distortion 402 (PSQM value) is shown plotted against bit number 404 on a bit-by-bit basis.
- the two quantisers shown are the hybrid 8,8,8,7,6,5 & 8,9,9,8,6,2 wideband/narrowband scheme 406, according to the preferred embodiment of the invention, and an 8,8,8,7,7,5 wideband-only scheme 408.
- the mode bit is the first bit and then the other core quantiser bits (8,8,8,7,6,2) are presented MSB first for each quantiser in-turn, followed finally by the three extra bits as depicted in FIG. 4.
- the bits are presented in MSB first natural order.
- the overall performance of the new quantiser in the presence of bit errors can be seen to be only very slightly worse than the wideband-only scheme (see rank-ordered sensitivities).
- the graph highlights that the sensitivity of the mode bit is 33rd out of 43, i.e. near, but not quite at, the bottom of the rank-ordered results.
- the explanation for the mode bit not being the least sensitive bit (as in the optimal case) positioned at the bottom of the rank ordering is that when a mode error occurs, several LSB changes (in the three-quantiser tables) occur which together are more significant than a single LSB change (bottom of the rank ordering). This clearly shows that the embedded structuring of the LSF VQ and bit stream has beneficially rendered the LSF VQ relatively immune to bit errors.
- the graph 450 shown in FIG. 7 demonstrates the error resilience of the preferred embodiment of the invention where the error sensitivity profile is shown rank-ordered, as compared to a bit-by-bit basis as shown in FIG. 6.
- Graph 450 shows the bit error sensitivity profiles, of the same two 43-bit quantisers, 456 and 458.
- the distortion 452 is shown plotted against re-ordered bit position 454 on a rank-ordered bit basis.
- the graph highlights that the two quantisers have broadly similar error sensitivity profiles and that the addition of the mode bit has not increased error sensitivity.
- bit-error robust embedded split vector quantiser for wideband line spectral frequencies (lsfs) in narrowband tandemming provides at least the following advantages.
- the invention provides for a single speech codec codebook that can quantise both wideband and narrowband signals in a near optimal manner to that of two independently-optimised speech codec codebooks. This provides for a reduced memory requirement of the codebook, in a memory constrained speech unit.
- inventive concepts described herein find particular use in speech processing units that are flexible enough to cope with a variety of bandwidth constrained speech input signals, such as future third generation cellular telecommunications systems
- any number of line spectral frequencies can be accommodated, in a LSF codebook arrangement.
- the present invention may be implemented outside of the line spectral frequency area, such as in video encoding and decoding.
- inventive concepts can benefit from such inventive concepts.
- inventive concepts can be applied to any LPC order, with any bit-division relationship.
- inventive concepts contained herein can be equally employed in any classified overlapping codebook arrangement, not necessarily limited to the overlapping arrangement between wideband and narrowband speech signals.
- bit-error robust speech codec is complementary to popular, proven speech codecs such as embedded split VQ codecs.
- the bit-error robust speech codec accommodates wideband line spectral frequencies in narrowband tandemming, and alleviates at least some of the aforementioned disadvantages.
Abstract
Description
- This invention relates to speech coding and methods of optimising the performance of speech codecs in communications systems. The invention is applicable to, but not limited to, speech codecs that accommodate wideband and narrowband speech signals without compromising the overall performance of the speech codec quantiser.
- Many present day voice communications systems, such as the global system for mobile communications (GSM) cellular telephony standard and the TErrestrial Trunked RAdio (TETRA) system for private mobile radio users, use speech processing units to encode and decode speech patterns. In such voice communications systems a speech encoder converts the analogue speech pattern into a suitable digital format for transmission and a speech decoder converts a received digital speech signal into an audible analog speech pattern.
- As frequency spectrum for such voice communications systems is a valuable resource, it is desirable to limit the channel bandwidth used by such speech signals, in order to maximise the number of users per frequency band. Hence, a primary objective in the use of speech coding techniques is to reduce the occupied capacity of the speech patterns as much as possible, by use of compression techniques, without losing fidelity.
- A popular solution in speech coding technology is the application of vector quantisation (VQ). A prime incentive in using VQ can be found in Shannon's rate distortion theory, as known to those skilled in the art, which states that better performance can always be achieved by coding vectors instead of scalars.
- The process of vector quantisation is to represent an input vector as a member of a set of fixed vectors.. This set of fixed vectors is known as the VQ codebook. The fixed vector in the VQ codebook which best represents the input vector is found by exhaustively searching all members of the VQ codebook and selecting the fixed vector which gives the minimum distance measure (or Euclidean distance) between it and the input vector.
- This procedure requires that every fixed vector in the VQ codebook is searched in order to find the best representation of the input vector. Consequently searching a full VQ codebook is computationally expensive and memory hungry. Although VQ has been shown to be very attractive and efficient in many areas of speech coding, it is not without its drawbacks.
- In the field of this invention it is known that wideband speech codecs are likely to find application in telephone conferencing. Wideband speech codecs have an input speech bandwidth covering the 50Hz to 7KHz range, compared to narrowband or telephone-band codecs that have an input speech bandwidth of 250Hz to 3.3KHz.
- The consequence of this is that wideband speech codecs will often be tandemmed with narrowband speech codecs. Tandemming is a term which is used to describe the situation where speech previously processed by one speech encoder/decoder is processed by a second speech encoder/decoder pair.
- Furthermore, in these situations, the speech quality requirement of such tandemmed codecs is to achieve equivalence to the best narrowband codecs i.e. GSM Enhanced full-rate codec (EFR). It is therefore appropriate to consider the performance of any wideband line spectral frequency (LSF) VQ scheme in the presence of narrowband speech.
