EP0415000B1 - Method and apparatus for spelling error detection and correction - Google Patents
Method and apparatus for spelling error detection and correction Download PDFInfo
- Publication number
- EP0415000B1 EP0415000B1 EP90108508A EP90108508A EP0415000B1 EP 0415000 B1 EP0415000 B1 EP 0415000B1 EP 90108508 A EP90108508 A EP 90108508A EP 90108508 A EP90108508 A EP 90108508A EP 0415000 B1 EP0415000 B1 EP 0415000B1
- Authority
- EP
- European Patent Office
- Prior art keywords
- word
- information signal
- information
- words
- tentative
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/232—Orthographic correction, e.g. spell checking or vowelisation
Definitions
- the invention relates to a method and an apparatus for detecting an error in an information signal.
- misspelled words are identified to the text processing operator by, for example, highlighting the word on a display device. Sometimes candidate words having spellings similar to the misspelled word are also displayed to the operator as proposed corrections.
- the known apparatus and methods for detecting and correcting spelling errors have several deficiencies. Most importantly, the known apparatus and methods cannot detect a "wrong word" erroneous spelling (where the erroneous spelling is itself a word in the spelling dictionary but is not the word that was intended).
- the prior apparatus and methods provide no means or only limited means for ranking alternative candidates for the correct spelling.
- the invention provides a method and apparatus for detecting and correcting spelling errors, where erroneously spelled words are correct entries in the spelling dictionary, but are not the intended words.
- an input string of words W i is provided.
- the spelling of a first word W 1 in the input string is changed to form a second word W 2 different from the first word, to form a candidate string of words W c .
- the probability P(W i ) of occurrence of the input string of words and the probability P(W c ) of occurrence of the candidate string of words are estimated.
- W c ) of misrepresenting the candidate string of words W c as the input string of words W i is also estimated.
- P(W i ) is compared with the product P(W c )P(W i
- a first output is produced if P(W i ) is greater than P(W c )P(W i
- the first output comprises the input string of words.
- the second output comprises the candidate string of words.
- the second output may be an error indication.
- W c ) of misrepresenting the candidate string of words as the input string of words may be estimated as the probability P(W 1
- each word in the input string and each word in the candidate string is a member of a set of correctly spelled words.
- the method and apparatus according to the invention further comprise the step of estimating the probability P(W i
- W i ) is compared with the product P(W c )P(W i
- the first output is produced if P(W i )P(W i
- W i ) of correctly spelling all of the words in the input string may be estimated as the probability P(W 1
- the spelling of the first word W 1 may be changed to form the second word W 2 by adding, deleting, transposing, or replacing one or more letters in the first word to form a tentative word.
- the tentative word is compared to each word in the set of words.
- the tentative word is used as the second word W 2 if the tentative word matches a word in the set of correctly spelled words.
- the spelling of the first word may be changed to form a second word by identifying a confusion group of M different words in the set of correctly spelled words.
- Each word in the confusion group may, for example, have a spelling which differs from the first word by no more than two letters.
- each word in the confusion group may be one which is confusable with the first word. At least one word in the confusion group is selected as the second word W 2 .
- the spelling error detection and correction method and apparatus are advantagecus because by comparing the probability of occurrence of the word being checked and the probabilities of occurrence of one or more spelling correction candidates, it is possible to detect and correct errors which are correct spellings of the wrong word.
- FIG. 1 is a block diagram of an embodiment of the spelling error detection and correction method according to the present invention.
- FIG. 2 is a block diagram of an example of the spelling error detection and correction method of FIG. 1.
- FIG. 3 is a block diagram of another example of the spelling error detection and correction method of FIG. 1.
- FIG. 4 is a block diagram of an embodiment of a routine for changing the spelling of a first word to form a second word in the spelling error detection and correction method according to the present invention.
- FIG. 5 is a block diagram of an alternative embodiment of a method of changing the spelling of a first word to form a second word.
- FIG. 6 is a block diagram of a preferred modification of the spelling error detection and correction method shown in FIG. 1.
- FIG. 7 is a block diagram of an embodiment of an apparatus for detecting and correcting an error in an information signal.
- the invention is a method of detecting and correcting an error in an information signal.
- each information signal represents a word which is a member of a set of correctly spelled words
- the invention provides a method of spelling error detection and correction.
- the spelling error detection and correction method starts with the step of providing an input string of words W i .
- Each word in the input string has a spelling.
- the input string and the candidate string each comprise three words.
- the input and candidate strings may be any length greater than or equal to two.
- Each string may be, for example, a sentence or a phrase.
- the probabilities P(W i ) of occurrence of the input string of words and P(W c ) of occurrence of the candidate string of words are estimated. These probabilities may be estimated empirically by examining large bodies of text, as discussed in more detail, below.
- W c ) of misrepresenting the candidate string of words W c as the input string of words W i may be chosen empirically by selecting different values until satisfactory results are obtained, as discussed in the Examples below.
- the probability P(W i ) is compared with the product of the probabilities P(W c )P(W i
- the first output may be the input string W 1 W M W N .
- the second output may be the candidate string W 2 W M W N .
- the second output may be an error indication.
- FIGS. 2 and 3 Two examples of the spelling error detection and correction method according to the present invention are shown in FIGS. 2 and 3.
- the input string is a string of three words: "the horse ran”. Each word in the input string of words is a member of a set of correctly spelled words.
- the first word W 1 is "horse”.
- the spelling of the first word “horse” is changed to form the second word W 2 , "house”.
- the candidate string of words W c is then "the house ran”.
- the second word "house” is also a member of the set of correctly spelled words.
- the probability P(W i ) of occurrence of the input string of words "the horse ran” is estimated to be 5x10 -5 .
- the probability P(W c ) of occurrence of the candidate string of words "the house ran” is estimated to be 1x10 -8 . While these probabilities are purely hypothetical for the purpose of illustrating the operation of the present invention, the hypothetical numbers illustrate that the probability of occurrence of "the horse ran” is much greater than the probability of occurrence of "the house ran”.
- W c ) of misrepresenting the candidate string of words as the input string of words is estimated to be equal to the probability P(W 1
- FIG. 3 illustrates the operation of the spelling error detection and correction method where the input string is "the house ran”. Now the first word W 1 is "house,” and the second word W 2 is "horse”.
- the probability of the input string (1x10 -8 ) is now less than the product of the probability of the candidate string multiplied by the probability of misrepresenting the candidate string as the input string (5x10 -8 ). Therefore, the input string is now rejected, and the candidate string is determined to be correct.
- the output is set to "the horse ran”.
- the spelling error detection and correction method according to the present invention is based on the following theory. For each candidate string of words (for example, for each candidate sentence) W c , the probability that the candidate sentence was actually intended given that the original sentence (input string of words) W i was typed is given by P(W c
- W i ) P(W c )P(W i
- W i ) that the original sentence was actually intended given that the original sentence was typed is compared to P(W c
- the sentence with the higher probability is selected as the sentence which was actually intended.
- conditional probabilities may be determined empirically by examining large bodies of text. For example, the conditional probability (W z
- W x W y ) n xyz n xy f 2 (W z
- the count n xyz is the number of occurrences of the trigram W x W y W x in a large body of training text.
- the count n xy is the number of occurrences of the bigram W x W y in the training text.
- n yz is the number of occurrences of the bigram W y W z in the training text
- n y is the number of occurrences of word W y
- n z is the number of occurrences of word W z
- n is the total number of words in the training text.
- the values of the coefficients ⁇ 1 , ⁇ 2 , ⁇ 3 , and ⁇ 4 in equations (2) and (7) may be estimated by the deleted interpolation method described in an article by Lalit R. Bahl et al entitled "A Maximum Likelihood Approach to Continuous Speech Recognition” ( IEEE Transactions on Pattern Analysis and Machine Intelligence , Vol. PAMI-5, No. 2, March 1983, pages 179-190).
- W c ) may be approximated by the product of the probabilities of misrepresenting each word in the candidate sentence as the corresponding word in the original typed sentence.
- W c ) can be estimated to be equal to the probability P(W 1
- the probability of misspelling any given word should be estimated to have a low value, for example 0.001. This value has been determined by experiment to yield satisfactory results. By increasing the probability of misspelling, the invention will find more misspellings; by decreasing the probability of misspelling, the invention will find fewer misspellings.
- the probability of each misspelling becomes 0.001 M in this example.
- W i ) of correctly spelling all of the words in the original typed sentence is not estimated as 1, it may be approximated by the product of the probabilities of correctly spelling each word in the original typed sentence. Where the original typed sentence and the candidate sentence differ by only one word, the probability P(W i
- FIG. 4 shows a subroutine which may be used to change the spelling of the first word W 1 to the second word W 2 .
- the changes may be made by, for example, adding a letter to the first word, deleting a letter from a first word, transposing two letters in the first word, or replacing a letter in a first word.
- the tentative word W T is then compared to each word in a set of words (a spelling dictionary) L. If the tentative word W T matches a word in the spelling dictionary L, then the second word W 2 is set equal to the tentative word.
- FIG. 5 shows an alternative subroutine for changing the spelling of a word.
- each word in the spelling dictionary is provided with an associated confusion group of words L c containing M different words.
- each word in the confusion group may have a spelling which differs from the spelling of the first word W 1 by no more than two letters.
- each word in a confusion group may be a word which sounds like and is therefore confusable with the first word (for example, "to", "two", and “too”, or "principle” and "principal”).
- one word is selected from the confusion group L c as the second word W 2 .
- FIG. 6 shows a modification of the spelling error detection and correction method of FIG. 1.
- the steps shows in FIG. 6 are intended to replace the steps in block 6 of FIG. 1.
- the method further includes the step of estimating the probability P(W i
- W i ) is compared with the product P(W c )P(W i
- An apparatus for detecting and correcting an error in an information signal is preferably in the form of a programmed general purpose digital computer.
- FIG. 7 shows an example of the organization of such an apparatus.
- a word processor 10 provides an input string of information signals W i .
- Each information signal represents information, such as a word.
- the word processor 10 is preferably a program running on a central processor 12 which is also executing the other functions of the apparatus. However, word processor 10 may alternatively be running on its own central processor.
- the central processor 12 changes a first information signal W 1 in the input string W i to form a second information signal W 2 representing information which is different from the information represented by the first information signal. This change forms a candidate string of information signals W c .
- central processor 12 compares the second information signal W 2 with the entries in the spelling dictionary store 16 to be sure that the second information signal is an entry in the spelling dictionary.
- central processor 12 Having produced the input and candidate strings, central processor 12 is instructed to retrieve estimates of the probabilities of occurrence of the input and candidate strings from the word string probability store 18. The probability P(W i
- the spelling error detection and correction method and apparatus according to the present invention were tested on 3,044 sentences which were systematically misspelled from 48 sentences.
- the 48 sentences were chosen from the Associated Press News Wire and from the Proceedings of the Canadian Parliament.
- Trigram conditional probabilities were obtained from a large corpus of text consisting primarily of office correspondence. Using a probability P(W i
- the input word string (the original typed sentence) is "I submit that is what is happening in this case.”
- the word W 1 whose spelling is being checked is “I”.
- the word "I” has only the following simple misspelling: "a”. Therefore, the second word W 2 is "a”, and the candidate word string W c (the candidate sentence) is "a submit that is what is happening in this case.”
- Table 1 shows the input and candidate sentences, the trigrams which make up each sentence, and the natural logarithms of the conditional probabilities for each trigram.
- Table 2 shows the totals obtained from Table 1. For all values of P t , the original sentence W i is selected over the alternative candidate sentence W c .
- the input word string W i is: "I submit that is what is happening in this case”.
- the first word W 1 whose spelling is being checked is “submit”.
- the word “submit” has two simple misspellings: “summit” or “submits”.
- the second word W 2 is selected to be "summit”. Therefore, the candidate word string W c (the candidate sentence) is "I summit that is what is happening in this case.”
- Table 3 shows the logarithms of the probabilities, and Table 4 provides the totals for Table 3. Again, for each value of P t , the original sentence is selected over the candidate.
- the input word string W i (the original typed sentence) is now "a submit that is what is happening in this case.”
- the first word W 1 whose spelling is being checked is “a”.
- the word “a” has the following ten simple misspellings: "I”, “at”, “as”, “an”, “am”, “ad”, “ab”, “pa”, "or”, "ha”.
- a second word W 2 is selected to be "I”. Therefore, the candidate string is "I submit that is what is happening in this case.”
- the input word string W i is "I summit that is what is happening in this case.”
- the first word W 1 whose spelling is being checked is “summit”.
- the word “summit” has two simple misspellings: “submit” or "summit”.
- the second word W 2 is selected to be "submit”. Therefore, the candidate word string W c is "I submit that is what is happening in this case.”
- W 2 ) P t 2 .
- Table 8 provides the totals from Table 7. For all values of P t , the candidate sentence is selected over the original typed sentence. A correction is therefore made in all cases.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Description
- The invention relates to a method and an apparatus for detecting an error in an information signal.
- In text processing apparatus, such as dedicated word processors or word processing programs which are run on general purpose digital computers, it is desirable to provide automatic detection and correction of spelling errors. Most spelling error detection apparatus and programs check each word in a text against the entries in a spelling dictionary. Words in the text which are not found in the spelling dictionary are assumed to be misspelled. The misspelled words are identified to the text processing operator by, for example, highlighting the word on a display device. Sometimes candidate words having spellings similar to the misspelled word are also displayed to the operator as proposed corrections.
- Other text processing systems are known from AFIPS Conference Proceedings 1982 National Computer Conference, 7 June 1982, Houston, Texas, US, pp. 501 - 508, S.N. Srihari et. al.: "Integration of botton-up and top-down contextual knowledge in text error correction" and IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. PAMI8, No. 6, November 1986, New York, US, pp. 742 - 749, A.M. Derouault & B. Merialdo: "Natural language modeling for phenome-to-text transcription".
- The known apparatus and methods for detecting and correcting spelling errors have several deficiencies. Most importantly, the known apparatus and methods cannot detect a "wrong word" erroneous spelling (where the erroneous spelling is itself a word in the spelling dictionary but is not the word that was intended).