- To accommodate the processing of both wideband and narrowband speech signals in a speech synthesis unit, one option may be to use a classified VQ scheme with two sets of codebooks: one to represent the wideband speech and one to represent the narrowband speech. In this case, a respective codebook would be selected by a special "mode" bit, where the mode bit indicates whether the subsequent data bits represent a wideband or narrowband speech signal.
- One problem that is inherent with this technique is that two individual codebooks are required, one arranged for wideband performance and one arranged for narrowband performance. Subsequent bit errors applied to the mode bit would result in large de-quantiser errors. To resolve any such mode bit error problems, heavy forward error correction (FEC) protection is required in the resulting speech codec.
- One disadvantage associated with quantising wideband LSFs, when there is a possibility that narrowband codec tandemming may be present, is highlighted below in Table 1.
- The representative codecs have been simulated with each predictor of the speech codec arranged to be an 18th order split vector quantiser, with the eighteen associated line spectral frequencies split into six groups of three bits each.
7KHz & 3KHz Spectral Distortion Results for the 1st order MA- PVQ 40 bit Quantisers.Quantiser Configuration Wideband Performance Narrowband Performance Mean SD (dB) % Frames 3-5 dB % Frames > 5 dB Mean SD (dB) % Frames 2-4 dB % Frames > 4 dB 6,8,7,7,6,6 1.418 0.887 0.019 1.292 5.754 0.058 6,7,7,7,7,6 1.417 1.012 0.010 1.384 8.047 0.087 7,7,7,7,6,6 1.418 0.916 0.019 1.301 6.062 0.077 7,8,7,7,6,5 1.389 0.771 0.019 1.202 4.163 0.058 6,8,8,7,6,5 1.396 0.684 0.019 1.231 4.597 0.029 7,7,7,7,7,5 1.387 0.810 0.010 1.300 6.081 0.077 7,7,8,7,6,5 1.397 0.723 0.019 1.240 4.857 0.058 7,8,8,7,6,4 1.379 0.646 0.019 1.137 3.094 0.039 7,9,9,6,5,4 1.453 0.896 0.029 1.033 1.744 0.000 7,9,9,7,5,3 1.431 0.752 0.000 1.017 1.677 0.010 8,8,8,7,6,3 1.390 0.723 0.010 1.073 2.274 0.029 8,9,8,7,6,2 1.419 0.964 0.010 0.993 1.484 0.019 8,8,8,8,5,3 1.419 0.867 0.019 1.067 2.101 0.029 8,9,8,7,5,3 1.428 0.848 0.000 0.995 1.503 0.029 8,9,8,8,5,2 1.447 1.224 0.010 0.986 1.378 0.019 8,9,9,7,5,2 1.459 1.245 0.010 0.947 1.051 0.010 - The wideband and narrowband distortion figures are presented in the form suggested by; "LSF Quantization in Wideband Speech Coders", Proceedings of 1999 IEEE Workshop on Speech Coding, pp 25-27, M. Ferhaoui & S. Van Gerven and "Efficient Vector Quantization of LPC Parameters at 24 Bits/Frame", IEEE Transactions on Speech and Audio Processing,
Vol 1,No 1, March 1993, K.K. Paliwal & B.S. Atal. - Table 1 details the wideband and narrowband spectral distortion figures for a 40-bit first order moving average quantiser trained on 50:50 wideband:narrowband speech. As mentioned, the configuration column denotes the number of bits allocated to each of six, moving-average predictive split-vector quantisers, applied to LSFs 1-3, 4-6, 7-9, 10-12, 13-15 and 16-18 respectively.
- It is worth noting that a wideband speech codec would typically be represented by an even distribution of bits allocated to each of the six split-vector quantisers, to provide an approximately even frequency response across the full range of the line spectral frequencies. In contrast, a narrowband speech codec would have an uneven distribution of bits associated with each quantiser, with more bits allocated to the lower frequencies of the LSFs.
- It is clear that the best wideband performance is obtained by a first configuration (7,8,8,7,6,4), whilst the best narrowband performance is obtained with a different second configuration (8,9,9,7,5,2). Both configurations consist of the same total number of bits, but with different distributions of the numbers of bits per quantiser.
- A compromise quantiser such as 8,9,8,7,6,2 provides substantially inferior performance to both of these. In addition, it is noteworthy that this dual quantiser approach would require a total of:
- Hence, a need exists to provide a bit-error robust speech codec, preferably complementary to popular, proven speech codecs such as embedded split VQ codecs, that can provide improved quantisation of wideband line spectral frequencies (lsfs) for wideband speech and also in narrowband tandemming.
- The present invention aims to provide a speech codec and method of optimising a performance of the speech codec to at least alleviate some of the aforementioned disadvantages.
- Published prior art documents known to the applicant include WO99/65017, WO97/27578, WO95/10760 and EP-A-411655.
- In a first aspect of the present invention, a speech coder for a speech communications unit in accordance with
claim 1 is provided. - In a second aspect of the present invention, a speech communications unit adapted to include the speech coder of any one of
claims 1 to 10 is provided. - In a third aspect of the present invention, a method of generating a speech vector codebook in a speech communications unit in accordance with
claim 12 is provided. - In a fourth aspect of the present invention, a speech communications unit adapted to include a speech vector codebook generated, in accordance with any one of
claims 12 to 20, is provided. - In a fifth aspect of the present invention, a method of encoding a speech signal, in accordance with
claim 22, is provided. - In a sixth aspect of the present invention, a speech communications unit adapted to employ a speech encoding method in accordance with any one of
claims 22 to 26 is provided. - In a seventh aspect of the present invention, a method of decoding a speech signal, in accordance with
claim 28, is provided. - In an eighth aspect of the present invention, a speech communications unit adapted to employ a speech decoding method in accordance with any one of
claims 28 to 31 is provided. - Exemplary embodiments of the present invention will now be described, with reference to the accompanying drawings, in which:
- FIG. 1 shows a block diagram of a code excited linear predictive speech encoder that can be adapted to support the various inventive concepts of a preferred embodiment of the present invention;
- FIG. 2 shows a block diagram of a code excited linear predictive speech decoder that can be adapted to support the various inventive concepts of a preferred embodiment of the present invention;
- FIG. 3 shows a 2-way split VQ codebook applied to eighteen wideband line spectral frequencies (LSFs) adapted to support the inventive concepts of the preferred embodiments of the present invention;
- FIG. 4 shows a preferred packing arrangement of bits for the 2-way split VQ codebook of FIG. 3, adapted to support the inventive concepts of the preferred embodiments of the present invention;
- FIG. 5 shows an octagon partitioned to reflect eight separate locations for the 2-way split VQ codebook of FIG. 3, in accordance with a preferred embodiment of the present invention;
- FIG. 6 shows a graph that demonstrates the error resilience of a preferred embodiment of the present invention in the presence of 10% bit errors applied on a per-bit basis with natural ordering; and
- FIG. 7 shows a further graph that demonstrates the error resilience of a preferred embodiment of the present invention in the presence of 10% bit errors applied on a per-bit basis with ranked ordering.
-
- Referring first to FIG. 1, a block diagram of a code excited linear
predictive speech encoder 100, according to a preferred embodiment of the present invention, is shown. An acoustic input signal to be analysed is applied tospeech coder 100 atmicrophone 102. The input signal is then applied to filter 104.Filter 104 will generally exhibit band-pass filter characteristics. However, if the speech bandwidth is already adequate,filter 104 may comprise a direct wire connection. - The analog speech signal from
filter 104 is then converted into a sequence of N pulse samples, and the amplitude of each pulse sample is then represented by a digital code in analog-to-digital (A/D)converter 108, as known in the art. The sampling rate is determined by sample clock (SC). The sample clock SC is generated along with the frame clock (FC) viaclock 112. - The digital output of A/
D 108, which may be represented as input speech vector s(n), is then applied tocoefficient analyser 110. This input speech vector s(n) is repetitively obtained in separate frames, i.e., blocks of time, the length of which is determined by the frame clock (FC), as is known in the art. - For each block of speech, a set of linear predictive coding (LPC) parameters is produced in accordance with a preferred embodiment of the invention by
coefficient analyser 110. The generated speech coder parameters may include the following: LPC parameters, long-term predictor (LTP) parameters, excitation gain factor (√) (along with the best excitation codeword I). Such speech coding parameters are applied tomultiplexer 150 and sent over thechannel 152 for use by the speech synthesizer at the decoder. The input speech vector s(n) is also applied tosubtractor 130, the function of which is described later. - In the preferred embodiment of the invention, a specially constructed family of embedded codebooks is used in order to best represent the LPC parameters of the input speech signal. Hence,
coefficient analyser 110 has been adapted to incorporate the specially constructed family of embedded codebooks. - It is within the contemplation of the invention that any number of embedded codebooks would benefit from the inventive concepts described herein. The inventive concepts of the embedded codebook arrangement are further described with reference to FIG. 3.
- Within the conventional CELP encoder of FIG. 1, the
codebook search controller 140 selects the best indices and gains from the adaptive codebook withinblock 116 and the stochastic codebook withinblock 114 in order to produce a minimum weighted error in the summed chosen excitation vector used to represent the input speech sample. The output of thestochastic codebook 114 and theadaptive codebook 116 are input into respective gain functions 122 and 118. The gain-adjusted outputs are then summed insummer 120 and input into theLPC filter 124, as is known in the art. - For each individual excitation vector ui(n), a reconstructed speech vector s'i(n) is generated for comparison to the input speech vector s(n).
Gain block 122 scales the excitation gain factor '√'. Such gain may be pre-computed bycoefficient analyser 110 and used to analyse all excitation vectors, or may be optimised jointly with the search for the best excitation codeword I, generated by codebooksearch controller 140. - The scaled excitation signal √ui (n) is then filtered by the linear
predictive coding filter 124, which preferably includes a long-term predictor (LTP) filter and a short-term predictor (STP) filter, to generate the reconstructed speech vector s'i(n).
The reconstructed speech vector s'i(n) for the i-th excitation code vector is compared to the same block of input speech vector s(n) by subtracting these two signals insubtractor 130. - The difference vector ei (n) represents the difference between the original and the reconstructed blocks of speech. The difference vector is perceptually-weighted by
weighting filter 132, utilising the weighting filter parameters (WTP) generated bycoefficient analyser 110. Perceptual weighting accentuates those frequencies where the error is perceptually more important to the human ear, and attenuates other frequencies. - An energy calculator function inside the
codebook search controller 140 computes the energy of the weighted difference vector e'i(n). The codebook search controller compares the i-th error signal for the present excitation vector ui(n) against previous error signals to determine the excitation vector producing the minimum error. The code of the i-th excitation vector having a minimum error is then output over the channel as the best excitation code I. - In the alternative,
codebook search controller 140 may determine a particular codeword that provides an error signal having some predetermined criteria, such as meeting a predefined error threshold. - A more detailed description of the functionality of a typical speech encoding unit can be found in "Digital speech coding for low-bit rate communications systems" by A. M. Kondoz, published by John Wiley in 1994.