- Moreover, even where the erroneous spelling does not appear in the spelling dictionary, the prior apparatus and methods provide no means or only limited means for ranking alternative candidates for the correct spelling.
- It is an object of the invention to provide a method and apparatus for detecting and correcting an error in an information signal, where the information signal represents the wrong information. When the information signal represents a word, the invention provides a method and apparatus for detecting and correcting spelling errors, where erroneously spelled words are correct entries in the spelling dictionary, but are not the intended words.
- It is another object of the invention to provide a method and apparatus for estimating the probability of occurrence of a word whose spelling is being checked, and to estimate the probabilities of one or more alternative words as candidates for replacing the word being checked.
- In a spelling error detection and correction method according to the present invention, an input string of words Wi is provided. The spelling of a first word W1 in the input string is changed to form a second word W2 different from the first word, to form a candidate string of words Wc. The probability P(Wi) of occurrence of the input string of words and the probability P(Wc) of occurrence of the candidate string of words are estimated. The probability P(Wi|Wc) of misrepresenting the candidate string of words Wc as the input string of words Wi is also estimated. Thereafter, P(Wi) is compared with the product P(Wc)P(Wi|Wc). A first output is produced if P(Wi) is greater than P(Wc)P(Wi|Wc), otherwise a second output is produced.
- In one aspect of the invention, the first output comprises the input string of words. The second output, comprises the candidate string of words. Alternatively, the second output may be an error indication.
- The probability P(Wi|Wc) of misrepresenting the candidate string of words as the input string of words may be estimated as the probability P(W1|W2) of misspelling the second word W2 as the first word W1.
- In the spelling error detection and correction method and apparatus according to the invention, each word in the input string and each word in the candidate string is a member of a set of correctly spelled words.
- Preferably, the method and apparatus according to the invention further comprise the step of estimating the probability P(Wi|Wi) of correctly spelling all of the words in the input string of words W1 In this case, the product P(Wi)P(Wi|Wi) is compared with the product P(Wc)P(Wi|Wc). The first output is produced if P(Wi)P(Wi|Wi) is greater than P(Wc)P(Wi|Wc), otherwise the second output is produced.
- The probability P(Wi|Wi) of correctly spelling all of the words in the input string may be estimated as the probability P(W1|W1) of correctly spelling the first word W1.
- According to an embodiment of the invention, the spelling of the first word W1 may be changed to form the second word W2 by adding, deleting, transposing, or replacing one or more letters in the first word to form a tentative word. The tentative word is compared to each word in the set of words. The tentative word is used as the second word W2 if the tentative word matches a word in the set of correctly spelled words.
- Alternatively, the spelling of the first word may be changed to form a second word by identifying a confusion group of M different words in the set of correctly spelled words. Each word in the confusion group may, for example, have a spelling which differs from the first word by no more than two letters. Alternatively, each word in the confusion group may be one which is confusable with the first word. At least one word in the confusion group is selected as the second word W2.
- Satisfactory results have been obtained in the method and apparatus according to the invention by estimating the probability of correctly spelling a word as 0.999. The probability of misspelling a word may be estimated to be

- The spelling error detection and correction method and apparatus according to the present invention are advantagecus because by comparing the probability of occurrence of the word being checked and the probabilities of occurrence of one or more spelling correction candidates, it is possible to detect and correct errors which are correct spellings of the wrong word.
- FIG. 1 is a block diagram of an embodiment of the spelling error detection and correction method according to the present invention.
- FIG. 2 is a block diagram of an example of the spelling error detection and correction method of FIG. 1.
- FIG. 3 is a block diagram of another example of the spelling error detection and correction method of FIG. 1.
- FIG. 4 is a block diagram of an embodiment of a routine for changing the spelling of a first word to form a second word in the spelling error detection and correction method according to the present invention.
- FIG. 5 is a block diagram of an alternative embodiment of a method of changing the spelling of a first word to form a second word.
- FIG. 6 is a block diagram of a preferred modification of the spelling error detection and correction method shown in FIG. 1.
- FIG. 7 is a block diagram of an embodiment of an apparatus for detecting and correcting an error in an information signal.
- The invention is a method of detecting and correcting an error in an information signal. In the case where each information signal represents a word which is a member of a set of correctly spelled words, the invention provides a method of spelling error detection and correction.
- Referring to FIG. 1, the spelling error detection and correction method starts with the step of providing an input string of words Wi. Each word in the input string has a spelling.
- Next, the spelling of a first word W1 in the input string is changed to form a second word W2 different from the first word, to form a candidate string of words Wc.
- In FIG. 1, the input string and the candidate string each comprise three words. According to the invention, the input and candidate strings may be any length greater than or equal to two. Each string may be, for example, a sentence or a phrase.
- Next, the probabilities P(Wi) of occurrence of the input string of words and P(Wc) of occurrence of the candidate string of words are estimated. These probabilities may be estimated empirically by examining large bodies of text, as discussed in more detail, below.
- Also estimated is the probability P(Wi|Wc) of misrepresenting the candidate string of words Wc as the input string of words Wi. The probability P(WiWc) may be chosen empirically by selecting different values until satisfactory results are obtained, as discussed in the Examples below.
- After the required probabilities are estimated, the probability P(Wi) is compared with the product of the probabilities P(Wc)P(Wi|Wc). If P(Wi) is greater than or equal to the product P(Wc)P(Wi|Wc), then a first output is produced. Otherwise, a second output is produced.
- As shown in FIG. 1, the first output may be the input string W1WMWN. The second output may be the candidate string W2WMWN.
- Alternatively, the second output may be an error indication.
- Two examples of the spelling error detection and correction method according to the present invention are shown in FIGS. 2 and 3. Referring to FIG. 2, the input string is a string of three words: "the horse ran". Each word in the input string of words is a member of a set of correctly spelled words. The first word W1 is "horse".
- Next, the spelling of the first word "horse" is changed to form the second word W2, "house". The candidate string of words Wc is then "the house ran". The second word "house" is also a member of the set of correctly spelled words.
- Continuing, the probability P(Wi) of occurrence of the input string of words "the horse ran" is estimated to be 5x10-5. The probability P(Wc) of occurrence of the candidate string of words "the house ran" is estimated to be 1x10-8. While these probabilities are purely hypothetical for the purpose of illustrating the operation of the present invention, the hypothetical numbers illustrate that the probability of occurrence of "the horse ran" is much greater than the probability of occurrence of "the house ran".
- Proceeding with the method, the probability P(Wi|Wc) of misrepresenting the candidate string of words as the input string of words is estimated to be equal to the probability P(W1|W2) of misspelling the second word W2 as the first word W1 From experiment it has been determined that an estimate of 0.001 produces satisfactory results.
- Finally, the value of P(Wi) is compared to the product P(Wc)P(Wi|Wc). Since the former (5x10-5) is greater than the latter (1x10-11), the input string of words is determined to be correct, and the candidate string of words is rejected. Accordingly, the output is "the horse ran".