- As mentioned earlier, the
coefficient analyzer 110 has also been adapted to employ at least some of the inventive concepts of the present invention. To accommodate vectors in either the wideband or narrowband vector space, thecoefficient analyser 110 is used to train the quantisers and to determine whether the input speech comprises wideband or narrowband speech. - The inventors of the present invention have recognised the opportunity to use the same training data, or at least very similar data, to train each of the quantisers. The different sized quantisers cover much the same signal vector space and hence a smaller quantiser is embedded within the larger quantiser leading to a more compact representation. In the present case, the storage may be reduced from the dual quantiser approach requiring a total of 3 x (640 + 1444) words = 6252 words to 3 x 1600 = 4800 words.
- In the preferred embodiment of the invention, it is desirable for the
coefficient analyser 110 to send an additional mode bit to indicate which quantiser set (i.e. which of the specially constructed family of embedded codebooks) is being used. The quantiser set will preferably refer to a wideband or narrowband arrangement. The codebook index transmission is structured in order to minimise the effect of errors to this mode bit, as described later with respect to FIG. 4. The consequence of such a careful structuring of the codebook index transmission means that any bit error(s) in the mode bit have much less impact than in any two or more independent-codebook prior art approach. - Referring now to FIG. 2, a block diagram of a code excited linear
predictive speech decoder 200 is shown, according to a preferred embodiment of the present invention. The decoder functionality is substantially the reverse of that of the encoder. - The received multiplexed signal is input into
demultiplexer 202, which separates theexcitation parameters 204 from theLPC parameters 206. - For each block of speech, a set of linear predictive coding (LPC) parameters were produced in the encoder by
coefficient analyser 110 as described with reference to FIG. 1. - In the preferred embodiment of the present invention, the LPC parameters are input into an LPC de-quantiser, stability check and correction block 210 to obtain a local stable version of the synthesis filter even in the presence of channel bit errors. The LPC de-quantise, stability check and
correction block 210 has been adapted to encompass the inventive concepts contained herein. - The LPC de-quantise, stability check and
correction block 210 receives the LPC parameters and mode bit sent from the corresponding encoder function. The LPC de-quantise function ofblock 210 includes the corresponding embedded codebook arrangement of the encoder, such that the determination of the at least one mode bit can select the embedded codebook arrangement that best describes the encoded and transmitted speech signal. The LPC de-quantise, stability check and correction block 210 also controls the filter co-efficients of theLPC synthesis filter 222 in order to reconstruct the transmitted speech vector s'i(n). The output from theLPC synthesis filter 222 is input to apost filter process 224, which subsequently outputs the reconstructedspeech 226. - The
excitation parameters 204 may include: excitation gain factor √ together with the best excitation codeword I, and are input into an adaptivenon-linear smoothing function 208. The output from the adaptivenon-linear smoothing function 208 provides the precise adaptive and stochastic codebook indices and gains that form the excitation for the synthesis filter. As such, the outputs from the adaptivenon-linear smoothing function 208 are input to stochastic codebook 218 andadaptive codebook 212. - The gain controls are input to adaptive
codebook gain block 214, which receives an output from theadaptive codebook 212, and stochasticcodebook gain block 220, which receives an output from the stochastic codebook 218. The output from the respective gain blocks 214, 220 are input to summingjunction 216, whose output is fed into theLPC synthesis filter 222 and fed back to theadaptive codebook 212, as known in the art. - It is again within the contemplation of the invention that any number of embedded codebooks would benefit from the inventive concepts described herein. The inventive concepts of the embedded codebook arrangement, applicable to either the encoder or decoder function are further described with reference to FIG. 3.
- A more detailed description of the functionality of a typical speech decoding unit can also be found in "Digital speech coding for low-bit rate communications systems" by A. M. Kondoz, published by John Wiley in 1994.
- The inventive concepts of the preferred embodiment of the invention are best illustrated with an example. FIG. 3 shows a 2-way split VQ codebook applied to eighteen wideband line spectral frequencies (LSFs). The number of split VQ codebooks together with the number of LSFs have only been selected to more easily show the benefits of the inventive concepts of the present invention.
- The input LSFs (L1-L18) 250 are quantised by
first quantiser 254 andsecond quantiser 268 to derive estimates and the two binary indices "I1" 270 and "I2" 272 using a respective first embeddedcodebook 256 and second embeddedcodebook 262. The LSFs (L1-L18) 250 are fed into a mode-bit detector 252, that selects the respective embedded codebook to provide the most appropriate one for the speech signal presented. - The first embedded
codebook 256 contains a first set of core entries, in this case appropriate forwideband speech 260, and additional entries appropriate fornarrowband speech 258. The second embeddedcodebook 262 contains a second set of core entries, this time appropriate fornarrowband speech 266, and additionalwideband entries 264. - In each case, the core entries are always searched in each quantiser and are indexed by a set of core bits. Additional entries are searched, depending upon the mode, and a set of "extra" bits are formed. The codebook is structured such that when the full codebook is searched, the "extra" bits are effectively zero for the core entries. This is depicted in FIG. 4.
- This arrangement of core bits provides for a constant sum of the bit allocations for each of the two modes, wideband or narrowband.
- FIG. 4 shows the preferred packing of bits for the 2-way split VQ of FIG. 3. The configuration of the
bit stream 320 comprises the mode bit 322 (indicating a wideband or narrowband input signal) followed by the "I1" core bits 324 (either wideband or narrowband) and the "I2" core bits. Finally the "I1" narrowband extra bits or the "I2" wideband extra bits complete the preferred packing configuration. - Since one of the codebooks is fully searched, and for the other codebook only the core entries are searched, advantageously only one set of extra bits needs to be sent. The extra bits for the partially searched codebook will effectively be zero i.e. either 302, 306 and 308 or 310, 312, 314 need to be sent since either 304 or 316 will convey no information.
- By packing the bits as shown in FIG. 4, the mode bit and core bits are beneficially always in the same locations. Hence, the impact of a mode bit error can be arranged to result in much smaller errors in the two quantisers than in prior art arrangements.
- Clearly, in order to first generate the embedded vector codebook arrangement described in FIGs 1-4, a series of "test" input speech signals may be used, to obtain the optimum set of vectors to represent all input speech signals.
- FIG. 5 shows two
octagons octagons - For simplicity, the example shows the case where three "extra" LSBs are used. The xxxx & yyyy represent core entry bit patterns for each of the respective embedded codebooks. For embedded entries, a potentially "non-zero extra" position will be appended instead of all zeros and the "extra" LSBs of the larger codebooks will be set to zero. As can be seen from
error arrows - In order to achieve this advantageous feature, the codebook entries of the embedded codebook, trained using relevant and appropriately varied speech patterns, must be interlaced regularly within the large codebook. In addition, index reassignment of the combined codebook must be performed such that LSB errors in the indices result in small perceptual distances. This may be arranged using a simulated annealing method as is well known to those skilled in the art.
- A set of codebooks was derived and selectively searched. In order to determine which codebook configuration to search during each frame an appropriate narrowband speech indicator was employed.
- Any reliable indicator may be used, but in this case the squared sum of the LSF VQ weights, w13-w18, corresponding to LSFs 13-18, (neglecting the split adjacent weighting) was filtered:
- This provides a reliable indication of whether the input is narrowband or wideband speech, except during silence periods, when the bias is slightly in favour of wideband speech.
- The results of the hybrid wideband/narrowband scheme, in accordance with a preferred embodiment of the invention, is shown in Table 2.
7KHz and 3KHz Spectral Distortion Results for the Hybrid 41-bit Quantiser. Quantiser Configuration Wideband Performance Narrowband Performance Mean SD (dB) % Frames 3-5 dB % Frames > 5 dB Mean SD (dB) % Frames 2-4 dB % Frames > 4 dB Hybrid 7,8,8,7,6,4 & 8,9,9,7,5,2 1.396 0.761 0.019 0.985 1.359 0.019 - As can be seen by comparing the results of Table 2 with the values in Table 1, the hybrid scheme performs very well for both wideband and narrowband speech and offers only slightly degraded performance to the optimum in either configuration.
- The
graph 400 shown in FIG. 6 demonstrates the error resilience of the preferred embodiment of the invention in the presence of 10% bit errors, applied on a per-bit basis measured using an objective distortion measure, such as the perceptual speech quality measure (PSQM value), as defined by the ITU-T Recommendation P.861. -
Graph 400 shows the bit error sensitivity profiles, this time for two 43-bit quantisers according to the embodiment. The distortion 402 (PSQM value) is shown plotted againstbit number 404 on a bit-by-bit basis. - The two quantisers shown are the hybrid 8,8,8,7,6,5 & 8,9,9,8,6,2 wideband/
narrowband scheme 406, according to the preferred embodiment of the invention, and an 8,8,8,7,7,5 wideband-only scheme 408. - For the hybrid quantiser the mode bit is the first bit and then the other core quantiser bits (8,8,8,7,6,2) are presented MSB first for each quantiser in-turn, followed finally by the three extra bits as depicted in FIG. 4. For the 8,8,8,7,7,5 wideband-only scheme the bits are presented in MSB first natural order.
- The overall performance of the new quantiser in the presence of bit errors can be seen to be only very slightly worse than the wideband-only scheme (see rank-ordered sensitivities). In particular, the graph highlights that the sensitivity of the mode bit is 33rd out of 43, i.e. near, but not quite at, the bottom of the rank-ordered results.
- The explanation for the mode bit not being the least sensitive bit (as in the optimal case) positioned at the bottom of the rank ordering (see FIG. 7) is that when a mode error occurs, several LSB changes (in the three-quantiser tables) occur which together are more significant than a single LSB change (bottom of the rank ordering). This clearly shows that the embedded structuring of the LSF VQ and bit stream has beneficially rendered the LSF VQ relatively immune to bit errors.
- The
graph 450 shown in FIG. 7 demonstrates the error resilience of the preferred embodiment of the invention where the error sensitivity profile is shown rank-ordered, as compared to a bit-by-bit basis as shown in FIG. 6. -
Graph 450 shows the bit error sensitivity profiles, of the same two 43-bit quantisers, 456 and 458. Thedistortion 452 is shown plotted against re-orderedbit position 454 on a rank-ordered bit basis. In particular, the graph highlights that the two quantisers have broadly similar error sensitivity profiles and that the addition of the mode bit has not increased error sensitivity. - It will be understood that the bit-error robust embedded split vector quantiser for wideband line spectral frequencies (lsfs) in narrowband tandemming described above provides at least the following advantages.
- The invention provides for a single speech codec codebook that can quantise both wideband and narrowband signals in a near optimal manner to that of two independently-optimised speech codec codebooks. This provides for a reduced memory requirement of the codebook, in a memory constrained speech unit.
- The inventive concepts described herein find particular use in speech processing units that are flexible enough to cope with a variety of bandwidth constrained speech input signals, such as future third generation cellular telecommunications systems
- It will, of course, be appreciated that the above description has been given by way of example only and that modifications in detail may be made within the scope of the present invention. For example, whilst the preferred embodiment discusses the application of the present invention to a split vector quantiser codebook, it is envisaged by the inventors that other codebooks and speech coder techniques can benefit from the inventive concepts contained herein.
- The skilled addressee will equally appreciate that any number of line spectral frequencies can be accommodated, in a LSF codebook arrangement. Indeed, the present invention may be implemented outside of the line spectral frequency area, such as in video encoding and decoding.
- It is within the contemplation of the invention that alternative quantiser configurations can benefit from such inventive concepts. Furthermore, the inventive concepts can be applied to any LPC order, with any bit-division relationship.