- FIG. 3 illustrates the operation of the spelling error detection and correction method where the input string is "the house ran". Now the first word W1 is "house," and the second word W2 is "horse". By using the same probabilities estimated in FIG. 2, the probability of the input string (1x10-8) is now less than the product of the probability of the candidate string multiplied by the probability of misrepresenting the candidate string as the input string (5x10-8). Therefore, the input string is now rejected, and the candidate string is determined to be correct. The output is set to "the horse ran".
- The spelling error detection and correction method according to the present invention is based on the following theory. For each candidate string of words (for example, for each candidate sentence) Wc, the probability that the candidate sentence was actually intended given that the original sentence (input string of words) Wi was typed is given by

- The probability P(Wi|Wi) that the original sentence was actually intended given that the original sentence was typed (that is, the probability of correctly spelling all of the words in the original sentence Wi) is compared to P(Wc|Wi). For simplicity, both sides of the comparison are multiplied by P(Wi) so that the product P(Wi)P(Wi|Wi) is compared with the product P(Wc)P(Wi|Wc) The sentence with the higher probability is selected as the sentence which was actually intended.
- In order to further simplify the comparison, it may be assumed that the probability P(Wi|Wi) that the original sentence was actually intended given that the original sentence was typed is equal to 1.
- The probabilities P(Wi) of occurrence of the input string of words and P(Wc) of occurrence of the candidate string of words may be approximated by the product of n-gram probabilities for all n-grams in each string. That is, the probability of a string of words may be approximated by the product of the conditional probabilities of each word in the string, given the occurrence of the n-1 words (or absence of words) preceding each word. For example, if n = 3, each trigram probability may represent the probability of occurrence of the third word in the trigram, given the occurrence of the first two words in the trigram.
- The conditional probabilities may be determined empirically by examining large bodies of text. For example, the conditional probability(Wz|WxWy) of word Wz given the occurrence of the string WxWy may be estimated from the equation


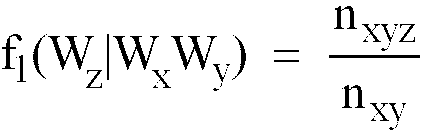




- In equations (3)-(6), the count nxyz is the number of occurrences of the trigram WxWyWx in a large body of training text. The count nxy is the number of occurrences of the bigram WxWy in the training text. Similarly, nyz is the number of occurrences of the bigram WyWz in the training text, ny is the number of occurrences of word Wy, nz is the number of occurrences of word Wz, and n is the total number of words in the training text. The values of the coefficients λ1,λ2,λ3, and λ4 in equations (2) and (7) may be estimated by the deleted interpolation method described in an article by Lalit R. Bahl et al entitled "A Maximum Likelihood Approach to Continuous Speech Recognition" (IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. PAMI-5, No. 2, March 1983, pages 179-190).
- In the comparison of P(Wi)P(Wi|Wi) with P(Wc)P(Wi|Wc) the probability P(Wi|Wc) may be approximated by the product of the probabilities of misrepresenting each word in the candidate sentence as the corresponding word in the original typed sentence. Where the original typed sentence and the candidate sentence differ by only one word (W1 in the original sentence and W2 in the candidate sentence), the probability P(Wi|Wc) can be estimated to be equal to the probability P(W1|W2) of misspelling the second word as the first word.
- The probability of misspelling any given word should be estimated to have a low value, for example 0.001. This value has been determined by experiment to yield satisfactory results. By increasing the probability of misspelling, the invention will find more misspellings; by decreasing the probability of misspelling, the invention will find fewer misspellings. When the word W1 in the original typed sentence has M misspellings which result in correct dictionary entries, the probability of each misspelling becomes

- If the probability P(Wi|Wi) of correctly spelling all of the words in the original typed sentence is not estimated as 1, it may be approximated by the product of the probabilities of correctly spelling each word in the original typed sentence. Where the original typed sentence and the candidate sentence differ by only one word, the probability P(Wi|Wi) may be estimated as the probability P(W1|W1) of correctly spelling the first word W1.
- FIG. 4 shows a subroutine which may be used to change the spelling of the first word W1 to the second word W2. First, one or more letters in the first word W1 are changed to form a tentative word WT. The changes may be made by, for example, adding a letter to the first word, deleting a letter from a first word, transposing two letters in the first word, or replacing a letter in a first word.
- The tentative word WT is then compared to each word in a set of words (a spelling dictionary) L. If the tentative word WT matches a word in the spelling dictionary L, then the second word W2 is set equal to the tentative word.
- FIG. 5 shows an alternative subroutine for changing the spelling of a word. In this routine, each word in the spelling dictionary is provided with an associated confusion group of words Lc containing M different words. For example, each word in the confusion group may have a spelling which differs from the spelling of the first word W1 by no more than two letters. Alternatively, each word in a confusion group may be a word which sounds like and is therefore confusable with the first word (for example, "to", "two", and "too", or "principle" and "principal"). For each candidate sentence, one word is selected from the confusion group Lc as the second word W2.
- FIG. 6 shows a modification of the spelling error detection and correction method of FIG. 1. The steps shows in FIG. 6 are intended to replace the steps in
block 6 of FIG. 1. - According to the modification, the method further includes the step of estimating the probability P(Wi|Wi) of correctly spelling all of the words in the input string of words Wi. The product of P(Wi)P(Wi|Wi) is compared with the product P(Wc)P(Wi|Wc). If the former is greater than or equal to the latter, a first output (for example, the input string) is produced. If the former is less than the latter, then a second output (for example, the candidate string) is produced.
- An apparatus for detecting and correcting an error in an information signal, for example where each information signal represents a word having a spelling, is preferably in the form of a programmed general purpose digital computer. FIG. 7 shows an example of the organization of such an apparatus.
- As shown in FIG. 7, a
word processor 10 provides an input string of information signals Wi. Each information signal represents information, such as a word. Theword processor 10 is preferably a program running on acentral processor 12 which is also executing the other functions of the apparatus. However,word processor 10 may alternatively be running on its own central processor. - Under the direction of the program instructions in
program instructions store 14, thecentral processor 12 changes a first information signal W1 in the input string Wi to form a second information signal W2 representing information which is different from the information represented by the first information signal. This change forms a candidate string of information signals Wc. Under the direction of the program instructions,central processor 12 compares the second information signal W2 with the entries in the spelling dictionary store 16 to be sure that the second information signal is an entry in the spelling dictionary. - Having produced the input and candidate strings,
central processor 12 is instructed to retrieve estimates of the probabilities of occurrence of the input and candidate strings from the wordstring probability store 18. The probability P(Wi|Wc) of misrepresenting the information represented by the candidate string of information signals as the input string of information signals is retrieved fromstore 20. Finally,central processor 12 compares P(Wi) with the product P(Wc)P(Wi|Wc). A first output signal is sent to, for example, adisplay 22 if the former is greater than or equal to the latter. Otherwise, a second output signal is sent to thedisplay 22. - The spelling error detection and correction method and apparatus according to the present invention were tested on 3,044 sentences which were systematically misspelled from 48 sentences. The 48 sentences were chosen from the Associated Press News Wire and from the Proceedings of the Canadian Parliament. Trigram conditional probabilities were obtained from a large corpus of text consisting primarily of office correspondence. Using a probability P(Wi|Wi) of 0.999, the method selected the changed sentence 78% of the time. Of those sentences that were changed, they were changed correctly 97% of the time.
- Several examples selected from the above-described tests are described below.
- In this example, the input word string (the original typed sentence) is "I submit that is what is happening in this case." The word W1 whose spelling is being checked is "I". The word "I" has only the following simple misspelling: "a". Therefore, the second word W2 is "a", and the candidate word string Wc (the candidate sentence) is "a submit that is what is happening in this case."
- Table 1 shows the input and candidate sentences, the trigrams which make up each sentence, and the natural logarithms of the conditional probabilities for each trigram. The experiment was performed with four different values of the probability Pt of correctly spelling each word: Pt = 0.9999, Pt = 0.999, Pt = 0.99, or Pt = 0.9.
- Since the logarithms (base e) of the probabilities are estimated in Table 1, the logarithms are added to produce estimates of the product of the probabilities.
- Table 2 shows the totals obtained from Table 1. For all values of Pt , the original sentence Wi is selected over the alternative candidate sentence Wc.


- In this example, the input word string Wi is: "I submit that is what is happening in this case". The first word W1 whose spelling is being checked is "submit". The word "submit" has two simple misspellings: "summit" or "submits". In this example, the second word W2 is selected to be "summit". Therefore, the candidate word string Wc (the candidate sentence) is "I summit that is what is happening in this case."
- Table 3 shows the logarithms of the probabilities, and Table 4 provides the totals for Table 3. Again, for each value of Pt, the original sentence is selected over the candidate.


- In this example, the input word string Wi (the original typed sentence) is now "a submit that is what is happening in this case." The first word W1 whose spelling is being checked is "a". The word "a" has the following ten simple misspellings: "I", "at", "as", "an", "am", "ad", "ab", "pa", "or", "ha".
- A second word W2 is selected to be "I". Therefore, the candidate string is "I submit that is what is happening in this case."
- The logarithms of the individual probabilities are shown in Table 5. Note that the probability P(W1|W2) is equal to

- Table 6 provides the totals from Table 5. For all values of Pt, except Pt = 0.9, the original sentence is selected over the candidate. When Pt = 0.9, the candidate is selected over the original.


- In this example, the input word string Wi is "I summit that is what is happening in this case." The first word W1 whose spelling is being checked is "summit". The word "summit" has two simple misspellings: "submit" or "summit".
- The second word W2 is selected to be "submit". Therefore, the candidate word string Wc is "I submit that is what is happening in this case."
- Table 7 shows the logarithms of the estimated probabilities of the trigrams and of correctly spelling or incorrectly spelling each word. Since M=2, the probability P(W1|W2)=

- Table 8 provides the totals from Table 7. For all values of Pt, the candidate sentence is selected over the original typed sentence. A correction is therefore made in all cases.


Claims (26)
- A computerized method of detecting an error in an information signal, said method comprising the steps of:providing an input string of information signals (Wi = W1WMWN), each information signal representing information;automatically changing a first information signal (W1) in the input string to form a second information signal (W2) representing information different from the information represented by the first information signal (W1), to form a candidate string of information signals (Wc=W2WMWN);automatically estimating the probability P(Wi) of occurrence of the input string (Wi = W1WMWN) of information signals on the basis of a body of information signals;automatically estimating the probability P(Wc) of occurrence of the candidate string (Wc = W2WMWN) of information signals on the basis of the body of information signals;automatically estimating the probability P(Wi|Wc) of misrepresenting the information represented by the candidate string (Wc = W2WMWN) of information signals as the input string (Wi = W1WMWN) of information signals;comparing P(Wi) with the product P(Wc)P(Wi|Wc); and outputting a first error signals if P(Wi) is greater than P(Wc)P(Wi|Wc), or outputting a second error signal if P(Wi) is less than P(Wc)P(Wi|Wc).
- A method as claimed in Claim 1, characterized in that:the first output signal comprises the input string of information signals;the second output signal comprises the candidate string of information signals; andthe probability P(Wi|Wc) is estimated as the probability P(W1|W2) of misrepresenting the information represented by the second information signal W2 as the first information signal W1.
- A method as claimed in Claim 2, characterized in that:the method further comprises the step of providing a set of words, each word having a spelling;each information signal in the input string of information signals represents a word which is a member of the set of words; andthe second information signal W2 represents a word which is a member of the set of words, the word represented by the second information signal being different from the word being represented by the first information signal.
- A method as claimed in Claim 3, characterized in that:the method further comprises the step of estimating the probability P(Wi|Wi) of correctly representing the information represented by all of the information signals in the input string of information signals Wi ;the step of comparing comprises comparing the product P(Wi)P(Wi|Wi) with the product P(Wc)P(Wi|Wc); andthe step of outputting comprises outputting the first output signal if P(Wi)P(Wi|Wi) is greater than P(Wc)P(Wi|Wc), or outputting the second output signal if P(Wi)P(Wi|Wi) is less than P(Wc)P(Wi|Wc).
- A method as claimed in Claim 4, characterized in that: the probability P(Wi|Wi) is estimated as the probability P(W1|W1) of correctly representing the information represented by the first information signal W1.
- A method as claimed in Claim 5, characterized in that the step of changing the first information signal W1 to form the second information signal W2 comprises:adding a letter to the word represented by the first information signal to form a tentative word;comparing the tentative word to each word in the set of words; andrepresenting the tentative word as the second information signal W2 if the tentative word matches a word in the set of words.
- A method as claimed in Claim 5, characterized in that the step of changing the first information signal W1 to form the second information signal W2 comprises:deleting a letter from the word represented by the first information signal to form a tentative word;comparing the tentative word to each word in the set of words; andrepresenting the tentative word as the second information signal W2 if the tentative word matches a word in the set of words.
- A method as claimed in Claim 5, characterized in that:the first information signal represents a word having at least two letters; andthe step of changing the first information signal W1 to form the second information signal W2 comprises:transposing at least two letters in the word represented by the first information signal to form a tentative word;comparing the tentative word to each word in the set of words; andrepresenting the tentative word as the second information signal W2 if the tentative word matches a word in the set of words.
- A method as claimed in Claim 5, characterized in that:the first information signal represents a word having at least one letter; andthe step of changing the first information signal W1 to form the second information signal W2 comprises:replacing a letter in the word represented by the first information signal to form a tentative word;comparing the tentative word to each word in the set of words; andrepresenting the tentative word as the second information signal W2 if the tentative word matches a word in the set of words.
- A method as claimed in Claim 5, characterized in that the step of changing the first information signal W1 to form the second information signal W2 comprises:identifying a confusion group of M different words in the set of words, each word in the confusion group having a spelling which differs from the spelling of the word represented by the first information signal by no more than two letters; andrepresenting one word in the confusion group as the second information signal W2.
- A method as claimed in Claim 5, characterized in that the step of changing the first information signal W1 to form the second information signal W2 comprises:identifying a confusion group of M different words in the set of words, each word in the confusion group being confusable with the word represented by the first information signal; andrepresenting one word in the confusion group as the second information signal W2.