- It is also within the contemplation of the present invention, that the inventive concepts contained herein can be equally employed in any classified overlapping codebook arrangement, not necessarily limited to the overlapping arrangement between wideband and narrowband speech signals.
- Thus, a bit-error robust speech codec has been provided that is complementary to popular, proven speech codecs such as embedded split VQ codecs. The bit-error robust speech codec accommodates wideband line spectral frequencies in narrowband tandemming, and alleviates at least some of the aforementioned disadvantages.
Claims (32)
- A speech coder (100, 200) for a speech communications unit, the speech coder comprising a set of at least two embedded vector codebooks capable of representing an input speech signal by a series of vectors, the speech coder (100, 200) characterised by the at least two embedded vector codebooks (256, 262) sharing at least some common vectors of the series of vectors and means for classifying (252) the input speech signal by selecting one of the at least two embedded vector codebooks (256, 262) in conjunction with at least a portion of said at least one other embedded vector codebook of the at least two embedded vector codebooks (256, 262) to represent the input speech signal.
- The speech coder of claim 1, wherein indices which address individual vector entries within the at least two embedded vector codebooks (256, 262) are assigned such that distortion resulting from incorrect classification is minimised.
- The speech coder of claim 1 or claim 2, further characterised by the speech codebook being a vector quantisation codebook, wherein the at least two embedded vector codebooks (256, 262) are classified as predominantly wideband or narrowband embedded codebooks having shared common vectors.
- The speech coder of any one of preceding claims 1 to 3, the speech coder further characterised by the selected one of the embedded vector codebooks (256, 262) providing a coarse resolution and the at least a portion of at least one other embedded vector codebook providing a fine resolution to represent the speech signal input to the speech coder.
- The speech coder of any one of the preceding claims, further characterised by quantisation means (110, 210) operably coupled to the means for classifying (252) for quantising a line spectral frequency input speech signal.
- The speech coder of any one of the preceding claims, further characterised by analysis means operably coupled to the speech vector codebook for analysing an incoming speech signal to determine a particular characteristic of the speech signal.
- The speech coder of claim 6, wherein the classifying means includes means for generating or recovering at least one mode bit to identify a characteristic of the speech signal associated with wideband or narrowband speech.
- The speech coder of claim 7, wherein the input speech signal comprises at least one core bit, the speech coder further characterised by positioning means to position said mode bit and said at least one core bit for both first and second embedded vector codebooks (256, 262) in the same vector space.
- The speech coder according to any one of the preceding claims, further comprising appending means, the appending means adapted to append at least one zero (304, 306) to a vector representation (300) to represent vector positions for either said first or second embedded speech vector codebook (256, 262) in a combined embedded speech vector codebook.
- The speech coder according to any one of the preceding claims, further comprising index reassignment means (350) for re-arranging the vector positions of the first and second codebook vectors in the combined embedded speech vector codebook to minimise perceptual distance between said embedded codebook vectors.
- A speech communications unit adapted to include the speech coder of any one of preceding claims 1 to 10.
- A method of generating a speech vector codebook in a speech communications unit, the method characterised by the steps of:representing speech signals by a series of vectors; andgenerating at least two embedded vector codebooks that share common vectors of the series of vectors, to generate said speech vector codebook, such that, in use, at least a portion of each of the at least two embedded vector codebooks is used to represent an input speech signal.
- The method of generating a speech codebook according to claim 12, wherein the step of generating at least two embedded vector codebooks includes the steps of:generating a first embedded vector codebook of the at least two embedded vector codebooks to substantially represent narrowband speech signals; andgenerating a second embedded vector codebook of the at least two embedded vector codebooks to substantially represent wideband speech signals.
- The method of generating a speech vector codebook according to claims 12 or 13, the method further characterised by the step of:quantising, by quantisation means, a line spectral frequency input speech signal.
- The method of generating a speech vector codebook according to any one of claims 12 to 14, wherein the step of generating at least two embedded vector codebooks includes generating one of the embedded vector codebooks to provide a coarse resolution, and generating the at least one other embedded vector codebook to provide a fine resolution, to represent a speech signal input to the speech coder.
- The method of generating a speech vector codebook according to any one of claims 12 to 15, the method further characterised by the step of:analysing an incoming speech signal by analysis means in the speech encoder to determine a particular characteristic of the speech signal associated with wideband or narrowband signals; andgenerating a mode bit (322) to represent the particular characteristic of the speech signal.
- The method of generating a speech vector codebook according to claim 16, wherein the speech signals include core speech bits (324, 326), the method further characterised by the step of:positioning the at least one mode bit and core speech bits for both embedded vector codebooks in substantially the same location of the speech vector codebook.
- The method of generating a speech vector codebook according to any one of preceding claims 12 to 17, the method further characterised by the step of:appending (304, 316) zeros to vector entries in either of the first or second embedded vector codebooks.
- The method of generating a speech vector codebook according to any one of preceding claims 12 to 18, the method further characterised by the step of:performing index re-assignment of the speech vector codebook to maintain a relatively small perceptual distance between respective vector positions thereby minimising distortion errors resulting from incorrect classification in a speech encoding or decoding process.
- The method of generating a speech vector codebook according to any one of preceding claims 12 to 19, the method further characterised by the step of:interlacing said vector entries at substantially evenly distributed positions within the combined speech vector codebook.
- A speech communications unit adapted to incorporate a speech vector codebook generated in accordance with any one of method claims 12 to 20.
- A method of encoding a speech signal, the method characterised by the steps of:receiving a speech signal;identifying a characteristic of the speech signal;selecting one of at least two embedded vector codebooks, in conjunction with at least a portion of at least one other embedded vector codebook of the at least two embedded vector codebooks, to represent the input speech signal based on the identified characteristic, the embedded vector codebooks sharing at least some common vectors; andtransmitting information identifying said selected one embedded vector codebook as a representation of said received speech signal.