- A method as claimed in Claim 11, characterized in that:the probability P(W1|W1) is estimated to be 0.999; andthe probability P(Wi|Wc) is estimated to be

- A method as claimed in Claim 1, characterized in that the second output signal comprises an error indication signal.
- A computerized apparatus for detecting an error in an information signal, said apparatus comprising:means for providing an input string of information signals (Wi = W1WMWN), each information signal representing information;means for automatically changing a first information signal (W1) in the input string to form a second information signal (W2) representing information different from the information represented by the first information signal, to form a candidate string of information signals (Wc=W2WMWN);means for automatically estimating the probability P(Wi) of occurrence of the input string (Wi = W1WMWN) of information signals on the basis of a body of information signals;means for automatically estimating the probability P(Wc) of occurrence of the candidate string (Wc=W2WMWN) of information signals on the basis of the body of information signals;means for automatically estimating the probability P(Wi|Wc) of misrepresenting the information represented by the candidate string (Wc=W2WMWN) of information signals as the input string (Wi = W1WMWN) of information signals;means for comparing P(Wi) with the product P(Wc)P(Wi|Wc); andmeans for outputting a first error signals if P(Wi) is greater than P(Wc)P(Wi|Wc), or outputting a second error signal if P(Wi) is less than P(Wc)P(Wi|Wc).
- An apparatus as claimed in Claim 14, characterized in that:the first output signal comprises the input string of information signals;the second output signal comprises the candidate string of information signals; andthe probability P(Wi|Wc) is estimated as the probability P(W1|W2) of misrepresenting the information represented by the second information signal W2 as the first information signal W1.
- An apparatus as claimed in Claim 15, characterized in that:the apparatus further comprises dictionary means for storing a set of words, each word having a spelling;each information signal in the input string of information signals represents a word which is a member of the set of words; andthe second information signal W2 represents a word which is a member of the set of words, the word represented by the second information signal being different from the word being represented by the first information signal.
- An apparatus as claimed in Claim 16, characterized in that:the apparatus further comprises means for estimating the probability P(Wi|Wi) of correctly representing all of the information represented by the input string of information signals Wi ;the means for comparing comprises means for comparing the product P(Wi)P(Wi|Wi) with the product P(Wc)P(Wi|Wc) ; andthe means for outputting comprises means for outputting the first output signal if P(Wi)P(Wi|Wi) is greater than P(Wc)P(Wi|Wc), or outputting the second output signal if P(Wi)P(Wi|Wi) is less than P(Wc)P(Wi|Wc).
- An apparatus as claimed in Claim 17, characterized in that:
the probability P(Wi|Wi) is estimated as the probability P(W1|W1) of correctly representing the information represented by the first information signal W1. - An apparatus as claimed in Claim 18, characterized in that the means for changing the first information signal W1 to form the second information signal W2 comprises:means for adding a letter to the word represented by the first information signal to form a tentative word;means for comparing the tentative word to each word in the set of words; andmeans for representing the tentative word as the second information signal W2 if the tentative word matches a word in the set of words.
- An apparatus as claimed in Claim 18, characterized in that the means for changing the first information signal W1 to form the second information signal W2 comprises:means for deleting a letter from the word represented by the first information signal to form a tentative word;means for comparing the tentative word to each word in the set of words; andmeans for representing the tentative word as the second information signal W2 if the tentative word matches a word in the set of words.
- An apparatus as claimed in Claim 18, characterized in thatthe first information signal represents a word having at least two letters; andthe means for changing the first information signal W1 to form the second information signal W2 comprises:means for transposing at least two letters in the word represented by the first information signal to form a tentative word;means for comparing the tentative word to each word in the set of words; andmeans for representing the tentative word as the second information signal W2 if the tentative word matches a word in the set of words.
- An apparatus as claimed in Claim 18, characterized in that:the first information signal represents a word having at least one letter; andthe means for changing the first information signal W1 to form the second information signal W2 comprises:means for replacing a letter in the word represented by the first information signal to form a tentative word;means for comparing the tentative word to each word in the set of words; andmeans for representing the tentative word as the second information signal W2 if the tentative word matches a word in the set of words.
- An apparatus as claimed in Claim 18, characterized in that the means for changing the first information signal W1 to form the second information signal W2 comprises:means for identifying a confusion group of M different words in the set of words, each word in the confusion group having a spelling which differs from the spelling of the word represented by the first information signal by no more than two letters; andmeans for representing one word in the confusion group as the second information signal W2.
- An apparatus as claimed in Claim 18, characterized in that the means for changing the first information signal W1 to form the second information signal W2 comprises:means for identifying a confusion group of M different words in the set of words, each word in the confusion group being confusable with the word represented by the first information signal; andmeans for representing one word in the confusion group as the second information signal W2.
- An apparatus as claimed in Claim 24, characterized in that:the probability P(W1|W1) is estimated to be 0.999; andthe probability P(Wi|Wc) is estimated to be

- An apparatus as claimed in Claim 14, characterized in that the second output signal comprises an error indication signal.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US401584 | 1989-08-31 | ||
| US07/401,584 US5258909A (en) | 1989-08-31 | 1989-08-31 | Method and apparatus for "wrong word" spelling error detection and correction |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| EP0415000A2 EP0415000A2 (en) | 1991-03-06 |
| EP0415000A3 EP0415000A3 (en) | 1992-01-02 |
| EP0415000B1 true EP0415000B1 (en) | 1997-07-23 |
Family
ID=23588329
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP90108508A Expired - Lifetime EP0415000B1 (en) | 1989-08-31 | 1990-05-07 | Method and apparatus for spelling error detection and correction |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US5258909A (en) |
| EP (1) | EP0415000B1 (en) |
| JP (1) | JPH079655B2 (en) |
| DE (1) | DE69031099D1 (en) |