- The method of encoding a speech signal according to claim 22, wherein the step of identifying a characteristic of the received speech signal encompasses identifying whether the speech signal is associated with wideband or narrowband speech.
- The method of encoding a speech signal according to claim 22 or 23, wherein the step of selecting includes selecting one of the embedded vector codebooks to provide a coarse resolution, and the at least a portion of at least one other embedded vector codebook to provide a fine resolution, to represent the speech signal input to the speech coder.
- The method of encoding a speech signal according to any one of claim 22 to 24, the method further characterised by the step of:generating at least one mode bit (322) to identify said characteristic of the speech signal.
- The method of encoding a speech signal according to any one of preceding claims 22 to 25, the method further characterised by the step of:appending (304, 316) at least one zero to a vector representation of the input speech signal to represent said vector position for either said first or second embedded speech vector codebook in the speech vector codebook.
- A speech communications unit adapted to employ a speech encoding method in accordance with any one of method claims 22 to 26.
- A method of decoding a speech signal, the method characterised by the steps of:receiving a speech signal;identifying a characteristic of the received speech signal; andselecting one of at least two embedded vector codebooks, in conjunction with at least a portion of at least one other embedded vector codebook of the at least two embedded vector codebooks, to represent the input speech signal based on the identified characteristic, the embedded vector codebooks sharing at least some common vectors.
- The method of decoding a speech signal according to claim 27, wherein the step of identifying a characteristic of the received speech signal encompasses identifying whether the speech signal is associated with wideband or narrowband speech.
- The method of decoding a speech signal according to claim 28 or 29, the method further characterised by the step of:recovering (322) at least one mode bit to identify said characteristic of the speech signal.
- The method of decoding a speech signal according to any one of preceding claims 28 to 30, the method further characterised by the step of:removing at least one zero appended to a vector representation of the input speech signal to represent a vector position in either said first or second embedded speech vector codebook.
- A speech communications unit adapted to employ a speech decoding method in accordance with any one of method claims 28 to 31.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| GB0026463A GB2368761B (en) | 2000-10-30 | 2000-10-30 | Speech codec and methods for generating a vector codebook and encoding/decoding speech signals |
| GB0026463 | 2000-10-30 | ||
| PCT/EP2001/012403 WO2002037477A1 (en) | 2000-10-30 | 2001-10-22 | Speech codec and method for generating a vector codebook and encoding/decoding speech signals |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| EP1334485A1 EP1334485A1 (en) | 2003-08-13 |
| EP1334485B1 true EP1334485B1 (en) | 2005-08-31 |
Family
ID=9902177
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP01993000A Expired - Lifetime EP1334485B1 (en) | 2000-10-30 | 2001-10-22 | Speech codec and method for generating a vector codebook and encoding/decoding speech signals |
Country Status (6)
| Country | Link |
|---|---|
| EP (1) | EP1334485B1 (en) |
| AT (1) | ATE303647T1 (en) |
| AU (1) | AU2002215972A1 (en) |
| DE (1) | DE60113144T2 (en) |
| GB (1) | GB2368761B (en) |
| WO (1) | WO2002037477A1 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB0703795D0 (en) * | 2007-02-27 | 2007-04-04 | Sepura Ltd | Speech encoding and decoding in communications systems |
| CN110428847B (en) * | 2019-08-28 | 2021-08-24 | 南京梧桐微电子科技有限公司 | Line spectrum frequency parameter quantization bit distribution method and system |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0365822A (en) * | 1989-08-04 | 1991-03-20 | Fujitsu Ltd | Vector quantization coder and vector quantization decoder |
| WO1995010760A2 (en) * | 1993-10-08 | 1995-04-20 | Comsat Corporation | Improved low bit rate vocoders and methods of operation therefor |
| US5621852A (en) * | 1993-12-14 | 1997-04-15 | Interdigital Technology Corporation | Efficient codebook structure for code excited linear prediction coding |
| GB2300548B (en) * | 1995-05-02 | 2000-01-12 | Motorola Ltd | Method for a communications system |
| WO1997027578A1 (en) * | 1996-01-26 | 1997-07-31 | Motorola Inc. | Very low bit rate time domain speech analyzer for voice messaging |
| JP4132154B2 (en) * | 1997-10-23 | 2008-08-13 | ソニー株式会社 | Speech synthesis method and apparatus, and bandwidth expansion method and apparatus |
| US5966688A (en) * | 1997-10-28 | 1999-10-12 | Hughes Electronics Corporation | Speech mode based multi-stage vector quantizer |
| ATE520122T1 (en) * | 1998-06-09 | 2011-08-15 | Panasonic Corp | VOICE CODING AND VOICE DECODING |
| SE519976C2 (en) * | 2000-09-15 | 2003-05-06 | Ericsson Telefon Ab L M | Coding and decoding of signals from multiple channels |
-
2000
- 2000-10-30 GB GB0026463A patent/GB2368761B/en not_active Expired - Fee Related
-
2001
- 2001-10-22 AU AU2002215972A patent/AU2002215972A1/en not_active Abandoned
- 2001-10-22 DE DE60113144T patent/DE60113144T2/en not_active Expired - Lifetime
- 2001-10-22 AT AT01993000T patent/ATE303647T1/en not_active IP Right Cessation
- 2001-10-22 EP EP01993000A patent/EP1334485B1/en not_active Expired - Lifetime
- 2001-10-22 WO PCT/EP2001/012403 patent/WO2002037477A1/en active IP Right Grant
Also Published As
| Publication number | Publication date |
|---|---|
| EP1334485A1 (en) | 2003-08-13 |
| ATE303647T1 (en) | 2005-09-15 |
| AU2002215972A1 (en) | 2002-05-15 |
| GB2368761B (en) | 2003-07-16 |
| DE60113144D1 (en) | 2005-10-06 |
| GB0026463D0 (en) | 2000-12-13 |
| WO2002037477A1 (en) | 2002-05-10 |
| GB2368761A (en) | 2002-05-08 |
| DE60113144T2 (en) | 2006-06-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5343098B2 (en) | LPC harmonic vocoder with super frame structure | |
| US5966688A (en) | Speech mode based multi-stage vector quantizer | |
| EP0573398B1 (en) | C.E.L.P. Vocoder | |
| US5778335A (en) | Method and apparatus for efficient multiband celp wideband speech and music coding and decoding | |
| US7016831B2 (en) | Voice code conversion apparatus | |