Families Citing this family (66)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5604897A (en) * | 1990-05-18 | 1997-02-18 | Microsoft Corporation | Method and system for correcting the spelling of misspelled words |
| US5572423A (en) * | 1990-06-14 | 1996-11-05 | Lucent Technologies Inc. | Method for correcting spelling using error frequencies |
| US5157759A (en) * | 1990-06-28 | 1992-10-20 | At&T Bell Laboratories | Written language parser system |
| KR950008022B1 (en) * | 1991-06-19 | 1995-07-24 | 가부시끼가이샤 히다찌세이사꾸쇼 | Charactor processing method and apparatus therefor |
| DE4323241A1 (en) * | 1993-07-12 | 1995-02-02 | Ibm | Method and computer system for finding incorrect character strings in a text |
| US5537317A (en) * | 1994-06-01 | 1996-07-16 | Mitsubishi Electric Research Laboratories Inc. | System for correcting grammer based parts on speech probability |
| US5485372A (en) * | 1994-06-01 | 1996-01-16 | Mitsubishi Electric Research Laboratories, Inc. | System for underlying spelling recovery |
| US5761689A (en) * | 1994-09-01 | 1998-06-02 | Microsoft Corporation | Autocorrecting text typed into a word processing document |
| JP2809341B2 (en) | 1994-11-18 | 1998-10-08 | 松下電器産業株式会社 | Information summarizing method, information summarizing device, weighting method, and teletext receiving device. |
| JPH08235182A (en) * | 1995-02-28 | 1996-09-13 | Canon Inc | Method and device for document processing |
| US5828991A (en) * | 1995-06-30 | 1998-10-27 | The Research Foundation Of The State University Of New York | Sentence reconstruction using word ambiguity resolution |
| US6064959A (en) * | 1997-03-28 | 2000-05-16 | Dragon Systems, Inc. | Error correction in speech recognition |
| GB2314433A (en) * | 1996-06-22 | 1997-12-24 | Xerox Corp | Finding and modifying strings of a regular language in a text |
| US5999896A (en) * | 1996-06-25 | 1999-12-07 | Microsoft Corporation | Method and system for identifying and resolving commonly confused words in a natural language parser |
| US5956739A (en) * | 1996-06-25 | 1999-09-21 | Mitsubishi Electric Information Technology Center America, Inc. | System for text correction adaptive to the text being corrected |
| WO1998020428A1 (en) * | 1996-11-01 | 1998-05-14 | Bland Linda M | Interactive and automatic processing of text to identify language bias |
| US6047300A (en) * | 1997-05-15 | 2000-04-04 | Microsoft Corporation | System and method for automatically correcting a misspelled word |
| US6016467A (en) * | 1997-05-27 | 2000-01-18 | Digital Equipment Corporation | Method and apparatus for program development using a grammar-sensitive editor |
| US6782510B1 (en) * | 1998-01-27 | 2004-08-24 | John N. Gross | Word checking tool for controlling the language content in documents using dictionaries with modifyable status fields |
| US6963871B1 (en) * | 1998-03-25 | 2005-11-08 | Language Analysis Systems, Inc. | System and method for adaptive multi-cultural searching and matching of personal names |
| US8812300B2 (en) | 1998-03-25 | 2014-08-19 | International Business Machines Corporation | Identifying related names |
| US8855998B2 (en) | 1998-03-25 | 2014-10-07 | International Business Machines Corporation | Parsing culturally diverse names |
| US6424983B1 (en) | 1998-05-26 | 2002-07-23 | Global Information Research And Technologies, Llc | Spelling and grammar checking system |
| US6131102A (en) * | 1998-06-15 | 2000-10-10 | Microsoft Corporation | Method and system for cost computation of spelling suggestions and automatic replacement |
| US6175834B1 (en) * | 1998-06-24 | 2001-01-16 | Microsoft Corporation | Consistency checker for documents containing japanese text |
| US6401060B1 (en) * | 1998-06-25 | 2002-06-04 | Microsoft Corporation | Method for typographical detection and replacement in Japanese text |
| US6618697B1 (en) * | 1999-05-14 | 2003-09-09 | Justsystem Corporation | Method for rule-based correction of spelling and grammar errors |
| US6848080B1 (en) | 1999-11-05 | 2005-01-25 | Microsoft Corporation | Language input architecture for converting one text form to another text form with tolerance to spelling, typographical, and conversion errors |
| US7165019B1 (en) | 1999-11-05 | 2007-01-16 | Microsoft Corporation | Language input architecture for converting one text form to another text form with modeless entry |
| US7403888B1 (en) * | 1999-11-05 | 2008-07-22 | Microsoft Corporation | Language input user interface |
| US7047493B1 (en) * | 2000-03-31 | 2006-05-16 | Brill Eric D | Spell checker with arbitrary length string-to-string transformations to improve noisy channel spelling correction |
| US7398467B1 (en) * | 2000-06-13 | 2008-07-08 | International Business Machines Corporation | Method and apparatus for providing spelling analysis |
| US7970610B2 (en) * | 2001-04-19 | 2011-06-28 | British Telecommunication Public Limited Company | Speech recognition |
| KR100405360B1 (en) * | 2001-05-21 | 2003-11-12 | 기아자동차주식회사 | Vehicle Toner cover |
| US7076731B2 (en) * | 2001-06-02 | 2006-07-11 | Microsoft Corporation | Spelling correction system and method for phrasal strings using dictionary looping |
| US6560559B2 (en) * | 2001-08-17 | 2003-05-06 | Koninklijke Philips Electronics N.V. | System and method for detecting and correcting incorrect hand position of a computer user |
| EP1288790A1 (en) * | 2001-08-29 | 2003-03-05 | Tarchon BV | Method of analysing a text corpus and information analysis system |
| US7613601B2 (en) * | 2001-12-26 | 2009-11-03 | National Institute Of Information And Communications Technology | Method for predicting negative example, system for detecting incorrect wording using negative example prediction |
| US20040002850A1 (en) * | 2002-03-14 | 2004-01-01 | Shaefer Leonard Arthur | System and method for formulating reasonable spelling variations of a proper name |
| US7440941B1 (en) * | 2002-09-17 | 2008-10-21 | Yahoo! Inc. | Suggesting an alternative to the spelling of a search query |
| US20040128230A1 (en) | 2002-12-30 | 2004-07-01 | Fannie Mae | System and method for modifying attribute data pertaining to financial assets in a data processing system |
| US7885889B2 (en) * | 2002-12-30 | 2011-02-08 | Fannie Mae | System and method for processing data pertaining to financial assets |
| WO2004061556A2 (en) | 2002-12-30 | 2004-07-22 | Fannie Mae | System and method of processing data pertaining to financial assets |
| US8543378B1 (en) | 2003-11-05 | 2013-09-24 | W.W. Grainger, Inc. | System and method for discerning a term for an entry having a spelling error |
| US7672927B1 (en) | 2004-02-27 | 2010-03-02 | Yahoo! Inc. | Suggesting an alternative to the spelling of a search query |
| US7254774B2 (en) * | 2004-03-16 | 2007-08-07 | Microsoft Corporation | Systems and methods for improved spell checking |
| US7406416B2 (en) * | 2004-03-26 | 2008-07-29 | Microsoft Corporation | Representation of a deleted interpolation N-gram language model in ARPA standard format |
| US20070005586A1 (en) * | 2004-03-30 | 2007-01-04 | Shaefer Leonard A Jr | Parsing culturally diverse names |
| US7478038B2 (en) * | 2004-03-31 | 2009-01-13 | Microsoft Corporation | Language model adaptation using semantic supervision |
| US7634741B2 (en) * | 2004-08-31 | 2009-12-15 | Sap Ag | Method and apparatus for managing a selection list based on previous entries |
| US20060293890A1 (en) * | 2005-06-28 | 2006-12-28 | Avaya Technology Corp. | Speech recognition assisted autocompletion of composite characters |