| KR100713677B1 (en) | Speech decoder, speech decoding method, and transmission system including the speech decoder | |
| EP0704088B1 (en) | Method of encoding a signal containing speech | |
| JP4390803B2 (en) | Method and apparatus for gain quantization in variable bit rate wideband speech coding | |
| US7031912B2 (en) | Speech coding apparatus capable of implementing acceptable in-channel transmission of non-speech signals | |
| JP2004526213A (en) | Method and system for line spectral frequency vector quantization in speech codecs | |
| JP2006525533A5 (en) | ||
| JPH08263099A (en) | Encoder | |
| JP2005202262A (en) | Audio signal encoding method, audio signal decoding method, transmitter, receiver, and wireless microphone system | |
| US6205423B1 (en) | Method for coding speech containing noise-like speech periods and/or having background noise | |
| US7072830B2 (en) | Audio coder | |
| US5987406A (en) | Instability eradication for analysis-by-synthesis speech codecs | |
| EP1334485B1 (en) | Speech codec and method for generating a vector codebook and encoding/decoding speech signals | |
| WO2000017858A1 (en) | Robust fast search for two-dimensional gain vector quantizer | |
| Drygajilo | Speech Coding Techniques and Standards | |
| KR100389898B1 (en) | Method for quantizing linear spectrum pair coefficient in coding voice | |
| Oshima et al. | Variable-length coding of ACELP gain using Entropy-Constrained VQ | |
| JPH11134000A (en) | Voice compression coder and compression coding method for voice and computer-readable recording medium recorded program for having computer carried out each process for method thereof |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| 17P | Request for examination filed |
Effective date: 20030530 |
|
| AK | Designated contracting states |
Designated state(s): AT BE CH CY DE DK ES FI FR GB GR IE IT LI LU MC NL PT SE TR |
|
| AX | Request for extension of the european patent |
Extension state: AL LT LV MK RO SI |
|
| GRAP | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOSNIGR1 |
|
| GRAS | Grant fee paid |
Free format text: ORIGINAL CODE: EPIDOSNIGR3 |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): AT BE CH CY DE DK ES FI FR GB GR IE IT LI LU MC NL PT SE TR |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: NL Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20050831 Ref country code: LI Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20050831 Ref country code: TR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20050831 Ref country code: ES Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20050831 Ref country code: AT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20050831 Ref country code: CH Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20050831 Ref country code: BE Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20050831 |
|
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: EP Ref country code: GB Ref legal event code: FG4D |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: FG4D |
|
| REF | Corresponds to: |
Ref document number: 60113144 Country of ref document: DE Date of ref document: 20051006 Kind code of ref document: P |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: CY Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20051022 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20051024 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: LU Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20051031 Ref country code: MC Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20051031 |
|
| REG | Reference to a national code |
Ref country code: SE Ref legal event code: TRGR |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DK Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20051130 Ref country code: GR Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20051130 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: PT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRESCRIBED TIME-LIMIT Effective date: 20060223 |
|
| NLV1 | Nl: lapsed or annulled due to failure to fulfill the requirements of art. 29p and 29m of the patents act | ||
| REG | Reference to a national code |
Ref country code: CH Ref legal event code: PL |
|
| ET | Fr: translation filed | ||
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed |
Effective date: 20060601 |
|
| REG | Reference to a national code |
Ref country code: IE Ref legal event code: MM4A |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: DE Payment date: 20101029 Year of fee payment: 10 |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: IT Payment date: 20101021 Year of fee payment: 10 |
|
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: CD |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 20110930 Year of fee payment: 11 Ref country code: FR Payment date: 20111005 Year of fee payment: 11 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R082 Ref document number: 60113144 Country of ref document: DE Representative=s name: SCHUMACHER & WILLSAU PATENTANWALTSGESELLSCHAFT, DE |
|
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: SE Payment date: 20111006 Year of fee payment: 11 Ref country code: FI Payment date: 20111007 Year of fee payment: 11 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R082 Ref document number: 60113144 Country of ref document: DE Representative=s name: SCHUMACHER & WILLSAU PATENTANWALTSGESELLSCHAFT, DE Effective date: 20120113 Ref country code: DE Ref legal event code: R081 Ref document number: 60113144 Country of ref document: DE Owner name: MOTOROLA SOLUTIONS, INC., US Free format text: FORMER OWNER: MOTOROLA, INC., SCHAUMBURG, US Effective date: 20120113 |
|
| GBPC | Gb: european patent ceased through non-payment of renewal fee |
Effective date: 20121022 |
|
| REG | Reference to a national code |
Ref country code: FR Ref legal event code: ST Effective date: 20130628 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: SE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20121023 Ref country code: GB Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20121022 Ref country code: DE Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20130501 |
|
| REG | Reference to a national code |
Ref country code: DE Ref legal event code: R119 Ref document number: 60113144 Country of ref document: DE Effective date: 20130501 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: FI Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20121022 Ref country code: IT Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20121022 Ref country code: FR Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20121031 |