| US7664629B2 (en) * | 2005-07-19 | 2010-02-16 | Xerox Corporation | Second language writing advisor |
| US8249873B2 (en) * | 2005-08-12 | 2012-08-21 | Avaya Inc. | Tonal correction of speech |
| US20070214189A1 (en) * | 2006-03-10 | 2007-09-13 | Motorola, Inc. | System and method for consistency checking in documents |
| EP1855210B1 (en) * | 2006-05-11 | 2018-01-03 | Dassault Systèmes | Spell checking |
| US7818332B2 (en) * | 2006-08-16 | 2010-10-19 | Microsoft Corporation | Query speller |
| US7877375B1 (en) * | 2007-03-29 | 2011-01-25 | Oclc Online Computer Library Center, Inc. | Name finding system and method |
| WO2009016631A2 (en) * | 2007-08-01 | 2009-02-05 | Ginger Software, Inc. | Automatic context sensitive language correction and enhancement using an internet corpus |
| US8700997B1 (en) * | 2012-01-18 | 2014-04-15 | Google Inc. | Method and apparatus for spellchecking source code |
| CN103578464B (en) * | 2013-10-18 | 2017-01-11 | 威盛电子股份有限公司 | Language model building method, speech recognition method and electronic device |
| KR102167719B1 (en) * | 2014-12-08 | 2020-10-19 | 삼성전자주식회사 | Method and apparatus for training language model, method and apparatus for recognizing speech |
| US10372814B2 (en) | 2016-10-18 | 2019-08-06 | International Business Machines Corporation | Methods and system for fast, adaptive correction of misspells |
| US10579729B2 (en) | 2016-10-18 | 2020-03-03 | International Business Machines Corporation | Methods and system for fast, adaptive correction of misspells |
| US11093709B2 (en) | 2017-08-10 | 2021-08-17 | International Business Machine Corporation | Confidence models based on error-to-correction mapping |
| US11157479B2 (en) * | 2019-04-08 | 2021-10-26 | Microsoft Technology Licensing, Llc | Leveraging a collection of training tables to accurately predict errors within a variety of tables |
| CN110852074B (en) * | 2019-11-07 | 2023-05-16 | 腾讯科技(深圳)有限公司 | Method and device for generating correction statement, storage medium and electronic equipment |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA1182570A (en) * | 1982-04-30 | 1985-02-12 | Frederick R. Lange | System for detecting and correcting contextual errors in a text processing system |
-
1989
- 1989-08-31 US US07/401,584 patent/US5258909A/en not_active Expired - Fee Related
-
1990
- 1990-05-07 DE DE69031099T patent/DE69031099D1/en not_active Expired - Lifetime
- 1990-05-07 EP EP90108508A patent/EP0415000B1/en not_active Expired - Lifetime
- 1990-08-16 JP JP2215111A patent/JPH079655B2/en not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| DE69031099D1 (en) | 1997-09-04 |
| US5258909A (en) | 1993-11-02 |
| EP0415000A2 (en) | 1991-03-06 |
| JPH079655B2 (en) | 1995-02-01 |
| JPH0398158A (en) | 1991-04-23 |
| EP0415000A3 (en) | 1992-01-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP0415000B1 (en) | Method and apparatus for spelling error detection and correction | |
| US5680628A (en) | Method and apparatus for automated search and retrieval process | |
| US5794177A (en) | Method and apparatus for morphological analysis and generation of natural language text | |
| US20150154173A1 (en) | Method of detecting grammatical error, error detecting apparatus for the method, and computer-readable recording medium storing the method | |
| WO1997004405A9 (en) | Method and apparatus for automated search and retrieval processing | |
| US20110106523A1 (en) | Method and Apparatus for Creating a Language Model and Kana-Kanji Conversion | |
| Yannakoudakis et al. | An intelligent spelling error corrector | |
| WILLETT | UsING ASTRING sIMILARITY MEAsURE | |
| WO2008059111A2 (en) | Natural language processing | |
| Volk et al. | Comparing a statistical and a rule-based tagger for German | |
| US7072827B1 (en) | Morphological disambiguation | |
| Kaur et al. | Spell checker for Punjabi language using deep neural network | |
| JPH117447A (en) | Topic extraction method, topic extraction model and its creation method used therefor, topic extraction program recording medium | |
| Ren et al. | A hybrid approach to automatic Chinese text checking and error correction | |
| Sharma et al. | Improving existing punjabi grammar checker | |
| JP4047895B2 (en) | Document proofing apparatus and program storage medium | |
| Bakar et al. | An evaluation of retrieval effectiveness using spelling‐correction and string‐similarity matching methods on Malay texts | |
| Minin et al. | Elaborating Russian spelling-correction algorithms with custom n-gram models | |
| Dalkiliç et al. | Turkish spelling error detection and correction by using word n-grams | |
| Ichioka et al. | Graph-based clustering for semantic classification of onomatopoetic words | |
| CN117150052A (en) | Patent retrieval method, device, computer equipment and medium | |
| JP4318223B2 (en) | Document proofing apparatus and program storage medium | |
| KR20000018924A (en) | Spacing mistake tolerance korean morphological analysis method and apparatus thereof | |
| JP2001022752A (en) | Method and device for character group extraction, and recording medium for character group extraction | |
| JPH04278664A (en) | Address analysis processing device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| 17P | Request for examination filed |
Effective date: 19901213 |
|
| AK | Designated contracting states |
Kind code of ref document: A2 Designated state(s): DE FR GB IT |
|
| PUAL | Search report despatched |
Free format text: ORIGINAL CODE: 0009013 |
|
| AK | Designated contracting states |
Kind code of ref document: A3 Designated state(s): DE FR GB IT |
|
| 17Q | First examination report despatched |
Effective date: 19940817 |
|
| GRAG | Despatch of communication of intention to grant |
Free format text: ORIGINAL CODE: EPIDOS AGRA |
|
| GRAH | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOS IGRA |
|
| GRAH | Despatch of communication of intention to grant a patent |
Free format text: ORIGINAL CODE: EPIDOS IGRA |
|
| GRAA | (expected) grant |
Free format text: ORIGINAL CODE: 0009210 |
|
| AK | Designated contracting states |
Kind code of ref document: B1 Designated state(s): DE FR GB IT |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: IT Free format text: LAPSE BECAUSE OF FAILURE TO SUBMIT A TRANSLATION OF THE DESCRIPTION OR TO PAY THE FEE WITHIN THE PRE;WARNING: LAPSES OF ITALIAN PATENTS WITH EFFECTIVE DATE BEFORE 2007 MAY HAVE OCCURRED AT ANY TIME BEFORE 2007. THE CORRECT EFFECTIVE DATE MAY BE DIFFERENT FROM THE ONE RECORDED.SCRIBED TIME-LIMIT Effective date: 19970723 Ref country code: FR Effective date: 19970723 |
|
| REF | Corresponds to: |
Ref document number: 69031099 Country of ref document: DE Date of ref document: 19970904 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: DE Effective date: 19971024 |
|
| EN | Fr: translation not filed | ||
| PLBE | No opposition filed within time limit |
Free format text: ORIGINAL CODE: 0009261 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: NO OPPOSITION FILED WITHIN TIME LIMIT |
|
| 26N | No opposition filed | ||
| PGFP | Annual fee paid to national office [announced via postgrant information from national office to epo] |
Ref country code: GB Payment date: 20000427 Year of fee payment: 11 |
|
| PG25 | Lapsed in a contracting state [announced via postgrant information from national office to epo] |
Ref country code: GB Free format text: LAPSE BECAUSE OF NON-PAYMENT OF DUE FEES Effective date: 20010507 |
|
| GBPC | Gb: european patent ceased through non-payment of renewal fee |
Effective date: 20010507 |